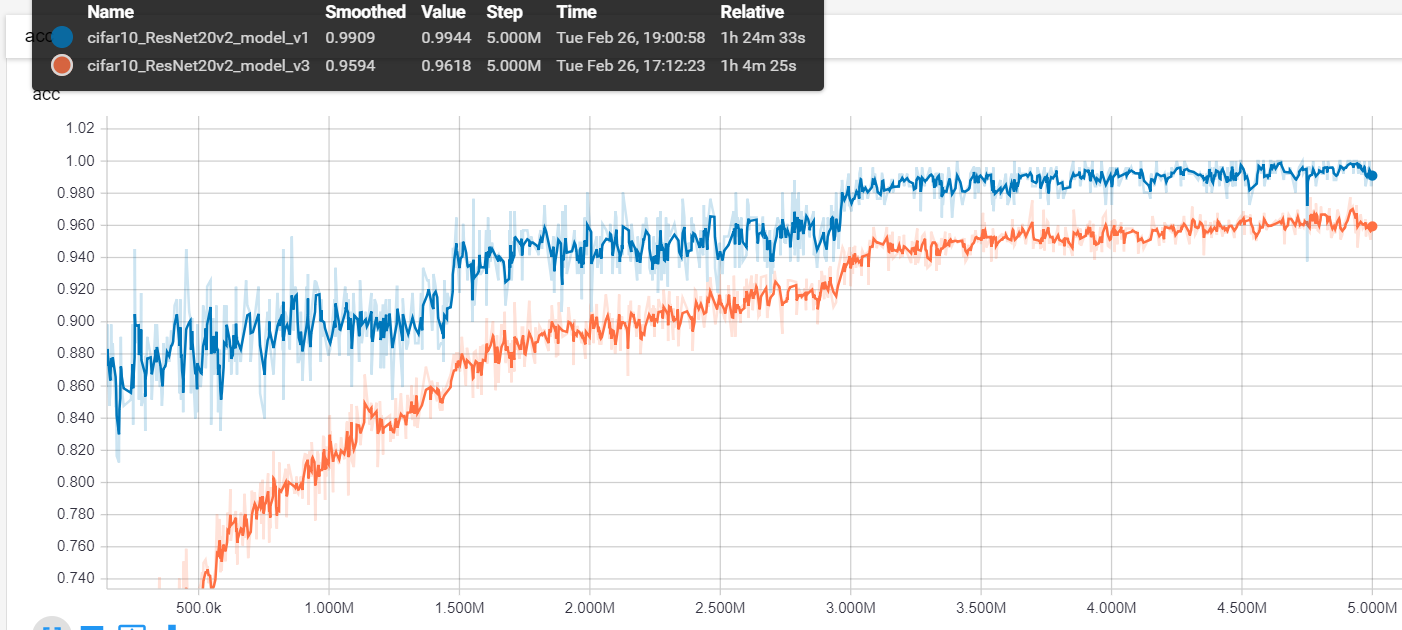
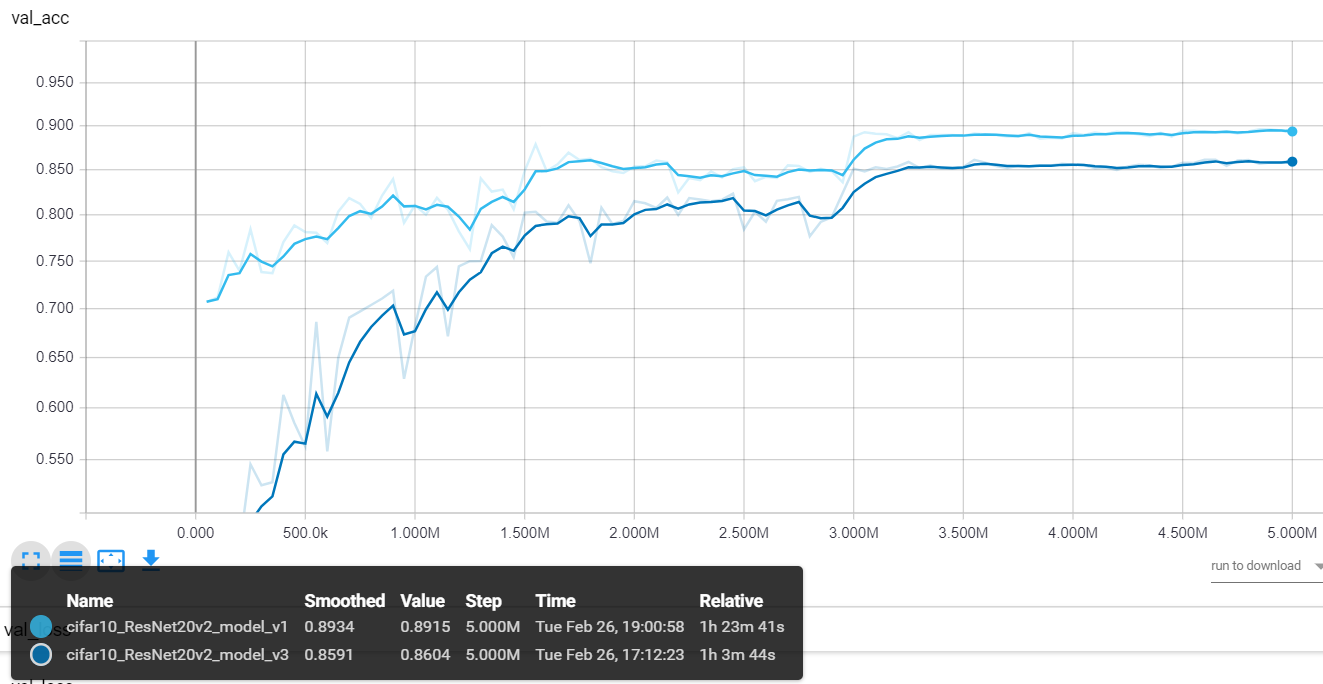
class AdaBound(Optimizer):
"""AdaBound optimizer.
Default parameters follow those provided in the original paper.
# Arguments
lr: float >= 0. Learning rate.
final_lr: float >= 0. Final learning rate.
beta_1: float, 0 < beta < 1. Generally close to 1.
beta_2: float, 0 < beta < 1. Generally close to 1.
gamma: float >= 0. Convergence speed of the bound function.
epsilon: float >= 0. Fuzz factor. If `None`, defaults to `K.epsilon()`.
decay: float >= 0. Learning rate decay over each update.
weight_decay: Weight decay weight.
amsbound: boolean. Whether to apply the AMSBound variant of this
algorithm.
tf_cpu_mode: only for tensorflow backend
0 - default, no changes.
1 - allows to train x2 bigger network on same VRAM consuming RAM
2 - allows to train x3 bigger network on same VRAM consuming RAM*2
and CPU power.
# References
- [Adaptive Gradient Methods with Dynamic Bound of Learning Rate]
(https://openreview.net/forum?id=Bkg3g2R9FX)
- [Adam - A Method for Stochastic Optimization]
(https://arxiv.org/abs/1412.6980v8)
- [On the Convergence of Adam and Beyond]
(https://openreview.net/forum?id=ryQu7f-RZ)
"""
def __init__(self, lr=0.001, final_lr=0.1, beta_1=0.9, beta_2=0.999, gamma=1e-3,
epsilon=None, decay=0., amsbound=False, weight_decay=0.0, tf_cpu_mode=0, **kwargs):
super(AdaBound, self).__init__(**kwargs)
if not 0. <= gamma <= 1.:
raise ValueError("Invalid `gamma` parameter. Must lie in [0, 1] range.")
with K.name_scope(self.__class__.__name__):
self.iterations = K.variable(0, dtype='int64', name='iterations')
self.lr = K.variable(lr, name='lr')
self.beta_1 = K.variable(beta_1, name='beta_1')
self.beta_2 = K.variable(beta_2, name='beta_2')
self.decay = K.variable(decay, name='decay')
self.final_lr = final_lr
self.gamma = gamma
if epsilon is None:
epsilon = K.epsilon()
self.epsilon = epsilon
self.initial_decay = decay
self.amsbound = amsbound
self.weight_decay = float(weight_decay)
self.base_lr = float(lr)
self.tf_cpu_mode = tf_cpu_mode
def get_updates(self, loss, params):
grads = self.get_gradients(loss, params)
self.updates = [K.update_add(self.iterations, 1)]
lr = self.lr
if self.initial_decay > 0:
lr = lr * (1. / (1. + self.decay * K.cast(self.iterations,
K.dtype(self.decay))))
t = K.cast(self.iterations, K.floatx()) + 1
# Applies bounds on actual learning rate
step_size = lr * (K.sqrt(1. - K.pow(self.beta_2, t)) /
(1. - K.pow(self.beta_1, t)))
final_lr = self.final_lr * lr / self.base_lr
lower_bound = final_lr * (1. - 1. / (self.gamma * t + 1.))
upper_bound = final_lr * (1. + 1. / (self.gamma * t))
e = K.tf.device("/cpu:0") if self.tf_cpu_mode > 0 else None
if e: e.__enter__()
ms = [K.zeros(K.int_shape(p), dtype=K.dtype(p)) for p in params]
vs = [K.zeros(K.int_shape(p), dtype=K.dtype(p)) for p in params]
if self.amsbound:
vhats = [K.zeros(K.int_shape(p), dtype=K.dtype(p)) for p in params]
else:
vhats = [K.zeros(1) for _ in params]
if e: e.__exit__(None, None, None)
self.weights = [self.iterations] + ms + vs + vhats
for p, g, m, v, vhat in zip(params, grads, ms, vs, vhats):
# apply weight decay
if self.weight_decay != 0.:
g += self.weight_decay * K.stop_gradient(p)
e = K.tf.device("/cpu:0") if self.tf_cpu_mode == 2 else None
if e: e.__enter__()
m_t = (self.beta_1 * m) + (1. - self.beta_1) * g
v_t = (self.beta_2 * v) + (1. - self.beta_2) * K.square(g)
if self.amsbound:
vhat_t = K.maximum(vhat, v_t)
self.updates.append(K.update(vhat, vhat_t))
if e: e.__exit__(None, None, None)
if self.amsbound:
denom = (K.sqrt(vhat_t) + self.epsilon)
else:
denom = (K.sqrt(v_t) + self.epsilon)
# Compute the bounds
step_size_p = step_size * K.ones_like(denom)
step_size_p_bound = step_size_p / denom
bounded_lr_t = m_t * K.minimum(K.maximum(step_size_p_bound,
lower_bound), upper_bound)
p_t = p - bounded_lr_t
self.updates.append(K.update(m, m_t))
self.updates.append(K.update(v, v_t))
new_p = p_t
# Apply constraints.
if getattr(p, 'constraint', None) is not None:
new_p = p.constraint(new_p)
self.updates.append(K.update(p, new_p))
return self.updates
def get_config(self):
config = {'lr': float(K.get_value(self.lr)),
'final_lr': float(self.final_lr),
'beta_1': float(K.get_value(self.beta_1)),
'beta_2': float(K.get_value(self.beta_2)),
'gamma': float(self.gamma),
'decay': float(K.get_value(self.decay)),
'epsilon': self.epsilon,
'weight_decay': self.weight_decay,
'amsbound': self.amsbound}
base_config = super(AdaBound, self).get_config()
return dict(list(base_config.items()) + list(config.items()))