yhzhtk / note Goto Github PK
View Code? Open in Web Editor NEW知识代码笔记
Home Page: https://github.com/Yhzhtk/note/issues
License: MIT License
知识代码笔记
Home Page: https://github.com/Yhzhtk/note/issues
License: MIT License




















































































































浅Clone:仅Clone对象,其内部的字段若存在其他对象便是引用
深Clone:会将整个对象全部 Clone 一遍,内部所有类和对象都会被Clone
任何类都默认基础 Object,而 Object 类有一个 protect 的方法
protected native Object clone() throws CloneNotSupportedException;
疑问
如果是对象内部的对象也实现了 Cloneable 接口,那么外部对象的 Clone 会 调内部的 clone,而不是引用吗?? 测试的答案是即便内部对象实现了 Cloneable,也是浅Clone
实现 Serializable 接口,可以使用如下方法来实现深度Clone
//将对象写到流中
ByteArrayOutputStream bo=new ByteArrayOutputStream();
ObjectOutputStream oo=new ObjectOutputStream(bo);
oo.writeObject(this);
//从流中读出来
ByteArrayInputStream bi=new ByteArrayInputStream(bo.toByteArray());
ObjectInputStream oi=new ObjectInputStream(bi);
return oi.readObject();
使用其他序列化方法,如 json、xml、kryo 等
看一下,以下代码会输出什么?
public static void main(String[] args) {
boolean t1 = true;
boolean t2 = true;
boolean f1 = false;
boolean f2 = false;
// 前面是||
System.out.println(t1 || f1 && f2);
System.out.println((t1 || f1) && f2);
System.out.println(t1 | f1 & f2);
System.out.println((t1 | f1) & f2);
// 前面是&&
System.out.println(t1 && f1 || t2);
System.out.println(t1 && (f1 || t2));
System.out.println(t1 & f1 | t2);
System.out.println(t1 & (f1 | t2));
}
还记得有过这样的说法吗?
1、当 || 时,只要前面的结果为true时,后面无论怎么都是true,
2、当 && 时,只要前面的结果为false,2后面的结果无论怎样都是false。
正确结果如下:你的答案是对的嘛:
true
false
true
false
true
true
true
true
很显然,说法1是正确的,但是说法2是错误的。
原因很简单,这个只是一个结论,而真正的计算方式应该考虑优先级。&& 的运算符优先级比 || 高。说法1、2都只是根据优先级来推论出来的,JVM会对指定的运算进行优化。
至于 &&,&,||,|的区别,看下面的说明吧:
boolean a, b;
Operation Meaning Note
--------- ------- ----
a && b logical AND short-circuiting
a || b logical OR short-circuiting
a & b boolean logical AND not short-circuiting
a | b boolean logical OR not short-circuiting
a ^ b boolean logical exclusive OR
!a logical NOT
short-circuiting (x != 0) && (1/x > 1) SAFE
not short-circuiting (x != 0) & (1/x > 1) NOT SAFE
short-circuiting 直译是短路的意思,具体为什么不安全,现在我也不太清楚。看到了可以讨论下。
OOM killer 是什么意思,可以在网上查一下,很多资料,这里不再解释。
其中有三个相关文件:
其中 oom_score 表示最终的分数,该分数越大,越可能被 Killer 杀掉。
而 oom_adj 是调整分数的,可以设置为负值,会对 oom_score减分。
从Linux 2.6.36开始都安装了/proc/$PID/oom_score_adj,此后将替换为/proc/$PID/oom_adj。详细内容请参考Documentation/feature-removal-schedules.txt。即使当前是对/proc/$PID/oom_adj进行的设置,在内核内部进行变换后的值也是针对/proc/$PID/oom_score_adj设置的。
通过 cat /proc/$PID/oom_score 可以查看进程的得分,下面的脚步是可以查询系统所有进程的 oom_score。
ps -eo pid,comm,pmem --sort -rss | awk '{"cat /proc/"$1"/oom_score" | getline oom; print $0"\t"oom}'
上面的命令会得到如下结果:
PID COMMAND %MEM
28810 java 36.1 178
4648 java 22.7 124
14489 java 18.3 119
30511 java 11.7 91
14135 salt-minion 0.2 1
29424 rsyslogd 0.1 1
23480 pickup 0.0 1
1343 qagent 0.0 1
5586 sshd 0.0 1
22999 collectd 0.0 1
其中第一列是PID,第二列是进程,第三列表示内存使用百分比,最后一列即为 oom_score。
最容易被杀掉的是 28810 这个 java 程序,因为分数最高。
脑裂
拜占庭问题
缓存击穿
热点库存扣减
Paxos算法
从昨天网上看到heroku,一个云平台服务,可以在上面搭建自己的应用,支持Java,Ruby,Python,而且在一定限额内都是免费。相比Github Pages,heroku最大的特点就是支持动态页面,可以用数据库,而Github Pages仅仅是个静态页托管。
知道了这个,我就琢磨起来,看看好不好用。打开主页,比较慢,注册,登录,看看基本的文档,很慢,但是等等都能打开,那就等了。看文档说Java可以安装Eclipse的Heroku插件可以开发时,那就安装插件,包括heroku,git,mvn,安装也很慢,那只能等了。
今天早上来,一切都安装好。创建应用,打开应用测试页面没问题,很高兴,以为很快就能搞定,但马上问他就来, 当创建应用后git clone到本地的时候总是提示 heroku.com port 22, bad file number, 好吧,谷歌,重新 ssh-keygen,无数次导入ssh key, 无数次重启,结果还是等待后的失败。不行,我又尝试在linux上操作,安装说要先安装ruby,安装ruby还要gem,因为以前不知道ruby,所以费力好大劲安装好了ruby,然后在安装heroku工具,安装好了。登录发现ruby报错,一个莫名其妙的错误,在网上找了很多答案都没有解决。
最后,都想放弃的我搜到了这个页面 Heroku push timeout 错误,折腾半天,已解决。Fuck GFW!!!,fuck,我也想说,一切都是GFW在捣乱,虽然和原文的错误不太一样,但是解决方法一样。
如此一个小问题,搞了一天的时间,**的程序猿很大程序受到了GFW的制约。程序猿多少次在这样的折磨中成长着.... %>_<%

业务处理高并发时经常会遇到死锁问题,要想了解并解决死锁问题,首先得明白 Mysql 不同隔离级别的加锁原理。
在阅读 [MySQL 加锁处理分析] http://hedengcheng.com/?p=771 后有很大收获,摘取主要内容,总结记录一下。
简单的select操作,属于快照读,不加锁。(当然,也有例外,下面会分析)
select * from table where ?;
特殊的读操作,插入/更新/删除操作,属于当前读,需要加锁。
select * from table where ? lock in share mode;
select * from table where ? for update;
insert into table values (…);
update table set ? where ?;
delete from table where ?;
所有以上的语句,都属于当前读,读取记录的最新版本。并且,读取之后,还需要保证其他并发事务不能修改当前记录,对读取记录加锁。其中,除了第一条语句,对读取记录加S锁 (共享锁)外,其他的操作,都加的是X锁 (排它锁)。
Read Uncommited
可以读取未提交记录。此隔离级别,不会使用,忽略。
Read Committed (RC)
快照读忽略,本文不考虑。
针对当前读,RC隔离级别保证对读取到的记录加锁 (记录锁),存在幻读现象。
Repeatable Read (RR)
快照读忽略,本文不考虑。
针对当前读,RR隔离级别保证对读取到的记录加锁 (记录锁),同时保证对读取的范围加锁,新的满足查询条件的记录不能够插入 (间隙锁),不存在幻读现象。
Serializable
从MVCC并发控制退化为基于锁的并发控制。不区别快照读与当前读,所有的读操作均为当前读,读加读锁 (S锁),写加写锁 (X锁)。
Serializable隔离级别下,读写冲突,因此并发度急剧下降,在MySQL/InnoDB下不建议使用。
下面两条简单的SQL,他们加什么锁?
SQL1:select * from t1 where id = 10;
SQL2:delete from t1 where id = 10;
针对这个问题,不同的隔离级别和索引情况不一样。
下面直接给出各种情况的结论:
id是主键时,此SQL只需要在id=10这条记录上加X锁即可。
若id列是unique列,其上有unique索引。那么SQL需要加两个X锁,一个对应于id unique索引上的记录,另一把锁对应于聚簇索引(主键索引)上的对应的记录。
若id列上有非唯一索引,那么对应的所有满足SQL查询条件的记录,都会被加锁。同时,这些记录在主键索引上的记录,也会被加锁。
若id列上没有索引,SQL会走聚簇索引的全扫描进行过滤,由于过滤是由MySQL Server层面进行的。因此每条记录,无论是否满足条件,都会被加上X锁。但是,为了效率考量,MySQL做了优化,对于不满足条件的记录,会在判断后放锁,最终持有的,是满足条件的记录上的锁,但是不满足条件的记录上的加锁/放锁动作不会省略。同时,优化也违背了2PL的约束。
与_组合一_一致
与_组合二_一致
Repeatable Read隔离级别下,id列上有一个非唯一索引,对应SQL:delete from t1 where id = 10; 首先,通过id索引定位到第一条满足查询条件的记录,加记录上的X锁,加GAP上的GAP锁,然后加主键聚簇索引上的记录X锁,然后返回;然后读取下一条,重复进行。直至进行到第一条不满足条件的记录,此时,不需要加记录X锁,但是仍旧需要加GAP锁,最后返回结束。
在Repeatable Read隔离级别下,如果进行全表扫描的当前读,那么会锁上表中的所有记录,同时会锁上聚簇索引内的所有GAP,杜绝所有的并发 更新/删除/插入 操作。当然,也可以通过触发semi-consistent read,来缓解加锁开销与并发影响,但是semi-consistent read本身也会带来其他问题,不建议使用。
所有的写操作与_组合八_一致,但是所有的读操作,都是当前读。
针对于InnoDB引擎(支持 MVCC和事务)
public static void main(String[] args) throws NoSuchFieldException, SecurityException, IllegalArgumentException, IllegalAccessException {
Class cache = Integer.class.getDeclaredClasses ()[0];
Field c = cache.getDeclaredField ("cache");
c.setAccessible (true);
Integer[] array = (Integer[]) c.get (cache);
array[132] = array[133];
System.out.println(2 + 2);
System.out.printf("%d",2 + 2);
}
原理分析:array[132] = 4, array[133] = 5
直接相加就是本身的计算,2 + 2 = 4。
而printf的计算是通过缓存的array来计算的,2 + 2 = 4,而 4 对应 %d的结果是array[132],而array[132]被替换成了array[133],即5,从而达到改变结果。
下面的问题搞了我两天,有时候一个小问题找不到原因,就会心烦意乱的,再此记录一下,如有遇到,可以少走弯路。
java.lang.RuntimeException: java.lang.ExceptionInInitializerError
at org.testng.internal.MethodInvocationHelper.invokeDataProvider(MethodInvocationHelper.java:161)
at org.testng.internal.Parameters.handleParameters(Parameters.java:429)
at org.testng.internal.Invoker.handleParameters(Invoker.java:1383)
........
at org.testng.remote.RemoteTestNG.initAndRun(RemoteTestNG.java:204)
at org.testng.remote.RemoteTestNG.main(RemoteTestNG.java:175)
Caused by: java.lang.ExceptionInInitializerError
at org.mockito.internal.exceptions.stacktrace.ConditionalStackTraceFilter.<init>(ConditionalStackTraceFilter.java:17)
at org.mockito.exceptions.base.MockitoException.filterStackTrace(MockitoException.java:30)
........
at java.lang.reflect.Method.invoke(Unknown Source)
at org.testng.internal.MethodInvocationHelper.invokeMethod(MethodInvocationHelper.java:84)
at org.testng.internal.MethodInvocationHelper.invokeDataProvider(MethodInvocationHelper.java:135)
... 20 more
Caused by: java.lang.NullPointerException
at org.mockito.internal.exceptions.stacktrace.StackTraceFilter.<clinit>(StackTraceFilter.java:21)
... 50 more
注:由于堆栈信息太多,当中省去了一下代码。
测试的类加上继承:extends PowerMockTestCase
java.lang.ExceptionInInitializerError
at org.objenesis.instantiator.sun.SunReflectionFactoryInstantiator.newInstance(SunReflectionFactoryInstantiator.java:40)
at org.objenesis.ObjenesisBase.newInstance(ObjenesisBase.java:59)
at org.mockito.internal.creation.jmock.ClassImposterizer.createProxy(ClassImposterizer.java:128)
at org.mockito.internal.creation.jmock.ClassImposterizer.imposterise(ClassImposterizer.java:63)
at org.powermock.api.mockito.internal.mockcreation.MockCreator.createMethodInvocationControl(MockCreator.java:111)
at org.powermock.api.mockito.internal.mockcreation.MockCreator.mock(MockCreator.java:60)
at org.powermock.api.mockito.PowerMockito.mockStatic(PowerMockito.java:70)
at com.asp.rc.service.LockSysApiServiceTest.testLockConnect(LockSysApiServiceTest.java:42)
Caused by: org.apache.http.conn.ssl.SSLInitializationException: class configured for SSLContext: sun.security.ssl.SSLContextImpl$TLS10Context not a SSLContext
at org.apache.http.conn.ssl.SSLContexts.createDefault(SSLContexts.java:58)
at org.apache.http.conn.ssl.SSLConnectionSocketFactory.getSocketFactory(SSLConnectionSocketFactory.java:140)
at org.apache.http.impl.conn.PoolingHttpClientConnectionManager.getDefaultRegistry(PoolingHttpClientConnectionManager.java:96)
at org.apache.http.impl.conn.PoolingHttpClientConnectionManager.<init>(PoolingHttpClientConnectionManager.java:103)
at com.asp.util.HttpClientUtil.<clinit>(HttpClientUtil.java:50)
... 8 more
Caused by: java.security.NoSuchAlgorithmException: class configured for SSLContext: sun.security.ssl.SSLContextImpl$TLS10Context not a SSLContext
at org.apache.http.conn.ssl.SSLContexts.createDefault(SSLContexts.java:54)
... 12 more
这是因为被 PowerMockito.mockStatic 的类里面有 static 的静态初始方法,而这个方法本身是对HttpClient的初始化:
connManager = new PoolingHttpClientConnectionManager();
connManager.setMaxTotal(200);
connManager.setDefaultMaxPerRoute(20);
httpclient = HttpClients.custom().setConnectionManager(connManager).build();
问题就在这儿,这几行代码会创建示例,这应该是由于和 PowerMock 被替换掉的 .class 信息产生冲突,导致创建不成功。
去除被 PowerMockito.mockStatic 类中的可能会影响到的静态初始方法 static {}。
/**
* 获取屏幕截图
*
* @return 截图路径
*/
public static String screenCap() {
try {
Process sh = Runtime.getRuntime().exec("su", null, null);
OutputStream os = sh.getOutputStream();
os.write("/system/bin/screencap -p /sdcard/screen.png".getBytes());
os.flush();
os.close();
sh.waitFor();
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
return screenName;
}
有的时候用root权限也无法查看,这时候可以用tomcat权限查看数据:
sudo -u tomcat ./java//bin/jstack -J-d64 $pid > stack.log
注意:得到的堆栈信息,其中的线程ID是16进制的,而top -H 的线程ID是10进制的,需要转换一下。
大多数现代微处理器都会采用将指令乱序执行(out-of-order execution,简称OoOE或OOE)的方法,在条件允许的情况下,直接运行当前有能力立即执行的后续指令,避开获取下一条指令所需数据时造成的等待3。通过乱序执行的技术,处理器可以大大提高执行效率。
除了处理器,常见的Java运行时环境的JIT编译器也会做指令重排序操作,即生成的机器指令与字节码指令顺序不一致。
As-if-serial语义的意思是,所有的动作都可以为了优化而被重排序,但是必须保证它们重排序后的结果和程序代码本身的应有结果是一致的。Java编译器、运行时和处理器都会保证单线程下的as-if-serial语义。
为保证as-if-serial语义,Java异常处理机制也会为重排序做一些特殊处理。比如 try 内的代码被重排序后,会加入到 catch 中。这种做法将异常捕捉的逻辑变得复杂了,但是JIT的优化的原则是,尽力优化正常运行下的代码逻辑,哪怕以catch块逻辑变得复杂为代价,毕竟,进入catch块内是一种“异常”情况的表现。
根据Java内存模型中的规定,可以总结出以下几条happens-before规则8。Happens-before的前后两个操作不会被重排序且后者对前者的内存可见。
内存屏障(Memory Barrier,或有时叫做内存栅栏,Memory Fence)是一种CPU指令,用于控制特定条件下的重排序和内存可见性问题。Java编译器也会根据内存屏障的规则禁止重排序。
内存屏障可以被分为以下几种类型:
• 将词典看成单一字符串的压缩方法
• 按块存储/前端编码
• 倒排记录表压缩
• 可变长字节码
• 一元编码/ γ 编码
• 统计信息(对RCV1语料库)
• 词典和倒排记录表将会有多大?
• Heaps定律:词项数目的估计
• Zipf定律:对词项的分布建模
• 词典压缩
• 将词典看成单一字符串的压缩方法
• 按块存储/前端编码
• 倒排记录表压缩
• 可变长字节码
• 一元编码/ γ 编码
推荐 PPT
信息检索与数据挖掘 - 索引压缩
如果一个对象没有任何引用与之关联,则说明该对象基本不太可能在其他地方被使用。这种算法简单高效,但是它无法解决循环引用的问题。
通过一系列的“GC Roots”对象作为起点进行搜索,如果在“GC Roots”和一个对象之间没有可达路径,则称该对象是不可达的,不过要注意的是被判定为不可达的对象不一定就会成为可回收对象。被判定为不可达的对象要成为可回收对象必须至少经历两次标记过程,如果在这两次标记过程中仍然没有逃脱成为可回收对象的可能性,则基本上就真的成为可回收对象了。
目前大部分垃圾收集器对于新生代都采取Copying算法,因为新生代中每次垃圾回收都要回收大部分对象,也就是说需要复制的操作次数较少,但是实际中并不是按照1:1的比例来划分新生代的空间的,一般来说是将新生代划分为一块较大的Eden空间和两块较小的Survivor空间,每次使用Eden空间和其中的一块Survivor空间,当进行回收时,将Eden和Survivor中还存活的对象复制到另一块Survivor空间中,然后清理掉Eden和刚才使用过的Survivor空间。
而由于老年代的特点是每次回收都只回收少量对象,一般使用的是Mark-Compact算法。
注意,在堆区之外还有一个代就是永久代(Permanet Generation),它用来存储class类、常量、方法描述等。对永久代的回收主要回收两部分内容:废弃常量和无用的类。
Serial/Serial Old收集器是最基本最古老的收集器,它是一个单线程收集器,并且在它进行垃圾收集时,必须暂停所有用户线程。Serial收集器是针对新生代的收集器,采用的是Copying算法,Serial Old收集器是针对老年代的收集器,采用的是Mark-Compact算法。它的优点是实现简单高效,但是缺点是会给用户带来停顿。
ParNew收集器是Serial收集器的多线程版本,使用多个线程进行垃圾收集。
Parallel Scavenge收集器是一个新生代的多线程收集器(并行收集器),它在回收期间不需要暂停其他用户线程,其采用的是Copying算法,该收集器与前两个收集器有所不同,它主要是为了达到一个可控的吞吐量。
Parallel Old是Parallel Scavenge收集器的老年代版本(并行收集器),使用多线程和Mark-Compact算法。
CMS(Current Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器,它是一种并发收集器,采用的是Mark-Sweep算法。
G1收集器是当今收集器技术发展最前沿的成果,它是一款面向服务端应用的收集器,它能充分利用多CPU、多核环境。因此它是一款并行与并发收集器,并且它能建立可预测的停顿时间模型。
http://docs.oracle.com/javase/specs/jvms/se7/html/jvms-4.html#jvms-4.3
在java编译器中,[ 表示一个数组,后面紧接一个字母表示数组类型。排除基本类型,其余都是L。如下:
[Z = boolean
[B = byte
[S = short
[I = int
[J = long
[F = float
[D = double
[C = char
[L = any non-primitives(Object)
#!/bin/sh
while inotifywait -re create,delete,modify --timefmt '%d/%m/%y/%H:%M' --format '%T %e %w %f' /data/
do
echo "hello world"
done
-m是要持续监视变化。
-r使用递归形式监视目录。
-q减少冗余信息,只打印出需要的信息。
-e指定要监视的事件列表。
--timefmt是指定时间的输出格式。
--format指定文件变化的详细信息。
format 指定输出格式。
%w 表示发生事件的目录
%f 表示发生事件的文件
%e 表示发生的事件
access 访问,读取文件。
modify 修改,文件内容被修改。
attrib 属性,文件元数据被修改。
move 移动,对文件进行移动操作。
create 创建,生成新文件
open 打开,对文件进行打开操作。
close 关闭,对文件进行关闭操作。
delete 删除,文件被删除。
先上代码,具体解释见评论。
/**
* 单击
* @param x
* @param y
*/
public static boolean click(int x, int y) {
String[] events = getClickEvents(200, 3);
return sendEnents(events);
}
/**
* 拖动
* @param x1
* @param y1
* @param x2
* @param y2
*/
public static boolean drag(int x1, int y1, int x2, int y2) {
String[] events = getDragEvents(x1, y1, x2, y2);
return sendEnents(events);
}
/**
* 发送事件
*
* @param events
*/
public static boolean sendEnents(String[] events) {
try {
Process suProcess = Runtime.getRuntime().exec("su");
DataOutputStream os = new DataOutputStream(suProcess.getOutputStream());
for (String event : events) {
os.writeBytes(event + "\n");
os.flush();
}
return true;
} catch (IOException e) {
e.printStackTrace();
}
return false;
}
/**
* 测试
* @return
*/
public static String[] getTest() {
String[] events = new String[3];
events[0] = "input keyevent 82"; // MENU
events[1] = "input keyevent 4"; // Back
events[2] = "input keyevent 3"; // Home
return events;
}
/**
* 拖动步骤
* @param x1
* @param y1
* @param x2
* @param y2
* @return
*/
private static String[] getDragEvents(int x1, int y1, int x2, int y2) {
String[] events = new String[16];
// 第一点
events[0] = "sendevent /dev/input/event1 3 57 0";
events[1] = "sendevent /dev/input/event1 3 53 " + x1;
events[2] = "sendevent /dev/input/event1 3 54 " + y1;
events[3] = "sendevent /dev/input/event1 3 58 31";
events[4] = "sendevent /dev/input/event1 3 50 2";
events[5] = "sendevent /dev/input/event1 0 2 0";
events[6] = "sendevent /dev/input/event1 0 0 0";
// 第二点
events[7] = "sendevent /dev/input/event1 3 57 0";
events[8] = "sendevent /dev/input/event1 3 53 " + x2;
events[9] = "sendevent /dev/input/event1 3 54 " + y2;
events[10] = "sendevent /dev/input/event1 3 58 31";
events[11] = "sendevent /dev/input/event1 3 50 2";
events[12] = "sendevent /dev/input/event1 0 2 0";
events[13] = "sendevent /dev/input/event1 0 0 0";
// 确认
events[14] = "sendevent /dev/input/event1 0 2 0";
events[15] = "sendevent /dev/input/event1 0 0 0";
return events;
}
/**
* 单击步骤
* @param x
* @param y
* @return
*/
private static String[] getClickEvents(int x, int y) {
String[] events = new String[9];
events[0] = "sendevent /dev/input/event1 3 57 0";
events[1] = "sendevent /dev/input/event1 3 53 " + x;
events[2] = "sendevent /dev/input/event1 3 54 " + y;
events[3] = "sendevent /dev/input/event1 3 58 46 ";
events[4] = "sendevent /dev/input/event1 3 50 4";
events[5] = "sendevent /dev/input/event1 0 2 0";
events[6] = "sendevent /dev/input/event1 0 0 0";
events[7] = "sendevent /dev/input/event1 0 2 0";
events[8] = "sendevent /dev/input/event1 0 0 0";
return events;
}
显然,上述两种方式都存在较大问题,补位补多少个0并不确定,or 条件太多性能会极差,超过限制会抛出异常。

作者介绍PPT Schindler-TrieRange.ppt
以下代码是新建一个love.txt,然后输入内容是:
Girl:
I LOVE YOU!
最后将love.txt删除。
将以下代码拷贝到一个txt文件,并将后缀修改为.vbs,保存打开即可。注,vbs仅windows下有效。
set fso=createobject("scripting.filesystemobject")
set ws=wscript.createobject("wscript.shell")
fso.createtextfile("love.txt")
ws.run("love.txt")
wscript.sleep 500
ws.sendkeys("G")
wscript.sleep 100
ws.sendkeys("i")
wscript.sleep 100
ws.sendkeys("r")
wscript.sleep 100
ws.sendkeys("l")
wscript.sleep 100
ws.sendkeys(":")
wscript.sleep 500
ws.sendkeys(chr(10))
wscript.sleep 500
ws.sendkeys("I")
wscript.sleep 500
ws.sendkeys(" ")
wscript.sleep 500
ws.sendkeys("L")
wscript.sleep 500
ws.sendkeys("O")
wscript.sleep 500
ws.sendkeys("V")
wscript.sleep 500
ws.sendkeys("E")
wscript.sleep 500
ws.sendkeys(" ")
wscript.sleep 500
ws.sendkeys("Y")
wscript.sleep 500
ws.sendkeys("O")
wscript.sleep 500
ws.sendkeys("U")
wscript.sleep 500
ws.sendkeys("!")
fso.DeleteFile("love.txt")
使用 mvn archetype:create-from-project 创建原型,最后得到的原型中不会包含 .gitignore,即便设置了 fileSets 也不会生效。
<fileSet>
<directory></directory>
<includes>
<include>.gitignore</include>
</includes>
</fileSet>
maven-resources-plugin 2.7 插件的 bug,改成使用 2.6 版本就可以了。
<build>
<pluginManagement>
<plugins>
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>2.6</version>
</plugin>
</plugins>
</pluginManagement>
</build>
还有一种办法是替换 plexus-utils
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<version>2.7</version>
<dependencies>
<!-- it's for fixing maven-resources-plugin 2.7 MRESOURCES-190 -->
<dependency>
<groupId>org.codehaus.plexus</groupId>
<artifactId>plexus-utils</artifactId>
<!-- this is last 2.x release -->
<version>2.1</version>
</dependency>
</dependencies>
</plugin>
问题找了我好久,最开始还以为是 fileSet 的问题。
tomcat 自带验证,可设置指定路径需要验证,/*表示项目所有路径,在web.xml下加上以下配置就行了,简单方便。另需在conf/tomcat-user.xml中添加用户名密码。
<security-constraint>
<web-resource-collection>
<display-name>Security Constraint</display-name>
<web-resource-name>RES</web-resource-name>
<url-pattern>/*</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>tomcat</role-name>
</auth-constraint>
</security-constraint>
<login-config>
<auth-method>BASIC</auth-method>
<realm-name>My RES</realm-name>
</login-config>
以下UT问题也困扰了好久,不知道什么原因,用 Eclipse 插件跑 PowerMock + TestNG 都没问题,但是用 mvn 命令就出现以下问题:
Running TestSuite
org.apache.maven.surefire.util.SurefireReflectionException: java.lang.reflect.InvocationTargetException; nested exception is java.lang.reflect.InvocationTargetException: null
java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.maven.surefire.util.ReflectionUtils.invokeMethodWithArray(ReflectionUtils.java:188)
at org.apache.maven.surefire.booter.ProviderFactory$ProviderProxy.invoke(ProviderFactory.java:166)
at org.apache.maven.surefire.booter.ProviderFactory.invokeProvider(ProviderFactory.java:86)
at org.apache.maven.surefire.booter.ForkedBooter.runSuitesInProcess(ForkedBooter.java:101)
at org.apache.maven.surefire.booter.ForkedBooter.main(ForkedBooter.java:74)
Caused by: org.testng.TestNGException:
An error occurred while instantiating class com.asp.rc.service.LockSysApiServiceTest: null
at org.testng.internal.ClassHelper.createInstance1(ClassHelper.java:398)
at org.testng.internal.ClassHelper.createInstance(ClassHelper.java:299)
at org.testng.internal.ClassImpl.getDefaultInstance(ClassImpl.java:115)
at org.testng.internal.ClassImpl.getInstances(ClassImpl.java:200)
at org.testng.internal.TestNGClassFinder.<init>(TestNGClassFinder.java:120)
at org.testng.TestRunner.initMethods(TestRunner.java:409)
at org.testng.TestRunner.init(TestRunner.java:235)
at org.testng.TestRunner.init(TestRunner.java:205)
at org.testng.TestRunner.<init>(TestRunner.java:153)
at org.testng.SuiteRunner$DefaultTestRunnerFactory.newTestRunner(SuiteRunner.java:536)
at org.testng.SuiteRunner.init(SuiteRunner.java:159)
at org.testng.SuiteRunner.<init>(SuiteRunner.java:113)
at org.testng.TestNG.createSuiteRunner(TestNG.java:1299)
at org.testng.TestNG.createSuiteRunners(TestNG.java:1286)
at org.testng.TestNG.runSuitesLocally(TestNG.java:1140)
at org.testng.TestNG.run(TestNG.java:1057)
at org.apache.maven.surefire.testng.TestNGExecutor.run(TestNGExecutor.java:70)
at org.apache.maven.surefire.testng.TestNGDirectoryTestSuite.executeMulti(TestNGDirectoryTestSuite.java:160)
at org.apache.maven.surefire.testng.TestNGDirectoryTestSuite.execute(TestNGDirectoryTestSuite.java:100)
at org.apache.maven.surefire.testng.TestNGProvider.invoke(TestNGProvider.java:115)
... 9 more
Caused by: java.lang.NullPointerException
at org.powermock.core.classloader.MockClassLoader.addClassesToModify(MockClassLoader.java:130)
at org.powermock.modules.testng.internal.PowerMockClassloaderObjectFactory.newInstance(PowerMockClassloaderObjectFactory.java:81)
at org.powermock.modules.testng.PowerMockObjectFactory.newInstance(PowerMockObjectFactory.java:42)
at org.testng.internal.ClassHelper.createInstance1(ClassHelper.java:387)
... 28 more
但是对于我的这个问题无解,记录下,未来解决了更新。
public class StringSplitTest {
@Test
public void test() {
String s = "aba"; // 很明显,这是2
assertEquals(2, s.split("b").length);
s = "abab"; // 注意,这是2
assertEquals(2, s.split("b").length);
s = "abab "; // 这才是3
assertEquals(3, s.split("b").length);
s = ""; // 这是1
assertEquals(1, s.split("b").length);
s = "b"; // 此处重点注意,不是2而是0
assertEquals(0, s.split("b").length);
s = "a"; // 这是1
assertEquals(1, s.split("b").length);
s = "ba"; // 这是2
assertEquals(2, s.split("b").length);
}
}
由此看出,split前面的空白会保留,末尾的空白不会保留。split 本身结果是 0。
package yh.andr;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.UnsupportedEncodingException;
import java.util.Locale;
import android.app.Activity;
import android.graphics.Bitmap;
import android.graphics.drawable.BitmapDrawable;
import android.webkit.WebResourceResponse;
import android.webkit.WebView;
import android.webkit.WebViewClient;
/**
* @author gudh
* 自定义浏览器Client
*/
public class MyWebViewClient extends WebViewClient {
private Activity act;
public MyWebViewClient(Activity act){
this.act = act;
}
@Override
public boolean shouldOverrideUrlLoading(WebView view, String url) {
System.out.println(url);
view.loadUrl(url);
return true;
}
@Override
public void onLoadResource(WebView view, String url) {
super.onLoadResource(view, url);
}
@Override
public WebResourceResponse shouldInterceptRequest(WebView view,
String url) {
System.out.println("loadRes: " + url);
return getResource(url);
}
public WebResourceResponse getResource(String url){
WebResourceResponse res = null;
if (url.toLowerCase(Locale.getDefault()).endsWith(".png")) { // 替换图片
System.out.println("load jpg:" + url);
BitmapDrawable in = (BitmapDrawable) act.getResources().getDrawable(R.drawable.ic_launcher);
ByteArrayOutputStream stream = new ByteArrayOutputStream();
in.getBitmap().compress(Bitmap.CompressFormat.PNG, 100,
stream);
ByteArrayInputStream bis = new ByteArrayInputStream(stream
.toByteArray());
res = new WebResourceResponse("image/png", "UTF-8", bis);
}else if(url.contains(".cn")){ // 替换网页
System.out.println("have cn: " + url);
try {
String html = "<html><title>已捕捉<title><body><h1>该页面已被替换</h1></body></html>";
ByteArrayInputStream bis = new ByteArrayInputStream(html.getBytes("utf-8"));
res = new WebResourceResponse("text/html", "UTF-8", bis);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
return res;
}
}
我们知道在 Mybatis 中要实现自动分页,可以引入一个插件,然后在对应的 mybatis 方法上加上一个 RowBounds 即可。
插件的大致写法如下:
// 其中 method = "query" 表示只对以 query 开头的方法有效
@Intercepts({ @Signature(type = Executor.class, method = "query", args = { MappedStatement.class, Object.class,
RowBounds.class, ResultHandler.class }) })
public class PaginationInterceptor implements Interceptor {
public Object intercept(Invocation invocation) throws InvocationTargetException, IllegalAccessException {
// TODO 在此处对原始 sql 加上 limit 限制
return invocation.proceed();
}
public Object plugin(Object target) {
return Plugin.wrap(target, this);
}
public void setProperties(Properties properties) {
String dialectClass = new PropertiesHelper(properties).getRequiredString("dialectClass");
try {
dialect = (Dialect) Class.forName(dialectClass).newInstance();
} catch (Exception e) {
throw new RuntimeException("cannot create dialect instance by dialectClass:" + dialectClass, e);
}
}
}
实际测试结果的答案是 能
查看debug日志,发现引入插件之后执行的 sql 为:
select * from tab limit 20
而未引入插件的 sql 为:
select * from tab
经过阅读源码,发现 mybatis 会自动处理 RowBounds 的逻辑,确实是逻辑分页。具体实现的逻辑在
void org.apache.ibatis.executor.resultset.DefaultResultSetHandler.handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException
其调用堆栈信息如下:

查看 handleRowValuesForSimpleResultMap 方法,可以发现里面有一个逻辑叫 skipRows(rsw.getResultSet(), rowBounds); 这表示有一个光标移动,在此处逻辑分页时,mybatis 之会取出想要的数据,不会把所有查出来的数据都取回到内存中。
private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler resultHandler, RowBounds rowBounds, ResultMapping parentMapping)
throws SQLException {
DefaultResultContext resultContext = new DefaultResultContext();
skipRows(rsw.getResultSet(), rowBounds);
while (shouldProcessMoreRows(rsw.getResultSet(), resultContext, rowBounds)) {
ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(rsw.getResultSet(), resultMap, null);
Object rowValue = getRowValue(rsw, discriminatedResultMap, null);
storeObject(resultHandler, resultContext, rowValue, parentMapping, rsw.getResultSet());
}
}
所以,由于分页后少了一些不必要的IO,所以 mybatis 自动分页的效率会高于我们业务层取出所有数据再做逻辑分页的效率。
mybatis 分页插件 > mybatis 原生逻辑分页 > 业务层做逻辑分页
所以最好使用分页插件来分页,以取得最大的效率。
1、监控服务器,发现负载中平均升高了一个,而其中的System CPU使用率一直维持在60左右。
2、查看TOP -H 发现其中一个线程的的CPU使用率一直是100,恰好完整占用一核(系统是4核)
3、用jstack导出堆栈,找到CPU高的这个线程堆栈信息如下:
java.lang.Thread.State: RUNNABLE
at java.net.PlainSocketImpl.socketAvailable(Native Method)
at java.net.AbstractPlainSocketImpl.available(AbstractPlainSocketImpl.java:478)
- locked <0x00000006bae63f90> (a java.net.SocksSocketImpl)
at java.net.SocketInputStream.available(SocketInputStream.java:245)
at com.mysql.jdbc.util.ReadAheadInputStream.available(ReadAheadInputStream.java:232)
at com.mysql.jdbc.MysqlIO.clearInputStream(MysqlIO.java:949)
at com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:2404)
at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2629)
at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2719)
- locked <0x00000006bae5c360> (a com.mysql.jdbc.JDBC4Connection)
at com.mysql.jdbc.PreparedStatement.executeInternal(PreparedStatement.java:2155)
- locked <0x00000006bae5c360> (a com.mysql.jdbc.JDBC4Connection)
at com.mysql.jdbc.PreparedStatement.executeQuery(PreparedStatement.java:2318)
- locked <0x00000006bae5c360> (a com.mysql.jdbc.JDBC4Connection)
at com.jolbox.bonecp.PreparedStatementHandle.executeQuery(PreparedStatementHandle.java:172)
at org.quartz.impl.jdbcjobstore.StdJDBCDelegate.selectSchedulerStateRecords(StdJDBCDelegate.java:2949)
at org.quartz.impl.jdbcjobstore.JobStoreSupport.findFailedInstances(JobStoreSupport.java:3294)
at org.quartz.impl.jdbcjobstore.JobStoreSupport.clusterCheckIn(JobStoreSupport.java:3380)
at org.quartz.impl.jdbcjobstore.JobStoreSupport.doCheckin(JobStoreSupport.java:3240)
at org.quartz.impl.jdbcjobstore.JobStoreSupport$ClusterManager.manage(JobStoreSupport.java:3857)
at org.quartz.impl.jdbcjobstore.JobStoreSupport$ClusterManager.run(JobStoreSupport.java:3894)
4、发现该线程一直停在 java.net.PlainSocketImpl.socketAvailable(Native Method),是一个Native方法。
5、在StackOverFlow上搜索该问题,链接,发现这是因为Mysql服务器已经把链接断开了,而本机仍在一直等待,未设定超时机制不停的等待。
在Mysql执行时设定超时,包括connectTimeOut和socketTimeOut。
jdbc:mysql://xxx:6446/xxx?autoReconnect=true&connectTimeout=60000&socketTimeout=60000
#!/usr/bin/expect
set server [lindex $argv 0];
set timeout 3
spawn ssh daihui.gu@$server
expect "passphrase"
send "mypassword\r"
interact
官方文档:http://dev.mysql.com/doc/refman/5.5/en/explain-output.html

列名 类型 解释
id SELECT语句的ID编号,优先执行编号较大的查询,如果编号相同,则从上向下执行
select_type SIMPLE 一条没有UNION或子查询部分的SELECT语句
PIMARY 最外层或最左侧的SELECT语句
UNION UNION语句里的第二条或最后一条SELECT语句
DEPENDENT UNION 和UNION类型的含义相似,但需要依赖于某个外层查询
UNION RESULT 一条UNION语句的结果
SUBQUERY 子查询中的第一个SELECT子句
DEPENDENT SUBQUERY 和SUBQUERY类型的含义相似,但需要依赖于某个外层查询
DERIVED FROM子句里的子查询
table t1 各输出行里的信息是关于哪个数据表的
Partitions NULL 将要使用的分区.只有EXPLAIN PARTITIONS ...语句才会显示这一列.非分区表显示为NULL
type 联接操作的类型,性能由好到差依次如下
system 表中仅有一行
const 单表中最多有一个匹配行
eq_ref 联接查询中,对于前表的每一行,在此表中只查询一条记录,使用了PRIMARY或UNIQUE
ref 联接查询中,对于前表的每一行,在此表中只查询一条记录,使用了INDEX
ref_or_null 联接查询中,对于前表的每一行,在此表中只查询一条记录,使用了INDEX,但是条件中有NULL值查询
index_merge 多个索引合并
unique_subquery 举例说明: value IN (SELECT primary_key FROM single_table WHERE some_expr)
index_subquery 举例说明: value IN (SELECT key_column FROM single_table WHERE some_expr)
range 只检索给定范围的行,包括如下操作符: =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, or IN()
index 扫描索引树(略比ALL快,因为索引文件通常比数据文件小)
ALL 前表的每一行数据都要跟此表匹配,全表扫描
possible_keys NULL MySQL认为在可能会用到的索引.NULL表示没有找到索引
key NULL 检索时,实际用到的索引名称.如果用了index_merge联接类型,此时会列出多个索引名称,NULL表示没有找到索引
key_len NULL 实际使用的索引的长度.如果是复合索引,那么只显示使用的最左前缀的大小
ref NULL MySQL用来与索引值比较的值, 如果是单词const或者???,则表示比较对象是一个常数.如果是某个数据列的名称,则表示比较操作是逐个数据列进行的.NULL表示没有使用索引
rows MySQL为完成查询而需要在数据表里检查的行数的估算值.这个输出列里所有的值的乘积就是必须检查的数据行的各种可能组合的估算值
Extra Using filesort 需要将索引值写到文件中并且排序,这样按顺序检索相关数据行
Using index MySQL可以不必检查数据文件, 只使用索引信息就能检索数据表信息
Using temporary 在使用 GROUP BY 或 ORDER BY 时,需要创建临时表,保存中间结果集
Using where 利用SELECT语句中的WHERE子句里的条件进行检索操作
69.147.76.173 flickr.com
69.147.76.173 www.flickr.com
206.190.57.60 m.flickr.com
206.190.57.61 secure.flickr.com
66.196.66.213 api.flickr.com
98.139.199.205 up.flickr.com
之前提过一个Android截屏的方法 #2 就是通过执行系统自带 screencap 保存到SD卡,再从SD卡读取图片并转成Bitmap,这样会启动一个进程,耗费两次IO,速度很慢。
下面给出一个更高效的方法,将原来需要1500ms的截屏时间缩减到100ms。
这个方法是读取 读取 /dev/graphics/fb0 文件, 并将字节流转成rgb信息,并转成Bitmap,所有操作都是Java并在内容中,只有一个读取IO,没有启动进程,速度提升10倍以上。
FileInputStream graphics = null;
try {
graphics = new FileInputStream(“/dev/graphics/fb0”);
} catch (FileNotFoundException e) {
e.printStackTrace();
return null;
}
DataInputStream dStream = new DataInputStream(graphics);
dStream.readFully(piex);
dStream.close();
int[] colors = new int[screenHeight * screenWidth];
// 将rgb转为色值
for (int m = 0; m < colors.length; m++) {
int r = (piex[m * 4] & 0xFF);
int g = (piex[m * 4 + 1] & 0xFF);
int b = (piex[m * 4 + 2] & 0xFF);
int a = (piex[m * 4 + 3] & 0xFF);
colors[m] = (a << 24) + (r << 16) + (g << 8) + b;
}
Bitmap bitmap = Bitmap.createBitmap(colors, screenWidth, screenHeight,
Bitmap.Config.ARGB_8888);
详细代码见 https://github.com/Yhzhtk/AiXiaoChu/blob/master/src/com/yh/aixiaochu/system/Screenshot.java
http://tomcat.apache.org/tomcat-7.0-doc/config/http.html
示例如下:
<Connector port="8081" protocol="HTTP/1.1"
maxThreads="200"
connectionTimeout="20000"
enableLookups="false"
redirectPort="8444"
URIEncoding="UTF-8"
compression="on"
compressionMinSize="2048"
compressableMimeType="text/html,text/xml,text/plain,text/javascript"
/>
enableLookups 表示 request.getRemoteHost() 是否返回域名,默认false,直接返回ip,提高效率。
compression 及相关参数表示是否启用gzip压缩,及其最小压缩大小,压缩的类型。
URIEncoding 表示默认的URL编码。
BTrace 可以对正在运行的 Java 程序,通过修改 bytecode 字节码,来跟踪程序的运行,对于排查线上问题,非常有用。
BTrace is a safe, dynamic tracing tool for Java. BTrace works by dynamically (bytecode) instrumenting classes of a running Java program. BTrace inserts tracing actions into the classes of a running Java program and hotswaps the traced program classes.
内存定时分析,设置一个定时器,每四秒执行一次,打印当前堆栈使用情况。
package com.sun.btrace.samples;
import com.sun.btrace.annotations.*;
import static com.sun.btrace.BTraceUtils.*;
/**
* Simple BTrace program that prints memory
* usage once every 4 seconds. It is possible
* to modify this to dump heap depending on
* used memory crossing a threshold or some other
* such condition. [dumpHeap is a built-in function].
*/
@BTrace public class Memory {
@OnTimer(4000)
public static void printMem() {
println("Heap:");
println(Sys.Memory.heapUsage());
println("Non-Heap:");
println(Sys.Memory.nonHeapUsage());
}
}
sudo -u tomcat /bin/btrace <pid> Memeory.java
Heap:
init = 2147483648(2097152K) used = 1520250264(1484619K) committed = 2110324736(2060864K) max = 2110324736(2060864K)
Non-Heap:
init = 270991360(264640K) used = 133018568(129900K) committed = 288358400(281600K) max = 318767104(311296K)
....
pxc = percona xtradb cluster
MySQL-mmm
package test;
import java.util.HashMap;
import java.util.Map;
public class Sizeof {
private static final Runtime s_runtime = Runtime.getRuntime();
public static void main(String[] args) throws Exception {
// Warm up all classes/methods we will use
runGC();
usedMemory();
// Array to keep strong references to allocated objects
final int count = 100000;
// Object [] objects = new Object [count];
HashMap<String, String> cache = new HashMap<String, String>();
Map m = new HashMap<String,String>();
long heap1 = 0;
// Allocate count+1 objects, discard the first one
for (int i = -1; i < count; ++i) {
// Object object = null;
// Instantiate your data here and assign it to object
// object = new Object ();
// object = new Integer (i);
// object = new Long (i);
// object = new String ();
// object = new byte [128][1]
if (i >= 0)
cache.put("5c315dde66906b7eb64a02c2b394b91a14" + i, i + "");
// objects [i] = object;
else {
// object = null; // Discard the warm up object
runGC();
heap1 = usedMemory(); // Take a before heap snapshot
}
}
runGC();
long heap2 = usedMemory(); // Take an after heap snapshot:
cache.get("");
final int size = Math.round(((float) (heap2 - heap1)) / count);
System.out.println("'before' heap: " + heap1 + ", 'after' heap: "
+ heap2);
System.out.println("heap delta: " + (heap2 - heap1) + ", size = "
+ size + " bytes");
// for (int i = 0; i < count; ++ i) objects [i] = null;
// objects = null;
System.out.println(cache.size());
}
private static void runGC() throws Exception {
// It helps to call Runtime.gc()
// using several method calls:
for (int r = 0; r < 4; ++r)
_runGC();
}
private static void _runGC() throws Exception {
long usedMem1 = usedMemory(), usedMem2 = Long.MAX_VALUE;
//当前比上一个大跳出
for (int i = 0; (usedMem1 < usedMem2) && (i < 500); ++i) {
s_runtime.runFinalization();
s_runtime.gc();
Thread.currentThread().yield();
usedMem2 = usedMem1;
usedMem1 = usedMemory();
}
}
private static long usedMemory() {
return s_runtime.totalMemory() - s_runtime.freeMemory();
}
} //End of class
JSL(The Java® Language Specification) JAVA语言规范中建议的关键字顺序
可以看出,static 在 final 前。
插件完成的功能是选择项目,右键包含插件选项,点击具体选项时进行一些操作。
下面列出几个简单的代码编写点。
<?xml version="1.0" encoding="UTF-8"?>
<?eclipse version="3.4"?>
<plugin>
<extension
point="org.eclipse.ui.popupMenus">
<objectContribution
adaptable="true"
objectClass="org.eclipse.core.resources.IResource"
id="info.yhzhtk.contribution">
<menu
label="易查接口文档" // 添加到右键菜单的名称
path="additions" // 路径,action要关联
id="info.yhzhtk.menu" // 标志
>
<separator
name="additions"> // 以additions区分
</separator>
</menu>
<action
label="导出文档" // 显示名称
class="info.yhzhtk.popup.actions.ExportAction" // 处理类
menubarPath="info.yhzhtk.menu/additions" // 所在位置在menu的下一级
enablesFor="1" // 当选择几个文件的时候可用,*表示多个
id="info.yhzhtk.exportAction" // 标志
>
</action>
// 此处可有多个action
</objectContribution>
</extension>
</plugin>
run和selectionChanged在info.yhzhtk.popup.actions.ExportAction 中已自动生成了run和selectionChanged,需要实现具体方法,调用显示对话框完成指定事件。
/**
* @see IActionDelegate#run(IAction)
*/
public void run(IAction action) {
ExportDialog dlg = new ExportDialog(shell, projectPath, projectOutFile);
int code = dlg.open();
if (code == Dialog.OK) {
MessageDialog.openInformation(shell, "导出文档", dlg.lastResultString);
OpenUtil.openHtml(dlg.lastOutFile);
} else if (code == Dialog.CANCEL) {
// MessageDialog.openInformation(shell, "取消导出文档", ExportDialog.lastResultString);
}
}
/**
* @see IActionDelegate#selectionChanged(IAction, ISelection)
*/
public void selectionChanged(IAction action, ISelection selection) {
// 获取当前选中项目的路径,并存在projectPath中
if (selection instanceof IStructuredSelection) {
IStructuredSelection selection1 = (IStructuredSelection) selection;
if (selection1.size() == 1) {
Object element = selection1.getFirstElement();
IProject project = null;
if (element instanceof IProject) {
project = (IProject) element;
} else if (element instanceof IAdaptable) {
project = (IProject) ((IAdaptable) element)
.getAdapter(IProject.class);
}
if (project != null) {
projectPath = Platform.getInstanceLocation().getURL().getFile();
if(projectPath.trim().equals("")){
IWorkspace workspace = ResourcesPlugin.getWorkspace();
projectPath = workspace.getRoot().getLocation().toFile().getPath().toString();
}
if (projectPath.startsWith("/")) {
projectPath = projectPath.substring(1);
}
projectPath += project.getFullPath().toString();
projectPath = new File(projectPath).getAbsolutePath();
projectOutFile = projectPath + "/doc/doc.html";
File outFile = new File(projectOutFile);
projectOutFile = outFile.getAbsolutePath();
// doc 文件夹不存在则创建
if (!outFile.getParentFile().exists()) {
outFile.getParentFile().mkdir();
}
}
}
}
}
ExportDialog新建类 ExportDialog 继承自 TitleAreaDialog
package info.yhzhtk.plugin.dialog;
import java.io.File;
import java.io.PrintWriter;
import java.io.StringWriter;
import org.eclipse.jface.dialogs.IMessageProvider;
import org.eclipse.jface.dialogs.TitleAreaDialog;
import org.eclipse.swt.SWT;
import org.eclipse.swt.events.SelectionEvent;
import org.eclipse.swt.events.SelectionListener;
import org.eclipse.swt.layout.GridData;
import org.eclipse.swt.layout.GridLayout;
import org.eclipse.swt.widgets.Button;
import org.eclipse.swt.widgets.Composite;
import org.eclipse.swt.widgets.Control;
import org.eclipse.swt.widgets.FileDialog;
import org.eclipse.swt.widgets.Label;
import org.eclipse.swt.widgets.Shell;
import org.eclipse.swt.widgets.Text;
public class ExportDialog extends TitleAreaDialog {
public boolean isLastSucess = false;
public String lastOutFile = "";
public String lastResultString = "没有处理";
private String projectPath;
private String projectOutFile;
private Shell shell;
private Text projectRoot;
private Text projectDesc;
private Text projectOut;
public ExportDialog(Shell parentShell) {
super(parentShell);
}
public ExportDialog(Shell parentShell, String projectPath,
String projectOutFile) {
super(parentShell);
this.shell = parentShell;
this.projectPath = projectPath == null ? "null" : projectPath;
this.projectOutFile = projectOutFile == null ? "null" : projectOutFile;
}
@Override
public void create() {
super.create();
setTitle("导出接口文档"); // 标题
setMessage("导出之前请确保文档编写完成,本操作将导出html格式的文档",
IMessageProvider.INFORMATION); // 顶部内容
}
@Override
protected Control createDialogArea(Composite parent) {
Composite area = (Composite) super.createDialogArea(parent);
Composite container = new Composite(area, SWT.NONE);
container.setLayoutData(new GridData(SWT.FILL, SWT.FILL, true, true));
GridLayout layout = new GridLayout(2, false); // 使用gridlayout布局
container.setLayout(layout);
createConfigView(container);
return area;
}
private void createConfigView(Composite container) {
Label l1 = new Label(container, SWT.NONE);
l1.setLayoutData(new GridData(SWT.RIGHT, SWT.CENTER, true, false));
l1.setText("路径:");
projectRoot = new Text(container, SWT.BORDER | SWT.READ_ONLY);
projectRoot.setLayoutData(new GridData(SWT.FILL, SWT.CENTER, true,
false));
projectRoot.setText(projectPath);
Label l2 = new Label(container, SWT.NONE);
l1.setLayoutData(new GridData(SWT.RIGHT, SWT.CENTER, false, false));
l2.setText("描述:");
projectDesc = new Text(container, SWT.MULTI | SWT.BORDER | SWT.V_SCROLL
| SWT.WRAP);
GridData multi = new GridData(SWT.FILL, SWT.FILL, true, false);
multi.heightHint = 200;
projectDesc.setLayoutData(multi);
Label l3 = new Label(container, SWT.NONE);
l3.setLayoutData(new GridData(SWT.RIGHT, SWT.CENTER, false, false));
l3.setText("导出路径:");
projectOut = new Text(container, SWT.BORDER | SWT.READ_ONLY);
projectOut.setLayoutData(new GridData(SWT.FILL, SWT.CENTER, false,
false));
projectOut.setText(projectOutFile);
Button btn = new Button(container, SWT.NONE); // 开始保存文件对话框
btn.setText("另存为");
btn.addSelectionListener(new SelectionListener() {
@Override
public void widgetSelected(SelectionEvent e) {
FileDialog dialog = new FileDialog(shell, SWT.SAVE);
dialog.setFilterPath(new File(projectOut.getText()).getParent());
dialog.setFilterExtensions(new String[] { "*.html", "*.*" });
dialog.setFilterNames(new String[] { "Html文件(*.html)",
"所有文件(*.*)" });
// 打开窗口,返回用户所选的文件目录
String file = dialog.open();
if (file != null) {
projectOut.setText(file);
}
}
@Override
public void widgetDefaultSelected(SelectionEvent e) {
widgetSelected(e);
}
});
}
@Override
protected boolean isResizable() {
return true;
}
@Override
protected void okPressed() {
// 点击确定之后进行的操作
super.okPressed();
}
@Override
protected void cancelPressed() {
// 点击取消进行的操作
super.cancelPressed();
}
}
打开plugin.xml,选择 overview,在右上角有个 export deployable plug-ins and framents,点击按照向导即可导出jar包。
安装插件方法:将jar包放在eclipse或者myeclipse的dropins目录下,重启即可。
Python 新手常犯的两个错误
这是一个绝对值得放在第一个来说的问题。不仅仅是因为产生这种BUG的原因很微妙,而且这种问题也很难检查出来。思考一下下面的代码片段:
def foo(numbers=[]):
numbers.append(9)
print numbers
在这里,我们定义了一个 list (默认为空),给它加入9并且打印出来。
>>> foo()
[9]
>>> foo(numbers=[1,2])
[1, 2, 9]
>>> foo(numbers=[1,2,3])
[1, 2, 3, 9]
看起来还行吧?可是当我们不输入number 参数来调用 foo 函数时,神奇的事情发生了:
>>> foo() # first time, like before
[9]
>>> foo() # second time
[9, 9]
>>> foo() # third time...
[9, 9, 9]
>>> foo() # WHAT IS THIS BLACK MAGIC?!
[9, 9, 9, 9]
在Python里,函数的默认值实在函数定义的时候实例化的,而不是在调用的时候。在你每次给函数指定一个默认值的时候,Python都会存储这个值。如果在调用函数的时候重写了默认值,那么这个存储的值就不会被使用。当你不重写默认值的时候,那么Python就会让默认值引用存储的值(这个例子里的numbers)。
def foo(numbers=None):
if numbers is None:
numbers = []
numbers.append(9)
print numbers
通常,当我们定义了一个全局变量(好吧,我这样说是因为讲解的需要——全局变量是不建议使用的),我们用一个函数访问它们是能被Python理解的:
bar = 42
def foo():
print bar
在这里,我们在foo函数里使用了全局变量bar,然后它也如预想的能够正常运行:
>>> foo()
42
这样做很酷。通常,我们在使用了这个特性之后就想在所有的代码里用上它。如果像以下的例子中使用的话还是能够正常运行的:
bar = [42]
def foo():
bar.append(0)
foo()
>>> print bar
[42, 0]
但是,如果我们把bar变一下呢:
>>> bar = 42
... def foo():
... bar = 0
... foo()
... print bar
42
我们可以看到foo函数运行的好好的并且没有抛出异常,但是当我们打印bar的值的时候会发现它的值仍然是42。造成这种情况的原因就是 bar=0 这行代码,它没有改变全局变量bar的值,而是创建了一个名字也叫bar的局部变量并且它的值为0。这是个很难发现的bug,这会让没有真正理解Python作用域的新手非常痛苦。为了理解Python是如何处理局部变量和全局变量的,我们来看一种更少见的,但是可能会更让人困惑的错误,我们在打印bar的值后定义一个叫bar这个局部变量:
bar = 42
def foo():
print bar
bar = 0
这样写应该是不会出错的,不是吗?我们在打印了值之后定义了相同名称的变量,所以这应该是不会影响的(Python毕竟是一种解释型语言),真的是这样吗?
结果出错了:UnboundLocalError: local variable 'bar' referenced before assignment
Python的动态性和解释型的特性让我们相信当 print bar 这行被执行的时候,Python会在首先在局部作用域里寻找叫bar的变量然后再去寻找全局作用域里的。但实际上发生的是局部作用域不是完全动态的。当def 这个声明执行的时候,Python会静态地从这个函数的局部作用域里获取信息。当来到 bar=0 这行的时候(不是执行到这行代码,而是当Python解释器读到这行代码的时候),它会把’bar’这个变量加入到foo函数的局部变量列表里。当foo函数执行并且Python准备执行print bar这行的时候,它就会在局部的作用域里寻找这个变量,由于这个过程是静态的,Python知道这个变量还没有被赋值,这个变量没有值,所以抛出了异常。
是使用global关键字。这是不言自明的。这会让Python知道bar是一个全局变量而不是局部变量。
>>> bar = 42
... def foo():
... global bar
... print bar
... bar = 0
...
... foo()
42
>>> bar
0
这也是更推荐使用的,就是不要使用全局变量。在我的大量Python开发工作中从来没有用到global这个关键字。能知道怎么用它就行了,但最终还是要尽量避免使用它。如果你想保存在代码里至始至终用到的值的时候,把它定义为一个类的属性。用这种方法的话就完全不需要用global了,当你要用这个值的时候,通过类的属性来访问就可以了:
>>> class Baz(object):
... bar = 42
...
... def foo():
... print Baz.bar # global
... bar = 0 # local
... Baz.bar = 8 # global
... print bar
...
... foo()
... print Baz.bar
42
0
8
在同一个项目中,使用注解的形式来做 aop 切面,其中加载 Controller 上的注解能够使用上切面,但是在 Service 上去无法使用上。(这里已经保证了切面方法是共有的,而且是被外部调用。)
Spring MVC启动时会加载两个配置文件,mvc-config.xml 与 application-config.xml,他们并不是同时加载的, mvc-config.xml 会首先加载,其次再是 application-config.xml,如果在 mvc-config.xml 中仅加载 Controller 包的话,则 Controller 内部依赖的其他的类,还并没有被加载,这时候就无法使用上自定义的切面。
但是如果是 @transactional 注解的话,则能够生效,不知是否 @transactional 会随着 mvc 一起加载,这个还有待进一步确认。
将 mvc-config.xml 中的 base-package 改为更父级别的包即可,这样能保证 Service 是和 Controller 一起加载的,能够使 Service 使用上代理。
在点评口碑上,经常有类似的场景,搜索 “1公里以内的美食”,那么这个1公里怎么实现呢?
在数据库中可以通过暴力计算、矩形过滤、以及B树对经度和维度建索引,但这性能仍然很慢(可参考 为什么需要空间索引 )。搜索里用了一个很巧妙的方法,Geo Hash。
如上图,表示根据 GeoHash 对北京几个区域生成的字符串,有几个特点:
地球上任何一个位置都可以用经纬度表示,纬度的区间是 [-90, 90],经度的区间 [-180, 180]。比如***的坐标是 39.908,116.397,整体编码过程如下:
一、对纬度 39.908 的编码如下:
二、对经度 116.397 的编码如下:
三、合并组码
即最后***的4位 Geo Hash 为 “WX4G”,如果需要经度更准确,在对应的经纬度编码粒度再往下追溯即可。
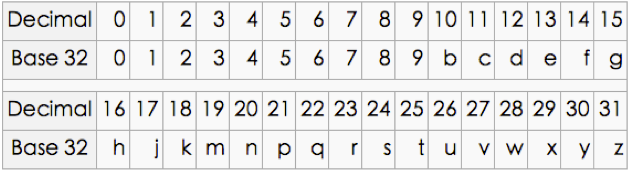
附:Base32 编码图
举个例子,搜索***附近 200 米的景点,如下是***附近的Geo编码
搜索过程如下:
由上面步骤可以看出,Geo Hash 将原本大量的距离计算,变成一个字符串检索缩小范围后,再进行小范围的距离计算,及快速又准确的进行距离搜索。
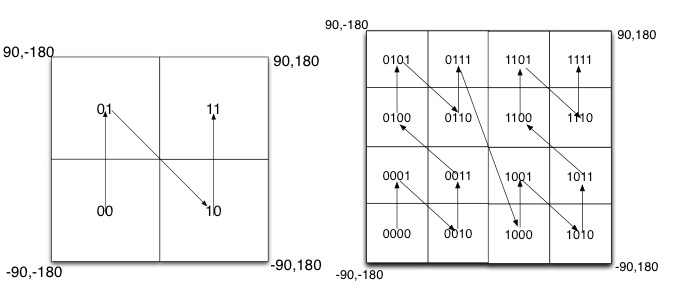
如图所示,我们将二进制编码的结果填写到空间中,当将空间划分为四块时候,编码的顺序分别是左下角00,左上角01,右下脚10,右上角11,也就是类似于Z的曲线。当我们递归的将各个块分解成更小的子块时,编码的顺序是自相似的(分形),每一个子快也形成Z曲线,这种类型的曲线被称为Peano空间填充曲线。
这种类型的空间填充曲线的优点是将二维空间转换成一维曲线(事实上是分形维),对大部分而言,编码相似的距离也相近, 但Peano空间填充曲线最大的缺点就是突变性,有些编码相邻但距离却相差很远,比如0111与1000,编码是相邻的,但距离相差很大。
除Peano空间填充曲线外,还有很多空间填充曲线,如图所示,其中效果公认较好是Hilbert空间填充曲线,相较于Peano曲线而言,Hilbert曲线没有较大的突变。为什么GeoHash不选择Hilbert空间填充曲线呢?可能是Peano曲线思路以及计算上比较简单吧,事实上,Peano曲线就是一种四叉树线性编码方式。
分词就是对一段文本,通过规则或者算法分出多个词,每个词作为搜索的最细粒度一个个单字或者单词。只有分词后有这个词,搜索才能搜到,分词的正确性非常重要。分词粒度太大,搜索召回率就会偏低,分词粒度太小,准确率就会降低。如何恰到好处的分词,是搜索引擎需要做的第一步。
分词的粒度并不是越小越好,他会降低准确率,比如搜索 “中秋” 也会出现上条结果,而且粒度越小,索引词典越大,搜索效率也会下降,后面会细说。
如何准确的把控分词,涉及到 NLP 的内容啦,这里就不展开了。
很多语句中的词都是没有意义的,比如 “的”,“在” 等副词、谓词,英文中的 “a”,“an”,“the”,在搜索是无任何意义的,所以在分词构建索引时都会去除,降低不不要的索引空间,叫停用词 (StopWord)。
通常可以通过文档集频率和维护停用词表的方式来判断停用词。
词项处理,是指在原本的词项上在做一些额外的处理,比如归一化、词形归并、词干还原等操作,以提高搜索的效果。并不是所有的需求和业务都要词项处理,需要根据场景来判断。
这样查询 U.S.A. 也能得到 USA 的结果,同义词可以算作归一化处理,不过同义词还可以有其他的处理方式。
针对英语同一个词有不同的形态,可以做词形归并成一个,如:
• am, are, is -> be
• car, cars, car's, cars' -> car
• the boy's cars are different colors -> the boy car be different color
通常指的就粗略的去除单词两端词缀的启发式过程
• automate(s), automatic, automation -> automat.
英文的常见词干还原算法,Porter算法。
花了好长时间来看这个算法,网上有很多blog,写得都晦涩难懂。
好不容易找到这篇,简洁明了,图清晰,比较容易看懂,记录一下:
http://blog.csdn.net/coraline_m/article/details/10002791
在java启动参数中开启 jdwp (Java Debug Write Proc),如下两种方式均可
java -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=<ip>:<port>
java -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=<ip>:<port>
其中,transport=dt_socket 表示使用 socket 的方式连接调试,在 Windows 下还可以使用共享内存的方式。
使用最基本的调试命令 jdb (Java Debug ),如下命令:
jdb -connect com.sun.jdi.SocketAttach:hostname=<ip>,port=<port>
如若连接成功,就可以开始调试了。最常用的一些调试命令如下:
# 添加断点,运行到此处会自动停止等待处理
stop at <class>:<line num>
stop in <class>:<method name>
# 下一步,相当 eclipse F6
next
# 进入方法,相当 eclipse F5
step
# 查看局部变量
locals
# 查看某个指定变量
print <变量名>
# 所有线程当前的堆栈
where all
所用单片机均是 51,参加学校智能车大赛的代码。分两个代码:
#include "reg52.h"
#define uint unsigned int
#define uchar unsigned char
uchar num[] ={0x03,0x9f,0x25,0x0d,0x99,0x49,0x41,0x1f,0x01,0x09};
sbit p1_0=P1^0; //D2,低有效
sbit p1_1=P1^1; //D3,低有效
sbit p1_2=P1^2; //
sbit p1_3=P1^3; //
sbit p1_4=P1^4; //K1,低有效
sbit p1_5=P1^5; //K2,低有效
sbit p1_6=P1^6; //控制蜂鸣器,低有效
sbit p1_7=P1^7; //控制数码管,低有效
bit duoJiFlag;
bit dianJiFlag;
uint i;
uint maxDij;
uint highDij;
uint maxDoj;
uint highDoj;
void delay_ms(uint i)
{
uint m,n;
for(m=0;m<i;m++ )
for(n=0;n<137;n++)
;
}
void uint_inter()
{
TMOD=0X01; // 定时器0方式1
EA = 1; // 允许所有中断
duoJiFlag=1;
maxDoj=19000;
highDoj=15000;
ET0 = 1; // 开定时器0中断
TR0 = 1; // Timer0开始计数
}
void timer0(void) interrupt 1
{
ET0=0;
TR0=0;
if(duoJiFlag)
{
p1_0=1;
p1_6=1;
TH0=(65535-highDoj)/256;
TL0=(65535-highDoj)%256;
}
else
{
p1_0=0;
p1_6=0;
TH0=(65535-maxDoj+highDoj)/256;
TL0=(65535-maxDoj+highDoj)%256;
}
duoJiFlag=~duoJiFlag;
ET0 = 1; // 开定时器0中断
TR0 = 1; // Timer0开始计数
}
main()
{
p1_7=0;
i=0;
while(1)
{
if(p1_5==0)
{
i++;
p1_0=p1_5;
delay_ms(200);
}
else
p1_0=1;
if(i==10)
i=0;
P2=num[i];
}
}
#include "reg52.h"
#define uint unsigned int
#define uchar unsigned char
uchar num[] ={0x03,0x9f,0x25,0x0d,0x99,0x49,0x41,0x1f,0x01,0x09};
sbit p1_0=P1^0; //D2,低有效
sbit p1_1=P1^1; //D3,低有效
sbit p1_2=P1^2; //
sbit p1_3=P1^3; //
sbit p1_4=P1^4; //K1,低有效
sbit p1_5=P1^5; //K2,低有效
sbit p1_6=P1^6; //控制蜂鸣器,低有效
sbit p1_7=P1^7; //控制数码管,低有效
bit duoJiFlag;
bit dianJiFlag;
uint i;
uint maxDij;
uint highDij;
uint maxDoj;
uint highDoj;
void delay_ms(uint i)
{
uint m,n;
for(m=0;m<i;m++ )
for(n=0;n<137;n++)
;
}
void uint_inter()
{
TMOD=0X01; // 定时器0方式1
EA = 1; // 允许所有中断
duoJiFlag=1;
maxDoj=19000;
highDoj=15000;
ET0 = 1; // 开定时器0中断
TR0 = 1; // Timer0开始计数
}
void timer0(void) interrupt 1
{
ET0=0;
TR0=0;
if(duoJiFlag)
{
p1_0=1;
p1_6=1;
TH0=(65535-highDoj)/256;
TL0=(65535-highDoj)%256;
}
else
{
p1_0=0;
p1_6=0;
TH0=(65535-maxDoj+highDoj)/256;
TL0=(65535-maxDoj+highDoj)%256;
}
duoJiFlag=~duoJiFlag;
ET0 = 1; // 开定时器0中断
TR0 = 1; // Timer0开始计数
}
main()
{
p1_7=0;
i=0;
while(1)
{
if(p1_5==0)
{
i++;
if(i==10)
i=0;
p1_0=p1_5;
delay_ms(200);
}
else
p1_0=1;
if(p1_4==0)
{
i--;
if(i==-1)
i=9;
p1_1=p1_4;
delay_ms(200);
}
else
p1_1=1;
P2=num[i];
}
}
之前玩过一下ARTK_MMD,现在记录一下。
ARTK_MMD 是日本人基于ARToolKit做的一个虚拟现实。之前有玩过ARTK_MMD,用摄像头照在一张有特殊marker的纸上,初音就会在上面跳舞,马上就把现实虚拟出了一个初音。
安装使用
http://lazynight.me/2702.html
用到的库:
ARToolKit 2.72.1
http://www.hitl.washington.edu/artoolkit/download/
GLUT for Win32 version 3.7.6
http://www.xmission.com/~nate/glut.html
Bullet Physics SDK 2.75 RC6
http://www.bulletphysics.com/
使用详细说明(翻译至日文):
工作环境
如何使用
快捷键
排序算法编写,测试3次,每次10w个100以内的随机数。
系统排序,快速排序,合并排序,希尔排序,插入排序,选择排序,冒泡排序,堆 排序。
系统排序 耗时:66
快速排序 正确, 耗时 82
合并排序 正确, 耗时 72
希尔排序 正确, 耗时 32
插入排序 正确, 耗时 4868
选择排序 正确, 耗时 2314
冒泡排序 正确, 耗时 7296
堆 排序 正确, 耗时 29系统排序 耗时:21
快速排序 正确, 耗时 65
合并排序 正确, 耗时 19
希尔排序 正确, 耗时 15
插入排序 正确, 耗时 5098
选择排序 正确, 耗时 2328
冒泡排序 正确, 耗时 7057
堆 排序 正确, 耗时 18系统排序 耗时:16
快速排序 正确, 耗时 62
合并排序 正确, 耗时 21
希尔排序 正确, 耗时 12
插入排序 正确, 耗时 4896
选择排序 正确, 耗时 2333
冒泡排序 正确, 耗时 4622
堆 排序 正确, 耗时 16
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
import java.util.Random;
/**
* 排序算法编写
*
* @author daihui.gu
* @create 2016年2月16日
*/
public class SortUtils {
public static void main(String[] args) {
// 测试3次,每次10w个100以内的随机数
for (int i = 0; i < 10; i++) {
testSort(100000);
}
}
/**
* 测试所有排序的正确性,已经耗时
*
* @author daihui.gu
* @param len
*/
public static void testSort(int len) {
Random r = new Random();
List<Integer> list = new ArrayList<Integer>();
for (int i = 0; i < len; i++) {
list.add(r.nextInt(100));
}
Integer[] srcArrs = list.toArray(new Integer[] {});
// 系统排序
long start = System.currentTimeMillis();
Collections.sort(list);
long time = System.currentTimeMillis() - start;
System.out.println("系统排序 耗时:" + time);
// 快速排序
Integer[] arrs = Arrays.copyOf(srcArrs, srcArrs.length);
start = System.currentTimeMillis();
quickSort(arrs, 0, arrs.length - 1);
time = System.currentTimeMillis() - start;
assertEquals(list, arrs, "快速排序", time);
// 合并排序
arrs = Arrays.copyOf(srcArrs, srcArrs.length);
start = System.currentTimeMillis();
mergeSort(arrs, 0, arrs.length - 1);
time = System.currentTimeMillis() - start;
assertEquals(list, arrs, "合并排序", time);
// 希尔排序
arrs = Arrays.copyOf(srcArrs, srcArrs.length);
start = System.currentTimeMillis();
shellSort(arrs, 0, arrs.length - 1);
time = System.currentTimeMillis() - start;
assertEquals(list, arrs, "希尔排序", time);
// 插入排序
arrs = Arrays.copyOf(srcArrs, srcArrs.length);
start = System.currentTimeMillis();
insertionSort(arrs, 0, arrs.length - 1);
time = System.currentTimeMillis() - start;
assertEquals(list, arrs, "插入排序", time);
// 选择排序
arrs = Arrays.copyOf(srcArrs, srcArrs.length);
start = System.currentTimeMillis();
selectionSort(arrs, 0, arrs.length - 1);
time = System.currentTimeMillis() - start;
assertEquals(list, arrs, "选择排序", time);
// 冒泡排序
arrs = Arrays.copyOf(srcArrs, srcArrs.length);
start = System.currentTimeMillis();
bubbleSort(arrs, 0, arrs.length - 1);
time = System.currentTimeMillis() - start;
assertEquals(list, arrs, "冒泡排序", time);
// 堆 排序
arrs = Arrays.copyOf(srcArrs, srcArrs.length);
start = System.currentTimeMillis();
heapSort(arrs, 0, arrs.length - 1);
time = System.currentTimeMillis() - start;
assertEquals(list, arrs, "堆 排序", time);
System.out.println();
}
public static void assertEquals(List<Integer> list, Integer[] arrs, String msg, Long time) {
for (int i = 0; i < list.size(); i++) {
if (!arrs[i].equals(list.get(i))) {
System.out.println(msg + " ERR Index:" + i);
System.exit(1);
}
}
System.out.println(msg + " 正确, 耗时 " + time);
}
/**
* 堆排序
*
* @author daihui.gu
* @param arrs
* @param s
* @param e
*/
public static void heapSort(Integer[] arrs, int s, int e) {
// 创建最大堆
int n = (e + s) / 2;
for (int i = n; i >= s; i--) {
heapAdjust(arrs, i, e);
}
for (int i = e; i >= s; i--) {
int tmp = arrs[s];
arrs[s] = arrs[i];
arrs[i] = tmp;
heapAdjust(arrs, s, i - 1);
}
}
/**
* 堆排序调整方法
*
* @author daihui.gu
* @param arrs
* @param s
* @param e
*/
public static void heapAdjust(Integer[] arrs, int s, int e) {
// s 到 e 之间,仅有 s 位置需要调整,其余均是最大堆
int tmp = arrs[s];
int i = s;
while (i * 2 + 1 <= e) {
int index = i;
int left = 2 * i + 1, right = left + 1;
if (arrs[i] < arrs[left]) {
index = left;
}
if (right <= e && arrs[i] < arrs[right] && arrs[left] < arrs[right]) {
index = right;
}
if (index > i) {
arrs[i] = arrs[index];
arrs[index] = tmp;
i = index;
} else {
break;
}
}
}
/**
* 合并排序
*
* @author daihui.gu
* @param arrs
* @param s
* @param e
*/
public static void mergeSort(Integer[] arrs, int s, int e) {
if (s >= e) {
return;
}
int n = (s + e) / 2;
mergeSort(arrs, s, n);
mergeSort(arrs, n + 1, e);
Integer[] sort = new Integer[e - s + 1];
int index = 0;
int i = s, j = n + 1;
while (i <= n && j <= e) {
if (arrs[i] <= arrs[j]) {
sort[index++] = arrs[i++];
} else {
sort[index++] = arrs[j++];
}
}
while (i <= n) {
sort[index++] = arrs[i++];
}
while (j <= e) {
sort[index++] = arrs[j++];
}
for (int x = 0; x < sort.length; x++) {
arrs[s + x] = sort[x];
}
}
/**
* 希尔排序
*
* @author daihui.gu
* @param arrs
* @param s
* @param e
*/
public static void shellSort(Integer[] arrs, int s, int e) {
int n = e - s;
for (int gap = n / 2; gap > 0; gap /= 2) {
for (int i = s + gap; i < e + 1; i++) {
if (arrs[i] < arrs[i - gap]) {
int tmp = arrs[i];
int j;
for (j = i - gap; j >= s && arrs[j] > tmp; j -= gap) {
arrs[j + gap] = arrs[j];
}
arrs[j + gap] = tmp;
}
}
}
}
/**
* 插入排序
*
* @author daihui.gu
* @param arrs
* @param s
* @param e
*/
public static void insertionSort(Integer[] arrs, int s, int e) {
for (int i = s; i < e + 1; i++) {
int val = arrs[i];
int loc = i;
for (int j = i - 1; j >= 0; j--) {
if (arrs[j] > val) {
arrs[j + 1] = arrs[j];
loc = j;
}
}
if (loc < i) {
arrs[loc] = val;
}
}
}
/**
* 选择排序
*
* @author daihui.gu
* @param arrs
* @param s
* @param e
*/
public static void selectionSort(Integer[] arrs, int s, int e) {
for (int i = s; i < e; i++) {
int min = arrs[i];
int loc = s;
for (int j = i + 1; j < e + 1; j++) {
if (min > arrs[j]) {
min = arrs[j];
loc = j;
}
}
if (loc > i) {
arrs[loc] = arrs[i];
arrs[i] = min;
}
}
}
/**
* 冒泡排序
*
* @author daihui.gu
* @param arrs
* @param s
* @param e
*/
public static void bubbleSort(Integer[] arrs, int s, int e) {
for (int i = s; i < e; i++) {
for (int j = i + 1; j < e + 1; j++) {
if (arrs[i] > arrs[j]) {
int tmp = arrs[i];
arrs[i] = arrs[j];
arrs[j] = tmp;
}
}
}
}
/**
* 快速排序
*
* @author daihui.gu
* @param arrs
* @param s
* @param e
*/
public static void quickSort(Integer[] arrs, int s, int e) {
int i = s, j = e;
int val = arrs[i];
while (i < j) {
while (val <= arrs[j] && i < j) {
j--;
}
if (i < j) {
arrs[i] = arrs[j];
arrs[j] = val;
i++;
}
while (val >= arrs[i] && i < j) {
i++;
}
if (i < j) {
arrs[j] = arrs[i];
arrs[i] = val;
j--;
}
}
// 递归
if (s < i - 1) {
quickSort(arrs, s, i - 1);
}
if (i + 1 < e) {
quickSort(arrs, i + 1, e);
}
}
}
package cn.yicha.tuijian.model.novel.read;
import cn.yicha.tuijian.model.novel.onShowListener;
import android.content.Context;
import android.graphics.Bitmap;
import android.graphics.Canvas;
import android.graphics.ColorMatrix;
import android.graphics.ColorMatrixColorFilter;
import android.graphics.Matrix;
import android.graphics.Paint;
import android.graphics.Path;
import android.graphics.PointF;
import android.graphics.Region;
import android.graphics.Typeface;
import android.graphics.drawable.GradientDrawable;
import android.view.MotionEvent;
import android.widget.Scroller;
/**
* 自定义View,实现翻页特效
* <br/>改自http://blog.csdn.net/hmg25/article/details/6342539
*
* <br/> 继承自HorizontalReadView,不再实现HorizontalReadView已有的读取设置等方法,只改动与HorizontalReadView不一致的地方。
*
* @author gudh
* @data 2014-1-7
*/
public class EffectReadView extends HorizontalReadView {
// 阴影相关
private GradientDrawable mBackShadowDrawableLR;
private GradientDrawable mBackShadowDrawableRL;
private GradientDrawable mFolderShadowDrawableLR;
private GradientDrawable mFolderShadowDrawableRL;
private GradientDrawable mFrontShadowDrawableHBT;
private GradientDrawable mFrontShadowDrawableHTB;
private GradientDrawable mFrontShadowDrawableVLR;
private GradientDrawable mFrontShadowDrawableVRL;
private PointF mBezierStart1 = new PointF(); // 贝塞尔曲线起始点
private PointF mBezierControl1 = new PointF(); // 贝塞尔曲线控制点
private PointF mBezierVertex1 = new PointF(); // 贝塞尔曲线顶点
private PointF mBezierEnd1 = new PointF(); // 贝塞尔曲线结束点
private PointF mBezierStart2 = new PointF(); // 另一条贝塞尔曲线
private PointF mBezierControl2 = new PointF();
private PointF mBezierVertex2 = new PointF();
private PointF mBezierEnd2 = new PointF();
private float mMaxLength = (float) Math.hypot(screenW, screenH); // 对角线长
private PointF mTouch = new PointF(); // 拖拽点
private int mCornerX = 0; // 拖拽点对应的页脚,计算出来的
private int mCornerY = 0;
private float mDegrees; // 旋转的角度
private float mTouchToCornerDis; // 触点到页脚的距离
private boolean mIsRTOrLB; // 是否属于右上或左下,阴影方向
private Path mPath0; // 当前页与背面的线
private Path mPath1; // 背面与下一页的线
private Paint mPaint; // 画笔,背面颜色处理
private Scroller mScroller; // 滑动器
private Bitmap mCurPageBitmap = null; // 当前页
private Bitmap mNextPageBitmap = null;
private Matrix mMatrix; // 背面形状
private float[] mMatrixArray = { 0, 0, 0, 0, 0, 0, 0, 0, 1.0f };
public EffectReadView(Context context,int fontSize,int[] rgb,Typeface fontFamliy,onShowListener mOnShow){
super(context, fontSize, rgb, fontFamliy, mOnShow);
// 创建阴影的GradientDrawable
createDrawable();
mPath0 = new Path();
mPath1 = new Path();
// 颜色矩阵
float array[] = { 0.55f, 0, 0, 0, 80.0f, 0, 0.55f, 0, 0, 80.0f, 0, 0,
0.55f, 0, 80.0f, 0, 0, 0, 0.2f, 0 };
ColorMatrix cm = new ColorMatrix();
cm.set(array);
ColorMatrixColorFilter mColorMatrixFilter = new ColorMatrixColorFilter(
cm);
mPaint = new Paint();
mPaint.setStyle(Paint.Style.FILL);
mPaint.setColorFilter(mColorMatrixFilter);
mMatrix = new Matrix();
mScroller = new Scroller(getContext());
resetCorner();
}
/**
* 重置触点
*/
public void resetCorner(){
// 初始化触点,不让x,y为0,否则在点计算时会有问题
mTouch.x = 0.01f;
mTouch.y = 0.01f;
calcCornerXY(mTouch.x, mTouch.y);
}
/**
* 处理拖动和弹起的操作事件
*
* @param event
* @return
*/
public boolean doTouchEvent(MotionEvent event) {
if (event.getAction() == MotionEvent.ACTION_MOVE) {
mTouch.x = event.getX();
mTouch.y = event.getY();
this.postInvalidate();
} else if (event.getAction() == MotionEvent.ACTION_UP) {
if (canDragOver()) {
startAnimation(1200);
} else {
mTouch.x = mCornerX - 0.09f;
mTouch.y = mCornerY - 0.09f;
}
this.postInvalidate();
}
return true;
}
/**
* 画当前页区域
*
* @param canvas
* @param bitmap
* @param path
*/
private void drawCurrentPageArea(Canvas canvas, Bitmap bitmap) {
mPath0.reset();
mPath0.moveTo(mBezierStart1.x, mBezierStart1.y);
mPath0.quadTo(mBezierControl1.x, mBezierControl1.y, mBezierEnd1.x,
mBezierEnd1.y);
mPath0.lineTo(mTouch.x, mTouch.y);
mPath0.lineTo(mBezierEnd2.x, mBezierEnd2.y);
mPath0.quadTo(mBezierControl2.x, mBezierControl2.y, mBezierStart2.x,
mBezierStart2.y);
mPath0.lineTo(mCornerX, mCornerY);
mPath0.close();
canvas.save();
canvas.clipPath(mPath0, Region.Op.XOR);
canvas.drawBitmap(bitmap, 0, 0, null);
canvas.restore();
}
/**
* 画下一页和背景页
*
* @param canvas
* @param bitmap
*/
private void drawNextPageAreaAndShadow(Canvas canvas, Bitmap bitmap) {
mPath1.reset();
mPath1.moveTo(mBezierStart1.x, mBezierStart1.y);
mPath1.lineTo(mBezierVertex1.x, mBezierVertex1.y);
mPath1.lineTo(mBezierVertex2.x, mBezierVertex2.y);
mPath1.lineTo(mBezierStart2.x, mBezierStart2.y);
mPath1.lineTo(mCornerX, mCornerY);
mPath1.close();
mDegrees = (float) Math.toDegrees(Math.atan2(mBezierControl1.x
- mCornerX, mBezierControl2.y - mCornerY));
int leftx;
int rightx;
GradientDrawable mBackShadowDrawable;
if (mIsRTOrLB) {
leftx = (int) (mBezierStart1.x);
rightx = (int) (mBezierStart1.x + mTouchToCornerDis / 4);
mBackShadowDrawable = mBackShadowDrawableLR;
} else {
leftx = (int) (mBezierStart1.x - mTouchToCornerDis / 4);
rightx = (int) mBezierStart1.x;
mBackShadowDrawable = mBackShadowDrawableRL;
}
canvas.save();
canvas.clipPath(mPath0);
canvas.clipPath(mPath1, Region.Op.INTERSECT);
canvas.drawBitmap(bitmap, 0, 0, null);
// 绘阴影
canvas.rotate(mDegrees, mBezierStart1.x, mBezierStart1.y);
mBackShadowDrawable.setBounds(leftx, (int) mBezierStart1.y, rightx,
(int) (mMaxLength + mBezierStart1.y));
mBackShadowDrawable.draw(canvas);
canvas.restore();
}
/**
* 绘制翻起页的阴影
*/
public void drawCurrentPageShadow(Canvas canvas) {
double degree;
if (mIsRTOrLB) {
degree = Math.PI
/ 4
- Math.atan2(mBezierControl1.y - mTouch.y, mTouch.x
- mBezierControl1.x);
} else {
degree = Math.PI
/ 4
- Math.atan2(mTouch.y - mBezierControl1.y, mTouch.x
- mBezierControl1.x);
}
// 翻起页阴影顶点与touch点的距离
double d1 = (float) 25 * 1.414 * Math.cos(degree);
double d2 = (float) 25 * 1.414 * Math.sin(degree);
float x = (float) (mTouch.x + d1);
float y;
if (mIsRTOrLB) {
y = (float) (mTouch.y + d2);
} else {
y = (float) (mTouch.y - d2);
}
mPath1.reset();
mPath1.moveTo(x, y);
mPath1.lineTo(mTouch.x, mTouch.y);
mPath1.lineTo(mBezierControl1.x, mBezierControl1.y);
mPath1.lineTo(mBezierStart1.x, mBezierStart1.y);
mPath1.close();
float rotateDegrees;
canvas.save();
canvas.clipPath(mPath0, Region.Op.XOR);
canvas.clipPath(mPath1, Region.Op.INTERSECT);
int leftx;
int rightx;
GradientDrawable mCurrentPageShadow;
if (mIsRTOrLB) {
leftx = (int) (mBezierControl1.x);
rightx = (int) mBezierControl1.x + 25;
mCurrentPageShadow = mFrontShadowDrawableVLR;
} else {
leftx = (int) (mBezierControl1.x - 25);
rightx = (int) mBezierControl1.x + 1;
mCurrentPageShadow = mFrontShadowDrawableVRL;
}
rotateDegrees = (float) Math.toDegrees(Math.atan2(mTouch.x
- mBezierControl1.x, mBezierControl1.y - mTouch.y));
canvas.rotate(rotateDegrees, mBezierControl1.x, mBezierControl1.y);
mCurrentPageShadow.setBounds(leftx,
(int) (mBezierControl1.y - mMaxLength), rightx,
(int) (mBezierControl1.y));
mCurrentPageShadow.draw(canvas);
canvas.restore();
mPath1.reset();
mPath1.moveTo(x, y);
mPath1.lineTo(mTouch.x, mTouch.y);
mPath1.lineTo(mBezierControl2.x, mBezierControl2.y);
mPath1.lineTo(mBezierStart2.x, mBezierStart2.y);
mPath1.close();
canvas.save();
canvas.clipPath(mPath0, Region.Op.XOR);
canvas.clipPath(mPath1, Region.Op.INTERSECT);
if (mIsRTOrLB) {
leftx = (int) (mBezierControl2.y);
rightx = (int) (mBezierControl2.y + 25);
mCurrentPageShadow = mFrontShadowDrawableHTB;
} else {
leftx = (int) (mBezierControl2.y - 25);
rightx = (int) (mBezierControl2.y + 1);
mCurrentPageShadow = mFrontShadowDrawableHBT;
}
rotateDegrees = (float) Math.toDegrees(Math.atan2(mBezierControl2.y
- mTouch.y, mBezierControl2.x - mTouch.x));
canvas.rotate(rotateDegrees, mBezierControl2.x, mBezierControl2.y);
float temp;
if (mBezierControl2.y < 0)
temp = mBezierControl2.y - screenH;
else
temp = mBezierControl2.y;
int hmg = (int) Math.hypot(mBezierControl2.x, temp);
if (hmg > mMaxLength)
mCurrentPageShadow
.setBounds((int) (mBezierControl2.x - 25) - hmg, leftx,
(int) (mBezierControl2.x + mMaxLength) - hmg,
rightx);
else
mCurrentPageShadow.setBounds(
(int) (mBezierControl2.x - mMaxLength), leftx,
(int) (mBezierControl2.x), rightx);
mCurrentPageShadow.draw(canvas);
canvas.restore();
}
/**
* 绘制翻起页背面
*/
private void drawCurrentBackArea(Canvas canvas, Bitmap bitmap) {
int i = (int) (mBezierStart1.x + mBezierControl1.x) / 2;
float f1 = Math.abs(i - mBezierControl1.x);
int i1 = (int) (mBezierStart2.y + mBezierControl2.y) / 2;
float f2 = Math.abs(i1 - mBezierControl2.y);
float f3 = Math.min(f1, f2);
mPath1.reset();
mPath1.moveTo(mBezierVertex2.x, mBezierVertex2.y);
mPath1.lineTo(mBezierVertex1.x, mBezierVertex1.y);
mPath1.lineTo(mBezierEnd1.x, mBezierEnd1.y);
mPath1.lineTo(mTouch.x, mTouch.y);
mPath1.lineTo(mBezierEnd2.x, mBezierEnd2.y);
mPath1.close();
GradientDrawable mFolderShadowDrawable;
int left;
int right;
if (mIsRTOrLB) {
left = (int) (mBezierStart1.x - 1);
right = (int) (mBezierStart1.x + f3 + 1);
mFolderShadowDrawable = mFolderShadowDrawableLR;
} else {
left = (int) (mBezierStart1.x - f3 - 1);
right = (int) (mBezierStart1.x + 1);
mFolderShadowDrawable = mFolderShadowDrawableRL;
}
canvas.save();
canvas.clipPath(mPath0);
canvas.clipPath(mPath1, Region.Op.INTERSECT);
float dis = (float) Math.hypot(mCornerX - mBezierControl1.x,
mBezierControl2.y - mCornerY);
float f8 = (mCornerX - mBezierControl1.x) / dis;
float f9 = (mBezierControl2.y - mCornerY) / dis;
mMatrixArray[0] = 1 - 2 * f9 * f9;
mMatrixArray[1] = 2 * f8 * f9;
mMatrixArray[3] = mMatrixArray[1];
mMatrixArray[4] = 1 - 2 * f8 * f8;
mMatrix.reset();
mMatrix.setValues(mMatrixArray);
mMatrix.preTranslate(-mBezierControl1.x, -mBezierControl1.y);
mMatrix.postTranslate(mBezierControl1.x, mBezierControl1.y);
canvas.drawBitmap(bitmap, mMatrix, mPaint);
// canvas.drawBitmap(bitmap, mMatrix, null);
// mPaint.setColorFilter(null);
canvas.rotate(mDegrees, mBezierStart1.x, mBezierStart1.y);
mFolderShadowDrawable.setBounds(left, (int) mBezierStart1.y, right,
(int) (mBezierStart1.y + mMaxLength));
mFolderShadowDrawable.draw(canvas);
canvas.restore();
}
/**
* 在指定时间内滑动出去
*
* @param delayMillis
*/
private void startAnimation(int delayMillis) {
int dx, dy;
// dx 水平方向滑动的距离,负值会使滚动向左滚动
// dy 垂直方向滑动的距离,负值会使滚动向上滚动
if (mCornerX > 0) {
dx = -(int) (screenW + mTouch.x);
} else {
dx = (int) (screenW - mTouch.x + screenW);
}
if (mCornerY > 0) {
dy = (int) (screenH - mTouch.y);
} else {
dy = (int) (1 - mTouch.y); // 防止mTouch.y最终变为0
}
mScroller.startScroll((int) mTouch.x, (int) mTouch.y, dx, dy,
delayMillis);
}
/**
* 滑动过程处理
*/
public void computeScroll() {
super.computeScroll();
if (mScroller.computeScrollOffset()) {
float x = mScroller.getCurrX();
float y = mScroller.getCurrY();
mTouch.x = x;
mTouch.y = y;
postInvalidate();
}
}
/**
* 计算各个点
*/
private void calcPoints() {
// 触电到页脚的中点
float mMiddleX = (mTouch.x + mCornerX) / 2;
float mMiddleY = (mTouch.y + mCornerY) / 2;
mBezierControl1.x = mMiddleX - (mCornerY - mMiddleY)
* (mCornerY - mMiddleY) / (mCornerX - mMiddleX);
mBezierControl1.y = mCornerY;
mBezierControl2.x = mCornerX;
mBezierControl2.y = mMiddleY - (mCornerX - mMiddleX)
* (mCornerX - mMiddleX) / (mCornerY - mMiddleY);
mBezierStart1.x = mBezierControl1.x - (mCornerX - mBezierControl1.x)
/ 2;
mBezierStart1.y = mCornerY;
// 当mBezierStart1.x < 0或者mBezierStart1.x > 480时
// 如果继续翻页,会出现BUG故在此限制
if (mTouch.x > 0 && mTouch.x < screenW) {
if (mBezierStart1.x < 0 || mBezierStart1.x > screenW) {
if (mBezierStart1.x < 0) {
mBezierStart1.x = screenW - mBezierStart1.x;
}
float f1 = Math.abs(mCornerX - mTouch.x);
float f2 = screenW * f1 / mBezierStart1.x;
mTouch.x = Math.abs(mCornerX - f2);
float f3 = Math.abs(mCornerX - mTouch.x)
* Math.abs(mCornerY - mTouch.y) / f1;
mTouch.y = Math.abs(mCornerY - f3);
mMiddleX = (mTouch.x + mCornerX) / 2;
mMiddleY = (mTouch.y + mCornerY) / 2;
mBezierControl1.x = mMiddleX - (mCornerY - mMiddleY)
* (mCornerY - mMiddleY) / (mCornerX - mMiddleX);
mBezierControl1.y = mCornerY;
mBezierControl2.x = mCornerX;
mBezierControl2.y = mMiddleY - (mCornerX - mMiddleX)
* (mCornerX - mMiddleX) / (mCornerY - mMiddleY);
mBezierStart1.x = mBezierControl1.x
- (mCornerX - mBezierControl1.x) / 2;
}
}
mBezierStart2.x = mCornerX;
mBezierStart2.y = mBezierControl2.y - (mCornerY - mBezierControl2.y)
/ 2;
mTouchToCornerDis = (float) Math.hypot((mTouch.x - mCornerX),
(mTouch.y - mCornerY));
mBezierEnd1 = getCross(mTouch, mBezierControl1, mBezierStart1,
mBezierStart2);
mBezierEnd2 = getCross(mTouch, mBezierControl2, mBezierStart1,
mBezierStart2);
/*
* mBeziervertex1.x 推导
* ((mBezierStart1.x+mBezierEnd1.x)/2+mBezierControl1.x)/2 化简等价于
* (mBezierStart1.x+ 2*mBezierControl1.x+mBezierEnd1.x) / 4
*/
mBezierVertex1.x = (mBezierStart1.x + 2 * mBezierControl1.x + mBezierEnd1.x) / 4;
mBezierVertex1.y = (2 * mBezierControl1.y + mBezierStart1.y + mBezierEnd1.y) / 4;
mBezierVertex2.x = (mBezierStart2.x + 2 * mBezierControl2.x + mBezierEnd2.x) / 4;
mBezierVertex2.y = (2 * mBezierControl2.y + mBezierStart2.y + mBezierEnd2.y) / 4;
}
/**
* 如果没有停止,则终止滑动
*/
public void abortAnimation() {
if (!mScroller.isFinished()) {
mScroller.abortAnimation();
}
}
/**
* 判断是否需要继续自动翻页至结束
*
* @return
*/
public boolean canDragOver() {
// 拖动距离超过宽度十分之一,则需要翻页,否则不需要
if (mTouchToCornerDis > screenW / 10) {
return true;
}
return false;
}
/**
* 是否从左边翻向右边
*/
public boolean DragToRight() {
return mCornerX == 0;
}
/**
* 计算拖拽点对应的拖拽脚
*/
public void calcCornerXY(float x, float y) {
mTouch.x = x;
mTouch.y = y;
if (x <= screenW / 2) {
mCornerX = 0;
} else {
mCornerX = screenW;
}
if (y <= screenH / 2) {
mCornerY = 0;
} else {
mCornerY = screenH;
}
if ((mCornerX == 0 && mCornerY == screenH)
|| (mCornerX == screenW && mCornerY == 0)) {
mIsRTOrLB = true; // corner在左下角或者右上角
} else {
mIsRTOrLB = false;
}
}
/**
* 创建阴影的GradientDrawable
*/
private void createDrawable() {
int[] color = { 0x333333, 0xb0333333 };
mFolderShadowDrawableRL = new GradientDrawable(
GradientDrawable.Orientation.RIGHT_LEFT, color);
mFolderShadowDrawableRL
.setGradientType(GradientDrawable.LINEAR_GRADIENT);
mFolderShadowDrawableLR = new GradientDrawable(
GradientDrawable.Orientation.LEFT_RIGHT, color);
mFolderShadowDrawableLR
.setGradientType(GradientDrawable.LINEAR_GRADIENT);
int[] mBackShadowColors = new int[] { 0xff111111, 0x111111 };
mBackShadowDrawableRL = new GradientDrawable(
GradientDrawable.Orientation.RIGHT_LEFT, mBackShadowColors);
mBackShadowDrawableRL.setGradientType(GradientDrawable.LINEAR_GRADIENT);
mBackShadowDrawableLR = new GradientDrawable(
GradientDrawable.Orientation.LEFT_RIGHT, mBackShadowColors);
mBackShadowDrawableLR.setGradientType(GradientDrawable.LINEAR_GRADIENT);
int[] mFrontShadowColors = new int[] { 0x80111111, 0x111111 };
mFrontShadowDrawableVLR = new GradientDrawable(
GradientDrawable.Orientation.LEFT_RIGHT, mFrontShadowColors);
mFrontShadowDrawableVLR
.setGradientType(GradientDrawable.LINEAR_GRADIENT);
mFrontShadowDrawableVRL = new GradientDrawable(
GradientDrawable.Orientation.RIGHT_LEFT, mFrontShadowColors);
mFrontShadowDrawableVRL
.setGradientType(GradientDrawable.LINEAR_GRADIENT);
mFrontShadowDrawableHTB = new GradientDrawable(
GradientDrawable.Orientation.TOP_BOTTOM, mFrontShadowColors);
mFrontShadowDrawableHTB
.setGradientType(GradientDrawable.LINEAR_GRADIENT);
mFrontShadowDrawableHBT = new GradientDrawable(
GradientDrawable.Orientation.BOTTOM_TOP, mFrontShadowColors);
mFrontShadowDrawableHBT
.setGradientType(GradientDrawable.LINEAR_GRADIENT);
}
/**
* 求解直线P1P2和直线P3P4的交点坐标
*/
public PointF getCross(PointF P1, PointF P2, PointF P3, PointF P4) {
PointF CrossP = new PointF();
// 二元函数通式: y=ax+b
float a1 = (P2.y - P1.y) / (P2.x - P1.x);
float b1 = ((P1.x * P2.y) - (P2.x * P1.y)) / (P1.x - P2.x);
float a2 = (P4.y - P3.y) / (P4.x - P3.x);
float b2 = ((P3.x * P4.y) - (P4.x * P3.y)) / (P3.x - P4.x);
CrossP.x = (b2 - b1) / (a1 - a2);
CrossP.y = a1 * CrossP.x + b1;
return CrossP;
}
/**
* 绘图方法
*/
@Override
protected void onDraw(Canvas canvas) {
if(mNextPageBitmap == mCurPageBitmap){
this.resetCorner();
}
// 计算各个点
calcPoints();
canvas.drawColor(0xFFAAAAAA);
drawCurrentPageArea(canvas, mCurPageBitmap);
drawCurrentPageShadow(canvas);
drawNextPageAreaAndShadow(canvas, mNextPageBitmap);
drawCurrentBackArea(canvas, mCurPageBitmap);
// 绘制title
if (title != null) {
canvas.drawText(title, super.screenW / 2
- (titlePaint.measureText(title) / 2), this.titleH,
titlePaint);
}
}
@Override
public boolean onTouchEvent(MotionEvent event) {
switch (event.getAction()) {
case MotionEvent.ACTION_DOWN:
showMenu=false;
touchStartX = event.getX();
touchStartY = event.getY();
// 记录 指针指向恢复使用
charStartPosTmp = charStartPos;
charEndPosTmp = charEndPos;
touchType = parseEvent(event.getX(), event.getY());
if(touchType == 0){
// 如果为弹框,则重设按点
this.resetCorner();
}else{
this.abortAnimation();
this.calcCornerXY(touchStartX, touchStartY);
}
switch (touchType) {
case -1:// prv
if (touchLock)
return false;
this.oldX = event.getX();
oldHideStepX = 20;
getPrvBitmap();
break;
case 0:// menu
// 当前置为最新
mCurPageBitmap = mNextPageBitmap;
showMenu=true;
break;
case 1:// next
if (touchLock)
return false;
this.oldX = event.getX();
oldHideStepX = -20;
getNextBitmap();
break;
}
break;
case MotionEvent.ACTION_MOVE:
if(showMenu){break;}
endX = event.getX();
endY = event.getY();
if (Math.abs(endX - touchStartX) > maxX)
maxX = Math.abs(endX - touchStartX);
this.oldX = endX;
//invalidate();
this.doTouchEvent(event);
break;
case MotionEvent.ACTION_UP:
if (showMenu&&mOnShow != null){
mOnShow.onShowBar();
break;
}
this.endX = -1;
this.oldX = event.getX();
if ((event.getX() - touchStartX) < maxX * 2 / 5 && oldHideStepX > 0) {// 取消往右滑动
oldHideStepX = -20;
mNextPageBitmap = mCurPageBitmap;
this.resetCorner();
// 回滚标记点
charStartPos = charStartPosTmp;
charEndPos = charEndPosTmp;
mOnShow.markReadPos(charStartPos);
} else if (oldHideStepX < 0
&& (touchStartX - event.getX()) < maxX * 3 / 5) {// 取消往左滑行
oldHideStepX = 20;
mNextPageBitmap = mCurPageBitmap;
this.resetCorner();
// 回滚标记点
charStartPos = charStartPosTmp;
charEndPos = charEndPosTmp;
mOnShow.markReadPos(charStartPos);
}
maxX = 0;
//invalidate();
this.doTouchEvent(event);
break;
}
return true;
}
@Override
public void getPrvBitmap() {
if(charStartPos <= 0) {//需要加载数据
this.lor=-1;
this.isButtonAction=false;
this.charStartPos=this.charEndPos=0;
mOnShow.getPrvChapter();
mCurPageBitmap = mNextPageBitmap;
return ;
}
charEndPos = charStartPos;
charStartPos = 0;// 上届标记为起始
getLinesToDraw(charStartPos, charEndPos, false);
// 修改real和now的关系
mCurPageBitmap = mNextPageBitmap;
mNextPageBitmap = getBitmap();
}
@Override
public void getNextBitmap() {
if (charEndPos >= this.textCharArr.length - 1) {// 需要加载下一章内容
this.lor=1;
this.isButtonAction=false;
mOnShow.getNextChapter();
mCurPageBitmap = mNextPageBitmap;
return;
}
charStartPos = charEndPos;
charEndPos = this.textCharArr.length - 1;
getLinesToDraw(charStartPos, charEndPos, true);
// 修改real和now的关系
mCurPageBitmap = mNextPageBitmap;
mNextPageBitmap = getBitmap();
if(mCurPageBitmap == null){
mCurPageBitmap = mNextPageBitmap;
}
}
@Override
public void setFontSize(int size) {
fontSize=size;
paint.setTextSize(size);
this.rebuildEnvironment();
paint.getTextWidths(textCharArr, 0, textCharArr.length,textCharArrWidth);
getLinesToDraw(charStartPos, textCharArr.length-1, true);
// 修改now也为当前,及时更新
mNextPageBitmap = getBitmap();
mCurPageBitmap = mNextPageBitmap;
invalidate();
}
@Override
public void setFontColor(int r,int g,int b) {
this.r = r;
this.g = g;
this.b = b;
setTextFrontColor(r, g, b);
// 修改now也为当前,及时更新
mNextPageBitmap = getBitmap();
mCurPageBitmap = mNextPageBitmap;
invalidate();
}
}
我们知道 utf8mb4 是向后兼容 utf8 字符集的,也就是说 utf8mb4 完全包含 utf8。
那么使用 utf8mb4、utf8 字符集的不同表,在 join 时能否用上索引,left join 顺序改变是否能改变结果呢?
如果关联字段的类型和编码集一样,不同的长度能否使用上索引呢?
如果关联字段的编码集一样,不同的类型能否使用上索引呢?
下面通过学生表、班级表的例子来
// 班级表
CREATE TABLE `clazz` (
`id` int(11) NOT NULL,
`class` varchar(10) DEFAULT NULL,
`class_name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
// 学生表
CREATE TABLE `student` (
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
`class` varchar(10) CHARACTER SET utf8 DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_class` (`class`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
explain select * from clazz left join student on student.class = clazz.class;
不同编码集能否使用索引
clazz.class | student.class | 能否使用索引
utf8 | utf8 | 能
utf8mb4 | utf8mb4 | 能
utf8 | utf8mb4 | 能
utf8mb4 | utf8 | 不能
不同长度能否使用索引
clazz.class | student.class | 能否使用索引
10 | 10 | 能
10 | 5 | 能
5 | 10 | 能
不同类型能否使用索引
clazz.class | student.class | 能否使用索引
char | varchar | 能
varchar | char | 能
varchar | int | 能
int | varchar | 不能
个人见解,如果有分析不正确的地方,欢迎指出交流!
JDK NIO的臭名昭著的epoll bug,它会导致Selector空轮询,最终导致CPU 100%。官方声称在JDK1.6版本的update18修复了该问题,但是直到JDK1.7版本该问题仍旧存在,只不过该bug发生概率降低了一些而已,它并没有被根本解决。该BUG发生后会导致CPU突然占用1000%以上,示例的堆栈如下:
"NettyClientWorker-thread-7" daemon prio=10 tid=0x00007ffbe80c3800 nid=0x3539 runnable [0x00007ffc2cccb000]
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:269)
at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:79)
at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:87)
- locked <0x0000000682334a28> (a sun.nio.ch.Util$2)
- locked <0x0000000682334a18> (a java.util.Collections$UnmodifiableSet)
- locked <0x0000000682333610> (a sun.nio.ch.EPollSelectorImpl)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:98)
at org.jboss.netty.channel.socket.nio.SelectorUtil.select(SelectorUtil.java:52)
at org.jboss.netty.channel.socket.nio.AbstractNioWorker.run(AbstractNioWorker.java:200)
at org.jboss.netty.channel.socket.nio.NioWorker.run(NioWorker.java:38)
at org.jboss.netty.util.internal.DeadLockProofWorker$1.run(DeadLockProofWorker.java:42)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:744)
我之前的一篇博客 数据库并发不一致分析 有提到过事务隔离级别以及相应加锁方式、能够解决的并发问题。
标准情况下,在 RR(Repeatable Read) 隔离级别下能解决不可重复读(当行修改)的问题,但是不能解决幻读的问题。
而之前有看过一篇 mysql 加锁的文章 MySQL 加锁处理分析,里面有提到一点:
对于Innodb,Repeatable Read (RR) 针对当前读,RR隔离级别保证对读取到的记录加锁 (记录锁),同时保证对读取的范围加锁,新的满足查询条件的记录不能够插入 (间隙锁),不存在幻读现象。
那么问题来了,到底 Innodb 中 RR 隔离级别是否能解决幻读呢?
在 MySQL 加锁处理分析这篇文章下面的评论中,有这样的一个交流:
ontheway
弱弱地问一句,我看的书里面都说的是RR隔离级别不允许脏读和不可重复读,但是可以幻读,怎么和作者说的不一样呢?hedengcheng(作者)
你说的没错,因此我在文章一开始,就强调了这一点。mysql innodb引擎的实现,跟标准有所不同。
MySQL Innodb 引擎的实现,跟标准有所不同,针对这个问题,我表示怀疑,于是查看 mysql 官方文档关于 RR的解释,里面有这么一段话:
For locking reads (SELECT with FOR UPDATE or LOCK IN SHARE MODE), UPDATE, and DELETE statements, locking depends on whether the statement uses a unique index with a unique search condition, or a range-type search condition. For a unique index with a unique search condition, InnoDB locks only the index record found, not the gap before it. For other search conditions, InnoDB locks the index range scanned, using gap locks or next-key locks to block insertions by other sessions into the gaps covered by the range.
大致意思就是,在 RR 级别下,如果查询条件能使用上唯一索引,或者是一个唯一的查询条件,那么仅加行锁,如果是一个范围查询,那么就会给这个范围加上 gap 锁或者 next-key锁 (行锁+gap锁)。
从这句话的理解来看,和文章里的解释一样,由于 RR 级别对于范围会加 GAP 锁,这个和 sql 的标准是有一些差异的。
后面又发现了一篇文章 Understanding InnoDB transaction isolation levels,文章中又提到:
This isolation level is the default for InnoDB. Although this isolation level solves the problem of non-repeatable read, but there is another possible problem phantom reads.
大概意思是,RR 能解决不可重复读的问题,但仍可能发生幻读,怀疑作者并不了解 Innodb 的特殊实现,评论中也有提到:
Do you mean 'write skew' instead of 'phantom reads'? The 'repeatable read' in SQL standard allows 'phantom reads', however, since InnoDB uses next-key locking this anomaly does not exist in this level. Looks like it's equivalent to 'snapshot isolation' in Postgres and Oracle.
再来看一篇文章 MySQL的InnoDB的幻读问题,这里面提供了一些例子,还没来得及分析,但最后的结论是:
MySQL InnoDB的可重复读并不保证避免幻读,需要应用使用加锁读来保证。而这个加锁度使用到的机制就是next-key locks。
Innodb 的 RR 隔离界别对范围会加上 GAP,理论上不会存在幻读,但是是否有例外呢,这个还需要进一步求证。
以前修改的一个打包工具,在此记录一下。待有用之时借鉴
windows 批处理运行命令
FOR /F "delims=, tokens=1,2" %%k in (path.txt) DO FOR /F "delims=, tokens=1-26" %%A in (devices.txt) do ant -f source\build.xml -DinPath=%%k,-DoutPath=%%l,-Dcategory=%%A,-Dcateid=%%B,-Dimgname=%%C,-Dimgsize=%%D,-Dimgnumber=%%E,-Dupmessage=%%F,-Dupnumber=%%G,-Dprice=%%H,-DsendNum=%%I,-Durl1=%%J,-Durl2=%%K,-Durl3=%%L,-Durl4=%%M
build.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project default="patch" basedir=".">
<target name="prepare">
<property file="platform.properties" />
<taskdef resource="defs.properties">
<classpath>
<pathelement path="${libs.j2me_ant_ext.classpath}"/>
</classpath>
</taskdef>
<property name="inPath" value="" />
<property name="outPath" value="" />
<property name="category" value=""/>
<property name="cateid" value="" />
<property name="imgname" value="" />
<property name="imgsize" value="" />
<property name="imgnumber" value="" />
<property name="upmessage" value="" />
<property name="upnumber" value="" />
<property name="price" value="" />
<property name="sendNum" value="" />
<property name="url1" value="" />
<property name="url2" value="" />
<property name="url3" value="" />
<property name="url4" value="" />
<property name="product" value="EMC" />
<property name="patchSrc" value="patch" />
<property name="binHome" value="bin"/>
<delete dir="${outPath}/unpack" />
<echo>Clean ok!</echo>
</target>
<target name="unjar">
<unzip src="jar/gsy.jar" dest="${outPath}/unpack" />
<replace file="${outPath}/unpack/META-INF/MANIFEST.MF" encoding="UTF-8">
<replacefilter token="@MIDLETNAME@" value="${imgname}"/>
<replacefilter token="@IMGNUM@" value="${imgnumber}"/>
</replace>
</target>
<target name="copy">
<copy todir="${outPath}/unpack/${binHome}">
<fileset dir="bin" />
<filterset>
<filter token="Chanel" value="${category}_${cateid}"/>
<filter token="name" value="${imgname}"/>
<filter token="imgnumber" value="${imgnumber}"/>
<filter token="imgsize" value="${imgsize}"/>
<filter token="url1" value="${url1}"/>
<filter token="url2" value="${url2}"/>
<filter token="url3" value="${url3}"/>
<filter token="url4" value="${url4}"/>
<filter token="upmessage" value="${upmessage}"/>
<filter token="upnumber" value="${upnumber}"/>
<filter token="price" value="${price}"/>
<filter token="sendNum" value="${sendNum}"/>
</filterset>
</copy>
<copy todir="${outPath}/unpack/" overwrite="true">
<fileset dir="${inPath}\${category}\${cateid}"/>
</copy>
<copy tofile="${outPath}/unpack/intro.txt" file="intro.txt" overwrite="true"/>
</target>
<target name="jar">
<mkdir dir="${outPath}/jar/${category}/${cateid}/"/>
<jar destfile="${outPath}/jar/${category}/${cateid}/${cateid}_${imgsize}.jar" basedir="${outPath}/unpack/" manifest="${outPath}/unpack/META-INF/MANIFEST.MF" manifestencoding="UTF-8"/>
<echo>size = ${size}</echo>
</target>
<target name="clean" >
<delete dir="${outPath}/unpack" />
<echo>Clean ok!</echo>
</target>
<target name="patch" depends="prepare, unjar, copy, jar, clean">
<echo>Applying patches...Success!</echo>
<echo>////渠道:${patchDst}...版本:${device}...Success!////</echo>
</target>
</project>
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.