The goal of this controller is to provide a way to start a kubernetes workload on demand (mean when there is incoming TCP traffic on it), and shutdown it after that. It very useful in order to :
- we do not need kubernetes nodes all the time (FinOps)
- distribute daily developments environments start according to real team needs
To achieve that, the controller takes control of the endpointslice associated to your application when the application is scaled to 0. The controller is aware of incoming traffic to your service, and can scale up the workload and give back endpointslice to your cloud provider controller.
Requires Kubernetes >= 1.20. Tested on GKE and k3s, with nginx ingress controller (not required).
A full example is in example-conf/echoserver/echoserver.yaml.
Your deployment must be labelized with standard kubernetes labels :
apiVersion: apps/v1
kind: Deployment
metadata:
name: echoserver-deployment
namespace: default
labels:
app.kubernetes.io/name: "echoserver"
app.kubernetes.io/instance: "echoserver"
scaling.neo9.io/is-scalable: "true"
[...]
Indeed, your service must have the same labels :
apiVersion: v1
kind: Service
metadata:
name: echoserver-deployment
namespace: default
labels:
app.kubernetes.io/name: "echoserver"
app.kubernetes.io/instance: "echoserver"
scaling.neo9.io/is-scalable: "true"
[...]
If you plan to use nginx as ingress source (not required, internal traffic is also handled), you must specify nginx.ingress.kubernetes.io/service-upstream to be sur that nginx will not bypass kubernetes services (in that case, the controller won't be able to determine the originally targeted service).
For internal calls (as pods to other service), there is no configuration needed.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/service-upstream: "true"
nginx.ingress.kubernetes.io/upstream-vhost: <service-name>.<service-namespace>
[...]
The upstream-vhost is override in order to have the same behaviour for internal and external service exchanges.
That's all ! Deploy the controller (see values/apply.sh for an example of helm deployment), and you will have an on demand (traffic) scale for your app.
You can specify additional (dependencies) workload to scale up on request. For example, when the workload A starts, it will trigger the workload A startup.
To do this, you need to annotate the source (A) workload with : scaling.neo9.io/before-scale-requirements: "name-of-workload-b". Indeed, the B workload must have the scaling label (scaling.neo9.io/is-scalable: "true").
You can also enable a waiting (splash screen) by annotating your workload with scaling.neo9.io/show-splash-screen: "true".
In Kubernetes, there is no direct relationship between deployments and services. That's why we use standard labels to link a service with the application : app.kubernetes.io/name and app.kubernetes.io/instance.
In order to be sur that the controller manages resources it's allowed to, you have to add this label on service and deployment : scaling.neo9.io/is-scalable: "true". You can have a look in example-conf/echoserver/echoserver.yaml.
That's all ! Your deployment will be detected by controller and follow the rules bellow.
Downscaling and Upscaling technicals actions are detailed bellow.
The goal is to be able to handle multiple downscale strategies.
Kube downscaler is a good way do periodically downscale your workloads. This controller will prevent kube downscaler to re-up.
In others words, the dowscale part is handled by Kube downscaler and the upscale part by this controller.
If the workload is annotated with scaling.neo9.io/scale-down-after-log-activity-delay-in-minutes, the specified interval
will be used to downscale the workload is the log is empty for the given window.
Note that you can exclude some pattern from log (healthcheck for example) with scaling.neo9.io/scale-down-exclude-log-activity.
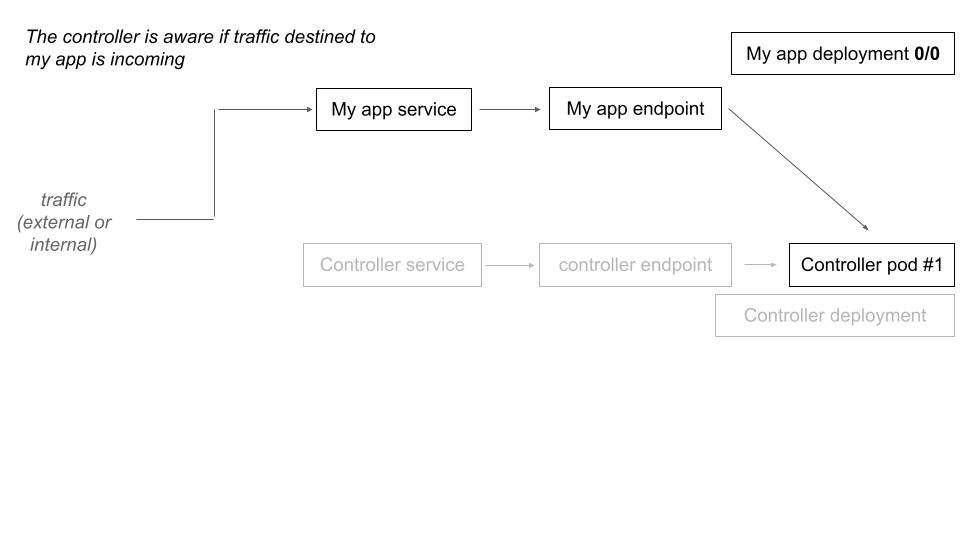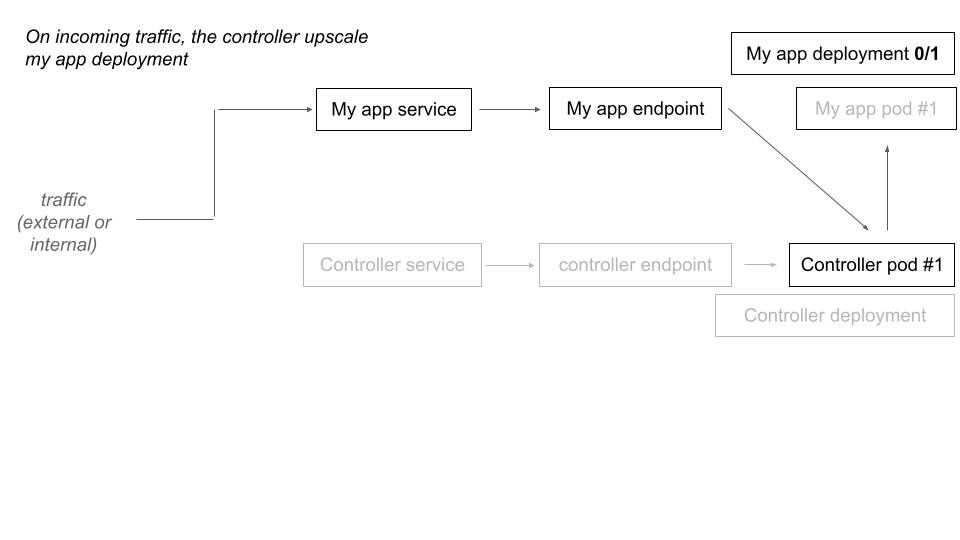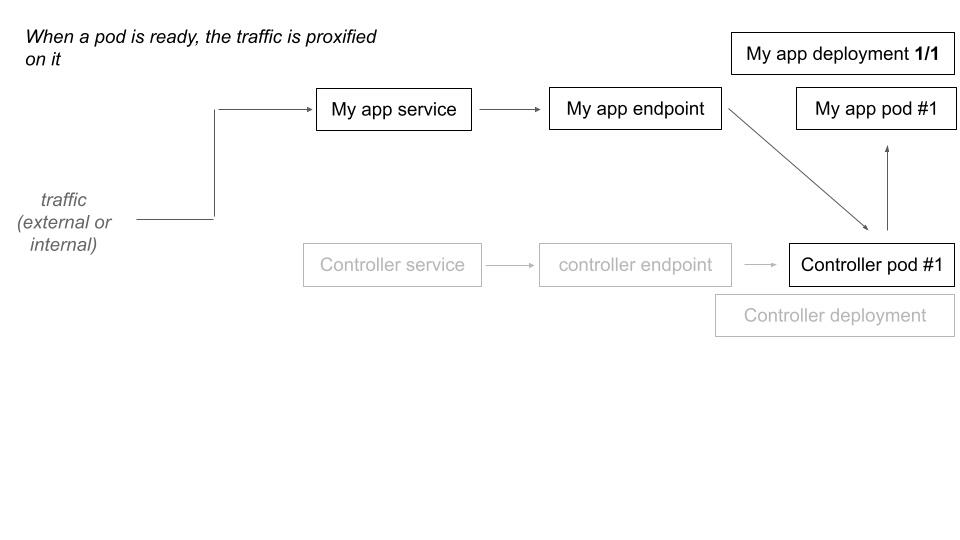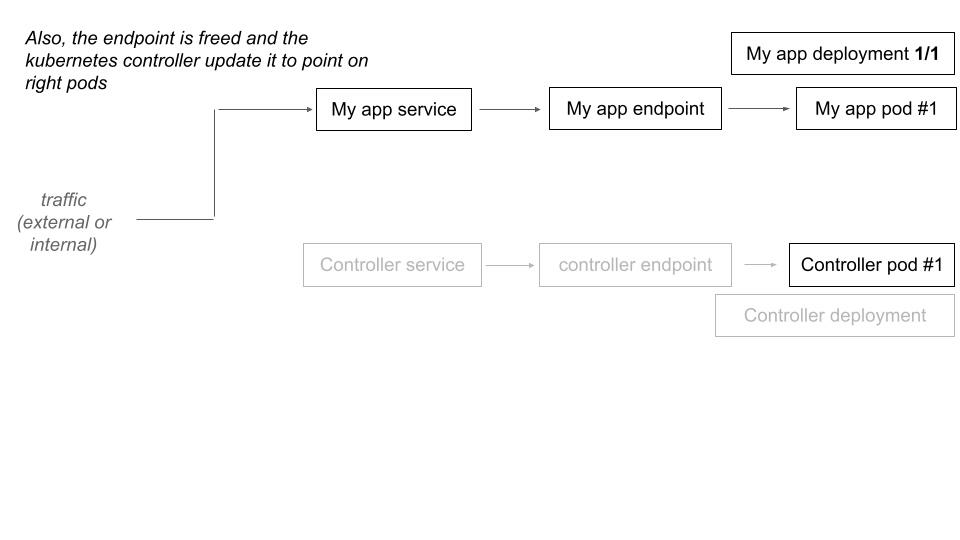
When a deployment have 0 replicas and is labelized for deployment, the controller proceed to a hijack of the traffic which would be at destination of this deployment.
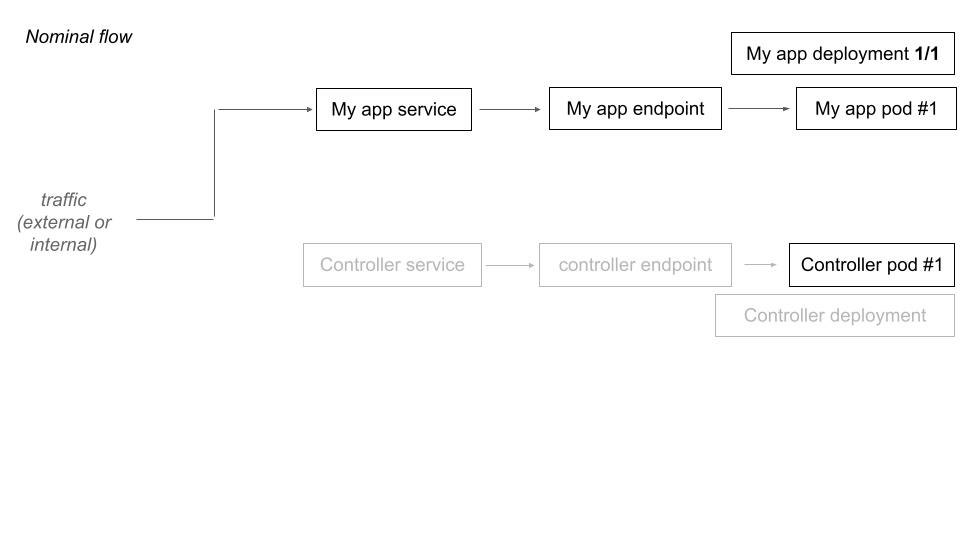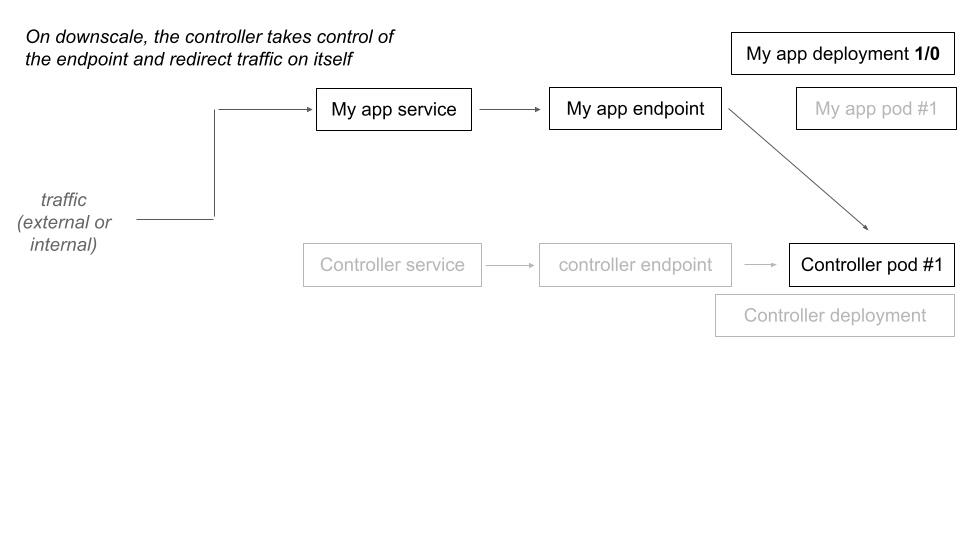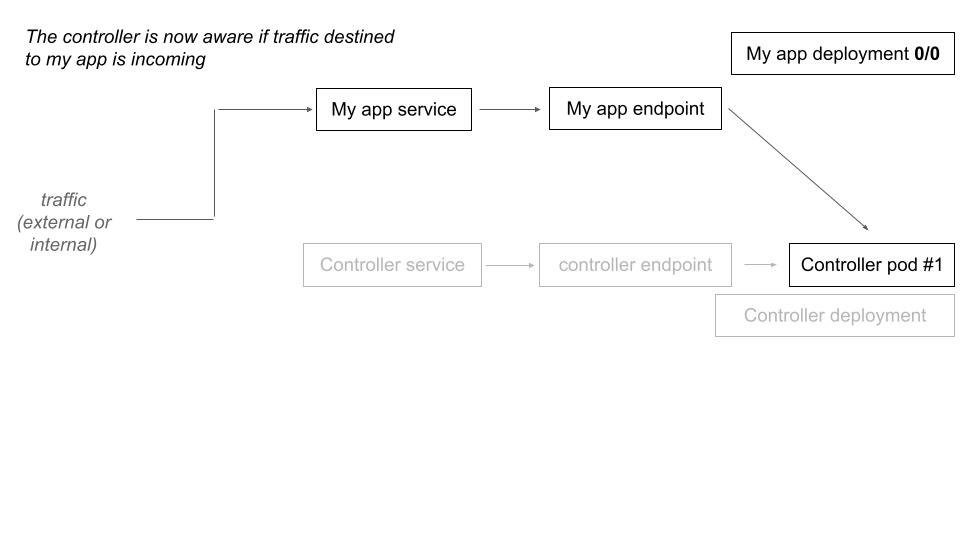
When the controller receive a request that is destined to a downscaled deployment, it scales up the deployment and make a transparent traffic forward (proxy) for the current request. The next one will directly hit the upscaled deployment.
This project is similar to osiris, knative, and/or keda but wants to :
- only handle upscale for http event
- focus on layer 4
- uses
endpointsliceinstead ofendpoints - not need root access in pods
- do not inject custom proxy
- be transparent as possible (only annotation driven behaviour)

