alexsax / 2d-3d-semantics Goto Github PK
View Code? Open in Web Editor NEWThe data skeleton from Joint 2D-3D-Semantic Data for Indoor Scene Understanding
Home Page: http://3dsemantics.stanford.edu
License: Apache License 2.0
The data skeleton from Joint 2D-3D-Semantic Data for Indoor Scene Understanding
Home Page: http://3dsemantics.stanford.edu
License: Apache License 2.0

















































































































In the dataset. there are area5a and area5b which are two half parts of area5, but there is a complete area5 at the website, right? is it available?
Hello Stanford Team, thanks for this amazing work!
I wonder if it's possible to render sequential RGB-D frames(as if they are captured by a hand-held RGB-D camera) with the meshes provided in the dataset. In order to use this dataset for many real-world tasks, we must assume the input is in raw RGB-D sequence format.
If you do believe it's possible, would you be kind enough to make your Blender rendering pipeline(and code presumably) public?
Thanks for your time!
I've seen this dataset used in a few papers and the RGB images they use seem to be the full equirectangular projection (e.g. 180x360 image with no black border). Is there a way to get these equirectangular projections from the provided RGB images?


Hi,
I find 2D images of some rooms missing, such as Area_3_hallway_5. Can you tell me why?
Thanks
Dear Stanford team,
I have troubles with camera poses for area5. In particular, camera poses for area5b seems to be aligned with the pointcloud, while area5a - not. I use "camera_location" as camera locations from the json file of folder "pose", pointclouds are taken from pointcloud.mat file. I don't have such an issue for any other areas. Screenshot is attached for your reference. Here colorful points are the camera locations, you can see that some of the them are outside of the building. Especially in the top part.

Best,
Dmytro Bobkov
I'd like to render some RGB images along with the semantic labels. Is it possible to do it with Blender?
From previous post #30, I see that the semantic ground-truth was generated this way. Just wondering how this is done?
I did find the material index after loading semantic.obj. Could you give me some direction?
Thank you very much for providing the dataset.
I am currently trying to access the data in the pointcloud.mat . Unfortunately I don't have access to matlab so I tried to open it with some HDF5 libraries with python but somehow I just got strange references, but no clear data structure (as can be seen in the screenshot in issue #14). Therefore my first question is if you used besides Matlab another program/Library to access the pointlcoud.mat file ?
As I am especially highly interested in the BBox data for the 3D point cloud I would also be interested if it is accessible also at another place (in the only 3D dataset I didn't find it) ?
Last question : The BBox parameter are estimated by looking at the pointcloud of the object and searching for the min/max values of this pointcloud for the different coordinates ?
Can you tell me how to find the coordinate relationship between 2D image and 3D point cloud by camera pose?
Hello.
To download the dataset, I filled in the following docs:
https://docs.google.com/forms/d/e/1FAIpQLScFR0U8WEUtb7tgjOhhnl31OrkEs73-Y8bQwPeXgebqVKNMpQ/viewform?c=0&w=1
After it, I got google cloud storage links for the XYZ and nonXYZ datasets, respectively.
(For your policy, I'll not write the links here...)
In the link, there were area_1.tar.gz, area_2.tar.gz, etc.
But I could not download the files.
When I clicked the download button, it only gave me "Forbidden Error 403".
Is it somewhat caused by that I don't have permission yet?
I also tried the links in #33, but it also brings me to the same google cloud storage.
Any help will be greatly appreciated.
This XML file does not appear to have any style information associated with it. The document tree is shown below.
<Error>
<Code>NoSuchBucket</Code>
<Message>The specified bucket does not exist.</Message>
</Error>
I am very interested in utilizing this dataset for my research, and I would greatly appreciate it if you could provide me with a valid link or an alternative source from which I could obtain the data.
I am using the 2d semantic maps in the dataset, it is mentioned in the paper that 2d semantically label is projected from 3d semantic point cloud.
Bur not sure how was this projection implemented detailedly, for example in the image below.


The white bookcase outside the door is not included in the label, it looks like an error annotation. I wonder is the point cloud outside the room not considered when generating 2d semantic label?
Hi,
Thank you for releasing the amazing dataset.
I wonder what is the correct way to correlate the pixels in the RGB image, and the points in the point-cloud? e.g., to generate an index map which has the same size of the RGB image. Or, can I directly correlate the gloabalXYZ with the points' coordinates?
Thanks
How to know which color label the wall in .png file
Hi, thanks for releasing this amazing dataset.
From the README, the surface normal of equirectangular image is in global coordinate. But I want to calibrate them into camera coordinate. I have checked the pose file but the rotation in it seems not consistent with the coordinate. Could you tell me how to do this conversion?
Thanks!
The file does not seem to be in the assets folder on the repo. Should I get it from somewhere else?
May I know how to convert semantic labels from semantic.png in pano folder? These are rgb images, and I am curious about how to map them to unique semantic ids.
In README.md it says global XYZ provides GT location in the mesh:
Line 159 in 54a5329
But I load the XYZ and mesh and they don't align with each other. What transformation do I need to make them align?

Dear Alex,
I am using this dataset for my master thesis, and it's been almost a month that I cannot access the http://buildingparser.stanford.edu website, could you tell me what the issue is and whether it is going to be fixed anytime soon?
Kind regards,
Anita
Hi,
According to the paper, the point cloud is obtained by sampling the reconstructed mesh and then annotated. So,
I have read #16 and follow the equation x = ARAx' + c, but I still can't align point clouds to exr points. Here is my code
#back projection
depth = depth / 512
n,m = np.meshgrid(np.arange(depth.shape[0]),np.arange(depth.shape[1]))
n = n.reshape(-1)
m = m.reshape(-1)
v = (n + 0.5) / depth.shape[0]
u = (m + 0.5) / depth.shape[1]
phi = (u - 0.5) * (2 * math.pi)
cita = (0.5 - v) * math.pi
x = np.cos(cita) * np.cos(phi)
y = np.cos(cita) * np.sin(phi)
z = np.sin(cita)
ray = np.stack([x,y,z],axis = 1)
points = ray * depth[n,m].reshape(-1,1)
And my transformation code:
pose = json.load(f)
R = pose["camera_rt_matrix"]
loc = pose["camera_location"]
A = np.array(pose["camera_original_rotation"])
A = A / 180 * math.pi
A = get_rot_from_xyz(A[0],A[1],A[2])
R = np.array(R)[0:3,0:3]
loc = np.array(loc).reshape(1,3)
fr = np.matmul(np.matmul(A,R),A)
points = points.transpose(1,0)
points = np.dot(fr,points).transpose(1,0) + loc
Is there any mistake?
Hi,
I found some rooms to be missing in the 2D data, especially for area 5, e.g. there are no images for area 5a, conferenceRoom_1. Why?
Thanks
Thanks for your great work first.
And I have some questions about the camera pose data.
As I understand, "final_camera_rotation" and "camera_rt_matrix" should have inverse relation.
But when I made inverse matrix of "final_camera_rotation", the signs of the second and third rows are opposite. Did I miss something?
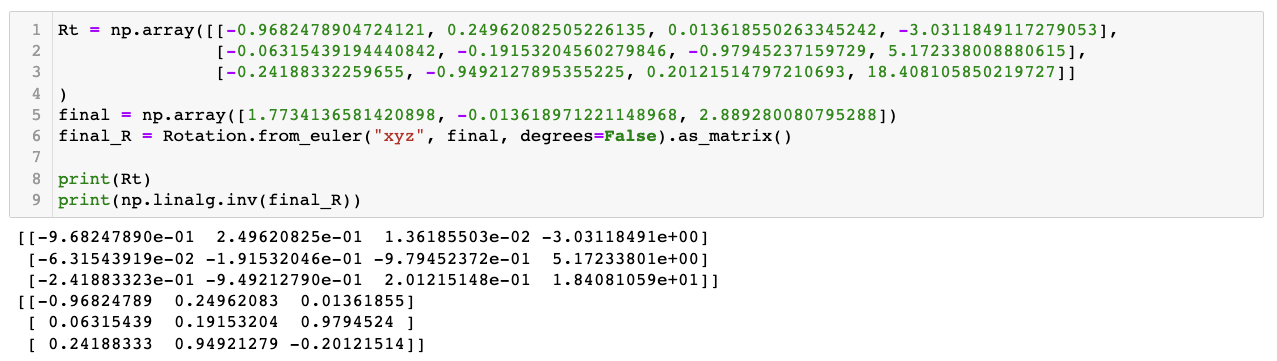
I can get "final_camera_rotation" by applying "rotation_from_original_to_point" to the "camera_original_rotation". But I don't understand the meaning of "camera_original_rotation". I thought that it would be a camera rotation of the first frame but it isn't. What is it and why do we need it?
Hi,
I am trying to project the available 2D perspective images (using their corresponding poses in folder area_x/data/pose) onto the provided semantic mesh (area_x/3d/semantic_obj) but I can't find the correct camera parameters to do that. The documentation is not clear regarding this issue . I tried different combinations using the so called "camera_rt_matrix", "final_camera_rotation", "camera_original_rotation"... still can't find the correct pose. I am using the mve environment to visualize both mesh and the camera poses. For instance this is an illustration when using the pose provided in camera_rt_matrix

Any help would be much appreciated @ir0
Thanks
@ir0
Dear Iro,
I am having a problem, which I thought you could help me with.
I have used panoramas and their corresponding depth images to create some 3D point clouds. However the point cloud that is achieved it this way, is not having the same alignment as the point cloud that already exists in the dataset!! I probably need to use the pose information and perform some transformation. I did try to apply camera_rt_matrix to the point cloud formed using panoramas, and I played a bit around with camera pose infos and point cloud transformation, but I couldn't solve the problem.
Do you have any idea how I should map these two point clouds?

Hi, Stanford team,
Firstly, thank you for providing such a great dataset (http://buildingparser.stanford.edu/dataset.html)!
We are confused about the provided Bbox coordinates of object stored in the 'Area_#/3d/pointcloud.mat' file.
In each object struct (Area --> Disjoint-Space --> object):
As described, [Xmin Xmax Ymin Ymax Zmin Zmax] is the object's bounding box. However, why are the coordinates of different objects are so similar as the attached screenshot shows. It seems like there are something wrong. Is there any other operations we need to do to get the correct 3D Bbox groundtruth? Could you please provide a specific README/Instructions to guide users correctly utilize the coordinates of 3D bounding box, both in world coordinate system and camera coordinate system?
Thank you for your reply!
Hi,
Thanks for your great work. However, I was confused about the split mesh of Area_5.
Area_5a + Area_5b :

Office_5 in Area_5a + Office_5 in Area_5b:

Best,
ZD
Hi,thanks for your good job!
And do you provide HHA?
Dear Stanford team.
Thank you very much for releasing your excellent dataset.
Your dataset will help us in our research in processing point cloud data.
However, when we extracted a part of the dataset, area_1.tar.gz (with XYZ), with the command tar -xvf area_1.tar.gz, we encountered one problem as following:
-------------- start of error message --------------
area_1/data/global_xyz/camera_531efeef59c348b9ba64c2bf8af4e648_hallway_7_frame_56_domain_global_xyz.exr
gzip: stdin: invalid compressed data--format violated
tar: Unexpected EOF in archive
tar: Unexpected EOF in archive
tar: Error is not recoverable: exiting now
-------------- end of error message ---------------
I have tried re-downloading the tar file from google drive and re-extracting it several times, but I could not extract it due to the same error.
Furthermore, I observed that the MD5 checksum of the downloaded file is different from the one you have published in https://github.com/alexsax/2D-3D-Semantics/wiki/Checksum-Values-for-Data.
Is there any way to extract the file completely?
Thanks in advance.
Hi,
I engage in the research about 3d semantic segmentation.
So I want to evaluate my method in terms of accuracy for each point cloud.
What I want to obtain is
(x, y, z, label)
(x, y, z, label)
.
.
.
.
..
I would be very grateful if you could provide specific processing and code.
Thank you in advance.
Sincerely,
Akiyoshi
Thank you for providing such a great dataset.
Question: In your sample figure, the depth map looks smooth with many grayscale variations. However, when I view the data, most are black/white, with very little grayscale or smoothness. Is this intended or am I reading the pngs incorrectly?
Hi,
It seems like the voxels are pretty low resolution (6x6x6) for objects? Are there particular reasons for this, and would it be plausible to re-voxelize to something higher like 64x64x64?
Thanks
The first element in semantic_labels.json. Does it correspond to any label?
I am trying to orient the back-projected pano pointclouds with the EXR ones. The pose file description is a little vague on the rotations and their order though.
I am confident that I've backprojected the points correctly (they are identical to the EXR pointclouds, just off by a rigid body transform).
Could you please articulate the rotation order concerning the two keys below:
"camera_original_rotation": # The camera's initial XYZ-Euler rotation in the .obj,
"camera_rt_matrix": # The 4x3 camera RT matrix, stored as a list-of-lists,
Letting camera_rt_matrix be the 3x3 array R and the 3 array t and the camera_original_rotation be the 3x3 array A, how do I align the back-projected points with the EXR pointcloud?
proj_pts is the Nx3 points back-projected from the pano
exr_pts is the Nx3 points loaded from the EXR file
I don't understand what "The camera's initial XYZ-Euler rotation in the .obj" means. Where is that applied?
Typically, I'd have thought that
transformed_proj_pts = np.matmul(R, proj_pts[...,None]).squeeze() + t
should do the trick. That's just applying the camera-coordinates-to-world-coordinates transform R * X + t. But the alignment is still off. I have to assume there is some application of the A matrix (camera_original_rotation) that I'm missing. I've spent a day trying various permutations and transposes of these transforms and visualizing the results, but I can't get the pointclouds aligned. What's the correct way to do this?
Note: my A matrix is formed as:
# eul is the 3-vector loaded from the 'camera_original_rotation'
phi = eul[0]
theta = eul[1]
psi = eul[2]
ax = np.array([
[1,0,0],
[0, cos(phi), -sin(phi)],
[0, sin(phi), cos(phi)]])
ay = np.array([
[cos(theta), 0, sin(theta)],
[0,1,0],
[-sin(theta), 0, cos(theta)]])
az = np.array([
[cos(psi), -sin(psi), 0],
[sin(psi), cos(psi), 0],
[0,0,1]])
A = np.matmul(np.matmul(az, ay), ax)
UPDATE: I ran a brute force approach where I computed all possible combinations and permutations of +/-t, +/-c, R/R^T, and A/A^T. None of them resulted in even a near-perfect match. I'm thoroughly confused.
Hi,
Thank you very much for opening a great dataset.
Can I ask some questions?
I engage in a research about semantic segmentation of 3D point clouds by using 2D semantic labels based on camera pose.
So, what I want to obtain ( and I don't still obtain) are:
I'm very happy that you respond.
Is a more detailed description available for the camera pose format?
I was unable to determine how to transform from the point-cloud into camera coordinates.
One might assume that the usual application of the RT matrix would be sufficient, but it appears not. The T appears to be correct, but R does not align the axes appropriately in many images. I suspect this has something to do with the fields:
"camera_original_rotation" and "rotation_from_original_to_point" but their correct use is not apparent to me.
Hi,
My goal is to create range images from the point clouds using PCL. For that, I use the camera poses. However, the resulting range images are not showing where the corresponding RGB images do. Camera's location seems to be correct, but its pose is different. The closed issue #26 does what I want to do with the mesh, but I can't recreate this behavior with point clouds. I inferred that the Euler angles are given as radians. When creating the range images, I had to change the yaw angle by 90 or 180 degrees in the trials I made to make the camera look at where the corresponding rgb image shows. Even then, the resulting image does not perfectly align with the RGB image like it does in the closed issue I mentioned. What might be the issue? I am doing my experiments on Area 3, and I took the point cloud from the S3DIS dataset instead of the .mat file.
Hello,
Thank you very much for opening a great dataset.
Can I ask a question?
When I do some research about back-projecting pixel to points, I encounter something confusing. There are two files related to the back-projection, ./global_xz/xxx.exr and ./depth/xxx.png.
As mentioned in README.md, depth images are stored as 16-bit PNGs and the valus are hundreds or thousands.
When I calculate the distance between the camera center (c2w matrix's last column; c2w matrix is the inverse of rt matrix in Pose folder) and the points from xxx.exr, I find the distance is 0 ~ a number less than 100. I guess the rt matrix in the Pose folder, camera center's coordinate, and the points' coordinate in xxx.exr are in the same world coordinate system, right?
Then, I think there may be a certain scale ratio between the depth_from_png and the depth_from_exr. When I divide the depth_from_png by the depth_from_exr and draw the ratio, I find it is not consistent as below. (The image is area_1/data/rgb/camera_0d600f92f8d14e288ddc590c32584a5a_conferenceRoom_1_frame_13_domain_rgb.png. The lightning-like part is due to missing data.)



Does the panorama to perspective transformation result in the inconsistency? If so, how to rectify it?
And I also want to ask how can I use ./depth/xxx.png to get the distance, which is consistent with the xyz of points and camera center.
Thanks for your help!
Best,
Tiancheng
You mention that the same convention is used as in NYU Depth, but the paper for NYU Depth v2 doesn't lay out their surface normals in detail either nor does their toolbox include an example of extracting normals from the image. What is the proper way to convert the RGB values to normals? I imagine the first step is to subtract 127.5, but after that I'm not quite sure.
From the paper:
The surface normals in 3D corresponding
to each pixel are computed from the 3D mesh instead of
directly from the depth image. The normal vector is saved
in the RGB color value where Red is the horizontal value
(more red to the right), Green is vertical (more green downwards),
and Blue is towards the camera. Each channel is
127.5-centered, so both values to the left and right (of the
axis) are possible. For example, a surface normal pointing
straight at the camera would be colored (128, 128, 255)
since pixels must be integer-valued.
Does this mean that I do n = (img - 127.5) / 127.5? If so, what do we do about quantization errors due to the integer casting? Also, this doesn't appear to be a right-handed coordinate system.
Dear researchers,
I want to find clusters among individual objects using only RGB and Semantic images. Can you share some approaches that help me achieve this task?
Thanks in advance.
They looks almost identical to each other in meshlab
Hi ,
I tried to download the dataset, however, every time when it's almost finished, an error comes out. The error is shown below:

Could you please help with this? thanks
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
{kind=link}