AAAI 2022: Enhancing Pseudo Label Quality for Semi-Supervised Domain-Generalized Medical Image Segmentation
This is a PyTorch implementation of Enhancing Pseudo Label Quality for Semi-Supervised Domain-Generalized Medical Image Segmentation.
The overall framework
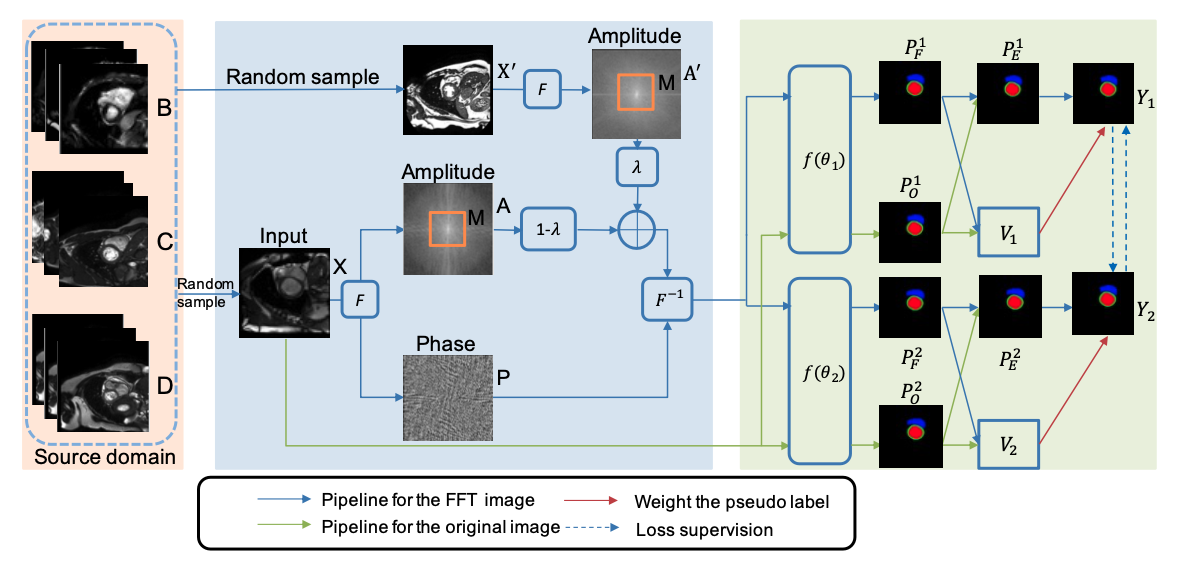
Architecture of the code:
- config.py(config file)
- inference_mms.py(inference file for M&Ms dataset)
- inference_scgm.py(inference file for SCGM dataset)
- mms_dataloader.py(dataloader for M&Ms dataset)
- scgm_dataloader.py(dataloader for SCGM dataset)
- mms_train.py(train file for M&Ms dataset)
- scgm_train.py(train file for SCGM dataset)
- network(network folder including deeplabv3p)
- utils(utils folder including some useful functions)
- We followed the setting of Semi-supervised Meta-learning with Disentanglement for Domain-generalised Medical Image Segmentation.
- We used two datasets in this paper: Multi-Centre, Multi-Vendor & Multi-Disease Cardiac Image Segmentation Challenge (M&Ms) datast and Spinal cord grey matter segmentation challenge dataset
We followed the preprocessing of Semi-supervised Meta-learning with Disentanglement for Domain-generalised Medical Image Segmentation, you can find the preprocessing code here. After that, you should change the data directories in the dataloader(mms_dataloader or scgm_dataloader) file.
We use wandb to visulize our results. If you want to use this, you may need register an account first.
Use this command to install the environments.
conda env create -f semi_dg.yaml
We use the resnet-50 as our backbone and it is pretrained on Imagenet. You can download this here.
You can find the trained model weights here
If you want to train the model on M&Ms dataset, you can use this command. You can find the config information in config.py.
python mms_train.py
If you want to evaluate our models on M&Ms dataset, you can use this command. And you should change the model name(line 320 and 321) and the test_vendor(line 318) to load different models.
python inference_mms.py

If this code is useful for your research, please consider citing:
@article{yao2022enhancing,
title={Enhancing Pseudo Label Quality for Semi-SupervisedDomain-Generalized Medical Image Segmentation},
author={Yao, Huifeng and Hu, Xiaowei and Li, Xiaomeng},
journal={arXiv preprint arXiv:2201.08657},
year={2022}
}






































