Домашнее задание по лекции "10.6. Инцидент-менеджмент" dev-17_10-monitoring-06-incident-management-yakovlev_vs
10-monitoring-06-incident-management
Составьте постмотрем, на основе реального сбоя системы Github в 2018 году.
Информация о сбое доступна в виде краткой выжимки на русском языке , а также развёрнуто на английском языке.
- Краткое описание инцидента - краткая выжимка об инциденте
- Предшествующие события - что произошло перед инцидентом
- Причина инцидента - из-за чего возник инцидент
- Воздействие - на что повлиял инцидент
- Обнаружение - когда и как инцидент был обнаружен
- Реакция - кто ответил на инцидент, кто был привлечен, какие каналы коммуникации были задействованы
- Восстановление - описание действий по устранению инцидента и поведение системы
- Таймлайн - последовательное описание ключевых событий инцидента с указанием времени
- Последующие действия - что нужно предпринять, чтобы инцидент не повторялся
| Раздел | Сбой системы GitHub 21 октября 2018 |
|---|---|
| 1. Краткое описание инцидента | После непродолжительной потери связи между сетевым узлом и датацентром нарушилась топология кластеров Оркестратора, что привело к деградированию системы |
| 2. Предшествующие события | Плановые работы по замене вышедшего из строя 100G оптического оборудования в дата-центре на восточном побережье США |
| 3. Причина инцидента | В результате временной потери связи кластеры MySQL перешли в "неожиданное" для Оркестратора состояние (только западные). Нормальное состояние: 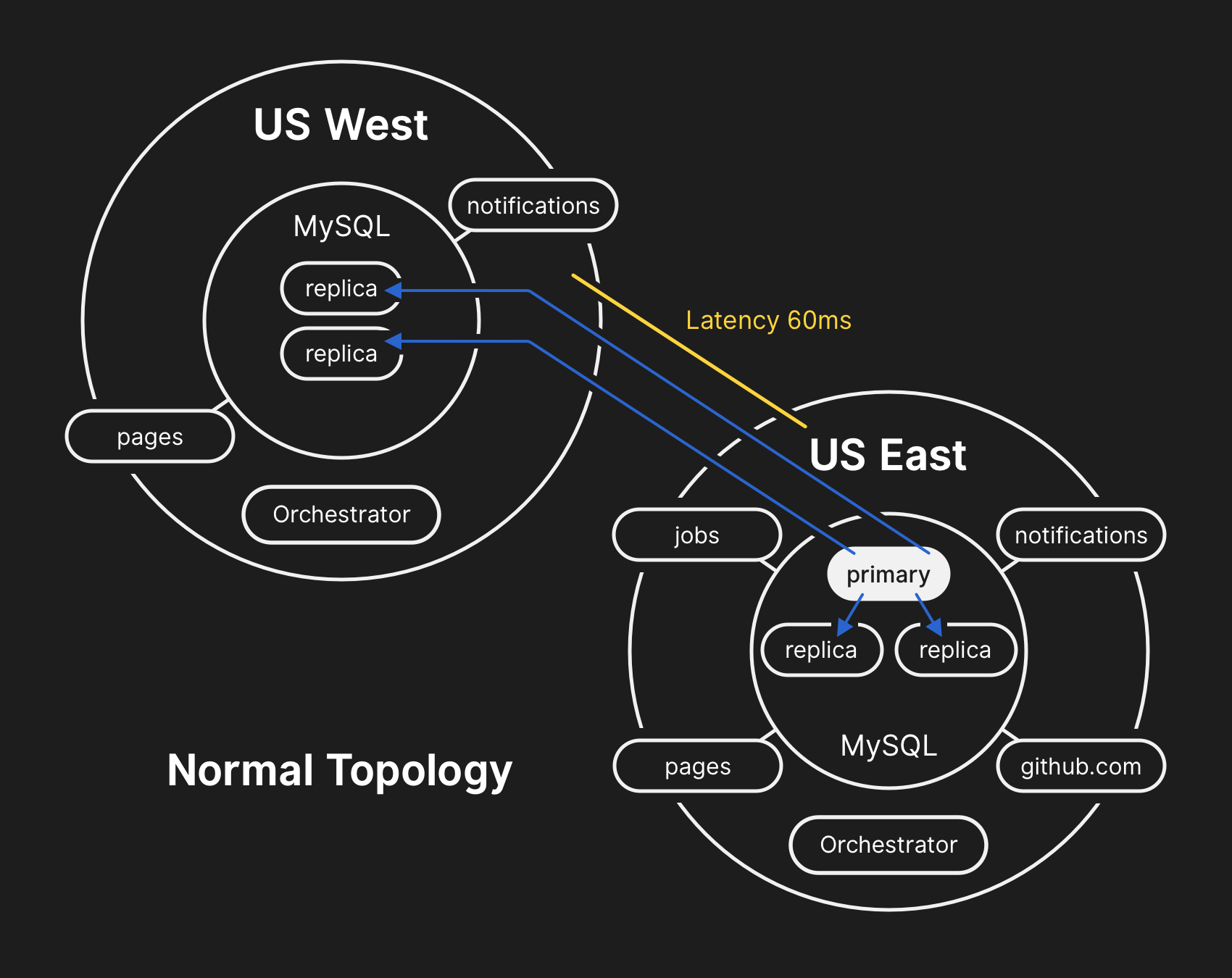 Состояние после сбоя: Состояние после сбоя: 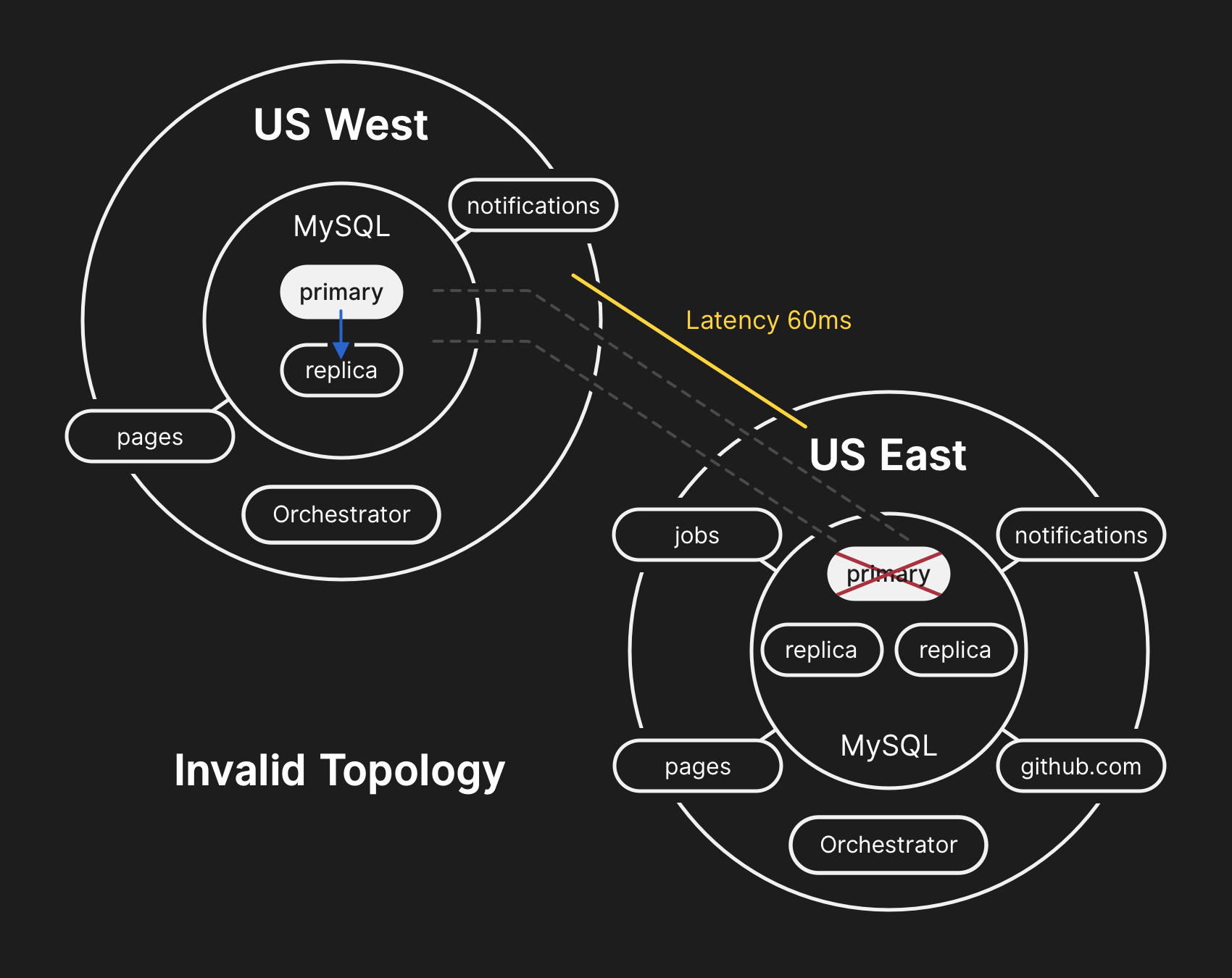 |
| 4. Воздействие | Отображение устаревшей и непоследовательной информации. Также в большинстве случаев не функционировали WebHook и сборка и публикация GitHub Pages |
| 5. Обнаружение | Инцидент был замечен дежурными инженерами через оповещения системы мониторинга |
| 6. Реакция | Группа реагирования провела минимизацию накопления сложности инцидента (отключила часть сервисов для минимизации изменений БД), после чего подключились к работе координатор и дополнительные разработчики из инженерной группы БД. Из-за приоритета целостности данных общее время восстановления составило 24 часа 11 минут |
| 7. Восстановление | Для исключения потери данных временно отключили часть сервисов для мининизации накопления изменений, после чего восстановили данные из резервных копий, а на них реплицировали накопленные. Далее вручную переконфигурировали топологию кластеров БД и включили деактивированный функционал. Завершающим этапом дождались отработки накопленных задач для чего даже потребовалось временно развернуть дополнительные реплики на чтение. 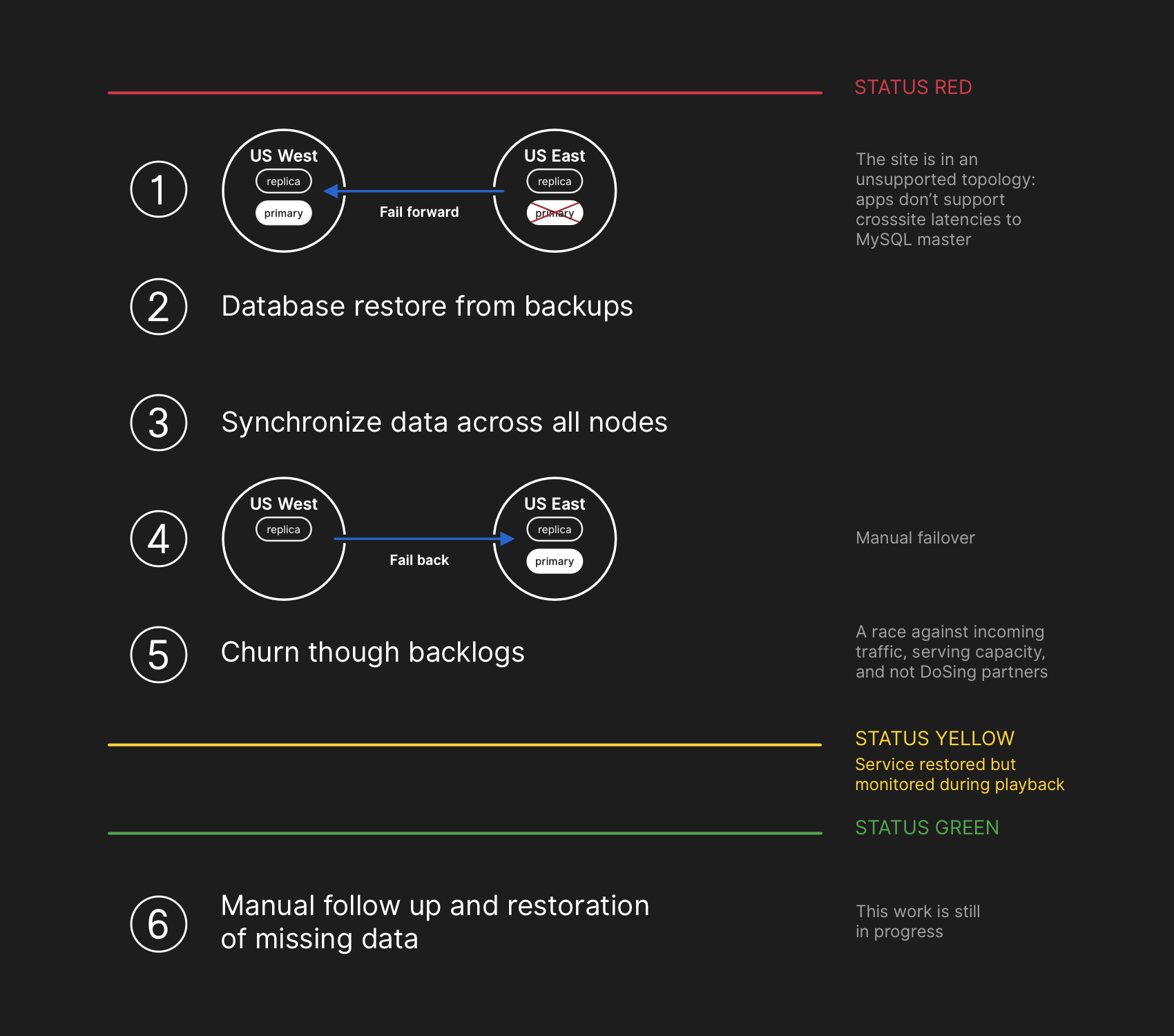 |
| 8. Таймлайн | 21 октября 2018, 22:52 UTC - Нарушилась связь между сетевым узлом и основным дата-центром на восточном побережье США 21 октября 2018, 22:52 UTC - Оркестратор в основном дата-центре запустил процесс выбора нового лидера, в результате чего начал создавать топологию кластера БД на западе. После восстановления подключения приложения направили трафик по записи на новые основные сервера на западе. Таким образом на обоих серверах образовались данные, отсутствующие у другого и не получилось вернуть первичный сервер не восток 21 октября 2018, 22:54 UTC - Внутренние системы мониторинга начали генерировать оповещения о многочисленных сбоях в работе систем 21 октября 2018, 23:02 UTC - Инженеры первой группы реагирования определили, что топологии для многочисленных кластеров БД находятся в неожиданном состоянии - при запросе API Оркестратора отображалась топология репликации БД, содержащая только серверы из западного ЦОД. 21 октября 2018, 23:07 UTC - Группа реагирования вручную заблокировала внутренние средства развёртывания, чтобы предотвратить внесение дополнительных изменений в БД 21 октября 2018, 23:09 UTC - Группа реагирования установила жёлтый статус работоспособности сайта (статус активного инцидента) 21 октября 2018, 23:11 UTC - Координатор присоединился к работе и через две минуты принял решение изменить статус сайта на красный. 21 октября 2018, 23:13 UTC - К работе привлекли дополнительных разработчиков из инженерной группы БД, которые начали исследовать текущее состояние для определения необходимых действий для ручной перенастроийки БД 21 октября 2018, 23:19 UTC - В целях сохранности данных принято решение об остановке выполнения заданий, которые пишут метаданные типа пуш-запросов 22 октября 2018, 00:05 UTC - Инженеры из группы реагирования начали разрабатывать план устранения несогласованности данных и запустили процедуры отработки отказа для MySQL 22 октября 2018, 00:41 UTC - Инициирован процесс резервного копирования для всех затронутых кластеров MySQL. Одновременно нескольок групп инженеров изучали способы ускорения передачи и восстановления без дальнейшей деградации сайта или риска повреждения данных 22 октября 2018, 06:51 UTC - Несколько кластеров на востоке завершили восстановление из резервных копий и начали реплицировать новые данные с Западным побережьем 22 октября 2018, 07:46 UTC - Публикация информационного сообщение об инциденте 22 октября 2018, 11:12 UTC - Все первичные БД вновь переведены на Восток, но не смотря на возросшую производительность сайта некоторые данные всё ещё отставали на несколько часов из-за отложенных реплик 22 октября 2018, 13:15 UTC - Зафиксировано возрастание отставания репликации до согласованного состояния (время увеличивалось, а не уменьшалось). Начали подготовку дополнительных реплик чтения MySQL в общедоступном облаке Восточного побережья 22 октября 2018, 16:24 UTC - Завершена синхронизация реплик - возврат к исходной топологии. Устранинены проблемы задержки и доступности. Однако, красный статус сохранён, так как нужно ещё обработать накопленные данные. 22 октяюря 2018, 16:45 UTC - Включение всех дэактивированных функций. Корректировка TTL более 200000 истекших за время восстановления задач из более 5 миллионов. 22 октября 2018, 23:03 UTC - Все незавершённые события webhook и сборки Pages обработаны, а целостность и правильная работа всех систем подтверждена. Статус сайта изменён на зелёный |
| 9. Последующие действия | Введена системная практика проверки сценариев сбоев, прежде чем они возникнут в реальности (Chaos Engineering) |
- В процессе восстановления, были собраны журналы MySQL с данными, которые не были реплицированы на западное побережье. Проводится анализ для определения автоматического восстановления данных.
- Необходимо поправить конфигурацию Orchestrator для того чтобы предотвратит передачу primary роли между регионами
- Переработать систему оповещения о статусе системы. Сделать её более информативной. Настроить оповещение о статусе отдельных компонентах сервиса.
- Закончить работу, которая началась за несколько недель до инцидента. Работа по улучшению отказоустойчивости сервиса, чтобы система оставалась доступной даже при отказе целого датацентра.
- Увеличить инвестиции компании в направление Chaos Engineering. Тестирование различных сценариев отказа.
Перевод оригинальной статьи October 21 post-incident analysis
