wjchumble / blog Goto Github PK
View Code? Open in Web Editor NEW分享编程和生活(Sharing programming and life)
分享编程和生活(Sharing programming and life)











































我想这两年,应该是「Webpack」受冲击最明显的时间段。前有「Snowpack」基于浏览器原生ES Module 提出,后有「Vite」站在「Vue3」肩膀上的迅猛发展,真的是后浪推前浪,前浪....
并且,「Vite」主推的实现技术不是一点点新,典型的一点使用「esbuild」来充当「TypeScript」的解释器,这一点是和目前社区内绝大多数打包工具是不同的。
在下一篇文章,我将会介绍什么是「esbuild」,以及其带来的价值。
但是,虽说后浪确实很强,不过起码近两年来看「Webpack」所处的地位是仍然不可撼动的。所以,更好地了解「Webpack」相关的原理,可以加强我们的个人竞争力。
那么,回到今天的正题,我们就来从零实现一个「Webpack」的 Bundler 打包机制。
Bundler 打包背景,即它是什么?Bundler 打包指的是我们可以将模块化的代码通过构建模块依赖图、解析代码、执行代码等一系列手段来将模块化的代码聚合成可执行的代码。
在平常的开发中,我们经常使用的就是 ES Module 的形式进行模块间的引用。那么,为了实现一个 Bundler 打包,我们准备这样一个例子:
目录
|—— src
|-- person.js
|-- introduce.js
|-- index.js ## 入口
|—— bundler.js ## bundler 打包机制代码
// person.js
export const person = 'my name is wjc'
// introduce.js
import { person } from "./person.js";
const introduce = `Hi, ${person}`;
export default introduce;
// index.js
import introduce from "./introduce.js";
console.log(introduce);除开 bundler.js 打包机制实现文件,另外我们创建了三个文件,它们分别进行了模块间的引用,最终它们会被 Bundler 打包机制解析生成可执行的代码。
接下来,我们就来一步步地实现 Bundler 打包机制。
Bundler 的打包实现第一步,我们需要知道每个模块中的代码,然后对模块中的代码进行依赖分析、代码转化,从而保证代码的正常执行。
首先,从入口文件 index.js 开始,获取其文件的内容(代码):
const fs = require("fs")
const moduleParse = (file = "") => {
const rawCode = fs.readFileSync(file, 'utf-8')
}获取到模块的代码后,我们需要知道它依赖了哪些模块?这个时候,我们需要借助两个 babel 的工具:@babel/parser 和 @babel/traverse。前者负责将代码转化为「抽象语法树 AST」,后者可以根据模块的引用构建依赖关系。
@babel/parser 将模块的代码解析成「抽象语法树 AST」:
const rawCode = fs.readFileSync(file, 'utf-8')
const ast = babelParser(rawCode, {
sourceType: "module"
})@babel/traverse 根据模块的引用标识 ImportDeclaration 来构建依赖:
const dependencies = {};
traverse(ast, {
ImportDeclaration({ node }) {
const dirname = path.dirname(file);
const absoulteFile = `./${path
.join(dirname, node.source.value)
.replace("\\", "/")}`;
dependencies[node.source.value] = absoulteFile;
},
});这里,我们通过 @babel/traverse 来将入口 index.js 依赖的模块放到 dependencies 中:
// dependencies
{ './intro.js' : './src/intro.js' }但是,此时 ast 中的代码还是初始 ES6 的代码,所以,我们需要借助 @babel/preset-env 来将其转为 ES5 的代码:
const { code } = babel.transformFromAst(ast, null, {
presets: ["@babel/preset-env"],
});index.js 转化后的代码:
"use strict";
var _introduce = _interopRequireDefault(require("./introduce.js "));
function _interopRequireDefault(obj) {
return obj && obj.__esModule ?
obj : {
"default": obj
};
}
console.log(_introduce["default"]);到此,我们就完成了对单模块的解析,完整的代码如下:
const moduleParse = (file = "") => {
const rawCode = fs.readFileSync(file, "utf-8");
const ast = babelParser.parse(rawCode, {
sourceType: "module",
});
const dependencies = {};
traverse(ast, {
ImportDeclaration({ node }) {
const dirname = path.dirname(file);
const absoulteFile = `./${path
.join(dirname, node.source.value)
.replace("\\", "/")}`;
dependencies[node.source.value] = absoulteFile;
},
});
const { code } = babel.transformFromAst(ast, null, {
presets: ["@babel/preset-env"],
});
return {
file,
dependencies,
code,
};
};接下来,我们就开始模块依赖图的构建。
众所周知,「Webpack」的打包过程会构建一个模块依赖图,它的形成无非就是从入口文件出发,通过它的引用模块,进入该模块,继续单模块的解析,不断重复这个过程。大致的逻辑图如下:
所以,在代码层面,我们需要从入口文件出发,先调用 moduleParse() 解析它,然后再遍历获取其对应的依赖 dependencies,以及调用 moduleParse():
const buildDependenceGraph = (entry) => {
const entryModule = moduleParse(entry);
const rawDependenceGraph = [entryModule];
for (const module of rawDependenceGraph) {
const { dependencies } = module;
if (Object.keys(dependencies).length) {
for (const file in dependencies) {
rawDependenceGraph.push(moduleParse(dependencies[file]));
}
}
}
// 优化依赖图
const dependenceGraph = {};
rawDependenceGraph.forEach((module) => {
dependenceGraph[module.file] = {
dependencies: module.dependencies,
code: module.code,
};
});
return dependenceGraph;
};最终,我们构建好的模块依赖图会放到 dependenceGraph。现在,对于我们这个例子,构建好的依赖图会是这样:
{
'./src/index.js':
{
dependencies: { './introduce.js': './src/introduce.js' },
code: '"use strict";\n\nvar...'
},
'./src/introduce.js':{
dependencies: {
'./person.js': './src/person.js'
},
code: '"use strict";\n\nObject.defineProperty(exports,...'
},
'./src/person.js':
{
dependencies: {},
code: '"use strict";\n\nObject.defineProperty(exports,...'
}
}构建完模块依赖图后,我们需要根据依赖图将模块的代码转化成可以执行的代码。
由于 @babel/preset-env 处理后的代码用到了两个不存在的变量 require 和 exports。所以,我们需要定义好这两个变量。
require 主要做这两件事:
eval(dependenceGraph[module].code)function _require(relativePath) {
return require(dependenceGraph[module].dependencies[relativePath]);
}而 export 则用于存储定义的变量,所以我们定义一个对象来存储。完整的生成代码函数 generateCode 定义:
const generateCode = (entry) => {
const dependenceGraph = JSON.stringify(buildDependenceGraph(entry));
return `
(function(dependenceGraph){
function require(module) {
function localRequire(relativePath) {
return require(dependenceGraph[module].dependencies[relativePath]);
};
var exports = {};
(function(require, exports, code) {
eval(code);
})(localRequire, exports, dependenceGraph[module].code);
return exports;
}
require('${entry}');
})(${dependenceGraph});
`;
};完整的 Bunlder 打包实现代码:
const fs = require("fs");
const path = require("path");
const babelParser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const babel = require("@babel/core");
const moduleParse = (file = "") => {
const rawCode = fs.readFileSync(file, "utf-8");
const ast = babelParser.parse(rawCode, {
sourceType: "module",
});
const dependencies = {};
traverse(ast, {
ImportDeclaration({ node }) {
const dirname = path.dirname(file);
const absoulteFile = `./${path
.join(dirname, node.source.value)
.replace("\\", "/")}`;
dependencies[node.source.value] = absoulteFile;
},
});
const { code } = babel.transformFromAst(ast, null, {
presets: ["@babel/preset-env"],
});
return {
file,
dependencies,
code,
};
};
const buildDependenceGraph = (entry) => {
const entryModule = moduleParse(entry);
const rawDependenceGraph = [entryModule];
for (const module of rawDependenceGraph) {
const { dependencies } = module;
if (Object.keys(dependencies).length) {
for (const file in dependencies) {
rawDependenceGraph.push(moduleParse(dependencies[file]));
}
}
}
// 优化依赖图
const dependenceGraph = {};
rawDependenceGraph.forEach((module) => {
dependenceGraph[module.file] = {
dependencies: module.dependencies,
code: module.code,
};
});
return dependenceGraph;
};
const generateCode = (entry) => {
const dependenceGraph = JSON.stringify(buildDependenceGraph(entry));
return `
(function(dependenceGraph){
function require(module) {
function localRequire(relativePath) {
return require(dependenceGraph[module].dependencies[relativePath]);
};
var exports = {};
(function(require, exports, code) {
eval(code);
})(localRequire, exports, dependenceGraph[module].code);
return exports;
}
require('${entry}');
})(${dependenceGraph});
`;
};
const code = generateCode("./src/index.js");
最终,我们拿到的 code 就是 Bundler 打包后生成的可执行代码。接下来,我们可以将它直接复制到浏览器的 devtool 中执行,查看结果。
虽然,这个 Bundler 打包机制的实现,只是简易版的,它只是大致地实现了整个「Webpack」的 Bundler 打包流程,并不是适用于所有用例。但是,在我看来很多东西的学习都应该是从易到难,这样的吸收效率才是最高的。
相信很多关注 Monorepo 生态的同学,应该大都看过这篇文章 monorepo.tools,其中列举了现存的几个主流的 Monorepo 相关的工具:
相应地,在这篇文章中也对各类工具进行了一一介绍。并且,我相信每个看过这篇文章的同学,都会留下这么个疑问:这么多 Monorepo Tool,我要如何进行选型?
这里,我给出的答案是 PNPM + Turborepo + Changesets。那么,又为什么是这 3 者呢?下面,我将会分别围绕这 3 个技术展开,来一一解答这个选型的原因以及怎么做。
PNPM 的动机(Motivation),如它在官方文档介绍的所说:“Saving disk space and boosting installation speed”,节省磁盘空间和提高安装速度。除开这个动机描述的显著优点外,PNPM 内置了对 Monorepo 的支持,并解决了很多令人诟病的问题。
其中,比较经典的就是 Phantom dependencies(幻影依赖)。由于,默认情况下 yarn、npm 安装的依赖都是会被提升。所以,有时候你可能会遇到 Monorepo 项目中的某个包中的 package.json 没有安装这个依赖,结果实际代码中却使用了这个依赖...
虽说,PNPM 可以解决这个问题,但是,默认情况下 PNPM 安装的依赖也是会被提升的。如果,需要 PNPM 禁止依赖提升,我们可以通过在 Monorepo 项目工作区下的 .npmrc 文件中 配置,例如只提升 lodash:
hoist-pattern[]=*lodash*
当然,还有一些其他的问题,有兴趣的同学可以看 ELab 团队写的这篇文章《Monorepo 的这些坑,我们帮你踩过了!》。
那么,在简单解答了为什么用 PNPM 后,下面我们来看一下要怎么用?
要使用 PNPM 的 Monorepo 很简单,只需要在 Monorepo 项目的工作区下新建 pnpm-workspace.yaml 文件并配置:
packages:
- 'packages/**'接下来,则是记忆常用依赖和多包任务执行相关的命令。由于,我们的技术选型中有 Turborepo,它会负责多包任务的执行。所以,这里只需要记忆常用依赖相关的命令。
在 PNPM 中,安装依赖可以用 pnpm i 来完成。在 Monorepo 的场景下,默认情况下 pnpm i 会安装所有的依赖(包括 packages/*)。此外,pnpm i 还需要用到 3 个选项(Option):
--filter <package>,安装依赖到指定的 package,不声明要安装的依赖包则默认安装 package.json 中的所有依赖--prod, P,安装依赖到 dependencies--dev, D,安装依赖到 devDependencies在 PNPM 中,删除在 package.json 中的某个依赖,可以用 pnpm remove 完成。它的选项(Option)使用和 pnpm i 大同小异。其中,不同地是当我们在工作区想要删除 packages 中所有包的 package.json 中的某个依赖的时候,需要使用 -r,例如移除所有包中的 lodash:
pnpm remove lodash -r当然,可能还有同学有一些其他的诉求,有兴趣的同学可以移步文档了解,这里不做展开。
经常维护开源项目的同学都知道的一点,每次包(Package)的发布,需要修改 package.json 的 version 字段,以及同步更新一下本次发布修改的 CHANGELOG.md。
这么一来,就会凸显一个问题,每次发布都需要手动地去更新 version、更新 CHANGELOG.md,未免有点繁琐。并且,用过 Lerna 的同学,应该都知道 Lerna 内置了对这块的支持。
但是,无论是 PNPM 又或者是下面要说的 Turborepo 都不支持这块,所以 2 者的官方文档都给大家推荐了用于支持这块能力的工具,例如 Changesets、Beachball、Auto 等。
那么,这里我们要介绍的就是 Changesets。下面,我们来看一下在前面建好的 PNPM 的 Monorepo 项目中如何使用 Changesets。首先,需要执行在 Monorepo 项目的工作区下,执行如下 2 个命令:
pnpm i -DW @changesets/cli
pnpm changeset init前者是安装 Changesets 的 CLI,后者是初始化 .changeset 文件夹以及对应的文件:
.changeset
|-- config.json
|__ README.md
这里,我们来看一下 config.json 文件:
{
"$schema": "https://unpkg.com/@changesets/[email protected]/schema.json",
"changelog": "@changesets/cli/changelog",
"commit": false,
"linked": [],
"access": "restricted",
"baseBranch": "master",
"updateInternalDependencies": "patch",
"ignore": []
}除开 $schema 这个不需要修改的字段, config.json 文件中列了 7 个字段,各个字段分别代表的作用为:
changelog 设置 CHANGELOG.md 生成方式,可以设置 false 不生成,也可以设置为定义生成行为的文件地址或依赖名称,例如 Changsets 提供的 changelog-git。其中,定义生成行为的文件固定代码模版为:async function getReleaseLine() {}
async function getDependencyReleaseLine() {}
export default {
getReleaseLine,
getDependencyReleaseLine
}commit 设置是否把执行 changeset add 或 changeset publish 操作时对修改用 Git 提交
linked 设置共享版本的包,而不是独立版本的包,例如一个组件库中主题和单独的组件的关系,也就是修改 Version 的时候,共享的包需要同步一起更新版本
access 设置执行 npm publish 的 --access 选项,通常情况下我们是公共的包,所以设置 public 即可(注意,它会被 package.json 中的 access 字段重写)
baseBranch 设置默认的 Git 分支,例如现在 GitHub 的默认分支应该是 main
updateInternalDependencies 设置互相依赖的包版本更新机制,它是一个枚举(major|minor|patch),例如设置为 minor 时,只有当依赖的包新了 minor 版本或者才会对应地更新 package.json 的 dependencies 或 devDependencies 中对应依赖的版本
ignore 设置不需要发布的包,这些会被 Changesets 忽略
在初始化 .changeset 文件夹后,就可以正常使用 changeset 相关的命令,主要是这 3 个命令:
pnpm chageset 用于生成本次修改的要添加到 CHANGELOG.md 中的描述pnpm changeset version 用于生成本次修改后的包的版本pnpm changeset publish 用于发布包此外,如果是在业务场景下,我们通常需要把包发到公司私有的 NPM Registry,而这有很多种配置方式。但是,需要注意的是 Changesets 只支持在每个包中声明 publicConfig.registry 或者配置 process.env.npm_config_registry,对应的代码会是这样:
// https://github.com/changesets/changesets/blob/main/packages/cli/src/commands/publish/npm-utils.ts
function getCorrectRegistry(packageJson?: PackageJSON): string {
const registry =
packageJson?.publishConfig?.registry ?? process.env.npm_config_registry;
return !registry || registry === "https://registry.yarnpkg.com"
? "https://registry.npmjs.org"
: registry;
}可以看到,如果在前面说的这 2 种情况下获取不到 registry 的话,Changesets 都是按公共的 Registry 去查找或者发布包的。
说起 Turborepo,可能大家会有点陌生。但是,对于 Vercel 我想大家都知道(毕竟 Rich Harris、Sebastian Markbåge 等都加入了),Turbrepo 则是 Vercel 旗下的一个开源项目。Turborepo 是用于为 JavaScript/TypeScript 的 Monorepo 提供一个极快的构建系统,简单地理解就是用 Turborepo 来执行 Monorepo 项目的中构建(或者其他)任务会非常快!
关于 Turborepo 其他优势,其官方文档写的很详尽,有兴趣的同学可以自行了解~
所以,你可以理解成快是选择 Turborepo 负责 Monorepo 项目多包任务执行的原因。而在 Turborepo 中执行多包任务是通过 turbo run <script>。不过,turbo run 和 lerna run 直接使用有所不同,它需要配置 turbo.json 文件,注册每个需要执行的 script 命令。
在 Turborepo 中有个 Pipelines 的概念,它是由 turbo.json 文件中的 pipline 字段的配置描述,它会在执行 turbo run 命令的时候,根据对应的配置进行有序的执行和缓存输出的文件。
举个例子,通常情况下我们一个 Monorepo 项目中的每个包可能会有 dev、build、test、clean 等 4 个命令,那么对应的 turbo.json 的配置会是这样:
{
"pipeline": {
"build": {
"dependsOn": ["^build"],
"outputs": ["dist/**"]
},
"clean": {
"dependsOn": ["^clean"]
},
"test": {
"dependsOn": ["build", "lint"]
},
"dev": {
"cache": false
}
}
}可以看到,pipeline 中的每个 key 则对应着每个需要执行的 turbo run 命令的名称,其中 dependsOn、outputs、cache 等 3 个字段分别作用为:
dependsOn 表示当前命令所依赖的命令,^ 表示 dependencies 和 devDependencies 的所有依赖都执行完 build,才执行 buildoutputs 表示命令执行输出的文件缓存目录,例如我们常见的 dist、coverage 等cache 表示是否缓存,通常我们执行 dev 命令的时候会结合 watch 模式,所以这种情况下关闭掉缓存比较切合实际需求这样一来,我们就可以使用诸如 turbo run build test 的命令,它则会按 pipeline 的配置依次执行对应的命令。
当然,如果你想每个命令都支持单独执行,可以直接配置为 {} 即可。此外,如果要使用 turbo run 命令,还需要在 package.json 中声明 packageManage 字段为指定的包管理工具及版本,例如 "packageManager": "[email protected]"。
阅读到此处,我想大家应该理解了 PNPM + Turborepo + Changesets 这个技术选型的原因以及要怎么做。当然,这个选型只是我个人的思考所得出的答案,相信也有同学仍然钟情于 Lerna,又或者喜欢 Rush 一把梭,这些观点并无对错,本质上这也是编程的魅力所在,各个轮子都有其存在的价值。
最后,如果文中存在表达不当或错误的地方,欢迎各位同学评论交流~
HTTP 报文可以分为请求报文和响应报文。
请求报文:
响应报文:
URI Uniform Resource Identifier(统一资源标识符),用字符串标识某一互联网资源
URL Uniform Resource Locator(统一资源定位符),用于表示资源的地点(即在互联网上所处的位置)
URL 是 URI 的子集
HTTP GET 方法请求指定的资源。使用 GET 的请求应该只用于获取数据。
HTTP POST 方法 发送数据给服务器. 请求主体的类型由 Content-Type 实体首部字段指定.
HTTP DELETE 请求方法用于删除指定的资源。
HTTP 的 OPTIONS 方法 用于获取目的资源所支持的通信选项。客户端可以对特定的 URL 使用 OPTIONS 方法,也可以对整站(通过将 URL 设置为“*”)使用该方法。
HTTP PUT 请求方法使用请求中的负载创建或者替换目标资源。
PUT 与 POST 方法的区别在于,PUT方法是幂等的:调用一次与连续调用多次是等价的(即没有副作用),而连续调用多次POST方法可能会有副作用,比如将一个订单重复提交多次。
在 HTTP 协议中,CONNECT 方法可以开启一个客户端与所请求资源之间的双向沟通的通道。它可以用来创建隧道(tunnel)。
例如,CONNECT 可以用来访问采用了 SSL (HTTPS) 协议的站点。客户端要求代理服务器将 TCP 连接作为通往目的主机隧道。之后该服务器会代替客户端与目的主机建立连接。连接建立好之后,代理服务器会面向客户端发送或接收 TCP 消息流。
HTTP HEAD 方法 请求资源的头部信息, 并且这些头部与 HTTP GET 方法请求时返回的一致. 该请求方法的一个使用场景是在下载一个大文件前先获取其大小再决定是否要下载, 以此可以节约带宽资源.
HEAD 方法的响应不应包含响应正文. 即使包含了正文也必须忽略掉. 虽然描述正文信息的 entity headers, 例如 Content-Length 可能会包含在响应中, 但它们并不是用来描述 HEAD 响应本身的, 而是用来描述同样情况下的 GET 请求应该返回的响应.
在HTTP协议中,请求方法 PATCH 用于对资源进行部分修改。
在HTTP协议中, PUT 方法已经被用来表示对资源进行整体覆盖, 而 POST 方法则没有对标准的补丁格式的提供支持。不同于 PUT 方法,而与 POST 方法类似,PATCH 方法是非幂等的,这就意味着连续多个的相同请求会产生不同的效果。
另外一个支持 PATCH 方法的隐含迹象是 Accept-Patch 首部的出现,这个首部明确了服务器端可以接受的补丁文件的格式。
HTTP TRACE 方法 实现沿通向目标资源的路径的消息环回(loop-back)测试 ,提供了一种实用的 debug 机制。
在 HTTP 协议中,状态码的作用是当客户端向服务端发送请求时,描述返回的请求结果。通过状态码,用户可以知道服务器是正常处理了请求,还是发生错误。
而状态码是由两个部分组成:3 位数数字、原因短语,例如 200 OK。
在状态码中,三位数字的第一个数字代表了响应的类别,具体的响应类别有以下 5 种:
| 类别 | 原因短语 | |
|---|---|---|
| 1xx | 任务信息状态码 | 接收的请求正在处理 |
| 2xx | 成功状态码 | 请求正常处理完毕 |
| 3xx | 重定向状态码 | 需要进行附加操作以完成请求 |
| 4xx | 客户端错误状态码 | 服务端无法处理请求 |
| 5xx | 服务器错误状态码 | 服务器处理请求出错 |

HTTP 状态码为 100 Continue 时,则表示目前为止请求正常, 客户端应该继续请求, 如果已完成请求则忽略。
HTTP 状态码为 101 Switching Protocol 时,则表示服务端根据客户端升级协议的请求(Upgrade 请求头),正在切换协议。
HTTP 状态码为 200 OK 时,则表示客户端发送的请求在服务器被正常处理了。相应地在响应报文中,会根据请求方法的不同返回不同的实体内容。例如 GET 方法请求时,对应的请求资源的实体会作为响应返回。
HTTP 状态码为 204 No Content 时,则表示服务器接收的请求已处理,并且在响应报文的实例中没有主体部分,即可以理解为没有返回的内容或信息。
HTTP 状态码为 206 Partial Content 时,则表示客户端对服务器发起了范围请求,并且服务器已接收并处理完成该请求,在响应报文中包含由 Content-Range 指定范围的实体内容。
HTTP 状态码为 301 Permanetly 时,表示请求的资源已被分配至新的 URI,以后应使用这个新的 URI 进行相应的请求。
HTTP 状态码为 302 Found 时,同样也是表示请求的资源已被分配至新的 URI,所不同于 301 的是,它只是暂时的,即只需要这一次请求新的 URI,即可(需要注意的是 302 禁止 POST 变换成 GET)。
HTTP 状态码为 303 See Other 时,则表示请求的资源存在另一个 URI,应使用 GET 请求方法获得请求相应资源。
HTTP 状态码为 304 Not Modified 时,则表示服务器允许访问资源,但是由于客户端请求时未满足条件,而直接返回 304 NotModified,即在响应报文的主体中不包含任何内容。
HTTP 状态码为 307 Temporary Redirect 时,与 302 相同的行为,只是它不会禁止从 POST 转为 GET。
HTTP 状态码为 4xx 时,表明客户端是请求资源发生错误的原因所在。
HTTP 状态码为 400 Bad Request 时,表示请求报文中存在语法错误,即客户端需要修改请求,再次发送请求。
HTTP 状态码为 403 Forbidden 时,表示客户端发送的请求被服务器拒绝了。
HTTP 状态码为 404 Not Found 时,表示服务器上找不到客户端所要请求的资源。
HTTP 状态码为 500 Internal Server Error 时,表示在请求过程中服务器发生了错误,例如可能是服务器存在 Bug 或其他临时的原因。
HTTP 状态码为 503 Unavailable 时,表示服务器暂时处于超负载或停机维护,此时无法处理请求。
| 首部字段名 | 说明 |
|---|---|
| Accept | 用户代理可处理的媒体类型( text/html,application/xhtml+xml 等) |
| Accept-Charset | 优先的字符集 |
| Accept-Encoding | 优先的内容编码 |
| Accept-Language | 优先的语言 |
| Authorization | Web 认知信息 |
| Expect | 期待服务器特定的行为 |
| From | 用户的邮箱地址 |
| Host | 请求资源所在的地址 |
| If-Match | 比较实体标记(ETag,常用于 Web 应用的缓存) |
| If-Modified-Since | 比较实体的更新时间 |
| If-None-Match | 比较实标记(和 If-Match 相反,即没有 Match 到) |
| If-Range | 资源未更新时发送实体 Byte 范围的请求 |
| If-Unmodified-Since | 比较资源的更新时间 |
| Max-Forwards | 最大传输逐跳数 |
| Proxy-Authorization | 代理服务器要求的客户端信息 |
| Range | 实体的字节范围请求 |
| Referer | 请求 URI 的原始获取方 |
| TE | 传输编码的优先级 |
| User-Agent | HTTP 客户端程序的信息(简称 UA) |
| 首部字段名 | 说明 |
|---|---|
| Accept-Ranges | 是否接收字节范围的请求 |
| Age | 推算资源创建经过时间 |
| ETag | 资源的匹配信息 |
| Location | 令客户端重定向至指定 URI |
| Proxy-Authenticate | 代理服务器对客户端的认证信息 |
| Retry-After | 对再次发起请求的时机要求 |
| Server | HTTP 服务器的安装信息 |
| Vary | 代理服务器缓存的管理信息 |
| WWW-Authenticate | 代理服务器对客户端的认知信息 |
| 首部字段名 | 说明 |
|---|---|
| Allow | 资源可支持的 HTTP 方法 |
| Content-Encoding | 实体主体支持的编码方式 |
| Content-Language | 实体主体的自然语言 |
| Content-Length | 实体主体的大小(Byte) |
| Content-Location | 替代资源对应的 URI |
| Content-MD5 | 实体主体的报文摘要 |
| Content-Range | 实体主体的位置范围 |
| Content-Type | 实体主体的媒体类型 |
| Expires | 实体主体过期的日期时间 |
| Last-Modified | 资源的最后修改日期时间 |
| 首部字段名 | 说明 |
|---|---|
| Cache-Control | 控制缓存的行为 |
| Date | 创建报文的日期时间 |
| Connection | 逐跳首部、连接的管理 |
| Progma | 报文指令 |
| Trailer | 报文末端的首部一览 |
| Transfer-Encoding | 指定报文主体的传输编码方式 |
| Upgrade | 升级为其他协议 |
| Via | 代理服务器通知 |
| Warning | 错误通知 |
描述:即服务端一方设定的可缓存内容,这个过程不需要沟通,只要这个缓存有效,那么你就可以去读取它。
缺点:其实这样简单的理解定义,就可以看出它的弊端,当服务端缓存的资源变了,可是浏览器缓存的资源还有效,那么这个资源的更新就没有及时同步,这无疑是不友好的。
强缓存有两种:Expires和 Cache-Control。
看到这个单词,应该都很容易的联想到 Cookie的 Expires,它在 Cookie 中作用就是设置 Cookie 的有效期。同样地,在这里它是 HTTP/1 中用来描述缓存资源有效时间的 HTTP 实体首部字段,它的值为 GMT 时间,由服务端定义好通过响应报文返回给前端。

缺点:由服务端定义好时间,这就会发生服务端和客户端时间不一致的问题。
Cache-Control 它是 HTTP/1.1 中提出用于缓存的 HTTP 通用首部字段。它则代表资源在一段时间内可以读取缓存,而不用重新请求。而与 Expires 不同,它的值为 max-age = **s,并且它还可以搭配一些指令(8 个)实现一些特定的效果:
private,表示 HTTP 请求从浏览器发送到最终的服务器这个过程,只有浏览器缓存,中间任何传递节点不能缓存(代理服务器之类的)public,表示都可以缓存,无论浏览器、服务器或者代理服务器。no-store,表示不需要缓存。no-cache,表示不使用强缓存,使用协商缓存。max-age,表示缓存有效的最大时间,单位为 s。s-maxage,表示代理服务器的缓存有效的最大时间。max-stale,表示浏览器可接受的失效缓存的最大失效时间。max-refresh,表示浏览器可接受的最短更新时间,不过这个时间是当前的 age 加上 max-refresh。当
Expires和Cache-Control同时存在时,Cache-Control的优先级较高
描述:即这个缓存的过程需要通过双方的确认,才能决定缓存资源是否可用,可用则返回状态码 304 Not Modified,不可用则返回状态码 200 OK和更新后的资源。
缺点:因为缓存的最终确定需要浏览器和服务器双方的确定,所以性能较低、耗时较长。
Last-Modified 是 HTTP/1.0 中用于协商缓存的 HTTP 响应首部字段,它表示该资源的最后修改时间,它会和 If-Modified-Since 一起使用。
这个过程大致是这样的,服务端在响应报文中添加 Last-Modified 首部字段即相应的值(同样是 GMT 时间),然后浏览器在接受响应后,会将资源进行缓存和记录 Last-Modified,在下次请求相同资源的时候添加 If-Modified-Since HTTP 请求首部字段 携带之前记录的 Last-Modified 的值一起发送到服务端,服务端识别到 If-Modified-Since 字段,并与该资源上次修改的时间进行比较,如果相同则返回状态 304 Not-Modified,如果不同则发送状态码 200 OK 以及在报文实体中携带上更新过的资源。
缺点:
Last-Modified 也会随着变化,那么此时就会造成服务端返回状态码 200 OK 情况和返回没有更新的资源(实际上资源并没有变化),即这个请求完全没有意义。Last-Modified 无法观察低于秒时的文件的修改,那么这就会造成文件已经更新了,但是服务端却认为它没有更新状态 304 Not-Modified,让浏览器去读缓存,即资源更新不精确。ETag 是 HTTP/1.1 中用于协商缓存的 HTTP 响应首部字段,它是由服务端为该资源生成的 Hash,它会和 If-No-Match 一起使用。
它的过程会是这样,服务端在响应报文中添加 ETag 首部字段及对应资源的 Hash,同样地,然后浏览器在接受响应后,会将资源进行缓存和记录 ETag,在下次请求相同资源时通过 If-No-Match HTTP 请求首部字段 携带之前记录的 ETag 的值一起发送到服务端,服务端识别到 ETag 字段,并与该资源此时的 Hash值进行比较,如果相同返回状态码 304 Not-Modified,如果不同则发送状态码 200 OK 以及在报文实体中携带上更新过的资源。
缺点:
ETag 需要服务端计算资源生成 Hash,这个过程无疑是比较慢的,所以性能较低。当
ETag和If-Modified同时存在时,ETag的优先级较高
HTTPS = HTTP + 加密 + 完整性保护 + 身份认证
首先,在开始讲解整个过程前,我们需要认识一下 Chrome 多进程架构。因为,从浏览器输入 URL 到页面渲染的整个过程都是由 Chrome 架构中的各个进程之间的配合完成。
Chrome 的多进程架构:
HTML 文档和 JavaScript 等转化为用户界面HTTP请求、WebSocket 模块GPU(图形处理器)进程,它负责对 UI 界面的展示发生这个过程的前提,用户在地址栏中输入了 URL,而地址栏会根据用户输入,做出如下判断:
URL 结构的字符串,则会用浏览器默认的搜索引擎搜索该字符串URL 结构字符串,则会构建完整的 URL 结构,浏览器进程会将完整的 URL 通过进程间通信,即 IPC,发送给网络进程在网络进程接收到 URL 后,并不是马上对指定 URL 进行请求。首先,我们需要进行 DNS 解析域名得到对应的 IP,然后通过 ARP 解析 IP 得到对应的 MAC(Media Access Control Address)地址。
域名是我们取代记忆复杂的
IP的一种解决方案,而IP地址才是目标在网络中所被分配的节点。MAC地址是对应目标网卡所在的固定地址。
1. DNS 解析
而 DNS 解析域名的过程分为以下几个步骤:
DNS 缓存DNS 缓存(即查找本地 host 文件)ISP(Internet Service Provider)互联网服务提供商(例如电信、移动)的 DNS 服务器2. 通信过程
首先,建立 TCP 连接,即三次握手过程:
SYN 的数据包,表示我将要发送请求。SYN/ACK 的数据包,表示我已经收到通知,告知客户端发送请求。ACK 的数据包,表示我要开始发送请求,准备被接受。然后,利用 TCP 通道进行数据传输:
TCP 的重发机制TCP 头中的需要进行排序,形成完整的数据最后,断开 TCP 连接,即四次握手过程:
而这整个过程的客户端则是网络进程。并且,在数据传输的过程还可能会发生的重定向的情况,即当网络进程接收到状态码为 3xx 的响应报文,则会根据响应报文首部字段中的 Location 字段的值进行重新向,即会重新发起请求
3. 数据处理
当网络进程接收到的响应报文状态码,进行相应的操作。例如状态码为 200 OK 时,会解析响应报文中的 Content-Type 首部字段,例如我们这个过程 Content-Type 会出现 application/javascript、text/css、text/html,即对应 Javascript 文件、CSS 文件、HTML 文件。
详细的
MIME类型讲解可以看 MDN
当前需要渲染 HTML 时,则需要创建渲染进程,用于后期渲染 HTML。而对于渲染进程,如果是同一站点是可以共享一个渲染进程,例如 a.abc.com 和 c.abc.com 可以共享一个渲染渲染进程。否则,需要重新创建渲染进程
需要注意的是,同站指的是顶级域名和二级域名相等
在创建完渲染进程后,网络进程会将接收到的 HTML、JavaScript 等数据传递给渲染进程。而在渲染进程接收完数据后,此时用户界面上会发生这几件事:
URLenable,显示正在加载状态大家都知道页面渲染的过程也是面试中单独会考的点,并且时常会由这个点延申出另一个问题,即如何避免回流和重绘。
渲染过程,是整个从理器输入 URL 到页面渲染过程的最后一步。而页面渲染的过程可以分为 9 个步骤:
HTML 生成 DOM 树CSS 生成 CSSOMJavaScript Render Tree)由于网络进程传输给渲染进程的是 HTML 字符串,所以,渲染进程需要将 HTML 字符串转化成 DOM 树。例如:
需要注意的是这个
DOM树不同于Chrome-devtool中Element选项卡的DOM树,它是存在内存中的,用于提供JavaScript对DOM的操作。
构建 CSSOM 的过程,即通过解析 CSS 文件、style 标签、行内 style 等,生成 CSSOM。而这个过程会做这几件事:
CSS,即将 color: blue 转化成 color: rgb() 形式,可以理解成类似 ES6 转 ES5 的过程CSS 样式会继承父级的样式,如 font-size、color 之类的。
CSS Object Model是一组允许用JavaScript操纵CSS的API。详细API讲解可以看 MDN
通常情况下,在构建 DOM 树或 CSSOM 的同时,如果也要加载 JavaScript,则会造成前者的构建的暂停。当然,我们可以通过 defer 或 sync 来实现异步加载 JavaScript。虽然 defer 和 sync 都可以实现异步加载 JavaScript,但是前者是在加载后,等待 CSSOM 和 DOM 树构建完后才执行 JavaScript,而后者是在异步加载完马上执行,即使用 sync 的方式仍然会造成阻塞。
而 JavaScript 执行的过程,即编译和运行 JavaScript 的过程。由于 JavaScript 是解释型的语言。所以这个过程会是这样的:
Token 化Token,生成 AST(Abstract Sytanx Tree) 抽象语法树和创建上下文AST,生成字节码。在有了 DOM 树和 CSSOM 之后,需要将两者结合生成渲染树 Render Tree,并且这个过程会去除掉那些 display: node 的节点。此时,渲染树就具备元素和元素的样式信息。
根据 Render Tree 渲染树,对树中每个节点进行计算,确定每个节点在页面中的宽度、高度和位置。
需要注意的是,第一次确定节点的大小和位置的过程称为布局,而第二次才被称为回流
由于层叠上下文的存在,渲染引擎会为具备层叠上下文的元素创建对应的图层,而诸多图层的叠加就形成了我们看到的一些页面效果。例如,一些 3D 的效果、动画就是基于图层而形成的。
值得一提的是,对于内容溢出存在滚轮的情况也会进行分层
对于存在图层的页面部分,需要进行有序的绘制,而对于这个过程,渲染引擎会将一个个图层的绘制拆分成绘制指令,并按照图层绘制顺序形成一个绘制列表。
有了绘制列表后,渲染引擎中的合成线程会根据当前视口的大小将图层进行分块处理,然后合成线程会对视口附近的图块生成位图,即光栅化。而渲染进程也维护了一个栅格化的线程池,专门用于将图块转为位图。
栅格化的过程通常会使用
GPU加速,例如使用wil-change、opacity,就会通过GPU加速显示
当所有的图块都经过栅格化处理后,渲染引擎中的合成线程会生成绘制图块的指令,提交给浏览器进程。然后浏览器进程将页面绘制到内存中。最后将内存绘制结果显示在用户界面上。
而这个整个从生成绘制列表、光栅化、显示的过程,就是我们常说的重绘的过程
不可否认,如今 TypeScript 已成为一个前端工程师的所需要具备的基本技能。严谨的类型检测,一方面是提高了程序的可维护性和健壮性,另一方面也在潜移默化地提高我们的编程思维,即逻辑性。
那么,今天我将会通过结合实际开发场景和 Vue 3.0 源码中的部分类型定义来简单聊聊 TypeScript 中的高级类型。
interface 被用于对所有具有结构的数据进行类型检测。例如,
在实际开发当中,我们会定义一些对象或数组来描述一些视图结构。
定义对象
常见的有对表格的列的定义:
const columns = [
{key: "username", title: "用户名"},
{key: "age", title: "年龄"},
{key: "gender", title: "性别"}
]而这个时候,我们就可以通过定义一个名为 column 的接口:
interface column {
key: string,
title: string
}
// 使用
const columns: column[] = [
{key: "username", title: "用户名"},
{key: "age", title: "年龄"},
{key: "gender", title: "性别"}
]定义函数
我们平常开发中使用的 axios,它的调用方式会有很多种,例如 axios.request()、axios.get()、axios.put()。它本质上是定义了这么一个接口来约束 axios 具备这些方法,它看起来会是这样:
export interface Axios {
request(config: AxiosRequestConfig): AxiosPromise
get(url: string, config?: AxiosRequestConfig): AxiosPromise
delete(url: string, config?: AxiosRequestConfig): AxiosPromise
head(url: string, config?: AxiosRequestConfig): AxiosPromise
options(url: string, config?: AxiosRequestConfig): AxiosPromise
post(url: string, data?: any, config?: AxiosRequestConfig): AxiosPromise
put(url: string, data?: any, config?: AxiosRequestConfig): AxiosPromise
patch(url: string, data?: any, config?: AxiosRequestConfig): AxiosPromise
}可复用性是我们平常在写程序时需要经常思考的地方,例如组件的封装、工具函数的提取、函数设计模式的使用等等。而对于接口也同样如此,它可以通过继承来复用一些已经定义好的 interface 或 class。
这里我们以 Vue 3.0 为例,它在 compiler 阶段,将 AST Element 节点 Node 分为了多种 Node,例如 ForNode、IFNode、IfBranchNode 等等。而这些特殊的 Node 都是继承了 Node:
Node 的 inteface 接口定义:
export interface Node {
type: NodeTypes
loc: SourceLocation
}IFNode 的 interface 接口定义:
export interface IfNode extends Node {
type: NodeTypes.IF
branches: IfBranchNode[]
codegenNode?: IfConditionalExpression
}可以看到 Node 的接口定义是非常纯净的,它描述了 Node 所需要具备最基本的属性:type 节点类型、loc 节点在 template 中的起始位置信息。而 IFNode 则是在 Node 的基础上扩展了 branches 和 codegenNode 属性,以及重写了 Node 的 type 属性为 NodeTypes.IF。
这里简单介绍一下 IFNode 的两个属性:
branches 表示它对应的 else 或 else if 的节点,它可能是一个或多个,所以它是一个数组。codegenNode 则是 Vue 3.0 的 AST Element 的一大特点,它描述了该节点的一些属性,例如 isBlock、patchFlag、dynamicProps 等等,这些会和 runtime 的时候靶向更新和靶向更新密切相关。近段时间,我也在写一篇关于 Vue 3.0 如何实现
runtime+compile优雅地实现靶向更新和静态提升的文章,应该会在下周末竣工。
对于 interface 的介绍和使用,我们这里点到即止。当然,它还有很多高级的使用例如结合泛型、定义函数类型等等。有兴趣的同学可以自行去了解这方面的实战。
交叉类型故名思意,有着交叉之效。我们可以通过交叉类型来实现多个类型的合并。例如,在 Vue3 中,compile 阶段除了会进行 baseParse 之外,还会进行 transform,这样最后的 AST 才会进行 generate 生成可执行的代码。所以,compile 阶段它就会对应多个 options,即它也是一个交叉类型:
export type CompilerOptions = ParserOptions & TransformOptions & CodegenOptions而这个 CompilerOptions 类型别名会用于 baseCompiler 阶段:
export function baseCompile(
template: string | RootNode,
options: CompilerOptions = {}
): CodegenResult {}而为什么是多个
options的交叉,是因为baseCompiler只是最基础的compiler,上面还有更高级的compiler-dom、compiler-ssr等等。
同样地,联合类型其有着合的效果。即有时候,你希望一个变量的类型是 String
或者是 number 的时候,你就可以使用联合类型来约束这个变量。例如:
let numberOrString: number | string
numberOrString = 1
numberOrString = '1'并且,在实际的开发中使用联合类型,我们通常会遇到这样的提示,例如:
interface student {
name: string
age: number
}
interface teacher {
name: string
age: number
class: string
}
let person: student | tearcher = {} as any
person.class = "信息161"
// property 'person' does not exit on type `student`这个时候,我们可以利用类型断言,告诉 TypeScript 我们知道 person 是什么:
(person as teacher).class = "信息161"对于交叉类型和联合类型,应该是属于我们平常开发中会使用频繁的部分。并且,从它们的概念上,不难理解,它们本质上就是数学中的并集和交集,只不过在基本类型上有着不同的表现而已。
在讲联合类型的时候,我们说了它本质上是交集,这也导致了我们不能直接使用交集之外的属性或方法。所以,我们得通过在不同情况下使用类型断言来告知 TypeScript 它是什么,从而使用交集之外的属性。
但是,频繁地使用类型断言无疑降低了代码的可读性。而针对这一问题,TypeScript 提供了类型保护的机制来减少类型断言,它是一个主谓宾句,例如仍然是上面的例子,我们可以实现这样的类型保护:
function isTeacher(person: Tearcher | Student): person is Teacher {
return (<Tearcher>person).class !== undefined
}然后通过 isTeacher 这个函数来判断当前类型,再进行相应地属性访问:
if (isTeacher(person)) {
// 这里访问 teacher 独有的属性
person.class = "信息162"
} else {
person.name = "wjc"
}有了类型保护,这个时候我们就会遇到这样的问题:如果我的联合类型中存在多个类型,那么岂不是得定义多个类似 isTeacher 这样的借助类型保护的函数?幸运的是,在 TypeScript 使用 typeof 或 instanceof 可以自动实现类型保护和区分。
在 TypeScript 中对基础类型使用 typeof 时,会自动进行类型保护,例如:
function isNumberOrString(param: string | number) {
if (typeof param === 'string') {
return param.split('')
} else {
return param++
}
}不同于 typeof 只能对基础类型进行类型保护,instanceof 可以实现对所有类型的类型保护。它是通过构造函数来实现类型保护。
interface Person {
name: string
age: string
}
class Teacher implements Person {
name: string
age: string
constructor(name: string, age: string) {
this.name = name
this.age = age
}
teach() {
console.log("i am a teacher.")
}
}
class Student implements Person {
name: string
age: string
constructor(name: string, age: string) {
this.name = name
this.age = age
}
study() {
console.log("i am a student.")
}
}
const person: Student | Teacher = null as any
if (person instanceof Teacher) {
person.teach()
} else {
person.study()
}对于 typeof 或 instanceof 其实在 JavaScript 中也是老生常谈的知识点,因为传统的类型检测我们会更偏向使用 Object.String.prototype.toString() 来实现。但是,反而在 TypeScript 中,它们两者反而混的如鱼得水。
类型别名,我想大家脑海中第一时间想到的就是 Webpack 中的 alias 为路径配置别名。但是,TypeScript 中的类型别名与它只是形同,但是意不同。通俗点讲,就是通过它可以给类型起一个名称:
type age = number
const getAge = () => age
// 等同于
interface Age {
getAge():number
}字面量类型是指我们可以通过使用类型别名和联合类型来实现枚举类型,例如:
type method = get | GET | post | POST | PUT | put | DELETE | delete对于索引类型和映射类型,这里我们通过 loadash 中常用的一个函数 pluck 来讲解:
在 JavaScript 中实现:
function pluck(object, names) {
return names.map(name => object[name])
}在 TypeScript 中实现:
function puck<T, K extends keyof T>(object: T, names: K[]): T[K][] {
return names.map(name => object[name])
}这里我们为 puck 函数定义了两个泛型变量 T 和 K,其中 K 是继承于 T 中所有属性名的类型,所以形参中 names 被约束为 T 中属性的数组,这个过程被称为类型索引。而对于 puck 函数的返回值 T[K][] ,则代表返回的值是一个数组,并且数组值被约束为 T 中属性值为 K 的值,这个过程被称为索引访问。
理解这两种概念可能会有点晦涩,但是对于每一者都分开去理解过程会比较有逻辑性。
虽然,TypeScript 已成为一项前端工程师的必备技能。但是,相信很多小伙伴还是用的 Javascript 比较多。所以,可能会存在困扰,我该如何提高 TypeScript 编程能力?其实,这个问题很简单,开源的时代,今天我们很多问题都可以通过阅读一些开源的项目源码来解决。这里,我推荐大家可以尝试着去阅读 Vue3.0 的源码,相信通过阅读,你的 TypeScript 编程能力会有质的飞跃。
写作不易,如果你觉得有收获的话,可以帅气三连击!!!
对于变量提升这个问题,我想从事前端的同学都或多或少认为我懂这个。曾经,我也是这样认为的,我懂变量提升,并且可以从变量在 Chrome 中的内存分配讲起,以及中间发生了什么。
但是,在一次面试中,我遇到了几个一起面前端的同学(当然技术水平参差不齐,并不是很高),在和他们聊这次笔试中的变量提升的问题时,发现大家都支支吾吾的,很多讲的都是值的覆盖。
当时的面试题是这样的:
function fn(a) {
console.log(a)
var a = 2
function a() {}
console.log(a)
}
fn(1)这个题目,最终会输出function a(){} 和 2。那么,为什么是这个答案,这个过程发生了什么很重要。所以,今天我们就来彻底刨析一下变量提升的过程。
在分析整个过程前,我们先来回顾一下 JavaScript 中变量在内存中的分配。
大家都知道的是,对于原始类型会存储在栈空间中,对于引用类型会将引用存储在栈空间中,将数据存储在堆空间中。
其实这个过程还牵扯到函数上下文的创建,而每一个函数上下文中又会创建一个变量环境、词法环境。有兴趣的同学可以去看李斌老师的浏览器工作原理与实践
所以,我们来看一个简单的栗子,分析一下它在内存中的分配:
栗子:
var a = 1
var b = 2
var student = {name: 'wjc', age: 22}它内存中的分配:
众所周知,JavaScript 是一门动态类型的语言,即它是在运行时确定变量的类型,不同于静态类型语言的先编译再运行的过程。但是,事实是 V8 引擎在解析运行 JavaScript 之前是会进行一次简单的编译,也就是我们通常所说的初始化过程。
这个初始化过程,会做这几件事:
undefined;二是对函数的初始化,即直接指向函数在堆空间中的内存那么,我们就来看一个简单的栗子:
console.log(a)
sayHi()
var a = 2
function sayHi() {
console.log('Hi')
}那么按照我们上面所说,这段代码的赋值只有 var a = 2,函数声明只有进行编译阶段的代码会是这样的:
// 编译代码
var a = undefined
var sayHi = function () {
console.log('Hi')
}此时,它在内存中的分布:
然后,在执行阶段的代码会是这样:
// 执行代码
console.log(a)
sayHi()
a = 2所以,也就是当我们真正执行的时候会走执行代码,所以很显然会输出:
undefined
Hi而当走完所有执行代码后,此时内存是这样的:
我想通过这个栗子,大家应该大致搞懂变量提升的过程。但是,仍然存在一个较为特殊的情况,就是当函数形参存在时的变量提升,也就是我们文章开头提及的面试题。
首先,我们需要对函数调用做一个简单的理解,在我们平常调用函数的时候,真正会经历两个步骤:
可以看到这里我们提到了当函数存在形参时,会先进行函数形参的编译和执行过程。
这里我们就来分析文章开头这个栗子:
function fn(a) {
console.log(a)
var a = 2
function a() {}
console.log(a)
}
fn(1)首先,此时是存在函数形参的,那么函数形参的编译和执行会是这样:
var a = undefined
a = 1然后,才会进行函数体的编译和执行:
// 编译
a = function a() {} // 重点!!!
// 执行
console.log(a)
a = 2
console.log(a)可以看到的是,如果函数体内的变量名和形参的变量名重复时,则不会进行普通变量的编译赋值 undefined 的过程。但是,如果存在该变量是函数时,那么则会进行函数变量的编译赋值,即直接指向函数在堆空间中的地址。
所以,我们这个栗子在编译后,可以看作是这样的:
function fn() {
var a = undefined
a = 1
a = function a() {}
console.log(a)
a = 2
console.log(2)
}很显然,它会输出会输出function a(){} 和 2
不知大家在深度理解过变量提升过程后,是否有和我一样的感受就是学习编程的本质是追溯本源。现今,虽然我们可以用 ES6 的 let 或 const 来声明变量来避免 var 的种种缺陷。但是,如果因为这样而不去思考 var 为什么会存在这些缺陷。我想这是非常遗憾的。
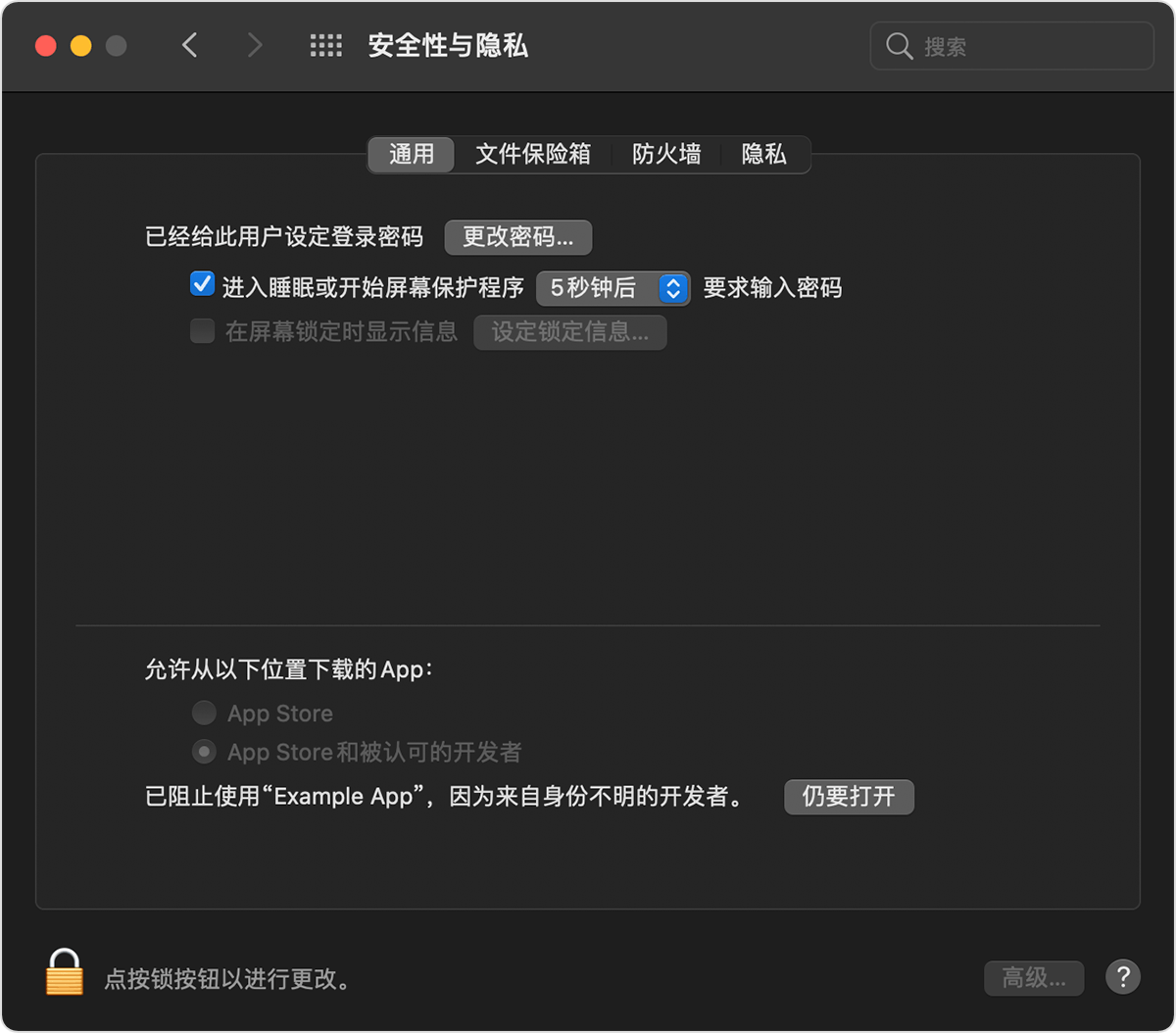
对于 macOS App 开发者来说,我们通常情况下可能会选择在网络上分发 App。但是,站在使用者的角度,如果下载的 App 没有经过 Apple Notary Service 公证(Notarizate)过,这在安装的时候系统则会提示“无法打开 xxx App,因为无法验证开发者”:
那么,这个时候的解决方法就是修改系统偏好——>安全性与隐私的设置,选择仍要打开该 App:
虽然,这样可以让使用者安装 App,但是,这并不是真正在解决这个问题的本质。从根上解决应该是让我们要分发到网络上的 App 通过 Apple Notary Service 公证(Notarizate),这样一来他人下载安装我们应用的时候则不会出现无法打开的提示,而是:
所以,今天本文也将围绕「macOS App 公证」展开如何通过手动或者自动化(Shell、工具)实现公证(Notarizate)过程。
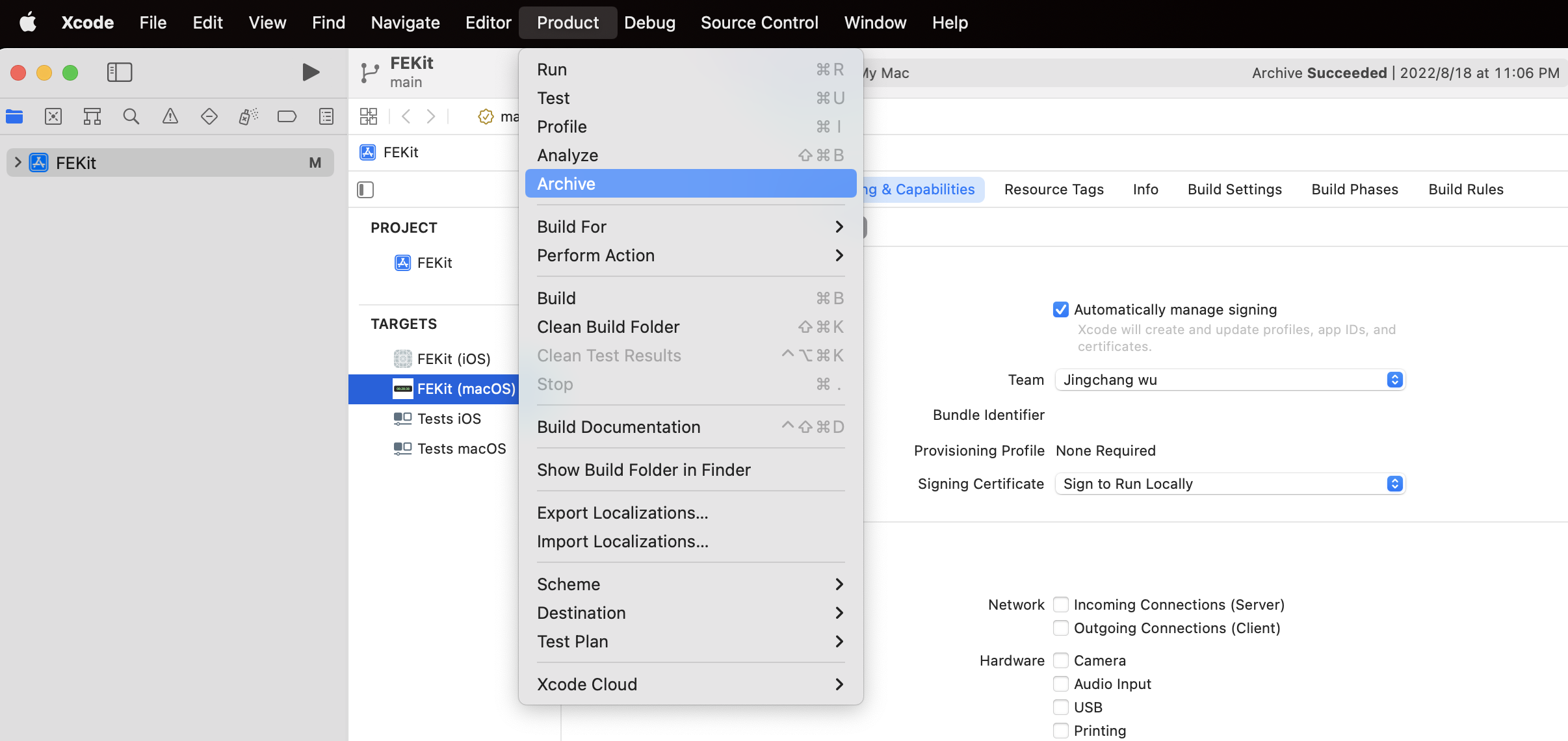
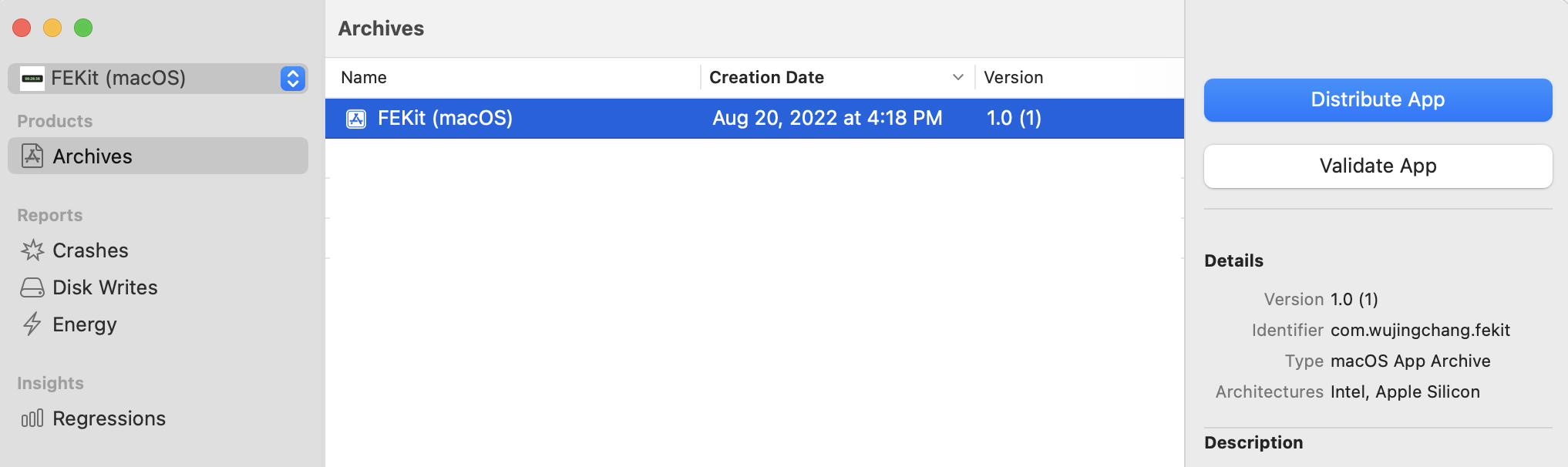
首先,我们先了解下如何手动公证?手动公证过程可以通过 Xcode 提供的 GUI 界面操作完成。同样地,首先我们需要构建 .xarchive 文件:
构建完后,Xcode 会弹出窗口让你选择 Distribute App 或 Validate App,这里我们选择前者:
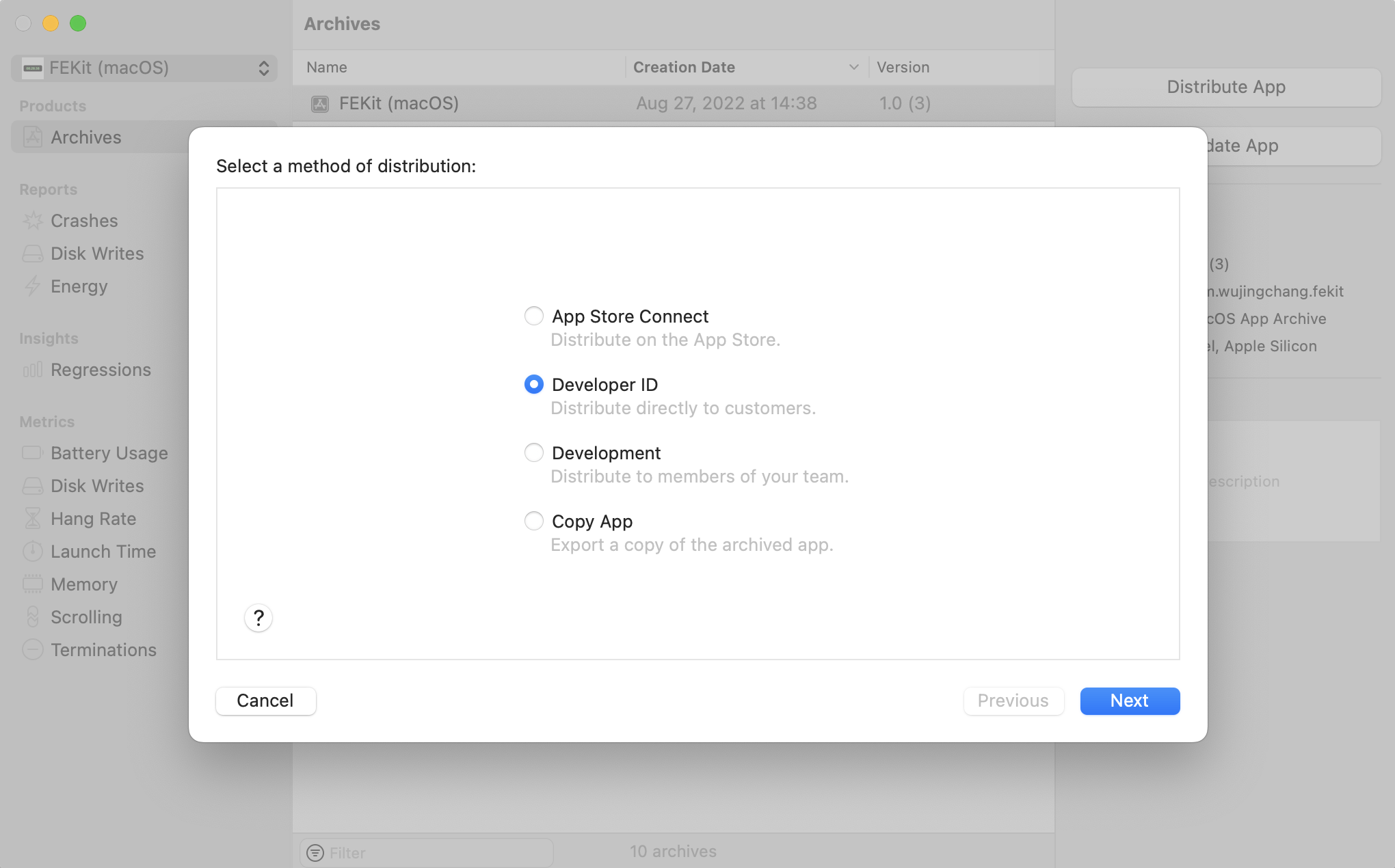
接着,不同于之前分发 App Store,我们需要选择 Developer ID,它表示的是在 App Store 之外分发 App:
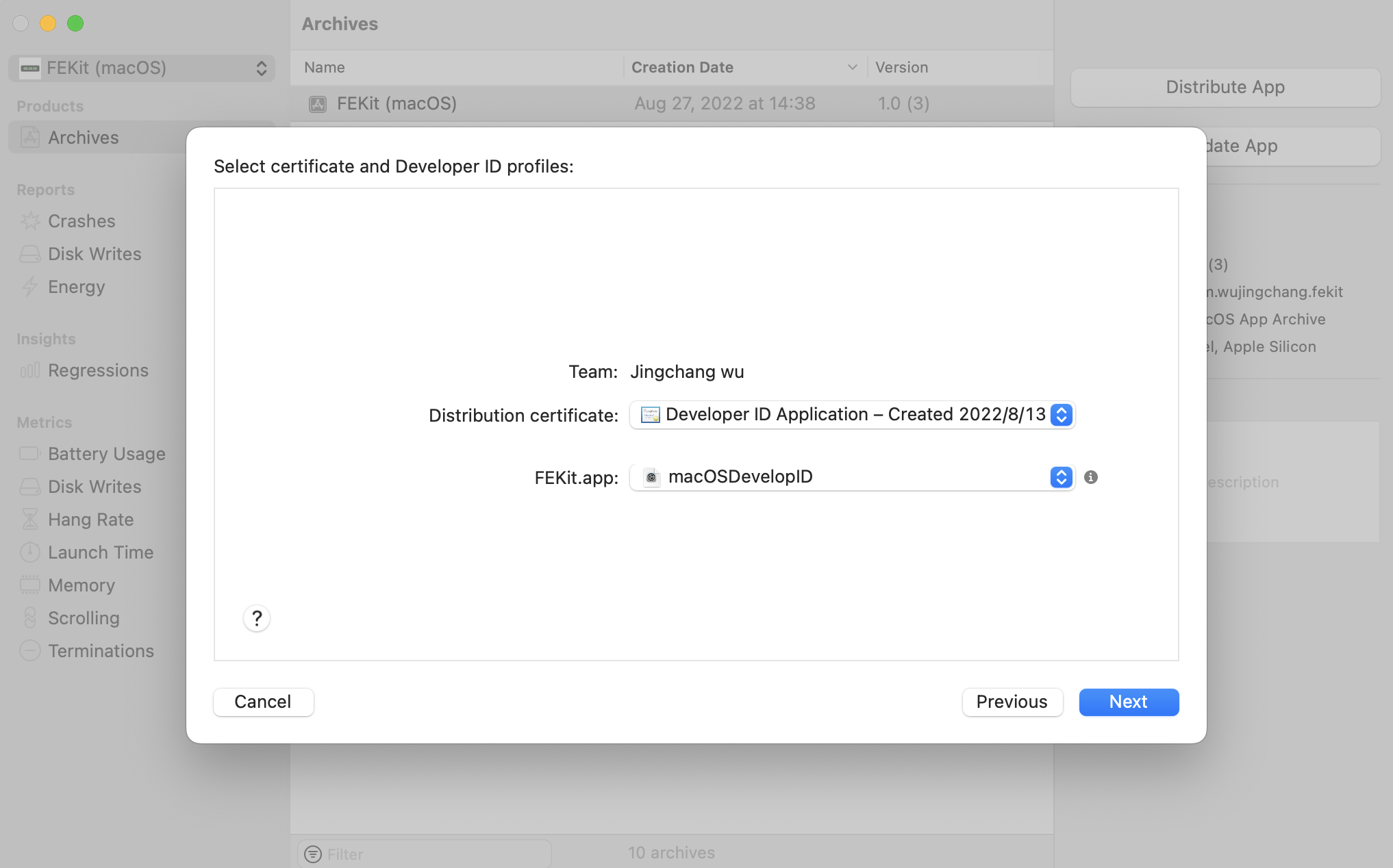
然后,我们需要选择 Upload ——> Development Team -> Manually manage signing,此时需要选择 Develop ID 对应的 Distribution 证书和 Provisioning Profile:
最后,则选择 Next ——> Upload,然后则会将我们的 App 上传到 Apple Notary Service 进行公证,通过则会提示我们可以分发 App。
如果,了解过 App Store 分发相关的同学应该熟悉这个手动操作的过程,因为使用 Xcode 公证 App 的过程和 App Store 分发大同小异。所以,在通过简单了解使用 Xcode 手动实现公证过程后,接下来,我们来认识下如何自动化实现公证的过程?
自动化公证则指的是我们通过代码实现前面介绍到的使用 GUI 手动公证的过程。那么,这里我列出了 4 种现在社区中实现的可以对 macOS App 自动化公证的方式:
altool --notarize-app 快了 10 倍notarytool 和 altool --notarize-app 等 2 种公证方式当然,更进一步的话我们可以把这个自动化公证也加入到 CI/CD 过程中,有兴趣的同学可以自行了解相关实现。所以,接着下面将会对这 4 个的使用做对应的展开介绍,首先是 altool --notarize-app。
altool 是一个内置于 Xcode 中的命令行工具,用于验证 App 的二进制文件并将其上传至 App Store 或者对 App 进行公证(Notarize)。而 altool --notarize-app 也是最早大家使用的实现自动化公证应用的方式,这在社区中也可以看到大量基于它的实践。
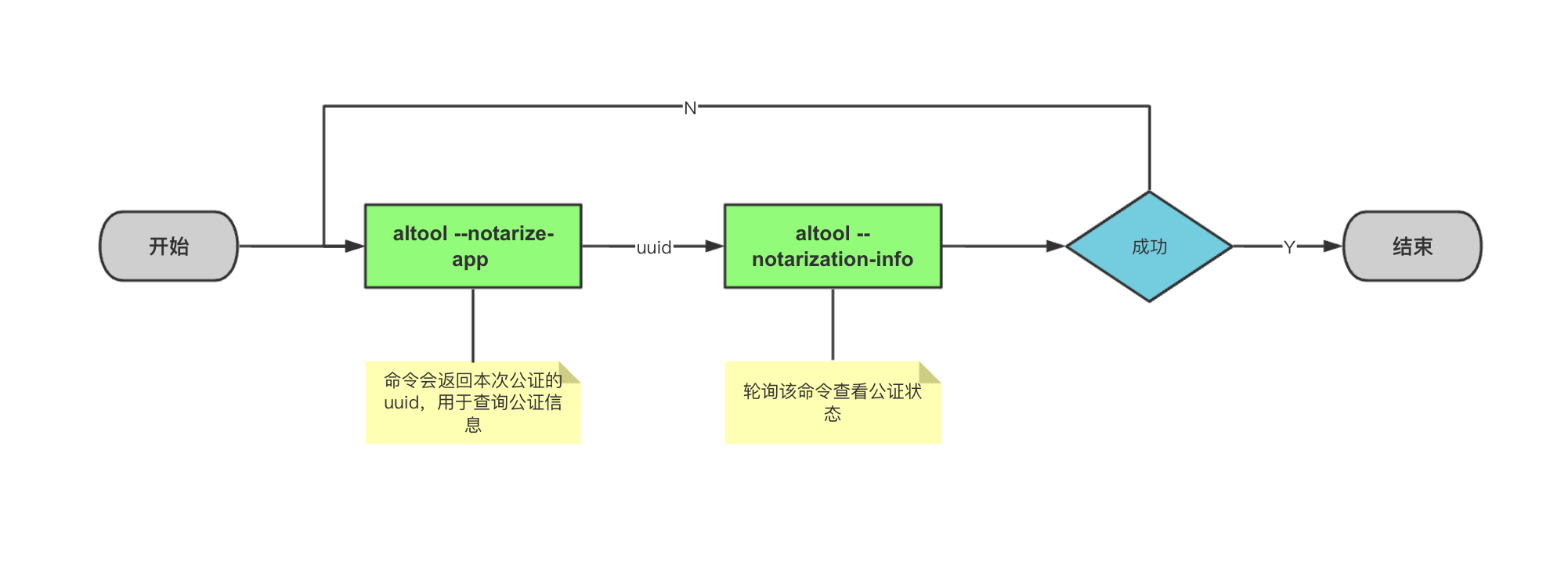
altool --notarize-app 则主要是将应用上传到 Apple Notary Service,但是并不会告知你公证成功与否,所以通常需要结合 altool --notarization-info 命令一起使用(核对公证成功与否),整个公证的过程会是这样:
可以看到,首先我们需要使用 altool --notarize-app 将应用上传公证,然后获取本次公证的 UUID:
xcrun altool --notarize-app \
# .app 的压缩包或 .dmg
--file ./Output/Apps/FEKit.zip \
--primary-bundle-id "com.xxxx.xxxx" \
# Apple ID
--username "xxxxx" \
# 应用专用密码,这可以在 https://appleid.apple.com/account/manage 申请
--password "xxxxx" \然后,终端中则会输出本次公证上传操作的信息和 RequestUUID,前者用于表示本次操作执行是否成功,后者可以用于 altool --notarization-info 命令查询本次公证过程的信息:
No errors uploading 'Output/Apps/FEKit.zip'.
RequestUUID = xxxxxxx-xxx-xxxx-xxxx-xxxxx进行完公证上传操作后,Apple Notary Service 则会对本次公证执行相关的操作,而这需要一定的时间,所以我们需要(定时)轮询执行 altool --notarization-info 命令实时地获取公证成功失败与否的信息:
# 加载 Apple ID($user)和 App 专用密码($pwd)
source "./Build/app_store_user_pwd.sh"
# 标识公证执行过程成功失败与否,失败 1,0 成功
success=1
i=0
while true; do
let i+=1
echo "Checking notarize progress...$i"
# 获取 altool --notarization-info 执行的输出信息
process=$(xrun altool --notarization-info $uuid --username $user --password $pwd 2>&1)
echo "${progress}"
# 如果上次命令执行结果 $? 不等于 0(表示失败),或者命令输出信息中包含 Invalid
if [ $? -ne 0 ] || [[ "${progress}" =~ "Invalid"]] then
echo "Error with notarization. Exiting"
break
if
# 如果命令输出信息中包含 success 表示成功
if [[ "${progress}" =~ "success"]]; then
success=0
break
else
echo "Not completed yet. Sleeping for 30 seconds.\n"
fi
sleep 30
done
if [ $success -eq 0 ]; then
echo "Notarize successed."
if其中,$uuid 则是执行 altool --notarize-app 命令后获取的返回结果:
echo xcrun altool --notarize-app \
--file xxxx \
--primary-bundle-id "com.xxxx.xxxx" \
--username $user \
--password $pwd \
2>&1 | grep RequestUUID | awk '{print $3}'这里我们来看下大家比较陌生的 2>&1、grep RequestUUID、awk '{print $3}' 等 3 个命令的作用:
2>&1 是为了将标准错误 stderr 输出重定向到标准输出 stdoutgrep RequestUUID 匹配标准输出中所有包含 RequestUUID 的行awk '{print $3}' 打印出第 3 列的结果,在 RequestUUID = xxxxxxx-xxx-xxxx-xxxx-xxxxx 就是 RequestUUID 的值 xxxxxxx-xxx-xxxx-xxxx-xxxxx| 管道,用于将上个命令的输出通过管道输入到下一个命令相比较 altool --notarization-info 而言,notarytool 使用起来心智负担少一些,并且快于前者很多,我们只需要记忆一些 Option,使用一行命令 xcrun notarytool 则可以实现上传公证和过程信息获取的过程:
xcrun notarytool submit ./Output/Apps/FEKit.zip \
# Apple ID
--apple-id $user \
--team-id $teamId \
# 应用专用密码
--password $pwd \
-v \
-f "json"其中,--team-id 指的是用户 ID(由数字和字母组成),这可以在本地 KeyChain 的证书中查看(或者 Apple 证书后台),-v 是 --verbose 的缩写,指的是输出公证过程的信息,-f "json" 则是表示最终结果以 JSON 的格式输出,例如:
{
"path":"\/Users\/wujingchang\/Documents\/project\/demo\/FEKit\/Output\/Apps\/FEKit.zip",
"message":"Successfully uploaded file",
"id":"xxxxxxxxxxxxxxxxxxxx"
}需要注意的是这里使用的是 Appple ID 和应用专用密码的方式做与公证服务的请求认证 Authentication,此外你还可以通过以下 3 种 Option 来进行认证:
--keychain-profile <keychain-profile>,使用 xcrun notarytool store-credentials 预先在本地钥匙串中新建一个应用程序密码,例如叫 AC_PASSWORD,那么在使用 notarytool submit 命令的时候则可以直接使用 --keychain-profile AC_PASSWORD 代替之前的 --apple-id $user --team-id $teamId --password $pwd--keychain <keychain>,不同于前者 --keychain-profile 这里是输入的 AC_PASSWORD 文件所在的位置--key <key-id> --key-id <key-id> --issuer <issuer>,这使用的是 App Store Connect API keys 的方式进行认证,本质上是生成一个和 App Store Connect 约定好的 JWT,然后每次请求的时候携带上它,从而通过认证electron-notarize 则是一个用 JavaScript 实现的公证工具,它的原理则是使用的 child_process 执行前面我们提及的 altool --notarization-info 和 notarytool 这 2 个命令。
electron-notarize 具名导出了 notarize 函数,我们只需要使用它以及指定的 Option 则可以完成公证的过程,这里我们来看下其函数的实现(伪代码):
// src/index.ts
export async function notarize({ appPath, ...otherOptions }: NotarizeOptions) {
if (otherOptions.tool === 'notarytool') {
// ...
await notarizeAndWaitForNotaryTool({
appPath,
...otherOptions,
});
} else {
// ....
const { uuid } = await startLegacyNotarize({
appPath,
...otherOptions,
});
// ...
await delay(10000);
// 获取公证过程信息
await waitForLegacyNotarize({ uuid, ...otherOptions });
}
await stapleApp({ appPath });
}可以看到,notarize 函数会根据 Option 中传入的 tool 为 notarytool 或 legacy 来执行不同的命令来完成公证,这里前者是 notarytool 后者则是 altool --notarization-info。所以,如果我们要用 notarytool 的方式进行公证会是这样:
import { notarize } from "electron-notarize"
await notarize({
appPath: "./Output/Apps/FEKit.zip",
// Apple ID
appleId: "xxxxxx",
// 应用专用密码
appleIdPassword: "xxxxxxxx",
teamId: "xxxxxxxxxxx",
tool: "notarytool"
})其中,如果你不希望密码直接明文暴露在代码中的话,electron-notarize 也支持了前面我们说的 --keychain、--keychain-profile 等 3 个 Option,你可以根据自己的需要选择对应的认证方式。
fastlane 是一个可以便捷地帮你完成证书管理、代码签名和发布等相关的工具,适用于 iOS、macOS 和 Android 应用。那么,我们也就可以使用 fastlane 来完成 macOS App 的公证。
首先,肯定是安装 fastlane,关于这方面的介绍官方文档讲解的很是详尽,这里就不重复论述。而当你安装好 fastlane,则可以在应用项目的根目录执行 fastlane init 来初始化它相关的配置,在初始化的过程会让你选择使用 fastlane 的方式,这里我们选择手动配置即可。
然后,它会在项目根目录下创建一个 fastlane/Fastfile 目录和文件,后续我们在执行 fastlane xxx 命令的时候则会根据该文件的代码实现执行具体的操作,默认生成的 Fastfile 文件的配置会是这样:
default_platform(:ios)
platform :ios do
desc "Description of what the lane does"
lane :custome_lane do
# add actions here: https://docs.fastlane.tools/actions
end
end其中,default_platform 用于定义一个默认的平台 Platform,例如当我们有 2 个平台(iOS 和 macOS)的时候,它的的配置需要这样:
default_platform(:ios)
platform :ios do
desc "Description of what the lane does"
lane :custome_lane do
# add actions here: https://docs.fastlane.tools/actions
end
end
platform :mac do
desc "Description of what the lane does"
lane :custome_lane do
# add actions here: https://docs.fastlane.tools/actions
end
end此时,如果我们执行 fastlane custome_lane,由于这里平台默认为 ios,所以则会执行 platorm:ios 下的 custome_lane,反之执行 fastlane mac custome_lane,则是 platform :mac 下的 custome_lane。那么,对于前面我们这个例子而言只需要 platform:mac:
default_platform(:ios)
platform :mac do
desc "Description of what the lane does"
lane :custome_lane do
# add actions here: https://docs.fastlane.tools/actions
end
end接着,则可以在 platform:mac 写我们需要实现的自动化分发 App Store 相关的代码。fastlane 便捷之处在于它实现了很多开箱即用的 Action,这里我们需要使用 notarize 这个 Action,它可以用于完成 macOS App 的公证:
default_platform(:mac)
platform :mac do
desc "Notarizes a macOS app"
lane :notarize_app do
notarize(
package: "./Output/Apps/FEKit.zip",
use_notarytool: "xcrun notarytool",
bundle_id: "com.xxxx.xxxx",
username: "xxxxxxxxxxxxxx",
verbose: true,
)
end
end其中,在使用 notarize 的时候需要注意的是,这里只是声明了你 App Store 的用户名 username,而专用密码需要预先在系统环境变量中添加 FASTLANE_APPLE_APPLICATION_SPECIFIC_PASSWORD(其他认证方式,有兴趣的同学可以自行了解),然后 fastlane 在执行 notarize_app Action 时会去读取该环境变量,从而进行并完成后续的公证过程。
看到这里,我想可能会有同学会问:“这几种实现公证的工具,选择哪个比较好?”,这里比较建议的是选择 fastlane,因为,除开前面提及它的使用方式非常便捷的优点,它具备的能力也很多,不仅仅可以做 App 公证,还可以做 App Store 分发、证书和版本管理等,所以,选择 fastlane 将来也可以支持我们别的诉求,何乐不为呢?
最后,如果文中存在表达不当或错误的地方,欢迎各位同学提 Issue ~
在 Vue2 中,有一个老生常谈的话题,如何避免 data 中一个复杂对象(自身或属性对象)被默认被创建为响应式(Non-reactive Object)的过程? 举个例子,有一个 Vue2 的组件的 data:
<script>
export default {
data() {
return {
list: [
{
title: 'item1'
msg: 'I am item1',
extData: {
type: 1
}
},
...
]
}
}
}
</script>这里我们希望 list.extData 不被创建为响应式的对象,相信很多同学都知道,我们可以通过 Object.defineProperty 设置对象 list.extData 的 configurable 属性为 false 来实现。
而在 Vue2 中,我们可以这么做,但是回到 Vue3,同样的问题又要怎么解决呢? 我想这应该是很多同学此时心中持有的疑问。所以,下面让我们一起来由浅至深地去解开这个问题。
首先,我们先来看一下 Reactivity Object 响应式对象,它是基于使用 Proxy 创建一个原始对象的代理对象和使用 Reflect 来代理 JavaScript 操作方法,从而完成依赖的收集和派发更新的过程。
然后,我们可以根据需要通过使用 Vue3 提供的 ref、compute、reactive、readonly 等 API 来创建对应的响应式对象。
这里,我们来简单看个例子:
import { reactive } from '@vue/reactivity'
const list = reactive([
{
title: 'item1'
msg: 'I am item1',
extData: {
type: 1
}
}
])可以看到,我们用 reactive 创建了一个响应式数据 list。并且,在默认情况下 list 中的每一项中的属性值为对象的都会被处理成响应式的,在这个例子就是 extData,我们可以使用 Vue3 提供的 isReactive 函数来验证一下:
console.log(`extData is reactive: ${isReactive(list[0].extData)}`)
// 输出 true控制台输出:
可以看到 extData 对应的对象确实是被处理成了响应式的。假设,list 是一个很长的数组,并且也不需要 list 中每一项的 extData 属性的对象成为响应式的。那么这个默然创建响应式的对象过程,则会产生我们不期望有的性能上的开销(Overhead)。
既然,是我们不希望的行为,我们就要想办法解决。所以,下面就让我们从源码层面来得出如何解决这个问题。
首先,我们可以建立一个简单的认知,那就是对于 Non-reactivity Object 的处理肯定是是发生在创建响应式对象之前,我想这一点也很好理解。在源码中,创建响应式对象的过程则都是由 packages/reactivity/src/reactive.ts 文件中一个名为 createReactiveObject 的函数实现的。
这里,我们先来看一下 createReactiveObject 函数的签名:
// core/packages/reactivity/reactive.ts
function createReactiveObject(
target: Target,
isReadonly: boolean,
baseHandlers: ProxyHandler<any>,
collectionHandlers: ProxyHandler<any>,
proxyMap: WeakMap<Target, any>
) {}可以看到 createReactiveObject 函数总共会接收 5 个参数,我们分别来认识这 5 个函数形参的意义:
target 表示需要创建成响应式对象的原始对象isReadonly 表示创建后的响应式对象是要设置为只读baseHandlers 表示创建 Proxy 所需要的基础 handler,主要有 get、set、deleteProperty、has 和 ownKeys 等collectionHandlers 表示集合类型(Map、Set 等)所需要的 handler,它们会重写 add、delete、forEach 等原型方法,避免原型方法的调用中访问的是原始对象,导致失去响应的问题发生proxyMap 表示已创建的响应式对象和原始对象的 WeekMap 映射,用于避免重复创建基于某个原始对象的响应式对象然后,在 createReactiveObject 函数中则会做一系列前置的判断处理,例如判断 target 是否是对象、target 是否已经创建过响应式对象(下面统称为 Proxy 实例)等,接着最后才会创建 Proxy 实例。
那么,显然 Non-reactivity Object 的处理也是发生 createReactiveObject 函数的前置判断处理这个阶段的,其对应的实现会是这样(伪代码):
// core/packages/reactivity/src/reactive.ts
function createReactiveObject(...) {
// ...
const targetType = getTargetType(target)
if (targetType === TargetType.INVALID) {
return target
}
// ...
}可以看到,只要使用 getTargetType 函数获取传入的 target 类型 targetType 等于 TargetType.INVALID 的时候,则会直接返回原对象 target,也就是不会做后续的响应式对象创建的过程。
那么,这个时候我想大家都会有 2 个疑问:
getTargetType 函数做了什么?TargetType.INVALID 表示什么,这个枚举的意义?下面,让我们分别来一一解开这 2 个疑问。
同样地,让我们先来看一下 getTargetType 函数的实现:
// core/packages/reactivity/src/reactive.ts
function getTargetType(value: Target) {
return value[ReactiveFlags.SKIP] || !Object.isExtensible(value)
? TargetType.INVALID
: targetTypeMap(toRawType(value))
}其中 getTargetType 主要做了这 3 件事:
target 上存在 ReactiveFlags.SKIP 属性,它是一个字符串枚举,值为 __v_ship,存在则返回 TargetType.INVALIDtarget 是否可扩展 Object.isExtensible 返回 true 或 false,为 true 则返回 TargetType.INVALIDtargetTypeMap(toRawType(value))从 1、2 点可以得出,只要你在传入的 target 上设置了 __v_ship 属性、或者使用 Object.preventExtensions、Object.freeze、Object.seal 等方式设置了 target 不可扩展,那么则不会创建 target 对应的响应式对象,即直接返回 TargetType.INVALID(TargetType 是一个数字枚举,后面会介绍到)。
在我们上面的这个例子就是设置 extData:
{
type: 1,
__v_ship: true
}或者:
Object.freeze({
type: 1
})那么,在第 1、2 点都不满足的情况下,则会返回 targetTypeMap(toRawType(value)),其中 toRawType 函数则是基于 Object.prototype.toString.call 的封装,它最终会返回具体的数据类型,例如对象则会返回 Object:
// core/packages/shared/src/index.ts
const toRawType = (value: unknown): string => {
// 等于 Object.prototype.toString.call(value).slice(8, -1)
return toTypeString(value).slice(8, -1)
}然后,接着是 targetTypeMap 函数:
// core/packages/reactivity/src/reactive.ts
function targetTypeMap(rawType: string) {
switch (rawType) {
case 'Object':
case 'Array':
return TargetType.COMMON
case 'Map':
case 'Set':
case 'WeakMap':
case 'WeakSet':
return TargetType.COLLECTION
default:
return TargetType.INVALID
}
}可以看到,targetTypeMap 函数实际上是对我们所认识的数据类型做了 3 个分类:
TargetType.COMMON 表示对象 Object、 数组ArrayTargetType.COLLECTION 表示集合类型,Map、Set、WeakMap、WeakSetTargetType.INVALID 表示不合法的类型,不是对象、数组、集合其中,TargetType 对应的枚举实现:
const enum TargetType {
INVALID = 0,
COMMON = 1,
COLLECTION = 2
}那么,回到我们上面的这个例子,由于 list.extData 在 toRawType 函数中返回的是数组 Array,所以 targetTypeMap 函数返回的类型则会是 TargetType.COMMON(不等于 TargetType.INVALID),也就是最终会为它创建响应式对象。
因此,在这里我们可以得出一个结论,如果我们需要跳过创建响应式对象的过程,则必须让 target 满足 value[ReactiveFlags.SKIP] || !Object.isExtensible(value) 或者命中 targetTypeMap 函数中的 default 逻辑。
阅读到这里,我想大家都明白了如何在创建一个复杂对象的响应式对象的时候,跳过对象中一些嵌套对象的创建响应式的过程。并且,这个小技巧在某些场景下,不可否认的是一个很好的优化手段,所以提前做好必要的认知也是很重要的。
最后,如果文中存在表达不当或错误的地方,欢迎各位同学提 Issue ~
近期,Vue3 提了一个 Ref Sugar 的 RFC,即 ref 语法糖,目前还处理实验性的(Experimental)阶段。在 RFC 的动机(Motivation)中,Evan You 介绍到在 Composition API 引入后,一个主要未解决的问题是 refs 和 reactive 对象的使用。而到处使用 .value 可能会很麻烦,如果在没使用类型系统的情况下,也会很容易错过:
let count = ref(1)
function add() {
count.value++
}所以,一些用户会更倾向于只使用 reactive,这样就不用处理使用 refs 的 .value 问题。而 ref 语法糖的作用是让我们在使用 ref 创建响应式的变量时,可以直接获取和更改变量本身,而不是使用 .value 来获取和更改对应的值。简单的说,站在使用层面可以告别使用 refs 时的 .value 问题:
let count = $ref(1)
function add() {
count++
}那么,ref 语法糖目前要怎么在项目中使用?它又是怎么实现的?这是我第一眼看到这个 RFC 建立的疑问,相信这也是很多同学持有的疑问。所以,下面让我们来一一揭晓。
由于 ref 语法糖目前还处于实验性的(Experimental)阶段,所以在 Vue3 中不会默认支持 ref 语法糖。那么,这里我们以使用 Vite + Vue3 项目开发为例,看一下如何开启对 ref 语法糖的支持。
在使用 Vite + Vue3 项目开发时,是由 @vitejs/plugin-vue 插件来实现对 .vue 文件的代码转换(Transform)、热更新(HMR)等。所以,我们需要在 vite.config.js 中给 @vitejs/plugin-vue 插件的选项(Options)传入 refTransform: true:
// vite.config.js
import { defineConfig } from 'vite'
import vue from '@vitejs/plugin-vue'
export default defineConfig({
plugins: [vue({
refTransform: true
})]
})那么,这样一来 @vitejs/plugin-vue 插件内部会根据传入的选项中 refTransform 的值判断是否需要对 ref 语法糖进行特定的代码转换。由于,这里我们设置的是 true,显然它是会对 ref 语法糖执行特定的代码转换。
接着,我们就可以在 .vue 文件中使用 ref 语法糖,这里我们看一个简单的例子:
<template>
<div>{{count}}</div>
<button @click="add">click me</button>
</template>
<script setup>
let count = $ref(1)
function add() {
count++
}
</script>对应渲染到页面上:
可以看到,我们可以使用 ref 语法糖的方式创建响应式的变量,而不用思考使用的时候要加 .value 的问题。此外,ref 语法糖还支持其他的写法,个人比较推荐的是这里介绍的 $ref 的方式,有兴趣的同学可以去 RFC 上了解其他的写法。
那么,在了解完 ref 语法糖在项目中的使用后,我们算是解答了第一个疑问(怎么在项目中使用)。下面,我们来解答第二个疑问,它又是怎么实现的,也就是在源码中做了哪些处理?
首先,我们通过 Vue Playground 来直观地感受一下,前面使用 ref 语法糖的例子中的 <script setup> 块(Block)在编译后的结果:
import { ref as _ref } from 'vue'
const __sfc__ = {
setup(__props) {
let count = _ref(1)
function add() {
count.value++
}
}可以看到,虽然我们在使用 ref 语法糖的时候不需要处理 .value,但是它经过编译后仍然是使用的 .value。那么,这个过程肯定不难免要做很多编译相关的代码转换处理。因为,我们需要找到使用 $ref 的声明语句和变量,给前者重写为 _ref,给后者添加 .value。
而在前面,我们也提及 @vitejs/plugin-vue 插件会对 .vue 文件进行代码的转换,这个过程则是使用的 Vue3 提供的 @vue/compiler-sfc 包(Package),它分别提供了对 <script>、<template>、<style> 等块的编译相关的函数。
那么,显然这里我们需要关注的是 <script> 块编译相关的函数,这对应的是 @vue/compiler-sfc 中的 compileScript() 函数。
compileScript() 函数定义在 vue-next 的 packages/compiler-sfc/src/compileScript.ts 文件中,它主要负责对 <script> 或 <script setup> 块内容的编译处理,它会接收 2 个参数:
sfc 包含 .vue 文件的代码被解析后的内容,包含 script、scriptSetup、source 等属性options 包含一些可选和必须的属性,例如组件对应的 scopeId 会作为 options.id、前面提及的 refTransform 等compileScript() 函数的定义(伪代码):
// packages/compiler-sfc/src/compileScript.ts
export function compileScript(
sfc: SFCDescriptor,
options: SFCScriptCompileOptions
): SFCScriptBlock {
// ...
return {
...script,
content,
map,
bindings,
scriptAst: scriptAst.body
}
} 对于 ref 语法糖而言,compileScript() 函数首先会获取选项(Option)中 refTransform 的值,并赋值给 enableRefTransform:
const enableRefTransform = !!options.refTransformenableRefTransform 则会用于之后判断是否要调用 ref 语法糖相关的转换函数。那么,前面我们也提及要使用 ref 语法糖,需要先给 @vite/plugin-vue 插件选项的 refTransform 属性设置为 true,它会被传入 compileScript() 函数的 options,也就是这里的 options.refTransform。
接着,会从 sfc 中解构出 scriptSetup、source、filename 等属性。其中,会先用源文件的代码字符串 source 创建一个 MagicString 实例 s,它主要会用于后续代码转换时对源代码字符串进行替换、添加等操作,然后会调用 parse() 函数来解析 <script setup> 的内容,即 scriptSetup.content,从而生成对应的抽象语法树 scriptSetupAst:
let { script, scriptSetup, source, filename } = sfc
const s = new MagicString(source)
const startOffset = scriptSetup.loc.start.offset
const scriptSetupAst = parse(
scriptSetup.content,
{
plugins: [
...plugins,
'topLevelAwait'
],
sourceType: 'module'
},
startOffset
)而 parse() 函数内部则是使用的 @babel/parser 提供的 parser 方法进行代码的解析并生成对应的 AST。对于上面我们这个例子,生成的 AST 会是这样:
{
body: [ {...}, {...} ],
directives: [],
end: 50,
interpreter: null,
loc: {
start: {...},
end: {...},
filename: undefined,
identifierName: undefined
},
sourceType: 'module',
start: 0,
type: 'Program'
}注意,这里省略了
body、start、end中的内容
然后,会根据前面定义的 enableRefTransform 和调用 shouldTransformRef() 函数的返回值(true 或 false)来判断是否进行 ref 语法糖的代码转换。如果,需要进行相应的转换,则会调用 transformRefAST() 函数来根据 AST 来进行相应的代码转换操作:
if (enableRefTransform && shouldTransformRef(scriptSetup.content)) {
const { rootVars, importedHelpers } = transformRefAST(
scriptSetupAst,
s,
startOffset,
refBindings
)
}在前面,我们已经介绍过了 enableRefTransform。这里我们来看一下 shouldTransformRef() 函数,它主要是通过正则匹配代码内容 scriptSetup.content 来判断是否使用了 ref 语法糖:
// packages/ref-transform/src/refTransform.ts
const transformCheckRE = /[^\w]\$(?:\$|ref|computed|shallowRef)?\(/
export function shouldTransform(src: string): boolean {
return transformCheckRE.test(src)
}所以,当你指定了 refTransform 为 true,但是你代码中实际并没有使用到 ref 语法糖,则在编译 <script> 或 <script setup> 的过程中也不会执行和 ref 语法糖相关的代码转换操作,这也是 Vue3 考虑比较细致的地方,避免了不必要的代码转换操作带来性能上的开销。
那么,对于我们这个例子而言(使用了 ref 语法糖),则会命中上面的 transformRefAST() 函数。而 transformRefAST() 函数则对应的是 packages/ref-transform/src/refTransform.ts 中的 transformAST() 函数。
所以,下面我们来看一下 transformAST() 函数是如何根据 AST 来对 ref 语法糖相关代码进行转换操作的。
在 transformAST() 函数中主要是会遍历传入的原代码对应的 AST,然后通过操作源代码字符串生成的 MagicString 实例 s 来对源代码进行特定的转换,例如重写 $ref 为 _ref、添加 .value 等。
transformAST() 函数的定义(伪代码):
// packages/ref-transform/src/refTransform.ts
export function transformAST(
ast: Program,
s: MagicString,
offset = 0,
knownRootVars?: string[]
): {
// ...
walkScope(ast)
(walk as any)(ast, {
enter(node: Node, parent?: Node) {
if (
node.type === 'Identifier' &&
isReferencedIdentifier(node, parent!, parentStack) &&
!excludedIds.has(node)
) {
let i = scopeStack.length
while (i--) {
if (checkRefId(scopeStack[i], node, parent!, parentStack)) {
return
}
}
}
}
})
return {
rootVars: Object.keys(rootScope).filter(key => rootScope[key]),
importedHelpers: [...importedHelpers]
}
}可以看到 transformAST() 会先调用 walkScope() 来处理根作用域(root scope),然后调用 walk() 函数逐层地处理 AST 节点,而这里的 walk() 函数则是使用的 Rich Haris 写的 estree-walker。
下面,我们来分别看一下 walkScope() 和 walk() 函数做了什么。
首先,这里我们先来看一下前面使用 ref 语法糖的声明语句 let count = $ref(1) 对应的 AST 结构:
可以看到 let 的 AST 节点类型 type 会是 VariableDeclaration,其余的代码部分对应的 AST 节点则会被放在 declarations 中。其中,变量 count 的 AST 节点会被作为 declarations.id ,而 $ref(1) 的 AST 节点会被作为 declarations.init。
那么,回到 walkScope() 函数,它会根据 AST 节点的类型 type 进行特定的处理,对于我们这个例子 let 对应的 AST 节点 type 为 VariableDeclaration 会命中这样的逻辑:
function walkScope(node: Program | BlockStatement) {
for (const stmt of node.body) {
if (stmt.type === 'VariableDeclaration') {
for (const decl of stmt.declarations) {
let toVarCall
if (
decl.init &&
decl.init.type === 'CallExpression' &&
decl.init.callee.type === 'Identifier' &&
(toVarCall = isToVarCall(decl.init.callee.name))
) {
processRefDeclaration(
toVarCall,
decl.init as CallExpression,
decl.id,
stmt
)
}
}
}
}
}这里的 stmt 则是 let 对应的 AST 节点,然后会遍历 stmt.declarations,其中 decl.init.callee.name 指的是 $ref,接着是调用 isToVarCall() 函数并赋值给 toVarCall。
isToVarCall() 函数的定义:
// packages/ref-transform/src/refTransform.ts
const TO_VAR_SYMBOL = '$'
const shorthands = ['ref', 'computed', 'shallowRef']
function isToVarCall(callee: string): string | false {
if (callee === TO_VAR_SYMBOL) {
return TO_VAR_SYMBOL
}
if (callee[0] === TO_VAR_SYMBOL && shorthands.includes(callee.slice(1))) {
return callee
}
return false
}在前面我们也提及 ref 语法糖可以支持其他写法,由于我们使用的是 $ref 的方式,所以这里会命中 callee[0] === TO_VAR_SYMBOL && shorthands.includes(callee.slice(1)) 的逻辑,即 toVarCall 会被赋值为 $ref。
然后,会调用 processRefDeclaration() 函数,它会根据传入的 decl.init 提供的位置信息来对源代码对应的 MagicString 实例 s 进行操作,即将 $ref 重写为 ref:
// packages/ref-transform/src/refTransform.ts
function processRefDeclaration(
method: string,
call: CallExpression,
id: VariableDeclarator['id'],
statement: VariableDeclaration
) {
// ...
if (id.type === 'Identifier') {
registerRefBinding(id)
s.overwrite(
call.start! + offset,
call.start! + method.length + offset,
helper(method.slice(1))
)
}
// ...
}位置信息指的是该 AST 节点在源代码中的位置,通常会用
start、end表示,例如这里的let count = $ref(1),那么count对应的 AST 节点的start会是 4、end会是 9。
因为,此时传入的 id 对应的是 count 的 AST 节点,它会是这样:
{
type: "Identifier",
start: 4,
end: 9,
name: "count"
}所以,这会命中上面的 id.type === 'Identifier' 的逻辑。首先,会调用 registerRefBinding() 函数,它实际上是调用的是 registerBinding(),而 registerBinding 会在当前作用域 currentScope 上绑定该变量 id.name 并设置为 true ,它表示这是一个用 ref 语法糖创建的变量,这会用于后续判断是否给某个变量添加 .value:
const registerRefBinding = (id: Identifier) => registerBinding(id, true)
function registerBinding(id: Identifier, isRef = false) {
excludedIds.add(id)
if (currentScope) {
currentScope[id.name] = isRef
} else {
error(
'registerBinding called without active scope, something is wrong.',
id
)
}
}可以看到,在 registerBinding() 中还会给 excludedIds 中添加该 AST 节点,而 excludeIds 它是一个 WeekMap,它会用于后续跳过不需要进行 ref 语法糖处理的类型为 Identifier 的 AST 节点。
然后,会调用 s.overwrite() 函数来将 $ref 重写为 _ref,它会接收 3 个参数,分别是重写的起始位置、结束位置以及要重写为的字符串。而 call 则对应着 $ref(1) 的 AST 节点,它会是这样:
{
type: "Identifier",
start: 12,
end: 19,
callee: {...}
arguments: {...},
optional: false
}并且,我想大家应该注意到了在计算重写的起始位置的时候用到了 offset,它代表着此时操作的字符串在源字符串中的偏移位置,例如该字符串在源字符串中的开始,那么偏移量则会是 0。
而 helper() 函数则会返回字符串 _ref,并且在这个过程会将 ref 添加到 importedHelpers 中,这会在 compileScript() 时用于生成对应的 import 语句:
function helper(msg: string) {
importedHelpers.add(msg)
return `_${msg}`
}那么,到这里就完成了对 $ref 到 _ref 的重写,也就是此时我们代码的会是这样:
let count = _ref(1)
function add() {
count++
}接着,则是通过 walk() 函数来将 count++ 转换成 count.value++。下面,我们来看一下 walk() 函数。
前面,我们提及 walk() 函数使用的是 Rich Haris 写的 estree-walker,它是一个用于遍历符合 ESTree 规范的 AST 包(Package)。
walk() 函数使用起来会是这样:
import { walk } from 'estree-walker'
walk(ast, {
enter(node, parent, prop, index) {
// ...
},
leave(node, parent, prop, index) {
// ...
}
});可以看到,walk() 函数中可以传入 options,其中 enter() 在每次访问 AST 节点的时候会被调用,leave() 则是在离开 AST 节点的时候被调用。
那么,回到前面提到的这个例子,walk() 函数主要做了这 2 件事:
1.维护 scopeStack、parentStack 和 currentScope
scopeStack 用于存放此时 AST 节点所处的作用域链,初始情况下栈顶为根作用域 rootScope;parentStack 用于存放遍历 AST 节点过程中的祖先 AST 节点(栈顶的 AST 节点是当前 AST 节点的父亲 AST 节点);currentScope 指向当前的作用域,初始情况下等于根作用域 rootScope:
const scopeStack: Scope[] = [rootScope]
const parentStack: Node[] = []
let currentScope: Scope = rootScope所以,在 enter() 的阶段会判断此时 AST 节点类型是否为函数、块,是则入栈 scopeStack:
parent && parentStack.push(parent)
if (isFunctionType(node)) {
scopeStack.push((currentScope = {}))
// ...
return
}
if (node.type === 'BlockStatement' && !isFunctionType(parent!)) {
scopeStack.push((currentScope = {}))
// ...
return
}然后,在 leave() 的阶段判断此时 AST 节点类型是否为函数、块,是则出栈 scopeStack,并且更新 currentScope 为出栈后的 scopeStack 的栈顶元素:
parent && parentStack.pop()
if (
(node.type === 'BlockStatement' && !isFunctionType(parent!)) ||
isFunctionType(node)
) {
scopeStack.pop()
currentScope = scopeStack[scopeStack.length - 1] || null
}2.处理 Identifier 类型的 AST 节点
由于,在我们的例子中 ref 语法糖创建 count 变量的 AST 节点类型是 Identifier,所以这会在 enter() 阶段命中这样的逻辑:
if (
node.type === 'Identifier' &&
isReferencedIdentifier(node, parent!, parentStack) &&
!excludedIds.has(node)
) {
let i = scopeStack.length
while (i--) {
if (checkRefId(scopeStack[i], node, parent!, parentStack)) {
return
}
}
}在 if 的判断中,对于 excludedIds 我们在前面已经介绍过了,而 isReferencedIdentifier() 则是通过 parenStack 来判断当前类型为 Identifier 的 AST 节点 node 是否是一个引用了这之前的某个 AST 节点。
然后,再通过访问 scopeStack 来沿着作用域链来判断是否某个作用域中有 id.name(变量名 count)属性以及属性值为 true,这代表它是一个使用 ref 语法糖创建的变量,最后则会通过操作 s(s.appendLeft)来给该变量添加 .value:
function checkRefId(
scope: Scope,
id: Identifier,
parent: Node,
parentStack: Node[]
): boolean {
if (id.name in scope) {
if (scope[id.name]) {
// ...
s.appendLeft(id.end! + offset, '.value')
}
return true
}
return false
}通过了解 ref 语法糖的实现,我想大家应该会对语法糖这个术语会有不一样的理解,它的本质是在编译阶段通过遍历 AST 来操作特定的代码转换操作。并且,这个实现过程的一些工具包(Package)的配合使用也是非常巧妙的,例如 MagicString 操作源代码字符串、estree-walker 遍历 AST 节点等。
最后,如果文中存在表达不当或错误的地方,欢迎各位同学提 Issue ~
又回到了经典的一句话:“先知其然,而后使其然”。相信很多同学都知道了 esbuild,其以飞快的构建速度闻名于众。并且,esbuild 作者 Evan Wallace 也在官网的 FAQ专门介绍了为什么 esbuild 会这么快?(有兴趣的同学可以自行了解 https://esbuild.github.io/faq/)
那么,回到今天本文,将会从 esbuild 源码的目录结构入手,围绕以下 2 点和大家一起走进 esbuild 底层的世界:
在 Go 中,是以 package (包)来划分模块,每个 Go 的应用程序都需要包含一个入口 package main,即 main.go 文件。那么,显然 esbuild 本身也是一个 Go 应用,即它的入口文件同样也是 main.go 文件。
而对于 esbuild,它的目录结构:
|—— cmd
|—— docs
|—— images
|—— internal
|—— lib
|—— npm
|—— pkg
|—— require
|—— scripts
.gitignore
go.mod
go.sum
Makefile
README.md
version.txt
似乎一眼望去,并没有我们想要的 main.go 文件,那么我们要怎么找到整个应用的入口?
学过 C 的同学,应该知道 Make 这个构建工具,它可以用于执行我们定义好的一系列命令,来实现某个构建目标。并且,不难发现的是上面的目录结构中有一个 Makefile 文件,它则是用来注册 Make 命令的。
而在 Makefile 文件中注册规则的基础语法会是这样:
<target> : <prerequisites>
[tab] <commands>
这里,我们来分别认识一下各个参数的含义:
target 构建的目标,即使用 Make 命令的目标,例如 make 某个目标名prerequisites 前置条件,通常是一些文件对应的路径,一旦这些文件发生变动,在执行 Make 命令时,就会进行重新构建,反之不会tab 固定的语法格式要求,命令 commands 的开始必须为一个 tab 键commands 命令,即执行 Make 命令构建某个目标时,对应会执行的命令那么,下面我们来看一下 esbuild 中 Makefile 文件中的内容:
ESBUILD_VERSION = $(shell cat version.txt)
# Strip debug info
GO_FLAGS += "-ldflags=-s -w"
# Avoid embedding the build path in the executable for more reproducible builds
GO_FLAGS += -trimpath
esbuild: cmd/esbuild/version.go cmd/esbuild/*.go pkg/*/*.go internal/*/*.go go.mod
CGO_ENABLED=0 go build $(GO_FLAGS) ./cmd/esbuild
test:
make -j6 test-common
# These tests are for development
test-common: test-go vet-go no-filepath verify-source-map end-to-end-tests js-api-tests plugin-tests register-test node-unref-tests
# These tests are for release (the extra tests are not included in "test" because they are pretty slow)
test-all:
make -j6 test-common test-deno ts-type-tests test-wasm-node test-wasm-browser lib-typecheck
....
注意:这里只是列出了 Makefile 文件中的部分规则,有兴趣的同学可以自行查看其他规则~
可以看到,在 Makefile 文件中注册了很多规则。而我们经常使用的 esbuild 命令,则对应着这里的 esbuild 目标。
根据上面对 Makefile 的介绍以及结合这里的内容,我们可以知道的是 esbuild 命令的核心是由 cmd/esbuild/version.go cmd/esbuild/*.go 和 pkg/*/*.go、internal/*/*.go go.mod 这三部分相关的文件实现的。
那么,通常执行 make esbuild 命令,其本质上是执行命令:
CGO_ENABLED=0 go build $(GO_FLAGS) ./cmd/esbuild下面,我们来分别看一下这个命令做了什么(含义):
CGO_ENABLED=0
CGO_ENABLED 是 Go 的环境(env)信息之一,我们可以用 go env 命令查看 Go 支持的所有环境信息。
而这里将 CGO_ENABLED 设为 0 是为了禁用 cgo,因为默认情况下,CGO_ENABLED 为 1,也就是开启 cgo 的,但是 cgo 是会导入一些包含 C 代码的文件,那么也就是说最后编译的结果会包含一些外部动态链接,而不是纯静态链接。
cgo可以让你在 .go 文件中使用 C 的语法,这里不做详细的展开介绍,有兴趣的同学可以自行了解
那么,这个时候大家可能会思考外部动态链接和静态链接之间的区别是什么?为什么需要纯静态链接的编译结果?
这是因为外部动态链接会打破你最后编译出的程序对平台的适应性。因为,外部动态链接存在一定的不确定因素,简单的说也许你现在构建出来的应用是可以用的,但是在某天外部动态链接的内容发生了变化,那么很可能会对你的程序运行造成影响。
go build $(GO_FLAGS) ./cmd/esbuild
go build $(GO_FLAGS) ./cmd/esbuild 的核心是 go build 命令,它是用于编译源码文件、代码包、依赖包等操作,例如我们这里是对 ./cmd/esbuild/main.go 文件执行编译操作。
到这里,我们就已经知道了 esbuild 构建的入口是 cmd/esbuild/main.go 文件了。那么,接下来就让我们看一下构建的入口都做了哪些事情?
虽然,Esbuild 构建的入口 cmd/esbuild/main.go 文件的代码总共才 268 行左右。但是,为了方便大家理解,这里我将拆分为以下 3 点来分步骤讲解:
package 导入--help 的文字提示函数的定义main 函数具体都做了哪些package 导入首先,是基础依赖的 package 导入,总共导入了 8 个 package:
import (
"fmt"
"os"
"runtime/debug"
"strings"
"time"
"github.com/evanw/esbuild/internal/api_helpers"
"github.com/evanw/esbuild/internal/logger"
"github.com/evanw/esbuild/pkg/cli"
)这 8 个 package 分别对应的作用:
fmt 用于格式化输出 I/O 的函数os 提供系统相关的接口runtime/debug 提供程序在运行时进行调试的功能strings 用于操作 UTF-8 编码的字符串的简单函数time 用于测量和展示时间github.com/evanw/esbuild/internal/api_helpers 用于检测计时器是否正在使用github.com/evanw/esbuild/internal/logger 用于格式化日志输出github.com/evanw/esbuild/pkg/cli 提供 esbuild 的命令行接口--help 的文字提示函数的定义任何一个工具都会有一个 --help 的选项(option),用于告知用户能使用的具体命令。所以,esbuild 的 --help 文字提示函数的定义也具备同样的作用,对应的代码(伪代码):
var helpText = func(colors logger.Colors) string {
return `
` + colors.Bold + `Usage:` + colors.Reset + `
esbuild [options] [entry points]
` + colors.Bold + `Documentation:` + colors.Reset + `
` + colors.Underline + `https://esbuild.github.io/` + colors.Reset + `
` + colors.Bold
...
}这里会用到我们上面提到的 logger 这个 package 的 Colors 结构体,它主要用于美化在终端输出的内容,例如加粗(Bold)、颜色(Red、Green):
type Colors struct {
Reset string
Bold string
Dim string
Underline string
Red string
Green string
Blue string
Cyan string
Magenta string
Yellow string
}而使用 Colors 结构体创建的变量会是这样:
var TerminalColors = Colors{
Reset: "\033[0m",
Bold: "\033[1m",
Dim: "\033[37m",
Underline: "\033[4m",
Red: "\033[31m",
Green: "\033[32m",
Blue: "\033[34m",
Cyan: "\033[36m",
Magenta: "\033[35m",
Yellow: "\033[33m",
}main 函数主要都做了哪些在前面,我们也提及了每个 Go 的应用程序都必须要有一个 main package,即 main.go 文件来作为应用的入口。而在 main.go 文件内也必须声明 main 函数,来作为 package 的入口函数。
那么,作为 esbuild 的入口文件的 main 函数,主要是做这 2 件事:
1. 获取输入的选项(option),并进行处理
使用我们上面提到的 os 这个 package 获取终端输入的选项,即 os.Args[1:]。其中 [1:] 表示获取数组从索引为 1 到最后的所有元素构成的数组。
然后,会循环 osArgs 数组,每次会 switch 判断具体的 case,对不同的选项,进行相应的处理。例如 --version 选项,会输出当前 esbuild 的版本号以及退出:
fmt.Printf("%s\n", esbuildVersion)
os.Exit(0)这整个过程对应的代码会是这样:
osArgs := os.Args[1:]
argsEnd := 0
for _, arg := range osArgs {
switch {
case arg == "-h", arg == "-help", arg == "--help", arg == "/?":
logger.PrintText(os.Stdout, logger.LevelSilent, os.Args, helpText)
os.Exit(0)
// Special-case the version flag here
case arg == "--version":
fmt.Printf("%s\n", esbuildVersion)
os.Exit(0)
...
default:
osArgs[argsEnd] = arg
argsEnd++
}
}并且,值得一提的是这里会重新构造 osArgs 数组,由于选项是可以一次性输入多个的,
但是 osArgs 会在后续的启动构建的时候作为参数传入,所以这里处理过的选项会在数组中去掉。
2. 调用 cli.Run(),启动构建
对于使用者来说,我们切实关注的是使用 esbuild 来打包某个应用,例如使用 esbuild xxx.js --bundle 命令。而这个过程由 main 函数最后的自执行函数完成。
该函数的核心是调用 cli.Run() 来启动构建过程,并且传入上面已经处理过的选项。
func() {
...
exitCode = cli.Run(osArgs)
}()并且,在正式开启构建之前,会根据继续处理前面的选项相关的逻辑,具体会涉及到 CPU 跟踪、堆栈的跟踪等,这里不作展开介绍,有兴趣的同学自行了解。
好了,到这里我们就大致过了一遍 esbuild 构建的入口文件相关源码。站在没接触过 Go 的同学角度看可能稍微有点晦涩,并且有些分支逻辑,文中并没有展开分析,这会在后续的文章中继续展开。但是,总体上来看,打开一个新的窗户看到了不一样的风景,这不就是我们作为工程师所希望经历的嘛 😎。最后,如果文中存在表达不当或错误的地方,欢迎各位同学提 Issue~
在前面「macOS App 自动化分发 App Store 探索与实践」和 「一文带你读懂何为 macOS App 公证,以及如何自动化实现」 2 篇文章中,分别给大家介绍了 macOS 分发自动化实现相关的内容。其中,我们总是会提及证书、App IDs 和 Provisioning Profile 等相关内容,并且证书和 Profiles 在不同的分发渠道(网络或 App Store)都有所区分。
虽然,直接通过 Apple Developer 的账户(Account)后台可以查看前面提及的内容。但是,由于这个的前提是要求我们注册 Apple Developer Program(付费 688),所以,存在一定的使用之前的成本(费用),那么或多或少就有同学对此存在一定的盲区,以及在了解后也会遇到协作和管理的问题。
那么,今天本文也将会从证书、App IDs、Provisioning Profile 作为开始,带大家一起从理论基础出发,再到如何使用工具(fastlane match)实现自动化管理。
在 Apple Developer 的账户(Account)后台,有专门用于查看 Certificates, Identifiers & Profiles 的页面,你可以在这里管理你的证书 Certificates、App IDs(Identifiers)和 Provisioning Profile:
下面,我们分别来看下这 3 者。那么,首先是 App IDs(Identifiers)。
App IDs(Identifiers),它是 Identifiers 的一种,用于使得你的 App、App Extension 或 App Clip 能够访问可用服务,以及可以在 Provisioning Profile 中标识你的 App。
也就是说,App IDs 是一个应用的唯一标识,是必须要创建的,它的命名遵循 reverse-domain 的风格,例如 com.domainname.appname。并且,我们可以通过查看 macOS 上 App 的包内容(应用程序->右键-> info.plist),例如 macOS 上的微信的 App IDs 会是 com.tencent.xinWeChat。
然后,接着是证书 Certificates,证书分为这 2 类:

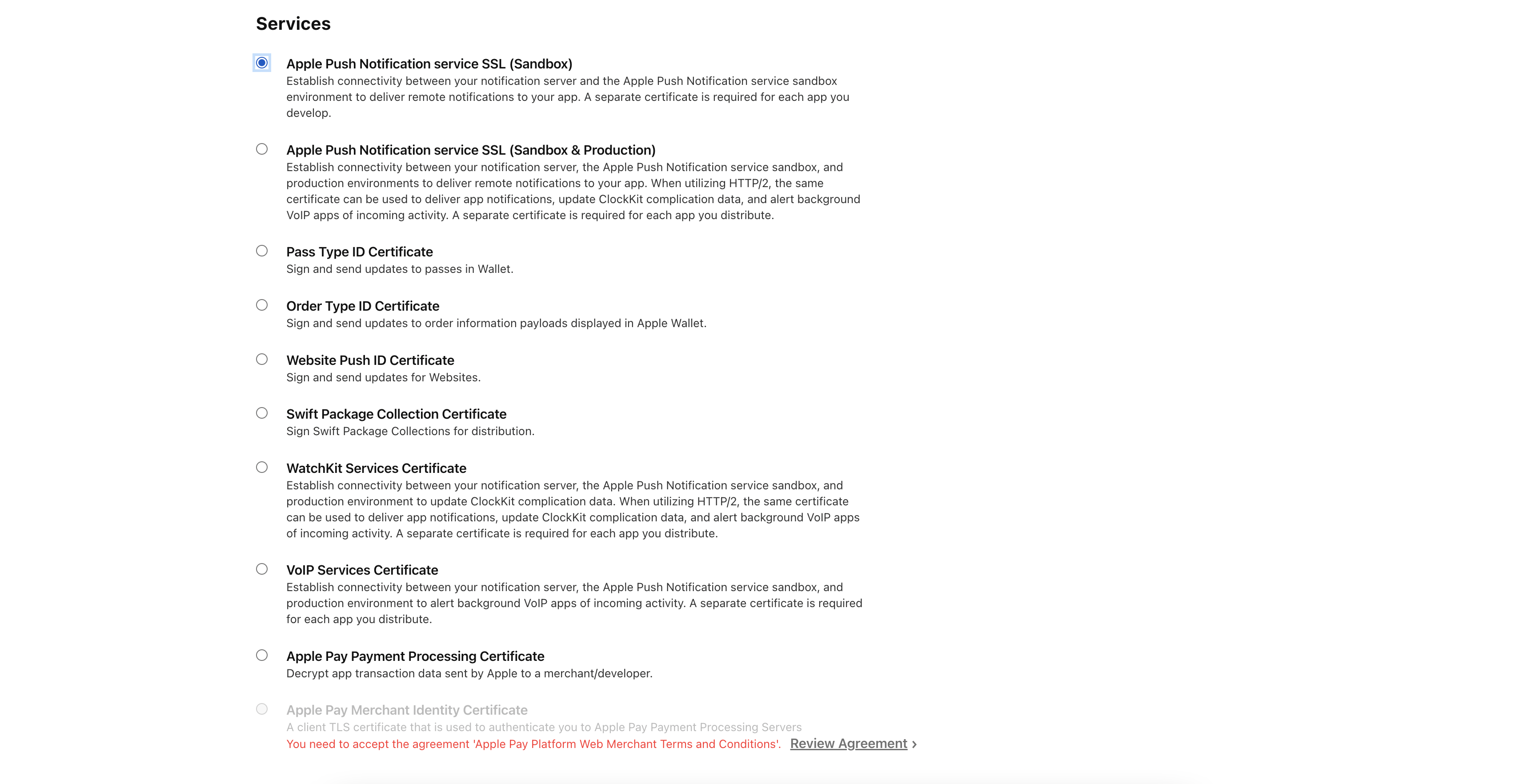
并且,值得一提的是证书的创建使用的是一种 创建证书签名请求 的方式,这种方式遵循的非对称加密(RSA),它会在本地创建一对公用密钥和专用密钥(以下统称私钥 Private Key),其中,公钥用于加密证书,私钥是保存在创建者本地的钥匙串 KeyChain 中。
那么,如果你想将证书分享给别人使用,但是由于非对称加密的限制(证书是加密的),我们还需要提供解密证书对应的私钥,所以,通常情况下我们是在钥匙串中导出个人信息交换(.p12)文件,它会包含证书本身和解密它需要的私钥:
此外,关于各个证书的详细作用有兴趣的同学可以自行了解。这里,我们来看下软件 Software 证书中 macOS 开发和分发相关的 4 个证书:
codesign 命令进行签名:codesign -s "Development" ./FEKit.appcodesign -s "Developer ID Application: Jingchang wu(xxxxxxxxxx)" ./FEKit.appMac Installer Distribution,用于对安装包(Install Package)进行代码签名以提交到 App Store
Mac App Distribution,用于对应用程序进行代码签名,以及配置分发 Provisioning Profile 用于提交到 App Store
最后,则是 Provisioning(配置)Profile,Provisioning Profile 分为这 2 类:
那么,对于 macOS 而言,我们则需要创建 **macOS App Development(配置开发版本应用的测试设备)、
Mac App Store(提交 AppStore)和 Developer ID(在网络上分发)**等 3 个 Provisioning Profile。
通常,我们一个项目会有多个开发者 Developer,那如何在多个开发者之间共享同一份 Mac Development、Developer ID Application 等证书或 Provisioning Profile 文件,就成为了一个比较琐碎的问题。
所以,fastlane 提供了一个名为 sync_code_signing 的 Action 用于解决上面提及的这个问题,它的 alias 是 match,也就是我们可以通过 fastlane match xxx 之类的命令来完成证书和 Provisioning Profile 文件的维护(创建、更新)和拉取(同步到开发者本地),而这些操作则是使用的 Apple Store Connect API 提供的接口实现的。
其中,由于 fastlane 需要指定的可以用于存储证书和 Provisioning Profile 文件的地方,你可以使用 Git Repo、Google Cloud 和 Amazon S3 其中的 1 种作为存储的选择,这里我们选择用 GitLab 的 Repo。
那么,首先是在你的项目中执行 fastlane match init 命令,它会提示你要选择的存储方式:
这里我们选择 Git,然后需要输入 Repo 的地址,最后它会在当前项目路径的 ./fastlane 文件目录中创建 Matchfile 文件:
git_url("https://gitlab.com/xxxxx/xxxxxxxxxx.git")
storage_mode("git")
type("development") # The default type, can be: appstore, adhoc, enterprise or development
# app_identifier(["tools.fastlane.app", "tools.fastlane.app2"])
# username("[email protected]") # Your Apple Developer Portal username可以看到,默认设置了 git_url 为前面输入的 Git Repo 的地址(以下统称 Match Repo),然后 storage_mode 设置的为 git,并且默认会设置 type 为 development,这意味着在执行 fastlane match development --readonly 命令的时候会获取所有 development 相关的证书和 Provisioning Profile 文件(如果没有则会重新创建)。
由于,很多情况下我们使用 fastlane match <type> 相关的命令的时候,我们可能已经创建好了各类的证书和 Provisioning Profile 文件。所以,不能直接使用 fastlane match <type> 的命令,这样会给你撤销之前已创建好的这些文件并创建一个新的。
因此,我们需要使用 fastlane match import 命令来将本地的证书(.cer)、个人信息交换(.p12)和 Provisioning Profile 文件手动导入到 Match Repo 中,例如我们需要把 Developer ID Application 相关的证书、p12、Provisioning Profile 文件导入:
1.首先,修改下之前的 Matchfile 文件的内容:
# 注意,默认为 master 分支
git_url("https://gitlab.com/xxxxx/xxxxxxxxxx.git")
storage_mode("git")
# 指定证书、.p12、Provisioning Profile 的类型
type("developer_id")
# 指定我们的 App IDs
app_identifier("com.xxx.xxxx")2.接着,将本地的上面提及的文件在钥匙串中分别导出到文件系统中。
3.最后,使用 fastlane match import 命令,此时会让你输入各个文件所在的位置,然后需要输入密码用于证书的加密,也就是说其他人从 Match Repo 拉取的时候需要输入对应的密码用于解密,接着则还会让你输入 Apple Developer Program 账户来对这些文件进行验证,如果你不期望验证可以使用 --skip_certificate_matching true Option 来跳过这个步骤。
在完成上述文件的导入后,在 Match Repo 中可以看到新增了 /certs/developer_id_application/ 和 /profiles/developer_id/ 等 2 个目录结构,后续我们导入别的的证书(.cer)、个人信息交换(.p12)和 Provisioning Profile 文件则会一并添加到 /certs 或 /profiles 目录下:
certs
|———— developer_id_application
|__ xxxxx.cert
|__ xxxxx.p12
profiles
|———— developer_id
|__ xxxxxxxxxxxxxxxxxxx.provisionprofile
然后,如果有同学在开发过程中需要使用到 Developer ID Application 相关的证书、私钥(.p12)和 Provisioning Profile 文件,则可以通过 fastlane match developer_id --readonly 命令获取这些文件到本地的钥匙串中,其中 --readonly 只拉取 Match Repo 中存在的 developer_id 相关文件,不会自动创建一个新的。
通过阅读,对于之前一直没有接触过这方面知识的同学,我想已经对证书、App IDs 和 Provisioning Profile 等相关内容都或多或少有了一定的了解。并且,通过简单地了解 fastlane match 提供的能力,也可以让团队在这方面的协作效率和维护管理都得到了提高。此外,值得一提的是 fastlane match 提供了很多参数,来支持更多个性化的操作,例如过期自动创建、撤销指定类型的证书等,所以有兴趣的同学也推荐在文档中继续了解一番。
最后,如果文中存在表达不当或错误的地方,欢迎各位同学提 Issue ~
距离尤大大在微博宣布「vite」的出现,不知不觉间已经过了一段时间了。
当时,「vite」只是支持对 .vue 文件的即时编译和 import 的 rewrite,相应地「Plugin」也没有几个。并且,最初在「GitHub」上「vite」的 slogan 是这样的:
—— No-bundle Dev Server for Vue 3 Single-File Components.
可以看到,起初介绍「vite」是一个不需要打包的开发阶段的服务器。但是,现在再回首,这句 slogan 已经消失了,而「vite」也已经处于 「beta」 阶段。并且,不仅仅是一个开发阶段的服务器这么简单。相应地也实现了很多「Feature」,例如:Web Assembly、JSX
、CSS Pre-processors、Dev Server Proxy 等等。
有兴趣了解这些「Feature」的同学,可以移步GitHub自行阅读
这两个月的时间,「vite」发展的劲头是非(xue)常(bu)猛(dong)的。并且,也出现了很多关于「vite」的文章,可以说是:“ 如雨后春笋般,络绎不绝 ”。
那么,作为一名「Vue」爱好者,我同样对「vite」充满了好奇。所以,回到本次文章,我会先浅析 webpack-dev-server的「HMR」,然后再循序渐进地讲解「vite」在「HMR」这个过程做了什么。
提及「HMR」,不可避免地是会想起现在我们家喻户晓的 webpack-dev-server 中的「HMR」。所以,我们先来了解一番webpack-dev-server的「HMR」。
首先,我们先对「HMR」建立一个基础的认知。「HMR」 全称即 Hot Module Replacement。相比较「live load」,它具有以下优点:
而在 webpack-dev-server 中实现「HMR」的核心就是 HotModuleReplacementPlugin ,它是「Webpack」内置的「Plugin」。在我们平常开发中,之所以改一个文件,例如 .vue 文件,会触发「HMR」,是因为在 vue-loader 中已经内置了使用 HotModuleReplacementPlugin 的逻辑。它看起来会是这样
<template>
<div>hello world</div>
</template>
<script lang="ts">
import { Vue, Component } from 'vue-property-decorator'
@Component
export default class Helloworld extends Vue() {}
</script>import Vue from 'vue'
import HelloWorld from '_c/HelloWorld'
if (module.hot) {
module.hot.accept('_c/HelloWorld', ()=>{
// 拉取更新过的 HelloWorld.vue 文件
})
}
new Vue({
el: '#app',
template: '<HelloWorld/>'
component: { HelloWorld }
})那么,这个就是 webpack-dev-server 实现「HMR」的本质吗?显然不是,上面说的只是,如果你要通过 webpack-dev-server 实现「HMR」,你可以这么写来实现。
如果究其底层实现,是有两个关键的点:
1.与本地服务器建立「socket」连接,注册 hash 和 ok 两个事件,发生文件修改时,给客户端推送 hash 事件。客户端根据 hash 事件中返回的参数来拉取更新后的文件。
2.HotModuleReplacementPlugin 会在文件修改后,生成两个文件,用于被客户端拉取使用。例如:
hash.hot-update.json
{
"c": {
"chunkname": true
},
"h": "d69324ef62c3872485a2"
}chunkname.d69324ef62c3872485a2.hot-update.js,这里的 chunkname 即上面 c 中对于 key。
webpackHotUpdate("main",{
"./src/test.js":
(function(module, __webpack_exports__, __webpack_require__) {
"use strict";
eval(....)
})
})
当然,在这之前还会涉及到对原模块代码的注入,让它具备拉取文件的能力。而这其中实现的细节就不去扣了,要不然有点喧兵夺主的感觉。
基于 native ES Module 的 devServer 是「vite」实现「HMR」的重要一环。总体来说,它会做这么两件事:
Plugin,例如 sourceMapPlugin、moduleRewritePlugin、htmlRewritePlugin 等等。所以,本质上,devServer 做的最重要的一件事就是加载执行 Plugin。目前,「vite」总共具备了 11 种 Plugin。
这里大致列举几点 Plugin 会做:
import 转化为 /@module/vue.js.ts、.vue 进行即时的编译以及 sass 或 less 的预编译importeeMap和客户端建立 socket 连接,用于实现「HMR」这里就列举 devServer 几个常见的
Plugin需要做的事,至于其他像wasmPlugin、webWorkerPlugin之类的Plugin会做些什么,有兴趣的同学可以自行去了解。
然后,我们再从代码地角度看看它是怎么实现我们上述所说的:
1.首先,我们执行 vite 命令.实际上是运行 cli.js 这个文件,这里我摘取了其中核心的逻辑:
(async () => {
const { help, h, mode, m, version, v } = argv
...
const envMode = mode || m || defaultMode
const options = await resolveOptions(envMode)
// 开发环境下,我们会命中 runServer
if (!options.command || options.command === 'serve') {
runServe(options)
} else if (options.command === 'build') {
runBuild(options)
} else if (options.command === 'optimize') {
runOptimize(options)
} else {
console.error(chalk.red(`unknown command: ${options.command}`))
process.exit(1)
}
})()
async function runServe(options: UserConfig) {
// 在 createServer() 的时候会对 HRM、serverConfig 之类的进行初始化
const server = require('./server').createServer(options)
...
}
可以看到,在自执行函数中,我们会命中 runServer() 的逻辑,而它的核心是调用 server.js 文件中的 createServer()。
createServer 方法:
export function createServer(config: ServerConfig): Server {
const {
...,
enableEsbuild = true
} = config
const app = new Koa<State, Context>()
const server = resolveServer(config, app.callback())
const watcher = chokidar.watch(root, {
ignored: [/\bnode_modules\b/, /\b\.git\b/]
}) as HMRWatcher
const resolver = createResolver(root, resolvers, alias)
const context: ServerPluginContext = {
...
watcher
...
}
app.use((ctx, next) => {
Object.assign(ctx, context)
ctx.read = cachedRead.bind(null, ctx)
return next()
})
const resolvedPlugins = [
...,
moduleRewritePlugin,
hmrPlugin,
...
]
// 核心逻辑执行 hmrPlugin
resolvedPlugins.forEach((m) => m && m(context))
const listen = server.listen.bind(server)
server.listen = (async (port: number, ...args: any[]) => {
...
}) as any
return server
}createServer 方法做了这么几件事:
koa 实例watcher,并传入 context 中context 上下文传入并调用每一个 Plugin到这里,「vite」的 devServer 的创建过程就已经完成。那么,接下来我们去领略一番属于「vite」的「HMR」过程!
在「vite」中「HMR」的实现是以 serverPluginHmr 这个 Plugin 为核心实现。这里我们以 .vue 文件的修改触发的「HMR」为例,这个过程会涉及三个 Plugin:serverPluginHtml、serverPluginHmr、serverPluginVue,这个过程看起来会是这样:
从前面的流程图可以看到,首先是 serverPluginHtml 这个 Plugin 向 index.html 中注入了获取 hmr 模块的代码:
export const htmlRewritePlugin: ServerPlugin = ({
root,
app,
watcher,
resolver,
config
}) => {
const devInjectionCode =
`\n<script type="module">\n` +
`import "${hmrClientPublicPath}"\n` +
`window.process = { env: { NODE_ENV: ${JSON.stringify(
config.mode || 'development'
)} }}\n` +
`</script>\n`
const scriptRE = /(<script\b[^>]*>)([\s\S]*?)<\/script>/gm
const srcRE = /\bsrc=(?:"([^"]+)"|'([^']+)'|([^'"\s]+)\b)/
async function rewriteHtml(importer: string, html: string) {
...
html = html!.replace(scriptRE, (matched, openTag, script) => {
...
return injectScriptToHtml(html, devInjectionCode)
}
app.use(async (ctx, next) => {
await next()
...
if (ctx.response.is('html') && ctx.body) {
const importer = ctx.path
const html = await readBody(ctx.body)
if (rewriteHtmlPluginCache.has(html)) {
...
} else {
if (!html) return
// 在这里给 index.html 文件注入代码块
ctx.body = await rewriteHtml(importer, html)
rewriteHtmlPluginCache.set(html, ctx.body)
}
return
}
})
}所以,当我们访问一个 「vite」 启动的项目的时候,我们会在「network」中看到服务器返回给我们的 index.html 中的代码会多了这么一段代码:
<script type="module">
import "/vite/hmr"
window.process = { env: { NODE_ENV: "development" }}
</script>而这一段代码,也是确保我们后续正常触发「HMR」的关键点。因为,在这里浏览器会向服务器发送请求获取 vite/hmr 模块,然后,在 serverPluginHmr 中会拦截 ctx.path===‘/vite/hmr’ 的请求,建立 socket 连接。那么,接下来我们看看 serverPluginHmr 是进行这些过程的。
上面我们说了 serverPluginHmr 它会劫持导入 /vite/hmr 的请求,然后返回 client.js 文件。所以,我们分点来细致化地分析这个过程:
1.读取 cliten.js 文件,劫持导入 /vite/hmr 的请求
export const hmrClientFilePath = path.resolve(
__dirname,
'../../client/client.js'
)
export const hmrClientPublicPath = `/vite/hmr`
const hmrClient = fs
.readFileSync(hmrClientFilePath, 'utf-8')
.replace(`__SW_ENABLED__`, String(!!config.serviceWorker))
app.use(async (ctx, next) => {
if (ctx.path === hmrClientPublicPath) {
ctx.type = 'js'
ctx.status = 200
ctx.body = hmrClient.replace(`__PORT__`, ctx.port.toString())
} else {
...
}
})这里通过 readFileSync() 读取 client.js 文件,然后分别 replace 读取到的文件内容(字符串),一个是用于判断是否支持 serviceWorker,另一个用于建立 socket 连接时的端口设置。
2.定义 send 方法,并赋值给 watcher.send,用于其他 Plugin 在热更新时向浏览器推送更新信息:
const send = (watcher.send = (payload: HMRPayload) => {
const stringified = JSON.stringify(payload, null, 2)
debugHmr(`update: ${stringified}`)
wss.clients.forEach((client) => {
// OPEN 表示已经建立连接
if (client.readyState === WebSocket.OPEN) {
client.send(stringified)
}
})
})3.client.js,它会做这两件事:
socket 连接,监听 message 事件,拿到服务器推送的 data,例如我们只修改 .vue 文件,它的 data 类型定义会是这样:export interface UpdatePayload {
type: 'js-update' | 'vue-reload' | 'vue-rerender' | 'style-update'
path: string
changeSrcPath: string
timestamp: number
}data.type 执行不同的逻辑,目前存在 type 有:vue-reload、vue-rerender、style-update、style-remove、js-update、custom、full-reload。本次我们只分析 vue-rerender 的逻辑,其实现的核心代码如下:const socketProtocol = location.protocol === 'https:' ? 'wss' : 'ws'
const socketUrl = `${socketProtocol}://${location.hostname}:${__PORT__}`
const socket = new WebSocket(socketUrl, 'vite-hmr')
// 监听 message 事件,拿到服务端推送的 data
socket.addEventListener('message', async ({ data }) => {
const payload = JSON.parse(data) as HMRPayload | MultiUpdatePayload
if (payload.type === 'multi') {
payload.updates.forEach(handleMessage)
} else {
// 通常情况下会命中这个逻辑
handleMessage(payload)
}
})
async function handleMessage(payload: HMRPayload) {
const { path, changeSrcPath, timestamp } = payload as UpdatePayload
...
switch (payload.type) {
...
case 'vue-rerender':
const templatePath = `${path}?type=template`
...
import(`${templatePath}&t=${timestamp}`).then((m) => {
__VUE_HMR_RUNTIME__.rerender(path, m.render)
console.log(`[vite] ${path} template updated.`)
})
break
...
}
}其实,这个过程还用到了
serviceWorker做一些处理,但是看了下提交记录是wip,所以这里就没有分析这个逻辑,有兴趣的同学可以自己了解。
前面,我们讲了 serverPluginHtml 和 serverPluginHmr 在 HMR 过程会做的一些前期准备。然后,我们这次分析的修改 .vue 文件触发的「HMR」逻辑,它的开始是在
serverPluginVue。
首先,它会解析 .vue 文件,做一些 compiler 处理,然后通过 watcher 监听 .vue 文件的修改:
watcher.on('change', (file) => {
if (file.endsWith('.vue')) {
handleVueReload(file)
}
})可以看到在 change 事件的回调中调用了 handleVueReload(),针对我们这个 case,它会是这样:
const handleVueReload = (watcher.handleVueReload = async (
filePath: string,
timestamp: number = Date.now(),
content?: string
) => {
const publicPath = resolver.fileToRequest(filePath)
const cacheEntry = vueCache.get(filePath)
const { send } = watcher
...
let needRerender = false
...
if (!isEqualBlock(descriptor.template, prevDescriptor.template)) {
needRerender = true
}
...
if (needRerender) {
send({
type: 'vue-rerender',
path: publicPath,
changeSrcPath: publicPath,
timestamp
})
}
})handleVueReload() 它会针对 .vue 文件中,不同情况走不同的逻辑。这里,我们只是修改了 .vue 文件,给它加了一行代码,那么此时就会命中 isEqualBlock() 为 false 的逻辑,所以 needRerender 为 true,最终通过 send() 方法向浏览器推送 type 为 vue-rerender 以及携带修改的文件路径的信息。然后,我们前面 client.js 中监听 message 的地方就会拿到对应的 data,再通过 import 发起获取该模块的请求。
到这里,整个「vite」实现「HMR」的逻辑已经分析结束了。当然,这次只是针对 .vue 文件的修改来分析整个 HMR 的逻辑,相应地还有 .js、.css 的文件的修改触发的 HMR 的逻辑,但是,可以说的是只要理解这个过程是如何进行的,那么每一个 case 的分析,也只是依葫芦画瓢。
并且,其实在「HMR」的过程中还有一些辅助变量和概念,例如 hrmBoundaries、import chain、child importer 等等,它们都是用于帮助更好地进行 HMR 处理。所以,这里我就没有提及这些。有兴趣的同学可以自己去看源码中的讲解这些辅助变量和概念的意义。
其实,在当初尤大大发微博的时候,我就想着写一篇关于「vite」源码分析的文章。这两个月,我也经历一些起起伏伏,所以,一直到现在才开始交上这份答卷。但是,现在再看「vite」源码,已经不是仅仅 devServer 这么简单了,所以这次只分析了「HMR」这个点的实现,其他方面后续有时间应该会继续写其他方面,例如 rewrite、bundle、compiler 等等
首先,我们来回忆一下「CSS 作用域」这一概念,它的本质是通过让每一个选择器成为一个「unique」的存在,这样就自然而然地形成了作用域。
而提到「Vue」中「作用域 CSS」,我想大家应该立即想到以 scoped 的方式形成的带有作用域的 css。但是,值得一提的是,在「Vue」中还支持了一种「作用域 CSS」,即「CSS Module」。
提及 「CSS Module」,想必大家会有点陌生,相信有很多同学在平常开发中都是用 scoped 来实现「Vue」组件中的「作用域CSS」。所以,今天我们就来详细认知一下这两者。
「scoped 作用域」是「Vue」通过「postcss」来实现对每一个在 scoped 标签中定义的选择器的特殊作用域标识,例如:
<template>
<div id="app">
<div class="out-box">
</div>
</div>
</template>
<style lang="scss" scoped>
#app {
.out-box {
width: 200px;
height: 200px;
background-color: #faa;
}
}
</style>标识后展示在页面上的:
<div data-v-7ba5bd90 id="app">
<div data-v-7ba5bd90 class="out-box">
</div>
</div>
<style>
#app .out-box[data-v-7ba5bd90] {
width: 200px;
height: 200px;
background-color: #faa;
}
</style>可以看到,本质上是在原有的「选择器」的基础上通过「postcss」加上了一串 attr。
并且,在我们平常开发中,很常见的场景就是我们在使用一些已有的组件或第三方组件时,我们需要对原有组件的样式进行一些微小的改动。那么,这个时候就需要使用穿透来实现样式的改动,例如:
<style>
div >>> .out-box {
background-color: #aaf;
}
</style>这里需要注意的是 >>> 只是一种穿透方式,并不是所有场景下都是可以用 >>> 实现。例如,「iView」需要使用 /deep/ 的方式,「ElementUI」需要使用 ::v-deep 的方式。
相比较「scoped 作用域」,「CSS Modeul 作用域」它所具备的能力更强,所以内容也相对较多。
「CSS Module」指的是可以将一个定义好的「CSS」文件以变量的形式导入,然后通过使用这个变量对「HTML」中的元素进行样式的修饰,例如:
a.css
.box {
width: 100%;
height: 100%;
background-color: #afa;
}b.js
import style from './a.css'
const boxElem = document.createElement('div');
boxElem.className = style.box然后,渲染到页面的时候,它对应的 HTML 看起来会是这样:
<div class="a-box_jlpNx"></div>可以看出,此时的「类选择器」同样是随机生成的,这也是「CSS Module」形成作用域的所在。
值得一提的是,「CSS Module」还具备其他的能力,例如可以定义全局的「选择器」,写起来会是这样:
:global(.title) {
color: green;
}接下来的使用和局部的一样。至于,其他用法,有兴趣的同学可以去 GitHub 上自行阅读
回到本文所说的,在「Vue」中也对「CSS Module」做了相应的支持,当我们在 style 标签上添加 module 属性时,「Vue」 会在当前「组件实例」上注入一个计算属性 $style,然后我们可以通过 $style 来使用我们定义好的「选择器」,例如:
HelloWorld.vue
<template>
<div>
<div :class="$style['inner-box']"></div>
</div>
</template>
<style lang="scss" module>
.inner-box {
width: 100px;
height: 100px;
background-color: #aaf;
}
</style>然后,它渲染到页面时,对于的 HTML 会是这样:
<div class="HelloWorld_inner-box_jlpNx"></div>那么,这个时候,又回到和「scoped 作用域」一样的问题,使用了「CSS Module」来定义组件的样式,那么我在使用它的时候,如何进行覆盖?
标准的答案,对于「CSS Module」并没有覆盖的说法,有的只是为一个组件设置不同的主题。
但是,如果真的需要弄,那只能通过对该模块对应的
style标签中定义你需要的样式,然后根据传入组件的props来动态绑定class
那么,为组件设置主题,我们需要在设计组件的时候,对这个组件预留 props ,并将该 props 添加到 $style 中,然后在这个组件中的相应元素中使用,例如:
Box.vue 组件
<template>
<div>
<div :class="$style[themeColor]"></div>
</div>
</template>
<script>
export default {
props: {
themeColor: {
type: String,
default: 'line'
}
}
};
</script>
<style lang="scss" module>
.line {
width: 100px;
height: 100px;
background-color: #aaf;
}
.card {
background-color: #aaf;
}
</style>然后,我们在使用该组件的时候通过 props 传入 line 或者 card,从而实现切换组件不同的背景色。
「scoped 作用域」:
「CSS Module 作用域」:
style 管理组件中的选择器这里所说的管理,是指通过
JavaScript便捷地控制组件样式。
其实,对比「scoped」和「CSS Module」两者,各有千秋。至于,要用哪一着得看具体需求,建议大项目中可以使用「CSS Module」,小项目的话用用「scoped」应该绰绰有余。
相信很多同学都自定了自己的 GitHub Profile,但是作为这个世界上最富有想象力的一个群体,我们总在不断地推成出新(造轮子)。
那么,对于 GitHub Profile 也是一样,这里我们直接看今天要实现的一个 GitHub Profile,贪吃蛇游戏:
这个 GitHub Profile 的想法来自 Platane ,它是根据 GitHub 的 Contributions 图来生成贪吃蛇游戏,最终会以 Gif 或 SVG 的形式展示。那么,下面我们就来亲自体验一番给自己的 GitHub Profile 设置贪吃蛇游戏!
Git Action 主要是根据你在当前仓库下的 .github/workflows 目录下的 .yml 文件生成对应的 Workflow。
那么,这里我们在任意一个仓库的 .github/workflows 目录下新建 .yml 文件,然后添加如下配置:
name: generate-snake
on:
schedule:
# 每 6 小时,执行一次
- cron: "0 */6 * * *"
workflow_dispatch:
jobs:
generate-snake:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- uses: Platane/snk@master
with:
# 你的 GitHub 的名称
github_user_name: WJCHumble
# 生成的 .gif 图存储的位置
gif_out_path: dist/github-snake.gif
# 生成的 .gif 图存储的位置
svg_out_path: dist/github-snake.svg
- uses: crazy-max/[email protected]
with:
target_branch: output
build_dir: dist
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
接着,你就可以在该仓库的 Action 面板中,看到新建好的名为 generate-snake 的 Workflow:
由于我们在 .yml 配置了 workflow_dispatch 事件,所以我们可以直接通过点击面板中的 Run workflow 按钮来启动 Workflow:
等待 Workflow 运行结束后,我们就可以在该仓库的 output 分支中看到创建好的 dist 目录下会有 github-snake.gif 和 github-snake.svg 这 2 个文件。
这里是我最后生成的:
每个人的 GitHub Profile 就是以自己 GitHub Name 命名的仓库的 README.md。
那么,我们需要做的是在前面的 dist 目录下右键复制 Gif 图的地址,然后再添加到 GitHub Profile 的 README.md 中。
Gif 图的地址看起来会是这样:
https://github.com/WJCHumble/WJCHumble/blob/output/github-snake.gif?raw=true
至于为什么是复制 Gif 图的地址,而不是上传到自己的图床?
因为,我们前面设置的 Workflow 是每 6 个小时会执行一次,也就是这个 Gif 图也会随之更新,即同步你的 GitHub Contributions 生成贪吃蛇游戏。
此外,Platane 还提供了在线地址可以输入指定的 GitHub Name 来获取其对应的 GitHub Contributions 生成贪吃蛇游戏的图片,有兴趣的同学可以体验一番。
最后,如果文中存在表达不当或错误的地方,欢迎各位同学提 Issue~
随着 Vite 2.0 的发布,其底层的设计也不断地被大家所认知。其中,大家十分津津乐道的就是采用 esbuild 来做 Dev 环境下的代码转换(快到飞起 😲)。
与此同时,这也给 esbuild 带来了很多曝光。并且,esbuild 生态也陆续出现了一些新的插件(Plugin),例如 esbuild-plugin-alias、esbuild-plugin-webpack-bridge 等。
那么,回到正题,今天我将和大家一起从 esbuild 插件基础知识出发,手把手教学如何实现一个 esbuild 插件 🚀!
在 esbuild 中,插件被设计为一个函数,该函数需要返回一个对象(Object),对象中包含 name 和 setup 等 2 个属性:
const myPlugin = options => {
return {
name: "my",
setup(build) {
// ....
}
}
}其中,name 的值是一个字符串,它表示你的插件名称
。 setup 的值是一个函数,它会被传入一个参数 build(对象)。
build 对象上会暴露整个构建过程中非常重要的 2 个函数:onResolve 和 onLoad,它们都需要传入 Options(选项)和 CallBack(回调)等 2 个参数。
其中,Options 是一个对象,它包含 filter(必须)和 namespace 等 2 个属性:
interface OnResolveOptions {
filter: RegExp;
namespace?: string;
}而 CallBack 是一个函数,即回调函数。插件实现的关键则是在 onResolve 和 onLoad 中定义的回调函数内部做一些特殊的处理。
那么,接下来我们先来认识一下 Options 的 2 个属性:namespace 和 filter(划重点,它们非常重要 😲)
默认情况下,esbuild 是在文件系统上的文件(File Modules)相对应的 namespace 中运行的,即此时 namespace 的值为 file。
esbuild 的插件可以创建 Virtual Modules,而 Virtual Modules 则会使用 namespace 来和 File Modules 做区分。
注意,每个
namespace都是特定于该插件的。
并且,这个时候,我想可能有同学会问:什么是 Virtual Modules 😲?
简单地理解,Virtual Modules 是指在文件系统中不存在的模块,往往需要我们构造出 Virtual Modules 对应的模块内容。
filter 作为 Options 上必须的属性,它的值是一个正则。它主要用于匹配指定规则的导入(import)路径的模块,避免执行不需要的回调,从而提高整体打包性能。
那么,在认识完 namespace 和 filter 后。下面我们来分别认识一下 onResolve 和 onLoad 中的回调函数。
onResolve 函数的回调函数会在 esbuild 构建每个模块的导入路径(可匹配的)时执行。
onResolve 函数的回调函数需要返回一个对象,其中会包含 path、namespace、external 等属性。
通常,该回调函数会用于自定义 esbuild 处理 path 的方式,例如:
重写原本的路径,例如重定向到其他路径
将该路径所对应的模块标记为 external,即不会对改文件进行构建操作(原样输出)
onLoad 函数的回调函数会在 esbuild 解析模块之前调用,主要是用于处理并返回模块的内容,并告知 esbuild 要如何解析它们。并且,需要注意的是 onLoad 的回调函数不会处理被标记为 external 的模块。
onLoad 函数的回调函数需要返回一个对象,该对象总共有 9 个属性。这里我们来认识一下较为常见 3 个属性:
contents 处理过的模块内容loader 告知 esbuild 要如何解释该内容(默认为 js)。例如,返回的模块内容是 CSS,则声明 loader 为 cssresolveDir 是在将导入路径解析为文件系统上实际路径时,要使用的文件系统目录那么,到这里我们就已经简单认识完有关 esbuild 插件的基础知识了 😎。
所以,下面我们从实际应用场景出发,动手实现一个 esbuild 插件。
这里我们来实现一个删除代码中 console 语句的 esbuild 插件。因为,这个过程需要识别和删除 console 对应的 AST 节点。所以,需要使用 babel 提供的 3 个工具包:
@babel/parser 的 parse 函数解析代码生成 AST(抽象语法树)@babel/traverse 遍历 AST,访问需要进行操作的 AST 节点@babel/core 的 transformFromAst 函数将 AST 转化为代码那么,首先是创建整个插件的整体结构,如插件名称、setup 函数:
module.exports = options => {
return {
name: "auto-delete-console",
setup(build) {
}
}
}其次,由于我们这个插件主要是对代码内容进行操作。所以,需要使用 onLoad 函数,并且要声明 filter 为 /\.js$/,即只匹配 JavaScript 文件:
module.exports = options => {
return {
name: "auto-delete-console",
setup(build) {
build.onLoad({ filter: /\.js$/ }, (args) => {
}
}
}
}而在 onLoad 函数的回调函数中,我们需要做这 4 件事:
1.获取文件内容
onLoad 函数的回调函数会传入一个参数 args,它会包含此时模块的文件路径,即 args.path。
所以,这里我们使用 fs.promises.readFile 函数来读取该模块的内容:
build.onLoad({ filter: /\.js$/ }, async (args) => {
const source = await fs.promises.readFile(args.path, "utf8")
}2.转化代码生成 AST
因为,之后我们需要找到并删除 console 对应的 AST 节点。所以,需要使用 @babel/parser 的 parse 函数将模块的内容(代码)转为 AST:
build.onLoad({ filter: /\.js$/ }, async (args) => {
const ast = parser.parse(source)
}3.遍历 AST 节点,删除 console 对应的 AST 节点
接着,我们需要使用 @babel/traverse 来遍历 AST 来找到 console 的 AST 节点。但是,需要注意的是我们并不能直接就可以找到 console 的 AST 节点。因为,console 属于普通的函数调用,并没有像 await 一样有特殊的 AST 节点类型(AwaitExpression)。
不过,我们可以先使用 CallExpression 来直接访问函数调用的 AST 节点。然后,判断 AST 节点的 callee.object.name 是否等于 console,是则调用 path.remove 函数删除该 AST 节点:
build.onLoad({ filter: /\.js$/ }, async (args) => {
traverse(ast, {
CallExpression(path) {
//...
const memberExpression = path.node.callee
if (memberExpression.object && memberExpression.object.name === 'console') {
path.remove()
}
}
})
}4.转化 AST 生成代码
最后,我们需要使用 @babel/core 的 transformFromAst 函数将处理过的 AST 转为代码并返回:
build.onLoad({ filter: /\.js$/ }, async (args) => {
//...
const { code } = core.transformFromAst(ast)
return {
contents: code,
loader: "js"
}
}那么,到这里我们就完成了一个删除代码中 console 语句的 esbuild 插件,用一句话概括这个过程:“没有比这更简单的了 😃”。
整个插件实现的全部代码如下:
const parser = require("@babel/parser")
const traverse = require("@babel/traverse").default
const core = require("@babel/core")
const esbuild = require("esbuild")
const fs = require("fs")
module.exports = options => {
return {
name: "auto-delete-console",
setup(build) {
build.onLoad({ filter: /\.js$/ }, async (args) => {
const source = await fs.promises.readFile(args.path, "utf8")
const ast = parser.parse(source)
traverse(ast, {
CallExpression(path) {
const memberExpression = path.node.callee
if (memberExpression.object && memberExpression.object.name === 'console') {
path.remove()
}
}
})
const { code } = core.transformFromAst(ast)
return {
contents: code,
loader: "js"
}
}
}
}
}总体上来说,esbuild 的插件设计是十分简约和强大的。这一点,如果写过 webpack 插件的同学对比一下,我想应该深有体会 😶。
并且,通过阅读本文,相信大家都可以随手甩出一个 esbuild 的插件,很可能将来官方提供的插件列表就有你实现的插件 😎。
我想大家都对 Vue 的 Scope CSS 耳熟能详了,但是说起 Vue 的 Scope CSS 实现的原理,很多人应该会说不就是给 HTML、CSS 添加属性吗 🙃️?
确实是这样的,不过这只是最终 Scope CSS 呈现的结果。而这个过程又是如何实现的?我想能回答上一二的同学应该不多。
那么,回到今天本文,我将会围绕以下 3 点,和大家一起从 Vue 的 Scope CSS 的最终呈现结果出发,深入浅出一番其实现的底层原理:
Scope CSS 即作用域 CSS,组件化所密不可分的一部分。Scope CSS 使得我们可以在各组件中定义的 CSS 不产生污染。例如,我们在 Vue 中定义一个组件:
<!-- App.vue -->
<template>
<div class="box">scoped css</div>
</template>
<script>
export default {};
</script>
<style scoped>
.box {
width: 200px;
height: 200px;
background: #aff;
}
</style>通常情况下,在开发环境我们的组件会先经过 vue-loader 的处理,然后结合运行时的框架代码渲染到页面上。相应地,它们对应的 HTML 和 CSS 分别会是这样:
HTML 部分:
<div data-v-992092a6>scoped css</div>CSS 部分:
.box[data-v-992092a6] {
width: 200px;
height: 200px;
background: #aff;
}可以看到 Scope CSS 的本质是基于 HTML 和 CSS 选择器的属性,通过分别给 HTML 标签和 CSS 选择器添加 data-v-xxxx 属性的方式实现。
前面,我们也提及了在开发环境下一个组件(.vue 文件)会先由 vue-loader 来处理。那么,针对 Scope CSS 而言,vue-loader 会做这 3 件事:
template、script、style 对应的代码块export 组件实例,在组件实例的选项上绑定 ScopIdstyle 的 CSS 代码进行编译转化,应用 ScopId 生成选择器的属性注意,这里讲的只是 vue-loader 对 .vue 文件的处理部分,不涉及 HMR、配合 Devtool 的逻辑,有兴趣的同学可以自行了解~
然而,之所以 vue-loader 有这么多的能力,主要是因为 vue-loader 的底层使用了 Vue 官方提供的包(package) @vue/component-compiler-utils,其提供了解析组件(.vue 文件)、编译模版 template、编译 style等 3 种能力。
那么,下面我们就先来看一下 vue-loader 是如何使用 @vue/component-compiler-utils 来解析组件提取 template、script、style 的。
vue-loader 提取 template、script、style 的过程主要是使用了 @vue/component-compiler-utils 包的 parse 方法,这个过程对应的代码(伪代码)会是这样:
// vue-loader/lib/index.js
const { parse } = require("@vue/component-compiler-utils");
module.exports = function (source) {
const loaderContext = this;
const { sourceMap, rootContext, resourcePath } = loaderContext;
const sourceRoot = path.dirname(path.relative(context, resourcePath));
const descriptor = parse({
source,
compiler: require("vue-template-compiler"),
filename,
sourceRoot,
needMap: sourceMap,
});
};我们来逐点分析一下这段代码,首先,会获取当前上下文 loaderContext,它会包含 webpack 打包过程核心对象 compiler、compilation 等。
其次,再构建文件资源入口 sourceRoot,一般情况下它指的是 src 文件目录,它主要用于构建 source-map 使用。
最后,则会使用 @vue/component-compiler-utils 提供的 parse 方法来解析 source(组件代码)。这里,我们先来看一下 parse 方法的几个参数:
soruce 源代码块,这里是组件对应的代码,即包含了 template、style、scriptcompiler 编译核心对象,它是一个 CommonJS 模块(vue-template-compiler),parse 方法内部会使用它提供的 parseComponent 方法来解析组件filename 当前组件的文件名,例如 App.vuesourceRoot 文件资源入口,用于构建 source-map 使用needMap 是否需要 source-map,parse 方法内部会根据 needMap 的值(true 或 false,默认为 true)来判断是否生成 script、style 对应的 source-map而 parse 方法的执行则会返回一个对象给 desciptor,它会包含 template、style、script 分别对应的代码块。
那么,可以看到的是 vue-loader 解析组件的过程,几乎外包给了 Vue 提供的工具包(package)。并且,我想这个时候肯定会有同学问:这些和 Vue 的 Scope CSS 有几毛钱关系 🙃️?
有很大的关系!因为 Vue 的 Scope CSS 可不是无米之炊,它实现的前提是组件被解析了,然后再分别处理 template 和 style 部分的代码!
那么,显然到这里我们已经完成了对组件的解析。接着,则需要构造和导出组件实例~
vue-loader 在解析完组件后,会分别处理并生成 template、script、style 的导入 import 语句,再调用 normalizer 方法正常化(normalizer)组件,最后将它们拼接成代码字符串:
let templateImport = `var render, staticRenderFns`;
if (descriptor.template) {
// 构造 template 的 import 语句
}
let scriptImport = `var script = {}`;
if (descriptor.script) {
// 构造 script 的 import 语句
}
let stylesCode = ``;
if (descriptor.styles.length) {
// 构造 style 的 import 语句
}
let code =
`
${templateImport}
${scriptImport}
${stylesCode}
import normalizer from ${stringifyRequest(`!${componentNormalizerPath}`)}
var component = normalizer(
script,
render,
staticRenderFns,
${hasFunctional ? `true` : `false`},
${/injectStyles/.test(stylesCode) ? `injectStyles` : `null`},
${hasScoped ? JSON.stringify(id) : `null`},
${isServer ? JSON.stringify(hash(request)) : `null`}
${isShadow ? `,true` : ``}
)
`.trim() + `\n`;其中,templateImport、scriptImport、stylesCode 等构造好的 template、script、style 部分的导入 import 语句看起来会是这样:
import {
render,
staticRenderFns,
} from "./App.vue?vue&type=template&id=7ba5bd90&scoped=true&";
import script from "./App.vue?vue&type=script&lang=js&";
// 兼容命名方式的导出
export * from "./App.vue?vue&type=script&lang=js&";
import style0 from "./App.vue?vue&type=style&index=0&id=7ba5bd90&scoped=true&lang=css&";不知道同学们注意 template 和 style 的导入 import 语句都有这么一个共同的部分 id=7ba5bd90&scoped=true,这表示此时组件的 template 和 style 是需要 Scope CSS 的,并且 scopeId 为 7ba5bd90。
当然,这仅仅是告知后续的 template 和 style 编译时需要注意生成 Scope CSS,也就是 Scope CSS 的第一步!那么,接着则会调用 normalizer 方法来对该组件进行正常化(Normalizer)处理:
import normalizer from "!../node_modules/vue-loader/lib/runtime/componentNormalizer.js";
var component = normalizer(
script,
render,
staticRenderFns,
false,
null,
"7ba5bd90",
null
);
export default component.exports;注意,
normalizer是重命名了原方法normalizeComponent,以下统称normalizeComponent~
我想同学们应该都注意到了,此时 scopeId 会作为参数传给 normalizeComponent 方法,而传给 normalizeComponent 的目的则是为了在组件实例的 options 上绑定 scopeId。那么,我们来看一下 normalizeComponent 方法(伪代码):
function normalizeComponent (
scriptExports,
render,
staticRenderFns,
functionalTemplate,
injectStyles,
scopeId,
moduleIdentifier, /* server only */
shadowMode /* vue-cli only */
) {
...
var options = typeof scriptExports === 'function'
? scriptExports.options
: scriptExports
// scopedId
if (scopeId) {
options._scopeId = 'data-v-' + scopeId
}
...
}可以看到,这里的 options._scopeId 会等于 data-v-7ba5bd90,而它的作用主要是用于在 patch 的时候,为当前组件的 HTML 标签添加名为 data-v-7ba5bd90 的属性。因此,这也是 template 为什么会形成带有 scopeId 的真正所在!
在构造完 Style 对应的导入语句后,由于此时 import 语句中的 query 包含 vue,则会被 vue-loader 内部的 Pitching Loader 处理。而 Pitching Loader 则会重写 import 语句,拼接上内联(inline)的 Loader,这看起来会是这样:
export * from '
"-!../node_modules/vue-style-loader/index.js??ref--6-oneOf-1-0
!../node_modules/css-loader/dist/cjs.js??ref--6-oneOf-1-1
!../node_modules/vue-loader/lib/loaders/stylePostLoader.js
!../node_modules/postcss-loader/src/index.js??ref--6-oneOf-1-2
!../node_modules/cache-loader/dist/cjs.js??ref--0-0
!../node_modules/vue-loader/lib/index.js??vue-loader-options!./App.vue?vue&type=style&index=0&id=7ba5bd90&scoped=true&lang=css&"
'然后,webpack 会解析出模块所需要的 Loader,显然这里会解析出 6 个 Loader:
[
{ loader: "vue-style-loader", options: "?ref--6-oneOf-1-0" },
{ loader: "css-loader", options: "?ref--6-oneOf-1-1" },
{ loader: "stylePostLoader", options: undefined },
{ loader: "postcss-loader", options: "?ref--6-oneOf-1-2" },
{ loader: "cache-loader", options: "?ref--0-0" },
{ loader: "vue-loader", options: "?vue-loader-options" }
]那么,此时 webpack 则会执行这 6 个 Loader(当然还有解析模块本身)。并且,这里会忽略 webpack.config.js 中符合规则的 Normal Loader(vue-style-loader 还会忽略前置 Loader)。
不了解内联 Loader 的同学,可以看一下这篇文章【webpack进阶】你真的掌握了loader么?- loader十问
而对于 Scope CSS 而言,最核心的就是 stylePostLoader。下面,我们来看一下 stylePostLoader 的定义:
const { compileStyle } = require("@vue/component-compiler-utils");
module.exports = function (source, inMap) {
const query = qs.parse(this.resourceQuery.slice(1));
const { code, map, errors } = compileStyle({
source,
filename: this.resourcePath,
id: `data-v-${query.id}`,
map: inMap,
scoped: !!query.scoped,
trim: true,
});
if (errors.length) {
this.callback(errors[0]);
} else {
this.callback(null, code, map);
}
};从 stylePostLoader 的定义中,我们知道它是使用了 @vue/component-compiler-utils 提供的 compileStyle 方法来完成对组件 style 的编译。并且,此时会传入参数 id 为 data-v-${query.id},即 data-v-7ba5bd90,而这也是 style 中声明的选择器的属性为 scopeId 的关键点!
而在 compileStyle 函数内部,则是使用的我们所熟知 postcss 来完成对 style 代码的编译和构造选择器的 scopeId 属性。至于如何使用 postcss 完成这个过程,这里就不做过多介绍,有兴趣的同学自行了解哈~
不知道同学们是否还记得在 3.2 构造并导出组件实例的时候,我们讲了在组件实例的 options 上绑定 _scopeId 是实现 template 的 Scope 的关键点!但是,当时我们并没有介绍这个 _scopeId 到底是如何应用到 template 上的元素的 😲?
如果,你想在 vue-loader 或者 @vue/component-compiler-utils 的代码中找到这个答案,我可以和你说找一万年都找不到! 因为,真正应用 _scopeId 的过程是发生在 Vue 运行时的框架代码中(没想到吧 😵)。
了解过 Vue 模版编译过程的同学,我想应该都知道 template 会被编译成 render 函数,然后会根据 render 函数创建对应的 VNode,最后再由 VNode 渲染成真实的 DOM 在页面上:
而 VNode 到真实 DOM 这个过程是由 patch 方法完成的。假设,此时我们是第一次渲染 DOM,这在 patch 方法中会命中 isUndef(oldVnode) 为 true 的逻辑:
function patch (oldVnode, vnode, hydrating, removeOnly) {
if (isUndef(oldVnode)) {
// empty mount (likely as component), create new root element
isInitialPatch = true
createElm(vnode, insertedVnodeQueue)
}
}因为第一次渲染 DOM,所以压根不存在什么
oldVnode😶
可以看到,此时会执行 createElm 方法。而在 createElm 方法中则会创建 VNode 对应的真实 DOM,并且它还做了一件很重要的事,调用 setScope 方法应用 _scopeId 在 DOM 上生成 data-v-xxx 的属性!对应的代码(伪代码):
// packages/src/core/vdom/patch.js
function createElm(
vnode,
insertedVnodeQueue,
parentElm,
refElm,
nested,
ownerArray,
index
) {
...
setScope(vnode);
...
}在 setScope 方法中则会使用组件实例的 options._scopeId 作为属性来添加到 DOM 上,从而生成了 template 中的 HTML 标签上名为 data-v-xxx 的属性。并且,这个过程会由 Vue 封装好的工具函数 nodeOps.setStyleScope 完成,它的本质是调用 DOM 对象的 setAttribute 方法:
// src/platforms/web/runtime/node-ops.js
export function setStyleScope (node: Element, scopeId: string) {
node.setAttribute(scopeId, '')
}如果,有在网上查找过关于 vue-loader 和 Scope CSS 的文章的同学会发现,很多文章都是说在 @vue/component-compiler-utils 包的 compilerTemplate 方法中应用 scopeId 生成了 template 中 HTML 标签的属性。但是,通过阅读本文,我们会发现这两者压根没有任何关系(SSR 的情况除外)!
并且,我想同学们也注意到了一点,本文中提及的 Vue 运行时框架的代码是 Vue 2.x 版本的(不是 Vue3)。所以,有兴趣的同学可以借助本文提供的路线推敲一下 Vue3 中 Scope CSS 的过程,相信你会收获满满 😎。最后,如果本文中存在表达不当或错误的地方,欢迎各位同学提 Issue~
在 ChatGPT 出现之时,社区内也出现过 把 React 官方文档投喂给它 ,然后对它进行提问的实践。但是,由于每次 ChatGPT 对话能接受的文本内容对应的 Token 是有上限的,所以这种使用方式存在一定的手动操作成本和不能复用的问题。
而 Documate 的出现则是通过工具链的集成,仅需使用 CLI 提供的命令和部署服务端的代码,就可以很轻松地实现上述的数据投喂模型 + 提问 ChatGPT 过程的自动化,让你的文档(VitePress、Docusaurus、Docsify)站点具备 AI 对话功能。
Documate 的官网文档对如何使用它进行现有文档站点的接入介绍的很为详尽,并且其作者(月影)也专门写了【黑科技】让你的 VitePress 文档站支持 AI 对话能力文章介绍,对接入 Documate 感兴趣的同学可以自行阅读文档或文章。
相信很多同学和我一样,对如何基于文档的内容实现 AI Chat 留有疑问,那么接下来,本文将围绕 Documate 的实现原理分别展开介绍:
Documate 主要由 2 部分构成,Documate CLI 和服务端(Backend)接口实现,其中 Documate CLI 主要职责是获取本地文档过程的文档和构造指定结构的文档数据,最终上传数据到 upload 接口,而服务端主要职责是提供 upload 和 ask 接口,它们分别的作用:
upload 接口,接收来自 CLI 上传的文档数据,对数据进行 Token 化、分片入库等操作ask 接口,接收来自文档站点的提问内容,校验内容合法性、生成内容的矢量坐标,基于所有文档进行矢量搜索、进行 Chat 提问获取结果并返回等操作整体实现机制如下图所示:
其中,关于 Documate CLI 主要支持了 init 和 upload 等 2 个命令,init 负责向文档工程注入 Documate 运行的基础工程配置,upload 负责上传文档工程的文档内容到服务端,2 者的实现并不复杂,有兴趣的同学可以自行了解。
相比较 CLI,在 Documate 的服务端实现的一系列能力是支持文档内容对话的关键技术点,那这些能力又是如何通过代码实现的?下面,我们来分别从代码层面深入认识下 Documate 服务端的各个能力的实现。
Documate 服务端主要负责接收并存储 documate upload 命令上传的文档内容、根据对话的提问内容返回与之关联的回答:
其中,后者需要使用 OpenAI 提供的 Text Embeddings 来实现 AI 对话的功能,所以,我们先来对 OpenAI Text Embeddings 建立一个基础的认知。
在 OpenAI 的开发者平台 提供了很多功能的 API 给开发者调用:
基于文档内容的 AI 对话的实现本质是根据关键词搜索得到答案,所以需要使用到 Embeddings,Embedding 主要用于衡量文本字符串之间的关联性,一个 Embedding 是由浮点数字构成的矢量数组,例如 [0.938293, 0.284951, 0.348264, 0.948276, 0.564720]。2 个矢量之间的距离表示它们的关联性。距离小表示它们之间的关联性高,反之关联性低。
文档内容的存储主要分为 2 个步骤:
1、根据模型每次能接受的 Token 最大长度去对内容进行分片 chunks
OpenAI 的模型调用所能接收的 Token 的长度是有限的,对应的 text-embedding-ada-002 模型可接收的 Token 最大长度是 1536。所以,在接收到 CLI 上传的文档内容后,需要根据 Token 的最大长度 1536 来对文档内容进行分片:
const tokenizer = require('gpt-3-encoder');
// Split the page content into chunks base on the MAX_TOKEN_PER_CHUNK
function getContentChunks(content) {
// GPT-2 and GPT-3 use byte pair encoding to turn text into a series of integers to feed into the model.
const encoded = tokenizer.encode(content);
const tokenChunks = encoded.reduce(
(acc, token) => (
acc[acc.length - 1].length < MAX_TOKEN_PER_CHUNK
? acc[acc.length - 1].push(token)
: acc.push([token]),
acc
),
[[]],
);
return tokenChunks.map(tokens => tokenizer.decode(tokens));
}首先,会先使用 gpt-3-encoder 来对文档内容进行 Byte Pair Encoding,将文档从文本形式转成一系列数字,从而用于后续投喂(Feed)给模型。其中, BPE 算法 的实现:
由于 BPE 编码后的结果 encoded 是一个 Token 数组,且模型每次能投喂是有最大长度的限制,所以根据 Token 最大长度进行分片,也就是代码中的 acc,acc 初始值是一个二维数组,每个值是一个 Token,每个元素数组主要用于存储模型最大 Token 限制下的数据,即将一个大的 Token 分片成模型允许传入的小 Token。
对文档内容进行分片的目的是用于后续将文档内容投喂(Feed)给模型的时候是有效(不会超出 Token 最大长度)和连续的。
2、构造指定的数据结构 ChunkItem 存入数据库中,ChunkItem 数据结构
因为,将文档的所有内容全部投喂给模型是有成本(Token 计费)并且收益低(问答内容关联性低),所以,需要在提问的环节通过矢量数据库查询的方式,查出关联的文档内容,然后再将对应的文档内容投喂给模型,模型根据对关联文档上下文和问题给出合理的回答。
那么,在前面根据 BPE 生成的 Token 和分片生成的基础上,需要将该结果按指定的数据结构(路径、标题等)存入数据库中,用于后续提问的时候查询矢量数据库:
const aircode = require('aircode');
const PagesTable = aircode.db.table('pages');
// 根据 BPE 和模型的 Token 上限限制去划分 chunk
const chunks = getContentChunks(content);
// 构造出存到数据库中的数据结构
const pagesToSave = chunks.map((chunk, index) => ({
project,
// 文档文件路径
path,
title,
// 文件内容生成的 hash 值
checksum,
chunkIndex: index,
// 内容
content: chunk,
embedding: null,
}))
// Save the result to database
for (let i = 0; i < pagesToSave.length; i += 100) {
await PagesTable.save(pagesToSave.slice(i, i + 100));
}这里会使用到 AirCode 提供的表操作的 PagesTable.save API,用于将构造好的数据入库。
OpenAI 要求输入的内容是需要符合它们规定的内容政策的,所以需要先对输入的问题进行内容检查,OpenAI 也提供相应的 API 用于检查内容安全,而 OpenAI 的 API 调用可以通过 OpenAI Node 来实现:
const OpenAI = require('openai');
// 创建 OpenAI 的实例
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
});
// 提问内容
const question = params.question.trim();
// https://platform.openai.com/docs/api-reference/moderations
const { results: moderationRes } = await openai.moderations.create({
input: question,
});
if (moderationRes[0].flagged) {
console.log('The user input contains flagged content.', moderationRes[0].categories);
context.status(403);
return {
error: 'Question input didn\'t meet the moderation criteria.',
categories: moderationRes[0].categories,
};
}如果,返回的结果 moderationsRes[0].flagged 则视为不符合,标识为错误的请求。反之符合,接着使用 Embeddings 来获取提问内容所对应的矢量坐标:
// https://platform.openai.com/docs/api-reference/embeddings/object
const { data: [ { embedding }] } = await openai.embeddings.create({
model: 'text-embedding-ada-002',
input: question.replace(/\n/g, ' '),
});那么,有了矢量坐标后,我们需要用先前存储到数据库的分片文本创建矢量数据库,这可以使用 Orama 完成,它提供了全文和矢量搜索的能力。
首先,需要先从数据库中查询出所有的文档数据:
const { project = 'default' } = params;
const pages = await PagesTable
.where({ project })
.projection({ path: 1, title: 1, content: 1, embedding: 1, _id: 0 })
.find();然后,通过 Orama 提供的 create 方法初始化一个矢量数据库 memDB,并且将文档内容 pages 插入到数据库中:
const memDB = await create({
// 建立好索引的 `schema`
schema: {
path: 'string',
title: 'string',
content: 'string',
embedding: 'vector[1536]',
},
});
await insertMultiple(memDB, pages);有了文档内容对应的矢量数据库后,我们就可以用前面 Emdeedings 根据提问内容生成的矢量坐标进行搜索,使用 Orama 提供的 searchVector 进行搜索:
const { hits } = await searchVector(memDB, {
vector: embedding,
property: 'embedding',
similarity: 0.8, // Minimum similarity. Defaults to `0.8`
limit: 10, // Defaults to `10`
offset: 0, // Defaults to `0`
});那么,为什么使用的是矢量搜索而不是文本搜索? 因为,矢量搜索的作用是为了搜索到和文本对应的矢量位置相近的内容,用于生成上下文本 GPT 整理最终的回答。
其中 hits 的数据结构:
{
count: 1,
elapsed: {
raw: 25000,
formatted: '25ms',
},
hits: [
{
id: '1-19238',
score: 0.812383129,
document: {
title: 'The Prestige',
embedding: [0.938293, 0.284951, 0.348264, 0.948276, 0.564720],
}
}
]
}由于,先前将文档内容根据 Embeddings 的 Token 最大长度分片进行存储,所以,这里需要将 hits 中的数据获取的内容组合起来:
let tokenCount = 0;
let contextSections = '';
for (let i = 0; i < hits.length; i += 1) {
const { content } = hits[i].document;
// 注意 encode,用于组合分片
const encoded = tokenizer.encode(content);
tokenCount += encoded.length;
// 判断是否达到 token 上限
if (tokenCount >= MAX_CONTEXT_TOKEN && contextSections !== '') {
break;
}
contextSections += `${content.trim()}\n---\n`;
}到这里,我们已经有了问题和问题关联的内容,可以用它们构造一个 Prompt 用于后续 AI 对话使用:
const prompt = `You are a very kindly assistant who loves to help people. Given the following sections from documatation, answer the question using only that information, outputted in markdown format. If you are unsure and the answer is not explicitly written in the documentation, say "Sorry, I don't know how to help with that." Always trying to anwser in the spoken language of the questioner.
Context sections:
${contextSections}
Question:
${question}
Answer as markdown (including related code snippets if available):`
下面,我们就可以调用 OpenAI 的 API 进行 AI 对话:
const messages = [{
role: 'user',
content: prompt,
}];
const response = await openai.chat.completions.create({
messages,
model: 'gpt-3.5-turbo',
max_tokens: 512,
temperature: 0.4,
stream: true,
})其中,response 是一个 OpenAI API 调用返回的自定义数据结构的 Streaming Responses,直接将 response 返回给 ask 接口请求方肯定是不合理的(请求方只需要拿到答案)。那么,这里可以使用这里可以使用 Vercel 团队实现的 ai 提供的 OpenAIStream 函数来完成:
const { OpenAIStream } = require('ai');
const stream = OpenAIStream(response);
return stream;OpenAIStream 会自动将 OpenAI Completions 返回的结果解析成可以正常读取的 Streaming Resonsese,如果使用的是 AirCode 则可以直接返回 stream,如果使用的是普通的 Node Server,可以进一步使用 ai 提供的 streamToResponse 函数来将 stream 转为 ServerResponse 对象:
const { OpenAIStream, streamToResponse } = require('ai');
const stream = OpenAIStream(response);
streamToResponse(stream);通过学习 Documate 内部的实现原理,我们可以知道了如何从实际的问题出发,结合使用 OpenAI API 提供的模型解决问题。在这个基础上,我们也可以去做别的场景探索,让 AI 成为现在或者将来我们解决问题的一种技术手段或尝试,而不是仅仅局限于会使用 ChatGPT 提问和获取答案。
提及自动化一词,我想很多同学会想到 CI/CD,这 2 者之间确实是存在一定的联系,可以简单理解成父、子集合之间的关系。
而正如文章标题所言,近期我在研究 macOS App 自动化分发 App Store 的事情,通俗点讲就是希望把原先手动构建 .xcarchive 文件、导出 .pkg 文件以及上传 App Store 的操作转为用 Shell 脚本自动化完成这些步骤。其中,增加的 Shell 脚本会基于现有的 CI/CD 的实现,加入到适当的位置。
那么,今天本文也会从 CI 基础出发,循序渐进地带着大家认识下 macOS App 自动化分发 App Store 实现的所以然。
持续集成,Continuous Integration,简称 CI。这里我们来看下 Wikipedia 上对 CI 的介绍:
—— In software engineering, continuous integration (CI) is the practice of merging all developers' working copies to a shared mainline several times a day. Grady Booch first proposed the term CI in his 1991 method, although he did not advocate integrating several times a day. Extreme programming (XP) adopted the concept of CI and did advocate integrating more than once per day – perhaps as many as tens of times per day.
通常情况下,这在我们实际开发场景中,CI 指的是将项目的构建过程集成到某个单独的软件的实践。例如,在前面所说 macOS App 自动化分发 App Store 的 Shell 实现会加入到现有的 CI/CD 过程,它的 CI 的过程会是这样:
其中,比较关键的则是构建机(Slave Node),我们的整个构建过程的脚本实现都会在构建机上执行,例如后面要讲的自动化分发 App Store 的实现。而这里脚本使用的是 Shell 编写,当然也可以用 Google 的 zx,有兴趣的同学可以自行了解,这里不做展开。
由于,在认识 macOS App 自动化分发 App Store 之前,我们需要先知道 macOS App 手动分发的过程是怎么样的,以便于后续用自动化脚本一一实现手动分发的步骤。
macOS App 手动分发 App Store 的过程,通俗点讲就是使用 Xcode 提供的 GUI 界面操作完成。但是,在进行正式的操作使用的前提是要有一个可以发布到 App Store 配置完备的 macOS App,这要求你需要满足以下 3 点:
关于第 1 点,我想应该没什么难理解的。下面,我们从创建一个 macOS App 出发来串联第 2、3 点要做的事情。
创建一个 macOS App 的项目,可以通过 Xcode 快速创建一个,打开 Xcode ——> Create a new Xcode Project ——> 选择创建应用的 Platform(macOS)——> 填写项目名称、Team、Organization Identifier 等信息 ——> 在 General 中选择 App Category 和 App Icons,这里我创建的应用叫 FEKit。
使用 Xcode 打开该项目的 .xcodeproj 文件,或者在终端输入,在我们这个例子则是:
open FEKit.xcodeproj选择构建的目标,这里我们选择 macOS 作为协议(Scheme)和目标(Target):
配置应用的 Bundle Identifier、Provision Profile、Signing Certificate,这可以在 Apple Developer 后台或者在 Xcode 的 Preferences 中添加 Apple ID 来创建,无论使用其中哪种方式创建的,都会在 Apple Developer 后台的 Certificates, Identifiers & Profiles 中展示:
其中,如果我们要分发 App Store,则需要这 2 个证书:
当然,除开这 2 个证书,我们还需要在 Certificates, Identifiers & Profiles 页面的 Identifiers 和 Profiles 中分别创建 App ID 和 Provisioning Profile,这 2 个步骤比较简单(这里不做展开)。
在证书、Indentifiers、Profiles 创建完后,则可以下载证书(.cer)和 Provisioning Profile(.provisionprofile)文件到本地,然后分别双击打开,其中证书则会加载到电脑登录对应的钥匙串(keychain)中,而 Provisioning Profile 则会被 Xcode 使用。并且,值得一提的是每个证书都是加密的,需要配套的密钥来解密使用,也就是一个证书(.cer 文件)对应一个密钥(.p12 文件),这个密钥则是由证书创建者生成的,所以,你在创建证书的时候需要选择一个 .certSigningRequest 文件:
然后在加载证书(.cer 文件)到本地,并且确保有证书对应的密钥( .p12 文件)后,最终登录的钥匙串中的证书会是这样:
接着,我们则可以使用 Xcode 的 Production -> Archive 来构建 .xcarchive 文件:
构建完后,Xcode 会弹出窗口让你选择 Distribute App 或 Validate App:
这里,我们选择 Distribution App -> App Store Connect -> Export -> 选择 Development Team -> Manually manage signing,此时会要求我们选择前面提及的 Distribution 证书、Installer 证书和 Provisioning Profile:
选择 Next -> Export 后,需要选择导出的文件目录,则在该目录下会生成 FEKit.pkg 文件,然后我们可以通过 Transporter 工具来将该文件上传到 App Store Connect(或者前面 Xcode 选择 Export 或 Upload 的时候选择 Upload),之后则可以在 App Store Connect 后台的 TestFlight 查看:
所以,我们通常所说的上传 App Store,指的是上传到 App Store Connect 的 TestFlight,后续再由这里的 App Store 中提交上传文件的审核,审核通过再进行上架的操作。并且,需要注意的是每次上传的 .pkg 文件的版本号都需要比上一次的版本号大一(类似于 NPM 的 Package Version)。
那么,到这里整个手动分发 App Store 的过程就介绍完毕了,总结起来主要是这 3 个步骤:
所以,下面我们需要用 Shell 脚本自动化实现这 3 个步骤,也就是 macOS App 自动化分发 App Store。
在介绍 macOS App 自动化分发 App Store 实现之前,我们先来认识这 3 个工具:
xrun altool、xrun xcode-select而在接下来讲解 macOS App 自动化分发 App Store 过程中,则会分别提及使用这些工具提供的能力来完成前面的手动步骤。那么,下面就让我们开始逐步认识下自动化的实现过程,首先是构建 .xcarive 文件。
我们可以使用 xcodebuild.xcarchive 命令来构建生成 .xcarchive 文件:
xcodebuild.xcarchive \
-scheme "FEKit (macOS)" \
-configuration Release \
-archivePath ./Output/FEKit可以看到,这里我们使用了 3 个 Option,它们分别的作用:
-scheme 构建的协议,不同的目标 Target 通常对应不同的协议,例如 FEKit (iOS) 或 FEKit (macOS),前者是 IOS,后者是 macOS-configuration 构建的配置,例如 Debug 或 Release,不同的配置对应的证书、签名配置会有不同-archivePath 构建 .xcarchive 导出的目录和文件名,这里则会导出到 Output 目录下并命名为 FEKit.xcarchive其中,关于项目已有的协议和配置,则可以使用 xcodebuild -list 命令查看。
构建完 .xcarchive 文件后,则需要根据改文件导出 .pkg 文件,这同样可以使用 xcodebuild 提供的 Option 命令完成:
xcodebuild -exportArchive \
-archivePath ./Output/FEKit.xcarchive \
-exportPath ./Output/Pkgs \
-exportOptionsPlist ./Build/ExportOptions.plist其中,关于 -exportOptionsPlist 则是你导出 .pkg 相关的配置,它会是这样:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>destination</key>
<string>export</string>
<key>installerSigningCertificate</key>
<string>你的 Mac AppStore Install 证书 ID</string>
<key>manageAppVersionAndBuildNumber</key>
<true/>
<key>method</key>
<string>app-store</string>
<key>provisioningProfiles</key>
<dict>
<key>你的 Bundle ID</key>
<string>你的 Provisioning Profile 的名称</string>
</dict>
<key>signingCertificate</key>
<string>你的证书 ID</string>
<key>signingStyle</key>
<string>manual</string>
<key>teamID</key>
<string>你的 Team ID</string>
<key>uploadSymbols</key>
<true/>
</dict>
</plist>当然,如果你不想手动创建或填写这些信息,可以用 Xcode 手动导出 .pkg 操作一次,ExportOptions.plist 文件会自动生成在导出的文件目录下。
执行完前面的命令后,导出的 .pkg 文件则会在 -exportPath 配置的文件路径下,在这里也就是在 /Outputs/Pkgs/ 文件目录下。
接着,则是最后一步验证和分发 .pkg 文件。这一步骤需要使用 xcrun 和 altool 完成。首先,执行 xcrun altool --validate-app 来验证 .pkg 文件,这个主要用于确认你的应用是否满足上传的条件,例如是否选择 App Category、App Icon 以及版本号递增等,相应的命令则是:
xcrun altool --validate-app \
-f ./Output/Pkgs/FEKit.pkg \
-t macOS \
-u xxxxx \
-p xxxxx \
--show-progress可以看到,这里使用到了 5 个 Options,它们各自的作用:
-f 需要验证的 .pkg 文件所在文件目录位置-t 验证的目标类型,例如 macOS 或 IOS-u 用于连接 App Store Connect 的 Apple Developer 账号(Apple ID)-p 和账号(Apple ID)对应的 App 专用密码--show-progress 用于输出验证过程的执行情况其中,关于 -p 的 App 专用密码则需要去Apple ID 后台申请。并且,为了避免将密码明文展示在执行的命令中,我们可以单独维护一个文件来存储账号和密码:
#!/bin/bash
# App Developer 账号(Apple ID)
user="xxxxxxxx"
# App 专用密码
pwd="xxxxxx"相应地,还需要根据 xcrun altool --validate-app 命令执行的结果(成功或失败)做不同的后续处理:
#!/bin/bash
# app_store_user_pwd.sh 可以单独放到一个隐藏目录,这里只是作为例子所以没有放到隐藏目录
source "./app_store_user_pwd.sh"
echo "Run xcrun altool --validate-app..."
xcrun altool --validate-app --f ./FEKit.pkg -t macOS -u $user -p $pwd --show-progress
if [ $? -eq 0 ]; then
echo "validate-app success"
# 执行上传的命令
else
echo "validate-app fail"
exit -1;
fi其中,$? 表示上个命令执行结果,0 表示成功,1 表示失败,所以这里我们使用 if [ $? -eq 0 ]; then 判断验证命令执行结果是否等于 0,是则进行后续上传的处理,不是则输出验证失败的信息并退出。
那么,如果在验证通过 .pkg 文件后,我们则可以上传 .pkg 文件至 App Store Connect,这需要执行 xcrun altool --upload-app 命令:
xcrun altool --upload-app \
-f ./Output/Pkgs/FEKit.pkg \
-t macOS \
-u xxxxx \
-p xxxxx \
--show-progress可以看到上传的命令和验证的命令使用上大同小异,只有第一个 Option 不同。那么,到这里整个实现自动化分发 App Store 的过程已经介绍完了,由于前面都是分步骤讲解的,所以 Shell 脚本的实现都是分开的,这里我们把上面讲到的 Shell 实现都合并到一个 .sh 文件中:
#!/bin/bash
echo "Run xcodebuild archive..."
xcodebuild archive \
-scheme "FEKit (macOS)" \
-configuration Release \
-archivePath ./Output/FEKit
ARCHIVE_FILE=./Output/FEKit.xcarchive
if [ ! -e "$ARCHIVE_FILE" ]; then
echo ".xarchive doesn't exist";
exit -1;
fi
echo "Run xcodebuild -exportArchive..."
xcodebuild -exportArchive \
-archivePath ./Output/FEKit.xcarchive \
-exportPath ./Output/Pkgs \
-exportOptionsPlist ./Build/ExportOptions.plist
PKG_FILE=./Output/Pkgs/FEKit.pkg
if [ ! -e "$PKG_FILE" ]; then
echo ".pkg doesn't exist";
exit -1;
fi
source "./Build/app_store_user_pwd.sh"
xcrun altool --validate-app --f $PKG_FILE -t macOS -u $user -p $pwd --show-progress
if [ $? -eq 1 ]; then
echo "altool validate-app fail"
exit -1;
fi
echo "altool validate-app success"
xcrun altool --upload-app --f $PKG_FILE -t macOS -u $user -p $pwd --show-progress
if [ $? -eq 0 ]; then
echo "altool --upload-app success"
else
echo "altool --upload-app fail"
fi最后,这里我们用一个流程图再回顾下整个自动化分发 App Store 的过程:
并且,我想可能有同学会问,作为前端我们需要懂这个吗?个人认为是需要的,因为在一些场景下,比如说做 React Native 或 Electron 开发的时候,不可避免地就会接触到原生应用的签名、构建、公证(Notarize)和分发 App Store 的概念,所以,通过亲身地体验一番原生应用实现这些的过程还是有一定收益的(知其然使其然)。此外,社区中也有支持开箱即用的实现前面步骤的工具 fastlane,有兴趣的同学可以了解下。
近期,在团队内推自动化表单,主要是为了去掉后台项目中繁多的表单代码。众所周知,表单一直都是后台代码的一个痛点,因为它的代码就是一个字 “长”...所以,作为一名 21 世纪的前端工程师,我们要时刻反省如何提效(能不写代码就不写代码)。
自动化表单的主要设计理念是围绕一个渲染器,通过配置对象来生成对应的表单。那么,这个时候就遇到了一个问题,对象和 UI 之间是脱离的,这就好比很多人习惯用 template 的方式写「Vue」,而不是更好性能的 render 函数,因为前者更加语义化~
那么,有办法实现语义化吗?答案是:当然可以。我们可以规定一个简易的「模版」语法,通过编译「模版」生成对应的 AST 抽象语法树,它的本质也是对象。那么,这个时候刚好“牛头对上马嘴了”,渲染器再基于这个 AST 来渲染表单,从而完成「模版」到 AST 到表单的转化过程~
并且,提及「模版」语法,我想大家立马会想起「Vue」的「模版」(template)语法。所以,今天我们也将借助「Vue」的核心编译能力 compiler-core 来玩转模版编译!
本次文章将分为以下三个部分进行:
compiler-core 的内部运行原理,掌握模版编译基础。正文开始~
首先,我们先来了解一下什么是「Monorepo」,维基百科上对它的介绍:
———— In revision control systems, a monorepo is a software development strategy where code for many projects is stored in the same repository.
简单理解,「Monorepo」指一种将多个项目放到一个仓库的一种管理项目的策略。当然,这只是概念上的理解。而对于实际开发中的场景,「Monorepo」的使用通常是通过 yarn 的 workspaces 工作空间,又或者是 lerna 这种第三方工具库来实现。使用「Monorepo」的方式来管理项目会给我们带来以下这些好处:
「Vue3」正是采用的 yarn 的 workspaces 工作空间的方式管理整个项目,而 workspaces 的特点就是在 package.json 中会有这么两句不同于普通项目的声明:
{
"private": true,
"workspaces": [
"packages/*"
]
}可以看到,packages 文件目录下根据「Vue3」实现所需要的能力划分了不同的项目。并且,这里的 compiler-core 目录则是我们本小节要介绍的 compiler-core。所以,packages 下的项目结构会是这样:
那么,了解什么是「Monorepo」以及其在「Vue3」中的运用后,接下来我们开始了解 compiler-core 的内部运行原理~
compiler-core 负责「Vue3」中核心编译相关的能力,这包括解析(parse)模板、转化 AST 抽象语法树(transform)、代码生成(generate)等三个过程,它们之间的工作流如下图所示:
可以看到,「Vue3」会先解析模版生成对应的 AST 抽象语法树,其次再 transform 抽象语法树,对 AST 做一些特殊处理,例如打上 shapeFlag 和 patchFlag 等操作,最后,generate 根据抽象语法树来生成对应的可执行代码,即 render 函数。
不知道什么是
shapeFlag或patchFlag的同学可以看这两篇文章:《compile 和 runtime 结合的 patch 过程》 、《从编译过程,理解静态节点提升》
那么,在「Vue3」源码层面,它们都是运行在 baseCompiler 方法中:
// packages/compiler-core/src/compiler.ts
export function baseCompile(
template: string | RootNode,
options: CompilerOptions = {}
): CodegenResult {
...
const ast = isString(template) ? baseParse(template, options) : template
...
transform(
ast,
extend({}, options, {
prefixIdentifiers,
nodeTransforms: [
...nodeTransforms,
...(options.nodeTransforms || []) // user transforms
],
directiveTransforms: extend(
{},
directiveTransforms,
options.directiveTransforms || {} // user transforms
)
})
)
return generate(
ast,
extend({}, options, {
prefixIdentifiers
})
)
}可以看到 baseCompiler 进行模版编译相关操作的也就是 baseParse、transform、generate 这三个方法,它们也分别对应着上面所说的三个阶段。那么,接下来我们将会借助这三者来玩转的模版编译!
既然要玩转模版编译,那么我们就搞点有趣的(*操作)。我们来实现一个栗子,通过它渲染模版,我们会对文字内容做替换操作,即乞丐版国际化。
我们定义一个函数它会根据 key 返回指定的语言 lang 下的文字:
function getWords(key, lang = "EN") {
const map = new Map([
["CN", {
hi: "你好",
}],
["EN", {
hi: "hello"
}]
])
return map.get(lang)[key]
}然后,我们需要对「模版」中出现的 hi 字符串转化为特殊语言下的文字。这里我们需要借助 compiler-core 的提供的四个方法:
baseParse 解析「模版」生成 AST 抽象语法树。getBaseTransformPreset 用于创建基础的 transform 函数(需要注意它是必须的)。transform 转化 AST 抽象语法树,可以实现对 AST 节点的替换、删除操作。generate 根据转化后的 AST 抽象语法树生成 render 函数。const compiler = require("@vue/compiler-core");
function render(template, lang = "CN") {
const ast = compiler.baseParse(template)
const transform = (rootNode) => {
if (rootNode.type === 2) {
rootNode.content = getWords(rootNode.content)
}
}
const prefixIdentifiers = true
const [nodeTransforms, directiveTransforms] = compiler.getBaseTransformPreset(
prefixIdentifiers
)
compiler.transform(ast, {
prefixIdentifiers,
nodeTransforms: [
...nodeTransforms,
myTransfrom
],
})
const render = compiler.generate(ast)
return render.code
}我们直接定义一个模版字符串,并将该模版字符串作为参数传给到上面定义好的 render 函数。
const template = `<div>hi</div>`
const renderStr = render(template)这里我们打印一下生成的 render 函数字符串 renderStr:
'const _Vue = Vue\n' +
'\n' +
'return function render(_ctx, _cache) {\n' +
' with (_ctx) {\n' +
' const { createVNode: _createVNode, openBlock: _openBlock, createBlock: _createBlock } = _Vue\n' +
'\n' +
' return (_openBlock(), _createBlock("div", null, "你好"))\n' +
' }\n' +
'}'然后,我们执行这一段代码生成的 HTML 会是这样:
<div>你好<div>如果,我们在调用前面定义的 render 函数时,传入的 lang 为 EN,那么输出的 HTML 的会是这样:
<div>hello<div>文中介绍的使用 compiler-core 玩转模版编译的栗子只是极简的,如果要具体要具体到业务场景,那就要 fork 一份 compiler-core 来处理一些自定义的操作,这样生成的 AST 才更加贴合我们自己的需求,这期间应该需要一些时间去理解 compiler-core 中更加底层的东西。
所以,这也是为什么文章标题是【前端进阶】的缘故,因为本次介绍的内容涉及到编译的场景,它的最佳演变是形成一种自己规定「模版语法」,你也可以称之为简易版的「DSL」。
对于不是从事音视频方面的同学来说,很多情况下都是通过 window.location.href 来下载文件。这种方式,一般是前后端的登录态是基于 Cookie + Session 的方式,由于浏览器默认会将本地的 cookie 塞到 HTTP 请求首部字段的 Set-Cookie 中,从而实现来带用户的 SessionId,所以,我们也就可以用 window.location.href 来打开一个链接下载文件。
当然,还有一种情况,不需要登录态的校验(比较che)。
众所周知,还有另一种登录态的处理方式 JWT (JSON Web Token)。这种情况,一般会要求,前端在下载文件的时候在请求首部字段中添加 Token 首部字段。那么,这样一来,我们就不能直接通过 window.location.href 来下载文件。
不过,幸运的是我们有 Blob,它是浏览器端的类文件对象,基于二进制数据,我们可以通过它来优雅地处理文件下载,不限于音视频、PDF、Excel 等等。所以,今天我们就从后端导出文件到 HTTP 协议、非简单请求下的预检请求、以及最后的 Blob 处理文件,了解一番何为其然、如何使其然?
首先,我们从后端导出文件讲起。这里,我选择 Koa2 来实现 Excel 的导出,然后搭配 node-xlsx 这个库,从而实现 Excel 的二进制数据的导出。它看起来会是这样:
const xlsx = require("node-xlsx")
router.get("/excelExport", async function (ctx, next) {
// 数据查询的结果
const res = [
["name", "age"],
["五柳", "22"],
];
// 生成 excel 对应的 buffer 二进制文件
const excelFile = xlsx.build([{name: "firstSheet", data: res}])
// 设置文件名相关的响应首部字段
ctx.set("Content-Disposition", "attachment;filename=test.xlsx;filename*=UTF-8")
// 返回给前端
ctx.body = buffer;
});这里就不对数据库查询做展开,只是模拟了一下查询后的结果
res
然后我们用浏览器请求一下这个接口,我们会看到在响应首部(Response Headers)字段中的 Content-Type 为 application/octet-stream,它是二进制文件默认的 MIME 类型。
Connection: keep-alive
Content-Disposition: attachment;filename=test.xlsx;filename*=UTF-8
Content-Length: 14584
Content-Type: application/octet-stream
Date: Sun, 23 Aug 2020 11:33:16 GMT
MIME类型,即Multipurpose Internal Mail Extension,用于表示文件、文档或字节流。
如果,我们没有参与后端返回 Excel 的这个过程。那么,HTTP 协议可以帮助我们减少交流,并且懂得我们前端需要如何进行相应的处理。这里会涉及到三个 HTTP 实体首部字段:
Content-TypeContent-LengthContent-Disposition那么,我们分别来看看它们在 HTTP 文件传输过程中的特殊意义。
Content-Type 我想这个老生常谈的实体首部字段,大家不会陌生。它用来说明实体主体内容对象的媒体类型,遵循 type/subtype 的结构。常见的有 text/plain、text/html、image/jpeg、application/json、application/javascript 等等。
在我们这里二进制文件,它没有特定的 subtype,即都是以 application/octet-stream 作为 Content-Type 的值。即如上面我们所看到:
Content-Type: application/octet-stream
所以,只要我们熟悉
Content-Type,那么在开发中的交流成本就可以减少。
Content-Length 又是一个眼熟的实体首部字段,它表示传输的实体主体的大小,单位为字节。而在我们这个栗子,表示传输的 Excel 二进制文件大小为 14584。
Content-Disposition 这个实体首部字段,我想前端同学大多数是会有陌生感。它用来表示实体主体内容是用于显示在浏览器内或作为文件下载。它对应的 value 有这么几个内容:
formdata 的形式。filename*=UTF-8 表示文件的编码,filename=test.xlsx 表示下载时的文件名。formdata 上传文件时,对应 type 为 file 的 input 的 name 值,例如 <input type="file" name="upload" />,此时对应的 name 则为 upload。需要注意的是,对于
Content-Disposition的formdata它仅仅是一个信息提示的作用,并不是实现实体主体内容为formdata,这是Content-Type负责的。
那么回到,今天这个栗子,它的 Content-Disposition 为:
Content-Disposition: attachment;filename=test.xlsx;filename*=UTF-8所以,现在我们知道它主要做了这么几件事:
test.xlsxUTF-8为什么说是优雅?因为,Blob 它可以处理很多类型文件,并且是受控的,你可以控制从接收到二进制文件流、到转化为 Blob、再到用其他 API 来实现下载文件。因为,如果是 window.location.href 下载文件,诚然也可以达到一样的效果,但是你无法在拿到二进制文件流到下载文件之间做个性化的操作。
并且,在复杂情况下的文件处理,
Blob必然是首要选择,例如分片上传、下载、音视频文件的拼接等等。所以,在这里我也推崇大家使用Blob处理文件下载。
并且,值得一提的是 XMLHttpRequest 默认支持了设置 responseType,通过设置 reposponseType 为 blob,可以直接将拿到的二进制文件转化为 Blob。
当然
axios也支持设置reponseType,并且我们也可以设置responseType为arraybuffer,但是我想没这个必要拐弯抹角。
然后,在拿到二进制文件对应的 Blob 对象后,我们需要进行下载操作,这里我们来认识一下这两种使用 Blob 实现文件下载的方式。
在浏览器端,我们要实现下载文件,无非就是借助 a 标签来指向一个文件的下载地址。所以 window.location.href 的本质也是这样。也因此,在我们拿到了二进制文件对应的 Blob 对象后,我们需要为这个 Blob 对象创建一个指向它的下载地址 URL。
而 URL.createObjectURL 方法则可以实现接收 File 或 Blob 对象,创建一个 DOMString,包含了对应的 URL,指向 Blob 或 File 对象,它看起来会是这样:
"blob:http://localhost:8080/a48aa254-866e-4c66-ba79-ae71cf5c1cb3"完整的使用 Blob 和 URL.createObjectURL 下载文件的 util 函数:
export const downloadFile = (fileStream, name, extension, type = "") => {
const blob = new Blob([fileStream], {type});
const fileName = `${name}.${extension}`;
if ("download" in document.createElement("a")) {
const elink = document.createElement("a");
elink.download = fileName;
elink.style.display = "none";
elink.href = URL.createObjectURL(blob);
document.body.appendChild(elink);
elink.click();
URL.revokeObjectURL(elink.href);
document.body.removeChild(elink);
} else {
navigator.msSaveBlob(blob, fileName);
}
};
同样地,FileReader 对象也可以使得我们对 Blob 对象生成一个下载地址 URL,它和 URL.createObject 一样可以接收 File 或 Blob 对象。
这个过程,主要由两个函数完成 readAsDataURL 和 onload,前者用于将 Blob 或 File 对象转为对应的 URL,后者用于接收前者完成后的 URL,它会在 e.target.result 上。
完整的使用 Blob 和 FileReader 下载文件的 util 函数:
const readBlob2Url = (blob, type) =>{
return new Promise(resolve => {
const reader = new FileReader()
reader.onload = (e) => {
resolve(e.target.result)
}
reader.readAsDataURL(blob)
})
}如果,仅仅是用一个 Blob 这个浏览器 API 处理文件下载,可能带给你的收益并没有多少。但是,通过了解从后端文件导出、HTTP 协议、Blob 处理文件下载这整个过程,就可以构建一个完整的技术思维体系,从而获取其中的收益。唯有知其然,方能使其然。 这也是前段时间看到的很符合我们作为一个不断学习的从业者的态度。也因此,良好的技术知识储备,能让我们拥有很好的编程思维和设计**。
文章对应的
DEMO,我已经上传到 GitHub 上了,有兴趣的同学可以去 clone 下来了解。
在维护 Jenkins Slave Node(这里指 macOS 构建机)的过程,不可避免地是你会遇到一些文件访问权限和进程常驻的问题。所以,如果要解决这些问题,就要求你了解 Linux 文件访问权(包括文件和目录,以下统称文件)和什么是守护进程(macOS launchd)。
那么,回到今天本文,也将会从常用 Linux 文件访问权相关命令开始,一步一步带你了解这些其中的所以然。
首先,我们需要建立的基础认知是在 Linux 系统中,文件的访问者身份划分这 3 类:
rootstaff、wheel下面,我们再来分别认识下在查看和修改文件访问权过程会使用到的命令。
ls 这个命令,我想应该很多同学都知道,可以用于查看某个目录下有哪些文件,例如:
wujingchang@wujingchangdeMacBook-Pro ant-design % ls
AUTHORS.txt README-zh_CN.md package-lock.json
CHANGELOG.en-US.md README.md package.json
CHANGELOG.zh-CN.md SECURITY.md renovate.json
CNAME components scripts
CODE_OF_CONDUCT.md docs site
LICENSE index-style-only.js tests
README-ja_JP.md index-with-locales.js tsconfig.json
README-pt_BR.md index.js tsconfig.node.json
README-sp_MX.md jest-puppeteer.config.js typings
README-uk_UA.md node_modules webpack.config.js而 ls 的 -l Option 可以用于查看文件属主、所属组、读写权限和文件大小等信息:
wujingchang@wujingchangdeMacBook-Pro ant-design % ls -l
-rw-r--r-- 1 wujingchang staff 50839 11 9 12:50 AUTHORS.txt
-rw-r--r-- 1 wujingchang staff 320126 11 9 12:50 CHANGELOG.en-US.md
-rw-r--r-- 1 wujingchang staff 334949 11 9 12:50 CHANGELOG.zh-CN.md
-rw-r--r-- 1 wujingchang staff 16 11 9 12:50 CNAME
-rw-r--r-- 1 wujingchang staff 3254 11 9 11:39 CODE_OF_CONDUCT.md
-rw-r--r-- 1 wujingchang staff 1099 11 9 11:39 LICENSE
-rw-r--r-- 1 wujingchang staff 10155 11 9 12:50 README-ja_JP.md
-rw-r--r-- 1 wujingchang staff 9903 11 9 11:39 README-pt_BR.md
-rw-r--r-- 1 wujingchang staff 9801 11 9 12:50 README-sp_MX.md
-rw-r--r-- 1 wujingchang staff 10623 11 9 11:39 README-uk_UA.md
-rw-r--r-- 1 wujingchang staff 9596 11 9 11:39 README-zh_CN.md
# 省略若干目录其中,如果当你还想隐藏文件的信息的时候则可以使用 ls -la。那么,可以看到这里主要 9 列,分别表示的含义为:读写权限信息、链接目录数和文件路径长度(例如 /demo/test 此时为 2)、属主、所属组、文件大小、创建月份、创建日、创建时间、文件名称,例如 AUTHORS.txt:
# 读写权限 链接目录数和文件路径长度 属主 所属组 文件大小 创建月 日 时间 文件名
-rw-r--r-- 1 wujingchang staff 50839 11 9 12:50 AUTHORS.txt很显然,我们关注的是第一列(文件读写权限信息),而它则是由长度为 10 的字符组成:
-、目录是 d 和链接目录是 l 等r 表示读(Read)权限,w 表示写(Write)权限,x 表示执行(execute)权限,- 则表示无权限例如,这里 AUTHORS.txt 的读写权限信息 -rw-r--r-- 则表示:
- 普通文件rw- 可读、可写、不可执行(因为是一个普通文件不是可执行程序)r-- 可读、不可写、不可执行,也就是说同样是 staff 组的用户(除开 wujingchang)只能读这个文件不能写r-- 同上chmod 是 change mode 的缩写,表示改变文件的权限。我们可以通过 chmod + 和要获取的权限 r、w、x 来更改具体的文件权限,例如 chmod +w 表示增加可写的权限,反之 -w 则表示移除可写的权限。
同样是 AUTHORS.txt 文件,我们把原本的可读权限去掉:
wujingchang@wujingchangdeMacBook-Pro ant-design % chmod -r AUTHORS.txt需要注意的是,-r 默认修改的是属主的访问权限,我们可以通过 u-r(属主)、g-r(所属组)、o-r(其他用户)的方式移除指定的读取权限。
那么,现在 AUTHORS.txt 文件的权限信息则是:
wujingchang@wujingchangdeMacBook-Pro ant-design % ls -l AUTHORS.txt
--w------- 1 wujingchang staff 50839 11 9 12:50 AUTHORS.txt可以看到原先的 r 都被移除了,此时,如果尝试打开 open AUTHORS.txt,则会提示:
此外,除了使用字符 r、w、x 的方式修改,我们还可以用数字的方式修改(4 可读,2 可写,1 可执行),例如同样是移除 AUTHORS.txt 的读权限:
wujingchang@wujingchangdeMacBook-Pro ant-design % chmod 020 AUTHORS.txtchown是 change ownership 的缩写,表示我们可以更改文件的访问权。例如,我们可以修改 AUTHORS.txt 文件的属主为 root:
wujingchang@wujingchangdeMacBook-Pro ant-design % sudo chown root AUTHORS.txt注意由于 root 是超级用户,所以需要 sudo。然后,此时 AUTHORS.txt 的属主则会变成 root:
wujingchang@wujingchangdeMacBook-Pro ant-design % ls -l AUTHORS.txt
-rw-r--r-- 1 root staff 50839 11 9 12:50 AUTHORS.txt那现在我们能使用 open AUTHORS.txt 打开吗?答案是可以,因为 wujingchang 和 root 属于同一个组 staff,而 -rw-r--r-- 的第 4~7 位 r-- 表示可读、不可写不可执行,并且其他用户也是 r--。所以,此时仍然是可以打开 AUTHORS.txt 文件,但是打开后会处于只读的模式:
那么,如果希望在修改文件属主的同时也修改文件所属组,可以在使用 chown 的时候通过 user:group 的方式修改:
wujingchang@wujingchangdeMacBook-Pro ant-design % sudo chown root:wheel AUTHORS.txt
wujingchang@wujingchangdeMacBook-Pro ant-design % ls -ls AUTHORS.txt
104 -rw-r--r-- 1 root wheel 50839 11 9 12:50 AUTHORS.txt然后,则是其他用户的可读权限,这可以通过 chmod 修改:
wujingchang@wujingchangdeMacBook-Pro ant-design % open AUTHORS.txt
wujingchang@wujingchangdeMacBook-Pro ant-design % sudo chmod o-r AUTHORS.txt
wujingchang@wujingchangdeMacBook-Pro ant-design % ls -ls AUTHORS.txt
104 -rw-r----- 1 daemon wheel 50839 11 9 12:50 AUTHORS.txt
The application cannot be opened for an unexpected reason, error=Error Domain=NSOSStatusErrorDomain Code=-5000 "afpAccessDenied: Insufficient access privileges for operation " UserInfo={_LSLine=3863, LSErrorDict={
Action = odoc;
Documents = (
"AUTHORS.txt"
);
ErrorCode = "-5000";
FullPaths = (
"/Users/wujingchang/Documents/repo/ant-design/AUTHORS.txt"
);
}, _LSFunction=_LSOpenStuffCallLocal}chgrp 是 change group 的缩写,表示我们可以更改文件的所属组的访问权。也就是说,除开使用 chmod 的时候指明用户组的方式修改所属组的访问权,我们还可以通过 chgrp 来直接修改 AUTHORS.txt 文件的所属组:
wujingchang@wujingchangdeMacBook-Pro ant-design % sudo chgrp wheel AUTHORS.txt 通常,我们在注册连接 Jenkins Slave Node 的时候是希望它常驻在内存中。这在 Windows 机器上,我们可以通过 Services 的方式实现。而在 macOS 上,我们可以通过launchd 提供的守护进程相关的能力实现。
launchd 则是 Apple Inc 创建的一个初始化和操作系统服务管理守护进程。在 Launchd 中有 2 个主要的程序 launchd 和 launchctl,前者用于启动系统和运行服务,后者用于控制服务。
所以,在 macOS 启动过程,会加载 launchd,launchd 则会运行 /etc/rc,扫描系统 System、用户 User 下、全局的 /Library/LaunchDaemons 和 /Library/LaunchAgents 目录下的脚本,根据需要在 plist 上调用 launchctl,然后 launchd 启动登录窗口。
其中 LaunchDaemons 和 LaunchAgents 处于不同的文件位置所执行的用户有所不同:
| 类型 | 文件位置 | 运行的用户 |
|---|---|---|
| User Agents | ~/Library/LaunchAgents | 当前登录用户 |
| Global Agents | /Library/LaunchAgents | 当前登录用户 |
| Global Daemons | /Library/LaunchDaemons | root 或者指定的用户 |
| Global Agents | /System/Library/LaunchAgents | 当前登录用户 |
| Aystem Daemons | /System/Library/LaunchDaemons | root 或者指定的用户 |
可以看到,LaunchAgents 是只能以当前的登录用户运行,而 LaunchDaemons 可以指定特定的用户,并且需要注意的是只有 LaunchAgents 可以访问 macOS GUI 的。
如果,我们期望通过 launchd 运行指定的程序(launch Job 或 Service,以下统称 launch Job),则需要在上述的文件目录下配置以 .plist 扩展名的 XML 文件,这通常也被称为 Plist 文件。那么,下面我们来一起看下如何创建一个 launchd Job?
用于创建 launchd Job 的 Plist 文件配置提供了诸多 Key-Value 来实现指定的声明,这里我们来看 4 个比较常用的 Key:
Label 用于表示 Daemon 的名称,唯一标识ProgramArguments 用于表示 Daemon 启动时需要执行的命令行相关UserName 用于表示启动 Daemon 的用户,例如你可以声明为 wujingchangKeepAlive 用于表示是否 Daemon 需要按需运行还是必须运行那么,以 Jenkins Slave Node 的连接为例,它需要我们在构建机器(macOS 机器)上通过指定的 Java 命令建立和 Jenkins 服务器的远程连接,这看起来会是这样:
java -jar agent.jar -jnlpUrl http://xxxxxxx/jenkins-agent.jnlp -secret xxxxxxxx -workDir D:\jenkins所以,它的 lauchd Job 的配置会是:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>Label</key>
<string>com.jenkins.slavenode</string>
<key>ProgramArguments</key>
<array>
<string>java</string>
<string>-jar</string>
<string>-jnlpUrl</string>
<string>http://xxxxxxx/jenkins-agent.jnlp</string>
<string>-secret</string>
<string>xxxxxxxx</string>
<string>-workDir</string>
<string>D:\jenkins</string>
</array>
<key>UserName</key>
<string>wujingchang</string>
<key>KeepAlive</key>
<true/>
</dict>
</plist>并且,需要注意的是 launchd Job 的 Plist 文件需要按前面提及的 LaunchDaemons 的文件位置存放(保证开机自启的行为),例如这里的 wujingchang 是当前用户,那么就把 Plist 文件放到 ~/Library/LaunchDaemons 文件目录下。
在创建好 launchd Job 的 Plist 文件后,后续在机器开启的过程则会执行对应的 Job。那么,也就是说我们刚创建的 launchd Job 需要等待下次开机才能运行。
所以,如果你新创建的 launchd Job 也需要马上运行,那么则可以使用 launchctl 提供的命令,常用的 launchctl 命令有:
launchctl load 加载启动 launchd Joblaunchctl unload 卸载停止 launchd Joblaunchctl list 查看已启动的访问 lauchd Job 信息那么,回到上面的例子,我们可以使用 launchctl load 命令运行刚创建的 launch Job:
launchctl load ~/Library/LaunchDaemons/slavenode.plist此外,我们还可以通过 brew services 相关的命令来启动和停止 launchd Job,具体大家可以通过 brew services --help 了解,这里不做展开。
通过,了解文件访问权修改和 launchd 相关的知识,可以让我们在 Jenkins 排障的维护过程处理访问权限更得心应手,避免由于知识盲区的存在导致问题迟迟不能解决或者解决的成本较高的情况出现。并且,需要注意的是每个修改文件访问权相关的命令(chmod、chown、chgrp)都支持使用 -h Option 查看相关的介绍,例如 chown -h:
wujingchang@wujingchangdeMacBook-Pro @ant-desgin % chown -h
usage: chown [-fhnvx] [-R [-H | -L | -P]] owner[:group] file ...
chown [-fhnvx] [-R [-H | -L | -P]] :group file ...最后,如果文中存在表达不当或错误的地方,欢迎各位同学提 Issue ~
Tree-shaking 这一术语在前端社区内,起初是 Rich Harris 在 Rollup 中提出。简单概括起来,Tree-shaking 可以使得项目最终构建(Bundle)结果中只包含你实际需要的代码。
而且,说到 Tree-shaking,不难免提及 Dead Code Elimation,相信很多同学在一些关于 Tree-shaking 的文章中都会看到诸如这样的描述:Tree-shaking 是一项 Dead Code Elimation(以下统称 DCE)技术。
那么,既然有了 DCE 这一术语,为什么又要造一个 Tree-shaking 术语?存在既有价值,下面,让我们一起来看看 Rich Harris 是如何回答这个问题的。
在当时 Rich Haris 针对这一提问专门写了这篇文章《Tree-shaking versus dead code elimination》,文中表示 DCE 和 Tree-shaking 最终的目标是一致的(更少的代码),但是它们仍然是存在区别的。
Rich Haris 举了个做蛋糕的例子,指出 DCE 就好比在做蛋糕的时候直接把鸡蛋放入搅拌,最后在做好的蛋糕中取出蛋壳,这是不完美的做法,而 Tree-shaking 则是在做蛋糕的时候只放入我想要的东西,即不会把蛋壳放入搅拌制作蛋糕。
因此,Tree-shaking 表达的不是指消除 Dead Code,而是指保留 Live Code。即使最终 DCE 和 Tree-shaking 的结果是一致的,但是由于 JavaScript 静态分析的局限性,实际过程并不同。并且,包含有用的代码可以得到更好的结果,从表面看(做蛋糕的例子)这也是一种更符合逻辑的方法。
此外,当时 Rich Haris 也认为 Tree-shaking 可能不是一个很好的名称,考虑过用 Live Code Inclusion 这个短语来表示,但是似乎会造成更多的困惑......让我们看一下 Rich Haris 的原话:
I thought about using the ‘live code inclusion’ phrase with Rollup, but it seemed that I’d just be adding even more confusion seeing as tree-shaking is an existing concept. Maybe that was the wrong decision?
所以,我想到这里同学们应该清楚一点,Tree-shaking 和 DCE 只是最终的结果是一致的,但是 2 者实现的过程不同,Tree-shaking 是保留 Live Code,而 DCE 是消除 Dead Code。
并且,当时 Rich Harris 也指出 Rollup 也不是完美的,最好的结果是使用 Rollup + Uglify 的方式。不过,显然现在的 Rollup v2.55.1 已经臻至完美。那么,接下来让我们沿着时间线看看 Tree-shaking 的演变~
Tree-shaking 在最初被提出的时候它只会做一件事,那就是利用 ES Module 静态导入的特点来检测模块内容的导出、导入以及被使用的情况,从而实现保留 Live Code 的目的。
也许这个时候你会问 Tree-shaking 不是还会消除 Dead Code 吗?确实,但是也不一定,如果你使用的是现在的 Rollup v2.55.1,它是会进行 DCE,即消除 Dead Code。但是,如果你用的是 Webpack 的话,那就是另一番情况了,它需要使用 Uglify 对应的插件来实现 DCE。
下面,我们以 Rollup 为例,聊聊过去和现在的 Tree-shaking。
在早期, Rollup 提出和支持 Tree-shaking 的时候,它并不会做额外的 DCE,这也可以在 15 年 Rich Haris 写的那篇文章中看出,当时他也提倡大家使用 Rollup + Uglify。所以,这里让我们一起把时间倒回 Rollup v0.10.0 的 Tree-shaking。
回到 Rollup v0.10.0 版本,你会发现非常有趣的一点,就是它的 GitHub README 介绍是这样的:
Rollup 的命名来源于一首名为《Roll up》的说唱歌曲,我想这应该出乎了很多同学的意料。不过话说 Evan You 也喜欢说唱,然后我(你)也喜欢说唱,所以这也许可以论证我(你)选择前端似乎没错?这里附上这首歌,你可以选择听这首歌来拉近 Rollup 的距离。
下面,我们使用 Rollup v0.10.0 版本来做一个简单示例来验证一下前面说的。并且,在这个过程中需要注意,如果你的 Node 版本过高会导致一些不兼容,所以建议用 Node v11.15.0 来运行下面的例子。
首先,初始化项目和安装基础的依赖:
npm init -y
npm i [email protected] -D
然后,分别新建 3 个文件:
utils.js
export const foo = function () {
console.log("foo");
};
export const bar = function () {
console.log("bar");
};main.js
import { foo, bar } from "./utils.js";
const unused = "a";
foo();index.js
const rollup = require("rollup");
rollup
.rollup({
entry: "main.js",
})
.then(async (bundle) => {
bundle.write({
dest: "bundle.js",
});
});其中,main.js 是构建的入口文件,然后 index.js 负责使用 Rollup 进行构建,它会将最终的构建结果写入到 bundle.js 文件中:
// bundle.js
const foo = function () {
console.log("foo");
};
const unused = "a";
foo();可以看到,在 bundle.js 中保留了 utils.js 中的 foo() 函数(因为被调用了),而导入的 uitls.js 中的 bar() 函数(没有被调用)则不会保留,并且定义的变量 ununsed 虽然没有被使用,但是仍然保留了下来。
所以,通过这么一个小的示例,我们可以验证得知 Rollup 的 Tree-shaking 最初并不支持 DCE,它仅仅只是在构建结果中保留你导入的模块中需要的代码。
前面,我们从过去的 Tree shaking 开始了解,大致建立起了对 Tree shaking 的初印象。这里我们来看一下现在 Rollup 官方上对 Tree shaking 的介绍:
Tree-shaking,也被称为 Live Code Inclusion,是指 Rollup 消除项目中实际未使用的代码的过程,它是一种 Dead Code Elimation 的方式,但是在输出方面会比其他方法更有效。该名称源自模块的抽象语法树(Abstract Sytanx Tree)。该算法首先会标记所有相关的语句,然后通过摇动语法树来删除所有的 Dead Code。它在**上类似于 GC(Garbage Collection)中的标记清除算法。尽管,该算法不限于 ES Module,但它们使其效率更高,因为它允许 Rollup 将所有模块一起视为具有共享绑定的大抽象语法树。
从这段话,我们可以很容易地发现随着时间的推移,Rollup 对 Tree-shaking 的定义已经不仅仅是 ES Module 相关,此外它还支持了 DCE。所以,有时候我们看到一些文章介绍 Tree-shaking 实现会是这样:
那么,在前面我们已经知道 Tree-shaking 基于 ES Module 静态分析的特点会做的事情。所以,这里我们来仔细看一下第 2 点,换个角度看,它指的是当代码没有被执行,但是它会存在副作用,这个时候 Tree shaking 就不会把这部分代码消除。
那么,显然对副作用建立良好的认知,可以让项目中代码能更好地被 Tree shaking。所以,下面让我们来通过一个简单的例子来认识一下副作用。
在 Wiki 上对副作用(Side Effect)做出的介绍:
在计算机科学中,如果操作、函数或表达式在其本地环境之外修改某些状态变量值,则称其具有副作用。
把这段话转换成我们熟悉的,它指的是当你修改了不包含在当前作用域的某些变量值的时候,则会产生副作用。这里我们把上面的例子稍作修改,把 sayHi() 函数的形参删掉,改为直接访问定义好的 name 变量:
utils.js
export const name = "wjc";
export const sayHi = function () {
console.log(`Hi ${name}`);
};main.js
import { sayHi } from "./maths.js";
sayHi();然后,我们把这个例子通过 Rollup 提供的 REPL 来 Tree shaking 一下,输出的结果会是这样:
const name = "wjc";
const sayHi = function () {
console.log(`Hi ${name}`);
};
sayHi();可以看到,这里我们并没有直接导入 utils.js 文件中的 name 变量,但是由于在 sayHi() 函数中访问了它作用域之外的变量 name,产生了副作用,所以最后输出的结果也会有 name 变量。
当然,这仅仅只是一个非常简单的产生副作用的场景,也是很多同学不会犯的错误。此外,一个很有趣的场景就是使用 Class 关键字声明的类经过 Babel 转换为 ES5 的代码(为了保证 Class 可枚举)后会产生副作用。
对上面提到的这个问题感兴趣的同学,可以看这篇文章 你的 Tree-Shaking 并没什么用 仔细了解,这里就不做重复论述了~
写这篇文章的动机主要是出于对 Tree shaking 和 DCE 这两个术语十分相似,但是 Tree-shaking 必然有其存在的意义,所以就诞生了这篇文章。虽然,文章中并没有涉及 Tree-shaking 的底层实现,但是我想有时候搞清楚一些模糊的概念的优先级是优于了解其底层实现的。
并且,通过对比 2015 年 Rich Harris 在提出 Tree-shaking 的初衷,到现在 Tree shaking 所具备的能力来说,随着时间的演变 Rollup 的 Tree-shaking 默认也支持了 DCE,这也难免会造成一些同学对 Tree-shaking 的理解产生混乱。所以,如果想要追溯本源(Tree-shaking 由来)的同学,我还是蛮推荐仔细阅读一下 《Tree-shaking versus dead code elimination》这篇文章的。
说到词法分析,我想很多同学第一时间想到的可能是 Babel、Acorn 等工具。不可否认,它们都很强大 😶。
但是,具体到今天这个话题 ES Module 语句的词法分析而言,es-module-lexer 会胜过它们很多!
那么,今天我们将围绕以下 2 点,深入浅出一番 es-module-lexer:
es-module-lexer 是一个可以对 ES Module 语句进行词法分析的工具包。它压缩后之后只有 4 KiB,其底层通过内联(Inline) WebAssembly 的方式来实现对 ES Module 语句的快速词法分析。
1KiB = 1,024Byte
那么,具体会有多快?根据官方给的例子,Angular1(720 KiB)使用 Acorn 解析所需要的时间为 100 ms,而 es-module-lexer 解析只需要 5 ms,也就是前者的 1/20 😵。
并且,es-module-lexer 的使用也非常简单,它提供了 init Promise 对象和 parse 方法,下面我们来看一下它们分别做了什么?
init 必须在 parse() 方法前 Resolve(解析),它的实现可以分为 3 个步骤:
WebAssembly.Module 的 Promise 对象WebAssembly.Instantiate() 方法创建一个实例exports 属性来获取调用的模块提供的方法这个过程对应的代码:
let wasm;
const init = WebAssembly.compile(
(binary => typeof window !== 'undefined' && typeof atob === 'function' ? Uint8Array.from(atob(binary), x => x.charCodeAt(0)) : Buffer.from(binary, 'base64'))
('WASM_BINARY')
).then(WebAssembly.instantiate)
.then(({ exports }) => { wasm = exports; });而这里的二进制代码,则是由 C 实现的对 ES Module 语句进行词法分析的代码编译得来。
并且,可以看到实例的 exports 会被赋值给 wasm。
parse() 方法则会使用在上面得到的 WebAssembly.Module 提供的方法(即 wasm)来实现对 ES Module 语法的词法分析。
这个过程对应的代码(伪代码):
function parse (source, name = '@') {
if (!wasm)
return init.then(() => parse(source));
// 调用 wasm 上的方法进行对应的操作
return [imports, exports, !!wasm.f()];
}注意,这里不对
wasm上提供的方法进行分析,有兴趣的同学可以自行了解~
可以看到,如果我们在调用 parse() 方法之前没有 Resolve(解析)init,parse() 方法会自己先 Resolve(解析) init。然后,在 .then 中调用并返回 parse() 方法,所以在这种情况下,parse() 方法会返回一个 Promise 对象。
当然,不管任何情况下,parse() 方法的本质是返回一个数组(长度为 3)。并且,和我们使用密切相关的主要是 imports 和 exports。
imports 和 exports 都是一个数组,其中每个元素(对象)代表一个导入语句的解析后的结果,具体会包含导入或导出的模块的名称、在源代码中的位置等信息。
接下来,我们通过一个简单的例子来认识一下 es-module-lexer 的基本使用。
首先,我们基于 es-module-lexer 定义一个 parseImportSyntax() 方法:
const { init, parse } = require("es-module-lexer")
async function parseImportSyntax(code = "") {
try {
await init
const importSpecifier = parse(code)
return importSpecifier
} catch(e) {
console.error(e)
}
}可以看到 parseImportSyntax() 方法会返回 parse 后的结果。假设,此时我们需要解析导入 ant-design-vue 的 Button 组件的语句:
const code = `import { Button } from 'ant-design-vue'`
parseImportSyntax(code).then(importSpecifier => {
console.log(importSpecifier)
})对应的输出:
[
[
{
n: 'ant-design-vue',
s: 24,
e: 38,
ss: 0,
se: 39,
d: -1
}
],
[],
true
]由于,我们只声明了导入语句,所以最后解析的结果只有 imports 内有元素,该元素(对象)的每个属性对应的含义:
n 表示模块的名称s 表示模块名称在导入语句中的开始位置e 表示模块名称在导入语句中的结束位置ss 表示导入语句在源代码中的开始位置se 表示导入语句在源代码中的结束位置d 表示导入语句是否为动态导入,如果是则为对应的开始位置,否则默认为 -1那么,在简单了解完 es-module-lexer 的实现原理和使用后,我想同学们可能会思考它在实际场景下中要如何运用?(请继续阅读 😎)
在同学们可能还没意识到哪里用到了 es-module-lexer 的时候,其实它已经走进了我们平常的开发中。
那么,这里我们以 vite-plugin-style-import 插件为例,认识一下它又是如何使用 es-module-lexer 的?(别走开,接下来会非常有趣 😋)
在正式开讲 es-module-lexer 在 vite-plugin-style-import 中的使用之前,我们需要知道 vite-plugin-style-import 做了什么?
它解决了我们按需引入组件时,需要手动引入对应组件样式的问题。例如,在使用 ant-design-vue 的时候,按需引入 Button 只需要声明:
import { Button } from "ant-design-vue"然后,经过 vite-plugin-style-import 处理后对应的代码片段:
import { Button } from 'ant-design-vue';
import 'ant-design-vue/es/button/style/index.js';而这个过程的实现可以分为以下 3 个步骤:
使用 es-module-lexer 对源代码的导入(import)语句进行词法分析
根据配置文件 vite.config.js 中的 vite-plugin-style-import 的配置项来构造样式文件的导入语句
根据环境(会区分 Dev 或 Prod),选择性地注入特定的代码到源代码中
在1.3 基础使用小节的部分,我们讲了 es-module-lexer 解析导入语句时,只会返回导入模块相关的信息,那么这在 vite-plugin-style-import 中显然是不够的!
因为,vite-plugin-style-import 还需要知道此时导入了该模块的什么组件,这样才能去拼接生成对应的样式文件的导入语句。
那么,这个时候使用 es-module-lexer 的黑魔法就来了,我们可以将原来的导入语句的 import 替换为 export,然后 es-module-lexer 就会解析出导出的组件信息(想不到吧 😲)!
例如,同样是上面导入 ant-design-vue 的 Button 的例子,替换 import 后会是这样:
export { Button } from "ant-design-vue"这个时候,使用 es-module-lexer 解析后返回的结果:
[
[
{
n: 'ant-design-vue',
s: 24,
e: 38,
ss: 0,
se: 39,
d: -1
}
],
[ 'Button' ],
true
]可以看到,Button 被放到了解析结果的(数组第二个元素) exports 中,这样一来我们就知道了使用导入模块的组件有哪些 😎。
而这个过程,在 vite-plugin-style-import 中是由 transformImportVar() 方法完成的:
function transformImportVar(importStr: string) {
if (!importStr) {
return [];
}
const exportStr = importStr.replace('import', 'export').replace(/\s+as\s+\w+,?/g, ',');
let importVariables: readonly string[] = [];
try {
importVariables = parse(exportStr)[1];
debug('importVariables:', importVariables);
} catch (error) {
debug('transformImportVar:', error);
}
return importVariables;
}很有趣的一点是 awesome-vite 上有两个支持按需引入组件样式文件的插件。通过阅读,我想同学们应该知道用哪个了吧 😎!
最后,用一句话总结 es-module-lexer 的优点,那就是:“快到飞起”。如果,文中存在表达不当或错误的地方,欢迎同学提 Issue~
前段时间,由于团队使用的 Monorepo 工程使用的工具是 Lerna,所以在思考如何改造的问题,最终整体的技术选型是 PNPM + Changeset + Turborepo。相应地,就需要在这个选型的背景下支持原先使用到的 Lerna 的能力。
其中,比较有意思的就是需要把 Package 发布到私有 Registry。因为,这里选择了 Changeset,所以最后执行发布的命令会是:
pnpm changset publish那这个时候,就牵扯到一个问题,项目中的私有 Registry 要配置在哪?这里我们不着急找答案,先来了解一下配置私有 Registry 的 4 种姿势。
我们可以通过设置 npm 或者 pnpm 的 config 来设置 Global Registry,例如:
# npm
npm config set registry=http://localhost:2000
# or pnpm
pnpm config set registry=http://localhost:2000这样一来,在代码层面就可以通过 process.env.npm_config_registry 读取到这里的配置。
无论是 npm 或 pnpm 默认都会从项目的 .npmrc 文件中读取配置,所以当我们需要 包的发布要走私有 Registry 的时候,可以这样设置:
registry = http://localhost:2000
在执行 npm publish 或 pnpm publish 的时候,我们也可以通过带上 --registry Option 来告知对应的包管理工具要将包发布的 Registry 是什么,例如:
# npm
npm publish --registry=http://localhost:2000
# or pnpm
pnpm publish --registry=http://localhost:2000PublishConfig 指的是我们可以在要执行 publish 命令的项目 package.json 中的 publishConfig.registry 来告知 npm 或 pnpm 要发布的 Registry,例如:
{
...
"publishConfig": {
"registry": "http://localhost:2000"
}
...
}
在了解完 4 种设置私有 Registry 的姿势后,我们回到文章开始的这个问题,如何让 pnpm changeset publish 知道要把发布包到指定的私有 Registry?如果,你觉得以上 4 种任选一种即可,那你可能需要踩些坑。
首先,我们需要知道的是 pnpm changeset publish 命令的本质是执行 changeset 的 publish。那么,也就是上面的 4 种设置 Registry 的方式,很可能不是每种都生效的,因为 Changeset 有一套自己的 publish 机制。而这个过程它主要会做这 3 件事:
1.首先,获取 Package Info,它会从指定的 Registry 获取 Package Info。举个例子,如果是获取 rollup 的 Package Info,那么在这里会是这样:
npm info rollup --registry="https://registry.npmjs.org/" --json2.其次,根据上面拿到的 Package Info 中的 versions 字段(它是一个包含所有已发布的版本的数组),对比本地的 package.json 的 version 字段,判断当前版本是否已发布
3.最后,如果未发布当前版本,则会根据当前使用的包管理工具执行 publish 命令,并且此时会构造一个它认为应该发布的 Registry 地址,然后重写 env 上的配置,对应的代码会是这样:
// packages/cli/src/commands/publish/npm-utils
const envOverride = {
npm_config_registry: getCorrectRegistry()
};
let { code, stdout, stderr } = await spawn(
// 动态的包管理工具,例如 pnpm、npm、yarn
publishTool.name,
["publish", opts.cwd, "--json", ...publishFlags],
{
env: Object.assign({}, process.env, envOverride)
}
);可以看到,整个 changeset publish 的过程还是很简单易于理解的。并且,非常重要的是这个过程牵扯到 Registry 获取的都是由一个名为 getCorrectRegistry() 的函数完成的,它的定义会是这样:
// packages/cli/src/commands/publish/npm-utils.ts
function getCorrectRegistry(packageJson?: PackageJSON): string {
const registry =
packageJson?.publishConfig?.registry ?? process.env.npm_config_registry;
return !registry || registry === "https://registry.yarnpkg.com"
? "https://registry.npmjs.org"
: registry;
}那这么一看,我想大家都明白了,为什么前面提及 4 种设置 Registry 的方式,很可能不是每种都生效的。
因为,在 Changeset 中只支持了 publishConfig 或 env 配置 Registry 的方式,所以如果你尝试其他 2 种方式就会 publish 到 https://registry.yarnpkg.com 或 https://registry.npmjs.org,并且在第一步获取 Package Info 的时候可能就会失败。
我想文章虽短,但是传达的知识点还是蛮有趣的。至于前面所说的 PNPM + Changeset + Turborepo 技术选型,起码目前我体验起来还是很丝滑的,无论是在依赖安装、多包任务执行、Version Or Publish 等方面都很优秀。所以,有兴趣的同学倒是可以尝试一下。
最后,如果文中存在表达不当或错误的地方,欢迎各位同学提 Issue ~
近期,在公司落地了一个社区内比较 新(踩)的(坑) 跨端框架 Chameleon,当时的需求是先实现快应用端,之后需要支持 H5、微信小程序、字节小程序等。由于公司用的技术栈是以 Vue.js 为主,在做了一番技术选型后,最终选择了 Chameleon(开始疯狂踩坑 😳)
这个时候,可能会有人问:为什么不选 uniapp?这么说吧,uniapp -> 快应用就不是一个坑了,是个炸弹 💣。后面,我会讲解为什么不选 uniapp 😲
不过,理性评价,Chameleon 确实是一个优秀的跨端框架。至于优秀在哪?(请继续阅读 😶)
本次文章将会分为以下三个部分,通过介绍、对比现有前端跨端框架,来逐点讲述 Chameleon 优秀之处 😍:
当然,了解这个缘由的同学,可以跳过这个小节哈~
这个问题,我们可以分为两个维度去解释:
需求的多变性
现今,小程序实在是太多了...而且,对于日异变更的需求,今天可能和你说的是微信小程序,过了一段时间,可能会和你说同样的产品,你写个快应用版的 😲。对于需求方来说,他们并不关注你是怎么实现的不同端,并且,可能还会觉得,你做个一样的东西只是平台不一样那不是很快吗?
技术的维护性
从技术维护维度思考,这是为了我们更好地维护代码,尽量通过维护一套代码来实现不同端的产品,例如微信小程序、字节小程序、快应用、H5 等等。所以,选择跨端框架开发的方式,给我们带来的好处:
现在,前端可选择的跨端框架有很多,Taro、uniapp、kbone、mpvue、Chameleon 等等。当然,其中部分还是有技术限制的,例如腾讯的 Kbone 只能支持 web 端和微信小程序同构,京东的 Taro 支持的 DSL 是 React,Uniapp 支持的 DSL 是 Vue。所以,框架虽多,但是还是那句大白话,适合自己所处技术团队的才是最好的 🤓️。
接下来,我们来简单认识一下支持 Vue 的 DSL 的四个跨端框架 mp-vue、uniapp、kbone、Chameleon:
mpvue 是 fork 自 [email protected] 版本,其保留了 Vue2.x 的一部分东西,例如使用 flow 来做静态类型检测、默认的一些语法等。mpvue 设计思路大体上是修改 Vue2.x 运行时和模版编译的部分,针对不同的平台对编译生成的 AST(抽象语法树)做语法转化到指定端的语法,从而完成对不同端的代码生成。
友情提示:mpvue 的 GitHub commit 最近一次 commit 是 17 个月前
uniapp 我想很多同学都耳熟能详,估计有些接触的前端同学,就是因为这个,毕竟 DCloud 也算是“大名鼎鼎”。前面,也提及 mpvue 最近的一次的 commit 已经是 17 个月前,而 uniapp 可以支持把 mpvue 的项目转为 uniapp 的项目(估计能多不少使用者 😏)。
uniapp 在跨端方面确实是很优秀,引入了条件编译的机制来支持不同端的表现,例如我们要在 H5 和微信小程序两个不同端显示用户头像,前者可以通过微信提供的数据显示用户头像,后者可以直接使用 open-data 组件获取。那么,通过条件编译我们可以这样写:
<!-- #ifdef MP-WEIXIN -->
<open-data class="img-avatar" type="userAvatarUrl"></open-data>
<!-- #endif -->
<!-- #ifdef H5 -->
<img :src="avatar" class="avatar" />
<!-- #endif -->条件编译,只会将符合这个条件的平台下的代码写入该平台的项目代码中
并且,uniapp 能跨端的类型也是很完善的,也支持快应用。但是,不同于其他小程序,快应用是自绘渲染引擎,而不是 webview 渲染。所以,目前 uniapp 对于快应用只支持了 vivo、oppo、华为这三种厂商。
因此,这也是我起初做技术选型的时候,放弃 uniapp 的原因。不过 uniapp 还支持转 webview 版的快应用,但是 webview 版的快应用又不是所有厂商都支持的...
kbone 是腾讯团队推出的一套支持 Web 端和微信小程序端进行同构的跨端框架。但是,显然相比较前面两者,kbone 的使用场景就略少一些,因为其受限于只支持 Web 端和微信小程序端。不过,如果需求只是 H5 和微信小程序,显然 kbone 是一个不错的选择,毕竟原装正版(腾讯)的技术支持。
那么,接下来就轮到 Chameleon 了,主角即将登场 😎~
Chameleon 作为跨端框架中的新兴势力,它同样有一套自己的 DSL(特色领域语言),即也可以称它为 CML。但是,不同于上述我们介绍的跨端框架,Chameleon 扩展多端的方式是采用的多态协议的方式,这里我们引用一下官方的介绍:
Chamleon 通过定义统一的语言框架 + 统一多态协议,从多端(对应多个独立服务)业务中抽离出自成体系、连续性强、可维护强的“前端中台服务”。
官方的介绍中出现了一个大家可能没有接触过的一个名词多态协议。那么,Chameleon 的多态协议是什么?
首先,我们从理论层面了解一下什么是多态协议,Chameleon 的多态协议设计的想法 💡 源于 Apache Thrift - 可伸缩的跨语言服务开发框架。那么,什么是 Apache Thrift ?
Apache Thrift 是一个采用接口描述语言定义并创建服务,支持可扩展的跨语言服务开发的框架。用大白话讲,就是 Apache Thrift 使得不同语言(Java、C、PHP)创建的服务可以被互相调用。
而 Chameleon 框架的核心机制之一 —— 多态协议则是借鉴了这种设计,提供了多态接口和多态组件的方式来扩展第三方端(微信小程序、快应用、字节小程序等)。例如,我们可以通过定义多态接口来实现不同端的特定 API,然后在业务代码层面直接使用定义好的多态接口就可以实现一个方法调用在不同端下的特定 API,这看起来会是这样:
并且,对于目前 Chameleon 默认支持的跨端平台来说,其编译生成的代码只是支持了 Chameleon 官方提供的基础组件和 API,例如在微信和快应用中常用到的组件 list、text,API setStorage 和 getStorage 等等。
那么,这些不同端是如何基于 Chameleon 规定的基础组件和 API 来扩展实现的呢?接下来,我会以 Chameleon 扩展快应用端的实现为例,带大家深入浅出一番其中的所以然 😲 ~
首先,不得不说的一点就是 Chameleon 可以完美支持跨快应用的开发,但是这个过程有一点点坑,不过踩掉就行~
那么,这里我们来了解一下基于 Chameleon 扩展快应用需要做什么?这个过程主要是由 6 个 packages 完成:
|—— cml-quickapp-api ## 实现 CML 提供的 api
|—— cml-quickapp-plugin ## 实现编译相关处理,例如生成 .ux 文件、manifest.json 文件
|—— cml-quickapp-runtime ## 实现 App、Page、Component 组件实例
|—— cml-quickapp-store ## 实现 CML 的状态管理
|—— cml-quickapp-ui ## 实现 CML 的普通组件
|—— cml-quickapp-ui-builtin ## 实现 CML 的 Native 组件
实际上快应用是 7 个 package,还有一个 cml-quickapp-mixins,它会对一些指令和事件(例如 c-model、touchstart)做兼容处理。
可以看到扩展一个端,我们至少需要 6 个 packages,而这 6 个 packages 完成了这 4 点:
而其中每一点需要实现的细节,官方文档已经讲解很详细了,这里就不重复论述。本小节只是简单介绍一下每个 packages 的职责,让同学们可以具备 debugger 源码的一点思路,有兴趣的同学可以自行了解其中的代码细节。
接下来,我们讲讲在业务开发中要如何扩展某个端的特定 API,即多态接口。
假设,此时我们处于快应用开发的场景,需要为应用添加桌面。而快应用添加桌面的 API 不在 Chameleon 官方文档规定的 API 中,所以这个时候就需要实现多态接口,即我们要需要自定义快应用添加桌面的 API。
首先,创建 shortcut.interface 文件,在该文件中定义 API 的类型:
<script cml-type="interface">
type successCallBack = (res: boolean) => void
type failCallBack = (res: boolean) => void
type obj = {
success: successCallBack,
fail: failCallBack
}
interface UtilsInterface {
installShortCut(obj): void;
hasInstalled(obj): void;
}
</script>相信大家可以看出来,其实接口的类型定义和 TypeScript 中的类型定义大同小异。
然后,在 shortcut.interface 文件中,定义添加桌面的类,其中包含两个方法 installShortCut() 和 hasInstalled(),在方法内部可以直接使用快应用的原生 API:
<script cml-type="quickapp">
class Method implements UtilsInterface {
installShortCut(obj) {
quickapp.shortcut.install(obj)
}
hasInstalled(obj) {
quickapp.shortcut.hasInstalled(obj)
}
}
export default new Method()
</script>
<script cml-type="web">
class Method implements UtilsInterface {
installShortCut(obj) {
}
hasInstalled(obj) {
}
}
export default new Method();
</script>
...并且,这里需要注意
quickapp.shortcut 的方式调用最后,我们就可以在业务代码中使用添加桌面的 API,并且它只会在快应用下有所表现:
<template>
<page title="index">
<text @click="addShortCut"></text>
</page>
</template>
<script>
import shortCut from "../../components/utils/shortcut.interface";
class Index {
methods = {
addShortCut() {
shortCut.installShortCut({
success: (res) => {
console.log(res)
},
fail: (err) => {
console.log(err)
}
})
}
}
}
</script>而扩展某个端的组件(多态组件)和扩展 API 大同小异。chameleon-tool 也提供了命令
cml init component来初始化一个多态组件模版,这一块官方文档也详细介绍了,这里就不做论述哈。
多态组件和多态接口都是多态协议的一部分,多态协议还支持多态模版,这会类似于 uniapp 的条件编译,可以指定 template 中展示的组件所属的端(仅作用于 root element)。并且,我想懂得了如何使用多态组件、多态接口、多态模版,那么使用 Chameleon 开发可以说是随心所欲。
最方便的是万不得已时我们可以改一点源码哈哈 😄
Chameleon 这个框架给我的感受,确实是又爱又狠 😷。因为,当时在项目开发过程中,快应用团队写的扩展有几个问题,我为了保证项目的正常上线,所以只能硬着头皮魔改源码抗着项目往前走 😳,最终项目也成功上线。然后,在周末的时间,我也整理了一些对 Chameleon 框架的理解,以及修复了几个快应用扩展存在的问题(顺手提了个 PR)。
最后,欢迎 👏 打算在业务中尝试 Chameleon 的同学一起交流心得(加我微信或公众号),如果在快应用实现中遇到了坑,我想我应该可以帮助一二。
关注「Vite」底层实现的同学,我想应该清楚它使用「esbuild」来实现对 .ts、jsx、.js 代码的转化。当然,在「Vite」之前更早使用「esbuild」的就是「Snowpack」。不过,相比较「Vite」拥有的巨大社区,显然「Snowpack」的关注度较小。
「Vite」的核心是基于浏览器原生的 ES Module。但是,相比较传统的打包工具和开发工具而言,它做出了很多改变,采用「esbuild」来支持 .ts、jsx、.js 代码的转化就是其中之一。
那么,接下来我们就步入今天的正题,What is esbuild, and how to use it?
「esbuild」官方的介绍:它是一个「JavaScript」Bundler 打包和压缩工具,它可以将「JavaScript」和「TypeScript」代码打包分发在网页上运行。
目前「esbuild」支持的功能:
这里,我们列出了几点常关注的,至于其他,有兴趣的同学可以移步官方文档自行了解。
目前对于「JavaScript」语法转化不支持的特性有:
需要注意的是对于不支持转化的语法会原样输出。
「esbuild」的作者对比目前现阶段类似的工具做了基准测试。最后的结果是:
对于这些基准测试,esbuild 比我测试的其他 JavaScript 打包程序 快至少 100 倍。
100 倍,可以说快到飞起了...而「esbuild」快的原因,这里我分两个层面解释:
当然,语言层面仅仅是官方解释中的一点的展开,其他解释有时间等后续分析其源码实现后讲解。
虽然,「esbuild」早已开源和使用,但是官方文档只是简单介绍了如何使用,而对于 API 介绍部分是欠缺的,建议读者自己去阅读源码中的定义。
「esbuild」总共提供了四个函数:transform、build、buildSync、Service。下面,我们从源码定义的角度来认识一下它们。
transform 可以用于转化 .js、.tsx、ts 等文件,然后输出为旧的语法的 .js 文件,它提供了两个参数:
sourcefile、需要加载的 loader,其中 loader 的定义:type Loader = 'js' | 'jsx' | 'ts' | 'tsx' | 'css' | 'json' | 'text' | 'base64' | 'file' | 'dataurl' | 'binary';transform 会返回一个 Promise,对应的 TransformResult 为一个对象,它会包含转化后的旧的 js 代码、sourceMap 映射、警告信息:
interface TransformResult {
js: string;
jsSourceMap: string;
warnings: Message[];
}build 实现了 transform 的能力,即代码转化,并且它还会将转换后的代码压缩并生成 .js 文件到指定 output 目录。build 只提供了一个参数(对象),来指定需要转化的入口文件、输出文件、loader 等选项:
interface BuildOptions extends CommonOptions {
bundle?: boolean;
splitting?: boolean;
outfile?: string;
metafile?: string;
outdir?: string;
platform?: Platform;
color?: boolean;
external?: string[];
loader?: { [ext: string]: Loader };
resolveExtensions?: string[];
mainFields?: string[];
write?: boolean;
tsconfig?: string;
outExtension?: { [ext: string]: string };
entryPoints?: string[];
stdin?: StdinOptions;
}build 函数调用会输出 BuildResult,它包含了生成的文件 outputFiles 和提示信息 warnings:
interface BuildResult {
warnings: Message[];
outputFiles?: OutputFile[];
}但是,需要注意的是
outputFiles只有在write为false的情况下才会输出,它是一个Uint8Array。
buidSync 顾名思义,相比较 build 而言,它是同步的构建方式,即如果使用 build 我们需要借助 async await 来实现同步调用,而使用 buildSync 可以直接实现同步调用。
Service 的出现是为了解决调用上述 API 时都会创建一个子进行来完成的问题,如果存在多次调用 API 的情况出现,那么就会出现性能上的浪费,这一点在文档中也有讲解。
所以,使用了 Service 来实现代码的转化或打包,则会创建一个长期的用于共享的子进程,避免了性能上的浪费。而在「Vite」中也正是使用 Service 的方式来进行 .ts、.js、.jsx 代码的转化工作。
Service 定义:
interface Service {
build(options: BuildOptions): Promise<BuildResult>;
transform(input: string, options?: TransformOptions): Promise<TransformResult>;
stop(): void;
}可以看到,Service 的本质封装了 build、transform、stop 函数,只是不同于单独调用它们,Service 底层的实现是一个长期存在可供共享的子进程。
但是,在实际使用上,我们并不是直接使用 Service 创建实例,而是通过 startService 来创建一个 Service 实例:
const {
startService,
build,
} = require("esbuild")
const service = await startService()
try {
const res = await service.build({
entryPoints: ["./src/main.js"],
write: false
})
console.log(res)
} finally {
service.stop()
}并且,在使用 stop 的时候需要注意,它会结束这个子进程,这也意味着任何在此时处于 pending 的 Promise 也会被终止。
在简单地认识「esbuild」,我们就来实现一个小而美的 Bunder 打包:
1.初始化项目和安装「esbuild」:
mkdir esbuild-bundler & npm init -y & npm i esbuild2.目录结构:
|——— src
|—— main.js #项目入口文件
|——— index.js #bundler实现核心文件3.index.js:
(async () => {
const {
startService,
build,
} = require("esbuild")
const service = await startService()
try {
const res = await service.build({
entryPoints: ["./src/main.js"],
outfile: './dist/main.js',
minify: true,
bundle: true,
})
} finally {
service.stop()
}
})()4.运行一下 node index 即可体验一下闪电般的 bundler 打包!
想必看完这篇文章,大家对「esbuild」应该建立起一个基础的认知。并且,文中的源码只是基于「Go」实现的底层能力上的,而真正的底层实现还是得看「Go」是如何实现的,由于脱离了大家熟知的前端,所以就不做介绍。那么,在一下篇文章中,我将会讲解在「Vite」的源码设计中是怎么使用 esbuild 来实现 .ts、jsx、.js 语法解析,以及我们如何自定义 plugin 来实现一些代码转化。
前段时间,尤雨溪回答了一个广大网友都好奇的一个问题:Vite 会不会取代 Vue CLI?
答案是:是的!
那么,你开始学 Vite 了吗?用过 Vite 的同学应该都熟悉,创建一个 Vite 的项目模版是通过 npm init @vitejs/app 的方式。而 npm init 命令是在 [email protected] 开始支持的,实际上它是先帮你安装 Vite 的 @vitejs/create-app 包(package),然后再执行 create-app 命令。
至于 @vitejs/create-app 则是在 Vite 项目的 packages/create-app 文件夹下。其整体的目录结构:
// packages/create-app
|———— template-lit-element
|———— template-lit-element-ts
|———— template-preact
|———— template-preact-ts
|———— template-react
|———— template-react-ts
|———— template-vanilla
|———— template-vue
|———— template-vue-ts
index.js
package.jsonVite 的 create-app CLI(以下统称为 create-app CLI)具备的能力不多,目前只支持基础模版的创建,所以全部代码加起来只有 160 行,其整体的架构图:
可以看出确实非常简单,也因此 create-app CLI 是一个很值得入门学习如何实现简易版 CLI 的例子。
那么,接下来本文将会围绕以下两个部分带着大家一起通过 create-app CLI 来学习如何实现一个简易版的 CLI:
create-app 中使用到的库(minimist、kolorist)
逐步拆解、分析 create-app CLI 源码
create-app CLI 实现用到的库(npm)确实很有意思,既有我们熟悉的 enquirer(用于命令行的提示),也有不熟悉的 minimist 和 kolorist。 那么,后面这两者又是拿来干嘛的?下面,我们就来了解一番~
minimist 是一个轻量级的用于解析命令行参数的工具。说起解析命令行的工具,我想大家很容易想到 commander。相比较 commander 而言,minimist 则以轻取胜!因为它只有 32.4 kB,commander 则有 142 kB,即也只有后者的约 1/5。
那么,下面我们就来看一下 minimist 的基础使用。
例如,此时我们在命令行中输入:
node index.js my-project那么,在 index.js 文件中可以使用 minimist 获取到输入的 myproject 参数:
var argv = require('minimist')(process.argv.slice(2));
console.log(argv._[0]);
// 输出 my-project这里的 argv 是一个对象,对象中 _ 属性的值则是解析 node index.js 后的参数所形成的数组。
kolorist 是一个轻量级的使命令行输出带有色彩的工具。并且,说起这类工具,我想大家很容易想到的就是 chalk。不过相比较 chalk 而言,两者包的大小差距并不明显,前者为 49.9 kB,后者为 33.6 kB。不过 kolorist 可能较为小众,npm 的下载量大大不如后者 chalk,相应地 chalk 的 API 也较为详尽。
同样的,下面我们也来看一下 kolorist 的基础使用。
例如,当此时应用发生异常的时候,需要打印出红色的异常信息告知用户发生异常,我们可以使用 kolorist 提供的 red 函数:
import { red } from 'kolorist'
console.log(red("Something is wrong"))又或者,可以使用 kolorist 提供的 stripColors 来直接输出带颜色的字符串:
import { red, stripColors } from 'kolorist'
console.log(stripColors(red("Something is wrong"))了解过 CLI 相关知识的同学应该知道,我们通常使用的命令是在 package.json 文件的 bin 中配置的。而 create-app CLI 对应的文件根目录下该文件的 bin 配置会是这样:
// pacakges/create-app/package.json
"bin": {
"create-app": "index.js",
"cva": "index.js"
}可以看到 create-app 命令则由这里注册生效,它指向的是当前目录下的 index.js 文件。并且,值得一提的是这里注册了 2 个命令,也就是说我们还可以使用 cva 命令来创建基于 Vite 的项目模版(想不到吧 😲)。
而 create-app CLI 实现的核心就是在 index.js 文件。那么,下面我们来看一下 index.js 中代码的实现~
上面我们也提及了 create-app CLI 引入了 minimist、enquire、kolorist 等依赖,所以首先是引入它们:
const fs = require('fs')
const path = require('path')
const argv = require('minimist')(process.argv.slice(2))
const { prompt } = require('enquirer')
const {
yellow,
green,
cyan,
magenta,
lightRed,
stripColors
} = require('kolorist')其中,fs 和 path 是 Node 内置的模块,前者用于文件相关操作、后者用于文件路径相关操作。接着就是引入 minimist、enquirer 和 kolorist,它们相关的介绍上面已经提及,这里就不重复论述~
从 /packages/create-app 目录中,我们可以看出 create-app CLI 为我们提供了 9 种项目基础模版。并且,在命令行交互的时候,每个模版之间的颜色各有不同,即 CLI 会使用 kolorist 提供的颜色函数来为模版定义好对应的颜色:
const TEMPLATES = [
yellow('vanilla'),
green('vue'),
green('vue-ts'),
cyan('react'),
cyan('react-ts'),
magenta('preact'),
magenta('preact-ts'),
lightRed('lit-element'),
lightRed('lit-element-ts')
]其次,由于 .gitignore 文件的特殊性,每个项目模版下都是先创建的 _gitignore 文件,在后续创建项目的时候再替换掉该文件的命名(替换为 .gitignore)。所以,CLI 会预先定义一个对象来存放需要重命名的文件:
const renameFiles = {
_gitignore: '.gitignore'
}由于创建项目的过程中会涉及和文件相关的操作,所以 CLI 内部定义了 3 个工具函数:
copyDir 函数
copyDir 函数用于将某个文件夹 srcDir 中的文件复制到指定文件夹 destDir中。它会先调用 fs.mkdirSync 函数来创建制定的文件夹,然后枚举从 srcDir 文件夹下获取的文件名构成的数组,即 fs.readdirSync(srcDir)。
其对应的代码如下:
function copyDir(srcDir, destDir) {
fs.mkdirSync(destDir, { recursive: true })
for (const file of fs.readdirSync(srcDir)) {
const srcFile = path.resolve(srcDir, file)
const destFile = path.resolve(destDir, file)
copy(srcFile, destFile)
}
}copy 函数
copy 函数则用于复制文件或文件夹 src 到指定文件夹 dest。它会先获取 src 的状态 stat,如果 src 是文件夹的话,即 stat.isDirectory() 为 true 时,则会调用上面介绍的 copyDir 函数来复制 src 文件夹下的文件到 dest 文件夹下。反之,src 是文件的话,则直接调用 fs.copyFileSync 函数复制 src 文件到 dest 文件夹下。
其对应的代码如下:
function copy(src, dest) {
const stat = fs.statSync(src)
if (stat.isDirectory()) {
copyDir(src, dest)
} else {
fs.copyFileSync(src, dest)
}
}emptyDir 函数
emptyDir 函数用于清空 dir 文件夹下的代码。它会先判断 dir 文件夹是否存在,存在则枚举该问文件夹下的文件,构造该文件的路径 abs,调用 fs.unlinkSync 函数来删除该文件,并且当 abs 为文件夹时,则会递归调用 emptyDir 函数删除该文件夹下的文件,然后再调用 fs.rmdirSync 删除该文件夹。
其对应的代码如下:
function emptyDir(dir) {
if (!fs.existsSync(dir)) {
return
}
for (const file of fs.readdirSync(dir)) {
const abs = path.resolve(dir, file)
if (fs.lstatSync(abs).isDirectory()) {
emptyDir(abs)
fs.rmdirSync(abs)
} else {
fs.unlinkSync(abs)
}
}
}CLI 实现核心函数是 init,它负责使用前面我们所说的那些函数、工具包来实现对应的功能。下面,我们就来逐点分析 init 函数实现的过程:
1. 创建项目文件夹
通常,我们可以使用 create-app my-project 命令来指定要创建的项目文件夹,即在哪个文件夹下:
let targetDir = argv._[0]
cwd = process.cwd()
const root = path.join(cwd, targetDir)
console.log(`Scaffolding project in ${root}...`)其中,argv._[0] 代表 create-app 后的第一个参数,root 是通过 path.join 函数构建的完整文件路径。然后,在命令行中会输出提示,告述你脚手架(Scaffolding)项目创建的文件路径:
Scaffolding project in /Users/wjc/Documents/project/vite-project...当然,有时候我们并不想输入在 create-app 后输入项目文件夹,而只是输入 create-app 命令。那么,此时 tagertDir 是不存在的。CLI 则会使用 enquirer 包的 prompt 来在命令行中输出询问:
? project name: > vite-project你可以在这里输入项目文件夹名,又或者直接回车使用 CLI 给的默认项目文件夹名。这个过程对应的代码:
if (!targetDir) {
const { name } = await prompt({
type: "input",
name: "name",
message: "Project name:",
initial: "vite-project"
})
targetDir = name
}接着,CLI 会判断该文件夹是否存在当前的工作目录(cwd)下,如果不存在则会使用 fs.mkdirSync 创建一个文件夹:
if (!fs.existsSync(root)) {
fs.mkdirSync(root, { recursive: true })
}反之,如果存在该文件夹,则会判断此时文件夹下是否存在文件,即使用 fs.readdirSync(root) 获取该文件夹下的文件:
const existing = fs.readdirSync(root)这里 existing 会是一个数组,如果此时数组长度不为 0,则表示该文件夹下存在文件。那么 CLI 则会询问是否删除该文件夹下的文件:
Target directory vite-project is not empty.
Remove existing files and continue?(y/n): Y你可以选择通过输入 y 或 n 来告知 CLI 是否要清空该目录。并且,如果此时你输入的是 n,即不清空该文件夹,那么整个 CLI 的执行就会退出。这个过程对应的代码:
if (existing.length) {
const { yes } = await prompt({
type: 'confirm',
name: 'yes',
initial: 'Y',
message:
`Target directory ${targetDir} is not empty.\n` +
`Remove existing files and continue?`
})
if (yes) {
emptyDir(root)
} else {
return
}
}2. 确定项目模版
在创建好项目文件夹后,CLI 会获取 --template 选项,即当我们输入这样的命令时:
npm init @vitejs/app --template 文件夹名如果 --template 选项不存在(即 undefined),则会询问要选择的项目模版:
let template = argv.t || argv.template
if (!template) {
const { t } = await prompt({
type: "select",
name: "t",
message: "Select a template:",
choices: TEMPLATES
})
template = stripColors(t)
}由于,TEMPLATES 中只是定义了模版的类型,对比起 packages/create-app 目录下的项目模版文件夹命名有点差别(缺少 template 前缀)。例如,此时 template 会等于 vue-ts,那么就需要给 template 拼接前缀和构建完整目录:
const templateDir = path.join(__dirname, `template-${template}`)所以,现在 templateDir 就会等于当前工作目录 + template-vue-ts。
3. 写入项目模版文件
确定完需要创建的项目的模版后,CLI 就会读取用户选择的项目模版文件夹下的文件,然后将它们一一写入此时创建的项目文件夹下:
可能有点绕,举个例子,选择的模版是
vue-ts,自己要创建的项目文件夹为vite-project,那么则是将create-app/template-vue-ts文件夹下的文件写到vite-project文件夹下。
const files = fs.readdirSync(templateDir)
for (const file of files.filter((f) => f !== 'package.json')) {
write(file)
}由于通过 fs.readdirSync 函数返回的是该文件夹下的文件名构成的数组 ,所以这里会通过 for of 枚举该数组,每次枚举会调用 write 函数进行文件的写入。
注意此时会跳过
package.json文件,之后我会讲解为什么需要跳过package.json文件。
而 write 函数则接受两个参数 file 和 content,其具备两个能力:
对指定的文件 file 写入指定的内容 content,调用 fs.writeFileSync 函数来实现将内容写入文件
复制模版文件夹下的文件到指定文件夹下,调用前面介绍的 copy 函数来实现文件的复制
write 函数的定义:
const write = (file, content) => {
const targetPath = renameFiles[file]
? path.join(root, renameFiles[file])
: path.join(root, file)
if (content) {
fs.writeFileSync(targetPath, content)
} else {
copy(path.join(templateDir, file), targetPath)
}
}并且,值得一提的是 targetPath 的获取过程,会针对 file 构建完整的文件路径,并且兼容处理 _gitignore 文件的情况。
在写入模版内的这些文件后,CLI 就会处理 package.json 文件。之所以单独处理 package.json 文件的原因是每个项目模版内的 package.json 的 name 都是写死的,而当用户创建项目后,name 都应该为该项目的文件夹命名。这个过程对应的代码会是这样:
const pkg = require(path.join(templateDir, `package.json`))
pkg.name = path.basename(root)
write('package.json', JSON.stringify(pkg, null, 2))其中,
path.basename函数则用于获取一个完整路径的最后的文件夹名
最后,CLI 会输出一些提示告诉你项目已经创建结束,以及告诉你接下来启动项目需要运行的命令:
console.log(`\nDone. Now run:\n`)
if (root !== cwd) {
console.log(` cd ${path.relative(cwd, root)}`)
}
console.log(` npm install (or \`yarn\`)`)
console.log(` npm run dev (or \`yarn dev\`)`)
console.log()虽然 Vite 的 create-app CLI 的实现仅仅只有 160 行的代码,但是它也较为全面地考虑了创建项目的各种场景,并做对应的兼容处理。简而言之,十分小而美。所以,我相信大家经过学习 Vite 的 create-app CLI 的实现,都应该可以随手甩出(实现)一个 CLI 的代码 😎 ~
前段时间,Vite 做了一个优化依赖预构建(Dependency Pre-Bundling)。简而言之,它指的是 Vite 会在 DevServer 启动前对需要预构建的依赖进行构建,然后在分析模块的导入(import)时会动态地应用构建过的依赖。
这么一说,我想大家可能立马会抛出一个疑问:Vite 不是 No Bundle 吗?确实 Vite 是 No Bundle,但是依赖预构建并不是意味着 Vite 要走向 Bundle,我们不要急着下定义,因为它的存在必然是有着其实际的价值。
那么,今天本文将会围绕以下 3 点来和大家一起从疑问点出发,深入浅出一番 Vite 的依赖预构建过程:
什么是依赖预构建
依赖预构建的作用
依赖预构建的实现(源码分析)
当你在项目中引用了 vue 和 lodash-es,那么你在启动 Vite 的时候,你会在终端看到这样的输出内容:
而这表示 Vite 将你在项目中引入的 vue 和 lodash-es 进行了依赖预构建!这里,我们通过大白话认识一下 Vite 的依赖预构建:
默认情况下,Vite 会将 package.json 中生产依赖 dependencies 的部分启用依赖预构建,即会先对该依赖进行构建,然后将构建后的文件缓存在内存中(node_modules/.vite 文件下),在启动 DevServer 时直接请求该缓存内容。
在 vite.config.js 文件中配置 optimizeDeps 选项可以选择需要或不需要进行预构建的依赖的名称,Vite 则会根据该选项来确定是否对该依赖进行预构建。
在启动时添加 --force options,可以用来强制重新进行依赖预构建。
需要注意,强制重新依赖预构建指的是忽略之前已构建的文件,直接重新构建。
所以,回到文章开始所说的疑问,这里我们可以这样理解依赖预构建,它的出现是一种优化,即没有它其实 No Bundle 也可以,有它更好(xiang)! 而且,依赖预构建并非无米之炊,Vite 也是受 Snowpack 的启发才提出的。
那么,下面我们就来了解一下依赖预构建的作用是什么,即优化的意义~
对于依赖预构建的作用,Vite 官方也做了详细的介绍。那么,这里我们通过结合图例的方式来认识一下,具体会是两点:
1. 兼容 CommonJS 和 AMD 模块的依赖
因为 Vite 的 DevServer 是基于浏览器的 Natvie ES Module 实现的,所以对于使用的依赖如果是 CommonJS 或 AMD 的模块,则需要进行模块类型的转化(ES Module)。
2. 减少模块间依赖引用导致过多的请求次数
通常我们引入的一些依赖,它自己又会一些其他依赖。官方文档中举了一个很经典的例子,当我们在项目中使用 lodash-es 的时候:
import { debounce } from "lodash-es"如果在没用依赖预构建的情况下,我们打开页面的 Dev Tool 的 Network 面板:
可以看到此时大概有 600+ 和 lodash-es 相关的请求,并且所有请求加载花了 1.11 s,似乎还好?现在,我们来看一下使用依赖预构建的情况:
此时,只有 1 个和 lodash-es 相关的请求(经过预构建),并且所有请求加载才花了 142 ms,缩短了足足 7 倍多的时间! 而这里节省的时间,就是我们常说的冷启动时间。
那么,到这里我们就已经了解了 Vite 依赖预构建概念和作用。我想大家都会好奇这个过程又是怎么实现的?下面,我们就深入 Vite 源码来更进一步地认识依赖预构建过程!
在 Vite 源码中,默认的依赖预构建过程会在 DevServer 开启之前进行。这里,我们仍然以在项目中引入了 vue 和 lodash-es 依赖为例。
需要注意的是以下和源码相关的函数都是取的核心逻辑讲解(伪代码)。
首先,Vite 会创建一个 DevServer,也就是我们平常使用的本地开发服务器,这个过程是由 createServer 函数完成:
// packages/vite/src/node/server/index.ts
async function createServer(
inlineConfig: InlineConfig = {}
): Promise<ViteDevServer> {
...
// 通常情况下我们会命中这个逻辑
if (!middlewareMode && httpServer) {
// 重写 DevServer 的 listen,保证在 DevServer 启动前进行依赖预构建
const listen = httpServer.listen.bind(httpServer)
httpServer.listen = (async (port: number, ...args: any[]) => {
try {
...
// 依赖预构建相关
await runOptimize()
}
...
}) as any
...
} else {
await runOptimize()
}
...
}可以看到在 DevServer 真正启动之前,它会先调用 runOptimize 函数,进行依赖预构建相关的处理(用 bind 进行简单的重写)。
runOptimize 函数:
// packages/vite/src/node/server/index.ts
const runOptimize = async () => {
// config.optimzizeCacheDir 指的是 node_modules/.vite
if (config.optimizeCacheDir) {
..
try {
server._optimizeDepsMetadata = await optimizeDeps(config)
}
..
server._registerMissingImport = createMissingImpoterRegisterFn(server)
}
}runOptimize 函数负责的是调用和注册处理依赖预构建相关的 optimizeDeps 函数,具体来说会是两件事:
1. 进行依赖预构建
optimizeDeps 函数是 Vite 实现依赖预构建的核心函数,它会根据配置 vite.config.js 的 optimizeDeps 选项和 package.json 的 dependencies 的参数进行第一次预构建。它会返回解析 node_moduels/.vite/_metadata.json 文件后生成的对象(包含预构建后的依赖所在的文件位置、原文件所处的文件位置等)。
_metadata.json 文件:
{
"hash": "bade5e5e",
"browserHash": "830194d7",
"optimized": {
"vue": {
"file": "/Users/wjc/Documents/FE/demos/vite2.0-demo/node_modules/.vite/vue.js",
"src": "/Users/wjc/Documents/FE/demos/vite2.0-demo/node_modules/vue/dist/vue.runtime.esm-bundler.js",
"needsInterop": false
},
"lodash-es": {
"file": "/Users/wjc/Documents/FE/demos/vite2.0-demo/node_modules/.vite/lodash-es.js",
"src": "/Users/wjc/Documents/FE/demos/vite2.0-demo/node_modules/lodash-es/lodash.js",
"needsInterop": false
}
}
}这里,我们来分别认识一下这 4 个属性的含义:
hash 由需要进行预构建的文件内容生成的,用于防止 DevServer 启动时重复构建相同的依赖,即依赖并没有发生变化,不需要重新构建。
browserHash 由 hash 和在运行时发现的额外的依赖生成的,用于让预构建的依赖的浏览器请求无效。
optimized 包含每个进行过预构建的依赖,其对应的属性会描述依赖源文件路径 src 和构建后所在路径 file。
needsInterop 主要用于在 Vite 进行依赖性导入分析,这是由 importAnalysisPlugin 插件中的 transformCjsImport 函数负责的,它会对需要预构建且为 CommonJS 的依赖导入代码进行重写。举个例子,当我们在 Vite 项目中使用 react 时:
import React, { useState, createContext } from 'react'此时 react 它是属于 needsInterop 为 true 的范畴,所以 importAnalysisPlugin 插件的会对导入 react 的代码进行重写:
import $viteCjsImport1_react from "/@modules/react.js";
const React = $viteCjsImport1_react;
const useState = $viteCjsImport1_react["useState"];
const createContext = $viteCjsImport1_react["createContext"];之所以要进行重写的缘由是因为 CommonJS 的模块并不支持命名方式的导出。所以,如果不经过插件的转化,则会看到这样的异常:
Uncaught SyntaxError: The requested module '/@modules/react.js' does not provide an export named 'useState'有兴趣继续往这方面了解的同学可以查看这个 PR https://github.com/vitejs/vite/pull/837,这里就不做过于详细的介绍了~
2. 注册依赖预构建相关函数
调用 createMissingImpoterRegisterFn 函数,它会返回一个函数,其仍然内部会调用 optimizeDeps 函数进行预构建,只是不同于第一次预构建过程,此时会传人一个 newDeps,即新的需要进行预构建的依赖。
那么,显然无论是第一次预构建,还是后续的预构建,它们两者的实现都是调用的 optimizeDeps 函数。所以,下面我们来看一下 optimizeDeps 函数~
optimizeDeps 函数被定义在 packages/vite/node/optimizer/index.ts 中,它负责对依赖进行预构建过程:
// packages/vite/node/optimizer/index.ts
export async function optimizeDeps(
config: ResolvedConfig,
force = config.server.force,
asCommand = false,
newDeps?: Record<string, string>
): Promise<DepOptimizationMetadata | null> {
...
}由于 optimizeDeps 内部逻辑较为繁多,这里我们拆分为 5 个步骤讲解:
1. 读取该依赖此时的文件信息
既然是构建依赖,很显然的是每次构建都需要知道此时文件内容对应的 Hash 值,以便于依赖发生变化时可以重新进行依赖构建,从而应用最新的依赖内容。
所以,这里会先调用 getDepHash 函数获取依赖的 Hash 值:
// 获取该文件此时的 hash
const mainHash = getDepHash(root, config)
const data: DepOptimizationMetadata = {
hash: mainHash,
browserHash: mainHash,
optimized: {}
}而对于
data中的这三个属性,我们在上面已经介绍过了,这里就不重复论述了~
2. 对比缓存文件的 Hash
前面,我们也提及了如果启动 Vite 时使用了 --force Option,则会强制重新进行依赖预构建。所以,当不是 --force 场景时,则会进行比较新旧依赖的 Hash 值的过程:
// 默认为 false
if (!force) {
let prevData
try {
// 获取到此时缓存(本地磁盘)中构建的文件信息
prevData = JSON.parse(fs.readFileSync(dataPath, 'utf-8'))
} catch (e) {}
// 对比此时的
if (prevData && prevData.hash === data.hash) {
log('Hash is consistent. Skipping. Use --force to override.')
return prevData
}
}可以看到如果新旧依赖的 Hash 值相等的时候,则会直接返回旧的依赖内容。
3. 缓存失效或未缓存
如果上面的 Hash 不等,则表示缓存失效,所以会删除 cacheDir 文件夹,又或者此时未进行缓存,即第一次依赖预构建逻辑( cacheDir 文件夹不存在),则创建 cacheDir 文件夹:
if (fs.existsSync(cacheDir)) {
emptyDir(cacheDir)
} else {
fs.mkdirSync(cacheDir, { recursive: true })
}需要注意的是,这里的
cacheDir则指的是 node_modules/.vite 文件夹
前面在讲 DevServer 启动时,我们提及预构建过程会分为两种:第一次预构建和后续的预构建。两者的区别在于后者会传入一个 newDeps,它表示新的需要进行预构建的依赖:
let deps: Record<string, string>, missing: Record<string, string>
if (!newDeps) {
;({ deps, missing } = await scanImports(config))
} else {
// 存在 newDeps 的时候,直接将 newDeps 赋值给 deps
deps = newDeps
missing = {}
}并且,这里可以看到对于前者,第一次预构建,则会调用 scanImports 函数来找出和预构建相关的依赖 deps,deps 会是一个对象:
{
lodash-es:'/Users/wjc/Documents/FE/demos/vite2.0-demo/node_modules/lodash-es/lodash.js'
vue:'/Users/wjc/Documents/FE/demos/vite2.0-demo/node_modules/vue/dist/vue.runtime.esm-bundler.js'
}而 missing 则表示在 node_modules 中没找到的依赖。所以,当 missing 存在时,你会看到这样的提示:
scanImports函数内部则是调用的一个名为dep-scan的内部插件(Plugin)。这里就不讲解dep-scan插件的具体实现了,有兴趣的同学可以自行了解哈~
那么,回到上面对于后者(newDeps 存在时)的逻辑则较为简单,会直接给 deps 赋值为 newDeps,并且不需要处理 missing。因为,newDeps 只有在后续导入并安装了新的 dependencies 依赖,才会传入的,此时是不存在 missing 的依赖的( Vite 内置的 importAnalysisPlugin 插件会提前过滤掉这些)。
4. 处理 optimizeDeps.include 相关依赖
在前面,我们也提及了需要进行构建的依赖也会由 vite.config.js 的 optimizeDeps 选项决定。所以,在处理完 dependencies 之后,接着需要处理 optimizeDeps。
此时,会遍历前面从 dependencies 获取到的 deps,判断 optimizeDeps.iclude(数组)所指定的依赖是否存在,不存在则会抛出异常:
const include = config.optimizeDeps?.include
if (include) {
const resolve = config.createResolver({ asSrc: false })
for (const id of include) {
if (!deps[id]) {
const entry = await resolve(id)
if (entry) {
deps[id] = entry
} else {
throw new Error(
`Failed to resolve force included dependency: ${chalk.cyan(id)}`
)
}
}
}
}5. 使用 esbuild 构建依赖
那么,在做好上述和预构建依赖相关的处理(文件 hash 生成、预构建依赖确定等)后。则进入依赖预构建的最后一步,使用 esbuild 来对相应的依赖进行构建:
...
const esbuildService = await ensureService()
await esbuildService.build({
entryPoints: Object.keys(flatIdDeps),
bundle: true,
format: 'esm',
...
})
...ensureService 函数是 Vite 内部封装的 util,它的本质是创建一个 esbuild 的 service,使用 service.build 函数来完成构建过程。
此时,传入的 flatIdDeps 参数是一个对象,它是由上面提及的 deps 收集好的依赖创建的,它的作用是为 esbuild 进行构建的时候提供多路口(entry),flatIdDeps 对象:
{
lodash-es:'/Users/wjc/Documents/FE/demos/vite2.0-demo/node_modules/lodash-es/lodash.js'
moment:'/Users/wjc/Documents/FE/demos/vite2.0-demo/node_modules/moment/dist/moment.js'
vue:'/Users/wjc/Documents/FE/demos/vite2.0-demo/node_modules/vue/dist/vue.runtime.esm-bundler.js'
}好了,到此我们已经分析完了整个依赖预构建的实现 😲(手动给看到这的大家👍)。
那么,接下来在 DevServer 启动后,当模块需要请求经过预构建的依赖的时候,Vite 内部的 resolvePlugin 插件会解析该依赖是否存在 seen 中(seen 中会存储构建过的依赖映射),是则直接应用 node_modules/.vite 目录下对应的构建后的依赖,避免直接去请求构建前的依赖的情况出现,从而缩短冷启动的时间。
通过了解 Vite 依赖预构建的作用、实现等相关知识,我想大家应该不会再去纠结 Bundle 或者 No Bundle 的问题了,仍然是那句话,存在即有价值。并且,依赖预构建这个知识点在面试场景下,可能也是一个很有趣的考题 😎。
在 5月22日的 Vue Conf 21 上,尤大介绍在介绍单文件组件(SFC)在编译阶段的优化的时候,讲了 SFC Style CSS Variable Injection 这个提案,即 <style> 动态变量注入。简单地讲,它可以让你在 <style> 中通过 v-bind 的方式使用 <script> 中定义好的变量。
这么一听,似乎很像 CSS In JS?确实,从使用的角度是和 CSS In JS 很类似。但是,大家都知道的是 CSS In JS 在一些场景下,存在一定的性能问题,而 <style> 动态变量注入却不存类似的问题。
那么, <style> 动态变量注入又是怎么实现的?我想这是很多同学都会抱有的一个疑问,所以,今天就让我们来彻底搞懂何为 <style> 动态变量注入,以及它实现的背后做了哪些事情。
<style> 动态变量注入<style> 动态变量注入,根据 SFC 上尤大的总结,它主要有以下 5 点能力:
下面,我们来看一个简单使用 <style> 动态变量注入的例子:
<template>
<p class="word">{{ msg }}</p>
<button @click="changeColor">
click me
</button>
</template>
<script setup>
import { ref } from "vue"
const msg = 'Hello World!'
let color = ref("red")
const changeColor = () => {
if (color.value === 'black') {
color.value = "red"
} else {
color.value = "black"
}
}
</script>
<style scoped>
.word {
background: v-bind(color)
}
</style>对应的渲染到页面上:
从上面的代码片段,很容易得知当我们点击 click me 按钮,文字的背景色就会发生变化:
而这就是 <style> 动态变量注入赋予我们的能力,让我们很便捷地通过 <script> 中的变量来操作 <template> 中的 HTML 元素样式的动态改变。
那么,这个过程又发生了什么?怎么实现的?有疑问是件好事,接着让我们来一步步揭开其幕后的实现原理。
<style> 动态变量注入的原理在文章的开始,我们讲了 <style> 动态变量注入的实现是源于在单文件(SFC)在编译阶段的优化。不过,这里并不对SFC 编译的全部过程进行讲解,不了解的同学可以看我之前写的文章 从编译过程,理解 Vue3 静态节点提升过程。
那么,下面让我们聚焦 SFC 在编译过程对 <style> 动态变量注入的处理,首先是这个过程实现的 2 个关键点。
<style> 动态变量注入的处理SFC 在编译过程对 <style> 动态变量注入的处理实现,主要是基于的 2 个关键点。这里,我们以上面的例子作为示例分析:
style,通过 CSS var() 在 CSS 中使用在行内 style 上定义的自定义属性,对应的 HTML 部分:color 变量来实现行内 style 属性值的变化,进而改变使用了该 CSS 自定义属性的 HTML 元素样式那么,显然要完成这一整个过程,不同于在没有 <style> 动态变量注入前的 SFC 编译,这里需要对 <style>、<script> 增加相应的特殊处理。下面,我们分 2 点来讲解:
1.SFC 编译 <style> 相关处理
大家都知道的是在 Vue SFC 的 <style> 部分编译主要是由 postcss 完成的。而这在 Vue 源码中对应着 packages/compiler-sfc/sfc/compileStyle.ts 中的 doCompileStyle() 方法。
这里,我们看一下其针对 <style> 动态变量注入的编译处理,对应的代码(伪代码):
export function doCompileStyle(
options: SFCAsyncStyleCompileOptions
): SFCStyleCompileResults | Promise<SFCStyleCompileResults> {
const {
...
id,
...
} = options
...
const plugins = (postcssPlugins || []).slice()
plugins.unshift(cssVarsPlugin({ id: shortId, isProd }))
...
}可以看到,在使用 postcss 编译 <style> 之前会加入 cssVarsPlugin 插件,并给 cssVarsPlugin 传入 shortId(即 scopedId 替换掉 data-v 内的结果)和 isProd(是否处于生产环境)。
cssVarsPlugin 则是使用了 postcss 插件提供的 Declaration 方法,来访问 <style> 中声明的所有 CSS 属性的值,每次访问通过正则来匹配 v-bind 指令的内容,然后再使用 replace() 方法将该属性值替换为 var(--xxxx-xx),表现在上面这个例子会是这样:
cssVarsPlugin 插件的定义:
const cssVarRE = /\bv-bind\(\s*(?:'([^']+)'|"([^"]+)"|([^'"][^)]*))\s*\)/g
const cssVarsPlugin: PluginCreator<CssVarsPluginOptions> = opts => {
const { id, isProd } = opts!
return {
postcssPlugin: 'vue-sfc-vars',
Declaration(decl) {
// rewrite CSS variables
if (cssVarRE.test(decl.value)) {
decl.value = decl.value.replace(cssVarRE, (_, $1, $2, $3) => {
return `var(--${genVarName(id, $1 || $2 || $3, isProd)})`
})
}
}
}
}这里 CSS var() 的变量名即 --(之后的内容)是由 genVarName() 方法生成,它会根据 isProd 为 true 或 false 生成不同的值:
function genVarName(id: string, raw: string, isProd: boolean): string {
if (isProd) {
return hash(id + raw)
} else {
return `${id}-${raw.replace(/([^\w-])/g, '_')}`
}
}2.SFC 编译 <script> 相关处理
如果,仅仅站在 <script> 的角度,显然是无法感知当前 SFC 是否使用了 <style> 动态变量注入。所以,需要从 SFC 出发来标识当前是否使用了 <style> 动态变量注入。
在 packages/compiler-sfc/parse.ts 中的 parse 方法中会对解析 SFC 得到的 descriptor 对象调用 parseCssVars() 方法来获取 <style> 中使用到 v-bind 的所有变量。
descriptor指的是解析 SFC 后得到的包含script、style、template属性的对象,每个属性包含了 SFC 中每个块(Block)的信息,例如<style>的属性scoped和内容等。
对应的 parse() 方法中部分代码(伪代码):
function parse(
source: string,
{
sourceMap = true,
filename = 'anonymous.vue',
sourceRoot = '',
pad = false,
compiler = CompilerDOM
}: SFCParseOptions = {}
): SFCParseResult {
//...
descriptor.cssVars = parseCssVars(descriptor)
if (descriptor.cssVars.length) {
warnExperimental(`v-bind() CSS variable injection`, 231)
}
//...
}可以看到,这里会将 parseCssVars() 方法返回的结果(数组)赋值给 descriptor.cssVars。然后,在编译 script 的时候,根据 descriptor.cssVars.length 判断是否注入 <style> 动态变量注入相关的代码。
在项目中使用了
<style>动态变量注入,会在终端种看到提示告知我们这个特性仍然处于实验中之类的信息。
而编译 script 是由 package/compile-sfc/src/compileScript.ts 中的 compileScript 方法完成,这里我们看一下其针对 <style> 动态变量注入的处理:
export function compileScript(
sfc: SFCDescriptor,
options: SFCScriptCompileOptions
): SFCScriptBlock {
//...
const cssVars = sfc.cssVars
//...
const needRewrite = cssVars.length || hasInheritAttrsFlag
let content = script.content
if (needRewrite) {
//...
if (cssVars.length) {
content += genNormalScriptCssVarsCode(
cssVars,
bindings,
scopeId,
!!options.isProd
)
}
}
//...
}对于前面我们举的例子(使用了 <style> 动态变量注入),显然 cssVars.length 是存在的,所以这里会调用 genNormalScriptCssVarsCode() 方法来生成对应的代码。
genNormalScriptCssVarsCode() 的定义:
// package/compile-sfc/src/cssVars.ts
const CSS_VARS_HELPER = `useCssVars`
function genNormalScriptCssVarsCode(
cssVars: string[],
bindings: BindingMetadata,
id: string,
isProd: boolean
): string {
return (
`\nimport { ${CSS_VARS_HELPER} as _${CSS_VARS_HELPER} } from 'vue'\n` +
`const __injectCSSVars__ = () => {\n${genCssVarsCode(
cssVars,
bindings,
id,
isProd
)}}\n` +
`const __setup__ = __default__.setup\n` +
`__default__.setup = __setup__\n` +
` ? (props, ctx) => { __injectCSSVars__();return __setup__(props, ctx) }\n` +
` : __injectCSSVars__\n`
)
}genNormalScriptCssVarsCode() 方法主要做了这 3 件事:
useCssVars() 方法,其主要是监听 watchEffect 动态注入的变量,然后再更新对应的 CSS Vars() 的值__injectCSSVars__ 方法,其主要是调用了 genCssVarsCode() 方法来生成 <style> 动态样式相关的代码<script setup> 情况下的组合 API 使用(对应这里 __setup__),如果它存在则重写 __default__.setup 为 (props, ctx) => { __injectCSSVars__();return __setup__(props, ctx) }那么,到这里我们就已经大致分析完 SFC 编译对 <style> 动态变量注入的处理,其中部分逻辑并没有过多展开讲解(避免陷入套娃的情况),有兴趣的同学可以自行了解。下面,我们就针对前面这个例子,看一下 SFC 编译结果会是什么?
<style> 动态变量注入实现细节这里,我们直接通过 Vue 官方的 SFC Playground 来查看上面这个例子经过 SFC 编译后输出的代码:
import { useCssVars as _useCssVars, unref as _unref } from 'vue'
import { toDisplayString as _toDisplayString, createVNode as _createVNode, Fragment as _Fragment, openBlock as _openBlock, createBlock as _createBlock, withScopeId as _withScopeId } from "vue"
const _withId = /*#__PURE__*/_withScopeId("data-v-f13b4d11")
import { ref } from "vue"
const __sfc__ = {
expose: [],
setup(__props) {
_useCssVars(_ctx => ({
"f13b4d11-color": (_unref(color))
}))
const msg = 'Hello World!'
let color = ref("red")
const changeColor = () => {
if (color.value === 'black') {
color.value = "red"
} else {
color.value = "black"
}
}
return (_ctx, _cache) => {
return (_openBlock(), _createBlock(_Fragment, null, [
_createVNode("p", { class: "word" }, _toDisplayString(msg)),
_createVNode("button", { onClick: changeColor }, " click me ")
], 64 /* STABLE_FRAGMENT */))
}
}
}
__sfc__.__scopeId = "data-v-f13b4d11"
__sfc__.__file = "App.vue"
export default __sfc__可以看到 SFC 编译的结果,输出了单文件对象 __sfc__、render 函数、<style> 动态变量注入等相关的代码。那么抛开前两者,我们直接看 <style> 动态变量注入相关的代码:
_useCssVars(_ctx => ({
"f13b4d11-color": (_unref(color))
}))这里调用了 _useCssVars() 方法,即在源码中指的是 useCssVars() 方法,然后传入了一个函数,该函数会返回一个对象 { "f13b4d11-color": (_unref(color)) }。那么,下面我们来看一下 useCssVars() 方法。
useCssVars() 方法是定义在 runtime-dom/src/helpers/useCssVars.ts 中:
// runtime-dom/src/helpers/useCssVars.ts
function useCssVars(getter: (ctx: any) => Record<string, string>) {
if (!__BROWSER__ && !__TEST__) return
const instance = getCurrentInstance()
if (!instance) {
__DEV__ &&
warn(`useCssVars is called without current active component instance.`)
return
}
const setVars = () =>
setVarsOnVNode(instance.subTree, getter(instance.proxy!))
onMounted(() => watchEffect(setVars, { flush: 'post' }))
onUpdated(setVars)
}useCssVars 主要做了这 4 件事:
获取当前组件实例 instance,用于后续操作组件实例的 VNode Tree,即 instance.subTree
定义 setVars() 方法,它会调用 setVarsOnVNode() 方法,并 instance.subTree、接收到的 getter() 方法传入
在 onMounted() 生命周期中添加 watchEffect,每次挂载组件的时候都会调用 setVars() 方法
在 onUpdated() 生命周期中添加 setVars() 方法,每次组件更新的时候都会调用 setVars() 方法
可以看到,无论是 onMounted() 或者 onUpdated() 生命周期,它们都会调用 setVars() 方法,本质上也就是 setVarsOnVNode() 方法,我们先来看一下它的定义:
function setVarsOnVNode(vnode: VNode, vars: Record<string, string>) {
if (__FEATURE_SUSPENSE__ && vnode.shapeFlag & ShapeFlags.SUSPENSE) {
const suspense = vnode.suspense!
vnode = suspense.activeBranch!
if (suspense.pendingBranch && !suspense.isHydrating) {
suspense.effects.push(() => {
setVarsOnVNode(suspense.activeBranch!, vars)
})
}
}
while (vnode.component) {
vnode = vnode.component.subTree
}
if (vnode.shapeFlag & ShapeFlags.ELEMENT && vnode.el) {
const style = vnode.el.style
for (const key in vars) {
style.setProperty(`--${key}`, vars[key])
}
} else if (vnode.type === Fragment) {
;(vnode.children as VNode[]).forEach(c => setVarsOnVNode(c, vars))
}
}对于前面我们这个栗子,由于初始传入的是 instance.subtree,它的 type 为 Fragment。所以,在 setVarsOnVNode() 方法中会命中 vnode.type === Fragment 的逻辑,会遍历 vnode.children,然后不断地递归调用 setVarsOnVNode()。
这里不对 FEATURE_SUSPENSE 和 vnode.component 情况做展开分析,有兴趣的同学可以自行了解
而在后续的 setVarsOnVNode() 方法的执行,如果满足 vnode.shapeFlag & ShapeFlags.ELEMENT && vnode.el 的逻辑,则会调用 style.setProperty() 方法来给每个 VNode 对应的 DOM(vnode.el)添加行内的 style,其中 key 是先前处理 <style> 时 CSS var() 的值,value 则对应着 <script> 中定义的变量的值。
这样一来,就完成了整个从 <script> 中的变量变化到 <style> 中样式变化的联动。这里我们用图例来简单回顾一下这个过程:
如果,简单地概括 <style> 动态变量注入的话,可能几句话就可以表达。但是,其在源码层面又是怎么做的?这是很值得深入了解的,通过这我们可以懂得如何编写 postcss 插件、CSS vars() 是什么等技术点。
并且,原本打算留有一个小节用于介绍如何手写一个 Vite 插件 vite-plugin-vue2-css-vars,让 Vue 2.x 也可以支持 <style> 动态变量注入。但是,考虑到文章篇幅太长可能会给大家造成阅读上的障碍。所以,这会在下一篇文章中介绍,不过目前这个插件已经发到 NPM 上了,有兴趣的同学也可以自行了解。
最后,如果文中存在表达不当或错误的地方,欢迎各位同学提 Issue~
说起「响应式编程」,大家可能并不陌生。但是,直接说「流」这个名称,可能大家会有点愣。其实,「流」的本质和「响应式编程」并不二般,都是衍生于前端经典的设计模式——「观察者模式」。但是,在一定程度上,可以说「流」则是基于这个模式的一个上层抽象,因为它所具备的能力更多、更加强大。
在我的认知里面,我又给「流」划分了一下,「玄学」。
而在我们平常开发中,使用「观察者模式」最经典的就是「Vue」。其中,一方面在「Vue」2x 版本中对应的就是基于 Object.defineProperty() 实现的一套依赖收集和派发更新。另一方面,在「Vue」3.0 版本中对应的就是基于 Proxy 实现的一套依赖收集和派发更新。
这里可以简单提提「Vue」中依赖收集和派发更新,在 2x 中对应
watcher和dep。在 3.0 中对应effect和dep。
那么,回到今天的正题,让我们来领略一下作为「流」中的经典代表之一「RxJS」的魅力。
官方文档介绍:「RxJS」是使用 Observables 的响应式编程的库,它使编写异步或基于回调的代码更容易。
建议,如果不了解
ObservableAPI 的同学,可以移步去学习一番 https://github.com/tc39/proposal-observable,再来继续阅读本文。
这样一看,我们可能会把「RxJS」来和 Promise 作一些列比较,因为 Promise 也是为了使得编写异步或基于回调的代码更容易而出现的。也确实,很多在谈论「RxJS」的文章都会举例子来比较两者的优缺点。
所以,在这里我就不举例比较,就简单列举几点「RxJS」解决了哪些使用 Promise 存在的痛点,如:
为什么这里说「RxJS」的真实面目?因为,前面所说的解决异步或基于回调的代码繁琐问题,仅仅是「RxJS」的一个很简单的一面,它真正玄幻的一面,在于它「流」的特性。
相信大家在此之前应该也听过「流」的概念,例如「Node」中的 Stream 流、「gulp」中的 Stream 流。所以,这里我们先来回忆一下这两个经典的用到「流」的知识点。然后,再循序渐进地进入「RxJS」中「流」的世界。
「Node」 中的 Stream 指的是一个「抽象接口」,例如文件读取、「Http Request」都实现了这个接口。并且,每一个「流」都是 EventEmitter 的实例。
EventEmitter 的本质就是一个简单的「观察者模式」,可以进行事件的分发和监听。
那么,我们通过简单的读取文件的例子,回忆一番「Node」中 Stream 的事件分发和监听:
const fs = require("fs")
let data = ''
// 创建文件读取流
const readFileStream = fs.createReadStream('stream.txt', 'UTF8')
// 监听流数据读取的事件
readFileStream.on(data, (chunk) => {
data += chunk
})
// 监听流数据读取结束的事件
readFileStream.on(end, (chunk) => {
console.log(`文件读取的结果是:${data}`)
})
// 监听流读取文件异常的事件
readerStream.on('error', (err) => {
console.error(err.stack)
});这里可以看出,文件读取流在没监听 data 的时候,我们并不能拿到需要的文件中的数据。
这个对于所有的「流」都是一样,它需要被订阅才能被使用,因为「流」是惰性的。
然后,我们再来回忆一下「Node」中 Stream 的「管道流」的概念,它指的是「流」可以通过 pipe 链式地调用,例如把文件读取流直接写入文件写入流中:
const fs = require("fs")
const readFileStream = fs.createReadStream('readStream.txt', 'UTF8')
const writeFileStream = fs.createWriteStream('outStream.txt', 'UTF8')
readFileStream.pipe(writeFileStream)不知道大家注意到没有,「gulp」官方文档是这样介绍的:gulp.js 基于流(stream)的自动化构建工具。而且,相信用过「gulp」的同学,应该知道在「gulp」中是以创建任务的形式使用「流」。
具体「流」涉及到插件使用、文件处理和监控的细节,有兴趣的同学可以移步gulp官方文档了解。
例如,我们想要配置一个 sass 的编译,它会是这样:
const gulp = require('gulp')
const sass = require('gulp-sass')
// 创建任务,对 scss 目录下的扩展名为 .sccss 执行编译并输出到 css 文件下
gulp.task('sass-compile', function(){
return gulp.src('scss/*.scss')
.pipe(sass({outputStyle: 'expanded'}).on('error', sass.logError))
.pipe(gulp.dest('css'))
})
// 监听文件变化执行 sass-compile 任务
gulp.watch('scss/*.scss', ['sass-compile'])可以看出,我们引入的 gulp 模块,本身就是 Stream。所以,也正如「gulp 官方文档」所说的一般:gulp.js 基于流(stream)的自动化构建工具。
那么,回忆了「Node」和「gulp」中的 Stream 之后。接下来,我们就进入「RxJS」中 Stream 的万千世界!
这里,我们通过「RxJS」 中的几个关键字来循序渐进地认知它:
1.Observable 可观察对象
数据就在 Observable 中流动,以及我们可以使用各种「操作符」Operators 来对流进行处理,例如过滤、去重。
例如:
import Rx from 'rxjs/Rx'
const observable = Rx.Observable.from([1,2,3])
observable.filter(val => val >= 2)
.subscribe(val => console.log(val)) // 2 32.Observer 观察者
它是一个「对象集合」,存放用于监听可观察对象的回调。
例如:
import Rx from 'rxjs/Rx'
const observable = Rx.Observable.from([1,2,3])
const observer = {
next: val => console.log(val),
error: err => console.error(err),
complete: () => console.log('completed')
}
observable.subscribe(observable)3.Subscription 订阅
用于取消对可观察对象的订阅,例如在一个组件的生命周期的结束理应取消订阅。
例如:
import Rx from 'rxjs/Rx'
import {Vue, Component} from 'vue-property-decorator'
@Component
export default class Dialog extends Vue {
private subscription
private created() {
const observable = Rx.Observable.fromEvent(this.refs.btnCommit, 'click')
this.subscription = observable.subscribe({ next: () => {
console.log('click')
}})
}
private destoryed() {
this.subscription.unsubscribe()
}
}4.Operators 操作符
它指的是一些数组的工具函数 filter()、some()、map、flatMap等等。
这里就不举例子了,就和第一个例子使用
filter()的方式一样。
Subject 主体它类似于前面提及的「Node」中的 EventEmitter,进行事件的分发,即广播。
需要注意的是,
Observable观察者的事件分发是单播的。
例如:
import Rx from 'rxjs/Rx'
const subject = new Rx.Subject()
subject.subscribe({
next: val => console.log(`监听对象1:${val}`)
})
subject.subscribe({
next: val => console.log(`监听对象2:${val}`)
})
subject.next(1)
subject.next(2)
/*
输出:
监听对象1:1
监听对象2:1
监听对象1:2
监听对象2:2
*/6.Schedules 调度器
它负责对任务的调度,例如控制事件的执行顺序和排序等等。它由这三部分组成:
例如:
import Rx from 'rxjs/Rx'
const observable = Rx.Observable.create(function (proxyOb) {
proxyOb.next(1)
proxyOb.next(2)
proxyOb.next(3)
proxyOb.complete()
})
.observeOn(Rx.Scheduler.async)
const observer = {
next: x => console.log(x),
error: err => console.error(err),
complete: () => console.log('completed'),
};
observable.subscribe(finalObserver)可以看到这里在创建观察者的时候调用了 observerOn(),以及使用了调度器的 async,这里则会按创建时的顺序将所有订阅的 next() 中的代码块放在消息队列中以宏任务 setTimeout 或 setInterval 的形式执行,默认时钟设置为 0。
其实,介绍了这几个关键点后,我想大家对于前面提及解决 Promise 的痛点的由来,应该心中明了。并且,针对一些场景 「RxJS」官方文档 也列举了如何使用它,例如:
所以,在这里我就不一一列举了,毕竟文档上已经讲的很好了,照搬讲一遍就没太大必要哈。有兴趣的同学可以自行了解。
这篇文章,其实在一个月之前,我就想着总结分享出来,但是各种因素不了了之。这次恰逢「端午节」,专门腾出几个小时时间思考和总结自己这段时间对「RxJS」和「流」的认知。当然,文章中会存在不足的地方,欢迎大家提「Issue」。
并且,个人认为「流」的存在,在将来很可能会改变一些东西。例如,之前携程的一位前辈写的面向Model编程的前端架构方式,其中就提及需要一种脱离平台的响应式编程处理,列举了如「Redux」、「Vue3.0 reactive API」、「RxJS」等等。有兴趣的同学,可以往这方面继续了解。
私有 npm 库,我想是每个团队都会实践和经历的一个阶段。实现私有 npm 的方式有很多种,例如基于私有 Git 仓库、npm 官方的托管(付费)、Verdaccio 等等。但是,综合比较各种因素下来(不要钱、还好用),Verdaccio 都略胜前面两者。
那么,今天本文也将带着大家一起使用 Verdaccio 来搭建一个企业级私有 npm 库!
Verdaccio 的安装启动过程较为简单。首先是全局安装 Verdaccio:
npm i -g verdaccio然后,在终端中输入 verdaccio 命令启动 Verdaccio:
verdaccio接着 Verdaccio 会在终端中输出提示,输出它的配置文件位置、启动的服务地址等信息:
默认 Verdaccio 启动的服务都会在 4873 这个端口,在浏览器中打开这个地址我们就会看到 Verdaccio 搭建的私有库 npm 的界面:
可以看到,默认的界面风格还是很简洁、美观的。并且,这里会提示我们要登陆、发布 npm 包需要执行的命令。
虽然,安装和启动好了 Verdaccio。但是,由于 Verdaccio 默认的配置和我们生产的需求不一致,所以我们需要修改一下 Verdaccio 的配置。
在生产环境下,私有 npm 库需要具备以下 3 个功能:
而 Verdaccio 的配置文件是在 ~/.config/Verdaccio 文件夹的 config.yaml 文件,默认的配置会是这样:
storage: ./storage
plugins: ./plugins
web:
title: Verdaccio
auth:
htpasswd:
file: ./htpasswd
uplinks:
npmjs:
url: https://registry.npmjs.org/
packages:
'@*/*':
access: $all
publish: $authenticated
unpublish: $authenticated
proxy: npmjs
'**':
access: $all
publish: $authenticated
unpublish: $authenticated
proxy: npmjs
server:
keepAliveTimeout: 60
middlewares:
audit:
enabled: true
logs:
- { type: stdout, format: pretty, level: http }这里我们来逐个认识一下默认配置中的几个值的含义:
storage 已发布的包的存储位置,默认存储在 ~/.config/Verdaccio/ 文件夹下
plugins 插件所在的目录
web 界面相关的配置
auth 用户相关,例如注册、鉴权插件(默认使用的是 htpasswd)
uplinks 用于提供对外部包的访问,例如访问 npm、cnpm 对应的源
packages 用于配置发布包、删除包、查看包的权限
server 私有库服务端相关的配置
middlewares 中间件相关配置,默认会引入 auit 中间件,来支持 npm audit 命令
logs 终端输出的信息的配置
接下来,我们就来修改 Verdaccio 的配置文件中对应的值来一一支持上述功能。
当我们私有 npm 库存在很多包的时候,我们想要查找某个包就会有些麻烦。而 Verdaccio 是支持搜索功能的,它是由 search 控制的,默认为 false,所以这里我们需要开启它:
search: true开启之后,我们就可以在私有 npm 库的页面上的搜索栏进行正常的搜索操作。
权限把控指的是我们需要私有 npm 库上发布的包只能团队成员查看,除此之外人员不能看到一切信息。那么,回到 Verdaccio,我们需要做这 2 件事:
相应地,这里我们需要修改配置文件的 pacakges 和 auth。前面我们也提及了 packages 是用于配置发布包、查看包、删除包相关的权限。我们先再来看看默认的配置:
packages:
'@*/*':
access: $all
publish: $authenticated
unpublish: $authenticated
proxy: npmjs
'**':
access: $all
publish: $authenticated
unpublish: $authenticated
proxy: npmjs这里的 key 代表对应权限需要匹配的包名,例如对于第一个,如果我们发布的包名是这样的 @wjc/test 就会命中。每个规则中对应 4 个参数。其中 proxy 代表如果在私有 npm 库找不到,则会代理到 npmjs(对应 unlinks 中的 npmjs 的 https://registry.npmjs.org/)。而剩下的 3 个参数,都是用来设置包相关的权限,它有三个可选值 $all(所有人)、$anonymous(未注册用户)、$authenticated(注册用户)。那么,下面我们分别看一下这 3 个参数的含义:
access 控制包的访问权限
publish 控制包的发布权限
unpublish 控制包的删除权限
显然,这里我们需要的是只有用户才能具备上述 3 个权限,即都设置为 $authenticated:
packages:
'@*/*':
access: $authenticated
publish: $authenticated
unpublish: $authenticated
proxy: npmjs
'**':
access: $authenticated
publish: $authenticated
unpublish: $authenticated
proxy: npmjs设置好 packages 后,我们还得更改 auth 的值,因为此时注册用户是没有限制的,也就是说如果你的私有 npm 库部署在外网环境的话,任何人都可以通过 npm adduser 命令注册用户。
显然,这是不允许出现的情况,所以这里我们需要设置 auth 的 max_users 为 -1,它代表的是禁用注册用户:
auth:
max_users: -1如果要开启用户注册,设置指定数字(大于 0)即可
发布包推送钉钉群,指的是我们每次发布包可以通过钉钉群的机器人来通知我们发布的包的信息。
首先,这里我们需要先有一个钉钉群的机器人对应的 Webhook(获取方式可以查看钉钉的文档)。然后,在 Verdaccio 的配置文件中添加 notify:
notify:
'dingtalk':
method: POST
headers: [{'Content-Type': 'application/json;charset=utf-8'}]
endpoint: https://oapi.dingtalk.com/robot/send?access_token=****, # 钉钉机器人的 webhook
content: '{"color":"green","message":"新的包发布了: * {{ name }}*","notify":true,"message_format":"text"}'其中,method 和 headers 分别表示请求的方法和实体的类型。endpoint 表示请求的 Webhook 地址。content 则表示获取发布信息的基础模版,模版中 message 的值会是钉钉群的机器人发送的消息内容(name 表示发布的包名)。
假设,此时我们发布了一个包名为 verdaccio-npm-demo 的私有包,相应地我们会在钉钉群里收到通知:
既然配置好了 Verdaccio。那么,我们就可以开始发布第一个私有包了 😎。
首先,我们需要注册一个用户:
npm adduser --registry http://localhost:4873/接着,它会要求你填写用户名、密码和邮箱,用于登陆私有 npm 库:
既然有注册用户,不可避免的需求是在一些场景下,我们需要删除某个用户来禁止其登陆私有 npm 库。
前面也提及了 Verdaccio 默认使用的是 htpasswd 来实现鉴权。相应地,注册的用户信息会存储在 ~/.config/verdaccio/htpasswd 文件中:
wuliu:pWxgur/1w5v1I:autocreated 2021-02-18T07:58:57.827Z这里一条记录对应一个用户,也就是如果这条记录被删除了,那么该用户就不能登陆了,即删除了该用户。
这里我们为了操作方面,通过 nrm 来切换源。没有安装 nrm 的同学,可以先安装一下:
npm i -g nrm然后,使用 nrm 添加一个源:
npm add mynpm http://localhostm:4873/这里的 mynpm 代表你这个源的简称,你可以因自己的喜好来命名。
接着,我们可以运行 nrm ls 命令来查看目前存在的源:
可以看到默认情况下 npm 使用的源是 https://registry.npmjs.org/,那么这里我们需要将它切换成私有 npm 库对应的源:
nrm use mynpm切换好源后,我们之后的 npm i 就会先去私有库查找包,如果不存在则会去 https://registry.npmjs.org/(因为上面配置了 proxy)查找包。
发布的话就直接在某个需要发布包的项目(假设这里我们的包叫 verdaccio-npm-demo2)的根目录下运行:
npm publish然后,在私有 npm 库的界面上就可以看到我们发布的包:
当然,Verdaccio 能做的还有很多,例如集成 Git Action 自动发包、自定义鉴权插件等。但是,经过我们上面的一番折腾,私有 npm 库已经初具规模可以投入生产使用了哈 😲。最后,文章中如果存在表达不当或错误的地方,欢迎各位同学提 Issue。
前段时间,写了一个 webpack-loader,auto-inject-async-catch-loader,晚上 8 点多发的 npm 包。昨天早上,上 npm 官网一看,才十几个小时下载量 282 次(着实有点意外😯)~
在之前,我写过一篇文章《现场教学,优雅地处理基于 Vue CLI 项目中的 async await 异常》介绍了如何在 Vue CLI 中给代码自动加 try catch,当时在文中也讲了这种做法欠妥。所以,上周末我花了一些时间,重新整理了一下如何使用 babel 的 tool 基于抽象语法树 AST 来实现对 Vue CLI 项目代码自动注入 try catch。
auto-inject-async-catch-loader 是一个 webpack-loader,基于 babel 提供的 tool 来通过遍历抽象语法树 AST 来实现对 AwaitExpression AST 节点添加 TryStatement AST 节点,从而完成对 async function自动注入 try catch 的机制。auto-inject-async-catch-loader 的工作机制如下图所示:
而 auto-inject-async-catch-loader 这个 loader 是 fork 的 async-catch-loader。所以,这里给上作者一个大大的 Respect 👍。起初,我是想着提个 PR,没必要反复造轮子,但是出于时间问题,就 fork 了一份改了改。
相比较 async-catch-loader ,auto-inject-async-catch-loader 做了以下两点优化:
1.优化了向上查找 parent 的过程,优化后的 traverse 如下所示:
traverse(ast, {
AwaitExpression(path) {
// 已经包含 try 语句则直接退出
if (
path.findParent(path => t.isTryStatement(path.node))
) {
return;
}
// 查找最外层的 async 语句
const blockParent = path.findParent(path => t.isBlockStatement(path.node) && isAsyncFuncNode(path.parentPath.node))
const tryCatchAst = t.tryStatement(
blockParent.node,
t.catchClause(
t.identifier(options.identifier),
t.blockStatement(catchNode)
),
finallyNode && t.blockStatement(finallyNode)
)
blockParent.replaceWithMultiple([tryCatchAst])
}
});2.支持使用 TypeScript + Vue CLI 开发的情况。此时 Vue 组件是 Class 语法,例如:
<template></template>
<script lang="ts">
import { Vue, Component } from "@vue-property-decorator"
@Component
export default class Login extends Vue {
private async created(): Promise<any> {
await Promise.resolve("user login")
}
}
</script>可以看到 created(async function)是写在 Class 内部的,即其对应的抽象语法树 AST 的 type 为 ClassMethod,所以在 isAsyncFunction 判断函数中增加加了对 ClassMethod 的判断:
const isAsyncFuncNode = node =>
t.isFunctionDeclaration(node, {
async: true
}) ||
t.isArrowFunctionExpression(node, {
async: true
}) ||
t.isFunctionExpression(node, {
async: true
}) ||
t.isObjectMethod(node, {
async: true
}) ||
t.isClassMethod(node, {
async: true
});相信很多同学对于配置 Vue CLI 的 Webpack 一头雾水,这里我就顺带地给大家的讲解一下如何在 Vue CLI 中使用 auto-inject-async-catch-loader。
首先,当然是安装 auto-inject-async-catch-loader 依赖:
npm i auto-inject-async-catch-loader -D然后,配置 Webpack。而通常情况下,使用 Vue CLI 开发的同学会分为两类:
1.使用 JavaScript 开发
使用 JavaScirpt 开发的同学只需要通过 chainwebpack 选项在 js rule 中添加一个 loader 就行。在 vue.config.js 的 chainWepack 中加入如下配置:
chainWepack: (config) => {
const jsRule = config.module.rule("js");
jsRule
.use("auto-inject-async-catch-loader")
.loader("auto-inject-async-catch-loader")
.end()
}2.使用 TypeScript 开发
使用 TypeScript 开发的同学则需要重写整个 ts rule 的 loader 配置。在 vue.config.ts 的 chainWepack 选项中加入如下配置:
chainWebpack: (config) => {
const tsRule = config.module.rule("ts");
tsRule.uses.clear();
tsRule
.use("cache-loader")
.loader("cache-loader")
.end()
.use("babel-loader")
.loader("babel-loader")
.end()
.use("auto-inject-async-catch-loader")
.loader("auto-inject-async-catch-loader")
.tap(() => {
return {
catchCode: 'console.error(e)'
}
})
.end()
.use("ts-loader")
.loader("ts-loader")
.tap(() => {
return {
transpileOnly: true,
appendTsSuffixTo: [
'\\.vue$'
],
happyPackMode: false
}
})
.end()
}至于为什么需要重写整个 ts 对应的 rule,因为此时项目中代码的 loader 的加载顺序是 ts-loader 到 babel-loader 再到 cache-loader,auto-inject-async-catch-loader 必须要在 babel-loader 之前、ts-loader 之后加载:
而 Vue CLI 的 Webpack 配置是使用 webpack-chain 生成的,但是 webapck-chain 并没有提供在某个 loader 后插入 loader 的方法(只对 plugin 支持 before 和 after 方法)。所以,这里我们需要重写整个 ts rule,保证 ts-loader 到 auto-inject-async-catch-loader 到 babel-loader 再到 caceh-loader 的加载顺序:
最后讲讲后期计划,写一个 babel-plugin 实现同样的功能,用 babel-plugin 实现则会精简地多,因为 babeld-plugin 本身提供了一些变量供于使用,例如可以使用 visitor 遍历抽象语法树 AST。当然,欢迎各位同学使用 auto-inject-async-catch-loader,如果有其他需求也可以给我提 Issue,或者微信(wu1957503379)联系我。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.