cvlab-unibo / real-time-self-adaptive-deep-stereo Goto Github PK
View Code? Open in Web Editor NEWCode for "Real-time self-adaptive deep stereo" - CVPR 2019 (ORAL)
License: Apache License 2.0
Code for "Real-time self-adaptive deep stereo" - CVPR 2019 (ORAL)
License: Apache License 2.0






























































































































Hi, I want to run the pre-trained model, and I downloaded from the link you provided, but I found no checkpoint archives in the pre-trained folder, can you provide your checkpoint archives,thank you so much!
Thank you for sharing the code first. But when I read your code (Train.py), I found some things that confused me, as follows:
I don't understand the function of "-20" and "20" in these two lines of code
op = tf.image.resize_images(tf.nn.relu(op * -20), [self._left_input_batch.get_shape()[1].value, self._left_input_batch.get_shape()[2].value]) lines in 70 of Train.py
u5 = tf.image.resize_images(V6, [image_height // scales[5], image_width // scales[5]]) * 20. / scales[5] lines in 282 of Train.py
rescaled_prediction = tf.image.resize_images(self._get_layer_as_input('final_disp'), [image_height, image_width]) * -20. lines in 371 of Train.py
When I trained on the Monkaa data set, I found that the value of loss always jumped back and forth, and the model did not converge. After many times of failures, I found that some code confused me in the process of network construction.
rescaled_prediction = tf.image.resize_images(self._get_layer_as_input('final_disp'), [image_height, image_width]) * -20. lines in 371 of Train.py
In my understand, this code pad the final disparity map to the size of groundtruth. Then use the padded map compute the loss. I think it is easier to converge by reducing the size of groudtruth in the process of computing the loss. I would appreciate it if you could answer my questions. Thank you very much.
Hi @AlessioTonioni , thanks for sharing your work! I have a basic question. In the correlation layer, why the range is from -max_disp to max_disp, instead of from 0 to max_disp? Is it because of the pre-process method crop_padding? Is reduce_mean also used in original DispnetC?
def correlation_tf(x, y, max_disp, stride=1, name='corr'):
with tf.variable_scope(name):
corr_tensors = []
y_shape = tf.shape(y)
y_feature = tf.pad(y,[[0,0],[0,0],[max_disp,max_disp],[0,0]])
for i in range(-max_disp, max_disp+1,stride):
shifted = tf.slice(y_feature, [0, 0, i + max_disp, 0], [-1, y_shape[1], y_shape[2], -1])
corr_tensors.append(tf.reduce_mean(shifted*x, axis=-1, keepdims=True))
result = tf.concat(corr_tensors,axis=-1)
return resultExcuse me, could I retrain your model on multi-GPU simply by os.environ["CUDA_VISIBLE_DEVICES"]="4,5"? Or adding the gradient towers? Because the one GPU is out of memory. Thanks a lot.
I'm trying to freeze the graph of MADNet pretrained module. What are the input and output node names?
Result saved in ./output
All Done, Bye Bye!
Traceback (most recent call last):
File "/home/giuser/miniconda3/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1356, in _do_call
return fn(*args)
File "/home/giuser/miniconda3/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1341, in _run_fn
options, feed_dict, fetch_list, target_list, run_metadata)
File "/home/giuser/miniconda3/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1429, in _call_tf_sessionrun
run_metadata)
tensorflow.python.framework.errors_impl.InvalidArgumentError: assertion failed: [Unable to decode bytes as JPEG, PNG, GIF, or BMP]
[[{{node decode_image/cond_jpeg/else/_1/cond_png/else/_1/cond_gif/else/_1/Assert/Assert}}]]
[[input_reader/IteratorGetNext]]
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "Stereo_Online_Adaptation.py", line 324, in
main(args)
File "Stereo_Online_Adaptation.py", line 208, in main
fetches = sess.run(tf_fetches)
File "/home/giuser/miniconda3/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 950, in run
run_metadata_ptr)
File "/home/giuser/miniconda3/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1173, in _run
feed_dict_tensor, options, run_metadata)
File "/home/giuser/miniconda3/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1350, in _do_run
run_metadata)
File "/home/giuser/miniconda3/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1370, in _do_call
raise type(e)(node_def, op, message)
tensorflow.python.framework.errors_impl.InvalidArgumentError: assertion failed: [Unable to decode bytes as JPEG, PNG, GIF, or BMP]
[[{{node decode_image/cond_jpeg/else/_1/cond_png/else/_1/cond_gif/else/_1/Assert/Assert}}]]
[[input_reader/IteratorGetNext]]
command used
python3 Stereo_Online_Adaptation.py -l ./image_list.csv -o ./output --weights ./pretrained_nets/MADNet/kitti/weights.ckpt --modelName MADNet --blockConfig "block_config/MadNet_full.json" --mode MAD --sampleMode PROBABILITY
Hi, thank you for sharing your code, it is really a great work!
I used your pretrained weights and it worked well on my own dataset after a few steps to finetune on. Then I wanted to reproduce the results from the very beginning, using the same synthetic dataset and KITTI dataset, but I found it lose 2% if I trained from random initialization.
So I am curious to know if you can tell me more about the training parameters for training on synthetic dataset and KITTI dataset separately?
Looking forward to your reply~
Hi, I have a question. Although finding a occlusion mask is a bit difficult in the unsupervised learning, but I think it masks sense as expressed in the picture below.

I am getting this error while running Stereo_Online_Adaptation.py. I would like to understand what is causing this to happen.
PS: My knowledge of tensorflow is limited.
Hi, I used live demo python code it's working good sometime and sometime it showing bad depth for same environment. it's continuously varying for same environment and also object are stationary.
any suggestion regarding to solve this problem.
because for calibration I am using linear regression. so that if I get 4.08 m i can map to 4m.but due to too much variation I unable to use the linear regression.
I also tried to train the model in mad mode then I tried but I am getting same variation.
basline : 0.110m
focal_length:792.8456
cmd : python3.7 Live_Adaptation_Demo.py --weights /home/giuser/MyWorkspace/Real-time-self-adaptive-deep-stereo/pretrained_nets/MADNet/synthetic/weights.ckpt
I used diy camera ,so I modified the grabber for my camera.
and also I am sending the rectified image.
Step 27: 0.09816490113735199
max : 340.11823 min: 24.168932
shape_disp: (320, 512, 1)
depth_max : 3.6084762 depth_min: 0.2564197
Step 28: 0.09606088697910309
max : 341.95813 min: 22.652584
shape_disp: (320, 512, 1)
depth_max : 3.850025 depth_min: 0.25504002
Step 29: 0.09736260026693344
max : 328.382 min: 29.71734
shape_disp: (320, 512, 1)
depth_max : 2.9347515 depth_min: 0.26558402
Step 30: 0.09974691271781921
max : 339.23883 min: 9.043276
shape_disp: (320, 512, 1)
depth_max : 9.643963 depth_min: 0.2570844
Step 31: 0.09843119233846664
max : 336.58228 min: 25.447483
shape_disp: (320, 512, 1)
depth_max : 3.4271765 depth_min: 0.2591135
Step 32: 0.09997092932462692
max : 317.42358 min: 24.566387
shape_disp: (320, 512, 1)
depth_max : 3.550095 depth_min: 0.2747528
Step 33: 0.09671687334775925
max : 327.99982 min: 24.208145
shape_disp: (320, 512, 1)
depth_max : 3.6026309 depth_min: 0.2658935
Step 34: 0.09664341807365417
max : 342.8994 min: 29.254269
shape_disp: (320, 512, 1)
depth_max : 2.9812064 depth_min: 0.25433993
Step 35: 0.09987105429172516
max : 329.02496 min: 21.65923
shape_disp: (320, 512, 1)
depth_max : 4.026598 depth_min: 0.26506504
Step 36: 0.09744423627853394
max : 342.30637 min: 22.168484
shape_disp: (320, 512, 1)
depth_max : 3.9340992 depth_min: 0.25478056
Step 37: 0.09748262912034988
max : 340.14005 min: 16.909391
shape_disp: (320, 512, 1)
depth_max : 5.157667 depth_min: 0.25640324
Step 38: 0.10002128779888153
max : 342.14606 min: 20.058685
shape_disp: (320, 512, 1)
depth_max : 4.3478928 depth_min: 0.25489995
Step 39: 0.09692289680242538
max : 347.4746 min: 24.163637
shape_disp: (320, 512, 1)
depth_max : 3.6092668 depth_min: 0.25099105
Step 40: 0.0976732149720192
max : 340.15384 min: 26.022049
shape_disp: (320, 512, 1)
depth_max : 3.3515043 depth_min: 0.25639284
Step 41: 0.09611301124095917
max : 332.27756 min: 31.099731
shape_disp: (320, 512, 1)
depth_max : 2.8043013 depth_min: 0.26247036
Step 42: 0.09700638800859451
max : 327.2958 min: 19.325695
shape_disp: (320, 512, 1)
depth_max : 4.5128007 depth_min: 0.26646543
Step 43: 0.09772888571023941
max : 334.38843 min: 23.648607
shape_disp: (320, 512, 1)
depth_max : 3.687871 depth_min: 0.26081347
Step 44: 0.10100344568490982
max : 335.46814 min: 14.885302
shape_disp: (320, 512, 1)
depth_max : 5.859002 depth_min: 0.25997406
Step 45: 0.09700295329093933
max : 341.30365 min: 25.402328
shape_disp: (320, 512, 1)
depth_max : 3.4332685 depth_min: 0.2555291
Step 46: 0.10043686628341675
max : 342.11014 min: 17.508682
shape_disp: (320, 512, 1)
depth_max : 4.9811296 depth_min: 0.2549267
Step 47: 0.09660971164703369
max : 342.87683 min: 23.009247
shape_disp: (320, 512, 1)
depth_max : 3.7903461 depth_min: 0.25435668
Step 48: 0.09604205936193466
max : 331.56754 min: 21.01507
shape_disp: (320, 512, 1)
depth_max : 4.1500225 depth_min: 0.26303244
Step 49: 0.10040544718503952
max : 336.10278 min: 9.170251
shape_disp: (320, 512, 1)
depth_max : 9.510428 depth_min: 0.25948316
Step 50: 0.09776761382818222
max : 335.4831 min: 19.53571
shape_disp: (320, 512, 1)
depth_max : 4.464287 depth_min: 0.25996247
Step 51: 0.09593342244625092
max : 322.93915 min: 25.418804
shape_disp: (320, 512, 1)
depth_max : 3.4310431 depth_min: 0.2700602
Step 52: 0.09986594319343567
max : 328.32758 min: 19.760132
shape_disp: (320, 512, 1)
depth_max : 4.4135847 depth_min: 0.26562804
Step 53: 0.09683622419834137
max : 328.09158 min: 22.77004
shape_disp: (320, 512, 1)
depth_max : 3.830165 depth_min: 0.2658191
Step 54: 0.09858302772045135
max : 343.56897 min: 22.25194
shape_disp: (320, 512, 1)
depth_max : 3.9193442 depth_min: 0.25384426
Step 55: 0.09800785779953003
max : 331.22284 min: 27.093431
shape_disp: (320, 512, 1)
depth_max : 3.2189727 depth_min: 0.26330617
Step 56: 0.09877340495586395
max : 342.5056 min: 22.059685
shape_disp: (320, 512, 1)
depth_max : 3.9535022 depth_min: 0.25463235
Step 57: 0.09741590917110443
max : 333.68042 min: 19.966022
shape_disp: (320, 512, 1)
depth_max : 4.3680716 depth_min: 0.26136687
Step 58: 0.09748111665248871
max : 336.98834 min: 20.162483
shape_disp: (320, 512, 1)
depth_max : 4.3255095 depth_min: 0.25880128
Step 59: 0.09806456416845322
max : 334.3465 min: 26.305145
shape_disp: (320, 512, 1)
depth_max : 3.3154354 depth_min: 0.2608462
Step 60: 0.09643004834651947
max : 332.56482 min: 24.784477
shape_disp: (320, 512, 1)
depth_max : 3.5188563 depth_min: 0.26224366
Step 61: 0.09784868359565735
max : 331.90765 min: 22.224346
shape_disp: (320, 512, 1)
depth_max : 3.9242105 depth_min: 0.26276287
Step 62: 0.10155725479125977
max : 340.5157 min: 14.950236
shape_disp: (320, 512, 1)
depth_max : 5.8335543 depth_min: 0.25612038
Step 63: 0.10066811740398407
max : 330.7791 min: 11.245592
shape_disp: (320, 512, 1)
depth_max : 7.7553062 depth_min: 0.26365936
Step 64: 0.09890112280845642
max : 332.29175 min: 21.645153
shape_disp: (320, 512, 1)
depth_max : 4.029217 depth_min: 0.26245916
Step 65: 0.09773185104131699
max : 339.99353 min: 27.148638
shape_disp: (320, 512, 1)
depth_max : 3.212427 depth_min: 0.25651374
Step 66: 0.09856224805116653
max : 345.18665 min: 27.773724
shape_disp: (320, 512, 1)
depth_max : 3.1401267 depth_min: 0.25265464
Step 67: 0.10059231519699097
max : 341.5364 min: 22.40047
shape_disp: (320, 512, 1)
depth_max : 3.8933563 depth_min: 0.25535494
Step 68: 0.10034771263599396
max : 334.68796 min: 13.772877
shape_disp: (320, 512, 1)
depth_max : 6.332229 depth_min: 0.26058006
Step 69: 0.09811978787183762
max : 327.84946 min: 26.435816
shape_disp: (320, 512, 1)
depth_max : 3.2990475 depth_min: 0.26601544
Step 70: 0.09709776937961578
max : 336.1238 min: 29.418407
shape_disp: (320, 512, 1)
depth_max : 2.964573 depth_min: 0.25946692
Step 71: 0.09988223016262054
max : 334.7636 min: 22.078262
shape_disp: (320, 512, 1)
depth_max : 3.9501755 depth_min: 0.26052117
Step 72: 0.09658467024564743
max : 329.68552 min: 26.856031
shape_disp: (320, 512, 1)
depth_max : 3.2474275 depth_min: 0.26453397
Step 73: 0.09921842068433762
max : 328.62988 min: 16.477346
shape_disp: (320, 512, 1)
depth_max : 5.292904 depth_min: 0.2653837
Step 74: 0.10068050026893616
max : 336.04236 min: 16.554989
shape_disp: (320, 512, 1)
depth_max : 5.26808 depth_min: 0.25952983
Step 75: 0.10103623569011688
max : 340.24564 min: 18.45589
shape_disp: (320, 512, 1)
depth_max : 4.725484 depth_min: 0.25632367
Step 76: 0.09824462980031967
max : 330.18896 min: 27.530098
shape_disp: (320, 512, 1)
depth_max : 3.167915 depth_min: 0.26413062
Step 77: 0.0993424579501152
max : 337.9097 min: 15.524535
shape_disp: (320, 512, 1)
depth_max : 5.6177535 depth_min: 0.25809562
Step 78: 0.09849735349416733
max : 333.8875 min: 26.08546
shape_disp: (320, 512, 1)
depth_max : 3.343357 depth_min: 0.26120478
Step 79: 0.10081659257411957
max : 331.29367 min: 16.75264
shape_disp: (320, 512, 1)
depth_max : 5.2059264 depth_min: 0.26324987
Step 80: 0.0999860018491745
max : 325.02478 min: 23.194695
shape_disp: (320, 512, 1)
depth_max : 3.7600415 depth_min: 0.26832727
Step 81: 0.09867776930332184
max : 332.46118 min: 29.91875
shape_disp: (320, 512, 1)
depth_max : 2.9149952 depth_min: 0.2623254
Step 82: 0.1008116751909256
max : 334.99695 min: 24.041918
shape_disp: (320, 512, 1)
depth_max : 3.6275399 depth_min: 0.26033974
Step 83: 0.0999288558959961
max : 331.01315 min: 20.677118
shape_disp: (320, 512, 1)
depth_max : 4.2178516 depth_min: 0.26347294
Step 84: 0.0983358770608902
max : 337.17862 min: 27.256302
shape_disp: (320, 512, 1)
depth_max : 3.1997375 depth_min: 0.25865522
Step 85: 0.10136320441961288
max : 333.1576 min: 15.041556
shape_disp: (320, 512, 1)
depth_max : 5.7981377 depth_min: 0.26177704
Step 86: 0.09810695797204971
max : 330.13412 min: 24.183144
shape_disp: (320, 512, 1)
depth_max : 3.6063554 depth_min: 0.2641745
Step 87: 0.09889024496078491
max : 336.52222 min: 21.0831
shape_disp: (320, 512, 1)
depth_max : 4.1366315 depth_min: 0.25915974
Step 88: 0.09982095658779144
max : 332.24713 min: 11.930489
shape_disp: (320, 512, 1)
depth_max : 7.310096 depth_min: 0.26249442
Step 89: 0.09888845682144165
max : 330.85913 min: 28.925856
shape_disp: (320, 512, 1)
depth_max : 3.0150537 depth_min: 0.2635956
Step 90: 0.10014571249485016
max : 332.61096 min: 16.913315
shape_disp: (320, 512, 1)
depth_max : 5.156471 depth_min: 0.26220727
Step 91: 0.10243596881628036
max : 339.77344 min: 24.393148
shape_disp: (320, 512, 1)
depth_max : 3.5753078 depth_min: 0.2566799
Step 92: 0.10243068635463715
max : 325.43582 min: 15.383979
shape_disp: (320, 512, 1)
depth_max : 5.6690803 depth_min: 0.26798835
Step 93: 0.10007596760988235
max : 332.2273 min: 25.080872
shape_disp: (320, 512, 1)
depth_max : 3.477272 depth_min: 0.2625101
Step 94: 0.09953679144382477
max : 331.67255 min: 23.796257
shape_disp: (320, 512, 1)
depth_max : 3.6649888 depth_min: 0.26294914
Step 95: 0.09818486869335175
max : 329.05035 min: 29.062828
shape_disp: (320, 512, 1)
depth_max : 3.000844 depth_min: 0.26504457
Step 96: 0.10310391336679459
max : 325.41806 min: 13.885269
shape_disp: (320, 512, 1)
depth_max : 6.280974 depth_min: 0.268003
Step 97: 0.09774727374315262
max : 325.9686 min: 26.708965
shape_disp: (320, 512, 1)
depth_max : 3.2653086 depth_min: 0.26755035
Step 98: 0.10923965275287628
max : 325.73315 min: 23.08259
shape_disp: (320, 512, 1)
depth_max : 3.7783027 depth_min: 0.26774374
Step 99: 0.10516759008169174
max : 345.40063 min: 25.015917
shape_disp: (320, 512, 1)
depth_max : 3.486301 depth_min: 0.25249812
any suggestion
thanks
Thanks for this great work.
I have trained the network on the simulated data and also later on I used the adaptive mode to get the depth for my real stereo images (clean images). What I am interested is to save the adapted weights and then use them later or in a nonadaptive set up, because my stereo images are noisy so I cannot not use the adaptive mode all the time. Is that possible?
Regards,
Jacob
thanks for this great work.
I want to do the following work on this work.
(1) supervised training on the kitti datasets
(2) based on 1, use our custom image pairs to do the unsupervised training, thus improving the generalization.
could you give me some advise? thanks very much.
thanks for your code!
here is my question, when i first use Stereo_Online_Adaptation.py, i have set the list, ouuput as follows:
parser.add_argument("-l","--list", help='path to the list file with frames to be processed', default='D:\zed\python\depth\Real-time self-adaptive deep stereo\Real-time-self-adaptive-deep-stereo-master\ex_list.csv',required=True)
parser.add_argument("-o","--output", help="path to the output folder where the results will be saved", default=r'D:\zed\python\depth\Real-time self-adaptive deep stereo\Real-time-self-adaptive-deep-stereo-master\output/', required=True)
parser.add_argument("--weights",help="path to the initial weights for the disparity estimation network",default=r'D:\zed\python\depth\Real-time self-adaptive deep stereo\MADNet\kitti\weights.ckpt',required=True)
parser.add_argument("--modelName", help="name of the stereo model to be used", default="MADNet", choices=Nets.STEREO_FACTORY.keys())
parser.add_argument("--numBlocks", help="number of CNN portions to train at each iteration",type=int,default=1)
parser.add_argument("--lr", help="value for learning rate",default=0.0001, type=float)
parser.add_argument("--blockConfig",help="path to the block_config json file",default=r'D:\zed\python\depth\Real-time self-adaptive deep stereo\Real-time-self-adaptive-deep-stereo-master\block_config/MadNet_full.json',required=True)
but there is a problem:Stereo_Online_Adaptation.py: error: the following arguments are required: -l/--list, -o/--output, --weights, --blockConfig
An exception has occurred, use %tb to see the full traceback.
how can do for it?
Hi there,
Thanks again for this work and making it publicly available.
I have a question about the adaptation mode.
I have stereo endoscope images without the ground truth. So I want to use them for the adaption mode. To train the network, using Blender, I created an environment to produce the stereo images and their corresponding depth maps. I used them for training your network (MADNet).
I noticed that in the Full adaption mode, right after training, if I feed the Blender stereo images (which were used for the training) to your network, then the resulting depth map is looking good. But after a few hundreds of iteration in the Full mode, the depth maps start to look flat and the variance becomes near zero. Theoretically if I use the same images for the adaption that I used the for training, then the network should perform the same if not better. But the Full mode makes the network fail. I attached two point clouds with 90degree angle to be able to see the drop in the variance of the depth map after adaption mode on 100 images.
Left image is test result right after training the network before running the adaption mode and right image is the same images after a 100 images (from the training) used for Full mode adaption.

The interesting point is that if I use my own stereo endoscope images for the Full mode adaptation, then after a few hundred iterations the result start to look good. So I am not sure pretraining the network using the Blender images make any improvement in depth estimation compared with if I just had used the unsupervised approach such as Godard 2017.
May i ask you that how did you connect the left and right feature to get the cost volume? In which dimension specifically? And i saw your code didn't use 3dCnn , is that correct?
I would appreciate it if you could answer what confusing me.Thanks.
请问作者,这个是立体匹配吗?
In function get_reprojection_loss, there is
disparity_scale_factor = tf.cast(tf.shape(current_disp)[2],tf.float32)/tf.cast(tf.shape(left)[2],tf.float32)
However, in function get_supervised_loss, there is
disparity_scale_factor = tf.cast(tf.shape(left)[2],tf.float32)/tf.cast(tf.shape(current_disp)[2],tf.float32)
Shouldn't these two be the same? I think the second one maybe right. Thanks for any help!
Thanks for providing the Live_Adaptation_Demo.py and luckily I have a first generation ZED camera, not the ZED_mini. After some simple modifications of the grabber.py, I can run the demo online with ZED images (720P@30fps), but the disparity looks not good and is very unstable. Here are the steps:
Thanks for sharing the code of your interesting work! I would like to run the pretrained MADNet model within my C++ project. I can successfully load the checkpoint of the provided pretrained model. However, to run the inference session using the tensorflow C++ API I need to know the exact names of the input and the output tensors.
In the code I found "left_img" and "right_img" to be the placeholders for the input images and the last layer added to the disparities is named "rescaled_prediction". However, using those names as input/output tensor names results in errors indicating I'm not using the correct tensor names.
May I ask what the correct tensor names are for an inference from raw-images to the highest quality disparity?
Thanks a lot!
Great work!
could you share your the disparity converting script on kitti?
Thanks a lot!
[email protected]
Hi, thanks for sharing the code.
In my experiments on Middlebury Motorcycle, I could not reproduce the reported result even when using full adaptation.
To force invalid disparity to zero, I addded the following line to Stereo_Online_Adaptation.py.
# line 46
gt_image_batch = tf.where(tf.is_finite(gt_image_batch), gt_image_batch, tf.zeros_like(gt_image_batch))| Adaptation | D1-all [%] | EPE |
|---|---|---|
| MAD (lr=1e-4) | 81.62 | 26.47 |
| MAD (lr=1e-5) | 42.79 | 13.79 |
| FULL (lr=1e-4) | 85.39 | 25.60 |
| FULL (lr=1e-5) | 41.91 | 13.95 |
Tab 1. Results on Middlebury Motorcycle using the model trained on synthetic dataset (you provided).


Fig 1. EPE curve on Middlebury Motorcycle.
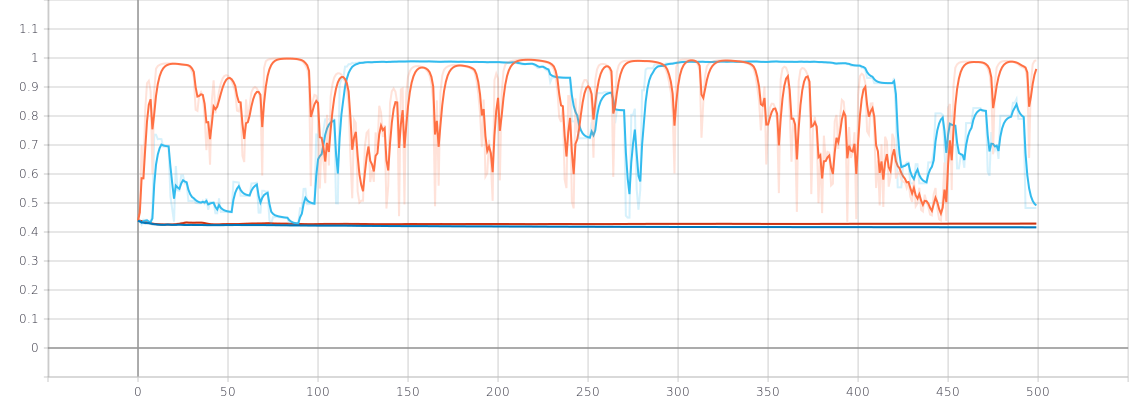
Fig 2. D1-all curve on Middlebury Motorcycle.
Should I modify the other parameters? Thank you.
I just want to give two pictures to predict depth without groundtruth, how should I run?
I'm trying to train MADNet from scratch so that I can compare it to an implementation that I made in Pytorch. Is there a training script that replicates the parameters used in your paper?
I have a few specific questions as well:
--lossType mean_l1 or --lossType sum_l1? The paper seems to indicate that it should be sum_l1, but this results in a huge loss value and I'm guessing mean_l1 is correct.--lossWeights 0.005 0.01 0.02 0.08 0.32 as stated in the paper? These cause an exception to be thrown, since there are 6 predicted disparity maps. If I add another weight to have 6, then I hit the exception:if args.lossWeights is not None and len(args.lossWeights)==len(predictions):
raise ValueError('Wrong number of loss weights provide, should provide {}'.format(len(predictions)))From the paper I read that domain shift is a remarkable work to adapt the model during online running. So is it possible to feed the network with raw stereo image pairs without calibration?
My question is, if the adapting ability is strong enough, even we feed raw image pairs, could the network be able to continuously fine-tune the disparity to a good state?
Right now the requirements.txt file contains
tensorflow-gpu
matplotlib
opencv-python
without any versions attached, however the code clearly does not work with tensorflow 2.0; and also numpy 1.17 complains about some code parts becoming deprecated.
It would be nice to specify the versions of those dependencies.
Hello, I have some questions about your residual refinement network.Can you tell me why you choose to concat disparity and left feature as input?Actually, it a little diffcult for me to understand why you seclect to concat two things which represent totally different physical meanings.
And it's really rare to directly do 2dconv to disparity map,maybe you can give me a straightforward answer why it can improve the accuracy of prediction.
Thanks.
Thanks again for this work.
My first question is that is there any parameter that I could adjust to be able to see the objects which are very close to the camera? In SGM you can change the Maximum Disparity to be able see the close objects.
I noticed the objects which are illuminated close to saturation tend to have a wrong depth estimation. This happens even when the object is still not saturated but is close to saturation. Below shows two images from the same spherical object with two illumination conditions. The upper row where the object is close to saturation, the depth appears flat, whereas the lower row with no saturation the depth appears correct. Is there any way to deal with this besides having the illumination fixed?

stereo_net = Nets.get_stereo_net(args.modelName, net_args)
the above code runs good, but when I start to train on scene_flow, got the following error.
I have done some debug methods:
(1) check the scene_flow input, but it's ok
(2) check the network, but I didn't find some errors
Could you help to find the bug, thanks very much. If more files needed, I will upload them.
Traceback (most recent call last):
File "/root/anaconda3/envs/MADNet/lib/python3.7/site-packages/tensorflow/python/client/session.py", line 1356, in _do_call
return fn(*args)
File "/root/anaconda3/envs/MADNet/lib/python3.7/site-packages/tensorflow/python/client/session.py", line 1341, in _run_fn
options, feed_dict, fetch_list, target_list, run_metadata)
File "/root/anaconda3/envs/MADNet/lib/python3.7/site-packages/tensorflow/python/client/session.py", line 1429, in _call_tf_sessionrun
run_metadata)
tensorflow.python.framework.errors_impl.InvalidArgumentError: 2 root error(s) found.
(0) Invalid argument: input depth must be evenly divisible by filter depth: 4 vs 3
[[{{node model/CNN_2/conv0/conv0_1/Conv2D}}]]
(1) Invalid argument: input depth must be evenly divisible by filter depth: 4 vs 3
[[{{node model/CNN_2/conv0/conv0_1/Conv2D}}]]
[[validation_error/truediv_1/_23]]
0 successful operations.
0 derived errors ignored.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "Train.py", line 191, in
main(args)
File "Train.py", line 140, in main
fetches = sess.run(tf_fetches,options=run_options)
File "/root/anaconda3/envs/MADNet/lib/python3.7/site-packages/tensorflow/python/client/session.py", line 950, in run
run_metadata_ptr)
File "/root/anaconda3/envs/MADNet/lib/python3.7/site-packages/tensorflow/python/client/session.py", line 1173, in _run
feed_dict_tensor, options, run_metadata)
File "/root/anaconda3/envs/MADNet/lib/python3.7/site-packages/tensorflow/python/client/session.py", line 1350, in _do_run
run_metadata)
File "/root/anaconda3/envs/MADNet/lib/python3.7/site-packages/tensorflow/python/client/session.py", line 1370, in _do_call
raise type(e)(node_def, op, message)
tensorflow.python.framework.errors_impl.InvalidArgumentError: 2 root error(s) found.
(0) Invalid argument: input depth must be evenly divisible by filter depth: 4 vs 3
[[node model/CNN_2/conv0/conv0_1/Conv2D (defined at /host/nfs/hs/code/research/Real-time-self-adaptive-deep-stereo/Nets/sharedLayers.py:59) ]]
(1) Invalid argument: input depth must be evenly divisible by filter depth: 4 vs 3
[[node model/CNN_2/conv0/conv0_1/Conv2D (defined at /host/nfs/hs/code/research/Real-time-self-adaptive-deep-stereo/Nets/sharedLayers.py:59) ]]
[[validation_error/truediv_1/_23]]
0 successful operations.
0 derived errors ignored.
Errors may have originated from an input operation.
Input Source operations connected to node model/CNN_2/conv0/conv0_1/Conv2D:
model/MirrorPad_2 (defined at /host/nfs/hs/code/research/Real-time-self-adaptive-deep-stereo/Data_utils/preprocessing.py:28)
model/CNN/conv0/conv0_1/weights/read (defined at /host/nfs/hs/code/research/Real-time-self-adaptive-deep-stereo/Nets/sharedLayers.py:57)
Input Source operations connected to node model/CNN_2/conv0/conv0_1/Conv2D:
model/MirrorPad_2 (defined at /host/nfs/hs/code/research/Real-time-self-adaptive-deep-stereo/Data_utils/preprocessing.py:28)
model/CNN/conv0/conv0_1/weights/read (defined at /host/nfs/hs/code/research/Real-time-self-adaptive-deep-stereo/Nets/sharedLayers.py:57)
Original stack trace for 'model/CNN_2/conv0/conv0_1/Conv2D':
File "Train.py", line 191, in
main(args)
File "Train.py", line 71, in main
val_stereo_net = Nets.get_stereo_net(args.modelName, net_args)
File "/host/nfs/hs/code/research/Real-time-self-adaptive-deep-stereo/Nets/init.py", line 15, in get_stereo_net
return STEREO_FACTORYname
File "/host/nfs/hs/code/research/Real-time-self-adaptive-deep-stereo/Nets/PSMNet.py", line 22, in init
super(PSMNet, self).init(**kwargs)
File "/host/nfs/hs/code/research/Real-time-self-adaptive-deep-stereo/Nets/Stereo_net.py", line 44, in init
self._build_network(args)
File "/host/nfs/hs/code/research/Real-time-self-adaptive-deep-stereo/Nets/PSMNet.py", line 54, in _build_network
conv4_left = self.CNN(self._left_input_batch)
File "/host/nfs/hs/code/research/Real-time-self-adaptive-deep-stereo/Nets/PSMNet.py", line 71, in CNN
activation=tf.nn.leaky_relu, batch_norm=True, apply_relu=True,strides=2, name='conv0_1',reuse=reuse))
File "/host/nfs/hs/code/research/Real-time-self-adaptive-deep-stereo/Nets/sharedLayers.py", line 59, in conv2d
x = tf.nn.conv2d(x, W, strides=[1, strides, strides, 1], padding=padding,dilations=dilation_rate)
File "/root/anaconda3/envs/MADNet/lib/python3.7/site-packages/tensorflow/python/ops/nn_ops.py", line 1953, in conv2d
name=name)
File "/root/anaconda3/envs/MADNet/lib/python3.7/site-packages/tensorflow/python/ops/gen_nn_ops.py", line 1071, in conv2d
data_format=data_format, dilations=dilations, name=name)
File "/root/anaconda3/envs/MADNet/lib/python3.7/site-packages/tensorflow/python/framework/op_def_library.py", line 788, in _apply_op_helper
op_def=op_def)
File "/root/anaconda3/envs/MADNet/lib/python3.7/site-packages/tensorflow/python/util/deprecation.py", line 507, in new_func
return func(*args, **kwargs)
File "/root/anaconda3/envs/MADNet/lib/python3.7/site-packages/tensorflow/python/framework/ops.py", line 3616, in create_op
op_def=op_def)
File "/root/anaconda3/envs/MADNet/lib/python3.7/site-packages/tensorflow/python/framework/ops.py", line 2005, in init
self._traceback = tf_stack.extract_stack()
Hello great work @AlessioTonioni and team!
I am trying to use the work for training on custom data which has dense depth maps as shown below:

These are not similar to that of kitti wherein the ground truth depth is obtained from lidar point cloud and is sparse.
So can I use the depth map as it is for supervised training or do I need to make some changes?
Also if I want to use unsupervised training, I need to change the following line :
Hi there,
Thanks for the great work. Help please!
I am trying to train it on my won simulated endoscopic stereo data.
I call the Train.py using this args:
python3 Train.py
--trainingSet ${TrainingSet}
--validationSet ${TrainingSet}
-o ${OUTPUT}
--modelName ${MODELNAME}
--imageShape 256 256
Traceback (most recent call last):
File "Train.py", line 188, in
main(args)
File "Train.py", line 99, in main
assert(len(args.lossWeights)==len(predictions))
TypeError: object of type 'NoneType' has no len()
Thanks
Jacob
I did not find the ground truth images on Kitti website.
Hi, thanks for the nice work! I just wonder how could I fine tune it through my own training set without groundtruth since it is an unsupervised learning in the paper.thanks
Hello, now I want to use your model to run the video captured by the camera, but I don't know how to do it, can you help me
how can we convert the disparsity image to real world depth into any camera and environment.
one more question, is getting out image is disparsity image or depth image.
First, thanks for sharing the codes. I tried to train the network from the scratch, but I encountered some questions. Hope the authors could help me out.
Where to download the training dataset?
Based on "example_list.csv", I assume KITTI raw dataset was used to train the network. However, I did not find "proj_disp/groundtruth" folder in the data. Do you create them yourselves?
If I train with other dataset, do I need to manually divide the ground truth by 20?
In #4 (comment), it said the ground truth is scaled by -20. Does that mean I have to do the same thing for the other dataset manually as well?
I am confused by the the additional value scaling for the disparity. Would you mind explaining it a little bit more?
For example, why we need "/ scale[5]", instead of "x 2", in the end of
What is the logic for the valid map in loss computation?
tf.logical_or(tf.equal(targets, 0), tf.greater(target, max_disp)) instead for the tf.where condition? Btw, when reading the disparity map, I think it might be needed to convert invalid value into 0, like INF in Middlebury dataset. Otherwise, the valid map mechanism might not work.
Please kindly let me know which question above are not clear enough. I will try to elaborate more. Thanks for your help.
Hi, I wanna ask a question about DispNet. Have you test the KITTI2015 pretrained model, have it achieved the performance illustrated in the original paper in 2016CVPR, and what's your training strategy during the both syn and kitti period. Thank you!
this input image


output image

output image is cropped
command
python3 Stereo_Online_Adaptation_edit.py -l ./image_list.csv -o ./output --weights ./pretrained_nets/MADNet/kitti/weights.ckpt --modelName MADNet --blockConfig "block_config/MadNet_full.json" --mode FULL --sampleMode PROBABILITY --logDispStep 1
I'm re-implementing MadNet in Pytorch, and having trouble understanding the scaling you use for disparity predictions. In particular, in make_disp:
def _make_disp(self,op,scale):
op = tf.image.resize_images(tf.nn.relu(op * -20), ...It seems that by design, each disparity module is outputting disparity in units of 1/20th of a pixel at full resolution, which you then rescale to pixels by multiplying by 20. I'm confused why the negative sign is there - I'm assuming it has to do with converting disparity from left to right or vice-versa?
If that's true, training with the nn.relu should force the network to learn negative disparities inside of op. Do you interpret the real_disp_vi outputs in your code as left or right disparity images?
Thanks for sharing your code, I'm looking forward to using the network!
I test the models (both DispNet and MADNet) on Flyingthing3D testset using the pretrained synthetic weights. I got poor performance:
DispNet: EPE=5.39, bad3=0.2255
MADNet: EPE=3.59, bad3=0.0833
According to DispNet paper, EPE of DispNet and DispNetCorr1D are 2.02 and 1.68 respectively.
Does anyone try this? What's your results? It won't take long too run the test since the testset is small.
Not sure whether it's because there are some bugs in my testing code or version differences in software packages or somehing else.
Hi there,
I have endoscopic stereo data with ground truth. How can I train them?
I can see the procedure for adaption of the pretrained weights but I cannot see anything about training the untrained weights.
Cheers,
jacob
Thanks to your good work, but I failed to reproduce your results on 2011_09_30_drive_0028_sync sequence. Here is the command that I used with the synthetic pretrained MADNet provided by you:
python Stereo_Online_Adaptation.py \
-l ${LIST of 2011_09_30_drive_0028_sync sequence} \
-o ${OUTPUT} \
--weights ${WEIGHTS_FOLDER}/MADNet/synthetic/weights.ckpt \
--modelName MADNet \
--blockConfig config/MadNet_full.json \
--mode ${MODE} \
--sampleMode PROBABILITY \
--logDispStep 1
According to your video, on frame 1998 (corresponding to the actual frame 0000002003.png),
When ${MODE} = MAD, then EPE = 0.30
When ${MODE} = FULL, then EPE = 0.16
However, here are what I get
When setting ${MODE} = MAD, then EPE = 4.29
When setting ${MODE} = FULL, then EPE = 2.62
which are unsatisfactory. (I do did center cropping on the ground truth before comparison. BTW, I used the following code to convert the depth on 2011_09_30 to disparity)
baseline = 0.54
focal_len = 7.070912e+02
disparity = focal_len * baseline / depth * 256
disparity[depth==0] = 0
disparity = disparity.astype('uint16')
Here are some printed intermediate results when I setting ${MODE}=FULL,
Step: 0 bad3:0.54 EPE:4.62 SSIM:0.14 f/b time:0.085308 Missing time:0:07:20.783953
Step: 100 bad3:0.46 EPE:4.11 SSIM:0.11 f/b time:0.083690 Missing time:0:07:04.058810
Step: 200 bad3:0.48 EPE:3.74 SSIM:0.14 f/b time:0.085709 Missing time:0:07:05.718425
Step: 300 bad3:0.30 EPE:2.82 SSIM:0.11 f/b time:0.078649 Missing time:0:06:22.782704
Step: 400 bad3:0.30 EPE:2.46 SSIM:0.11 f/b time:0.076860 Missing time:0:06:06.390148
Step: 500 bad3:0.28 EPE:2.62 SSIM:0.11 f/b time:0.077608 Missing time:0:06:02.194405
Step: 600 bad3:0.47 EPE:5.23 SSIM:0.16 f/b time:0.078980 Missing time:0:06:00.702607
Step: 700 bad3:0.25 EPE:2.23 SSIM:0.17 f/b time:0.079465 Missing time:0:05:54.969689
Step: 800 bad3:0.41 EPE:4.13 SSIM:0.09 f/b time:0.078717 Missing time:0:05:43.755819
Step: 900 bad3:0.31 EPE:2.69 SSIM:0.10 f/b time:0.077609 Missing time:0:05:31.156342
Step:1000 bad3:0.25 EPE:2.25 SSIM:0.17 f/b time:0.078229 Missing time:0:05:25.981169
Step:1100 bad3:0.14 EPE:1.65 SSIM:0.12 f/b time:0.078017 Missing time:0:05:17.293466
Step:1200 bad3:0.28 EPE:2.58 SSIM:0.13 f/b time:0.077899 Missing time:0:05:09.024494
Step:1300 bad3:0.22 EPE:2.09 SSIM:0.13 f/b time:0.080689 Missing time:0:05:12.023805
Step:1400 bad3:0.21 EPE:2.05 SSIM:0.12 f/b time:0.083007 Missing time:0:05:12.688912
Step:1500 bad3:0.14 EPE:1.70 SSIM:0.14 f/b time:0.083191 Missing time:0:05:05.061603
Step:1600 bad3:0.21 EPE:2.20 SSIM:0.11 f/b time:0.081222 Missing time:0:04:49.718330
Step:1700 bad3:0.38 EPE:3.53 SSIM:0.13 f/b time:0.082633 Missing time:0:04:46.489179
Step:1800 bad3:0.14 EPE:1.63 SSIM:0.10 f/b time:0.079664 Missing time:0:04:28.229809
Step:1900 bad3:0.35 EPE:2.52 SSIM:0.13 f/b time:0.079072 Missing time:0:04:18.326887
Step:2000 bad3:0.27 EPE:2.33 SSIM:0.09 f/b time:0.080154 Missing time:0:04:13.848781
Could you please advise?
such as PSMNet, GANet?
ubuntu 16.04 tensorflow 1.12.0 numpy 1.16.4
when i 'make ' in path 'Nets/Native/'
the error is following:
nvcc -std=c++11 -c -o shift_corr.cu.o shift_corr.cu.cc -I/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include -D_GLIBCXX_USE_CXX11_ABI=0 -x cu -Xcompiler -fPIC --expt-relaxed-constexpr -D GOOGLE_CUDA=1
In file included from /home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/../../../Eigen/Core:269:0,
from /home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/Tensor:14,
from /home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/third_party/eigen3/unsupported/Eigen/CXX11/Tensor:1,
from shift_corr.cu.cc:4:
/usr/local/cuda-10.0/bin/..//include/host_defines.h:54:2: warning: #warning "host_defines.h is an internal header file and must not be used directly. This file will be removed in a future CUDA release. Please use cuda_runtime_api.h or cuda_runtime.h instead." [-Wcpp]
#warning "host_defines.h is an internal header file and must not be used direct
^
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/absl/strings/string_view.h(496): error: constexpr function return is non-constant
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/google/protobuf/arena_impl.h(55): warning: integer conversion resulted in a change of sign
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/google/protobuf/arena_impl.h(309): warning: integer conversion resulted in a change of sign
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/google/protobuf/arena_impl.h(310): warning: integer conversion resulted in a change of sign
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/../src/SpecialFunctions/SpecialFunctionsImpl.h(651): warning: missing return statement at end of non-void function "Eigen::internal::igammac_cf_impl<Scalar, mode>::run [with Scalar=float, mode=Eigen::internal::VALUE]"
detected during:
instantiation of "Scalar Eigen::internal::igammac_cf_impl<Scalar, mode>::run(Scalar, Scalar) [with Scalar=float, mode=Eigen::internal::VALUE]"
(855): here
instantiation of "Scalar Eigen::internal::igamma_generic_impl<Scalar, mode>::run(Scalar, Scalar) [with Scalar=float, mode=Eigen::internal::VALUE]"
(2096): here
instantiation of "Eigen::internal::igamma_retval<Eigen::internal::global_math_functions_filtering_base<Scalar, void>::type>::type Eigen::numext::igamma(const Scalar &, const Scalar &) [with Scalar=float]"
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/../src/SpecialFunctions/SpecialFunctionsHalf.h(34): here
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/../src/SpecialFunctions/SpecialFunctionsImpl.h(712): warning: missing return statement at end of non-void function "Eigen::internal::igamma_series_impl<Scalar, mode>::run [with Scalar=float, mode=Eigen::internal::VALUE]"
detected during:
instantiation of "Scalar Eigen::internal::igamma_series_impl<Scalar, mode>::run(Scalar, Scalar) [with Scalar=float, mode=Eigen::internal::VALUE]"
(863): here
instantiation of "Scalar Eigen::internal::igamma_generic_impl<Scalar, mode>::run(Scalar, Scalar) [with Scalar=float, mode=Eigen::internal::VALUE]"
(2096): here
instantiation of "Eigen::internal::igamma_retval<Eigen::internal::global_math_functions_filtering_base<Scalar, void>::type>::type Eigen::numext::igamma(const Scalar &, const Scalar &) [with Scalar=float]"
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/../src/SpecialFunctions/SpecialFunctionsHalf.h(34): here
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/../src/SpecialFunctions/SpecialFunctionsImpl.h(651): warning: missing return statement at end of non-void function "Eigen::internal::igammac_cf_impl<Scalar, mode>::run [with Scalar=float, mode=Eigen::internal::DERIVATIVE]"
detected during:
instantiation of "Scalar Eigen::internal::igammac_cf_impl<Scalar, mode>::run(Scalar, Scalar) [with Scalar=float, mode=Eigen::internal::DERIVATIVE]"
(855): here
instantiation of "Scalar Eigen::internal::igamma_generic_impl<Scalar, mode>::run(Scalar, Scalar) [with Scalar=float, mode=Eigen::internal::DERIVATIVE]"
(2102): here
instantiation of "Eigen::internal::igamma_der_a_retval<Eigen::internal::global_math_functions_filtering_base<Scalar, void>::type>::type Eigen::numext::igamma_der_a(const Scalar &, const Scalar &) [with Scalar=float]"
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/../src/SpecialFunctions/SpecialFunctionsHalf.h(38): here
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/../src/SpecialFunctions/SpecialFunctionsImpl.h(712): warning: missing return statement at end of non-void function "Eigen::internal::igamma_series_impl<Scalar, mode>::run [with Scalar=float, mode=Eigen::internal::DERIVATIVE]"
detected during:
instantiation of "Scalar Eigen::internal::igamma_series_impl<Scalar, mode>::run(Scalar, Scalar) [with Scalar=float, mode=Eigen::internal::DERIVATIVE]"
(863): here
instantiation of "Scalar Eigen::internal::igamma_generic_impl<Scalar, mode>::run(Scalar, Scalar) [with Scalar=float, mode=Eigen::internal::DERIVATIVE]"
(2102): here
instantiation of "Eigen::internal::igamma_der_a_retval<Eigen::internal::global_math_functions_filtering_base<Scalar, void>::type>::type Eigen::numext::igamma_der_a(const Scalar &, const Scalar &) [with Scalar=float]"
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/../src/SpecialFunctions/SpecialFunctionsHalf.h(38): here
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/../src/SpecialFunctions/SpecialFunctionsImpl.h(651): warning: missing return statement at end of non-void function "Eigen::internal::igammac_cf_impl<Scalar, mode>::run [with Scalar=float, mode=Eigen::internal::SAMPLE_DERIVATIVE]"
detected during:
instantiation of "Scalar Eigen::internal::igammac_cf_impl<Scalar, mode>::run(Scalar, Scalar) [with Scalar=float, mode=Eigen::internal::SAMPLE_DERIVATIVE]"
(855): here
instantiation of "Scalar Eigen::internal::igamma_generic_impl<Scalar, mode>::run(Scalar, Scalar) [with Scalar=float, mode=Eigen::internal::SAMPLE_DERIVATIVE]"
(2108): here
instantiation of "Eigen::internal::gamma_sample_der_alpha_retval<Eigen::internal::global_math_functions_filtering_base<Scalar, void>::type>::type Eigen::numext::gamma_sample_der_alpha(const Scalar &, const Scalar &) [with Scalar=float]"
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/../src/SpecialFunctions/SpecialFunctionsHalf.h(42): here
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/../src/SpecialFunctions/SpecialFunctionsImpl.h(712): warning: missing return statement at end of non-void function "Eigen::internal::igamma_series_impl<Scalar, mode>::run [with Scalar=float, mode=Eigen::internal::SAMPLE_DERIVATIVE]"
detected during:
instantiation of "Scalar Eigen::internal::igamma_series_impl<Scalar, mode>::run(Scalar, Scalar) [with Scalar=float, mode=Eigen::internal::SAMPLE_DERIVATIVE]"
(863): here
instantiation of "Scalar Eigen::internal::igamma_generic_impl<Scalar, mode>::run(Scalar, Scalar) [with Scalar=float, mode=Eigen::internal::SAMPLE_DERIVATIVE]"
(2108): here
instantiation of "Eigen::internal::gamma_sample_der_alpha_retval<Eigen::internal::global_math_functions_filtering_base<Scalar, void>::type>::type Eigen::numext::gamma_sample_der_alpha(const Scalar &, const Scalar &) [with Scalar=float]"
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/../src/SpecialFunctions/SpecialFunctionsHalf.h(42): here
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/../src/SpecialFunctions/SpecialFunctionsImpl.h(651): warning: missing return statement at end of non-void function "Eigen::internal::igammac_cf_impl<Scalar, mode>::run [with Scalar=double, mode=Eigen::internal::VALUE]"
detected during:
instantiation of "Scalar Eigen::internal::igammac_cf_impl<Scalar, mode>::run(Scalar, Scalar) [with Scalar=double, mode=Eigen::internal::VALUE]"
(855): here
instantiation of "Scalar Eigen::internal::igamma_generic_impl<Scalar, mode>::run(Scalar, Scalar) [with Scalar=double, mode=Eigen::internal::VALUE]"
(2096): here
instantiation of "Eigen::internal::igamma_retval<Eigen::internal::global_math_functions_filtering_base<Scalar, void>::type>::type Eigen::numext::igamma(const Scalar &, const Scalar &) [with Scalar=double]"
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/../src/SpecialFunctions/arch/CUDA/CudaSpecialFunctions.h(120): here
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/../src/SpecialFunctions/SpecialFunctionsImpl.h(712): warning: missing return statement at end of non-void function "Eigen::internal::igamma_series_impl<Scalar, mode>::run [with Scalar=double, mode=Eigen::internal::VALUE]"
detected during:
instantiation of "Scalar Eigen::internal::igamma_series_impl<Scalar, mode>::run(Scalar, Scalar) [with Scalar=double, mode=Eigen::internal::VALUE]"
(863): here
instantiation of "Scalar Eigen::internal::igamma_generic_impl<Scalar, mode>::run(Scalar, Scalar) [with Scalar=double, mode=Eigen::internal::VALUE]"
(2096): here
instantiation of "Eigen::internal::igamma_retval<Eigen::internal::global_math_functions_filtering_base<Scalar, void>::type>::type Eigen::numext::igamma(const Scalar &, const Scalar &) [with Scalar=double]"
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/../src/SpecialFunctions/arch/CUDA/CudaSpecialFunctions.h(120): here
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/../src/SpecialFunctions/SpecialFunctionsImpl.h(651): warning: missing return statement at end of non-void function "Eigen::internal::igammac_cf_impl<Scalar, mode>::run [with Scalar=double, mode=Eigen::internal::DERIVATIVE]"
detected during:
instantiation of "Scalar Eigen::internal::igammac_cf_impl<Scalar, mode>::run(Scalar, Scalar) [with Scalar=double, mode=Eigen::internal::DERIVATIVE]"
(855): here
instantiation of "Scalar Eigen::internal::igamma_generic_impl<Scalar, mode>::run(Scalar, Scalar) [with Scalar=double, mode=Eigen::internal::DERIVATIVE]"
(2102): here
instantiation of "Eigen::internal::igamma_der_a_retval<Eigen::internal::global_math_functions_filtering_base<Scalar, void>::type>::type Eigen::numext::igamma_der_a(const Scalar &, const Scalar &) [with Scalar=double]"
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/../src/SpecialFunctions/arch/CUDA/CudaSpecialFunctions.h(135): here
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/../src/SpecialFunctions/SpecialFunctionsImpl.h(712): warning: missing return statement at end of non-void function "Eigen::internal::igamma_series_impl<Scalar, mode>::run [with Scalar=double, mode=Eigen::internal::DERIVATIVE]"
detected during:
instantiation of "Scalar Eigen::internal::igamma_series_impl<Scalar, mode>::run(Scalar, Scalar) [with Scalar=double, mode=Eigen::internal::DERIVATIVE]"
(863): here
instantiation of "Scalar Eigen::internal::igamma_generic_impl<Scalar, mode>::run(Scalar, Scalar) [with Scalar=double, mode=Eigen::internal::DERIVATIVE]"
(2102): here
instantiation of "Eigen::internal::igamma_der_a_retval<Eigen::internal::global_math_functions_filtering_base<Scalar, void>::type>::type Eigen::numext::igamma_der_a(const Scalar &, const Scalar &) [with Scalar=double]"
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/../src/SpecialFunctions/arch/CUDA/CudaSpecialFunctions.h(135): here
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/../src/SpecialFunctions/SpecialFunctionsImpl.h(651): warning: missing return statement at end of non-void function "Eigen::internal::igammac_cf_impl<Scalar, mode>::run [with Scalar=double, mode=Eigen::internal::SAMPLE_DERIVATIVE]"
detected during:
instantiation of "Scalar Eigen::internal::igammac_cf_impl<Scalar, mode>::run(Scalar, Scalar) [with Scalar=double, mode=Eigen::internal::SAMPLE_DERIVATIVE]"
(855): here
instantiation of "Scalar Eigen::internal::igamma_generic_impl<Scalar, mode>::run(Scalar, Scalar) [with Scalar=double, mode=Eigen::internal::SAMPLE_DERIVATIVE]"
(2108): here
instantiation of "Eigen::internal::gamma_sample_der_alpha_retval<Eigen::internal::global_math_functions_filtering_base<Scalar, void>::type>::type Eigen::numext::gamma_sample_der_alpha(const Scalar &, const Scalar &) [with Scalar=double]"
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/../src/SpecialFunctions/arch/CUDA/CudaSpecialFunctions.h(154): here
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/../src/SpecialFunctions/SpecialFunctionsImpl.h(712): warning: missing return statement at end of non-void function "Eigen::internal::igamma_series_impl<Scalar, mode>::run [with Scalar=double, mode=Eigen::internal::SAMPLE_DERIVATIVE]"
detected during:
instantiation of "Scalar Eigen::internal::igamma_series_impl<Scalar, mode>::run(Scalar, Scalar) [with Scalar=double, mode=Eigen::internal::SAMPLE_DERIVATIVE]"
(863): here
instantiation of "Scalar Eigen::internal::igamma_generic_impl<Scalar, mode>::run(Scalar, Scalar) [with Scalar=double, mode=Eigen::internal::SAMPLE_DERIVATIVE]"
(2108): here
instantiation of "Eigen::internal::gamma_sample_der_alpha_retval<Eigen::internal::global_math_functions_filtering_base<Scalar, void>::type>::type Eigen::numext::gamma_sample_der_alpha(const Scalar &, const Scalar &) [with Scalar=double]"
/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/include/unsupported/Eigen/CXX11/../src/SpecialFunctions/arch/CUDA/CudaSpecialFunctions.h(154): here
1 error detected in the compilation of "/tmp/tmpxft_00007891_00000000-6_shift_corr.cu.cpp1.ii".
Makefile:52: recipe for target 'shift_corr.cu.o' failed
make: *** [shift_corr.cu.o] Error 1
As the title mentioned, I am not sure how to get the ground-truth data.
I think we need that for using Stereo_Online_Adaptation.py.
failed to load pretrained weights
here is the error:
Traceback (most recent call last):
File "/home/lvhao/MADNet/Stereo_Online_Adaptation.py", line 324, in
main(args)
File "/home/lvhao/MADNet/Stereo_Online_Adaptation.py", line 150, in main
var_to_restore = weights_utils.get_var_to_restore_list(args.weights, [])
File "/home/lvhao/MADNet/Data_utils/weights_utils.py", line 27, in get_var_to_restore_list
reader = tf.train.NewCheckpointReader(ckpt_path)
File "/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/python/pywrap_tensorflow_internal.py", line 636, in NewCheckpointReader
return CheckpointReader(compat.as_bytes(filepattern))
File "/home/lvhao/.local/lib/python3.6/site-packages/tensorflow/python/pywrap_tensorflow_internal.py", line 648, in init
this = _pywrap_tensorflow_internal.new_CheckpointReader(filename)
tensorflow.python.framework.errors_impl.InvalidArgumentError: Unsuccessful TensorSliceReader constructor: Failed to get matching files on /home/lvhao/MADNet/MADNet/synthetic/weights.ckpt: Not found: /home/lvhao/MADNet/MADNet/synthetic; No such file or directory
Process finished with exit code 1
the directory "/home/lvhao/MADNet/MADNet/synthetic" is existed. and have "weights.ckpt.data-00000-of-00001" "weights.ckpt.index" "weights.ckpt.meta" downloaded from your link.
how to solve it? thanks
how to use DIY stereo camer like below example
https://erget.files.wordpress.com/2014/02/img_20140131_114640-resized.jpg
how to connect two separate webcam as a stereo in Live_Adaptation_Demo.py any idea
Thanks
Thanks for the code, but is there a possibility to train the model before self-adaptation without pretrained weights, if yes, what do i need to do?
Hi,
I am trying to run the Stereo_Online_Adaptation script with the following arguments:
python Stereo_Online_Adaptation.py -l ~/Desktop/deep-stereo/data/kitti/list.txt -o ~/Desktop/deep-stereo/outputs --weights ~/Desktop/deep-stereo/pretrained/MADNet/kitti/weights.ckpt --modelName MADNet --blockConfig ~/Desktop/deep-stereo/block_config/MadNet_full.json --mode MAD --sampleMode PROBABILITY
The first row of list.txt looks like this:
/home/dp92/Desktop/deep-stereo/data/kitti/image_02/data/0000000000.png,/home/dp92/Desktop/deep-stereo/data/kitti/image_03/data/0000000000.png,/home/dp92/Desktop/deep-stereo/data/kitti/image_00/data/0000000000.png
I am using /home/dp92/Desktop/deep-stereo/data/kitti/image_00/data/0000000000.png as fake GT, is it OK? or how should it run it without GT?
Anyway the process is not completed successfully, What could be the problem?
Full log:
https://pastebin.com/TJmcDH81
Hello. I get the following error when trying to run Stereo_Online_Adaptation.py:
Traceback (most recent call last):
File "Stereo_Online_Adaptation.py", line 325, in <module>
main(args)
File "Stereo_Online_Adaptation.py", line 267, in main
f_out.write('time,{},{}\n'.format(exec_time,exec_time/step))
ZeroDivisionError: division by zero
I use your instructions to run Stereo_Online_Adaptation.py:
LIST=IMG_LIST.csv
OUTPUT="/mnt/sdb1/datasets/kitti_detection/training/depth_maps_0_to_100"
WEIGHTS="weights.ckpt"
MODELNAME="MADNet"
BLOCKCONFIG="block_config/MadNet_full.json"
python Stereo_Online_Adaptation.py -l ${LIST} -o ${OUTPUT} --weights ${WEIGHTS} --modelName MADNet --blockConfig ${BLOCKCONFIG} --mode MAD --sampleMode PROBABILITY --logDispStep 1
I am using the pre-trained weight provided by you. Please tell me why I am getting this error. Thank you.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
{kind=link}