Documentation | Torch4keras | Examples | build_MiniLLM_from_scratch
安装稳定版
pip install bert4torch安装最新版
pip install git+https://github.com/Tongjilibo/bert4torch- 注意事项:pip包的发布慢于git上的开发版本,git clone注意引用路径,注意权重是否需要转换
- 测试用例:
git clone https://github.com/Tongjilibo/bert4torch,修改example中的预训练模型文件路径和数据路径即可启动脚本 - 自行训练:针对自己的数据,修改相应的数据处理代码块
- 开发环境:原使用
torch==1.10版本进行开发,现已切换到torch2.0开发,如其他版本遇到不适配,欢迎反馈
-
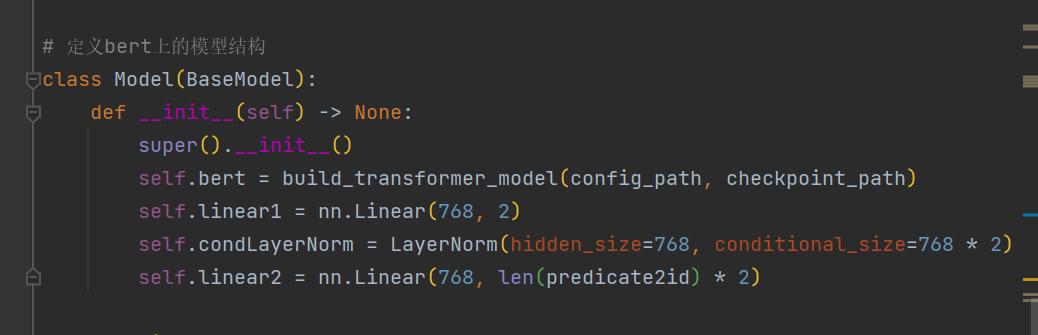
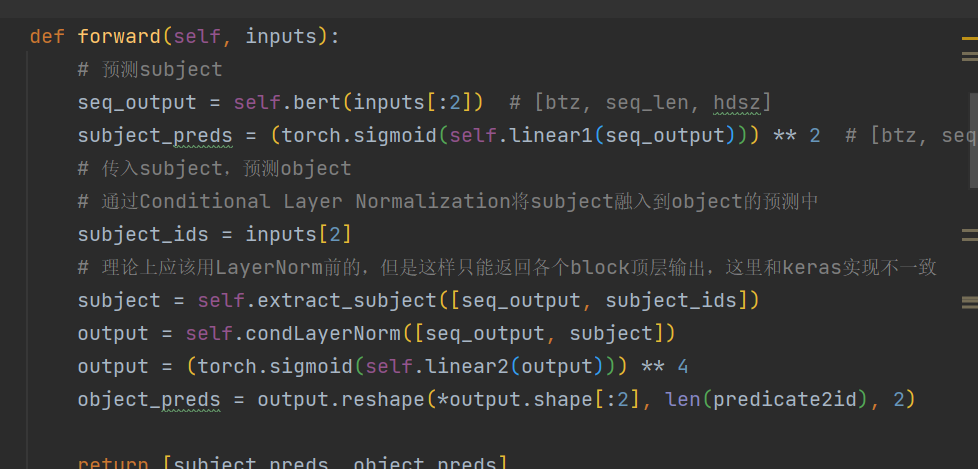
LLM模型: 加载chatglm、llama、 baichuan、ziya、bloom等开源大模型权重进行推理和微调
-
核心功能:加载bert、roberta、albert、xlnet、nezha、bart、RoFormer、RoFormer_V2、ELECTRA、GPT、GPT2、T5、GAU-alpha、ERNIE等预训练权重继续进行finetune、并支持在bert基础上灵活定义自己模型
-
丰富示例:包含llm、pretrain、sentence_classfication、sentence_embedding、sequence_labeling、relation_extraction、seq2seq、serving等多种解决方案
-
实验验证:已在公开数据集实验验证,使用如下examples数据集
-
易用trick:集成了常见的trick,即插即用
-
其他特性:加载transformers库模型一起使用;调用方式简洁高效;有训练进度条动态展示;配合torchinfo打印参数量;默认Logger和Tensorboard简便记录训练过程;自定义fit过程,满足高阶需求
-
训练过程:
2022-10-28 23:16:10 - Start Training 2022-10-28 23:16:10 - Epoch: 1/2 5000/5000 [==============================] - 13s 3ms/step - loss: 0.1351 - acc: 0.9601 Evaluate: 100%|██████████████████████████████████████████████████| 2500/2500 [00:03<00:00, 798.09it/s] test_acc: 0.98045. best_test_acc: 0.98045 2022-10-28 23:16:27 - Epoch: 2/2 5000/5000 [==============================] - 13s 3ms/step - loss: 0.0465 - acc: 0.9862 Evaluate: 100%|██████████████████████████████████████████████████| 2500/2500 [00:03<00:00, 635.78it/s] test_acc: 0.98280. best_test_acc: 0.98280 2022-10-28 23:16:44 - Finish Training
| 功能 | bert4torch | transformers | 备注 |
|---|---|---|---|
| 训练进度条 | ✅ | ✅ | 进度条打印loss和定义的metrics |
| 分布式训练dp/ddp | ✅ | ✅ | torch自带dp/ddp |
| 各类callbacks | ✅ | ✅ | 日志/tensorboard/earlystop/wandb等 |
| 大模型推理,stream/batch输出 | ✅ | ✅ | 各个模型是通用的,无需单独维护脚本 |
| 大模型微调 | ✅ | ✅ | lora依赖peft库,pv2自带 |
| 丰富tricks | ✅ | ❌ | 对抗训练等tricks即插即用 |
| 代码简洁易懂,自定义空间大 | ✅ | ❌ | 代码复用度高, keras代码训练风格 |
| 仓库的维护能力/影响力/使用量/兼容性 | ❌ | ✅ | 目前仓库个人维护 |
| 更新日期 | bert4torch | torch4keras | 版本说明 |
|---|---|---|---|
| 20240418 | 0.5.0 | 0.2.2 | 修复chatglm3的bug, 修复save_pretrained时多文件的bug,增加CausalLMLoss, 修改deepspeed的传参逻辑,修改Text2Vec的bug, 完善openai client, 增加get_weight_decay_optim_groups |
| 20240317 | 0.4.9.post2 | 0.2.1.post2 | 增加get_weight_decay_optim_groups函数, attention中允许is_causal,修改repetition_penalty的bug,把baichuan从llama中剥离,修复config_path的bug,允许num_key_value_heads参数,torch4keras-v0.2.1.post2更新特性 |
| 20240221 | 0.4.8 | 0.2.0 | fastapi发布服务允许闲时offload到cpu, build_transformer_model允许从hf下载, 添加FillMask的pipeline, 添加SequenceClassificationTrainer |
- 预训练模型支持多种代码加载方式
from bert4torch.models import build_transformer_model
# 1. 仅指定config_path: 从头初始化模型结构, 不加载预训练模型
model = build_transformer_model('./model/bert4torch_config.json')
# 2. 仅指定checkpoint_path:
## 2.1 文件夹路径: 自动寻找路径下的*.bin/*.safetensors权重文件 + bert4torch_config.json/config.json文件
model = build_transformer_model(checkpoint_path='./model')
## 2.2 文件路径/列表: 文件路径即权重路径/列表, config会从同级目录下寻找
model = build_transformer_model(checkpoint_path='./pytorch_model.bin')
## 2.3 model_name: hf上预训练权重名称, 会自动下载hf权重以及bert4torch_config.json文件
model = build_transformer_model(checkpoint_path='bert-base-chinese')
# 3. 同时指定config_path和checkpoint_path(本地路径名或model_name排列组合):
config_path = './model/bert4torch_config.json' # 或'bert-base-chinese'
checkpoint_path = './model/pytorch_model.bin' # 或'bert-base-chinese'
model = build_transformer_model(config_path, checkpoint_path)*注:
高亮格式(如bert-base-chinese)的表示可直接build_transformer_model()联网下载- 国内镜像网站加速下载
HF_ENDPOINT=https://hf-mirror.com python your_script.pyexport HF_ENDPOINT=https://hf-mirror.com后再执行python代码- 在python代码开头如下设置
import os os.environ['HF_ENDPOINT'] = "https://hf-mirror.com"
- 感谢苏神实现的bert4keras,本实现有不少地方参考了bert4keras的源码,在此衷心感谢大佬的无私奉献;
- 其次感谢项目bert4pytorch,也是在该项目的指引下给了我用pytorch来复现bert4keras的想法和思路。
@misc{bert4torch,
title={bert4torch},
author={Bo Li},
year={2022},
howpublished={\url{https://github.com/Tongjilibo/bert4torch}},
}
- Wechat & Star History Chart
 微信号 |
 微信群 |
Star History Chart |