wooorm / nspell Goto Github PK
View Code? Open in Web Editor NEW📝 Hunspell compatible spell-checker
License: MIT License
📝 Hunspell compatible spell-checker
License: MIT License













































































































I have absolutely no idea how the .dic format works, all I can say is that practically any infinitve german word is marked as misspelt when using this in retext-spell.
For example, "markieren" is a normal word and has several entries in the dictionary, but somehow just "markieren" doesn't work, while "Markieren", "markierend", "markierens" or even "-markieren" work. What is the issue here?
"würde" is another case, even though that isn't an infinitive. "würde" is a verb, meaning "would", "Würde" (which works), meaning "dignity", is a substantive. It seems like every infinitive verb you could also write in uppercase (so basically any german verb) is not allowed when written in lowercase.
It would be nice to have @types/nspell in DefinitelyTyped for TypeScript users.
Hi @wooorm,
Thank you so much for abut the maintenance of the library!
How could I add to the library a group of words.
Thank you!
First of all, thanks for all the great work you've been doing on nspell. This is a great library.
I'm a big believer in adding Typescript definitions to libraries as a way to boost usage and improve new developer experience. Unfortunately, I think having separate type definitions comes with some maintainability problems and additional setup friction.
Is there any interest in this project for somebody to help migrate over to Typescript? Seems like it could be a reasonably straightforward process with some nice benefits if you're open to it.
nspell sometimes fails to add words to the German dictionary (taken from wooorm/dictionaries).
The gist of the bug is that nspell fails to add words to the German dictionary if those words are lowercase forms of words that should be capitalised (nouns in German are always capitalised).
The test words used in the repo are "zeit" and "kablam". Adding "kablam" works as expected and the same is true for other words that do not have a correct German form. Adding "zeit" (or "brot") both exhibit the bug, and the thing they have in common is that they are both German nouns that should be capitalised.
This is the test repo with the code required to reproduce the bug.
npm install nspellnpm install dictionary-de - installs the German dictionary from https://github.com/wooorm/dictionaries/tree/main/dictionaries/deconst nspell = require('nspell')
const dictionaryDe = require('dictionary-de')
// wrap dictionary functions so we can populate languageCodes in order of dictionaries loaded
// (dictionary callbacks return error or dictionary only)
function onload (err, dictionary) {
const spell = nspell(dictionary)
spell.correct('zeit')
spell.add('zeit')
if (!spell.correct('zeit')) console.log('\x1b[31m%s\x1b[0m', `"zeit" still incorrect!`)
spell.remove('zeit')
spell.add('zeit')
if (spell.correct('zeit')) console.log('\x1b[32m%s\x1b[0m',`"zeit" is now correct (after removing and then adding it again)`)
spell.correct('kablam')
spell.add('kablam')
if (spell.correct('kablam')) console.log('\x1b[32m%s\x1b[0m',`"kablam" is now correct`)
}
dictionaryDe(onload)The work around is to remove the word from the dictionary if it is still incorrect, which will allow us to add it successfully and have it marked as correct by nspell.
var dictionary = require('dictionary-ko');
var nspell = require('nspell');
dictionary(ondictionary);
function ondictionary(err, dict) {
if (err) {
throw err
}
var spell = nspell(dict);
console.log(spell.correct('hello'));
}
Hi there,
Wondering how to fix a strange behaviour : when we ask for a suggestion on a mispelled accentued word (ex: chomage instead of chômage) the first suggestion is a character correction (ex: chaumage). The most probable suggestion should be chômage.
Here are some examples :
| Input | Suggestion | Expected |
|---|---|---|
| chomage | chaumage | chômage |
| conge | longe | congé |
| annee | Anne | année |
Also another question, maybe related, while France exist in the dictionnary, the suggestion for france is fronce while we should see France.
Hey!
Love the library, been really helpful in solving an issue we had. We have this repo successfully working with 'dictionary-en-gb', 'dictionary-fr', and 'dictionary-de'. However, we also need to use 'dictionary-it'.
The Italian dictionary callback gets called (their repo loads the files into memory) but when I pass it into nspell It hangs and eventually crashes because it ran out of memory.
const nspell = require("nspell");
const dict = require('dictionary-it');
dict((err, cb) => {
// we get here, cb is an obj containing 'aff' and 'dic'.
const data = nspell(cb);
// we never get to the cb below, cpu and memory usage spike
console.log(data);
})I even tried upping the default memory allowance in node (via --max_old_space_size=2048) but that just causes it to indefinitely hang.
Note: if I load just the 'aff' file and not the 'dic' file it gets to the console.log, but the dic file seems to be causing issues.
Could this be because the Italian dictionary is simply too big? Although running on a 2.5 GHz Intel Core i7 with 16gb of ram it should load eventually.
I'd love some help debugging the problem if possible!
Hi, thanks for the wonderful library. The Italian (also Portuguese) languages hang my app that uses nspell. Is there anything new on that front (there is a closed issue on Italian dic). Will that problems be fixed in the future? Is there a workaround?
Thanks,
i.
To save time, you can skip the examples and go straight to the solution.
I've found a longstanding bug in nspell/main in the suggest function. In short, lines 93 and 94 are to blame.
Unexpectedly, a position from each group is used to slice the value. This is like slicing oranges with an apple slicer. I could show the problem for any word, at any point as we iterate through value and iterate through groups.
value === "Frivolouy"value[8] === "y" and group === "sy"
position === 1 because group[1] === "y"Here is the main problem with edits like "Fsivolouy" instead of "Frivolous". In our replacement for value[8], we actually replaced value[1]! So, we sliced at the wrong index. What's the big deal? Well, none of the replacements in the edit phase will ever change that "y" end of "Frivolouy".
value === "Bo"value[0] === "B" and group === "yxcvbnm"
position === 4 because group[4] === "b"This problem actually results in "BoY" and "BoX" in the final result of suggest, falling in line with the capitalization issue I found a few days ago. But it shows another problem beyond capitalization...
I'll admit that the generate function tends to operate just fine despite the strange and widespread bugs in edits. However, I'm a big nerdo and wanted to do something to add method to the madness.
This one commit simply altered two lines of code to fix the long-word problem, the short-word problem, and the capitalization issue.
However, the fix caused the failure of three tests. Two of the tests only failed with changes to the order of results, but test #46 failed big time due to the test's reliance on the combination of the long-word problem and the capitalization issue.
I've added a new commit that matches all the tests (except #46) by reproducing the long-word problem without the confusing slice of value based on position within each group. I believe it more clearly expresses what's really going on with the keyboard replacements. As I've mentioned in a comment on PR #39, I plan to rework this approach to be even more explicit about the fact that the "edit phase" only touches the first few characters in words.
Namely, we can completely fix the short-word problem as well as the capitalization issue. To keep compatibility with the tests, I believe it is wise to allow the long-word problem to remain as an "optimization": we can be explicit that we only visit the first few characters of every word (characters 0-8 with defaultKeyboardLayout) when making the edits.
aff 0.5MB
dic 16MB
Is there any solution?
Is it possible to use database?
Hi, I'm trying to create a chrome extension Armenian spellchecker using NSpell as the underlying technology and bundling it with webpack, but whenever I load in the dictionary-hyw as a string or buffer, I get:
at String.replace (<anonymous>)
at V (VM433 contentscript.js:23)
...
It seems to work just fine with dictionary-en, so I'm not sure what it is about the Armenian Western dictionary that is causing this. Any help would be greatly appreciated!
I can't get .add to work properly. Bug?
var dictionary = require('dictionary-en-us')
var nspell = require('nspell')
dictionary(ondictionary)
function ondictionary(err, dict) {
if (err) {
throw err
}
var spell = nspell(dict)
spell.add("datapoint", "point")
console.log(spell.correct("point")) // => true
console.log(spell.correct("points")) // => true
console.log(spell.correct("datapoint")) // => true
console.log(spell.correct("datapoints")) // => false
}I have an issue with nspell, it yields "unterminated char class" in node_modules/nspell/lib/util/affix.js:300:10.
/node_modules/nspell/lib/util/affix.js:300
return new RegExp(source + C_DOLLAR);
^SyntaxError: Invalid regular expression: /[aeiouyáéíóúýůěr][^aeiouyáéíóúýůěrl][^aeiouy$/: Unterminated character class
at new RegExp ()
at end (/node_modules/nspell/lib/util/affix.js:300:10)
at affix (/node_modules/nspell/lib/util/affix.js:210:59)
at new NSpell (/node_modules/nspell/lib/index.js:50:9)
at NSpell (/node_modules/nspell/lib/index.js:26:12)
at dictionary ([stdin]:12:18)
at /node_modules/dictionary-cs/index.js:21:9
at FSReqWrap.readFileAfterClose [as oncomplete] (fs.js:528:3)
Sometimes parsing a dictionary is a major bottleneck as that can take multiple seconds:
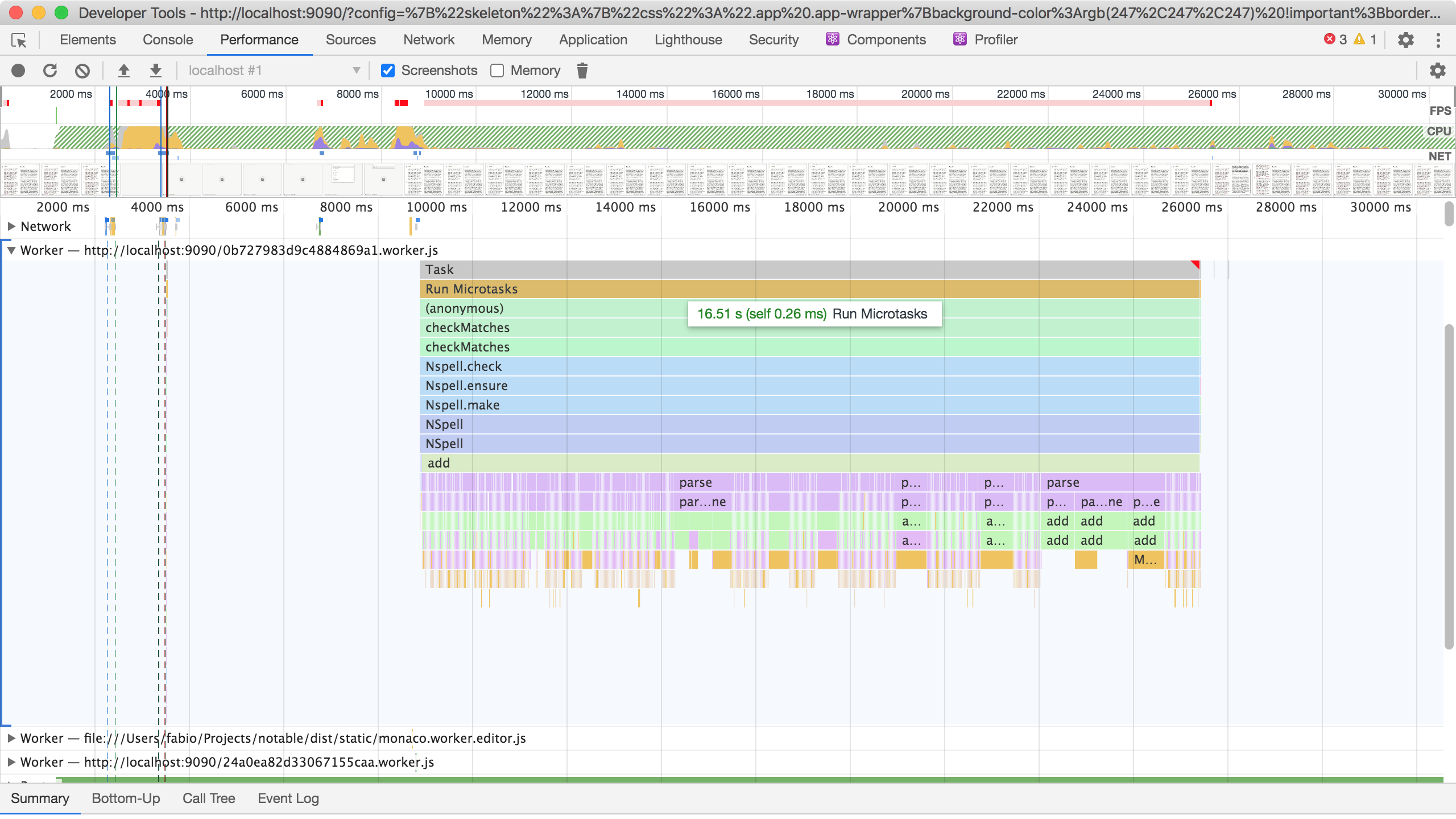
If it takes that long in the best case scenario the app's spell checking, or whatever feature built on top of nspell, is going to feel broken, in the worst case scenario (single-core machines or machines where all other cores are busy) the app may become pretty unresponsive and slow for long enough that the user will just kill it.
I think a potential way to address this problem would be pre-parsing dictionaries, essentially skipping building the internal data structures from the raw dictionary file and loading them directly.
Would that be possible? If so could you give me some pointers on how I should go about implementing that? I'm thinking perhaps a serialize and deserialize methods could be implemented for this purpose.
This issue seeks to change how suggest.js/generate replaces, switches, and appends characters of different cases from surrounding characters. This issue notes two problems in nspell/main where the results of suggest should be Sentence Case instead of lowercase/UPPERCASE and one problem in nspell/main where the results of suggest should be UPPERCASE instead of lowercase. I'm totally open to the idea that this issue should not be addressed, or should be addressed differently.
This issue is resolved in PR #45.
This issue is ignored in PR #39.
Here is the status of main. I've unchecked all inconsistent behaviors:
"Colour" -> ["Color"]"Ghandi" -> ["shandy", ...]"Aolor" -> ["color", ...]"COLOUR" -> ["COLOR"]"COLORFU" -> ["colorful"]"canada" -> ["Canada"]"acnada" -> ["CANADA"]"Acnada" -> ["CANADA"]"CaNaDa" -> ["CANADA", ...]While console.log(spell.correct('Stephan')); //=> true and console.log(spell.correct('stephan')); //=> false there might be some name detection in nspell. Does there exists a way to configure nspell that console.log(spell.correct('Stephan')); yields false? I need a way to ignore names.
I'm trying to require nspell module in a js file and use it on the browser.
However, it is not working and throwing below error.
It is throwing error in index.js or 'node_modules/dictionary-en-us/index.js.
I need a solution for it urgently.
Uncaught TypeError: read is not a function
at one (index.js:15)
at load (index.js:11)
at eval (spellCheck.js:6)
at Object../src/spellCheck.js (bundle.js:818)
at webpack_require (bundle.js:20)
at eval (index.js:5)
at Object../src/index.js (bundle.js:807)
at webpack_require (bundle.js:20)
at eval (webpack:///multi_(:8081/webpack)-dev-server/client?:2:1)
at Object.1 (bundle.js:829)
Defect title:
Swedish dictionary seems to don't detect if word is spellt incorrectly and takes nonsense as correct
Description:
When trying to load the Swedish dictionary the spell.correct takes any nonsense input
as correct and returns true. Even a word that is not even in the .DIC or .AFF file.
Steps-to-reproduce:
Expected behvaiour:
Nspell should return that nonsense or incorrect spellings as false
Code for defect:
var dictionary = require('dictionary-sv')
var nspell = require('nspell')
dictionary(ondictionary)
function ondictionary(err, dict) {
if (err) {
throw err
}
var spell = nspell(dict);
let nonsense = 'gegetr13';
let hej = 'hje';
let hejda = 'hejdåå';
console.log('Input: ', nonsense, '\t| Expected: false \t| Actual: ', spell.correct('gegetr13'));
console.log('Input: ', hej, '\t\t| Expected: false \t| Actual: ', spell.correct(hej));
console.log('Input: ', hejda, '\t\t| Expected: false \t| Actual: ', spell.correct(hejda));
console.log('Input: ', hej, '\t\t| Expected: [\'hej\'] \t| Actual: ', spell.suggest(hej));
}Attachments:

I'm trying to create a vue.js SPA with this module. I can't seem to get it to work and was wondering if you know what I'm doing wrong?
[HMR] Waiting for update signal from WDS...
index.js?ef10:15 Uncaught TypeError: read is not a function
at one (index.js?ef10:15)
at load (index.js?ef10:11)
at Function.Vue.use (vue.runtime.esm.js?2b0e:5103)
at eval (main.js?56d7:9)
at Module../src/main.js (app.js:2552)
at __webpack_require__ (app.js:724)
at fn (app.js:101)
at Object.1 (app.js:2566)
at __webpack_require__ (app.js:724)
at app.js:791
one @ index.js?ef10:15
load @ index.js?ef10:11
Vue.use @ vue.runtime.esm.js?2b0e:5103
(anonymous) @ main.js?56d7:9
./src/main.js @ app.js:2552
__webpack_require__ @ app.js:724
fn @ app.js:101
1 @ app.js:2566
__webpack_require__ @ app.js:724
(anonymous) @ app.js:791
(anonymous) @ app.js:794
It seems to be referencing the variable "read" in the following:
function one(name) {
read(join(__dirname, 'index.' + name), function (err, doc) {
pos++;
exception = exception || err;
result[name] = doc;
if (pos) {
callback(exception, exception ? null : result);
exception = null;
result = null;
}
});
}
I'd like to implement a "loose" spell checking mode, where if a word is not correct but there are no suggestions for it then the spell checker doesn't yell at the user.
I can currently do something like this to check if there are any suggestions:
const hasSuggestions = !!instance.suggest ( word ).length;But that would compute all possible suggestions, and I don't really care about having them available to me at that point in time, so I'd like nspell to have a method that allows me to implement that in a much more efficient way, like:
const hasSuggestions = instance.hasSuggestions ( word );Which more practically would exit early from unnecessary expensive loops like this one:
Lines 274 to 276 in c929021
Hi!
Nspell looks very promising. I would like to use it for stemming with hunspell dictionaries (similar to Solr's Hunspell Stemmer). Is that possible? If so, could you give me a hint in the right direction maybe?
Thanks!
Benjamin
For steps to quickly reproduce with a related gist, see the original issue I've opened on retext-spell.
TLDR: see PR 38 and PR 39 that I've opened against this repo.
I have found over 200 5-letter dictionary words for which retext-spell produces suggestions such as the following:
/^Thre[f-ln-racuvxyz]$//^Ma[d-ho-raluwxz]or$//^Ch[d-hj-np-xabz]me$/There is nothing to suggest this problem is limited to 5-letter dictionary words, as I've stumbled across the following:
/^Tinp[bcdfhlmqvx]$/ais "t" at index 0before="Twin" and after = ""b="e"
This is how we arrive at the confusing suggestion of "TwinE".
When creating the initial array of edits based on keyboard groups, the current logic of nspell is as follows:
aa is uppercase in the input worda
a within the groupa's position within the group (note, this defaults to splitting at the very end of the word when the character's position in the group exceeds the length of the input word)b != a
This results in uppercase characters inserted at seemingly random positions in the text because the position of character a within the group is not the index of character a within the input word.
Note, the notion of "Keyboard groups" doesn't really make sense in the current approach in main. The suggest function inserts each replacement character at a position (of a in group) that is unrelated to the original position (of a in word). This "root problem" is ignored in PR 38 and addressed in PR 39.
In Dutch, the combination ij is very common. Every word containing this combination, is considered misspelled.
From looking into the Dutch aff I noticed that the unicode character ij is used for this. I have never seen this character before.
I notifed that something is going on here, however I am not familiar with the hunspell format.
The following code snippet should log true:
const nspell = require('nspell');
const dictionary = require('dictionary-nl');
dictionary((err, dict) => {
const spell = nspell(dict);
console.log(spell.correct('wij'));
});Tried integrating nspell with the dictinary-en library.
But it is showing read is not function in the node_modules/dictionary-en/index.js: 16

Seems there is some dependencies issues with the fs module.
Therefore, then tried it using (fx-extra) :
_var read = require('fs-extra').readFile;
Which then shows this error--

Can anyone faces this similar issue or if anybody have the solution.
PLEASE DO COMMENT_
Words can be added and removed from a dictionary, but I don't see any APIs for reversing those actions 🤔
My use case is essentially doing the following: Add words -> remove those added words -> add new words.
The "remove those added words" there is not clear how to do it. Like some of those added words might have been already in the dictionary, calling remove for them would remove them from the dictionary while I only want to remove them from the list of added words.
I suppose I could instantiate new instances of nspell and then just add the updated words to those, but presumably instantiating nspell instances is not a cheap operation 🤔
I think potentially adding a reset method to nspell instances would be a good enough solution to this, assuming that that implements the reset functionality much more efficiently than just reloading the dictionary and affix files.
Hello there Titus Wormer, first of all a big thanks! Thanks to your native JavaScript Hunspell wrapper I have been able to develop
a smart language detecting spell checker plugin without doing any of the NLP heavy lifting. Awesome, thank you, keep up the great work!
Now for the fun part 😸: I'm using nspell.personal() to add a list of user added words from browser storage.
Here are the offending lines from my user class:
// add word to user.ownWords and update existing spell checker instances
addWord (word) {
this.ownWords.push(word)
Object.keys(this.spellers).forEach((language) => {
this.spellers[language].personal(this.ownWords.join('\n'))
})
}
// remove word from user.ownWords and update existing spell checker instances
removeWord (word) {
this.ownWords.remove(word)
Object.keys(this.spellers).forEach((language) => {
this.spellers[language].personal(this.ownWords.join('\n'))
// assuming personal() will here overwrite existing dictionary given lack of add/remove methods
})
}ownWords is just an array of strings with no affix rules or slashes for modelling - just words users think are words (strings
cleaned of numeric and nonword characters). I would like to know how to overwrite the existing personal dictionary, or alternatively, how to remove a word from a personal dictionary once it has been added. nspell.personal.remove() is undefined (as expected and per the docs), from what I understand of the personal file, is the nspell.personal() method actually just a wrapper around nspell.add()?
Referring to this:
Line 41 in c929021
To provide the final bit of context: I was originally just adding all words from user.ownWords to each nspell instance with nspell.add(). The problem is if a user adds the word "dark" and has British English, American English, and German spellers enabled, that word is added to all of those dictionaries. When the user removes the word, it is also removed from the British and English dictionaries and now "dark" is marked as incorrect in those languages. Enter nspell.personal(). Since I don't persist changes to core dictionaries, the bug thankfully goes away after restarting the plugin/browser, but I'm digging deep on this one!
One of the features of the extension is that users can add a word in one language to have it marked as correct in all the
languages they use, and I'd love to keep it that way.
Package.json versions
"dictionary-en": "3.0.1"
"nspell": "2.1.4"
I've built the dictionary file into nspell.js and have been having issues with the spell checking suggestions. If a word is missing an apostrophe it's suggesting the correct spelling but in all capital letters.
For example:
dont -> DON'T (should be don't)
node 12.10.x
nspell 2.1.2
I'm not sure if this is a bug or my misinterpretation of the documentation.
Adding extra dictionaries via
new nspell([{aff: mainaff_buff, dic: maindic_buff}, {dic: extradic_buff}]), or
nspell_instance.dictionary(<extradic_buff>), or
nspell_instance.dictionary(['some','new',words'].join('\n'));
appears to cause all inputs to be considered correct by .correct and .suggest
I do see that the nspell_instance object contains all of the words from both maindic and extradic as well as all of the affix information, but it does not seem to be used 😕
However, using .personal to add extra words does work as expected and testing with both maindic and the extra words produces correct .correct and .suggest outputs.
I'm not sure if I am missing something in the documentation or if this is an issue. I am using the dictionary-en package to load the main aff & dic, and the extra dictionaries are plain word lists in utf-8 loaded into a buffer.
Steps to reproduce:
A. baseline, single dictionary
const maindic = require('dictionary-en')
const nspell = new NSpell(maindic)
nspell.correct('ultrasonogram') // => false; OK b/c not in dictionary
nspell.correct('ultrasongram') // => false; OK
nspell.correct('feleing') // => false; 👍
nspell.suggest('ultrasonogram') // => [ ]; OK
nspell.suggest('ultrasongram') // => [ ]; OK
nspell.suggest('feleing') // => ['feeling', 'fleeing', ...]; 👍
B. add words via .dictionary (same behavior if it's another buffer passed in to constructor)
const maindic = require('dictionary-en')
const nspell = new NSpell(maindic)
nspell.dictionary(['ultrasonogram','ultrasonosurgery'].join('\n'))
nspell.correct('ultrasonogram') // => true
nspell.correct('ultrasongram') // => true; 👎
nspell.correct('feleing') // => true; 👎
nspell.suggest('ultrasonogram') // => []
nspell.suggest('ultrasongram') // => []
nspell.suggest('feleing') // => []
C. add words via .personal
const maindic = require('dictionary-en')
const nspell = new NSpell(maindic)
nspell.dictionary(['ultrasonogram','ultrasonosurgery'].join('\n'))
nspell.correct('ultrasonogram') // => true
nspell.correct('ultrasongram') // => false
nspell.correct('feleing') // => false
nspell.suggest('ultrasonogram') // => []
nspell.suggest('ultrasongram') // => ['ultrasonogram'] 👍
nspell.suggest('feleing') // => ['feeling', 'fleeing', ...] 👍
I would like to implement spelling check in the browser. It could be in a web-worker.
I noticed that the dictionaries use filesystem from nodejs. Is there a way to bypass that?
I tried NSpell out because of its richer API versus other Hunspell-compatible solutions, but I found that, for example, it did not recognize the Russian word очень, despite the word being in the dictionary file with no flags whatsoever.
Perhaps I'm missing something?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.