Hi, firstly i thank you @madhawav for providing a very simple and easily understandable repo. Seriously i've been looking for some days for codes that support video, webcam and image with yolo model. finally found this repo. I admire your work.
Now coming to my issue- Hi, I'm trying to create a custom Yolo model in v2( or v3) to detect certain objects in my custom dataset. I tried so many times on this task, but i'm failing. i hope you can help me. Let me clearly mention my issue below:-
Hi i'm trying to do training on custom dataset as per the https://pjreddie.com/darknet/yolov2/ .
I have an image dataset of 9 objects in train(69K) and test(10K) folder. i also have annotation files for all these images in another separate folders train(69K) and test(10K). The Annotation files have same name as that of image with .txt format.
eg of an annotation file is and see the its format below-:
2 0.398 0.451 0.026 0.036
8 0.331 0.451 0.047 0.062
2 0.170 0.459 0.075 0.081
class_no xmin_yolo ymin xmax_yolo ymax_yolo
where - class_no is the classnumber of object(starting from 0, 1, 2, 3, 4.....8, assigned to each object as their unique identifier)
xmin_yolo = float((float((xmax-xmin)/2) + xmin)/width)
ymin_yolo = float((float((ymax-ymin)/2) + ymin)/height)
xmax_yolo = float((xmax-xmin)/width)
ymax_yolo = float((ymax-ymin)/height)
In above equation- xmin, ymin is the x1, y1 coordinates of the bounding box. xmax, ymax is the x2, y2 coordinates of the bounding box
for example, xmin=393, ymin=302, xmax=453, ymax=347, height=720 , width=1280
gives this - 8 0.331 0.451 0.047 0.062, where 8 is the class number
Next created a train.txt, and test.txt file which has path to all images in text and test folders. train.txt looks like:-
/Image-dataset/images/val/ca4071a6-6fa1a1c8.jpg
/Image-dataset/images/val/ca40ddd3-102f3b02.jpg
I created a objects.names file and added these:-
bike
book
car
table
person
woman
trafficlight
trafficsign
truck
Then i created a objects.data file and added these:-
classes= 9
train = /new-dataset/Image-dataset/trainval.txt
valid = /new-dataset/Image-dataset/testval.txt
names = /Yolo/darknet/cfg/objects.names
backup = backup
And the objects.cfg file is this which is yolov2-voc.cfg, modified with classnumber and filter only:-
[net]
batch=20
subdivisions=10
height=416
width=416
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.001
burn_in=1000
max_batches = 80200
policy=steps
steps=40000,60000
scales=.1,.1
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
#######
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[route]
layers=-9
[convolutional]
batch_normalize=1
size=1
stride=1
pad=1
filters=64
activation=leaky
[reorg]
stride=2
[route]
layers=-1,-4
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=70
activation=linear
[region]
anchors = 1.3221, 1.73145, 3.19275, 4.00944, 5.05587, 8.09892, 9.47112, 4.84053, 11.2364, 10.0071
bias_match=1
classes=9
coords=4
num=5
softmax=1
jitter=.3
rescore=1
object_scale=5
noobject_scale=1
class_scale=1
coord_scale=1
absolute=1
thresh = .6
random=1
I also downloaded a pre-trained model - darknet19_448.conv.23
Now i enter the command - ./darknet detector train cfg/objects.data cfg/objects.cfg darknet19_448.conv.23 .
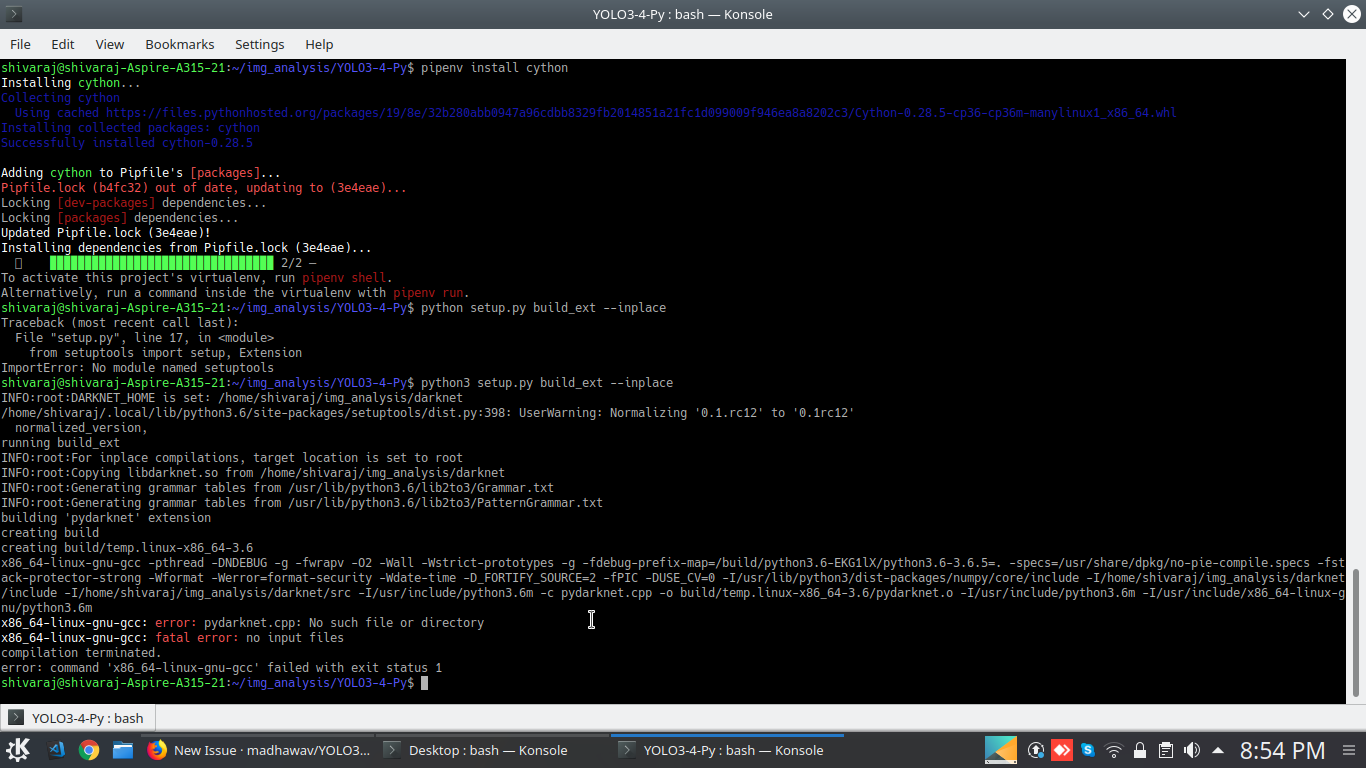
After so many hours i the iteration where completed successfully without any errors(memory errors was cleared) and got inside backup folder. Next i tried the the testing with this command:-
./darknet detector demo cfg/objects.data cfg/objects.cfg backup/vehicles-yolov2-voc_80000.weights '/Test-data/Driving.mp4'
- where vehicles-yolov2-voc_80000.weights is a the model created during iterations.
- and Driving.mp4 is the video
But im not getting any results. also tried with image and webcam. i tried this in command - -thresh 0 . still no results. Do i need to make any change in objects.cfg or any files?
or should i replace any pretrained model or .cfg file with anything else?
i have simply looked into AlexeyAB . still no luck
@madhawav Please help me

 Image source: http://absfreepic.com/free-photos/download/crowded-cars-on-street-4032x2272_48736.html
Image source: http://absfreepic.com/free-photos/download/crowded-cars-on-street-4032x2272_48736.html