
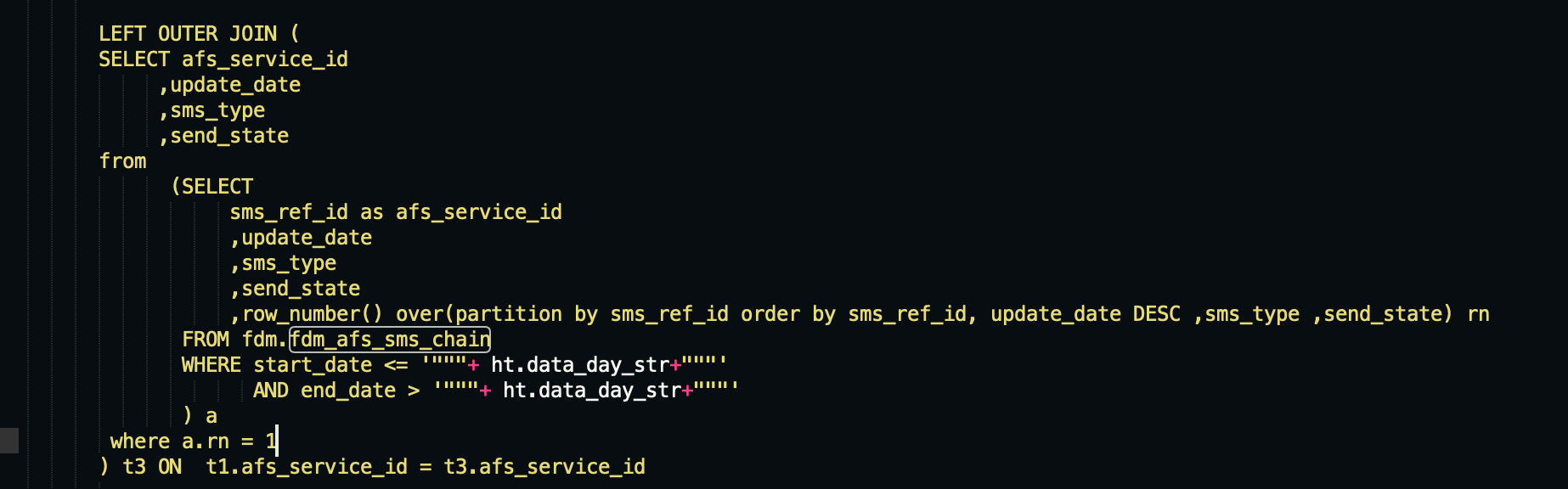
注意:一般start_date和end_date为同一天,离线任务一天跑一次,一天归档一次,这样能保证都是最新的一条记录。
1.Hive是一个数据仓库
2.Hive基于Hadoop
总结为一句话:hive是基于hadoop的数据仓库。
https://blog.csdn.net/scgaliguodong123_/article/details/60135385
https://blog.csdn.net/qq_31807385/article/details/84777349
取top n:
- hive中的排序函数
- row_number()
-- 去重
select * ,row_number() over(partition by sale_ord_id order by last_update_tm desc) as rn from gdm.gdm_m04_ord_sum where dp='ACTIVE' and to_date(last_update_tm)>=sysdate(-7) ) t where rn=1-
rank()
-
dense_rank()
rank()、dense_rank()、row_number()区别
rank()、dense_rank()有并列值,rank()跳过并列值排序,dense_rank()不跳过
rank()就是排序 相同的排序是一样的,但是下一个小的会跳着排序,比如 等级 排序 23 1 23 1 22 3
dense_rank()相同的排序相同,下一个小的会紧挨着排序,比如 等级 排序 23 1 23 1 22 2 这样总个数是相对减少的,适合求某些指标前几个等级的个数。
row_number()就很简单,顺序排序。比如 等级 排序 23 1 23 2 22 3 这种排序 总个数是不变的,适合求某些值的前几名。
-
不使用group by实现按组计算年龄平均值
-- 建表 -- 学生表 CREATE TABLE `student`( `sno` string, `sname` string, `ssex` string, `sage` int, `sdept` string) -- 使用group by select avg(sage),ssex from student group by ssex; -- 使用窗口函数over() select sno,sname,avg(sage) over(partition by ssex) avg_age,ssex from student order by sno; -- 总结 使用窗口函数可以在select后选择想要显示的字段
ORDER BY 全局排序,只有一个Reduce任务
SORT BY 只在本机做排序
-
hive中的注释
--
("#","/**/")不能用
-
if函数
语法: if(boolean testCondition, T valueTrue, T valueFalseOrNull)
返回值: T
说明: 当条件testCondition为TRUE时,返回valueTrue;否则返回valueFalseOrNull
// if语句相当于三目运算符,注意:等价于用单等号'='和双等号'=='都可以
hive> select if(1<2,100,200);
OK
_c0
100
Time taken: 0.127 seconds, Fetched: 1 row(s)
// 单等号'='
hive> select if(1=1,100,200);
OK
_c0
100
Time taken: 0.111 seconds, Fetched: 1 row(s)
// 双等号'=='
hive> select if(1==1,100,200);
OK
_c0
100
Time taken: 0.274 seconds, Fetched: 1 row(s)
- 非空查找函数: COALESCE
语法: COALESCE(T v1, T v2, …)
返回值: T
说明: 返回参数中的第一个非空值(不为NULL);如果所有值都为NULL,那么返回NULL
hive> select coalesce(null,'Z');
OK
_c0
Z
Time taken: 0.189 seconds, Fetched: 1 row(s)-
CASE a WHEN b THEN b' [WHEN c THEN c'][ELSE d] END
注意:和java中的switch case差不多
如果a等于b b'
如果a等于c c‘
如果a既不等于a又不等于b d
hive> select case 1 when 1 then 1 end; OK _c0 1 Time taken: 0.074 seconds, Fetched: 1 row(s) hive> select case 5 when 1 then 1 when 2 then 2 else 3 end; OK _c0 3 Time taken: 0.096 seconds, Fetched: 1 row(s)
-
CASE WHEN a THEN a' [WHEN c THEN c']* [ELSE d] END
相当于多层if...else 嵌套
hive> select case when 90<60 then 'unqualified' when 90>60 then 'qualified' end; OK _c0 qualified Time taken: 0.206 seconds, Fetched: 1 row(s)
-
hive中提供了两种针对json数据格式解析的函数,即get_json_object(…)与json_tuple(…)
-- get_json_object() -- 建表 create external table test_get_json_object (id string, content string ) ; -- 插入数据 //注意json格式外部的引号用双引号会报错 insert into test_get_json_object values(1,'{"name":"zhangsan","age":24}'); -- 查询 select * from test_get_json_object; -- 利用get_json_object()解析json格式 select id,get_json_object(content,'$.name') from test_get_json_object;
-
Hive的一些参数设置
-
Hive多表插入
Hive支持多表插入,可以在同一个查询中使用多个insert子句,这样的好处是我们只需要扫描一遍源表就可以生成多个不相交的输出!
语法
-- from ...... insert ...... insert ...... -
Hive排除查询字段
select `(name|id|pwd)?+.+` from tableName;
-
Hive regexp_replace函数
-- ware_ids字段:[{"skuid":"100273","skunum":1}] -- regexp_replace(string INITIAL_STRING, string PATTERN, string REPLACEMENT) select id ,get_json_object( regexp_replace(regexp_replace(ware_ids,'\\[','') ,'\\]',''),'$.skuid') skuid ,get_json_object( regexp_replace(regexp_replace(ware_ids,'\\[','') ,'\\]',''),'$.skunum') skunum from fdm.fdm_refundfc_refund_major_chain where dp='ACTIVE' and ware_ids <> '' limit 10
-
统计某个字段大于2条的记录
-- 第一种,嵌套查询 select * from ( select ref_id,count(ref_id) ref_id_count from fdm.fdm_refundfc_refund_detail_chain where dp = 'ACTIVE' and pay_type in(31, 32, 33, 34, 35, 36, 39, 38) group by ref_id )b where b.ref_id_count > 2; -- 第二种,group by ... having ... select ref_id, count(ref_id) ref_id_count from fdm.fdm_refundfc_refund_detail_chain where dp = 'ACTIVE' and pay_type in(31, 32, 33, 34, 35, 36, 39, 38) group by ref_id having ref_id_count > 2
-
group by 后面多个字段
-- group by后出现多个字段会现在找字段1分组,再按照字段2分组 -
select后边的别名是否能在where、groupby、having、orderby后出现的问题
-- 建表 -- 学生表 CREATE TABLE `student`( `sno` string, `sname` string, `ssex` string, `sage` int, `sdept` string) -- where 后的age不识别 -- 查询年龄大于18岁的学生 -- 错误 Invalid table alias or column reference 'age': (possible column names are: sno, sname, ssex, sage, sdept) -- sage 别名 age select sno,sname,ssex,sage age,sdept from student where age>18; -- group by后age不识别 select sage age from student group by age -- having后的sex识别 select avg(sage),ssex sex from student group by ssex having sex='F';
参考:
SQL语句的语法顺序:
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> DISTINCT -> UNION -> ORDER BY因此一般不能在having condition中使用select list中的alias。
但是mysql对此作了扩展。在mysql 5.7.5之前的版本,ONLY_FULL_GROUP_BY sql mode默认不开启。在5.7.5或之后的版本默认开启。
如果ONLY_FULL_GROUP_BY sql mode不开启,那么mysql对标准SQL的扩展可以生效:
- 允许在select list、having condition和order by list中使用没有出现在group by list中的字段。此时mysql会随机选择没有出现在group by list中的字段的值。效果和使用ANY_VALUE()是相同的。
- 允许在having condition中使用select list中的alias
-
group by后面没有出现的字段能否出现在select后
-- 建表 CREATE TABLE `student`( `sno` string, `sname` string, `ssex` string, `sage` int, `sdept` string) -- 按性别统计平均年龄 -- 正确 select avg(sage),ssex from student group by ssex; -- 错误 Expression not in GROUP BY key 'sno' select sno,avg(sage),ssex from student group by ssex; -- 总结 只有在group by后出现的字段才能出现在select后,或者没在group by后出现的字段在聚合函数中
-
查看数据库
show databases; -
查看表
show tables; -
join、outer join、full join、left join、right join、left outer join,right outer join
-- join 笛卡尔积 相同类会保留 -- 会有两列sno,可以用student.sno,sc.sno分别访问 select * from student join sc on student.sno = sc.sno;
-
union、union all
-
explode()函数
-- explode() -- 注意:explode不能写在别的函数内 -- 建表 create external table test_get_json_object (id string, content string ) ; -- 插入数据 //注意json格式外部的引号用双引号会报错 insert into test_get_json_object values(1,'{"name":"zhangsan","age":24}'); insert into test_get_json_object values(2,'{"name":"lisi","age":25}'); insert into test_get_json_object values(3,'[{"name":"zhao","age":66},{"name":"qian","age":88}]') -- 查询 select * from test_get_json_object; ----------------------------------------------------------------------------------- ----------------------------------------------------------------------------------- -- 利用get_json_object()解析json格式 一行转多列 select id,get_json_object(content,'$.name') from test_get_json_object; -- 结果:zhangsan -- 利用json_tuple()解析json格式,一行转多列 select json_tuple(content,'name','age')as (name,age) from test_get_json_object ----------------------------------------------------------------------------------- ----------------------------------------------------------------------------------- -- explode(ARRAY<T> a) -- explode(MAP<Tkey,Tvalue> m) -- eg select explode(array('A','B','C')) as col; -- col -- A -- B -- C select explode(map('A',10,'B',20,'C',30)) as (key,value); -- key value -- A 10 -- B 20 -- C 30 ----------------------------------------------------------------------------------- ----------------------------------------------------------------------------------- -- explode将json转换为键值对,借助regexp_replace()函数 -- json数据:{"name":"zhangsan","age":24} -- 解析后:"name":"zhangsan","age":24 select regexp_replace(content,'\\{','') from test_get_json_object; select regexp_replace(regexp_replace(content,'\\{',''),'\\}','') from test_get_json_object; ----------------------------------------------------------------------------------- ----------------------------------------------------------------------------------- -- split()函数 -- 将字符串用分隔符切分成数组 "xiang,wo,zhe,yang,ren" -> ["xiang","wo","zhe","yang","ren"] select split("xiang,wo,zhe,yang,ren",",") ----------------------------------------------------------------------------------- ----------------------------------------------------------------------------------- -- regexp+split -- json数据:{"name":"zhangsan","age":24} -- 解析后:["\"name\":\"zhangsan\"","\"age\":24"] select split(regexp_replace(regexp_replace(content,'\\{',''),'\\}',''),',') from test_get_json_object; ----------------------------------------------------------------------------------- ----------------------------------------------------------------------------------- -- explode+regexp+split 将json{"name":"zhangsan","age":24}转换为键值对 select explode(split(regexp_replace(regexp_replace(content,'\\{',''),'\\}',''),',')) from test_get_json_object; -- 转换后 -- col -- "name":"zhangsan" -- "age":24 ----------------------------------------------------------------------------------- ----------------------------------------------------------------------------------- -- 我们还想把转换后的键值对的建和值分别作为一列,这里设计了 -- name age -- zhangsan 24
-
lateral view
SELECT id, col2 FROM test_get_json_object LATERAL VIEW explode(array(1,2,3,4)) myTable1 AS col2;
id col1 1 1 1 2 1 3 1 4 -- 以下两种写法都可以 select id,name,age from test_get_json_object lateral view json_tuple(content,'name') table1 as name lateral view json_tuple(content,'age') table2 as age select id,name,age from test_get_json_object a lateral view json_tuple(a.content, 'name','age') b as name, age;
id name age 1 zhangsan 24 2 lisi 25 -
hive解析json数据日志

