trevphil / cryptosym Goto Github PK
View Code? Open in Web Editor NEWSAT-based, MILP, and belief propagation preimage attacks on SHA-256 and other cryptographic hash functions
SAT-based, MILP, and belief propagation preimage attacks on SHA-256 and other cryptographic hash functions
I think there are some important random variables which are not being captured in the internals, holding back LBP from converging. Look at algo more closely.
Not working:
Working:
What do the ones that don't work have in common? The AND gate inputs are the same random variable
Fix:
It's a hack, but if the same RV goes into an AND gate as both inputs, create a child RV from the original RV and feed the original and the child into the AND gate. However this introduces a small loop in the undirected graph which may cause issues with LBP convergence.
With the final 32 out of 512 input bits unknown, LBP can correctly get the SHA-256 at level 15 difficulty with only 2 LBP iterations.
But the Bayesian network is NOT acyclic (not a polytree) since we need to consider cycles in the undirected version of the BN. If it was acyclic, 2 iterations would be enough and everything would converge to the true marginals.
If bits which are close to the hash are predicted very accurately, you can potentially "freeze" them as observed variables, then re-run BP and keep doing this. No, if bits near the hash could take either 0 or 1 based on their constraints (children bits), you would need to track both hypotheses for upstream.
Try this one: https://bitbucket.org/pypy/pypy/src/tip/lib_pypy/_sha256.py
Current version doesn't work with < 512 bits
Can possibly use GTSAM with DCS to identify graph topology and perform inference?
Try to derive LBP in the log domain, on your own. Because messages often diverge to inf and 1e-70.
It's not necessary to calculate separately for 00, 01, 10, and 11. The results of 11 can bootstrap the others.
It's not symmetric for 01 and 10 cases. Is it a bug?
See how LLR for each node changes as the LBP algorithm runs. Maybe it gives an insight about convergence
./experiments for each run and log the graphML files to that, as well as output logsProbs won't work but you can give it a shot (MCMC, Gibbs sampling)
1 round is already working, but not 2.
Graph pruning algorithm is shit right now. Look more into graph sparsening/roughening.
The AND gate does not seem to work for either GTSAM or LBP.
Additionally for LBP, the initialization of factor/RV messages for observed RVs needs to be double-checked.
DiscreteBayesNet). Can use PyMC3.Love your work here. Exactly the kind of stuff I find fascinating to obsess about even that it's "impossible" to solve.
You wrote,
Something happens in the 17th round that causes a major spike in complexity. My best guess is that an AND gate between bits "very far apart" in the computation is the issue. If you look at the maximum distance between the indices of random variable bits which are inputs to an AND gate, the maximum gap is around 126,000 bits apart up to 16 rounds. At 17 rounds, the gap increases to 197,000 bits. For a SAT solver, this could mean that it doesn't detect an invalid variable assignment until values have been propagated a long way. For the full 64-round SHA-256, the maximum gap is 386,767.
This sounds plausible to me, and I'd just like to, as someone who knows very little about this subject but is curious enough to think about it a little, propose a mechanism for this.
In the first 16 rounds the SHA-256 algorithm is still just ingesting straight words from the message. At each round it takes the next word from the unmodified input message.
If you were to look at the equation for each internal bit variable it would be almost entirely linear. The only source of non-linearity comes from CH and MAJ in the compression function but since they only affect 2 words per round it's like that non-linearity as a function of the input is spreading only very "slowly" through the internal state. Like you wrote, the "distance" between significant AND gates is still small.
(Side note: in your case since you convert XOR to AND, I guess there's actually a bunch of additional apparent non-linearity in the equations you feed to the SAT solver, but it's "fake" non-linearity, in some sense, which especially CryptoMiniSat just might "see through" since it wants to use its hallmark Jordan Gauss elimination.)
Then look at what happens at round 17: we take the first word from the message schedule that wasn't a straight copy from the input message. It mixes bits from 4 different input words using rotations and 32 bit addition. At the boolean bit vector level we now have true non-linearity from the input since we have to use AND gates to implement that carry flag. And it's "long distance" since word 17 mixes in input all the way back from the 1st word.
So that's my take on the complexity explosion. (I could be completely wrong, something about hashing functions just is so inherently unintuitive to me I keep catching myself believing they can't actually work at all. It's like... they have to be reversible, right? Just haven't seen the trick.)
Try normal CPD then remove 1, 2, 3... edges randomly until a valid probability is found
Given the fully connected graph as an adjacency matrix, how to efficiently prune the graph to get a good Bayesian network structure?
There should be a maximum number of neighbors for each node.
Linear algebra will probably give the best solution. Look into eigenvectors/eigenvalues of the adjacency matrix and properties of the Laplacian matrix.
For example, with the noisy-OR model.
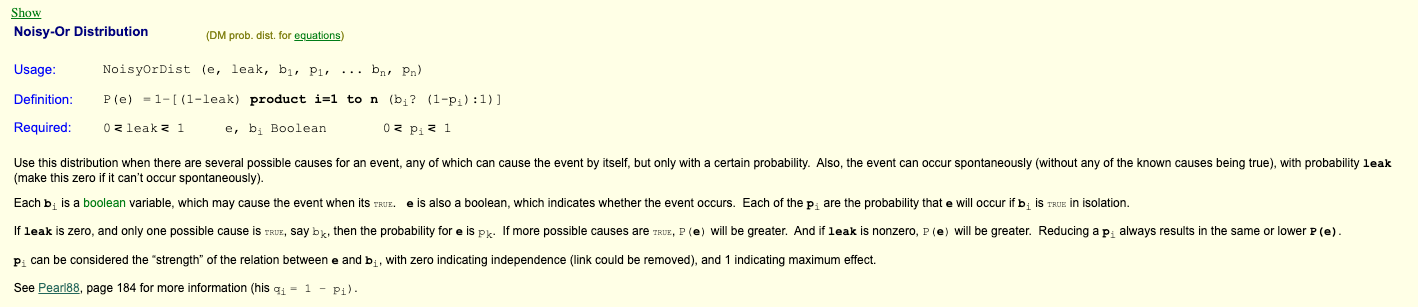
Try normal CPD then remove 1, 2, 3... edges randomly until a valid probability is found
This project and readme is impressive! Wondering if you could consider adding either MIT, Apache 2.0, or GNU GPLv3? This would give users permissions to run the code locally, make modifications on their local machine, and if something is interesting is discovered, contribution a pull request upstream. Thanks for considering this issue!
Add config YAML file for each dataset so that information does not have to be derived from the filename
This should also enable me to remove HASH_INPUT_NBITS from main.py
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.