algorithm's Introduction
algorithm's People
Contributors

Watchers

algorithm's Issues
위상정렬
위상정렬 ( 그래프 정렬 )
-
위상정렬이 가능하려면 DAG 그래프 여야함!
-
Directed Acyclic Graph의 약자로 방향성이 있고, 사이클이 없는 그래프
-
위상 정렬이 필요한 경우는 그래프에서 반드시 자신보다 선행되어야 할 일을 다 끝내야만 작업에 들어갈수 있는 조건이 주어질 때
-
진입차수가 0이라는 것은 자신보다 선행되어야 할 노드 일이 다끝나서 이제 진행해도 된다는 뜻!
-
예) 대학교 수업 듣는 순서, 스타 건물 짓는 순서
위상정렬 구현 시나리오
- 인접 리스트 형식의 그래프 생성 한 뒤, 각 노드별로 진입차수를 기록
- indegree ( 진입차수 ) 0인 노드들을 탐색 후 ==> 큐 삽입
- 입접리스트 이용하여 이동하면서 방문한 노드는 진입 차수 -1 변경
- 큐를 이용하여 연결된 노드들을 방문하는데 방문할때마다 degree를 하나씩 낮춰주며 degree 가 0이 되는 노드들을 큐에 넣고 계속하여 탐색
예 ) 가수 출연 순서
- 1 4 3
- 6 2 5 4
- 2 3
== > 6 2 1 5 4 3 또는 1 6 2 5 4 3


사이클 확인
- N개의 노드를 한번씩 돌기도 전에 큐가 비어 버린다면 위상 정렬 불가능!!!!!!!
- 사이클이 생겼다면 싸이클에 속하는 정점들 중엔 indegree가 0인 정점 한개도 없음
즉 N개의 노드들을 한번씩 다 도는지 확인 하던지 indegree 의 값이 전부 0인지 확인 하는 방법
for(int i=1; i<= N; i++) // inddegree 0 인 노드 큐에 삽입
{
if(degree[i] == 0) que.add(i);
}
solve();
if(!flag) // 사이클 발생 안한 경우
{
for(int i=0; i< temp.size(); i++)
{
System.out.println(temp.get(i));
}
}
}
public static void solve()
{
for(int i=0; i< N; i++)
{
if(que.isEmpty()) // N 번 돌지 못하고 끝이 나는 것은 사이클 발생
{
System.out.println(0);
flag = true;
return;
}
int n = que.poll();
temp.add(n);
for(int next : adj.get(n))
{
degree[next]--; //연결된 노드 indegree --
if(degree[next] == 0) // indegree 0 인 노드는 큐에 삽입
{
que.add(next);
}
}
}
}
- 백준 2252 줄세우기 , 1766 문제집 , 2623 음악프로그램, 1516 게임 개발, 1005 acm craft , 9470 strahler 순서
단절점 / 단절선
단절점
하나의 컴포넌트로 이루어진 무방향 그래프에서 한 정점을 제거했을 때 그래프가 두개 이상의 컴포넌트(그래프)로 나누어지는 정점을 단절점
단절점 특징
-
어떤 정점 A에 연결된 모든 정점들 중 두 정점들 간에 정점 A를 거치지 않고 갈 수 있는 우회경로가 존재하지 않는 경우가 존재한다면 정점 A는 단절점으로 판단 가능
즉, 단절점에 바로 인접해 있는 정점들의 쌍은 단절점이 없으면 우회로로 인해 연결되어 있지 않다! -
비효율적인 방법 : 모든 정점을 한번씩 선택(V) 하여 제거한 후 그래프가 나뉘어지는지 파악 ( V * E)
==> 시간복잡도 O( V * ( V + E)) -
DFS 스패닝 트리를 이용하여 단절점을 빠른시간내에 구할수 있음
구현 방법
- dfs 를 이용하여 정점들의 방문 순서를 기록
- 특정 A번 정점에서 자식 노드들이 정점 A를 거치지 않고 정점 A보다 빠른 방문번호를 가진 정점으로 갈수 없다면 단절점이다.

예외 케이스
- 루트노드로 잡은 특정 노드의 자식 수가 2개 이상이면 무조건 단절점이다!
정점 A가 루트라면
==> 자식 수가 2개 이상이면 단절짐이다.
정점 A가 루트가 아니라면
==> A번 정점에서 자식 노드들이 정점 A를 거치지 않고 정점 A보다 빠른 방문번호를 가진 정점으로 갈 수 없다면 단절점
==>한번의 dfs 로 답을 구할수 있기 때문에 O(N + M)
public class baek11266 {
static int V, E, number;
static boolean[] cut = new boolean[10005]; // 단절점 여부 확인 배열 !
static int[] order = new int[10005]; // 방문 순서 기록 !!
static ArrayList<ArrayList<Integer>> adj = new ArrayList<ArrayList<Integer>>();
public static void main(String[] args) throws IOException {
V = Integer.parseInt(st.nextToken());
E = Integer.parseInt(st.nextToken());
number =0; // 방문 순서 기록 할 숫자
for(int i=1; i<= V; i++)
{
if(order[i] > 0) continue;
dfs(i, 0);
}
int cnt =0;
for(int i=1; i<= V; i++)
{
if(cut[i]) cnt++;
}
bw.write(cnt+"\n");
for(int i=1; i<= V; i++)
{
if(cut[i])
{
bw.write(i+" ");
}
}
bw.flush();
}
public static int dfs(int cur, int p)
{
order[cur] = ++number; // 방문순서 지정
int ret = order[cur];
int child = 0; // root 자식 수가 2개 확인하기 위함
for(int next : adj.get(cur))
{
if( next == p ) continue;
if(order[next] > 0) // 이미 방문한 지점이라면 가장 작은 순서 찾아서 업데이트
{
ret = min(ret, order[next]);
continue;
}
child++;
int prev = dfs(next, cur);
if(p != 0 && prev >= order[cur]) {
cut[cur] = true; // 단절점
}
ret = min(ret, prev);
}
if(p ==0 && child >= 2) cut[cur] = true;
return ret;
}
}
단절선
public class Main {
static int N, K, number;
static int[] order = new int[100005];
static ArrayList<Node> result = new ArrayList<>();
static ArrayList<ArrayList<Integer>> adj = new ArrayList<ArrayList<Integer>>();
public static void main(String[] args) throws IOException {
for(int i=1; i<= N; i++)
{
if(order[i] > 0) continue;
dfs(i, 0);
}
}
public static int dfs(int cur, int p)
{
order[cur] = ++number;
int ret = order[cur];
for(int next : adj.get(cur))
{
if(next == p) continue;
if(order[next] > 0)
{
ret = min(ret, order[next]);
continue;
}
int prev = dfs(next, cur);
if(prev > order[cur])
{
result.add(new Node(min(cur, next), max(cur, next)));
}
ret = min(prev, ret);
}
return ret;
}
}
트리 에서의 단절점과 단절선 !! ( 사이클이 없는 ) / 주의!!
트리에서는 사이클이 존재하지 않기 때문에 단절선이 아닌 선은 없다!
단절점 같은 경우는 연결된 간선이 2개 이상이면 단절점 이다.
백준 14675 단절점과 단절선 문제
동전 교환 / 냅색 알고리즘
관련 문제
백준 11047 동전0 https://www.acmicpc.net/problem/11047
2293 동전1 https://www.acmicpc.net/problem/2293
2294 동전2 https://www.acmicpc.net/problem/2294
7579 앱 https://www.acmicpc.net/problem/7579
1660 캡틴 이다솜 https://www.acmicpc.net/problem/1660
4781 사탕 가게 https://www.acmicpc.net/problem/4781
9084 동전 https://www.acmicpc.net/problem/9084
2624 동전 바꿔주기 https://www.acmicpc.net/problem/2624
2629 양팔저울 https://www.acmicpc.net/problem/2629
1398 동전 문제 https://www.acmicpc.net/problem/1398
크루스칼 알고리즘 - 최소 신장 트리(Minimum Spanning Tree / MST ) // Using 서로소 집합 ( Disjoint Set, Union-Find)
신장 트리 (스패닝 트리, Spanning Tree) 란?
- 그래프의 모든 정점이 간선으로 연결되어 있다.
- 그래프 안에 사이클이 포함되어 있지 않다.
최소 신장트리 (최소 스패닝 트리, Minimum Spanning Tree) 란?
- 최소 비용으로 만들어진 신장 트리, 가중치 합이 가장 작은 신장 트리
크루스칼 알고리즘
- 시작점을 정하지 않고, 최소 비용의 간선을 차례로 대입하여 mst를 구성하므로, 그 과정에서 사이클을 이루는지 항상 확인해야 함. 사이클 확인 방법으로 Union-Find(Disjoint-Set) 방법
- O(E logE)

dfs(depth first search) / bfs(breadth first search)
dfs
==> 스택 으로도 구현 가능!!!! 알아보기
- 해가 존재할 가능성이 있으면 재귀호출을 이용하여 계속 깊게 전진 후 더이상
- 스택의 특징(Last In First Out)
- 장점 : 목표노드가 깊은 단계에 있을 경우 해를 빨리 찾을 수 있음
- 단점 : 목표 노드가 없는 경로에 깊이 빠질 수 있음
- 시간 복잡도 : 인접행렬로 구현시 - O(V^2) / 인접리스트 - O(V+E)
==> 모든 정점을 한번씩 방문하며, 정점을 방문 할 때 마다 인접한 모든간선을 검사하기 때문
( 한 정점을 검사하는 dfs()를 수행하면 모든 간선을 정확히 한 번(방향 그래프의 경우) 혹은 두 번(무향 그래프의 경우) 확인하므로 ) - 공간 복잡도 : 인접행렬로 구현시 - O(V^2) / 인접리스트 - O(V+E)
bfs
- 생성된 순서에 따라 노드를 확장한다. ( 시작 정점을 출발로 큐 구조에 방문한 정점을 넣어가며 탐색을 함)
- 다음 레벨의 노드를 조사하기 전에 트리의 같은 레벨의 노드 부터 검사 하는 방법
(자식의 자식들이 고려되기 전에 현 노드의 바로 밑에 있는 자식 노드가 조사된다는 것을 의미) - 큐의 특징(First In First Out)
- 장점 : 출발노드에서 목표노드까지의 최단 길이 경로를 보장한다
- 단점 : 경로가 매우 길 경우에는 탐색 가지가 급격히 증가함에 따라 보다 많은 기억 공간을 필요로 하게 된다.
- 시간 복잡도 : 인접행렬로 구현시 - O(V^2) / 인접리스트 - O(V+E)
==> 모든 정점을 한번씩 방문하며, 정점을 방문 할 때 마다 인접한 모든간선을 검사하기 때문 - 공간 복잡도 : 인접행렬로 구현시 - O(V^2) / 인접리스트 - O(V+E)
소스 코드
public static int[][] map = new int[1002][1002]; // 인접 행렬
public static int[] visited = new int[1002]; // 방문 기록
public static void dfs(int v) {
if(visited[v] == 1 ) return; // base case
visited[v] = 1; // 방문 체크
System.out.print(v+" ");
for(int i= 1; i<= V ; i++) {
if(map[v][i] == 1) {
dfs(i); // 다음 노드로 이동
}
}
}
public static void bfs(int v) {
Queue<Integer> que = new LinkedList<Integer>();
que.add(v); // 시작점
visited[v]=1;
while(!que.isEmpty()) {
int num = que.peek();
System.out.print(num+" ");
que.poll();
for(int i= 1; i<= V ; i++) {
if(map[num][i] == 1 && visited[i] == 0) { // 방문 기록이 없다면
visited[i] = 1;
que.add(i);
}
}
}
}
dfs+dp 문제 유형
- 1890 점프
- 1520 내리막길

기하 ( ccw / 선분 교차 / 볼록 껍질 / rotating 캘리퍼스 / Line sweeping / Convex hull trick )
ccw
public static int ccw(Point a, Point b, Point c)
{
long op = ( (a.dx*b.dy)+(b.dx*c.dy)+(c.dx*a.dy) - (a.dy*b.dx) + (b.dy*c.dx)+(c.dy*a.dx) );
if(op > 0) return 1; // 반시계 방향
else if(op < 0) return -1; // 시계 방향
else return 0; // 세점이 평행
}
다각형의 내부 외부 판별

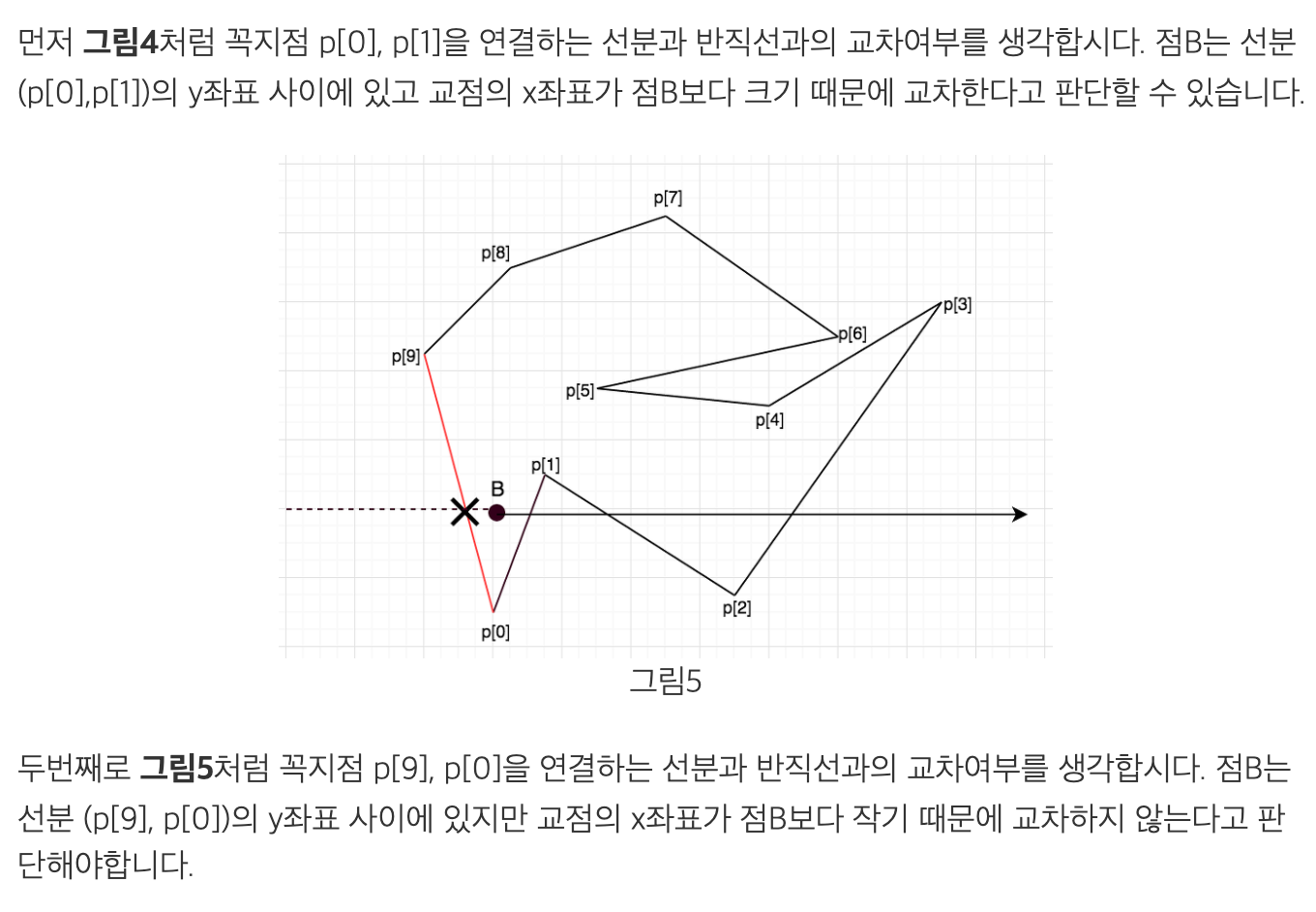
다각형의 내부 외부 판별 구현
- 반직선은 항상 x축에 평행한 수평선임을 이용
반직선과 선분 사이에 교점이 존재하기 위한 조건은 2가지
1) 점 B의 y좌표가 두 선분 꼭지점의 y좌표 사이에 있다.
2) 점 B를 지나는 수평선과 선분 사이의 교점의 x좌표가 점 B의 좌표보다 크다.
=> 조건1을 만족하면 점 B를 지나는 수평 직선과 선분사이에 반드시 교점이 존재. 이때 오른쪽
반직선과의 교점만 세야 하므로 조건 2를 추가로 만족해야 반직선과 선분 사이의 교점 존재 여부를
올바르게 판별 가능!

public static boolean isCross(long tx, long ty)
{
int crossCnt = 0;
long mindy =0, maxdy =0;
for(int i=0; i< N; i++)
{
Point p1 = p[i];
Point p2 = p[(i+1) % N];
mindy = min(p1.dy, p2.dy);
maxdy = max(p1.dy, p2.dy);
if(mindy <= ty && maxdy >= ty) // 선분 y 좌표 사이에 있는지 확인
{
long tmp = p2.dy - p1.dy; // 분모가 0 일 경우 제외
if(tmp == 0) continue;
// 점과 직선사이의 수선의 발 좌표 공식
long target = (ty - p1.dy)*(p2.dx - p1.dx) / (p2.dy - p1.dy) + p1.dx;
if(tx < target) crossCnt++;
}
}
if(crossCnt % 2 != 0) return true;
else return false;
}
참고 링크 : https://bowbowbow.tistory.com/24
교차 판별
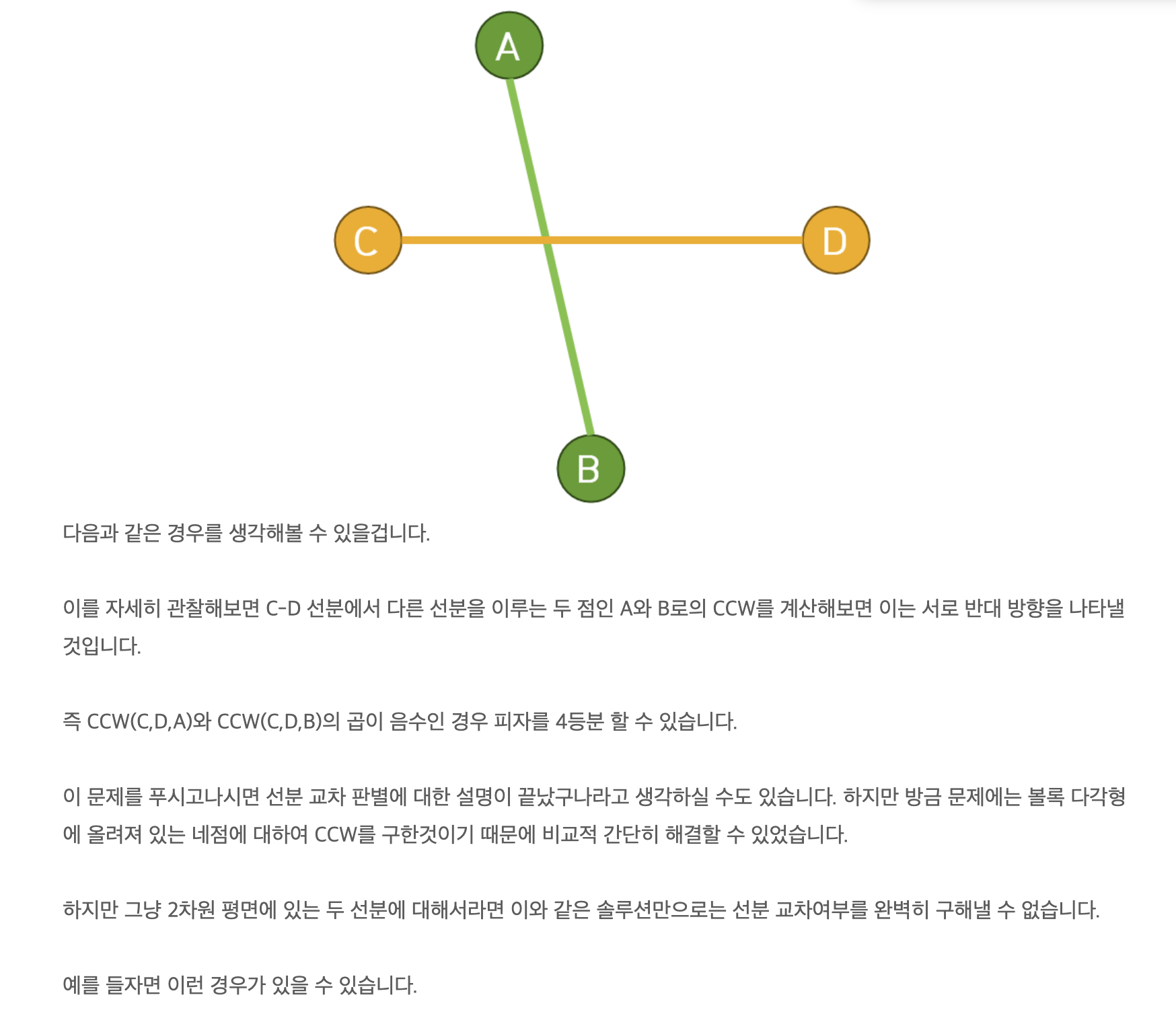
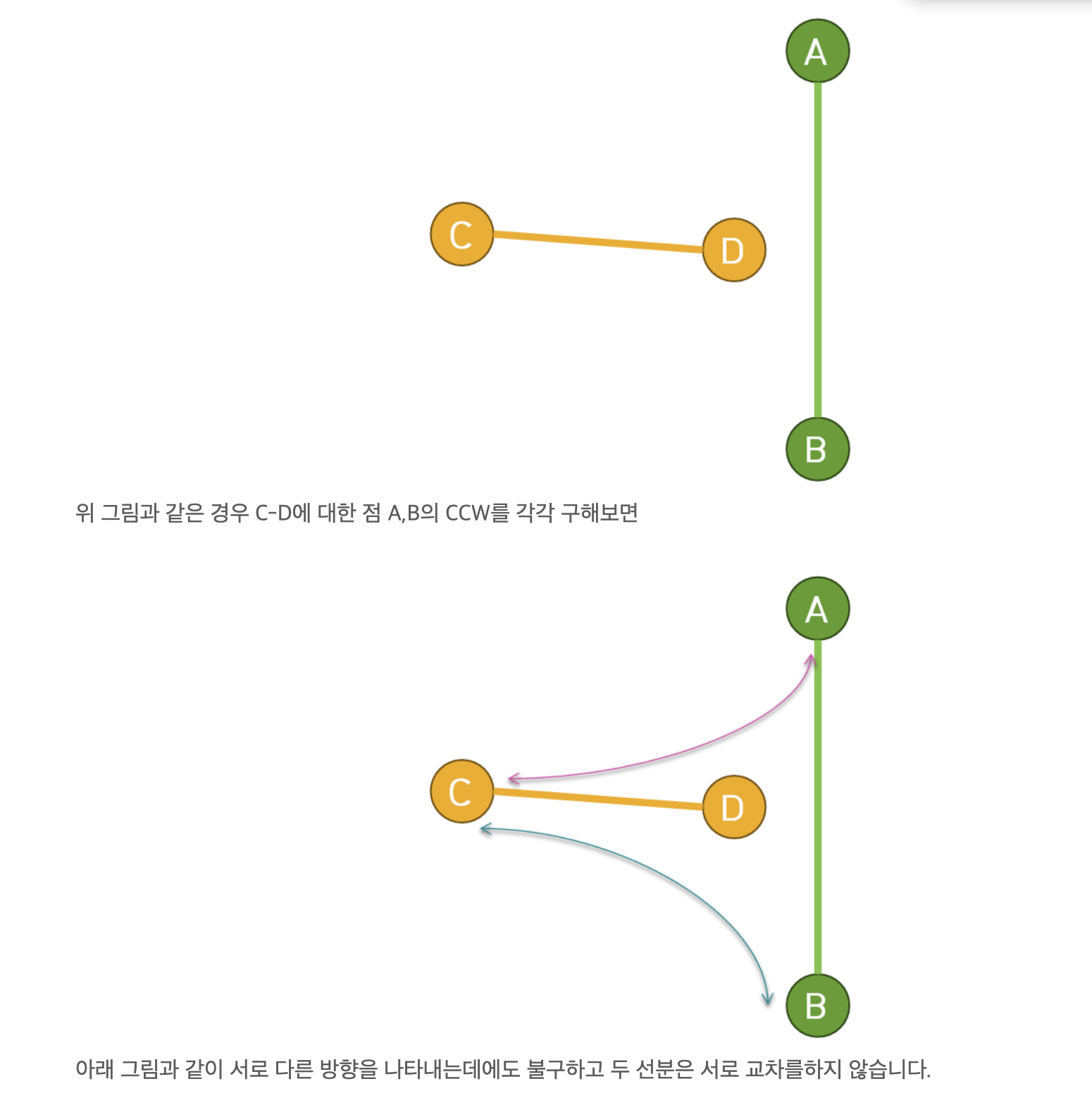

DP / (Bitonic Tour )
현상금 사냥꾼 김정은 / 백준 10272
아이디어
- 두사람을 동시에 출발시켜 N으로 이동 !
- 두사람이 동시에 똑같은 곳에 가면 안됨
DP[i][j] : A 라는 사람이 i 지점에, B라는 사람이 j 라는 지점에 있을때의 최단 거리
일반적 방법
- for문을 쉽게 구현하기 위해서
i < j 조건 ==> dp[6][3] 과 dp[3][6] 똑같은 값이기 때문에
2차원 배열을 절반만 사용!!
(1,2) (1,3) (1,4) (2,3) (2,4) (3,4) 순으로 이동!
dp[1][1] = 0; // 똑같은점 있음 안됨
dp[1][2] = dis(1,2); // i < j 처음 이동시켜 놓고 시작
for(int i=1; i < N; i++)
{
for(int j = i+1; j < N; j++) // 1 ~ N-1 까지 이동
{
int k = j + 1; // k : 다음 방문할 곳 /
// i에서 이동할 경우 => dp[k][j] = dis(i,k) + dp[i][j]
// j에서 이동할 경우 => dp[i][k] = dis(j,k) + dp[i][j]
dp[j][k] = min(dp[j][k], dis(i,k) + dp[i][j]); // i < j 로 정의 했으니 바꿔도 동일함!
dp[i][k] = min(dp[i][k], dis(j,k) + dp[i][j]);
}
}
double ans = INF;
for(int i=1; i < N; i++) // N-1 ~ 에서 N
{
ans = min(ans, dp[i][N] + dis(i,N));
}
System.out.println(ans);
public class baek10272 {
static final double INF = 2e9;
static int N;
static double[][] point = new double[550][2];
static double[][] dp = new double[550][550];
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int testCase = Integer.parseInt(st.nextToken());
for(int n=1; n <= testCase; n++)
{
st = new StringTokenizer(br.readLine());
N = Integer.parseInt(st.nextToken());
int dx =0, dy =0;
for(int i=1; i<= N; i++)
{
st = new StringTokenizer(br.readLine());
dx = Integer.parseInt(st.nextToken());
dy = Integer.parseInt(st.nextToken());
point[i][0] = dx; point[i][1] = dy;
for(int j=1; j<= N; j++)
{
dp[i][j] = INF;
}
}
dp[1][1] = 0; // 똑같은점 있음 안됨
dp[1][2] = dis(1,2); // i < j 처음 이동시켜 놓고 시작
for(int i=1; i < N; i++)
{
for(int j = i+1; j < N; j++) // 1 ~ N-1 까지 이동
{
int k = j + 1; // k : 다음 방문할 곳 /
// i에서 이동할 경우 => dp[k][j] = dis(i,k) + dp[i][j]
// j에서 이동할 경우 => dp[i][k] = dis(j,k) + dp[i][j]
dp[j][k] = min(dp[j][k], dis(i,k) + dp[i][j]);
dp[i][k] = min(dp[i][k], dis(j,k) + dp[i][j]);
}
}
double ans = INF;
for(int i=1; i < N; i++) // N-1 ~ 에서 N
{
ans = min(ans, dp[i][N] + dis(i,N));
}
System.out.println(ans);
}
}
public static double min(double a, double b) { return a > b ? b : a; }
public static double dis(int a, int b)
{
return Math.sqrt( (point[a][0]-point[b][0])*(point[a][0]-point[b][0]) + (point[a][1]-point[b][1])*(point[a][1]-point[b][1]) );
}
}
메모이제이션
관련 문제
데이터베이스
4장 관계 데이터 베이스 언어
SQL 정의어 : 스키마, 도메인, 테이블, 뷰, 인덱스의 정의하거나 제거하는데 사용
- CREATE 문
- ALTER 문
- DROP 문 : 구조 제거되고 데이터까지 같이 지워짐
SQL 조작어
SELECT, INSERT, UPDATE, DELETE
SQL 뷰
- 하나 이상의 테이블로부터 유도되어 만들어진 가상 테이블
- 뷰가 정의된 기본 테이블이 제거(변경)되면, 뷰도 자동적으로 제거(변경)된다.
- 외부 스키마는 뷰와 기본테이블의 정의로 구성된다.(사용자가보니까)
- 뷰에 대한 검색은 기본 테이블과 거의 동일 (삽입, 삭제, 갱신은 제약)
- DBA는 보안 측면에서 뷰를 활용 할수 있다.
- 뷰는 CREATE문에 의해 정의, 한번 정의된 뷰는 변경할수 없으며, 삭제한 후 다시 생성
- 뷰의 정의는 alter문을 이용하여 변경 할수 없다.
- 뷰를 제거할때는 drop문을 사용한다.
==> 사용자가 기본테이블 접근하면 변경가능성 있으니 검색만 가능하게 만듬!
뷰의 장단점
-
장점
- 논리적 독립성 제공 (필요한 것만 볼 수있음)
- 데이터 접근 제어로 보완 가능
- 사용자의 데이터 관리를 간단하게 함
- 하나의 테이블로 여러 개의 상이한 뷰를 정의
-
단점
- 독자적인 인덱스를 가질수 없음( 테이블에만 있는것 )
- 정의를 변경할수 없다 / 삽입 삭제 갱신 연산에 많은 제약이 따름
5장 데이터베이스 설계
- 요구 조건 분석
- 사용자가 원하는 데이터베이스의 용도를 파악
- 개념적 설계
- 사용자들의 요구사항을 이해하기 쉬운 형식으로 간단히 기술하는 단계
- 논리적 설계
- 개념적 설계에서 만들어진 구조를 구현 가능한 data 모델로 변환하는 단계 / 스키마 설계 단계
- 물리적 설계
- 논리적 데이터베이스 구조를 내부 저장 장치 구조와 접근 경로 등을 설계
- 응답시간, 경로, 저장공간의 효율화, 트랜잭션 처리도(처리능력) 고려사항!!
- 구현, 운영, 감시 및 개선
6장 관계 데이터 베이스 정규화
정규화의 개념
정규화 : 이상 문제를 해결하기 위해 어트리뷰트 간의 종속관계를 분석하여 여러개의 릴레이션으로 분해하는 과정
이상(anomaly)현상 : 어트리뷰트간에 존재하는 여러 종속관계를 하나의 릴레이션에 표현함으로 인해 발생하는 현상 ( 삽입이상, 삭제이상, 갱신 이상)
함수종속 : 어떤 릴레이션에서 속성들의 부분 집합을 X, Y라고 할때 임의 튜플에서 X의 값이 Y의 값을 함수적으로 결정한다면, Y가 X에 함수적으로 종속되었다고 하고 , 기호로는 X -> Y로 표기
제1 정규형(1NF)
- 모든 도메인이 원자값(atomic value) 만으로 된 릴레이션 / 다중 attribute 허용 X
제2 정규형(2NF)
- 1NF이고, 모든 어트리뷰트들이 기본키에 완전 함수 종속인 경우
제3 정규형(3NF)
- 2NF이고, 모든 어트리뷰투들이 기본키에 이행적 함수 종속이 아닌 경우
보이스/코드 정규형(BCNF)
- 릴레이션의 모든 속성이 후보키인 경우
제4 정규형(4NF)
- 릴레이션에서 다치종속 관계가 성립하는 경우
제5 정규형(5NF)
- 릴레이션에서 조인 종속이 성립하는 경우
중앙값 찾기 / [인덱스트리, pq ]
인덱스 트리 이용
- 백준 9426
- 각 노드를 숫자로 받고 트리를 구성
- 입력을 받자마자 tree[idx]++ update 해주고 해당 구간까지 도달하면 query를 날려서
k 번째를 찾아감 - left, right 자식노드를 확인하는데 if(k <= left) 라면 오른쪽은 볼필요 없으므로 왼쪽 자식노드 이동
- 그러지 않고 k 가 더 크다면 k = k - left 로 갱신하여 오른 쪽 확인
- 리프 노드 도달할때까지 반복
sorting / 기수 정렬, 계수 정렬
Selection Sort
정렬되지 않은 전체 자료중에서 해당 위치에 맞는 자료를 선택하여 위치를 교환하는 방식
for(int i = 0; i < N-1; i++)
{
int min = i;
for(int j = i + 1; j < N; j++)
{
if(data[min] > data[j]) min = j; // 가장 작은 값 찾아가기
}
int temp = data[min]; // 두번째 for 문이 끝난 후 가장 작은 값과 i 를 swap
data[min] = data[i];
data[i] = temp;
}
- 연산 및 이동 연산 횟수가 고정된 값 ( N^2) 이므로 최악의 연산 횟수의 경우나 평균 연산 횟수 값이나 정렬의 효율성은 N^2 ( 두개의 for문 종료 후 반드시 교환 연산이 이루어지므로 최선, 최악 의미 X)
- 같은 값의 인덱스끼리도 교환 연산 발생 가능성
Insertion Sort
자료 배열의 모든 요소를 앞에서부터 차례대로 이미 정렬된 배열 부분과 비교하여, 자신의 위치를 찾아 삽입
int j=0;
for(int i=1; i< N; i++) // 두번째 인덱스 부터 시작
{
j= i -1;
int target = data[i]; // 삽입할 숫자
while(j >= 0 && data[j] > target) // target 위치 찾기
{
data[j+1] = data[j]; // target 보다 큰 숫자 앞으로 한칸 씩 당기기
j--;
}
data[j+1] = target; // 자리 삽입
}
- target 이전 인덱스의 배열은 이미 정렬되어 있고 그 배열에 target 숫자의 위치를 삽입
- 이미 정렬되어 있는 경우라면 while을 거치지 않으므로 비교 횟수 줄임 O(N)
- 선택, 버블 정렬보다 성능이 좋지만 평균 O(N^2) 시간 복잡도
Bubble Sort
인접한 두수를 비교해서 큰 수를 뒤로 보내는 정렬, 느리지만 코드가 코드가 단순
for(int i=0; i< N-1; i++)
{
for(int j = 0; j< N - i -1; j++)
{
if(data[j] > data[j+1])
{
int temp = data[j];
data[j] = data[j+1];
data[j+1] = temp;
}
}
}
- 한번 순회를 마칠때마다 비교대상이 하나씩 줄어듬! (맨 뒤 부터 큰수가 정렬)
- 이미 정렬되어있을때 자리 교환이 일어나지 않으므로 시간을 줄일 수 있지만 평균 O(N^2) 시간복잡도
Quick Sort
재귀를 이용한 분할 정복 알고리즘, 다른 NlogN 정렬 알고리즘 보다 속도가 빠르다(pivot을 적절하게 선택했을 때)
이유는 불필요한 데이터의 이동을 줄이고 먼 거리의 데이터를 교환 할뿐 아니라, 한번 결정된 기준은 추후 연산에서 제외되는 성질을 가지고 있기 때문!
-
평균 복잡도는 nlogn 최악의 경우 n^2
-
일반적인 퀵소트 O(N^2) // 빅오표기법은 최악의 경우를 표현하므로
-
하지만 pivot 개선을 통해서 O(NlogN) 가능
-
분할 정복 : 큰 문제에서 작은 문제 단위로 쪼개면서 해결하는 방식
public class quickSort {
static int N;
static int[] data = new int[1000005];
public static void main(String[] args) throws IOException {
qSort(0, N-1);
}
public static void qSort(int left, int right)
{
if(left >= right) return;
int pivot = partition(left, right);
qSort(left, pivot-1);
qSort(pivot+1, right);
}
public static int partition(int left, int right) // pivot
{
int mid = (left + right) / 2; ////////// 중요!!! 중간값과 처음값 swap
swap(left, mid); ////////// 이 과정이 있어야 n^2 피할수 있다
int j = left ; // 처음은 pivot 의 위치 !
int pivot = data[left];
for(int i= left+1; i<= right; i++)
{
if(data[i] < pivot)
{
j++; // 왼쪽에는 pivot 보다 작은 값들로 바뀌게 됨 !
swap(i, j);
}
}
swap(j, left);
return j;
}
}
==> Devide
- 먼저 배열 중에 임의의 데이터 pivot으로 선택( 왼쪽, 오른쪽, 중간, 랜덤으로 선택 방식이 있다.) 에 따라 속도 달라짐
- 배열에 있는 데이터들의 pivot 보다 작은 데이터 그룹과 큰 데이터 그룹으로 나눈다.
- partition 이라고 부름
==> Conquer
- Pivot 을 중심으로 나누어진 두 그룹을 recursive 하게 반복
- 평균 O(NlongN), 최악 시간복잡도는 O(N^2) 이므로 불안정

MergeSort
분할 정복 알고리즘 중 하나이며, O(NlogN) 안정정렬에 속함
- Divide(분할) : 해결하고자 하는 문제를 작은 크기의 동일한 문제로 분할
- Conquer(정복) : 각각의 문제를 해결한다
- Merge(합병) : 작은 문제의 해를 합하여 원래의 문제에 대한 해를 구함
public class mergeSort {
static int N;
static int[] data = new int[1000005];
static int[] temp = new int[1000005];
public static void main(String[] args) throws IOException {
mSort(0, N-1);
}
public static void mSort(int left, int right)
{
if(left == right) return;
int mid = (left + right) / 2;
mSort(left, mid);
mSort(mid+1, right);
merge(left, mid, right);
}
public static void merge(int left,int mid, int right)
{
for(int i= left; i<= right; i++)
temp[i] = data[i];
int i, j, k;
i = k = left; //temp 첫번째 시작 인덱스 i, data 시작 인덱스 k
j= mid+1; // temp 두번째 시작 인덱스 k
while(i<= mid && j <= right)
{
if(temp[i] <= temp[j]) data[k++] = temp[i++];
else data[k++] = temp[j++];
}
// 남은 배열은 그대로 넣기
while(i<= mid)
data[k++] = temp[i++];
while(j <= right)
data[k++] = temp[j++];
}
}
Heap Sort
Heap
힙은 완전 이진 트리( Complete binary tree ) 일종으로 우선 순위 큐를 위하여 만들어진 자료구조
여러 개의 값들 중에서 최대값, 최소값을 빠르게 찾는 장점
힙 속성
- heap order property : 각 노드의 값은 자신의 자식노드가 가진 값보다 크거나 같다 (Max heap)
각 노드의 값은 자신의 자식노드가 가진 값보다 작거나 같다 ( Min heap) - heap shape property : 모양은 완전 이진 트리
Heap vs Binary Search Tree 구분 할 것!
- 힙은 각 노드의 값이 자식노드보다 큰 반면, 이진탐색트리는 왼쪽 자식노드가 제일 작고 부모노두가 그다음 크며 오른쪽 자식노두가 가장 큰 값을 가짐
-힙은 우선순위 정렬 / 이진탐색트리는 탐색에 강점을 지닌 자료구조 !
힙의 삽입
- 힙에 새로운 요소가 들어오면, 새로운 노드를 힙의 마지막 노드에 삽입
- 새로운 노드를 부모 노드들과 교환해서 힙의 성질을 만족 시킴

힙의 삭제
- 최대 힙에서 최대값은 루트 노드이므로 루트 노드가 삭제됨
- 삭제된 루트에는 힙의 마지막 노드를 가져옴
- 힙을 재구성

public class heapSort {
static int N;
static int[] data = new int[1000005];
public static void main(String[] args) throws IOException {
hSort(N);
}
public static void hSort(int n)
{
for(int i = n/2; i >=1; i--) // 자식을 가진 부모를 뒤에서 부터 업데이트 ! ( 처음 힙 만들기 !)
{
heapify(n, i);
}
for(int i= n; i>=2 ; i--)
{
swap(1, i); // 정렬된 가장 큰 값을 맨뒤 요소와 swap
heapify(i-1, 1); // 1 번부터 다시 힙 정렬 / 이때 전체 n 범위를 하나씩 줄여나감 !
}
}
public static void heapify(int n, int i) // 힙 속성에 맞게 구성
{
int p, left, right;
p = i; // 노드의 자식노드들 중 큰 값을 올리기 위한 부모노드 인덱스 설정
left = i*2; // 왼쪽 자식
right = i*2 +1; // 오른쪽 자식
if(left <= n && data[p] < data[left]) p = left; // 두 자식들 중 큰 값 찾기
if(right <= n && data[p] < data[right]) p = right;
if(p != i) // 값이 다르다는 얘기는 두 자식들 중 부모노드보다 큰값이 있어서 업데이트 필요하단 얘기
{
swap(p, i);
heapify(n, p); // 바뀐 값 자식들도 내려가면서 확인하기 위해 재귀
}
}
public static void swap(int a, int b)
{
int temp = data[a];
data[a] = data[b];
data[b] = temp;
}
}
안정 정렬과 불안정 정렬 설명
관련 링크 : http://mygumi.tistory.com/94
안정 정렬 : 삽입 정렬, 버블정렬, 합병 정렬
불안정 정렬 : 선택정렬, 퀵 정렬, 힙 정렬
트리 / Lazy Propagation / Persistent Segment Tree / sqrt Decomposition
Segment Tree / Index Tree
백준 관련 문제 2042, 10868, 2357 ( 구간 합, 곱, 최대 최소 구할때 )
- 75, 30, 100, 38, 50, 51, 52, 20, 81, 5 나열되어있는 수 들 중 구간의 합 ==> O(N)
- 하지만 중간의 값들이 계속 바뀌고 그때마다 구간의 합을 구한다면??
- 세그먼트 트리는 자료를 구간별로 나누어 트리에 저장하여 연산을 O(logN) 에 할수 있도록
- 포화 이진트리 형태(full binary tree) 형태로 사용
- 값이 N개일때 반드시 트리의 높이가 O(logN)으로 균형 잡혀 있기 때문
트리 시작점
- 리프 노드에 입력값을 모두 넣어야 하므로 루트 인덱스 1 부터 자식 노드로 내려오면서 N보다 커지는 인덱스가 시작 위치로 지정
s = 1
while(N > s) s *=2;
==> N이 10일땐 시작인덱스 16 ( 1 , 2 ,4 ,8 , 16 )
- 값이 N일때 트리 구성하기 위한 전체 배열을 N*4 로 구성 !
- N = 9 일 때 포화 이진트리 구성하기 위한 전체 배열은 31개가 나오므로
트리 구성
- 구간합 : 나머지 값들 0 초기화
- 구간 최소값 : 나머지 값들 가장 큰 수로 초기화
- 구간 최대값 : 나머지 값들 가장 작은 수로 초기화

구간 값 구하기

구간 합 구하기

참고 문제

이분 매칭(Bipartite Matching)
이분매칭
- 네트워크 플로우 개념중에서 이분 그래프에서의 최대 유량을 구하는 경우를 이분 매칭





출처 : https://jason9319.tistory.com/149
DFS 를 이용한 이분매칭 O(V*E)
열혈 강호 11375
public class baek11375 {
static int N, M, result;
static ArrayList<ArrayList<Integer>> adj = new ArrayList<>();
static int[] visit = new int[1005];
static int[] match = new int[1005];
public static void main(String[] args) throws IOException {
int result = bmatch();
System.out.println(result);
}
public static int bmatch()
{
int ret = 0;
for(int i=1; i<= N; i++) // 모든 직원들에 대해서 매칭 시도
{
for(int j=1; j<= N; j++) visit[j] = 0;
if(dfs(i) == 1) ret++; // 직원과 일이 매칭 된다면 카운트
}
return ret;
}
public static int dfs(int cur)
{
if(visit[cur] == 1) return 0; // 방문한 직원 매칭 불가
visit[cur] = 1;
for(int next : adj.get(cur))
{
// 매칭한 적이 없거나 매칭 되어 있다면 매칭 된 직원에게 되돌아 가서 다른 일이 가능한지 확인 작업
if(match[next] == 0 || dfs(match[next]) == 1)
{
match[next] = cur; // 매칭이 된다면 1 리턴
return 1;
}
}
return 0;
}
}
열혈강호 2
- 한사람당 최대 2가지 일 매칭 가능
각 사람에 대해 이분 매칭 2번 돌려주면 끝
public static int bmatch()
{
int ret =0;
for(int i=1; i<= N; i++)
{
for(int j=1; j<= 2; j++)
{
for(int k=1; k<= N; k++) visit[k] = 0;
if(dfs(i) == 1) ret++;
}
}
return ret;
}
열혈강호 3
- N명 중 K명이 최대 2개 일을 할수 있는데 , K명은 누구든 상관 없음
=> N+K 개로 열혈강호 2처럼 돌린다면 반례가 생김
ex) N = 5, K =3 일때 최대 2개 일할수 있는 사람이 3명이 되야 하는데
4명이 생길수 있음 / 1,2,3,4 직원이 2개씩 일하고 5 직원이 1개 일하는 경우 발생 / ( 총 유량 8 )
==> 첫번 째 정점 그룹 P, 두번 째 정점 그룹 Q로 나누고
일단 맨 처음은 P그룹의 N개 정점들에 대해서만 최대 매칭을 구함
그 다음, Q 그룹의 N개의 정점들에 대해서만 최대 매칭을 구하는대 이때 K개 발생하면 중단
==> 성립 이유는 Q그룹에서 매칭을 새로 찾다가 원래 매칭이 있던 P 그룹의 정점이 매칭이 없어지는
일은 발생하지 않음
public static int bmatch()
{
int ret = 0, count = 0;
for(int i=1; i<= N; i++)
{
for(int j=1; j<= N; j++) visit[j] = 0;
if(dfs(i) == 1) ret++;
}
for(int i=1; i<= N; i++)
{
for(int j=1; j<= N; j++) visit[j] = 0;
if(dfs(i) == 1) {
ret++;
count++;
}
if(count == K) break;
}
return ret;
}
트리
트리
- 트리란 연결 리스트와 유사한 자료 구조지만 연결 리스트가 단순히 다음 노드를 가르키는 선형이라면 트리는 각 노드가 여러 개의 노드를 가리키는 비선형입니다.
- 트리 구조는 그래프의 한 종류로 1개 이상의 노드로 구성되며 사이클이 없는 그래프로 임의의 두 노드간에 하나의 경로만이 존재
- 트리의 root는 부모를 가지지 않고 최대 하나의 root 노드가 있을 수 있습니다.
- edge는 부모와 자식을 잊는 연결 선입니다. 자식이 없는 노드를 leaf 노드라고 부릅니다.
- 자식이 하나라도 있는 노드 internal 노드
- 노드의 차수(degree) 는 특정 노드의 자식 수 / 트리의 차수는 트리의 모든 노드 중에 가장 높은 차수
- 자식 노드에 대하여 상위 노드(부모) / 동일한 부모를 가진 자식노드(형제) / 특정 노드의 부모노드의 집합 (조상)이라하고 반대로 특정 노드의 부속 트리의 모든 노드 집합을 자손
- sibilings , ancestor, descendant
- 노드의 depth는 root 에서 해당 노드까지 경로의 길이 (트리에서 가장 큰 레벨 )
- 노드의 height 는 해당 노드에서 가장 깊은 노드까지 경로의 길이 ( 하나의 노드를 가진 트리의 높이는 0)
- 노드의 크기는 자신을 포함한 descendant 들의 수를 말합니다.
- level은 루트 노드 아래로 한단계식 레벨을 가지며 루트가 레벨 1
- 모든 노드들이 자식을 하나만 가질 때 이를 skew 트리(편향 트리)라고 부름 ( left skew, right skey)
이진 트리
모든 노드들이 둘 이하의 자식을 가질 때 이를 이진 트리
- 순 이진 트리( Strict Binary Tree ) : 노드들이 정확히 자식 노드를 가지거나 아예 안가질때
- 전 이진 트리 ( Full Binary Tree ) : 각 노드가 정확히 두 개의 자식노드를 가지고 모든 leaf 노드들이 동일한 레벨 이진 트리
- 완전 이진 트리( Complete Binary Tree) : root 에서 시작하여 왼쪽에서 오른쪽으로 노드들이 번호를 매겼을 때 그 번호가 1부터 노드들의 수까지 완전히 연속적인 수를 얻게 됩니다. / 설명
- 레벨이 n인 이진트리의 최대 노드 수는 2^n-1 이다. ( ex 레벨이 2면 최대 노드수 3개)
- 이진트리에서 단말 노드(terminal node)의 개수는 분지수(degree)가 2인 내부노드(internal node)의 개수 보다 하나 더 많다.
트리 순회
http://3dmpengines.tistory.com/423
먼저 트리 순회 방법이 있는 이유는 트리는 선형이 아닌 비선형이기 때문에 모든 노드들을 거쳐가기 위한 방법이 필요하게 된다.
- 전위순회
- 중위순회
- 후위순회
- 레벨순회 : 트리의 각 노드를 레벨 순서로 방문 ( 같은 레벨에서는 왼쪽에서 오른쪽 순)
사용 자료구조로는 큐를 사용 합니다

수식 트리
Binary Search / 이진 트리 / 파라메트릭 서치
이진 탐색 트리 : 이진 트리 기반의 탐색을 위한 자료 구조
조건
- 모든 노도의 키는 유일
- 왼쪽 서브 트리의 키들은 루트의 키보다 작다. / 오른쪽도 동일
- 왼쪽과 오른쪽 서브트리도 이진 탐색 트리



이진 탐색 트리의 시간 복잡도
- 탐색, 삽입, 삭제 연산의 시간 복잡도는 트리의 높이를 h 라고 했을 때 O(h)
따라서 n개의 노드를 가지는 이진 탐색 트리의 경우, 균형 잡힌 이진 트리의 높이는 logN 이므로 이진 탐색 트리 연산의 평균적인 경우는 O(logN)


투 포인터 / 슬라이딩 윈도우
https://www.acmicpc.net/problem/2003 // 투 포인터
https://www.acmicpc.net/problem/11003 ( 데크 사용!) // 슬라이딩 윈도우
- 2905 홍준이와 울타리
슬라이딩 윈도우 (데크 이용)
ex) 11003 예시
- 데크의 앞쪽 : 문제에서 주어진 조건을 만족하는 최소값 유지 / 윈도우 범위가 넘어 갈때는 만족하는 범위가 나올때까지
빼줌
-데크의 뒤쪽 : 넣을 num 값 보다 같거나 크면 num 보다 작은 값 나올때까지 pollLast
for(int i=1; i<= N; i++)
{
num = Integer.parseInt(st.nextToken());
data[i] = num;
Node first = null, last = null;
while(!que.isEmpty()) // 조건 만족할때 가지 데크 뒤 빼기 ////////빼는 구간
{
last = que.peekLast();
if(last.num >= num) que.pollLast();
else break;
}
que.addLast(new Node(num, i));
int target = 0;
while(!que.isEmpty()) ///////////////////////////////// 넣는 구간
{
first = que.peekFirst();
last = que.peekLast();
target = first.num;
if(last.idx - first.idx < X)
{
break;
}
que.pollFirst();
}
}
Comparator Sorting

백준 10825 국영수 문제 중 일부 소스
순열, 조합
순열

모든 순열 10974 백준 / 다음 순열 10972/ 이전 순열
조합
- nCr ==> n 개의 숫자에서 r개를 뽑는 경우의 수
n 개의 공에서 r개를 뽑는 경우의 수 == n-1개의 공에서 r개를 뽑는 수와 n-1개의 공에서 이미 하나를 뽑았다고 생각하고 r-1개를 뽑는 수를 더한 것과 같기 때문 - 파스칼 삼각형
==> 파스칼 삼각형은 수학에서 이항계수(서로 다른 몇개의 물건 중에 순서없이 물건을 선택할 수 있는 경우의 수)를 삼각형 모양의 기하학적 형태로 배열 한 것


Dijkstra / Bellman-ford / (SPFA ) / Floyd-Warshall 알고리즘
다익스트라 알고리즘은
그래프의 어떤 정점 하나를 시작점으로 선택하고,
나머지 정점들로의 최단거리를 모두 구함 시작점 자신은 0
정점 개수가 V, 간선 개수가 E일 때 기본적인 최적화를 거치면 O(ElogV)의 시간복잡도
- 각 정점들 중 최단거리를 찾는 과정에서 우선순위 큐를 쓰지 않게되면 모든 정점을 확인해야 하므로
시간복잡도는 O(N^2) - 우선순위 큐 이용 ( cost 값이 제일 작은 정점을 찾아 방문)
static int V, E, S; // 정점의 갯수, 간선의 갯수,시작 점
static ArrayList<ArrayList<Node>> adj = new ArrayList<ArrayList<Node>>(); // 인접 리스트
static final int MAX = 20001, INF = 300005 * 10;
static int[] dis = new int[MAX];
// 인접 리스트 정점 갯수만큼 할당 해주고 인접리스트 연결 할 것
// dis 배열 모두 INF 로 초기화 해주고 시작점 0으로 놓고 시작 !
public static void solve()
{
PriorityQueue<Node> que = new PriorityQueue<>(new Mysort());
que.add(new Node(S,0)); // 시작점
dis[S] = 0;
while(!que.isEmpty())
{
Node n = que.poll();
if(n.cost > dis[n.dx]) continue;
for(Node next : adj.get(n.dx)) // 연결된 다음 노드들을 보면서 최단경로 탐색
{
// 현재 노드에서 다음 노드로 가는 가중치를 더한 값이 dis[next.dx] 보다 작으면 그 경로가 최단 경로가 되니 업데이트
if(dis[next.dx] > next.cost + dis[n.dx])
{
dis[next.dx] = next.cost + dis[n.dx];
que.add(new Node(next.dx, dis[next.dx]));
}
}
}
}
만약 음수사이클 있다면 이 과정이 성립하지 않아서, 최단 경로를 구하지 못함
이때는 조금 더 느리지만 전용 알고리즘인 벨만 포드 알고리즘을 써야 함
백준 관련문제(최단경로) : https://www.acmicpc.net/problem/1753
우선순위 큐 다익스트라 : http://manducku.tistory.com/32
벨만포드 알고리즘
- V개의 정점과 E개의 간선을 가진 가중 그래프에서 특정 출발정점에서부터 모든 정점까지의 최단 경로를 구하는 알고리즘
- 음의 가중치 가지는 간선이 있어도 가능
- 음의 사이클의 존재 여부도 확인 가능
- 최단 거리를 구하기 위해서 V-1 번 E개의 모든 간선을 확인하고 , 음의 사이클 존재여부 확인하기 위해 E개의 간선을 확인하므로 시간복잡도는 O(VE)

/**
* 타임머신 (벨만 포드 알고리즘 ) : V개의 정점과 E개의 간선을 가진 가중 그래프에서
* 출발정점에서 다른 모든 정점까지의 치단경로를 구하는 알고리즘
* 최소 간선의 갯수 V-1 ==> 즉, V번째 모든 간선을 확인하였을때 거래배열이 갱신된다면 음수 사이클 확인 가능하다
* O(V*E)
*
*/
public class Main {
static int N, M;
static int[][] data = new int[6001][3]; // input 간선 표
static int[] d = new int[501]; // cost 정보 배열
static final int INF = 6005*10000;
public static void main(String[] args) throws IOException {
int dx,dy,cost;
for(int i=1; i<= M; i++)
{
data[i][0] = dx; data[i][1] = dy; data[i][2] = cost;
}
for(int i=1; i<= N; i++)
{
d[i] = INF;
}
d[1] = 0; // 1번 도시에서 출발
for(int i=1; i<= N-1; i++) // 사이클 없이 모든 노드를 연결할수 있는 최소 간선의 갯수 N-1
{
for(int j=1; j<= M; j++) // 모든 간선 표 확인
{
if(d[data[j][0]] != INF && d[data[j][1]] > d[data[j][0]]+ data[j][2])
{
d[data[j][1]] = d[data[j][0]]+ data[j][2]; // 더 적은 비용으로 이동할수 있는 거리 찾음
}
}
}
for(int j=1; j<= M; j++) // 사이클이 존재하는지 존재 하는 방법 !
{
if(d[data[j][0]] != INF && d[data[j][1]] > d[data[j][0]]+ data[j][2])
{
System.out.println(-1);
return; // 바로 종료
}
}
for(int i=2; i<= N; i++)
{
if(d[i] == INF) System.out.println(-1);
else System.out.println(d[i]);
}
}
}
참고 링크 : http://blog.naver.com/PostView.nhn?blogId=kks227&logNo=220796963742
플로이드 워셜 알고리즘
- V개의 정점과 E개의 간선을 가진 가중 그래프 에서 모든 정점 사이의 최단 경로를 구하는 알고리즘
- 순환만 없다면 음수 가중치도 가능!
- 동적계획법으로 접근 !
- 시간복잡도 O(N^3) 이기 때문에 제한시간 1초 이내에 들어오려면 N=500 이내만 사용할 것!

- 2차원 배열 ans 에는 두 정점 간의 비용이 초기화 되어 있어야함
- 두 정점 간의 연결이 없다면 무한대로 초기화
- 무한대로 초기화 하는 이유는 이 무한대를 이용하여 두 정점간의 연결 여부를 파악하기 위해
- 대부분 같은 정점끼리는 주어지지 않기때문에 i == j 인 경우는 0으로 초기화
관련 문제 : 2660번 회장뽑기, 1956번 운동, 1613번 역사, 10159번 저울, 1238번 파티, 1389번 케빈 베이컨의 6단계 법칙
LIS / ( lower_bound , upper_bound )
N^2 방법
dp[i] = data[i] 를 마지막 원소로 하는 증가 부분 수열의 최장 길이
for(int i=1; i<= N; i++)
{
for(int j=0; j < i; j++)
{
if(data[i] > data[j] && dp[i] < dp[j] + 1)
{
dp[i] = dp[j] + 1;
}
}
result = max(result, dp[i]);
}
System.out.println(result);
Lower Bound 를 이용한 방법 / nlogn
dp 는 길이가 x인 최장증가수열의 마지막 수의 최소값을 의미
- 배열을 하나 생성해서 매번 수열을 구할때 마다 배열의 맨 뒤 원소와 현재 보고 있는 수열의 원소를 비교하여 수열의 원소가 더 클 시 배열 뒤에 push 해준 후 사이즈 +1
- 만약 수열의 원소가 배열의 맨 뒤 원소보다 작을 경우 lower_bound를 이용하여 최적의 자리를 찾은 뒤 그자리값을 해당 수열의 원소로 교체
ex ) 10, 20, 40, 30, 70, 50, 60
- 처음값 10을 넣어줌 : 배열의 최대 배열 사이즈 1
- 20 값은 배열 마지막 값인 10보다 크므로 배열 뒤에 추가 : 배열 사이즈 2
- 40 추가 : 배열 사이즈 3 / (10, 20, 40)
- 30 값은 배열의 마지막 값인 40보다 작으므로 lower_bound 를 이용하여 40자리에 30을 치환 / (10,20, 30)
- 70 추가 : 배열 사이즈 4 ( 10, 20, 30, 70)
- 50 값을 70과 치환 (10, 20, 30, 50) : 배열사이즈 4
- 60 추가 : 배열 사이즈 5 (10, 20, 30, 50, 60)
고려해야 할 부분
- 자기 뒤에 참조를 한다면 더 적은 값에서 참조를 하는 것이 유리하기 때문에 6번과 같이 70을 50과 치환이 가능
- 주의할 점은 dp 배열에 있는 값들은 LIS를 이루는 요소과 무관한 값들!! ( 수열상에서 뒤에 있던 원소가 먼저 들어온 원소보다 lower_bound로 탐색된 최적의 위치가 앞에 있을 수도 있기 때문!!)
size = 1;
dp[1] = data[1];
for(int i=2; i<= N; i++)
{
if(data[i] > dp[size]) // dp 맨뒤에 있는 자리와 비교하여 더 큰값이면 이어 붙이기
{
dp[++size] = data[i];
}
else if(data[i] < dp[size])
{
int tdx = lower_bound(1,size,data[i]);
dp[tdx] = data[i];
}
}
}
System.out.println(size);
lower_bound 방식 ( lis 요소들 추적 가능한 방법! )
-
위의 방식은 LIS 길이를 구하는 방식이지만 해당 길이의 요소를 알수없다. ( 주의 )
ans 라는 pair 배열을 새로 만들고 정의해야함 -
ans[].dx : 실제 그 값이 들어갈수 있는 위치
-
ans[].dy : 실제 해당하는 값
실제 lis 배열을 구하는 알고리즘을 보자
예를들면 다음과 같다.
1 6 2 5 7 3 5 6인 경우
ans배열에는 다음과 같이 들어간다.
dx :: 0 1 1 2 3 2 3 4
dy :: 1 6 2 5 7 3 5 6
이 값을 dx를 기준으로 뒤에서 부터 조사해오면
dx가 4일때 (6) - > dx가 3일때 (5) -> dx가 2일때 (3)
-> dx가 1일때 (2) -> dx가 0일때(1)이다.
이것을 스택에 담아 역출력하면 1,2,3,5,6이라는 실제 배열을 구할 수 있다.
public class baek14002 {
static int N;
static int[] data = new int[1005];
static int[] dp = new int[1005];
static Node[] ans = new Node[1005];
static Deque<Integer> que = new ArrayDeque<>();
public static void main(String[] args) throws IOException {
st = new StringTokenizer(br.readLine());
for(int i=1; i<= N; i++)
{
data[i] = Integer.parseInt(st.nextToken());
ans[i] = new Node(-1,-1);
}
dp[1] = data[1];
ans[1].dx = 1; // 실제 인덱스 1로 처음 시작
ans[1].dy = dp[1]; // 실제 값
int size = 1;
for(int i=2; i<= N; i++)
{
if(dp[size] < data[i])
{
dp[++size] = data[i];
ans[i].dx = size;
ans[i].dy = data[i];
}
else {
int idx = lower_bound(1, size, data[i]);
dp[idx] = data[i];
ans[i].dx = idx;
ans[i].dy = data[i];
}
}
System.out.println(size);
// 인덱스 i=2 부터 계속 해서 업데이트 해왔으므로
// 맨뒤 인덱스 부터 찾아 나감
int t = size;
for(int i = N; i > 0; i--)
{
if(t == ans[i].dx)
{
que.addLast(ans[i].dy);
t--;
}
}
while(!que.isEmpty())
{
int num = que.pollLast();
System.out.print(num+" ");
}
}
static class Node {
int dx, dy;
Node(int a, int b) {
dx=a; dy=b;
}
}
}
lower_bound 란?
- 이분 탐색을 통해 해당 위치를 return 해주는 방식
인덱스 트리를 이용한 방법 / nlogn
설명 : https://m.blog.naver.com/kks227/220791986409
(그림 확인)
- A[i] = x 값들을 모두 받아서 (x, i) pair 들을 만든 후 x 기준 오름차순 정렬
A[i]=x 인 i에 대해 구간 [0,i]에 지금까지 존재하는 lis 길이 +1이 x로 끝나는 lis 길이
주의 사항
- 중복된 값이 발생할 경우
==> 중복되는 값들 중에서는 가장 큰 인덱스 부터 방문해야 함!!!
==> 정렬할때 값 기준 오름차순 / 같은 값있을 경우는 인덱스 기준 내림차순
public class Main {
static int N, start, result;
static final int max_node = 500005;
static ArrayList<Node> arr = new ArrayList<>();
static int[] tree = new int[4*max_node];
static int[] dp = new int[max_node];
static Deque<Integer> que = new ArrayDeque<>();
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
N = Integer.parseInt(st.nextToken());
start = 1; result = 0;
int chk = 0; // 트리의 시작 인덱스를 찾기 위한 최대 노드 값
int dx = 0, dy = 0;
for(int i=1; i<= N; i++)
{
st = new StringTokenizer(br.readLine());
dx = Integer.parseInt(st.nextToken());
dy = Integer.parseInt(st.nextToken());
arr.add(new Node(dy,dx));
chk = max(chk, dx);
}
while(chk > start) start *= 2;
Collections.sort(arr, new mySort());
for(Node cur : arr)
{
int cnt = query(1, cur.idx); // 1 ~ i-1 까지의 최대 lis
update(cur.idx, cnt+1);
result = max(result, cnt+1);
dp[cur.idx] = cnt+1;
}
bw.write( (N-result) +"\n");
int size = result;
for(int i = chk; i > 0; i--)
{
if(dp[i] == 0) continue;
if(dp[i] == size) {
size--;
continue;
}
que.addLast(i);
}
while(!que.isEmpty())
{
int num = que.pollLast();
bw.write(num+"\n");
}
bw.flush();
}
public static void update(int idx, int num)
{
int s = start + idx - 1;
while(s > 0)
{
if(tree[s] < num)
{
tree[s] = num;
s /= 2;
}
else break;
}
}
public static int query(int sdx, int edx)
{
int ret = 0;
int s = start + sdx - 1;
int e = start + edx - 1;
while(s <= e)
{
if(s % 2 == 1)
{
if( ret < tree[s])
{
ret = tree[s];
}
}
if(e % 2 == 0)
{
if( ret < tree[e])
{
ret = tree[e];
}
}
s = (s+1) / 2;
e = (e-1) / 2;
}
return ret;
}
public static int max(int a, int b)
{
return a > b ? a : b;
}
static class mySort implements Comparator<Node>{ // 값에 대한 오름차순으로 정렬 하고 동일한 값이 있을 때는 인덱스가 큰 값 기준으로 내림 차순 정렬
@Override
public int compare(Node a, Node b) {
// TODO Auto-generated method stub
if(a.num < b.num) return -1;
else if(a.num > b.num) return 1;
else {
if(a.idx > b.idx) return -1;
else if(a.idx < b.idx) return 1;
else return 0;
}
}
}
static class Node {
int num, idx;
Node(int a, int b){
num=a; idx=b;
}
}
}
거듭제곱 알고리즘 [백준 1629번 ]
일반적인 방법

분할정복 알고리즘
- O(logN)


public static long pow(long a, long b)
{
long k =0;
if ( b == 0 ) return 1;
else if(b % 2 == 0) { // 거듭제곱이 짝수일 때
k = pow(a, b/2);
return (k * k) ;
}
else { // 거듭제곱이 홀수일 때
k = pow(a, (b-1)/2);
return (a * k *k) ;
}
}
지수를 2의 거듭제곱 형태로 표현
- O(log지수)
7^21 = ( 7^16 ) * ( 7^4 ) * ( 7 )
==> 21 을 비트로 표현 해보면 10101
모듈러 연산
모듈러 연산
몇 가지 중요한 암호 시스템은 계산 결과가 항상 0 - (m-1) 범위에있는 경우 모듈러 연산을 사용한다.
이때 m은 %를 하고자 하는 modular 값이다.
우리가 익히 알고있는 모듈러 연산을 해보자.
17 mod 5 = 2
7 mod 11 = 7
20 mod 3 = 2
11 mod 11 = 0
음수의 경우에도 모듈러 연산이 가능하다.
-3 mod 11 = 8
-1 mod 11 = 10
25 mod 5 = 0
-11 mod 11 = 0
음수를 mod 할 경우에는 양수라 생각하고 mod를 한 후 + m을 해주면 된다.
예를 들어 -20 mod 11이면 20 mod 11 = 9 에서 -9 + 11 = 2와 같다.
출처: https://www.crocus.co.kr/1231 [Crocus]
관련 문제
- Subarray Sums Divisible by K
링크드 리스트 ( LinkedList ), 사이클 / 이중 연결리스트 || 스택
링크드 리스트
- 자바는 객체지향 언어이기 때문에 노드는 객체로 만들기 좋은 대상
- 노드 객체는 리스트의 내부 부품이기 때문에 외부에는 노출되지 않는 것이 좋다. ==> private
- 사용자는 이 객체에 대해서 알 필요가 없습니다. 단지 값을 넣고 빼는 것으로 충분
- head : 처음 노드 위치 기억
- tail : 노드의 끝 위치 ( 링크드 리스트는 tail 없이도 구현 가능 , 하지만 리스트 끝 데이터 수정하는 작업을 할때 효율적으로 하기 위해서 사용)
package com.company.etc;
class NodeList {
private Node head; // 맨 처음
private Node tail; // 맨 끝
private int size; // 노드 갯수
private class Node{
int data;
Node next; // 노드의 다음 노드를 가르킴
public Node(int data)
{
this.data = data;
}
}
public void addFirst(int data) // 맨 앞 노드 추가
{
Node newNode = new Node(data); // 노드 생성
newNode.next = head; // 새로 만든 노드를 이전에 헤드 였던에랑 연결!!!
head = newNode; // haed가 새로 만들어진 노드를 가르키도록 !
if(head.next == null)
{
tail = head; // 현재 노드가 하나밖에 없어서 head 의 다음이 없다면 그곳이 tail 자리도 되니까
}
size++;
}
public void addLast(int data)
{
Node newNode = new Node(data);
if(size == 0) {
addFirst(data);
}
tail.next = newNode; // 이전 tail 의 노드 값과 새로운 노드 연결
tail = newNode; // tail 을 새로운 노드로 갱신
size++;
}
public Node node(int index) // 특정 인덱스 노드 찾아가기
{
Node target = head;
for(int i=0; i< index; i++)
{
target = target.next;
}
return target;
}
public void add(int index, int data) // 특정 인덱스 노드에 삽입
{
if(size ==0) {
addFirst(data);
}
else
{
Node preNode = node(index-1); // 그전 노드 가져오기
Node nextNode = preNode.next; // 그 다음 노드 가져오기
Node newNode = new Node(data); // 중간에 삽입할 노드
preNode.next = newNode; // 이전 노드랑 연결
newNode.next = nextNode; // 새로만든 노드를 다음 노드와 연결
size++;
if(newNode.next == null ) // 다음 노드가 없다는건 해당 노드가 끝 이니까 tail 로 갱신
{
tail = newNode;
}
}
}
public int removeFirst() { // 가지고 있던 데이터 리턴이 원칙
Node temp = head; // 헤드가 가르키고 있는 첫번째 값을 임시로 저장 (삭제전)
head = temp.next; // 헤드를 다음 노드를 가르키게
int deleteDate = temp.data; // 삭제 시킬 데이터
temp = null; // 삭제
size--;
return deleteDate;
}
public int remove(int k) {
if(k ==0) {
return removeFirst();
}
Node temp = node(k-1); // 삭제시킬 바로 이전 노드 가져오기
Node todoDelete = temp.next; // 삭제할 노드
temp.next = temp.next.next; // 삭제 할 노드 다음 노드
int returnData = todoDelete.data;
if(todoDelete == tail)
{
tail = temp; // 이전 노드로 갱신
}
size--;
todoDelete = null;
return returnData;
}
public int removeLast()
{
return remove(size-1);
}
public String toString() {
if(head == null) {
return "[ ]";
}
Node temp = head;
String str ="[";
while(temp.next != null)
{
str += temp.data + ",";
temp = temp.next;
}
str += temp.data;
return str+"]";
}
}
public class LinkedList {
public static void main(String[] args) {
// TODO Auto-generated method stub
NodeList list = new NodeList();
list.addFirst(10);
list.addFirst(20);
list.addLast(30);
System.out.println(list.removeFirst());
System.out.println(list);
}
}
1406 번 직접 구현 해보기 !
1158
효율적인 소수 구하기 ( 백준 1978 / 1929 )
첫번째 방법 : 단순하게 for문을 다 돌면서 나누어 떨어지는 값이 있는지 확인
value = scanner.nextInt();
int i;
for(i=2 ;i< value; i++)
{
if( value % i == 0) break; // 소수 아님
}
if(i == value) // 소수!
두번째 방법 : 배열에 미리 소수를 넣어 놓고 검사할 값이 들어오게 되면 그 값보다 작은 소수 까지만 검사!
세번째 방법 : 에라토스테네스 체 알고리즘!
입력받은 수를 입력받은 수보다 작은 수 들로 나누어서 떨어지면 소수가 아니다.
그러나 모두 나누어볼 필요없이, 루트 n 까지만 나누어서 떨어지면 소수가 아니다.
==> 해당 값이 소수인지 아닌지 판별할때는 2<= <= sqrt(n) 까지만 확인 하면 된다!
public static int isPrime(int value) {
if(value <= 1) return 0;
for(int i=2; i * i <= value ; i++)
{
if(value % i ==0) return 0;
}
return 1;
}
==> 2~N 까지 소수를 모두 구할때 가장 빠른 알고리즘!
for(int i =2; i<= 1000000; i++)
{
if(map[i] == 0 ) continue;
isPrime[index++] = i;
for(int j= i+i; j<= 1000000; j += i)
{
if(map[j] ==0) continue;
map[j] = 0;
}
}
public static int N;
public static int[] arr = new int[1000001];
public static int start, end;
public static void isPrime() { // 소수 판별 함수
for(int i =2; i * i<= end; i++) {
if( arr[i] == 0 ) continue;
for(int j = i+i; j<= end; j+=i) {
arr[j] =0;
}
}
}
public static void init() {
for(int i = 2; i<=end; i++) {
arr[i] =i;
}
}
부분집합구하기( 비트마스킹, 비트연산자, 비트마스크)
SHIFT연산자 (<<, >>) : 모든 비트를 해당 방향으로 밀어줌 (곱셈, 나눗셈의 효과)
public class Shift {
public static void main(String[] args) {
// TODO Auto-generated method stub
int number =1; // 0000 0001
System.out.println("원래 숫자 : "+ number); // 1 출력
number = number << 1; // 0000 0010
System.out.println("왼쪽으로 1칸 쉬프트 : "+ number);// 2 출력
number = number << 2; // 0000 1000
System.out.println("왼쪽으로 2칸 쉬프트 : "+ number);// 8 출력
number = number >> 1; // 0000 0100
System.out.println("오른쪽으로 1칸 쉬프트 : "+ number);// 4출력
}
}
부분집합 구하기 : ( 1 << N ) == (2^n) 따라서 부분집합의 전체 갯수(공집합 포함) / 백준 1182
- 주의 : 백준 1208 (배열 범위 40은 비트마스크 자료형 int 로 해결 불가능 !!)
- signed int [-(2^31) ~ 2^31-1 ] 이기 때문에 2^40 를 해결하려면 다른 방법 필요
public class Subset {
public static int[] arr = {1,2,3};
public static void main(String[] args) {
// TODO Auto-generated method stub
int N = arr.length; // 배열 전체 길이
for(int i=0; i< (1 << N); i++) // 0 ~ 7
{
for(int j=0; j < N; j++) // 원소의 갯수만큼 for문
{
if( ( i&(1<<j) ) != 0 )// i의 j 번째 bit가 1인지 아닌지 확인
{
System.out.print(arr[j]+" ");
}
}
System.out.println();
}
}
}
출력 결과
(공집합)
1
2
1 2
3
1 3
2 3
1 2 3


Hash ( HashCode )
객체 해시코드 ( HashCode() )
- 객체마다 객체를 식별할수 있는 정수 값을 가지고 있음
- 자바에서 Object 클래스에서 hashCode() 를 이용해 객체의 메모리 주소를 리턴받아 사용
- Object 의 hashCode 는 객체마다 다 다른 값을 가지고 있기 때문에 재정의해서 사용해야함
equals 와 hashCode 반드시 둘다 정의 필요
객체의 변수 2개 이상 비교할 경우
static class Node {
int dx, dy;
Node(int a, int b) {
dx=a; dy=b;
}
@Override
public boolean equals(Object obj) {
if(obj instanceof Node) {
Node n = (Node)obj;
if(dx == n.dx && dy == n.dy) return true;
}
return false;
}
@Override
public int hashCode() {
// TODO Auto-generated method stub
return Objects.hash(dx,dy);
}
}
객체 변수 하나만 비교할 경우
static class Node {
int dx;
Node(int a) {
dx=a;
}
@Override
public boolean equals(Object obj) {
if(obj instanceof Node) {
Node n = (Node)obj;
if(dx == n.dx ) return true;
}
return false;
}
@Override
public int hashCode() {
// TODO Auto-generated method stub
return dx;
}
}
운영체제
운영체제 개요
정의
- 사람들 대신하여 컴퓨터 시스템의 각종 자원을 보다 효율적으로 관리하고 운영하는 시스템 소프트웨어
- 사용자에게 편리성 제공하도록 하기 위한 컴퓨터 하드웨어와 사용자간의 매개체 역할을 하는 시스템 프로그램
- 커널 : 운영체제의 핵심 요소, 하드 디스크 엑세스 부터 메모리 관리에 이르기까지 모든 것을 제어
목적
- 사용자에게 편리한 환경 제공
- 시스템의 성능 향상
- 신뢰도(reliability)의 향상 ==> 시스템이 정확하게 작동되는 정도
- 처리량(throoughput) 향상 ==> 일정시간 내에 시스템이 처리하는 일의 양을 극대화
- 응답시간(response time) 단축 ==> 일의 처리를 컴퓨터에 지시하고 나서 결과를 얻을 때 까지 걸리는 시간
- 사용가능도(availability) ==> 컴퓨터 시스템 내의 한정된 자원을 여러 사용자가 요구할 때, 신속하고 충분히 지원해 줄수 있는가
역할
- 프로세스 관리, 기억장치 관리, 입출력장치 관리, 자원 관리
프로그램 빌드 되는 과정 (링커와 로더)
-
링커 : 컴파일러가 프로그래밍 언어를 해석해서 기계어로 바꾸는 것이라면 링커는 컴파일러가 만든 결과물을 서로 연결시키는 역할을 함
-
로더 : 컴퓨터 운영체제의 일부분으로, 하드디스크와 같은 저장 장치에 있는 특정 프로그램을 찾아서 주기억장치에 적재하고, 그 프로그램이 실행되도록 하는 역할을 담당
-
로더의 기능
- 할당(Allocation) - 목적프로그램이 적재될 주기억 장소 내에 공간을 확보
- 연결(Linking) - 필요할 경우 여러 목적 프로그램 또는 라이브러리 루틴과 링크작업, 외부기호를 참조할 때 이 주소값들을 연결
- 재배치(Relocation) - 목적 프로그램을 실제 주기억 장소에 맞추어 재배치, 상대주소를 절대 주소로 변경
- 적재(Loading) - 실제 프로그램과 데이터를 주기억 장소에 적재
운영체제의 유형별 특징
일괄처리시스템(Batch Processing System)
- 유사한 작업끼리 묶어서 한번에 한 작업씩 순서대로 처리하는 시스템

다중프로그래밍 시스템(Multi-Programming System) : CPU 1개
- 하나의 CPU로 여러 개의 사용자 프로그램이 마치 동시에 실행되는 것처럼 처리하는 방식
- 한 프로세스가 입출력을 실행하는 동안 다른 프로세스에 CPU를 할당하여 실행 시킬 수 있다. ( 시스템 자원을 효율적으로 이용)
- 여러 작업을 준비 상태로 두기 위해 메모리에 보관해야 하고 일정 형태의 메모리 관리가 필요하며, 준비상태의 여러 작업 중 하나를 선택하기 위한 결정 방법(스케줄링) 필요

시분할 시스템(Time Sharing System)
- 프로세서 스케줄링과 다중 프로그래밍을 사용하여 각 사용자에게 컴퓨터를 시간적으로 분할 하여 사용 할수 있도록 / 라운드 로빈 방식

분산 처리 시스템
- 시스템마다 운영체제와 메모리를 가지고 독립적으로 운영 되며 필요할 때 통신하는 시스템
- 자원 공유, 연산속도 향상, 신뢰성, 통신 등의 목적으로 여러개의 물리적 프로세서에 연산을 분산시킬 수 있음
- 단점: 보완성 문제

다중 처리 시스템 : CPU N개
-
여러개의 프로세서(CPU)를 이용해 신뢰성, 가용성, 컴퓨터 능력 증가등의 목적을 달성
-
비대칭 주 / 종 다중처리 시스템 : 마스터 프로세서가 주가 되어 관리, 마스터 프로세서는 연산과 입출력 관리를 하며, 슬레이브 프로세서는 연산만 가능
==> 형태가 단순하지만 마스터 프로세서에 부하가 많아 신뢰도, 자원 사용에는 비효율적 -
대칭 다중 처리 시스템 : 모든 프로세서 동일
==> 신뢰성이 높고 자원을 효율적으로 사용할수 있는 방식

프로세스와 스레드
프로세스 정의

-
실행 중인 프로그램 ( 주기억장치 ,CPU에서 실행 하는 단위 / 동적인 개념 )
-
비동기적(Asynchronous) 행위
==> 어떤 작업을 요청했을 때 그 작업이 종료될 때까지 기다리지 않고 다른 작업을 하고 있다가, 요청했던 작업이 종료되면 그에 대한 추가 작업을 수행하는 방식! -
디스크에 저장되어 있던 실행 가능한 프로그램이 메모리에 적재되어 운영체제의 제어를 받는 상태이다.
-
운영체제에 존재하는 PCB(Process Control Block : 프로세스 제어 블록) 할당 받는 개체
-
프로세스 1개당 PCB 1개 존재
PCB(프로세스 제어블록) : 특정 프로세스에 대한 중요한 정보를 제공해 주는 데이터 블록
==> 프로세스를 생성 할때 만들어지며 주기억장치에 유지되며 운영체제 내에서 한 프로세스의 존재를 정의함, 프로세스의 실행이 종료되면 같이 삭제된다.- 프로세스의 고유번호(PIN ; Process Identification Number)
==> 커널이 프로세스 관리하는데 있어서 편리성을 위하여 프로세스마다 다르게 부여되는 번호 / 프로세스 생성될때 부여 됨 - 프로세스의 우선순위 ( ex) 다른 프로세스와 경쟁 했을때 우선순위 )
- 프로세스 현재 상태(생성, 준비, 실행, 대기, 완료)
- 프로세스가 할당받은 자원 정보
- 프로세스의 고유번호(PIN ; Process Identification Number)
인터럽트 : 컴퓨터 시스템에서 발생하는 예외적인 사건을 신속히 처리하기 위한 기법으로, 인터럽트가 발생하면 해당 인터럽트 처리 루틴을 먼저 수행한 후 원래의 프로그램으로 되돌아 온다.
문맥교환( Context Switching )
- 프로세서를 다른 프로세스로 전환하려면 이전의 프로세스 상태 레지스터 내용을 보관하고, 다른 프로세스의 레지스터를 적재하는 과정
- 여기서 context 에는 pc(프로그램 카운트), 레지스터, 프로세스 상태가 들어있음
- 실행하던 프로그램이 중단되고 인터럽트 처리를 수행하기 전에 발생 !
( ex) 프로세스가 준비 -> 실행 / 실행 -> 준비 / )
==> 즉, CPU가 현재 처리 중인 프로세스의 PCB를 저장하고, 다른 PCB를 가져오는 것 ! - 문맥교환은 모두 과부하 발생
- 운영체제에서 문맥교환은 자주 발생하므로 가능한 효율적으로 구현되어야 하는데 이를 위해 스레드 사용 !

스레드 ( Thread )
- 프로세스와 마찬가지로 시스템의 여러 자원을 할당 받아 실행하는 프로그램 단위( 프로세스 안에서 실행되는 흐름의 단위)
==> 어떤 프로그램을 실행시킨게 프로세스 인데, 그 프로세스는 운영체제로 부터 프로그램을 돌리기 위해 메모리를 포함해서 이것저것 할당 받는다. 그리고 스레드는 프로세스에 할당된 자원을 마구 써재낀다.
즉, 프로세스를 여러개로 나누면 스레드가 되는건데, 서로 프로세스에 할당된 자원을 함께 공유하며 처리 - 명령어를 독립적으로 실행할 수 있는 하나의 제어 흐름 (고유한 레지스터 사용 ! , 스레드간 공유 X)
- 한개의 프로세스가 처리할 양이 많을 때, 다수 개의 스레드를 통해서 동시에 처리 ==> 멀티 스레딩
- 프로세스 생성이나 문맥교환 등 오버헤드가 줄어 운영체제 성능 개선
- 멀티 스레드 : 여러 스레드가 독립적으로 작업을 병렬로 처리
ex ) 수강신청을 100명이 동시에 하러 들어옴 -> A라는 사람이 수강신청을 하고 있을때 B라는 사람도 동시에 수강신청을 진행하는 것처럼 느껴짐 ( 여러 스레드 운용 )
100개의 스레드를 사용했을때 101번째 학생의 수강신청은 100개 스레드 중 하나가 비어서 일을 처리할 수 있는 상태가 될때까지 기다리면 된다.
스케줄링 ( Scheduling )
- 실행중인 모든 프로세스들에게 골고루 CPU를 할당 하는 일
스케줄링 하는 이유
- 시스템 입장
=> cpu 이용률 증가
=> 일의 처리량 향상 - 프로세스 입장
=> 반환시간
=> 대기시간
=> 응답시간
프로세스 스케줄링 종류
비선점 ( non-preemptive )
- 현재 실행중인 프로세스가 끝나야 다음 프로세스 CPU 를 할당
- 우선순위 존재 X
- 응답시간을 쉽게 예측 못함
- 짧은 작업이 긴 작업을 기다리는 경우가 종종 발생
1) FCFS 스케줄링
- FIFO ( 준비큐에 도착한 순서에 따라 CPU를 할당 받는다)
2) SJF 스케줄링( Shortest Job First )
- 준비상태에 대기 중인 작업 중에서 CPU 사용시간이 가장 짧다고 판정된 것을 먼저 수행


3) HRN 스케줄링
- SJF의 약점이였던 긴 작업과 짧은 작업간의 불평등을 보완하여 우선순위를 정하는 기법
==> (대기시간 + 서비스 받을 시간 ) / 서비스 받을 시간 ==> 계산한 것이 크다면 우선순위 높음 판정

선점 ( preemptive )
- 현재 실행중인 프로세스보다 높은 우선순위를 가진 프로세스가 등장하면 스케줄러에 의해 실행 순서 조절
- 높은 우선순위를 가진 프로세스 들이 빠른 처리를 요구하는 시스템에서 유용
- 인터럽트와 문맥교환에 따른 오버헤드가 발생
1) SRT 스케줄링 ( Shortest Remaining Time First )
- SJF 에 선점 정책을 도입

- 단점: 기아현상 ( 시스템 부하가 많아서 낮은 등급에 있는 준비 큐에 있는 프로세스가 무한정 기다리는 현상)
**에이징 기법 : ** - 기아현상을 해결하기 위한 기법으로 오랫동안 기다린 프로세스에게 우선순위를 높여줌으로서 처리하는 기법
2) Round Robin
- time-slice 정해놓고 그 시간만큼만 CPU 사용
- time-slice 너무짧게 정하면 오버헤드 발생 <-> 너무 길게하면 FCFS 와 동일해짐

3) 다단계 큐 알고리즘
4) 다단계 피드백 큐 알고리즘
병행 프로세스와 교착상태
임계구역 ( Critical Section )
다중 프로그래밍 운영체제에서 여러 개의 프로세스가 공유하는 데이터 및 자원에 대하여 어느 한 시점에서는 하나의 프로세스만 자원 또는 데이터를 사용하도록 지정된 공유 자원을 의미
- 임계구역에는 하나의 프로세스만 접근 가능하며, 다른 프로세스의 진입을 막는다. (상호배제)
- 여러 프로세스가 사용해야 하므로 구역 내 작업은 신속하게
상호배제 ( Mutual Exclusion ) 와 동기화
- 상호배제 : 특정 프로세스가 공유 자원을 사용하고 있을 경우 다른 프로세스가 해당 공유 자원을 사용하지 못하게 제어하는 기법
- 동기화 : 시스템의 자원은 한정적인데 이 한정적인 자원에 여러 스레드가 동시에 접근해서 사용하려면 문제 발생, 이런 문제 방지하기 위해 스레드들에게 하나의 자원에 대한 처리 권한을 주거나 순서를 조정해주는 기법
세마포어 ( Semaphore )
- 프로세스의 순차적 처리를 위해 만든기법으로 프로세스들끼리 경쟁을 막아 원할한 자원 공유를 가능하게 함 !
- 상호배제 해결을 위해 세마포어라고 부르는 새로운 동기 도구가 다익스트라에 의해 제안
모니터 ( Monitor)
- 세마포어와 비슷한 역할을 하지만 제어가 쉽다.
- 모니터 안에서 정의된 프로시저는 모니터 안에서 지역적으로 정의된 변수들과 형식적인 매개변수들만 접근할수 있다.
교착상태(Deadlock)
- 프로세스들이 서로 작업을 진행하지 못하고 영원히 대기 상태로 빠지는 현상을 교착상태라고 한다. 이러한 교착상태가 발생하는 원인은 프로세스 사이에 할당된 자원의 충돌로 인하여 발생하게 된다. 예를 들어 A와 B라는 2개의 프로세스가 동작을 한다고 하자. 그리고 이들은 각각 a와 b라는 자원을 할당 받아 사용하고 있다고 가정하자. 이때 프로세스 A 에서는 작업을 계속 진행하기 위해서 b라는 자원을 요청하고 프로세스 B에서는 a라는 자원을 요청하게 되면 각각 프로세스가 요청한 자원이 이미 다른 프로세스에 할당되어 있기 때문에 할당이 풀릴 때 까지 대기 상태에 들어가게 된다. 그런데 A와B 프로세스 모두 상대방이 자원을 내놓기를 기다리면서 대기 상태로 들어가기 때문에 이들은 영원히 대기상태에 머무는 교착상태에 빠지게 되는 것이다.
==> 다중프로그래밍에서 한정된 자원을 사용할때 발생!
Deadlock 발생 조건 : 한 시스템 내에서 다음의 네가지 조건이 동시에 성립할 때 발생
- 상호 배제 : 자원은 한번에 한 프로세스만 사용 할수 있다.
- 점유 대기 : 적어도 하나의 자원을 보유하고 현재 다른 프로세스에 할당된 자원을 얻기 위해 기다리는 프로세스가 있어야한다.
- 비선점 : 자원을 강제로 빼앗을 수 없고 그 자원을 점유하고 있는 프로세스가 끝나야 그 자원이 해제 될수 있다.
- 순환대기 : 프로세스와 자원들이 원형을 이루며, 각 프로세스는 자신에게 할당된 자원을 가지면서, 상대 방 프로세스의 자원을 상호 요청하는 상황
교착상태 처리 기법
-
교착상태 예방(Prevention) : 교착상태 발생 조건 들 중 하나를 제거함으로써 해결 / 자원 낭비가 심함!
-
상호배제 부정 : 여러개의 프로세스가 공유 자원을 사용할수 있도록 ///3개 아닌가? 확인할것 => 제외해야 되는지 확인 !
-
점유와 대기조건 방지 : 프로세스가 실행되기 전 필요한 모든 자원을 할당
-
비선점 조건의 방지 : 자원을 점유하고 있는 프로세스가 다른 자원을 요구할때 점유하고 있는 자원을 반납하고, 요구한 자원을 사용하기 위해 기다리게 함
-
순환 대기 조건의 방지 : 자원에 고유한 번호를 할당하고, 번호 순서대로 자원을 요구하도록 함
-
-
교착상태 회피( Avoidance ) : 교착 상태가 발생하면 피해나가는 방법 / 은행원 알고리즘
-
프로세스가 자원을 요구할때 시스템은 자원을 할당한 후에도 안정 상태로 남아있게 되는지를 사전에 검사하여 교착 상태를 회피하는 기법
-
안전상태에 있으면 자원을 할당하고, 그렇지 않으면 다른 프로세스들이 자원을 해지할때 까지 대기함
-
-
교착 상태 탐지 ( Detection ) : 자원 할당 그래프를 통해 교착 상태 탐지
- 자원을 요청할때마다 탐지 알고리즘을 실행하면 오버헤드가 발생
-
교착 상태로부터 회복 ( Recovery ) : 교착 상태를 일으킨 프로세스를 종료하거나, 할당된 자원을 해제함으로써 회복하는 것을 의미 / 프로세스 종료하는 방법
최대공약수/ 최소공배수 (유클리드 호제법)
일반적인 최대공약수 구하기 ( Brute Force )

최대 공약수는 a , b 둘 다 나누어떨어질수 있는 수 중에서 가장 큰 값이므로 1 ~ min(a,b)
를 전부 for 문 돌며 확인 하는 방법
여기서 시간을 조금더 줄이려면 for 문을 1부터 말고 뒤에서 부터 돌리게 된다면 가장 처음 발견 한
수가 최대 공약수!
하지만 서로서인 경우는 어차피 끝까지 가야하므로 똑같은 시간 복잡도
- 서로소 : 1 이외의 공약수가 없음을 이르는 말!
- 약수 : 어떤수를 나머지 없이 나눌수 있는 자연수
유클리드 호제법
- 2개의 자연수의 최대공약수를 구하는 알고리즘
- a 를 b 로 나눈 나머지를 r 이라하면 (a > b), a와 b의 최대공약수는 b 와 r의 최대공약수와 같다는 성질 !
최대공약수 ( 24, 18 의 최대 공약수 6)
- 0이 아닌 두 정수나 다항식의 공통되는 약수 중 가장 큰 수 G
- 최대 공약수 G는 두 정수 24, 18 에 만족하는 x, y 존재 ( x, y는 6으로 나눈 값)
- 최소 공배수 643
- O(log(min(a,b)) (나머지 연산자의 특성을 이용하여 log 시간 복잡도)
**a mod b 라는 것은 [0,b-1] 이라는 범위를 가지게 되며, 평균적으로 해당 범위의 중간값을 가지게 됨 **
최소공배수
- 두 정수가 공통적으로 가지는 배수 중 가장 작은 값 ( ==> Gxy )

LCS (Longest Common Subsequence)
최장 공통 부분 수열 (LCS)
- substring 은 연속된 부분 문자열
- subsequence 은 연속적이지 않은 부분 문자열!! 구분할 것!

LCS 구하기
DP를 이용하여 특정 범위까지의 값을 구하고 다른 범위까지의 값을 구할때 이전에 구해 둔 값을 이용하여 해결
주의 : LCS는 substring을 구하는 것과 다르게 연속적이지 않아도 되기 때문에 같은 길이의 다른해가 나타날 수 있다!


LCS 출력


소스코드
for(int i=1; i<= N; i++) // base case
{
sn[i] = s.charAt(i-1);
L[i][0] = 0;
}
for(int i=1; i<= M; i++) // base case
{
tm[i] = t.charAt(i-1);
L[0][i] = 0;
}
for(int i=1; i<= N; i++)
{
for(int j=1; j<= M; j++)
{
if(sn[i] == tm[j]) // 같다면
{
L[i][j] = L[i-1][j-1] + 1;
}
else // 다르다면 둘중 큰값으로
{
L[i][j] = max(L[i-1][j], L[i][j-1]);
}
}
}
System.out.println(L[N][M]);
전체 소스코드 ( lcs 문자열 출력 함수 포함)
public class baek9252 {
static int N, M;
static char[] sn = new char[4005];
static char[] tm = new char[4005];
static String s, t, result;
static int[][] L = new int[4005][4005]; // LCS 길이
static int[][] S = new int[4005][4005]; // LCS 문자 추적하기 위한 배열
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
s = t = "";
s = br.readLine();
t = br.readLine();
result = "";
N = s.length();
M = t.length();
for(int i=1; i<= N; i++) // base case
{
sn[i] = s.charAt(i-1);
L[i][0] = 0;
}
for(int i=1; i<= M; i++) // base case
{
tm[i] = t.charAt(i-1);
L[0][i] = 0;
}
for(int i=1; i<= N; i++)
{
for(int j=1; j<= M; j++)
{
if(sn[i] == tm[j])
{
L[i][j] = L[i-1][j-1] + 1;
S[i][j] = 0;
}
else
{
L[i][j] = max(L[i-1][j], L[i][j-1]);
if(L[i][j] == L[i][j-1]) { // 왼쪽에서 왔다면 1로 체킹
S[i][j] = 1;
}
else { // 오른쪽에서 왔다면 2로 체킹
S[i][j] = 2;
}
}
}
}
solve(N, M);
System.out.println(L[N][M]);
System.out.println(result);
}
public static void solve(int dx, int dy)
{
if(!isRange(dx, dy)) return;
if(S[dx][dy] == 0)
{
solve(dx-1,dy-1);
result += sn[dx];
}
else if(S[dx][dy] == 1) solve(dx,dy-1);
else if(S[dx][dy] == 2) solve(dx-1, dy);
}
참고 링크 : http://twinw.tistory.com/126
Chained Matrix Multiplication
연쇄 행렬 최소 곱셈 알고리즘
두개 이상의 행렬을 곱할 때, 최소 곱셈 횟수를 구하는 문제
-> 행렬의 곱셈은 아래와 같이 결합법칩이 성립한다.
A*(B*C) = (A*B)*C
그러나, 행렬을 곱하는 순서에 따라 곱하는 횟수가 달라진다.
예를들어 설명하면,
행렬 A,B,C,D 4개가 존재한다.
각각 행렬의 차수는 20x1, 1x30, 30x10, 10x10이라고 한다.
4개의 행렬은 여러가지 방법으로 곱할 수 있지만,
다음 4개의 경우에 대하여 생각해볼때, 곱셈 횟수를 비교하면 아래와 같다.
((AB)C)D) = (20130) + (203010) + (201010) = 8,600
A(B*(CD)) = (301010) + (13010) + (20110) = 3,500
(AB)(CD) = (20130) + (301010) + (203010) = 9,600
(A*((BC)D) = (13010) + (11010) + (20110) = 600
위와 같이 곱셈을 하는 순서에 따라 600~9600번의 곱셈 횟수가 나오게 되는데,
그 중 최소 곱셈 횟수는 600번이다.
점화식

풀이
위 관계식을 아래의 행렬로 하나씩 예를 들어보자.
A(20x1),B(1x30),C(30x10),D(10x10) 일때,
d0=20, d1=1, d2=30, d3=10, d4=10
-
M[1][2] (행렬 A~B까지의 곱의 횟수) (1<=k<=1)
= minimum(M[1][k] + M[k+1][2] + d0dkd2
= M[1][1] + M[2][2] + d0d1d2
= 0 + 0 + 20130
= 600 -
M[2][3](행렬 B~C까지의 곱의 횟수) (2<=k<=2)
= minimum(M[2][k] + M[k+1][3] + d1dkd3)
= M[2][2] + M[3][3] + d1d2d3
= 0+0+13010
= 300 -
M[1][3](행렬 A~C까지의 곱의 횟수)(1<=k<=2)
= minimum(M[1][k] + M[k+1][3] +d0dkd2
= minimum(M[1][1] + M[2][3] + d0d1d3, M[1][2] + M[3][3] + d0d2d3)
= minimum(0 + 300+20110, 600+0+203010)
= minimum(500, 6600)
= 500
행렬 A~D까지의 곱의 횟수 (M[1][4])는
M[1][4] = minimum( M[1][1] + M[2][4] + d0d1d4, M[1][2] + M[3][4] + d0d2d4, M[1][3] + M[4][4] + d0d3d4)
M[1][4]를 구하려면
M[1][1]~M[1][4]의 값이 필요하고,(구하려는 값의 테이블 좌측값)
M[2][4]~M[4][4]의 값이 필요하고,(구하려는 값의 테이블 아랫값)
M[i][j]의 값은,
대각선을 하나씩 증가시키며 아래와 같이 구할 수 있다.
참고링크 :
MCMF (Minimum Cost Maximum Flow)
MCMF
- 최소 비용을 구하여 그 최소 비용에 해당하는 간선으로 최대 유량을 구하는 문제
- 최소 비용이라 함은 최단 거리를 구하는 문제가 되고 이때, 최단 거리는 최단 거리알고리즘을
쓰면 되지만, 이 문제에서는 비용이 음수가 될 수 있기에 벨만 포드 알고리즘을 써도 가능
하지만 벨만포드 성능을 향상시킨 SPFA 알고리즘 이용 - SPFA 를 통한 최소 비용을 구하고 그때의 최대 유량을 구하면 되니 결과값은
경로 비용의 합 * 유량
11408 열혈강호 5
큐 / 스택
원형큐 ( Circular Queue )
- 원형 큐는 선형 큐의 문제점을 보완하기 위한 자료구조 입니다. 선형큐의 문제점은 rear가 가르키는 포인터가 배열의 마지막 인덱스를 가르키고 있을 때 앞쪽에서 Dequeue로 발생한 배열의 빈 공간을 활용 할수가 없었습니다.
public class Circular_Queue {
int rear = 0; //최초 0에서부터 시작
int front = 0; //최초 0에서부터 시작
int maxsize = 0; //배열의 크기
int[] circular_Queue; //배열
public Circular_Queue(int maxsize)
{
this.maxsize = maxsize;
circular_Queue = new int[this.maxsize];
}
public boolean Isempty() //배열이 공백 상태인지 체크하는 메서드입니다.
{
if(rear == front)
{
return true;
}
return false;
}
public boolean Isfull() //배열이 포화 상태인지 체크하는 메서드입니다.
{
if((rear+1)%maxsize == front)
{
return true;
}
return false;
}
public void EnQueue(int num)
{
if(Isfull()) //배열이 포화상태일경우
{
System.out.println("큐가 가득 찼습니다");
}
else //배열이 포화상태가 아닐경우
{
rear = (rear+1) % maxsize;
circular_Queue[rear]=num;
}
}
public int DeQueue()
{
if(Isempty()) //배열이 공백상태이면 -1반환
{
return -1;
}
else //배열이 공백상태가 아니라면
{
front = (front+1)%maxsize;
return circular_Queue[front];
}
}
}
링크드리스트를 이용하여 큐 구현
원형큐를 이용하여 선형큐의 단점을 극복하였지만, 원형큐의 경우도 원소가 없을 때도 배열의 크기를
유지하고 있어야하므로 메모리 낭비가 있을수 있다는 단점이 있다.
public class LinkedQueue{
Node front;
Node rear;
public class Node {
int data;
Node next;
}
public LinkedQueue() {
front = null;
rear = null;
}
@Override
public boolean isEmpty() {
return (front==null);
}
@Override
public void enQueue(int item) {
QueueNode node = new QueueNode(item);
if(isEmpty()){ // 처음 만든 경우는 font rear 같은 노드로 설정
front = node;
rear = node;
}else{
rear.next = node;
rear = node;
}
}
@Override
public char deQueue() {
if(isEmpty()){
System.out.println("큐의 내용이 존재하지 않습니다.");
return 0;
}else{
int item = front.item;
front = front.next;
if(front==null){ // 삭제전 front 랑 rear 같은 위치에 있었던 경우 해당 노드가 삭제됬으니 rear null
rear=null;
}
return item;
}
}
최소 공통 조상(LCA) Lowest Common Ancestor
Lowest Common Ancestor
가장 가까운 위치의 공통 조상을 찾는데 쓰이거나 두 노드의 가장 가까운 거리를 찾는데 사용
LCA
- 단순하게 loop 를 이용 / 시간초과 날 가능성 / O(N)
- parent : 노드의 부모노드를 저장
- depth : 트리의 깊이를 저장
시나리오
- 두 노드가 주어지게 되면 두 노드의 깊이를 구함 ( depth 배열 이용 )
- 두 노드들 중 더 깊은 곳에 있는 노드를 더 얖은 곳에 있는 노드 위치까지 끌어 올려줌
2-1) 부모노드로 계속 한칸씩 끌어올리면서 깊이를 확인 / 두 노드가 같은 깊이 상태까지 - 두 노드 깊이가 같으나 두 노드의 값이 같지 않다면 두 노드 모두 부모노드로 끌어올리면서 같은지 확인
3-1) 두 노드가 같아질때가 최소 공통 조상
public class baek11437 {
static int N, M;
static ArrayList<ArrayList<Integer>> adj = new ArrayList<ArrayList<Integer>>();
static int[] parent = new int[50005];
static int[] depth = new int[50005];
public static void main(String[] args) throws IOException {
int dx=0, dy=0;
for(int i=1; i<= N-1; i++)
{
st = new StringTokenizer(br.readLine());
dx = Integer.parseInt(st.nextToken());
dy = Integer.parseInt(st.nextToken());
adj.get(dx).add(dy);
adj.get(dy).add(dx);
}
dfs(1,1,0); // parent, depth 배열 완성하기
st = new StringTokenizer(br.readLine());
M = Integer.parseInt(st.nextToken());
for(int i=1; i<= M; i++)
{
st = new StringTokenizer(br.readLine());
dx = Integer.parseInt(st.nextToken());
dy = Integer.parseInt(st.nextToken());
int xDepth = depth[dx];
int yDepth = depth[dy]; // 각각의 depth 가져와서 확인!
while(xDepth > yDepth) // x 가 클 경우 낮춰주면서 부모노드로 이동
{
dx = parent[dx];
xDepth--;
}
while(xDepth < yDepth)
{
dy = parent[dy];
yDepth--;
}
while( dx != dy ) // 같은 depth 일때 둘다 부모노드로 올라가면서 찾기
{
dx = parent[dx];
dy = parent[dy];
}
System.out.println(dx);
}
}
public static void dfs(int cur, int d, int p) // 현재 노드, 깊이, 부모 노드
{
depth[cur] = d;
parent[cur] = p;
for(int next : adj.get(cur))
{
if(next != p) // 해당 노드에서 depth 가 더 깊은 곳으로만 이동 / 부모노드로 이동하지 않는다
{
dfs(next, d+1, cur); // 다음 depth 로 이동 / 현재 노드가 부모 노드가 됨
}
}
}
}
LCA2
DP를 이용하여 해결
- 시간 복잡도 O(logN) / 쿼리가 함께 존재할 경우 O(MlogN)

시나리오
- 깊이가 더 깊은 노드를 깊이가 더 낮은 노드까지 노드를 올려준다
- 이때 노드의 조상들을 이용 / 2^k 번째 조상 중 가장 큰 조상부터 조사함
public class baek11438 {
static int N, M, max_level;
static final int MAX_NODE = 100005;
static int[] depth = new int[MAX_NODE]; // 노드의 깊이(레벨)
static int[][] parent = new int[MAX_NODE][20]; // parent[x][y] :: x 의 2^y번째 조상을 의미
static ArrayList<ArrayList<Integer>> adj = new ArrayList<ArrayList<Integer>>();
public static void main(String[] args) throws IOException {
max_level = 0;
int result =1;
while(result < N) // max_level 구하기
{
result *= 2;
max_level++;
}
int dx =0, dy=0;
depth[0] = -1; // 루트 노드 깊이를 0으로 만들어 주기 위해 !
makeTree(1,0); // 트리 만들기 !!
st = new StringTokenizer(br.readLine());
M = Integer.parseInt(st.nextToken());
for(int i=1; i<= M; i++)
{
st = new StringTokenizer(br.readLine());
dx = Integer.parseInt(st.nextToken());
dy = Integer.parseInt(st.nextToken());
if(depth[dx] != depth[dy]) // 두 노드의 깊이가 다를 경우 같게 맞춰 줘야함
{
if(depth[dx] > depth[dy]) // dy 의 깊이가 더 크다라고 가정하고 끌어올린후 깊이를 같게 만든다
{
int tmp = dx;
dx = dy;
dy = tmp;
}
for(int k = max_level; k >= 0; k--)
{
if(depth[dx] <= depth[parent[dy][k]])
dy = parent[dy][k];
}
}
int lca = dx;
if(dx != dy)
{
for(int k = max_level; k >= 0; k--)
{
if(parent[dx][k] != parent[dy][k])
{
dx = parent[dx][k];
dy = parent[dy][k];
}
lca = parent[dx][k];
}
}
bw.write(lca+"\n");
}
bw.flush();
}
public static void makeTree(int cur, int p)
{
depth[cur] = depth[p] + 1; // 부모 노드의 깊이에서 +1 ==> 현재 노드 깊이
parent[cur][0] = p; // 바로 위 부모 노드
/*
Node 의 2^i 번째 조상은 tmp 의 2^(i-1) 번째 조상의 2^(i-1)번째 조상과
같다는 의미
예 ) i =3 일때
Node의 8번째 조상은 tmp(Node의 4번째 조상)의 4번째 조상과 같다.
i=4 일때는 Node 16번째 조상은 Node 의 8번째 조상(tmp)의 8번째와 같다.
*/
for(int i=1; i<= max_level; i++)
{
int tmp = parent[cur][i-1];
parent[cur][i] = parent[tmp][i-1];
}
for(int next : adj.get(cur)) // 자식 노드 내려가면서 확인
{
if(next != p) // 사이클 방지 아래로만 내려가기
{
makeTree(next, cur);
}
}
}
}
LCA2 를 이용한 정점들간의 거리

- dist[parent] 배열의 의미는 1(root)에서 부모까지 내려온 거리이고 cost 값은 부모와 자식 노드의 거리 둘을 더하게 되면 1에서 자식까지의 거리를 생성 가능
==> dist[cur] = dist[parent] + cost
public class Main {
static int N, M, max_level;
static int max_node = 40005;
static int[][] par = new int[max_node][20];
static int[] depth = new int[max_node];
static int[] cost = new int[max_node];
static ArrayList<ArrayList<Node>> adj = new ArrayList<ArrayList<Node>>();
public static void main(String[] args) throws IOException {
max_level = 0;
int mul = 1;
while(N > mul) { // 확인
mul *= 2;
max_level++;
}
int dx = 0, dy = 0, c = 0;
for(int i=1; i<= N-1; i++)
{
st = new StringTokenizer(br.readLine());
dx = Integer.parseInt(st.nextToken());
dy = Integer.parseInt(st.nextToken());
c = Integer.parseInt(st.nextToken());
adj.get(dx).add(new Node(dy, c));
adj.get(dy).add(new Node(dx, c));
}
depth[0] = -1;
dfs(1, 0, 0);
st = new StringTokenizer(br.readLine());
M = Integer.parseInt(st.nextToken());
for(int i=1; i<= M; i++)
{
st = new StringTokenizer(br.readLine());
dx = Integer.parseInt(st.nextToken());
dy = Integer.parseInt(st.nextToken());
int result = 0;
int rdx = dx, rdy = dy;
if(depth[dx] != depth[dy])
{
if(depth[dx] > depth[dy])
{
int tmp = dx;
dx = dy;
dy = tmp;
}
for(int k = max_level; k >= 0; k--)
{
if(depth[dx] <= depth[par[dy][k]]) {
dy = par[dy][k];
}
}
}
int lca = dx;
if(dx != dy)
{
for(int k = max_level; k >= 0; k--)
{
if(par[dx][k] != par[dy][k])
{
dx = par[dx][k];
dy = par[dy][k];
}
lca = par[dx][k];
}
}
result = ( cost[rdx] + cost[rdy] ) - ( 2 * cost[lca] );
bw.write(result+"\n");
}
bw.flush();
}
public static void dfs(int cur, int p, int c)
{
depth[cur] = depth[p] + 1;
cost[cur] = c;
par[cur][0] = p;
int tmp = 0;
for(int i=1; i<= max_level; i++)
{
tmp = par[cur][i-1];
par[cur][i] = par[tmp][i-1];
}
for(Node next : adj.get(cur))
{
if(next.dx != p)
{
dfs(next.dx, cur, next.cost + c);
}
}
}
}
출처 링크 : https://www.crocus.co.kr/660
접근 제어 지시자 / overloading, overriding
Java

Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.