w3cmark / blog Goto Github PK
View Code? Open in Web Editor NEW我在前端方面的学习、思考、探索?扯淡~
Home Page: http://www.w3cmark.com/
License: MIT License
我在前端方面的学习、思考、探索?扯淡~
Home Page: http://www.w3cmark.com/
License: MIT License





无论哪种方案,前提你都需要有两套格式的图片。可以通过各种工具进行批量转换。
前端处理
<picture>
<source srcset="img/awesomeWebPImage.webp" type="image/webp">
<source srcset="img/creakyOldJPEG.jpg" type="image/jpeg">
<img src="img/creakyOldJPEG.jpg" alt="Alt Text!">
</picture>
对于每个浏览器都可以用,而不只是支持<picuture>元素的浏览器。这是因为不支持<picture>的浏览器只会显示img指定的图片。
前端处理
这种方案的原理就是通过先检测当前浏览器是否支持
webp格式来决定图片和图片背景采用哪种图片格式来展示。
webp格式document.createElement('canvas').toDataURL('image/webp');
如果浏览器支持webp格式,返回的结果带有data:image/webp;:
data:image/webp;base64,UklGRrgAAABXRUJQVlA4WAoAAAAQAAAAKwEAlQAAQUxQSBIAAAABBxARERCQJP7/H0X0P+1/QwBWUDgggAAAAHANAJ0BKiwBlgA+bTaZSaQjIqEgKACADYlpbuF2sRtACewD32ych77ZOQ99snIe+2TkPfbJyHvtk5D32ych77ZOQ99snIe+2TkPfbJyHvtk5D32ych77ZOQ99snIe+2TkPfbJyHvtk5D32ych77ZOQ99qwAAP7/1gAAAAAAAAAA
如果浏览器不支持webp格式,返回的结果不带有data:image/webp;:
data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAASwAAACWCAYAAABkW7XSAAAAAXNSR0IArs4c6QAAAylJREFUeAHt0DEBAAAAwqD1T20IX4hAYcCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYMCAAQMGDBgwYOAdGL/UAAEPpnR6AAAAAElFTkSuQmCC
或者可以一开始,通过触发一张只有1像素的webp图片,监听它的onload事件,如果成功,说明浏览器支持webp格式,如果不支持,说明浏览器不支持啦。
不过这种首先你得准备这张图片,其次,你要每次都去请求这张图片。
在第一步,外面通过js知道浏览器支持情况,然后把两种格式的图片都放到img标签的自定义属性,根据不同情况取不同的图片地址显示出来即可。
<img data-src="https://xxx.w3cmark.com/f7b07c8.jpg" data-webp="https://xxx.w3cmark.com/f7b07c8.webp">
至于样式,可以直接根据检测的结果在body标签加入一个特殊样式,然后把webp的背景图写在这个样式下即可。
服务端处理
前端统一请求图片地址,比如https://xxx.w3cmark.com/f7b07c8.jpg,服务端接受到客户端请求时,根据request头的accept字段来判断,返回哪种格式的图片。
客户端支持webp格式时,request头的accept字段会有image/webp,如下图:

不支持时:

官方对accept字段的解释:
The Accept request-header field can be used to specify certain media types which are acceptable for the response. Accept headers can be used to indicate that the request is specifically limited to a small set of desired types, as in the case of a request for an in-line image.
google翻译一下:
Accept request-header字段可用于指定响应可接受的某些媒体类型。 接受标头可用于指示请求特别限于一小组所需类型,如在请求内嵌图像的情况下。
这种方案前端不用做特殊处理,但是服务端返回处理写死后,就不太灵活了,如果有某些场景就是想要访问非webp呢?
需要具体方案看业务的具体场景来用哈。
最近在接触基于PHP框架laraval的一个nova项目,它 官方文档 在介绍安装有些步骤不是很详细,所以记录一下整个安装流程:
1、需要确保安装mysql、php、composer环境
2、安装laraval框架,通过larval框架创建新project项目
# 安装laraval
composer global require "laravel/installer"
# 创建名字为blog项目
laravel new blog
# 如果提示laraval命令没找到,需要设置环境变量,比如mac下:
vim ~/.zshrc
# 添加以下path
export PATH="$HOME/.composer/vendor/bin:$PATH"
3、进入创建好的新project项目,修改composer.json文件
// 新加repositories字段
"repositories": [
{
"type": "path",
"url": "./nova" // 下载源码解压后存放的相对路径
}
],
// 修改require字段
"require": {
…
"laravel/nova": "*" // 新加
},
4、修改composer.json文件后,按顺序执行:
执行 composer update
执行 php artisan nova:install
5、本地数据库创建
修改.env文件里面数据库相关信息,比如数据库名、用户名、密码
执行 php artisan migrate
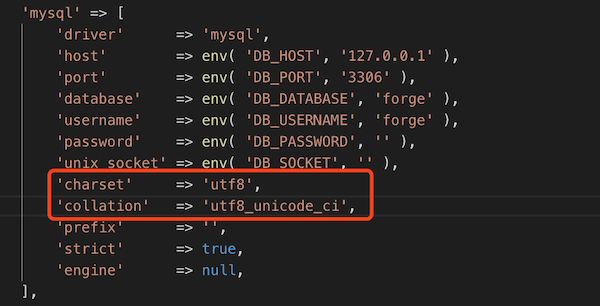
(本人测试发现在mysql8.xx版本会出现连接报错,暂时没能解决,连接5.xx的mysql没问题)
但是又遇到Unknown character set: 'utf8mb4'报错,解决方案是修改项目里的 /config/database.php
6、创建用户(用于访问时的登录)
php artisan nova:user
7、启动服务 php artisan serve
访问路径 http://127.0.0.1:8000/nova/
即可看到后台界面啦
从刚入门前端时,从table年代到div年代,很多实际的HTML开发基本都停留在几个常用的标签,比如html、head、body、div、meta、a、p、span、i、em、img、canvas、video、audio、h1、h2...
而有很多相对于我来说,是很少用甚至没用过的标签。
这些标签不熟,说明svg不熟
<rect> <circle><ellipse><line><polyline><polygon><path><figure>、<figcaption><figure>:用作文档中插图的图像
<figcaption>:figure插图里如果带有一个标题可以使用
app.js 的 onShow 和 onHide 时 getCurrentPages() 查询页面栈,可能获取到空数组发现时间:20180517
系统环境:IOS
如果有在这两个场景使用,建议对当前页面对象进行判断是否为
undefined
wx.getSystemInfo 的 windowHeight 小于实际高度(大约少了一个tabBar的距离)发现时间:20180517
系统环境:android部分机
onTabItemTap事件在首次切换不会触发,要在页面onShow后再切换才触发发现时间:20180517
系统环境:iOS
sdk 1.9.97有问题、更新到2.0.7正常
小程序的open-type是button特有的属性,所以使用小程序原生button组件在所难免,比如:
<button open-type="share" class="btn">
点击分享
</button>
但是原生的button可能不太适合业务,所以需要去掉默认样式,比如去掉背景色和边框:
.btn {
background-color: transparent;
border: 0;
}
咦!意不意外?背景是去掉了,边框还在。。。
原来原生button的边框是写在 伪元素 after的,所以,需要这样才能去掉:
.btn::after {
border: 0;
}
canvas.draw 回调一直不执行,也没报错(sdk在1.7.1以上都不可以)如果你用了很多方式也排查不出原因,可以试下把绘画的canvas标签放到page页面级别的html,而不是放到自定义的组件html。貌似放到自定义组件,无法找到画布,导致绘画不成功(它没报错,但回调又不执行)。
回头看来官方api,原来createCanvasContext方法有第二个参数 Object this,
在自定义组件下,当前组件实例的this,表示在这个自定义组件下查找拥有 canvas-id 的 ,如果省略则不在任何自定义组件内查找
错误示范
.footer {
padding-bottom: calc(0 + constant(safe-area-inset-bottom)); /* 兼容 iOS < 11.2 */
padding-bottom: calc(0 + env(safe-area-inset-bottom));
}正确示范
.footer {
padding-bottom: calc(0rpx + constant(safe-area-inset-bottom)); /* 兼容 iOS < 11.2 */
padding-bottom: calc(0rpx + env(safe-area-inset-bottom));
}先上一张gif效果图:
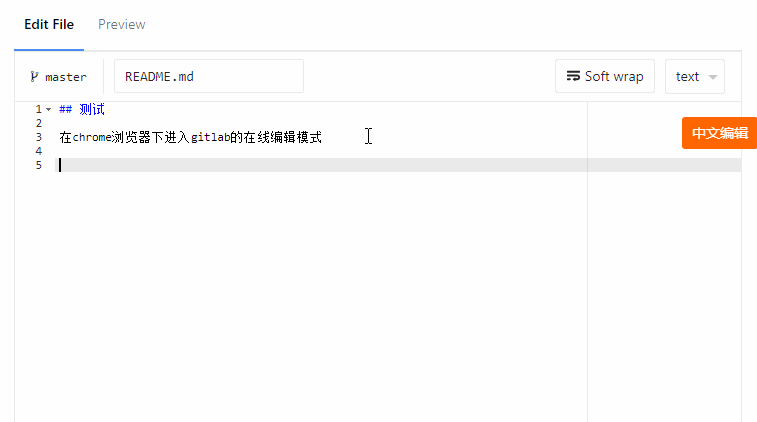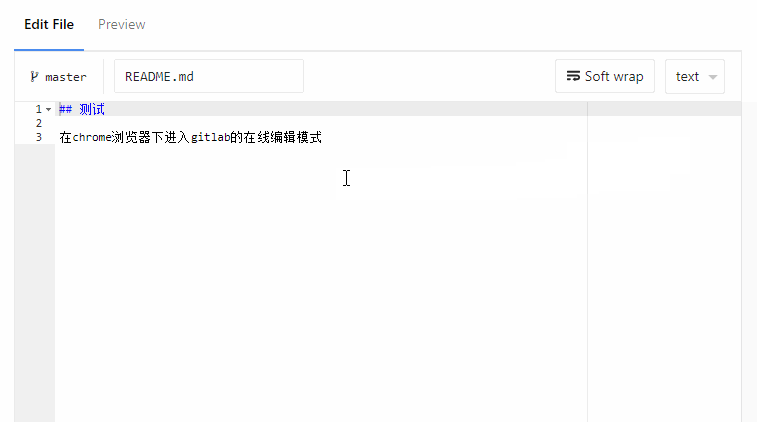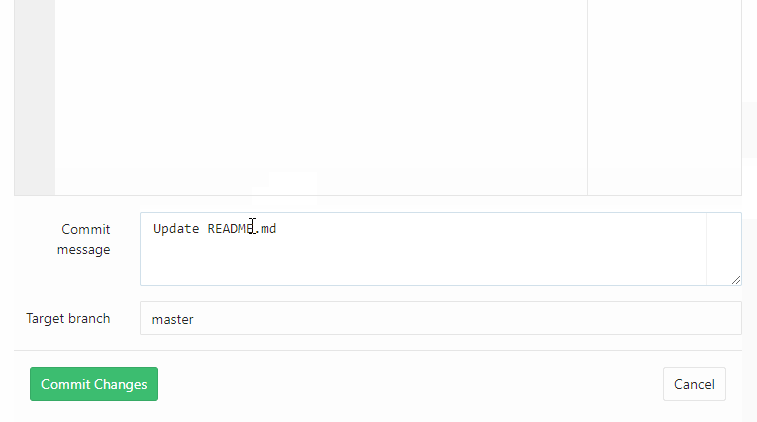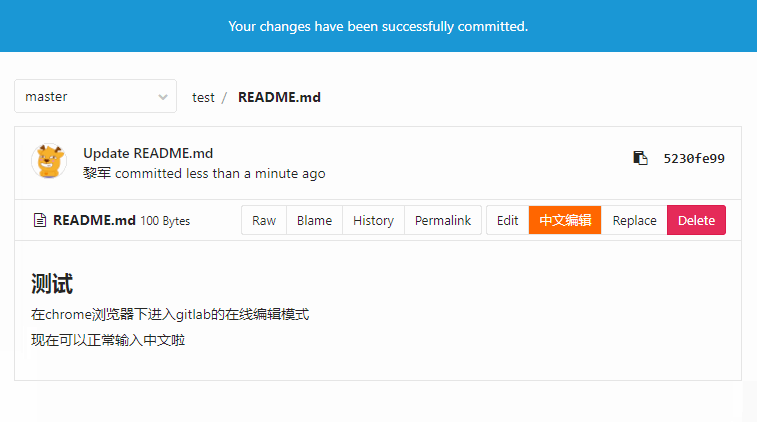
我们团队内部搭建了gitlab作为代码托管,目前的版本是GitLab Community Edition 8.17.5 9a564a8,在升级到这个版本时,发现在chrome下,在线编辑无法正常输入中文了,出现如上动图的错乱效果,而在firefox是正常的。
一开始怀疑是chrome更新版本后的问题,但是github的在线编辑是正常的,后来通过chrome开发者工具debug,发现是gitlab使用的在线编辑器有问题。无论gitlab还是github,这种在线编辑代码都是借助于一些web编辑器实现的,比如aceeditor,而这里gitlab用的正是aceeditor,因此第一时间跑去aceeditor官网,嗯,人家的是正常的。所以gitlab出现这种问题的原因就是aceeditor编辑器的版本在新版chrome下的bug。
找到问题源头,解决办法也就有眉目了:
直接更新GitLab Community Edition版本到最新版,看看官方是否更换了aceeditor编辑器的版本解决了这个问题。
升级gitlab,可能会担心升级过程会不会有什么新问题,特别是大版本更新就更要慎重。既然这样,那就直接自己在现版本手动去更新aceeditor编辑器,理论上找到gitlab的安装,找到编辑器的相关文件,替换成新的版本。前提是你要摸索清gitlab的目录结构,完整替换编辑器版本。听起来有点麻烦,而且也有一定风险~
这里介绍另一种思路,通过chrome extension在打开编辑页时替换编辑器。这种不是治本的方案,但感觉也是一种思路,刚好团队本身有一个在用从chrome插件,所以把解决方案放进现有的插件即可。这个方案可能适用性和参考意义不大,但这种思路说不定能给到你一些新的想法呢
下面详细说下第三种方案的操作细节:
(涉及到chrome extension的相关细节,这里就不详细描述,默认你拥有chrome extension的开发能力)
这一步很简单,直接去官网下载即可aceeditor,然后把编辑器的相关文件放到chrome插件下,比如:
|--src //插件源码
| |--js
| | |--lib
| | | |--src-min-noconflict //aceeditor
到时候打包插件时会一起打包的。
什么时候去加载新版的编辑器文件呢?因为我们只需要在gitlab编辑界面才用到,所以通过URL匹配来识别当前是编辑界面,然后再去加载aceeditor相关文件。另外还可以根据当前的编辑文件类型,来加载对应的编辑器文件,然后再通过chrome.tabs.executeScript来实现。
chrome.tabs.onUpdated.addListener(function (tabId, changeInfo, tab) {
// when complete
if (changeInfo.status === 'complete') {
if(/https:\/\/(你的系统域名)\/.+\/(edit|blob)\/.+/ig.test(tab.url)){
var newurl = tab.url.replace('(你的系统域名)',''),
r_file_suffix = /((?!(\.|\/))[\s\S])+\.([a-z]+)/ig;
newurl.match(r_file_suffix);
var file_suffix = RegExp.$3,
jsFiles = [
'/js/lib/jquery-2.1.3.min.js',
'/js/lib/src-min-noconflict/ace.js'
];
//根据文件类型
switch(file_suffix){
case 'js':
jsFiles.push('/js/lib/src-min-noconflict/mode-javascript.js');
break;
case 'tmpl':
jsFiles.push('/js/lib/src-min-noconflict/mode-html.js');
break;
case 'md':
jsFiles.push('/js/lib/src-min-noconflict/mode-markdown.js');
break;
default :
jsFiles.push('/js/lib/src-min-noconflict/mode-'+ file_suffix +'.js');
}
//替换编辑器以及保存等逻辑
jsFiles.push('/js/fixgitlabinput.js');
chrome.tabs.executeScript(tabId, {
code: 'var injected = window.octotreeInjected; window.octotreeInjected = true; injected;',
runAt: 'document_start'
}, function (res) {
var cssFiles = ['/css/fixgitlabedit.css'];
eachTask([function (cb) {
return eachItem(cssFiles, inject('insertCSS'), cb);
}, function (cb) {
return eachItem(jsFiles, inject('executeScript'), cb);
}]);
function inject(fn) {
return function (file, cb) {
chrome.tabs[fn](tabId, { file: file, runAt: 'document_start' }, cb);
};
}
});
}
}
});加载到编辑器文件,那最后一步就是进行编辑器替换,以及新编辑器的初始化,最后还要在保存时把新编辑器的内容提交。
这些逻辑放进了单独js文件fixgitlabinput.js处理。
这里我选择通过插入一个新的按钮来进行新编辑器的切换:
var fix_btn = '<span class="fix-btn" id="js-fix-btn">中文编辑</span>';
$('body').append(fix_btn);当点击这个按钮时,会做两件事:
(1)根据当前地址,获取目前编辑文件的内容
(2)把获取到的文件内容用新的编辑器初始化,并隐藏旧版的编辑器,显示新版的编辑器
var fix_btn = '<a href="#fixgitlabedit" class="fix-btn" id="js-fix-btn">中文编辑</a>';
$('body').append(fix_btn);
if(location.hash == '#fixgitlabedit'){
//传入当前地址和文件类型
fixeditor(curhref, file_mode);
$('#js-fix-btn').hide();
}
function fixeditor(curhref, file_mode){
//隐藏旧的编辑器
$('#editor').hide();
var fix_div = '<pre id="js-fix-editor" class="fix-editor"><pre>',
new_editor,
$old_editor_par = $('#editor').parent();
// 插入新的编辑器
$old_editor_par.append(fix_div);
var $form_actions = $('form .form-actions');
//隐藏旧的保存按钮
$form_actions.find('.btn.commit-btn.js-commit-button.btn-create').hide();
var new_submit_btn = '<button name="button" class="btn btn-create new-submit-btn">Commit Changes</button>';
//插入新的保存按钮
$form_actions.prepend(new_submit_btn);
//保存操作
$form_actions.on('click', '.new-submit-btn', function(e){
if($(this).hasClass('disabled')){return;}
e.preventDefault();
$(this).addClass('disabled');
//获取编辑器的内容,aceeditor提供的方法
var new_val = new_editor.getValue();
$('#file-content').val(new_val);
$("form.form-horizontal.js-quick-submit.js-requires-input.js-edit-blob-form")[0].submit();
})
// 根据当前地址获取文件内容
getHttpRequest(curhref, function(data){
var r_editor_text = /\<pre class="js-edit-mode-pane" id="editor"\>([\s\S]*)\<\/pre\>/igm;
data.match(r_editor_text);
var editor_text = RegExp.$1;
$old_editor_par.find('#js-fix-editor').html(editor_text);
//获取编辑器的内容,aceeditor提供的方法
new_editor = ace.edit("js-fix-editor");
new_editor.session.setMode("ace/mode/"+file_mode);
});
}
function getHttpRequest(href, callback){
var xhr = new XMLHttpRequest();
xhr.open("GET", href, true);
xhr.onreadystatechange = function() {
if (xhr.readyState == 4) {
var data = xhr.responseText;
typeof callback == 'function' && callback(data);
}
}
xhr.send();
}到这里,就可以正常输入中文并保存了,对于没有接触chrome插件开发的人来说可能比较麻烦,so,就当新想法的折腾呗~
| 节点名称 | 测试IP | LG链接 | PING值 |
|---|---|---|---|
| Los Angeles, CA | 107.173.137.3 | la.lg.virmach.com |  |
| Frankfurt, Germany | 50.3.75.98 | ffm.lg.virmach.com |  |
| Amsterdam, Netherlands | 104.206.242.2 | ams.lg.virmach.com |  |
| New York, United States | 107.173.176.5 | ny.lg.virmach.com |  |
| Piscataway, NJ (NYC) | 107.174.64.68 | nj.lg.virmach.com |  |
| Dallas, United States | 23.95.41.200 | dal.lg.virmach.com |  |
| Phoenix, United States | 1173.213.69.188 | phx.lg.virmach.com |  |
| Los Angeles (Voxility Protection) | 45.43.7.8 | filtered-la.lg.virmach.com |  |
| Chicago, United States | 170.130.139.3 | chi.lg.virmach.com |  |
| Seattle, United States | 104.140.22.36 | sea.lg.virmach.com |  |
| Atlanta, United States | 107.172.25.131 | atl.lg.virmach.com |  |
| San Jose, United States | 107.172.96.135 | sj.lg.virmach.com |  |
有些机房是丢包很严重的,可以不用考虑了。
web网站和各种网络服务
系统工具和脚本
作为“胶水”语言把其他语言开发的模块包装起来方便使用
解析型语言,执行速度比 c(编译成机器码)/java(编译成字节码) 都慢
源码不能加密
代码量少,开发速度快
版本兼容问题,2.7和3.3代码存在不兼容的情况
如果中文字符串在Python环境下遇到 UnicodeDecodeError,这是因为.py文件保存的格式有问题。可以在第一行添加注释
# -*- coding: utf-8 -*-运营在做一些私域(企业微信的相关运营,比如把海报发动一些群或者发到朋友圈)发海报营销时,流程是设计师把海报底图做好,然后运营把需要推的商品生成小程序二维码,最后再把小程序码贴到海报底图,合成最终的营销海报图发给用户。
设计师生产的海报底图:

看到这里,咦!很简单嘛,让设计师把留空的小程序码坐标和尺寸给一下前端,前端做个简单页面,运营填个商品链接和上传海报底图,点一下【合成】按钮,前端把小程序码用canvas贴上去就完事啦。
但是,海报底图还有这样的:

和这样的:

也就是设计师生产的海报底图的尺寸和样式都有可能不一样,导致小程序码留空的位置和尺寸也有可能有差异
接到这个需求,最简单粗暴的实现想法有两个:
想法一:前端做一个简单页面,页面提供商品链接输入、海报底图上传、小程序码尺寸输入、小程序码位置输入,运营同学在使用的时候,把所有东西都填好,然后前端获取到小程序码后来放到指定的位置,合成海报,下载使用
想法二:看官可以看出想法一太挫太难用了,几乎毫无技术可言。所以做了一个改进,在页面运营同学只需要输入商品链接和上传海报底图,前后前端把小程序码拿回来后,把小程序码放到海报底图上面用canvas渲染出来,然后小程序码支持缩放和拖拽。这样做的目的是,运营同学不需要记什么坐标什么尺寸,看着拖就完事了
如果到这里就完事,好像就没这篇文章什么事了。
上面的方法都不够智能,使用者还是不够方便!!!
我们再来观察一下上面的海报底图,小程序码的留空位置都比较有规律:一定范围大小尺寸、底色几乎纯白、圆形。
能不能自动识别这个有规律的区域,可以把小程序码精准的贴上去呢?
官网请移步:OpenCV
OpenCV的全称是Open Source Computer Vision Library,是一个跨平台的计算机视觉库。OpenCV是由英特尔公司发起并参与开发,以BSD许可证授权发行,可以在商业和研究领域中免费使用。OpenCV可用于开发实时的图像处理、计算机视觉以及模式识别程序。(最基本的滤波到高级的物体检测皆有涵盖)
而这里,我们就需要用到OpenCV的物体检测功能,把海报底图的留空区域识别出来。
首先我们是通过前端解决问题,所以用到的是OpenCV的js版本(它还有很多语言版本,可以在官网查看)。本文中的例子使用的是4.5.4版本号,你可以从这里获取:https://docs.opencv.org/4.5.4/d0/d84/tutorial_js_usage.html
又或者直接引用:https://docs.opencv.org/3.4.0/opencv.js
(整个js文件有8M多,还是挺大的,所以本方案比较适合B端的工具类型,如果是用在C端产品,可能还要看一下怎么优化。)
基础的使用也可以看上面贴出的tutorial_js_usage页面,都是官方的教程,里面还有在线栗子可以自己玩。
下面回归到本文整体,如何通过OpenCV把一张图片上的“一定大小的白色圆形区域”识别出来。
简单看一下htlm:
<div>
<div class="inputoutput"><!-- 输入的图片展示区域 -->
<img id="imageSrc" alt="No Image" style="width: 400px;"/>
<div class="caption">imageSrc <input type="file" id="fileInput" name="file" /></div>
</div>
<div class="inputoutput"><!-- 输出的图片展示区域 -->
<canvas id="canvasOutput" ></canvas>
<div class="caption">canvasOutput</div>
</div>
</div>js代码:
// 获取图片上传按钮DOM节点
let inputElement = document.getElementById('fileInput');
// 监听按钮变化
inputElement.addEventListener('change', (e) => {
imgElement.src = URL.createObjectURL(e.target.files[0]);
}, false);
// 获取展示的输入图片DOM节点
let imgElement = document.getElementById('imageSrc');
// 测试用的二维码
let qrcode = 'https://raw.githubusercontent.com/w3cmark/blog/master/assets/qrcode.png';
let qrcodeElement = new Image()
qrcodeElement.src = qrcode
imgElement.onload = function() {
let mat = cv.imread(imgElement); // cv是引入OpenCV库,暴露的全局对象,
let point = getRoundShapePoint(mat); // 获取 “一定大小的白色圆形区域” 返回 {x: x坐标,y: y坐标, r: 半径}
console.log(point)
mat.delete();
// 画二维码区域
var c=document.getElementById("canvasOutput");
var ctx=c.getContext("2d");
c.width = imgElement.width;
c.height = imgElement.height;
ctx.drawImage(qrcodeElement, 0, 0, imgElement.width, imgElement.height);
ctx.beginPath();
ctx.arc(point.x, point.y, point.r, 0, 2*Math.PI);
ctx.stroke();
};# 安装
npm install -g nrm
Usage: nrm [options] [command]
Commands:
ls List all the registries
use <registry> Change registry to registry
add <registry> <url> [home] Add one custom registry
del <registry> Delete one custom registry
home <registry> [browser] Open the homepage of registry with optional browser
test [registry] Show the response time for one or all registries
help Print this help
Options:
-h, --help output usage information
-V, --version output the version number
npm ERR! cb() never called!)出现环境:OS X/macOS
官方issue:npm/npm#17839
这个报错无论是在官方的issue还是Stack Overflow,都有人反馈,解决思路主要有两种:
(1)来自Stack Overflow的解决方案:npm cache verify 和 npm cache clean(网上搜索还有就是安装node的助手,但是我实践是不行的,因为在安装 npm install -g n 本身也会报这个错)
(2)来自官方的issue评论的解决方案:删除node相关的安装,然后重装node(但看起来操作比较复杂,又要删这,又要删哪的)
我的最终解决方案:
去官方下载对应的安装包(尝试过brew install node安装,但是报错:Error: Checksum mismatch,而且我一开始不是通过brew安装的,所以放弃折腾了),我直接选的是当前长期支持版的最新版,直接安装覆盖即可。

第一步:申请一个属于自己的域名
第二步:在域名提供商,进入域名解析设置,以我的http://w3cmark.github.io为例
(1)先添加一个CNAME,主机记录写@,后面记录值写上你的w3cmark.github.io
(2)再添加一个CNAME,主机记录写www,后面记录值也是w3cmark.github.io
这样别人用www和不用www都能访问你的网站(其实www的方式,会先解析成http://w3cmark.github.io,然后根据CNAME再变成http://wwww.3cmark.com,即中间是经过一次转换的)。

第三步:在GitHub Pages项目的Setting-->GitHub Pages-->Custom domain(自定义域名)去直接填写
你自己的域名,如www.w3cmark.com,前面不需要http://,然后点击旁边的save按钮保存即可。(也可以不需要带www,如w3cmark.com。两者的区别是,如果带www,访问时不管是否带有www,浏览器地址栏访问的都是www.w3cmark.com,反之亦然。)


上面介绍的是CNAME别名记录,也可以使用A记录,后面的记录值是写GitHub Pages里面的ip地址,但有时候IP地址会更改,导致最后解析不正确,所以还是推荐用CNAME别名记录要好些,不建议用IP。
上面三步做完,一般等几分钟,解析生效,就可以用你自己域名访问下试试啦~
2018.05.01官方支持https Custom domains on GitHub Pages gain support for HTTPS
如果你是采用CNAME别名记录的方式,开启https很简单,只需要在在GitHub Pages项目的Setting去勾选即可(如果你是用ip做解析的,需要更新一下ip,具体可以看GitHub官方博客)

# 同一个域名根据不同的path指向不同的ip
/api.w3cmark.com\/(?!column)(.*)/ http://127.0.0.1:9529/$1
^api.w3cmark.com/column/*** host://10.199.133.253/column/$1
# 修改hosts
sudo vi /etc/hosts
# 打开当前路径的finder
open .
# 全局命令存放路径
/usr/local/bin
# 全局命令代码存放路径
/usr/local/lib
注意:以下问题出现的场景都是基于vue2.x,如果是vue 1.x的没有参考意义
@click="onClick($event, others)"
在使用vue的cli 3.x后,webpack的打包配置都通过项目根目录的vue.config.js进行配置,而默认这个文件是不存在的,需要自己创建和书写配置。
假如现在有个需求,我想在不同的打包命令下,打包后的文件输出在不同的本地文件夹:
在package.json文件配置了两个命令
(1)当我执行npm run build时,进行文件打包,打包后的文件输出在当前项目目录的dist文件夹(vue cli默认的配置就是如此)
(2)当我执行npm run publish时,进行文件打包,打包后的文件输出在某个指定的本地目录的某个文件夹
方法:
通过修改打包命令进行传参数,让
vue.config.js文件获取到参数来区分不同的打包操作,从而修改打包后的输出文件路径
package.json文件配置:
"scripts": {
"build": "vue-cli-service build",
"publish": "npm_config_publish=true npm run build'"
},
vue.config.js文件配置:
module.exports = {
baseUrl: '',
// 打包输出文件目录
outputDir: process.env.npm_config_publish ? '/Users/xxx/Documents/host/test/projectname' : 'dist' ,
}
以上的打包配置,在npm run publish时,打包后的文件就会存在你本地的'/Users/xxx/Documents/host/test/projectname里。
例子代码片段(row-click为表格当某一行被点击时会触发该事件):
<el-table
ref="fieldsTable"
@row-click="onRowClick"
>
</el-table>
而该事件默认有三个参数:row, column, event,参数的意义可以看element-ui官方文档
问题:如果我的table是个数组循环渲染,需要传个当前table下标index
第一反应的方案是:
<template v-for="(item, index) in data">
<el-table
ref="fieldsTable"
@row-click="onRowClick(row, column, event, index)"
>
</el-table>
</template>
这种写法虽然能够获取到index的值,但是,row column event这三个变量的值就变成undefined
因为如果在绑定的时,给
onRowClick传入的三个参数,是当前上下文的三个新变量,而当前上下文并没有声明有这三个变量,所以是undefined,而传入的undefined就覆盖了row-click事件的三个默认参数。
我们可以改造一下写法:
<template v-for="(item, index) in data">
<el-table
ref="fieldsTable"
@row-click="(row, column, event)=>{return onRowClick(row, column, event, index)}"
>
</el-table>
</template>
这样,在onRowClick就可以正常获取到四个参数的值。
得益于各种自动化工具,如今前端开源项目的目录结构越来越复杂了,在看别人代码时可能一脸懵逼,在这里整理了常见的目录结构。
存放CircleCI持续集成相关,目前只支持github和Bitbucket代码管理工具
webpack的相关配置,包括基本配置、开发环境配置、生产环境配置等
针对开发环境,生产环境,测试环境的配置信息
存放编译打包后的文件
存放例子
flow(JavaScript静态类型检查器,貌似Eslint)的 libdef 相关,用来存放引入一些第三方库或是自定义类型库
存放项目用于模拟的数据
安装依赖时自动生成的,用于存放项目依赖包
项目源码
静态资源,此目录下的文件不会被webpack处理。在webpack打包后,此目录下的文件会默认被直接复制到dist/static/中
用于存放测试文件,比如unit单元测试、e2e测试等
babel配置文件
编辑器编码规范配置文件,用于告诉编辑器本项目的一些编码规范,比如用多少个空格
ESLint语法检查忽略配置文件,用于配置忽略语法检查的目录文件
ESLint规则配置文件,用于语法检查
flow(一个 js 静态类型检测器)项目的配置文件
用于告诉Git系统要忽略掉跟踪哪些文件
用于跟踪项目中的空文件(默认情况Git 不跟踪空文件夹)
以行为单位设置一个路径下所有文件的属性
postcss配置文件
Travis CI(持续集成服务)的配置文件,指定了 Travis 的行为,Github 仓库里面,一旦代码仓库有新的 Commit,Travis 就会去找这个文件,执行里面的命令
首页静态html,可能是主入口
开源协议
Make(主要用于C语言的项目构建工具,也有些前端开源项目会支持)构建规则
使用npm安装依赖时自动生成的确切依赖配置文件,用于后续安装或跨机器安装能够生成相同版本的依赖,即使安装的依赖有更新也不影响
npm 模块配置文件,用于定义了这个项目所需要的各种模块,以及项目的配置信息(比如名称、版本、许可证等元数据)
使用用Yarn CLI 增加/升级/删除依赖时自动生成的确切依赖配置文件,准确存储每个安装的依赖是哪个版本,用于后续安装或跨机器安装能够生成相同版本的依赖
项目自述说明,用于概述本项目相关信息:是什么、做什么、有什么用、怎么用等
为了提高用户体验,在做一些比较多资源的项目,我们经常会用资源预加载的方式,一打开页面会先看到一个loading动画效果或者loading进度条,再或者加载百分比,用来暗示用户,页面资源比较多,正在加载中啦,你再等等哈,不要走喔。。。
而这里的资源预加载,就是通过js去预先请求某些资源,以备页面展示时可以直接使用,比如图片预加载,我们可能会这样实现:
var img = new Image();
img.onload = function () {
// 加载成功...
};
img.onerror = function () {
// 加载出错...
};
img.src = 'https://dummyimage.com/90x90/ddd/79c';通过创建一个不可见的img来触发图片请求,上面演示的只是加载一张,一般情况做预加载都会有多资源才做啦,所以批量预加载只需要加入循环:
var iFileData = [//预加载图片资源
'https://dummyimage.com/90x90/ddd/79c',
'https://dummyimage.com/100x100/ddd/79c',
'https://dummyimage.com/200x200/ddd/79c',
'https://dummyimage.com/300x300/ddd/79c',
'https://dummyimage.com/400x400/ddd/79c',
'https://dummyimage.com/500x500/ddd/79c'
],
_total = iFileData.length,
_loaded = 0;
for(var i = 0; i < _total; i++) {
loadImage(iFileData);
}
loadImage = function(iData){
var img = new Image();
img.onload = img.onerror = function () {
_loaded++;
checkLoadComplete();
};
img.src = iData;
},
checkLoadComplete = function(){
if(_loaded == _total) {
console.log('加载完毕');
}
};上面可以实现简单的预加载了,但好像没有当前加载的进度喔
下面加上一个当前加载进度的百分比:
checkLoadComplete = function(){
var per = (_loaded/_total).toFixed(2);
if(per > 1) {
per = 1;
}
console.log('当前加载进度:' + per);
if(_loaded == _total) {
console.log('加载完毕');
}
}到这,资源预加载的功能基本就ok了,然后展示进度跟进上面的进度返回,转成数字百分比或者一个进度条就可以了。
另外,这个功能很常用,可以再做一下封装,方便使用,还可以加入其它资源的支持,比如多媒体文件?
完了?
但,这个不是本文的重点,本文的重点是线性。
上面的预加载有个问题,体验不好。比如,你要预加载10个资源,显示的百分比就是0%,10%,20%,30%...这样10个数字的跳动,极端点,当你只有一个资源(当然这里是极端考虑,像前文说的,一个资源,你估计不会用预加载了)时,进度就是0%~100%,一下就从0跳到100了。
还有,即使是10个资源,当用户第二次打开页面,因为资源有缓存,这个loading效果就会可能一闪而过,因为有缓存加载太快了,进度都看不清就没了,体验也不好(或者即使第一次,如果用户网速很好,也会出现一闪而过)。
所以,上面的预加载体验不够好,不稳定,导致动画效果不线性。
预想的线性是怎样的呢?比如进度百分比数字,我预想的是无论多少资源,第几次打开,网速如何,都是从0%,1%,2%,3%,4%,5%,6%....这样直到100的,只有这样,数字展示才不会大幅度跳动或者进度条的宽度才不会跳跃。
那怎么达到这样的数字累加效果呢?咦?累加?那可以用定时器啊:
var _num = 0;
var _num_interval = setInterval(function(){
_num++;
if(_num > 99){
clearInterval(_num_interval);
_num = 100;
}
console.log(_num);
}, 50)嗯,这样数字就不跳动啦,很线性!!从0100,每隔50毫秒加1,到100就停止,so easy
线性数字有了,但和我加载进度有毛关系?而且资源加载是会根据网速不同而不同,这50毫秒。。。假的进度,明显不行啊
第一个问题,线性数字和实际资源加载联系起来,这个还是很容易的。从第一个资源开始,就同时触发触发上面的计时器,当最后一个资源加载完而且计算到100了,就完成了预加载过程。
第二个问题,定时器的时间怎么和实际资源加载联系起来呢?定时器先根据资源数定一个初始值,加载过程通过把假的计算进度和真实的加载进度进行比较,实时调整定时器的时间,以达到尽可能的模拟实际进度:
var _time = 50;
var linearLoad = function(){
if(_num_interval){
clearInterval(_num_interval);
}
_num_interval = setInterval(function(){
_num++;
if(_num > 99 && (_loaded == _total)){
clearInterval(_num_interval);
_num = 100;
console.log(_num);
// 加载完毕
console.log('加载完毕');
return;
}else if(_num > 99){
clearInterval(_num_interval);
return;
}
console.log(_num);
if(_time > 1){
adjustSpeed(_time_range);
}
}, _time)
},
adjustSpeed = function(range){
//调节数字变化速度
var per = (_loaded/_total).toFixed(2);
if(parseInt(per*100) > _num){
//如果实际加载速度快,提高线性数字速度
_time = _time - range;
_time = _time < 1 ? 1 : _time;
linearLoad();
}else{
//如果实际加载慢,降低线性数字速度
_time = _time + range;
linearLoad();
}
}逻辑细节请移步测试demo:http://www.w3cmark.com/staticdemo/loading/

接到一个前端跨域请求(GET和POST)相关的需求
一调试,咦!浏览器提示跨域报错了~
简单!让服务端童鞋加上跨域请求头,开启CORS:
Access-Control-Allow-Credentials: true
Access-Control-Allow-Headers: x-requested-with,content-type,x-xsrf-token
Access-Control-Allow-Methods: GET,POST,OPTIONS
Access-Control-Allow-Origin: http://w3cmark.com
以下是错误示范(冒号前面多了个空格):
Access-Control-Allow-Credentials : true
Access-Control-Allow-Headers : x-requested-with,content-type,x-xsrf-token
Access-Control-Allow-Methods : GET,POST,OPTIONS
Access-Control-Allow-Origin : http://w3cmark.com
服务端设置搞定!前端再次请求,请求响应头带上上面的返回,GET请求顺利过关。。。
如果接口需要登录,前端设置请求withCredentials: true,请求就带上cookie,顺利过关。。。
再来一个POST请求
咦!浏览器多发了一个OPTIONS请求,一查,原来是preflight request,预校验请求
这里的请求被分成两种:简单请求和复杂请求,只有复杂请求才会发OPTIONS请求,详情介绍移步:https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Access_control_CORS
----------说了那么多坑终于来了---------------
因为服务端对请求做登录校验(包括OPTIONS请求),校验通过后,才会给请求加跨域头返回,而OPTIONS请求是无法携带cookie的
来自SO的截图:

所以服务端无法接收到cookie,一直认为未登录,导致发OPTIONS请求时浏览器直接报跨域了。
解决方案,服务端不需要对OPTIONS请求做cookie校验的操作
一般配置如下:
splitChunks: {
chunks: 'all',
cacheGroups: {
libs: {
name: 'chunk-libs',
test: /[\\/]node_modules[\\/]/,
priority: 10,
chunks: 'initial'
},
elementUI: {
name: 'chunk-elementUI', // 单独将 elementUI 拆包
priority: 20, // 权重要大于 libs 和 app 不然会被打包进 libs 或者 app
test: /[\\/]node_modules[\\/]element-ui[\\/]/
}
}
}
cacheGroups设置了两组规则,把npm包的elementUI拆出来,其它打进libs包。
但发现 libs 包有点大,想再增加一组规则:
splitChunks: {
chunks: 'all',
cacheGroups: {
libs: {
name: 'chunk-libs',
test: /[\\/]node_modules[\\/]/,
priority: 10,
chunks: 'initial'
},
elementUI: {
name: 'chunk-elementUI', // 单独将 elementUI 拆包
priority: 20, // 权重要大于 libs 和 app 不然会被打包进 libs 或者 app
test: /[\\/]node_modules[\\/]element-ui[\\/]/
},
echarts: {
name: 'chunk-echarts', // 单独将 echarts 拆包
priority: 22,
test: /[\\/]node_modules[\\/]echarts[\\/]/
}
}
}
结果并没有如此的拆出 echarts 包,规则没效果。
后来查到splitChunks有个 maxInitialRequests 配置参数。(类似的配置还有maxAsyncRequests)
maxInitialRequests参数是表示允许入口并行加载的最大请求数,该配置对于 chunks 为 initial 和 all 情况下均可行,对于 async 无效,同时对按需加载的模块也是无效的;
所以最终规则:
splitChunks: {
chunks: 'all',
maxInitialRequests: 6, // 最大初始化请求数
cacheGroups: {
libs: {
name: 'chunk-libs',
test: /[\\/]node_modules[\\/]/,
priority: 10,
chunks: 'initial'
},
elementUI: {
name: 'chunk-elementUI', // 单独将 elementUI 拆包
priority: 20, // 权重要大于 libs 和 app 不然会被打包进 libs 或者 app
test: /[\\/]node_modules[\\/]element-ui[\\/]/
},
echarts: {
name: 'chunk-echarts', // 单独将 xlsx 拆包
priority: 22,
test: /[\\/]node_modules[\\/]echarts[\\/]/
}
}
}
疑问:maxInitialRequests默认值不是30吗?为什么不设置的时候不行,设为6却可以?

A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.