zhiqiang21 / blog Goto Github PK
View Code? Open in Web Editor NEW记录前端开发日常点滴。为梦想Coding...
License: MIT License
记录前端开发日常点滴。为梦想Coding...
License: MIT License


























































































































































































声明:这个系列为阅读《JavaScript设计模式与开发实践》 ----曾探@著一书的读书笔记
保证一个类仅有一个实例,并且提供一个访问它的全局访问点。
var Singleton = function(name) {
this.name = name;
this.instance = null;
};
Singleton.prototype.getName = function() {
alert(this.name);
};
Singleton.getInstance = function(name) {
if (!this.instance) {
this.instance = new Singleton(name);
}
return this.instance;
};
var a = Singleton.getInstance('seven1');
var b = Singleton.getInstance('seven2');或者使用闭包的形式创建单例模式,同时符合惰性单例的特性
var Singleton = function(name) {
this.name = name;
};
Singleton.prototype.getName = function() {
alert(this.name);
};
//利用闭包的特性创建单例,同时符合惰性单例的特性
Singleton.getInstance = (function(name) {
var instance;
return function(name){
if (!instance) {
instance = new Singleton(name);
}
}
})();
var a = Singleton.getInstance('seven1');
var b = Singleton.getInstance('seven2');
console.log(a===b); //true//反面的单例模式的例子
var CreateDiv = (function() {
var instance;
var CreateDiv = function(html) {
if (instance) {
return instance;
}
this.html = html;
this.init();
return instance = this;
};
CreateDiv.prototype.init = function() {
var div = document.createElement('div');
div.innerHTML = this.html;
document.body.appendChild(div);
}
return CreateDiv;
})();
var a = new CreateDiv('seven1');
var b = new CreateDiv('seven2');这样编写单例模式的缺点:
为了把instance封装起来,我们使用了自执行的匿名函数和闭包,并且让这个匿名函数返回真正的Singleton构造方法,这增加了一些程序的复杂度。
CreateDiv的构造函数负责了两件事情。1.创建对像和执行初始化init方法,第二是保证只有一个对象。不符合设计模式中的单一职责的概念。
var CreateDiv = function(html) {
this.html = html;
this.init();
};
CreateDiv.prototype.init = function() {
var div = document.createElement('div');
div.innerHTML = this.html;
document.body.appendChild(div);
}
var ProxySingletonCreateDiv = (function() {
var instance;
return function(html) {
if (!instance) {
instance = new CreateDiv(html);
}
return instance;
}
})();
var a = new ProxySingletonCreateDiv('seven1');
var b = new ProxySingletonCreateDiv('seven2');引入代理实现单例模式的特点:
我们负责管理单例的逻辑移到了代理类ProxySingletonCreateDiv中。这样一来,CreateDiv就变成了一个普通的类,他跟ProxySingletonCreateDiv组合起来可以达到单例模式的效果。
在以上的代码中实现的单例模式都混入了传统面向对象语言的特点。而没有利用JavaScript这们语言的特点来实现一个单例模式。
概念描述:
惰性单例指的是在需要的时候才创建对象的实例。惰性单例是单例模式的重点。
var createLoginLayer=(function(){
var div;
return function(){
if(!div){
div=document.createElement('div');
//创建一个登录框
}
return div;
}
})();
document.getElementById('loginBtn').onclick=function(){
var loginLayer=createLoginLayer();
loginLayer.style.display='block';
};代码解析:
这里的对惰性单例的实现主要是只有单例了网页上的登录按钮,才会去创建,登录框的dom节点,并且只是创建一次。
根据3.1的代码示例,我们的单例对像,但是并不是通用的,比如我们要创建的不是div而是iframe,那要怎么办呢?
//获取单例
var getSingle = function(fn){
var result;
return function (){
return result || (result=fn.apply(this,arguments));
};
};
//创建div登录框
var createLoginLayer=function (){
var div= document.createElement('div');
div.innerHTML='我是登录框';
document.body.appendChild(div);
return div;
};
//创建iframe的dom节点
var createIframe=function(){
//创建irame节点的代码
}
var createSingleLoginLayer = getSingle(createLoginLayer);
var createSingleIframe=getSingle(createIframe);
var loginLayer1 = createSingleLoginLayer();
var loginLayer2 = createSingleLoginLayer();
var iframe1=createSingleIframe();
var iframe2=createSingleIframe();
console.log(loginLayer1 === loginLayer2);通用的单例创建的例子就是通过封装一个getSingle需要实现单例模式的对象。而且只是会只创建一次。因为使用了闭包的原因通过getSingle创建的result会在内存中一直存在不会销毁(除非页面关闭,或者手动释放)。
单例模式是一种简单但非常实用的模式,特别是惰性单例技术,在合适的时候才创建对像,并且只创建唯一的一个。更奇妙的是,创建对象和管理单例的职责被分布在两个不同的方法中,这两个方法组合起来才具有单例模式的威力。
关于微信小程序之前只是听说,并没有引起我太大的兴趣。周一被小程序刷屏,然后就顺手搜索了解了一下。发现小程序已经火遍了整个程序员圈子。刚好团队内部有个需求需要微信小程序。就紧急对微信小程序进行了调研,阅读过开发者文档后总结了以下的几个开发者比较关心的问题:
注意:这篇文章删除了一些跟我当前业务相关的一些内容。如果有兴趣小程序开发的我们可以一起交流哈。
Request请求
上传,下载
Websocket请求
媒体
设备
界面
开放的接口
微信小程序有自己的设计规范,需要UI同学按照微信小程序的设计规范评估我们当前的UI是否符合微信的设计规范,否则会存在审核不通过的可能。
微信小程序的UI规范地址:https://mp.weixin.qq.com/debug/wxadoc/design/?
微信小程序借鉴了当前非常流行的前端框架react和vue的开发**,组件化的开发方式。一个页面就是一个组件,一个组件由以下4个部分组成:
所以在开发微信小程序的过程中我们需要学习微信小程序的wxml语法。个人认为wxml的语法相对还是比较容易掌握的。而wxss的语法就是我们熟知的css的语法,只是不支持一些高级的css选择器。
通过下图了解小程序的页面的渲染过程
由上面的流程可以知道在小程序的渲染引擎渲染页面的时候,页面需要的数据都是通过接口获取的。而我们现在的开发模式基本都是后端php渲染smarty模板,渲染过程中会将某些前端需要的变量或者是参数写到Html页面中。如果以后要在小程序中拓展Pass的能力,后端会有一定的开发成本;
如果你当前的开发模式跟我们的一样,如果想要在小程序中开发自己的页面,也是会有一定的后端开发成本的;
以上就是对支持产品线在微信小程序中登录面临的问题的调研结果和对我们当前服务能力的影响。大家如果对微信小程序有兴趣可以跟我交流哈。
此文件目录中文件主要是关于sublime的插件配置,快捷键配置,主题和字体配置。
所有插件都可以使用Package Control安装,具体的安装方法可以自行谷歌安装,不在本文的介绍范围之内。也可以是使用git 手动安装。
该插件主要使编写css更加的方便和快捷,可以配置快捷键给标签属性添加浏览器厂商前缀。安装前需要确定电脑安装node。
配置快捷键如下:
//autoprefixer快捷键设置
{ "keys": ["command+alt+p"], "command": "autoprefixer" }
具体配置和文档请参看官方文档
比如我在编写 CSS 的时候是不用关心哪些属性是需要添加厂商前缀的,当我需要保存测试的时候,只需要按下快捷键,该插件会自动给需要添加厂商前缀的属性添加前缀,如下:
{
display: -webkit-box;
display: -ms-flexbox;
display: flex;
display: -webkit-flex;
-webkit-flex-flow: row;
-ms-flex-flow: row;
flex-flow: row;
}当然该插件也可以加入到自己开发项目的自动化工具中去,比如:Gulp ,Grunt
ES6终将是要取代 ES5 的但是在从 ES5 到 ES6 过度的过程中,各个浏览器厂商对 ES6 支持的也不是很好。
主要是将ES6的代码编译为ES5。至于为什么要这么做,不是本文的内容,可以自行谷歌了解。
javascript ,jQuery , Bootstrap 等js库的自动补全。该插件的特点就是可以自定义配置需要自动补全的库。
安装完以后它的配置文件可以配置自己需要补全的库
{
// --------------------
// sublime-better-completions-Package (sbc package)
// --------------------
// API files is contains the *keyword* such as `html`, `jquery`, `myglossary` with lowercase as filename `sbc-api-${filename}.sublime-settings` place in `/packages/User/` (your own) or `/packages/${this-package}/sublime-completions/` (package build-in).
// After you enable, disable or added new your own completions, you might need restart your Sublime Text Editor.
//
// Your own setting file `sbc-setting.sublime-settings` need to place in `/packages/User/` and contains all your api setting property that you want to enable.
//
// --------------------
// APIs Setup
// --------------------
// `true` means enable it.
// `false` means disable it.
"completion_active_list": {
// build-in completions
"css-properties": false,
"gruntjs-plugins": false,
"html": false,
"lodash": false,
"javascript": false,
"jquery": false,
"jquery-sq": false, // Single Quote
"php": false,
"phpci": false,
"sql": false,
"twitter-bootstrap": false,
"twitter-bootstrap-less-variables": false,
"twitter-bootstrap3": false,
"twitter-bootstrap3-sass-variables": false,
"underscorejs": false,
"react": false,
// Your own completions?
// ~/Library/Application\ Support/Sublime\ Text\ 3/Packages/User/sbc-api-my-angularjs.sublime-settings
"my-angularjs": false,
// ~/Library/Application\ Support/Sublime\ Text\ 3/Packages/User/sbc-api-my-glossary.sublime-settings
"my-glossary": false,
// ~/Library/Application\ Support/Sublime\ Text\ 3/Packages/User/sbc-api-my-html.sublime-settings
"my-html": false,
// ~/Library/Application\ Support/Sublime\ Text\ 3/Packages/User/sbc-api-my-javascript.sublime-settings
"my-javascript": false
}
}
括号高亮匹配插件。
借用一张官网的截图:
该插件可以显示在CSS文件中说使用的颜色的色值。包括HTML中嵌套的css样式也可以显示。
如下图:
还可以调节显示的样式,比如当我鼠标放到颜色上的时候
具体的可以参考官网的说明。
该插件可以对css3属性进行高亮和自动补全。
具体效果如下:
安装完以后的设置如下:
View → Syntax → Open all with current extension as... → CSS3
这个插件可以非常智能对js文件添加注释,这个非常的方便。
参考一张官网的截图:
传说中快速的编写html代码的“神器”。具体的就不再介绍了。网上的教程一搜一大坨啊。
文件差异对比插件。
之前格式化 js,css 文件使用的都是 JsFormat 和 CSSFormat。每次在不同的文件中都要去使用两个不同的插件。后来找到一个可以支持三种语言格式化的插件。
对Html,css,js文件进行格式化。
//html-css-jsprettify插件快捷键
{"keys": ["command+alt+l"],"command": "htmlprettify"},
如果平时模板语言使用 jade 的话还是安装一个吧,这个可以让 Sublime 的显示更加的友好。jade相关插件,代码高亮
javascript ES6 语法高亮的支持。
这个插件主要包括 jQuery 语法高亮,代码段。
这两个插件主要是平时使用 scss 或者是 sass 这些预编译语言有用,支持语法高亮。
这个插件还是很有用的。当我们在跟后端联调的时候,通常都会有一台开发机,暂时存放我们的代码,这个时候如果我们要做一些修改。通常的步骤是:
1.上传 svn 2.登上开发机 svn up 一下。这个过程中很浪费时间
如果我们使用 SFTP 插件就可以保存的时候自动上传到服务器。配置方法:
1.在项目根目录建立 sftp-config.json 文件
2.配置该文件,详细配置如下图
Sublime 侧边栏增强插件。
语法,函数跳转。但是我在使用的过程中觉得这个插件并不怎么好用。
这个插件主要使 Sublime 对 markdown 语法的高亮支持。效果如下图:
去除代码末尾的空格键
安装完以后需要,另外安装需要检测语言的插件。
在安装完SublimeLinter 后安转该插件对 JavaScript 语言进行语法检测。
在安装完SublimeLinter 后安转该插件对 css 语言进行语法检测。
该插件主要能够使sublime 兼容mac的retina屏幕
需要在自己的配置文件内启动
{
"theme": "Soda Light 3.sublime-theme"
}
如果您觉得不错,请访问 github(点我) 地址给我一颗星。谢谢啦!
这篇文章的内容如题目一样,主要分为两个部分,
建议在读这篇文章的时候先读下这篇文章《高清屏概念解析与检测设备像素比的方法_20161005》,因为这些文章涉及的很多概念在这篇文章中都会提到。
在我们的项目中大量的使用百分比来解决页面在宽度上的自适应,其实在高度上并没有很好的自适应。所以在我们的前端页面会出现一些比较奇怪的问题。比如下面这样:
还有一个比较明显的问题就是:在任何机型上我们的按钮的高度是不会变化自适应的,所以小屏手机我们的按钮看起来很臃肿。
在谈我为什么在我们的项目中引入rem单位的时候,先来详细的了解几个常用的单位概念。
px像素(Pixel)。相对长度单位。像素px是相对于显示器屏幕分辨率而言的(也就是说是跟物理设备有关的)。拿高清屏和普通屏来做对比就是普通屏幕的1个像素点就是1个物理像素点,而高清屏的1个像素点是4个物理像素点。em相对长度单位。相对于当前对象内文本的字体尺寸。如当前对行内文本的字体尺寸未被人为设置,则相对于浏览器的默认字体尺寸。em单位的特点:1. em的值并不是固定的;2. em会继承父级元素的字体大小。rem相对长度单位。rem是CSS3新增的一个相对单位,这个单位引起了广泛关注。这个单位与em有什么区别呢?区别在于使用rem为元素设定字体大小时,仍然是相对大小,但相对的只是HTML根元素。这个单位可谓集相对大小和绝对大小的优点于一身,通过它既可以做到只修改根元素就成比例地调整所有字体大小,又可以避免字体大小逐层复合的连锁反应。任意浏览器的默认字体高都是16px。所有未经调整的浏览器都符合: 1rem=16px。那么12px=0.75rem,10px=0.625rem。为了简化font-size的换算,需要在css中的html选择器中声明font-size=62.5%,这就使rem值变为 16px*62.5%=10px, 这样12px=1.2rem, 10px=1rem, 也就是说只需要将原来的px数值除以10,然后换上rem作为单位就行了。
注意:当我们在根节点<html>上设置了font-size基准值以后,在文档中有使用rem单位的属性值都是相对于根节点font-size的一个相对值。比如说一些元素的属性如width height margin等。也正是这个原因,现在很多网站的移动端网站都在使用rem单位作为适配工具。
在使用rem的时候比较麻烦的就是px和rem换算的问题。上面的除10的方案是比较简单的。但是根据设置基准值的不同换算方法也不一样。如果我们使用scss来写我们的样式表的话,解决方法就比较简单了,代码如下:
@function px2rem($px){
@return ($px/10)/2 + rem; // 相当于$px/20 +rem
}
width:px2rem(100px); //5rem
height:px2rem(200px); //10rem
由上面的内容已经知道百分比单位在多屏幕适配上的缺点和rem单位的优点。那么rem单位能为我们的开发带来什么呢?来看一个常见的多列布局,淘宝移动端的商品列表页,如下图:
设计稿(不管是iphone6的二倍稿还是iphone5的二倍稿)中给展示商品的坑位的宽高比是固定的。为了能够使这个列表在不同的屏幕上达到最佳的显示效果,需要保持宽度和高度比一致。如果使用百分比肯定是满足不了这个需求的,因为高度上我们没有办法控制。
iphone6和iphone5的屏幕宽度和高度比不一样,当我们使用百分比做多列布局的时候就会出现下面的这种情况:
所以为了满足商品坑位在不同屏幕上的宽高比一致,淘宝使用的是rem的解决方案,也是目前最好的解决方案。
font-size值的js放在head标签中设置根节点font-size值的方法,第一种是使用css的Media queries,示例代码如下:
@media (min-device-width : 375px) and (max-device-width : 667px) and (-webkit-min-device-pixel-ratio : 2){
html{font-size: 37.5px;}
}上面的这种方式在我之前做过的项目中使用了一段时间。上面的设置方法有一个很明显的问题font-size是在一个屏幕宽度的区间上有一个基准值。像安卓手机种类的繁多,屏幕大小就更多的情况下,上面的方法很鸡肋。
第二种解决方案,就是使用JavaScript根据当前屏幕的宽度动态计算font-size值,这种方法可以保证屏幕宽度连续变化的时候,font-size基准值也是连续变化的。
计算方法可以参考这篇文章《根据iPhone6设计稿动态计算rem值》
那么最后一个问题也来了:为什么将计算rem单位的js放在head标签里面?
一句话总结:在浏览器中文档流是从上往下加载渲染的。为了保证发生不必要的_重绘_或者是_重排_肯定是越早给根节点设置font-size值越好。
1px像素线的地方,仍旧使用border-width:1px;而不是border-width:.1rem;在前言中推荐阅读的那篇文章中已经知道在 高清屏(Retina)中控制显示的最小的物理单元包括4个基本的像素点,而普通屏幕1个点像素就是1个物理像素单元。所以在高清屏(Retina)出来之前,就算我们在css中写 0.5px,对于显示屏幕也是不识别的。但是在高清屏(Retina)中我们可以通过间接的方法实现0.5px的效果。
下面的这张图可能能让我们迅速回忆上篇文章的内容
来看一段简单的示例代码加深理解:
<div class="item1"></div>
<div class="item2"></div>css代码如下:
.item1{
width:100px;
height:50px;
border-top:1px solid #000;
float: left;
margin-top:10px;
}
.item2{
width:100px;
height:50px;
margin-top:10px;
border-top:.5px solid #de1dfb;
float: left;
}chrome中的显示效果如下图:
我把这张图截取下来放到 PS 中放大可以很明显的看到一些问题。就是高清屏实际上是用了两排的物理像素点来显示1px的像素线。且不做特殊处理的话1px和0.5px的在Chrome浏览器中显示效果是相同的。也就是说Chrome浏览器不识别0.5px。
但是相同的代码我在 safari浏览器中的效果却是下面的效果:
下面的效果是我在PS中做了放大后的效果。
所以,我们可以得出一个结论:对于0.5px不同浏览器对它的识别是存在差异的。
以下这张图是一位网友对一些常用设备是否识别0.5px做的统计:
其实从视觉的感受上来说0.5px像素的显示效果确实是比1px的显示效果要好很多。大多数情况下也更符合设计稿上的1px线的效果。那么我们有没有办法可以让1px在不同的浏览器和设备中显示真正的1像素的效果呢?
答案是肯定定的。
伪元素 + css3的缩放巧妙地实现;
基本步骤就是:
先来看一个1像素和0.5像素的显示效果,下面的截图是在chrome中:
实现的代码如下:
<div class="item4">测试用的边框</div>
<div class="item5">测试用的边框</div>.item4, .item5 {
width: 200px;
height: 100px;
position: relative;
}
.item4 {
border: 1px solid #000;
}
.item5::before {
content: '';
position: absolute;
width: 200%;
height: 200%;
border: 1px solid #000;
transform-origin: 0 0;
transform: scale(0.5, 0.5);
box-sizing: border-box;
}可以很明显的看到缩放前和缩放后的效果。在ps中把上面的截图放大很多倍以后我们可以看到显示细节。**缩放以后确实是使用的最小的物理像素单元来显示边框。**如下图:
注意:按照css3 transform 的scale的定义,理论上边框可以任意细(1/n px)。但是上图中已经是物理设备能够使用的最小的物理单元了,那么我们继续缩放会有什么现象呢?
使用一下代码
<div class="item6">测试用的边框</div>.item6::before {
content: '';
position: absolute;
width: 400%;
height: 400%;
border: 1px solid #000;
transform-origin: 0 0;
transform: scale(0.25, 0.25);
box-sizing: border-box;
}chrome中显示效果如下,可以很明显的看到颜色变浅了,但是是否变得更细了我们肉眼无法分辨:
在PS中放大以后的效果:
很明显可以看到线并没有变细,但是线的颜色确实是变浅了。这样的结果也符合我们的预期,就是已经到了物理设备能够显示一块颜色的最小的物理单元了。
viewport的方案一些大厂(所谓的淘宝)的解决方案就是使用js动态获取屏幕的设备像素比,然后动态设置viewport。当然也是我认为目前最好的解决方案。
meta.setAttribute('content', 'initial-scale=' + 1/dpr + ', maximum-scale=' + 1/dpr + ', minimum-scale=' + 1/dpr + ', user-scalable=no');我们知道,一般我们获取到的视觉稿大部分是iphone6的,所以我们看到的尺寸一般是双倍大小的,在使用rem之前,我们一般会自觉的将标注/2,其实这也并无道理,但是当我们配合rem使用时,完全可以按照视觉稿上的尺寸来设置。
由以上两个部分的内容可以知道,不管是在做多终端适配还是实现点5像素的线,都是存在css和js两种解决方案的。两种方案相比来说,我都认为使用JavaScript的解决方案都胜一筹。唯一的缺点就是会在html的head标签中引入一段js代码 。
记得刚入行的时候,业内有一个叫“雅虎军规”的东西,是好多前端做页面优化参考的标准。其中有一条就是要将js文件放在body标签的底部。到现在很多年了,时代在变化,我们的网络带宽也在提升,“雅虎军规”中的一些内容,可能有些已经不适合我们现在应用开发的场景。而且我觉的做技术不应该拘泥于已有的一些规定,而应该按照我们的场景选择适合我们的技术和解决方案。
纵然有瑕疵,有些也是可以通过技术手段来解决的。比如在head标签中引入计算font-size和检测设备独立像素比的js的时候,会担心js的执行阻塞页面的渲染。而我们完全可以通过review的方式确定js代码的执行不会出现阻塞,而影响文档流的加载。
还是那句话:没有十全十美的技术方案,只有适合不合适当前业务场景的技术方案。。
css3的字体大小单位[rem]到底好在哪?
移动端高清、多屏适配方案
使用Flexible实现手淘H5页面的终端适配
lib-flexible源代码
最近看了两本书,书中有些内容对自己还是很新的,有些内容是之前自己理解不够深的,所以拿出来总结一下,这两本书的名字如下:
如果对于 JavaScript 面向对象编程理解不够深的话,第一本书还是强烈推荐的。第二本书比较适合初中级的开发者阅读。对各种知识点都有代码示例。内容中规中矩。
#1.JavaScript 中的变量类型和类型检测
C#和Java等编程语言用栈存储原始类型,用堆存储引用类型,JavaScript则完全不同:它使用一个变量对象追踪变量的生存期。原始值被直接保存在变量对象内,而引用值则作为一个指针保存在变量对象内,该指针指向实际对象在内存中的存储位置。
在 JavaScript 中有5中原始类型,分别如下:
| 类型表达式 | 类型描述 |
|---|---|
| boolean | 布尔,值为 false或者 true |
| number | 数字,值为任何整型或者浮点数值 |
| string | 字符串,值由单引号或者双引号括出的单个字符或者连续字符(JavaScript不区分字符类型) |
| null | 空类型,该原始类型仅有一个值:null |
| undefined | 未定义,该原始类型仅有一个值:undefined(undefined会被赋给一个还没有初始化的变量) |
| Symbol | 基本数据类型,标识独一无二的值 |
Symbol是ES6引入的基本类型,主要为了解决对对象属性的命令出现重复的情况。比如自己声明的类继承了一个其它的类,自己的类的属性可能会跟父类重复。所以ES6中对象属性的类型有 字符串和Symbol类型
所有原始类型的值都有字面形式,字面形式是不被保存在变量中的值。
//string
var name='zhiqiang';
var selection='a';
//number
var count=235;
var cost=1.51;
//boolean
var found=true;
//null
var object=null;
//undefined
var flag=undefined;
var ref;
console.log(ref); //undefined原始类型的变量直接保存原始值(而不是一个指向对象的指针)。当将原始值赋值给一个变量时,该值将被复制到变量中。也就是说,如果你使一个变量等于另一个时,每个变量有它自己的一份数据拷贝。
示例代码如下:
var color1='red';
var color2=color1;内存中的保存形式,如下图:
引用类型是在JavaScript中找到最能接近类的东西。引用值是引用类型的实例,也是对象的同义词。属性包含键(始终是字符串)和值。如果一个属性的值是函数,它就被称为方法。JavaScript中函数其实是引用值,除了函数可以运行以外,一个包含数组的属性和一个包含函数的属性没有区别。
创建引用类型的两种方式看下面的一段代码:
//第一种使用new操作符
var obj1 = new Object(); //
var obj2 = obj1;
//第二种
var obj3 = {}以上两种创建对象的方式并没有本质的区别,是等价的。
那么当我们创建了一个对象,且发生了赋值的时候,在内存中发生了什么呢?
看下图:
1.当发生了new操作的时候,先在内存中开辟一块空间,存放创建的对象,并且使obj1指向这块开辟的空间;
2.引用类型发生赋值的时候,仅仅是引用地址指向了内存中的同一块区域;
JavaScript语言有"垃圾回收"功能,所以在使用引用类型的时候无需担心内存分配。但是为了防止"内存泄露"还是应该在不实用对象的时候将该对象的引用赋值为null。让"垃圾回收"器在特定的时间对那一块内存进行回收。
JavaScript中的內建类型如下:
| 类型 | 类型描述 |
|---|---|
| Array | 数组类型,以数字为索引的一组值的有序列表 |
| Date | 日期和时间类型 |
| Error | 运行期错误类型 |
| Function | 函数类型 |
| Object | 通用对象类型 |
| RegExp | 正则表达式类型 |
內建引用类型有字面形式。字面形式允许你在不需要使用new操作符和构造函数显式创建对象的情况下生成引用值。(包括字符串,数字,布尔,空类型和未定义);
创建函数的三种方式:
//第一种函数声明
function abc(){
console.log(1);
}
//使用构造函数的形式
var value = new Function('','console.log(1)');
//函数表达式
var a = function(){
console.log(1);
};使用构造函数的方式创建函数,不易读,且调试不方便,不建议使用这种方式创建函数。
在JavaScript中使用正则表达式有两种方式:
var a1 = /\d+/g;//使用字面形式
var a2 = new RegExp('\\d+','g');//使用构造函数的形式在JavaScript中建议使用字面形式的正则表达式,因为不需要担心字符串中的转义字符。比如上面示例代码中字面形式使用\d而构造函数使用的是\\d;
使用typeof运算符可以完成对原始类型的检测,看下面的一段代码:
上面的代码中有一段比较特殊就是
typeof null //object这里其实是不准确的,如果我们要判断一个值是否为空类型的最佳的方式是直接和null进行比较
console.log(value === null);==和===之间的最主要的区别就是前者在进行比较的时候会进行类型转化,而后者不会;
console.log(5==5);//true
console.log('5'==5);//false
console.log('5'===5);//fasleJavaScript中对于引用类型的检测较为复杂。对于函数类型的引用使用typeof返回的是Function,而对于非函数的引用类型返回的则是object。所以在JavaScript中鉴别引用类型的类型引入了instanceof。
instanceof操作符以一个对象和一个构造函数作为参数;
function a (){}
var b = {};
var c =[];
typeof a // function
typeof b //object
typeof c //object
a instanceof Function //true
b instanceof Object //true
c instanceof Array //true有前一小结可以知道鉴别数组类型可以使用instanceof。但是在ECMAScript5中,Array对象提供了更好的方式来鉴别一个变量是不是数组类型。
var a = [];
var b =3;
Array.isArray(a); //true
Array.isArray(b); //false注意:IE8及更早的IE不支持该方法
JavaScript中的原始封装类型共有3种。这些特殊引用类型的存在使得原始类型用起来和对象一样方便。当读取字符串,数字,布尔类型时,原始封装类型被自动创建。
var a ='qwer';
var firstChar = a.chatAt(0);
console.log(firstChar);// q在JavaScript引擎中发生了如下的过程:
var a ='qwer';
var temp = new String(a);
var firstChar = temp.chatAt(0);
temp =null;
console.log(firstChar);// q由于要把字符串当成对象使用,JavaScript引擎创建了一个字符串实体让charAt可以工作,字符串对象(temp)的存在仅仅用于该语句(temp.chatAt(0)),随后便被销毁(temp =null)。
我们可以简单测试一下
var a ='qwer';
a.temp ='122';
console.log(a.temp); //undefined上面代码的过程如下:
var a ='qwer';
var temp = new String(a);
temp.temp ='122';
temp=null;
var temp = new String(a);
console.log(a.temp); //undefined
temp=null;由上面的代码我们可以看到我们实际上是在一个立刻就会被销毁的对象上而不是字符串上添加了一个新属性。当试图访问这个属性时,另一个不同的临时对象被创建,而新属性并不存在。虽然原始封装类型会被自动创建,但是在这些值上进行instanceof检查对应类型的返回值却都是false;
var a ='1234';
var num = 10;
a instanceof String //false
num instanceof Number //false这是因为临时对象仅在值被读取的时候创建,随即被销毁。instanceof操作符并没有读取到任何东西,也没有临时对象的创建,因此它告诉我们这些值并不属于原始封装类型;
但是我们可以手动创建原始封装类型,但是此时使用typeof没办法检测对象的实际类型,只能够使用instanceof来检测变量类型;
在JavaScript中函数就是对象。函数不同于其他对象的决定性特点是,函数存在一个被称为[[Call]]的内部属性。内部属性无法通过代码访问而是定义了代码执行时的行为。ECMAScript为JavaScript的对象定义了多种内部属性,这些内部属性都用双重中括号来标注。
[[Call]]属性是函数独有的,表明该对象可以被执行。由于仅函数拥有该属性,ECMAScript定义了typeof操作符对任何具有[[Call]]属性的对象返回**function**>
函数声明是以function关键字开头,这也是区别函数声明和函数表达式的一个重要的方法。函数声明会在编译期对整个作用域内的变量名字进行查询,函数声明的变量被提升至上下文的顶部,也就是说可以先使用函数后声明它们。
abc();
function abc(){
console.log(2);
}函数表达式是function关键字后边不需要加上函数的名字。这种函数被称为匿名函数。因为函数对象本身没有名字,所以函数表达式通常会被一个变量或者属性引用。
abcd()
var abcd=function(){
console.log(1)
};
var aaa={
abc:function(){
}
}函数表达式只能通过变量引用,无法提升匿名函数的作用域。在使用函数表达式之前必须先创建它们,否则代码会报错。看示例代码的运行结果:
JavaScript函数参数与很多语言函数参数不一样。你可以给函数传递任意数量的参数却不造成错误。那是因为函数实际上被保存在一个被称为arguments的类似数组的对象中。arguments可以自由增长来包含任意个数的值,这些值可以通过数字索引来引用。arguments的length属性会告诉你目前有多少个值(函数接受了多少个参数)。
arguments是一个类数组对象,它本身并不具有JavaScript数组应该具有的全部的属性和方法。
这里我们思考一个问题,我们怎么将一个类数组转化为真正的数组?
for循环将类数组中的每一项添加到新的数组中;Zepto或者jQuery的话,会有一个toArray()的方法可以使用;Array.from(arrayLike[, mapFn[, thisArg]])可以将类数组转化为数组对象;借用原型的方式把一个类数组转化为真正的数组的示例代码:
function abc(){
console.log(arguments);
var arrTemp = [].slice.apply(arguments); //相当于Array.prototype.slice == [].slice
console.log(arrTemp);
console.log(Array.isArray(arrTemp));
}
abc(1,2,3);输出结果:
依稀的记得在学习的从C# 的时候,这些强类型语言对重载的定义:函数名相同,参数不同,或者是参数类型不同都可以叫做函数的重载。
但是在JavaScript这样的语言中因为 arguments的存在,JavaScript的函数根本就不存在所谓的签名,所以重载在JavaScript中实际是不存在的。
但是我们可以根据arguments传入函数体的参数个数来模拟_函数重载_:
function abc(){
if (arguments.length ===1){
//A
}
if(arguments.length ===2){
//B
}
}
abc(11);
abc(11,22);这里主要是满足某些特殊场合的需求吧。
关于this,call,apply,bind这几个概念在之前博客文章已经介绍过很多遍了。在这里还是做一下简单的介绍。
this的指向在函数定义的时候是确定不了的,只有函数执行的时候才能确定this到底指向谁,实际上this的最终指向的是那个调用它的对象;
this指向的对象是在代码的运行期决定的。既上面说的,谁调用了它,就指向谁。一个很简单的总结就是,在函数中使用this,当前this指向的是当前window对象。在对象的方法中使用this,this指向的是当前对象(这个也是最容易出错的地方)。
关于这两个概念,之前的博客文章也介绍多很多次。这里也简单总结介绍一下。call和apply主要是在执行某个对象的方法的时候来改变当前this的指向。主要用在对象继承的时候。
bind也是改变对象this指向的一个方法。这个方法是ECMAScript5中新添加的一个方法。但是bind和call,apply的主要区别就是bind的第一个参数是要传给新函数的this的值。其它所有参数代表需要被永久设置在新函数中的命名参数。可以在之后继续设置任何非永久参数。
来看一段示例代码:
function abc (lab){
console.log(lab + this.name);
}
var person1 = {
name:'xiaogang'
}
var person2={
name:'zhiqiang21'
}
var sayNamePer1 =abc.bind(person1);
sayNamePer1('person1');
var sayNamePer2 =abc.bind(person2,'person2');
sayNamePer2();
person2.sayName = sayNamePer1;
person2.sayName('person2');上面的代码中:
sayNamePer1在绑定的时候没有传入参数,所以仍需要后续执行sayNamePer1来传入lab参数;sayNamePer2不仅绑定了this为person2,还绑定了输入的第一个参数是person2。意味着可以可以直接执行sayNamePer2()。最后一个是将sayNamePer1设置位person2的sayName方法。由于其this的值已经绑定,所以虽然sayNamePer1是person2的方法,但是输出的仍然是person1.name的值。
其实总结一句话call,apply和bind的主要区别就是:
call和apply是绑定既执行。bind是有返回值的,先绑定后执行。
2016年09月17日,下午五点四十左右我将车子停到了小区地下车库中。20点50左右我去推车,发现车子不见了。第一个想到的可能是车子被盗了。当时内心还想,“喔槽,终于被盗了!”。
在车库找了一圈没有找到后,看到车库出口有监控。遂想是不是可以查下监控。虽然我当时已经不抱着能找回来的心态了。想到如果自己去物业查监控,仅仅凭借自己丢车的一口说词不知道行不行。想着还是打110找警察叔叔来比较好一些。说实话,虽然从开始上小学就学习,火警119,匪警110,救护车112。但是26年中却重来没有用过其中任何一个。这次终于有机会用其中的一个了。如果说当时内心还是有点儿小激动不知道你们会不会相信。😅
21点7分左右接通北京110指挥中心电话。我跟值班民警叔叔讲了我遇到的情况。民警叔叔电话登记后说,后续会有辖区民警联系我。我说好。大约20分钟后接到辖区派出所民警的电话,问了我具体的位置。大约15分钟民警叔叔开着一辆现代伊兰特,前排座位坐一辅警哥哥,就到了我所在的小区。
首先民警叔叔让我带他去我丢车的车库去,中间打开了身上的录音装置。到了我丢车的位置后,民警叔叔重点问了我几个问题,大致如下:
👮:大概几点停的车?
🙁:五点四十左右。
👮:几点发现丢车的?
🙁:八点五十左右。
👮:车子什么牌子,多少钱买的,有发票么?
🙁:捷安特,4000+,有发票
👮:你现在想怎么办?
🙁:我想查查监控。
然后就有小区的保安队长带着我们去了小区物业查看监控录像。进了物业办公室后,警察叔叔让我先找个凳子坐下,然后教了我三句话。
👮:要求查监控,决定登记处理,如果发现有人推我车子的情况,会及时跟警察叔叔联系。
🙁:好……
👮:再次打开身上的录音装置……
🙁:我个人要求查看物业监控……及时跟警察叔叔联系。
👮:警察叔叔又拿了笔记本,要我把刚才说的话写在笔记本上,让我签字。
🙁:我个人要求查看物业监控……及时跟警察叔叔联系。(中间夸我字写的比他漂亮😓)
然后警察叔叔就跟物业大哥说,让他帮我按照我说的时间给我调取录像。
👮:那个小伙子,你先看监控,如果发现情况,就及时跟我电话联系……我先去处理其它事情了……
然后警察叔叔就开车走了……
当我开始认认真真的开始看录像的时候才发现他妈的好好的监控不拍门口,竟然拍路面,具体情况就是只有正对着车库入口才可以拍到,在车库入口左右两边都是死角,肯本什么也看不到,对小区物业无语……结果是可想而知的,最后什么也没有发现。
对于这次报警感受:我个人还是能够接受的,在整个过程中,警察叔叔跟我说话态度很好,征求我的想法,然后帮我解决我想看监控的问题。我也能够理解最后这种处理方式,毕竟也就是丢一辆车子,价值也不是很高。
由前段时间大学生被骗学费猝死也可以想象得到。帝都警察叔叔处理这些经济损失不高的案件方式就是这样,更不用说在农村基层派出所了。并不是说警察处理问题的方式有问题,在某些情况下也许这是正常的,正确的处理方式。
4千块对我来说我心理上是可以承受,但是对于很多学生来说,这肯定是一大笔钱。这一路走来,见识过人性的善良,也见识过人性的丑陋。好事也都不能全部发生在自己一个人身上,这个世界有阴暗就会有阳光,有小偷,骗子就会有警察,虽然警察叔叔有时候不一定好使。
车子终究是丢了,依赖的警察叔叔也没能帮上什么忙,也只能安慰自己:“塞翁失马,焉知非福!”。
参考文章链接在文章末尾,简单的语言总结如下:
经典的“粘连”footer布局就是。我们有一块内容<main>。当<main>的高度足够长的时候,紧跟在<main>后面的元素<footer>会跟在<main>元素的后面。当<main>元素比较短的时候(比如小于屏幕的高度),我们期望这个<footer>元素能够“粘连”在屏幕的底部。如下图所示:
当main足够长时
当main比较短时
上面布局的实现方法在参考文章中已经有提到。下面主要探讨我们项目中遇到的情况:
我们需要实现的布局就是 按钮“提交”所在的区域能够自由伸缩。当屏幕较低时,最就是“提交”按钮和表单所在的区域接触或者有一定的间隙。 示例图就是下面的:
当屏幕足够高的时候
当屏幕比较低的时候
上面的布局在移动端需要考虑以下因素对布局的影响:
absolute和fixed产生影响;bottom相对于屏幕的底部定位;为了解决以上的两个问题的解决方案:
min-height防止,父级元素太低时,绝对定位元素“溢出”父级元素;(min-height >= 绝对定位元素 + bottom);根据“粘连”footer布局的**,结合弹性盒布局。我们需要的这种布局可以有两种方式,分别介绍如下:
vh单位先来了解下vh和vw这两个单位。
vh相对于视口的高度。视口被均分为100单位的vh。vw相对于视口的宽度。视口被均分为100单位的vw。上面两个单位通俗的意义就是在css中获取当前屏幕的高度和宽度(不通过js计算)。
示例代码如下:
<body>
<div class="item1"></div>
<div class="item2"></div>
<div class="item3">
<div class="btn-item">你好</div>
</div>
</body>css代码如下:
* {
margin: 0;
padding: 0;
}
body {
/*主要就是这里获取视窗口的高度*/
min-height: 100vh;
display: -webkit-box;
display: -webkit-flex;
display: -moz-box;
display: -ms-flexbox;
display: flex;
-webkit-flex-flow: column;
-ms-flex-flow: column;
flex-flow: column;
}
.item1 {
height: 100px;
background-color: #ddd
}
.item2 {
height: 300px;
background-color: #fea0a0
}
.item3 {
/*防止绝对定位的元素溢出父级元素*/
min-height: 30px !important;
border: 1px solid #481eff;
position: relative;
height: 0;
-webkit-box-flex: 1;
-webkit-flex: 1;
-moz-box-flex: 1;
-ms-flex: 1;
flex: 1;
-webkit-flex-basis: 0;
-ms-flex-preferred-size: 0;
flex-basis: 0;
max-height: 100%;
}
.btn-item {
position: absolute;
bottom: 10px;
border: 1px solid #000;
}以上就是完全使用css来实现我们项目中布局的方法,但是这个方法有一个很明显的缺点就是vh单位的兼容性问题。兼容列表如下:
因为兼容性问题,纯css的方法在我们的项目中使用还是不现实。但是我们想下问题的本质:在使用弹性盒的基础上,我们唯一需要做的就是知道弹性盒元素的高度(就是我们项目中屏幕的高度)。
就是在dom树渲染完成以后给body设置高度未屏幕的高度。为了避免不必要的“重绘”或者是“重排”在head标签中添加如下js。
var callback = function(){
document.body.style.height=window.screen.height+'px';
};
//是否是页面加载触发绑定了事件
if ( document.readyState === "complete" || (document.readyState !== "loading" && !document.documentElement.doScroll) ) {
callback();
} else {
//DOMContentLoaded 仅支持ie9+ 和移动端 <=ie8 使用 onreadystatechange 可以监听dom是否加载完毕
document.addEventListener("DOMContentLoaded", callback);
}使用 jQuery 或者是 Zepto 的方法,仍然在head标签中添加如下js。
$(function(){
$('body').height($(window).height());
})所以在我们的项目中结合弹性盒布局和添加简单的动态js计算屏幕的高度。就可以完美实现我们项目中需要的布局。
body {
/*使用js动态计算就可以不使用vh单位*/
/*min-height: 100vh;*/
display: flex;
}因为是一个
cssstickyfooter.com
ryanfait.com/sticky-footer
css-tricks.com/snippets/css/sticky-footer
pixelsvsbytes.com/blog/2011/09/sticky-css-footers-the-flexible-way
mystrd.at/modern-clean-css-sticky-footer
做移动端h5开发很久了,从开始入行到现在。很多知识和工具都是在用前辈留下的遗产,都没有深入的研究过原因,了解为什么要这么去做。
也许自己也是过了交给自己做什么就做什么的阶段了。在国庆节有一个大块的时间,把最近看到的知识总结一下,也算是对这方面的知识划上一个句号。想想着实把国庆节过成了劳动节,没办法,自己就是这样的一个人,“应该去做的,而且有能力做的,如果不去做,心里面总是不舒服”。
这篇文章的内容主要分为两个部分:
高清屏和普通屏幕,并且衍生出的适配方案;注:本篇文章的所有图片来源于网络,如有侵权请告知。
高清屏(Retina)概念的兴起主要是从乔帮主发布 Retina 设备开始兴起。主要功能如下:
具备足够高的物理像素密度而使人体肉眼无法分辨其中单独像素点的液晶屏。
特点如下:
看一张乔帮主当年发布 **高清屏(Retina)**时的一张照片:
由乔帮主背后的那两张图可以发现,高清屏和普通平的主要区别:高清屏(Retina)和普通屏相比,相同区域的物理像素点数,高清屏是普通屏的4倍。
先来看一张图:
由上面的图我们可以知道,当我们使用css设置了一个区域以后,高清屏含有的像素点数是普通屏的4倍。而css设置的像素值(px)属于普通像素点,或者是标准像素点。
那么我们平时在普通屏幕中正常显示的位图图像放在高清的屏幕上会有什么问题呢?由上面的知识可以知道,普通屏幕的1个CSS像素点对应4个高清屏幕的像素点,1个分成4个,不够分的情况下,颜色会取近似值。所以在高清屏上,在普通屏幕正常显示的图片会变的模糊。
可以看下图来加深理解:
这就是为什么我们现在的设计稿为什么都会设计成2倍稿的原因。为了兼容高清屏幕的图片高清晰显示,我们的裁切图是2倍图,在css中使用的时候会使用css压缩2倍。
比如,我们有一个icon.png的文件,切图大小是 200x200 。而我们使用的时候却是使用css设置其大小为100x100。这样基本上就会保证普通屏和高清屏显示一致。
看了一些网友的文章。css压缩会使图片边缘的锐度减小。
下面是我做的一个简单的实验,比如说我现在有一个276x90的图标文件。我直接把它设置为一个div的背景,在浏览器中看效果:
代码如下:
<div class="item3"></div>.item3{
height:45px;
width:138px;
background:url(./4.png) no-repeat center;
background-size:100% 100%;
}在网页中的效果如下图:
我把这张图截取下来放到 PS 中放大,之后的效果如下图,可以明显看到在有颜色的字体边缘的颜色变浅,图像周围的锐度减小。
其实,在我们的开发过程中完全没有必要去在意这里的这个细节问题,图像边缘的锐度也是在 PS 中放大了好多倍以后才看出来的,如果是人的肉眼是根本看不出来的。
由上面的知识可以知道。当我们在高清屏中使用普通图片的时候,相当于图片被放大了一倍(可以这么理解:普通屏幕的1px相当于高清屏的2px)。
因为安卓产品的参差不齐和厂商对屏幕制造标准的标准不一样。这个放大的比例并不是固定的。还好我们有一个叫设备像素比的东西来检测当前屏幕是不是属于高清屏幕。
设备像素比的英文单词为devicePixelRatio。它有一个计算公式如下:
devicePixelRatio=屏幕物理像素/设备独立像素
devicePixelRatio其实就是window对象的一个属性,它被大多数的webkit浏览器所支持。看下图是我在我的MacBook Pro上的Chrome中做的测试。很明显是属于高清屏哈ヾ(=^▽^=)ノ
上面是对设备像素比的东西 做了一个简单的了解,下面就来详细了解下几个比较重要的概念。
**设备独立像素(device independent pixels)**又叫dip或者是dp。它可以用来辅助区分高清屏幕和非高清屏幕。
我们可以通过两个典型的手机来理解上面的概念。iphone3gs和iphone4的屏幕最大的区别就是前者是普通屏幕而后者是使用了高清的retina屏幕。以下是我查到的一些参数信息:
下面的是iphone3gs屏幕信息:
下面是iphone4s屏幕信息:
在iphone3gs垂直的时候,屏幕的宽度为320物理像素。当我们使用<meta name="viewport" content="width=device-width">的时候,会设置视窗布局宽度为屏幕的宽度320px,于是页面就很自然的覆盖在屏幕上。
所以在iphone3gs上屏幕的物理像素位320像素,独立像素也是320像素。因此window.devicePixelRatio=1。
而对于iphone4s来说,当屏幕纵向显示的时候,屏幕的物理像素是640像素,而视区宽度不是640像素而是320像素。
这样在iphone4s上,屏幕的物理像素为640像素,独立像素还是320像素,因此window.devicePixelRatio=2。
由上面的举例相信已经对设备的物理像素和独立像素有了一个认识,那么总结如下:
通过对于第一部分的了解,我们可能已经知道怎么区分高清屏和普通屏了。网上网友总结的结论如下:
通过计算 devicePixelRatio 的值,是可以区分普通显示屏和高清显示器,当devicePixelRatio值等于1时(也就是最小值),那么它普通显示屏,当devicePixelRatio值大于1(通常是1.5、2.0),那么它就是高清显示屏。
那么这部分,就来简单的了解下我们平时在开发过程中,对于我们使用的图片怎么适配高清屏和普通屏。
原理也很简单,就是根据不同的设备像素比来加载不同的图片:
根据屏幕的设备像素比来加载不同图片可以使用css 的media queries来解决,当然使用css来解决也是兼容性最好的解决方案(其实意味这我们要切两套图片1倍图和2倍图)。
示例的demo如下:
.css{/* 普通显示屏(设备像素比例小于等于1.3)使用1倍的图 */
background-image: url(img_1x.png);
}
@media only screen and (-webkit-min-device-pixel-ratio:1.5){
.css{/* 高清显示屏(设备像素比例大于等于1.5)使用2倍图 */
background-image: url(img_2x.png);
}
}使用js对“window.devicePixelRatio”进行判断,然后根据对应的值给Retina屏幕选择图像。
$(document).ready(function(){
if (window.devicePixelRatio > 1) {
var lowresImages = $('img');
images.each(function(i) {
var lowres = $(this).attr('src');
var highres = lowres.replace(".", "@2x.");
$(this).attr('src', highres);
});
}
});前段时间大部门下新成立了一个推广百度OCR、文字识别、图像识别等科技能力在金融领域应用的子部门。因为部门刚成立,基础设施和人力都是欠缺的。当时分到我们部门的任务是抽调一个人做新部门主站前端开发工作。本来说的是只负责页面的开发工作。当我参加过需求品审会后,了解到新部门人力不足,而我今年主要任务又是在我们部门做基于Nodejs的前端后端分离的架构升级工作。
在这之前就是用Nodejs写了两个内部系统,并没有大型的线上Web开发经验,也想趁着这个机会锻炼下。然后就主动的跟老板商量了这件事,老板非常支持。之后又跟新部门的产品商量,本来就缺人手的他们也非常乐意我这边承担更多的开发任务。
这篇文章和自己之前的文章的风格会有很大的区别,不会再去写一些具体技术点和遇到问题的具体解决办法,主要谈的是我整个开发过程中遇到的一些问题和思考解决他们的方法。
在文章的最开头背景介绍中大概说了网站后端采用Nodejs的开发。为了突出科技能力,网站要求了一些特效。因为我要用CSS3来写这些特效,跟产品PK后结果是浏览器兼容性是IE8.0以上,特效满足大多数主流浏览器即可。那么基于Nodejs的其它技术选型如下:
以下选择这些技术的原因:
确定了技术选型之后就是开始申请服务,主要包括以下相关内容:
以上都是走的公司的内部流程,具体的就不介绍了。主要介绍下一些服务的作用。一个在网络上运行的网站肯定是需要一个域名的,能让网站跑起来很定是需要线上服务器的。存储用户的注册数据需要数据库。因为使用OCR进行人脸识别,要满足识别一张图片上的多张脸。是需要对用户的图片裁切。因为网站是部署在多台机器上,肯定不能存储在网站运行的服务器上需要将裁切好的图片存储在专门的存储服务器上,并且返回给网站图片链接,
使用Nodejs开发的话,前端的工程的概念可能还要广一些会涉及到Nodejs相关的工程化。这部分分两部分介绍:
目标:
以上的这些目标都可以使用 FIS3和相关插件来实现。
拆分公共模块为组件
当我们观察一个页面的时候可以发现一个页面的这几块是不同页面间可以公用的。我把这些页面的js、css(scss)、html(tpl)写在一个目录以方便管理他们。就是我没一次一次就可以在所有页面应用自己的修改。
组织组件的目录:
当我在不同页面间使用相同的nav 和footer的时候,只需要include一次就可以了。
因为我们线上大规模使用的Nodejs版本是6.x版本。但是开发过程中处理异步又是使用async和await。所以需要借助编译引擎将这些es7的语法编译成6.x支持的语法。
另外就是借助process.env.NODE_ENV可以读取环境变量的特性,来区分配置一些线上和线下的配置,比如:
const YOG_DEBUG = process.env.YOG_DEBUG;
const PANSHI_DEBUG = process.env.PANSHI_DEBUG;
let mysqlConf;
if (PANSHI_DEBUG === 'true') {
mysqlConf = {
host: '10.00.00.00',
user: 'ppui',
password: 'ppui',
database: 'excel',
port: '5003'
};
} else if (YOG_DEBUG === 'true') {
mysqlConf = {
host: '127.0.0.1',
user: 'root',
password: '',
database: 'pass_panshi',
port: '3306'
};
}这里主要谈一些前端的技术目标
之前开发过程中经常遇到的情况是我需要该一个html节点的样式,不小心改了class类名。而js又恰恰使用了这个class操作了dom。这个时候页面运行的时候肯定会报错的,增加了项目的维护成本。
有两种方案可以有效的解决这种问题,第一就是添加自定义属性,比如<div class="section" node-type="pagesecond"></div>当我需要操作dom的时候就通过jQuery的属性选择器来操作这个dom而不会去使用class。这样在我调整样式、需要修改class名称的时候也不会影响js代码。第二种就是根据大家经常说的使用-来做html 类名的连接符,而我们就规定一个规范就是使用下划线(_)来标记我要操作dom节点的名称,比如<div class="section _pagesecond"></div>。
这两种方式,如果是在开发多人维护的项目是都是需要提前预定规范,我在项目中是使用的前者。
在前面已经介绍过就是使用cmd规范来组织前端代码。比如为了能够满足我使用属性选择器来作为操作dom的需求。我特地自己封装了一些代码段,比如在base.js文件中有一段这样的代码:
/**
* 根据node-type获取节点信息
*
* @param {any} params 获取节点元素
* @param {any} context 上下文环境
* @returns
*/
exports.nodeTypeDom = function (params, context) {
if (context && context !== '') {
return $('[node-type="' + params + '"]', $('[node-type="' + context + '"]'));
} else {
return $('[node-type="' + params + '"]');
}
};
我在其他文件中需要使用这个代码段的时候,只需要像下面这样就可以了。
var baseJs = require('../libjs/base');
var node = baseJs.nodeTypeDom;
// ��需要选择 dom 的地方,直接传入自定义属性的�值
node('pagesecond').xxxx除了一些常用的代码段这样封装,一些组件也按照这样的方式封装。比如:轮播图组件、文件上传组件、表单校验组件、tab滚动组件。
以上两种方式的好处都能够极大的提高代码的可维护性、阅读性。
我在开发过程中关注的Web安全主要是
sql注入简单些说就是指一些违法用户拼接一个特殊的用户名或者是密码,因为我们要把用户名和密码插入数据库,肯定会根据这个用户名和密码拼接一个sql语句。而违法用户的这个特殊用户名语句有可能删掉我们数据库的所有数据。
因为使用的是mysql数据库。Nodejs模块使用的也是npm上使用最多的Mysql模块。本身这个模块已经提供了访问mysql集群的能力和防注入的能力。
具体方法可以参考官方文档点击这里直达
这里要做的就是有些违法用户拿到我们接口的时候,写一个循环频繁的访问我们的接口。为了防止有些违法用户就是给请求加token。就是在向服务端发起请求的时候返回给前端的一个token,前端请求后端的时候带上这个token。如果token在后端校验通过就销毁这个token 。还有比如验证请求的源IP,这里注意的是我们验证IP的时候应该获取的是HTTP协议header字段中的x-forwarded-for属性的值。(这两种方法可以一起使用)
不过后来从后端RD那边了解到公司有专门的服务可以用来做反作弊,而且策略更全面些。目前在研究准备接入。
关于跨机房访问、同机房访问和内网访问外网,这些基本上都会涉及到运维的话题。百度内部有现成的服务接入文档。各个公司可能提供能力的方式不一样。这里不多介绍。
这里谈一些小的细节点。先看下面的一张图:
一句话总结:当一条请求到达接入层之前是不知道要访问内网环境下那个机房的服务器的。相反的内网的机器上如果有一条请求外网的链接,比如:http://weibo.com 。需要通过一个proxy访问外网服务器。
访问接口我使用request模块。配合promise npm上有request-promise由名字我们就知道他的每个方法或者是调用结果返回的是什么了。这个模块默认已经提供了代理参数的相关配置。具体的可以参考文档点击直达
这里涉及的知识比较多,比如代理隧道、https请求的代理。在阅读官方配置文档的时候搜索一些关键字了解一些其它相关知识即可。
如果有相关的需求,可以参考我的配置,如果我的配置不能解决你的问题,请仔细阅读官方文档哈。、
let options = {
'url': params.url,
'encoding': 'binary',
'rejectUnauthorized': false // 取消https证书的校验
};
// 解决代理https请求的行为 测试机需要配置环境变量 PANSHI_HTTPS_PROXY
if (process.env.PANSHI_DEBUG !== 'true' || PANSHI_HTTPS_PROXY) {
options.tunnel = false;
options.proxy = 'http://xxxx.proxy.com:8080';
}到这里关于开发相关介绍已经完毕。这里介绍的就是运营和产品需求的一些功能开发。每天将注册的用户发送给相应的责任人。
如果要满足这个功能需要有邮件服务器。这个在公司内部有公用的可以很容易找到。其它就是配置服务的crontab定时执行脚本查询数据库发送邮件。
这里主要使用了nodejs模块nodemailer。具体的相关配置和发送邮件的方法可以参考官方文档配置点击直达
上面列举的是比较典型的几个点。比如像css放head标签头部,script标签放到body标签底部。这些应该属于一个前端工程师的常识吧。
静态文件部署CDN这个不多介绍,每个公司都会自己的一套方法。这里主要介绍下合并静态文件和缓存静态文件。
默认FIS3是有插件支持合并静态文件的。因为我这次开发的页面较多(总共11个主站页面),且因为采用的分块开发加载模块和静态文件。如果不做合并的话,一个页面加载完需要有10-20条的静态文件的请求。会影响页面的加载速度。
当我准备使用FIS3的插件来合并静态文件的时候发现还是有些麻烦的需要一个页面一个页面去配置要打包合并的静态文件。最后请教了下其它部门的同事使用我们接入层服务器提供的comb功能,由服务器帮我们合并静态文件(其实就是Nginx 的concat模块提供的功能)。这里也不做过多的介绍,自行搜索文章了解就可以了。
先来看下一张图
上图中红色框出来的都是跟静态文件缓存有关的http协议的字段。如果对这些字段的概念比较模糊可以阅读这篇文章加深下印象《HTTP缓存》点击直达
不管使用express还是koa(koa可以使用koa-static-cache中间件)都用相应的静态文件服务的中间件提供配置这几个字段的能力。express可以通过一下方式配置(具体的可以阅读express文档)
const express = require('express')
// 配置与静态文件相关的参数
express.static('xxxxx')最后就是谈谈这次开发的收获
在这个过程经历的好多事情,心态上也是考验。既然下决心做一件事情了,自己不放弃自己,就没有人能够有放弃自己。
抱歉,在这里发issue,麻烦之后close掉。
因为最近遇到了rsa的问题,看到了这篇文章微信小程序开发rsa加密,所以希望可以参考下你的相关代码,谢谢
人生下半场,当所有的心高气傲被磨平,是时候接纳平凡的自己了。
在写这篇文章的时候我特地翻看了下自己博客的文章记录,确实是很久没有写文章了。最近的一篇文章还是2017年7月份写的年中总结----《工作三年小结----我依然是那个不变初心的少年_20170710》,看名字就知道当初的意气风发。当我开始在键盘上敲下这篇文章题目的时候,我知道这将是一个横跨两年的漫长的自我总结的故事。
这两年自己经历了很多事情,很多都涉及到了自身的个人发展,多么希望当时的自己思考问题能够更加的成熟些,忍耐力更加的强大些。这篇文章里我会写下当时面临这些事情时没有跟同事或者朋友说过的最终做出那样的决定的真实想法,也许那都是错的。
文章开始前我想说,我不是想表达我多么牛逼炫耀多么厉害。那就是真实的我,当时的环境和个人条件让做出了那样的选择。如果不幸被大佬看到这篇文章请理性对待。
现在觉的重大的、无法忍受的事情,那是因为你的心胸还不够强大到容纳它。不同的人生阶段,不同的心理承受能力,不同的选择结果。有些事,你越是在乎,痛的就越厉害,放开了,看淡了,慢慢就淡化了。
一年多过去了我想我已经想明白了当初发生的一些事情,能够平平淡淡的记录下它们。当我现在开始写下它们的时候我想我已经能够真正的放下它们,我可以不用再去想它们,我对他们的看法都停留在了文章里。
我是在2018年2月底也就是刚过完年回到北京上班的第一天办理的离职手续。当时在ERP提离职和办理离职手续的时候是很不舍的,这家教会我很多东西,给了我很多机会的公司我真的不舍得离开,但是现在我却真的要离开了。我认为我是带着遗憾离开的。
这段经历是从2016年5月份开始的,那时我从新浪微博离职,抱着对BAT光环的渴望进入了百度。刚入职的我,在工作上犯了一些的错误,多谢部门同事和领导的宽容,帮我一步一步融入到工作中去。
在入职之后5个月的时候,因为上线合并代码的时候冲突没有处理干净,导致了线上故障。这个问题应该是程序员最不应该犯的低级的错误了。当时被大领导通报批评。那次事件后切切实实的给自己上了一课。也对我之后的上线操作起到了警醒作用。
在2017年2月份百度春季晋升的时间节点,自己刚入职10个多月的时候,竟然在部门指标有限的情况下老板帮我提了晋升,并且晋升成功。这也就意味着不到一年自己就升职加薪了。
背后有很多故事,不然好运不可能平白无故的降临到我身上。我是一个能在工作中发现别人发现不了的问题,肯自己花费时间去解决这些问题。遇到工作中影响工作效率的事情,肯花费时间专研解决这些问题,并且分享给同事,提高同事的工作效率。这些事情使得大家都很认可我。记得那个时候自己是上6天班的,周六自己会自动加班一天。周围同事认可,技术能力强,能解决别人解决不了的问题。自恋的说自己应该是部门“自带光环”的人物。
当然更高的职位代表着更多的责任(其实也不算高)。当时我们部门前端有很多业务痛点,老板破格晋升我也是看到我是有能力来改变这些事情的人。所以整个17年我的主要精力都是在解决这些事情。比如:技术架构升级,以及技术架构升级之后所带来的周围同事对新技术应用的技术培训和指导。另外为了满足新技术架构所要开发的衍生技术产品。
技术架构升级并不是说哪个技术好玩我们就用哪个技术。**技术选型是要结合当前业务的特点以及升级技术架构能不能解决当前业务开发的瓶颈来做的。**所以我自己做了很多技术调研,过程中我自己摸索、学习了很多东西。
当我觉得一切都成熟的时候我开始在我们的线上项目做实践。结合当时我们部门的业务特点使用MVVM框架(业内代表React或者是Vue)和Nodejs是最佳的解决方案。第一个实践的项目是百度账号检测的项目。如果是使用旧的技术开发可能不需要多少时间,但是上了新的业务架构后,我不仅仅要解决业务问题还要解决应用新框架之后的问题。
前面我说是**“当我觉得”**。自我感觉良好应该是大多数人都会犯的错误。是的我也犯了这样的错误。其实我当时做调研得到的信息并不能完全解决我在实际业务开发过程中的所有问题。**解决这些问题需要更多的知识储备,当然也就要更多的时间去学习自己陌生的领域。**那段时间对于我来说是辛苦的、煎熬的。因为是线上业务需求,产品对于上线是有最终的DeadLine的。记得有几次为了解决问题我都在公司通宵了。虽然延期但是最后业务还是上线了,并且运行还算稳定。这次虽然业务模块不大,但是在公司走通了应用新业务框架的流程,比如:开发模式、上线机制、CDN机制、线上Nodejs报警机制、线上Nodejs服务部署机制等。
后续我又接手独立开发了我们部门线上一个核心的业务重构工作。当然这次是涉及到一块业务的整个流程的重构。开发量大而且业务较为复杂。过程是艰辛的,自己遇到了很多问题,都是边学习边开发。当然不仅仅是能够开发完就行了,还要考虑性能问题。而且这块流程主要是跑在移动端,万恶的安卓系统上总会遇到各种各样的问题。解决这些兼容性问题让我心力交瘁了。当时应该是延期2-3周将项目上的线。让人欣慰的是,项目上线后性能和业务稳定性都很高。之前这块流程线上客诉率很高,新框架上线后大大的降低了客诉率。
这次项目开发对我个人想法影响很大,之前我认为我个人能力强可以自己搞定一切。现在我发现靠我一个人的力量来推动部门的技术升级是不够的。那段时间我的精神和肉体的压力(加班、熬夜)让我喘不过气来。我想要协调部门前端的人力资源来做技术升级分担我一个人的压力。但是恰巧的是现在前端的主要负责人是跟我同级别的另外一个比我来的早的同事。所以我想做的事情就有了局限性----我不可能越过她去调配人力做事情。那段时间我们的关系很微妙也很复杂。
工作上的压力和环境的压抑让我慢慢的有了看看新机会的想法。后续就接连看了新机会,在年前的时候就拿个几个不错的offer。京东,腾讯,搜狗等。因为提前就跟直属领导沟通过,他也有劝过不要走继续做事情,但是那个时候的工作状态让我的态度很坚决。按照百度的流程,会有一个总监面谈了解离职的原因以及哪些因素导致的离职。在聊之前我的直属领导已经提前沟通过,当时我们聊了很长时间,过程中我get到的信息,我的直属领导还是不希望我走,而且对我的工作能力评价很高。当我表达出对部门和对公司的不舍时,她也建议我转岗到其它部门去。当时外部的offer中的条件对我的诱惑很大,最终还是选择了离职。
如果让现在的我做决定,我应该是不会选择离开的。因为这一年我得到的远远比我失去的要多得多。如果当时我的忍耐力再大一些,我的心再柔软一些,现在的我可能会更加的强大。
工作之外还有生活。生活上的压力也会让人不得不改变。
从百度离职之后我去了搜狗。我当时考虑去搜狗的原因很简单,钱给的最多。当时我想先挣更多的钱。工作之外自己好好的沉静两年,把自己的技术功底更加的深化一下。
当时进入的是搜狗搜索APP这个部门,这个部门的技术负责人和周围的同事还是很nice的。跟技术负责人沟通的过程中了解到他也是一个爱折腾的人,当前部门的很多技术应用都是他率先搭建起来的,而且做了相关服务化的工作。但是我来之后不久他就离职创业了,这也对我之后考虑离职的有一定的影响。
当时我主要负责做搜狗号的相关开发工作。当时做的工作还是很杂的,前端页面,后端Nodejs,服务端数据库等都需要自己来写代码。当然这些都难不倒我,过去的经历能够让我在大多数的前端工作面前游刃有余。后来又做了2018年世界杯预测的一个活动项目。这个过程中让我了解公司的职能部门以及他们的特点。
搜狗作为一个在美股上市的公司,我认为整体还是很不错的。作为一个搜索为主流业务的公司要说好肯定没有百度的技术氛围浓厚,要说不好肯定比小公司(创业公司)的业务稳定,技术栈稳定。但是目前公司其实并没有一款产品在业内占有绝对的优势,我当时就发现搜狗做的东西,百度很久都做了,不知道谁做的早还是晚,但是百度的产品用户占有率还是高。这是一家中规中矩的公司。
在北京上班的朋友肯定体会过早上乘坐公共交通的痛苦。当时我是从我住的地方开车到五道口上班。因为公司自己没有停车位,我到目的地之后面对的一个主要的问题就是怎么停车,其实只能停收费停车场。如果去的晚的话可能收费停车场也没得停,着急上班的话,只能随便找个地方停车。所以在短短的2-3个月时间我交了接近2k的违章停车罚款。后来我干脆放弃了开车上班,坐公共交通上班。但是我住的小区附近没有直达的公交和地铁只能通过中间换站的方式到公司。
在这种状态下,我就开始想找一个离家近上班停车方便的公司。做程序员的应该都收到过猎头的电话。在猎头的推荐下我的**开始松动了,后来我面试了滴滴和小米的职位,并且都拿到了offer。我之所以最后选择了滴滴。是因为我对这家颠覆了一个行业的公司一直很感兴趣。我想要去体验下这家公司的公司文化。
这段经历很短暂,但是让我明白了每个公司都会有自己的文化,相应的会体现在每个员工身上。比如说话和做事的方式。搜狗可能不是一家很厉害的公司但是还是一家不错的公司。
事情不总会朝着自己预期的方向发展。不幸的事情可能会突然降临。
我在2018年7月份入职了滴滴。这家公司对我的印象整体还是很好的。唯一我觉得有问题的地方就是加班文化。公司9点之后是提供免费打车服务的。有一个很特别的现象,一些家远的同学会选择每天到9点后打车回家,但老板每天走的也很晚。慢慢的就造成了整个部门都走的很晚。在这种环境中,就算平时想早走也会不自觉的考虑到大家也都还没走。
**“四十二岁了,还是程序员,刚辞职,发现工作不好找了。怎么破?”**这是之前在脉脉上看到的。当时刚好是在换工作的时间段,看到后感触很深,就把它记下来了。
年龄越大做的一些不慎重的决定,可能需要自己做更多的事儿或者是要经历好几年才能够弥补,有些甚至永远也弥补不了。以前做决定,认为年轻就是资本,不行老纸从头再来。不知不觉发现从头再来真的好辛苦。不是自己变得懒惰了,只是自己离年轻这个词越来越远了。
滴滴要裁员这个新闻应该是2019年初互联网圈比较大的新闻了。对于我这个局内人来说很突然。后来知道我所在的部门在公司今年的战略上属于“关停”状态,裁员将是重灾区就更加突然----突然自己就要被裁了。
新闻上说的这波裁员滴滴给的补偿还是很丰厚的。确实是,我能拿大概10w左右的补偿。这些钱对我来说真的挺多的。本来我是准备拿着补偿走的,也想要拿着补偿走,因为我知道按照我的能力出去找工作肯定不是问题。
在裁员的同时,公司也提供了转岗到其它部门的机会。一个偶然的机会有个其它部门的同事联系到问我愿不愿意到他们部门去。当时我的想法是就先聊下呗,如果感觉不错就过去,不行的话就拿补偿走人。现在我是选择了到那个部门去。
我到滴滴的时间还很短,如果现在出去,虽然我可以得到一些经济上的收益,但是对我个人的职业发展并不是特别好。在我的简历上会显示在很短的一段时间内我换了两份工作,虽然其中一次是因为不可抗因素。但是时间久了别人可能看不到这些。
之前对我人生比较重要的一次决定,在利益和发展上我选择了短暂的获取利益。让后来的我吃了很多亏。一时的利益带来的快感总是短暂的。我认为我在滴滴还有很大的发展空间,这次我要跟随自己的内心留下来。
这次裁员让我思考的另外一个问题是,如果这次真的是被裁掉而且是必须走,对于现阶段的我来说影响不大。我还年轻,出去找工作也能找到更好的工作。但是如果我已经40岁或者是更大50岁的时候,突然被宣布自己要被公司裁掉。自己的心情一定会非常复杂。当自己因为年龄而渐渐失去竞争力的时候,自己身上其它的软素质能不能让自己在面对裁员是更加坦然一些呢?其实我很庆幸在我还年轻的时候经历了这次裁员,知道了生活的残酷。让我更加坚定了在不幸面前人人平等,如果想要在不幸降临时,更加的坦然。唯有让自己更加强大。
过去的一年或是两年自己经历了很多事情。让自己想明白了很多人生道理。它们对自己的人生有影响的同时,也让自己收获很多。人生之事岂能尽如我意,哭笑皆由人,悲喜自己定。经历过,体会过,有所感悟就不妄自己的人生。
你说,生活就是一场将就,
将就彼此,将就着过。
你说,生活就是一场苟且,
既无远方,也无诗歌。
其实,生活就是一碗面,
即便匆匆,亦不失落。
有时候我们开发 h5页面的时候需要动态的去更新title 的名字,这个时候使用
document.title='修改后的名字';就可以解决我们的问题。
或者使用
//当前firefox对 title 参数不支持
history.pushstate(state,title,url);这种方法不仅能够修改 title 而且能够修改 url 的值,并且将这些信息存储到浏览器的历史堆栈中,当用户使用返回按钮的时候能够得到更加好的体验。
当我们在做一个无刷新更新页面数据的时候,可以使用这种方法来记录页面的状态,使得页面能够回退。
有这样的一个场景:
在做电商类的产品的时候,我们要对每个产品的点击数进行统计(其实就是出发一个ajax请求)。PC端的交互大多数是点击商品后新开页面。这个时候ajax是同步发送或者异步发送对统计没有影响。
但是嵌套在客户端中,长长是在当前 tab 中跳页。如果我们仍旧使用异步的ajax 请求,有请求会被阻断,统计结果不准确。
这部分内容之前也是看过很多次,但是都不能够理解深层次的含义。后来看的多了,也就理解了。
var ab = {
'a': 1,
'b': 2,
'c': 3,
abc:function(){
// 对象的方法中,this是绑定的当前对象
var that=this;
console.log('abc');
var aaa=function(){
//that指向的是当前对象
console.log(that.a);
//函数中this的值绑定的是全局的window对象
console.log(this);
};
aaa();
}
};
console.log('---------');
ab.abc();以上代码浏览器中输出结果如下:
var BBB=function(){
var a=0;
this.b=1;
return this;
}
var bb= new BBB();在浏览器中输入一下的内容查看输出:
我们对代码做一下修改,如下:
var BBB=function(){
var a=0;
this.b=1;
}
var bb= new BBB();与之上相同的输入,查看一下输出是什么
由上可知 new 操作符的执行过程:
一个新对象被创建。它继承自BBB.prototype。
构造函数 BBB 被执行。执行的时候,相应的传参会被传入,同时上下文this会被指定为这个新实例。new BBB 等同于new BBB(), 只能用在不传递任何参数的情况。
如果构造函数返回了一个“对象”,那么这个对象会取代整个new出来的结果。如果构造函数没有返回对象,那么new出来的结果为步骤1创建的对象。
一般情况下构造函数不返回任何值,不过用户如果想覆盖这个返回值,可以自己选择返回一个普通对象来覆盖。当然,返回数组也会覆盖,因为数组也是对象。
定义在闭包中的函数可以“记忆”它创建时候的环境。
var test=function(string){
return function(){
console.log(string);
}
};
var tt=test();
tt();//li列表点击每一行 显示当前的行数
var add_li_event=function(node){
var helper=function(i){
return function(e){
alert(i);
}
};
for (var i = 0, len =node.length; i < len; i++) {
node[i].onclick=helper(i);
}
};我自己在写 js 的事件绑定的时候也经历了一个过程,刚开始的时候onclick,bind,live,delegate,on 这样一个过程。
之所以会有这样的需求就是因为我们页面上的 DOM 是动态更新。比如说,某块内容是点击页面上的内容显示出来,然后在这块新出现的内容上使用click肯定是满足不了需求的。
live 和delegate 属于较早版本的事件委托(代理事件)的写法。最新版本的 jquery 都是使用on 来做代理事件。效率上比 live 和 delegate更高。
live是将事件绑定到当前的document ,如果文档元素嵌套太深,在冒泡的过程中影响性能。
而 delegate和on 的区别就是
jQueryObject.delegate( selector , events [, data ], handler )
//或者
jQueryObject.delegate( selector, eventsMap ) jQueryObject.on( events [, selector ] [, data ], handler )
//或者
jQueryObject.on( eventsMap [, selector ] [, data ] )由此可知,使用on的话,子代元素的选择器是可选的。但是 delegate的选择器是必须的。on比delegate更加的灵活。
很多时候我们都是只声明事件绑定,而不管事件的销毁。但是在编写前端插件的时候,我们需要提供事件销毁的方法,提供给插件使用者调用。这样做的好处就是使,使用者对插件更加可控,释放内存,提供页面的性能。
var that={};
$('.event_dom').on('click','.childK_dom',function(){});
$(window).on('scroll',scrollEvent);
var scrollEvent=function(){};
//事件销毁
that.desrory=function(){
$('.event_dom').off();
//window 方法的销毁必须使用事件名称和回调函数,主要是 window 上可能绑定这系统自定义的事件和回掉
$(window).off('scroll',scrollEvent);
};2016年6月29日补充:
最近做了一些与表单相关的项目,使用了h5的input控件,在使用过程中遇到了很多的坑。也包括与这篇文章相关的。
首先我们应该知道使用h5新提供的属性getUserMedia这个属性,是可以调取系统的摄像头进行拍照或者是摄像的,但是兼容性支持的不好,所以当我们需要获取系统的多媒体权限时我们都不会采用这个属性。
使用标签我们可以间接的呼起系统选择文件的窗口,来读取系统文件。但是在WebView中,因为安卓权限的问题,我们是没办法直接获取读取文件这个操作的。而在原生的浏览器中是不存在这个问题的。所以选择使用这个input的时候一定要注意自己的页面是主要运行在webview中还是浏览器中。如果注意运行在客户端的webvie中,是需要客户端的同学支持的。
在IOS的某些系统版本中也会出现这个问题。具体的可以参考下面的参考文章。
参考文章:
http://blog.csdn.net/hvkcoder/article/details/51365191
https://forums.developer.apple.com/thread/22726
http://www.cnblogs.com/soaringEveryday/p/4495221.html
http://stackoverflow.com/questions/25942676/ios-8-sdk-modal-uiwebview-and-camera-image-picker
最近公司项目有个需求,微博客户端中, h5 的页面上的某个按钮能够与native 交互呼起摄像头,扫描二维码并且解析。在非微博客户端中(微信或者是原生浏览器,如:safari)呼起系统的拍照或者上传图片按钮,通过拍照或者上传图片解析二维码。
第二种方案需要在前端 js 解析二维码。这样依赖一个第三方的解析库**jsqrcode**。这个库已经支持在浏览器端呼起摄像头的操作了,但是依赖一个叫getUserMedia的属性。该属性移动端的浏览器支持的都不是很好,所以只能间接的上传图片的方式解析二维码。
**getUserMedia**属性兼容浏览器列表:
首先感谢 jsqrcode 的开发者,提供这么优秀的解析二维码的代码,为我减少了很大的工作量。jsqrcode 地址:点我
我的代码库地址:点我
1.能够在微博客户端呼起摄像头扫描二维码并且解析;
2.能够在原生浏览器和微信客户端中扫描二维码并且解析;
web端或者是 h5端可以直接完成扫码的工作;
图片不清晰很容易解析失败(拍照扫描图片需要镜头离二维码的距离很近),相对于 native 呼起的摄像头解析会有1-2秒的延时。
此插件需要配合zepto.js 或者 jQuery.js使用
**1.**在需要使用的页面按照下面顺序引入lib目录下的 js 文件
<script src="lib/zepto.js"></script>
<script src="lib/qrcode.lib.min.js"></script>
<script src="lib/qrcode.js"></script>**2.**自定义按钮的 html 样式
为自定义的按钮添加自定义属性,属性名称为node-type
为 input 按钮添加自定义的属性, 属性名称为node-type
因为该插件需要使用
<input type="file" />,该 html 结构在网页上面是有固定的显示样式,为了能够自定义按钮样式,我们可以按照下面的示例代码结构嵌套代码
<div>
<div class="qr-btn" node-type="qr-btn">扫描二维码1
<input node-type="jsbridge" type="file" name="myPhoto" value="扫描二维码1" />
</div>
</div>然后设置 input 按钮的 css 隐藏按钮,比如我使用的是属性选择器
input[node-type=jsbridge]{
display:none;
}这里我们只需要按照自己的需要定义class="qr-btn"的样式即可。
**3.**在页面上初始化 Qrcode 对象
//初始化扫描二维码按钮,传入自定义的 node-type 属性
$(function() {
Qrcode.init($('[node-type=qr-btn]'));
});(function($) {
var Qrcode = function(tempBtn) {
var _this_ = this;
var isWeiboWebView = /__weibo__/.test(navigator.userAgent);
if (isWeiboWebView) {
if (window.WeiboJSBridge) {
_this_.bridgeReady(tempBtn);
} else {
document.addEventListener('WeiboJSBridgeReady', function() {
_this_.bridgeReady(tempBtn);
});
}
} else {
_this_.nativeReady(tempBtn);
}
};
Qrcode.prototype = {
nativeReady: function(tempBtn) {
$('[node-type=jsbridge]',tempBtn).on('click',function(e){
e.stopPropagation();
});
$(tempBtn).bind('click',function(e){
$(this).find('input[node-type=jsbridge]').trigger('click');
});
$(tempBtn).bind('change', this.getImgFile);
},
bridgeReady: function(tempBtn) {
$(tempBtn).bind('click', this.weiBoBridge);
},
weiBoBridge: function() {
window.WeiboJSBridge.invoke('scanQRCode', null, function(params) {
//得到扫码的结果
$('.result-qrcode').append(params.result + '<br/>');
});
},
getImgFile: function() {
var _this_ = this;
var inputDom = $(this).find('input[node-type=jsbridge]');
var imgFile = inputDom[0].files;
var oFile = imgFile[0];
var oFReader = new FileReader();
var rFilter = /^(?:image\/bmp|image\/cis\-cod|image\/gif|image\/ief|image\/jpeg|image\/jpeg|image\/jpeg|image\/pipeg|image\/png|image\/svg\+xml|image\/tiff|image\/x\-cmu\-raster|image\/x\-cmx|image\/x\-icon|image\/x\-portable\-anymap|image\/x\-portable\-bitmap|image\/x\-portable\-graymap|image\/x\-portable\-pixmap|image\/x\-rgb|image\/x\-xbitmap|image\/x\-xpixmap|image\/x\-xwindowdump)$/i;
if (imgFile.length === 0) {
return;
}
if (!rFilter.test(oFile.type)) {
alert("选择正确的图片格式!");
return;
}
oFReader.onload = function(oFREvent) {
qrcode.decode(oFREvent.target.result);
qrcode.callback = function(data) {
//得到扫码的结果
$('.result-qrcode').append(data + '<br/>');
};
};
oFReader.readAsDataURL(oFile);
},
destory: function() {
$(tempBtn).off('click');
}
};
Qrcode.init = function(tempBtn) {
var _this_ = this;
tempBtn.each(function() {
new _this_($(this));
});
};
window.Qrcode = Qrcode;
})(window.Zepto ? Zepto : jQuery);
作为程序员平时主要是使用 shadowsocks 作为代理工具的。shadowsocks 有个很明显的优点儿就是可以设置白名单和黑名单。白名单是会走shadowsocks的自动代理模式。
shadowsocks 代理是分白名单和黑名单的。当我访问某个网站,而恰好这个网站的域名和静态文件域名都在白名单里,访问这个网站的http请求就会自动走代理模式;
如果访问某个网站的域名没有在白名单里,就需要手动设置 全局代理模式 ;这有一个缺点就是电脑的所有的网络访问都会走代理,如果这个时候访问国内的网站,就会很慢或者是打不开。
最好的办法就是编辑shadowsocks的.ShadowsocksX/gfwlist.js文件。将没办法走自动代理模式的域名添加到这个文件里面。但是一个网站的在显示完全,需要访问的域名不止一个,那么手动添加就会很麻烦。那么可不可以使用程序来实现呢?
.txt的文件,也可以直接打印在控制台;1.打开chrome的开发者模式,并且将shadowsocks 设置为全局代理模式访问自动代理模式无法访问的网站;
2.在chrome的network面板,右键导出 har文件,保存到自己想要的位置;
如下图:
按照提示运行程序:
运行效果展示:
因为 har 文件的内容就是一个json格式文件。所以就是读取文件的内容,并且将文件内容转化为json,将所有的请求的url分类写入一个数组,最后选择方式输出;
python主要代码如下:
with open(filePath, 'r') as readObj:
harDirct = json.loads(readObj.read())
requestList = harDirct['log']['entries']
for item in requestList:
urlString = (item['request']['url'])
start = urlString.index('://')
tempStr = urlString[start + 3:]
end = tempStr.index('/')
resultStr = tempStr[:end]
# 判断是否是www开头的域名
if 'www' in resultStr:
resultStr = resultStr[4:]
if resultStr not in hostList:
hostList.append(resultStr)
if str(outputType) is '1':
with open(outputPath, 'w') as ff:
for item in hostList:
ff.write('"' + item + '",' + '\n')
else:
print '=============host start=============='
for item in hostList:
print '"' + item + '",'
print '=============host end================'声明:这个系列为阅读《JavaScript设计模式与开发实践》 ----曾探@著一书的读书笔记
** 装饰者(decorator) **模式能够在不改变对象自身的基础上,在程序运行期间给对像动态的添加职责。与继承相比,装饰者是一种更轻便灵活的做法。
可以动态的给某个对象添加额外的职责,而不会影响从这个类中派生的其它对象;
//模拟传统语言的装饰者
//原始的飞机类
var Plan = function () {
};
Plan.prototype.fire = function () {
console.log('发射普通子弹');
};
//装饰类
var MissileDecorator = function (plan) {
this.plan = plan;
}
MissileDecorator.prototype.fire = function () {
this.plan.fire();
console.log('发射导弹!');
};
var plan = new Plan();
plan = new MissileDecorator(plan);
plan.fire();装饰者模式将一个对象嵌入到另一个对象之中,实际上相当于这个对象被另一个对像包装起来,形成一条包装链。请求随着这条包装链依次传递到所有的对象,每个对象都有处理这条请求的机会。
var Plan1 = {
fire: function () {
console.log('发射普通的子弹');
}
};
var missileDecorator= function () {
console.log('发射导弹!');
};
var fire = Plan1.fire;
Plan1.fire=function () {
fire();
missileDecorator();
};
Plan1.fire();在JavaScript中可以很方便的给某个对象扩展属性和方法,但却很难在不改动某个函数源代码的情况下,给该函数添加一些额外的功能。也就是在代码运行期间,我们很难切入某个函数的执行环境。
//对window.onload的处理
window.onload=function () {
console.log('test');
};
var _onload= window.onload || function () {};
window.onload=function () {
_onload();
console.log('自己的处理函数');
};主要是以为在JavaScript中会存在随着函数的调用,this的指向发生变化,导致执行结果发生变化。
在需要执行的函数之前执行某个新添加的功能函数
//是新添加的函数在旧函数之前执行
Function.prototype.before=function (beforefn) {
var _this= this; //保存旧函数的引用
return function () { //返回包含旧函数和新函数的“代理”函数
beforefn.apply(this,arguments); //执行新函数,且保证this不被劫持,新函数接受的参数
// 也会被原封不动的传入旧函数,新函数在旧函数之前执行
return _this.apply(this,arguments);
};
};在需要执行的函数之后执行某个新添加的功能函数
//新添加的函数在旧函数之后执行
Function.prototype.after=function (afterfn) {
var _this=this;
return function () {
var ret=_this.apply(this,arguments);
afterfn.apply(this,arguments);
return ret;
};
};var before=function (fn, before) {
return function () {
before.apply(this,arguments);
return fn.apply(this,arguments);
};
};
function func1(){console.log('1')}
function func2() {console.log('2')}
var a=before(func1,func2);
// a=before(a,func1);
a();使用装饰者模式动态的改变ajax函数,传输的参数
//是新添加的函数在旧函数之前执行
Function.prototype.before=function (beforefn) {
var _this= this; //保存旧函数的引用
return function () { //返回包含旧函数和新函数的“代理”函数
beforefn.apply(this,arguments); //执行新函数,且保证this不被劫持,新函数接受的参数
// 也会被原封不动的传入旧函数,新函数在旧函数之前执行
return _this.apply(this,arguments);
};
};
var func = function (param) {
console.log(param);
};
func = func.before(function (param) {
param.b = 'b';
});
func({b:'222'});
//给ajax请求动态添加参数的例子
var ajax=function (type,url,param) {
console.log(param);
};
var getToken=function () {
return 'Token';
};
ajax=ajax.before(function (type, url, param) {
param.token=getToken();
});
ajax('get','http://www.jn.com',{name:'zhiqiang'});装饰者模式分离表单验证和提交的函数
Function.prototype.before=function (beforefn) {
var _this= this; //保存旧函数的引用
return function () { //返回包含旧函数和新函数的“代理”函数
beforefn.apply(this,arguments); //执行新函数,且保证this不被劫持,新函数接受的参数
// 也会被原封不动的传入旧函数,新函数在旧函数之前执行
return _this.apply(this,arguments);
};
};
var validata=function () {
if(username.value===''){
alert('用户名不能为空!')
return false;
}
if(password.value===''){
alert('密码不能为空!')
return false;
}
}
var formSubmit=function () {
var param={
username=username.value;
password=password.value;
}
ajax('post','http://www.mn.com',param);
}
formSubmit= formSubmit.before(validata);
submitBtn.onclick=function () {
formSubmit();
}装饰者模式和代理模式的区别:
项目上线前是专门针对 webpack 打包做了优化的,但是在之后做网络优化的时候通过webpack-bundle-analyzer这个插件发现一些公共的js文件重复打包进了业务代码的js中。这些代码体积虽然很小,但是为了将优化做到极致还是想要将其优化一下。这个过程最大的收获就是让自己对 webpack4.x 相关配置项更加的熟悉,能够使用 webpack 游刃有余的实现自己想要的打包方式。
记得之前的一位前辈同事说过一句前端优化的话:前端优化就是权衡各种利弊后做的一种妥协。
这里先看下优化结果,因为项目是多入口打包的模式(项目脚手架点击这里)每一个页面一个链接且每一个页面都会有自己的一个js文件。
结果如下:
移动端项目能够在原有的基础上减少20kb已经不小了,而且这20kb是属于重复打包产生的。网络优化方面通过我们公司内部监控平台看到的数据也非常明显,项目上线后统计3天内平均数据,页面加载时间节省了接近800ms(上面的500ms是一个保守的写法,因为会存在网络抖动等不可抗因素)。
优化前的数据统计
优化后的数据统计
在 html 的 head 标签中通过 meta 标签指定开启DNS 预解析和添加预解析的域名,实例代码如下:
<!--告诉浏览器开启DNS 预解析-->
<meta http-equiv="x-dns-prefetch-control" content="on" />
<!--添加需要预解析的域名-->
<link rel="dns-prefetch" href="//tracker.didiglobal.com">
<link rel="dns-prefetch" href="//omgup.didiglobal.com">
<link rel="dns-prefetch" href="//static.didiglobal.com">先来看下添加上面的代码之前,页面中静态资源的解析时间
添加了DNS 预解析的代码之后与上面的图片比较之后可以明显发现tracker.didiglobal.com 这个域名在需要加载的时候已经提前完成了预解析。如果这个js文件是影响页面渲染的(比如按需加载的页面),可以提高页面的渲染性能。
平时移动端开发过程中我们都会引用一些第三方的js依赖,比如说调用客户端 jsbridge 方法的 client.js和接入打点服务的console.log.js。
通常的方法也是比较暴力的方法就是将这些依赖的第三方js加入到 head 标签中,在 dom 解析到 head 标签的时候提前下载这些js并且在之后需要的时候能够随时的调用。但是这些放在head 标签中的js下载时间和执行时间无疑会影响页面的渲染时间。
下面的那张图是我们的项目优化前的一个现状,浅绿色的竖线是开始渲染的时间。从下面的图种可以发现我们引用客户端方法的 fusion.js 和打点的 omega.js (这两个js都是放在head标签中的)都影响了页面的渲染的开始时间。
其实我们的业务场景在页面渲染出来之前是不需要这些js的执行结果的,那我们为什么不能将这些js做成异步加载呢?
js的异步加载就是选择合适的时机,使用动态创建 script标签的方式,将需要的js加载到页面中来。我们的项目使用的是 vue ,我们选择在 vue 的生命周期 mounted 中将需要打点的js给加载进来,在我们需要调用客户端方法的地方去加载 fusion.js 通过异步加载库回调的方式,当js加载完之后执行用户的操作。
下面是一段简单的示例代码:
export default function executeOmegaFn(fn) {
// 动态加载js到当前的页面中来,并且当js加载完之后执行回调,注意需要判断js是否已经在当前环境加载过了
scriptLoader('//xxx.xxxx.com/static/tracker_global/2.2.2/xxx.min.js', function () {
fn && fn();
});
}
// 异步加载 需要加载的js
mounted() {
executeOmegaFn();
},下图是修改之后的效果,可以发现,页面开始渲染的时间提前了,页面渲染完成的时间也比上面图种的渲染完成的时间提前了 2s 左右。可以很明显的看出页面的渲染和下载执行 omega 的时间是互不影响的。
总结:
默认的 webpack4.x 在 production 模式下会对代码做 tree shaking。但是看完这篇文章之后会发现大多数情况下,tree shaking 并没有办法去除重复的代码。 你的Tree-Shaking并没什么卵用
在我的项目中有个lib目录下面放着根据业务需要自己编写的函数库,通过 webpack-bundle-analyzer 发现它重复的打包进了我们的业务代码的js文件中。下面的图是打包后业务代码包含的js文件,可以看到 lib 目录下的内容重复打包了
看到这种情况的时候就来谈谈自己的优化方案:
vendor依赖;先来看下我的 webpack 关于拆包的配置文件,具体看注释:
splitChunks: {
chunks: 'all',
automaticNameDelimiter: '.',
name: undefined,
cacheGroups: {
default: false,
vendors: false,
common: {
test: function (module, chunks) {
// 这里通过配置规则只将 common lib cube-ui 和cube-ui 组件scroll依赖的better-scroll打包进入common中
if (/src\/common\//.test(module.context) ||
/src\/lib/.test(module.context) ||
/cube-ui/.test(module.context) ||
/better-scroll/.test(module.context)) {
return true;
}
},
chunks: 'all',
name: 'common',
// 这里的minchunks 非常重要,控制cube-ui使用的组件被超过几个chunk引用之后才打包进入该common中否则不打包进该js中
minChunks: 2,
priority: 20
},
vendor: {
chunks: 'all',
test: (module, chunks) => {
// 将node_modules 目录下的依赖统一打包进入vendor中
if (/node_modules/.test(module.context)) {
return true;
}
},
name: 'vendor',
minChunks: 2,
// 配置chunk的打包优先级,这里的数值决定了node_modules下的 cube-ui 不会打包进入 vendor 中
priority: 10,
enforce: true
}
}
}在项目中写了一个 js 将整个项目需要使用的 cube-ui 组件统一引入。具体的代码看这里,调用方法看这里。
这里需要注意下,就是不要将使用频率低的体积大的组件在这个文件中引入,具体的原因可以看下面代码的注释。
/**
* @file cube ui 组件引入统一配置文件 建议这里只引入每个页面使用的基础组件,对于复杂的组件比如scroll datepicer组件
* 在页面中单独引入,然后在webpack中同过 minChunk 来指定当这些比较大的组件超过 x 引用数时才打进common中否则单独打包进页面的js中
* @date 2019/04/02
* @author [email protected]
*/
/* eslint-disable */
import Vue from 'vue';
import {
Style,
Toast,
Loading,
// 这里去除 scroll是在页面中单独引入,以使webpack打包时可以根据引用chunk选择是否将该组件打包进入页面的js中还是选择打包进入common中
// Scroll,
createAPI
} from 'cube-ui';
export default function initCubeComponent() {
Vue.use(Loading);
// Vue.use(Scroll);
createAPI(Vue, Toast, ['timeout'], true);
}项目中目前只有pay_history这个页面使用了 cube-ui 的 scroll 组件,单独打包进业务代码的js中所以该页面的js较大。
当有超过两个页面使用了 scroll 这个组件的时候,根据 webpack 的配置会自动打包进入common中。下图是打包结果,页面的js大小缩小了,commonjs文件的体积变大了。
总结:
有时候我在写代码的时候没有注意,通过 import 引用了一个第三方依赖但是最后没有使用它或者是上线的时候并不需要将执行的表达式注释掉,而没有注释掉 import 语句 ,打包结果也会包含这个import的js的。比如以下代码:
import VConsole from 'vconsole';
// 测试的时候我们可能打开了下面的注释,但是在上线的时候只是注释了下面的代码,webpack打包的时候仍然会将vconsole打包进目标js中。
// var vConsole = new VConsole();总结:
目前使用 babel + ES6 组合编写前端代码已经很少使用 babel-polyfill 了。 主要是它会污染全局变量,而且是全量引入 polyfill ,打包后的目标js文件会非常的大。
现在大多数情况下都会使用 babel-preset-env 来做 polyfill。更智能或是高级的做法是使用在线的polyfill服务,参考链接
在使用 preset-env 的时候,大多数情况都会忽略去配置兼容的 browsers 列表。或者直接从网络上搜索到配置,不深究其产出结果直接复制、粘贴使用。其实这里的配置会影响我们的js文件的大小。
如果使用 autoprefix 给css自动添加厂商前缀时,也是需要配置一个 browsers 列表。这个配置列表也是会影响css文件大小的。 browserslist官方文档
举个例子,现在 windows phone 手机几乎绝迹,对于现在的移动端项目是不需要考虑兼容 pc 和 wp手机的,那我们在添加 polyfill 或是 css 厂商前缀时是不是可以去掉 -ms- 前缀呢,那么该怎么配置呢?
我的配置如下:
"browsers": [
"> 1%",
"last 2 versions",
"iOS >= 6.0",
"not ie > 0",
"not ie_mob > 0",
"not dead"
]这里简单提一下,正确使用css新特性的重要性。下面这段代码是我在我们的一个比较旧的项目中看到的。其实咋一看没有什么问题,但是在现代浏览器中浏览却出现了问题?
.example {
display: flex;
display: -webkit-box;
}
.test {
flex:1
}这总写法就是对 flex 布局 解析不一致导致的问题。 在chrome 中 .example生效的是 display: -webkit-box 这个弹性盒布局过渡期的写法。 在 .test 中生效的是 flex:1 而这个是新标准的写法。导致布局显示出现问题。
autoprefix之后的代码
.example {
display: -ms-flexbox;
display: flex;
display: -webkit-box;
}
.test {
-webkit-box-flex:1;
-ms-flex:1;
flex:1
}同样的也会导致上面没有 autoprefix 之前的问题,布局发生错误。
总结:
使用webpack编译代码,当代码生成了多个chunk时,webpack是怎么加载这些chunk呢?
webpack 自己实现了一个模块加载器来维护不同模块间的关系(webpack 文章中称它为 runtime 模块)。标识不同模块是通过一串数字来做标识的(具体的可以写个简单的demo来看下编译结果)。
当修改了一个文件的代码,在 runtime 模块中这串数字会发生变化,如果在webpack 打包时对这部分代码不做处理,它会默认的产出到我们的 vendor 代码中。导致只要修改代码,生成的 vendor 文件的hash就会发生变化,没办法充分利用浏览器缓存。
webpack 已经提供了配置可以将这部分代码单独抽离出来生成一个文件。因为这部分代码经常发生变化,而且代码体积很小,为了减少 http 请求可以在打包的时候选择将这部分代码内联进html模板文件中。
在webpack4.x中可以通过以下配置实现 optimization.runtimeChunk: 'single'。如果想要将生产的runtime代码内联进入html,可以使用这个webpack插件inline-manifest-webpack-plugin。
async和await语法糖能够很好的解决异步编程问题。在编写前端代码的过程中也可以使用该语法糖。不管是使用 babel 和 typescript 编译代码其实都是将 async和 await 编译成了 generator。
如果对代码体积有极致的需求,我是不太建议在前端代码中使用 async 和await的。因为现在很多第三方依赖处理异步的方式都是使用 Promise ,我们使用的 node_modules依赖一般也都是编译后的 ES5 的源文件,都是对 Promise 做了 Polyfill 的。而且我们自己的 babel 配置也会对 Promise 做 Polyfill, 如果混合使用 async 和 await ,babel又会增加相关 generator run time 代码。
看一个真实的代码案例:以下代码中出现了一个 async 表达式,但是在任何调用这个方法地方的时候都没有使用await ,通过阅读代码也确定这里不需要使用 async 表达式
添加了一个async表达式后,编译结果如下图。可以发现在产出的目标文件中多了一个generaotr runtime 的代码,而且这部分代码的体积还是比较大的
这是编译前的文件大小
去掉这个不必要的 async 表达式后,下图可以看到编译后的文件大小,代码体积缩小了将近 3KB。
在第一小节中已经简单了介绍了优化第三方依赖的打包方法了,这里再做下总结:
后编译,就是在使用的时候编译,可以解决代码重复打包的问题。按需引入是指,假如我使用的cube-ui有20个组件但是我只使用了其中的一个 alert 组件,避免全部引入,增加产出文件的体积;
lodash这个库确实挺好用的,但它有个缺点,全量引入打包后体积较大。那么lodash能不能按需引入呢?
当然是可以的,可以在 npm上搜索 lodash-es这个模块,然后根据文档执行命令可以将 lodash 导出为 es6 modules。 然后就可以通过 import 方式单独导入某个函数的方式使用。
其实lodash到底怎么优化,有没有必要优化,这个也是有一些争议的,具体的可以阅读下百度高T灰大的这篇文章 lodash在webpack中的各项优化的尝试。灰大的这篇文章也论证了文章开头所说的,优化就是根据业务需求做了各种权衡后的一种妥协。
hash 是跟整个项目的构建相关,只要项目里有文件更改,整个项目构建的hash值都会更改,并且全部文件都共用相同的hash值;
chunkhash 采用hash计算的话,每一次构建后生成的哈希值都不一样,即使文件内容压根没有改变。这样子是没办法实现缓存效果,我们需要换另一种哈希值计算方式,即chunkhash。chunkhash和hash不一样,它根据不同的入口文件(Entry)进行依赖文件解析、构建对应的chunk,生成对应的哈希值。我们在生产环境里把一些公共库和程序入口文件区分开,单独打包构建,接着我们采用chunkhash的方式生成哈希值,那么只要我们不改动公共库的代码,就可以保证其哈希值不会受影响。
contenthash 使用 webpack 编译代码时,我们可以在js文件里面引用css文件的。所以这两个文件应该共用相同的chunkhash值。但是有个问题,如果js更改了代码,css文件就算内容没有任何改变,由于是该模块发生了改变,导致css文件会重复构建。这个时候,我们可以使用 extra-text-webpack-plugin 里的 contenthash 值,保证即使css文件所处的模块里其它文件内容改变,只要css文件内容不变,那么就不会重复构建。
目前网络上能够查询到的 webpack4.x 的文档对于 splitChunks 并没有完整的中文翻译,如果对于英文阅读没有障碍,可以直接去阅读官方文档,如果英文不好可以参考下面的参数和中文释义:
首先 Webpack4.x 会根据下述条件自动进行代码块分割:
// 配置项解释如下
splitChunks: {
// 默认作用于异步chunk,值为all
//initial模式下会分开优化打包异步和非异步模块。而all会把异步和非异步同时进行优化打包。也就是说moduleA在indexA中异步引入,indexB中同步引入,initial下moduleA会出现在两个打包块中,而all只会出现一个。
// all 所有chunk代码(同步加载和异步加载的模块都可以使用)的公共部分分离出来成为一个单独的文件
// async 将异步加载模块代码公共部分抽离出来一个单独的文件
chunks: 'async',
// 默认值是30kb 当文件体积 >= minsize 时将会被拆分为两个文件 某则不生成新的chunk
minSize: 30000,
// 共享该module的最小chunk数 (当>= minchunks时才会被拆分为新的chunk)
minChunks: 1,
// 最多有5个异步加载请求该module
maxAsyncRequests: 5,
// 初始话时最多有3个请求该module
maxInitialRequests: 3,
// 名字中间的间隔符
automaticNameDelimiter: '~',
// 打包后的名称,如果设置为 truw 默认是chunk的名字通过分隔符(默认是~)分隔开,如vendor~ 也可以自己手动指定
name: true,
// 设置缓存组用来抽取满足不同规则的chunk, 切割成的每一个新的chunk就是一个cache group
cacheGroups: {
common: {
// 抽取的chunk的名字
name: 'common',
// 同外层的参数配置,覆盖外层的chunks,以chunk为维度进行抽取
chunks: 'all',
// 可以为字符串,正则表达式,函数,以module为维度进行抽取,
// 只要是满足条件的module都会被抽取到该common的chunk中,为函数时第一个参数
// 是遍历到的每一个模块,第二个参数是每一个引用到该模块的chunks数组
test(module, chunks) {
// module.context 当前文件模块所属的目录 该目录下包含多个文件
// module.resource 当前模块文件的绝对路径
if (/scroll/.test(module.context)) {
let chunkName = ''; // 引用该chunk的模块名字
chunks.forEach(item => {
chunkName += item.name + ',';
});
console.log(`module-scroll`, module.context, chunkName, chunks.length);
}
},
// 优先级,一个chunk很可能满足多个缓存组,会被抽取到优先级高的缓存组中, 数值打的优先被选择
priority: 10,
// 最少被几个chunk引用
minChunks: 2,
// 如果该chunk中引用了已经被抽取的chunk,直接引用该chunk,不会重复打包代码 (当module未发生变化时是否使用之前的Module)
reuseExistingChunk: true,
// 如果cacheGroup中没有设置minSize,则据此判断是否使用上层的minSize,true:则使用0,false:使用上层minSize
enforce: true
}
}
};
[toc]
每次写这样总结性文章的时候,开头的引子都会花费好多时间和心思去写。而且是写了改,改了写。本来开头是想写写老狼的《青春无悔》的,想写写前段时间看的电视剧《白鹿原》的,想写写最近读的一本书《历史在你我身边》的。反反复复的写了几次结果是都放弃了。
上周末去看了《战狼2》,很不错的电影,满满的爱国情怀。看着非洲人民的生活环境真的是水深火热,体会到了有国才有家这句话的含义。第二天早上看了习大大的沙场点兵。明白我们的祖国再也不是那个任人欺负的**了。
写自己好也罢,写自己不好也罢,反正这篇文章的目的就是对这一年发生在自己身上的事情的反思。
现在看这些时间点跟巧合似的,发生的那么接近。刚到北京一切都是新奇的,从对BAT的仰望,到现在身处其中。一路走来明白“怒力”、“奋斗”这些词语的意义。
“只要自己不怀疑自己,自己不放弃自己,谁都不能够放弃你”。
从去年的年中到现在还是发生了好多事情,有些在16年年终的时候记录了,这里就简单的谈谈2017年这半年。
2017年5月3号是入职现在公司整一年的日子。
yog2 。在这个过程中提升了自己工程化的能力和对一些框架原理的理解;感谢在这个过程中我的老板,给我提供了充足的空间和时间让我去尝试。
前段时间看了一部电视剧----《白鹿原》。明白了陈忠实老先生的《白鹿原》为什么�被国内外热爱**文学的人所熟知。陈忠实老先生笔下的�“白鹿原”就是旧**人民大众的一个缩影,一个真实的旧**。电视剧结尾的几张插画也是很有时代感。对,那就是我们的“旧**”。
被故事本身吸引之外最喜欢的�还是朱先生。朱先生身上凝缩着狭义和豪情。记得有一段朱先生带白嘉轩到清兵大营说服主帅方升退兵时的场景。满山遍野的清军帐篷,彼时彼景朱先生哼唱起王维的**“劝君更近一杯酒,西出阳关无故人!”**充满着一股悲壮。
从毕业到到现一直在强迫自己没有放弃一个习惯----每月读1-2本书(非专业类的)。记忆犹新的两本书是孙皓晖先生的《大秦帝国》和大冰的《乖,摸摸头》。
对大秦帝国的钟情,是因为孙先生把战国的列国人物写活了。通过文字能够感受到历史中的人物就在眼前。苏秦的“配六国相印”,张仪的“以舌取国”读起来让人热血沸腾。
《乖,摸摸头》是一本非常接地气的书,书中的故事应该都是真实的。有些生活感觉离自己很遥远,但是确实是每时每刻都有人在经历着。书中有赵雷,有大鹏有一些自己熟悉的人。印象最深刻的的一个故事是《一个叫木头,一个叫马尾》。还记得故事开头的那个介绍:
毛毛捏着木头的手,对我说:“……五年前的一天,我陪她逛街,我鞋带松了,她发现了,自自然然地蹲下来帮我系上……我吓了一跳, 扭头看看四周,此时此刻这个世界没有人在关注我们,我们不过是两个最普通的男人和女人……我对自己说,就是她了,娶她娶她!”
平凡的故事,读起来总能让人不自觉的动容。
经常�收到一些猎头的电话。这里想谈谈自己选择看新机会或者是新工作的动机。
第一点也是最重要的一点:这里的人和做的事都让我不爽,我一分钟都不想待了。不过到目前为止还没有遇到过这种情况。
刚来北京的时我想我和大多数人想的一样“也许我在这个城市也就呆个两三年吧”。没想到现在已经三个年头,而且已经有了扎根下去的迹象。杭州、深圳、“魔都”都是自己曾经向往过的城市,想要去闯一闯,多看看这个世界的精彩。随着自己的年龄越来越大,从最开始想着能在这个城市活着就好。到现在觉得自己在这个城市还可以活的更好。慢慢的对这个城市�有了依赖感。
�说实话每次看一些招聘岗位和薪资的时候,自己会心动、**会动摇。想要去挣更多的钱。也相信以自己的能力和做事的态度,在新的岗位也一定能够做的很好。但最后还是放弃了。
随着时间的推移,自身会跟周围的人和事儿产生融合。慢慢的都会有一些东西让自己不是那么容易的放下。比如说,信任,影响力,朋友圈。这也就是为什么看到一个好的机会但我仍会选择留在一家公司的原因吧。
其实是信仰也好,是梦想也好,甚至说矫情也罢。做自己,就是最好的。
前半年在团队做成了一些事情,得到了团队和老板的肯定。现在来看这些事情,都已经尘埃落定做成了。但是在事情开始和过程中自己是不知道自己能不能做好、做成的。有时候自己会怀疑自己,也能清楚的认识到有些事情和当前自己的“能力”不符。但既然选择去做,选择了去拼一把,那有什么理由中途掉链子呢?。
要做出一些成绩�你就会碰壁。清楚的记的,过程中有人毫无保留的当面提出过质疑“这些事情,我觉的你搞不定,你不用做了。”。“我们是要写线上服务,不是要你写个玩具上线的。我不知道你们听到这样质疑的时候心里会怎么想,反正我的内心肯定是不好受的。
现在想想自己做的最正确的一件事情就是能够放低自己的心态,你既然说我写的是玩具,那就帮我review代码吧。既然遇到这么多困难,那就一件一件解决该找谁找谁呗。
要做成一件有挑战的事情肯定是会碰壁的。再牛的人也有自己陌生的领域和知识,大牛也是一点一点学习进步变成大牛的。做这些事情的过程中遇到的困难是巨大的,最后的结果收获也是巨大的。
有一种力量,无能能挡,他永不言败,生来倔强。
工作和职场好像没有区别。但是好像有有一些不一样,工作就是具体的做哪些事情。职场更广泛些是指一种文化,做好事情处理好同事关系的文化。
每次当我要认真开始做一件事情的时候,就会发现,这件事情的工作量远远超出了我的预期。一方面跟自己过高的高估自己的能力有关,另一方面也跟自己的规划能力不足有关(大多数时候还是不上心吧)。目前自己也在努力的改善这些问题。
当开始思考一劳永逸解决重复劳动并且开始行动的时候,就是一个人能力开始提高的时候。所以思考和总结是个人能力提高的软素质,值得庆幸的是自己在这方面一直做的不错。在处理问题或者是工作中如果不能正确面对别人的质疑我认为也是不能够做好事情的。
有时候感觉自己就像一个职场新人。前段时间跟一个朋友聊天,聊到了职场文化这个话题。她说:“你的努力和优秀如果给周围人带来的是有利的影响,毫无疑问你做的是对的,而且大家也会认可你。如果你的努力和优秀成为了别人的负担,你就应该思考是不是应该换种方式让大家接受你的优秀。特别是在职场,更应该思考处理这种关系的方式”。
以前经常在知乎看一个话题,“是什么让毕业三四年之后,同学之间的差距会拉大?”。体制内教育下,大家的起跑线基本都是一样的。学一样的课本,上一样的课。这个阶段主要是拼智商。毕业后,就是八仙过海各显神通了,之前很多学习不是很好但是**活跃的人可能会很快脱颖而出。
最近面试了一些人,有一些是名校的硕士毕业生。但是面试过程中所表现出的技术水平却与面试前我的预期差距很大。大多数都是毕业后进入一家公司,然后做一些边边角角的工作。其实站在过来人的角度来看,边边角角的工作并不是主要因素,主要是没有自己对工作的思考,没有实践过自己的一个想法。印象最深刻的一个候选人,名校本硕毕业。在一家公司维护一个数据提交的表单做了一年,我面试他大概有30分钟都在给我讲这个表单。我觉得挺可惜的。
但是也有些能够很明显的感觉到能力、主动性还是很不错的。可能是目前公司的环境和自己技术视野的狭窄限制了个人的发展。如果有一个正确的学习方向还是有很大的发展潜力的。对于这些人我想对你们说:
别放弃自己,如果你不放弃自己,谁也不能放弃你。
最近读了一些书。
长安十二时辰是马王爷的新书,自从读完他的《古董局中局》就爱上了这位作家的写过手法。根据书名也可以看出来整个故事的时间线是发生在十二个时辰中的。第一本书时间感很紧凑,恨不得一口气读完,到第二部的时候,根据史实已经能够大概猜出结局,时间感慢了好多。不过当做故事书来读还不错。
说实话看到《大败局》这书封皮的时候,有种地摊山寨书的感觉。不过读起来之后发现内容还是相当不错的,文章内容是作者尽量采访当事人和参考一些权威资料所写成的。在书中见识了在幼时就熟悉的一些公司和品牌,怎么慢慢从自己的视野中消失的。比如:健力宝,999,三株等。见识了用几百箱火车皮山货换苏联飞机的牛B故事。
1979年改革开发以后,邓爷爷说的“摸着石头过河”是有特殊的时代意义的。因为将来的**怎么走,改革层没有经验不知道,只能走一步说一步。所以当时存在很多法律的灰色地带(法制不健全)。真的有人可以一夜暴富。包括我们现在所熟知的一些企业,步步高、哇哈哈、脑白金等都是在那个时代的经济变革的产物。后来网上了解了下作者吴晓波,著名的高产财经作家,写了好多高质量的财经书籍,比如最近出版的《腾讯传》。
写到末尾的时候又再次去看了下去年的年中总结。看看去年的自己和今天的自己有什么不一样。很明显的两个方面是:
前段时间看了TED上的一个关于拖延症的视频。在具有拖延症的一类人大脑中都住着一只“猴子”。造成“拖延”的根本原因就是人在决定做一些事情的时候,往往被这只猴子给“捣乱”、“勾搭”去做了其它没有意义的事情。最后主讲人也给出了克服拖延症的方法:要给自己不断的设定deadline,给自己制造恐惧。
按照我个人的体会就是生活、工作中大多数事情不会朝着预期的方向或既定的目标发展。有了目标就立即着手去做,考虑的太多只会停止不前,最终可能会演变成不了了之。这样只会让自己养成拖延的习惯。
去年说的要培养自己的独挡一面的能力。我觉的自己用一些事情的结果证明了自己已经有了独挡一面的能力。工作中看到一些不好的地方,能坚持自己的想法并且肯花费时间去做一些事情。能够独立的承担大的项目,能解决一些比较棘手的问题。有的可能对团队有些影响,有的可能没有影响。结果并不重要,重要的是自己做了。
这是自己工作三年做的最好也是自己最满意的两件事情。自己正在朝着自己的人生目标“优秀的程序员,优秀的架构师,优秀的人”努力。
“你为什么那么拼?”有时候自己也会问自己。周末的时候经常会去公司写会儿代码,想想一周七天大概有六天都会呆在公司。前段时间在回家的路上听广播,听到一段李宗盛评价自己的话“才气不足,努力不止”(抱歉,原话记不住了)。
作为华语音乐界的泰山北斗,我不知道李宗盛是不是真的才气不足,靠自己后天奋斗才有了现在歌坛的地位。但我知道我肯定是一个平凡的人。平凡的人总被生活推着走,平凡的人才需要更加的努力。
**IT业始终是年轻人的天下,工作几年的人永远比不过刚毕业的小伙子。都说自己能力强,其实我自己心里特清楚,我就是比别人付出的多了一点。自己离30岁还有两年,身体上还有拼一拼的资本,让自己的知识和事业在30岁之前上升一个高度。如果在30岁有了家庭和孩子以后,自己还需要把大部分的时间花费在写代码上,那对于自己来说我的人生是失败的。希望30岁以后的自己是因为兴趣而继续写代码。
人这一辈子,最怕某一天突然听懂了一首歌。
也许我们从未成熟
还没能晓得 就快要老了
尽管心里活着的还是那个 年轻人
因为不安而频频回首
无知地索求 羞耻于求救
不知疲倦地翻越 每一个山丘
....
转眼又是一年,2016年7月3号是自己正式参加工作两年,入职一家新公司工作两个月的日子。每年到这个时间点,总是想要写点儿什么总结一下。前半年除了学习提高专业技能外,主要读了几本书《余罪》,沉默的羔羊系列。这里我想说《余罪》原著比现在爱奇艺播出的网剧真的好看一百倍。我是先看完书,再看了2集电视剧,然后真的看不下去了,因为张一山刻画的余罪跟自己心中的那个余罪落差太大。我甚至觉得夏雨来主演会更好一些。ಥ_ಥ
对于现阶段的自己来说,更多的是想在工作上有一些突破,能够做一些有意义和对团队发展有利的事情,能够得到同事和周围人的认可。每天经历的事情都会让自己有一些感触,大多数时候都是在微博,朋友圈或者QQ空间发一两句话感叹一下,也就过去了。像这种专门的总结下来,然后写成文章真的很少了。现在每年有动力必须去写的两篇文章就是** “工作xx年小结” 和** “XXXX年年终总结”** 了。因为前者是对自己离开大学以后,每年变化的总结,后者是对这一年自己的工作和生活的总结。
每次开始敲下这些文章第一个字的时候,都有一种“无力”和“恐惧”。因为又要开始对这一年的自己开始复盘了,做了什么,哪些是有意义的,哪些是想做而没有做完的或者说根本就是一点儿没有做的。每当复盘完以后才会发现,自己远远没有成为心中预期的那个自己是有原因的。
在面试中感触最深的一个问题:“你在这个项目中做了什么?”,“你在这家公司做了什么?”。刚开始的时候也会被问的哑口无言,这恰恰证明了自己虽然参加了某项目或者是在某家公司做了两年,但是自己的工作是没有意义的,自己都没有认可自己。后来直到自己认真的去总结了,才发现做了一两件自己说的出口的事情,比做了一些事情重要。
所以一直希望自己每年不管是对自己还是对工作,都能做出一两件自己和周围人都认可事情。
对于没有完成的事情:
很大一部分是因为自己身上的惰性在作怪,也有一部分是这些内容不是自己当前工作所迫切需要的。优先级就被其它事情所代替了。之所一直把它们放在自己未完成事情列表里面,还是觉得做了后对自己还是有很大的意义的。
对于已经做了的一些事情:
1.骑行是自己热爱的一项运动,爱上她有很多理由。当前找不到合适的语言来形容,借用网上的一句话:
骑行是一件看上去风光无限的事情。一路爬坡无数,风餐露宿。那些累,那些苦只有自己才真正体会。向勇敢的骑行者致敬!
2.关于在CSDN社区做的一些事情,自己并没有刻意的去做什么。只是定时的更新一些自己平时开发总结。然后就是刚好在那个时间点,有了那个机会,刚好自己有那个能力,才被找去做那些事情。所以这句话反过来就是,当自己想要去做一些事情的时候,首先要有能力,然后在恰好的时间点有了个机会。
3.受刚工作时导师的影响,很早就了解到开源的重要性。鉴于之后工作中Github对自己工作内容和工作效率的提高,自己慢慢变成了一个热爱开源,崇尚开源精神的人。
“大浪”的公司文化:“一切由你开始!”,“狼厂”的文化:“简单可依赖。”。这俩家公司的公司文化都着重强调的是人,但是“大浪”作为一家老牌的业务成熟的互联网公司,当前在移动互联网崛起的浪潮下又没有新的业务突围,在我工作的两年中看到很多公司同事离职,人才流失很严重。“狼厂”在注重个人发展上面我认为比“大浪”要好很多(我觉得是业务线多,赚钱的部门也多吧)。
强调个人能力,先有信任才有可依赖。
在参加新员工培训的课上,讲师讲的“事后验证”和“以结果为导向”都在强调着在这家公司做事情的重要性。“少承诺,多兑现,证明自己,用结果说话!”都在强调着这家公司需要实干家不是空想家。这也就是为什么之前了解的“狼厂”加班比较严重,其实大家在这样的氛围下都知道对自己做的事情有一个好的结果的重要性,这样才可以得到同事和领导的认可。
当然关于“加班”这里持保留态度,我相信在很多互联网公司加班都是跟自己负责的业务当前的进度有关的。还有工作之外自己做的一些事情(当前对于工作内容的思考,想要做一个产品解决当前工作中经常遇到的问题)。
对于外界对“狼厂”的评价我持保留态度,但是这些对工程师影响真的很小,可以说根本没有,大家每天想着还是做好自己的事情,在新闻上看到一些负面新闻也仅仅是了解一下。但是不得否认的是“狼厂”给工程师提供的发展机会真的很多,如果你有想法都可以去实践。
听多数人的意见,和少数人商量,自己做决定!
这里我只是想表达自己眼中看到的,我热爱我毕业后的第一家公司,同样也热爱我现在的公司,也想做些有意义的事情实现个人价值。
这是在参加新员工培训时,在一些老前辈的故事中听到的。从他们的真实的故事中,自己开始反思自己的初心和梦想。
自己并不是一个善于学习的人。换句话说大学的时候自己应该修的课程并不是很好。这也直接导致了自己的计算机基础并不扎实。“我要去北京”,这个想法是大二就开始有的,因为大学课程并不优秀的我甚至觉的大学并不适合我。想要到这个世界大都市去经历一些大风大浪,去实现个人价值。
大三进入大四的暑假开始找实习,我仍然清晰的记得7,8月份的郑州“热火朝天”,为了参加面试找到一份儿实习工作,又为了省公交钱走几公里去面试。为了能够证明自己,自己是带着电脑,随时准备给面试官看自己在学校做的一些小Web项目。当然面试了3家公司,只有一家公司的面试官简单看了我做的一些小玩意,后来也是这家公司收留了我。
但是我在这家公司待的时间并不长,只是觉得这家公司做的业务并不是自己想做的,然后就有了后来的“武汉故事”,然后一个很巧的机会在武汉得到了北京创新工场的面试offer。后来只身到北京参加面试,拿到自己的实习offer。实现了自己的北漂梦。
怀念当时自己的那个冲劲!
当初自己踏上去往北京的火车时候,在内心狠狠的对自己说:
成为一个优秀的人,优秀的程序员,优秀的架构师。
从焦作到郑州,武汉,北京,当梦想成为现实,自己经历了很多。由最开始的,认为自己应该随遇而安到现在扎根帝都,其中有很多故事,只不过是随着生活条件的提高冲淡了自己内心的那种感觉和冲劲。也许真的是:
生于忧患,死于安乐!
毕业两年,自己距当初的目标还有很大的一段距离,也意识到“成为一个优秀的人,优秀的程序员,优秀的架构师”这句话的顺序是错误的。大家会说你一毕业进入的都是大公司难道还不优秀么?我想借用网上看到的一句话表达“以这个世界上努力的人之少,根本轮不到拼天赋。”我也仅仅是体会到这句话的内在意义,克服了自己身上的惰性,努力了一点点而已。
优秀的程序员很多特点,我可以总结出一些标签“严于律己”,“强悍的执行力”,“对新技术的敏感”,“思考问题的方式”,“处理问题的方式”。这些特点不是你想学就能一下学会的,是需要时间的积累慢慢去培养的。
上面提到的那句话的正确的顺序应该是:
成为一个优秀的程序员,优秀的架构师,优秀的人。
而自己距实现第一个目标还有很长的路要走。
“大学就是一个让你犯错的年代。”是的,在大学我犯过很多错误,不考虑周围人的感受,处理不好跟周围人的关系。这些都让自己尝到了一些教训。“那个时候觉的不可思议的事情”,现在自己再回头去看也觉的没有什么,其实就是时间冲淡了一切。但是留给我的教训会让我铭记一生。
突然发现自己身上的冲劲是不是也被时间冲淡了呢?ಥ_ಥ
还好一直都能够清醒的认识到自己不属于聪明人的行列,但是到哪都能遇到比自己优秀的人。在工作中能够判断出自己做的事情是对是错,能够听取别人的意见,做自己认为对的事情。
有时候会被一些老同学问一些问题,“我想学前端,该怎么入门啊,学哪些课程啊?”,“我想学安卓,该学哪些课程啊?”。大多数时候我是不想回答这些问题的,不是问题本身简单不简单的问题,一个在校生问这些问题可以理解,但是对于一个工作1-2年的人,在问这些问题的时候都没有思考过,也不会自己动手去找答案,自己不敢去踩坑,就是期望别人给你指一条路,你才敢去走。这样永远都是原地踏步,不会有进步。
记得跟之前的同事聊过一个话题,不管在一个多么平凡的团队或者是一个优秀的团队,总是会有人脱颖而出,有些人碌碌无为。因为某些人的身上天生带着某种韧性,当外在环境不好的时候,总是能凭借自身的韧性突破周围的环境的限制,而有些人身上天生带着“鸵鸟精神”,就算有优越的外在环境,也会沉沦为默默无闻。
就好比戚继光,大家可能都说,他天生就是做将军的人,我到认为是,当时的环境让他有参军的想法,参军后又有自己对于战争的思考,又知道通过某种方式,找资源实现自己的想法。然后成为了一位优秀的将领。如果说当时的大环境是好的,戚继光是去经商,我觉得他也会是一个优秀的商人,因为他身上的主动性,注定了他肯定不是一个平凡的人。
有很长一段时间自己早上到公司的第一件事就是去浏览一些自己收藏网站的文章,比如:开发者头条,前端大全等,直到看到昨天已经看过的内容为止。当时感觉自己收获了很多新鲜的知识,时间长了发现自己从这些网站收获的知识几乎为0;因为这些网站上看到的内容很多自己平时工作中都用不到,没有实践的机会,对于自己来说看完一遍之后,等待的就是大脑对它们慢慢遗忘。但自己每天在上面却花费了大量时间。
自己开始思考自己系统的掌握某个知识是通过什么方式:
通过系统阅读某个技术经典的纸质书籍,
在网络上阅读别人的博客也仅仅能够做到了解,不能够做到掌握。在工作中遇到特定的问题,通过搜索引擎来查询这些文章来解决遇到的问题,是非常正确的。大多数时候网上看到的很多东西都会让人迷惑,因为缺少辨别它们对与错的基础知识。是有很多知识需要学习,但不是说这些网站推送的每篇文章都应该看,想要通过这些文章去系统性的掌握某项知识是不切合实际的。
最近在看《JavaScript设计模式与开发实践》这本书,被书中一些场景的代码实现所“震撼”(这里感觉用这个词不是很恰当,但是示例代码写的真的是好)。自己也在思考怎么才算是掌握了一个设计模式?
我认为首先应该是模仿,吃透了示例代码的思路,有所体会。当遇到相似场景可以想到用某个模式编写自己的代码能够让自己的代码更健壮和扩展性更高。这个时候才应该是对一个设计模式开始掌握了。
工作中很多时候都在维护别人的代码。当看到一个庞然大物的时候,首先不应该抱怨别人的代码写的不好,可能是自己的水平还没达到那个程度,理解不了。如果真的是别人的代码写的不好,那么也是自己的机会来了,“重构”对于一个人的架构能力和代码组织能力是一个很大的提高。
世界上阅读的方式有两种:
①泛读②精度;
现在觉得对于“泛读”这个词语的理解有一些偏差。应该是“广泛的阅读”。不是说在读书的时候,可以跳着读。这是一种很不好的读书方式。而自己恰恰在很早的时候就养成了“跳着读”,这种读书方式。
也深刻的体会到了这个习惯的养成对自己的影响:
当然自己现在是非常不建议泛读的,间接的能让人养成很多不好的习惯。我现在就在跟自己养成的坏习惯做着强烈的斗争。锻炼自己的专注力,做一件事情不分神,这其实是很痛苦的一件事情。
曾经想过一个问题:
世界上有很多土豪,就算是他们不上同班,每天都去旅游,住最好的宾馆,吃最好的食物,一辈子可能都有花不完的钱,那么他们为什么还要努力的上班赚钱呢?
有人说这些人是有更高的追求,想赚更多更多的钱。我倒是觉的这些人还是在把自己当一个正常人来看,知道活着就应该做点儿有意义的事情。一千个人会有一千个对生活的理解,这也仅仅就是我现在的感受,可能再过两年我的观点也是会变的。
引用书上看到的一段话:
生活不能等待别人来安排,要自己去争取和奋斗;而不论其结果是喜是悲,但可以慰藉的是,你总不枉在这世界上活了一场。有了这样的认识,你就会珍重生活,而不会玩世不恭;同时,也会给人自身注入一种强大的内在力量。
勿忘初心,不负梦想:做一个优秀的程序员,优秀的架构师,优秀的人!
想到了自己学过的一篇课文的内容:
你站在桥上看风景
看风景的人在楼上看你
明月装饰了你的窗子
你装饰了别人的梦
故事是你自己的,同时你也成了别人故事的一部分。当我发布这篇文章可能距7月3号开始写这篇文章已经有一段时间了,对于文章中的每个标题都是每天自己经过深刻的思考写下的。一些时间性的东西就不改变了,保持它的原汁原味。愿我和读到这篇文章的同学都能跟@十年踪迹 老师的网名一样,以一个十年来计量自己的人生。
这篇文章主要是总结最近开发过程中遇到的问题。有几个问题又是不容易发现原因的问题,但是最后的结果又是很简单的。
对于我自己开发的版本来说还是集成了这个操作的。但是参考了京东,天猫,淘宝电商网站首页的 slider 图片轮播插件都没有支持点按操作。那么是为什么呢?
我想到的答案可能如下:
对于移动端来说,屏幕太小,轮播图上的显示当前图片状态的圆点,人的手指不容易选中。
JavaScript 中this在使用过程中比较容易出错的。那么this到底是指向谁呢?我看到最多的一句话是:
this的指向在函数定义的时候是确定不了的,只有函数执行的时候才能确定this到底指向谁,实际上this的最终指向的是那个调用它的对象;
来看两段代码:
var a = {
m: 12,
b: {
m: 13,
func: function() {
console.log(this.m); //result: 13
}
}
};
a.b.func();通过输出的结果,我们这个知道,当调用this的时候,this指向的是对象b;
var a = {
m: 12,
b: {
m: 13,
func: function() {
console.log(this.m); //undefined
console.log(this); //window
}
}
};
var cc=a.b.func;
cc(); //相当于 window.cc();由以上代码的输出结果是当this被调用的时候 this 指向的是当前的 window 相当于window.cc(),这个时候实际上是 window 调用了 this;
上面的代码也印证了小结开头提到的那句话。但是很多时候根据实际情况我们需要改变this的指向,那我们该怎么做呢?
比如下面这样,我有一个公共的 js 对象来保存一些公用的 DOM 操作的方法,比如:
var Doing.prototype={
likeSport:function(){
//这里使用原型的方式定义对象,就是想要这里的 this 始终指向送的都是 Doing
console.log(this.test2()'like speak');
},
getName:function(){
// console.log('zhiqiang');
return 'zhiqiang'
}
}我的应用场景如下,当我单击 test 节点的时候,打印出我喜欢的运动。
<div class="father">
<div class="test">我喜欢的运动是什么?</div>
</div>new Dong();
var Dong = function(){
var _this = this;
$('.father').on('click','.test',function(){
console.log(this); //this 指向的是 test 节点对象
_this.likeSport(); //这时 likeSport方法中的 this 指向的是 .test 节点对象
});
};根据以上的代码,虽然我使用了 _this 缓存了 this 的只想,以使在单击函数的回掉中可以使用,但是这样直接调用 Dong 对象的方法,会改变 likeSport 中 this 的指向。
那么我们怎么让我们在单击函数的回掉中调用 likeSport的方法时,likeSport 的方法中的this仍然指向的是Dong呢?
这个时候就要用到 call或者 apply 来解决问题了。
call 和 apply 都是可以指定 function函数运行时,this 的值。两者唯一的区别就是 call 第二个参数接受的是参数列表,而 apply 接受的是一个参数数组。
fun.call(this,tp1,tp2);
fun.apply(this,[tp1,tp2]);按照以上的知识点来修改我们的代码
$('.father').on('click','.test',function(){
console.log(this); //this 指向的是 test 节点对象
_this.likeSport().call(_this); //这时 likeSport方法中的 this 指向的是 Dong
});为什么使用 css3属性来做动画?使用 css 3做动画有什么好处呢?
我们先借助 chrome 开发者工具对动画渲染做一个检测,先来看使用margin-left来做动画发生了什么

再来看使用 translate3d 做动画发生了什么

我们可以很明显的看到,在使用 margin-left做动画的过程中,浏览器每时每刻都在发生渲染操作,而使用 translate3d 只是在开始和结束的时候发生渲染操作。
来看看 csstrigger 网站上对 margin-left 和 transform 的区别:


由上面可以知道,我们在使用 margin-left 这样的属性的时候,会触发页面的重排和重绘,而使用 transform 的时候,可以调用 gpu 对渲染进行帮助。
1. 在使用 jQuery 或者 Zepto 的 animate 方法做动画的时候,我的代码可能是这样的
test.animate({left:'15px'},1000);
test.animate({transform:'translate3d(0,15px,0)'},1000);但是根据 API 文档,我们可以直接这样写
test.animate({translate3d:'0,15px,0'},1000);这种写法比上面的写法简洁一些。
2. 在使用 CSS3 属性做动画的时候,数值要加单位,不然会没有效果,比如下面的代码
var size = 150;
test.animate({'translate3d': '-' + size + ',0,0'},1000)这样写是正确的:
var size = 150;
test.animate({'translate3d': '-' + size + 'px,0,0'},1000)我们会有这样的业务场景,需要从页面的最低部返回页面的头部,或者是返回到页面的某个部分。
能够想到的解决方案有两种:
使用锚点没有什么可以多说的,也很简单,但是滚动效果比较生硬。使用 js 来滚动页面的话,可以设置滚动动画,来使页面的滚动的效果更加友好。
在网上如果搜索scroll 动画最多的答案就是使用下面这样的代码:
$('.body1').animate({scrollTop:200},2000);但是我在使用这样代码的时候,却没有出现我想要的效果,最后通过各种尝试还是找到原因的。就是的父级元素没有设置overflow:auto
overflow 这个属性还是很有用的。比如:触发盒子的 BFC 还有就是禁止元素在水平或者竖直方向滚动。
注意:
jQuery 支持这样的滚动动画,但是 Zepto 不支持这个操作滚动动画;
[TOC]
2015年7月3号是自己工作整一年的日子。一直想写一篇文章,对这一年做一下总结。这篇文章在今年7月3号左右的时候是已经写出来了的,但是自己在反复读了几遍以后感觉写的不是怎么的好,就想着要再修改修改。
之后就是在团队里面因为一个紧急的项目,忙忙碌碌了好几周,记得这个过程中有两个周末还需要到公司加班,甚至到了凌晨2-3点左右才回家。哈哈,不过也算是毕业以后经历了一段难忘苦逼的日子。这里开个不恰当的玩笑就是**“有产品经理的项目对程序猿来说真的是一个考验生理和心理的一个过程啊”**。
下周就是全国反法西斯放假了,虽然说是全国人民都应该纪念和庆贺的日子,但是好像还是跟自己关系不是很大。自己也将要迎来一个11天的小长假。当然自己也已经计划好了去哪里,要做些什么,抱着什么样的心态去做。其实我是不知道自己到那里能不能坚持下来的,而且自从定了这事,每天只要是有空的时候,心里面都会有两个自己在做斗争**“不要去了,不去了还可以省钱,好好的在家睡觉看电影多爽”,而另外一个自己却说,“你已经推迟一年了,如果这次还不能下定决心,那你以后也只能这样的将就了,趁年轻,去吧,给青春留点回忆。。。”**
对于_“编码”_之外,要想让自己集中精力来做一件事情有时候是一件非常难熬(甚至是十分困难)的事情。虽然自己一直都有写博客的习惯,但是对于写文字来说还真是件痛苦的事情。就好比有些事情,有些人是因为热爱去做,有些人是因为不得不做而去做。
大学毕业前自己乱七八糟的学了很多种技术,实习的时候也做过专职的前端工程师,反正是跟运维工程师是没有半毛钱关系的。而自己毕业后也想要做的是java工程师,但是毕业后却阴差阳错的做了_运维工程师_。
先谈谈一个合格的初级运维工程师应该掌握哪些技能吧。首先Linux系统知识是必须了解熟练的,然后就是shell。然后按照职位的不同开始细分,比如说,mysql 运维工程师(也可以说是DBA,两者是不分家的),系统运维工程师,非关系型数据库运维工程师(比如redis)等(反正有很多种,我一个巴掌数不过来的),根据每个职位的不同,需要掌握不同专业的技能。而我就是做了非关系性数据库运维工程师。这个职位需要掌握的技能和知识跟我实际会的技能是有很大差距的。比如说Linux,Redis,MemCached,python,这些大学听都没听过的东西,“老大,请问这是什么东东,做这些干什么?”。
当然自己也没傻到真的这样去问老大,不管了解不了解,慢慢的学习吧。按照市场的需求,现在纯运维工程师已经很难满足市场的需求了,运维开发工程师这个职位对于小,中,大公司都是很抢手的,更是市场的发展方向。所以学习python是必须的。
这一年中自己都在跟着**@大闪** @樊亮 开发新浪的自动化运维平台。刚开始还是遇到很多困难的,不过还是那句话**“困难面前,只要你自己不先放弃,或者是妥协,最终都是能够克服的!”**,所以喽,最后反正也对什么都算是熟悉的程度了。
对于我个人来说,我是很不喜欢运维这项工作的,出了开发之外每天都是跟机器打交道,还有打电话跟业务打交道,有很多事情感觉做的很没有意义。所以,到今年6月份之前自己都是一个不怎么合格的运维工程师。但是我还是非常感谢这段经历的。虽然很多知识在我现在的工作中用不到,但是它们对我知识面的广度还是很有影响的。特别是Linux,全世界公认的开源的优秀的操作系统,在大学对它的了解几乎为0,也从最初的排斥,慢慢的了解,然后接受,最后喜爱(怎么突然觉的有点儿恋爱的感觉啊)。对于python这门编程语言也同样经历了这样一个过程。**python虽然不是世界上最好的编程语言,但他绝对是世界上最好用,好学,功能强大的语言。**然后呢?都这样了还要什么然后啊,好用就行了呗,而且关键点也是薪资水平也是行业内数一数二的。(偷笑中...)
上面道貌岸然的把自己称为**工程师**,感觉还是有点心虚的啊,其实我就是社会最底层的一个还有点梦想和理想的小码农而已!
生活就是这样,不是任何时候,都有机会去做自己喜欢做的事情,应该从当下应该做的事情中,发现自己的兴趣点儿,不要刻意的去排斥,到最后都会有不一样的收获。
14届新员工集训

作为团队里仅有的两个应届毕业生之一,有时候还是需要做除了工作之外的一些其它的事情。第一件,组织TEAM的每周分享,工作包括:前期联系分享人,发通知邮件,预定会议室。第二件就是组织大家进行一些工作之外的活动。比如说,周末组织大家一起去奥森公园跑跑步,打打球什么的。
那个时候每周都要组织团队成员进行内部分享,,分享人有自己TEAM内部的,有从其它TEAM邀请的。这些分享大多数时候都能让人了解很多自己工作之外的知识,也能够了解其它部门同事在做什么工作。另外就是组织大家一起出去活动,比如一起去奥森公园打球,一起去沙河水库烧烤等,这些活动都能够很好的让TEAM同事之间交流感情。
虽然都是一些小事和杂事,但是却需要组织者在前期去做很多工作的。那段时间自己内心也会有些小情绪,比如说:“**,为什么要做这些事情”。其实这些都不是最重要的,最重要的是你很难做到每个人对你的组织或者说付出都满意。但是最后想想做这些事情还是有很多的收获的,想把这些事情做好需要一个有耐心的人,而且也需要一个好的心态来面对来自他人的质疑。对于我来说,很多事情是没有做好的,第一方面自己缺乏组织活动的经验,第二就是自己耐心不足。记得在自己犯错误或者有事情做的不够好的时候,谢谢老板@海潮 的用心批评和建议(学习了很多管理经验),把我从错误的道路上拉回来,并且教我怎么去做事儿,怎么把事儿做好。
记得那个时候已经是14年的11-12月份了吧,那个时候@启盼还没有离职,下班的时候经常和@启盼一起吃饭,然后一起到公车站坐车回家。所以也和@启盼经常交流,“有些阶段每个人都要去经历,有些事情总要有人去做,当你不得不去做某件事情的时候,你应该考虑已经不应该是愿不愿意做这件事,而是怎么把这件事做好。”。
@启盼是一个少数民族,来自**,那段时间@启盼 也给我讲了很多他自己经历的真实的**生活。对于没有经历过那样生活的人来说,听到那样的事情还是很难以置信的,有种_xinjiang_人民生活在水深火热中的感觉。当然@启盼 也给我看了漂亮的**妹纸(不知道比我大的还能不能叫妹纸),过了年的时候在Facebook上看到@启盼 已经和青梅竹马的女友领证了,这里只能默默的送上一个祝福了。
前团队,那个时候大部分人都还在,不过有些人已经算团队新员工了

这个是前段时间在知乎上看到的两个话题。《什么样的人一毕业就月薪 1 万以上?》和《月薪 2 万元是一种怎样的人生体验?》。看了大家的答案,讨论(也可以是争论)的还是很火热的。可能有很多应届大学毕业工资水平没有过10k这个水平的学生,想要知道什么毕业生可以拿到这个薪资水平。还有一部分人,就是工资水平处于10k-20K之间,想要知道别人是怎么突破20k这个临界值的。
其实我也不是一个很厉害的人,但是我还是想谈谈自己对这个话题的看法,和背后所隐藏的意义。应届毕业能够拿到10k以上月薪的基本上都是进入国内一线或者二线的互联网公司的吧。但是对于这些公司来说,这个薪资水平也是最基本的起薪而已,所以没什么好谈的(就跟体制内和体制外的生活一样,各有各样的烦恼,也各有各样的好)。
我想说说,这背后所隐藏的一些潜在的问题吧。最起码这群人应该算是一群聪明的人,一群“聪明”的人在一起工作,效率肯定会高很多。第二就是对一个人视野的提升,比如说我之前的运维部门,我们TEAM全盛时期17个人,运维线上3k多台服务器,如果在小公司,一个十几台的服务器就敢称_“集群”,可能连自己的服务主机都没有,但是这样的公司还敢说自己在搞什么_大数据。试想一下,十几个人,运维这么多服务器,那么多业务,怎么管理都是一件很复杂的事情,更不要说去处理和排查故障了。恰恰在IT行业,一个优秀的架构师是应该具有很深的技术功底和广阔的视野的。技术功底自己可以培养和苦练,但是视野,是小公司永远给不了的。,当然还有很多...
好吧,好吧,不谈这么沉重的话题了。接下来我是来“炫富”的(求乱棍不要打死...)。
当然一个应届毕业生可以拿到这样的薪资的时候,说明自己可以绝对的经济独立和自由了。然后就可以去做自己很多自己想要做和喜欢做的事情。
这是毕业四个月后,除了了__单反__是大学时候买的,自己已经有能力买的起苹果三件套了

当自己觉得3个显示器在工作的时候效率才是最高的,可以有能力去尝试

大学的时候自己都想组装一台自己的主机。第一是考验自己有没有这样的能力,第二就是台式机确实比笔记本的性能高啊。然后就是前段时间终于忍不住,自己在天猫买了零件装了一台。因为之前没有实际经验,就是装了拆,拆了装,慢慢的摸索,从开始到最后正常运行,大概花了6个小时左右吧(其实我还是很享受这个过程的...高兴ing...)

前段时间刚好跟学妹聊到一个话题。就是关于欲望的话题,“大学的时候,是最不需要花很多钱的时候,但是还是有很多人为了钱去给别人当小三。”
这种事情在现代社会是很正常和普遍的。人的欲望是无止尽的,当自己的能力满足不了当下自己的欲望和虚荣心的时候,欲望就会引诱着人们去堕落。So, desire is so fear !
自己在之前的岗位经历过新浪微博1次A级,两次B级运维故障。距自己经历的最近一次故障就是“陈赫离婚的长微博”。可能对于外行人,很难理解,一个计数器写满会引发那么大的故障。这里就不谈具体的原理和原因了,反正从那之后,微博上就在流传说,某个明星你再要发离婚帖或者结婚帖,出轨帖的时候先给我们**“渣浪”**(这个称呼是历史原因了,我们都这么自嘲)的运维工程师打个招呼,让我们提前预备资源,也最好别在半夜发,还得我们的工程师好不容易把老婆孩子都哄睡了的时候,正准备躺下,突然收到报警短信,又爬起来处理报警...
“zhiqiang 啊,咱们好像跑题了... 0.0”
一个好的运维工程师,绝对是一个有责任心的人。因为服务器的故障(包括:硬件和系统)的发生时间是不定,所以就需要工程师24小时待命。记得有次自己还在公交上,我直接领导打电话问我到家了没有,说有一台服务器的磁盘要被写满,马上就要挂了...(这是一件很严重的问题)。但是我还没有到家,刚好自己带了电脑。在一个面馆借着人家的WiFi给处理故障。(是不是觉得很苦逼...)
前几天跟学长在群里偶然谈到了责任这个话题。有人说:“40岁的时候应该懂的责任这个词”。其实我是极度的不赞成的,**“我反问到40岁不晚么?”**我觉得人成年以后就应该懂得这个词的分量了,首先应该懂的对自己的负责,才可能懂的对朋友和对家人负责。
回想自己的从小学到上大学之前的生活,总是被家长“强迫”做一些自己不喜欢的事儿(当然还是可以理解家长还是对孩子好的嘛),所以我经常会对自己说,将来如果自己有了孩子,肯定让他自己选择喜欢做的事情。然而,我竟然一直以为这是对的。正好前段时间跟一个同学聊天,偶然谈到这个话题,她说道:“…当孩子还仅仅是孩子的时候,他可能不会选择,可能他根本还没有辨是非的能力,或者说他根本就不知道做与不做意味着什么的时候,作为大人应该去替他选择”。之后几天我都在反复思考这个问题,最后我自己也释然了,原来我一直都是错误的。替孩子去做选择也是大人应该为孩子承担的责任。
突然想到了教父里面的一段话:
第一步要努力实现自我价值;第二步要全力照顾好家人;第三步要尽可能帮助善良的人;第四步为族群发声;第五步为国家争荣誉。事实上作为男人,前两步成功,人生已算得上圆满,做到第三步堪称伟大,而随意颠倒次序的那些人,一般不值得信任。
其实第一条已经很清楚的说名我们首先应该对自己的负责,让自己变得优秀后才有可能有能力去照顾好自己的家人。
一起欣赏下,教父那睿智的眼神...

感谢@海朝 和 @栋哥 还有我的所有同事在工作中给我的宝贵建议,使我能够快速成长。
在工作红有人肯直接指出你的错误是一件非常荣幸的事情(至少对于我来说是这个样子的...)。平时我很喜欢直接指出我错误人,也很乐意别人给我一些意见,这样就是我再也不用花费大量的时间和心思去想我到底哪一点错了。而我只需要关注问题的本质。
不知道从什么时候开始,觉的自己的脑袋不够用了,没之前好使了。每次想要做什么事情,可能下秒就会突然忘记自己要做什么了,所以很多时候,自己每到要做什么事儿的时候,都是干劲拿手机记录到备忘录里去。要不然很多能一会儿就给忘了。有时候会怀疑自己是不是变笨了或者是更年期了,更可能随着年龄的增长,需要自己去操心的事情多了。
好了,好了,赶紧谈正事吧,要不然下班又回不了家了...优秀的员工,你当然应该能够做好小事和杂事,然后能够让领导及时了解工作的进度,遇到意外延期,更要及时上报(这个背后的意义,自己体会吧), 如果是让领导主动找你了解情况,按照@栋哥说的**“你已经输了!意外也可能变成了借口”,最后是要让领导知道自己对工作的计划**,这样他才知道你的时间是饱和的,没有闲着(公司不养闲人,机会也是留给有准备的人)。不管何时不要先提出自己的需求,你都应该先做好自己的事情。
已经记不清在哪看到的这个话题了。“很多男生都比较介意自己的女人比自己优秀”。 我只想说,这样的事情为什么没有让我碰到?婚姻和家庭本来就是一个互补的过程,谁有能力就多承担一些那又有什么呢?为什么非要去在意谁承担的多一些或者少一些。
只有两个人足够的优秀才会有更多的时间和精力花费在家庭中去。如果每天都在为财米油盐争论不休,还谈什么幸福的家庭。
一个成功男人永远不会嫌弃自己女人太优秀,除非他驾驭不了!就像一个女人永远不会嫌弃一件衣服太漂亮,除非她穿不上或买不起!
我有一个女同事,每次因为工作她跟别人发生矛盾的时候,最后她也知道是自己的错。但是总会说是自己的脾气不好,就是这个样子来给自己找借口。我们再往深了去思考这个话题就是,平时生活中爱说这句话的人,都是想让别人来迁就自己罢了。但是?为什么别人平白无故的要迁就你呢?
看到过一段话,大致是,“很多女孩子可以利用自己是女孩子的身份,去做成很多事情,但是很多女孩不把自己当女孩子而是当作普通人(不分性别)去做事情。前者是女孩,而后者是好女孩儿。”
很久之前看到一篇**《其实,你只是看起来很努力》的文章,对自己影响很大。自己也开始反思为什么高中的时候总是觉得自己很努力,但是总是考不好的问题。也终于能让自己释然一些,原来还是自己自身的问题。前几天又看到一篇《你不是太直,你只是自私》**的文章。这些文章写的都很好,能引导人从自身的问题去思考问题。往往读完后都能让自己的心里有种释然的感觉。
我一直觉得自己运气是非常好的,不管到哪里都能碰到谈的开的人,碰到很厉害的人,能够碰到肯帮助自己人。直到最近才想明白,不是自己运气好,只是好人本来就很多而已。
在这里很感谢初毕业就能加入新浪数据系统服务平台这个优秀的团队。在其中遇见的领导**@海潮 ,@启盼**,@大闪,@蕃亮,@曾涛,还有**@栋哥**等,谢谢你们这一年在工作和生活上给我的指导使我一生收益。
过年后,因为一些**“问题”,@启盼先离职了,然后是老板@海潮,最后大家陆陆续续的都开始离职了,几乎上我送走了团队的每一个人。这个问题**我现在还不能谈,第一我觉得我个人看的可能比较浅,第二就是会涉及到领导,和领导的领导。
谈谈一直都很佩服的@栋哥吧,我们团队的架构师。@栋哥的工作路线也很牛b,淘宝,大学老师,百度,渣浪。就像之前的TEAM年后变化还是挺大的,80%的老员工都离职了。但是@栋哥一直不见动静,而且一直在沉着心做事情。@栋哥在新浪做了很多有意义的事情,Redis版本开发,databus数据迁移系统(在github上开源后,大概两周就收到200多个star),还有一个给忘了...(智商捉急啊...)。其实也更@栋哥聊过有没有辞职换个工作的想法,@栋哥说:“有是有,但是他想做的事情还没有做完,总不能做了一半就走吧”。拿什么来形容@栋哥呢?其实@栋哥并不是一个为了工作而工作的人,只是借助公司这个平台来实现自己的价值和梦想的人吧。对于新浪这家公司,我也是有很多感情的,它是我毕业后的第一家公司,我已经不记得哪位同事说过的这句话了:
“当你还是菜鸟时候,是新浪接纳了你,当你变成大牛时,是新浪培养了你”。
不管是什么时候我都不会忘记这句话。
前几天看了老罗的“坚果”手机发布会,有很多感触。从老罗身上可以明显看出他和“商业巨子”雷军,还有新秀“刘作虎”做手机的风格完全不一样地方。雷军是个地地道道的企业家,刘作虎追求的是对品味的把玩,但是在老罗身上可以看到一个踏踏实实做产品,一切为用户的企业家。先不说老罗开了几次发布会,捐了几次门票是炒作还是作秀,但是这些钱真的是捐出去了,而且真真实实帮到了很多人。就像很多人在网络上议论的:
对于现在很多处于80后尾巴,90后甚至是00后们来说,它们并不知道老罗为甚么砸了冰箱,怎么在新东方教的英语,但是它们确确实实是开始喜欢上了老罗。
是的,我也是属于这拨人中的一个,对于做手机前的老罗了解的不多,但是我也开始喜欢上这个总是能够带给我正能量的“胖子”了。现实生活和工作中,负能量很多,有时候自己也会成为一个负能量的散播者。对工作对生活要拥有这种积极向上的态度,还是很需要这种精神的感染的。
写到这个标题的时候,自己都是一愣一愣的。早都不是学生了还谈什么青春,还谈什么梦想。上面也已经提到了,自己下周将要去做一件事情。这也是自己给自己这次旅行想的一个口号。
一路走来自己确实是定过太多计划,有过太多的梦想。大多数都夭折,连自己都不记得了。但是有件事自己还是一只都记得,而且一直记在自己的QQ邮箱的记事本里面
记的14年1月份那个时候,还没毕业,自己都开始计划,一些自己毕业后要做的事情。记的那个时候自己还做了一个计划,美其名曰:“人生计划”。

当然还不止这些

当我从自己的QQ邮箱的记事本里找到自己写的这些东西,打开看的时候自己都笑了,那个时候是要去骑行川臧线的,但是最后一个也没有实现。
还好明天就要踏上去环青海湖骑行的火车了,终于能为自己曾经的一个梦想和计划画上一个句号了。
每年都有写年终总结的习惯,眼看着元旦已经过了好几十天了,步入2016年。是应该对2015年做一个总结了。最近一段时间有空的时候也在整理这一年经历的事情,也在思考自己在其中的得与失。
也许一个人确实容易空虚,找不到奋斗努力的方向。有段事件自己也迷茫过,自暴自弃过。做事说话心浮气躁,不思考。想想那个时候的自己确实有点可怕,那是浪费了多少时间啊。所以,
当一个人不在思考的时候,说明生活过着非常的空虚,这是一件非常可怕的事情。
首先,我想感谢在这一年给过我帮助的所有@同事,@亲人和@朋友。正因为你们的出现,才使我成为一个有精彩故事的人。之前,这段引子写了很长,后来也是觉得冗余,还是总结成了一句话:
磕磕绊绊,虽然迷失过,但愿自己能不忘初心!
今年年终总结的文字是从收到的公司的一份邮件开始的,这里我要谢谢我所在的公司,作为校招生从最开始的新员工培训,到现在已经入职一年半了,每周一到公司打开邮箱还能收到 hr 们的鼓励邮件。有时候看到非常切合自己心态的文字确实很受鼓舞的。
记得在9月份的时候写过一篇《工作一年小结》的文章,基本上也讲清楚了自己前半年经历的一些事情和对这些事情的一些感悟。从小就听说过_“铁打的营盘流水的兵”_这句话,工作后发现这句话来形容 IT 行业也是非常贴切。还是那句话: 只有经历过,才会有感触。
当然送走了旧同事,我依然有故事...
因为房子合同到期,重新换了房子,搬了家。那段时间也是挺忙的,每天需要上班,下班后还要忙着找房子。在北京要想在自己理想的价位找到一间适合自己的房子不是一件容易的事情。而且在北京这样一个房价只增不减的城市,租房子的价格也在上涨的情况下,想找到一间价廉物美的房子更加难了。
记得13年12月份的时候刚来北京(是的来北京已经两年了),住的是八九百的房子(小黑屋),没有窗户是客厅的隔断。后来毕业了,挣得钱多了,一千五换了个大点儿的房子。到现在房租已经接近2K。说实话这个价位自己心里还是着实心疼了一下。
前段时间身份证有效时间到期,回家办理了一张新的。高中第一次办身份证,有效时间是10年。新办理的身份证有效时间20年。我看到那个20年的时候一想,等到自己再换身份证的时候已经快年过半百了,不知道那个时候自己会是什么样子。内心一阵波涛汹涌。时间真的是荏苒。
现在自己特喜欢听五月天的歌曲,特别是后青春的诗中的那首笑忘歌(一定要听 live版啊)其中的有段歌词真的很有意义
青春是手牵手坐上了
永不回头的火车
总有一天我们都老了
不会遗憾就OK了
伤心的都忘记了
只记得这首笑忘歌
那一年天空很高风很清澈
从头到脚趾都快乐
我和你都约好了
要再唱这首笑忘歌
这一生只愿只要平凡快乐
谁说这样不伟大呢
对啊,正向歌词中写的 “这一生只愿只要平凡快乐,谁说这样不伟大呢”
刚毕业的时候陌生的领域很多,一切对自己都是新鲜的。无缘无故选择做了一名运维工程师,整天和服务器数据库打交道,这个选择自己是没有经过深思熟虑过的。但是现在想想,当初选职业跟很多年前高考选大学专业一样。选择的都是一知半解。所以,就算自己再深思熟虑也考虑不到多少东西,毕竟自己的知识有限,眼界有限。
**我想做开发,要做开发。**所以在15年刚过完年回到北京,大概3月份儿的时候也尝试着找了一些机会,想去做自己想要做的事情。当然有时候不是你想去做,就能够去做的。
最近两年前端这个行业发展比较好,而且以后的发展前景也不错。大学期间学过一些前端的东西,毕业后在做后端运维的时候,也写过一些 jQuery ,自己也想要去尝试前端职位这个方向。
后来在几次的面试中,没有多少实际前端开发经验的我,都失败了。但这些经历也让我收获了很多东西,第一,做这个职业需要的知识结构,以及对于一年到两年的工程师应该拥有多少的知识积累。第二,心态!毕竟每次都被别人打击,能够还继续尝试也不是一件容易的事。
之后在同事的鼓励下,我找老大表述了自己的想法。在老大的支持下,后来我转岗到了公司一个很厉害的前端部门(也就是我现在的部门),开始在前端这个行业打怪兽升级。
自己一直信奉的一句话,“记住自己想做什么,要做什么,并为之付之行动!”。如果没有机会,一定要为自己创造机会。如果现在不去做,以后可能就没有机会了。**活着,总要追求点什么。**所以,就算没后之后的那次转岗,我仍旧是会继续寻找机会的。
4,5月份的时候,团队来了两个校招实习生。这个时候团队已经换了新领导。当时关于谁带的问题,小组开了个会,因为小组长在我毕业的时候带过我,最后他也把带实习生的任务交给了我。
那个时候带他们做一个小项目,用 Python 解析 HDF 文件,将获取的数据绘制成图表。当时服务器上的数据是每天生成都会生成,代码是获取包括当天和往前推7天的数据。
这里要抱怨一下我们天朝的 GFW 使用 pip安装 Python 包,不挂代理有时候竟然都无法安装,更可恶的是 PyPI 如果不挂代理竟然连网站都打不开(当然我们可以配置国内的代理,阿里镜像,豆瓣镜像)。
之前服务器上的代码是别人的,我当时也并没有仔细的阅读,只是大概看了一遍。刚开始做的时候我就给了他们一次数据文件。后来他们一直在说代码有问题,从文件读取的数据有问题。当时我也没有意识到是数据的问题,只是让他们再看看。直到第二天我重新读了一边代码才发现了问题问题所在。那个事情也是自己比较在意的,自己的疏忽浪费了别人很多的事件。后来我也跟他们聊聊,表达了自己的歉意。
6月份转岗到的公司一个前端部门。后来就连续做了几个项目。积分商城,运营活动。因为刚开始经验的缺乏和知识储备的不足,自己也经历了加班到凌晨的过程,但是自己在那段事件确实积累了很多知识和开发经验。
不管对于前端还是后端,开发经验都很重要,特别是前端 css 的某些属性在哪些系统的手机上有问题或者是客户端中浏览会有问题,多终端适配的问题。相对于传统pc端 web 页面的开发, 因为移动端对 css3新属性支持的很好,h5页面的开发可能会方便一些。当然这些新属性的出现也让 h5端的开发出现了无限可能。当然这都要开发者去尝试。
在前后端协作开发,与产品沟通项目需求的过程中也暴露了自己很多的问题。比如说在问题面前,自己之前会特别较真的区别这个是你的问题,还是谁我的问题,还有这件事该你去做还是我去做。有时候同事之间会显的很尴尬。后来慢慢的意识到了自己的问题,在之后的工作中也改变了自己的态度。感谢同事对自己的包容。
毕业后自己变了很多,性格上的棱角也慢慢的被磨平。以前在自己的圈子里,自己很牛逼,性格也会显得很狂妄。当从一个自己牛逼的环境到周围都是比自己牛逼的人中间,刚开始还是吃了很多亏。后来自己也慢慢学会了谦卑。后来我才发现自己是一个:
只有是犯过一次错了,才知道事情该怎么做,话该怎么说的人。
前几天看了火影忍者剧场版博人传,其中佐助对名人有一段话的评价,我觉得很贴切:
他浑身都是弱点,简直一无是处,但是他靠自己的力量一点一滴的进步最终成为了火影,你不必理解现在的鸣人是怎样的,你需要认识一路走来成就了自己的鸣人。
对啊,我是有很多缺点的人,但是我没有丧失辨别是非,对与错的能力。如果我认为我做的事情和说的话是错的,不关多么的不好意思,我都会道歉,也会努力控制自己不让同样的事情发生第二次。
这段时间因为天气不是很热也不是很凉,周末自己最经常做的事情就是骑行了。比如说骑行十三陵,***,城郊等。最后强烈建议,如果想在北京骑行的话,一定要选择城郊(十三陵这条线很不错,周末骑行的人很多),不要选择市区,就算没有雾霾,你也会被汽车尾气“熏死”。
9月底的时候自己带着车子去了一趟青海,环了一次青海湖。9月底已经错过了最佳的环湖时间(最佳时间7月左右),什么万亩油菜花田,我去的时候都没有了。自己也不是平白无故的想去就去的。也是为了完成大学时候对自己的一个约定。
那次环湖是自己有生以来做的的最痛快的一件事情。从西宁出发,经塔尔寺,湟源,西海镇,二郎剑,黑马河,刚察,再回到西海镇,全程大约450公里,自己骑了6天时间。经历过孤独无助,精疲力竭。但是我也遇到了很多人,听到了很多故事。那才是我最开心的事情。
就像有人写过的那样,“从小到大,我们在不同的人生阶段有自己的梦想,但是最后完成的有几个呢?”。有些事情没有必要去做,去做了也没有意义。就像电影《谜城》中最后古天乐的那句台词:“只是人生多了一段经历,换来一段永远追不回的时间。”
但是那又有什么关系呢?我觉得我的人生应该是有故事的,我的青春也应该是有故事的。
“青春不散场,对梦想不妥协”,这是我当时给自己想的口号。之后也成我做人做事的人生态度。也许这就是青春吧,某天我回头的时候不会说,我的青春喂了狗。就算没有了青春,我也是一个有故事的人。
11和12月份的时候自己重点负责了公司两个项目的开发。双十一和双十二活动。经过几个月的工作,自己积累了一些知识也了解了一些新知识。在这两个项目中自己也尝试使用了他们(当然自己也踩了很多坑)。
比如说,现在h5端的弹性盒模型,CSS3动画等。使用过程中遇到了很多问题。因为之前学习的时候都会去参考,淘宝,天猫和京东的 h5页面。所以,在遇到问题网络搜索解决不了问题的时候,都会尝试去研究一下这三个网站的源码,找到解决方案。
也是在工作中跟同事聊天理解最深刻的两个词,“知道”和“理解”。某个知识点当同事提到的时候,能接上话,并能说出一些东西,这叫知道。当遇到问题知道能用哪个知识点解决问题,这叫理解。大多数时候,不是说这个知识点不知道,而是想不到去用,或者说不知道怎么去用。所以
知道和理解是有很大的距离的。
现在前端最火的框架无非就是angular 和 react ,当然还有 node。我们公司也会根据自己的业务类型开发我们自己的前端框架。有时候跟同事聊天也会聊到这些问题,为什么像 react ,angular 已经很好用了啊,而且还有大公司的技术支持。我们为什么还要重复造轮子,不直接拿过来用呢?我记的最经典的一个回答如下:
“angular 和 react 刚出来的时候也有很多毛病,被很多人指责,但是这么多年过去,从被指责到被很多人接受,并且引领者一个行业的发展。这是需要公司的持续支持和开发者持续支持的。我们学习别人是应该的,但是走自己的路我们自己才会有发展,只是一味的跟着别人走,始终不会有质的超越,时间长了也不会有自己的沉淀。”
我一直非常佩服滴滴打车的创始人,佩服它创造的生活方式(跟马云一样)。滴滴创造的模式,不仅改变了人们的生活方式,也改变了一个行业的生产结构。肯定是会被历史记住的。
前段时间,大学同学来找我。期间我们聊了很多大学的事情。大学,那是个荷尔蒙激荡的年代啊。有时候工作中遇到困难的时候,自己也拿现在去对比那个无忧无虑的时期,想到一些事情也会嘴角上扬的傻笑。但是,很多事情可能永远也不会发生了。
大学那会儿因为无聊,空虚很喜欢喝酒,而且是白酒。也喜欢跟宿舍的哥们或者是专业的哥们拼酒,感觉我比你能喝,我就比你牛逼啊。那是一件多么长脸的一件事情啊。
聊天的过程中,我同学也跟我说起了大学喝醉酒后喊的几个妹纸的名字。其实这些事情后来我并不记得,现在听他们一提起还真有点儿脸红,不自在。但是那个时候自己确实是没勇气去追自己的喜欢的女孩,也只能喝醉后瞎喊喊而已了。当然了现在也是。
就像有句话话说的那样:
人生是一场没有彩排的话剧,演出顺序真的很重要。在错的时间里,你一出场就输了。
15年自己断断续续读了一些书,大部分都是用 kindle 在做公车的时候读的,后来有一段时间自己骑车子上班,阅读的效率低了很多。统计了一下大约有39本吧。技术书就不列举了,因为自己读技术书都是读一半。今年也会对自己有一个小要求,就是每读完一本书,都要写简单的书评。
Python 学习今年就放一放吧。
终于到了尾声了,自己也确实是写不下去了(絮絮叨叨。。。)。曾经觉得很艰难的时候,时间让所有过不去的都过去了,现在想想也就那么回事。每个人的生命中都会有最艰难的那一年将人生变得美好而辽阔,也许我生命中的“最艰难的那一年”已经来过了也或者还在远方等着我。但是谁去想呢,如果没有考验了哪里来的人生。
看到这篇文章的小伙伴,让我们今年都更加努力一些,如果某天我们突然面对了属于自己的“最艰难的那一年”,我们能够更加坦然些。。。加油!!!
而到如今,我明白过来,无论怎样肆无忌惮地去过这一场青春,都不可能在白发苍苍时觉得这一切无愧于心。所有故事都会有遗憾,这才是实实在在的人生,值得被想起,庆幸曾经历。--摘自 《一个》
本文发表于CSDN《程序员》杂志2016年8月期,未经允许不得转载!
随着移动互联网的兴起,前端开发工程师的岗位也随着兴起。前端工程师不仅在用户和产品之间扮演着越来越重要的角色,而且前端的职能也能够(开始)朝着服务端延伸。所以不仅小公司缺人在招前端,大公司同样面临着缺少优秀前端工程师的尴尬处境。
当我们在谈论或者招聘前端工程师的时候,都会提到熟练或者是熟悉 h5(html5) 开发。那么所谓的 h5 开发是什么呢?这篇文章主要就是为大家介绍 h5 的基本内容和学习指南。
从2006年 html5 标准被提出到2014年10月29号,html5规范制定完成并且发布,这中间经历了8年时间。从被提出到最终规范定稿,html5 包含的很多新特性,同步的在被同时期的现代浏览器(Chrome,Firefox等)所实现。所以 html5 对于很多开发者来说,已经不能算是一项新技术了。在 html5 发展的过程中,移动互联网的兴起,html5标准委员会 为了满足在移动设备上实现复杂多媒体功能,设计了一些新特性来支持移动互联网的发展。
严格意义上来说,我们现在口中的 h5开发 并不仅仅指的是 html5 这一项技术,而是包含了html5 ,css3,javascript。所以在我们励志成为一名优秀的前端工程师的时候,应该多关注这三方面的技术。
<!DOCTYPE> 声明方式,告诉浏览器对所要解析的html文档的文档类型。来规范浏览器的解析行为。该声明方式比 html4.x 声明更加简洁和灵活;<footer> <article> 等,可以使我们创建更友好的页面结构,便于搜索引擎抓取;number email autocomplete等,可以让我们规定表单元素的输入类型,长度,表单元素的行为;<video> <audio>。可以让我们定义多媒体文件的类型和行为;<canvas> <svg> 标签可以让我们在网页上绘制复杂的图形和显示复杂的图形;drag drop 事件可以让我们在网页上对元素进行拖放操作;localStorage sessionStorage可以让开发者根据用户行为在客户端缓存数据,提高网站性能和用户体验;geolocation 可以让我们不依赖客户端就可以获取用户位置;EventSource 对象可以让我们的应用程序不主动发送HTTP 请求的情况下接收服务端推送的消息,并且做出响应;上面介绍了那么多html5新特性,那么这些新特性普及能为开发者带来哪些便利呢?
对于经常使用微信的朋友来说,在 发现 一栏里可以看到 京东购物 的标签,当我们打开后会发现它几乎跟我们使用京东客户端一样。我们会想,难道微信在自己的客户端内,单独为京东开发了展示商品的模块呢?假如说,微博的客户端也要为京东添加这样的一个入口,是不是微博的工程师也需要开发这样的模块呢?
答案是否定的,首先两家不同类型且独立的公司,先不说技术储备问题,这么复杂的页面开发起来在协调沟通和开发成本都会很大。如果某天XX活动京东要对网站首页改版,为了保持一致性微信的工程师也得同步的开发京东的新版页面。这明显违背软件设计 解耦 的**。那么什么技术可以改变这种现状呢?
因为html5新增的特性,已经可以让开发者开发出接近原生 native 体验的页面,也有满足多终端适配的解决方案。京东只需要使用 html5 来开发自己的页面,为需要提供入口的客户端提供页面的URL地址即可。不仅可以极大的减少开发成本,人力成本和沟通成本,而且也不会因为客户端版本更新迭代慢而影响产品的生效效率。事实上京东是这么做的。国内很多公司都是这么做的。
对于已经有html和css开发经验的人来说,我认为学习html5应该是很快的。我们应该根据自己的工作需要来选择学习哪些内容。比如:SVG 和 Canvas 已经属于Web图形学方面的内容,内容很多也比较复杂,如果平时工作中接触和使用的不多,仅仅作为了解就可以了。不必要投入太多的精力和时间。
除了以上两个知识点之外,我们就可以把html5新增的内容分成以下几点进行学习,各个击破:
对于刚入门的选手,就不要刻意的区分html5和html了。现在随便买一本html书(最近3年出版的书ಥ_ಥ),其中都会包含html5的内容。你的关注点应该是把自己对html包含的内容整体的把握起来。并且多写一些demo来练习,知道这些标签在网页上的表现和具有的特性。
前端开发就是跟浏览器打交道。所以我们在工作中应该关注自己的产品必须兼容浏览器的版本。当我们在使用html5一些新特性的时候,可以在 caniuse 上查询是否满足自己的兼容标准,对这些新特性有选择的使用。
说了这么多html5开发的优点,也应该了解一些html5页面的缺点:
注:移动端浏览器几乎兼容所有的html5新特性。
真名侯志强,昵称:zhiqiang21 。
zhiqiang21是自己工作后入职第一家公司的邮箱前缀。对!在我入职之前已经有20位叫x志强的前辈了。后来在注册一些网站的时候用自己名字的拼音作为ID,大多数情况下都已经被注册了,所以就干脆用了这个zhiqiang21的ID。还好没有重复的。
技能树:
生活:
作为一名"猿",不知不觉就会陷入IDE,编辑器(Vim,Emacs,sublime,atom等)之争中去。
当然选择适合自己的一款编辑器还是很有必要的。而自己平时使用的又比较杂,只是让它们做我认为最擅长的事情。
vscode
Vim
webstorm
Atom
2010-09至2014-06 就读于河南理工大学计算机学院 本科学历 学士学位
2014年07月-2016年-04月就职于 新浪 and 微博 :
2016年05月至今 就职于 百度 ,职任高级前端研发工程师;
QQ:1187691302
我们团队有个项目由于开发时间较长,且是前后端杂糅的开发方式,维护成本很高,在线上暴露的问题很多。而且因为对接了公司一百多条产品线,每天都会接到大量的客诉和产品线反馈的问题。2017年11月份以产品为主导,从产品层面对流程进行重新设计,对该项目进行了前后端的重构。作为前端的负责人我用这篇文章分享下,整个过程从技术选型,开发,上线的一些经验。
首先我们先看下下面我们项目中的几个页面,来总结下一些他们的特点。
我们的页面主要是需要用户填写的表单居多,在页面加载的时候不需要去请求获取和渲染大量的数据。而且一个页面需要显示的状态较多(比如上面的3张图,在项目中是一个组件)。还有一个最主要的业务需求,百度公司内部产品线较多,不同的业务都有其独特的账号标签,这些账号除了会走一些通用流程还要走一些对应产品线特色的流程。
结合这些业务特色和之前有Nodejs和React的开发经验,我整体的一个技术选型是FIS3+Nodejs+React+Redux+React-Router。那么这些技术选型能带来什么呢?
这里简单的聊下工程化工具的选择。目前在业内最火的工程化工具就是Webpack了吧。除了看过文档之外,并没有太多的实际应用经验。我一直认为使用工具就是来帮助开发者解决一些开发过程中遇到的一些需要人为频繁去操作的无异议的工作。抛开Webpack我们依旧可以手动去编译代码,手动部署,手动刷新页面来开发,使用工具只是让这一系列的流程能够连贯起来,降低开发成本。
在我的所有跟公司有关的项目中选择的都是FIS3,我也认为他足够的好用,能满足我各色各样的工程化需求。我并不是排斥Webpack。我只是还没有找到一个理由,让我选择放弃现在使用的FIS3去使用Webpack。
这里简单介绍下,决定了技术选型之后,对于渲染页面渲染机制的一些区别。
之前旧项目使用PHP+Smarty的渲染模式,将页面在服务端渲染完成之后再统一吐给前端浏览器。而使用新的技术架构之后,我们渲染页面的方式更加的灵活。可以选择在服务端渲染,可以完全交给浏览器渲染,可以同构渲染。因为我们的页面在首屏的时候不需要加载大量的数据,所以我还是让大部分页面在浏览器端进行渲染。
还有一种区别就是之前所有来自用户的请求都会落到PHP的服务器上去。而新框架的请求都会落到前端的Nodejs服务器上去。所以前端工程师不仅仅是写好页面和做好兼容性。对前端工程师的技术能力也会带来考验。
前面谈的技术选型已经提到了使用React-Router来做页面路由控制。而且React-Router提供了异步加载组件的功能,这为我们上线优化页面的异步加载提供了技术基础。
<Route path="/v4/appeal/fillname" component={FillName} />
{* 这里对某些组件做异步加载 *}
<Route
path="/v4/appeal/selectuser"
getComponent={selectUser()}
/>
function selectUser() {
return (location, cb) => {
require(['../accountselect/container/AccountSelect'], function (component) {
cb(null, component);
});
};
}通过React-Router来做路由控制除了前端代码之外,服务端也许呀做些配置。不然我们的页面在回退的时候就会出现问题(页面找不到路由)。其实就是在我们通常说的action成面做下路由控制,因为我使用的是Nodejs,所以我的配置下面这样子的。
router.get('/fillname', router.action('index'));
router.get('/selectuser', router.action('index'));在前端事件因为开源协议的问题曾经短暂使用过Preact。React和Preact最大的区别就是对于一些事件的封装。这些造成了Preact相对于React体积小很多。
做移动端开发,前端经常会面临的一个问题就是click事件 300ms 延时的问题。在React中提供的onClick事件同样也会出现这样的问题。如果如果我们想要在点击一个按钮之后,在其它地方立即出现反馈,最好就是使用onTouchEnd事件,或者就是使用开源的Npm包react-fastclick能很好的解决click事件 **300ms**延时的问题。
使用的方法就是在我们代码的入口地方,声明以下语句,他默认会改变react的onClick事件的行为
import initReactFastclick from 'react-fastclick';
initReactFastclick();在使用React的时候可能都会面临的问题,我的组件应该是无状态的还是有状态的。我的组件状态怎么共享。什么时候我应该使用Redux来管理组件的状态。刚开始接触react都会有这样的疑问吧。
一种比较极端的做法就是,不管状态需不需要共享,组件的所有状态都试用Redux来管理。这样的做法就是我们需要写大量的Action。如果是一两个页面还好,如果是十几个页面,真的写action是能把人写崩溃的。
那么最佳实践是什么呢?看下图
当我们要写一个组件的时候,首先想下这个组件是不是需要与其它组件共享它本身的状态。如果需要我们应该把它当做有状态的组件来设计,而且共享的状态使用Redux来管理。如果简单的就是无状态组件或者是这个组件本身的状态改变不会影响其它的组件,就可以将组件设计为无状态组件(虽然叫无状态组件,其实组件本身的状态也是可以使用this.state来管理的)。
React的一大热点就是组件化的开发**。小到页面上的一个按钮都是可以设计成一个组件。既然是组件我们首先就应该考虑这个组件怎么被其它组件复用。
举个简单的例子,在整个项目中都会用到的弹窗组件:
class AlertForm extends Component {
constructor(props) {
super(props);
this.state = {
showlayout: false, // false 以tip的方式提示错误, true以弹层的方式提示错误
btnlist: false,
formbtn: false
};
}
componentWillReceiveProps(nextProps) {
}
handleHideLayout = () => {
}
handleMobile = () => {
}
handleChangeCheck = () => {
history.go(-1);
}
render() {
return (
<div className="component-alertform" style={this.state.showlayout ? {display: 'block'} : {display: 'none'}}>
</div>
);
}
}
export default AlertForm;我们将这种可能在其他页面都用的组件单独抽象成出来,在需要用的地方import。
import AlertForm from '../../components/AlertForm';
<AlertForm
errno={errno}
stateObj={fillAppealName}
actions={actions}
/>完成项目之后肯定要做的一项工作就是上下前的优化,上线前我做的工作主要如下:
前面已经谈到错对于大多数用户来说都只是会走一些普通流程。有些具有产品线特色的用户会走一些特殊流程。所以在上线前肯定要拆包,和做组件的异步加载。具体的前面已经提到过了。在打包的时候对这些页面的js需要使用打包工具做单独的处理。
其实除了这些需要异步加载的页面之外还会存在一些其他自己编写的lib库(自己编写的小函数)。还有比如全国省市地区对应关系,电话区号对应关系。因为这些函数或者是地区关系映射图在上线以后基本上都是不会再变化的,所以与业务的js分开打包。
我们的打包的配置文件如下:
前面已经谈到使用Nodejs做中间层,做路由控制和服务端渲染。下面的这张图是我写这篇文章的时候截取的额以上服务实时状态图。可以发现,整个应用对于内存、磁盘IO利用率还是很正常的,对于CPU的利用率有点儿高,这也是后续需要优化的地方。
这里想要说的是,如果使用了Nodejs,使用了服务端渲染,对于前端工程师的个人素质要求会比较高,因为需要处理很多服务端的问题。前面也分享过一篇处理安全工单的问题,不仅仅要面对服务端的问题,还有面对来自互联网安全的问题。
使用Nodejs除了来做服务端渲染。我还在使用Nodejs做了一些其它的工作。
比如我在服务端使用Nodejs管理了这样一个JSON文件。PHP端不在维护错误码和错误码显示的文案。所有前端需要显示文案放在Nodejs端做统一的管理。而且,我线下也可以同通过系统对这些错误文案进行动态的更新。提高系统的可用性。
虽然说是记录fis3+react的一次开发经历。但是在项目的上线前几天收到公司TC委员会的邮件,因为react的开源协议让找到react的替代方案,并且逐步下线线上的react项目。真的是可以用“出师未捷身先死”来形容这次开发了。
不过经过调研以后发现在业界已经有了一些开源方案来替代react 。最有名的就是preact的了吧。而且按照官网的方案来做迁移的话,迁移的成本也挺小的。后续会介绍下迁移的情况。本文也是主要介绍下,使用react+fis3开发的一些经验和其中遇到的问题的解决方案。
下面的文章也统一用react这个名词。
目前在选择使用Vue或者是React的时候,总要说些为什么要用。其实我的想法很简单。因为我们的产品是偏向业务型的,复杂的数据交互不多,但是流程多,而且很多业务要复用一些页面流程。按照我们旧的开发模式来说,我们的模板文件存在着很多的if...else来做流程判断。这样对于我们维护项目来说是非常的不方便的。我们希望引入一项技术来解决不同流程公用一些页面的问题,而且可以在不同的流程中自定义这个页面的表现的技术。
React的组件**是一种解决方案。页面的每一个元素都可以作为一个组件来抽象。扩大到一个页面也可以作为一个组件。所以这是我选择React来开发我的页面。
按照业内主流做法使用react搭配webpack是最主流的。但是在公司内主推fis3的情况下还是选择了fis3。而且fi3的维护团队也产出过一篇引导文章和demo来介绍使用fi3开发react应用(参考文章见文章末尾)。
在项目开始前也在分析要不要引入redux。我们的页面是偏向业务的,很多页面都是表单的提交和验证。并没有很多的状态需要维护,而且我们的数据源也很单一。不过在经过一个页面的开发后还是发现一些页面引入redux会对开发工作带来很大的便利。
react的开发模式基本上都差不多。因为这次我并没有引入redux。所以我的目录结构也相对简单一些。如下:
.
├── components //组件目录
├── containers //组件容器
├── language //语言包目录,为项目做国际化预留的能力
├── node_modules //npm依赖
├── package-lock.json
├── package.json
├── page //页面模块
├── routes //路由模块
├── state //因为没有引入redux但是有一个页面的状态实在太多还是单独为它做了一个文件管理state
├── static //静态文件模块
└── yarn.lock
使用react的第一项工作就是要拆分自己页面。把自己的页面拆分成“一块一块”
的组件。所以看下图我的页面结构。
我是这样拆分我的页面的,红色的线就是我的拆分模式。
所以我的components目录下的文件是这样的,分别对应这我对页面拆分后的组件。
├── components
│ ├── Header.jsx
│ ├── Input.jsx
│ ├── PassBtn.jsx
│ ├── SafeCenter.jsx
│ ├── SafeList.jsx
│ ├── header.styl
│ ├── input.styl
│ ├── passbtn.styl
│ ├── safecenter.styl
│ └── safelist.styl
而我的comtainers目录就是对应着我的页面文件,其实就是一个个零散组件的容器。
├── containers
│ ├── BankList.jsx
│ ├── EditUserInfor.jsx
│ ├── EditUserInfor.styl
│ ├── SafeCenterIndex.jsx
│ ├── VerifyBank.jsx
│ ├── VerifyRealName.jsx
│ ├── banklist.styl
│ ├── verifybank.styl
│ └── verifyrealname.styl
还有最有一个值得介绍的就是routes目录,管理整个项目的路由。
├── routes
│ └── index.jsx
因为使用的preact-router这里的写法和react-router的有一些不同。代码如下:
export default (
<Router history={createBrowserHistory()} >
<SafeCenterIndex path="/v4/security/"/>
<VerifyRealName path="/v4/security/verifyname"/>
<VerifyBank path="/v4/security/verifybank"/>
</Router>
);写react时,我们在享受着react的visual dom的高性能和不依赖dom的编程的便利时,面对最大的问题就是对组件的state的管理吧。当然最好的解决方案肯定是引入redux做状态管理。但是当我们没有引入redux时怎么办呢?
我先来举个简单的例子。我们有以下一个对像来管理页面的显示状态:
var obj= {
"aaa": {
"bbb": {
"ccc": {
"ddd": {
"header": "istrue"
}
}
}
}
}当我们的一个state嵌套太深时,按照我们使用js的一般做法要更新header的值的做法如下:
obj.aaa.bbb.ccc.ddd.header='isfalse'; 有时候我们为了能够让代码更健壮可能会这么写:
obj.aaa || obj.aaa.bbb || obj.aaa.bbb.ccc || obj.aaa.bbb.ccc.ddd || obj.aaa.bbb.ccc.ddd.header = 'isfalse'会发现这样做真的繁琐。当然我在做的时候也面临着这样的问题。通过查询相关资料,最佳的解决方案当然还是引入redux。那么次佳的解决方案呢。其实就是引入第三方库,最具代表性的就是facebook自己的facebook/immutable-js。这个库能让我们方便、安全、高效的更新一个层次较深的state。但是也有一个缺点就是文件体积较大。当然与之相对应的就是开源大神做了优化后的版本immutability-helper和immutability-helper。
这三个库中文分析介绍的文档挺多的可以自行搜索了解。当然最后我上面的都没有用。因为之前的我的项目中已经引入了lodash这个开源库。而它也提供了较安全的更新一个深层次object的方法
如果使用lodash更新上面header的值,写法如下:
import * as _ form 'lodash';
_.set(obj, 'aaa.bbb.ccc.ddd.header', 'isfalse'); //更新header的值
var header = _.get(obj, 'aaa.bbb.ccc.ddd.header') //获取header的值还有一个值得注意的地方就是在我们更新state之前,都是“克隆”而且是“深克隆”一个state去更新。“深克隆”肯定是会影响程序性能的,所以facebook的facebook/immutable-js提供了高效的方法去“深克隆”一个对象。
当然使用lodash也会更方便一些。但是这样的操作不应该经常的发生。
import * as _ form 'lodash';
var initState = {};
var deepCloneState = _.cloneDeep(initState); // 我们操作的其实都是这个clone的备份第三个,出现的比较坑的问题。浏览器或者是webview缓存GET请求。
这个问题主要发生在需要多次以**GET**的方式请求同一个接口。解决的方案也挺简单就是在我们发起的GET请求后面加上时间戳。以使用axios为例:
axios.get('/v4/xxx/action?v=' + (new Date).getTime())
.then(data => {})
.catch(err => {})本来想统一的使用typescript插件来编译jsx的。因为迁移preact原因,要修改全局pragma。所以编译前端的jsx就使用了babel-5.x插件,以下是全局的配置文件介绍。
// 定义一个全局的变量目录
const dirList = '{actions,components,constants,routes,containers,page,state,language,reducers,store}';
fis.match('/client/(' + dirList + '/**.{js,es,jsx,ts,tsx})', {
parser: fis.plugin('babel-5.x', {
sourceMaps: false,
optional: ['es7.decorators', 'es7.classProperties'],
jsxPragma: 'h' // 这里也是最重要的迁移preact后必须加的一个参数
}),
// 页面中显示的url并且加上自定义的v4前缀
url: '/v4${static}/${namespace}/$1$2$3$4$5$6$7$8$9$10',
isJsXLike: true,
// 设置位模块目录最后的编译结果都是会用define包裹
isMod: true
})
// 这里都是为了给静态文件加上v4自定义前缀
.match('/client/({components,containers}/**.styl)', {
url: '/v4${static}/${namespace}/$1',
})
// 这里都是为了给静态文件加上v4自定义前缀
.match('/client/static/({img,js,styl}/**.{png,js,ico,styl})', {
url: '/v4${static}/${namespace}/static/$1$2$3'
})
// 因为使用的stylus做位css的预编译工具,这里的配置是编译stylus的配置
.match('*.styl', {
rExt: '.css',
parser: fis.plugin('stylus', {
sourcemap: false
}),
preprocessor: fis.plugin('autoprefixer', {
'browsers': ['Android >= 2.1', 'iOS >= 4', 'ie >= 8', 'firefox >= 15'],
'cascade': false
})
})以上的配置文件是开发环境的配置,在页面加载的时候也是对静态文件逐条加载的。
而且页面的加载时间也比较长不符合我们线上的加载静态文件的需求。
紧接着对打包脚本进行优化
fis.media('prod')
// 压缩css
.match('*.{styl,css}', {
'useHash': true,
'optimizer': fis.plugin('clean-css')
})
.match('/client/node_modules/**.{js,jsx}', {
'isMod': true
})
.match('/client/**.{js,es,jsx,ts,tsx}', {
'preprocessor': [
fis.plugin('js-require-file'),
fis.plugin('js-require-css')
]
})
//合并静态文件
.match('::packager', {
'packager': fis.plugin('deps-pack', {
// 将所有的npm依赖打包成一个文件
'/client/pkg/npm/bundle.js': [
'/client/page/index.js:deps',
'!/client/' + dirList + '/**'
],
//将所有的业务代码打包成一个文件
'/client/pkg/npm/index.js': [
'/client/page/index.js',
'/client/page/index.js:deps'
],
//将所有的css文件打包成一个文件
'/client/pkg/npm/bundle.css': [
'/client/**.{styl,css}',
'!/client/static/**.{styl,css}'
]
})
})
//给所有打包完的文件加前缀
.match('/client/(pkg/npm/**.{js,css})', {
'url': '/v4${static}/${namespace}/$1',
});这样做最后线上的页面加载时,加载的静态文件(除了图片)只有3个。页面的加载时间也保留在**200ms**以内。而所有的npm依赖最后的bundle文件也只有80kb的大小。这个对于现代的前端网络是可以接受的。
排除非首屏的加载,使用缓存加载页面的。这个时间已经缩短的极小了。
以下是我在一APP内打开页面后,每次都使用缓存文件加载的结果。所有的静态文件都使用了本地缓存,http状态码都是304。
在这个过程中也发现一个问题,就是使用时间戳的方式和使用hash戳的方式,缓存静态文件。观察下面的截图发现,使用时间戳的方式,并不能有效的缓存我们的静态文件,每次进入页面,静态文件都重新发起了请求。因为又没有使用CDN加速,这样其实也间接的对我们的服务器造成压力。
最后就是介绍下迁移react到preact我都是做了那些工作吧。当然按照官网提供的步骤一步一步走肯定是没有错的。
首先是修改库的引入方式
import {h, render, Component} from 'preact';因为使用了preact-router。所以路由的配置方式和react-router的有些不一样的
import {h, render, Component} from 'preact';
import {Router} from 'preact-router';
// import {Router} from 'react-router';
import SafeCenterIndex from '../containers/SafeCenterIndex';
import VerifyRealName from '../containers/VerifyRealName';
import VerifyBank from '../containers/VerifyBank';
import {createBrowserHistory} from 'history';
export default (
//这里的写法和react-router不一样。
<Router history={createBrowserHistory()} >
<SafeCenterIndex path="/v4/security/"/>
<VerifyRealName path="/v4/security/verifyname"/>
<VerifyBank path="/v4/security/verifybank"/>
</Router>
);第二就是修改编译的打包脚本。按照官网的介绍就是要修改最后编译结果的jsx的包裹方式。在前面的关于打包脚本的配置已经介绍过了.主要就是配置jsxPragma属性。
fis.match('/client/(' + dirList + '/**.{js,es,jsx,ts,tsx})', {
parser: fis.plugin('babel-5.x', {
sourceMaps: false,
optional: ['es7.decorators', 'es7.classProperties'],
jsxPragma: 'h'
}),
url: '/v4${static}/${namespace}/$1$2$3$4$5$6$7$8$9$10',
isJsXLike: true,
isMod: true
})之前使用Nodejs开发的一个网站。在网站上有一个页面有个功能,允许用户上传图片或者粘贴一张图片链接。服务端读取用户上传的图片信息或者是请求用户填写的图片链接获取图片信息。
如果是用户使用上传功能,前端可以在input控件上做下限制上传文件的类型,后端再做下校验,以保障获取图片文件的合法(或者是安全)。
如果是用户填写的图片链接,其中隐藏的安全隐患就比较大了。如果用户填写不是正常的http、https或者是ftp类的链接,而是curl这种可以在服务端执行的命令,服务端拿到用户的链接不作处理直接请求的话,可能会对公司造成不可估量的额损失(比如:内网服务器信息泄露、更严重是内网服务器被攻击)。
在公司是有专门的安全组来做Web安全这块儿工作的。这个事件发生的时候,我首先是短信收到了服务器的报警,线上出现了大量的FATAL日志。这个时候立刻是登上服务器排查,紧接着就被公司的安全组某位同事在内部聊天工具上通知,网站收到了ssrf(服务器端请求伪造)攻击。第一时间对这个接口进行了下线处理,然后评估了安全的解决方案,再次上线该接口。
那么在服务端具体的防范ssrf攻击的方法时什么呢,请接着往下看。
ssrf具体原理就是在服务端伪造请求,请求服务器的资源。上面的案例场景我也提到了。我有个功能是会请求一张外网图片链接获取图片信息的。而用户填写的这个图片链接很可能就是违法的请求。当我服务端拿到这个链接后,并没有按照预期去请求外网资源,而是请求了内网服务的资源。这样我的服务器就被攻击。
那么什么原因可能造成ssrf漏洞呢:
由上面提到的原因其实已经可以知道一些解决方法:
在拿到用户填写的链接时做下校验。看是否是合法的http、https、ftp协议头。当然这个校验为了减轻服务器压力应该在前端和后端都校验。如不过不是合法的请求协议头直接拒绝和返回请求资源失败的错误消息。(伪代码如下)
const allowReqprotocol = [
'http',
'https',
'ftp',
];
const reqProtocol = request.protocol;
// 强制校验用户输入图片链接的协议头是否为自己网站允许的协议头
if (allowReqprotocol.indexOf(reqProtocol) < 0) {
yog.log.warning(imgUrl);
res.json(errorMsg.imgTypeError());
return;
}上面已经介绍过仅仅通过正则没办法完全校验是否是合法的IP段。其实还有一种方法就是把我们的IP段转化为int来进行判断。刚好npm上有个包ip-to-int可以满足我们的需求。我们可以把两者结合起来一起来判断请求链接的IP是否为内网IP。
const dns = require('dns');
const url = require('url');
const ipToInt = require('ip-to-int');
const parseUrl = url.parse(rqUrlString);
const hostname = parseUrl.hostname;
// 使用Nodejs的dns模块根据域名解析出域名对应的ip地址
dns.lookup(hostname, (err, address, family) => {
//加入我的内网IP段为 180.xxx.xxx.xxx 180.255.255.255
const ipRegx = /^180\./;
const ipArr = [ipToInt(180.0.0.0).toInt(), ipToInt(180.255.255.255).toInt()];
if(ipRegx.test(address) || ipRang(address)){
// 拒绝请求
} else {
// 继续请求
}
});
// 判断一个ip是否在一个数组之间
function ipRang(ip, array) {
// ip在给定的ip段之间
return true;
// ip不在给定的ip段之间
return false;
}
经过上面的检验已经基本上可以保证如果有请求外网的Url ,请求的在服务端执行以后指向的也是外网资源。那么当资源到达服务端以后,为了保障资源的安全性。我们对请求的内容做最后的校验。比如我仅仅是想请求图片资源,而且是限制了几种格式。比如:png、jpg、jpeg。
const allowImgContentType = [
'image/jpeg',
'image/png',
'image/gif'
];
if( allowImgContentType.indexOf(response.headers['content-type']) < 0){
// 返回的内容为非法资源
}上面的方法基本上都是如果请求的是内网资源都是直接拒绝掉了。但是假如有请求内网的需求怎么办呢。如果内网的资源对外部开发,肯定也是特定的机器。这些机器也肯定是经过op做特殊的隔离处理的、没有敏感的公司信息资源。那么当我们的请求到达公司内网后怎么保证该请求始终请求的是特定的IP呢?
其实我们只需要将请求的链接的host和在header投中和请求机器的ip做下绑定就好。
// 通过dns模块解析出host对应的ip 这里是address
// 并且通过url模块解析出port path 和querystring 重新拼接请求的url
const bindURLString = `${parseUrl.protocol}//${address}:${reqUrlPort}${pathName}?${queryString}`;
// 然后在请求发出去的时候设置下header头,下面是我使用request模块发出请求时设置参数
const options = {
'url': bindURLString,
'encoding': 'binary',
'rejectUnauthorized': false,
'headers': {
'Host': bindDnsObj.hostname //这里绑定请求的host
}
};这样做就是强制请求去请求特定的机器。而不会请求其它机器。
将某个功能灰度发布(逐渐放量)给特定线上人群,避免新功能全量上线带来的风险。
上面的图可以通过两个方面来理解:
举个简单的例子:将http请求cookie中含有test=1字段的请求都转发到灰度代码的机房;
上面通过通过配置特定Nginx规则的方法来达到产品灰度的方法虽然可以满足一定业务量的需求,但是他也有很多的缺点:
那么有没有更好的方法来做灰度发布呢?当然是有的,A/B测试就能够弥补上面通过Nginx规则来做灰度的缺点。
将线上一部分真实人群流量随机拆分成多个组,对每个分组的人群应用不同策略或功能,通过计算每组人群的业务指标(转化率、成交率等)来衡量策略或功能的实际效果。
我们通过下面的这张图简单的了解下A/B测试的原理:
由上图我们可以知道A/B和传统的灰度方法的区别:
传统的灰度是通过Nginx分发流量到服务器,A/B测试是通过业务代码区分流量访问不同的代码块。
那么A/B测试的优缺点是什么呢?
优点:
if...else分支语句。但是这样还好,因为根据SDK的规范来书写代码,还是很好管理的。前端跟后端很大的区别就是直接面对用户,就算很简单的修改一次按钮的颜色就需要一次上线。这种操作对用户是可感知的。
现代前端有个特点就是脱离了后端模板引擎的渲染,大多数是使用React、Vue这种MVVM框架的前端(浏览器)渲染。这种情况下后端其实仅仅是给用户提供一个空的html文件(工作中经常称作为壳)。大多数业务代码开发完以后都是作为静态文件上线到服务器,经过用户访问后缓存到CDN节点上的。而且这个过程大多数是增量上线的。
其实我们每次上线完之后服务器上缓存的html文件就包含不同的版本信息。如果我们把这些版本信息管理起来,并且通过特定的手段(对用户请求应用A/B测试)就可以完成前端不同版本的灰度发布。
我们可以观察下Webpack或者是其它打包工具打包后的html文件。每次外联的静态文件都包含不同的hash戳。这些外链的文件又都是增量缓存到服务其上的。
index.html (我们页面的“壳”)
一些 xxx.js文件 (渲染页面+页面的业务逻辑)
xxx.css 文件 (控制页面显示样式)
大概就是下面的这个样子
基于以上的特点,我们能不能尽量减少对业务代码侵入,而可以覆盖业务改动较大的需求进行灰度或者是A/B测试呢?
看下下面的这个这个请求的图:
每次我们打包编译完之后,就将相关的css文件和js文件信息保存到本地的一个json文件中。这些信息的key可以是我们的git的tag信息(主要来描述本次发版信息包含的功能等)。
基本上json文件包含的信息如下:
const version = {
// 可以描述本次的上线内容/ 或者是git tag
'tag1': {
'css': 'xxxxxxx.css',
'app': 'app_xxx.js',
'ventor': 'ver_xxx.js'
}
}这里仅仅是一个简单的demo示例,可以使用Nodejs写文件的特性直接将文件版本号写入到index.html返回给前端浏览器
Nodejs服务的特点是每次更新完代码需要重启之后才能生效。每次上完线重启服务就会先检查本地代码根目录下的这个json文件。看下这个其中包含的tag是否在DB中存储,如果有存储就不做操作,如果没有就将它存储DB做持久化。
上面图上面的Apollo就是用来配置那些用户访问新功能的平台。在Nodejs端,每次接收到用户请求的时候都会判断用户的信息是否满足相关条件,然后从DB中读取相关静态文件信息渲染到index.html中去。
简单总结下:将每次打包的静态文件信息先存储下来,之后请求到达Nodejs的时候判断用户是否满足相关条件,如果满足就读取DB将相关的静态文件信息返回给Nodejs,Nodejs将静态页渲染好之后返回给用户,达到灰度的目的。
使用Nodejs之前我们的页面就是直接部署在服务其上,这次使用了Nodejs后,会有很多其它的问题需要做,比如说Nodejs服务的监控,多机房部署等。这些在大部分的公司应该都有相关的运维工程师来做。我这里简单介绍一些其它的内容
这里的规范包括本地开发时工程目录的规范和线上用户访问url的规范。
11.10版本了,最新的LTS版本是10.15.1版本。建议使用Nodejs的同学都升级自己的Node到8.0版本以上,因为8.0版本是一个官方原生支持async...await语句的版本。.
├── client // 放置客户端的代码
├── index.html
├── index.js
├── node_modules
├── output
├── package-lock.json
├── package.json
├── server // 放置服务端Nodejs代码
├── test.sh
需要注意的就是在编写webpack打包工具的时候将server目录下的给排除掉。放置不必要的编译和产出,增加打包速度。
// 域名/产品线/模块/
http://wwww.aaa.com/driver/bus/index.html
// 域名/产品线/模块/静态文件目录
http://wwww.aaa.com/driver/bus/static/js/index.js
http://wwww.aaa.com/driver/bus/static/css/index.html前面提到这次业务升级我们使用了新的url,但是为了保证业务的稳定性我们不是一次性将所有的流量都切到新服务上去的。我们也是通过批量的切的,所以会存在线上用户有的地区访问新服务有地区访问旧服务。那么有一天会有全部切换的一天,但是还是会有一些用户访问到旧链接,这个时候可以通过配置Nginx 的``rewrite`来讲旧链接都转成新的链接。
前端路由可以分为两种方式,hash和path切换。因为对于前端渲染页面来说,当第一次请求完成后,其实所有的页面都已经下载到了本地(页面异步加载除外)。在我们通过path切换页面的时候,每次都会向服务端发送请求,其实这些请求是不需要到达Nodejs服务的。我们可以通过Nginx配置将这些无用的流量抵挡在Nginx这一层,减少服务器的压力。
如果是使用hash的方式则不存在这样的问题,但是会有另外的问题就是对搜索引擎不友好。当然前端路由切换还是应该根据自己的业务做取舍。
当我们应用了Nodejs服务之后,可以拓展的技术点有哪些,一下简单列举一些:
当然这种方案也不仅仅是可以使用Nodejs来做,也可以使用其它语言。因为我们公司已经有基于A/B测试的Nodejs-SDK。我这我就不具体介绍原理了。原理可以参考百度百科。如果有问题需要一起讨论可以留言或者是邮箱联系我:[email protected]
根据微信的官方文档,是支持@import的方式一如外联的公共样式的
文档地址:https://mp.weixin.qq.com/debug/wxadoc/dev/framework/view/wxss.html
但是在实际的开发过程中如果通过@import '../../common.wxss' 的方式引入外联的公共样式common.wxss 却是不生效的。如果是引用文件和被引用文件在相同的目录下是生效的。即@import 'common.wxss'的方式
那么怎么管理我们的公共样式呢?根据官方文档。在根目录的app.wxss中定义的样式在所有页面中都生效。
所以我们的wechat-sdk的公共样式都是在根目录的app.wxss中定义的。
toast提示微信小程序的 API 默认是支持toast的。 但是wx.showToast(OBJECT)方法的弹层却是默认带有一个icon。只可以配置success和loading两种方式。在我们的项目中不实用。所以在我们的项目中使用自定义的方式。
使用方法:
在需要使用toast的wxml中添加下面一段代码(因为是fixed定位可以放在任意位置,一般放在页面最底部):
<view style="display:{{toast?'block':''}}" class="bd-toast">{{toasttxt}}</view>
在对应的.js文件中通过import的方式引入toast方法
import { toastFn } from '../../utils/toastFn';
在需要弹层的地方直接调用就可以了
/**
*@ _this 指向当前的page对象
*@text toas中显示的文案
*/
toastFn(_this,[text]);小程序是默认支持ES6语法的,而且在上传代码的时候会自动把ES6编译为ES5。
在第二小节中使用import 的方式引入toastFn就是使用ES6的import
那么使用它有什么好处呢?好处之一就是不用引入第三方库就可以实现代码模块化。
比如我在目录requestapi主要定义的是关于接口请求的代码块。在 utils 中定义的是功能代码块。在需要他们的地方直接通过 import的方式引入就可以直接使用。import可以把代码做很好的隔离。
config.js 配置文件的使用为了便于线下联调和测试。把依赖环境的项通过配置文件的方式管理起来。在需要的地方直接import来引用。如果需要上线的话只需要在这一个文件中打开相应的注释和关闭相应的注释就可以了。
//qatestc测试环境域名
export const hostName='https://wappass.qatest.baidu.com/';
//线上环境域名
// export let hostName='https://wappass.baidu.com/';
//产品线配置验证成功后跳转的url
export const jumpProductUrl = '/testsuccess/testsuccess';
//产品线配置的tpl
export const tpl = 'waimai';
//是否开启debug模式
export const DEBUG=false;比如说接口的请求都是通过以下的方式来写,达到统一管理测试环境和线上环境的目的:
import {hostName} from '../config';
wx.request({
//接口请求
url: hostName+'wp/api/security/checkvcode',
data: {
verifycode: vcode,
codestring: _this.data.imgcode
},
method: 'GET',
header: {
'content-type': 'application/x-www-form-urlencoded'
},
success: function (res) {
}
})
因为小程序的开发**是借鉴 Vue.js 这类MVVM框架的数据绑定的**。我们是没办法直接操作所谓的“DOM”的。那我们怎么获取页面的数据或者是更新页面上的数据呢?下面介绍下数据绑定的**
比如页面上有下面这样的一个input输入框。
<input type="number" bindinput="phoneInput" maxlength="13" class="bd-phonenum" placeholder="请输入手机号(无需注册)" value="{{inputValue}}" />
Page({
data:{
inputValue:'input的默认值' //wxml中会把使用{{inputValue}}的地方的值和这里绑定起来
},
phoneInput:function(e){
let value = e.detail.value;//获取输入框的值
},
updatePageData:function(){
//这里是去更新页面中input 中的值
this.setData({
inputValue:'更新的值' //会更新页面中绑定了{{inputValue}}的节点
})
}
})
从上面的代码可以了解到为什么基于数据绑定的类MVVM框架火起来的原因。前端一直再谈就是操作DOM影响页面性能。要尽量少的操作DOM。而上面的代码在没有操作的DOM的情况下就完成了获取页面上的数据和更新页面的数据。而且代码更加的简洁。
mock.js因为能够拦截ajax请求,然后返回特定格式的数据。而被广泛的应用于前后端分离的开发模式中。那么在微信小程中是否可以使用mock.js呢?
答案是否定的。因为微信小程序中的所有接口请求都必须经过客户端转发并不是原生的ajax请求。但是可以借助mock.js的**封装一个根据特定的url返回特定数据的方法。在config.js中配置变量**DEBUG**是否开启调试模式。
然后再apiAjax.js中配置,如下图
import * as Mock from '../mock/mock';
const apiAjax = (api, dataMethod, method = 'POST', fnSucc, thisData) => {
if (!DEBUG) {
wxRequestApi(api, dataMethod, method = 'POST', fnSucc, thisData);
} else {
/**
* 模拟数据可以在这里配置switch 的方式
* case 的条件判断语句即为要请求的接口
*/
switch (api) {
case hostName + '/wp/api/security/getphonestatus':
fnSucc(Mock.testApi(api), thisData);
break;
default:
wxRequestApi(api, dataMethod, method = 'POST', fnSucc, thisData);
}
}
}所有关于特定接口的返回数据都是在mock/mock.js中进行配置,配置方式可以参考配置示例:
/**
* 测试接口返回数据样式
*
* @returns
*/
const testApi = ()=>{
return {
a:1,
b:2
}
}
/**
* 这里导出相应模拟数据的函数名
*/
export {
testApi
}开发过程中需要使用RSA加密。我在微信小程序中引入了我们线上项目的RSA加密算法源文件。但是却不能够正常运行。尝试建立测试的html页面加入该加密算法文件。代码可以正常运行。使用node test.js运行js文件也能够正常运行。但在微信小程序中就是不能够正常运行。
在花费了大约有3个多小时的时候后还是找到了问题的原因。问题的原因也很简单:微信小程序会把js文件默认按照"use strict" 运行。而RSA加密算法的源文件并没有使用"use strict"。
看下面的两段代码,如果不加头部的"use strict"声明。两段代码都是可以正常运行。如果运行在"use strict"的声明下就会报错。之所以花了很长时间解决这个问题,也就是看到这样的错误的时候,根本就没有往这方面考虑,因为他们看起来确实是正常的。
"use strict"
for(i=0;i<10;i++){//i is not defined
//....
}
for(var i=0;i<10;i++){
//....
}最近的项目中做了一个“跑马灯”的抽奖特效插件。上篇文章已经分享过html和css 的相关知识。这篇文章主要分享一些 JavaScript 相关的知识。这几天在写这篇文章的时候,也顺便把自己的代码重构了一下。
这里主要是来写写自己的优化过程。俗话说:
一个程序猿的进步是从对自己的代码不满意开始的。
开始之前先来看上篇文章遗漏的两个问题和几个知识点,是自己重构的过程中需要用到的:
对于设计师给我的手机端网页的设计稿都是2倍图。按照道理来说,在写网页的时候,所有对象的实际尺寸都是会除2。但是对于1像素的线呢?
先来看两张图,设计稿的效果:
在三星 S4下的实际显示效果:
可以看到这个时候1px的线竟然显示不出来了。这个问题是跟 S4手机的屏幕像素密度有关。关于屏幕像素密度和1px 线的关系有很多文章介绍,可以自行搜索了解。我这里的解决方案是,对1px 的线不做处理。是多少就写多少。就算我的基础单位是rem,也不是其它单位。
{
position: absolute;
width: 13rem;
height: 9.2rem;
border:1px solid #000;
}先来看一段代码:
$('[node-type=row-a').find('div');很明显可以发现,我使用的选择器是有语法错误的。但是在浏览器中运行会有什么结果呢?看下图:
很明显可以看出对于属性选择器,就算我有语法错误,PC 端浏览器也是可以正确解析的。但是在手机端,这种写法是不能够正确解析,代码不能够运行。
所以写代码的时候一定要注意一些小细节哈。。。
在使用 jQuery 或者是 Zepto 的过程中最经常使用的选择器的写法就是下面这样吧,
$('div.testClass')只是在$() 中写上自己需要的 Dom 节点的 class或者 ID 或 者使用属性选择器。
在查看 jQuery的文档,对于$()会有这样的描述:
jQuery([selector,[context]])
最重要的是看看对 context (它也是我们平时使用中最容易忽略,但是却非常有用的一个参数)的描述:
默认情况下, 如果没有指定context参数,$()将在当前的 HTML document中查找 DOM 元素;如果指定了 context 参数,如一个 DOM 元素集或 jQuery 对象,那就会在这个 context 中查找。在jQuery 1.3.2以后,其返回的元素顺序等同于在context中出现的先后顺序。
刚开始学习 JavaScript 那会儿,就听说了操作 DOM 是很损耗浏览器性能,遍历 DOM 也是很影响程序性能的。
如果我们在指定的范围内查找需要的 Dom 会不会比从整个document 中查找快很多。**而且在我们写 web 组件的过程中,一个页面上组件可能出现很多次,那我们怎么判断我们要操作哪个组件呢?这个context参数就会起到决定行的作用。**具体请继续看哇。。。
刚开始学习 jQuery的时候在一本书上看到一句话:
jQuery对象就是一个 JavaScript 数组。
而且在使用 jQuery的过程中,都会遇到,js对象转 jQuery对象,jQuery对象转 js对象。关于这些基础不做过多介绍。
但是有时候我们会想在 jQuery对象上运用一些原生Array对象的方法或者属性。来看一个简单的例子:
由图中的代码运行结果,可以知道在 jQuery对象上是没有我们要使用reverse方法的。尽管test是一个数组。
那么我们怎么办才可以让 jQuery对象使用原生的 Array对象的方法呢?
比如下面的代码:
jQuery.prototype.reverse=function(){
//一些操作
}使用prototype来扩展方法的时候,大家一直比较认为是缺点的就是可能会污染已经存在的原型链上的方法。还有就是访问方法的时候需要查找原型链。
看下面的代码
var test = $('div.test');
var a=[];
$(test).each(function(){
a.push($(this));
});
a.reverse();这样就可以将 jQuery对象翻转。
这种方法也是自己在编写插件过程中使用的方法。看一下文档描述:
Array.from() 方法可以将一个类数组对象或可迭代对象转换成真实的数组。
个人感觉使用这个代码比较简洁。暂时还不知道有没有性能的影响。继续看下面的代码:
var test = $('div.test');
var a= Array.from(test);
a.reverse();
因为setTimeout()和setInterval()这两个函数在 JavaScript 中的实现机制完全一样,这里只拿 setTimeout()验证
那么来看两段代码
var a ={
test:function(){
setTimeout(this.bbb,1000);
},
bbb:function(){
console.log('----');
}
};
a.test()输出结果如下:
看下面的代码输出是什么
var a ={
test:function(){
setTimeout(function(){
console.log(this);
this.bbb();
},1000);
},
bbb:function(){
console.log('----');
}
};
a.test();运行这段代码的时候,代码报错
由以上的结果可以知道,当我们在使用setInterval()和setTimeout()的时候,在回掉中使用this的时候,this的作用域已经发生了改变,并且指向了 window。
setTimeout(fn,0)的含义是,指定某个任务在主线程最早可得的空闲时间执行,也就是说,尽可能早得执行。它在"任务队列"的尾部添加一个事件,因此要等到同步任务和"任务队列"现有的事件都处理完,才会得到执行。
意思就是说在我们设置 setTimeout()之后,也可能不是立即等待多少秒之后就立即执行回掉,而是会等待主线程的任务都处理完后再执行,所以存在 "等待"超过自己设置时间的现象。同时也会存在异步队列中已经存在了其它的 setTimeout() 也是会等待之前的都执行完再执行当前的。
看一个 Demo:
setTimeout(function bbb(){},4000);
function aaa(){
setTimeout(function ccc(){},1000);
}
aaa();如果运行上面的代码,当执行完 aaa() ,JavaScript 线程空闲,这时开始计时:等待1秒后将 ccc()加入执行队列,等待4s 将 bbb() 加入执行队列。这时从 ccc()加入执行队列到 bbb()加入执行队列中间时间间隔是3s。
执行结果如下图:
本来应该是2016年年末或者2017年年初的时候写完这篇文章的,最终还是事与愿违,没有能够按计划完成这件事情(写作真的是一件困难的事情)。
2016年的最后一天看了一场电影《血战钢锯岭》。抛开惨烈的,逼真的剧情不说,女主真的很漂亮,是我喜欢的类型。而我也是被男主的撩妹技折服。主人公说的那句:
“如果我不坚持自己的信仰,我不知道活着还有什么意义!”。
是啊,明白自己人生方向的人,是多么的让人羡慕。
上半年的一些经历在《工作两年小结----勿忘初心不负梦想》中做了记录。这里就简单对2016年一整年做下简单的回顾吧。
WebComponent仓库,搜集了自己平时开发中编写的插件。目前收获了132个star;blog仓库目前也已经收获了147个star;对于2015年末对2016年的计划,基本上完成。缺憾的地方就是想要精读一遍的《JavaScript高级程序设计》还是没有读完。
2016年11月3号是自己进入一家新公司刚好半年的日子。这半年在新团队做了一些事情,也成功推动了一些事情的发展,当然有些事情做的也不好,不过瑕不掩瑜,2017年继续努力奋斗。
rem来适配移动端的项目;Nodejs主动为团队成员开发了值班数据查询平台,为团队成员写值班报告节省了大量的时间。得到了老板和团队成员的认可;技术类:
文化故事类:
半年的收获:
好的态度会影响一个人的工作和生活。自己也是某次在思考一个问题的时候想到,优秀的程序员不就是应该把平时的工作变成对问题的思考么!项目进度,业务环境可能都是产生BUG的原因。一些解决方案可能因为需求的改变,会变得不适合当前的代码运行环境。找到最合适的方法来解决业务的问题是需要花费时间去思考的。我相信优秀的程序员都会花费时间去找到一个优秀的解决方案,而不是说代码能运行我的工作就结束了。
我不仅想把工作变成对问题的思考,也更想把生活也变成对问题的思考。2015年末的时候,自己在GitHub上创建了一个 blog 的仓库。这个仓库的内容都是自己平时对生活的感悟和对技术问题的解决方案和总结。
以下是2016年自己GitHub活动的时间线:
突然发现一个问题,下半年commit的次数明显减少了!
汤唯一直是自己很喜欢的**女演员之一(当然不是因为《色戒》😉 😉)。如果说我喜欢的女演员还有谁,《离婚前规则》中的白百合,《大话西游》中的唐嫣,《北京青年》中的马苏。不过汤唯绝对在我心中可以称得上一个“最”字。
这个电影最感动我的是秦沛老先生和吴秀波的那些诗词对话。记得我高中的英文老师说他自己平时喜欢读古文和唐诗宋词,说他享受的是咬文嚼字的去解读古文中那些生涩的文字,去体会诗词中诗人表达的意境。还是因为年轻的缘故吧,当年学习它们的时候,那些诗词描绘的意境,在自己眼中只是空洞的文字,没有任何的感受。但是秦沛老先生的一句“去国怀乡”当时还真的让自己眼眶有些湿润。很大一部分原因都是当时电影所营造的氛围和发生在两位老人身上的故事,让自己身临其境,触景生情了吧。
几十年旅居国外,几句诗词代表了两位老人的人生。自己每年都在坚持写的“年终总结”怎么就不是自己的人生呢?
一谈“人生”这个词,逼格不自觉就上升了好几个档次。大学时代,寂寞、苦闷一辆破单车去过学校周边很多地方。毕业后,经济自由了,有能力买更好的单车去更远的地方了。
出发前会有各种担心,最惨的是每次都会问自己“这次不会回不来吧?”😂😂。但是内心痒痒的还是想出发。骑出第一个100km是困难的。但是当自己真的骑出了第一个100km后,剩下的就只是对目的地的遥望和坚持。骑行的人是为了看沿途的风景么,反正我不是,让我每天感到自豪的是按照预定计划到达了目的地,是战胜路途中的孤独无助和声嘶力竭。
28岁是一个尴尬的年纪,是一个自己应该知道自己做什么的年级,而不是别人安排自己做什么就做什么的年纪。是一个应该有勇气去尝试陌生事情的年纪,而不是在未知面前不知所措。
“心学”大师王阳明的金句“知行合一”这个词在中学时代就知道了,但是那个时候并不能真正的理解它的意思,也没有深究过。但是在阅读《晚清最后十八年》这本书,通过东乡平八郎战胜俄罗斯太平洋舰队和黑海舰队的故事,才对这个词有了深刻的理解。放在现代来说,就是“理想”和“梦想”区别,就是知道怎么做可以达到什么目标,而自己也坚持去这么做,并且把事情做完了。
骑出第一个100km是困难的,只有不断的尝试,才能知道不足,才能走创新的源泉。
当前团队面临着一些问题,比如说:技术栈陈旧。虽然说这不是主要问题,但对一个优秀团队来说与时俱进的尝试和引入业界优秀技术方案是一项基本素质。技术架构落后,在旧的框架和开发模式下新功能添加都是在旧的业务逻辑上进行堆叠,造成代码越来越臃肿,维护和阅读越来越困难。更让人无法接受的是,项目本身有很多问题,却没有人作为。
下半年在团队推动了一些事情,比如基于Nodejs的前后端开发模式,将公共样式使用SASS封装成CSS组件库。虽然在推动前已经有文档和实际项目产出,但是面对的阻力还是非常大。刚开始觉的是大家技术水平、视野、关注点有差异的问题。那么就写写文档给大家分享下,等大家慢慢的都接受了再去做。
后来发现这样做事情效率非常低,一件事情可能一两个月根本启动不起来。也发现我根本没有义务在做一件事情之前,要把周围的人都教会,我要做的是说明为什么要这么做,做了之后对项目有什么提升,然后主动学习应该是其它人的事情。
“靠热情去感染身边的人”这句话本身就是不靠谱的。因为大家都会有自己的想法,在工作上的追求不一样,有自己的事情要忙。我也很想做一个“好好程序员”,与世无争的做好该做的事情就算了,争什么争,让别人看到自己不爽,面对别人的质疑,自己的心也挺累的。
如果能把事情做好为什么要压抑自己呢?如果事情本身对团队发展是好的,适时的强势,那又有什么关系呢?如果不去争取,可能永远带不来“改变”。社会就是这样,不存在谁抢了谁的工作,“适者生存”。很多问题如果仅仅停留在讨论,那么什么也做不成。只有真的实践了才会知道到底适合不适合。
以结果为导向,走自己的路让别人说去吧!
2017年对自己的职业生涯会是比较重要的一年。很多事情要去做,要去推动,也要去学习,更要去承担更大的压力和责任。前段时间看到Facebook文化墙上的一句话:“Done is better than perect.”(比完美更重要的是完成)。想想还是挺有道理的。
既然不甘堕落要做一个有技术追求的人,那就战斗吧。这个世界不缺乏有勇气的人,很多人都会想做各种惊天动地的事业。而最缺乏的,是耐心和坚持。2017年让自己拥有耐心和坚持把能做的事情做好。
在2017年,工作中但愿自己实事求是,坚持自己的初心,把应该做的事情做完。生活中继续为寻找心爱姑娘努力!
最近的一个项目中使用了axios来代替XMLHttpRequest来发送请求。也是遇到了一些问题。这里做下简单的记录。
官方文档我们可以看到的示例demo如下:
// 直接在请求理解里面拼接参数get参数
axios.get('/user?ID=12345')
.then(function (response) {
console.log(response);
})
.catch(function (error) {
console.log(error);
});
// 或者是使用对象的方式填写params参数
axios.get('/user', {
params: {
ID: 12345
}
})
.then(function (response) {
console.log(response);
})
.catch(function (error) {
console.log(error);
});上面的示例代码看起来是一样的,其实有个细节还是不一样的,就是使用第二种方式会对参数值执行encodeURIComponent。
看我的一段代码:
// 直接在请求理解里面拼接参数get参数
axios.get('/user?testurl=http://test.aaa.com')
.then(function (response) {
console.log(response);
})
.catch(function (error) {
console.log(error);
});
// 或者是使用对象的方式填写params参数
axios.get('/user', {
params: {
testurl: 'http://test.aaa.com'
}
})
.then(function (response) {
console.log(response);
})
.catch(function (error) {
console.log(error);
});在浏览器端测试后观察请求的url的参数可以发现。
第一种方式,没有对参数进行编码。第二种方式可以看到对参数进行了encodeURIComponent操作。所以在使用的过程中,如果我们的后端需要前端在传递参数前对某些参数进行encodeURIComponent。在使用这两种方式的时候可以注意一下,防止多encode一次造成后端接受参数错误。
我主要是在浏览器端使用axios来发送请求。而且它的请求返回的是一个Promise对象。我可以很方便的处理请求的结果。
在官方文档中是这样描述的,如果在浏览器端需要发送post请求,需要使用URLSearchParams。
var params = new URLSearchParams();
params.append('param1', 'value1');
params.append('param2', 'value2');
axios.post('/foo', params);但是在官方文档中也很明确的说明了URLSearchParams不是支持所有的浏览器的。我们需要使用polyfill来兼容一些低版本的浏览器。
或者是使用qs来对url进行编码。
// npm install qs --save or yarn add qs
var qs = require('qs');
axios.post('/foo', qs.stringify({ 'bar': 123 }));这里说下使用polyfill会遇到的问题。官方推荐的polyfill是url-search-params。说明中是这样描述的:
Note that URLSearchParams is not supported by all browsers (see caniuse.com), but there is a polyfill available (make sure to polyfill the global environment)。
当我们的使用webpack或者是fis3开发的 时候默认都是把npm依赖作为依赖包来处理的。这里的global其实就是让我们不要把这个文件作为一个Npm依赖包,而且直接引入到我们的Html中。
比如在我们的body标签的底部
<body>
<script src="../xxxx/url-search-params.js"></script>
</body>那么我如果我想使用CMD规范或者是ES6 的import呢?我们可以使用url-search-params-polyfill
参考文档后,如果我们想要使用CMD规范:
require('url-search-params-polyfill');ES6的写法
import 'url-search-params-polyfill';也可以直接在Html标签中直接引用:
<script src="index.js"></script>声明:这个系列为阅读《JavaScript设计模式与开发实践》 ----曾探@著一书的读书笔记
使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系,将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止。
故事背景:用户可以支付定金购买手机,并且可以获得优惠券。没有支付定金的就是普通用户,进入普通购买模式,没有优惠券,且库存不足的情况下不一定能够买到手机。
/**
*
* @param orderType 订单类型
* @param pay 用户是否已经支付过定金 true or false
* @param stock 表示手机的库存量
*/
var order = function (orderType, pay, stock){
if (orderType === 1) {
if (pay === true) {
console.log('500定金预购,得到100元优惠券');
}
else {
if (stock > 0) {
console.log('普通购买,没有优惠券');
}
else {
console.log('手机库存不足');
}
}
}
else if (orderType === 2) {
if (pay === true) {
console.log('200定金预购,得到50元优惠券');
}
else {
if (stock > 0) {
console.log('普通购买,没有优惠券');
}
else {
console.log('手机库存不足');
}
}
}
else if (orderType === 3) {
if (stock > 0) {
console.log('普通购买,没有优惠券');
}
else {
console.log('手机库存不足');
}
}
};主要通过拆分功能语句,来使用职责链重构:
//500元订单
var order500 = function (orderType, pay, stock){
if (orderType === 1 && pay === true) {
console.log('500定金预购,得到100元优惠券');
}
else {
order200(orderType, pay, stock); //将请求传递给200
}
};
//200元订单
var order200 = function (orderType, pay, stock){
if (orderType === 2 && pay === true) {
console.log('200定金预购,得到50元优惠券');
}
else {
order(orderType, pay, stock);
}
};
//普通购买订单
var order = function (orderType, pay, stock){
if (stock>0) {
console.log('普通购买,没有优惠券');
}
else {
console.log('手机库存不足');
}
};
//测试调用
order500(1,true,500);
order500(3,false,0);总结:
上面的代码违反了开放-封闭的原则,请求在链条中传递的顺序非常僵硬,传递请求的代码被耦合在了业务函数中:
var order500 = function (orderType, pay, stock){
if (orderType === 1 && pay === true) {
console.log('500定金预购,得到100元优惠券');
}
else {
order200(orderType, pay, stock); //将请求传递给200
}
};为什么要拆分职责链的节点,因为某天需要添加新的职责,就需要修改业务代码(要修改的话,就需要先去了解他,熟悉它,花费大量的时间)。这显然不是每一个人所需要的。
//500元订单
var order500 = function (orderType, pay, stock){
if (orderType === 1 && pay === true) {
console.log('500定金预购,得到100元优惠券');
}
else {
return 'nextSuccessor';
}
};
//200元订单
var order200 = function (orderType, pay, stock){
if (orderType === 2 && pay === true) {
console.log('200定金预购,得到50元优惠券');
}
else {
return 'nextSuccessor';
}
};
//普通购买订单
var order = function (orderType, pay, stock){
if (stock>0) {
console.log('普通购买,没有优惠券');
}
else {
console.log('手机库存不足');
}
};
var Chain=function (fn){
this.fn=fn;
this.successor=null;
};
Chain.prototype.setNextSuccessor=function (successor){
return this.successor=successor;
};
Chain.prototype.passRequest=function(){
var ret= this.fn.apply(this,arguments);
if(ret==='nextSuccessor'){
return this.successor && this.successor.passRequest.apply(this.successor,arguments);
}
return ret;
};
var chainOrder500=new Chain(order500());
var chainOrder200=new Chain(order200());
var chainOrderNormal=new Chain(order());
chainOrder500.setNextSuccessor(chainOrder200);
chainOrder200.setNextSuccessor(chainOrderNormal);
chainOrder500.passRequest(1,true,500);
chainOrder500.passRequest(2,true,500);
chainOrder500.passRequest(1,false,0);加入某天网站添加了300元定金购买的职责,我只需要添加特定的节点就可以了:
//300元订单
var order300=function (){
};
var chainOrder300=new Chain(order300());
chainOrder500.setNextSuccessor(chainOrder300);
chainOrder500.setNextSuccessor(chainOrder200);这样的话只需要编写简单的功能函数,改变职责链中的相关节点的顺序即可。
上面的职责链代码中,每个节点函数同步返回一个特定的值nextSuccessor,来表示是否把请求传递给下一个节点。而现实开发中会遇到一些异步的问题,比如在一个节点中发起一个ajax异步请求,异步请求的结果才能决定是否继续在职责链中passRequest。
可以给Chain类添加一个原型方法Chain.prototype.next,表示手动传递请求给职责链中的下一个节点:
Chain.prototype.next=function(){
return this.successor && this.successor.passRequest.apply(this.successor,arguments);
};
//异步职责链的例子
var fn1=new Chain(function (){
console.log(1);
return 'nextSuccessor';
});
var fn2=new Chain(function (){
console.log(2);
var self=this;
setTimeout(function (){
self.next();
},1000);
});
var fn3=new Chain(function (){
console.log(3);
});
fn1.setNextSuccessor(fn2).setNextSuccessor(fn3);
fn1.passRequest();优点:
缺点:
AOP的具体概念可以参考装饰者模式
Function.prototype.after=function(fn){
var self=this;
return function(){
var ret=self.apply(this,arguments);
if(ret==='nextSuccessor'){
return fn.apply(this,arguments);
}
return ret;
}
};
var order=order500yuan.after(order200yuan).after(orderNormal);
order(1,true,500);
order(1,false,500);AOP实现职责链简单又巧妙,但这种把函数叠在一起的方式,同时也叠加了函数的作用域,如果链条太长的话,也会对性能造成太大的影响。
职责链模式最大的优点:请求发送者只需要知道链中的第一个节点,从而弱化了发送者和一组接收者之前的强联系。
在JavaScript开发中,职责链模式是最容易被忽视的模式之一。但是只要运用得当,职责链模式可以很好的帮助我们管理代码,降低发起请求的对象和处理请求的对象之间的耦合性。且职责链中节点的数量和数序是可以自由变化的。可以在运行时决定链中包含哪些节点。
无论是作用域链,原型链,还是DOM节点中的事件冒泡,我们都能从中找到职责链模式的影子。
自从有了车子以后就计划着每年都进行一次长途骑行。今年04月份从微博离职,趁着离职到入职这段真空期进行了一次长途骑行。
对于长途骑行来说最重要的就是出发前的前期准备吧。包括:骑行装备,线路规划等。
这次的骑行路线是根据 马蜂窝 上的一位网友规划的。但也不是完全按照他的路线来骑行。
我的骑行路线列表如下:
酝酿这个长途骑行好长时间了,现在终于有时间上路了。要不要上路我还是纠结了一些时间的。当然考虑的最多的还是安全问题。在规划路线的时候,查了一些资料,除了每天需要前进一百五十公里左右的路程外,就是这一路可能会遇到的大货车。这才是我最担心的。也想过算了,在家吃饭睡觉,闲的时候再去网吧打打游戏,好好休息休息,下周直接去新单位报道上班多好啊。但是最后还是按耐不住自己内心的躁动,我想要去啊!!!当我翻看了去年环青海湖的照片后,内心的躁动再也停不下来了,怀念那一路遇见的人和听到的故事。没有骑过长途的人可能认为骑行的人主要是为了欣赏沿路的风景,但是我知道,很多人享受的都是战胜那一路的孤独无助和声嘶力竭,至于风景那只是顺便看看而已!
**路线:**北京->通州->香河县->宝坻区
**行时:**7小时
**里程:**116公里
天气:阴,部分路段遇见了小雨
早上上班高峰期八点左右出发的。刚出发没多久,在一个拥挤的路段,因为前面有人急刹车,导致我也急刹车被后面的一辆电动车撞了,但是关系不大,继续上路。骑到三元桥的时候把一大姐的手机给碰掉了,但是也是关系不大,继续上路。不得不说北京真的很大啊,到下午2点的时候才骑出北京。
按照出发前指定的第一天计划,并没有完成,而是到了天津宝坻就停车休息了。这一路上自己思考了很多事情,包括在出发前自己也在担忧的一些事情。不过还好自己担忧的事情并没有发生。很重要的一个经验就是,**尽量选择宽阔的大路,国道走。**到天津宝坻的时候还在感叹,这个城市为什么20多岁的人那么少,可能是挨着北京和天津两个大城市的缘故吧。
想想工作中也会遇到跟出发前一样的那种状态,担心自己做不好,或者说是根本不会做,最正确的面对的方法,应该是不管怎么样,去做就好,如果自己迈出去一步也是成功的!
不知者无畏,按照一般冒险剧情的片子,一般都会是一些人要去一个地方探险寻宝,都会去找一个去过的人带路,而去过的那个人第一次都会拒绝,因为自己经历过九死一生活下来,知道要面临的危险和困难。所以,在想要去做一件事情的时候,一定要思考清楚,并且对自己做出决定产生的结果负责。
**路线:**天津宝坻区->窝洛沽乡->唐山->开平区->古冶区->滦县
**行时:**8小时
**里程:**148公里
**天气:**晴
今天算是自己骑行最长的一天吧。出发的时候天气晴,室外温度25度,中午有段时间竟然33度,当时有些怀疑码表是不是不准确(现在可以肯定自己的码表温度计确实不准确)。经过昨天的一天,找到了自己的骑行节奏,每10公里休息10分钟,骑行速度保持平均20公里/小时。今天的骑行路线是从天津宝坻区出发,经过窝洛沽乡到达唐山市,参观了,抗震救灾纪念碑和地震遇难者名单墙。之后出发经过开平区,古冶区,到达滦县。总里程148公里,行时8小时14分。今天和昨天还有以后的几天相比会是路程最长的一天。唐山果然是河北的工业重镇,这一路过来之道滦县看到了很多的工厂(大部分是钢厂),对周边的城镇产生了严重的污染。我是使用的百度地图导航,走的是国道(G205),路上对我的小命威胁最大的那些大的半挂货车(连绵不绝),每次经过我身边都让我心惊肉跳。都有点想放弃明天的骑行,坐车到下一站。今天想明白了一些一直积攒在自己心里的一些事情。还是很有收获的!
在参观地震遇难者公园的时候,确实被那个遇难者墙给震撼了。24万人看到的时候确实就是一个简单的数字,但是如果看到那些密密麻麻刻在500米巨墙上的文字,就会发现那真的是很多人,而且是一夜之间就死了那么多人。
**路线:**滦县->昌黎县->黄金海岸风景区->北戴河
**行时:**5小时57分
**里程:**99公里
**天气:**晴
出发的时候天气晴,室外温度25度左右,但是晚上的时候温度略低。今天从滦县出发,经过滦州古城,昌黎县,到达秦皇岛黄金海岸风景区,在那里第一次见到了大海!然后开始延滨海路骑行经过南戴河风景区到达北戴河鸽子窝公园附近(这里也是明天看日出的地点)。行时5小时57分,总里程99公里。秦皇岛真是个不错的,非常棒的好城市啊!城区的道路规划的很棒,有滨海路(路旁边就是大海,真的很棒)而且市区内的道路也很宽敞,有专门的人行道和自行车道。骑行北戴河滨海路的时候,看到路边有很多小别墅和大别墅。大别墅有卫兵站岗,听本地人说有些是国家领导人的院子。出来的时候跟朋友聊天,说了路上可能的危险,朋友担心我劝我不要去,但是我说我都决定了,如果不去,心里会一直躁动。朋友说,那好吧既然你已经决定了,那就注意安全,一个人在路上也可以顺便思考下人生。谢谢朋友的支持!
本来想上南戴河仙螺岛看看的,到了之后遗憾没开门。北戴河是一个更棒的城市,很适合骑行,在海边铺设有专门的道路。而且路上也会看到很多本地骑行的人。
成长环境,个人经历都会造就不一样的一个人。可能在之前同学圈子中,自己属于比较优秀的那类人吧,经常想把自己的想法强加给别人身上(虽然那是对的),但是没有考虑过别人能不能做的到。那么别人给我在一起的时候会不会很有压力或者是对我厌烦呢?所以这是一个问题。朋友间相处很多时候都应该多聊些共同话题,对于同一件事情的看法应该抱着求同存异的态度去面对。
**路线:**北戴河->秦皇岛->山海关
**行时:**3小时58分
**里程:**52公里
北戴河,天气晴,微风2-3度,中午温度28度左右。骑行路线从北戴河出发,到达秦皇岛市区,参观了秦皇求仙入海口,然后直接赶往山海关。今天是骑行难度最小的一天,行时3小时58分,总里程52公里。在北戴河赶往秦皇岛市区的路上,大声的吼着歌曲,心情真的很好。到了秦皇岛市区我才发现环境比北戴河(环境比北京也好很多)差好多啊,甚至比北京还差些。但是两个地区有个共同的特点,风沙特别大(比北京凶),可能是沿海沙滩的缘故。因为属于旅游淡季,到了秦皇入海处有些景点没有开放,4d电影也没播放。很多小店铺都在收拾为五一做准备。之后就到了山海关,记住喽,山海关是东边长城第一大关隘,而不是起点,起点是老龙头。这里长城是直接修到了海里的。在老龙头碰见两个骑友,细谈后发现还是老乡,而且两个人最小的都70岁高龄了!明天我们会一起骑行到我的最终目的地辽宁省葫芦岛市,而他们会继续向北到达沈阳,大连,然后坐轮船到烟台,从烟台骑行回老家。今天晚上跟他们一起住,我发现旅游淡季,到店面谈居住比糯米,美团上还要便宜。我的人生不能就这么算了,所以工作我知道选哪一家了在小米,天猫,优酷,滴滴之间,我会选百度(虽然不是最高的)。因为我毕业那年百度校招我三面挂掉的,自己也一直有点儿遗憾,这次算是给当初自己的梦想画一个句号吧。这几天的骑行,让我的膝盖已经有些不舒服了,有刺痛感!明天的山海关到葫芦岛的路程(130公里),在出发前我是计划两天走完的,但是跟两位大爷商量都想一天骑到,所以挑战也不会小,如果顺利的话,明天晚上就可以回北京了。好了,今天写了很多,但愿明天一切顺利。
今天总结出自己工作中自身的一些问题:
**路线:**山海关->葫芦岛
**行时:**10小时
**里程:**141公里
山海关天气晴,但是过了绥中县以后有3-4级的逆风。本来计划两天走完的路程,今天一天走完了,全程141公里,行时10小时左右,最后到达葫芦岛市,提前结束了这次骑行(总里程556公里)。今天的骑行挑战还是蛮大的,逆风加上坡但是也发现了自己的体力比之前好多了。出发的时候是跟两位大爷一起的,但是在绥中的时候我们分开了,因为我跟着两位大爷的节奏走的话,个人体力消耗非常大。最后我还是想按照我自己的节奏来骑。葫芦岛还是一个环境非常棒的城市的。但是也有一些问题,因为是在山坡上,所以城市的道路比较麻烦,特别是兴城到葫芦岛这段路。还有就是有的十字路口只有机动车红绿指示灯,没有行人和非机动车指示灯。到达火车站的时候还是出了些意外,本来想直接把车子拆了直接带上车子,工作人员说必须打包。我说办托运吧,工作人员跟我说托运站还在建,当时我的下巴差点掉了。无奈的我只能来到汽车站,到的时候,客运站已经下班了,只能再住一晚,等待明天早上了。
有时候选择做一件的事情的时候,自己的内心会有反对的生意和赞成的声音。会在一直做斗争。但是一定要不愧对自心。
之前写过一版图片“懒加载”的文章,刚好周末在整理文件的时候,大概又看了一遍之前写的代码发现有很多可以优化的地方。
这篇文章主要就是结合上篇《“瀑布流式”图片懒加载代码示例》再来看看图片“懒加载”的一些知识。
图片“懒加载”的主旨:
按照需要加载图片,也就是说需要显示的时候再加载图片显示,减少一次性加载的网络带宽开销。
先来看一段代码:
var conf = {
'loadfirst': true,
'loadimg': true
};
for (var item in conf) {
if (item in co) {
conf.item = co.item;
}
}这里我主要是想实现,用户配置和默认配置的合并,这样写代码并不是很优雅,现在使用$.extend来做优化,代码如下:
_this.setting = {
"mobileHeight": 0, //扩展屏幕的高度,使第一屏加载个数可配置
"loadNum": 1 //滚动时,当前节点之后加载个数
};
$.extend(_this.setting, _this.getSetting());这里重点介绍下,我新添加的两个参数mobileHeight,loadNum
mobileHeight 默认客户端的高度,值越大,首屏加载的图片越多;loadNum 如果当前节点出现在屏幕上以后,可以一次性加载当前节点之后的若干个节点,可以跳高图片的加载速度;之前我的代码是这样子写的:
_this.loadFirstScreen = function() {
if (conf.loadfirst) {
lazyNode.each(function(i) {
currentNodeTop = $(this).offset().top;
//这里的800就是上面提到的mobileHeight
if (currentNodeTop < mobileHeight + 800) {
_this.replaceImgSrc($(this));
}
});
}
};
_this.loadImg = function() {
if (conf.loadimg) {
$(window).on('scroll', function() {
var imgLazyList = $('[node-type=imglazy]', node);
//这里的5就是上面提到的loadNum
for (var i = 0; i < 5; i++) {
_this.replaceImgSrc(imgLazyList.eq(i));
}
});
}
};按照可配置的想法来优化我现在的代码就是下面的这个样子的:
loadFirstSrceen: function() {
// 加载首屏
var _this = this;
var currentNodeTop;
var imgNodeList = _this.imgNode;
$(imgNodeList).each(function() {
currentNodeTop = $(this).offset().top;
if (currentNodeTop < _this.mobileHeight() + _this.setting.mobileHeight) {
_this.replaceImgSrc($(this));
}
});
},
scrollLoadImg: function() {
//滚动的时候加载图片
var _this = this;
var currentNodeTop;
var scrollTop = $('body').scrollTop();
var imgLazyList = $('[node-type=imglazy]');
$(imgLazyList).each(function() {
currentNodeTop = $(this).offset().top;
if (currentNodeTop - scrollTop < _this.mobileHeight()) {
//加载当前节点后的规定个数节点
for (var i = 0, len = _this.setting.loadNum; i < len; i++) {
_this.replaceImgSrc($(imgLazyList).eq(i));
}
return false;
}
});
}更重要的一个方面就是按照编写插件的**来组织现在的代码结构。代码如下:
;(function($) {
var LoadImgLazy = function(imgNode) {
var _this = this;
_this.imgNode = imgNode;
_this.setting = {
"mobileHeight": 0, //扩展屏幕的高度,使第一屏加载个数可配置
"loadNum": 1 //滚动时,当前节点之后加载个数
};
$.extend(_this.setting, _this.getSetting());
_this.loadFirstSrceen();
$(window).on('scroll', function() {
_this.scrollLoadImg();
});
};
LoadImgLazy.prototype = {
mobileHeight: function() {
return $(window).height();
},
loadFirstSrceen: function() {
// 加载首屏
var _this = this;
var currentNodeTop;
var imgNodeList = _this.imgNode;
$(imgNodeList).each(function() {
currentNodeTop = $(this).offset().top;
if (currentNodeTop < _this.mobileHeight() + _this.setting.mobileHeight) {
_this.replaceImgSrc($(this));
}
});
},
scrollLoadImg: function() {
//滚动的时候加载图片
var _this = this;
var currentNodeTop;
var scrollTop = $('body').scrollTop();
var imgLazyList = $('[node-type=imglazy]');
$(imgLazyList).each(function() {
currentNodeTop = $(this).offset().top;
if (currentNodeTop - scrollTop < _this.mobileHeight()) {
//加载当前节点后的规定个数节点
for (var i = 0, len = _this.setting.loadNum; i < len; i++) {
_this.replaceImgSrc($(imgLazyList).eq(i));
}
return false;
}
});
},
replaceImgSrc: function(loadImgNode) {
//动态替换图片
var srcValue;
var imgDataSrc;
var _this = this;
var imgUrlList = $(loadImgNode).find('img[data-lazysrc]');
if (imgUrlList.length > 0) {
imgUrlList.each(function(i) {
imgDataSrc = $(this).attr('data-lazysrc');
srcValue = $(this).attr('src');
if (srcValue === '#') {
if (imgDataSrc) {
$(this).attr('src', imgDataSrc);
$(this).removeAttr('data-lazysrc');
}
}
});
//移除已经运行过懒加载节点的node-type 对性能提升
$(loadImgNode).removeAttr('node-type');
}
},
getSetting: function() {
var userSetting = $('[lazy-setting]').attr('lazy-setting');
if (userSetting && userSetting !== '') {
return $.parseJSON(userSetting);
} else {
return {};
}
},
destory: function() {
//销毁方法区
$(window).off('scroll');
}
};
LoadImgLazy.init = function(imgNode) {
new this(imgNode);
};
window.LoadImgLazy = LoadImgLazy;
})(Zepto);示例 Demo 地址,欢迎 下载 及反馈问题。
发现自己是一个有强烈的时间恐惧症的人,怕一年过去自己碌碌无为,更怕一事无成。明明知道“祸”从口出。这么多年过去了,年龄在一年一年变大,按理说应该变得越来越成熟才对,有时候看到对现状的不满还是会脱口而出。工作不能谈情怀,大家关注的都是结果。爱情不能谈情怀,自己的感受可能对方根本感受不到。
不得不说,总有种感觉,有些自己说不出的东西在慢慢的丢失。不知道从什么时候开始喜欢上听五月天的歌。因为五月天总能让自己找到一种“小伙子,要战斗啊!”的感觉。
一年,两年,三年。从实习算起,来北京已经3个年头了。当年从学校来北京的那个晚上还专门找时间看了《那些年,我们一起追的女孩》。柯景腾说的那句话现在还历历在目“我要成为一个很厉害的人…让这个世界因为有了我而有一点点的不一样”。
“大部分人当下过的生活都不是自己想要的”。是啊,程序员真的不是自己理想中的憧憬的生活。但是那又能怎么样呢?就算自己有今天辞了工作不作程序员,也有养活自己的能力,但自己真的不敢保证有养活一个家庭的能力。
信任。我特能理解一份儿无条件的信任有多重要。如果有这样一份儿信任,唯一值得的回报就是履行自己的承诺。
想做一个技术的领头人是困难的。第一你要面对别人的质疑。对于无法忍受别人质疑的人来说,**上的压力是巨大的。第二,你要将你的**透彻的讲解给别人。让别人认为你是对的,愿意按照你说的去做。对于自己就经常推翻自己的人来说这就更加的困难了。
梦想,情怀,喜欢的人,慢慢的都成了放在心底的东西,不敢轻易示人。不过那又有什么关系呢,梦想对于自己来说从来都是有能力去争取的肯定会去争取,就是所谓的对梦想不妥协吧。情怀的话,下次有就只跟朋友聊吧,反正跟太多的人说,别人也不一定能理解。喜欢的人,不是我不知道放手去追,以我个人的条件,我更想把尊重你放在第一位。因为选择我你确实会面对很多压力。如果你愿意,我只想对你说:“我会把你捧在手心”。
经常关注知乎上的一个话题:“人这一生为什么要努力?”鲁迅说过:“人生最大的痛苦是,梦醒了无路可走。”而我一直在努力的结果就是,在很多事情上,我有选择的权利。
亲,有兴趣加入掌阅吗?期待你的回复,之前给你E-mail了。
做前端已经有几年了,现在的知识储备已经能够解决工作中大多数的问题了。但是平时在做移动端项目的时候在一些特殊的机型上还是会遇到一些“奇葩”的问题。这个时候再查询文档才发现其实自己不经常使用的属性就是解决这些“奇葩”问题的方法,或者说是对文档理解的不够充分。
flex-shrink和flex-grow和flex-basis平时在工作中在使用弹性盒布局的时候最经常使用的就是flex:1。大多数的情况下可以满足弹性盒的布局。但是也会有一些特殊的情况。
先来看一个demo:
<div class="test-flex">
<div class="test1"></div>
<div class="test2">sssssssssssssssssssss</div>
<div class="test3"></div>
</div>.test-flex
width 100px
border 1px solid #000
height 20px
display flex
flex-flow row nowrap
.test1
border 1px solid red
height 20px
width 20px
.test2
flex 1代码的显示效果如下:
由上面的最终的显示结果可以看出来当我们给弹性盒的子元素设置了固定的宽度的时候,当其它可伸缩的子元素内容超出了剩余空间(弹性盒元素-固定宽度元素的宽度)的时候会压缩固定宽度元素。
这个时候深入研究下flex:1 这个属性的意义就知道是什么原因了。查阅文档可以知道:flex属性的值就是flex-grow、flex-shrink 、flex-basis 这3个属性值的缩写方式。 flex: 1其实就是 flex: 1 1 0%
这是三个属性的意义分别如下:
flex-basis:用来指定伸缩基准值,即在根据伸缩比率计算出剩余空间的分布之前,「flex子项」长度的起始数值。在「flex」属性中该值如果被省略则默认为 0% 。在「flex」属性中该值如果被指定为「auto」,则伸缩基准值的计算值是自身的 width设置,如果自身的宽度没有定义,则长度取决于内容。
flex-basis属性的作用相当于width属性的替代品。如果子容器设置了flex-basis或者是width,那么在分配空间之前,他们会先跟父容器预约这么多的空间,然后剩下的才是归入到剩余空间。然后父容器再把剩余空间分配给设置了flex-grow 的容器。 如果同事设置了flex-basis和width,width属性会被覆盖,也就是说flex-basis的优先级比width属性高。另外如果flex-basis和width属性中有一个是auto,那么另外一个非auto属性的优先级会更高。
flex-basis可取值的如下: length(固定的宽度值) | <percentage> (可以设置百分比宽度) | auto | content
flex-grow: 用了指定扩展比率,即剩余空间是正值时此「flex子项」相对于「flex容器」里其他「flex子项」能分配到的空间比例。 在「flex」属性中该值如果被省略则默认为 「1」
flex-shrink:用来指定收缩比率,即剩余空间是负值时此「flex子项」相对于「flex容器」里其它「flex子项」能收缩的空间比例。在收缩的时候收缩比率会以伸缩基准值加权。在「flex」属性中该值如果被省略则默认为 「1」。
还是前面的demo 我们做一下简单的修改
.test-flex
width 100px
border 1px solid #000
height 20px
display flex
flex-flow row nowrap
.test1
border 1px solid #fe0f3c
height 20px
width 20px
.test2
border 1px solid #0f31fe
flex-basis 0%
flex-grow 1
.test3
flex-basis 0%
flex-grow 2
border 1px solid #fef00f代码的显示效果如下:
**flex-grow 的默认值是0,如果没有显示的定义该属性,是不会拥有分配剩余空间的权利的。**那么上面代码 test2和test3的宽度分别是多少呢,
flex 容器剩余空间的长度为 100px - 20px =80px
test2 宽度 = 80 * (1/3) = 26.6666px
test3 宽度 = 80 * (2/3) = 53.3333px
那我们再对以上的代码做些简单的修改,这个时候我们仅仅修改html不对css做修改。我们仅仅在test3的容器内添加了一些文本并且,这些文本超出了容器的本身宽度。看下显示效果
可以很明显的看出来test1和test2的容器的宽度都被压缩了。
那么这是为什么呢,这个时候就轮到我们的flex-shrink出场了。
flex-shrink属性的默认值为1.如果没有显示定义该属性,将会自动按照默认值1在所有因子相加之后计算比率来进行空间收缩。
先来对代码做简单的修改看个简单的例子
.test-flex
width 100px
background-color #000
height 20px
display flex
.test2, .test3
width 50px
.test1
background-color #fe0f3c
height 20px
width 20px
.test2
background-color #0f31fe
flex-shrink 1
.test3
flex-shrink 2
background-color #fef00f根据定义我们来猜测下最后的显示效果应该是什么样子的。因为test1没有显式的声明 flex-shrink 所以使用默认值为1 所以弹性盒被分成了4份,他们的比例分别是 test1 : test2 : test3 = 1:1:2
容器定义为100px 子容器的宽度相加以后为 20px+50px+50px=120px 超出父容器20px 那么这20px就要被 a,b,c消化掉,通过收缩因子加权可得 20x1 + 50x1 + 50x2 = 170px
溢出的计算量 = (子容器宽度*flex-shrink的值/加权值)* 溢出值
由上可以计算出test1 test2 test3 将被移除的溢出量是多少,那么弹性盒的子容器的宽度分别为
test1 (20x1/170)x 20 = 2.35
test2 (50x1/170)x 20 = 5.88
test3 (50x2/170)x 20 = 11.76
那么压缩后伸缩子容器的宽度分别是
test1的宽度= 20-5 = 17.65px
test1的宽度= 50-5.88 = 44.12px
test1的宽度= 50-11.76 = 38.24
然后使用chrome开发者工具分别查看三个子容器的宽度,大约都是等于我们刚刚计算出来的值。
那我们再来验证一个问题就是flex-basis 和width的关系以及同时设置他们以后的优先级
.test-flex
width 100px
background-color #000
height 20px
display flex
.test2, .test3
width 50px
.test1
background-color #fe0f3c
height 20px
width 20px
flex-basis auto
.test2
background-color #0f31fe
width 10px
flex-basis 20px
flex-shrink 1
.test3
flex-shrink 2
flex-basis 0
background-color #fef00f
从以下的显示效果可以看出来,当我们设置了flex-basis:0的时候伸缩子容器的宽度变为了 0 .当我们同时设置了 flex-basis 和 width 时且都为数值时,flex-basis的优先级高于width ,当其中有一个设置了值为auto时,值为非auto 的属性的优先级更高。
由了以上的基础知识储备,我们一定知道为什么设置了固定宽度的子容器 test1 被压缩了。因为当其它的容器的内容超出了父容器的剩余空间时,会压缩子容器不是设置了flex-shrrink != 0的容器,因为test1的容器没有设置flex-shrink所以默认值为1 会被压缩。如果不想被压缩就设置flex-shrink 0
在开发过程中遇到了题目描述的问题,使用 Google 搜索,中文答案很少,而且没有令人满意的。就在**segmentfault**上提了一个问题,而且很快我就发现被很多人收藏了该问题(SF网站问题被收藏时,会收到消息提醒)。也有一些网友回答该问题,但是一直没有优质的答案。
后来在 Stack overflow 找到比较好的答案,这个回答也是点“赞”数想当高的。英文好的同学建议直接阅读英文,英文不好的同学可以阅读下面我的翻译(英文水平有限,没有按照字句翻译,只是根据我对他们的理解来翻译)。
这个问题主要发生在当**Blink**(Chrome的渲染引擎)决定延时执行一个定时器函数的时候。比如:通过requestAnimationFrame,setTimeout,setInterval这些对象执行的函数。因为这些对象在执行函数时至少要花费 50ms的时间,如果在这个时候刚好有用户在网页上输入操作,Blink会优先执行用户的输入操作(比如:scrolls事件,tap事件)。
如果你的JavaScript代码在运行时也出现了这样的问题,可能是使用者触发了同样的“行为”(指在执行定时器函数时,刚好有用户在操作)。下面有几种方式来复现这个问题:
timer(定时器函数)触发了一段执行时间比较长的JavaScript代码;JavaScript代码执行时间,可以让你有更好的时机去复现该问题;在console(控制台)中打印的消息指向的问题(chromium平台bug列表),可以从第40条评论中直接找到解决该问题的方法:
如果阅读中文后还无法理解可以参考英文截图
看了下博客的更新时间,发现9月份一篇也没有更新。一直想着都要抽时间写一篇的,不然今年的更新记录就会断在了9月份。但是还是应为各种各样的事情给耽搁了。当内心突然涌起一股必须写点什么的时候,突然发现自己把写博客的“套路”都忘了。(●´ω`●)φ
一直认为自己还是一个比较热爱思考的人。最近一直在思考两个问题:
当然这两篇文章自己也在润色之中,相信很快会跟大家见面。
废话不多说。来正菜。
好吧。至从自己到了新的工作环境以后,开发环境又从只需要兼容 IE8 以上回到了必须兼容 IE6 浏览器上来。所以在第一次做项目的时候,还是遇到一些兼容低版本IE浏览器的问题。
首先来看一个背景透明的问题,背景透明有三种解决方案:
但是他们也有些细微的差别总结如下:
示例效果如下(如果可以的话,自己可以写一个简单的demo看下效果):
第一个是opcity和rgab的区别
第二张是在ie6中的效果:
当我们在兼容低版本浏览器的时候可能下面的写法可以满足我们的需求(两个属性都写上,浏览器识别的属性直接覆盖前者的属性):
.item1{
opacity:0.1;//IE8以上浏览器识别
filter: progid:DXImageTransform.Microsoft.Alpha(opacity=70);//滤镜低版本IE7-8支持
}做html5开发的过程中,我们可能会有这样的需求:
点击按钮,呼起系统的发送短信的窗口,并且自动填充发送到的号码和内容;
网络上可以很容易的找到这方面的demo ,并且也可以找到在安卓上和ios上是有却别的:
<!-- ios-->
<a href="sms:10086&body=发送的内容">点击我发送短信</a>
<!-- android-->
<a href="sms:10086?body=发送的内容">点击我发送短信</a>但是在实际的开发过程中却遇到了很多坑。主要原因是:
除了安卓和IOS系统的写法不同外,ios不同系统版本写法也不同。而且在不同的app中也有不同。
上面的原因是在生产环境遇到的问题。刚开始因为找不到相关可以查阅的文档只能不做兼容。偶然一次在 stackoverflow 发现了问题的原因。
原文内容如下:
翻译后总结如下:
所以,如果在生产环境中有呼起系统发件箱并且填充号码和内容的请注意以上的区别。
在html5中 input标签提供给了开发者访问系统文件的能力。说实话如果仅仅在移动端的系统浏览器中使用input控件真的没有发现什么问题。但是在app的**webview**中却处处是坑。以下是总结出的一些经验。
<input type="file">在webview中访问系统文件遇到的一些问题:
详细的可以参考这篇文章一起阅读:《h5端呼起摄像头扫描二维码并解析》
在开发过程曾经遇到过这样的问题:
很多个页面,比如说a-z。当我在a页面的时候,浏览器中的url会带有某些参数,当我在做完一系列的操作到达z页面。
某天有个需求,用户在页面a的时候会带上一个参数,决定用户在z页面做完操作后页面最终跳向哪里。那么这个参数该怎么传递到z页面呢?
第一种解决方案:
从a页面到z页面跳转的过程中,通过 GET 的方式在url中带上这个参数;
这种方案是比较常规,也是比较不错的解决方案。但是需要在页面中的逻辑跳都加上需要的参数。这样工作量比较大,而且容易出现遗漏。不建议使用。
第二种解决方案:
使用html5新特性sessionStorage来解决问题。在a页面的时候,把新添加的需要传给z页面的参数放在sessionStorage中。在z页面直接从sessionStorage中取需要获取的参数值,然后决定页面最终的跳转。
这样解决问题不仅减少了很大的工作量,也解决了工作量大会遗漏的问题。
sessionStorage的优点:
因为数据是存储在内存中,当会话结束,页面关闭以后这些数据就会被销毁。
html5移动端存储的一些坑:
当然在移动端浏览器中使用localStorage和sessionStorage是没有任何问题的。但是在安卓webview中却出现了localStorage无法向移动的磁盘写数据的问题。最后通过网络搜索发现。在安卓上webview是默认不开启localStorage想磁盘写文件的权限的。所以如果需要使用localStorage的同学需要找客户端支持。详细信息如下:
做过一个JavaScript生成二维码的需求。当时调研了两个方案:
在使用的过程中还是遇到一些坑,总结如下:
所以在前端有需求做生成二维码需求的时候,可以参考以上的两个点,确定自己选择哪个开源库更适合自己的项目。
当看到题目的时候,可能会“一脸蒙逼”为什么要在本地存储js字符串啊。好吧,有时候业务场景的需求确实是比较变态,且看我描述的一个业务场景。
业务场景:
因为历史的原因,我们的html5页面是跑在客户端的webview中,但是客户端的titlebar上的那个返回按钮却是调用了前端js的back方法进行页面返回的。这个时候就会出现一个问题,如果在我们的h5页面中跳出了我们自己的页面,到了第三方的页面。第三方页面的js肯定是没有我们客户端返回按钮需要的js返回方法的。
可能有人会说,“卧槽,为什么要这么搞,当初谁这么设计的。。。”或者是“让客户端同学发版,用客户端自己的返回不就解决问题了么”。
好吧,都说了是历史原因了其它的都不要说,而且找客户端同学发版也不太现实的情况下只能想其它的解决方案了。
之前已经聊到过html5的客户端存储技术sessionStorage。当然我要做的就是把那段前端的back方法存到sessionStorage中。当加载第三方的页面的时候直接从sessionStorage中读取back方法的字符串,转化为js代码,并且赋值给客户端调用的方法。
其实这里的难点是怎么把js字符串转化为可执行的js代码。
eval执行js代码语句,看下面简单的示例:由上面的代码可以知道,eval可以把简单的js字符串转化为js代码并且执行它。但是当我们的js字符串比较复杂呢?比如下面这样:
function aaa(){
console.log(1);
}那么使用eval函数还行不行呢?看下面的示例:
由上面的执行结果可以知道,不管怎么执行都得不到我们的预期的结果,但是有没有办法得到我们预期的结果呢?答案是:有。
new 关键字的使用在JavaScript中一切皆是对象。当我们创建一个函数的时候除了函数声明和函数表达式外,还可以通过new Function的方式来创建函数(这种方式并不常用,但是特殊的场景还是很有用的)。
那么使用new Function怎么解决上面的问题呢?请看示例代码:
由上面的示例代码和c的执行结果我想很多人已经知道怎么做了,其实只需要对b的字符串函数做一下简单的修改即可,看代码:
上面的代码执行结果的b()就是我们我想要的保存的函数体。
来看一个比较常见的布局
上面的这个布局 因为footer是相对于页面底部绝对定位的,所以当屏幕太小的时候会有一个问题footer区域覆盖了内容区域,如下图:
那我们怎么解决这个问题呢?我看到在我们项目的源代码中是通过js给footer和内容区域所在的父容器设置一个最小的高度来解决这个为题的,这样做不好。除了会增加复杂的判断也会造成页面的重绘:
var webViewHeight = window.innerHeight;
var iosCampatibleValue = 64;
if(webViewHeight<500){
webViewHeight =500;
}
$('#pageWrapper').css('height', webViewHeight);很明显上面的代码会造成页面的重绘(当然这个对系统性能消耗并不是那么容易感知)。但是用css可不可以解决这个问题呢?
当然是可以的,就是为内容容器设置一个padding-bottom它的值就是底部footer的高度,如下图:
当移动端的屏幕比较低的时候就会是下面的这种情况:
padding-bottom和footer重合。但是footer永远不会覆盖内容区域的内容。这时页面会出现滚动条。可能我们最初的设计是为了用户体验不让用户的屏幕出现滚动条,但是还是那句话没有十全十美的程序,在一些小众机型上为了保证页面的正常显示保证用户正常浏览我们只能牺牲一下这样的用户体验了。
现在大多数的安卓系统和ios系统,当输入框获取焦点呼起系统键盘的时候,系统键盘都会将input输入框给推上键盘的上方,方便用户的输入。但是不外乎例外,特别是在某些app中,这个本身是系统的操作并不生效,这个时候如果需要达到完美的用户体验就需要人为的参与进来。
解决办法:
思路很简单,就是检测输入框的focus事件,当输入框获取焦点的时候,用js去把页面滚动一下。最好维护一个系统无法正常推起输入框的软件列表(可以通过HTTP的UA来获取软件的唯一标识)。如果可以使用系统默认的滚动就用系统的,如果不可以再人为的调用js干预。
function inputScroll(dom){
var tplList=['ss','bb'] ;
var tpl = $.fn.getQueryString(tpl);
if(tplList.indexOf(tpl)){
dom.focus(function(){
var clientHeight = $(window).height();
var contentHeight = clientHeight + clientHeight/2;
var smsInputTop= $(this).offset().top;
content.height(contentHeight);
window.scrollTo(0,smsInputTop-76);
});
}
}本来以为很容易就能把这两个知识点总结完,但是在写line-height的时候,写一些示例demo总是会发现一些奇怪的细节问题(平时开发的过程中不关注可能对产品最后的样式并不会产生特别大的影响),但是既然要深入理解,那肯定是要刨根问底,追究其根本原因的。知识的积累就是多问自己几个为什么,然后去寻找答案。
先来看一个示例demo,以及在浏览器的显示效果。来切入我们这篇文章的主题,代码很简单如下:
由上图可以看到浏览器的解析结果:可以看到默认的情况下,在不设置.test-span 和 .test-div 的高度的时候,可以明显的看到字体和边框之间有一段很小的空白间隙。
是的,这篇文章我们就来探究下这段空白间隙的由来。然后了解下我们并不熟悉的line-height。
首先我们先准备一个不常用的基础知识,window.getComputedStyle MDN文档地址 ,文档定义如下:
返回一个对象,该对象在应用活动样式表并解析这些值可能包含的任何基本计算后报告元素的所有CSS属性的值。 私有的CSS属性值可以通过对象提供的API或通过简单地使用CSS属性名称进行索引来访问。
使用方法:
// 详细的使用方法请参考文档
/*
* @param [element] 用于获取计算样式的element
* @param [pseudoElt] 指定一个要匹配的伪元素的字符串。必须对普通元素省略(或null)
*/
let style = window.getComputedStyle(element, [pseudoElt]);我们一步一步由浅入深,先来看看什么是行高?来看下下图:
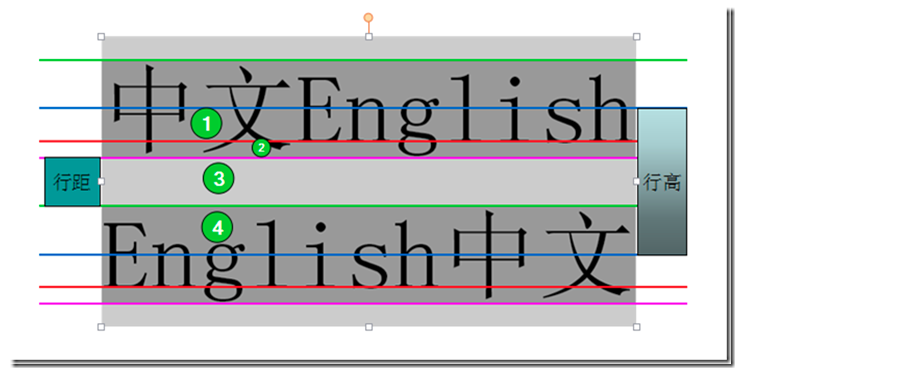
上面图种不同颜色的从上到下名称分别为(类似于我们初中开始学习英文时使用的拼音格):
行高: 上下文本行的基线间的垂直距离。
就是上图中的两条红线间的垂直距离(即图种:1+2+3+4的高度)。那么我们很容易的根据图可以知道其实行高也是两条顶线(或者说两条中线、两条底线)之间的距离。
**行距:**指一行底线到下一行顶线的垂直距离。就是上图中的第一行的粉色到下一行绿色之间的距离。
字距(字体大小):即上图中的1+2+4的高度,就是四条线中显示文字的区域,即顶线和底线间的空间。
内容区(content area): 在上图中内容只在绿线和粉色的线之间显示。这就是我们所说的内容区。
其实除了以上的几个概念在学习css的时候还会有一下的几个概念:行内框和行框呢和内容盒。
行内框(inline boxes): 浏览器渲染模型中的一个概念。无法显示出来。每个行内元素都会生成一个行内框。在没有其它因素影响的时候(比如padding),行内框等于内容区域。当设置line-height时,行内框并不会变化。半行距分别增加/减少到内容区域的上下两边。
行框(line boxes): 浏览器渲染模型中的一个概念。是本行的一个虚拟的矩形框。并没有实际的显示。行框的高度等于本行内所有元素中的行内框最大的值(以行高值最大的行为框为基准,其它行内框采用自己的对齐方式向基准对齐,最终计算行框的高度),当多行内容是,每行都会有自己的行框。
内容盒(containing box): 外层盒子模型,包含了其他的boxes,即下面的整个灰色的区域。
下面的这张图能够更加形象的来表示出各个盒子所占用的区域。
那么到底是什么原因导致的这个空白的间隙呢?我们根据前面的JS脚本的特性来获取当前元素的一些计算属性,代码如下:
const testSpan = document.getElementsByClassName('test-span')[0];
const testDiv = document.getElementsByClassName('test-div')[0];
const test3span = document.getElementsByClassName('test3-span')[0];
const test3 = document.getElementsByClassName('test3')[0];
console.log('************testSpan style*****************');
const testSpanStyle = window.getComputedStyle(testSpan)
console.log(`font:${testSpanStyle.font}`);
console.log(`lineHeight:${testSpanStyle.lineHeight}`);
console.log(`fontFamily:${testSpanStyle.fontFamily}`);
console.log('*******************************');代码在浏览器(chrome)中的输出结果如下:
由上图的输出结果可以知道当我们不给元素显式的设置line-height属性时,元素是会有一个默认值normal的。那么这个normal到底是一个什么东西呢,继续查询 MDN文档 可以知道,line-height的取值范围:
normal这个取决于浏览器。大多数浏览器的默认值是1.2左右,这取决于元素的font-family。最重要的是这句话,如果我们不显式的声明元素的line-height的时候浏览器会给元素设置一个默认值。line-height=15pxfont-size进行换算。不允许为负值。根据定义可以知道当我们不显式的设置line-height时,浏览器默认使用乘积因子的方式给元素设置行高。有下面的一个计算默认行高的公式:
默认的行高 = 1.2 * font-size
那么根据以上的概念我们得出文章开头示例代码test-span的 line-height = 16 * 1.2 = 19.2 (浏览器默认字体大小16px)那么行间距= (19.2-16)/2 约等于 2。其实那段空隙就是这么来的。
那么怎么解决 demo 中文字和边框间的间隙呢。根据定义当我们不知道具体的字体大小时我们只需要设置 line-height=100% 其实就是行高和字体大小相等 (行高=100% * 16)。
来看下效果,当元素是一个block元素时,文字撑满了父级容器。但是当父级元素是一个
inline 元素时,设置 line-height =100%对内部的文本竟然没有影响。
接下来继续探究line-height对inline元素的影响
首先当我们给块级元素内的内联元素什么也不设置的时候,连块级元素也没有宽和高。
当我给块级元素内部的inline元素设置了内容的时候,根据下图,内联元素的高度完全由内容给撑开,然后又撑开了父级元素。
当我给块级元素内部的inline元素设置了inline-block属性的时候
到这里的时候我们可能会猜测是**line-height**影响了inline元素的内容区域的显示,其实我也是这么想的,不过当我使用前面提到的js脚本获取浏览器对该元素的计算属性的时候我惊呆了,看下图竟然是lineHeight=30px,也就是说当父元素设置的line-height是具体的像素值的时候,当子元素没有显式的设置line-height时,会直接继承父级元素的line-height。
那么到底是什么影响了内联元素的内容区域呢?内联元素的特点是什么?内联元素是没有宽和高的元素(设置width和height对元素的大小没有影响),那么当浏览器渲染一个有内容的内联元素,这个内联元素内容区的大小跟具体浏览器的渲染引擎和字体(font-family)是有关系的(其实就是开头示例demo中内联元素文字和边框的那个空白间隙开发者无法改变)。也就是我们前面提到的行内框的概念,改变行高并不能影响行内框的高度,这个由内联元素的字体大小决定。
如果父元素的line-height 属性有单位且为 px 、% 、 em那么继承的值则是换算后的一个具体的px级别的值。举例如下:
当设置 test1 的line-height:150%且font-size:16px时,时根据概念我们可以知道子元素span 继承的line-height值为 150% * 16 = 24px 那么行间距我们可以计算出来 行间距=(24-30)/2 = -3px。根据代码的显示效果确实看到了两行文本出现了重叠的效果。
那么当父元素的line-height是一个的像素值时,子元素的line-height是什么呢?
根据文章开头我们的探究已经知道了,子元素直接继承这个line-height,但是当子元素是inline元素是,这个line-height并不会影响内容区的大小。
如果属性值没有单位,则浏览器会直接继承这个“因子(数值)”,而非计算后的具体值,此时line-height会根据本身的font-size 值重新计算得到新的line-height值。
看下面的demo ,如果根据 上面的概念,子元素的行高应该是 3 * 20 = 60px
根据前面的js脚本来验证一下,由下图完全验证了我们的定义。
根据以上知识的储备,当我们设置父级元素的line-height和父级元素容器的高度一样时,为什么子元素在不换行时可以垂直居中了?因为子元素继承了父级元素的line-height 行距就是(line-height - font-size) 这个值除以2刚好填满字体的顶线和父容器上边距和字体的底线和父容器下边距。
先看来一个简单的示例demo 的效果如下图:
我们平时最常见的场景就是将图种的icon相对于父级元素垂直居中。那么有什么方法呢?
前面的两种不是本文的内容。这里主要研究下 vertical-align 这个属性使元素相对于父级容器垂直居中(近似垂直居中x-height/2)。
先来了解vertical-align的的可选属性的概念:

那么上面概念的后半段的是什么意思呢?我们将子元素的内容删除,给子元素添加宽和高。来看下效果,如下图可以看出来这个时候黄色盒子的下边界对齐的是父元素文字的基线。
sub: 当前盒的基线降低到合适的位置作为父级盒的下标(该值不影响该元素文本的字体大小)
super: 当前盒的基线提升到合适的位置作为父级盒的上标(该值不影响该元素文本的字体大小)
text-top: 当前盒的top和父级盒的内容区的top对齐
text-bottom: 把当前盒的bottom和父级的内容区的bottom对齐
middle: 当前盒的垂直中心和父级盒的基线加上父级元素的x-height的一半对齐(关于什么是x-height看这篇文章);
top: 把当前盒的top与行盒的top对齐
bottom: 把当前盒的bottom与行盒的bottom对齐
[percentage]: 把当前盒提升(正值)或者是降低(负值)这个距离,百分比相对于line-height计算。当值为0%时等同于baseline。
[length]: 把当前盒提升(正值)或者降低(负值)这个距离。当值为0时等同于baseline
当尝试给子元素设置vertical-align属性,那么最后的结果是怎么样呢(下面的demo我添加了一些文字作为参照)
由上图发现这个时候文字和图标并没有按照我们的预期垂直居中。根据第一部分的知识,我们尝试把容器内文字的4个基本线划出来。看下图蓝色的线依次从上到下是顶线,中线,基线,底线。当我们对子元素 span.icon设置vertical-align后,只是将图标的中线和文字的中线对齐而已。

由本片文章的第一部分可以知道给父级元素设置line-height = 容器高度可以使子容器内的元素垂直居中。这个时候的显示效果是什么样子呢?看下图:
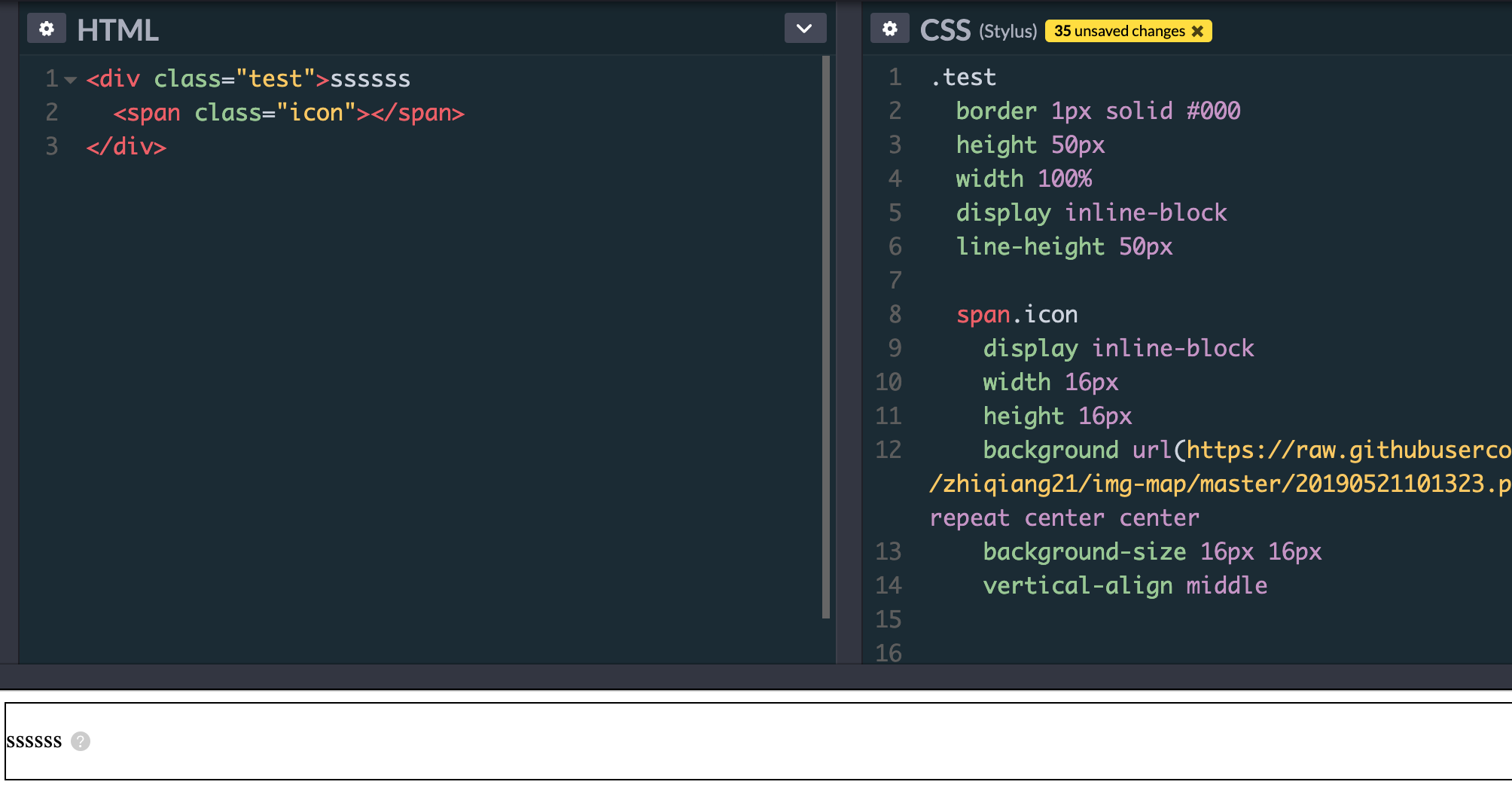
根据上图我们可以看出,当我们对父元素设置了line-height=容器高度的时候文字不仅居中对齐了,图标也居中对齐了。那么是为什么呢?由第一部分的知识可知当我们给元素设置line-height > font-size时,会在上下行的文字间添加行间距。我们再看下图:

当设置line-height时,因为行间距的增加,影响容器内显示字体的4条基本线的位置。如果是单行文本元素时刚好能够居中文本。当我们对span.icon设置vertical-align时,就是将当前盒的垂直中心和父元素的中线对齐。就实现了我们看到的垂直居中的效果。
如果平时主要在Mac 和 Linux 环境下工作,对于文件和目录权限应该不陌,看下面这张我电脑上的截图:
当我们看到上面这张图的时候能不能很快的理解每一列的意思,如果你能够很快读懂那么下面的文章可以节省时间不看了,如果不是很清楚可以再详细的学习下每一列代表的意义。
Linux的权限分为3中:
文件所有者通常是文件的创建者(root用户可以修改文件的所属)。
文件的创建者自动成为文件所有者(属主),文件的所有权可以转让,转让“手续”必须由root用户办理。
可以(也必须)把文件交给一个组,这个组就是文件的属主。组是一群用户组成的一个集合,文件属主中的用户按照设置对该文件享有特定的权限。
举个例子来说:
当A用户创建了一个文件File,File的属主就是A,File的属组是包含一个用户的A的A组。
可以通过root权限设置文件的属组是一个不包含文件所有者的组。文件所有者执行文件操作时,系统只关心属主权限,而组权限对属主是没有影响的。
可以设置用户对文件或者是目录拥有3种权限:
| 权限 | 意义 |
|---|---|
| 读(r) | 可以打开并且查看文件内容 |
| 写(w) | 可以修改文件内容 |
| 可执行(x) | 可以执行文件(1、可以由cpu执行的二进制代码 2、shell脚本程序等) |
能否删除和重命名一个文件是由其父目录的权限设置所控制的。
有了上面的用户和权限系统的基础知识我们就来分析下开头看到的那张图每一列的意义。我们直接看下图:
文件修改时间这一列不同的系统上显示的信息可能不同。
具有Linux基础知识的都知道Linux上的一切都被表示为文件。Linux具有7种文件类型,分别如下:
| 文件类型 | 符号 | 意义 |
|---|---|---|
| 普通文件 | - | |
| 目录 | d | |
| 字符设备文件 | c | 能够从它那里读取成字符序列的设备,如:磁带和串行线路 |
| 块设备文件 | b | 用来存储数据并对其各部分内容提供同等访问权限的设备,如:磁盘 |
| 本地域套接口 | s | |
| 有名管道 | p | |
| 符号链接 | l |
chown可以用于改变文件的所有权。基本的语法如下:
chown [option] ... [owner] [[:group]] filename
属组前的冒号可以省略如果要修改属组时,冒号不可以省略。
例如:
sudo chown zhiqiang:staff a.js
只修改属主(冒号后可以省略)
sudo chown zhiqiang a.js
只修改属组(冒号不可以省略)
sudo chown :staff a.js
这条命令的意思是将a.js文件的owner设置为zhiqiang 属组设置为staff。
chown 具有一个 -R选项,可以修改一个目录及其下所有文件(包括子目录)的所有权的设置。
例如:
将test目录下的所有文件和目录的所有权(属主)设置为zhiqiang
chown -R zhiqiang test/
Linux单独提供了另外一个命令chgrp用于设置文件的属组。
chgrp [option] [group] filename
例如:
将a.js的属组设置为 staff
sudo chgrp staff a.js
同样的chgrp 也提供了 -R 选项递归的设置目录及子目录的所属组。
Linux提供了chmod命令来改变文件的权限。这个命令使用“用户组+/-权限”的表述方式来增加/删除相应的权限。
代表用户组的英文简写字符如下:
例如:
增加属主的可执行权限
chmod u+x a.js
可以通过 a同时指定所有的3种人。例如删除所有人的可执行权限
sudo chmod a-x a.js
可以通过“用户组=权限”的规则直接设置文件权限。
chmod gu=rwx,o=rw a.js
这里的意思死设置a.js文件的所属组和属主用户具有读、写、可执行的权限。设置其他人用户具有读、写权限。
chmod也提供 -R 选项递归的对文件和目录,目录下的文件设置文件权限。
符号链接(软链接)需要使用带 -s参数的 ln命令来创建。命令格式如下:
创建一个软链接
ln -s path/to/file path/to/symlink
创建一个软链接覆盖旧链接
ln -sf path/to/file path/to/symlink
创建一个硬链接 。用于将两个独立的文件联系在一起。与软链接的本质区别在于:硬链接是直接引用,而符号链接是通过名称进行引用。两个文件拥有相同的内容,对其中一个修改会直接反应在另一个文件中。硬链接很少使用。
ln path/to/file path/to/symlink
创建软链接相当于给文件命名一个别名,访问别名文件相当于访问源文件,删除别名文件不会影响源文件。如果删除源文件,别名文件仍会保留,但是其已经没有任何意义。
本文主要内容摘自--《Linux从入门到精通》
很多时候我们会有下面的场景,如下图中所显示的那样。点击1区域(从图上看1区域包含2区域)和2区域跳转不同的链接。
正常的代码结构应该是:
<ul>
<li>
<a href="#1">
<div>内容1区域
<a href="#2">
<div>按钮2</div>
</a>
</div>
</a>
</li>
</ul>但是上面的代码浏览器的编译结果是下面这样
很明显可以发现,浏览器的渲染结果并不是我们想要的结果。那么是为什么呢?
根据 W3C 规范,a 标签是不是嵌套 a 标签的。如果出现 a 标签嵌套 a 标签的情况就会将 a 标签内的 a 标签渲染在外部。
其实按照设计图上虽然是包含的关系,但是我们可以按照下面的方式布局,通过定位解决,不同的跳转问题。
<ul>
<li>
<a href="#1">
<div>内容1区域
</div>
</a>
<a href="#2">
<div>按钮2</div>
</a>
</li>
</ul>编写 css 的时候,都会遇到选择器优先级的问题。这里给出一个优先级列表
div{
font-size:12px !important; //!important 的优先级最高,而且比内联的样式的优先级高
}那么除了 important 之外的选择器呢?
| 元素 | 权重 |
|---|---|
| 内联样式 | 1000 |
| ID选择器 | 100 |
| 类选择器(包括属性选择器和伪类) | 10 |
| 元素(标签)和伪元素选择器 | 1 |
| 结合符和通配符 | 0 |
根据上面的选择器的权重列表,就对我们在编写 css 的过程中对样式优先级有一个比较清晰的计算方法
.img-list > li {
width: 32rem; /*权重=11*/
}
.img-btn-list li:first-child {
margin-left: 0; /*权重=21*/
}
.v-list a>span:nth-child(1) {
margin-right: .7rem; /*权重=22*/
}flex布局的一些优点思考:
flex (弹性盒)布局一个最大的优点就是解决不同移动设备的适配问题。flex与具体的单位无关性 ,所以可以解决不同项目间单位不统一,但是又需要引用公用样式的需求。问题2的参考网站:天猫 h5页面。 淘宝 h5 页面全站使用
rem单位适配,而天猫页面有百分比,rem 单位的混用。
当然 flex 解决上面的问题还有一个问题就是浏览器的兼容性。如果自己的网站或者是 H5页面需要兼容低版本的浏览器,我们可以参考使用百分比单位解决适配的问题。
参考网站:京东 h5页面(全站使用百分比单位解决多设备适配的问题)。
body{
-webkit-overflow-scrolling:touch;
}2.1 改变元素位置使用 css3 新属性,触发 GPU (硬件加速)辅助渲染动画 扩展阅读点这里
2.2 使用 chrome 开发者工具,查看动画元素是否造成周围大量 DOM 节点的重排(reflow),如果是则对动画元素使用 absolute 定位,脱离所在文档流,减少对周围元素的影响。
2.3 对要做动画的元素使用backface-visibility,opacity,perspective
这里属性主要是设置动画元素只渲染面向用户的一面。减少动画渲染对系统性能的消耗。
{
-webkit-backface-visibility:hidden;
backface-visibility:hidden;
-webkit-perspective: 1000;
perspective: 1000;
}因为 Team 本身工作性质的问题,平时需要值班。值班数据可以导出为本地的Excel文件。之后需要对Excel中的结果数据做分析,并且制作图表写周报发给老大。
对于我这种对word都玩不转的人,别说用Excel中强大的公式分析数据了😓。轮到我值班的时候就用nodejs写了一个脚本自动处理Excel中的数据,并且将数据再写入Excel文件。后来分享给同事,得到了老大的夸奖,自信心爆棚 😂
之前仅仅为了满足工作的需要写的比较的随便,刚好国庆有时间按照CMD规范重写一下。然后分享给大家。
读取Excel文件,分析Excel中的数据,并且将结果写入Excel中。
在这个过程中使用了两个第三方的包分别如下:
require('date-utils');
var xlsx = require('node-xlsx');使用date-utils主要是用来做一些时间上的处理。比如说时间差,当前时间向后加七天的日期。这个包非常的强大。可以看下API:
上面的两片文档可以结合着看。
<static>这些方法扩展的是Date对象,而后面的这些方法这些用于对象的实例。实例代码如下:
//当前日期推后7天的日期
var time = '2016-10-04 14:30:24'
var nextSevenDay = (new Date(time)).add({'day':7});
//比较时间差
var temp = Date.compare(time1,time2); //结果位数值node-xlsx主要做一些excel相关的处理比如说读取Excel 文件:
var workExcel = xlsx.parse('xxx.xls');比如创建excel文件对象:
var buffer = xlsx.build([{name: name, data: datalist}]);如果对CMD规范不熟悉的话可以参考这里
我的脚本的目录结构如下:
如果对package.json文件配置不是很熟悉的话可以参考这里
主要代码解析:
通过node-xlsx 读取的excel文件就是一个json数据。我们应该都知道一个Excel文件可以包含多张表,每张表都可以管理自己的数据。
看照上面已知内容,代码如下:
//读取某个excel文件
var chatExcel = xlsx.parse('./历史记录.xls');
//获取需要excel某个表中的数据
var tableData = excelFunc.getDataContent('历史记录', chatExcel);
//获取当前表中获取第一行数据,通常在excel中这一行就是每一列的title
var tableTitle = tableData[0];在使用nodejs的过程中可能最大的一个迷惑就是区别exports和module.exports吧,它们两者的主要区别如下:
1. 简单的代码示例:
一个test1.js文件,其中代码如下:
module.exports="test";
exports.fileName = function(){
console.log('test1');
};在test2.js文件中使用test1.js模块的方法:
var test1 = require('test1');
test1.fileName(); //TypeError: Object test! has no method 'fileName'2. 如果模块是一个类如有一个consoleName.js的文件,其中代码如下:
module.exports=function(name){
this.name =name;
this.consoleName = function(){
console.log(this.name);
}
}其它模块中的调用模块的方法:
var ConsoleName = require('consoleName');
var con = new ConsoleName('zhiqiang');
con.consoleName(); //zhiqiang3. 如果模块是一个数组,例如有一个test1.js的文件,其中的代码如下:
module.exports =['zhiqiang1','houzhiqiang'];在其它模块的调用方法
var arr =require('test1')
console.log(arr[1]) //houzhiqiang其它的代码就没有什么别的了,都是关于公式的存计算的问题。如果有兴趣的同学可以访问源码看一下。源码地址
MDN社区(即Mozilla开发者社区)具有很多高质量中英文文档。它是我开发时遇到概念模糊的地方经常访问的网站。因为默认搜索一些代码,优先显示的都是英文。但是恰恰这些显示的英文文档是有中文的。每次都是自己手动切换下中文显示。所以就想着在点击英文链接的时候,能够自动跳到中文链接。
其实在MDN的每篇文档的页面上都提供了一个select表单供用户手动切换显示语言。其实我要做的也很简单,就是在页面加载的时候,使select表单选择中文简体然后重新提交一次表单即可。
使用JS实现上面的一个提交表单的操作并不难,主要是在页面加载的时候执行JS代码(并且不是每次手动指定JS代码)。
解决方案就是使用JS代码选择中文简体并且提交表单。点击到代码地址
这里需要借助chrome插件Tampermonkey 选择在页面加载的时候执行脚本即可。在一切配置妥当以后,就算我们在网站上点击的英文文档的搜索结果,在显示的时候也会自动跳转到中文的搜索结果。
既然是要编写插件。那么叫做“插件”的东西肯定是具有的某些特征能够满足我们平时开发的需求或者是提高我们的开发效率。那么叫做插件的东西应该具有哪些基本特征呢?让我们来总结一下:
如果按照以上的几个特征来写插件的话,我们可以总结出一个基本的代码结构,我们一个一个的来看:
html中配置容器节点
//这里的node-type="reward-area" 是标识我们插件的容器节点
<div class="re-area" node-type="reward-area" >
DOM加载完成以后初始化插件
$(function() {
//这里的 test 是代表容器的 class
window.LightRotate.init($('[node-type=reward-area]'));
});
JavaScript 具有块级作用域的标识符就是function了。那我们怎么声明我们的变量才可以使它不污染全局变量呢?
这里我们需要用到的一个 JavaScript 函数的自执行的知识点。代码如下:
(function(){
// do something
})();
这就要用到我们面向对象的知识点,把我们的功能代码抽象成对象,在我们需要使用的时候,实例化对象就可以了。那我们接着第二部的代码继续写,
//
(function($){
// 创建功能对象
var LightRotate = function (select) {
// do something
};
LightRotate.init = function (select) {
var _this = this;
//根据不同的容器实例化不同的对象
select.each(function () {
new _this($(this));
});
};
window.LightRotate = LightRotate;
})(jQuery);首先我们应该有默认的参数设定,比如下面这样
//
(function($){
// 创建功能对象
var LightRotate = function (select) {
// 自定义的参数
this.setting = {
liAutoPlay: false, //周围的灯是否自动旋转
roLiSpeed: 100, //灯旋转的速度ms
roPrSpeed: 200, //奖品旋转速度ms
liDirection: true, //旋转方向 true 正方向 false 反方向
randomPrize: false //空格是否随机选取
};
};
LightRotate.init = function (select) {
var _this = this;
//根据不同的容器实例化不同的对象
select.each(function () {
new _this($(this));
});
};
window.LightRotate = LightRotate;
})(jQuery);其实这样写的话,使用者已经可以修改我们的 JavaScript 文件来完成自定义了。但是为了能够让我们的差价足够的好用,比如说,我们的使用者一点儿都不懂 js 呢?该怎么办?
这样我们可以把这些参数用自定义属性配置在 html中,如下:
<div class="re-area" node-type="reward-area" data-setting='{
"liAutoPlay":false,
"roLiSpeed":100,
"roPrSpeed":200,
"liDirection":true,
"randomPrize":false}'>
这样用户只需要在 html的节点中就可以配置当前容器运行的参数。这样的好处还可以使同一页面上的不同容器,可以单独的配置参数,减少耦合。
那么在 js 中我们该怎么获取这些参数呢?在上面的代码中,已经有了功能对象函数。那么我们想扩展对象方法来获取用户的自定义参数,怎么办呢?我们一般使用prototype的东西来扩展我们已有对象的方法,代码如下:
//
(function($){
// 创建功能对象
var LightRotate = function (select) {
// 自定义的参数
this.setting = {
liAutoPlay: false, //周围的灯是否自动旋转
roLiSpeed: 100, //灯旋转的速度ms
roPrSpeed: 200, //奖品旋转速度ms
liDirection: true, //旋转方向 true 正方向 false 反方向
randomPrize: false //空格是否随机选取
};
//这里调用对象的获取用户自定义参数的方法,并且将默认参数合并
$.extend(_this.setting, _this.getSettingUser());
};
LightRotate.prototype = {
//扩展获取用户自定义参数的方法
getSettingUser: function () {
var userSetting = this.LightArea.attr('data-setting');
if (userSetting && userSetting !== '') {
return $.parseJSON(userSetting);
} else {
return {};
}
}
};
LightRotate.init = function (select) {
var _this = this;
//根据不同的容器实例化不同的对象
select.each(function () {
new _this($(this));
});
};
window.LightRotate = LightRotate;
})(jQuery);最后一个就是我们的插件应该具有销毁自身变量和参数的功能。我们该怎么写呢?还是在上面的代码基础上继续扩展功能对象的可调用方法,代码如下:
LightRotate.prototype = {
//扩展获取用户自定义参数的方法
getSettingUser: function () {
var userSetting = this.LightArea.attr('data-setting');
if (userSetting && userSetting !== '') {
return $.parseJSON(userSetting);
} else {
return {};
}
},
//销毁对象参数
destory: function () {
$(_this.LightArea).off();
this.closeAnimation();
this.rewardTimer = null;
}
};
由以上我们的内容我们可以大概了解了一个成熟的插件应该具有的基本功能。
刚好这个项目是在春节放假前的一个紧急的项目,当时为了赶进度就没有详细思考自己的代码结构,这样野味自己的后续优化提供了机会。
由上一节介绍的定时器的内容可以知道 JavaScript 是单线程的。所以
如果一段代码运行效率很低,就会影响后续代码的执行。所以对于 JavaScript ,代码优化是必须的。
先来看看我们的“跑马灯”插件应该具有哪些功能:
这里就不详细的介绍这些功能点的开发过程,仅仅介绍优化过程。如果有兴趣可以看我文章最后附上的源代码地址,进行下载阅读。
因为周围的灯我是使用绝对定位来做的,所以我需要“顺序”的获取他们的列表,然后操作。
首先获取 DOM节点。
//获取外围的灯,可以看到我这里使用的选择器多了一个 select,是为了获取当前容器下的某些元素,避免有多个容器存在时冲突
this.topLight = $('[node-type=re-top]', select).find('span');
this.rightLight = $('[node-type=re-right]', select).find('span');
this.bottomLight = $('[node-type=re-bottom]', select).find('span');
this.leftLight = $('[node-type=re-left]', select).find('span');
然后就应该“顺序”的获取“灯”节点的 DOM 元素列表。
我的第一版是这样做的:
Zepto(topLight).each(function() {
lightList.push(this);
});
Zepto(rightLight).each(function() {
lightList.push(this);
});
for (var j = bottomLight.length - 1; j >= 0; j--) {
lightList.push(bottomLight[j]);
}
for (var m = leftLight.length - 1; m >= 0; m--) {
lightList.push(leftLight[m]);
}
因为“下”和“左”方向的灯是需要倒序的,所以我使用了两个倒序的 for循环,其实当循环出现的时候,我们都应该思考我们的代码是否有可优化的空间。
优化后的代码是这样子的,在这里我减少了4次循环的使用
function () {
var lightList = [];
var bottomRever;
var leftRever;
bottomRever = Array.from(this.bottomLight).reverse();
leftRever = Array.from(this.leftLight).reverse();
lightList = Array.from(this.topLight).concat(Array.from(this.rightLight));
lightList = lightList.concat(bottomRever);
lightList = lightList.concat(leftRever);
}
列表倒序我使用了原生 Array对象的reverse方法。
为了能够使我们的“灯”顺序的跑起来,第一版的思路是:
_给__每一个“灯”(注意,这里是每一个,罪过...罪过...)_定义一个
setTimeout(),执行时间就是数序的加入 js 执行队列中去。
代码是下面这样子的:
var zepto_light = Zepto(lightList);
var changeTime = 100;
var lightLength = zepto_light.length;
var totleTime = changeTime * lightLength;
function lightOpen() {
for (var i = 0; i < lightLength; i++) {
(function temp(i) {
lightTimer = setTimeout(function() {
if (stopAnimation === false) {
Zepto(zepto_light).removeClass('light_open');
Zepto(zepto_light[i]).addClass("light_open");
} else {
return;
}
}, changeTime * i);
})(i);
}
}
这样子写的缺点很明显:如果我有100个“灯”那么就会在当前的 js 执行队列中加入100个setTimeout(),再次强调的是我这里又使用了for循环,在时间复杂度上又增加了。代码的执行效率又下降了。
后来思考了下,JavaScript 中“闭包”符合我当前的使用场景,就想着用闭包优化一下,优化后代码如下:
lightRun: function () {
var _this = this;
function tempFunc() {
var lightList = _this.getLightList();
var lightLength = lightList.length;
var i = 0;
return function () {
$(lightList, _this.LightArea).removeClass('light_open');
$(lightList[i], _this.LightArea).addClass("light_open");
i++;
//使一轮循环结束后能够继续下次循环
if (i === lightLength) {
i = 0;
}
};
}
var lightRunFunc = tempFunc();
lightRunFunc();
_this.lightInterVal = setInterval(lightRunFunc, _this.setting.roLiSpeed);
}
由以上的代码可以很明显的发现两个优点:第一,就是减少了 for循环的使用,降低了代码的时间复杂度,第二就是,每次我仅仅在当前代码执行的队列中创建一个setInterval()。减小了执行队列的复杂度。
到这里关于“跑马灯”插件的代码解析详和优化就已经完了。详细的代码和使用文档请点击链接。如果有什么问题可以随时在 github 上反馈给我。
之前写过两篇开发中遇到的问题和解决方案。当时是CSS 和 JavaScript 分开写的。现在写这篇文章的时候感觉很多内容都是有内在联系的,所以不好分开。
给大家分享一下这半年来的感受吧:
知道和理解之间是有很大距离的。别人谈到一个知识点,能接上嘴并且能发表一下自己的意见,这叫知道。遇到问题能够想到用什么知识点解决问题,这叫理解。
所以有很多知识点自己确实在书上都看到过但是在平时遇到问题的时候却不知道怎么去用或者说想到去用,有时候会有同事给一下指导说用什么解决问题。关键时候还是多看(看书,看别人的代码)和多用。
display:none 关闭一个元素的显示(对布局没有影响);其所有后代元素都也被会被关闭显示。文档渲染时,该元素如同不存在。(不会显示在文档流中的位置,但是 DOM 节点仍会出现在文档流中)
visibility:hidden visibility属性让你能够控制一个图形元素的可见性,但是仍会占用显示时候在文档流中的位置。
使用 display:none 的时候虽然元素不会显示,但是DOM 节点仍会出现,所以我们就可以使用选择器对该元素进行操作。如下图中的示例:
这个问题是发生在自己上篇文章《h5端呼起摄像头扫描二维码并解析》中的。详细的代码可以看那篇文章。
先看一段html 代码:
<div class="qr-btn" node-type="qr-btn">扫描二维码1
<input node-type="jsbridge" type="file" name="myPhoto" value="扫描二维码1" />
</div>之前我的想法是这个样子的:
1.我先触发qr-btn的 click 事件,在回调中触发 input 的click 事件click 事件
2.然后触发input 的 change 事件,获取上传图片的信息 。
按照我的思路代码应该是下面的这个样子的
//点击父级元素的事件
$('.qr-btn').bind('click',function(){
//触发子元素的事件
$('[node-type=jsbridge]').trigger("click");
});
$('[node-type=jsbridge]').bind('change',function(){
//做一些事情
});上面的代码,按照正常的思路应该是没有问题的,但是,在实际的运行过程中却发生了问题。浏览器的报错信息如下:
这是因为堆栈溢出的问题。那么为什么会出现这样的问题呢?我把断点打在了以下的位置,然后点击子元素
发生的情况是:**代码无限次的触发$('.qr-btn').bind(...) **,就出现了上面的报错信息。那么是什么原因导致的呢?
思考一下发现:是因为事件冒泡的问题。我单击父元素触发子元素的 click 事件,子元素的 click 事件又冒泡到父元素上,触发父元素的 click 事件,然后父元素再次触发了子元素的 click 事件,这就造成了事件的循环。
尝试阻止事件的冒泡,看能够解决问题?
那我们尝试在触发子元素的click的时候,尝试组织子元素的冒泡,看能否解决我的问题?添加如下的代码:
$('[node-type=jsbridge]').bind('click',function(e){
// console.log(e.type);
e.stopPropagation();
});经过我的测试,代码是能够正常的运行的。
那么我们有没有更好的方法来解决上面的问题呢?请看接下来的内容
先来看 lable 标签的定义:
<label>标签为input元素定义标注(标记)。
label元素不会向用户呈现任何特殊效果。不过,它为鼠标用户改进了可用性。如果您在 label 元素内点击文本,就会触发此控件。就是说,当用户选择该标签时,浏览器就会自动将焦点转到和标签相关的表单控件上。
<label>标签的for属性应当与相关元素的 id 属性相同。
看想一下 w3school 的示例代码和效果:
<form> <label for="male">Male</label>
<input type="radio" name="sex" id="male" />
<br /> <label for="female">Female</label>
<input type="radio" name="sex" id="female" />
</form>效果如下图:
到这里应该之道我们该怎么改进我们的代码了,
<lable class="qr-btn" node-type="qr-btn" for="qr-input">扫描二维码1
<input node-type="jsbridge" id="qr-input" type="file" name="myPhoto" value="扫描二维码1" />
</lable>除了 lable 标签的样式我们自己需要自己定义外,还有两个优点:
lable 标签和 input 标签没有必要是包含关系最近做了一个抽奖的活动,其中就有一个轮盘的旋转的动画效果(注意啦,中间的那个卡顿是 gif 图片又重新开始播放了)。,效果如下图:
关于动画实现在下一篇文章中会继续介绍,这里主要来关注下布局的问题。因为我们页面会在 pc 和移动移动各出一套。所以在 pc 和移动我分别用了两种方案,pc 传统布局实现,h5 "弹性盒"实现。
外围的那些灯是使用绝对定位来做的,就不过过多的介绍,主要的是看中间的奖品九宫格的部分。html 代码如下:
<div class="re-middle">
<div class="row-a" node-type="row-a">
<div>mac pro</div>
<div>扫地机器人</div>
<div>iphone6s</div>
</div>
<div class="row-b" node-type="row-b">
<div>20积分</div>
<div></div>
<div>优惠券</div>
</div>
<div class="row-c" node-type="row-c">
<div>ps4</div>
<div>
<p>猴年限定</p>公仔</div>
<div>祝福红包</div>
</div>
<div node-type="reward-layer"></div>
</div>css代码如下:
.re-middle {
position: absolute;
width: 28.3rem;
height: 16rem;
top: 0;
left: 0;
right: 0;
bottom: 0;
margin: auto;
background-color: #f69f75;
color: #ffdece;
font-size: 1.8rem;
}
.row-a,
.row-b,
.row-c {
height: 5.3rem;
display: -webkit-box;
display: -webkit-flex;
display: -ms-flexbox;
display: flex;
-webkit-flex-flow: row nowrap;
-ms-flex-flow: row nowrap;
flex-flow: row nowrap;
}
.row-a div,
.row-b div,
.row-c div {
-webkit-box-flex: 1;
-webkit-flex: 1;
-ms-flex: 1;
flex: 1;
text-align: center;
line-height: 5.3rem;
background-color: #f69f75;
}由上面的 css 代码可以看出来我仅仅是在水平方向上使用了“弹性盒”,而在竖直的方向上,还是使用了固定高度(因为我是用的 rem 单位,这里的固定也是不准确的,高度会根据 fontsize 值进行计算。)
那么可不可以在竖直和水平都是用“弹性盒”呢?
来看一下下面的css代码:
.re-middle {
position: absolute;
width: 28.3rem;
height: 16rem;
top: 0;
left: 0;
right: 0;
bottom: 0;
margin: auto;
background-color: #f69f75;
display: -webkit-box;
display: -webkit-flex;
display: -ms-flexbox;
display: flex;
-webkit-box-orient: vertical;
-webkit-box-direction: normal;
-webkit-flex-direction: column;
-ms-flex-direction: column;
flex-direction: column;
color: #ffdece;
font-size: 1.8rem;
}
.row-a,
.row-b,
.row-c {
/*height: 5.3rem;*/
-webkit-box-flex: 1;
-webkit-flex: 1;
-ms-flex: 1;
flex: 1;
display: -webkit-box;
display: -webkit-flex;
display: -ms-flexbox;
display: flex;
-webkit-flex-flow: row nowrap;
-ms-flex-flow: row nowrap;
flex-flow: row nowrap;
}
.row-a div,
.row-b div,
.row-c div {
-webkit-box-flex: 1;
-webkit-flex: 1;
-ms-flex: 1;
flex: 1;
text-align: center;
line-height: 5.3rem;
background-color: #f69f75;
/*position: relative;*/
-webkit-box-align:center;
-webkit-align-items:center;
-ms-flex-align:center;
align-items:center;
}周末的时候关于这个布局自己又翻书看了下“弹性盒”的文档,终于实现了在竖直和垂直方向上都实现内容的水平垂直居中内部元素。其实上面的代码只需要把内容的父级元素再次定义为display:flex再添加两个属性justify-content和align-items就可以了。前者是控制弹性盒的内容垂直方向居中,后者控制内容水平方向居中。
详细代码如下:
.row-a div,
.row-b div,
.row-c div {
-webkit-box-flex: 1;
-webkit-flex: 1;
-ms-flex: 1;
flex: 1;
border: 1px solid #000;
-webkit-box-align: center;
-webkit-align-items: center;
-ms-flex-align: center;
align-items: center;
-webkit-box-pack: center;
-webkit-justify-content: center;
-ms-flex-pack: center;
justify-content: center;
display: -webkit-box;
display: -webkit-flex;
display: -ms-flexbox;
display: flex;
}与 h5 端相比,我在 pc 端的实现是传统的浮动方式.我的 HTML 代码如下:
<div class="re-middle">
<div class="row-a">
<div>mac pro</div>
<div class="row-a-sec">祝福红包</div>
<div class="row-a-last"> iphone 6s</div>
</div>
<div class="row-b clearfix">
<div>优惠券</div>
<div class="row-b-sec"></div>
<div class="row-b-last">20积分</div>
</div>
<div class="row-c">
<div>扫地机器人</div>
<div class="row-c-sec">猴年限定
<p>公仔</p>
</div>
<div class="row-c-last">ps4</div>
</div>
<div class="reward-btn"></div>
</div>css 代码如下:
.re-middle {
background-color: #f89f71;
width: 530px;
height: 320px;
position: absolute;
top: 0;
right: 0;
bottom: 0;
left: 0;
margin: auto;
}
.row-a,
.row-b,
.row-c {
/*height: 106px;*/
font-size: 0;
overflow: hidden;
}
.row-a > div,
.row-c > div {
float: left;
width: 176px;
height: 106px;
text-align: center;
}
.row-b div {
float: left;
width: 176px;
height: 106px;
text-align: center;
line-height: 106px;
background-color: #f69f75;
}由上面的 css 代码对比看我们可以显然看出传统的浮动方式的布局和“弹性盒”布局的一些优缺点:
float布局代码简洁,但是必须确定的指定盒子的宽度和高度,多屏幕的适配上会差一些(rem动态计算除外)。flex自身会去适配。遇到的一个小问题,多行文本的处置居中:
这个九宫格内的文本元素,如果只是单行的话,只要使用 line-height 就可以解决问题,但是如果多行呢?会出什么情况呢,看下图:
所以这里只能考虑不使用line-height,使用padding 来解决问题 ,尝试padding后的效果。如下图:
可以看到容器的下面多出了一部分。那也是我们使用的padding的问题,那么怎么解决这个问题呢?这就要用到之前提到过的box-sizing来解决问题。
.row-c-sec {
color: #ffdece;
font-size: 30px;
padding-top: 17px;
background-color: #f69f75;
/*使容器的高=内容高度+padding +border*/
box-sizing: border-box;
}在做“跑马灯”插件的时候遇到了一个问题,就是用户点击开始抽奖按钮以后在还没有返回结果的时候用户又第二次点击抽奖按钮,那个时候机会出现“奇葩”的问题。比如说:第一次请求和第二次请求重合返回的结果显示哪一个,就算允许用户进行二次抽奖,交互也不友好。而且如果前端页面不做限制的话,显示也会出现奇葩的问题。比如下面这样:
这样是不是很糟糕啊。。。
那么我是怎么解决这个问题呢?
答案很简单,我就是在点击按钮之后,使用绝对定位弹起了一个透明的弹层,将按钮给覆盖,等结果返回并显示以后,我在同时去掉弹层。这样就避免了用户的重复提交。详细看一下代码:
<div node-type="cover_layer"></div>.cover-layer{
width:100%;
height:100%;
top:0;
position:absolute;
z-index:9999;
}这里保证我的这个透明的弹层能够覆盖在抽奖按钮的上面。当然这个class 是我通过JavaScript动态的添加和删除的。
$(node).on('clcik','.reward-btn',function(){
//呼起弹层
$('[node-type=cover_layer]',node).addClass('cover-layer');
.....
//返回结果以后去掉弹层
$('[node-type=cover_layer]',node).removeClass('cover-layer');
.....
});这次的分享就到这里,下一次会分享“轮盘”抽奖效果的 JavaScript 开发过程。
较早的Nodejs开发者为了实现程序的同步都会使用几个“工具”,回调,promise,co,或者是generator。记得写过一个递归删除目录下文件和文件夹的需求,用以上方法都是各种不爽(关键我就是想简单的写个递归啊)。
就在前几天Nodejs发布了v7.6.0版本。Nodejs开发者终于不用使用第三方模块就可以使用async和await让自己的程序在不需要异步的地方保持同步的特性了。
就在Nodejs v7.6.0刚发布不久,koa的作者也正式的发布的koa2。
一句话总结:使用async和await是极大的解放生产力,减少脑细胞的消耗。
因为之前使用koa做了一个小项目,想着就把它给升级一下,及做一下网络请求方面的优化。
因为koa1.x和koa2.x区别还是挺大的。大部分的中间件目前已经做了针对koa2.x的兼容。没有做兼容的中间件,koa2.x本身也提供了方法进行兼容(后面会提到用法)。
升级的方法也很简单就是针对每一个中间件执行:yarn add koa-xxxxx@next 就可以升级到最新版本;
以下就是项目所依赖所有的中间件,都已经升级了最新的支持koa2。
"koa-bodyparser": "^3.2.0",
"koa-compress": "^2.0.0",
"koa-convert": "^1.2.0",
"koa-router": "^7.0.1",
"koa-static": "^3.0.0",
"koa-static-cache": "^4.0.0",
"koa-views": "^5.2.1",koa1.x的特点就是使用genetator来控制项目的同步,而koa2.x最大的特点就是使用async和await
generator的写法:
myRouter.get('/', function *(){
let body ;
let peopleList =configParams.onDutyPeople();
body = yield render('index', {'peopleList':peopleList});
this.body = body;
this.type='text/html; charset=utf-8';
});await的写法
router
.get('/', async(ctx, next) => {
let peopleList = configParams.onDutyPeople();
await ctx.render('index.jade', { 'peopleList': peopleList });
ctx.type = 'text/html; charset=utf-8';
})在做网络优化的时候用到一个中间件koa-static-cache。这个中间件目前是不兼容koa2.x的,那么怎么在Koa2.x中使用呢?
运行的时候报错信息如下:
通过网络查询得出原因如下:
解决方法如下,使用koa-convert中间件把generator转化一下,使用方法如下:
const convert = require('koa-convert');
const staticCache = require('koa-static-cache');
//静态文件服务
app.use(convert(staticCache(path.join(__dirname, 'public'), {
maxAge: 365 * 24 * 60 * 60
})));对于代码的重构就是这样子,在需要使用promise来控制异步的地方,可以换写成async和await降低了代码的复杂度。第二就是对不支持koa2.x的中间件使用koa-convert来做兼容。
通过下面的图片可以发现,页面在加载过程中请求了多个静态文件。这无疑会影响页面的加载速度。从打开页面到页面加载完成总共花费了2.59s
那么怎么优化呢?其实就是借用了请打的fis对静态文件进行了压缩和合并。使页面在加载过程需要多个静态文件,变成只请求两个静态文件。最后优化的结果是页面加载只需要1.76s比之前快了将近1s。效果还是很明显的。
当我在观察这些网络请求的时候发现一个问题。每次我刷新页面或者是关闭浏览器重新打开页面的时候,浏览器都没有使用本地的缓存文件,而是重新向服务器发送请求,下载需要的静态文件。看下面的截图:
做法也很简单,就是使用koa中间件koa-static-cache控制服务端的静态文件在客户单进行缓存。
//静态文件服务
app.use(convert(staticCache(path.join(__dirname, 'public'), {
maxAge: 365 * 24 * 60 * 60
})));我们来看看这样做到底有没有什么效果?看下面的截图(我多刷了几次页面):
与前面的那张截图做对比可以明显的发现,静态文件的下载时间变短了。页面加载时间变为了1.44s。比之前还是有所缩短的。而且在size那一栏会看到from memorycache和from disk cache这样的字段。而不再是显示具体的文件大小。关于这里的区别可以看文章最后的参考文章。
大多数情况下,我们的网站不仅仅就是存文字的还要包含一些其他类型的文件,比如:图片,mp3等。我们知道浏览器是支持加载gzip压缩过的网页的,所以以nginx为代表的静态文件服务器默认都会开启gzip压缩。那么我们Nodejs服务能不能对资源文件进行压缩呢?
答案是肯定的。Koa的作者写了一个中间件compress,支持对请求的response进行压缩,具体的使用如下:
var compress = require('koa-compress')
var Koa = require('koa')
var app = new Koa()
app.use(compress({
filter: function (content_type) { //配置过滤的压缩文件的类型
return /text/i.test(content_type)
},
threshold: 2048, //要压缩的最小响应字节
flush: require('zlib').Z_SYNC_FLUSH //同步的刷新缓冲区数据;
}))因为当前项目中并没有提价较大的文件,所以该中间件并没有在项目中使用。这里仅仅介绍koa有中间件提供这样的能力供开发者使用。
像这样node app.js来维护线上的服务肯定是不行。因为端口可能会不知不觉让linux给kill掉。目前在业界普遍使用的都是pm2来维护nodejs服务。提供了日志,端口被Kill后自动重启,性能监控等强大的功能。
使用pm2启动Nodejs进程后,会默认吧代码运行异常的错误和标准输出日志(比如:console.log)打到以下的目录下面。
提供了进行运行时相关信息;
提供了内存监控和cpu监控的命令。
FE到现在在大多数的后端工程师眼中都是切切页面,用js写写“特效”的角色。所以被大家戏称为“页面仔”。这也是为什么说FE是一个很容易遇到职业瓶颈的行业。
自从基于Nodejs的前后端开发模式在业界得到越来越多的实践后,前端工程师在其中扮演着重要的角色。由以上内容可以看出,在使用Nodejs以后,虽然前端技术栈得到了机房,但对FE的个人素质要求也会有所提高,性能优化,网络请求优化都是前端工程师需要去面临的问题。因为我们会成为用户发起的网络请求在服务端的第一层接收者,我们也会面临着web安全的问题。
简单说下为什么要来更新这篇博客的原因吧。这篇博客计算rem的方式是自己2014年刚毕业的时候做移动端项目写的。本身这段代码没有什么问题,但是在本地开发调试(比如chrome上) 因为设置 html 根元素的font-size=62.5% 导致在chrome上使用了rem单位的容器计算出来的正常的尺寸会有偏差(实际上在移动端设备上显示的又没有问题)。
这个问题的主要原因就是在pc上默认浏览器的字体最小只能显示 12px大小的字体**(当然这个说法也是指的大多数浏览器)。所以当使用这篇博客脚本的来做rem 的动态计算的时,如果元素的尺寸小于12px,在chrome上调试就会看到一个错误的容器尺寸。当时的一个简单的解决办法就是自己手动到chrome设置里面去设置chrome的可以显示的最小字体。**
先来看下在chrome 浏览器里面的测试效果: 第一张和第二张图分别是浏览器计算出的容器的宽度和高度,可以明显发现test1 的宽度多了2像素
同样的代码在safari中浏览器却可以计算出正确的大小,下图可以看到test1和test2的宽度和高度是一样的。
就在我修改这篇文章的时候,chome已经是v74.0xxxx版本。通过设置chrome的最小显示字体已经无法让刚才的测试demo正常显示出计算结果了。意思就是说当我们设置跟节点的html font-size 62.5% 时(根据 1rem=16px, 0.625rem = 10px),计算得到的是10px,chrome也会强制的将计算结果设置为 12px。所以在浏览器中就是 1rem=12px了。
下面再来简单介绍下为什么设置 font-size 62.5% 和怎么规避上面在chrome浏览器中计算误差的问题。
| rem | px |
|---|---|
| 1 | 16 |
| 0.625 | 10 |
| 6.25 | 100 |
由上面的表格可以知道当我们假设1rem = 16px时,那么10px=0.625rem,所以当我们选择10px为基准值的时候,假设我们需要设置的rem 值为 Y,设计稿的尺寸为 X,我们可以得出一个方程式:
10 * Y = 0.625 * X
也就是实际的rem设置的值就是
Y = (0.625 * X) / 10
又因为 rem 是一个相对于 html 跟节点 font-size 的一个相对值。当我们设置了根节点的 html 的font-size 62.5%时,需要设置的rem的值就是
Y = X / 10 (这里是一倍稿,当是2倍稿时,Y=X/10*2)
由以上的解析我们已经知道为什么设置font-size 62.5% 的由来了,而且存在的问题。那么怎么规避在chrome上会计算错误的问题呢?
规避这个问题的方式就是我们将基准值设置为大于chrome能够显示的最小字体 12px。为了方便计算,如上面的表格我们可以使用100px作为基准值。也就是设置根节点的font-size 625%。所以当我们根据设计稿尺寸计算rem尺寸的时候直接除100(如果是2倍稿就除2*100)。
下图可以看出来这种选择更大的基准值时,chrome浏览器可以正确的计算出元素的尺寸。
以上设置根节点font-size为百分比单位是一种使用rem适配的方案。还有一种设置font-size为动态的像素值(px),比如淘宝的 lib-flexible。那么简单解释下淘宝方案的换算方法。
我们都知道iphone6/7/8手机的屏幕宽度是375px。当我们的设计稿是以iphone6为标准输出时(假设是1倍稿),在lib-flexible中有一句代码注释如下:
它的意思就是 lib-flexible 认为 1rem = viewwidth/10,那么就有了下面的一个关系:
以一倍的iphone6设计稿为标准:
| rem | px |
|---|---|
| 1 | 37.5 |
当我们设置 37.5px 为基准值,也就是 font-size 37.5px 时,由前面介绍的换算公式当我们要设置rem值时,就是
Y = X / 37.5 (浏览器在计算的时候,实际是 37.5 * x / 37.5)
查看lib-flexible的源码可以看到这段js代码
if (dpr >= 2) {
var fakeBody = document.createElement('body')
var testElement = document.createElement('div')
testElement.style.border = '.5px solid transparent'
fakeBody.appendChild(testElement)
docEl.appendChild(fakeBody)
if (testElement.offsetHeight === 1) {
docEl.classList.add('hairlines')
}
docEl.removeChild(fakeBody)
}上面代码的意思就是检测屏幕的 dpr 是不是大于等于2,当满足条件是就在 html 根节点上添加 class="hairlines" 的属性,当我们要使用 0.5像素的时候可以这么写代码
.test1 {
width: 100px;
height: 100px;
border: 1px solid red;
}
.test2 {
width: 100px;
height: 100px;
border: 1px solid goldenrod;
}
/* 当满足dpr>=2时这段代码会生效,否者不会生效 */
.hairlines .test2 {
border: .5px solid goldenrod;
}建议使用淘宝的rem 方案解决移动端适配的问题。地址:https://github.com/amfe/lib-flexible
使用 rem 我们可以控制元素在不同设备上面等比例的缩放和扩大,根据设备的dpr可以实现真实的一像素。那么字体的大小使用什么适配呢?
在我的工作中(移动端项目)很少需要对字体进行适配。主要也是产品或者是UE、UI都对这里没有需求。直接使用的设计稿的 px尺寸。
如果是需要对字体进行适配我们应该怎么做呢?
rem使用
rem会有点儿小问题,在安卓手机上dpr不统一,以及宽度的不统一,上面的两种方法都是尽可能的接近适配需要的大小。
这里介绍个前端关于字体使用最经常使用的两个概念。
**衬线体:**具有装饰性(有边角);代表字体:Times New Roman。常用于印刷品(书本杂志等),适用于长篇文章段落,因为边角易于辨别每个字母,读者在阅读较多的段落时会变得轻松。
**非衬线体:**顾名思义就是无装饰性(无边角),易识别;代表字体:Helvetica (iOS7、iOS8的预设字体)、San Francisco(iOS9、iOS10的预设字体)、Roboto(Android L的预设字体)、Arial(windows的预设字体);缺点:某些字母相对难区分,如大些的I(i)与小写的l(L)。常用语电子设备。
rem 单位在做移动端的h5开发的时候是最经常使用的单位。为解决自适应的问题,我们需要动态的给文档的更节点添加font-size 值。使用mediaquery 可以解决这个问题,但是每一个文件都引用一大串的font-size 值很繁琐,而且值也不能达到连续的效果。
就使用js动态计算给文档的fopnt-size 动态赋值解决问题。
使用的时候,请将下面的代码放到页面的顶部(head标签内);
/**
* [以iPhone6的设计稿为例js动态设置文档 rem 值]
* px和 rem的换算方式是 设计稿尺寸除100 如果是2倍稿 则是设计稿尺寸 除 2*100=200 3倍稿尺寸可以类推。
* @param {[type]} currClientWidth [当前客户端的宽度]
* @param {[type]} fontValue [计算后的 fontvalue值]
* @return {[type]} [description]
*/
<script>
var currClientWidth, fontValue,originWidth;
//originWidth用来设置设计稿原型的屏幕宽度(这里是以 Iphone 6为原型的设计稿)
originWidth=375;
__resize();
//注册 resize事件
window.addEventListener('resize', __resize, false);
function __resize() {
currClientWidth = document.documentElement.clientWidth;
//这里是设置屏幕的最大和最小值时候给一个默认值
if (currClientWidth > 640) currClientWidth = 640;
if (currClientWidth < 320) currClientWidth = 320;
//
fontValue = ((625 * currClientWidth) /originWidth).toFixed(2);
document.documentElement.style.fontSize = fontValue + '%';
}
</script>声明:这个系列为阅读《JavaScript设计模式与开发实践》 ----曾探@著一书的读书笔记
将不变的部分和变化的部分隔开是每个设计模式的主题。
定义一系列的算法,把它们一个个封装起来,并且使它们可以相互替换。
将算法的使用与算法的实现分离开来。
使用策略模式来实现计算奖金
var performances = function () {};
performances.prototype.calculate = function (salary) {
return salary * 4;
};
var performanceA =function () {};
performanceA.prototype.calculate=function (salary) {
return salary * 3;
};
var performanceB =function () {};
performanceB.prototype.calculate=function (salary) {
return salary * 2;
};
//定义奖金类Bonus
var Bonus =function () {
this.salary = null; //原始工资
this.strategy = null;//绩效等级对应的策略对象
};
Bonus.prototype.setSalary=function (salary) {
this.salary=salary; //设置员工的原始工资
};
Bonus.prototype.setStrategy=function (strategy) {
this.strategy=strategy;//设置绩效等级对应的策略对象
};
Bonus.prototype.getBonus =function () { //取得奖金数额
return this.strategy.calculate(this.salary);//把计算奖金的操作委托给对应的策略对象
};
var bonus = new Bonus();
bonus.setSalary(10000);
bonus.setStrategy(new performances());//设置策略对象
console.log(bonus.getBonus());
bonus.setStrategy(new performanceA());
console.log(bonus.getBonus());定义有系列的算法,把它们各自封装成策略类,算法被封装在策略类内部的方法里。在客户端对Context发起请求的时候,Context总是把请求委托给这些策略对象中间的某一个进行计算。
//封装的策略算法
var strategies={
"S":function (salary) {
return salary * 4;
},
"A":function (salary) {
return salary * 3;
},
"B":function (salary) {
return salary * 2;
}
};
//具体的计算方法
var calculateBonus=function (level, salary) {
return strategies[level](salary);
};
console.log(calculateBonus('S',1000));
console.log(calculateBonus('A',4000));使用策略模式重构代码,可以消除程序中大片的条件分支语句。在实际开发中,我们通常会把算法的含义扩散开来,使策略模式也可以用来封装一系列的“业务规则”。只要这些业务规则指向的目标一致,并且可以被替换使用,我们就可以使用策略模式来封装他们。
//策略对象
var strategies = {
isNonEmpty: function (value, errorMsg){
if (value === '') {
return errorMsg;
}
},
minLength: function (value, length, errorMg){
if (value.length < length) {
return errorMg;
}
},
isMobile: function (value, errorMsg){
if (!/(^1[3|5|8][0-9]{9}$)/.test(value)) {
return errorMsg;
}
}
};
/**
* Validator 类
* @constructor
*/
var Validator = function (){
this.cache = [];
};
Validator.prototype.add = function (dom, rules){
var self = this;
for (var i = 0, rule; rule = rules[i++];) {
(function (rule){
var strategyAry=rule.strategy.split(':');
var errorMsg=rule.errorMsg;
self.cache.push(function (){
var strategy=strategyAry.shift();
strategyAry.unshift(dom.value);
strategyAry.push(errorMsg);
return strategies[strategy].apply(dom,strategyAry);
})
})(rule)
}
};
Validator.prototype.start=function (){
for (var i=0,validatorFunc;validatorFunc=this.cache[i++];){
var errorMsg=validatorFunc();
if(errorMsg){
return errorMsg;
}
}
};
//客户端调用的代码
var registerForm=document.getElementById('registerForm');
var validataFunc=function (){
var validator=new Validator();
validator.add(registerForm.userName,[{
'strategy':'isNonEnpty',
'errorMsg':'用户名不能为空'
},{
'strategy':'minLength',
'errorMsg':'用户名长度不能小于10位'
}]);
// validator.add(registerForm.password,[])
var errorMsg =validator.start();
return errorMsg;
};
registerForm.onsubmit=function (){
var errorMsg=validataFunc();
if(errorMsg){
alert(errorMsg);
return false;
}
};优点:
strategy中,使得它们易于切换,易于理解,易于扩展。Context拥有执行算法的能力,这也是继承的一种更轻便的替代方案。缺点:
strategy和他们之间的不同点,这样才能选择一个合适的strategy。在函数作为一等对象的语言中,策略模式是隐形的。strategy就是值为函数的变量。
在JavaScript中,除了使用类来封装算法和行为之外,使用函数当然也是一种选择。这些“算法”可以被封装到函数中并且四处传递,也就是我们常说的“高阶函数”。
实际上在JavaScript这种将函数作为一等对象的语言里,策略模式已经融入到了语言本身当中,我们经常使用高阶函数来封装不同的行为,并且把它传递到另一个函数中。当我们对这些函数发出“调用”的消息时,不同的函数会返回不同的执行结果。所以在JavaScript中,“函数对象的多态性”会更加简单些。
在JavaScript语言的策略模式中,策略类往往被函数所代替,这时策略模式就成了一种“隐形”的模式。
h5端开发下面这段话是必须配置的
<meta name="viewport" content="width=device-width, initial-scale=1, user-scalable=no">其它相关配置内容如下:
之前在做移动端开发的时候,为了适配多屏幕。使用的是rem 单位。这个时候就需要根据屏幕的尺寸来来动态的设置根节点html 的font-size 值。这样可以解决多屏幕适配的问题。
比如下面的 媒体查询代码
html {
//iphone5
font-size: 62.5%;
}
@media (max-width: 414px) {
html {
//iphone6+
font-size: 80.85%;
}
}
@media (max-width: 375px) {
html {
//iphone6
font-size: 73.24%;
}
}
这样做的结果,有两个很明显的缺点。
后来参考淘宝移动端页面适配规则,使用 js 获取客户端的宽度,根据设计稿的原型动态的计算font-size 的值。
详细的内容请看这里 根据iPhone6设计稿动态计算rem值
大多数时候我们都会给一片区域加上点击跳转的功能。如下图:
很可能我们商品区域都是使用的div 标签。很容易我们会给最外层加上一个 a 标签。因为a 是行内元素,是没有宽和高的。不能够把容器撑开。
一种解决办法就是给a 标签设置block 属性。如下:
<style>
a{display:block;}
</style>
<a>
<div></div>
</a>功能上已经没有问题。但是在语义化的层面上,上面的代码是不标准的。
最好的做法就是做如下的修改,这样不会使自己的 html 代码显的太突兀:
<style>
a{display:block;}
span{dispaly:block;}
</style>
<a>
<span></span>
<span></span>
<span></span>
</a>如果我们使用的是rem 单位,使用 js 动态计算font-size 值的话,我们可以无限适配最大和最小的终端屏幕。但是当用户的屏幕超过一定的尺寸以后还继续显示h5页面的话对用户会很不友好。
我们参看下京东和淘宝的h5 页面
我们看到了都是定义了页面的最大和最小宽度。这样在屏幕超过一定的尺寸以后可以更友好的展示(当然这不是必须的)。
我给自己的产品页面定义的最大的宽度和最小宽度分别是:
{
max-width:640px;
min-width:320px;
}在移动端使用 a标签做按钮的时候,点按会出现一个“暗色”的背景,去掉该背景的方法如下
a,button,input,optgroup,select,textarea {
-webkit-tap-highlight-color:rgba(0,0,0,0); /*去掉a、input和button点击时的蓝色外边框和灰色半透明背景*/
}使用 a标签的时候,移动端长按会出现一个 菜单栏,这个时候禁止呼出菜单栏的方法如下:
a, img {
-webkit-touch-callout: none; /*禁止长按链接与图片弹出菜单*/
}body{
-webkit-overflow-scrolling:touch;
}单行截断字符串,这里必须指定字符串的宽度
{
/*指定字符串的宽度*/
width:300px;
overflow: hidden;
/* 当字符串超过规定长度,显示省略符*/
text-overflow:ellipsis;
white-space: nowrap;
}之前在做布局的时候使用calc 出现了很严重的线上 BUG。后来就深究了下这个属性的使用。
calc好用的地方就是,可以在任何单位之间进行换算。但是浏览器支持的不是很好。看一下 can i use 截图:
而且在使用的时候要加上厂商前缀,达到兼容性。不过现在不推荐使用,毕竟,浏览器支持有限。
示例代码:
#formbox {
width: 130px;
/*加厂商前缀,操作符(+,-,*,/)两边要有空格)*/
width: -moz-calc(100% / 6);
width: -webkit-calc(100% / 6);
width: calc(100% / 6);
border: 1px solid black;
padding: 4px;
}研究过淘宝,天猫,京东的 h5端页面看到这个单位用的不多,主要还是兼容性的问题吧。
解决盒模型在不同浏览器中表现不一致的问题。但是仍然会有兼容性问题。看最下面的浏览器支持列表。
box-sizing 属性用来改变默认的 CSS 盒模型 对元素高宽的计算方式。这个属性用于模拟那些非正确支持标准盒模型的浏览器的表现。
它有三个属性值分别是:
content-box默认值,标准盒模型。 width 与 height 只包括内容的宽和高, 不包括边框,内边距,外边距。注意: 内边距, 边框 & 外边距 都在这个盒子的外部。 比如. 如果 .box {width: 350px}; 而且 {border: 10px solid black;} 那么在浏览器中的渲染的实际宽度将是370px;
padding-boxwidth 与 height 包括内边距,不包括边框与外边距。
border-boxwidth 与 height 包括内边距与边框,不包括外边距。这是IE 怪异模式(Quirks mode)使用的 盒模型 。注意:这个时候外边距和边框将会包括在盒子中。比如 .box {width: 350px; border: 10px solid black;} 浏览器渲染出的宽度将是350px.
浏览器支持:
可以看之前写定位的一篇文章,末尾有讲到各种定位:【从0到1学Web前端】CSS定位问题三(相对定位,绝对定位)
这里实现一个相对定位和绝对定位配合实现水平垂直居中的样式。看效果:
html 代码如下:
<div class="parent-div">
<div class="child-div"></div>
</div>css代码如下:
.parent-div{
width: 100px;
height: 100px;
background-color:red;
position:relative;
}
.child-div{
width:50px;
height:50px;
background-color:#000;
position: absolute;
margin:auto;
top:0;
left:0;
right:0;
bottom:0;
}绝对定位在布局中可以很方边的解决很多问题,但是大多数时候都不去使用绝对定位,而是使用浮动等方法。而当需要 DOM 元素脱离当前文档流的时候才使用绝对定位。如: 弹层,悬浮层等。
line-height 一个很重要的用途就是让我们的文本可以在父级元素中垂直居中,但是在使用它的过程中也会遇到一些问题。
先来看一个实例,如下图:
代码也很简单,就是当我们在div 中定义的字体很大的情况下,我们看到字体和父级元素之间有一些空隙。那么这是为什么?
我们查一下 line-height 的定义,如下:
normal默认。设置合理的行间距。
number设置数字,此数字会与当前的字体尺寸相乘来设置行间距。
length设置固定的行间距。
%基于当前字体尺寸的百分比行间距。
inherit规定应该从父元素继承 line-height 属性的值。
所以在以上的情况我们要想使,我们的字体能够撑满我们的容器,就需要给父级容器添加 line-height属性且值为 100%
代码和效果如下:
那么为什么会出现上面的问题呢?
line-height 与 font-size 的计算值之差(行距)分为两半,分别加到一个文本行内容的顶部和底部。
所以,可以得出下面的一个公式:
空白间距 = line-height - font-size
所以,当设置为line-height 的值为100%的时候,line-height的值就等于 font-size的尺寸,此时的空白间距为0。
很多时候我们要把图标和文字配合使用,而且需要图标和文字都能够垂直居中。如下图所示:
如果要实现文字的垂直居中很容易,只需要使用line-height=父容器高度 。但是要想使图标能够垂直居中就比较麻烦。
正常情况下我们的文字或者说相邻的容器,都应该和文字保持在相同的底线上,如下图:
明显的可以看到我们的返回图标不是垂直居中的。那么应该怎么样使图标垂直居中呢?
首先,我们先来搞清楚几个线的关系(图片来源于网络,侵权请告知):
这样我们就要用到 vertical-align 这个属性,最重要的一点是:
指定了行内(inline)元素或表格单元格(table-cell)元素的垂直对齐方式
baseline:将支持valign特性的对象的内容与父级元素基线对齐
sub:元素基线与父元素的下标基线对齐。
super:元素基线与父元素的上标基线对齐。
top: 元素及其后代的顶端与整行的顶端对齐。
text-top:元素顶端与父元素字体的顶端对齐。
middle:元素中线与父元素的基线对齐。
bottom:元素及其后代的底端与整行的底端对齐。
text-bottom:元素底端与父元素字体的底端对齐。
percentage:用百分比指定由基线算起的偏移量。可以为负值。基线对于百分数来说就是0%。
length:用长度值指定由基线算起的偏移量。可以为负值。基线对于数值来说为0。(CSS2)
看下边的一段 html :
<div class="title-div">
<img src="1_icon.png" alt="返回图标">
<!-- <span >图标位置</span> -->
<span>我就是标题</span>
</div>最初的结果是这样子的
我们想实现如下图所示的结果,图标相对于右边的字体居中:
这个时候我们就要使用vertical-align属性和设置他的length属性,即设置我们的图标相对与文字基线的偏移量。
当我们加入属性的时候很容易使图标和文字都垂直居中。
{
vertical-align:15px;
}这个时候就会是我们的图标和字体相对于父级元素居中。
flex 现在 pc 端支持的不好(主要是因为还有很多 IE8,9的用户存在。)大多情况下我们都是在移动端使用flex布局。但是就算是这样,也会有很多坑人的 bug出现。
谈谈一些基本的使用经验吧,什么时候使用 flex 。
先来看一个产品模型如下图
我的左边商品和右边商品的宽度是一样的。当我看到这个模型的时候,第一件就是想就是使用 flex 让我们两列商品列表平分屏幕区域。这个时候就是用flex 来做。
父级元素如下定义
{
margin-bottom: .5rem;
display: box;
display: -webkit-box;
display: -ms-flexbox;
display: flex;
display: -webkit-flex;
-webkit-flex-flow: row;
-ms-flex-flow: row;
flex-flow: row;
}使用 flex 的时候一定要记得加厂商前缀(目前使用方式都有三种写法:1,旧的2,过度的3,新的)。不然肯定会有兼容性问题。
{
display: -webkit-box;
display: -ms-flexbox;
display: flex;
display: -webkit-flex;
}先看我的代码:
{
box-flex: 1;
-webkit-box-flex: 1;
-webkit-flex: 1;
-ms-flex: 1;
flex: 1;
width: 18.5rem;
}这里只是让左右两边平分屏幕的宽度。
之前使用 flex在安卓4.3的手机上遇到一个问题。正常的页面应该如下图所示,
但是在 安卓4.3的手机上却是如下的结果
后来研究了下天猫的页面(因为之前使用这个 flex 就是参考天猫来学习的),看到他们在定义flex值的时候 都会有这样的一个属性width=0;
而且当我给我的页面也加上这个属性的时候,页面的布局也变得正常了。我现在想不明白愿意是什么,只能当一个 hack 来使用。如果大家也遇到这个问题,请试一下添加这个属性。如果大家知道为什么这么用,请指教一下。
给大家推荐一个网站(点击这里)可以检测我们平时使用的 css 属性改变元素样式的时候,触发的是 cpu还是 gpu ,特别是在做动画的时候,如果使用 gpu 渲染图形,可以减少 cpu 的消耗,提高程序的性能。
比如我们做一个 slider 动画切换图片位置的时候,会使用margin-left的属性,通过网站查询该属性值得到如下的结果
由上可以知道使用margin-left 的时候会处罚页面的重绘和重排。
但是当我们使用css3新属性transform 来代替传统的 margin-left 来改变元素位置的时候对页面有什么影响呢?先来看下网站查询的结果:
由查询结果可以知道,使用transform 不会触发任何的重绘。而且会触发 gpu 来帮助页面的排版。即使用GPU操作渲染动画,减少cpu的消耗,提高性能。
css动画简单实例,css代码如下:
.lottery-animation {
-webkit-animation: lottery-red 2s;
animation: lottery-red 2s;
-webkit-animation-iteration-count: infinite;
animation-iteration-count: infinite;
}
@-webkit-keyframes lottery-red {
from {
-webkit-transform: rotateY(0deg);
transform: rotateY(0deg);
}
to {
-webkit-transform: rotateY(360deg);
transform: rotateY(360deg);
}
}
@keyframes lottery-red {
from {
-webkit-transform: rotateY(0deg);
transform: rotateY(0deg);
}
to {
-webkit-transform: rotateY(360deg);
transform: rotateY(360deg);
}
}效果如下图:
这里我只是对图像标签添加了一个 class="lottery-animation"
我截取动态图片软件的问题,我的这个gif 截图动画有些卡顿,不流畅。在正常机器上是没有问题的(如果大家有mac下好用的 gif截图软件可以推荐给我,谢谢!)。
关于 css3 动画性能优化推荐阅读文章:
1.前端性能优化之更平滑的动画(更新)
2.CSS3硬件加速也有坑!!!
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
































































































































































































































