taolei87 / rcnn Goto Github PK
View Code? Open in Web Editor NEWRecurrent & convolutional neural network modules
License: Apache License 2.0
Recurrent & convolutional neural network modules
License: Apache License 2.0


























































































































Hi. In the code/sentiment section, it is mentioned to run below command. However, there is only one main.py in the directory, there is no model.py. Does main.py does the job?
python model.py --embedding word_vectors/stsa.glove.840B.d300.txt.gz \ --train data/stsa.binary.phrases.train \ --dev data/stsa.binary.dev --test data/stsa.binary.test \ --save output_model
In evaluating the rationale, the code prints values like what is shown below:
rationale mser=0.0341 p[1]r=0.65 prec1=0.1381 prec2=0.1367
What is p[1]r, prec1 and prec2 here? Is it described somewhere?
Looking through the code I don't see where you're producing the text files contained in the example_rationales directory.
Can you point me toward how those files are produced?
Hi Tao Lei,
Recently I was trying to develop a Lucene based BM25 baseline method using the Askubunbtu dataset you provided. While writing the indexwriter I used title+body from all the 167765 questions and while testing I searched for title+body for all the 189 queries (11 queries have no similar questions). The indexsearcher similarity I set as BM25similarity in Apache Lucene 6.1.0. I have used all Lucene settings as default apart from the analyzer (EnglishAnalyzer).
But the problem is: I am getting a MAP value of around 0.11 which is not at all comparable to the performance you mentioned for BM25. Hence, I feel that somewhere I am missing some steps. Can you please help me in that issue?
Congratulation for your results! I really enjoyed your method :)
I wonder if somehow it would be possible to try rcnn on the medical dataset? Shall I ask some to get the data?
Thank you!
Thanks.
Some questions on data:
reviewsx... files, for beer reviews, is laid out as follows?[look] [smell] [feel] [taste] [overall] [input words ...]
? (I used the values for the 'deep brown color with a thin tan head that quickly dissipated' review, to obtain this sequence, by comparison with the page at https://www.beeradvocate.com/beer/profile/144/30806/?ba=Will_Turner , and the numbers in the dataset)
[look]?[smell]?, and[feel]?Hi,
I tried to train a model using rationale.py on a small dataset (with not rationale 'gold data'). It seems that the model is able to learn, and the loss decreases from one epoch to another. However, when the training ended the model wasn't saved and I wasn't able to use it.
How can I save the model? and how can it be loaded and used to classify new documents?
The command I use to train the model is:
python rationale\rationale.py --embedding --train --dev --save_model model.pkl.gz --batch 50
Thanks,
Shai
Hello!
I have implemented the rationalizing neural prediction dependent model in Tensorflow. It works for the most part. It manages to create some rationalisations and its losses decrease at about the same rate as yours do.
However after about 20 iterations (depending on the Seed) it suddenly only predicts 0 for z, causing the MSE to become a NaN, and other errors to become -inf, 0 or Nan as well. My guess is that this is either due to exploding gradients, or because, that is the easiest way the model can decrease the loss, by setting its regularizers lambda_1 and lambda_2 to 0. Since I have already tried gradient clipping, I doubt it is exploding gradients. So its probably that it learns to set regularizers to 0. Did you have to deal with this during your theano experiments?
kind regards,
Riaan
PS: I have the code on my Github account: https://github.com/RiaanZoetmulder/Master-Thesis/tree/master/step_one
Hi, taolei,
I am trying to use the code in "pt" and "qa" to train and finetune your rcnn model. Firstly, I use your pt code to pretrain your rcnn model. I set the hidden-dim =200 , the other arguments are set as you suggest. The pertrained model is saved in model.pkl.gz.pkl.gz and its gunzip file size is 1.3M. So I want to ask whether the file size of the pretrained model is reasonable?
When I use the pretrained model to finetune your rcnn model, that is I ues the code in "qa" to finetune rcnn model with the pretrained model. The get the following message:
0 empty titles ignored.
100406 pre-trained embeddings loaded.
vocab size=100408, corpus size=167765
/usr/lib64/python2.7/site-packages/numpy/core/fromnumeric.py:2652: VisibleDeprecationWarning: rank is deprecated; use the ndim attribute or function instead. To find the rank of a matrix see numpy.linalg.matrix_rank.
VisibleDeprecationWarning)
23.4045739174 to create batches
315 batches, 35312679 tokens in total, 360602 triples in total
h_title dtype: float64
h_avg_title dtype: float64
h_final dtype: float64
num of parameters: 160400
p_norm: ['nan', 'nan', 'nan', 'nan', 'nan']
The question is "p_norm:['nan', 'nan', 'nan', 'nan', 'nan']". The p_norm result is "nan". Here, the only difference is that I set hidden-dim = 200, the other arguments are set as you suggest. So could you tell me the reason that the p_norm result is "nan". I see your code, but I still can figure out the probelm. Look forward to your help. Thank you very much.
Hi Taolei,
First of all, thank you for the awesome code. It's really helpful.
However when I tried to use it I was confused about the condition statement in LSTM and GRU model.
In the forward_all() function, the input 'x' is a (n x d) matrix or a (batch x n x d) tensor, so x.ndim is always equal to/larger than 2, isn't it?
On the other hand, when x.ndim == 1, it seems that it's impossible for forward_all() function to scan forward() function, if n_in != 1.
I'm not sure if I have misunderstood the model.
In my opinion, x.ndim is 2 when x is a matrix, and 3 when x is a tensor. So I wonder if the condition statement in these two models should be 'x.ndim > 2', does it?
I'm not so good at English and I hope I had described it clearly.
Thank you.
Hi @taolei87 . I am running your sentiment classification code. I used the dataset that was specified in the description. However, I am getting this error. First, I ran the code on my own train/dev/test sets and got the error. Then I tried your dataset and got the same issue. Do you have any idea of what is wrong. I am not changing anything in the code.
Traceback (most recent call last): File "main.py", line 539, in <module> main(args) File "main.py", line 394, in main embs = load_embedding_iterator(args.embedding) File "\rcnn-master\rcnn-master\code1\nn\basic.py", line 220, in __init__ for word, vector in embs: File "\rcnn-master\rcnn-master\code1\utils\__init__.py", line 14, in load_embedding_iterator for line in fin: File "\anaconda3\envs\py3\lib\encodings\cp1252.py", line 23, in decode return codecs.charmap_decode(input,self.errors,decoding_table)[0] UnicodeDecodeError: 'charmap' codec can't decode byte 0x9d in position 2776: character maps to <undefined>
The command that I ran:
python main.py --embedding glove.6B.100d.txt --train stsa.binary.phrases.train --dev stsa.binary.dev --test stsa.binary.test --save output_model
Hey Tao,
I am trying to implement your rationale model in pytorch right now and I keep running into the problem, that after a couple iterations z becomes all one's. This obviously makes the encoder quite strong but does not do what I want.
The generator's loss function is cost(x,y,z) * logp(z|x). While the first term is large, logpz becomes all zeros (since the model learns to predict all ones with 100% prob and log(1) = 0). Therefore, the overall loss (and derivative) for the generator becomes zero, leading to this all one's phenomenon.
How did you address this in your code?
Hi @taolei87 ,
I would like to run the code in qa/api.py to see how the model ranks instances.
I used:
myqrapi = QRAPI(
<model_path>,
<corpus_path>,
<emb_path>
)
results = myqrapi.rank(
{
"query": "why does n't ubuntu 12.04 upgrade libreoffice , as firefox ? i use ubuntu 12.04 in a machine for working , and do n't know why libreoffice does n't upgrade to last version , and firefox does .",
"candidates": [
"why no menu bar in libreoffice when you move your cursor to the top of the screen in libreoffice you do n't get a menu . you do for other applications like firefox and thunderbird but not for libreoffice .",
"how do i install the latest stable version of libreoffice ? libreoffice is seeing some dramatic improvements each version and subversion that goes out . i would like to have always the latest version of libreoffice on my machine ( s ) . i know of the ppa that exists but is it recommended to use it with 12.04 for daily use ? what are the pro and cons of using the ppa ? will it break my system/libreoffice installation ? does libreoffice get eventually also upgraded in the ubuntu repositories or does this upgrade happen only with new releases ? who manages the upgrades of libreoffice in ubuntu and in the ppa ?",
"why does unity launcher start the wrong program ? when i left click the libreoffice icon firefox launches instead . a right click gives me a choice of new document firefox lock to launcher . until some recent updates this never happened before . other programs do n't exhibit this behaviour . why ?",
"ibreoffice version now , i use libreoffice writer 3.5.7.2 . according to http : //ask.libreoffice.org/en/question/34088/selecting-copying-pasting-text/ and further things i need libreoffice writer 4.0 or higher . when it may be in the ubuntu software center for my ubuntu 12.04 ? if it is there , is it offered by my upgrade manager without my request ? thanks .",
"libreoffice-core seems to have corrupted i had libreoffice version 3.x installed along with my ubuntu version 11 . after i did the upgrade to 12.04 , my libreoffice behavior changed . i decided to upgrade tto libre office 4x . during the setup since i was getting errors on desktop integration , i tried removing version 3 of libreoffice . this seems to have caused problem with some of libreoffice files , which seems to be essential to run different application . libreoffice-core- depends libreoffice-common has unmet dependencies now , my update manager does n't work and i having problems installing any new apps . is there a solution to fix this problem without having to re-install ubuntu ? i tried to do repair of libreoffice.. did n't work . cheers anil rao"
]
}
)
With this, the batch shape created in QRAPI.rank() is (124,6) and gives 5 scores, therefore line assert len(scores) == len(batch)-1 gives an error.
I suppose this is a small bug, otherwise am I using the QRAPI wrongly?
Thanks
eg:
fopen = gzip.open if path.endswith(".gz") else open
with fopen(path) as fin:
python3 would need 'rt':
fopen = gzip.open if path.endswith(".gz") else open
with fopen(path, 'rt') as fin:
Dear @taolei87 ,
As part of my thesis project I have replicated your work in question retrieval using Tensorflow.
In your code you provide the loss for the training, as well as the performance for the dev set, but no loss for the dev set.
I have tried the following function:
def devloss0(labels, scores):
per_query_loss = []
for query_labels, query_scores in zip(labels, scores):
pos_scores = [score for label, score in zip(query_labels, query_scores) if label == 1]
neg_scores = [score for label, score in zip(query_labels, query_scores) if label == 0]
if len(pos_scores) == 0 or len(neg_scores) == 0:
continue
pos_scores = np.array(pos_scores)
neg_scores = np.repeat(np.array(neg_scores).reshape([1, -1]), pos_scores.shape[0], 0)
neg_scores = np.max(neg_scores, 1)
diff = neg_scores - pos_scores + 1.
diff = (diff > 0)*diff
per_query_loss.append(np.mean(diff))
return np.mean(np.array(per_query_loss))
but it seems to get increased after few batches, while the dev performance keeps increasing.
Only using the soft loss function that accounts for each pair loss i.e.
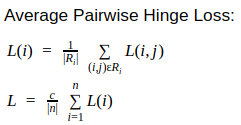
def devloss2(labels, scores):
query_losses = []
for query_labels, query_scores in zip(labels, scores):
pos_scores = [score for label, score in zip(query_labels, query_scores) if label == 1]
neg_scores = [score for label, score in zip(query_labels, query_scores) if label == 0]
if len(pos_scores) == 0 or len(neg_scores) == 0:
continue
pos_scores = np.array(pos_scores).reshape([-1, 1])
neg_scores = np.repeat(np.array(neg_scores).reshape([1, -1]), pos_scores.shape[0], 0)
diff = neg_scores - pos_scores + 1.
diff = (diff > 0).astype(np.float32)*diff
query_losses.append(np.mean(diff))
return np.mean(np.array(query_losses))
# example input to the functions:
# labels = [np.array([1,1,0,0,1,0,0,0]), np.array([1,1,0,0,1,0,0,0])]
# scores = [np.array([0.9,0.8,0.7,0.6,0.5,0.4,0.3,0.2]), np.array([0.9,0.8,0.7,0.6,0.5,0.4,0.3,0.2])]
does decrease the dev loss.
Do you know what's going on here? I suppose the model does not overfit, but is something that has to do with the data?
Results training a GRU model (devloss0 and devloss2 are called inside this function )

(showing MAP, MRR, P@1, P@5)
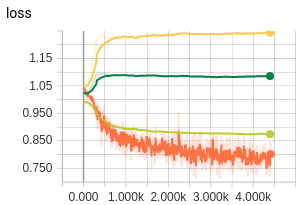
(showing devloss0 in green, devloss2 in light green and train loss in orange)
+-------+------+---------+---------+---------+---------+---------+---------+---------+---------+
| Epoch | Step | dev MAP | dev MRR | dev P@1 | dev P@5 | tst MAP | tst MRR | tst P@1 | tst P@5 |
+-------+------+---------+---------+---------+---------+---------+---------+---------+---------+
| 0 | 1 | 48.869 | 62.072 | 48.677 | 39.259 | 47.989 | 59.916 | 43.011 | 36.882 |
| 0 | 101 | 52.073 | 66.782 | 54.497 | 40.635 | 50.759 | 63.231 | 47.312 | 39.032 |
| 1 | 616 | 57.113 | 67.541 | 52.91 | 46.349 | 57.33 | 70.901 | 54.839 | 43.226 |
| 2 | 731 | 56.988 | 69.193 | 56.614 | 46.667 | 57.975 | 72.129 | 57.527 | 43.871 |
| 2 | 931 | 58.394 | 70.026 | 56.614 | 47.407 | 58.874 | 72.642 | 59.14 | 44.194 |
| 3 | 1046 | 58.385 | 70.601 | 58.201 | 46.878 | 59.244 | 74.14 | 61.29 | 44.194 |
| 4 | 1261 | 59.195 | 71.692 | 58.201 | 47.513 | 58.857 | 73.435 | 59.677 | 44.086 |
| 4 | 1361 | 58.408 | 71.76 | 58.201 | 47.831 | 58.423 | 71.093 | 55.914 | 44.086 |
| 5 | 1576 | 59.333 | 72.075 | 58.73 | 47.513 | 58.63 | 72.592 | 59.14 | 44.731 |
+-------+------+---------+---------+---------+---------+---------+---------+---------+---------+
Hi I get this error while running main.py with specified data mentioned in the directory.Any idea how to resolve this?I am running in my own laptop having 8GB RAM
MemoryError: failed to alloc sm output
Apply node that caused the error: CrossentropySoftmaxArgmax1HotWithBias(Dot22.0, b, Reshape{1}.0)
Toposort index: 360
Inputs types: [TensorType(float64, matrix), TensorType(float64, vector), TensorType(int32, vector)]
Inputs shapes: [(5888, 100410), (100410,), (5888,)]
Inputs strides: [(803280, 8), (8,), (4,)]
Inputs values: ['not shown', 'not shown', 'not shown']
Outputs clients: [[Reshape{2}(CrossentropySoftmaxArgmax1HotWithBias.0, MakeVector{dtype='int64'}.0)], [CrossentropySoftmax1HotWithBiasDx(Reshape{1}.0, CrossentropySoftmaxArgmax1HotWithBias.1, Reshape{1}.0)], []]
HINT: Re-running with most Theano optimization disabled could give you a back-trace of when this node was created. This can be done with by setting the Theano flag 'optimizer=fast_compile'. If that does not work, Theano optimizations can be disabled with 'optimizer=None'.
HINT: Use the Theano flag 'exception_verbosity=high' for a debugprint and storage map footprint of this apply node.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.