![]()

chromiumoxide provides a high-level and async API to control Chrome or Chromium over the DevTools Protocol. It comes with support for all types of the Chrome DevTools Protocol and can launch a headless or full (non-headless) Chrome or Chromium instance or connect to an already running instance.
use futures::StreamExt;
use chromiumoxide::browser::{Browser, BrowserConfig};
#[async_std::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
// create a `Browser` that spawns a `chromium` process running with UI (`with_head()`, headless is default)
// and the handler that drives the websocket etc.
let (mut browser, mut handler) =
Browser::launch(BrowserConfig::builder().with_head().build()?).await?;
// spawn a new task that continuously polls the handler
let handle = async_std::task::spawn(async move {
while let Some(h) = handler.next().await {
if h.is_err() {
break;
}
}
});
// create a new browser page and navigate to the url
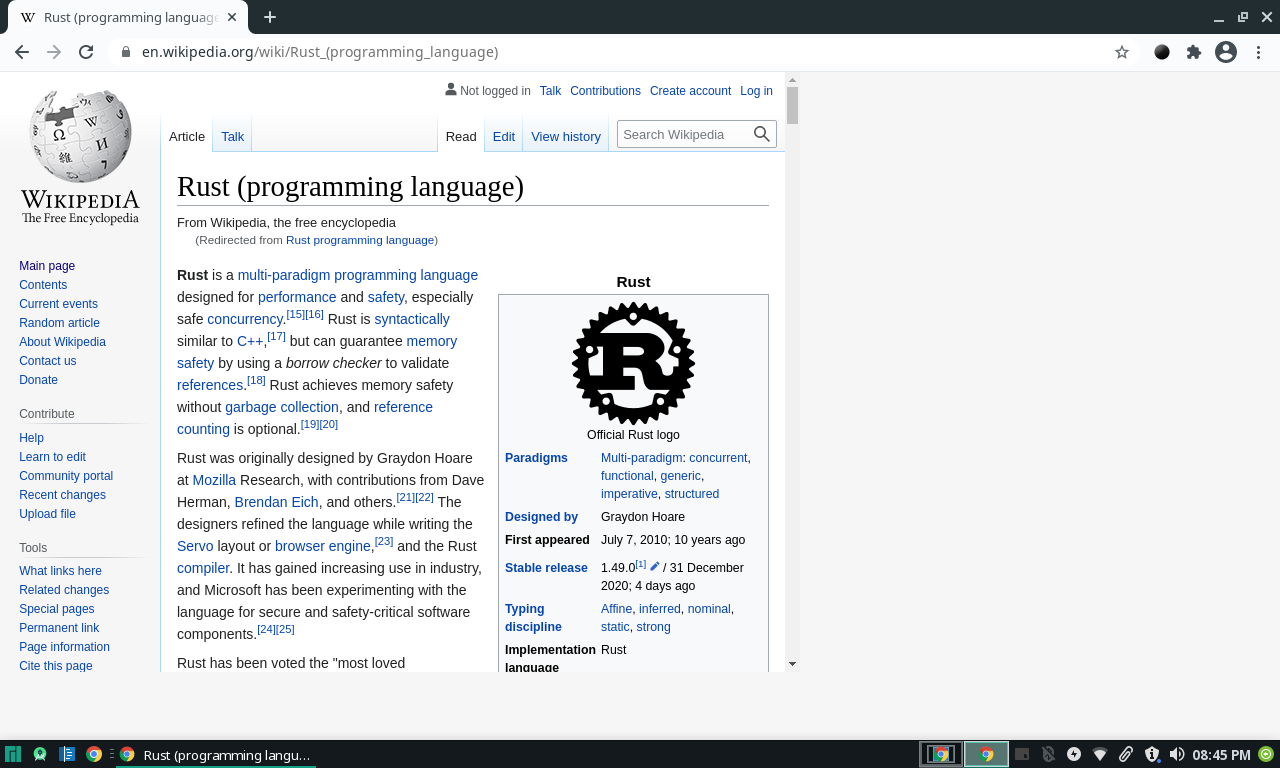
let page = browser.new_page("https://en.wikipedia.org").await?;
// find the search bar type into the search field and hit `Enter`,
// this triggers a new navigation to the search result page
page.find_element("input#searchInput")
.await?
.click()
.await?
.type_str("Rust programming language")
.await?
.press_key("Enter")
.await?;
let html = page.wait_for_navigation().await?.content().await?;
browser.close().await?;
handle.await;
Ok(())
}The current API still lacks some functionality, but the Page::execute function allows sending all chromiumoxide_types::Command types (see Generated Code). Most Element and Page functions are basically just simplified command constructions and combinations, like Page::pdf:
pub async fn pdf(&self, params: PrintToPdfParams) -> Result<Vec<u8>> {
let res = self.execute(params).await?;
Ok(base64::decode(&res.data)?)
}If you need something else, the Page::execute function allows for writing your own command wrappers. PRs are very welcome if you think a meaningful command is missing a designated function.
chromiumoxide comes with support for the async-std and tokio runtime.
By default chromiumoxide is configured with async-std.
Use chromiumoxide with the async-std runtime:
chromiumoxide = { git = "https://github.com/mattsse/chromiumoxide", branch = "main"}To use the tokio runtime instead add features = ["tokio-runtime"] and set default-features = false to disable the default runtime (async-std):
chromiumoxide = { git = "https://github.com/mattsse/chromiumoxide", features = ["tokio-runtime"], default-features = false, branch = "main"}This configuration is made possible primarily by the websocket crate of choice: async-tungstenite.
The chromiumoxide_pdl crate contains a PDL parser, which is a rust rewrite of a python script in the chromium source tree and a Generator that turns the parsed PDL files into rust code. The chromiumoxide_cdp crate only purpose is to invoke the generator during its build process and include the generated output before compiling the crate itself. This separation is done merely because the generated output is ~60K lines of rust code (not including all the proc macro expansions). So expect the compiling to take some time.
The generator can be configured and used independently, see chromiumoxide_cdp/build.rs.
Every chrome pdl domain is put in its own rust module, the types for the page domain of the browser_protocol are in chromiumoxide_cdp::cdp::browser_protocol::page, the runtime domain of the js_protocol in chromiumoxide_cdp::cdp::js_protocol::runtime and so on.
vanilla.aslushnikov.com is a great resource to browse all the types defined in the pdl files. This site displays Command types as defined in the pdl files as Method. chromiumoxid sticks to the Command nomenclature. So for everything that is defined as a command type in the pdl (=marked as Method on vanilla.aslushnikov.com) chromiumoxide contains a type for command and a designated type for the return type. For every command there is a <name of command>Params type with builder support (<name of command>Params::builder()) and its corresponding return type: <name of command>Returns. All commands share an implementation of the chromiumoxide_types::Command trait.
All Events are bundled in single enum (CdpEvent)
By default chromiumoxide will try to find an installed version of chromium on the computer it runs on.
It is possible to download and install one automatically for some platforms using the fetcher.
Ther features are currently a bit messy due to a Cargo bug and will be changed once it is resolved. Based on your runtime and TLS configuration you should enable one of the following:
_fetcher-rustls-async-std_fetcher-rusttls-tokio_fetcher-native-async-std_fetcher-native-tokio
use std::path::Path;
use futures::StreamExt;
use chromiumoxide::browser::{BrowserConfig};
use chromiumoxide::fetcher::{BrowserFetcher, BrowserFetcherOptions};
#[async_std::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let download_path = Path::new("./download");
async_std::fs::create_dir_all(&download_path).await?;
let fetcher = BrowserFetcher::new(
BrowserFetcherOptions::builder()
.with_path(&download_path)
.build()?,
);
let info = fetcher.fetch().await?;
let config = BrowserConfig::builder()
.chrome_executable(info.executable_path)
.build()?,
}- The rust files generated for the PDL files in chromiumoxide_cdp don't compile when support for experimental types is manually turned off (
export CDP_NO_EXPERIMENTAL=true). This is because the use of some experimental pdl types in the*.pdlfiles themselves are not marked as experimental.
Q: A new chromium instance is being launched but then times out.
A: Check that your chromium language settings are set to English. chromiumoxide tries to parse the debugging port from the chromium process output and that is limited to english.
Licensed under either of these:
- Apache License, Version 2.0, (LICENSE-APACHE or https://www.apache.org/licenses/LICENSE-2.0)
- MIT license (LICENSE-MIT or https://opensource.org/licenses/MIT)
- chromedp
- rust-headless-chrome which the launch config,
KeyDefinitionand typing support among others is taken from. - puppeteer