PaddleSlim是一个专注于深度学习模型压缩的工具库,提供低比特量化、知识蒸馏、稀疏化和模型结构搜索等模型压缩策略,帮助开发者快速实现模型的小型化。
-
🔥 2022.01.18: 发布YOLOv8自动化压缩示例,量化预测加速2.5倍。
-
【直播分享】2022-12-13 20:30 《自动化压缩技术详解及ViT模型实战》,微信扫码报名

2022.08.16:自动化压缩功能升级
- 支持直接加载ONNX模型和Paddle模型导出至ONNX
- 发布量化分析工具,发布YOLO系列离线量化工具
- 更新YOLO-Series自动化压缩模型库
| 模型 | Base mAPval 0.5:0.95 |
ACT量化mAPval 0.5:0.95 |
模型体积压缩比 | 预测时延FP32 |
预测时延INT8 |
预测加速比 |
|---|---|---|---|---|---|---|
| PPYOLOE-s | 43.1 | 42.6 | 3.9倍 | 6.51ms | 2.12ms | 3.1倍 |
| YOLOv5s | 37.4 | 36.9 | 3.8倍 | 5.95ms | 1.87ms | 3.2倍 |
| YOLOv6s | 42.4 | 41.3 | 3.9倍 | 9.06ms | 1.83ms | 5.0倍 |
| YOLOv7 | 51.1 | 50.9 | 3.9倍 | 26.84ms | 4.55ms | 5.9倍 |
| YOLOv7-Tiny | 37.3 | 37.0 | 3.9倍 | 5.06ms | 1.68ms | 3.0倍 |
历史更新
-
2022.07.01: 发布v2.3.0版本
-
2021.11.15: 发布v2.2.0版本
- 支持动态图离线量化功能.
-
2021.5.20: 发布V2.1.0版本
- 扩展离线量化方法
- 新增非结构化稀疏
- 增强剪枝功能
- 修复OFA功能若干bug
更多信息请参考:release note
PaddleSlim支持以下功能,也支持自定义量化、裁剪等功能。
| Quantization | Pruning | NAS | Distilling |
|---|---|---|---|
注:
- *表示仅支持静态图,**表示仅支持动态图
- 敏感度裁剪指的是通过各个层的敏感度分析来确定各个卷积层的剪裁率,需要和其他裁剪方法配合使用。
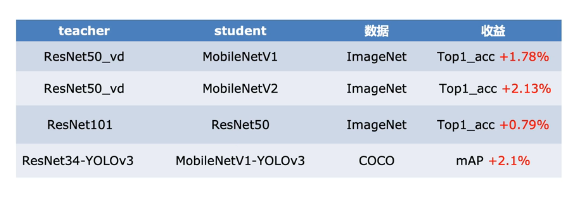
PaddleSlim在典型视觉和自然语言处理任务上做了模型压缩,并且测试了Nvidia GPU、ARM等设备上的加速情况,这里展示部分模型的压缩效果,详细方案可以参考下面CV和NLP模型压缩方案:

表1: 部分场景模型压缩加速情况
注意事项
- YOLOv3: 在移动端SD855上加速3.55倍。
- PP-OCR: 体积由8.9M减少到2.9M, 在SD855上加速1.27倍。
- BERT: 模型参数由110M减少到80M,精度提升的情况下,Tesla T4 GPU FP16计算加速1.47倍。
自动压缩效果

表3: 自动压缩效果
离线量化效果对比

表2: 多种离线量化方法效果对比
安装发布版本:
pip install paddleslim安装develop版本:
git clone https://github.com/PaddlePaddle/PaddleSlim.git & cd PaddleSlim
python setup.py install- 验证安装:安装完成后您可以使用 python 或 python3 进入 python 解释器,输入import paddleslim, 没有报错则说明安装成功。
- 版本对齐:
| PaddleSlim | PaddlePaddle | PaddleLite |
|---|---|---|
| 2.0.0 | 2.0 | 2.8 |
| 2.1.0 | 2.1.0 | 2.8 |
| 2.1.1 | 2.1.1 | >=2.8 |
| 2.3.0 | 2.3.0 | >=2.11 |
| 2.4.0 | 2.4.0 | >=2.11 |
| develop | develop | >=2.11 |
进阶教程详细介绍了每一步的流程,帮助您把相应方法迁移到您自己的模型上。
-
通道剪裁
-
低比特量化
-
NAS
-
蒸馏
本系列教程均基于Paddle官方的模型套件中模型进行压缩,若您不是模型套件用户,更推荐使用快速教程和进阶教程。
-
检测模型压缩
-
压缩方案
-
方法应用-静态图
-
方法应用-动态图
-
-
分割模型压缩
-
OCR模型压缩
-
压缩方案
-
方法应用-静态图
-
方法应用-动态图
-
答:这是因为量化后保存的参数是虽然是int8范围,但是类型是float。这是因为Paddle训练前向默认的Kernel不支持INT8 Kernel实现,只有Paddle Inference TensorRT的推理才支持量化推理加速。为了方便量化后验证量化精度,使用Paddle训练前向能加载此模型,默认保存的Float32类型权重,体积没有发生变换。
答: 请参考#1258
本项目的发布受Apache 2.0 license许可认证。
我们非常欢迎你可以为PaddleSlim提供代码,也十分感谢你的反馈。
-
如果你发现任何PaddleSlim存在的问题或者是建议, 欢迎通过GitHub Issues给我们提issues。
-
欢迎加入PaddleSlim 微信技术交流群