
TNN: A high-performance, lightweight neural network inference framework open sourced by Tencent Youtu Lab. It also has many outstanding advantages such as cross-platform, high performance, model compression, and code tailoring. The TNN framework further strengthens the support and performance optimization of mobile devices on the basis of the original Rapidnet and ncnn frameworks. At the same time, it refers to the high performance and good scalability characteristics of the industry's mainstream open source frameworks, and expands the support for X86 and NV GPUs. On the mobile phone, TNN has been used by many applications such as mobile QQ, weishi, and Pitu. As a basic acceleration framework for Tencent Cloud AI, TNN has provided acceleration support for the implementation of many businesses. Everyone is welcome to participate in the collaborative construction to promote the further improvement of the TNN inference framework.
| Face Detection(blazeface) | Face Alignment (from Tencent Youtu Lab) |
Hair Segmentation (from Tencent Guangying Lab) |
|---|---|---|
 model link: tflite tnn |
 model link: tnn |
 model link: tnn |
| Pose Estimation (from Tencent Guangliu) |
Pose Estimation (blazepose) |
Chinese OCR |
|---|---|---|
 model link: tnn |
 model link: tflite tnn |
 model link: onnx tnn |
| Object Detection(yolov5s) | Object Detection(MobilenetV2-SSD) | Reading Comprehension |
|---|---|---|
 model link: onnx tnn |
 model link: tensorflow tnn |
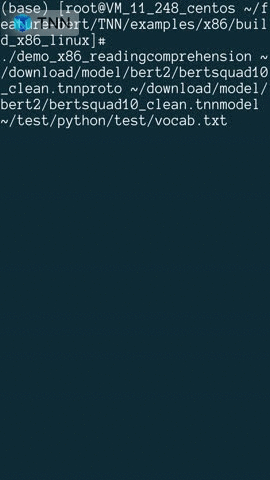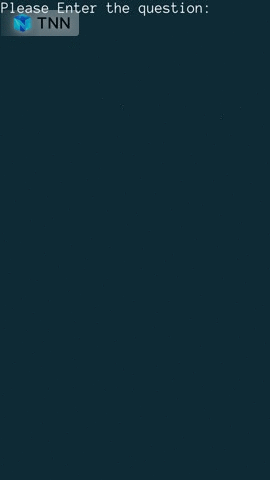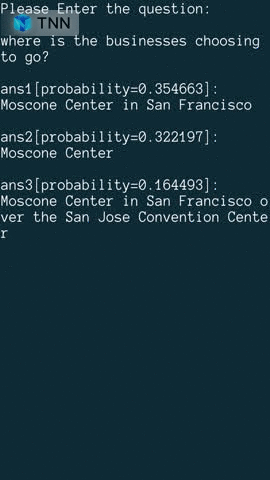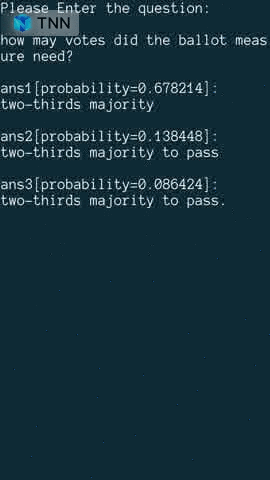 model link: onnx tnn |
Chinese OCR demo is the TNN implementation of chineseocr_lite project. It is lightweight and supports tilted, rotated and vertical text recognition.
The support for each demo is shown in the following table. You can click the ✅ and find the entrance code for each demo.
| demo | ARM | OpenCL | Metal | Huawei NPU | Apple NPU | X86 | CUDA |
|---|---|---|---|---|---|---|---|
| Face Detection (blazeface) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Object Detection (yolov5s) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Face Alignment | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Hair Segmentation | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Pose Estimation (from Tencent Guangliu) |
✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Pose Estimation (blazepose) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Chinese OCR | ✅ | ✅ | ✅ | ✅ | ✅ | ||
| Reading Comprehension | ✅ | ✅ |
It is very simple to use TNN. If you have a trained model, the model can be deployed on the target platform through three steps.
-
Convert the trained model into a TNN model. We provide a wealth of tools to help you complete this step, whether you are using Tensorflow, Pytorch, or Caffe, you can easily complete the conversion. Detailed hands-on tutorials can be found here How to Create a TNN Model.
-
When you have finished converting the model, the second step is to compile the TNN engine of the target platform. You can choose among different acceleration solutions such as ARM/OpenCL/Metal/NPU/X86/CUDA according to the hardware support. For these platforms, TNN provides convenient one-click scripts to compile. For detailed steps, please refer to How to Compile TNN.
-
The final step is to use the compiled TNN engine for inference. You can make program calls to TNN inside your application. We provide a rich and detailed demo as a reference to help you complete.
At present, TNN has been launched in various major businesses, and its following characteristics have been widely praised.
-
Computation optimization
- The backend operators are primely optimized to make the best use of computing power in different architectures, regarding instruction issue, throughput, delay, cache bandwidth, cache delay, registers, etc..
- The TNN performance on mainstream hardware platforms (CPU: ARMv7, ARMv8, X86, GPU: Mali, Adreno, Apple, NV GPU, NPU) has been greatly tuned and improved.
- The convolution function is implemented by various algorithms such as Winograd, Tile-GEMM, Direct Conv, etc., to ensure efficiency under different parameters and sizes.
- Op fusion: TNN can do offline analysis of network graph, fuse multiple simple operations and reduce overhead such as redundant memory access and kernel startup cost.
-
Low precision computation acceleration
- TNN supports INT8/FP16 mode, reduces model size & memory consumption, and utilizes specific hardware low-precision instructions to accelerate calculations.
- TNN supports INT8 WINOGRAD algorithm, (input 6bit), further reduces the model calculation complexity without sacrificing the accuracy.
- TNN supports mixed-precision data in one model, speeding up the model's calculation speed while preserving its accuracy.
-
Memory optimization
- Efficient "memory pool" implementation: Based on a full network DAG analysis, the implementation reuses memory between non-dependent nodes which reduces memory cost by 90%.
- Cross-model memory reduces: This supports external real-time design for network memory so that multiple models can share mutual memory.
-
The performance of mainstream models on TNN: benchmark data
-
TNN architecture diagram:

-
TNN supports TensorFlow, Pytorch, MxNet, Caffe, and other training frameworks through ONNX, leveraging the continuous improvement of the ONNX open-source society. Currently, TNN supports 100+ ONNX operators, consisting of most of the mainstream CNN, NLP operators needed.
-
TNN runs on mainstream operating systems (Android, iOS, embedded Linux, Windows, Linux), and is compatible with ARM CPU,X86 GPU, NPU hardware platform.
-
TNN is constructed through Modular Design, which abstracts and isolates components such as model analysis, graph construction, graph optimization, low-level hardware adaptation, and high-performance kernel. It uses "Factory Mode" to register and build devices, that tries to minimize the cost of supporting more hardware and acceleration solutions.
-
The size of the mobile dynamic library is only around 400KB, and it provides basic image conversion operations, which are light-weight and convenient. TNN uses unified models and interfaces across platforms and can switch easily by configuring just one single parameter.
TNN referenced the following projects:
-
Everyone is welcome to participate to build the best inference framework in the industry.
-
Technical Discussion QQ Group: 704900079 Answer: TNN
-
Scan the QR code to join the TNN discussion group:



























































































































































































































