很少有只描述算法的书籍,一般都是数据结构和算法结合起来进行描述。但是数据结构和算法不是同一个概念,在这里我们要做一下区分,以便进入误区,“数据结构=算法”。
根据维基百科对数据结构的释义
在计算机科学中,数据结构(英语:data structure)是计算机中存储、组织数据的方式。
根据维基百科对算法的释义
算法(algorithm),在数学(算学)和计算机科学之中,为任何良定义的具体计算步骤的一个序列,常用于计算、数据处理和自动推理。精确而言,算法是一个表示为有限长列表的有效方法。算法应包含清晰定义的指令用于计算函数。
让我们来回顾一下,在计算机领域解决一个问题的步骤。
- 分析问题,从问题中提取出有价值的数据,将其存储
- 对存储的数据进行处理,最终得出问题的答案
数据结构在这个过程中,承担的任务就是解决数据存储,也就是步骤1。针对数据的不同逻辑结构和物理结构,可以选出最优的数据存储结构来存储数据。
当然,步骤2就是算法应该承担的责任。从表面的意思来看,算法就是用来解决问题的方法。我们知道,评价要给算法的好坏,取决在解决相同问题的前提下,哪种算法的效率高,而这里的效率指的就是处理数据、分析数据的能力。
补充,其实在解决问题的过程中不能只考虑算法的高效,还要考虑算法过程中,数据存储空间是否合理。
因此,我们得出来结论,数据结构用于存储数据,而算法用于处理和分析数据,他们是完全不同的学科,但是他们是相辅相成的。
总结一下,在解决问题的过程中,数据结构要配合算法选择最优的存储结构来存储数据,而算法也要结合数据存储的特点,用最优的策略来分析并处理数据,由此可以最高效地解决问题。
这里对应的是两个概念,时间复杂度和空间复杂度,后面会展开论述。
我们先从客观方面来描述一下,很多大公司,比如BAT,Google,Facebook面试的时候都喜欢考算法,让人现场写代码。很多人技术不错,但是基本上每次面试都“跪“在算法上面。因此为了找一份好工作,学好算法是很重要的。
接下来我们从主观方面来描述一下,掌握数据结构和算法,不管对应阅读框架源码,还是理解其背后的设计**,或者说在实际应用中解决问题,都是至关重要的。能给你工作的场景带来快速高效的解决问题。因此,学习好算法和数据结构也是势在必行的事情。
想要学习数据结构和算法,首页要掌握一个数据结构与算法中最重要的概念——复杂度分析。
这个概念很重要。可以这么说,它几乎占了数据结构和算法这门课的半壁江山,是数据结构和算法的精髓。
数据结构和算法解决的是如何更省,更快的存储和处理数据问题。因此,我们就需要一个考量效率和资源消耗的方法,这就是复杂度分析。只有学会了复杂度分析,你才能了然于胸。
我们都知道,数据结构和算法本身解决的是”快“和”省“的问题,即如何让代码运行得更快,同时如何让代码消耗的空间更少。因此,执行效率是算法一个非常重要的考量指标。那如何来衡量你编写的算法代码的执行效率呢?两方面,时间复杂度和空间复杂度。
对于算法不是很了解的同学,可能会认为我把代码执行一遍,通过统计、监控,就能获得算法执行的时间和内存占用的大小。为什么还要做时间和空间的复杂度分析呢?
首先,上述描述的估算算法执行效率的方法是正确的。这个方法有个名词,事后评估法。但是这种统计方法具有很大的局限性。
测试环境中硬件的不同会对测试结果造成很大的影响。比如,我们同样的一段代码,分别用Intel Core i9和Intel Core i3处理器来执行,不用说,i9比i3执行的要快。
拿排序来举个例子,如果给予的数据是已经排好序的,那么执行的时间和没有排序的数据差别会很明显。 因此,我们需要一个不用具体的测试数据来测试,就可以粗略的估计算法的执行效率的方法。
算法的执行效率,也就是算法的执行时间。但是如何在不运行代码的情况下,直接分析出代码的执行时间呢?
这里我们通过一段代码来进行算法时间分析:
1 int cal(int n) {
2 int sum = 0;
3 int i = 1;
4 for (; i <= n; i++) {
5 sum = sum + i;
6 }
7 return sum;
}
这段代码,基本描述的就是类似操作,读数据-运算-写数据。尽管不同的机器执行的时间不同,但是我们可以通过粗略估计,来给每段代码执行的时间定义一个常量,unit_time。基于这个常量,我们来给上述代码进行执行时间预估。
第2行和第3行代码需要一个unit_time执行时间,第4行和第5行执行了n遍,因此2*n*unit_time,因此可以得出代码的总执行市场是(2n+2)*unit_time。在这里可以看出,代码的执行时间T(n)与每行代码的执行次数成正比。
按照这个思路,我们再来分析一段代码
1 int cal(int n) {
2 int sum = 0;
3 int i = 1;
4 int j = 1;
5 for (; i <= n; i++) {
6 j = 1;
7 for (; j <= n; j++) {
8 sum = sum + i * j;
9 }
10 }
11 }
第2,3,4行代码执行了一次,因此执行时间是3*unit_time, 第5,6行代码执行了n次,需要2n*unit_time的执行时间,第7,8行代码执行了n²遍,需要2n²*unit_time的执行时间。因此,整段代码的执行时间是(2n²+2n+3)*unit_time。
尽管我们不清楚unit_time的具体值,但是我们通过这两段代码,可以推导出一个重要的规律,所有代码的执行时间T(n)与每行代码的执行次数n成正比。
所以我们可以总结如下公式,大O表示法:T(n) = O(f(n))
具体解释下公式。其中T(n)是表示代码的执行的时间,n表示数据的规模,f(n)表示每行代码执行的次数总和。因为这是一个公式,所以用f(n)来表示。公式中的O,表示代码的执行时间T(n)和f(n)表达式成正比。
所以,第一个例子中,T(n) = O(2n+2),第二个例子中,T(n) = O(2n²+2n+3)。这就是大O时间复杂度表示法。大O时间复杂度实际上并不具体表示代码的真正执行时间,而是表示代码执行时间随数据规模增长的变化趋势,所以,也叫做渐进时间复杂度(asymptotic time complexity),简称时间复杂度。
以上例子,当n变得很大的时候,比如100000,10000000。而公式中的低阶、常量、系数三部分不左右增长趋势,所以都可以忽略。我们只要记住最大数量级的就可以了。因此以上两个例子大O表示法,可以简化如下,T(n) = O(n),T(n) = O(n²)。
以下开始算法正片内容
我们先来介绍下快速排序的**:如果要排序数组中下标从p到r之间的一组数据,我们选择p到r之间的任意一个数据作为pivot(分区点)。
我们遍历p到r之间的数据,将小于pivot的数据放到左边,将大于pivot的数据放到右边,将pivot放到中间。经过这一个步骤,数据p到r之间的数据就被分割成了三部分,前面p到q-1之间都是小于pivot的,中间是pivot,后面的q+1到r之间的数据都是大于pivot的。

在这里需要解释两个名次,分治,递归。 根据维基百科对分治的释义:
在计算机科学中,分治法是建基于多项分支递归的一种很重要的算法范式。字面上的解释是“分而治之”,就是把一个复杂的问题分成两个或更多的相同或相似的子问题,直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。
根据维基百科对递归的释义:
在数学与计算机科学中,是指在函数的定义中使用函数自身的方法。递归一词还较常用于描述以自相似方法重复事物的过程。例如,当两面镜子相互之间近似平行时,镜中嵌套的图像是以无限递归的形式出现的。也可以理解为自我复制的过程。
这里快速的排序用到了分治和递归的**,因此我们可以用递归排序下标从p到q-1之间的数据和下标q+1到r之间的数据,直到区间缩小为1,就说明所有的数据都有序了。
如果我们用递推公式来描述上面的公式,就是这样:
递推公式:
quick_sort(p...r) = quick_sort(p...q-1) + quick_sort(q+1...r)
终止条件
p >= r
我们将递推公式转化为递归代码,我们用伪代码来实现:
// 快速排序,A是数组, n表示数组的大小
quick_sort(A, n) {
quick_sort_c(A, 0, n-1);
}
// 快速排序递归函数,p, r 为下标
quick_sort_c(A, p, r) {
if (p >= r) {
return;
}
q = partition(A, p, r); // 获取分区点(pivot)
quick_sort_c(A, p, q-1);
quick_sort_c(A, q+1, r);
}
这里partition()分区函数,就是随机选择一个元素作为pivot(一般情况下,可以选择p到r区间最后一个元素),然后对A[p...r]进行分区,函数返回pivot下标。
partition(A, p, r) {
pivot := A[r];
i := p;
for (j := p; j <= r-1; j++) {
if (A[j] < pivot) {
swap A[i] with A[j];
i := i + 1
}
}
swap A[i] with A[r]
return i
}
在这里,我们通过游标i把A[p...r-1]分成两部分,A[p...i-1]的元素都是小于pivot的,我们暂且叫它“已处理区间“,A[i...r-1]是”未处理区间“。我们每次都从未处理的区间A[i...r-1]中取第一个元素A[j],与pivot相比,如果小于pivot,则将其加入到已处理区间的尾部,也就是A[i]的位置。
数组的插入操作,比较耗时,因此我们可以采取交换操作的**。
以下,通过图来解释会更清楚一些:

因为分区的过程设计交换操作,如果数组中有两个相同元素,比如序列6,8,7,6,3,5,9,4,在经过第一次分区操作之后,两个6的相对先后顺序就会改变。所以,快排是一个不稳定的排序算法。
以下是一张快速排序的图:

快速排序,是自上而下的处理过程,先分区,然后再处理子问题。
现在,我们来分析下快速排序的性能。
快排是用递归来实现的。如果每次分区操作,都能正好把数组分成大小接近相等的两个小区间,那快排的时间复杂度递推公式跟归并是相同的。所以,快排的时间复杂度也是O(nlogn)。
T(1) = C; n=1时,只需要常量级的执行时间,所以表示为C。
T(n) = 2*T(n/2) + n; n > 1。d
选择排序是一种简单直观的排序算法,无论什么数据进去都是 O(n²) 的时间复杂度。所以用到它的时候,数据规模越小越好。唯一的好处可能就是不占用额外的内存空间。
首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。 再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。 重复第二步,直到所有元素均排序完毕。
def selection_sort():
# 选择排序
arr = [86, 12, 211, 114, 45, 15, 3, 21312, 212]
for i in range(len(arr)-1):
# 记录最小数的索引
min_index = i
print ('i=%d' % i)
for j in range(i + 1, len(arr)):
print ('j=%d' % j)
if arr[j] < arr[min_index]:
min_index = j
# i 不是最小数时,将 i 和最小数进行交换
if i != min_index:
arr[i], arr[min_index] = arr[min_index], arr[i]
print (arr)
return arr
if __name__ == "__main__":
selection_sort()
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。堆排序可以说是一种利用堆的概念来排序的选择排序。分为两种方法: 大顶堆:每个节点的值都大于或等于其子节点的值,在堆排序算法中用于升序排列; 小顶堆:每个节点的值都小于或等于其子节点的值,在堆排序算法中用于降序排列; 堆排序的平均时间复杂度为 Ο(nlogn)。
创建一个堆 H[0……n-1]; 把堆首(最大值)和堆尾互换; 把堆的尺寸缩小 1,并调用 shift_down(0),目的是把新的数组顶端数据调整到相应位置; 重复步骤 2,直到堆的尺寸为 1。

#-*- encoding=utf8 -*-
import math
def build_max_heap(arr):
# 创建堆
for i in range(int(math.floor(len(arr)/2)), -1, -1):
heapify(arr, i)
def heapify(arr, i):
# 取最大值的位置
left = 2 * i + 1
right = 2 * i + 2
largest = i
if left < arr_len and arr[left] > arr[largest]:
largest = left
if right < arr_len and arr[right] > arr[largest]:
largest = right
if largest != i:
# print (i)
swap(arr, i, largest)
# print (arr)
heapify(arr, largest)
def swap(arr, i, j):
arr[i], arr[j] = arr[j], arr[i]
def heap_sort():
arr = [31, 33, 19, 82, 13, 11, 19]
global arr_len
arr_len = len(arr)
build_max_heap(arr)
print (arr)
for i in range(len(arr)-1, 0, -1):
swap(arr, 0, i)
arr_len -= 1
heapify(arr, 0)
return arr
if __name__ == "__main__":
print(heap_sort())
插入排序(Insertion sort)是一种简单直观且稳定的排序算法。适用于少量数据的排序,时间复杂度为O(n^2)。基于以上特点,插入排序适用于较少的数据量排序
每步将一个待排序的记录,按其关键码值的大小插入前面已经排序的文件中适当位置上,直到全部插入完为止
插入算法把要排序的数组分成两部分:第一部分包含了这个数组的所有元素,但将最后一个元素除外(让数组多一个空间才有插入的位置),而第二部分就只包含这一个元素(即待插入元素)。在第一部分排序完成后,再将这个最后元素插入到已排好序的第一部分中。
就像许多人排序一手扑克牌。
开始时,我们左手为空,并且桌子上的牌面朝下。
然后,我们每次从桌子上拿走一张牌并将它插入左手中正确的位置。(为了找到一张牌的正确位置,我们从右到左将他与在手中的每张牌进行比较)
拿在手中的牌总是排序好的,原来这些牌是桌子上牌堆中顶部的牌
INSERTION_SORT(A)
1 for j ← 2 to Length(A)
2 key = A[i]
3 // Insert A[j] into the sorted sequence A[1, j - 1]
4 i = j - 1
5 while i > 0 and A[i] > key
6 A[i+1] = A[i]
7 i -= 1
8 A[i+1] = key
折半插入排序(binary insertion sort)是对插入排序算法的一种改进,由于排序算法过程中,就是不断的依次将元素插入前面已排好序的序列中。由于前半部分为已排好序的数列,这样我们不用按顺序依次寻找插入点,可以采用折半查找的方法来加快寻找插入点的速度。
在将一个新元素插入已排好序的数组的过程中,寻找插入点时,将待插入区域的首元素设置为a[low],末元素设置为a[high],则轮比较时将待插入元素与a[m],其中m=(low+high)/2相比较,如果比参考元素小,则选择a[low]到a[m-1]为新的插入区域(即high=m-1),否则选择a[m+1]到a[high]为新的插入区域(即low=m+1),如此直至low<=high不成立,即将此位置之后所有元素后移一位,并将新元素插入a[high+1]
func binInsertionSort(_ array: inout Array<Int>){
for i in 1..<array.count {
var low = 0;
var high = i - 1
var mid = 0
while high >= low {
mid = (high + low) / 2
if array[i] < array[mid]{
high = mid - 1
}else{
low = mid + 1
}
}
let key = array[i]
for j in stride(from: i, to: low, by: -1){
array[j] = array[j - 1]
}
array[low] = key
}
}| 最坏 | 最好 | 稳定性 | 空间复杂度 |
|---|---|---|---|
| O(n^2) | O(nlog2n) | 稳定 | O(1) |
p.s.
最好情况:
每次插入的位置k都是已序数组的最后的位置,则无需再执行移位赋值操作 O(n*log2n)
最坏情况:
每次插入的位置k都是已序数组的最前的位置,则整个已序数组需要移位赋值 O(n^2) 二分查找时间复杂度 O(log2n)
希尔排序(Shell Sort)是插入排序的一种。也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法。该方法因DL.Shell于1959年提出而得名
希尔排序是记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止
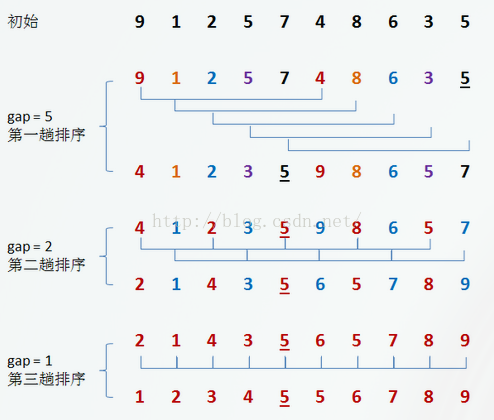
初始时,有一个大小为 10 的无序序列。
-
在第一趟排序中,我们不妨设 gap1 = N / 2 = 5,即相隔距离为 5 的元素组成一组,可以分为 5 组。
-
接下来,按照直接插入排序的方法对每个组进行排序。
在第二趟排序中,我们把上次的 gap 缩小一半,即 gap2 = gap1 / 2 = 2 (取整数)。这样每相隔距离为 2 的元素组成一组,可以分为 2 组。
-
按照直接插入排序的方法对每个组进行排序。
-
在第三趟排序中,再次把 gap 缩小一半,即gap3 = gap2 / 2 = 1。 这样相隔距离为 1 的元素组成一组,即只有一组。
-
按照直接插入排序的方法对每个组进行排序。此时,排序已经结束
func shellInsertionSort(_ array: inout Array<Int>){
var step = array.count / 2
while step > 0 {
for group in 0..<step {
for i in stride(from: group + step, to: array.count - 1, by: step) {
let key = array[i]
var backIndex = i - step
while backIndex >= 0 && array[backIndex] > key {
array[backIndex + step] = array[backIndex]
backIndex -= step
}
array[backIndex + step] = key
}
}
step = step / 2;
}
}时间复杂度:
最好情况:由于希尔排序的好坏和步长gap的选择有很多关系,因此,目前还没有得出最好的步长如何选择(现在有些比较好的选择了,但不确定是否是最好的)。所以,不知道最好的情况下的算法时间复杂度。
最坏情况下:O(N*logN),最坏的情况下和平均情况下差不多。
已知的最好步长序列是由Sedgewick提出的(1, 5, 19, 41, 109,...)。
这项研究也表明“比较在希尔排序中是最主要的操作,而不是交换。”用这样步长序列的希尔排序比插入排序和堆排序都要快,甚至在小数组中比快速排序还快,但是在涉及大量数据时希尔排序还是比快速排序慢。
空间复杂度
由直接插入排序算法可知,我们在排序过程中,需要一个临时变量存储要插入的值,所以空间复杂度为1。
算法稳定性
希尔排序中相等数据可能会交换位置,所以希尔排序是不稳定的算法。