Unofficial implementation of MVSNet: Depth Inference for Unstructured Multi-view Stereo using pytorch-lightning
An improved version of MVSNet: CasMVSNet is available!
Official implementation: MVSNet
A pytorch implementation: MVSNet_pytorch. This code is heavily borrowed from his implementation. Thank xy-guo for the effortful contribution! Two main difference w.r.t. his repo:
homo_warpingfunction is rewritten in a more concise and slightly faster way.- Use Inplace-ABN in the model to reduce GPU memory consumption (about 10%).
- OS: Ubuntu 16.04 or 18.04
- NVIDIA GPU with CUDA>=10.0 (tested with 1 RTX 2080Ti)
- Python>=3.6.1 (installation via anaconda is recommended, use
conda create -n mvsnet_pl python=3.6to create a conda environment and activate it byconda activate mvsnet_pl) - Python libraries
- Install core requirements by
pip install -r requirements.txt - Install Inplace-ABN by
pip install git+https://github.com/mapillary/[email protected]
- Install core requirements by
Download the preprocessed DTU training data from original MVSNet repo and unzip. For the description of how the data is created, please refer to the original paper.
Run
python train.py \
--root_dir $DTU_DIR \
--num_epochs 6 --batch_size 1 \
--n_depths 192 --interval_scale 1.06 \
--optimizer adam --lr 1e-3 --lr_scheduler cosine
Note that the model consumes huge GPU memory, so the batch size is generally small. For reference, the above command requires 5901MB of GPU memory.
IMPORTANT : the combination of --n_depths and --interval_scale is important: you need to make sure 2.5 x n_depths x interval_scale is roughly equal to 510. The reason is that the actual depth ranges from 425 to 935mm, which is 510mm wide. Therefore, you need to make sure all the depth can be covered by the depth planes you set. Some common combinations are: --n_depths 256 --interval_scale 0.8, --n_depths 192 --interval_scale 1.06 and --n_depths 128 --interval_scale 1.6.
See opt.py for all configurations.



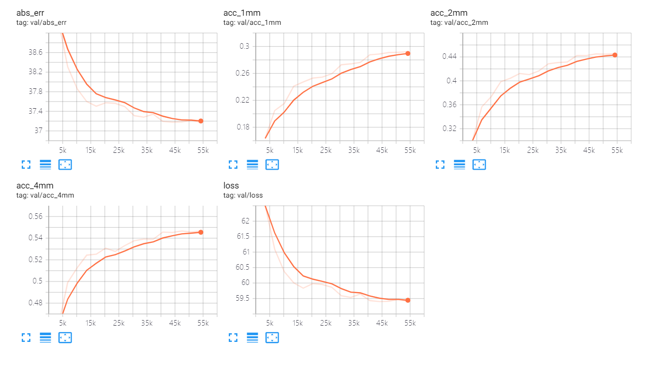
The metrics are collected on the DTU val set.
| abs_err | 1mm acc | 2mm acc | 4mm acc | |
|---|---|---|---|---|
| Paper | 7.25mm* | N/A | N/A | N/A |
| This repo | 6.374mm | 54.43% | 74.23% | 85.8% |
*From P-MVSNet Table 2.
- Larger
n_depthstheoretically gives better results, but requires larger GPU memory, so basically thebatch_sizecan just be1or2. However at the meanwhile, largerbatch_sizeis also indispensable. To get a good balance betweenn_depthsandbatch_size, I found thatn_depths 128 batch_size 2performs better thann_depths 192 batch_size 1given a fixed GPU memory of 11GB. Of course to get even better results, you'll definitely want to scale up thebatch_sizeby using more GPUs, and that is easy under pytorch-lightning's framework! - Longer training epochs produces better results. The pretrained model I provide is trained for 16 epochs, and it performs better than the model trained for only 6 epochs as the paper did.
- Image color augmentation worsen the result, and normalization seems to have little to no effect. However, BlendedMVS claims otherwise, they obtain better results using augmentation.
- Download pretrained model from release.
- Use test.ipynb for a simple depth inference for an image.
The repo is only for training purpose for now. Please refer to the other repositories mentioned at the beginning if you want to evaluate the model.