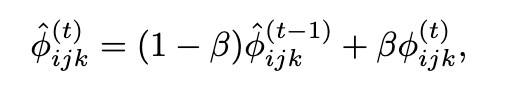LibMTL is an open-source library built on PyTorch for Multi-Task Learning (MTL). See the latest documentation for detailed introductions and API instructions.
⭐ Star us on GitHub — it motivates us a lot!
- [Feb 08 2024] Added support for DB-MTL.
- [Aug 16 2023]: Added support for MoCo (ICLR 2023). Many thanks to the author's help @heshandevaka.
- [Jul 11 2023] Paper got accepted to JMLR.
- [Jun 19 2023] Added support for Aligned-MTL (CVPR 2023).
- [Mar 10 2023]: Added QM9 and PAWS-X examples.
- [Jul 22 2022]: Added support for Nash-MTL (ICML 2022).
- [Jul 21 2022]: Added support for Learning to Branch (ICML 2020). Many thanks to @yuezhixiong (#14).
- [Mar 29 2022]: Paper is now available on the arXiv.
- Features
- Overall Framework
- Supported Algorithms
- Supported Benchmark Datasets
- Installation
- Quick Start
- Citation
- Contributor
- Contact Us
- Acknowledgements
- License
- Unified:
LibMTLprovides a unified code base to implement and a consistent evaluation procedure including data processing, metric objectives, and hyper-parameters on several representative MTL benchmark datasets, which allows quantitative, fair, and consistent comparisons between different MTL algorithms. - Comprehensive:
LibMTLsupports many state-of-the-art MTL methods including 8 architectures and 16 optimization strategies. Meanwhile,LibMTLprovides a fair comparison of several benchmark datasets covering different fields. - Extensible:
LibMTLfollows the modular design principles, which allows users to flexibly and conveniently add customized components or make personalized modifications. Therefore, users can easily and fast develop novel optimization strategies and architectures or apply the existing MTL algorithms to new application scenarios with the support ofLibMTL.

Each module is introduced in Docs.
LibMTL currently supports the following algorithms:
| Optimization Strategies | Venues | Arguments |
|---|---|---|
| Equal Weighting (EW) | - | --weighting EW |
| Gradient Normalization (GradNorm) | ICML 2018 | --weighting GradNorm |
| Uncertainty Weights (UW) | CVPR 2018 | --weighting UW |
| MGDA (official code) | NeurIPS 2018 | --weighting MGDA |
| Dynamic Weight Average (DWA) (official code) | CVPR 2019 | --weighting DWA |
| Geometric Loss Strategy (GLS) | CVPR 2019 Workshop | --weighting GLS |
| Projecting Conflicting Gradient (PCGrad) | NeurIPS 2020 | --weighting PCGrad |
| Gradient sign Dropout (GradDrop) | NeurIPS 2020 | --weighting GradDrop |
| Impartial Multi-Task Learning (IMTL) | ICLR 2021 | --weighting IMTL |
| Gradient Vaccine (GradVac) | ICLR 2021 | --weighting GradVac |
| Conflict-Averse Gradient descent (CAGrad) (official code) | NeurIPS 2021 | --weighting CAGrad |
| Nash-MTL (official code) | ICML 2022 | --weighting Nash_MTL |
| Random Loss Weighting (RLW) | TMLR 2022 | --weighting RLW |
| MoCo | ICLR 2023 | --weighting MoCo |
| Aligned-MTL (official code) | CVPR 2023 | --weighting Aligned_MTL |
| DB-MTL | arXiv | --weighting DB_MTL |
| Architectures | Venues | Arguments |
|---|---|---|
| Hard Parameter Sharing (HPS) | ICML 1993 | --arch HPS |
| Cross-stitch Networks (Cross_stitch) | CVPR 2016 | --arch Cross_stitch |
| Multi-gate Mixture-of-Experts (MMoE) | KDD 2018 | --arch MMoE |
| Multi-Task Attention Network (MTAN) (official code) | CVPR 2019 | --arch MTAN |
| Customized Gate Control (CGC), Progressive Layered Extraction (PLE) | ACM RecSys 2020 | --arch CGC, --arch PLE |
| Learning to Branch (LTB) | ICML 2020 | --arch LTB |
| DSelect-k (official code) | NeurIPS 2021 | --arch DSelect_k |
| Datasets | Problems | Task Number | Tasks | multi-input | Supported Backbone |
|---|---|---|---|---|---|
| NYUv2 | Scene Understanding | 3 | Semantic Segmentation+ Depth Estimation+ Surface Normal Prediction |
✘ | ResNet50/ SegNet |
| Office-31 | Image Recognition | 3 | Classification | ✓ | ResNet18 |
| Office-Home | Image Recognition | 4 | Classification | ✓ | ResNet18 |
| QM9 | Molecular Property Prediction | 11 (default) | Regression | ✘ | GNN |
| PAWS-X | Paraphrase Identification | 4 (default) | Classification | ✓ | Bert |
-
Create a virtual environment
conda create -n libmtl python=3.8 conda activate libmtl pip install torch==1.8.1+cu111 torchvision==0.9.1+cu111 -f https://download.pytorch.org/whl/torch_stable.html
-
Clone the repository
git clone https://github.com/median-research-group/LibMTL.git
-
Install
LibMTLcd LibMTL pip install -r requirements.txt pip install -e .
We use the NYUv2 dataset as an example to show how to use LibMTL.
The NYUv2 dataset we used is pre-processed by mtan. You can download this dataset here.
The complete training code for the NYUv2 dataset is provided in examples/nyu. The file main.py is the main file for training on the NYUv2 dataset.
You can find the command-line arguments by running the following command.
python main.py -hFor instance, running the following command will train an MTL model with EW and HPS on NYUv2 dataset.
python main.py --weighting EW --arch HPS --dataset_path /path/to/nyuv2 --gpu_id 0 --scheduler step --mode train --save_path PATHMore details is represented in Docs.
If you find LibMTL useful for your research or development, please cite the following:
@article{lin2023libmtl,
title={{LibMTL}: A {P}ython Library for Multi-Task Learning},
author={Baijiong Lin and Yu Zhang},
journal={Journal of Machine Learning Research},
volume={24},
number={209},
pages={1--7},
year={2023}
}LibMTL is developed and maintained by Baijiong Lin.
If you have any question or suggestion, please feel free to contact us by raising an issue or sending an email to [email protected].
We would like to thank the authors that release the public repositories (listed alphabetically): CAGrad, dselect_k_moe, MultiObjectiveOptimization, mtan, MTL, nash-mtl, pytorch_geometric, and xtreme.
LibMTL is released under the MIT license.