Shubham Tulsiani, Saurabh Gupta, David Fouhey, Alexei A. Efros, Jitendra Malik.
Note: Also see 3D-RelNet that improves on this work by incporporating relationships among objects.
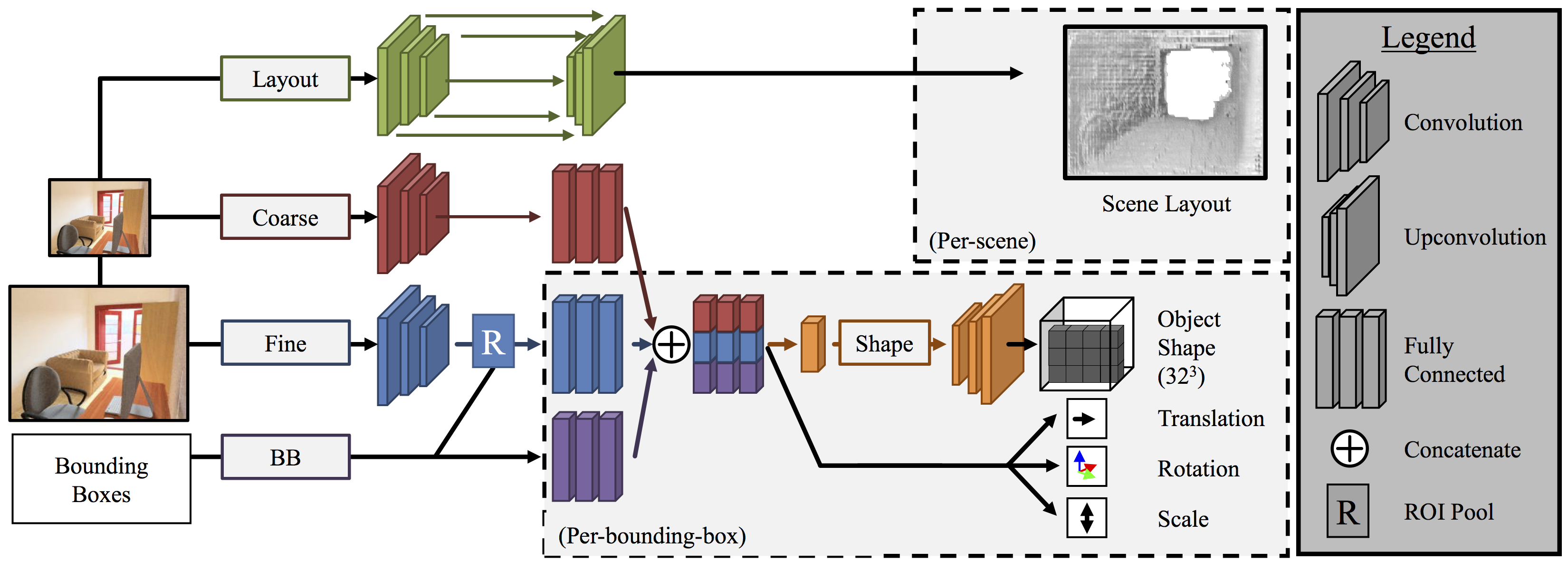
Please check out the interactive notebook which shows reconstructions using the learned models. To run this, you'll first need to follow the installation instructions to download trained models and some pre-requisites.
To train or evaluate the (trained/downloaded) models, it is first required to download the SUNCG dataset and preprocess the data. Please see the detailed README files for Training or Evaluation of models for subsequent instructions.
If you use this code for your research, please consider citing:
@inProceedings{factored3dTulsiani17,
title={Factoring Shape, Pose, and Layout from the 2D Image of a 3D Scene},
author = {Shubham Tulsiani
and Saurabh Gupta
and David Fouhey
and Alexei A. Efros
and Jitendra Malik},
booktitle={Computer Vision and Pattern Regognition (CVPR)},
year={2018}
}












































































































