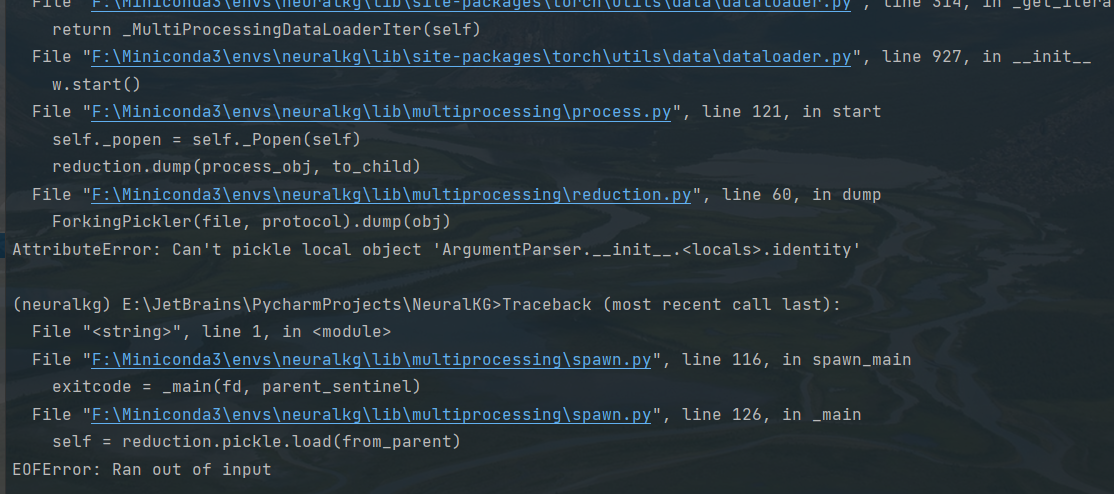
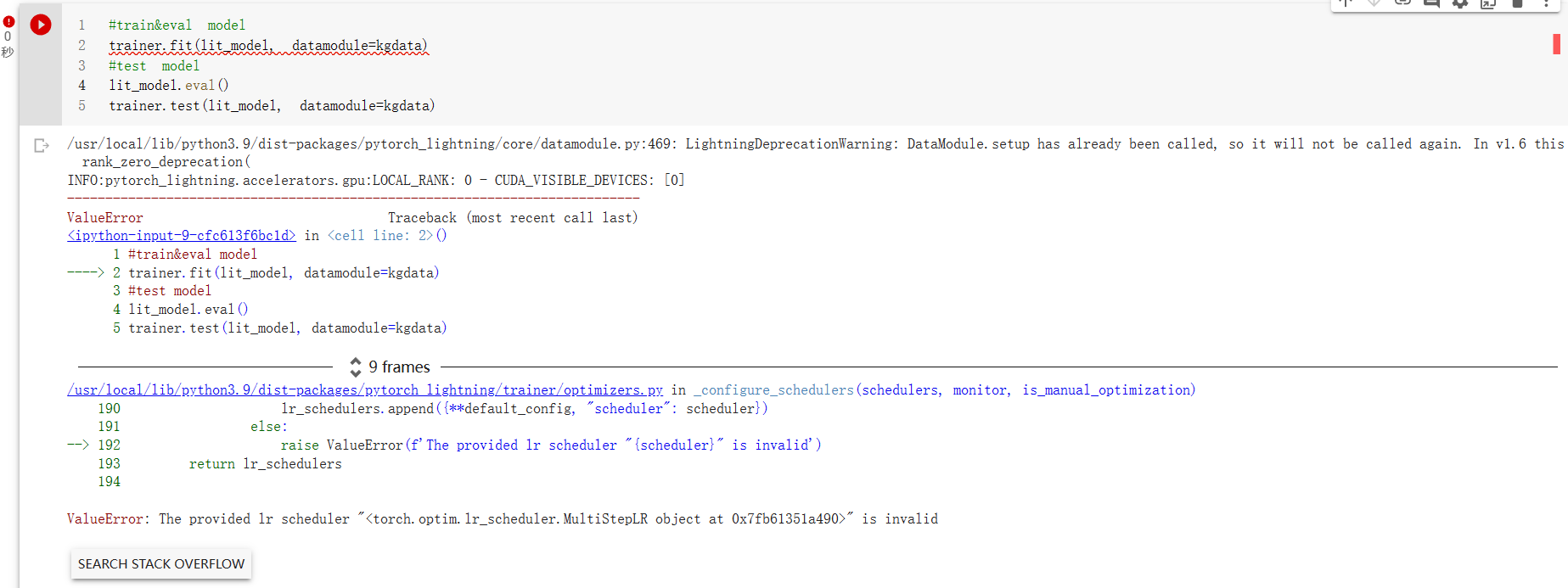
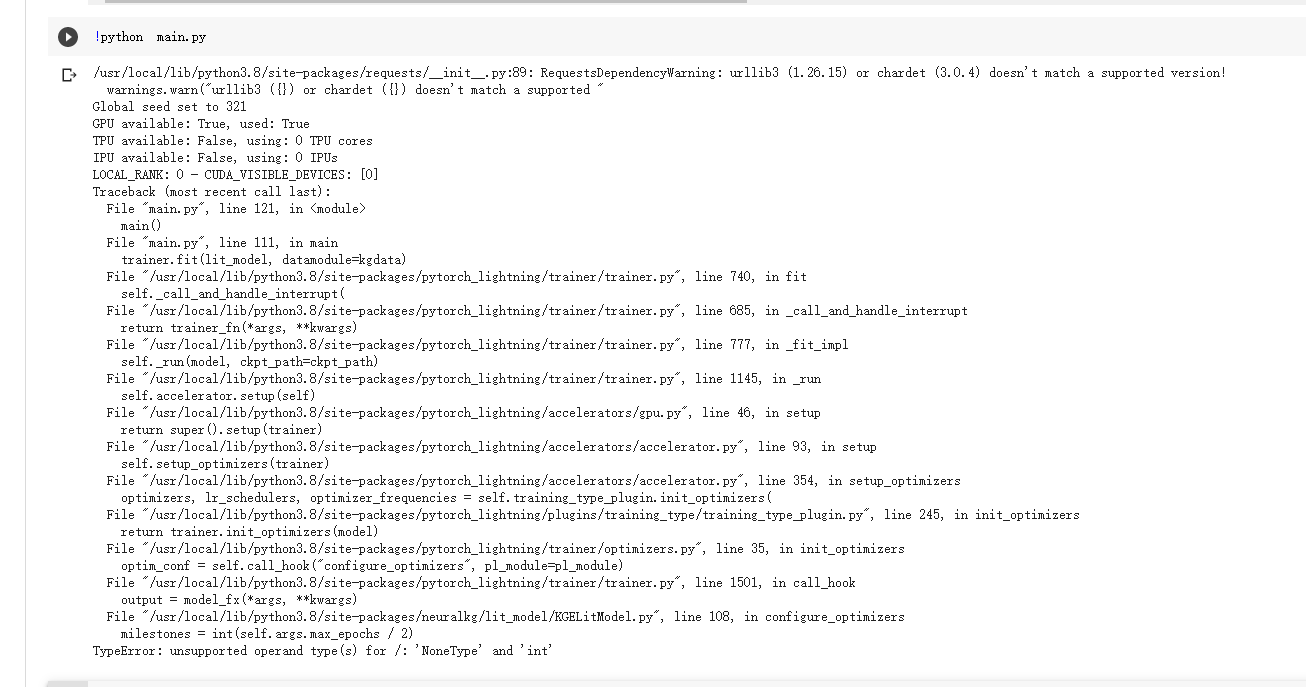
Hi, when I set num_workers > 0, an error are raised. I think it one reason raising the error is the DGL, but i am not sure.
Here is the error code
`Sanity Checking: 0it [00:00, ?it/s]Traceback (most recent call last):
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/pytorch_lightning/trainer/call.py", line 38, in _call_and_handle_interrupt
return trainer_fn(*args, **kwargs)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 650, in _fit_impl
self._run(model, ckpt_path=self.ckpt_path)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 1103, in _run
results = self._run_stage()
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 1182, in _run_stage
self._run_train()
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 1195, in _run_train
self._run_sanity_check()
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 1267, in _run_sanity_check
val_loop.run()
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/pytorch_lightning/loops/loop.py", line 199, in run
self.advance(*args, **kwargs)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/pytorch_lightning/loops/dataloader/evaluation_loop.py", line 152, in advance
dl_outputs = self.epoch_loop.run(self._data_fetcher, dl_max_batches, kwargs)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/pytorch_lightning/loops/loop.py", line 199, in run
self.advance(*args, **kwargs)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/pytorch_lightning/loops/epoch/evaluation_epoch_loop.py", line 121, in advance
batch = next(data_fetcher)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/pytorch_lightning/utilities/fetching.py", line 184, in next
return self.fetching_function()
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/pytorch_lightning/utilities/fetching.py", line 275, in fetching_function
return self.move_to_device(batch)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/pytorch_lightning/utilities/fetching.py", line 294, in move_to_device
batch = self.batch_to_device(batch)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/pytorch_lightning/loops/dataloader/evaluation_loop.py", line 142, in batch_to_device
batch = self.trainer._call_strategy_hook("batch_to_device", batch, dataloader_idx=dataloader_idx)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 1485, in _call_strategy_hook
output = fn(*args, **kwargs)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/pytorch_lightning/strategies/strategy.py", line 273, in batch_to_device
return model._apply_batch_transfer_handler(batch, device=device, dataloader_idx=dataloader_idx)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/pytorch_lightning/core/module.py", line 332, in _apply_batch_transfer_handler
batch = self._call_batch_hook("transfer_batch_to_device", batch, device, dataloader_idx)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/pytorch_lightning/core/module.py", line 320, in _call_batch_hook
return trainer_method(hook_name, *args)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 1347, in _call_lightning_module_hook
output = fn(*args, **kwargs)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/pytorch_lightning/core/hooks.py", line 632, in transfer_batch_to_device
return move_data_to_device(batch, device)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/lightning_fabric/utilities/apply_func.py", line 101, in move_data_to_device
return apply_to_collection(batch, dtype=_TransferableDataType, function=batch_to)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/lightning_utilities/core/apply_func.py", line 70, in apply_to_collection
return {k: function(v, *args, **kwargs) for k, v in data.items()}
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/lightning_utilities/core/apply_func.py", line 70, in
return {k: function(v, *args, kwargs) for k, v in data.items()}
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/lightning_fabric/utilities/apply_func.py", line 95, in batch_to
data_output = data.to(device, kwargs)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/dgl/heterograph.py", line 5709, in to
ret._graph = self._graph.copy_to(utils.to_dgl_context(device))
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/dgl/heterograph_index.py", line 255, in copy_to
return _CAPI_DGLHeteroCopyTo(self, ctx.device_type, ctx.device_id)
File "dgl/_ffi/_cython/./function.pxi", line 295, in dgl._ffi._cy3.core.FunctionBase.call
File "dgl/_ffi/_cython/./function.pxi", line 227, in dgl._ffi._cy3.core.FuncCall
File "dgl/_ffi/_cython/./function.pxi", line 217, in dgl._ffi._cy3.core.FuncCall3
dgl._ffi.base.DGLError: [16:47:07] /opt/dgl/src/runtime/cuda/cuda_device_api.cc:343: Check failed: e == cudaSuccess || e == cudaErrorCudartUnloading: CUDA: unspecified launch failure
Stack trace:
[bt] (0) /home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/dgl/libdgl.so(+0x8b0b95) [0x7f396a58eb95]
[bt] (1) /home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/dgl/libdgl.so(dgl::runtime::CUDADeviceAPI::CopyDataFromTo(void const, unsigned long, void, unsigned long, unsigned long, DGLContext, DGLContext, DGLDataType)+0x82) [0x7f396a590ff2]
[bt] (2) /home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/dgl/libdgl.so(dgl::runtime::NDArray::CopyFromTo(DGLArray, DGLArray)+0x10d) [0x7f396a4074cd]
[bt] (3) /home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/dgl/libdgl.so(dgl::runtime::NDArray::CopyTo(DGLContext const&) const+0x103) [0x7f396a443033]
[bt] (4) /home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/dgl/libdgl.so(dgl::UnitGraph::CSR::CopyTo(DGLContext const&) const+0x1f0) [0x7f396a5619d0]
[bt] (5) /home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/dgl/libdgl.so(dgl::UnitGraph::CopyTo(std::shared_ptrdgl::BaseHeteroGraph, DGLContext const&)+0xd1) [0x7f396a550d01]
[bt] (6) /home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/dgl/libdgl.so(dgl::HeteroGraph::CopyTo(std::shared_ptrdgl::BaseHeteroGraph, DGLContext const&)+0xf6) [0x7f396a44f876]
[bt] (7) /home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/dgl/libdgl.so(+0x7802b6) [0x7f396a45e2b6]
[bt] (8) /home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/dgl/libdgl.so(DGLFuncCall+0x48) [0x7f396a3ec558]
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "main.py", line 122, in
main()
File "main.py", line 112, in main
trainer.fit(lit_model, datamodule=kgdata)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 608, in fit
call._call_and_handle_interrupt(
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/pytorch_lightning/trainer/call.py", line 63, in _call_and_handle_interrupt
trainer._teardown()
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 1166, in _teardown
self.strategy.teardown()
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/pytorch_lightning/strategies/strategy.py", line 496, in teardown
self.lightning_module.cpu()
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/lightning_fabric/utilities/device_dtype_mixin.py", line 78, in cpu
return super().cpu()
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/torch/nn/modules/module.py", line 967, in cpu
return self._apply(lambda t: t.cpu())
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/torch/nn/modules/module.py", line 810, in _apply
module._apply(fn)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/torch/nn/modules/module.py", line 810, in _apply
module._apply(fn)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/torch/nn/modules/module.py", line 833, in _apply
param_applied = fn(param)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/torch/nn/modules/module.py", line 967, in
return self._apply(lambda t: t.cpu())
RuntimeError: CUDA error: unspecified launch failure
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
Exception in thread Thread-3:
Traceback (most recent call last):
File "/home/test/anaconda3/envs/lrz/lib/python3.8/threading.py", line 932, in _bootstrap_inner
self.run()
File "/home/test/anaconda3/envs/lrz/lib/python3.8/threading.py", line 870, in run
self._target(*self._args, **self._kwargs)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/torch/utils/data/_utils/pin_memory.py", line 54, in _pin_memory_loop
do_one_step()
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/torch/utils/data/_utils/pin_memory.py", line 31, in do_one_step
r = in_queue.get(timeout=MP_STATUS_CHECK_INTERVAL)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/multiprocessing/queues.py", line 116, in get
return _ForkingPickler.loads(res)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/torch/multiprocessing/reductions.py", line 355, in rebuild_storage_fd
fd = df.detach()
File "/home/test/anaconda3/envs/lrz/lib/python3.8/multiprocessing/resource_sharer.py", line 57, in detach
with _resource_sharer.get_connection(self._id) as conn:
File "/home/test/anaconda3/envs/lrz/lib/python3.8/multiprocessing/resource_sharer.py", line 87, in get_connection
c = Client(address, authkey=process.current_process().authkey)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/multiprocessing/connection.py", line 508, in Client
answer_challenge(c, authkey)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/multiprocessing/connection.py", line 752, in answer_challenge
message = connection.recv_bytes(256) # reject large message
File "/home/test/anaconda3/envs/lrz/lib/python3.8/multiprocessing/connection.py", line 216, in recv_bytes
buf = self._recv_bytes(maxlength)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/multiprocessing/connection.py", line 414, in _recv_bytes
buf = self._recv(4)
File "/home/test/anaconda3/envs/lrz/lib/python3.8/multiprocessing/connection.py", line 379, in _recv
chunk = read(handle, remaining)
ConnectionResetError: [Errno 104] Connection reset by peer
terminate called after throwing an instance of 'c10::Error'
what(): CUDA error: unspecified launch failure
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
Exception raised from c10_cuda_check_implementation at ../c10/cuda/CUDAException.cpp:44 (most recent call first):
frame #0: c10::Error::Error(c10::SourceLocation, std::string) + 0x57 (0x7f3a2d21d617 in /home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/torch/lib/libc10.so)
frame #1: c10::detail::torchCheckFail(char const*, char const*, unsigned int, std::string const&) + 0x64 (0x7f3a2d1d898d in /home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/torch/lib/libc10.so)
frame #2: c10::cuda::c10_cuda_check_implementation(int, char const*, char const*, int, bool) + 0x118 (0x7f3a2d2cec38 in /home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/torch/lib/libc10_cuda.so)
frame #3: + 0x126123e (0x7f3a2e5fa23e in /home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/torch/lib/libtorch_cuda.so)
frame #4: + 0x519806 (0x7f3a97efe806 in /home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/torch/lib/libtorch_python.so)
frame #5: + 0x55ca7 (0x7f3a2d202ca7 in /home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/torch/lib/libc10.so)
frame #6: c10::TensorImpl::~TensorImpl() + 0x1e3 (0x7f3a2d1facb3 in /home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/torch/lib/libc10.so)
frame #7: c10::TensorImpl::~TensorImpl() + 0x9 (0x7f3a2d1fae49 in /home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/torch/lib/libc10.so)
frame #8: + 0x7ca2c8 (0x7f3a981af2c8 in /home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/torch/lib/libtorch_python.so)
frame #9: THPVariable_subclass_dealloc(_object*) + 0x325 (0x7f3a981af675 in /home/test/anaconda3/envs/lrz/lib/python3.8/site-packages/torch/lib/libtorch_python.so)
frame #10: python() [0x4d39ff]
frame #11: python() [0x4e0970]
frame #12: python() [0x4f1828]
frame #13: python() [0x4f1811]
frame #14: python() [0x4f1811]
frame #15: python() [0x4f1811]
frame #16: python() [0x4f1811]
frame #17: python() [0x4f1811]
frame #18: python() [0x4f1811]
frame #19: python() [0x4f1811]
frame #20: python() [0x4f1811]
frame #21: python() [0x4f1811]
frame #22: python() [0x4f1811]
frame #23: python() [0x4f1811]
frame #24: python() [0x4f1489]
frame #25: python() [0x4f983a]
frame #26: python() [0x4f144d]
frame #27: python() [0x4c9310]
frame #33: __libc_start_main + 0xe7 (0x7f3ac90e1c87 in /lib/x86_64-linux-gnu/libc.so.6)
frame #34: python() [0x579d3d]`
My system is ubuntu 16.04 and GPU is A100, Thanks!