Hi.
I am new with DQL. I am working with AirSim simulator, and I coded an algorithm on Python on Visual Studio, using keras, to teatch to the drone to avoid obstacles. When I launched the train, the algorithm looks like to work normaly in the begining, but after iteration 400, 1300 or 2308 (it always changes) I have the following error that appear.
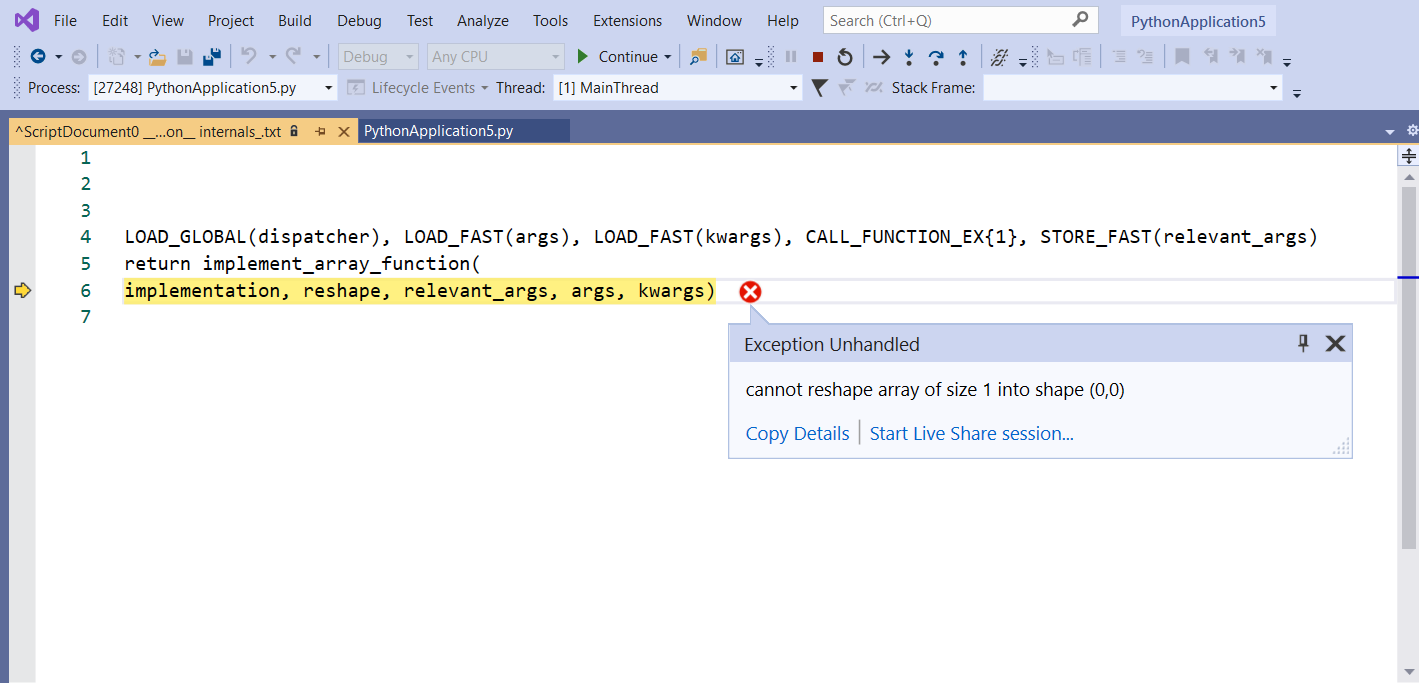
I used 'reshape' function only in 2 functions :


Here below is my full code.
`
import numpy as np
import airsim
import time
import math
import tensorflow as tf
import keras
from airsim.utils import to_eularian_angles
from airsim.utils import to_quaternion
from keras.layers import Conv2D,Dense
from keras.layers import Activation
from keras.layers import MaxPool2D
from keras.layers import Dropout
from keras.layers import Input
import keras.backend as K
from keras.models import load_model
from keras import Input
from keras.layers import Flatten
from keras.activations import softmax,elu,relu
from keras.optimizers import Adam
from keras.optimizers import adam
from keras.models import Sequential
from keras.optimizers import Adam, RMSprop
from keras.models import Model
#tf.compat.v1.disable_eager_execution()
import random
from collections import deque
client=airsim.MultirotorClient()
z=-5
memory_size=10000000
#pos_0=client.getMultirotorState().kinematics_estimated.position
#state_space=[84, 84]
#action_size=3
def OurModel(state_size,action_space):
X_input=Input(state_size,name='Input')
X=Conv2D(filters=32,kernel_size=(8,8),strides=(4,4),padding='valid',activation='relu')(X_input)
X=MaxPool2D(pool_size=(2,2))(X)
X=Conv2D(filters=64,kernel_size=(4,4),strides=(2,2),padding='valid',activation='relu')(X)
X=MaxPool2D(pool_size=(2,2))(X)
X=Conv2D(filters=64,kernel_size=(1,1),strides=(1,1),padding='valid',activation='relu')(X)
X=Flatten()(X)
X=Dense(525,activation='relu')(X)
X=Dense(300,activation='relu')(X)
X_output=Dense(action_space,activation='softmax')(X)
model=Model(inputs = X_input, outputs = X_output)
model.compile(loss="mse", optimizer=RMSprop(lr=0.0005, rho=0.95, epsilon=0.01), metrics=["accuracy"])
model.summary()
return model
class MemoryClass():
def init(self,memory_size):
self.memory_size=memory_size
self.buffer=deque(maxlen=memory_size)
self.batch_size=64
#self.start_training=20
def add(self,experience):
self.buffer.append(experience)
def sample(self):
buffer_size=len(self.buffer)
idx=np.random.choice(np.arange(buffer_size),self.batch_size,False)
return [self.buffer[k] for k in idx]
def replay(self):
batch=self.sample()
next_states_mb=np.array([each[0] for each in batch],ndmin=3)
actions_mb=np.array([each[1] for each in batch])
states_mb=np.array([each[2] for each in batch],ndmin=3)
rewards_mb=np.array([each[3] for each in batch])
dones_mb=np.array([each[4] for each in batch])
return next_states_mb, actions_mb, states_mb, rewards_mb,dones_mb
class Agent():
def init(self):
self.state_size=(84, 84,1)
self.action_space=3
#self.DQNNetwork=DQNN(state_size,action_space)
self.model1=OurModel(self.state_size,self.action_space)
self.memory_size=10000000
self.memory=MemoryClass(memory_size)
self.gamma=0.75
self.epsilon_min=0.001
self.epsilon=1.0
self.epsilon_decay=0.995
self.episodes=120
self.max_step=120
self.step=0
self.count=0
self.pos0=client.getMultirotorState().kinematics_estimated.position
self.z=-5
self.goal_pos=[50,50]
self.initial_position=[0,0]
self.initial_distance=np.sqrt((self.initial_position[0]-self.goal_pos[0])**2+(self.initial_position[1]-self.goal_pos[1])**2)
self.batch_size=30
def generate_state(self):
responses = client.simGetImages([airsim.ImageRequest("0", airsim.ImageType.DepthPerspective, True, False)])
img1d = np.array(responses[0].image_data_float, dtype=np.float)
#img1d = 255/np.maximum(np.ones(img1d.size), img1d)
img2d = np.reshape(img1d, (responses[0].height, responses[0].width))
from PIL import Image
image = Image.fromarray(img2d)
im_final = np.array(image.resize((84, 84)).convert('L'))
im_final=np.reshape(im_final,[*self.state_size])
return im_final
def load(self, name):
self.model1 = load_model(name)
def save(self, name):
self.model1.save(name)
def get_yaw(self):
quaternions=client.getMultirotorState().kinematics_estimated.orientation
a,b,yaw_rad=to_eularian_angles(quaternions)
yaw_deg=math.degrees(yaw_rad)
return yaw_deg,yaw_rad
def rotate_left(self):
client.moveByRollPitchYawrateZAsync(0,0,0.2,self.z,3)
n=int(3*5)
D=[]
done=False
for k in range(n):
collision=client.simGetCollisionInfo().has_collided
done=collision
D.append(collision)
time.sleep(3/(n*300))
if True in D:
done=True
time.sleep(3/300)
time.sleep(5/300)
new_state=self.generate_state()
return done,new_state
def rotate_right(self):
client.moveByRollPitchYawrateZAsync(0,0,-0.2,self.z,3)
n=int(3*5)
D=[]
done=False
for k in range(n):
collision=client.simGetCollisionInfo().has_collided
done=collision
D.append(collision)
time.sleep(3/(n*300))
if True in D:
done=True
time.sleep(3/300)
time.sleep(5/300)
new_state=self.generate_state()
return done,new_state
def move_forward(self):
yaw_deg,yaw_rad=self.get_yaw()
#need rad
vx=math.cos(yaw_rad)*0.25
vy=math.sin(yaw_rad)*0.25
client.moveByVelocityAsync(vx,vy,0,10,airsim.DrivetrainType.ForwardOnly,airsim.YawMode(False))
done=False
n=int(10*5)
D=[]
done=False
for k in range(n):
collision=client.simGetCollisionInfo().has_collided
D.append(collision)
time.sleep(3.4/(n*300))
if True in D:
done=True
new_state=self.generate_state()
time.sleep(15/300)
return done,new_state
def step_function(self,action):
# Returns action,new_state, done
# Move forward 3 meters by Pitch
done=False
if action==0:
done,new_state=self.move_forward()
# Rotate to right by 20 degress
elif action==1:
done,new_state=self.rotate_right()
# Rotate to left by 30 degress
elif action==2:
done,new_state=self.rotate_left()
self.count+=1
return action,new_state,done
def compute_reward(self,done):
reward=0.0
pos_now=client.getMultirotorState().kinematics_estimated.position
dist=np.sqrt((pos_now.x_val-self.goal_pos[0])**2+(pos_now.y_val-self.goal_pos[1])**2)
print('dist: ',dist)
if done==False and self.step<self.max_step:
reward+=(self.initial_distance-dist)*6
if 10<self.step<40 and dist>self.initial_distance*3/4:
reward=-2-(self.step-10)
elif 50<self.step<80 and dist>self.initial_distance*2/4:
reward=-36-(self.step-50)
elif 80<self.step<self.max_step and dist>self.initial_distance*1/4:
reward=-80-(self.step-80)
elif dist<3:
reward+=650.0
elif done==True and dist>3:
reward-=180.0
print('reward: ',reward)
return reward
def choose_action(self,state):
r=np.random.rand()
print('r: ',r)
print('epsilon: ',self.epsilon)
print()
if r>self.epsilon and self.count>64:
#print('predicted action')
state=np.reshape(state,[1,*self.state_size])
#action=np.argmax(self.DQNNetwork.OurModel.predict(state))
action=np.argmax(self.model1.predict(state))
else:
action=random.randrange(self.action_space)
return action
def reset(self):
client.reset()
def initial_pos(self):
client.enableApiControl(True)
v=0.6
#z0=client.getMultirotorState().kinematics_estimated.position.z_val
#t=np.abs(z0-self.z)/v
client.moveToZAsync(self.z,v).join()
#time.sleep(t+1)
def epsilon_policy(self):
# Update epsilon
if self.epsilon>self.epsilon_min:
self.epsilon*=self.epsilon_decay
def train(self):
for episode in range(self.episodes):
self.initial_pos()
self.step=0
state=self.generate_state()
done=False
total_reward,episode_rewards=[],[]
while self.step<self.max_step:
self.step+=1
print('count:', self.count)
choice=self.choose_action(state)
self.epsilon_policy()
action,next_state,done=self.step_function(choice)
reward=self.compute_reward(done)
episode_rewards.append(reward)
if done==True:
total_reward.append(sum(episode_rewards))
self.memory.add([next_state,action,state,reward,done])
self.step=self.max_step
self.reset()
print("episode: {}, epsilon: {:.5}, total reward :{}".format(episode, self.epsilon,total_reward[-1]))
self.save("airsim-dqn.h5")
else:
state=next_state
self.memory.add([next_state,action,state,reward,done])
if len(self.memory.buffer)>64:
next_states_mb, actions_mb, states_mb, rewards_mb,dones_mb=self.memory.replay()
target = self.model1.predict(states_mb)
target_next = self.model1.predict(next_states_mb)
for k in range(len(dones_mb)):
if dones_mb[k]==True:
target[k][actions_mb[k]] = rewards_mb[k]
elif dones_mb[k]==False:
target[k][actions_mb[k]] = rewards_mb[k] + self.gamma * (np.amax(target_next[k]))
self.model1.fit(x=states_mb,y=target,batch_size=self.batch_size)
agent=Agent()
agent.train()
`


















































































































































































































