- Abstract:
Data augmentation has been established as an efficacious approach to supplement useful information
for low-resource datasets. Traditional augmentation techniques such as noise injection and image
transformations have been widely used. In addition, generative data augmentation (GDA) has been shown
to produce more diverse and flexible data. While generative adversarial networks (GANs) have been
frequently used for GDA, they lack diversity and controllability compared to text-to-image diffusion
models. In this paper, we propose TTIDA (Text-to-Text-to-Image Data Augmentation) to leverage the
capabilities of large-scale pre-trained Text-to-Text (T2T) and Text-to-Image (T2I) generative models
for data augmentation. By conditioning the T2I model on detailed descriptions produced by T2T models,
we are able to generate photo-realistic labeled images in a flexible and controllable manner.
Experiments on in-domain classification, cross-domain classification, and image captioning tasks show
consistent improvements over other data augmentation baselines. Analytical studies in varied settings,
including few-shot, long-tail, and adversarial, further reinforce the effectiveness of TTIDA in
enhancing performance and increasing robustness.
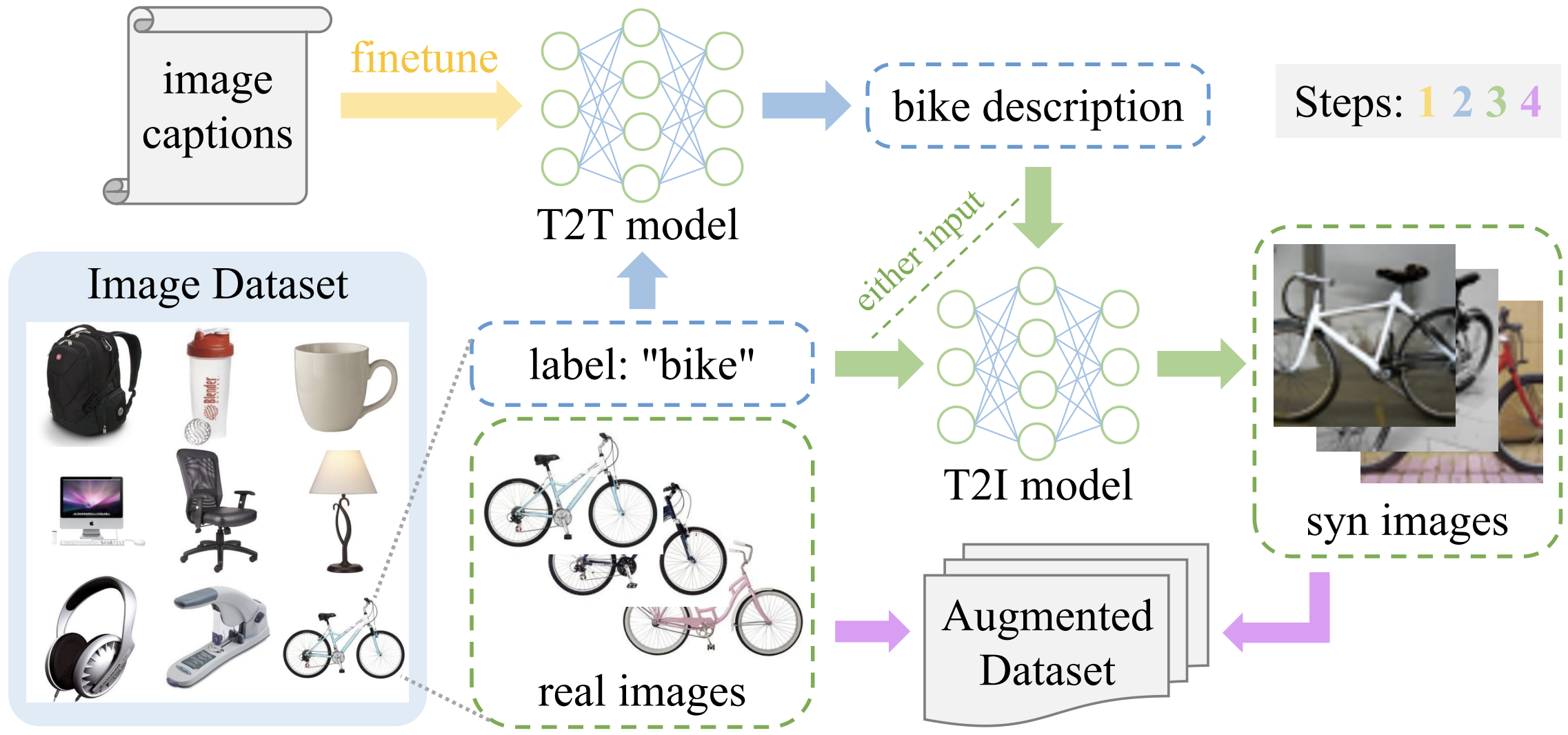
In the overview Figure, arrows in different colors denote different pipeline steps. For each object category, i.e., bike, we input the label text "bike" to the T2I model such as GLIDE to generate multiple photo-realistic images of this object (Step 3). Then we combine the real images from the original dataset with the generated synthetic images together (Step 4). The augmented dataset is directly used for model training. Usually, the label text is a word or short phrase. To automatically obtain a finer prompt for the T2I model, we can first input the label text to a text-to-text (T2T) generative model finetuned with image captions (Step 1) to produce a longer object description (Step 2), e.g., "a white bike near the wall". Step 1 and Step 2 are optional since the T2I model can still generate high-quality images with the label text input. Yet the T2T model can produce precise or personalized object descriptions with a richer context, increasing the diversity of synthetic images to a large extent.
conda create -n ttida python=3.9
conda activate ttida
pip install -r requirements.txt- In-domain Image classification
- CIFAR-100: https://www.cs.toronto.edu/~kriz/cifar.html
data/cifar100/apple/0.png,data/cifar100/aquarium_fish/, ...,data/cifar100/worm/
- CIFAR-100: https://www.cs.toronto.edu/~kriz/cifar.html
- Cross-domain Image classification
- Office-31: https://faculty.cc.gatech.edu/~judy/domainadapt/#datasets_code
data/cross_domain/office-31/amazon/,data/cross_domain/office-31/dslr/,data/cross_domain/office-31/webcam/
- Office-Home: https://www.hemanthdv.org/officeHomeDataset.html
data/cross_domain/office-home/Art/,data/cross_domain/office-home/Clipart/, ...
- Office-31: https://faculty.cc.gatech.edu/~judy/domainadapt/#datasets_code
- Image Captioning
- COCO 2015 Image Captioning Task: https://cocodataset.org/#captions-2015
data/COCO_2015_Captioning/train2014/
- COCO 2015 Image Captioning Task: https://cocodataset.org/#captions-2015
| Dataset (Domain) | #img total | #classes | #img per class |
|---|---|---|---|
| CIFAR-100 | 50000 | 100 | 500 |
| Office-31 (Amazon) | 2817 | 31 | 91 |
| Office-31 (DSLR) | 498 | 31 | 16 |
| Office-31 (Webcam) | 795 | 31 | 26 |
| Office-Home (Art) | 2427 | 65 | 37 |
| Office-Home (Clipart) | 4365 | 65 | 67 |
| Office-Home (Product) | 4439 | 65 | 68 |
| Office-Home (Real-World) | 4357 | 65 | 67 |
- In-domain Image classification
- Cross-domain Image classification
- CDTrans: https://github.com/CDTrans/CDTrans
- Image Captioning
- Img Trans: https://github.com/facebookresearch/moco-v3
- DCGAN: https://github.com/pytorch/examples/tree/main/dcgan
- CycleGAN: https://github.com/junyanz/CycleGAN
- StyleGAN: https://github.com/NVlabs/stylegan3
- TTIDA (Ours):
- In-domain Image classification (ResNet-101 on CIFAR-100 of different settings)
cd img_clf
bash run_train_cifar100.sh
bash run_train_cifar100_adv.sh
bash run_train_cifar100_gan.sh
bash run_train_cifar100_lt.sh
bash run_train_cifar100_trans.sh- Cross-domain Image classification (CDTrans on Office-31 and Office-Home)
cd cdtrans
bash run_train_office_31.sh
bash run_train_office_home.sh- Image Captioning (mPLUG on COCO 2015 Image Captioning Task)
cd mplug
bash run_train_coco.shPlease refer to the LICENSE file for more details.
@article{yin2023ttida,
title = {TTIDA: Controllable Generative Data Augmentation via Text-to-Text and Text-to-Image Models},
author = {Yin, Yuwei and Kaddour, Jean and Zhang, Xiang and Nie, Yixin and Liu, Zhenguang and Kong, Lingpeng and Liu, Qi},
journal = {arXiv preprint arXiv:2304.08821},
year = {2023},
url = {https://arxiv.org/abs/2304.08821},
}




