Welcome to the repository, where I've fine-tuned the Mistral 7B model specifically for the generation of HTML code.
- Model Section.
- Data Preparation.
- Tokenization.
- Fine-Tuning with LoRA
- Evaluation
- API dev
The primary goal of this assignment was to fine-tune the Mistral 7B model for generating HTML code from natural language prompts.
I utilized the jawerty/html_dataset from Hugging Face Datasets, containing 43 examples of natural language prompts paired with corresponding HTML code.
- At the core of Mistral 7B lies a Transformer architecture, a fundamental component of modern language models. Nevertheless, it introduces several groundbreaking innovations that contribute to its exceptional performance. In comparison to Llama, it brings about some significant changes:
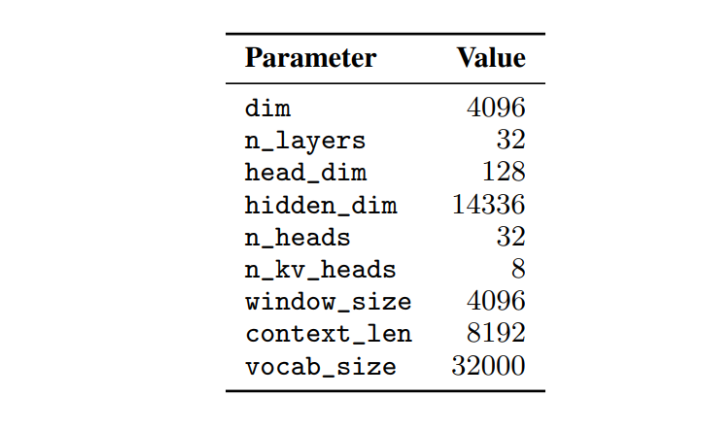
- The Mistral 7B model, a 7.3B parameter transformer with Grouped-query attention (GQA) and Sliding Window Attention (SWA), was selected for its optimal balance between performance and efficiency. GQA enhances inference speed, while SWA handles longer sequences effectively.
I carefully prepared the data by splitting it into training and testing sets, adding special tokens, padding, and masking. Token distribution visualizations were employed, experimenting with LangChain Recursive Splitter and SWA features to handle large token lengths in HTML code.
The fine-tuning process involved the use of Low Rank Adaptation (LoRA), a parameter-efficient approach that outperformed full finetuning in certain cases.
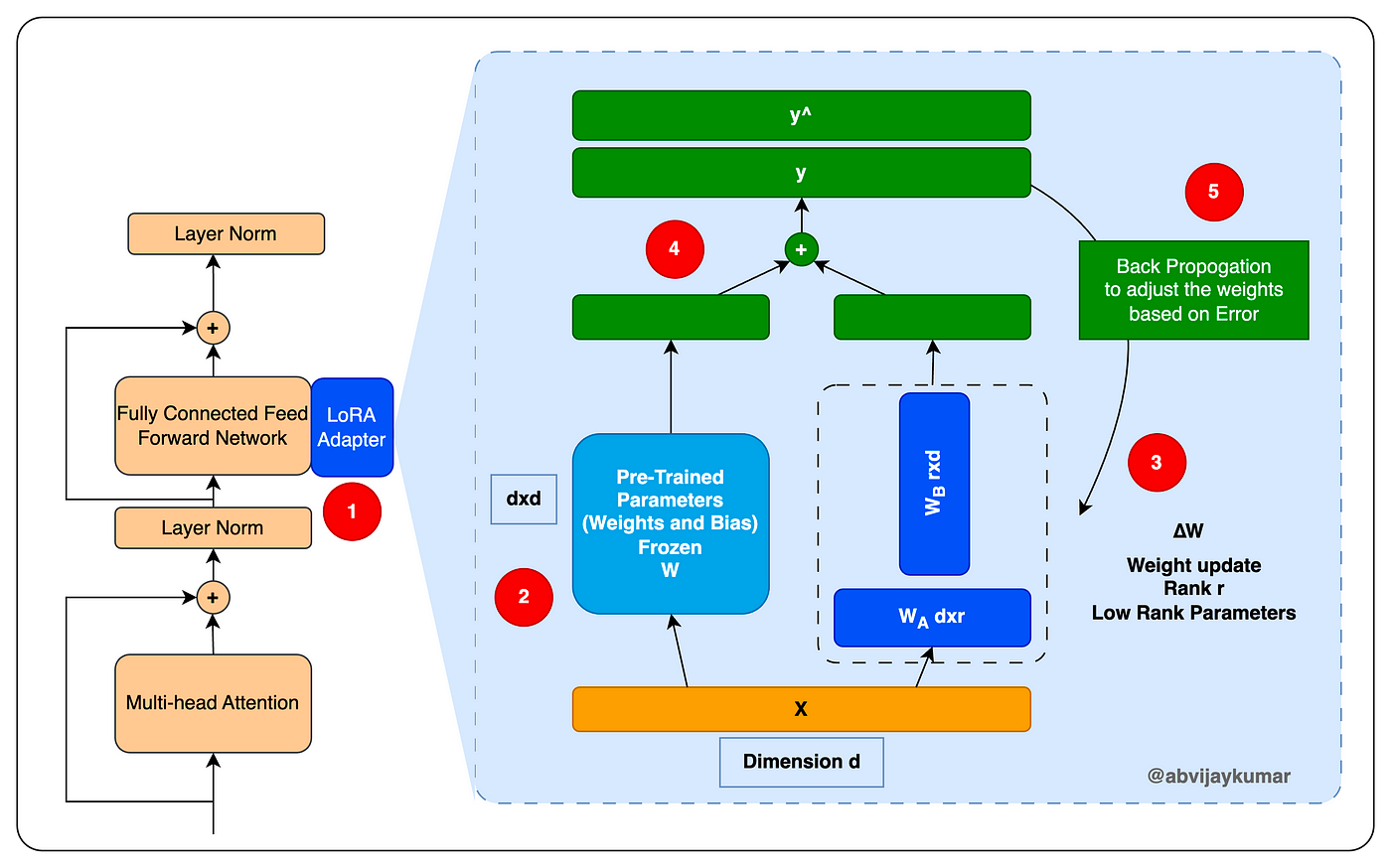
Leveraging the Hugging Face PEFT library, I set hyperparameters based on model documentation and employed the PyTorch Trainer class for efficient training. WandB was used for visualization and tracking during training.
To facilitate user interaction with the fine-tuned model, I implemented an API using Flask. Users can input natural language queries, and the model will generate corresponding HTML code. This enhances the practical application of the model by making it accessible and user-friendly.
The model's performance was evaluated using ROUGE scores (1, 2, L), perplexity, and visual inspection of generated HTML code. WandB facilitated result logging and comparison between different data preparation methods.
Challenges included GPU interruptions during training in Colab, handling large token lengths in HTML codes, and the complexity of tensor manipulation and training parameters.
- Token Distribution Visualizations

Check out the documentation at this link -> Access Here👆
In conclusion, my journey from model selection to fine-tuning, evaluation, and API development has been both challenging and rewarding. Thank you for reading, and I hope you find this Readme.md was helpful and informative.
This project is licensed under the terms of the MIT license. See the LICENSE file for details.
