neuromatchacademy / course-content-dl Goto Github PK
View Code? Open in Web Editor NEWNMA deep learning course
Home Page: https://deeplearning.neuromatch.io/
License: Creative Commons Attribution 4.0 International
NMA deep learning course
Home Page: https://deeplearning.neuromatch.io/
License: Creative Commons Attribution 4.0 International











![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")









































































































































Problem description
Accessing this notebook,
submitting the answer on Think! 3.1 and Think! 5 results in NameError: name 'q1' is not defined.
Suggested solution
Change def_button_clicked current function body into the following:
def on_button_clicked(b):
atform.add_answer('q1', text.value)
print("Submission successful!")
The same solution can be applied to Think! 5, by changing the current function body onto:
def on_button_clicked(b):
atform.add_answer('q2', text.value)
print("Submission successful!")
Thanks!
hidden_unit_nums should be a list of int, not int per function documentation
TA feedback on discord.
Hi, it seems that today's tutorial relies on a legacy version of torchtext; to use it, we need to reinstall the entire Pytorch package every time we run the tutorial. This could be very inconvenient if the student's Colab session somehow disconnects during the discussion. Is it possible to migrate the code to use the new torchtext API?
In coding exercise 2.4, there are no specifications neither for tensors x, y, z nor for expected outcomes.
On the other hand, no docstring is provided for the helper function timeFun so don't know what f refers to.
video 3 and video 6 are not clearly embedded in notebooks.
The hyperlink from that should redirect to the notebook has a typo for the Computer Vision project on Image Alignment. The slide can be found here
Currently it is set as: https://colab.research.google.com/github/NeuromatchAcademy/course-content-dl/blob/main/projects/ComputerVision/Image_Alignment.ipynb
but it should be (according to the corresponding GitHub repo), hence no capital letters for Image and Alignment: https://colab.research.google.com/github/NeuromatchAcademy/course-content-dl/blob/main/projects/ComputerVision/image_alignment.ipynb
Some students want to download locally the slides. In week 2, we have added a download link in the markdown of the slides code cell.
Thanks for sharing the course content! I'm going through W2D4 Tutorial 4: Deploying Neural Networks on the Web using Google Colab, and ran into a problem in Section 2.1:
# Create a Flask app object
app = Flask(__name__)
# Define a function to be called when the user accesses the root URL (/)
# Handler
@app.route("/")
def home():
# Return a very simple HTML response
return "<h1>Welcome to Neuromatch</h1>"
# You need ngrok to expose the Flask app outside of the notebook
run_with_ngrok(app)
## Uncomment below to run the app
app.run()
This cell generates
* Running on http://xx-xx-xx.ngrok.io
which leads to an error page:

Did I miss some step when following this tutorial, or should there be a code cell that imports the ngrok authtoken before running the flask app? Perhaps it can be implemented using pyngrok?
Thanks for your help!
Hello!
I hope you are doing well!
We are a security research team. Our tool automatically detected a vulnerability in this repository. We want to disclose it responsibly. GitHub has a feature called Private vulnerability reporting, which enables security research to privately disclose a vulnerability. Unfortunately, it is not enabled for this repository.
Can you enable it, so that we can report it?
Thanks in advance!
PS: you can read about how to enable private vulnerability reporting here: https://docs.github.com/en/code-security/security-advisories/repository-security-advisories/configuring-private-vulnerability-reporting-for-a-repository
drop_last=True used on train loader but on the test
the same is for shuffle=True vs shuffle=False in both W1D3 notebooks. Incosistency?
The formulas for the derivative of LR and update rule might have some typos.
The correct formulas should be
\frac{\partial L_r}{\partial w^{(r)}{ij}}=\frac{\partial L}{\partial w^{(r)}{ij}} + 2\lambda w^{(r)}_{ij}
(add 2 in front of the last term and remove 'cdot')
w^{(r)}{ij}←w^{(r)}{ij}−η\frac{\partial L}{\partial W^{(r)}{ij}}−2 \eta \lambda w^{(r)}{ij}=(1−2 \eta \lambda)w^{(r)}{ij} − \eta \frac{\partial L}{\partial w^{(r)}{ij}}
(reflect the above correction)
TA report: We noticed a weird thing in exercise 4.1: the top 5 categories should be ['gas pump', 'chain saw', 'jinrikisha', 'French horn', 'laptop'], but the fifth category is different for different people! Someone got 'laptop', someone got 'crutch', someone got 'miniskirt'.
We noticed that using the CPU leads to different results comparing with the GPU. The seed seems to work if running the cells multiple times. The issue comes when the notebook runs on the CPU.
For Analytical Exercise 1.1: Loss Gradients (W1D2_Tutorial2):
The current solution is:
∂𝑙𝑜𝑠𝑠/∂𝑤_1 = 2 𝑤_2⋅𝑥⋅(𝑦−𝑤_1⋅𝑤_2⋅𝑥)
∂𝑙𝑜𝑠𝑠/∂𝑤_2 = 2 𝑤_1⋅𝑥⋅(𝑦−𝑤_1⋅𝑤_2⋅𝑥)
It seems that the solution should be:
∂𝑙𝑜𝑠𝑠/∂𝑤_1 = - 2 𝑤_2⋅𝑥⋅(𝑦−𝑤_1⋅𝑤_2⋅𝑥)
∂𝑙𝑜𝑠𝑠/∂𝑤_2 = - 2 𝑤_1⋅𝑥⋅(𝑦−𝑤_1⋅𝑤_2⋅𝑥)
(which also matches the solution provided for dloss_dw() in ShallowNarrowExercise(); coding exercise 1.1)
docstring of the init() method of the Net(nn.Module) class says:
"hidden_unit_nums: int
Number of units in the hidden layer"
suggested correction:
"hidden_unit_nums: list[int]
Number of units per hidden layer"
Class used in both tutorials.
1. Dependency error:
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
torchtext 0.11.1 requires torch==1.10.1, but you have torch 1.9.0+cu111 which is incompatible.
Successfully installed torch-1.9.0+cu111 torchaudio-0.9.0 torchvision-0.10.0+cu1112. !pip3 install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html needs to run with --quiet option.
I remember for people who subscribed to the course last year, you said that the course would be accessible forever. It seems that it is no longer accessible to me. Was the content from 2021 relocated?
Thank you,
-Loïc
When running import tensorflow.compat.v2 as tf, an error shows
AttributeError: module 'tensorflow.python.training.experimental.mixed_precision' has no attribute '_register_wrapper_optimizer_cls'The problem is the incomparable karas installed by !pip install keras-nightly==2.5.0.dev2021020510 --quiet and this line should be deleted.
Another problem is !pip install dm-acme[tf] --quiet, it seems jax is also required when from acme import wrappers. So this should be !pip install dm-acme[jax,tensorflow] --quiet.
import tensorflow.compat.v2 as tf and tf.enable_v2_behavior() is unnecessary for the current tensorflow 2.
In Section 3, Loss function - The loss that we are going to be optimizing, which is often combined with regularization terms (conming up in few days).
Should be coming
Youtube "Video 1: Intro to Representation Learning" is titled W1D3 instead of W1D2

Error because of the manual nltk download. The code is running on colab with no errors.
LookupError. Seems that book does not take into account the NLTK_DATA environment variable.---------------------------------------------------------------------------
LookupError Traceback (most recent call last)
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/nltk/corpus/util.py in __load(self)
83 try:
---> 84 root = nltk.data.find(f"{self.subdir}/{zip_name}")
85 except LookupError:
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/nltk/data.py in find(resource_name, paths)
582 resource_not_found = f"\n{sep}\n{msg}\n{sep}\n"
--> 583 raise LookupError(resource_not_found)
584
LookupError:
**********************************************************************
Resource omw-1.4 not found.
Please use the NLTK Downloader to obtain the resource:
>>> import nltk
>>> nltk.download('omw-1.4')
For more information see: https://www.nltk.org/data.html
Attempted to load corpora/omw-1.4.zip/omw-1.4/
Searched in:
- 'nltk_data/'
- '/home/runner/nltk_data'
- '/opt/hostedtoolcache/Python/3.7.12/x64/nltk_data'
- '/opt/hostedtoolcache/Python/3.7.12/x64/share/nltk_data'
- '/opt/hostedtoolcache/Python/3.7.12/x64/lib/nltk_data'
- '/usr/share/nltk_data'
- '/usr/local/share/nltk_data'
- '/usr/lib/nltk_data'
- '/usr/local/lib/nltk_data'
**********************************************************************
During handling of the above exception, another exception occurred:
LookupError Traceback (most recent call last)
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/ipywidgets/widgets/interaction.py in observer(change)
78 with out:
79 clear_output(wait=True)
---> 80 f(**kwargs)
81 show_inline_matplotlib_plots()
82 for k,w in controls.items():
/tmp/ipykernel_75209/2863717633.py in sample_from_biggan(category, z_magnitude)
7 unit_vector = np.ones((1, 128))/np.sqrt(128)
8 z = z_magnitude * unit_vector
----> 9 y = one_hot_from_names(category, batch_size=1)
10
11 z = torch.from_numpy(z)
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pytorch_pretrained_biggan/utils.py in one_hot_from_names(class_name_or_list, batch_size)
196 class_name = class_name.replace(" ", "_")
197
--> 198 original_synsets = wn.synsets(class_name)
199 original_synsets = list(filter(lambda s: s.pos() == 'n', original_synsets)) # keep only names
200 if not original_synsets:
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/nltk/corpus/util.py in __getattr__(self, attr)
119 raise AttributeError("LazyCorpusLoader object has no attribute '__bases__'")
120
--> 121 self.__load()
122 # This looks circular, but its not, since __load() changes our
123 # __class__ to something new:
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/nltk/corpus/util.py in __load(self)
87
88 # Load the corpus.
---> 89 corpus = self.__reader_cls(root, *self.__args, **self.__kwargs)
90
91 # This is where the magic happens! Transform ourselves into
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/nltk/corpus/reader/wordnet.py in __init__(self, root, omw_reader)
1174 )
1175 else:
-> 1176 self.provenances = self.omw_prov()
1177
1178 # A cache to store the wordnet data of multiple languages
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/nltk/corpus/reader/wordnet.py in omw_prov(self)
1283 provdict = {}
1284 provdict["eng"] = ""
-> 1285 fileids = self._omw_reader.fileids()
1286 for fileid in fileids:
1287 prov, langfile = os.path.split(fileid)
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/nltk/corpus/util.py in __getattr__(self, attr)
119 raise AttributeError("LazyCorpusLoader object has no attribute '__bases__'")
120
--> 121 self.__load()
122 # This looks circular, but its not, since __load() changes our
123 # __class__ to something new:
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/nltk/corpus/util.py in __load(self)
84 root = nltk.data.find(f"{self.subdir}/{zip_name}")
85 except LookupError:
---> 86 raise e
87
88 # Load the corpus.
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/nltk/corpus/util.py in __load(self)
79 else:
80 try:
---> 81 root = nltk.data.find(f"{self.subdir}/{self.__name}")
82 except LookupError as e:
83 try:
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/nltk/data.py in find(resource_name, paths)
581 sep = "*" * 70
582 resource_not_found = f"\n{sep}\n{msg}\n{sep}\n"
--> 583 raise LookupError(resource_not_found)
584
585
LookupError:
**********************************************************************
Resource omw-1.4 not found.
Please use the NLTK Downloader to obtain the resource:
>>> import nltk
>>> nltk.download('omw-1.4')
For more information see: https://www.nltk.org/data.html
Attempted to load corpora/omw-1.4
Searched in:
- 'nltk_data/'
- '/home/runner/nltk_data'
- '/opt/hostedtoolcache/Python/3.7.12/x64/nltk_data'
- '/opt/hostedtoolcache/Python/3.7.12/x64/share/nltk_data'
- '/opt/hostedtoolcache/Python/3.7.12/x64/lib/nltk_data'
- '/usr/share/nltk_data'
- '/usr/local/share/nltk_data'
- '/usr/lib/nltk_data'
- '/usr/local/lib/nltk_data'
**********************************************************************PermissionError . Set the environment variable NLTK_DATA. Take a look here, in "Manual Installation" subsection.---------------------------------------------------------------------------
PermissionError Traceback (most recent call last)
/tmp/ipykernel_76242/1588152815.py in <module>
14
15 with zipfile.ZipFile(fname, 'r') as zip_ref:
---> 16 zip_ref.extractall('/usr/local/lib/nltk_data/corpora')
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/zipfile.py in extractall(self, path, members, pwd)
1634
1635 for zipinfo in members:
-> 1636 self._extract_member(zipinfo, path, pwd)
1637
1638 @classmethod
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/zipfile.py in _extract_member(self, member, targetpath, pwd)
1680 upperdirs = os.path.dirname(targetpath)
1681 if upperdirs and not os.path.exists(upperdirs):
-> 1682 os.makedirs(upperdirs)
1683
1684 if member.is_dir():
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/os.py in makedirs(name, mode, exist_ok)
211 if head and tail and not path.exists(head):
212 try:
--> 213 makedirs(head, exist_ok=exist_ok)
214 except FileExistsError:
215 # Defeats race condition when another thread created the path
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/os.py in makedirs(name, mode, exist_ok)
221 return
222 try:
--> 223 mkdir(name, mode)
224 except OSError:
225 # Cannot rely on checking for EEXIST, since the operating system
PermissionError: [Errno 13] Permission denied: '/usr/local/lib/nltk_data'IndexError: list index out of range!pip install torchtext==0.4.0 --quiet is a quite old version. Many functions are moved to torchtext.legacy.
Section 9 ('Section 9: Transformers beyond Language models') lists Dalle-2 by OpenAI as an example for artistic use. The original dall-e model was transformer based (as is the derivative dalle-mini) but Dalle 2 uses diffusion models instead. A more appropriate link might be Google's Parti, which does use transformers: https://parti.research.google/
In Coding Exercise 1, it would be good to be able to inspect the weights, besides the relu activations. Otherwise it might not be clear how one can achieve a downward slope using relus.
Btw, I'm not sure if this is the right place to make suggestions. It might be that only issues should be reported here. If that's the case, could you point to me where suggestions should be made?
Thanks!
The top 5 names provided in the solution given for Coding Exercise 4.1 does not match with the results obtained:

The last two entries are different.
There might be some error in W2D2's tutorial1, section 3.1 and section 3.2 should be in section 2 because these two talked about kernels instead of pooling. In addition, in the last part of W2D2 tutorial 1, the content should be updated since we no longer talk about RNN. Should modify the following paragraph 'Summary In this Tutorial we have familiarized ouselves with CNNs. We have leaned how the convolution operation works and be applied in various images. Also, we have learned to implement our own CNN. In the next Tutorial, we will go deeper in the training of CNNs!
Next we will talk about RNNs, which shares parameters over time.'
In section 3.2, 1 output layer of size 2 (we want the have the scores for the two classes)
Should be we want to have.
In section 4 under ResNet, the tutorial doesn't run, it fails with the following error:
AttributeError Traceback (most recent call last)
in
19
20 dataiter = iter(imagenette_val_loader)
---> 21 images, labels = dataiter.next()
22
23 # Show images
AttributeError: '_MultiProcessingDataLoaderIter' object has no attribute 'next'
changing it to read like this fixed it:
images, labels = next(dataiter)
Videos aren't loading in the book! All areas where the youtube video box should appear are empty.
In the tutorial page, the YouTube Playlist for W1D3 links to the playlist for W1D1 (instead of W1D3).
In W1D3_Tutorial1:
Video 3: Build MLP is not set up properly. It seems that the video id is missing:
video = YouTubeVideo(id=f"", width=854, height=480, fs=1, rel=0)
(Never mind if the video is not ready. But it seems all other videos are set properly, at least for Youtube)
Two errors are shown in the book, however, the code is running both in colab and kaggle, with and without GPU.
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
/tmp/ipykernel_78156/4063079351.py in <module>
31 num_episodes=500,
32 logger_time_delta=1.,
---> 33 log_loss=True)
/tmp/ipykernel_78156/2897171516.py in run_loop(environment, agent, num_episodes, num_steps, logger_time_delta, label, log_loss)
61 # Have the agent observe the timestep and let the agent update itself.
62 agent.observe(action, next_timestep=timestep)
---> 63 agent.update()
64
65 # Book-keeping.
/tmp/ipykernel_78156/3895108329.py in update(self)
57 # Note: each of these tensors will be of shape [batch_size, ...].
58 s = torch.tensor(transitions.state)
---> 59 a = torch.tensor(transitions.action,dtype=torch.int64)
60 r = torch.tensor(transitions.reward)
61 d = torch.tensor(transitions.discount)
TypeError: can't convert np.ndarray of type numpy.object_. The only supported types are: float64, float32, float16, complex64, complex128, int64, int32, int16, int8, uint8, and bool.---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
/tmp/ipykernel_78156/3921631369.py in <module>
45 agent=agent,
46 num_episodes=num_episodes,
---> 47 num_steps=100000)
/tmp/ipykernel_78156/2897171516.py in run_loop(environment, agent, num_episodes, num_steps, logger_time_delta, label, log_loss)
61 # Have the agent observe the timestep and let the agent update itself.
62 agent.observe(action, next_timestep=timestep)
---> 63 agent.update()
64
65 # Book-keeping.
/tmp/ipykernel_78156/3414276715.py in update(self)
64 # Note: each of these tensors will be of shape [batch_size, ...].
65 s = torch.tensor(transitions.state)
---> 66 a = torch.tensor(transitions.action,dtype=torch.int64)
67 r = torch.tensor(transitions.reward)
68 d = torch.tensor(transitions.discount)
TypeError: can't convert np.ndarray of type numpy.object_. The only supported types are: float64, float32, float16, complex64, complex128, int64, int32, int16, int8, uint8, and bool.(Just before Section 2.1) The notebook tries to compare the results of models with and without dropout and the results (losses) are quite similar (I guess they are supposed to be different?)
It seems that both the losses for the model with dropout (test_loss_dp; in the section above "Animation! (Run Me!)") and losses for the model without dropout (test_loss; in the "Run to train the default network" section) are obtained from the Net() model, in which the Dropout is applied.
Maybe the model used in the 'Run to train the default network' section should be a certain model without Dropout.
Hope I do not understand the codes incorrectly.
The run the loop section in the human_rl notebook produces a very large piece of output, making the rest of the notebook difficult to reach due to the scrolling.
Either discarding the outputs or setting the n_episodes=10 would resolve the issue (it's in the second line of the cell below the section title).
the instruction was not clear on what to put for the parameters (mean and STD) of the function transforms.Normalize()
Section 5.1: Linear Regression
The second paragraph says:
"The independent variables are collected... , where N denotes the number of independent variables. ..."
The N seems to denote the number of dependent (instead of independent) variables.
Interactive Demo 3.3: Solving XOR
Do you think we can solve the discrete XOR (only 4 possibilities) with only 2 hidden units?
The correct answer shows to be "no".
We can solve XOR using MLP (2 hidden units in a hidden layer). So I think the answer should be yes.
There is a misspell in the solution of Exercise 7.5.1, line 6
Torch code that I ran with no problem on Google Colab (default configuration) a year ago is now failing with an out-of-memory error. Specifically, calling torch.nn.functional.cosine_similarity() seems to require around double the amount of memory it used to, to the point where this fails:
import torch
mat = torch.nn.functional.cosine_similarity(torch.rand((1, 4000, 100)), torch.rand((4000, 1, 100)), dim=2)
as the operation requires more than the amount of RAM available (12.7 GB). If I run the same but on a GPU (15 GB of RAM), I get the following error when it crashes:
OutOfMemoryError: CUDA out of memory. Tried to allocate 5.96 GiB (GPU 0; 14.75 GiB total capacity; 12.05 GiB already allocated; 2.57 GiB free; 12.06 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
These errors occur with torch==2.0.1+cu118 and torchvision==0.15.2+cu118. If we downgrade to torch==1.11.0+cu102 and torchvision==0.12.0+cu102, the code runs fine.
For more see the Issue report on pytorch github page pytorch/pytorch#104564
Hey, it seems the link to the google collab in robolympics.ipynb is broken (at least for me...).
Thanks for fixing :)
W3D3_Tutorial1: Coding Exercise 5
In the last line (Line 48), the win_rate_player1 is not calculated based on the result in Line 46. win_rate_player1 still displays the value calculated in Section 3.
Probably win_rate_player1 = result[0]/num_games # result[0] is the number of times that player 1 wins should be added after Line 46.
W3D3_Tutorial1: Section 5.1
The title does not match the two players in the codes.
According to the title (if I understand correctly), this section would like to compare the sample-based player and the "greedy" player, which duplicates Section 5.3.
But according to the code, this section compares the sample-based player with a random player.
Maybe the title for Section 5.1 should be updated to match the codes.
Several Errors appear in the book:
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in _dep_map(self)
3030 try:
-> 3031 return self.__dep_map
3032 except AttributeError:
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in __getattr__(self, attr)
2824 if attr.startswith('_'):
-> 2825 raise AttributeError(attr)
2826 return getattr(self._provider, attr)
AttributeError: _DistInfoDistribution__dep_map
During handling of the above exception, another exception occurred:
AttributeError Traceback (most recent call last)
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in _parsed_pkg_info(self)
3021 try:
-> 3022 return self._pkg_info
3023 except AttributeError:
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in __getattr__(self, attr)
2824 if attr.startswith('_'):
-> 2825 raise AttributeError(attr)
2826 return getattr(self._provider, attr)
AttributeError: _pkg_info
During handling of the above exception, another exception occurred:
FileNotFoundError Traceback (most recent call last)
/tmp/ipykernel_74829/233875289.py in <module>
29
30 # textattack
---> 31 from textattack.transformations import WordSwapQWERTY
32 from textattack.transformations import WordSwapExtend
33 from textattack.transformations import WordSwapContract
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/textattack/__init__.py in <module>
9 TextAttack provides components for common NLP tasks like sentence encoding, grammar-checking, and word replacement that can be used on their own.
10 """
---> 11 from .attack_args import AttackArgs, CommandLineAttackArgs
12 from .augment_args import AugmenterArgs
13 from .dataset_args import DatasetArgs
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/textattack/attack_args.py in <module>
11
12 import textattack
---> 13 from textattack.shared.utils import ARGS_SPLIT_TOKEN, load_module_from_file
14
15 from .attack import Attack
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/textattack/shared/__init__.py in <module>
13 from . import validators
14
---> 15 from .attacked_text import AttackedText
16 from .word_embeddings import AbstractWordEmbedding, WordEmbedding, GensimWordEmbedding
17 from .checkpoint import AttackCheckpoint
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/textattack/shared/attacked_text.py in <module>
10 import math
11
---> 12 import flair
13 from flair.data import Sentence
14 import numpy as np
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/flair/__init__.py in <module>
18
19 from . import data
---> 20 from . import models
21 from . import visual
22 from . import trainers
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/flair/models/__init__.py in <module>
----> 1 from .sequence_tagger_model import SequenceTagger, MultiTagger
2 from .language_model import LanguageModel
3 from .text_classification_model import TextClassifier
4 from .pairwise_classification_model import TextPairClassifier
5 from .relation_extractor_model import RelationExtractor
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/flair/models/sequence_tagger_model.py in <module>
15 from tqdm import tqdm
16
---> 17 import flair.nn
18 from flair.data import Dictionary, Sentence, Label
19 from flair.datasets import SentenceDataset, DataLoader
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/flair/nn/__init__.py in <module>
1 from .dropout import LockedDropout, WordDropout
----> 2 from .model import Model, Classifier, DefaultClassifier
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/flair/nn/model.py in <module>
14 from flair import file_utils
15 from flair.data import DataPoint, Sentence, Dictionary, SpanLabel
---> 16 from flair.datasets import DataLoader, SentenceDataset
17 from flair.training_utils import Result, store_embeddings
18
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/flair/datasets/__init__.py in <module>
275
276 # Expose all relation extraction datasets
--> 277 from .relation_extraction import RE_ENGLISH_SEMEVAL2010
278 from .relation_extraction import RE_ENGLISH_TACRED
279 from .relation_extraction import RE_ENGLISH_CONLL04
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/flair/datasets/relation_extraction.py in <module>
10
11 import conllu
---> 12 import gdown
13
14 import flair
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/gdown/__init__.py in <module>
9
10 __author__ = "Kentaro Wada <[email protected]>"
---> 11 __version__ = pkg_resources.get_distribution("gdown").version
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in get_distribution(dist)
480 dist = Requirement.parse(dist)
481 if isinstance(dist, Requirement):
--> 482 dist = get_provider(dist)
483 if not isinstance(dist, Distribution):
484 raise TypeError("Expected string, Requirement, or Distribution", dist)
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in get_provider(moduleOrReq)
356 """Return an IResourceProvider for the named module or requirement"""
357 if isinstance(moduleOrReq, Requirement):
--> 358 return working_set.find(moduleOrReq) or require(str(moduleOrReq))[0]
359 try:
360 module = sys.modules[moduleOrReq]
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in require(self, *requirements)
899 included, even if they were already activated in this working set.
900 """
--> 901 needed = self.resolve(parse_requirements(requirements))
902
903 for dist in needed:
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in resolve(self, requirements, env, installer, replace_conflicting, extras)
793
794 # push the new requirements onto the stack
--> 795 new_requirements = dist.requires(req.extras)[::-1]
796 requirements.extend(new_requirements)
797
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in requires(self, extras)
2744 def requires(self, extras=()):
2745 """List of Requirements needed for this distro if `extras` are used"""
-> 2746 dm = self._dep_map
2747 deps = []
2748 deps.extend(dm.get(None, ()))
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in _dep_map(self)
3031 return self.__dep_map
3032 except AttributeError:
-> 3033 self.__dep_map = self._compute_dependencies()
3034 return self.__dep_map
3035
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in _compute_dependencies(self)
3040 reqs = []
3041 # Including any condition expressions
-> 3042 for req in self._parsed_pkg_info.get_all('Requires-Dist') or []:
3043 reqs.extend(parse_requirements(req))
3044
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in _parsed_pkg_info(self)
3022 return self._pkg_info
3023 except AttributeError:
-> 3024 metadata = self.get_metadata(self.PKG_INFO)
3025 self._pkg_info = email.parser.Parser().parsestr(metadata)
3026 return self._pkg_info
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in get_metadata(self, name)
1420 return ""
1421 path = self._get_metadata_path(name)
-> 1422 value = self._get(path)
1423 if six.PY2:
1424 return value
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in _get(self, path)
1625
1626 def _get(self, path):
-> 1627 with open(path, 'rb') as stream:
1628 return stream.read()
1629
FileNotFoundError: [Errno 2] No such file or directory: '/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/tqdm-4.62.3.dist-info/METADATA'---------------------------------------------------------------------------
PermissionError Traceback (most recent call last)
/tmp/ipykernel_74829/1089349718.py in <module>
33
34 with tarfile.open(fname) as ft:
---> 35 ft.extractall('/root/.cache')
36 print('Files have been extracted.')
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/tarfile.py in extractall(self, path, members, numeric_owner)
2000 # Do not set_attrs directories, as we will do that further down
2001 self.extract(tarinfo, path, set_attrs=not tarinfo.isdir(),
-> 2002 numeric_owner=numeric_owner)
2003
2004 # Reverse sort directories.
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/tarfile.py in extract(self, member, path, set_attrs, numeric_owner)
2042 self._extract_member(tarinfo, os.path.join(path, tarinfo.name),
2043 set_attrs=set_attrs,
-> 2044 numeric_owner=numeric_owner)
2045 except OSError as e:
2046 if self.errorlevel > 0:
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/tarfile.py in _extract_member(self, tarinfo, targetpath, set_attrs, numeric_owner)
2104 # Create directories that are not part of the archive with
2105 # default permissions.
-> 2106 os.makedirs(upperdirs)
2107
2108 if tarinfo.islnk() or tarinfo.issym():
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/os.py in makedirs(name, mode, exist_ok)
221 return
222 try:
--> 223 mkdir(name, mode)
224 except OSError:
225 # Cannot rely on checking for EEXIST, since the operating system
PermissionError: [Errno 13] Permission denied: '/root/.cache'---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
/tmp/ipykernel_74829/2608392114.py in <module>
19 # @markdown **NOTE:** *Some pre-trained models might not work well with longer texts!*
20
---> 21 generated_responses = generator(input_text, max_length=512, num_return_sequences=num_output_responses)
22
23 print("\n *********** INPUT PROMPT TO THE MODEL ************ \n")
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/transformers/pipelines/text_generation.py in __call__(self, text_inputs, **kwargs)
169 -- The token ids of the generated text.
170 """
--> 171 return super().__call__(text_inputs, **kwargs)
172
173 def preprocess(self, prompt_text, prefix="", handle_long_generation=None, **generate_kwargs):
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/transformers/pipelines/base.py in __call__(self, inputs, num_workers, batch_size, *args, **kwargs)
1099 return self.iterate(inputs, preprocess_params, forward_params, postprocess_params)
1100 else:
-> 1101 return self.run_single(inputs, preprocess_params, forward_params, postprocess_params)
1102
1103 def run_multi(self, inputs, preprocess_params, forward_params, postprocess_params):
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/transformers/pipelines/base.py in run_single(self, inputs, preprocess_params, forward_params, postprocess_params)
1106 def run_single(self, inputs, preprocess_params, forward_params, postprocess_params):
1107 model_inputs = self.preprocess(inputs, **preprocess_params)
-> 1108 model_outputs = self.forward(model_inputs, **forward_params)
1109 outputs = self.postprocess(model_outputs, **postprocess_params)
1110 return outputs
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/transformers/pipelines/base.py in forward(self, model_inputs, **forward_params)
1032 with inference_context():
1033 model_inputs = self._ensure_tensor_on_device(model_inputs, device=self.device)
-> 1034 model_outputs = self._forward(model_inputs, **forward_params)
1035 model_outputs = self._ensure_tensor_on_device(model_outputs, device=torch.device("cpu"))
1036 else:
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/transformers/pipelines/text_generation.py in _forward(self, model_inputs, **generate_kwargs)
204 input_ids = None
205 prompt_text = model_inputs.pop("prompt_text")
--> 206 generated_sequence = self.model.generate(input_ids=input_ids, **generate_kwargs) # BS x SL
207 return {"generated_sequence": generated_sequence, "input_ids": input_ids, "prompt_text": prompt_text}
208
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/torch/autograd/grad_mode.py in decorate_context(*args, **kwargs)
26 def decorate_context(*args, **kwargs):
27 with self.__class__():
---> 28 return func(*args, **kwargs)
29 return cast(F, decorate_context)
30
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/transformers/generation_utils.py in generate(self, inputs, max_length, min_length, do_sample, early_stopping, num_beams, temperature, top_k, top_p, repetition_penalty, bad_words_ids, bos_token_id, pad_token_id, eos_token_id, length_penalty, no_repeat_ngram_size, encoder_no_repeat_ngram_size, num_return_sequences, max_time, max_new_tokens, decoder_start_token_id, use_cache, num_beam_groups, diversity_penalty, prefix_allowed_tokens_fn, logits_processor, stopping_criteria, output_attentions, output_hidden_states, output_scores, return_dict_in_generate, forced_bos_token_id, forced_eos_token_id, remove_invalid_values, synced_gpus, **model_kwargs)
1144 return_dict_in_generate=return_dict_in_generate,
1145 synced_gpus=synced_gpus,
-> 1146 **model_kwargs,
1147 )
1148
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/transformers/generation_utils.py in sample(self, input_ids, logits_processor, stopping_criteria, logits_warper, max_length, pad_token_id, eos_token_id, output_attentions, output_hidden_states, output_scores, return_dict_in_generate, synced_gpus, **model_kwargs)
1681 # sample
1682 probs = nn.functional.softmax(next_token_scores, dim=-1)
-> 1683 next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
1684
1685 # finished sentences should have their next token be a padding token
RuntimeError: Inplace update to inference tensor outside InferenceMode is not allowed.You can make a clone to get a normal tensor before doing inplace update.See https://github.com/pytorch/rfcs/pull/17 for more details.---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
/tmp/ipykernel_74829/2987933151.py in <module>
11 save_steps=50,
12 logging_steps=10,
---> 13 report_to="tensorboard"
14 )
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/transformers/training_args.py in __init__(self, output_dir, overwrite_output_dir, do_train, do_eval, do_predict, evaluation_strategy, prediction_loss_only, per_device_train_batch_size, per_device_eval_batch_size, per_gpu_train_batch_size, per_gpu_eval_batch_size, gradient_accumulation_steps, eval_accumulation_steps, learning_rate, weight_decay, adam_beta1, adam_beta2, adam_epsilon, max_grad_norm, num_train_epochs, max_steps, lr_scheduler_type, warmup_ratio, warmup_steps, log_level, log_level_replica, log_on_each_node, logging_dir, logging_strategy, logging_first_step, logging_steps, logging_nan_inf_filter, save_strategy, save_steps, save_total_limit, save_on_each_node, no_cuda, seed, bf16, fp16, fp16_opt_level, half_precision_backend, bf16_full_eval, fp16_full_eval, tf32, local_rank, xpu_backend, tpu_num_cores, tpu_metrics_debug, debug, dataloader_drop_last, eval_steps, dataloader_num_workers, past_index, run_name, disable_tqdm, remove_unused_columns, label_names, load_best_model_at_end, metric_for_best_model, greater_is_better, ignore_data_skip, sharded_ddp, deepspeed, label_smoothing_factor, adafactor, group_by_length, length_column_name, report_to, ddp_find_unused_parameters, ddp_bucket_cap_mb, dataloader_pin_memory, skip_memory_metrics, use_legacy_prediction_loop, push_to_hub, resume_from_checkpoint, hub_model_id, hub_strategy, hub_token, gradient_checkpointing, fp16_backend, push_to_hub_model_id, push_to_hub_organization, push_to_hub_token, mp_parameters)
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/transformers/training_args.py in __post_init__(self)
828 ):
829 raise ValueError(
--> 830 "Mixed precision training with AMP or APEX (`--fp16` or `--bf16`) and half precision evaluation (`--fp16_full_eval` or `--bf16_full_eval`) can only be used on CUDA devices."
831 )
832
ValueError: Mixed precision training with AMP or APEX (`--fp16` or `--bf16`) and half precision evaluation (`--fp16_full_eval` or `--bf16_full_eval`) can only be used on CUDA devices.Augmenter Class: AttributeError---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in _dep_map(self)
3030 try:
-> 3031 return self.__dep_map
3032 except AttributeError:
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in __getattr__(self, attr)
2824 if attr.startswith('_'):
-> 2825 raise AttributeError(attr)
2826 return getattr(self._provider, attr)
AttributeError: _DistInfoDistribution__dep_map
During handling of the above exception, another exception occurred:
AttributeError Traceback (most recent call last)
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in _parsed_pkg_info(self)
3021 try:
-> 3022 return self._pkg_info
3023 except AttributeError:
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in __getattr__(self, attr)
2824 if attr.startswith('_'):
-> 2825 raise AttributeError(attr)
2826 return getattr(self._provider, attr)
AttributeError: _pkg_info
During handling of the above exception, another exception occurred:
FileNotFoundError Traceback (most recent call last)
/tmp/ipykernel_74829/1241122631.py in <module>
3 ===================
4 """
----> 5 from textattack.constraints import PreTransformationConstraint
6 from textattack.shared import AttackedText, utils
7
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/textattack/__init__.py in <module>
9 TextAttack provides components for common NLP tasks like sentence encoding, grammar-checking, and word replacement that can be used on their own.
10 """
---> 11 from .attack_args import AttackArgs, CommandLineAttackArgs
12 from .augment_args import AugmenterArgs
13 from .dataset_args import DatasetArgs
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/textattack/attack_args.py in <module>
13 from textattack.shared.utils import ARGS_SPLIT_TOKEN, load_module_from_file
14
---> 15 from .attack import Attack
16 from .dataset_args import DatasetArgs
17 from .model_args import ModelArgs
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/textattack/attack.py in <module>
11
12 import textattack
---> 13 from textattack.attack_results import (
14 FailedAttackResult,
15 MaximizedAttackResult,
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/textattack/attack_results/__init__.py in <module>
6 """
7
----> 8 from .attack_result import AttackResult
9 from .maximized_attack_result import MaximizedAttackResult
10 from .failed_attack_result import FailedAttackResult
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/textattack/attack_results/attack_result.py in <module>
8
9 from textattack.goal_function_results import GoalFunctionResult
---> 10 from textattack.shared import utils
11
12
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/textattack/shared/__init__.py in <module>
13 from . import validators
14
---> 15 from .attacked_text import AttackedText
16 from .word_embeddings import AbstractWordEmbedding, WordEmbedding, GensimWordEmbedding
17 from .checkpoint import AttackCheckpoint
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/textattack/shared/attacked_text.py in <module>
10 import math
11
---> 12 import flair
13 from flair.data import Sentence
14 import numpy as np
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/flair/__init__.py in <module>
18
19 from . import data
---> 20 from . import models
21 from . import visual
22 from . import trainers
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/flair/models/__init__.py in <module>
----> 1 from .sequence_tagger_model import SequenceTagger, MultiTagger
2 from .language_model import LanguageModel
3 from .text_classification_model import TextClassifier
4 from .pairwise_classification_model import TextPairClassifier
5 from .relation_extractor_model import RelationExtractor
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/flair/models/sequence_tagger_model.py in <module>
15 from tqdm import tqdm
16
---> 17 import flair.nn
18 from flair.data import Dictionary, Sentence, Label
19 from flair.datasets import SentenceDataset, DataLoader
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/flair/nn/__init__.py in <module>
1 from .dropout import LockedDropout, WordDropout
----> 2 from .model import Model, Classifier, DefaultClassifier
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/flair/nn/model.py in <module>
14 from flair import file_utils
15 from flair.data import DataPoint, Sentence, Dictionary, SpanLabel
---> 16 from flair.datasets import DataLoader, SentenceDataset
17 from flair.training_utils import Result, store_embeddings
18
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/flair/datasets/__init__.py in <module>
275
276 # Expose all relation extraction datasets
--> 277 from .relation_extraction import RE_ENGLISH_SEMEVAL2010
278 from .relation_extraction import RE_ENGLISH_TACRED
279 from .relation_extraction import RE_ENGLISH_CONLL04
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/flair/datasets/relation_extraction.py in <module>
10
11 import conllu
---> 12 import gdown
13
14 import flair
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/gdown/__init__.py in <module>
9
10 __author__ = "Kentaro Wada <[email protected]>"
---> 11 __version__ = pkg_resources.get_distribution("gdown").version
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in get_distribution(dist)
480 dist = Requirement.parse(dist)
481 if isinstance(dist, Requirement):
--> 482 dist = get_provider(dist)
483 if not isinstance(dist, Distribution):
484 raise TypeError("Expected string, Requirement, or Distribution", dist)
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in get_provider(moduleOrReq)
356 """Return an IResourceProvider for the named module or requirement"""
357 if isinstance(moduleOrReq, Requirement):
--> 358 return working_set.find(moduleOrReq) or require(str(moduleOrReq))[0]
359 try:
360 module = sys.modules[moduleOrReq]
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in require(self, *requirements)
899 included, even if they were already activated in this working set.
900 """
--> 901 needed = self.resolve(parse_requirements(requirements))
902
903 for dist in needed:
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in resolve(self, requirements, env, installer, replace_conflicting, extras)
793
794 # push the new requirements onto the stack
--> 795 new_requirements = dist.requires(req.extras)[::-1]
796 requirements.extend(new_requirements)
797
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in requires(self, extras)
2744 def requires(self, extras=()):
2745 """List of Requirements needed for this distro if `extras` are used"""
-> 2746 dm = self._dep_map
2747 deps = []
2748 deps.extend(dm.get(None, ()))
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in _dep_map(self)
3031 return self.__dep_map
3032 except AttributeError:
-> 3033 self.__dep_map = self._compute_dependencies()
3034 return self.__dep_map
3035
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in _compute_dependencies(self)
3040 reqs = []
3041 # Including any condition expressions
-> 3042 for req in self._parsed_pkg_info.get_all('Requires-Dist') or []:
3043 reqs.extend(parse_requirements(req))
3044
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in _parsed_pkg_info(self)
3022 return self._pkg_info
3023 except AttributeError:
-> 3024 metadata = self.get_metadata(self.PKG_INFO)
3025 self._pkg_info = email.parser.Parser().parsestr(metadata)
3026 return self._pkg_info
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in get_metadata(self, name)
1420 return ""
1421 path = self._get_metadata_path(name)
-> 1422 value = self._get(path)
1423 if six.PY2:
1424 return value
/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/pkg_resources/__init__.py in _get(self, path)
1625
1626 def _get(self, path):
-> 1627 with open(path, 'rb') as stream:
1628 return stream.read()
1629
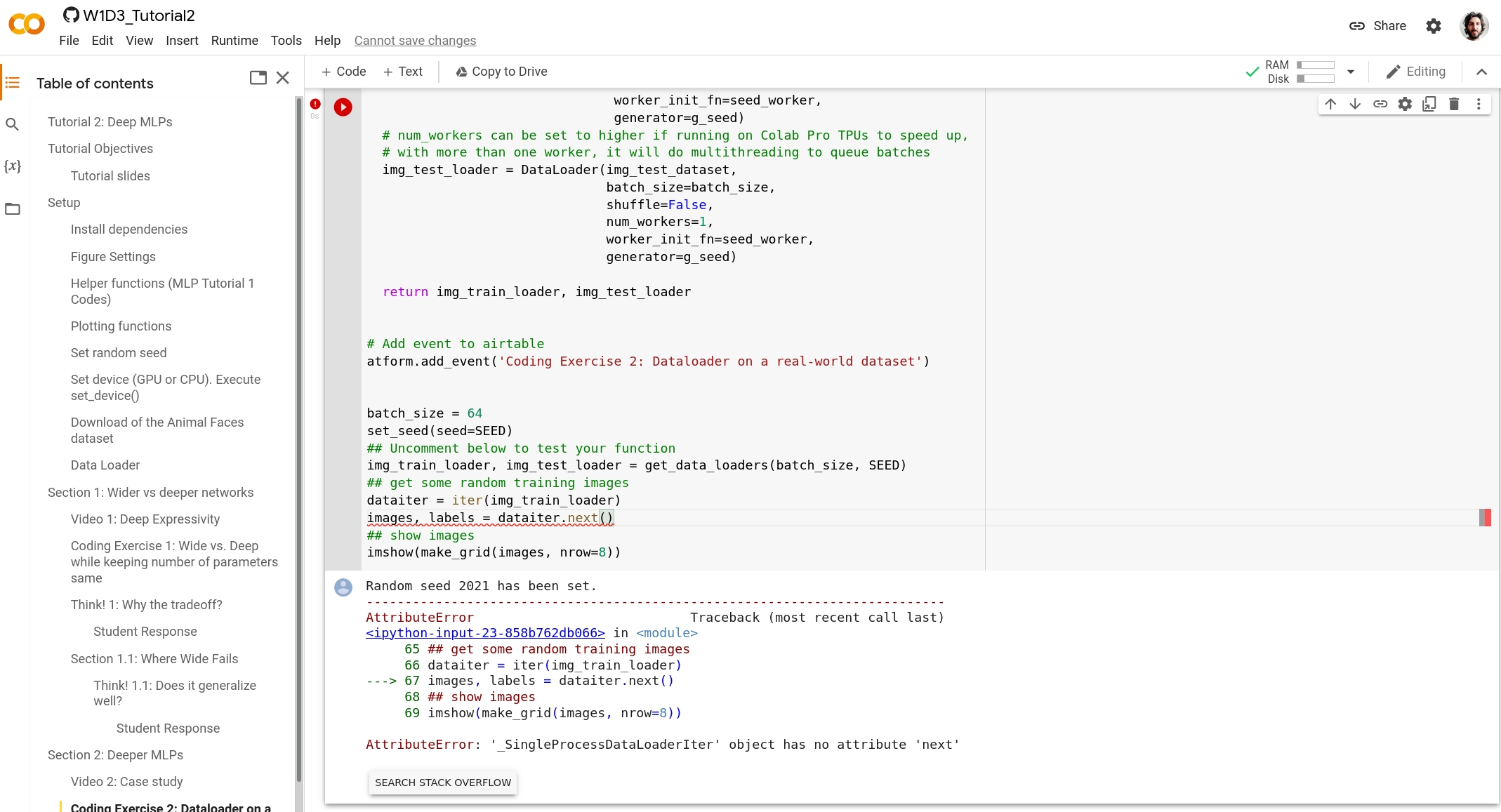
FileNotFoundError: [Errno 2] No such file or directory: '/opt/hostedtoolcache/Python/3.7.12/x64/lib/python3.7/site-packages/urllib3-1.26.7.dist-info/METADATA'In Coding Exercise 2: Dataloader on a real-world dataset, the return for the function seems missing.
Specifically, probably return img_train_loader, img_test_loader should be added for function get_data_loaders(batch_size, seed).
The code produce no error during the book generation process. But, the videos are not shown in the book. See here: https://deeplearning.neuromatch.io/tutorials/W2D1_ConvnetsAndRecurrentNeuralNetworks/student/W2D1_Tutorial1.html
Add all text-based links in [text](url) format for being clickable on jupyterbook.
In Coding Exercise 1: Function approximation with ReLU. The plotting only consists of basis ReLu functions and approximated function. This is very confusing because the basis functions are non-zero everywhere, but the approximated function is a sine function. I recommend adding a weighted Relu activations subplot after the subplot of basis ReLu functions.
The plotting code will be updated to:
def plot_function_approximation(x, combination_weights, relu_acts, y_hat):
"""
Helper function to plot ReLU activations and
function approximations
Args:
x: torch.tensor
Incoming Data
relu_acts: torch.tensor
Computed ReLU activations for each point along the x axis (x)
y_hat: torch.tensor
Estimated labels/class predictions
Weighted sum of ReLU activations for every point along x axis
Returns:
Nothing
"""
fig, axes = plt.subplots(3, 1)
fig.set_figheight(12)
fig.set_figwidth(12)
# Plot ReLU Activations
axes[0].plot(x, relu_acts.T);
axes[0].set(xlabel='x',
ylabel='Activation',
title='ReLU Activations - Basis Functions')
labels = [f"ReLU {i + 1}" for i in range(relu_acts.shape[0])]
axes[0].legend(labels, ncol = 2)
weighted_relu = relu_acts * combination_weights[:,None]
axes[1].plot(x, weighted_relu.T);
axes[1].set_ylim([-2, 2])
axes[1].set(xlabel='x',
ylabel='Activation',
title='Weighted ReLU Activations')
# Plot Function Approximation
axes[2].plot(x, torch.sin(x), label='truth')
axes[2].plot(x, y_hat, label='estimated')
axes[2].legend()
axes[2].set(xlabel='x',
ylabel='y(x)',
title='Function Approximation')
#plt.tight_layout()
plt.show()
**And the coding excise will be updated to:**
def approximate_function(x_train, y_train):
"""
Function to compute and combine ReLU activations
Args:
x_train: torch.tensor
Training data
y_train: torch.tensor
Ground truth labels corresponding to training data
Returns:
relu_acts: torch.tensor
Computed ReLU activations for each point along the x axis (x)
y_hat: torch.tensor
Estimated labels/class predictions
Weighted sum of ReLU activations for every point along x axis
x: torch.tensor
x-axis points
"""
# Number of relus
n_relus = x_train.shape[0] - 1
# x axis points (more than x train)
x = torch.linspace(torch.min(x_train), torch.max(x_train), 1000)
## COMPUTE RELU ACTIVATIONS
# First determine what bias terms should be for each of `n_relus` ReLUs
b = -x_train[:-1]
# Compute ReLU activations for each point along the x axis (x)
relu_acts = torch.zeros((n_relus, x.shape[0]))
for i_relu in range(n_relus):
relu_acts[i_relu, :] = torch.relu(x + b[i_relu])
## COMBINE RELU ACTIVATIONS
# Set up weights for weighted sum of ReLUs
combination_weights = torch.zeros((n_relus, ))
# Figure out weights on each ReLU
prev_slope = 0
for i in range(n_relus):
delta_x = x_train[i+1] - x_train[i]
slope = (y_train[i+1] - y_train[i]) / delta_x
combination_weights[i] = slope - prev_slope
prev_slope = slope
# Get output of weighted sum of ReLU activations for every point along x axis
y_hat = combination_weights @ relu_acts
return combination_weights, y_hat, relu_acts, x
# Add event to airtable
atform.add_event('Coding Exercise 1: Function approximation with ReLU')
# Make training data from sine function
N_train = 10
x_train = torch.linspace(0, 2*np.pi, N_train).view(-1, 1)
y_train = torch.sin(x_train)
## Uncomment the lines below to test your function approximation
combination_weights, y_hat, relu_acts, x = approximate_function(x_train, y_train)
with plt.xkcd():
plot_function_approximation(x, combination_weights, relu_acts, y_hat)
Section 2.1 and 2.3 in Tutorial 2 have broken image links
When running W1D3_Tutorial2.ipynb in Colab, the following call:
images, labels = dataiter.next()yields the following AttributeError:
In some tutorials, videos are not shown in the jupyterbook and the code seems to have terminated due to a KeyboardError.
The links and some figures are shown properly. We are looking into this.
Example: https://deeplearning.neuromatch.io/tutorials/W1D5_Regularization/student/W1D5_Tutorial2.html
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
/tmp/ipykernel_4387/2960207448.py in <module>
16 reg_train_loader,
17 reg_val_loader,
---> 18 img_test_dataset)
19
20 # Train and Test accuracy plot
/tmp/ipykernel_4387/2580397162.py in main(args, model, train_loader, val_loader, test_data, reg_function1, reg_function2, criterion)
124 trained_model = train(args, model, train_loader, optimizer, epoch,
125 reg_function1=reg_function1,
--> 126 reg_function2=reg_function2)
127 train_acc = test(trained_model, train_loader, loader='Train', device=device)
128 val_acc = test(trained_model, val_loader, loader='Val', device=device)
/tmp/ipykernel_4387/2580397162.py in train(args, model, train_loader, optimizer, epoch, reg_function1, reg_function2, criterion)
60 device = args['device']
61 model.train()
---> 62 for batch_idx, (data, target) in enumerate(train_loader):
63 data, target = data.to(device), target.to(device)
64 optimizer.zero_grad()
/opt/hostedtoolcache/Python/3.7.11/x64/lib/python3.7/site-packages/torch/utils/data/dataloader.py in __next__(self)
519 if self._sampler_iter is None:
520 self._reset()
--> 521 data = self._next_data()
522 self._num_yielded += 1
523 if self._dataset_kind == _DatasetKind.Iterable and \
/opt/hostedtoolcache/Python/3.7.11/x64/lib/python3.7/site-packages/torch/utils/data/dataloader.py in _next_data(self)
1184
1185 assert not self._shutdown and self._tasks_outstanding > 0
-> 1186 idx, data = self._get_data()
1187 self._tasks_outstanding -= 1
1188 if self._dataset_kind == _DatasetKind.Iterable:
/opt/hostedtoolcache/Python/3.7.11/x64/lib/python3.7/site-packages/torch/utils/data/dataloader.py in _get_data(self)
1150 else:
1151 while True:
-> 1152 success, data = self._try_get_data()
1153 if success:
1154 return data
/opt/hostedtoolcache/Python/3.7.11/x64/lib/python3.7/site-packages/torch/utils/data/dataloader.py in _try_get_data(self, timeout)
988 # (bool: whether successfully get data, any: data if successful else None)
989 try:
--> 990 data = self._data_queue.get(timeout=timeout)
991 return (True, data)
992 except Exception as e:
/opt/hostedtoolcache/Python/3.7.11/x64/lib/python3.7/multiprocessing/queues.py in get(self, block, timeout)
102 if block:
103 timeout = deadline - time.monotonic()
--> 104 if not self._poll(timeout):
105 raise Empty
106 elif not self._poll():
/opt/hostedtoolcache/Python/3.7.11/x64/lib/python3.7/multiprocessing/connection.py in poll(self, timeout)
255 self._check_closed()
256 self._check_readable()
--> 257 return self._poll(timeout)
258
259 def __enter__(self):
/opt/hostedtoolcache/Python/3.7.11/x64/lib/python3.7/multiprocessing/connection.py in _poll(self, timeout)
412
413 def _poll(self, timeout):
--> 414 r = wait([self], timeout)
415 return bool(r)
416
/opt/hostedtoolcache/Python/3.7.11/x64/lib/python3.7/multiprocessing/connection.py in wait(object_list, timeout)
919
920 while True:
--> 921 ready = selector.select(timeout)
922 if ready:
923 return [key.fileobj for (key, events) in ready]
/opt/hostedtoolcache/Python/3.7.11/x64/lib/python3.7/selectors.py in select(self, timeout)
413 ready = []
414 try:
--> 415 fd_event_list = self._selector.poll(timeout)
416 except InterruptedError:
417 return ready
KeyboardInterrupt: In these Interactive Demos the magic cell %%html is used. However, to correctly run the book workflow and to run without error on kaggle, the magic cell call should be placed on top of the corresponding cell. This destroys the hidden cell. Also, these demos contain a lot of coding lines, thus it is hard for the readers if they are not using google colab.
I think they may have skipped a video after the introduction.
In the second video Professor Ganguli starts by saying: "Okay, we've seen that biological neurons are non-linear". And there's a tutorial slide for this content, but I think the video is missing because it wasn't covered.

I tried to search youtube for the missing video but had trouble finding anything.
Thank you
The book generation workflow runs on CPU via github actions. The complete process needs approx. 3.5 hours. This is too much especially during the course. The process must be faster.
Possible workarounds:
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
{kind=link}