whilefor / blog Goto Github PK
View Code? Open in Web Editor NEW前端那么大我想去看看
前端那么大我想去看看


最近一直在研究关于Headless browsers一些东西,最先接触到的就是相当有名的phantomJS,无UI界面,基于WebKit内核,多用于在JS测试的一些方面,当然还有网络监控,网页截图等。以JS为结尾,但它既不是一个node的模块,也不是一个普通的js的库。这个JS和Node.js的js类似含义,运行javascript,CommonJS规范,由几个phantomjs自有的模块和一些node里功能差不多的模块(child_process ,fs,system等)构成。当使用phantomJS加载了一个页面时候,你就可以对这个页面做你任何想要的事情了,增加cookie,注入js,操作DOM等等。
官网的例子:
// Simple Javascript example
console.log('Loading a web page');
var page = require('webpage').create();
var url = 'http://phantomjs.org/';
page.open(url, function (status) {
//Page is loaded!
phantom.exit();
});运行:
phantomjs hello.js很多人会问为什么不做成一个node的模块,官网上的回答:http://phantomjs.org/faq.html 最后第二个问题
项目需求是使用phantomJS捕获所加载页面的所有http请求生成一个har格式文件进行分析,官网上直接提供了一个例子netsniff.js,因为只能捕获到浏览器触发onload事件,想获取到更多请求信息就自己改造了下。但网络请求信息方面,毕竟不是真实的浏览器环境,所以信息不太准确,具体问题有:gzip压缩文件大小问题,http请求信息不全,同一个页面onload时间有时差别会很大, 不支持flash(官方解释由于违背了headless,和各种issues和bugs)。
phantomJS提供了Mac OX S和Windows的可执行文件,linux因为一些原因还没有提供,只能拿源代码自己编译,因为linux系统版本不同编译出来大多不能通用,目前已经测试centos6编译的版本不兼容centos7上运行,不同发型版本的linux应该更加不一。
phantomJS做一个js的自动化测试或者对请求信息要求不高的事情还是想当不错的,提供的API丰富,所以出现了很多基于phantomJS平台的很有趣的项目,比如Casper.js等等 http://phantomjs.org/related-projects.html
就像浏览器,phantomJS的内核是基于webkit。所以就出现了基于Gecko内核的SlimerJS,支持自己手动指向操作系统里面安装的firefox版本或者直接使用它提供的XulRunner,支持运行firefox的插件(flash等)。和使用 .NET WebBrowser Class利用v8引擎的triflejs, 没怎么关注,因为基于.NET好像只能跑在windows上。 API基本兼容phantomJS的API,有一些不同官网也有详细说明Differences with PhantomJS。
个人感觉,phantomJS到2.0版本,不支持flash对有flash的网站其实不是很友好,虽然Github上有个人fork出了分支写了个支持flash的版本,但是好像没怎么更新了。SlimerJS,支持运行插件,可能会比phantomjs能做的事情多一些,也安装运行过,感觉还是有很多诡异的问题, 还没1.0的版本。triflejs,用的人比较少,没怎么研究。
因为比较上面几个都不是真实的浏览器环境,所以必定会有各种各样的问题出现。比起在安装真实浏览器的情况下去运行测试js、收集信息,就会比较可靠。
linux下的一个工具,提供了一个容器,可以让程序在无界面的情况下执行,所以你可以这样访问一个网页:
xvfb-run firefox https://www.google.com推荐文章:http://tobyho.com/2015/01/09/headless-browser-testing-xvfb/
另一个web应用测试的世界,功能强大,社区完整,完全模拟真实浏览器的环境。正在尝试中。
Remote debugging protocol,无意中在stackoverflow中发现一个方案,是chrome官方提供的一个远程访问的使用方法。在任何一台机器上只要装了chrome,用命令行形式开启一个进程
chrome.exe --remote-debugging-port=9222 --user-data-dir=<some directory>会自动打开一个chrome,然后就可以使用chrome-remote-interface,一个node.js的模块来操作9222端口的chrome,完全模拟真实的访问。但是提供的功能API比较简单,一次只能一个客户端连接。
capture performance data from browsers,和Selenium搭配使用获取har文件,但是好像各种问题。
stackoverflow上的一个回答,列出了很详细的Headless Browser的一些工具。
在Webpack已经是霸主地位的构建打包天下,杀出一个Rollup。Vue, Ember, Preact, D3, Three.js, Moment, etc. 一些很有名的js库,甚至最近React,都使用纷纷使用Rollup来作为打包工具。所以Rollup想必有它的优势。
Rollup的语法比Webpack更加简单,文档教程比Webpack更加循序渐进,按顺序全部看一遍,虽然没有中文,但英文读下来基本没有障碍。有JavaScript-API的使用方法,也有指定配置文件形式的CLI的方法,这里就只介绍配置文件的用法。
// rollup.config.js
import resolve from 'rollup-plugin-node-resolve';
import babel from 'rollup-plugin-babel';
import buble from 'rollup-plugin-buble';
export default {
// 入口文件
entry: 'src/main.js',
// 指定打包后js的代码格式 - 'amd', 'cjs', 'es', 'iife', 'umd'
format: 'cjs',
// 使用的插件
plugins: [
buble(),
resolve(),
babel({
exclude: 'node_modules/**' // only transpile our source code
})
],
// 可以同时打包输出多个格式的js文件
targets: [
{ dest: 'dist/bundle.cjs.js', format: 'cjs' },
{ dest: 'dist/bundle.umd.js', format: 'umd' },
{ dest: 'dist/bundle.es.js', format: 'es' },
],
//也可以是一个
dest: 'bundle.js'
};如果使用balel插件,就需要在src目录下新建.babelrc文件
// src/.babelrc
{
"presets": [
["latest", {
"es2015": {
// 指定babel不要把es2015的模块转换为commonjs的
"modules": false
}
}]
],
"plugins": ["external-helpers"]
}这个概念是Rollup提出来的。
Rollup推荐使用ES2015 Modules来编写模块代码,这样就可以使用Tree-shaking来对代码做静态分析消除无用的代码,可以查看Rollup网站上的REPL示例,代码打包前后之前的差异,就会清晰的明白Tree-shaking的作用。
打包前的js代码
// main.js (entry module)
import { cube } from './maths.js';
console.log( cube( 5 ) ); // 125// ./maths.js
// This function isn't used anywhere, so
// Rollup excludes it from the bundle...
export function square ( x ) {
return x * x;
}
// This function gets included
export function cube ( x ) {
return x * x * x;
}打包后的js代码
'use strict';
// This function isn't used anywhere, so
// Rollup excludes it from the bundle...
// This function gets included
function cube ( x ) {
return x * x * x;
}
console.log( cube( 5 ) ); // 125主要为以下四个原因(摘自尤雨溪在知乎的回答):
- import只能作为模块顶层的语句出现,不能出现在 function 里面或是 if 里面。
- import 的模块名只能是字符串常量。
- 不管 import 的语句出现的位置在哪里,在模块初始化的时候所有的 import 都必须已经导入完成。
- import binding 是 immutable 的,类似 const。比如说你不能 import { a } from ‘./a’ 然后给 a 赋值个其他什么东西。
Rollup作者最近的一片文章里分析了Webpack和Rollup的不同之处。总结是说Webpack适合在单页应用Web App上使用,Rollup适合使用在独立的js库上。
Use Webpack for apps, and Rollup for libraries
Webpack核心功能包括Code-splitting(按需加载js)和Static assets(处理各种格式的资源)。
Rollup到目前为止不支持Code-splitting和hot module replacement (热更新),它更趋向专注于构建分发类的js库,也就是说大多只会生成一个js文件来被其他项目依赖,更好的利用ES2015 modules的优势来缩小和优化代码。
Rollup在15年时候就已经发布,支持Tree-shaking,当时Webpack还是1.的版本,没有使用Tree-shaking,而且每个模块外还要包一层函数定义,再通过合并进去的 define/require 相互调用,模块越多,这些包在外层的模块系统的函数就越多,造成打包后代码量的增大。
然而Webpack2. 今年1月份才上线正式的版本,Rollup经过二年左右的发展也取向成熟,所以许多js库从纷纷使用了Rollup。
Webpack and Rollup: the same but different
Google开发的一个优化js代码的工具,能对源码做更深层次静态分析,更全面的优化达到高度压缩源码的效果,直接看一下的示例,在这不多做介绍。
Google Closure Compiler
如何评价 Webpack 2 新引入的 Tree-shaking 代码优化技术?
今天,你升级Webpack2了吗?
Webpack and Rollup: the same but different
使用 Rollup 和 Buble 编译 JS 库
Closure Compiler Advanced
文章内容来源于《编程与类型系统》(《Programming with Types》),本文作为分享总结类型简介、基本类型这二个章节的要点。
在底层的硬件机器中,代码和数据都是0和1,类型首要的作用是区分是代码还是数据。不同类型执行的方式不同,执行方式错误可引发严重错误。
console.log(eval("40+2")); // 40+2 是一个表达式,可以执行,在控制台打印 42
// 试图将数据解释为代码
console.log(eval("Hello world!")); // 引发 SyntaxError: Unexpected identifier 错误 相同的一段01位序列数据,使用不同的方式解析,可赋予数据不同的意义。
011000010101000110 可以表示为无符号16位整数49827、带符号整数-15709、UTF-8 编码字符’£’、等等。
可用不同的方式来解释一个位序列
**类型:**一种数据的分类,定义了允许取值的集合(通常还包括数据可执行的操作、数据的意义)。
例如:布尔值类型取值为 true 和 false ;Int16 值类型表示值介于-32768 到+32767 之间的有符号整数集合。
**类型系统:**一组规则,为编程语言的元素分配和实施类型。这些元素可以是变量、表达式、函数和其他高级结构。
例如:声明定义该元素是会是存放字符串、数字数组、函数、等;或者像 JavaScript 中使用 let,在运行时候会判断元素是什么类型;
或者由类型系统隐式的判断该元素的类型。
类型系统的主要优点在于正确性、不可变性、封装、可组合性和可读性。
正确性
function scriptAt(s: string): number { // 参数类型为 string
return s.indexOf("Script");
}
console.log(scriptAt("TypeScript"));
console.log(scriptAt(42)); // 由于参数类型不匹配,这行代码在编译时会报错
// Argument of type '42' is not assignable to parameter of type 'string'不可变性
function safeDivide(): number {
const x: number = 42; // 使用关键字 const 来声明不可变的常量
if (x == 0) throw new Error("x should not be 0");
x = x - 42; // 因为 x 是不可变的,不能被重新复制,这行代码在编译时会报错
return 42 / x;
}
// Cannot assign to 'x' because it is a constant.封装
class SafeDivisor {
private divisor: number = 1; // 使用 private 关键字来声明是私有变量
setDivisor(value: number) {
if (value == 0) throw new Error("Value should not be 0");
this.divisor = value;
}
divide(x: number): number {
return x / this.divisor;
}
}
function exploit() {
let sd = new SafeDivisor();
sd.divisor = 0; // 因为 divisor 是私有变量,不能被外部使用,这行代码在编译时会报错
sd.divide(42);
}可组合性
// 使用泛型类型,抽象类型,不必为每种类型都写一个函数
function first<T>(range: T[], p: (elem: T) => boolean)
: T | undefined {
for (let elem of range) {
if (p (elem)) return elem;
}
}
function findFirstNegativeNumber(numbers: number[])
: number | undefined {
return first(numbers, n => n < 0);
}
function findFirstOneCharacterString(strings: string[])
: string | undefined {
return first(strings, str => str.length == 1);
}可读性
// 使用类型申明和泛型,可以清楚知道该函数的实参和返回数据类型
declare function first<T>(range: T[],
p: (elem: T) => boolean): T | undefined;相比最底层的类型区分代码和数据,现代类型系统之间的主要区别在于检查类型的时机以及检查的严格程度。
静态类型和动态类型
静态类型在编译时检查类型,动态类型则将类型检查推迟到运行时。
静态类型能更快的发现程序中的错误,让程序更加健壮,这是业界的共识;动态类型则更加灵活,然而对编写程序的人则要求更高。
// 动态类型,未使用 TypeScript 情况下的 JavaScript
function quacker(duck) {
duck.quack();
}
quacker({ quack: function () { console.log("quack"); } });
quacker(42); // 这行代码将在运行时报错:Uncaught TypeError: duck.quack is not a function
// 静态类型,使用 Typescript 声明一个 Duck 接口,并在函数参数中声明该类型
interface Duck {
quack(): void;
}
function quacker(duck: Duck) {
duck.quack();
}
quacker({ quack: function () { console.log("quack"); } });
quacker(42); // 这行代码将在编译时报错:Argument of type ‘42’ is not assignable to parameter of type ‘Duck’.弱类型和强类型
这二个术语并没有非常明确的定义,都是约定俗称,表示对一个类型系统的强度衡量。
强类型系统只会做很少的(甚至不做)隐式类型转换,而弱类型系统则允许更多隐式类型转换。
// 弱类型,未指定变量类型,对于字符串和数字类型,在运算时会自动做隐式类型转换
const a = "hello world";
const b = 42;
console.log(a == b); // false, 在 JavaScript 允许不同类型进行比较
console.log("42" == b); // true, 在 JavaScript 中 == 运算符会隐式的将二边的值转化为相同类型
console.log("42" === b); // false, === 运算符会对比是否不同类型
// 强类型,使用 Typescript 声明具体的类型
const a: string =c"hello world";
const b: number = 42;
console.log(a == b); // 编译时报错:Typescript 不允许不同类型进行比较
console.log("42" == b); // 编译时报错:Typescript 不允许不同类型进行比较
console.log("42" === b); // 编译时报错:Typescript 不允许不同类型进行比较类型推断
在一些静态类型系统中,有些值的类型并不需要显式的指定,类型系统在编译时可以自动推断出。
function add(x: number, y: number) { // 函数并没有指定返回值类型,但编译器可以自动推断出为 number 类型
return x + y;
}
let sum = add(40, 2); // sum 并没有显式的指定为 number 类型,但编译器可以自动推断出常见的基本类型分为以下几种,根据类型的定义,这些类型为数据赋予了意义、限制了值的取值范围、并为组合这些类型规定了一组规则。
空类型代表不能有任何值的类型,其取值范围为空集合。
// 在 TypeScript 中 nerver 可以代表空类型
function raiseError(message: string): never { // 该函数只会抛出错误,不会有任何的返回值,因为抛错时程序已经终止
console.error(`Error "${message}" raised`);
throw new Error(message);
}单元类型代表没有任何意义的值类型,其取值范围为一个没有意义的值。
// 在 TypeScript 中 void 可以代表单元类型
function greet(): void { // 该函数只会打印一段字符串,并不会返回任何有意义的值
console.log("Hello world!");
}
greet();空类型和单元类型的区别在于,返回单元类型的函数执行完会继续执行下面的程序,而返回空类型的函数程序会停止运行。
布尔值是一个有二个取值的数据类型,其二个取值为 true 和 false 。
提供了三种运算符,&& 代表 AND,|| 代表 OR,! 代表NOT。下表是true 和 false 进行三种运算的计算结果。
数字分为无符号整数、有符号整数、浮点数、大数。
无符号整数
例如一个4位无符号整数可以表示015之间的任意值。7之间的值。
4位无符号整数编码。最小取值为0,即全部4个位均为0。最大取值为15,即全部位均为 1(1×23 + 1×22 + 1×21 + 1×20)
有符号整数
一个4位带符号整数可表示–8
4位带符号整数编码。–8被编码为24 – 8(二进制为1000),–3被编码为24 – 3(二进 制为1101)。对于负数,第一位总是1,对于正数,第一位总是0
浮点数
IEEE 754 是美国电气和电子工程师协会为表示浮点数(带小数部分的数字)制定的标准。
0.10的浮点数表示。最上面显示了浮点数的三个部分(符号位、指数和尾数)在内存中的二 进制表示。中间显示了将二进制表示转换为数字的公式。最下面显示了应用公式的结果:0.1被近似 为0.100000000000000005551115123126
因为 IEEE 754 表示浮点数的方式,JS 中直接比较浮点数会导致问题。JS 中提供了一个值叫 Number.EPSILON (最大圆整误差),只要比较二个值的差值小于或等于这个误差则可以认定为相等。
function epsilonEqual(a: number, b: number): boolean {
return Math.abs(a - b) <= Number.EPSILON; // 检查二个数是否在最大圆整误差内
}
console.log(0.1 + 0.1 + 0.1 == 0.3); // false,因为JS中处理浮点数的误差,0.1+0.1+0.1为0.30000000000000004
console.log(epsilonEqual(0.1 + 0.1 + 0.1, 0.3)); // true,因为0.3和0.30000000000000004在最大圆整误差内字符串是一个有无限个值的基本类型,其取值为0个或多个字符组成。
一个字节有八个二进制位,00000000到11111111最多可以表示为256个字,也就是最初的 ACSII 码,到现在的 Unicode 可以表示超过百万个字符,包括全世界的字符和表情字符。
对于正常的文本,我们可以很方便的对文本做任何的操作,对于表情等特殊字符,则需要了解更多的字符编码知识。
例如女警官表情符号 ♀️ 在 JavaScript 中则由5个字符表示, ♀️.length 返回5。尝试拆分这个符号则发现这个符号由警官表情符号 和女性表情符号♀组成。这二个表情符号由\u200d 零宽连接字符组成。整个女警官表情符号为5个Unicode转义字符组成:\ud83d、\udc6e、\u200d、\u2640和\ufe0e。
使用UTF-16字符串编码的内存中的位、UTF-16字节序列、Unicode代码点序列和书写位的形 式表示女警官表情符号
使用数组和引用可以构建更高级的数据结构,例如列表和树等。
默认把固定长度和数据类型的数组视为基本类型。数据存储在一个连续的内存区域,并且存储了相同位数的值类型,使得访问数组中任何一个值的速度都很快。
将5个32位整数存储在一个固定大小数组中。在固定大小数组中查询元素非常快,因为我们能够计算出它的准确位置。
引用类型则并不保存实际的值,存放实际值的地址,根据该地址则可以快速找到该值。如果二个引用类型的对象,保存着相同的地址,则根据一个对象改变该值的数据,则另外一个引用类型中的值也可以看到做出的修改。
将5个32位整数存储在一个链表中。链表要求我们沿着next元素前进,直到找到要寻找的元素。元素可能存储在内存中的任何位置。
利用数组和引用类型可以构建更高级的数据结构内容比较多,有些晦涩,大家可自行找资料阅读。
基础知识非常枯燥,可以坚持看到最后的同学非常难得。
类型系统在大学的计算机课程中肯定会接触到,本文则记录分享扩展一些基本知识。
JavaScript 从一开始缺乏类型系统,运行时错误满天飞,在 TypeScript 类型系统的加持下,我们可以编写出更好、更加安全的代码。
Teahour.fm 由Terry,玎玎, Daniel, Kevin 和滚滚主持,会专注程序员感兴趣的话题,包括 Web 设计和开发,移动应用设计和开发,创业以及一切 Geek 的话题。
《IT 公论》由 IPN 出品、不鸟万如一和 Rio 主持。
科技博客,谈论的话题涉及科技的、非科技的,时而文艺时而装逼,提升你的广度。
《内核恐慌》(Kernel Panic) 是由 IPN 出品、吴涛和 Rio 做的播客。
还是IPN出品的,针对人群非常偏向开发者,很多专业名称,大量英文名词,非该行业的一般听不懂也不感兴趣。
就像它名字的意境一样,这个播客的口号是:“开源发展很快,快跟上”,致力于让你跟上最新的开源技术。
A weekly podcast about JavaScript, including Node.js, Front-End Technologies, Careers, Teams and more.
学习前端、英语两不误。
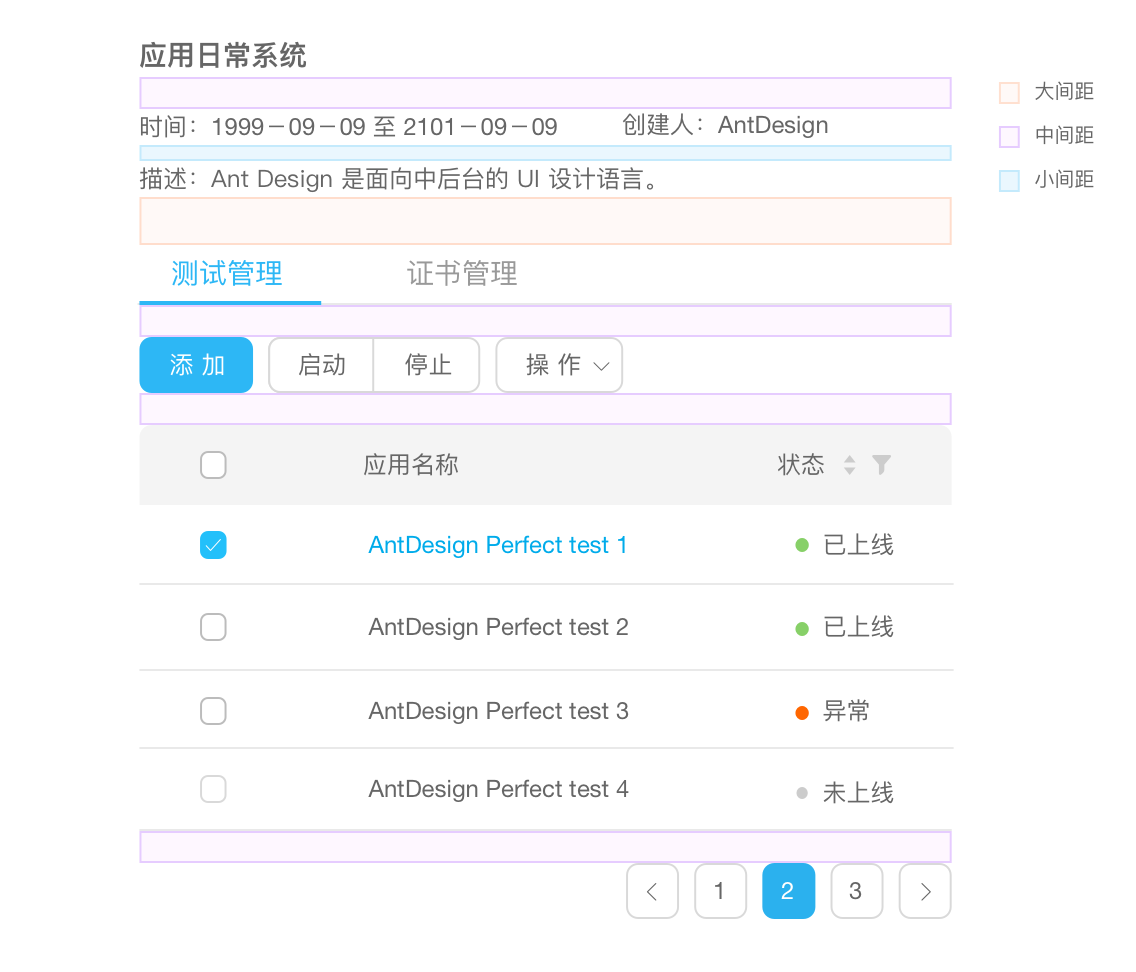
自从material design推出后Google收到了不少赞,如果只推出一套UI界面,是不会引起这么大的反响的,是背后的一套设计理念和设计规范,强有力的支撑起了material design,扁平化和拟物化的完美结合,使得设计的界面分类清晰,功能突显。
Ant Design是蚂蚁金服体验技术部推出的中台设计语言(介于前台设计和后台设计之间?),它不只是一个React组件的UI框架,背后也是有一套设计语言的支撑。比起前端花花世界中知其然而不知其所以然各式各样的UI框架,Ant Design仔细研究了很多经典书籍《About Face 4》、《Web 界面设计》、《界面设计模式》、《写给大家看的设计书》、《设计心理学》、《Web 表单设计:点石成金的艺术》等上的设计方法,详细说明了为什么需要这样设计,通过对比错误和正确的案例,使得组件的用户体验极好,值得一试。
在中台产品的研发过程中,会出现不同的设计规范和实现方式,但其中往往存在很多类似的页面和组件,给设计师和工程师带来很多困扰和重复建设,大大降低了产品的研发效率。我们(蚂蚁金服体验技术部)经过大量的项目实践和总结,沉淀出一个中台设计语言 Ant Design。旨在统一中台项目的前端 UI 设计,屏蔽不必要的设计差异和实现成本,解放设计和前端的研发资源。
Ant Design 是一个致力于提升『用户』和『设计者』使用体验的中台设计语言。它模糊了产品经理、交互设计师、视觉设计师、前端工程师、开发工程师等角色边界,将进行 UE 设计和 UI 设计人员统称为『设计者』,利用统一的规范进行设计赋能,全面提高中台产品体验和研发效率。
看得出是经过了很多产品的沉淀,在作者看来是比较的舒服、简洁、小清新。
字体的大小、加粗、明暗、鲜艳的颜色运用,显示信息的轻重角色。
大量运用了动画、渐入渐出,使得出现和消失没有那么的生硬。
借鉴了《写给大家看的设计书》、《Web 界面设计》对设计原则的总结和推理。
如果信息之间关联性越高,它们之间的距离就应该越接近,也越像一个视觉单元;反之,则它们的距离就应该越远,也越像多个视觉单元。亲密性的根本目的是实现组织性,让用户对页面结构和信息层次一目了然。
通过『小号间距』、『中号间距』、『大号间距』这三种规格来划分信息层次。
通过解释了为什么需要不同距离来划分详细层次,而不是随便的距离分开就好,对细节把控和原理运用很好。
官方提供了一个Ant Design的React的实现,基于 npm + webpack + babel 的工作流,支持 ES2015。
而且提供了一个脚手架工具 antd-init 让你很快的可以创建一个项目,里面帮你配置好了webpack作为构建的工具,可以很方便的开发调试,构建部署。
没有计算机的时代,数据被显式的记录存储在具体的物品上,石头、木头、竹子、羊皮,纸等等。一旦被记录,调整和修改都是相当困难,数据之间大多不能交互,几乎都是静态,数据的传播大多靠口头或物品相传观看。
计算机的出现,数据突然可以隐式的被存储在某个介质中。变得容易修改、可以交互、动态显示、快速分析等等。这已经是革命性的了,人们保存数据和获取数据的方便性得到了质的提升。
互联网的出现,让数据变得可以快速传播,几乎每个人都可以方便获取到比之前多得多的数据,并且可以获取这些数据对它们做任何的操作。从不能方便的获取数据到突然可以有大量的数据,我们沉浸在这些具体的数据之中。
浏览器的出现,让普通人就可以获取到的数据资讯开始指数型的增加,人们的选择性大大提高。这时,数据的如何展现、数据之间的交互、数据交互展现中的用户体验等等,对数据的各种包装在人们选择时占据了一席之地。
对数据交互展示的愈发重视,出现了产品、设计、视觉、交互、前端等职业,人们除了对数据内容的重视之外,数据的”颜值”和”体验”也是成了人们选择看这些数据的因素之一。
之后,人们追求数据的交互展示精益求精。深入人心的功能点、眼前一亮的视觉冲击、符合直觉的操作体验 、毫秒级别的加载速度,这些有形无形的存在,也是决定着一个产品的生存因素之一。
浏览器出现之初,人们获取资讯的方式就是就是几大门户网站。资讯呈现的方式是文字和图片等,到现在,也是这几种主要的元素形式,只不过随着人们审美的迭代,交互、排版、颜色、字体、图片等等都有些许变化。如果让我们回去看90年代的网站,我们会觉得丑、用户体验差,但使用上基本没有任何障碍。
很多东西的本质都没有变化,与出现计算机、出现互联网时代的巨变,这些变化微不足道。但是,我们还是不断的在发展,在发展中寻找发现更多更深刻的东西,刚开始的出现我们可能看到的只是表象,现在的我们可能慢慢理解了它的本质。一个时代的开启不是一蹴而就,而是在发展中寻觅打开下一个时代大门的钥匙。
从简单数据的展示,到复杂数据的交互展示,随着浏览器的发展,我们有了简洁、多样的功能,顺畅、极佳的体验。
这个过程诞生了专门的web前端工程师。在我们对用户体验的要求越来越高,数据量的增加、复杂逻辑的增加、交互多样性的增加,都是前端工程师的挑战。有挑战就有思考,有发展就有探索,诞生了许多的框架/工具/概念,百花齐放、百家争鸣,就像中世纪的文艺复兴时代,大师辈出,有幸我们可以站在巨人的肩膀上。
这是最好的时代,这是最坏的时代。
许多概念的出现、封装的框架、构建流程的自动化,选择不断的增加、选择不断的减少。对工程师的能力是一个考验,可能会让部分人在最基础的HTML、JS、CSS浏览器基础知识和直接使用最新的框架/工具/全家桶之间产生一个知识断层。基础是重要的,掌握框架也是需要的,掌握知识的原理,你才能对公式有着深刻的理解。就像了解历史,在面对新事物时候,你能思考过去,去其糟粕,取其精华。
前端在用户体验细节方面是有追求的。我们会为了减少几毫秒的加载时间、过渡的更加顺畅、显示更好看的字体等等去找到最优解。也是对这些细节方面的零容忍,我们从浏览器里看到数据内容的感受体验是噌噌噌的上升。
所以,我认为,如果你正确地估量自己,善于抓住所有的机遇,然后尽快行动起来,去争取,去努力,去做,你就能发现该做些什么,就能真正把你自己生活中的这个时代变为“最好的时代”。
或许以后的前端,不再会直接使用HTML、JS、CSS,出现更高级的语言或使用方式,就像机器语言=>汇编语言=>其他语言,HTML、JS、CSS变成了前端的底层语言,发展出更高级的语言。
现在已有趋势,JSX、TypeScript、Sass、Babel、WebAssembly等等,通过编译器转化为HTML、JS、CSS(WebAssembly 例外),再放到浏览器运行。可能以后浏览器就直接运行JSX、TypeScript等或一个全新的更强大的语言。
不过,可能以后我们不使用浏览器了
可能我们以后使用的不是电脑手机了
可能…
本文,如有雷同,纯属意外,如有错误,也是必然
前端从一个页面作为点缀装饰的脚本;到jQuery的流行特效插件遍地开花;到大谈MVC,MVVM等模式;到模块化、组件化、工程化,自动化等等……而且还在快速的变化着。现在已经不是精通jQuery就能走天下的时代了,你需要熟悉Angular、React、Vue等这些近些年很火的框架,Less、Sass、PostCss这些进阶型的CSS;Gulp、Webpack、Babel等前端构建的工具。
CSS从CSS2到CSS3,增加了很多新的属性,让以前只能js实现的效果现在可以只用CSS3来实现;Less、Sass、PostCss等这些实现,让CSS动态起来,变得更加的可维护,可扩展。
Javascript从ES5到ES6,很多新的功能特性都变得原生支持。针对不支持的浏览器,Babel的出现让我们优先使用ES6来开始我们的项目;ES6的模块化功能,让RequireJS,SeaJS瞬间黯淡无光;Promise和Generator的出现让我们告别了callback hell;等等……
从Angular的双向绑定到React的数据单向流;从Facebook提出的flux前端架构,到改进后火起来的redux架构;一个优秀的架构对快速发展前端来说是必不可少的。
Web app相对于原生应用一直处于弱势,React Native/Weex的出现却让前端一下子有了能与iOS和安卓的原生应用对抗的力量。
这种快速的发展,让前端从简单到复杂,已经成为一种既需要知识的深度,又需要全局广度的工种。
Node.js的出现就像把前端从农业化时代一下子拉向了工业化时代。npm上的模块出现了百花齐放的现象,各种构建的工具,自动化测试的工具,部署的工具,检测的工具等让前端一下子有了很强的能力来维护逐渐庞大前端工程。
Gulp、Webpack等优秀的构建可以让你轻松的配置好文件来构建前端工程,Mocha、karma、Jasmine、phantomJs等优秀的测试工具可以让你编写Javascript的单元测试自动化测试等,这些功能让前端慢慢便的强大。
Koa、Express等web应用框架可以用来搭建web服务;更大更全的也有Sail.js、Meteor、Mean可以帮你快速创造你想要的应用。
HTML5开发的web app和原生app之间战争一直进行着,期间HTML5的API不断的丰富着,体验度也不断增加。很多原生app只是外面有个壳,内在既是HTML5页面;但也有很多产品出于体验原因只考虑原生app,HTML5成了附加的分享页,导流量页面。
见很多前端后端的同学转向学习Objective-C,swift开发iOS应用,自己也偶尔会看看这方面的知识。前端的路固然精彩,但也少不了路边的风景的美丽,坚持你选择的路,走好自己选择的路。
因为前端快速发展,我们需要从广度和深度来不断的学习填充自己。前端很精彩,前端圈里的大神们都会写很多好的文章,我们可以从中学到很多,所以我开了一个微信订阅号,不时的会推送一些前端圈里精彩的文章和大家分享,让我们一起学习进步。
根据 SlashData 2021 年发布的开发者调研分析,JavaScript 在全球拥有最多的开发者数量,成为世界上最流行的编程语言。
JavaScript 主要运行在浏览器端,随着技术不断发展出现很多服务端 JavaScript 运行时,甚至可以做硬件相关的嵌入式开发。
开发 Web 站点时,使用 SSG (Static Site Generation) 或 SSR (Server Side Render)等相关技术时 ,前后端开发可以使用同一种编程语言,对开发者的体验是相当友好。
但不同端的 JavaScript 运行时环境,会有一些差异。
JavaScript 标准规范是由 ECMA International 组织制定,但很多 Web APIs 不属于 ECMAScript 规范标准。
这些 Web APIs 规范标准是由 WHATWG 和 W3C 来制定,包括 HTML、DOM、调试用的 Console API、编码相关的 Encoding、请求相关的 Fetch API、存储相关的 Storage 等等,都有相关的规范标准。
浏览器端几乎所有的 Web APIs 都有规范标准,服务器端则会选择性的遵循部分 Web APIs 标准规范,而一些则是服务端特有的,比如 Node.js 的 Common JS 模块规范等。
JavaScript 的运行时环境就是各家的 JS 引擎,包括 Chrome 的 V8、Firefox 的 SpiderMonkey、Safari 的 JavaScriptCore,另外还有轻量化的 QuickJS、Hermes 等。
尽管都使用 JavaScript 语言,但到了服务端,JavaScript 就是一门后端语言,它没有 DOM、Window、Canvas、Cookies 等一些浏览器相关的 Web APIs,进而会有文件系统、网络相关 API、与底层操作系统交互的各种 API 等等。
现有服务端 JavaScript 运行时环境著名的有 Node.js、Deno,都基于 V8 引擎,Deno 则使用 Rust 来原生支持了 TypeScript 。
做为后端语言,优势为异步非阻塞、事件驱动机制。同时支撑着庞大的前端工程化相关体系,包括很多的脚手架、打包工具、一些前端相关的编译器等等。
CDN 作为内容存储分发,用户可以就近取得所需内容;边缘计算则提供计算能力,让服务端的能力在靠近用户的边缘节点上就可以提供。
依托覆盖全球的边缘节点,在提供存储的基础上提供一定的计算能力,边缘计算可以更好的提高应用性能和延迟。
现有主流边缘计算相关的产品有:
他们都提供支持使用 JavaScript 来编写在边缘节点运行的后端代码(无需自己的服务器),Lambda@Edge、Cloudflare Workers、Vercel Edge Functions 采用 Node.js 来作为他们的 JavaScript 运行时,Netlify Edge Functions 则选择使用 Deno。
因为是边缘节点的 JavaScript 运行时,所以在使用一些 API 上会有所限制,比如不能使用本地文件系统、对代码大小的限制、执行时间限制等,并且会提供一些扩展的 APIs 来满足自己的相关业务需求。
普通的 CDN 中,你只能存取静态文件内容,没有命中则会从源站中取得然后缓存在节点中。边缘计算则可以将本来放在单个地区的服务器的一些业务逻辑放到靠近用户的边缘节点中,比如一些 A/B 测试、权限授权验证、缓存 API 内容、API 请求限制等等。
在嵌入式设备上运行 JavaScript,需要在内存和计算资源都及其有限的情况下运行,并针对硬件有相关的优化。
大多会选择性的遵循 ECMAScript 部分标准和一些 Web APIs 规范标准,一切为了在嵌入式设备上可以流畅运行。
相关的 JavaScript 运行时:
许多应用也会利用 JavaScript 运行时来实现自己的需求。比如因为 Node.js 的特性,很多 NoSQL 都使用 Node.js 来查询数据和管理应用。
Nginx 则通过自研 JavaScript 的运行时 njs 来扩展 Nginx 功能,参考 Nginx 中运行 JavaScript 详细介绍。
前端跨平台方案,小程序、React Native、Weex 等,都会使用 JS 引擎,iOS 上一般会是 JavaScriptCore、Android 上则是 V8。因为使用在移动端,需要兼顾引擎的大小、性能、内存使用等,React Native 团队则自己研发了 JS 引擎 Hermes 。
WinterCG 社区(Web-interoperable Runtimes Community Group),是由 Cloudflare 、Node.js、Deno 合作最近正式成立的一个社区组。
致力于促进 Web APIs 标准的发展。让开发者可以在不同的 JavaScript 运行时中编写可移植的代码,包括浏览器端、服务端、嵌入式应用、边缘计算等,即 Write once, run everywhere.
我把 Web APIs 分为三种:
WinterCG 的定位是,与现有的 Web APIs 标准规范组织(如 WHATWG 、 W3C)合作,充分考虑浏览器端和非浏览器端 JavaScript 运行时所需要的异同 ,让标准可以通用化。
如果一些标准在浏览器端和非浏览器端需要有必要的差异,则提供描述这些差异的清晰文档。
不排除如果一些功能只适合于非浏览器端,并且不于现在的 Web API 标准相冲突,则可能会发布自己的规范进行推进。比如只存在于服务端的文件系统等、未来发展的边缘计算 JavaScript 运行时中,必定会有只适合在该运行时的标准规范需要创建推进。
WHATWG 和 W3C 在浏览器端的 Web APIs 标准规范已经很全。但随着不同类型的 JavaScript 运行时的发展,每种运行时的使用场景和解决的问题可能都会有所差异。
如果所有的 JavaScript 运行时都可以使用同一套标准规范,这必定有利于各 JavaScript 运行时的发展,各运行时可以直接使用已有的标椎规范来实现,而非自己实现临时的方案。
开发者可以以最小的代价移植应用程序到不同平台,比如可以无缝的在不同提供边缘计算服务的厂商中迁移,Node.js 和 Deno 的代码可以完全复用。
优秀的技术方案很多,大部分时候我们感觉只是在现有技术方案里面做排列组合、求笛卡尔积、选择最优解,做出一个最适合当前项目的方案。未来,人类应该编写最核心的业务代码、设置规则,由云端和AI来根据当前项目情况自动选择和调整到最优的架构和方案。
前端项目的工程化,不只对开发层面的组件化、模块化、规范化等,更涉及到构建、部署的工程化和自动化。工程化的一些概念,编译、构建、部署、发布、CI/CD、灰度等概念,其实都是软件工程中很成熟的概念,现在前端项目中也快速发展起来。
大部分知识在前后端项目中都是通用的,有些则根据项目有不同之处。
很多人对一些名词的理解是会有或多或少的误差的,在做一些事情之前,必然得把这些概念理解。
编译(compile)和构建(build)概念有一些区别。
编译是指将源代码变为目标代码的过程,从源代码的语言转变为另外一种计算机语言(一般为比源代码语言更为底层的语言)。
构建是指一些列的处理,包括编译。不同的语言构建会有不通的处理步骤,最终产生可在具体特性环境运行的Artifact。
前端的编译。为了更好的编程体验和更高的可维护性,会使用一些超集的语言,然后再转译为浏览器可以运行的语言。例如对 es5/6/7 等语法的转译为对应环境支持的代码;less、sass 等转译为 css;typescript、coffeescript 等转译 javascript 。
前端构建过程一般包括以下几个过程:
构建结果一般生成为一个或多个文件,里面包括直接可以在部署在特定环境中的所有内容。
每一次成功构建后产出的结果,被称为 Artifacts。Artifacts 可以直接部署到特定环境中并正常运行。每个构建结果一般都会版本保存,为后续部署、回滚、灰度等。
可能是因为构建的速度,后端都会有一个 Artifacts 制品库。而早期一般的前端项目对 Artifacts 的概念比较弱化(更早的前端项目直接没有构建的概念)一般会从 Code 直接构建部署到指定的环境。现有的规范化的项目都会有对构建产物所有版本的保存,一般都提供CND来访问。
部署(deploy) 是指把构建后的新版本应用或服务“安装”到目标环境(开发、测试或者生产)中。这时候部署好的应用或服务应该是在目标环境中正常运行着(或者待着),但是不会有任何访问的流量。
发布(release) 则是把新版本应用或者服务交付给最终用户使用的过程。相当于把流量切到部署好的新版本的过程。
前端项目部署一般是指文件的增量替换或全量替换。根据项目按需决定,部署和发布可以同时进行,也可以分开进行,前提是在不影响用户访问的同时,把前端的代码更新到相应的版本。
CI,Continuous Integration,持续集成。 指代码集成到主干之前,必须通过自动化测试。只要有一个测试用例失败,就不能集成。目的就是让产品可以快速迭代,同时还能保持高质量。
CD 对应有两个意思:
CD,Continuous Delivery,持续交付。 指的是任何的修改都经过验证,可以随时实施部署到生产环境。
CD,Continuous Deployment,持续部署。 持续部署是持续交付的更高阶段,指的是任何修改后的内容都经过验证,自动化的部署到生产环境。
两者的区别,在于是否自动部署到生产环境。持续交付,需要用户手动点击“部署”按钮才能部署到生产环境。
前端项目的 CI/CD ,因为一定的特殊性,对通用化的库或框架可以有覆盖率很高的单元测试/自动化测试,然而对业务代码的单元测试、端对端测试则成本很高,所以 CI 的过程一般就是运行构建脚本,未报错的生成静态文件则为成功。一般不会有 CD(持续部署) 的过程,合并到 develop 分支触发 CI 成功后快速发布部署到测试或预发布环境通过测试人员的测试和一定的自动化测试。到需要发布的时间点,再拉取 master 分支来构建部署发布。
蓝绿部署中,绿色代表代表正在给用户提供正常服务的系统;蓝色代表另外一套准备发布的系统,还未对外提供,可以做线上测试。
二套系统必须有相同的基础设置和配置环境,当蓝色系统测试通过,达到上线标准,就把绿色系统的流量全部切到蓝色系统中,一旦蓝色系统出现问题,把所有流量切回到绿色系统中,待蓝色系统稳定后就成为新的绿色系统,之前的绿色系统资源就可以释放用于下一个蓝色系统。
蓝绿部署能够简单快捷实施的前提假设是目标系统是非常内聚的,如果目标系统相当复杂,那么如何切换、两套系统的数据是否需要以及如何同步等,都需要仔细考虑。
有多个集群实例的服务中,在不影响服务的情况下,停止一个或多个实例,进行版本更新,再启动加入到集群中提供正常服务,直到所有实例都更新到最新版本。
比起蓝绿部署不需要准备二套一样的集群,通过现有的机器或增加少量的机器就可以做到版本升级。但也引入了复杂度,需要控制好更新过程中服务会有新老版本用户共存的兼容情况、防止部署过程中自动伸缩的触发导致实例中版本的不确定、部署过程中出错的回滚策略等。
一种比滚动部署更有控制力度的发布策略。
准备一个或多个服务实例(使用新机器或已有的机器都可),并确保该实例服务没有服务于线上的用户,在上面部署新版本的服务,并经过测试的验证。
通过定制好的策略,只更新部分服务实例到最新,使一部分用户使用到最新版本,如果服务正常,逐渐更新所有服务实例到最新。
发布过程中,需要有一些流量控制的策略跟随部署的过程,一般可以在负载均衡、路由、应用程序中做处理。
A/B测试指的是效果测试,同一时间有多个版本的服务在线上运行,并通过一定的策略控制多个版本的流量分配,最终通过信息的收集,分析各个版本服务的实际效果,选出效果最好的版本。
A/B测试强调的是通过不同版本对比效果来选择出最好的版本,而然金丝雀发布(灰度发布)的方式正好可以满足A/B测试的需求。
现有的 CI/CD 方案都已经很成熟,Jenkins、Travis、Gitlab-CI 等。docker、k8s 让这些工具简直带上了无限手套,因为构建部署是需要机器资源的,相比之前固定的资源抢占和空置,k8s 让资源动态创建、销毁,提升资源利用率。
方案的选择应该都是需要具备上下文的,根据项目的规模、当前的境况。一个前端项目,发展越来越庞大之后,自然而然都会出现需要重构来更新技术方案和更适应已有的项目规模。之前简单的构建、部署、灰度方案的弊端会越来越显现。
前后端项目,对构建和部署的流程可能会有所不同,后端程序的发布上线相对来说复杂度更高。
相比之前手动的构建部署,现有相对优的方案步骤是这样的:
流程很简单清晰,Jenkins、Gitlab-CI/CD 等工具完全可以快速上手和实践。
但隐藏了很多的细节,具体以下几点来看:
构建由 CI 工具来具体负责,只要定制好具体的规范和脚本。后端项目部署的过程由 k8s 的出现变成风险可控。我们要做的就是把构建和部署做规范的制定、系统的打通、数据的整合。
前端构建后产物都会带版本号,采用hash指纹,构建出来的文件没有改变则hash也不会变,可以先发布新版的静态资源文件,旧版同时存在。控制好入口文件(一般为html)的发布的顺序,一般就可正常上线。如果有依赖的后端接口的更改便需要先上线新版本的接口(向上兼容或新版本),再上线前端项目。
静态资源大多会使用 CDN,发布到源站后,CDN 则会自动拉取源站的文件。
后端服务一般都会在负载均衡层(nginx居多)做灰度方案等,业界成熟的方案大多为:
前端静态资源要做到灰度或 A/B 测试的效果,几种方案为:
方案1,对业务的入侵性大,灰度规则与代码耦合,增加了文件的大小。
方案2,因为控制了渲染入口,能做的很多,但也增加了服务端渲染的复杂度,使用场景有限。
方案3,前端入口一般都是一个 html 文件,后再去加在各种静态资源,通过对入口文件的控制,结合 nginx 方案可以做到很好的灰度和 A/B 测试方案。
首屏渲染速度对大多数应用来说都是一个重要的衡量指标,但不排除对首屏渲染速度要求不高,复杂度高,需要有灰度的需求,如内部管理系统、部分企业级应用等。
方案的选择应该考虑项目需求,俗话说,没有银弹。
类似于方案3,新增一个服务,增加对入口文件的控制,来实现访问不同版本。
该服务保存所有构建时候生成的入口文件(包括分支、描述等信息),其他静态资源的发布部署和之前流程一样发布到对应的服务器和 CDN。
请求入口文件时,通过 upstream 到该服务来获取,服务可以设置特征规则等匹配条件(UA、cookie等),没有则默认获取最新版本。
性能则可以通过优化该服务,设置缓存等,没有规则时则完全直接返回。
通过增加一个静态资源管理服务。
该服务保存所有构建时候生成的静态资源列表(包括分支、描述等信息),发布部署和之前流程一样发布到对应的服务器和 CDN。
入口文件则通过访问这个服务来获取自己所需要加载的静态资源列表,服务可以设置特征规则等匹配条件(UA、cookie等),没有则默认获取最新版本。
上述提到的后二种方案大同小异,增加一个中心服务,通过特征规则匹配判断来实现不同版本的灰度控制和 A/B 测试。对复杂度高和业务逻辑比较多的,比如微前端方案、有较多独立的功能和页面需要做到灰度和 A/B 测试的项目则会比较合适。
二种方式可结合使用在微前端方案中。
优点:
缺点:
即使每天枯燥重复的工作或天天都是在挑战自己,重要的都是人,我们在对自己所做事情的观察、沉淀和思考。虽然科技的创新很难,需要持续不断的投入。我们大部分人都是直接利用现有的方案来快速发展我们的业务,然而在发展中不断向社区反馈自己沉淀的优秀的东西,这是才是可持续的发展。
Headless Browser的定义是无界面的浏览器。多用于测试web应用,自动截图,测试js代码,爬虫抓取信息等等。
简而言之,现代浏览器是给用户使用,而Headless Browser则更多的是给程序使用。
Chrome的Headless模式出来之前,其他现代浏览器也都是没有提供Headless模式。现有的Headless Browser都是基于现有的几个浏览器内核来封装开发的。
比较常见的几个Headless Browser:
因为毕竟不是真实的用户浏览器环境,使用起来还是有不少的诟病。此前一段时间研究使用过PhantomJS,功能虽然够用,不过对比在真实的浏览器里面访问的数据信息还是有所差别。
最近Chrome Headless模式的发布(虽然还是开发版本里的,不过终究会变成稳定版本的功能),使得许多使用Headless Browser的纷纷替换成了Chrome,优势不言自明。
Chrome 59 beta版本开始支持Headless mode,过不久就会是稳定版本的功能。Chrome Platform Status中有详细的每个版本新增的功能。
Headless模式可以让Chrome无界面的运行,相当于开了一个无界面的浏览器的进程,然后可以通过接口或者Chrome开发者调试工具来操作Chrome,包括加载页面、获取元数据(DOM信息等)等等,所有Chrome提供的功能都可以使用。
chrome --headless --remote-debugging-port=9222 https://chromium.org --disable-gpu--disable-gpu ,Linux服务器一般没有GPU,所以不禁用可能会产生一些错误。
用正常的Chrome浏览器打开http://localhost:9222, 就能看到用开发者调试工具可以操作你正在打开的页面。
需要使用到一个Node.js的库,chrome-remote-interface
使用该库获取加载一个页面然后获取它的DOM信息:
const CDP = require('chrome-remote-interface');
CDP((client) => {
// Extract used DevTools domains.
const {Page, Runtime} = client;
// Enable events on domains we are interested in.
Promise.all([
Page.enable()
]).then(() => {
return Page.navigate({url: 'https://example.com'});
});
// Evaluate outerHTML after page has loaded.
Page.loadEventFired(() => {
Runtime.evaluate({expression: 'document.body.outerHTML'}).then((result) => {
console.log(result.result.value);
client.close();
});
});
}).on('error', (err) => {
console.error('Cannot connect to browser:', err);
});该库实现的各个模块详细的文档:Chrome debugger protocol viewer
chrome-remote-interface其实是Chrome debugging protocol的实现,它才是基石。我在另外一篇文章里有简单介绍它的使用。 Chrome之远程调试协议(Remote debugging protocol)
Chrome Developer Tools是用HTML,Javascript,CSS编写的chrome开发者工具,然而Remote debugging protocol就是它用来与浏览器页面(pages)交互和调试的协议通道。采用websocket来与页面建立通信通道,由发送给页面的commands和它所产生的events组成。chrome的开发者工具是这个协议主要的使用者,第三方开发者也可以调用这个协议来与页面交互调试。
Chrome Headless模式的出现让PhantomJS的作者停止维护了他的项目,可以预见不久所有主流的浏览器也会提供Headless模式,从而现有的Headless Browser的项目都会慢慢停止维护。
各大浏览器提供Headless模式可以让程序运行的环境更贴近用户访问的真实环境,得出的数据也会更加准确可靠。
很多文章中,作者在直接介绍主题之前,都会介绍该主题一些的发展历史做一些考古工作,这在一定程度会加强我们对该主题的印象,并且可以从一定方面上以史为鉴,从历史预测未来。从之前的做法除却缺点、提取优点、归纳总结,一定程度的向前预测,新的设计便会越来越好。
1995 年,从浏览器刚刚出现不久开始,JavaScript 的设计初衷就是为了网页可以更加的动态和用户有些许交互,从此奠定了前端的基础,就是负责人机交互的领域,让数字世界的内容可以更好的与人交互,实现更好的用户体验,这是前端的核心价值,至此未变。
很快,Server-side JavaScript 发布,可以运行在 Web Server 上,包括 Netscape Enterprise Server、 IIS web-server(JScript)等。
2009年1月29日,Kevin Dangoor 发布了一篇文章 《What Server Side JavaScript needs》,并在 Google Groups 中创建了一个 ServerJS 小组,旨在构建更好的 JavaScript 生态系统,包括服务器端、浏览器端,而后更名为 CommonJS 小组。
CommonJS 社区产生了许多模块化的规范 Modules ,大牛云集,各显神通,不同**的碰撞和斗争,产生了许多浏览器端的模块化加载库,如 RequireJS、Sea.js、Browserify 等。
Node.js 的发布已是 2009 年末,基于 CommonJS 社区最初的主流规范实现模块化,但是之后赢得了 Server-side JavaScript 战争的 Node.js 更加看重实际开发者的声音而不是 CommonJS 社区许多腐朽化的规范,虽然大体上的使用方法未变,但之后 Node.js modules 发展其实于 CommonJS 已分道扬镳。
随着2015年6月,ECMAScript 对 ES6 Modules 的正式发布,浏览器厂商和 Node.js 随之纷纷跟进实现,市面上的模块化加载库随之暗淡失色,间接给 CommonJS 社区判了死刑。在浏览器端取而代之流行的做法的是大家都使用 ES6 Modules 写法,然后使用 Babel 等的 transpiler 来应对不同浏览器版本的支持程度和在浏览器端异步特性产生的一些待解决的问题。Node.js 的模块还是大量的采用 CommonJS 模式,随着对 ES6 Modules 的支持力度的提高和可以兼容之前 CommonJS 模块,CommonJS 写法过渡到 ES6 Modules 只是时间的问题。
前端模块化,默认聊的就是 JavaScript 模块化,从一开始定位为简单的网页脚本语言,到如今可以开发复杂交互的前端,模块化的发展自然而然,目的无非是为了代码的可组织重用性、隔离性、可维护性、版本管理、依赖管理等。
前端模块跑在浏览器端,异步的加载 JavaScript 脚本,使模块化的考虑需要比后端从直接可以快速的本地加载模块的实现需要考虑的更多。
JavaScript 模块化的发展,这里根据一些特征,划分为三个阶段。以阶段二 CommonJS 的出现最为开创性的代表,引领多种规范竞争,利于发展,最终标准化。
作为初期阶段,一些简单粗暴的约定封装,方式许多,优势劣势各有不同。大多利用 JavaScript 的语言特性和浏览器特性,使用 Script 标签、目录文件的组织、闭包、IIFE、对象模拟命名空间等方法。
一些典型的示例:
// 1. 命名空间
// app.js
var app = {};
// hello.js
app.hello = {
sayHi: function(){
console.log('Hi');
},
sayHello: function(){
console.log('Hello');
}
}
// main.js
app.hello.sayHi();
// 2. 利用IIFE
var hello = (function (module1) {
var module = {};
var names = ['hanmeimei', 'lilei'];
module.sayHi = function () {
console.log(names[0]);
};
module.sayHello = function (lang) {
console.log(names[2]);
};
return module;
}(module1));
// 3. 沙箱模式 (YUI3)
// hello.js
YUI.add('hello', function(Y) {
Y.hello = {
sayHi: function(){
console.log('Hi');
},
sayHello: function(){
console.log('Hello');
}
}
})
// main.js
YUI().use('hello', function(Y){
Y.hello.sayHi();
Y.DOM.doSomeThing();
},'3.0.0',{
requires:['dom']
})这一阶段,解决了一些问题,但对日渐复杂的前端代码和浏览器异步加载的特性,很多问题并没有解决,有了需求和问题,解决方案就自然而然的被带了出来。
这一阶段的发展,开始了对模块化规范的制定。以 CommonJS 社区为触发点,发展出不同了规范如 CommonJS( Modules/*** )、AMD、CMD、UMD 等和不同的模块加载库如 RequireJS、Sea.js、Browserify 等,这里面的悲欢离合暂且按下不表。
解决了浏览器端 JavaScript 依赖管理、执行顺序等在之前一个阶段未被解决的许多问题被有了一定程度的解决,随着 browserify 和 webpack 工具的出现,让写法上也可以完全和服务端 Node.js 的模块写法一样,通过 AST 转为在浏览器端可运行的代码,虽然多了一层预编译的过程,但对开发来说是很友好的,预编译的过程完全可以由工具自动化。
一些典型示例:
// 1. CommonJS Modules
// hello.js
var hello = {
sayHi: function(){
console.log('Hi');
},
sayHello: function(){
console.log('Hello');
}
}
module.exports.hello = sayHello;
// main.js
var sayHello = require('./hello.js').sayHello;
sayHello();
// 2. AMD
// hello.js
define(function() {
var names = ['hanmeimei', 'lilei'];
return {
sayHi: function(){
console.log(names[0]);
},
sayHello: function(){
console.log(names[1]);
}
};
});
// main.js
define(['./hello'], function(hello) {
hello.sayHello();
});
// 3. CMD
// hello.js
define(function(require, exports, module) {
var names = ['hanmeimei', 'lilei'];
module.exports = {
sayHi: function(){
console.log(names[0]);
},
sayHello: function(){
console.log(names[1]);
}
};
});
// main.js
define(function(require) {
var hello = require('./hello');
hello.sayHi();
});有了模块化的规范标准,虽然规范写法各不相同,但还是给开发者带来了许多便利,封装出许多模块化的包,在不同的项目之间使用,基础设施搭建愈发完善,一定程度上的竞争关系,不过随时间发展,市场会选择一个最优解。
相比于之前的规范,ECMAScript 标准对原生语言层面提出了声明式语法的模块化规范标准 ES Modules,历经多年,相比之前的模块化的规范,必定取其精华,去其槽粕。各大浏览器对 ES Modules 逐渐的实现,在未实现的浏览器上也可以通过 Babel 等工具预编译来兼容,ES Modules 逐渐在前端成了公认的编写模块化的标准。
在 Node.js 端,虽然最新的 Node.js 版本(v13.0.1)的 ES Modules 还处于 Stability: 1 - Experimental 阶段,需要增加后缀 .mjs ,而且还需要增加 --experimental-modules 参数来开启,不过相信完全稳定的版本也不会很远。而且还一定程度的支持 CommonJS 和 ES Modules 之间互相引用,通过 BaBel 或 Rollup 等工具则完全可以兼容。
示例:
// hello.js
var names = ['hanmeimei', 'lilei'];
export const hello = {
sayHi: function(){
console.log(names[0]);
},
sayHello: function(){
console.log(names[1]);
}
}
// file main.js
import { hello } from "./lib/greeting";
hello.sayHello();import 命令会提升到文件顶部执行,被 JavaScript 引擎静态分析,并且不能使用在非顶部的作用域里。所以缺少可以在运行时动态加载的方法,之后出来的 import() 题案,大部分浏览器也已支持。
虽然大部分浏览器都已实现,大部分开发人员,还是会使用打包构建工具。除了浏览器的兼容性问题,这也是一个 trade-off 问题。在 HTTP/1.1 下,虽然有 keep-alive 一段时间内不会断开 TCP 连接,但是 HTTP 的开销还是不能忽略,必要时需合并请求、减少开销;HTTP/2.0 的多路复用,在一定程度上可以让开发者直接在浏览器上使用 ES Modules 而不必担心加载的文件过多。二种方法其实都会有一个最优比例,这时配合打包构建工具可以来做到一个最好的平衡优化。
JavaScript 的 ES Modules 规范趋向成熟,经过一定程度的竞争和合作,多样化成员的标准规范化对开发者是极度的有利。然而因为 HTML、CSS 其图灵不完全的特性,HTML、CSS 模块化的发展没有那么迅速。
HTML 的历史其实早于 JavaScript ,在开发者社区的反馈之下,出现了 HTML Modules 题案,不是重造一个新模块化的系统,而是集成在现有的 ES6 Modules 中,虽然浏览器厂商还处于公开支持和开发中,相信社区的推动,会很快落地。
让后端开发人员最头疼的 CSS 。因为其特殊性,发展到 CSS3 虽然支持了更多的特性,但总归没有标准规范的模块化。但社区力量是强大的,利用预编译,发展出 less、sass、scss、styled-component 等,像极了 JavaScript 模块化发展的前期阶段。
模块化的完善,更有利于我们更快更好的构建极致前端交互,但这只不过是前端浩大工程中的一部分,我们就活在历史中,以史为鉴,可以知兴替,也需要从更多的角度看问题,不识庐山真面目,只缘生在此山中。
关于作者:Jeff Atwood
原文链接:http://blog.codinghorror.com/the-magpie-developer/
我经常感觉,开发人员很像我们所说的喜鹊,以不停的获取很多小玩意来装饰他们的窝而著称。就像喜鹊一样,开发人员通常都被定义为聪明的、好奇的生物。但是我们太容易被一些时髦的新鲜事物分心。
Scott Hanselman的终极开发工具列表( Ultimate Developer Tool list)不会再使我有新鲜感。相反,它越发使我疲劳。软件开发的改变速度是非常迅速的,而我们太沉迷于一些自身概念就在不断瓦解的新鲜事物,就像一个英语单词如果一遍一遍的不断重复就会变成毫无意义的元音和辅音,新事物最终都会变为平凡常见的,当他们被称为新事物时他们便不会是独一无二的、有趣的。最终,你会厌倦这无止境的新鲜玩意儿。
无独有偶,Jeremy Zawodny也注意到了《新事物的不断黯淡无光》(the diminishing luster of shiny new things):
一年前我退订了Steve的博客,因为他每天不断的更新最新最潮的一些小东西,频率实在是太高了。而我认识中的很多人都被卷入到了这令人窒息的新事物的喧嚣中,而往往忘记了去思考那些新出现的事物在我们的长期发展中是不是真的那么重要。
Dave Slusher也一致同意:
[Robert Scoble]说他收到过太多通过邮件来获取他的PR releases,但这并没有什么卵用。他建议你应该到他的Facebook wall中留言,Dear god and/or Bob… 在我关注Scoble期间,我看到他说了太多类似这样的话:别发邮件、发推特,别发推特、通过Jaiku联系我,在留言板留言、发短信给我,不要打我电话、发邮件给我,不要发邮件给我、不要打电话给我… 真的是够了!我甚至都没尝试去联系过他,我发现我已经厌倦了他高频的从一个平台迁移另一个平台,这简直就是Bullshit!当我一年前抛弃TechCrunch时我也有这样的感觉。我已经十分反感听到用另一种只有细微差别的方法来代替我们现在已经在做的事情,这些细微差别何以能让我们抛弃一切然后奔向它?我正式宣布放弃搜寻一些光鲜亮丽的事物。
不只有永无止境的新技术,而且还有永不消停的软件宗教战争(thousand software religious wars )都使我们疲乏,就像激流中的巨石那么的讨厌。我相信David Megginson概括的这些过程听起来会十分熟悉:
- 一些顶尖的开发者们注意到太多的菜鸟们都在使用他们正在使用的编程语言,然后他们开始寻找一些新的东西来区分他们更优秀于一些普通的同事。
- 他们会丢掉一些他们看起来非常烦人的一系列旧东西,从而寻找一种新的、鲜为人知的语言让他们看起来明显成为少数精英部分。
- 他们开始促进新语言的发展,提交代码,编写框架等等,推广新语言。然而,高级开发者们也跟着这些顶尖开发者们转向新语言,创造一些列的图书,培训等等,并且加速发展着这门新语言。
- 这些高级开发者对社区有着很大的影响,开始把新语言推向平常的工作中。
- 大量菜鸟们又开始意识到他们必须去买一些书,上一些课来学习这门新语言。
- 顶尖的开发者们注意到太多的菜鸟们都在使用他们使用的编程语言,然后他们开始寻找一些东西来区分他们更优秀于一些普通的同事。
希望你安静的坐着,因为我还有一个坏消息给你。你对Ruby on Rails很感兴趣对吗,但它已经过时了,我们已经抛弃它使用新的东西了。
大量主力的开发人员从没有接触过任何一门动态语言,更别说Ruby。但一些动态语言的特征已经慢慢的不同层次的渗透进了Java和.NET的堡垒。这些所谓的**领袖留下了一座其他人没有机会到达的虚拟鬼城。
我成为了一名开发者是因为我热爱计算机,然而热爱计算机,你必须拥抱变化,然而,我愿意。但是我在想,喜鹊开发者们有时候喜欢通过改变来削弱他自身的技能。Andy Hunt 和 Dave Thomas在2004 IEEE column (pdf)上说的很好:
用户才不关心你是否用了J2EE、Cobol或者一些奇妙的东西。他们只需要他们的信用卡授权被正确的处理,账单被正确的打印出来。你帮助他们发现了他们真正的需求和一个他们设想中的系统。
相反的,被想要艰难登上最新技术的巅峰而冲昏头脑的,Pete正在集中精力为客户构建一个系统(使用COBOL)。它很简单,几乎是简单的最高标准。但是它易用,易懂,可快速部署。Pete的框架混合了一些技术:模型,核心的生成器,可复用的组件等等。他实践了最基本实用原则、什么技术适合用什么技术,而不只是什么最新使用什么。
当我们尝试想造出一个全功能的应用框架来替换市面上所有的应用框架,我们肯定会失望。也许是压根没有这一类大一统的理论。就像后现代主义的其中一个印记:没有宏大叙事,没有大事件来指引我们,相反的,是有许多小的故事而组成。一些人认为,这就是我们这个时代的特点。
别因为自己没有去尝试那些新鲜事物而感到自己不够好。谁会去关心你使用了什么技术,只要它运行的流畅,你和你的用户都满意,这就足够了。
新事物的美丽之处在于:永远都会有新的东西出现。不要让追求新鲜事物无意中成为你的目标。避免成为一个喜鹊开发者。有选择性的追求一些新的东西,你将会发现你会成为一个更好的开发者。
放弃phantomJS方案,决定采用Remote debugging protocol方案来获取性能数据生成har文件。第一,phantomJS还是不稳定、不是真实浏览器环境,第二,Remote debugging protocol调用真实浏览器,更加强大,DIY自由性更高。
Chrome Developer Tools是用HTML,Javascript,CSS编写的chrome开发者工具,然而Remote debugging protocol就是它用来与浏览器页面(pages)交互和调试的协议通道。采用websocket来与页面建立通信通道,由发送给页面的commands和它所产生的events组成。chrome的开发者工具是这个协议主要的使用者,第三方开发者也可以调用这个协议来与页面交互调试。
在命令行开启一个chrome的实例,加上合适的参数,会自动打开一个chrome。
chrome --remote-debugging-port=9222 --user-data-dir=<some directory>--user-data-dir 必须得加,然后打开 http://loacalhost:9222 ,就能看到你开启的chrome实例中所有打开的标签页面
获取所有开打标签的信息,返回一个json数组, type 为 page 的为打开中的页面。 webSocketDebuggerUrl就是连接到该标签页的websocket地址。
http://loacalhost:9222/json返回
[ {
"description": "",
"devtoolsFrontendUrl": "/devtools/inspector.html?ws=localhost:9222/devtools/page/B7F2D344-197B-4F57-A945-939F29AE2922",
"id": "B7F2D344-197B-4F57-A945-939F29AE2922",
"title": "localhost:9222/json",
"type": "page",
"url": "http://localhost:9222/json",
"webSocketDebuggerUrl": "ws://localhost:9222/devtools/page/B7F2D344-197B-4F57-A945-939F29AE2922"
}, {
"description": "",
"devtoolsFrontendUrl": "/devtools/inspector.html?ws=localhost:9222/devtools/page/575FBA99-453B-40F1-9112-139D995246D6",
"faviconUrl": "https://www.baidu.com/favicon.ico",
"id": "575FBA99-453B-40F1-9112-139D995246D6",
"title": "百度一下,你就知道",
"type": "page",
"url": "https://www.baidu.com/",
"webSocketDebuggerUrl": "ws://localhost:9222/devtools/page/575FBA99-453B-40F1-9112-139D995246D6"
}, {
"description": "",
"devtoolsFrontendUrl": "/devtools/inspector.html?ws=localhost:9222/devtools/page/477810FF-323E-44C5-997C-89B7FAC7B158",
"id": "477810FF-323E-44C5-997C-89B7FAC7B158",
"title": "Worker pid:12089",
"type": "service_worker",
"url": "https://www.google.com.sg/_/chrome/newtab-serviceworker.js",
"webSocketDebuggerUrl": "ws://localhost:9222/devtools/page/477810FF-323E-44C5-997C-89B7FAC7B158"
} ]新建一个标签页,空白页或者带参数默认加载URL,返回创建之后该页面信息的json对象,格式同上。
http://localhost:9222/json/new
http://localhost:9222/json/new?http://www.baidu.com关闭一个标签页,传入该页面的id。
http://localhost:9222/json/close/477810FF-323E-44C5-997C-89B7FAC7B158激活标签页。
http://localhost:9222/json/activate/477810FF-323E-44C5-997C-89B7FAC7B158查看chrome和协议的版本信息。
http://localhost:9222/json/version该协议分为不同的功能模块(debugger-protocol-viewer),类似与chrome开发者工具里的不同功能模块。
比如 Network中 有一个 Commands 是 clearBrowserCache , 清除缓存。使用方法就是,用websocket连接到该页面之后用send方法发送一个对象。到本文编写时暂时只支持一个websocket地址只允许一个client连接。
ws.send('{"id": 1, "method": "Network.clearBrowserCache", "params": {}}')有很多扩展应用使用了该协议来与页面做交互调试,官网上有很多Sample Extensions
很多工具都使用了Chrome debugging protocol,包括phantomJS,Selenium的ChromeDriver,本质都是一样的实现,它就相当于Chrome内核提供的API让应用调用。官网列出了很多有意思的工具:链接,因为API丰富,所以才有了这么多的chrome插件。
实现了Remote debugging protocol的node的库:
- chrome-debug-protocol 使用了ES6和TypeScript
- chrome-remote-interface 官网推荐的
- chrome-har-capturer 传入url,直接获取har format文件
有些人说前端入门容易,尤其现在配套工程齐全、组件化程度高,运行几行命令,改动一些代码,就可以实现一些需求。但知识点多,新概念层出不穷,既有深度又有广度的话,非常考验能力。
在编程本质中,有二个非常有名的表达式:
前者大家听的很多,后者是由 Robert Kowalski 在一篇论文中提到:
任何算法都会有两个部分,一个是 Logic 部分,这是用来解决实际问题的。另一个是 Control 部分,这是用来决定用什么策略来解决问题。Logic 部分是真正意义上的解决问题的算法,而 Control 部分只是影响解决这个问题的效率。程序运行的效率问题和程序的逻辑其实是没有关系的。我们认为,如果将 Logic 和 Control 部分有效地分开,那么代码就会变得更容易改进和维护。
前端也有个很有名的表达式:UI = f(state)
UI = f(state)
这些简洁的公式,都已经是对基础和原理进行了多层的抽象。在实际的项目中,如果你不知道背后的基础和原理、没有自己的思考和理解,是不会有很深刻的理解的。
学习就是在自己的领域内一定程度的探索其基础和原理,你知道的越多,越感到自己不知道的越多,于是你就想了解的更多,形成一种螺旋式上升的过程,熟能生巧,巧能生通。
无论干哪一行,想要胜任愉快,离不开 4 样东西:才能、兴趣、方法和努力。没有才能则难以胜任,没有兴趣则难以愉快,没有方法则事倍功半,没有努力则一事无成。
要抓住一些不变的东西,更能让你在快速更新迭代中保持竞争力,遇到新的东西能更快融会贯通。因为本质的东西几乎是不变,从计算机被发明到现在本质运行还是 0 和 1 ,或是量子计算机能突破 0 和 1 的限制,本质一旦被建立,就会非常稳固,在这基础上就能构建各种丰富东西。
前端工程师,前提是一名工程师,了解计算机的一些基本知识。然后作为 Web 前端工程师,所需要了解的大致可分为:
不管什么端,编程语言永远是工程师的核心利器。HTML/CSS/JS 作为 Web 前端三驾马车,重要性不明自言。如果语言发展的好,语言规范必然一直更新迭代,增加新特性。系统的阅读图书和文档,花时间,可以快速熟练的应用起来,但一些很深刻的东西,你可能需要在实际编程中不断学习。
掌握语言的使用最基本,深入理解,从术至道,就需要更深刻的基础理论作为支撑。编程范式作为一门语言的基本风格或典范模式,是一门语言的世界观和方法论。常见的编程范式有:命令式编程、声明式编程和面向对象编程,我们谈论多的函数式编程属于声明式的一种。一种范式可以在不同的语言中实现,一种语言也可以同时支持多种范式,JS 就是一种多范式的语言。
命令式编程( imperative programming ),其核心是:程序是由若干指令组成的有序列表,依次执行;用变量来存储数据,用语句来执行指令。下面 JS 代码的风格就是命令式编程:
// 求连续自然数的平方和
function sumOfSquares(nums) {
let sum = 0, squares = [];
for (let i = 0; i < nums.length; i++) {
squares.push(nums[i]*nums[i]);
}
for (let j = 0; j < squares.length; j++) {
sum += squares[j];
}
return sum;
}
console.log(sumOfSquares([1, 2, 3, 4, 5]));声明式编程(declarative programming ),其核心是:对一系列行为进行有序陈述,强调做什么,而非怎么做,不提供细节的执行。下面 JS 代码相比于上面的代码就是函数式编程:
// 求连续自然数的平方和
function sumOfSquares(nums) {
return nums
.map(num => num * num)
.reduce((start, num) => start + num, 0)
;
}
console.log(sumOfSquares([1, 2, 3, 4, 5]));在以交互、事件驱动的 Web 应用,其实充斥了命令式范式。无可厚非计算机语言就是在命令式的基础上发展起来的,JS 虽然做为一门面向对象编程语言,和 Java、C# 等的面向对象编程的语言不同处太多。JS 的继承是通过原型( prototype )机制来实现,数据类型更是弱类型,动态类型的。但这不排斥 JS 保持开放和包容的心态采用不同范式的写法,取长补短。
相比编程范式,设计模式则类似战术,把一些经常出现的问题提出行之有效的设计解决方案,无关于什么语言。常见的设计模式则有工厂模式、单例模式、适配器模式、装饰器模式、代理模式、享元模式、策略模式、观察者模式、迭代器模式。
TS 是 JS 的超集,让 JS 具有了不同编程范式的优点,比如泛型、强类型等,使 JS 能适应越加复杂的现代 Web 应用,加上 ES 规范的不断迭代,JS/TS 是在不断进化。
Angular/Vue/React 作为 JS 的框架/库。Angular 完全拥抱 TS ,结合面向对象和函数式的优点,大而全,处处都为你考虑到了。Vue 和 React 则在拥抱函数式的同时在 Mutable 和 Immutable 中都有各自的建树。(Mutable 和 Immutable的概念简单的可以看这里:https://www.digitalocean.com/community/tutorials/js-mutability)如果项目中使用比较多的框架,适当了解框架中的一些设计原理,有助于写出好的代码。
Web Assembly 让其他语言编译为二进制代码可直接运行在浏览器上,这极大提高了前端的性能和扩展可以使用其他语言的新特性,特别在计算量大和性能要求高的场景还是很有用处的。
前后端编程虽然差异不小,但接触不同的范式和不同的编程语言,对学习能力的提高有益无害。Stay hungry. Stay foolish.
前端应用代码运行在浏览器上,对浏览器的了解,前端进阶所必须的。
现代浏览器发展到现在极度复杂,而且 Chrome 版本更新迭代飞快,源码大小都达到了 15 GB。介绍浏览器原理的文章虽然已经很图文并茂,但也是覆盖掉了很多细节,实际情况肯定复杂更多。况且大部分文章都有时效性,现在的实现可能已经有更好的方案。
下面的文章是发布在 Google 开发者网站上,应该是介绍现代浏览器内部最详细的文章了:
相对于前端,了解浏览器的大致原理,工作上的帮助不是很直接,但这其实就是不变或变化慢的部分,理解底层的部分,对你构建上层知识的体系有着质的帮助。至少大致的了解浏览器怎么把一个 URL 变成一个可以交互的页面的。
浏览器怎么把 URL 变为一个网页的大致过程:
JS 运行是单线程的,但浏览器执行 JS 代码是异步非阻塞的,所以才会有 Event Loop(事件循环)机制来确保异步代码同步代码事件等的执行顺序。Event Loop 其实也有规范,在 WHATWG 下的 https://html.spec.whatwg.org/#event-loops ,所以跟着规范来理解,其实是最好的。
https://yu-jack.github.io/2020/02/03/javascript-runtime-event-loop-browser/
JavaScript 中的对象一般分为二类:
浏览器环境的 API 其实非常繁杂,操作 CSS 和 DOM 的一些浏览器提供的 API 我们可能很熟悉,但是更多的 API 来自不同的规范标准比如 ECMA、WHATWG、W3C 等,还有些 API 根本没有被标准化。推荐在实际工作需要中如果碰到需要用到的 API 再去深入学习。
大前端大致包含:
技术和资本一样,都是追逐着成本降低的。如果有方案可以用一套代码适配多个平台的话,增加业务代码复用率、降低开发成本,趋势肯定往这方向发展。从一开始的 Cordova/phoneGap/Ionic,到 React Native/Weex,到 Flutter、小程序、PWA。
各方案体验不断的在提高,这是因为技术方案越来越向底层进行改造。下面四张图分别描述了不同方案 App 代码和平台之间的关联。
使用 Native 性能和体验最好。
WebView 因为需要遵守通用的 Web 规范,实现的复杂度高,又缺乏直接调用系统 Services 的能力,所以性能和体验一直不佳。
React Native 则抛弃了 WebView,使用 JS 制定自己的开发规范,自己实现 Bridge 层调用原生 Widgets 和系统 Services。
Flutter 则更激进,抛弃了 JS 语言和系统原生 Widgets ,完全调用平台底层能力自己实现了一套 Widgets ,在性能和体验上其实更趋向于原生应用。
PWA 则本质还是 Web 的,依赖于 Web 标准的发展和 WebView 的发展。
按照现在各方案的势头,Flutter 最火,但是 Web 下的 Hybrid 和 PWA 还是很有机会,像极了战国时期各国的纷争,但谁又会是秦国。
随着前端复杂度提高,前端工程化自然而然发展起来。Node.js 极大推进了前端工程化。包括 Docker、BFF 概念、Serverless,让前端触手其实伸向了后端。
工程化包含的东西太多主要分为:
开发规范的目的是在团队中统一项目的编码规范,便于团队协作和代码维护。各团队需要根据自身的情况制定开发规范,并且需要通过工具在编码阶段或代码提交阶段根据 eslint 等工具快速提示开发者采取正确的编码规范。
现代前端项目已经都使用 ES Module 来作为模块化,组件化的**在前端三大框架中体现很多,包括 Web Components 标准。复杂的应用中会需要数据流管理,或使用独立的数据流管理框架,或使用框架推荐的规范方式。更复杂的项目或有特殊需求的一些页面则会使用前端微服务框架,国内比较火的则是蚂蚁开源的 qiankun 。
开发调试主流就是使用 Webpack 在本地开启服务,提供代理、热加载等一系列功能,代码的修改实时的反馈在浏览器上,并且不同框架也提供了浏览器 Developer Tools 插件,更方便查看组件的嵌套结构和数据分析。
构建/部署/发布则会集成 CI/CD ,然后集成进每个公司各自的发布流程中。具体可以在我另外一篇文章中了解更多。 https://zhuanlan.zhihu.com/p/71562853
通过在浏览器端,需要把用户行为的数据和前端错误日志上报,来分析用户和定位用户发生的报错信息,这二个方面的需求,虽然不是必要,但也算有价值,开源中比较有名的则是 Sentry 和 Matomo 。
可视化
可视化是将数据组织成易于为人所理解和认知的结构,然后用图形的方式形象地呈现出来的理论、方法和技术。
简单点描述就是,将数据信息有效的组织起来,以图形的方式呈现出来。我们接触比较多的就是使用图表库来绘制大量的图表,比如 EChats 等,但可视化远远比这个复杂。
可视化相比于一般通用意义上的 Web 前端,在数学/图形学、图形(SVG、Canvas、WebGL)/图形库工具(D3.js、ThressJS 等)、数据处理/分析、性能优化这些领域上需要有更加深入的研究。
富文本编辑器/WebIDE
一个功能齐全的 Web 富文本编辑器的复杂度是非常非常高的。比如语雀、谷歌文档等,富文本编辑器都是这些产品的核心,需要有无数的细节处理。因为开发成本太大,所以如果产品中需要有富文本编辑器并且需要比较多的定制化,大多想到的是使用开源的产品上进行定制化的开发,如 Draft.js 、 Slatejs 。
VS Code 是使用 Electron 开发的,也就是 Web 那一套,所以证明在 Web 上实现体验流畅的 IDE 是可行的。WebIDE 远不止把 IDE 从本地搬到了浏览器上,必定需要集成一套开发流程和云端环境,代码的编译/运行/调试都在云端进行,开发者只需要一个浏览器就可以开发,未来可期。
搭建系统
Pro-Code、Low-Code、No-Code 前端对解放生产力、提高效率的追求永不停止。可视化搭建系统,能在中后台领域抽象出经典的场景、组件、数据流等,这个是很能提高效率的。但是没有银弹,只能在特定的领域中发挥作用。
智能化
最近出现很多前端智能化的声音。比如根据机器学习来让系统自动切图等,但感觉生搬硬套,非要使用机器学习那一套提高前端效率生产力,前端工程化/自动化那一套我们还没玩的炉火纯青,步子大了可能容易扯着蛋。
知识点实在太多,如果没有一个系统框架的学习方法,填鸭式的不断学习零散的知识点,太容易迷失了。
在知识管理领域的理论中,有一个 DIKW 模型,这套理论可以实践在你的任何学习的地方。它代表了知识管理的四个层级,也是学习的四个层次,分别是:Data(数据),Information(信息),Knowledge(知识),以及 Wisdom(智慧)。
把这套理论放置到编程语言的学习中。举例:
起初你没接触过任何编程语言时,你看到 let、var、for、while 等这些关键字时,你只知道他是英文单词,完全不知道他在编程语言中的意义,不知道他能干什么,这时候,它对你来说,就只是 Data 。
当你学习了所有的 JS 的语法,看到 let、if else、for 等就马上能知道这是什么意思,它在 JS 中能用来做什么,这时候它就从 Data 变成了 Information。每当你新学了一个语法或者一个API 使用,一些单词或者符号就会从 Data 变成 Information。
当你看到下面的代码,知道 b = a 只是将 a 的引用地址赋值给 b ,a 和 b 都指向了一个对象,知道值类型和引用类型在堆和栈中是以怎么样的形式存在的。这就是 Knowledge(知识)。
let a = { t1: 5, t2: 9 }
let b = a;
b.t1 = 6
delete b.t2;
b.t3 = 8
console.log(a) // {t1: 6, t3: 8}
console.log(a === b) // true如果你看到一个业务场景,根据现有的信息,从前端到服务端的情况都会有自己的判断,对技术选型、工程化,是否适合 Serverless、加入 BFF、Docker 等等都在脑海中可以浮现出来,看业务场景选择合适的编程范式提高效率等等。从细节到全局的把控都有一个自己的认知,知其然,还知其所以然。这时,这整套东西就是你的 Wisdom(智慧)。
这是我在一个公众号上看到管理知识方面的方法,我把它应用到学习的实践中。在笔记软件里建立 4 个笔记本,分别叫 Inbox、Note、Knowledge 和 Project。
可以使用 Notion,配合 Chrome 插件。
1)Inbox:存放一切收集到的内容
2)Note:存放已经完善好的信息,以备日后使用
3)Knowledge:存放按照主题组织起来的索引
4)Project:存放项目的必要信息
把你每天看到的需要看完或者需要做笔记没有完成的文章放到【阅读清单】中,几天或者每周来清理这些文章,阅读完把他们标记为已读。
如果发现有意义或者你想深入的主题,把这个主题放到 【 Inbox 】中,【Inbox】中存放你觉得有意义的主题。
待补充完善之后放入到 【Note】中,【Note】应该是比较稳定的一个主题的内容,但不是不变的,之后有更新,继续更新到这个主题之中。
【Knowledge】其实就是对主题做的索引,因为知识点其实不是树状的,它是网状的,很多的知识点都会有关联。
上面的知识点,都只是很粗的提了一下,肯定有遗漏的点,不可能只看一篇文章,就事无巨细的了解了前端的方方面面,我和大家一样也在不断的学习中,在遇到不懂的知识点时候,官网文档、书、谷歌、付费知识等都是你的学习渠道,你需要主动的去求知,把所有的点花时间产生个熵减的过程,慢慢的构建自己的知识架构。
Docker、k8s、Serverless,工程师们没少听,只不过不同工程师们的对他们的关注程度各不相同,出发点都是希望技术方案能在项目中更好的解决一些实际问题。这些技术即能抹平一些工程师之间的边界,也能加深一些工程师之间的鸿沟。
有过一些面试其他前端同学的经历,可能他们很熟悉 JS 基础、React、Vue等框架,但是谈到他们开发的前端应用的背后的东西,对他们就感觉是一个黑盒。很多公司大多是通过运维人员或 Leader 来去操作,很多人并不知道他们自己开发的前端应用背后是什么 Web 服务器、CDN,是使用了 nginx、Apache,或使用了容器、k8s等。
这些技术的出现,我们可能完全不需要去关注背后是怎么部署和运维的,交给专业人员和云服务商去做,就像我们使用水电一样,我们完全不需要知道背后是怎么发电的。可以更加专注于自己的业务逻辑,这也是一种发展。
我们正处在这个过渡的时代。
一般的物理服务器都会有很强的 CPU 核心、内存、网卡等。为了充分利用这些硬件资源,就有了虚拟化技术,物理服务器上可以虚拟出很多的虚拟机(VM),每个虚拟机都拥有独立的操作系统(windows、linux等)。根据需求来分配具体的硬件资源(CPU、内存等),就可以尽量大的利用物理服务器资源。
Docker 的出现,原因肯定有对虚拟机的资源利用率还是不满意,继续提高服务器的资源利用率。Docker 就是对机器的利用率到了进程级别,更细的控制 CPU、内存等。
Docker 可以在一台机器上快速的启动、关闭容器,但是缺乏对大量容器自动编排、管理和调度。k8s 就是一套管理系统,对容器进行更高级更灵活的管理。你只需要提供服务器,k8s 通过对容器的编排可以帮你最大化的利用这些服务器的资源。
云服务可以让我们选择合适配置的虚拟的云主机,然后按时、按月、按年的收费,但不管你使用与否,费用都在那里,不增不减。Serverless 则可以让你只在使用时,根据使用时间、内存占用等一些你具体使用的东西来收费,不管你使用的频率高低都可以承受,就像水和电,用了多少就是多少费用。
不同与服务端很多程序,前端代码运行在客户机器上。Docker 在前端工程上的使用,出发点和服务端程序,会有所不同。
通常的前端应用构建部署流程:
加入 Docker 理念后,前二个步骤几乎相同,理想的流程大致为:
步骤 3 中,构建出的镜像里面包括:
一部分静态资源在构建完成之后也可以上传到 CDN 上,但是因为静态资源的大小几乎不会很大,所以放到镜像中没有多大问题。
步骤 5 中,对容器的编排,最流行的应该就是 k8s ,上传完镜像后,就交由 k8s 来做一系列的发布编排等。
构建完的静态资源,不像后端的程序,其实它对环境的感知是很低的,因为只是简单的存储在机器上,没有运行。所以就算是很多前端应用,Web 服务器就是它的 Docker,通过管理好不同的目录,每个应用就可以很好的做到相应的隔离来等待客户端去请求它。
现代前端应用的项目开发,已经不是只用浏览器就能跑起来了。项目中的依赖少不了 node、npm,如果复杂项目就会带入更多的东西。多个项目中开发依赖大多都会不同,node 版本,npm 包的版本,或其他依赖的版本都可能是不同的。
这时候,引入 Docker ,给每个项目都生成一个容器镜像包括该项目的所有的依赖,并配置好基于容器来开发的命令,规范和统一了开发的环境。开发人员只需要安装好 Docker ,下载好代码,下载这个镜像,可以省去很多的开发环境搭建的麻烦,而且受益者众多。
但是随着 Web IDE 的发展,之后,应该是 Web IDE 在云端就会帮你解决项目中所有的环境依赖,你只需要打开浏览器,专注于代码的业务逻辑即可。
首先它是一个理念,不同云计算厂商针对这个理念出了不同的产品。
前端和服务器的前端(对整个请求链路来说,前端是相对的,只要离客户请求更近的角色都可以称自己为前端)
前端在使用 CDN、调用 API,相对于前端来说这些就是 Serverless 的理念,我们不会去关心这些 API 部署了多少机器、架构是怎么样的,这些方面后端和运维工程师都帮我们处理好了。同样,Serverless 可以帮后端工程师们处理掉很多与业务逻辑不相关的工作,更专注于业务逻辑的代码编写。
在前端技术领域 BFF 层和 SSR 渲染,非常适合 Serverless 技术的落地。
BFF 层,负责适配前端(PC端、移动端等)和后端服务的一个适配层。一般在 BFF 层前面,还会有 API Gateway 层负责统一的入口、鉴权、服务分发等功能。因为 BFF 层通常不会涉及到持久化的逻辑,使用 Serverless 非常合适,不用在关心负载均衡、扩缩容、高并低延等一系列问题,更专注于本身的业务逻辑处理。BFF 层因为更靠近客户请求,除去这些问题,前端工程师便可以更好的胜任这一层的开发。
SSR 渲染可以在服务端更快的渲染出页面,提供给客户端展示。不止是页面,所有的组件也可以在服务端渲染,直接提供给客户端展示。和 BFF 层类似,Serverless 可以让 SSR 服务专注于渲染组件和页面的处理,而不用关心这个服务背后的一些运维、服务健壮性等服务端的知识,Serverless 可能让 SSR 重回主流位置。
想象一下 5G 的出现,低延时、高速度,利用 Serverless 和其他云服务的结合,客户端的计算处理能力可以极低,硬件的大头只有显示设备或者投屏显示,可能激发出更多的创新,科幻电影里的一些场景也是不远了。
云服务的出现,就是让我们可以更专注于业务逻辑;中台的出现,是在我们的业务逻辑中抽象出通用的部分,变成业务的“基础设施”,目标都是为了快速的可以把我们的业务想法变为实际的应用落地。所以,在公司中,特别是在发展的不同阶段,对“基础设施”的提供和业务研发的资源分配,是一个很大的挑战。
在使用前端许多工具插件的时候,我们大多知道每个工具库、每个插件能做什么,不过很多同学其实并不清楚背后用到的技术,如webpack、rollup、UglifyJS、Lint等很多的工具和库的核心都是通过Abstract Syntax Tree 抽象语法树这个概念来实现对代码的检查、分析等操作的。通过了解抽象语法树这个概念,你也可以随手编写类似的工具,发现一个新的世界。
理论的知识总是有些枯燥乏味,不过客官别急,一步一步来。
其实这些工具的原理都是通过JavaScript Parser把代码转化为一颗抽象语法树(AST),这颗树定义了代码的结构,通过操纵这颗树,我们可以精准的定位到声明语句、赋值语句、运算语句等等,实现对代码的分析、优化、变更等操作。
wikipedia定义:
In computer science, an abstract syntax tree (AST), or just syntax tree, is a tree representation of the abstract syntactic structure of source code written in a programming language.
翻译为:
在计算机科学中,抽象语法树(abstract syntax tree或者缩写为AST),或者语法树(syntax tree),是源代码的抽象语法结构的树状表现形式,这里特指编程语言的源代码。
Javascript的语法是为了给开发者更好的编程而设计的,但是不适合程序的理解。所以需要转化为AST来更适合程序分析,浏览器编译器一般会把源码转化为AST来进行进一步的分析等其他操作。
以下只介绍Javascript相关的抽象语法树
比如说有一段代码:
var a = 3;
a + 5;那么它的抽象语法树就类似:
JavaScript Parser,把js源码转化为抽象语法树的解析器。
浏览器会把js源码通过解析器转为抽象语法树,再进一步转化为字节码或直接生成机器码。
一般来说每个js引擎都会有自己的抽象语法树格式,Chrome的v8引擎,firefox的SpiderMonkey引擎等等,MDN提供了详细SpiderMonkey AST format的详细说明,算是业界的标准。
发展到现在可能不同的JavaScript Parser的AST格式会不同,或基于SpiderMonkey AST format,或重新设计自己的AST format,或基于SpiderMonkey AST format优化改进。通过优化抽象语法树,来使程序运行的更快,也是一种提高效率的方法。
常用的JavaScript Parser有:
在Esprima的官网有一个比较各个Parser解析速度的列表Speed Comparison。 看下来Acorn是公认的最快的。
UglifyJS2的作者自己实现了一套js的抽象语法树,用到了继承,和现有的扁平的抽象语法树都有所不同,但作者也提供使用不同的抽象语法树来解析代码。
AST explorer可以在线看到不同的parser解析js代码后得到的AST。
JavaScript AST visualizer 可以在线可视化的看到AST。
通过 esprima , 把一个名字为ast的空函数的源码生成一颗AST树:
var esprima = require('esprima');
var code = 'function ast(){}';
var ast = esprima.parse(code);生成的抽象语法树长这样:
{
"type": "Program",
"body": [
{
"type": "FunctionDeclaration",
"id": {
"type": "Identifier",
"name": "ast",
"range": [
9,
12
]
},
"params": [],
"body": {
"type": "BlockStatement",
"body": [],
"range": [
14,
16
]
},
"generator": false,
"expression": false,
"range": [
0,
16
]
}
],
"sourceType": "module",
"range": [
0,
16
]
}通过 estraverse 遍历并且更新抽象语法树,把函数名称改为ast_awsome:
...
var estraverse = require('estraverse');
estraverse.traverse(ast, {
enter: function (node) {
node.name += "_awsome";
}
});通过 escodegen 将AST重新生成为源码:
...
var escodegen = require("escodegen");
var regenerated_code = escodegen.parse(ast)AST三板斧:
esprima 把源码转化为ASTestraverse 遍历并更新ASTescodegen 将AST重新生成源码浏览器最先就会把源码解析为抽象语法树,对浏览器而言AST的作用非常重要。
对开发者而言,AST的作用就是可以精准的定位到代码的任何地方,它就像是是你的手术刀,对代码进行一系列的操作。
常见的几种用途:
抽象语法树在前端领域中的应用广泛,通过抽象语法树大家可以实现很多功能,发现编写工具提高效率带来的乐趣。
最近一直在想前端与 DSL 的一些联系与发展,DSL 的概念在后端工程师中可能会更加熟悉,但在前端领域中也是充斥着 DSL 的身影。
DSL(Domain Specific Language)中文翻译为领域特定语言,例如 SQL、JSON、正则表达式等。与之形成对比的是 GPL(General Purpose Language),中文翻译为通用编程语言,我们熟悉的C、C++、JavaScript、Java 语言等就是。
DSL 的特点,在《领域特定语言》这本书中的描述,按照我自己的理解为:
主要分为三类:外部 DSL、内部 DSL、语言工作台 。
// jQuery
$('#my-div')
.slideDown()
.find('button')
.html('follow');
// Mocha
describe('User', function () {
describe('#save()', function () {
it('should save without error', function (done) {
var user = new User('Luna');
user.save(done);
});
});
});<div>
<header>title</header>
<section>content</section>
<footer>footer</footer>
</div>Web 前端并不是只有 HTML/CSS/JS ,其实历史的洪流中还有 Silverlight、Flash、ActiveX 等,然而各种原因互联网选择了 HTML/CSS/JS 。JS 的初衷并不是为了构建复杂 UI 而设计的,所以对于越发复杂的 Web 前端,前端的 UI DSL 也是在循序渐进的发展,HTML/CSS/JS 的规范不断的在改进迭代,业界更是不满足于现在标准而不断的扩展,从 CSS 到 Less/Sass 、 JS/JSX、Vue 和 Angular 都有各自的组件和 Template 实现,再使用转译器,最终运行等效的代码。
通过基于现有语言,扩展或结合创造一种新的 UI DSL,对于前端开发者的接受程度可能会高,但现实原因只可能更复杂,各种标准规范委员会、浏览器厂商、前端 Runtime 等等。小程序则为了提高交互体验结合 Native 和 WebView 的各自优势,UI DSL 趋向于 Web 端语法,对 Web 前端开发人员友好。
相比 Web 端,移动端因为其原生的独特性 UI DSL 则是出现了断崖般的升级。例如 Object-C 到 Swift UI、Android 的 Kotlin Anko、跨平台 Flutter 的 Dart。各语言背后都是大厂商的支持,初衷都是想开发出更好构建 UI 的语言,大家的趋势都是 UI as Code 。
本质上移动端、Web 端虽然有些许不同,但都是前端,问题领域高度一致。UI as Code 在我看来,这个 Code 的意思,就是一门通用编程语言,然后基于这个编程语言来创建一门内部 DSL 来构建 UI ,逻辑和 UI 的编程都是同一门语言,更加高效并减轻开发者的负担。
Web 前端也有类似的发展趋势。CSS 出现了各种 CSS in JS 的方案,JS/HTML 扩展为 JSX,虽然还是有着浓重的 HTML/CSS 色彩。随着现在许多成熟的组件框架库出现,在开发中后台的时候,除了JS ,很多时候就几乎只组装组件和一些简单的布局,已经没有写很多 CSS 和直接操作 DOM。这就感同身受了一句话:“编程就是在为自己的应用程序设计 DSL “ ,就是使用组件针对你开发的应用程序构建内部 DSL(封装组件、方法),通过牺牲一部分通用性灵活性提高开发效率。
Facebook 可以构建出 JSX ,Microsoft 可以创造出 TS ,国内也有 Vue ,相信前端在语言层面上的更大的机遇是会抽象出更加好用的 DSL。
前端搭建系统/可视化平台,难点多难度大,投入风险高,潜在的回报也巨大。大厂商都在投入研发通用性更高的可视化搭建平台,适用范围更广;小厂商则会针对特定业务来开发搭建系统,难度稍低见效快。如果把范围限定在二者之前,在一个适当的业务领域里,研发与业务领域专家充分沟通,投入研发相关的模型和 DSL ,以可视化作为辅助,在灵活性和效率上找到一个平衡点,可以大大提高领域生产力。
我们经常会去尝试创建拖拽加配置的可视化搭建系统来解决各种不同的业务。没有银弹,系统的复杂度不会消失,只会转移,这里就容易产生 COBOL 谬论:”编程语言很难是因为它不像我们平常交流的语言,如果把编程语言设计为像我们平常用的语言,就会容易多了“。"前端很难,我们把它做成可拖拽的可视化平台,就不需要前端开发了"。
antd 相当于是就是构建了基于 JSX 的 DSL ,在中后台前端开发领域,通过抽象基础的交互展示逻辑, 牺牲了极少的的可扩展性,通用性和灵活性都达到了一定程度。
可视化搭建系统中有一个难题是,当可视化搭建无法实现某些需求,开发者通过修改代码来实现需求后,之后可能就无法再继续转到平台上。对于代码和可视化搭建的互转是一个难题。如果换一个思路,可视化搭建转成的代码,不是直接的 HTML/CSS/JS,而是一个新的内部 DSL 或外部 DSL ,这个 DSL 背后的模型的在灵活性和代码/可视化的互转上有特定的设计,代码修改,只要符合这个 DSL 的规范,则可以转为可视化的平台中。这就又回到上面的讨论,没有银弹,以 UI as Code 为趋势,在某一方面上牺牲,缩小领域,换取高效。
不管是内部 DSL 或外部 DSL,盲目的创造 DSL ,造成的问题就是,大家学习与理解的负担越来越大,因为使用多种语言比使用一种语言复杂得多,开发可能没有提效反而更加复杂而容易造成 bug 。
但程序的复杂性不会消失,不使用 DSL,也会需要使用不同的程序库,好的程序库的设计就必不可少,可谓 “程序库设计就是语言设计”。然而一个好的 DSL 也应该是让人容易理解并且容易使用,降低学习成本。
当大家陷入大量业务开发的时候,不防跳出细节,看看一些抽象和理论的东西来找找灵感。随着网络的提速 5G、6G ,还是 AI、AR/VR 的高速发展,前端交互模式的改变和创新,前端可以探索的东西应该是越来越多的。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.




















{kind=link}