isl-org / multiobjectiveoptimization Goto Github PK
View Code? Open in Web Editor NEWSource code for Neural Information Processing Systems (NeurIPS) 2018 paper "Multi-Task Learning as Multi-Objective Optimization"
License: MIT License
Source code for Neural Information Processing Systems (NeurIPS) 2018 paper "Multi-Task Learning as Multi-Objective Optimization"
License: MIT License

























































































































Hi, thanks for releasing this awesome code! Currently, i am working on reproducing the result on cityscapes in paper. I found that in paper the description of mtl update equation say the weights of task specific subnetwork should be updated with original learning rate, then the shared weights of network is updated with the MGDA algorithm. But i didnt find the corresponding implementation in code where both the shared weights and task specific weights are updated consistently by timing loss of different task with a weight factor determined by MGDA. Am i missing something here, or is this a implemention trick?
In this paper, it seems only to conduct experiments on a hard sharing network for MTL, if there exist some differences when using MGDA on a soft sharing network? And if it's yes, Why?
Both the find_min_norm_element (https://github.com/isl-org/MultiObjectiveOptimization/blob/master/multi_task/min_norm_solvers.py#L120) and find_min_norm_element_FW (https://github.com/isl-org/MultiObjectiveOptimization/blob/master/multi_task/min_norm_solvers.py#L166) functions define a while loop based on an iter_count variable.
Line 13 of Algorithm 2 in the paper (https://arxiv.org/pdf/1810.04650.pdf) notes that optimization is done until a number of iterations or convergence threshold is reached. However, the code never actually increments iter_count, and so optimization only terminates based on the convergence threshold.
Hi,
thanks for the open-source code!
I'm looking to implement something like https://openreview.net/forum?id=HJewiCVFPB (Gradient Surgery for Multi-Task Learning) using/on top of this repo, but i'm a little confused about whether the projected descent method that is mentioned in the Readme is something similar already present.
Could you add citations and sources for any additional algorithms and tricks that this repo implements apart from the main paper?
That would be very helpful!
(or alternatively it would be helpful to just get some pointers on what/where to modify to get what i want working)
PS: ^ the paper i mentioned just involves projecting the gradients of all tasks onto the planes of the gradients of the other tasks before doing updates, to avoid gradient conflicts, (for some quick context)
Thanks
I find the input size of CityScapes is 256x512, but in the transform, the target is resize into 32x64. what's more, the measure metrix is based on 32x64.
So, why the target size is not 256x512, just same as the input size?
I use "
"algorithm": "mgda",
"use_approximation": true,", That's mean the MGDA_UB is used。
When I trained the task,At the begin time, It can run true. But when it run some steps, It will get error: "RuntimeError: CUDA out of memory." ,I use torch_version==v1.1.0, Is it torch_version question?
In my test, I found change below code in _min_norm_2d func may spped up train procedure.
def _min_norm_2d(self, vecs, dps):
"""
Find the minimum norm solution as combination of two points
This is correct only in 2D
ie. min_c |\sum c_i x_i|_2^2 st. \sum c_i = 1 , 1 >= c_1 >= 0 for all i, c_i + c_j = 1.0 for some i, j
"""
dmin = 1e8
for i in range(len(vecs)):
for j in range(i + 1, len(vecs)):
if (i, j) not in dps:
dps[(i, j)] = 0.0
# for k in range(len(vecs[i])):
# dps[(i, j)] += torch.dot(vecs[i][k], vecs[j][k]).data[0]
dps[(i, j)] = torch.mm(vecs[i].transpose(1,0), vecs[j])
dps[(j, i)] = dps[(i, j)]
if (i, i) not in dps:
dps[(i, i)] = 0.0
# for k in range(len(vecs[i])):
# dps[(i, i)] += torch.dot(vecs[i][k], vecs[i][k]).data[0]
dps[(i, i)] = torch.mm(vecs[i].transpose(1, 0), vecs[i])
if (j, j) not in dps:
dps[(j, j)] = 0.0
# for k in range(len(vecs[i])):
# dps[(j, j)] += torch.dot(vecs[j][k], vecs[j][k]).data[0]
dps[(j, j)] = torch.mm(vecs[j].transpose(1, 0), vecs[j])
c, d = self._min_norm_element_from2(dps[(i, i)], dps[(i, j)], dps[(j, j)])
if d < dmin:
dmin = d
sol = [(i, j), c, d]
return sol, dpsHi,Thanks you code.
Could you provide the cityscape dataset depth ground truth?
thanks!
I found that if the vecs input into func _min_norm_2d is too large, the whole procedure becomes very slow. In my experiment, the vecs.shape = [39321600,1], and one single training iteration costs 40s, while the _min_norm_2d spends 35s+.
The experiment in your paper assume that the share layers shape is much smaller mine, so I guess maybe this is the point.
I encounter an error UnboundLocalError: local variable 'sol' referenced before assignment
In min_norm_solvers.py,
def _min_norm_2d(vecs, dps):
"""
Find the minimum norm solution as combination of two points
This is correct only in 2D
ie. min_c |\sum c_i x_i|_2^2 st. \sum c_i = 1 , 1 >= c_1 >= 0 for all i, c_i + c_j = 1.0 for some i, j
"""
dmin = 1e8
for i in range(len(vecs)):
for j in range(i+1,len(vecs)):
if (i,j) not in dps:
dps[(i, j)] = 0.0
for k in range(len(vecs[i])):
dps[(i,j)] += torch.mul(vecs[i][k], vecs[j][k]).sum().data.cpu()
dps[(j, i)] = dps[(i, j)]
if (i,i) not in dps:
dps[(i, i)] = 0.0
for k in range(len(vecs[i])):
dps[(i,i)] += torch.mul(vecs[i][k], vecs[i][k]).sum().data.cpu()
if (j,j) not in dps:
dps[(j, j)] = 0.0
for k in range(len(vecs[i])):
dps[(j, j)] += torch.mul(vecs[j][k], vecs[j][k]).sum().data.cpu()
c,d = MinNormSolver._min_norm_element_from2(dps[(i,i)], dps[(i,j)], dps[(j,j)])
if d < dmin:
dmin = d
sol = [(i,j),c,d]
return sol, dps
The sol variable is only assigned if d < dmin, what if d >= dmin always, what should the sol variable be?
I assume that it will be sol = [(i,j),c,dmin], is that right?
Hi, thanks for providing code for your paper
I was wondering, when you do the actual update there:
It looks to me that you are not exactly performing the same thing as what's stated in the paper
https://proceedings.neurips.cc/paper/2018/file/432aca3a1e345e339f35a30c8f65edce-Paper.pdf
On line 2, the "heads" parameters are updated through theta_t = theta_t - eta * grad, but here you do theta_t = theta_t * scale_t * eta * grad
is that correct ?
best
antoine
Thanks for you code.
I want to know where can I find the MultiMNIST dataset used in your paper if it's avaliable now.
Could you please publish the best config for MultiMNIST experiments? I tried with the following but only got ~70% testing accuracy for both tasks, which is much lower than what's reported in your paper.
{
"optimizer": "SGD",
"batch_size": 256,
"lr": 0.0005,
"dataset": "mnist",
"tasks": ["L", "R"],
"normalization_type": "none",
"algorithm": "mgda",
"use_approximation": true,
"scales": {"L":0.5, "R":0.5}
}
Thanks!
Hi, @ozansener, I find that there may be some mismatch among the depth loss, metric and reported results in the paper. In the depth loss, those pixels with <0 loss are excluded, but in the depth metric, pixels with <250 target depth (normalized by mean and std) are all included, So I think they include all the pixels, maybe this is a bug because 250 should be used for segmentation but not depth regression. Also, in Tab. 4 of your paper w.r.t disparity error, are they the direct output of the depth branch of the model in your code? Thanks.
PS: For evaluating the depth regression performance, why should the gt and pred be cast as int?https://github.com/intel-isl/MultiObjectiveOptimization/blob/5d8e8343c56cf3184081f71cc4a661af64e7cf7e/multi_task/metrics.py#L46-L54
how can i get the file named params.json?
Hi Ozen,
I notice that your function encoding_instancemap in cityscapes_loaders.py is strange.
The ignore pixel in variable ins is set to self.ignore_index, as default 250. But those pixel is not instance and 250 are in the range of x_map (I sample a image and calculate it. x_map max is 1038, min is -800, 250 is in the range)
Is it right? or it will be set to (0, 0) for y_map and x_map respectively?
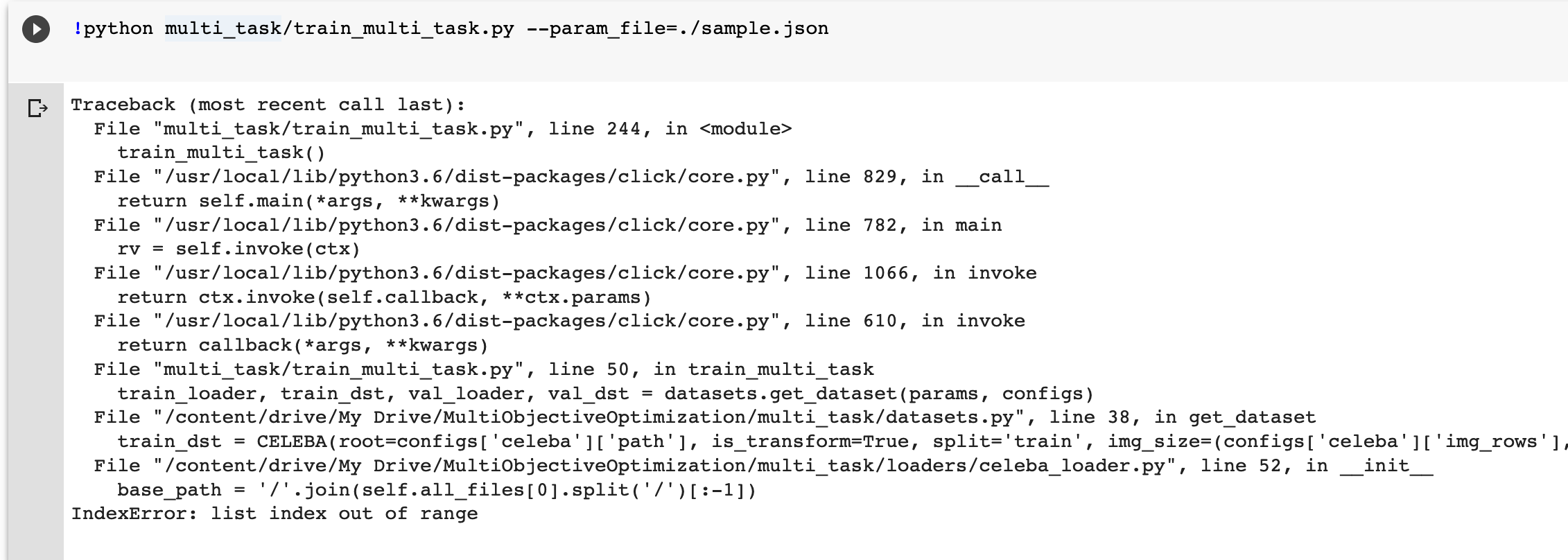
Hi Ozan,
May I ask how to solve this issue? When I read the path in "celeba_loader.py", line 52, it shows an index error. I followed some suggestions from the website but they all do not work. May you help me figure out how to fix this? BTW, I am using a Mac and Google Colab. Both face this error.
Thanks in advance.
Best,
Haolun
Seems like the code only provide classification accuracy and negative log-likelihood loss instead of the mean of error shown in Table 1 in the paper. Is there any way that we can get that number? Thanks!
MultiObjectiveOptimization/multi_task/min_norm_solvers.py
Lines 121 to 122 in d45eb26
Are these lines corresponding to algorithm 2 line 10? For e_{\hat_{t}} ?
This comment mentions a notebook which cannot be found in the repository. Is it available somewhere else?
There are two calls of optimizer.zero_grad()
before optimizer.zero_grad() is called finally in line:
and optimizer.step() is applied.
Are the first two calls of optimizer.zero_grad() necessary or redundant?
Thx
Hello, my backbone has two output. For example, q0, q4 are both reps that will be used in one task head. I don't know how to adjust the code. Could you give me some advices? thanks!
After executing the python multi_task/train_multi_task.py --param_file=./sample.json,
i got error below:
from models.gradient_scaler import MinNormElement
ModuleNotFoundError: No module named 'models.gradient_scaler'
Hi,
Thanks for open sourcing the code, this is great!
Could you share your json parameter file for cityscapes?
Also, I think it is is missing the file depth_mean.npy to be able to run it.
Thanks.
Hello, can anybody tell me how to fix this issue? Is this a version inconsistency with the tensorboardX?
Cuz I am exactly run the code offered on the github without changing anything.
Appreciate in advance.

For example:
model_task0 = ResNet() + FaceAttributeNet()
model_task1 = ResNet() + FaceAttributeNet()
How can i convert the .pkl data to onnx model
Hi, if I use different datasets to each task. Does this algorithm still works? e.g. Three classification tasks on datasets MNIST, ImageNet, Celebra, using multi objective optimization method proposed in your paper. Can I get better performances both on these three classification tasks?
Thanks for your code!
Here is my question.
According to the following code:
# Compute gradients of each loss function wrt z
for t in tasks:
optimizer.zero_grad()
out_t, masks[t] = model[t](rep_variable, None)
loss = loss_fn[t](out_t, labels[t])
loss_data[t] = loss.item()
loss.backward()
grads[t] = []
if list_rep:
grads[t].append(Variable(rep_variable[0].grad.data.clone(), requires_grad=False))
rep_variable[0].grad.data.zero_()
else:
grads[t].append(Variable(rep_variable.grad.data.clone(), requires_grad=False))
rep_variable.grad.data.zero_()
The grads is in the following format:
grads = {'Task_1': [grad_1], 'Task_2': [grad_2]}
where grad_1 and grad_2 are tensors of shape [batch_size, N]
Then the argument vecs of MinNormSolver.find_min_norm_element is in the following format:
vecs = [[grad_1], [grad_2]]
In this way, the vecs[i][k] is not a 1D vector and will lead to error.
def _min_norm_2d(vecs, dps):
"""
Find the minimum norm solution as combination of two points
This is correct only in 2D
ie. min_c |\sum c_i x_i|_2^2 st. \sum c_i = 1 , 1 >= c_1 >= 0 for all i, c_i + c_j = 1.0 for some i, j
"""
dmin = 1e8
for i in range(len(vecs)):
for j in range(i+1,len(vecs)):
if (i,j) not in dps:
dps[(i, j)] = 0.0
for k in range(len(vecs[i])):
dps[(i,j)] += torch.dot(vecs[i][k], vecs[j][k]).item()
dps[(j, i)] = dps[(i, j)]
if (i,i) not in dps:
dps[(i, i)] = 0.0
for k in range(len(vecs[i])):
dps[(i,i)] += torch.dot(vecs[i][k], vecs[i][k]).item()
if (j,j) not in dps:
dps[(j, j)] = 0.0
for k in range(len(vecs[i])):
dps[(j, j)] += torch.dot(vecs[j][k], vecs[j][k]).item()
c,d = MinNormSolver._min_norm_element_from2(dps[(i,i)], dps[(i,j)], dps[(j,j)])
if d < dmin:
dmin = d
sol = [(i,j),c,d]
return sol, dps
Hi,
Thanks for open-sourcing the awesome code.
I am using PyTorch 3.6 to run the equal-weights setup(without using mgda) on Cityscapes with a single GPU, but the GPU usage is extremely unstable and keeps shifting between 0 - 99. Do you know what could cause that?
Thanks
During the inference, i predict instance vectors for x/y coordinates,
How can i get the final instance output?
Thanks for your amazing code. I want to reproduce the cityscapes result.
I use one P40 card and run the training code. However, it doesn't finish one epoch in 4 hours.
I want to know if there are some problems and how long did you train the net in cityscapes dataset.
Thank you very much.
May I ask what should be the correct dimension of grads?
Suppose the output feature map size is 100, and the batch_size is 512, should the rep and grads be of size [512, 100]? And how do you deal with the results of batch_size in the following calculation? Do you average the batchsize results into single result?
In my experiments, when I compute the _min_norm_2d, the input vec is like [[tensor1], [tensor2], [tensor3]], and each tensor is of size 512x100. Therefore, the issue occurs with dps[(i,j)] += torch.dot(vecs[i][k], vecs[j][k]).data[0], RuntimeError: 1D tensors expected, got 2D
The average error on celeba is 8.25 in the paper, but my result is 10.14, which is obtained by directly using the codes in this repo. I list the configurations I used below, is there any problem?
in configs.json
"celeba": {
"path": "data/celeba",
"all_tasks": ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "10", "11", "12", "13", "14", "15", "16", "17", "18", "19", "20",
"21", "22", "23", "24", "25", "26", "27", "28", "29", "30", "31", "32", "33", "34", "35", "36", "37", "38", "39"],
"img_rows": 64,
"img_cols": 64
}
in sample.json
{
"optimizer": "Adam",
"batch_size": 128,
"lr": 0.0005,
"dataset": "celeba",
"tasks": ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "10", "11", "12", "13", "14", "15", "16", "17", "18", "19", "20",
"21", "22", "23", "24", "25", "26", "27", "28", "29", "30", "31", "32", "33", "34", "35", "36", "37", "38", "39"],
"normalization_type": "loss+",
"algorithm": "mgda",
"use_approximation": true,
"scales": {"0":0.025, "1":0.025, "2":0.025, "3":0.025, "4":0.025, "5":0.025, "6":0.025, "7":0.025, "8":0.025, "9":0.025, "10":0.025,
"11":0.025, "12":0.025, "13":0.025, "14":0.025, "15":0.025, "16":0.025, "17":0.025, "18":0.025, "19":0.025, "20":0.025,
"21":0.025, "22":0.025, "23":0.025, "24":0.025, "25":0.025, "26":0.025, "27":0.025, "28":0.025, "29":0.025, "30":0.025,
"31":0.025, "32":0.025, "33":0.025, "34":0.025, "35":0.025, "36":0.025, "37":0.025, "38":0.025, "39":0.025}
}
and the learning rate is multiplied by 0.85 every 10 epochs:
if (epoch+1) % 10 == 0:
# Every 50 epoch, half the LR
for param_group in optimizer.param_groups:
param_group['lr'] *= 0.85
logger.info('Multiply the learning rate by {} [{} steps]'.format(0.85, n_iter))
I find that "loss_data[t] = loss.data[0]" will cost 0.5s.
Is there any way to decrease the cost?
The average error on celeba is 8.25 in the paper, but my result is 10.14, which is obtained by directly using the codes in this repo. I list the configurations I used below, is there any problem?
in configs.json
"celeba": {
"path": "data/celeba",
"all_tasks": ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "10", "11", "12", "13", "14", "15", "16", "17", "18", "19", "20",
"21", "22", "23", "24", "25", "26", "27", "28", "29", "30", "31", "32", "33", "34", "35", "36", "37", "38", "39"],
"img_rows": 64,
"img_cols": 64
}
in sample.json
{
"optimizer": "Adam",
"batch_size": 256,
"lr": 0.0005,
"dataset": "celeba",
"tasks": ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "10", "11", "12", "13", "14", "15", "16", "17", "18", "19", "20",
"21", "22", "23", "24", "25", "26", "27", "28", "29", "30", "31", "32", "33", "34", "35", "36", "37", "38", "39"],
"normalization_type": "loss+",
"algorithm": "mgda",
"use_approximation": true,
"scales": {"0":0.025, "1":0.025, "2":0.025, "3":0.025, "4":0.025, "5":0.025, "6":0.025, "7":0.025, "8":0.025, "9":0.025, "10":0.025,
"11":0.025, "12":0.025, "13":0.025, "14":0.025, "15":0.025, "16":0.025, "17":0.025, "18":0.025, "19":0.025, "20":0.025,
"21":0.025, "22":0.025, "23":0.025, "24":0.025, "25":0.025, "26":0.025, "27":0.025, "28":0.025, "29":0.025, "30":0.025,
"31":0.025, "32":0.025, "33":0.025, "34":0.025, "35":0.025, "36":0.025, "37":0.025, "38":0.025, "39":0.025}
}
and the learning rate is multiplied by 0.85 every 10 epochs:
if (epoch+1) % 10 == 0:
# Every 50 epoch, half the LR
for param_group in optimizer.param_groups:
param_group['lr'] *= 0.85
logger.info('Multiply the learning rate by {} [{} steps]'.format(0.85, n_iter))
and I train the model on two GPUs.
Hi. thanks for sharing.
what is the structure for sample.json and config.json when I want to use code for multiMnist dataset?
Hi,
I'm wondering how I can get the test accuracy for MultiMNIST. Right now, it seems to me that the metric results logged at each epoch are the test accuracies. Can you clarify how you obtain the test accuracy numbers in the paper? Thanks!
First, thank you for the nice work. If you don't mind, I have a question:
You mention right after defining the upper bound (Eq. 6) that the derivative wrt. representations, i.e. \nabla_Z L^t, can be computed in a single backward pass for all tasks. But all tasks are sharing the same representation nodes, so how is this possible? Wouldn't this also apply then to the original derivative wrt. to the shared parameters?
There is a bug in the depth loss.
All entries smaller than zero are masked. This causes most of the entries to be excluded in the loss, as the depth map has been normalized. The correct way would be to mask only the zero entries in the loss.
Hi, thanks for sharing your code!
I have one question about the size of gradient. I found that in the current code, only 2D gradient is supported. But if the parameter has 4 dimensional, such as (batch-size, N, width, height), how should I modify the min-norm solver ?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.