I'm glad that the HTCDS 1.0 was just published this sunday.
While I, here as lexicographer, have no problem with the creators of HTCDS and the United Nations International Organization for Migration employee trying to intermediate on what to do, the lawyers responsible to give copyright advice are the real target of confusing license. Note: we are still trying to follow what license we use, and this is not clear.
Note that lawyers, who still have not replied to any request for clarification after months, if likely trying to copycat the failed model of ISO organization while obviously the HTCDS requires much more help because systems world-wide are incompatible. The problem is that trying to use ISO as role model is that ISO actively DMCA down any serious translation initiative even for COVID-19 response (with they "freely available in read-only format" only for Englsh/French), which makes it unfit for humanitarian usage where wrong translation kills people and there is no reference resource for an average developer who uses English to not create tooling that will fail when exchanging personal data.
1. Serious data exchange flaws for (at least) common persons name from Latin America and Asia
It seems that one requirement to be "compatible with off-the-shelf existing systems", a software from an US based company focused on marketing called Salesforce, actually makes data exchange with serious flaws. I will repeat what has already been said here #7 (comment).
A trafficked person with common names used in Latin America, if shared using the current standard proposed to UN IOM, will get an incomplete name. For names originally not writing in Latin script, in addition to name order be likely to be swapped, there not only one organization can share using original script, but there is more than one transliteration strategy, with makes data exchange of people from Asia much more likely to get wrong, because the reference of IOM is doing wrong.
Let me repeat: trafficked Latin Americans and Asians when exchanged using the current HTCDS 1.0 terminology are known to be specially lost. This reason alone is sufficient to care about, even if HTCDS persist as it is in English.
1.2. Why am I citing the issue already in English
I'm doing this in public not to shame current work on HTCDS (because this is a very important project, and in fact terminology like this is a generic need, and also because by creating Portuguese version, we're also criticized), but in case of lawyers keeping this conflict license, the work needed to "translate" (in special the generic salesforce fields) actually requires complete rework.
The closest existing work related to persons data is https://github.com/SEMICeu/Core-Person-Vocabulary. And most corner cases the SEMICeu/Core-Person-Vocabulary uses are very common on humanitarian data. Even if HTCDS 1.0 rename fields (which already would make it a 2.0) it would at least need to consider people who have more than one official name. (yes, one person actually can have more than one name; then add these people who have birth names in non-Latin scripts while having their name transliterated, and there is more than one way to transliterate names).
Even if we could comply with such a confusing license, the people who could help us from HXL-CPLP would need to try implementations outside the HTCDS repository, in particular how to deal with non-Latin written names.
2. Our approach to this conflict license
We from HXL-CPLP will release the concepts (extra descriptions, translations, examples, etc) and templates to build glossaries and data schemas under public domain. Actually it has been since HTCDS v0.2.
Cease-and-desist-letters (or ask for help from other implementers getting DMCA requests) are welcomed at [email protected].
The standard HTCDS can keep whatever license is. But we here will not wait while people still bury their heads in sand, but we will not stop just because a thing known to get our names wrong just because it was easier to require a standard be compatible with a software used for marketing. I will explain why we will do public domain from our terminology while still making it reusable for humanitarian usage.
2.1. Why we, initial team from HXL-CPLP, refuse to allow copyright holding for all concepts to any organization
The way lexicography is done is close to words in a dictionary. We even developed software to convert not only to translator formats like XLIFF, but to TBX. This means our average spreadsheet is a frontend like Europe IATE https://iate.europa.eu/.
So, while maybe the name and the description of HTCDS could be copyrightable, concepts like how to break a person's name or birthdate are clearly insane any implicit implication with the current license that try to deny reuse for other cases. It's like trying to copyright a word in English. This is absurd.
2.1.1 Some quick context (for technical people, not the lawyers, to get idea of building blocks)
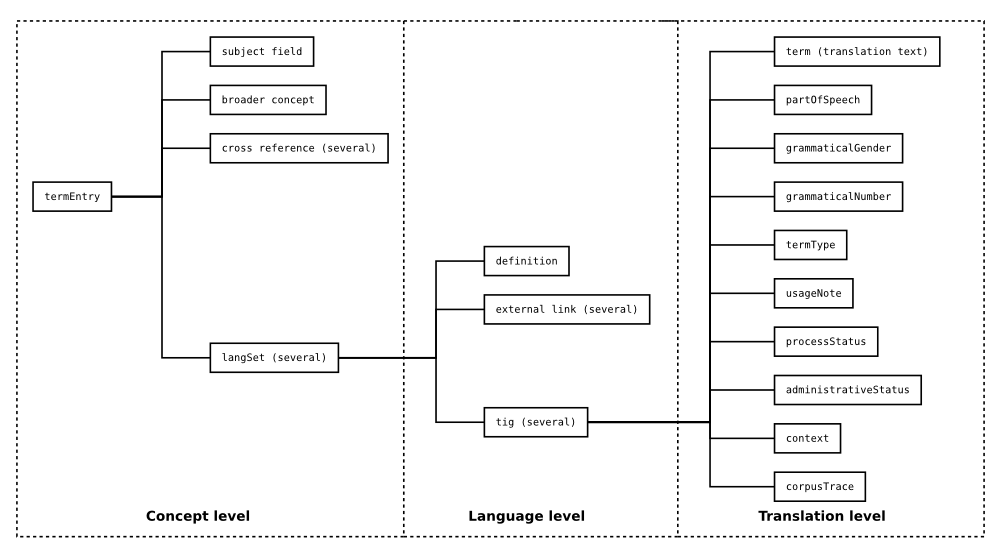
What for HTCDS is a standard (as a composition of words and definitions), in our case is a work break in concepts (as in concept-based translation, instead of term-based translation), that should have added explanations to aid translate differentiate ambiguous terms, then the final result could both be exported to create a glossary (like a PDF) or templated files where terms can be extracted back and generate something like a data schema or even scripts to convert data from one format to another. From the more "end user collaborator", what started with HTCDS 0.2, was this:
Every script is public domain and optimized to go from new terms to actionable scripts ready to be published at the speed needed in case of emergency response. This means, for example, if the same way new scripts/data schemas/documentations can be templated to new versions of something related to HTCDS, previous terminologies can be used to new implementations also related to humanitarian response.
There was one problem we empirically realized while doing technical translations around HTCDS 0.2 (that actually is reason why is harder to scale up translations, but since there is no one to do this, is unlikely this will even happen beyond English):
- This type of "translation" actually is a type of multilingual controlled vocabulary, which makes orders of magnitudes hard to bootstrap "translations" if initial concepts are not well planned (which, by the way, most fields based on Salesforce are beyond repair).2. And even if well planned, some terms are so new that this means introducing new terms to target languages (which makes step necessary as "provisional terms" years while actively publishing explanations on sites like Wiktionary and incentiving publication on traditional dictionaries). And, by "target language" this can even be English (like the case of decine how to break persons name)
Our point here is: serious terminological translation would need to also (as we did with software) allow glossary exportation for key terms and is inherently reusable. The HTCDS is actually just one of the items of our current Request For Feedback (https://docs.google.com/spreadsheets/d/1ysjiu_noghR1i9u0FWa3jSpk8kBq9Ezp95mqPLD9obE/edit#gid=846730778). We for example are aiming like the Lexicography of common terms used on COVID-19 data exchange (focus public data) (which also have other complaints like https://www.sciencediplomacy.org/article/2020/we-can-do-better-lessons-learned-data-sharing-in-covid-19-pandemic-can-inform-future).
2.2 Copyright over generic concepts are against promises needs to be done to volunteer translators/terminologist
Average person whilling to help not only are doing in good intent, but likely to actually either be a victim of human trafficking or know the real bad situation. Especially after this crisis of Afghanistan of interpreters left behind, I'm hearing a level so high of distrust that the bare minimum we can do for them is make sure things can be usable even assuming the current copyright holder will not be interested (or may be forced to DMCA down) their work.
Also, like I said earlier (about known issues with nomenclature that is flawed with common names in Latin America) translators are scared to the point that we have to rewrite the thing because it is beyond repair. Again: I'm not complaining about current people editing the HTCDS, because I know this is much more complicated. The point is that this would need much more help from outside and licensing is not clear enough if this already in next years will be "orphan work".
While we already were concerned with translation from HTCDS 0.2, we would like to point that even if IOM tries to go the fantastic reference, the standard UN M49 path, and have accredited translations to UN working languages, the Portuguese would not be one of them. That's one reason why I'm trying to make some workflow easier here.
This means that even if the current copyright holder of HTCDS tries it's best, we realistically would not have accredited translations like Hindi or Portuguese. This makes UN IOM announcing one standard while potentially denying (even if volunteers based, because of public interest) translations to, for example, Portuguese (like ISO organizations do), a threat to implement on countries like Angola, Brazil and Portugal. Remember: we're already stressed with ISO's way of "protecting" their standards, and saying out loud that current copyright holders don't have the infrastructure to have the Portuguese version is realistic.
I'm not complaining, I'm just saying that we here would need a higher threshold. But as is the interest from everyone, there is no need to make it harder. Remember: average people willing to help in these subjects really care about.
2.3 Copyright over generic concepts on multilingual controlled vocabularies are against other UN agencies, Red Cross, Amnesty, etc
Except for concepts too specific to human trafficking, a lot of concepts of one project (as in forms to exchange data) are usable between other organizations. Salesforce fields are not a good reference. Having multilingual controlled vocabularies very well reviewed with implementers for generic terms like person's name is a serious need for humanitarian organizations. The IOM lawyers clearly don't know how bad other humanitarian organizations need this in particular for private data. Or, again, be inspired by the failed ISO approach.
Organizations like Amnesty have interest in existence of standards on sharing police cases as a way to allow strategies like identify police torture.
Implementers (like the ones who give aid) even use biometry because something as simple as a person's name is not standardized, which makes private data storage likely to put a lot of pressure on few developers. This means software writing in English gets wrong data even when inserted by information managers reading people official identification cards which leads to no alternative but collect biometry that is known to be pressured to be shared even with governments that may target the person later.
I could cite so many examples here were the lack of authoritative terminology is a problem beyond human trafficking data exchange. But, again, the point here from the view of a lexicographer is to maximize usage/reuse of vocabulary and even if the best approach would donate translations to the organizations who actually can endorse it, I'm not even sure donate work to HTCDS will be allowed to be reused by other humanitarian organizations.
End comments
Since even after HTCDS 1.0 still no license (and no clarification on what to do beyond no response), we will keep the drafts under public domain. This makes it reusable in the middle of such confusion.
The people behind this data are not numbers. If the English-Speaking community is so accustomed with this to a point of not at least make easier to other languages, seriously, just do the paperwork. Age or experience don't make this type of thinking any good role model for people from other regions.