whatwg / html Goto Github PK
View Code? Open in Web Editor NEWHTML Standard
Home Page: https://html.spec.whatwg.org/multipage/
License: Other
HTML Standard
Home Page: https://html.spec.whatwg.org/multipage/
License: Other

































































































































































































































https://html.spec.whatwg.org/multipage/interaction.html#the-tabindex-attribute
The tabIndex IDL attribute must reflect the value of the tabindex content attribute. Its default value is 0 for elements that are focusable and −1 for elements that are not focusable.
There is an inconsistency here. Let's consider a custom Web Component named foo-bar. The markup <foo-bar tabindex="-1"></foo-bar> means the element is still focusable, but not reachable by pressing Tab. This means the user can click on the element to give it focus.
However, <foo-bar></foo-bar> without the tabindex HTML attribute means the element is not focusable at all, not even after clicking on it.
The HTMLElement.tabIndex IDL attribute will have the -1 value in both cases. This means two different behaviors under the same value. It also means it is impossible to make the custom element unfocusable by assigning a number to .tabIndex; instead we need to removeAttribute('tabindex').
The following show up as 404s in the console:
The source also contains code to load
Some of these are presumably related to the notification about updates, which has been removed in aaa19d5. So we should maybe remove them too?
Others we should get from @Hixie.
The following
commit 1b438067d84da2ee95988842cdd8fe2655444936 named "deprecate <keygen> and appcache" has not be registered as an issue, meaning it may not be visible to people who should care about it, and the discussion may get lost later on, so I am posting this in the issues database.
See WICG/webcomponents#110 (comment)
What should this flag be called? "Cannot have shadow trees"? "Has complex rendering"?
What should the text look like and where in the element descriptions should it be placed?
Should it be a new kind of content ? That seems like a nice way to categorize, and would allow us to avoid having a sentence in each element, instead just adding it to the non-normative header and then maintaining the central list in https://html.spec.whatwg.org/#kinds-of-content.
I put together a "write-only" strawman a few months ago that might be worth evaluating: https://mikewest.github.io/credentialmanagement/writeonly/
Discussed briefly on https://lists.w3.org/Archives/Public/public-whatwg-archive/2014Oct/0181.html and http://discourse.wicg.io/t/write-only-input-fields/598.
In whatwg/webidl@079cbb8 the T[] Web IDL type was removed.
After #10, the remaining uses in the spec of T[] will be:
I haven't looked yet whether these can be completely replaced with FrozenArray or whether something trickier might be needed.
Context :
<p><table><tr><td></table><p class="bad"> line.</table> token</table> is not in table scope (table node not current in stack and table scope contains 'table' in html namespace so returns failure)Per spec, a parser error must occur and the token must be ignored, but doing so, the table is not closed and the rest of the document is considered children of the unclosed <td>
A proposed fix would be :
</table> token, pop elements from the stack of open elements until a "table" node has been popped of the stackI hope I did not got confused somewhere :)
Potential things to address:
We don't care about IANA, IANA doesn't care about us. There's not much point having all this boilerplate.
<button>'s rendering is currently defined in the "Bindings" section as opposed to either the "Replaced elements" or "Non-replaced elements" sections. I couldn't find anything else in the spec that clarifies this either.
Is the <button> element a replaced element, or a non-replaced element? Or does/can its replaced-ness vary by circumstance? (If yes to the latter, please spell out the various circumstances.)
Firefox treats it as a replaced element; I presume other browsers don't, otherwise we'd be seeing the referenced bug in other browsers too.
(This is an intentional duplicate of https://www.w3.org/Bugs/Public/show_bug.cgi?id=27913 since that bug is in the wrong WG and an obscure Bugzilla Component.)
Basically, https://html.spec.whatwg.org/multipage/interaction.html#focus-update-steps doesn't seem to mention anything about scrolling the focused element into view if it was outside the viewport, even though all browsers do this in practice (simple testcase) most of the time (there are apparently some exceptional cases). So a step (presumably invoking https://drafts.csswg.org/cssom-view/#scroll-an-element-into-view) should be added to make the spec reflect reality. I haven't dug deep enough to suggest exactly where in that algorithm the new step should be inserted.
By the current spec, requestAnimationFrame returns animation frame callback identifier as WebIDL's long type.
However, animation frame callback identifier can be incremented but is not decremented in the current spec. It will not be a negative value. So I propose to change the type of animation frame callback identifier which is returned from requestAnimationFrame.
I suspect that we might be able to change this by these reasons, but I don't have conclusive...
origin: w3c/requestidlecallback#17
(From the spec:)
"<code data-x="">foo</code>" vs <code>foo</code>)</dfn> algorithm", "</span> algorithm")<i>? <code>?)<code>Document</code> consistently instead of 'document'. <li><img alt="A text field with editable sections for each
value, with a button to pop up a dialog showing a calendar or
clock." src="sample-datetime-ui-2"></li>
<li><img alt="A calendar grid with a clock in the upper right
hand corner." src="sample-datetime-ui-3"></li>https://html.spec.whatwg.org/multipage/infrastructure.html#dependencies
Currently references ARIA 1.0 and is missing role values and aria-* attributes implemented in browsers. Suggest these should be updated to reference ARIA 1.1 http://rawgit.com/w3c/aria/master/aria/aria.html
am happy to PR this.
Reviewing the server logs, there are a lot of unsuccessful attempts to access multipage URLs. E.g. /multipage/interactive-elements.html and more.
Can we edit the .htaccess to redirect any 404s to the https://html.spec.whatwg.org/multipage/#the-hash-in-the-request, which will then subsequently (via JS) go to the right sub-page?
My .htaccess-fu is not great. @Hixie?
Please correct me if this is an incorrect place or form for submitting issues. It seems the repository is new and I could not find any guidelines.
Since d534237, placeholder attribute of textarea elements can contain newlines. (W3C version still forbids newlines. There is an open bug about it.)
However, the specification still mentions the prohibition of newlines in the section on placeholder and does not mention an exception: html.spec.whatwg.org, developers.whatwg.org.
In addition, the version at html.spec.whatwg.org directly links from the section on textarea to the misleading section on placeholder.
(It seems I got very tired looking at all specs and my previous observations are mostly incorrect.)
The common section on placeholder in the spec, the one that shows up if I search on developers.whatwg.org for placeholder, forbids newlines and mentions no exceptions for textareas. Perhaps a note is in order?
It took me a while to figure all this out, it was considerably confusing.
Currently the HTML standard does not provide any advice in regards to the outline algorithm not being implemented, This has lead to some developers believing that the outline algorithm has an effect in browsers and assitive technology which it does not. THis can lead to developers using markup patterns that don't convey document structure. Suggest adding a warning, for example this is the warning in the W3C HTML spec
There are currently no known implementations of the outline algorithm in graphical browsers or assistive technology user agents, although the algorithm is implemented in other software such as conformance checkers. Therefore the outline algorithm cannot be relied upon to convey document structure to users. Authors are advised to use heading rank (h1-h6) to convey document structure.
@izh1979 suggested to me that it's frustrating for people to have lots of files with names like "print.pdf" on their computer. As such we could rename the file to html-standard.pdf and install a redirect from the old URL.
What do people think?
Testcase: http://jsbin.com/kufika/edit?html,js,output
None of Edge, Firefox [edit: <43], Chrome, or Safari include <head> in the return value of getElementsByName() even when an appropriate name attribute is tacked onto it, but https://html.spec.whatwg.org/multipage/dom.html#dom-document-getelementsbyname does not seem to include or reference any logic that would special-case the <head> element.
E.g. https://html.spec.whatwg.org/multipage/webappapis.html#processing-model-8. There is no #file-issue-link so it fails.
I think the best fix here is to make file-issue.js also look for document.currentScript.getAttribute("data-link") and use <script src="...file-issue.js defer data-link="..."></script>. Will do soon.
See #34 (comment)
Consider the following example:
This seems to essentially allow applications to bypass tainting.
The "PDF Version" link at the top does not work as /print.pdf is missing. @Hixie, where do we get one of those?
Reference URL:
https://html.spec.whatwg.org/multipage/semantics.html#the-hgroup-element
The spec doesn't make it clear whether or not I can add equivalent headings for content. I'm trying to do something to the effect of:
In theory, this should be doable with:
<hgroup>
<h1>List Title 1</h1>
<h1>List Title 1 Alternative</h1>
</hgroup>
<ul>[...]</ul>However, the only example utilizing the hgroup element in the spec shows how to create a subtitle, and the spec has this confusing text: "Other elements of heading content in the hgroup element indicate subheadings or subtitles". The quoted text indicates that the second h1 element might be considered a subtitle of the first h1 element.
Edits: I had to reformat the post with Markdown since HTML is apparently interpreted. I modified the phrasing of the last paragraph.
@plinss and @tabatkins maintain a tool that Bikeshed specifications use for cross-references. At the moment HTML works poorly with that tool, for instance by defining "origin" three times. We should find some way to work better.
https://html.spec.whatwg.org/#bindings attempts to define rendering in terms of http://www.w3.org/TR/becss/, which is an unimplemented spec. It contains a lot of good information about how to render things, but I think tying those rendering recommendations to the binding CSS property is wrong.
Thoughts, @Hixie, @tabatkins?
When does something get added? E.g., why is <event-source> not there, but framespacing is?
Right now, the 404 page informs users to "email Ian Hickson" if they find a broken link on the WHATWG site.
We should probably have either CONTRIBUTING.md or STYLE.md elaborate on the various conventions in use around wattsi, citations, etc.
Originally brought this up at https://lists.w3.org/Archives/Public/public-html/2015Jul/0025.html
I think it would be appropriate to make the datetime attribute as one of the normative attributes for the mark element. As I understand <mark>, it generally indicates that there was some marking/highlighting activity done on text. I see this is a similar activity to <del> and <ins>, which may be accompanied with the datetime attribute.
A use case for this is where a user (not necessarily the author of the document) marks/highlights a piece of text where the timestamp of that activity is preserved, so that information could later be collected. It grants the possibility where all editorial - pardon me for the lack of a better term - changes or interactions fit into a timeframe.
I have considered employing the data attribute e.g., data-datetime, but figured that the datetime attribute would be most suitable in this case.
#101 is trying to sort out the parser. Here is some data on the UA styling:
ruby { display: ruby; }
rt { display: ruby-text; }ruby { display: ruby; }
rb { display: ruby-base; white-space: nowrap; }
rt {
display: ruby-text;
white-space: nowrap;
font-size: 50%;
font-variant-east-asian: ruby;
text-emphasis: none;
}
rbc { display: ruby-base-container; }
rtc { display: ruby-text-container; }
ruby, rb, rt, rbc, rtc { unicode-bidi: isolate; }ruby, rt {
text-indent: 0; /* blocks used for ruby rendering should not trigger this */
}
rt {
line-height: normal;
-webkit-text-emphasis: none;
}
ruby > rt {
display: block;
font-size: 50%;
text-align: start;
}
ruby > rp {
display: none;
}ruby, rt {
text-indent: 0; /* blocks used for ruby rendering should not trigger this */
}
rt {
line-height: normal;
-webkit-text-emphasis: none;
}
ruby > rt {
display: block;
font-size: -webkit-ruby-text;
text-align: start;
}
ruby > rp {
display: none;
}ruby {
display: ruby;
}
rb {
display: ruby-base;
white-space: nowrap;
}
rp {
display: none;
}
rt {
display: ruby-text;
}
rtc {
display: ruby-text-container;
}
rtc, rt {
white-space: nowrap;
font-size: 50%;
line-height: 1;
font-variant-east-asian: ruby;
}
@supports (text-emphasis: none) {
rtc, rt {
text-emphasis: none;
}
}
rtc:lang(zh), rt:lang(zh) {
ruby-align: center;
}
rtc:lang(zh-TW), rt:lang(zh-TW) {
font-size: 30%; /* bopomofo */
}
rtc > rt {
font-size: inherit;
}
ruby, rb, rt, rtc {
unicode-bidi: -moz-isolate;
}It seems likely we should not have any styling rules for rb and rtc, as those are only in Gecko (plus W3C HTML).
From https://www.w3.org/Bugs/Public/show_bug.cgi?id=25145
CSS pseudo-selectors for which this spec assigns the HTML-specific semantics
should be listed in the index
The newer CSS spec documents have a handy feature where each section has a "§" next to it which is a fragment ID link to that same particular section. For example, the "§" next to "1.2. Values" links to https://drafts.csswg.org/mediaqueries/#values
It would be handy if the HTML spec document had a similar feature. Currently, I have to either open the heading in dev tools or go back to the TOC if I want to get a link to the (sub^N)section which I'm currently viewing.
@zcorpan is fine with this, but he would like to preserve history, which may be tricky as the <picture> repository includes all of the HTML history.
Also, if we preserve history, we probably want to disable tweeting for a while as it would be quite the flood.
Anyway, things to be done:
source<picture><piccture> in more places, https://www.w3.org/Bugs/Public/show_bug.cgi?id=27570<img sizes><img media><img srcset><source> elementsSee https://www.w3.org/Bugs/Public/show_bug.cgi?id=17898
#0 [email protected] 2011-08-24 09:09:47 +0000
--------------------------------------------------------------------------------
Specification: http://www.whatwg.org/specs/web-apps/current-work/complete/timers.html
Multipage: http://www.whatwg.org/C#custom-handlers
Complete: http://www.whatwg.org/c#custom-handlers
Comment:
Make "registerProtocolHandler" and "registerContentHandler" appear in the TOC
Posted from: 88.131.66.80 by [email protected]
User agent: Opera/9.80 (Macintosh; Intel Mac OS X 10.5.8; U; en) Presto/2.9.168 Version/11.50
================================================================================
#1 Ian 'Hixie' Hickson 2011-10-12 19:04:44 +0000
--------------------------------------------------------------------------------
Why? Or even, how? The section title would be really long if it included both
those method names, not to mention the other method names defined in that section...
================================================================================
#2 Simon Pieters 2011-10-13 05:02:04 +0000
--------------------------------------------------------------------------------
Why? To make it easier to find (some sections have the relevant API in the ToC,
e.g. designMode). But I guess that applies to any method. Maybe we should have
an index of APIs as an appendix or something.
================================================================================
#3 Ian 'Hixie' Hickson 2011-10-24 18:20:13 +0000
--------------------------------------------------------------------------------
An index would make a lot of sense.
An IDL index would be something we can completely automate. The IDL blocks are
computer-readable, and for each IDL field there's a corresponding <dfn>. If someone
can hack together a quick script that just scans all the IDL blocks and extracts out
all the methods and fields and forms an alphabetical index of them, I'd be happy to
add that script to my publishing pipeline.
================================================================================
#4 Ian 'Hixie' Hickson 2011-10-25 05:13:43 +0000
--------------------------------------------------------------------------------
(Please reassign to me if you have such a script.)
Currently demos are not in source control and are hosted at https://whatwg.org/demos/. The build script then curls them from that URL into the spec.
We should move the demos into this repo, and have the build script inline them from source plus copy them to the output directory. This will then create demo URLs at https://html.spec.whatwg.org/demos/. We should then set up a redirect from the original URLs to these new URLs.
Related: https://www.w3.org/Bugs/Public/show_bug.cgi?id=28200
TODO before we can close this issue:
TODO after this issue:
There's an intent to deprecate and remove <applet> in Blink:
https://groups.google.com/a/chromium.org/d/msg/blink-dev/E9LKKtcKbv8/BTB6dSxACgAJ
If this plan moves forward, we should deprecate it in the spec, and also remove it once it's clear whether removing it is web compatible.
The main element was designed and implemented based on the concept of there being a single instance within a document, the markup pattern was based on data of id value usage in the wild. The whatwg definition differs markedly from the orginal definition. This leads to confusion for developers.
The W3C nu html checker, which is used by many, throws an error when main is used as per whatwg. Data derived from webdevdata.org shows that >97% of usage of the <main> element is as per the W3C definition and anecdata from users that consume the semantics suggests that one main element per page is the expected and most useful pattern. In general consumers landmark semantics report that the utility of landmarks is reduced as the number/instances of landmark elements in a document increases.
The alignment would involve changes to the main and body element definitions.
current W3C definitions:
Currently, authors can turn image smoothing on and off with imageSmoothingEnabled, but they have no control over the quality or speed of the image smoothing technique used by the engine. Unfortunately, authors desiring a higher quality, lower speed image smoothing technique (Twitter, for instance) end up rolling their own image smoothing in JavaScript. It would be better to let authors opt in to higher quality smoothing directly.
In our prototype of this feature we have an imageSmoothingOption property which can be "default", "fast", or "quality". I don't particularly care what the property or options are called. That said, generic values like these that let the author make the speed/quality tradeoff they need to make without tying implementations to specific image scaling algorithms seem best.
If you'd like I can provide a pull request with the relevant spec addition.
(This was previously discussed on the WHATWG list in December 2013 and March 2014.)
<keygen> has been deprecated a few days ago, and the issue has been taken up by @timbl on the Technical Architecture Group as it removes a useful tool in the asymmetric public key cryptography available in browsers.
One reason given for deprecating that recurs often is that keygen uses MD5, as for example argued by Ryan Sleevi in his mail on blink-dev on the intent to deprecate keygen
- itself is problematically and incompatibly insecure - requiring the use of MD5 in a signing algorithm as part of the SPKAC generated. This can't easily be changed w/o breaking compatibility with UAs.
What is the problem with MD5? Well it was shown to make it possible to create collisions, thereby allowing a major attack vector on the whole Certificate Authority System which is currently central behind web security. This was presented in a very good paper "MD5 considered harmful today" at the Chaos Communication Congress in Berlin in 2008 by a number of researchers of which Jacob Appelbaum ( aka. @ioerror ) . ( That was the time when Julian Assange was working freely on Wikileaks, so you can even hear him ask a question at the end )
The slides are here:
https://www.trailofbits.com/resources/creating_a_rogue_ca_cert_slides.pdf
The video is here:
http://chaosradio.ccc.de/25c3_m4v_3023.html
In short they were able to create a fake Certificate Authority (CA) because the CA signed its certificates with MD5 and they were able to create hash collisions, to use the certificate signed by the CA
and change some information in it to produce their own top level certificate, with which
they could create a certificate for any site they wished to! ( Pretty awesomely bad - though they did this carefully to avoid misuse ). This is why projects such as IETFs DANE, DNSSEC, and many other improvements to the internet infrastructure are vital.
This was 7 years ago, so all of this should be fixed by now. There should be no CA signing
Server Certificates with MD5 anymore.
Great. But that has nothing to do with what is going on with <keygen>. The problem
may well be that the documentation of <keygen> is misleading here. The WHATWG documentation on keygen currently states:
If the keytype attribute is in the RSA state: Generate an RSA key pair using the settings given by the user, if appropriate, using the md5WithRSAEncryption RSA signature algorithm (the signature algorithm with MD5 and the RSA encryption algorithm) referenced in section 2.2.1 ("RSA Signature Algorithm") of RFC 3279, and defined in RFC 3447. [RFC3279] [RFC3447]
By whether or not keygen wraps the key and signs it with MD5 is of not much importance, since this is the keyrequest we are speaking of here, not the generated certificate!
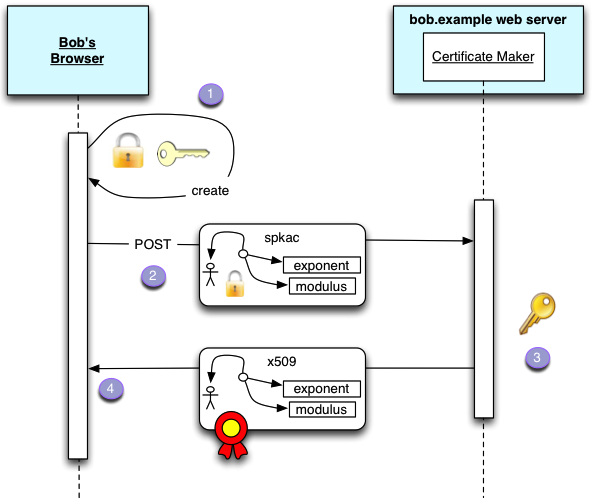
To summarise how the keygen is actually used:
Here is an illustration of the flow that we use in the WebID-TLS spec to illustrate this:
To see some real code implementing this I point you to my ClientCertificateApp.scala code that receives a certificate Request, and either returns an error or a certificate.
The key parts of the code are extracted below:
def generate = Action { implicit request =>
certForm.bindFromRequest.fold(
errors => BadRequest(html.webid.cert.genericCertCreator(errors)),
certreq => {
Result(
//https://developer.mozilla.org/en-US/docs/NSS_Certificate_Download_Specification
header = ResponseHeader(200, Map("Content-Type" -> "application/x-x509-user-cert")),
body = Enumerator(certreq.certificate.getEncoded)
)
}
)
}CertForm just takes the data from the html form (verifies all fields are ok) and generates a CertReq object. ( or it can also take a CertReq object and generate a form, so that errors can be shown to the user )
val certForm = Form(
mapping(
"CN" -> email,
"webids" -> list(of[Option[URI]]).
transform[List[URI]](_.flatten,_.map(e=>Some(e))).
verifying("require at least one WebID", _.size > 0),
"spkac" -> of(spkacFormatter),
"years" -> number(min=1,max=20)
)((CN, webids, pubkey,years) => CertReq(CN,webids,pubkey,tenMinutesAgo,yearsFromNow(years)))
((req: CertReq) => Some(req.cn,req.webids,null,2))
)The spkacFormatter just returns a public key. ( It plays around with testing the challenge, but I am not sure what that is for - would like to know ).
Anyway as I wrote above: if successful the generate method returns an encoded certificate with the right mime type. And as you can see we create a certificate with SHA1withRSA
val sigAlgId = new DefaultSignatureAlgorithmIdentifierFinder().find("SHA1withRSA")
val digAlgId = new DefaultDigestAlgorithmIdentifierFinder().find(sigAlgId)
val rsaParams = CertReq.issuerKey.getPrivate match {
case k: RSAPrivateCrtKey =>
new RSAPrivateCrtKeyParameters(
k.getModulus(), k.getPublicExponent(), k.getPrivateExponent(),
k.getPrimeP(), k.getPrimeQ(), k.getPrimeExponentP(), k.getPrimeExponentQ(),
k.getCrtCoefficient());
case k: RSAPrivateKey =>
new RSAKeyParameters(true, k.getModulus(), k.getPrivateExponent());
}
val sigGen = new BcRSAContentSignerBuilder(sigAlgId, digAlgId).build(rsaParams);
x509Builder.build(sigGen)So the MD5 plays no serious role in all this.
This should not be a big surprise. The only thing of value sent to the server is the public key. It sends
back a certificate based on that public key ( and other information it may have on the user ). But the only one to be able to use that certificate is the person owning the private key.
Now my code could presumably be improved in many places I doubt not. But this should show how
<keygen> is actually used. After all remember that <keygen> was added 10 years after it appeared in browsers, and that there was not that much discussion about the documentation when it was added.
(From the spec:)
var library = new ZipFile("data.zip");
library.onload = function() {
var sound1 = library.getAudio("sound1.wav"); // returns an Audio object
var image1 = library.getImage("image1.png"); // returns an HTMLImageElement
var doc1 = library.getXMLDocument("doc1.xml"); // returns a Document (XML Document mode)
var doc2 = library.getHTMLDocument("doc1.html"); // returns a Document (HTML Document mode)
}or:
var library = new ResourceLoader("data.zip");
library.add("moredata.zip");
library.onload = function() { ... }
library.onloading = function() {
reportLoadProgress(library.progress); // 0.0 .. 1.0
}or:
var library = new AudioZip("sounds.zip");
library.onload = function() {
var sound1 = library["sound1.wav"];
sound.play();
}<input accesskey="m" value="Submit"> browser <input type="text" group="contact" name="voicephone"> Voice phone
<input type="text" group="contact" name="fax"> Fax
<input type="text" group="contact" name="mobile"> Mobile phone
<input type="text" group="contact" name="email"> E-mail if the user fills out none of the form fields in the "contact" group, an error message is
shown and the form is not submitted.
- Peter-Paul Koch
<textarea> so it looks different from wrapping text<fieldset enabled-if-checked="myCheckboxOrRadioButton"><select> or <datalist>: _________________
|_New_York______|V|_________________ <- input with a table link and a down arrow
|_City__________|_State_|_Country_|_| <- header of the table
| Montreal | QC | Canada |A| <- top arrow of the scroll
|>New York <| NY | US | | <- selected row
| Washington | DC | US |X| <- cursor scroll
| San Francisco | CA | US | |
|_Toronto_______|__ON___|_Canada__|V| <- bottom arrow of the scroll
<fieldset readonly>?In other words, that <input type="number" min="100" max="300"> is valid if the user has no entered a value at all.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.