NEW(April 20, 2020): Check out our recent CVPR'20 work Temporal Pyramid Networks (TPN) for action recognition, which outperforms TRN with a large margin and achieves close to SOTA results on many video benchmarks with RGB stream only. Bonus: bolei_juggling_v2.mp4 is attached in that repo!
We release the code of the Temporal Relation Networks, built on top of the TSN-pytorch codebase.
NEW (July 29, 2018): This work is accepted to ECCV'18, check the paper for the latest result. We also release the state of the art model trained on the Something-Something V2, see following instruction.
Note: always use git clone --recursive https://github.com/metalbubble/TRN-pytorch to clone this project
Otherwise you will not be able to use the inception series CNN architecture.
Download the something-something dataset or jester dataset or charades dataset. Decompress them into some folder. Use process_dataset.py to generate the index files for train, val, and test split. Finally properly set up the train, validation, and category meta files in datasets_video.py.
For Something-Something-V2, we provide a utilty script extract_frames.py for converting the downloaded .webm videos into directories containing extracted frames. Additionally, the corresponding optic flow images can be downloaded from here.
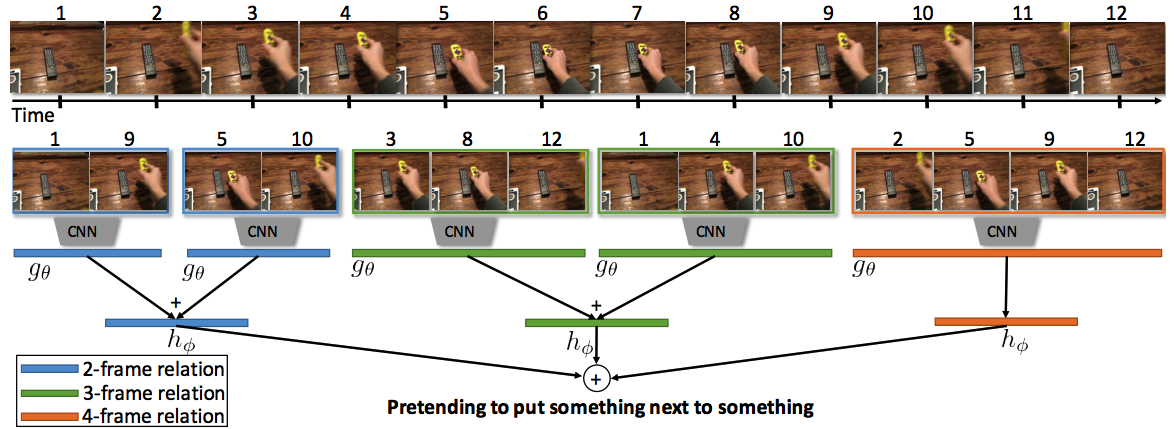
Core code to implement the Temporal Relation Network module is TRNmodule. It is plug-and-play on top of the TSN.
- The command to train single scale TRN
CUDA_VISIBLE_DEVICES=0,1 python main.py something RGB \
--arch BNInception --num_segments 3 \
--consensus_type TRN --batch-size 64- The command to train multi-scale TRN
CUDA_VISIBLE_DEVICES=0,1 python main.py something RGB \
--arch BNInception --num_segments 8 \
--consensus_type TRNmultiscale --batch-size 64- The command to test the single scale TRN
python test_models.py something RGB model/TRN_something_RGB_BNInception_TRN_segment3_best.pth.tar \
--arch BNInception --crop_fusion_type TRN --test_segments 3- The command to test the multi-scale TRN
python test_models.py something RGB model/TRN_something_RGB_BNInception_TRNmultiscale_segment8_best.pth.tar \
--arch BNInception --crop_fusion_type TRNmultiscale --test_segments 8- Download pretrained models on Something-Something, Something-Something-V2, Jester, and Moments in Time
./download.sh- Download sample video and extracted frames. There will be mp4 video file and a folder containing the RGB frames for that video.
cd sample_data
./download_sample_data.shThe sample video is the following

- Test pretrained model trained on Something-Something-V2
python test_video.py --arch BNInception --dataset somethingv2 \
--weights pretrain/TRN_somethingv2_RGB_BNInception_TRNmultiscale_segment8_best.pth.tar \
--frame_folder sample_data/bolei_juggling
RESULT ON sample_data/bolei_juggling
0.500 -> Throwing something in the air and catching it
0.141 -> Throwing something in the air and letting it fall
0.072 -> Pretending to throw something
0.024 -> Throwing something
0.024 -> Hitting something with something
- Test pretrained model trained on Moments in Time
python test_video.py --arch InceptionV3 --dataset moments \
--weights pretrain/TRN_moments_RGB_InceptionV3_TRNmultiscale_segment8_best.pth.tar \
--frame_folder sample_data/bolei_juggling
RESULT ON sample_data/bolei_juggling
0.982 -> juggling
0.003 -> flipping
0.003 -> spinning
0.003 -> smoking
0.002 -> whistling- Test pretrained model on mp4 video file
python test_video.py --arch InceptionV3 --dataset moments \
--weights pretrain/TRN_moments_RGB_InceptionV3_TRNmultiscale_segment8_best.pth.tar \
--video_file sample_data/bolei_juggling.mp4 --rendered_output sample_data/predicted_video.mp4The command above uses ffmpeg to extract frames from the supplied video --video_file and optionally generates a new video --rendered_output from the frames used to make the prediction with the predicted category in the top-left corner.
- Gesture recognition web-cam demo script python fps_dem_trn.py
- TODO: Web-cam demo script
- TODO: Visualization script
- TODO: class-aware data augmentation
B. Zhou, A. Andonian, and A. Torralba. Temporal Relational Reasoning in Videos. European Conference on Computer Vision (ECCV), 2018. PDF
@article{zhou2017temporalrelation,
title = {Temporal Relational Reasoning in Videos},
author = {Zhou, Bolei and Andonian, Alex and Oliva, Aude and Torralba, Antonio},
journal={European Conference on Computer Vision},
year={2018}
}
Our temporal relation network is plug-and-play on top of the TSN-Pytorch, but it could be extended to other network architectures easily. We thank Yuanjun Xiong for releasing TSN-Pytorch codebase. Something-something dataset and Jester dataset are from TwentyBN, we really appreciate their effort to build such nice video datasets. Please refer to their dataset website for the proper usage of the data.






























































































































