Warning
This script has been superseded by my new extension, Unprompted, which has the same powerful masking features and a lot more. I do not plan on updating the original script and I cannot guarantee that it will continue working in new versions of the A1111 WebUI. Thank you for understanding.
Automatically create masks for inpainting with Stable Diffusion using natural language.
txt2mask is an addon for AUTOMATIC1111's Stable Diffusion Web UI that allows you to enter a text string in img2img mode which automatically creates an image mask. It is powered by clipseg. No more messing around with that tempermental brush tool. 😅
This script is still under active development.
Simply clone or download this repo and place the files in the base directory of Automatic's web UI.
From the img2img screen, select txt2mask as your active script:

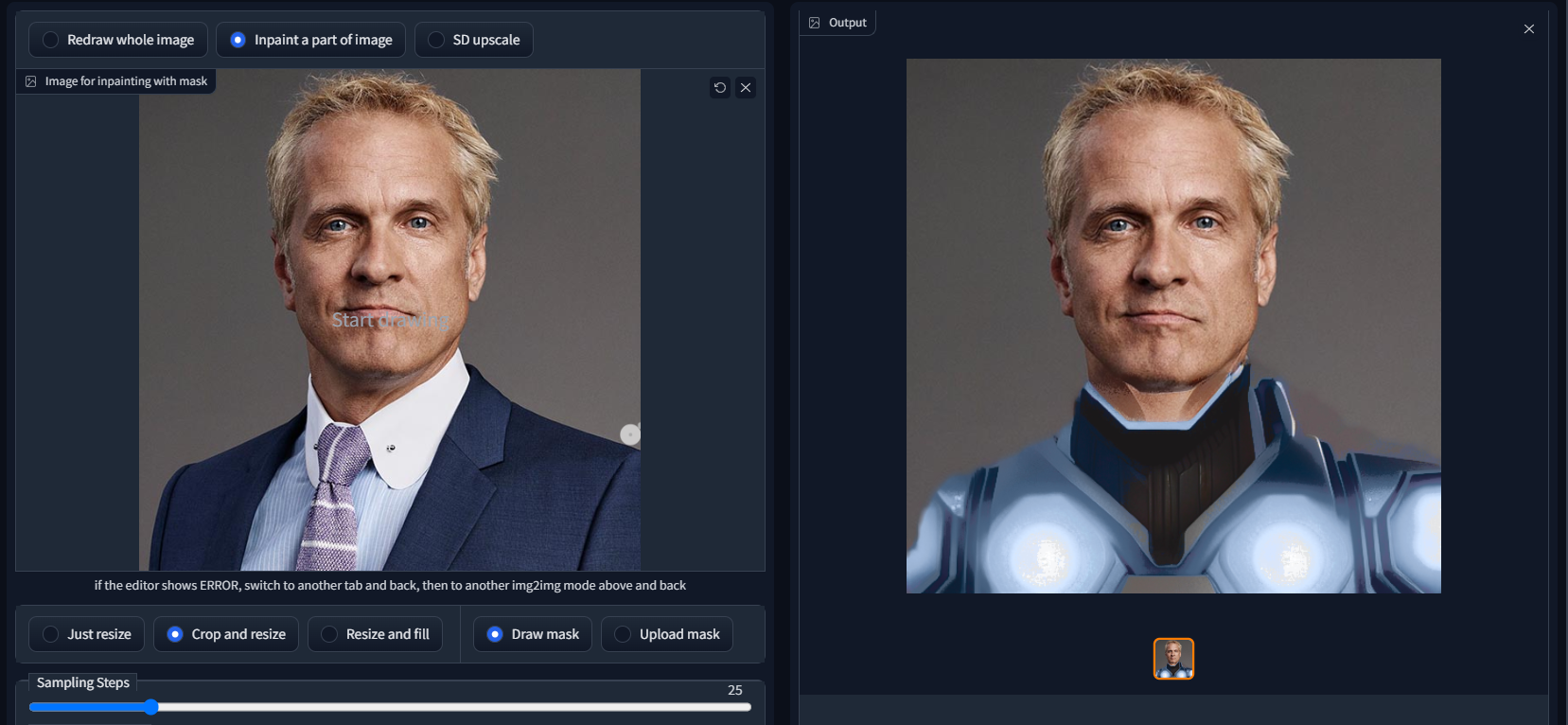
In the Mask Prompt field, enter the text to search for within your image. (In the case of the topmost screenshot, this value would be 'business suit' and the prompt box at the top of your UI would say 'sci-fi battle suit.')
Adjust the Mask Precision field to increase or decrease the confidence of that which is masked. Lowering this value too much means it may select more than you intend.
Press Generate. That's it!
- The Mask Prompt allows you to search for multiple objects by using
|as a delimiter. For example, if you entera face|a tree|a flowerthen clipseg will process these three items independently and stack the resulting submasks into one final mask. This will likely yield a better result than had you searched fora face and a tree and a flower. - You can use the
Mask Paddingoption to increase the boundaries of your selection. For example, if you entera red shirtas your prompt but find that it's not quite selecting the whole shirt, andMask Precisionisn't helping, then padding may be a good way to address the issue. - Use the
Negative mask promptto subtract from areas selected byMask prompt. For example, if your prompt isa faceand the negative prompt iseyesthen the resulting mask will select a face without selecting the eyes. - (NEW) You can combine your text mask with the brush tool or uploaded image mask using the
Brush mask modesetting. Get the best of both worlds. - In general, less is more for masking: instead of trying to mask "a one-armed man doing a backflip off a barn" you will probably have more luck writing "a man."




















































































































