medspacy / medspacy Goto Github PK
View Code? Open in Web Editor NEWLibrary for clinical NLP with spaCy.
License: MIT License
Library for clinical NLP with spaCy.
License: MIT License
Dear medspacy developers,
Dr Chapman and I found out the UnicodeDecodingError of trying to run medspacy.load function during the workshop in Sydney held by Dr Chapman. I've later investigated this error and found it is due to one potential shortage in the PyFastNER that this package depends on.
My Windows 10 system was originally a Chinese(Mainland) one whose default coding scheme was called gbk, while the read function of the IOUtils.py file of PyFastNER assumed that every system is an ascii, which is the reason that this problem arises.
I've found that to solve this, I simply changed the function as follows:
#At the start of the file IOUtils.py, adding:
import sys
def read(self, file_name, delimiter):
# read function of IOUtils.py file of the module PyFastNER
# this line was originally:
# with open(file_name, newline='') as csvfile: which causes this problem since not all systems in this world is coded on ascii
with open(file_name, newline='', encoding=sys.getdefaultencoding()) as csvfile:
self.parse(csvfile, delimiter)
pass
The getdefaultencoding function of sys module would automatically manage the default encoding scheme of the user system and therefore get users rid of the UnicodeDecodingError.
and then works all well from my system. I would sincerely suggest to medspacy and PyFastNER that there are more systems than ascii in this world and if on my gbk system this module does not work, it means it would also not work in big-5 systems built for Hongkong and Taiwan who speaks another type of Chinese (Traditional Chinese), and maybe other systems having different encoding schemes such as French, Spanish or German, while the solution is just changing one line of code in your distribution and this multi-language problem can just gone, since utf8 is the encoding system that everyone supports.
I would sincerely hope that you can change this line of coding to add this feature for supporting cross-language use of medspacy. Thank you very much for your attention.
best wishes,
Sam Y.
I am testing out the spacy-v3 branch, on a couple of pretty simple target rules below:
target_rules = [
TargetRule("obsessive-compulsive", "CONDITION",
pattern=[
{"LOWER": {"IN": ["obsessive-compulsive", "obsessive compulsive"]}}]
),
TargetRule("OCD", "CONDITION",
pattern=[
{"LOWER": "ocd"}])
]
However the first rule doesn't seem to match anything even on an obvious sentence:
I have obsessive compulsive disorder also known as OCD.
The second rule is able to find the OCD instance, I really can't figure out why the first rule doesn't work at all. Shouldn't it just match whatever is in {"LOWER": {"IN": ["obsessive-compulsive", "obsessive compulsive"]}} or am I completely missing anything obvious here? Thanks.
Hi,
We currently use from clinical_sectionizer to parse sections from clinical documents. I'd like to migrate to medspacy, but it's not clear from the documentation or test (which are commented out) how to do that.
I currently have this in my code:
from clinical_sectionizer import TextSectionizer
self.textSectionizer=TextSectionizer()
self.textSectionizer.add(patterns=self.new_patterns)
What's the equivalent in medspacy? Thanks for the help!
I tried to use medspacy, but I'm not able to do from the beginning as below:

In a team discussion, we agreed that it would be great to have CI that ensures periodically (maybe every push?) that this runs without problem:
pip install medspacy
The fastest way to process texts with spaCy is:
docs = list(nlp.pipe(texts, n_process=2))However, this raises an exception due to multiprocessing (see examples below). This was first reported in #34
I think that fixing this requires implementing some serialization methods for custom components and classes being used in those components. SpaCy gives some instructions about serialization methods, but we haven't yet taken the time to understand them in detail.
For this to be implemented, this line of code should run:
import medspacy
nlp = medspacy.load("en_core_web_sm", enable="all")
texts = ["Hello, world!"]
docs = list(nlp.pipe(texts, n_process=2))Specifying the section_parent attribute for ents in DocConsumer results in a table in which all the attributes of the section_parent are listed in one cell.


Is there a way to just pick out a single attribute of the section_parent in DocConsumer? For example, accesssing the doc directly, one can write:

If I load quickumls as a ner module, context rules does not work. If I load the same entities manually with TargetRules context rules do work, in the same example.
What: Add SemType/SemGroup lookup for Semantic Type IDs in medspacy (i.e. transform T038 to Biologic Function)
Why: Currently QuickUMLS only attaches Semantic Type IDs (e.g. T038) to extractions, but these friendly names and taxonomy will help to navigate the concepts
During another project, I did this by automating download of NLM files to build lookup tables. This code may be useful, but only as reference. We'll need to add a utility function or some way of looking these up. Note that this uses a pandas DataFrame, but it would be better to not use pandas to associate, but likely use a dict instead.
# let's load UMLS data from these two URLs:
UMLS_SEMANTIC_TYPES_URL = 'https://metamap.nlm.nih.gov/Docs/SemanticTypes_2018AB.txt'
UMLS_SEMANTIC_GROUPS_URL = 'https://metamap.nlm.nih.gov/Docs/SemGroups_2018.txt'
def load_dataframe_from_url(url, delimiter):
f = requests.get(url)
return pd.read_csv(StringIO(f.text), sep=delimiter)
# let's load these into strings and then dataframes
# The format of the file is "Abbreviation|Type Unique Identifier (TUI)|Full Semantic Type Name"
semtypes_df = load_dataframe_from_url(UMLS_SEMANTIC_TYPES_URL, '|')
#The format of the file is "Semantic Group Abbrev|Semantic Group Name|TUI|Full Semantic Type Name"
semgroups_df = load_dataframe_from_url(UMLS_SEMANTIC_GROUPS_URL, '|')
# let's set up column names using the format above
semtypes_df.columns = ["Abbreviation", "TUI", "Full Semantic Type Name"]
semgroups_df.columns = ["Semantic Group Abbrev", "Semantic Group Name", "TUI", "Full Semantic Type Name"]
print(semtypes_df.head())
print(semgroups_df.head())
After merging in changes from the merged-repos branch, the CI jobs failed. It looks to be something with the new package structure, but the tests succeed when run locally.
DocConsumer for some reason does not display the "similarity" attribute correctly when added to the ent attributes. The attached screen shot shows a doc from which I can print the QuickUMLS attributes directly, but when run through DocConsumer, all the attributes except "similarity" print correctly. The error suggests an expectation that "similarity" is a function instead of the float that the attribute is in actuality.

Hey,
I am interested in finding the context (negation, family, uncertain, past history, etc) of the medical text.
As I was going through example notebooks, it was understood that these rules are given explicitly.
Does it mean that all the rules we need to specify for the algorithm? Is it possible to print the output as given by clinspacy (which is mentioned on medspacy page? like (is_negated, is_family, is_historical, is_uncertain etc. )
Thank you.
We'll strip down the custom pipeline to consist of:
The following text is a fragment of a clinical note:
"HEENT: Tympanic membranes are normal bilaterally. Oropharynx is normal, no exudate no erythema. Neck is supple no anterior cervical lymphadenopathy. 3+ kissing tonsils"
I have successfully defined "HEENT:" as a section title with the remaining text as the section body. I want to do two things with the content of the section body.
I find that if I create custom spans for the whole sentences using an on_match function in the SectionRule for HEENT:, I can successfully get the "Medical_Condition" tags that I want. However, doing so causes QuickUMLS skip processing of the tokens in the section body, perhaps because overlapping entities are not allowed or perhaps for some other reason.
Are there any suggestions for how to accomplish both of the things I want to do?
Thanks!
https://www.sciencedirect.com/science/article/pii/S1532046418301576
makes a pretty strong claim of their implementation of ConText being 2 orders of magnitude faster (which I doubt is achievable in spacy) but also more accurate. I think it would be worth trying to match the performance:
https://github.com/jianlins/FastContext
I have some section rules where where two distinct literals map to a single category and that common category is the parent of some subcategories. The Sectionizer allows this but gives a warning asking whether the rules as specified are intentional, which they are in this case. I want to suppress the warning message, but the following code does not do the job. Can someone explain why and what would work?

Hi MedSpaCy,
Thanks for creating such a great library -- I've found it incredibly helpful!
I wonder if you have any thoughts on creating a "temporality" component. That is, for a given entity, when did that entity start happening? This would be useful for symptoms in an HPI (e.g., "Pt initially presented with 2 weeks of productive cough and developed fever 3 days ago.") Symptom duration might give a sense of where a patient is in the course of an illness (e.g., COVID).
I've been developing a naïve approach of a TemporalityComponent, which is an extension on a Span that just looks for the nearest Span labelled as a "DATE". SpaCy's native models (e.g., "en_core_web_sm") label "DATE"s out-of-the-box so it's an easy implementation.
Curious to know if you've considered/evaluated a more sophisticated rules-based approach.
Thanks!
Example:
doc = nlp.tokenizer("PAST MEDICAL HISTORY: ")
list(doc)
>>> [P, A, S, T, M, E, D, I, C, A, L, H, I, S, T, O, R, Y, :]Is it possible to create a context rule where the target entity (or entities) exists within the span of the modifier?
More specifically, where the target rule defines the terms that occur before and after the target entity.
This is relevant for phrases that stretch around other words, such as two-word verbs in English: Cross [entity] off, rule [entity] out, turn [entity] off/on.
For example:
text="Cross diabetes off the list of possibilities"The goal is to capture the negation: cross [entity] off.
I tried the following:
import medspacy
from medspacy.context import ConTextRule, ConTextComponent
from spacy.tokens import Span
nlp = medspacy.load()
doc = nlp(text)
doc.ents = (Span(doc, 1, 2, "CONDITION"),)
context = ConTextComponent(nlp, rules=None)
context_rules = [ConTextRule(literal="cross off",
category="NEGATED_EXISTENCE",
direction="bidirectional",
pattern=[{"LOWER": "cross"},
{"IS_ALPHA": True, "OP":"+"},
{"LOWER": "off"}])]
context.add(context_rules)
context(doc)
print(doc.ents)
print(doc._.context_graph)
print(doc._.context_graph.targets)
print(doc._.context_graph.modifiers)(diabetes,)
<ConTextGraph> with 1 targets and 1 modifiers
(diabetes,)
[<ConTextModifier> [Cross diabetes off, NEGATED_EXISTENCE]]
Both the target and the modifier are found. But they are not linked; the negation of the entity is not registered:
print(doc._.context_graph.edges)
print(doc.ents[0]._.is_negated)
print(doc.ents[0]._.modifiers)[]
False
()
This probably has something to do with the direction settings (forward, backward, bidirectional). These options do not consider a target to be "inside" the modifier.
Is there currently a way to make this work? Maybe by using a different rule definition or another specific setting?
Or would this require a modification of the code with maybe an additional "within" direction?
Thanks!
This function would take a list of docs and return a pandas DataFrame where each row is an entity and columns contain attributes.
If we want to add python 3.6 compatibility back to medspacy, need to fix typechecking of compiled regex patterns in the preprocessor.
Writing down some possible improvements to the visualization tool:
General purpose:
medspacy.visualizer.visualize_ent(doc) -> medspacy.visualizer.render(doc,style='ent')Extensions on displaCy (might be more challenging, not worth the dev time at the moment):
Hi, why in the medspacy-v3 setup file spacy>=2.3.0,<=2.3.2 is being instructed instead of spacy v.3?
Thanks.
I'm attempting to download medspacy using pip install in a Conda environment. When I try nlp = medspacy.load(), I get an error regarding the quicksect package which is imported sequentially by PyRuSHSentencizer. I've checked the quicksect package documentation, and I can't seem to find a definition for quicksect1.

This are the requirements that pip install medspacy downloaded:
PyRuSH-1.0.3.5
jsonschema-3.2.0
medspacy-0.1.0.2
medspacy-quickumls-2.4.1
spacy-2.3.2
I've also tried installing quicksect separately and that fails too with 'tp_print' instead of 'tp_dict' errors that I'm not sure how to interpret.
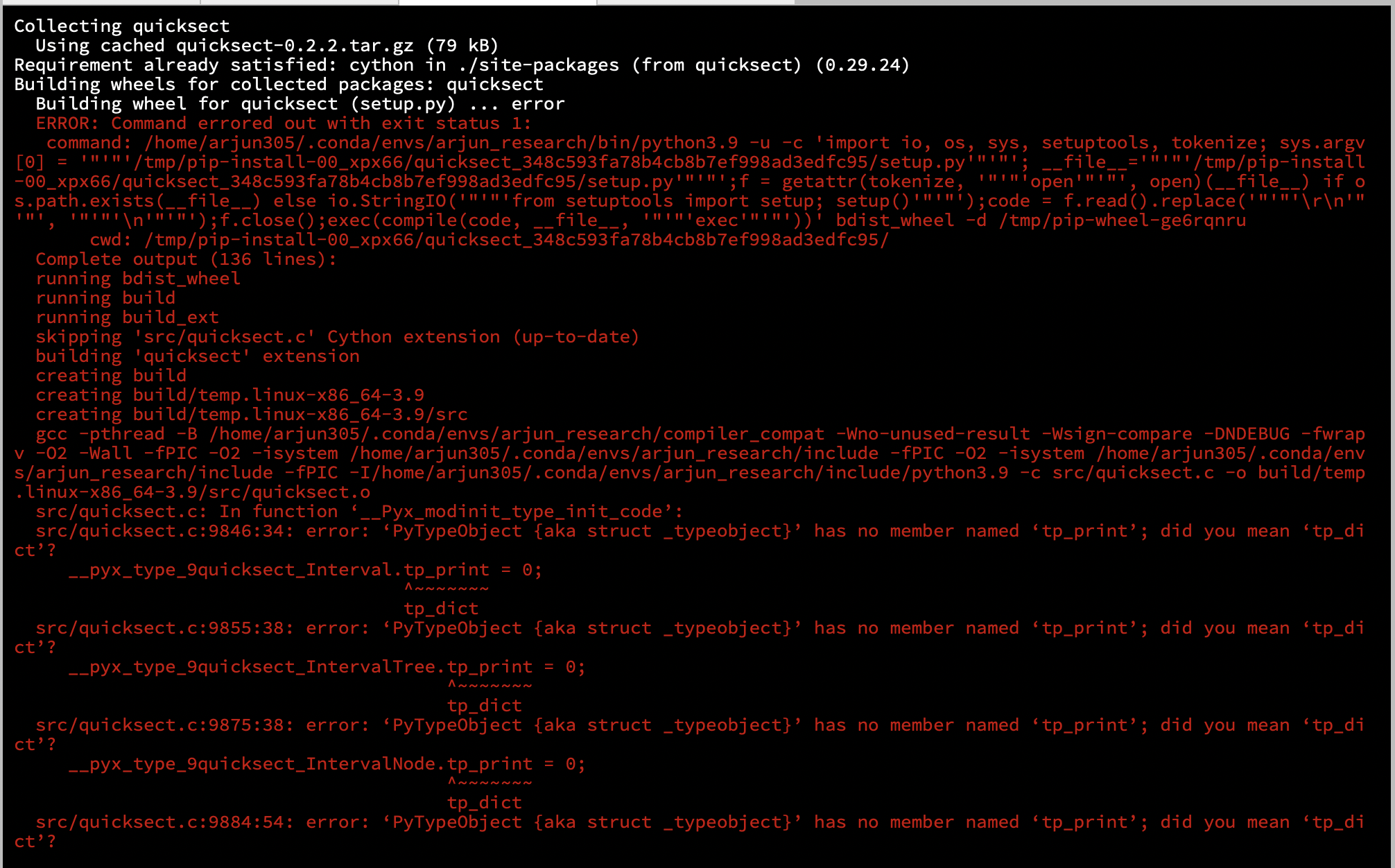
Any help would be appreciated! Thank you!
These notebooks are currently being skipped for one of the following reasons:
en_info_3700_i2b2_2012)en_core_med7_trf might take some time3-Advanced-Modifiers.ipynb)These models are currently being "skipped" by name checking in test_notebooks.py
This seems to be the only line that prevents the usecase. Is this a feature that was abandoned / deprecated ? It seems as long as the targets is a list of Span objects this should work.
I can see this quite often in clinical text where a list like:
Consult:
-2-day history of X
-today Y
-history of Z a few years ago
-Symptom 1: none
-Symptom 2: none
gets processed wrong by PyRUSH:
text_listicle = "Consult\n-2-day history of X\n-Today Y\n-history of Z a few years ago \n-Symptom A: None \n-Symptom B: None\n\n"
for sent in nlp(text_listicle).sents:
print(sent)
print(len(sent))
gives:
Consult
-2-day history of X
-Today Y
-history of Z a few years ago
20
-Symptom A: None
5
-Symptom B: None
5
Versus using PySBD:
Consult
2
-2-day history of X
7
-Today Y
3
-history of Z a few years ago
8
-Symptom A: None
5
-Symptom B: None
5
I could submit a PR with adding PySBD as a spacy 3.0 component since I have it ready if you guys would like (since their repo does not have spacy 3.0 support out of the box right now)
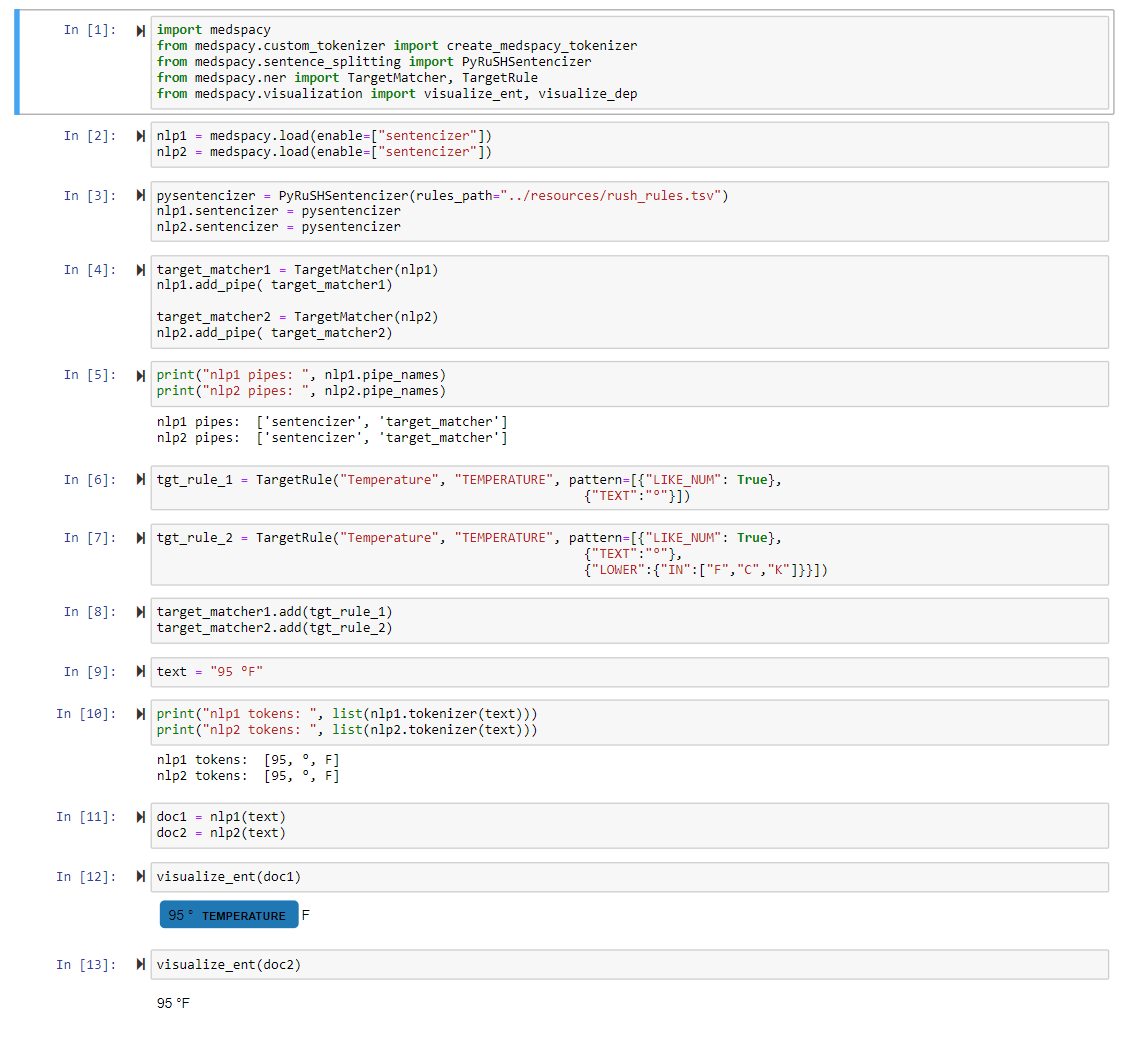
Given that the tokenization for text "95 °F" is [95, °, F], I would expect both of the rules in this test code to work.
Am I doing something wrong or is there a bug?
It would probably be a good idea to show not just which entities where negated, but what was the trigger for the negation. This should not be too much of a problem since the matcher returns the position and all that is needed is to persist that.
are there currently any plans on making medspacy compatible with the 3.0 release?
nlp = medspacy.load("es_core_news_sm", disable={"ner"})
throws an error: line 32, in create_medspacy_tokenizer
infixes = nlp.Defaults.infixes + (r'''[{}]'''.format(re.escape(punctuation_chars)),)
Only way it works is:
nlp = medspacy.load("es_core_news_sm", disable={"tokenizer"})
print(nlp.pipe_names) shows:
['tagger', 'parser', 'ner', 'target_matcher', 'context'], it is not shure which tokenizer is working.
I want to check for medication dosage frequency abbreviations only in the medications section of my document. The Matcher rules in Spacy say I can use syntax like:
TargetRule("Dose Frequency Abbrev.", "DOSE_FREQUENCY", pattern=[{"TEXT": {"IN":["BID","PR","PRN","TOP","QID"], "_":{"section.category":"medications"}}}]),
The syntax for using the "_" keyword in matches as described in the Spacy documenttion is:

However, even with the Sectionizer in the pipeline and my confirming that manually entering for example: doc.ents[10]._.section.category displays the section category correctly, adding in the target rule produces the error:
AttributeError: [E046] Can't retrieve unregistered extension attribute 'section.category'. Did you forget to call the
set_extensionmethod?
I think the problem is that "section" is the registered extended attribute, and its value is a section object that has the property "category", so "section.category" itself is not a recognized extended attribute. Am I right? If so, is there a way I can access this section property in a match rule? Would it require a callback function or just some fancy syntax in the rule?
Hi, I am a spacy user and was looking to explore this library. But I can't find any written documentation and it will take significantly more time to explore the code from source. Is there any written guide for this library or any documentation other than the made with medspacy projects? Any help would highly be appreciated.
With spacy 3.1, overlapping sections of text can now be handled. This is a common issue with clinical concepts where they may overlap and with spacy Entity we choose only 1 based on scores or length since Entity does not allow overlap.
Spacy 3.1 now supports SpanCategorizer and SpanGroup which might be a preferable data structure since it allows overlapping text spans and also probabilities. We may want to change QuickUMLS to emit SpanGroup either in addition to or instead of Entity:
I would like the text "Qual" to be flagged as "qualitative lab result" only if the text occurs in a Section with the section_category "lab_results". The TargetMatcher pattern I tried is:
[{"TEXT":"Qual", "_":{"section_category":"lab_results"}}]
which uses the SpaCy custom attribute specifier to check the value of "section_category". This works fine as long as the entire document has sections. If any portion of the document is not in a section, so that "section_category" is None in that portion, a slightly misleading (at least to me) "integer required" error is generated when trying to process the text.
How can I get around this?
Is there a way to modify the argument of the "_" specifier to handle it?
Or should I write the pattern without the "_" and use an on_match routine to check that I'm in the right section instead? Something like:
TargetRule("Qualitative Result", pattern=[{"TEXT":"Qual"}], on_match=keep_only_if_in_lab_results_section )
pseudo-code for keep_only_if_in_lab_results_section( matcher, doc, i, matches)
if section_category for this part of doc is None, then return
if section_category for this part of doc is not "lab_results", then return
Create Span entity called "Qualitative Result"
return
I suspect this is because we haven't updated medSpaCy to use spaCy 2.3.
Following condition in the sectionizer module does not pass if the id of the candidate parent section's id (candidate_i) is 0
This causes unexpected behavior if a subsection is dependent on the first parent-section of the document.
I assume it's better to replace this check by
if identified_parent is not None or not required:
Hi thanks for the library! I am integrating the sectionizer in my data pipeline, which uses Spacy v3. In sectionizer.py it writes:
Section attributes will be registered for each Doc, Span, and Token in the following attributes:
Doc._.sections: A list of namedtuples of type Section with 4 elements:
- section_title
- section_header
- section_parent
- section_span.
A Doc will also have attributes corresponding to lists of each
(ie., Doc._.section_titles, Doc._.section_headers, Doc._.section_parents, Doc._.section_list)
(Span|Token)._.section_title
(Span|Token)._.section_header
(Span|Token)._.section_parent
(Span|Token)._.section_span
However, I don't see where they are registered? Is this due to the difference between the older version of Spacy and Spacy v3? Is below not needed in the older version?
Token.set_extension("section", default=None, force=True)
Doc.set_extension("sections", default=[], force=True)
Doc.set_extension("section_categories", default=[], force=True)
Doc.set_extension("section_titles", default=[], force=True)
And indeed I get the following error when I test-run the sectionization code:
File "D:\newspacy\section_detection\sectionizer.py", line 322, in __call__
doc._.sections = []
File "D:\bo\env\lib\site-packages\spacy\tokens\underscore.py", line 60, in __setattr__
raise AttributeError(Errors.E047.format(name=name))
AttributeError: [E047] Can't assign a value to unregistered extension attribute 'sections'. Did you forget to call the `set_extension` method?
It seems to be working after I have done set_extension necessary section attributes, but, doc._.section_categories and doc._.section_titles seem to return empty lists always now.
Any suggestions? Thanks again!
Hi, first of all, thanks for creating and open-sourcing this awesome module!
I was wondering how I should approach the problem of sectionizing a text with an incomplete list of SectionRules. For example: I'm only interested in a few sections, so I added SectionRules for those categories in my language. Currently, sections following my section of interest are also included in my section_span of interest. I could make a rule to catch those, but I expect that list could be quite long. Is there a way to put all other sections in an "other"-section? All my sections are separated by an empty line.
I noticed that there isn't a negation pattern that is simply:
"no"
(going forward)
I'm wondering if this is intentional or just an oversight?
We should be able to make sure that all Jupyter notebooks can be executed without problems.
This might be a recipe to follow:
https://github.com/ghego/travis_anaconda_jupyter
When I try to execute "from helpers import create_medspacy_demo_db" in the 12-IO Jupyter Notebook, I get the following error:
ImportError Traceback (most recent call last)
in
----> 1 from helpers import create_medspacy_demo_db
ImportError: cannot import name 'create_medspacy_demo_db' from 'helpers' (C:\Users\Ron\anaconda3\lib\site-packages\helpers_init_.py)
Adding the sectionizer to a pipeline makes it non-picklable, which prevents us from using multiprocessing / n_process argument.
`import spacy
from medspacy.section_detection import Sectionizer
nlp = spacy.load("en")
sect = Sectionizer(nlp, patterns="path_to_patterns")
nlp.add_pipe(sect)
for x in nlp.pipe(["this is text 1", "this is text 2"], n_process=2):
print(x)
PicklingError: Can't pickle <function at 0x7f9337addb80>: attribute lookup on medspacy.section_detection.sectionizer failed`
Getting below error on running the code from one of the notebook (https://github.com/medspacy/medspacy/blob/master/notebooks/01-Introduction.ipynb):
import spacy
nlp2 = spacy.load("en_core_web_sm", disable={"ner"})
nlp2 = medspacy.load(nlp2)
nlp2.pipe_names
context = nlp.get_pipe("context")
context.item_data[:10]
**AttributeError Traceback (most recent call last)
in
----> 1 context.item_data[:10]
AttributeError: 'ConTextComponent' object has no attribute 'item_data'**
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.