sunwoo0706 / til Goto Github PK
View Code? Open in Web Editor NEWToday I learned
Today I learned
























로힛 바르가바가 제창한 단어로, 소셜 미디어 최적화(Social Media Optimization, SMO)는 소셜 미디어, 온라인 커뮤니티, 커뮤니티 웹사이트 등을 통해 저명성을 획득하는 기법을 말한다.
웹사이트 등의 네트워크를 통해 생성되어 전달된다는 점에서 SMO는 바이럴 마케팅과 여러모로 연관되어 있다.
요즘에는 바이럴 마케팅의 뜻이 넓어져 바이럴 마케팅의 하위개념으로 포함되는 경우가 꽤 있다.
제창자 로힛 바르가바가 제안한 방법 5가지이다. 웹사이트 등의 네트워크를 통해서 최대한 컨텐츠 노출 횟수를 늘리는것이 핵심이다.
SMO 방법 4의 단점이다. 스팸덱싱 같은 것들로 인해 소셜 미디어 일각에서는 스팸이 많이 생성되어 흘러다니기도 한다.
링크드인, 페이스북 등 많은 소셜 서비스 또는 미디어에서는 스팸을 없애려는 조치를 취하고 있다. 특히 디그(Digg)에서는 저질성 콘텐츠나 스팸성 콘텐츠를 묻어버리는 bury(digg 뜻의 반대) 행위를 장려하고 있다.
그러므로 적당하게 사용자에게 폐를 끼치지 않을 정도로 컨텐츠를 바이럴시키는것이 핵심이라고 한다.
브라우저의 창이나 프레임을 프로그래밍적으로 제어할 수 있게 해주는 객체모델이다. 이를 통해서 브라우저의 새 창을 열거나 다른 문서로 이동하는 등의 기능을 실행시킬 수 있다. 전역 객체로 window가 있으며 하위 객체들로 location, navigator, document, screen, history 가 포함되어 있다.
BOM은 DOM의 상위 집합이다.
BOM은 DOM과 다르게 표준 명세가 존재하지 않아서 각 브라우저별로 구현방법이 상이하다.
웹페이지를 프로그래밍적으로 제어할 수 있게 해주는 객체모델이다. 최상위 인터페이스로 Node가 있으며 이는 아래와 같은 구조로 나타난다.

위의 트리구조에서도 나오다시피 엘리먼트 뿐만 아니라 텍스트와 주석도 DOM 트리에 포함된다.
Array.reduce() 메서드를 사용하면 값 배열을 가져와서 배열의 각 항목을 한 번에 하나씩 처리하여 단일 최종 결과를 반환할 수 있다. 한 마디로 배열을 하나의 값으로 줄이는 것 이라고 생각할 수 있다.
Array.reduce() 배열의 각 항목에 대해 한 번 호출되는 콜백 함수를 인수로 사용한다. 두 가지 인수가 필요하다.
previousResult : 이전에 콜백이 반환한 값currentItem : 배열의 현재 항목처음 콜백이 실행될때, previousResult 는 사용할 수 없다. 따라서 첫 번째 이전 결과로 사용될 초깃값을 전달해야 한다.
총계가 무엇인지 알아내기 위해 숫자 배열을 더하고 싶다면 다음과 같은 reduce 콜백을 작성할 수 있다.
const numbers = [2, 5, 8]
const addNumbers = (previousResult, currentItem) => {
console.log({ previousResult, currentItem })
return previousResult + currentItem
}
const initialValue = 0
const total = numbers.reduce(addNumbers, initialValue)
// {previousResult: 0, currentItem: 2}
// {previousResult: 2, currentItem: 5}
// {previousResult: 7, currentItem: 8}
console.log(total)
// 15Redux의 reducer 함수는 addNumbers 즉 reduce callback 과 정확히 같다. reduce callback은 previous result (state)와 current item (action 객체)을 인자로 취하여 해당 인수를 기반으로 새 상태 값을 결정하고 해당 새 상태를 반환한다.
Redux의 방법을 reduce로 구현해보면
const actions = [
{ type: 'counter/increment' },
{ type: 'counter/increment' },
{ type: 'counter/increment' }
]
const initialState = { value: 0 }
const finalResult = actions.reduce(counterReducer, initialState)
console.log(finalResult)
// {value: 3}과 같이 동일한 방식으로 최종 결과를 얻을 수 있다.
Redux의 reducer는 시간이 지남에 따라 일련의 작업을 단일 상태로 줄인다고 말할 수 있다. 차이점은 reduce 메서드는 함수를 호출할때 한번에 일어나지만 Redux에서는 런타임으로 발생한다는것에 있다.
HTML 문서의 모든 요소와 스타일로 이루어진 DOM은 하나의 큰 글로벌 범위 내에 있다.
그래서 페이지의 요소가 문서 내에 깊이 중첩되어 있거나 어디에 배치되어있는지 상관없이 querySelector 같은 메서드를 사용하여 접근이 가능하다. 마찬가지로 CSS 스타일 또한 글로벌 범위 내의 어떤 요소든 선택이 가능하다.
문서 전체에 스타일을 일괄 적용하고 싶은 때 이러한 방식은 매우 유용하다. 예를 들어, box-sizing 속성을 사용한 한 줄의 코드를 통해 페이지에 있는 모든 단일 요소를 선택 가능하다.
* { box-sizing: border-box }반면에 어떤 요소는 완전한 캡슐화를 필요로 하는 경우가 있고, 이것이 글로벌 스타일에 영향을 받는 것을 원하지 않을 수 있다. 이에 대한 좋은 예는 iframe으로 외부에서 가져온 위젯을 예로 들 수 있다. 이 요소또한 다음과 같이 작은 문서를 로드할 수 있다.
<iframe> 은 호스팅 문서의 전역 CSS에 영향을 받지 않고 의도된 스타일을 보장할 수 있는 방법이다. 같은 결과를 얻기 위해 캐스케이드를 이용할 수 있지만, 다른 방법으로는 <iframe> 과 같은 보장이 주어지지 않으며 이상적인 방법은 아니다.
Shadow DOM은 <iframe> 과 같은 도구에 의존할 필요 없이, 웹 플랫폼에서 기본적으로 캡슐화와 구성요소화를 허용하기 위해 만들어졌다.
Shadow DOM을 DOM의 하위 요소로 생각할 수도 있지만, 원래의 DOM 트리에서 완전히 분리된 고유의 요소와 스타일을 가진 DOM 트리입니다. Shadow DOM은 웹 작성자가 사용하도록 최근에 지정되었지만, 사용자 에이전트에서 폼 요소와 같이 복잡한 구성요소를 만들고 스타일을 입히기 위해 수년 동안 사용되어 왔다.
예를 들어 범위 입력 요소를 살펴보자. 페이지에 해당 요소를 생성하기 위해서는 아래의 코드를 추가해야 한다.
<input type="range">더 깊게 파고들면, <input> 요소가 실제로 여러 작은 <div> 요소로 구성되어 트랙과 슬라이더를 자체적으로 제어하는 것을 볼 수 있다.
이처럼 Shadow DOM을 사용하여 위와 같은 결과를 얻을 수 있다. 호스트 HTML 문서에는 단순한 <input> 요소가 노출되지만, 그 내부에는 DOM의 글로벌 범위에 포함되지 않는 HTML 요소와 스타일 구성 요소들이 있다.
먼저 <iframe> 대신 shadow DOM을 사용하여 트위터의 "follow" 버튼을 만들어 보지.
먼저 shadow host로 시작합니다.
shadow host는 새로운 shadow DOM을 붙일 원본 DOM의 일반 HTML 요소를 사용합니다. Follow 버튼과 같은 구성요소의 경우, 페이지에 Javascript가 활성화되지 않았거나 shadow DOM이 지원되지 않을 경우 포시할 fallback 요소를 포함할 수 있다.
<span class="shadow-host">
<a href="https://twitter.com/ireaderinokun">
Follow @ireaderinokun
</a>
</span>주로 상호 작용하는 특정 요소들은 shadow host가 될 수 없기 때문에, 단순하게도 <a> 요소를 shadow host로 사용할 수 없다.
shadow host에 shadow DOM을 붙이기 위해, attachShadow() 메서드를 사용한다.
const shadowEl = document.querySelector(".shadow-host");
const shadow = shadowEl.attachShadow({mode: 'open'});이 코드는 shadow host의 자식 요소인 빈 shadow root를 생성합니다. <html> 요소가 DOM의 시작인 것처럼 shadow root는 shadow DOM의 시작점 역할을 한다.
일반 HTML 자식 요소는 검사기에서 확인될지라도 shadow root가 차지하면서 더 이상 페이지에 보이지 않게 됩니다.
다음으로, 새로운 shadow tree를 만들기 위해 콘텐츠를 생성해야 합니다. shadow tree는 DOM tree와 비슷하지만 일반 DOM 대신 shadow DOM을 사용합니다. follow 버튼을 생성하기 위해서는 이미 가지고 있는 폴백 링크와 거의 동일하지만 아이콘이 있는 새로운 <a> 요소가 필요합니다.
const link = document.createElement("a");
link.href = shadowEl.querySelector("a").href;
link.innerHTML = `
<span aria-label="Twitter icon"></span>
${shadowEl.querySelector("a").textContent}
`;DOM과 같은 방법으로 appendChild() 메서드를 사용하여 shadow DOM에 새로운 요소를 추가합니다.
shadow.appendChild(link);어떤 면에서 shadow DOM은 DOM의 "lite" 버전입니다.
DOM과 같이 HTML 요소의 구조화된 표현이며, 페이지에 무엇을 표시할지 결정하고 요소의 수정을 가능하게 합니다. 하지만 DOM과 다르게 완전한 독립 문서를 기반으로 하지 않습니다.
이름에서 알 수 있듯이 shadow DOM은 항상 일반 DOM 내의 요소에 부착됩니다. DOM이 없으면 shadow DOM도 존재하지 않습니다.
오늘 다른 사람의 프로젝트 구조를 뜯어보다가 신기한 파일을 발견했다.
.gitkeep 이름만 들으면 .gitignore와 반대의 기능을 할 것 같이 생긴 파일명
찾아보니 이 녀석은 gitlab 웹상에서 디렉터리를 만들면 이 파일이 생성된다고 한다.
그런데 .gitkeep 파일은 Git의 기능이 아니다.
디렉토리 내의 다른 파일들이 모두 삭제되더라도 혼자 남아서 디렉토리를 지킨다(keep)는 의미이다.
이 글을 읽는 당신들도 마찬가지로 Git은 파일의 변경사항만을 기록한다.
따라서 디렉터리 안에 파일이 삭제되면 그 디렉터리도 자연스레 Git에서 없어지게 되는데, 디렉토리를 없어지지 않게 하기 위해 일종의 더미(dummy)로서 이 파일을 함께 추가해주는 것이다.
나는 주로 test.md 파일을 만들어서 유지 시켰는데 앞으로는 .gitkeep을 사용하도록 해야겠다.
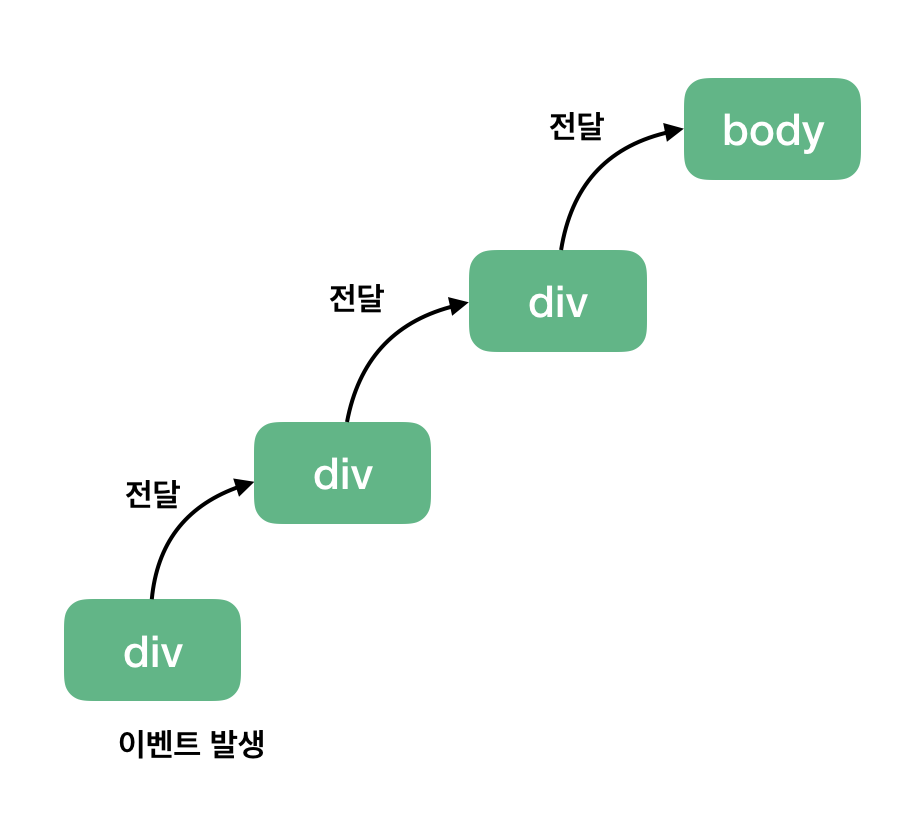
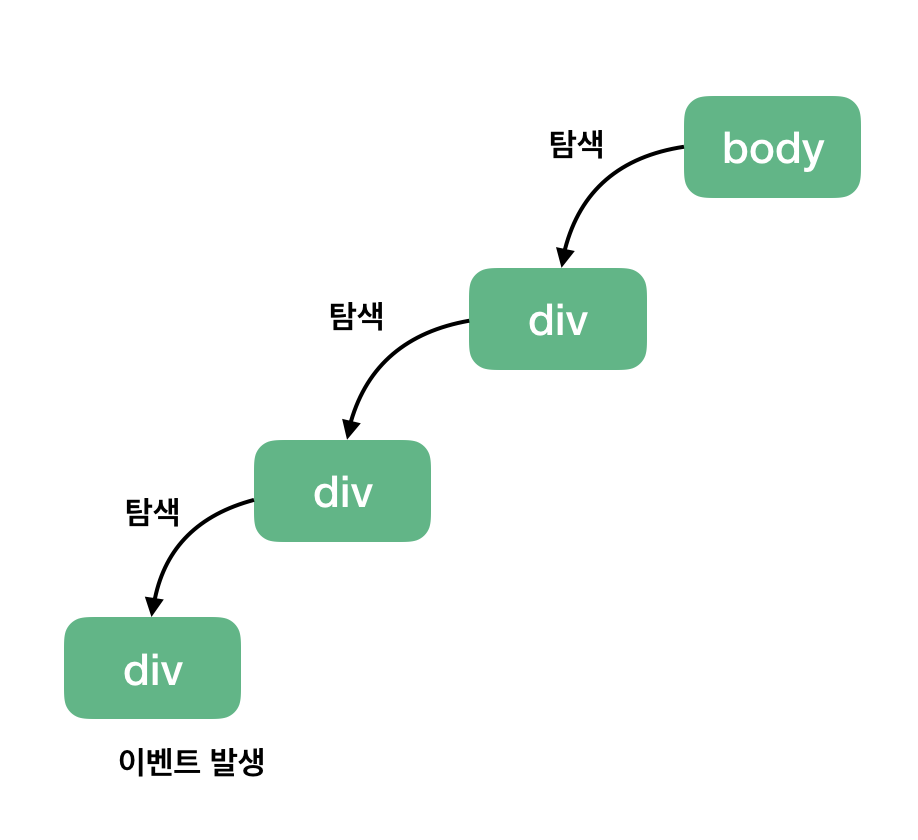
이벤트 버블링은 특정 화면 요소에서 이벤트가 발생했을 때 해당 이벤트가 더 상위의 화면 요소들로 전달되어 가는 특성을 의미한다. 아래 그림을 보자.
HTML 요소는 기본적으로 트리 구조를 갖습니다. 여기서는 트리 구조상으로 한 단계 위애 있는 요소를 상위 요소라고 하며 body 태그를 최상위 요소라고 부르겠다.
위 그림은 아래에 예시로 들 코드를 미리 도식화한 그림이다. 세 개의 div 태그가 있고 가장 아래에 있는 div 태그에서 이벤트가 발생했을 때 최상위 요소인 body 태그까지 이벤트가 전달되는 모습을 나타내었다. 그럼 코드를 봐보자
<body>
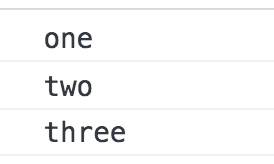
<div class="one">
<div class="two">
<div class="three">
</div>
</div>
</div>
</body>var divs = document.querySelectorAll('div');
divs.forEach(function(div) {
div.addEventListener('click', logEvent);
});
function logEvent(event) {
console.log(event.currentTarget.className);
}위 코드는 세 개의 div 태그에 모두 클릭 이벤트를 등록하고 클릭 했을 때 logEvent 함수를 실행시키는 코드이다. 여기서 위 그림대로 최하위 div 태그 <div class="three"></div> 를 클릭하면 아래와 같은 결과가 실행된다
div 태그 한 개만 클릭했을 뿐인데 왜 3개의 이벤트가 발생되는 것일까? 그 이유는 브라우저가 이벤트를 감지하는 방식에 있다.
브라우저는 특정 화면 요소에서 이벤트가 발생했을 때 그 이벤트를 최상위에 있는 화면 요소까지 이벤트를 전파시킨다. 따라서, 클래스 명 three -> two -> one 순서로 div 태그에 등록된 이벤트들이 실행된다. 마찬가지로 two 클래스를 갖는 두 번째 태그를 클릭했다면 two -> one 순으로 클릭 이벤트가 동작할 것 이다.
여기서 주의해야 할 점은 각 태그마다 이벤트가 등록되어 있기 때문에 상위 요소로 이벤트가 전달되는 것을 확인할 수 있다. 만약 이벤트가 특정 div 태그에만 달려 있다면 위와 같은 동작 결과는 확인할 수 없다.
이와 같은 하위에서 상위 요소로의 이벤트 전파 방식을 이벤트 버블링이라고 한다.
버블 정렬 마냥 버블버블하게 묶인다는 의미에서 버블링으로 네이밈된게 아닐까 생각해본다.
자기계발은 복리로 돌아온다
저자는 일이 끝다면 항상 회고라는 활동을 한다.
연말에 1년 회고를 할때 자신에 대한 투자를 얼마나 많이 했나를 본다.
자기계발 (자신에 대한 투자)로 얻는 지식이나 능력들은 복리로 지금 당장의 큰 피드백이 오지 않을수 있지만 이자가 차곡차곡 붙어 기하급수적 배로 돌아오게된다.
더 빠르게 돈을 벌고 싶다면 == 더 빠르게 성장하고 싶다면
어떻게 이율을 높일 것인가
지속적으로 현명한 투자를 하려면 어떻게 할까
지식이나 능력이 쌓여있다면 새로운 지식이나 능력을 더 빠르게 얻을 수 있다.
이는 현명하고 이율이 아주 높은일
#복리 는 아주 대단한 개념 (아인슈타인도 놀랐다! 는 아직 논란이 많은 확인되지 않은 논팩트)
기존 가치가 시간가치가 부여되며 이자의 이자를 얻으며 기하급수적으로 돈이 복사가 된다
복리 이미지
개인뿐만 아니라 조직에도 적용가능하다 GUI, 하이퍼텍스트, 마우스의 고안자인 더글러스 엥겔바트 . Douglas Engelbart 는 작업 단위를 세가지로 나누어 A, B, C 작업을 고안했는데,
A작업은 한 task
B작업은 A작업을 개선하고 강화하는것
C작업은 B작업을 개선하고 강화하는것
여기서 전작업을 개선하고 강화하는것이 복리의 이자 개념
"우리가 더 잘하는 것을 더 잘하게 될수록 우리는 더 잘하는 걸 더 잘 그리고 더 빨리 하게 될 것이다" - 잘함의 복리
개인 생각 : 괜히 잘못된 즉 0이 되는 일을하면 오히려 다음 작업에도 안 좋은 영향을 끼칠 수 있지 않을까? 하지만 이 또한 성장이라 말할 수 있나?
일반적인 조직의 작업 플로우
조직이 일을 하여 결과물을 만들어낸다. 의 사이클이 반복적으로 일어나기만 함 이런식으로는 저번달과 이번달의 차이(이자) 가 없다
복리 조직의 작업 플로우
조직이 만들어낸 결과물을 거름삼아서 다음 주기에 더 높은 위치에서 결과물을 "잘" 만들어낸다.
이런 기술을 #부트스트래핑 이라고 한다.
자기가 신은 신발에 달린 끈 (신발끈이 아닌 신발 뒤쪽에 태그형 끈)을 들어올려 자신의 몸을 공중에 띄운다. 의 뜻을 가지고 있다. 이렇게 작업시 매일 더 나은 작업을 할 수 있다. - 작업의 복리
복리 개념을 효율적으로 다루기 위해서는 다음 2가지를 질문해보자
어떻게 하면 더하기보다 곱하기를 할 수 있을까
어떻게 하면 곱하는 비율과 이자 적용 주기를 단축화시킬 수 있을까
저자의 팁
자신이 이미 갖고 있는 것들을 잘 활용하라
새로운 곱셈만을 찾아가는 이미 있는것들이 사라질 수 있다. 책 읽고 찍어서 인스타에 올리지 말고 그 지식을 얼마나 어떻게 활용하는지 반성하자
이미 갖고 있는것들을 하이퍼링크로 연결해라 (제텔카스텐)
도입할때 충돌을 시도하라
외부 자극을 수용하고 소화하라
내부에만 있다가는 일정 수준에서 체류될 수 있다. 외부 자극을 주기적으로 받되, 빠르게 자기화 시켜라
외부와 내부의 충돌을 해결하는데 노력해라 서로에게 상생적일 수 있도록
자신을 개선하는 프로세스에 대해 생각해보라
자신을 반성하는 즉 회고하는 프로세스를 만들어라
위 과정을 또 어떻게하면 개선할 수 있을지 고민해라 A, B, C 작업
빠른 피드백을 받아라
사이클 타임을 줄이고 완벽하기보다 한달 혹 한주씩 (스프린트) 자주 실패하고, 이 실패에서 학습해라
자신의 능력을 높여주는 도구와 환경을 점진적으로 만들어라
마인크래프트 서바이벌처럼 현재 단계가 다음 단계를 쉽게 이루는데 도움이 될 수 있도록
이벤트란 여러분이 프로그래밍하고 있는 시스템에서 일어나는 사건 혹은 발생을 뜻한다. 이는 여러분이 원한다면 사건이나 발생들에 어떠한 방식으로 응답할 수 있도록 시스템이 말해주는 것이다.
target은 이벤트가 일어날 객체를 의미한다. 아래 코드에서 타겟은 버튼 태그에 대한 객체가 된다.
<input type="button" onclick="alert(window.location)" value="alert(window.href)" />이벤트의 종류를 의미한다. 위의 예제에서는 click이 이벤트 타입이다. 그 외에도 scroll은 사용자가 스크롤을 움직였다는 이벤트이고, mousemove는 마우스가 움직였을때 발생하는 이벤트이다.
이벤트의 종류는 이미 약속되어 있다. 여러가지 이벤트 종류를 보고 싶다면 링크를 타고 들어가 봐보자
이벤트가 발생했을 때 동작하는 코드를 의미한다. 위의 예제에서는 alert(windwo.location)이 여기에 해당한다.
이벤트 등록 방법에는 3가지가 있다.
인라인 방식은 이벤트를 이벤트 대상의 태그 속성으로 지정하는 것이다. 다음은 버튼을 클릭했을 때 Hello world를 경고창으로 출력한다.
이벤트가 발생한 대상을 필요로하는 경우 this를 통해서 참조할 수 있다.
<!--자기 자신을 참조하는 불편한 방법-->
<input type="button" id="target" onclick="alert('Hello world, '+document.getElementById('target').value);" value="button" />
<!--this를 통해서 간편하게 참조할 수 있다-->
<input type="button" onclick="alert('Hello world, '+this.value);" value="button" />프로퍼티 리스너 방식은 이벤트 대상에 해당하는 객체에 프로퍼티로 이벤트를 등록하는 방식이다. 인라인 방식에 비하여 HTML과 JavaScript를 분리할 수 있다는 점에서 선호하는 방식이다.
이벤트가 발생한 대상을 필요로하는 경우 파라미터로 넘어온 이벤트객체에 target을 체이닝하여 사용할 수 있다.
<body>
<input type="button" id="target" value="button" />
<script>
var t = document.getElementById('target');
t.onclick = function(event){
alert('Hello world, '+event.target.value)
}
</script>ie8 이하 버전에서는 이벤트 객체를 핸들러의 인자가 아니라 전역객체의 event 프로퍼티로 제공한다. 또한 target 프로퍼티ㅗ 지원하지 않는다. 아래는 이 문제를 해소하기 위한 코드다.
<input type="button" id="target" value="button" />
<script>
var t = document.getElementById('target');
t.onclick = function(event){
var event = event || window.event;
var target = event.target || event.srcElement;
alert('Hello world, '+target.value)
}
</script>장점 : 인라인 방식에 비하여 관심사의 분리가 가능하다
단점 : 이벤트 타입별로 오로지 하나의 이벤트 리스너만 등록이 가능하다.
addEventListener는 이벤트를 등록하는 가장 권장하는 방식이다. 이 방식을 이용하면 여러개의 이벤트 핸들러를 등록할 수 있다.
<input type="button" id="target" value="button" />
<script>
var t = document.getElementById('target');
t.addEventListener('click', function(event){
alert('Hello world, '+event.target.value);
});
</script>이 방식은 ie8 이하에서는 호환되지 않는다. ie에서는 attachEvent 메서드를 사용해야 한다.
var t = document.getElementById('target');
if(t.addEventListener){
t.addEventListener('click', function(event){
alert('Hello world, '+event.target.value);
});
} else if(t.attachEvent){
t.attachEvent('onclick', function(event){
alert('Hello world, '+event.target.value);
})
}이 방식의 중요한 장점은 하나의 이벤트 대상에 복수의 이벤트 타입 리스너를 등록할 수 있다는 점이다.
<input type="button" id="target" value="button" />
<script>
var t = document.getElementById('target');
t.addEventListener('click', function(event){
alert(1);
});
t.addEventListener('click', function(event){
alert(2);
});
</script>이벤트 객체를 이용하면 복수의 엘리먼트에 하나의 리스너를 등록해서 재사용할 수 있다.
<input type="button" id="target1" value="button1" />
<input type="button" id="target2" value="button2" />
<script>
var t1 = document.getElementById('target1');
var t2 = document.getElementById('target2');
function btn_listener(event){
switch(event.target.id){
case 'target1':
alert(1);
break;
case 'target2':
alert(2);
break;
}
}
t1.addEventListener('click', btn_listener);
t2.addEventListener('click', btn_listener);
</script>장점 : 하나의 이벤트 대상에 복수의 이벤트 리스너를 등록가능하며 이벤트 리스너를 취소할 수 있다.
단점 : attachEvent()의 경우 this의 값이 이벤트가 바인드되어 있는 요소 대신에, window객체에 대한 참조가 된다.
var i;
var els = document.getElementsByTagName('*');
// Case 1
for(i=0 ; i<els.length ; i++){
els[i].addEventListener("click", function(e){/*do something*/}, false);
}위의 경우 반복이 돌때마다 새로운 익명 핸들러 함수가 생성된다.
그에 반해 아래의 경우에는 이전에 선언한 동일한 함수를 이벤트 핸들러로 사용하므로, 메모리 소비가 줄어든다.
// Case 2
function processEvent(e){
/*do something*/
}
for(i=0 ; i<els.length ; i++){
els[i].addEventListener("click", processEvent, false);
}또한 첫번째 경우에는 removeEventListener 를 호출할 수 없다. 익명 함수에 대한 참조가 유지되지 않기 때문이다. (루프가 생성할 수 있는 여러개의 익명 함수 중 하나에 보관되지 않는다.) 두 번째 경우에는 processEvent가 함수 참조이기 때문에, myElement.removeEventListener("click", processEvent, false)를 수행할 수 있다.
사실, 메모리 소비와 관련하여, 함수 참조를 유지하는 것은 진짜 문제가 아니다. 오히려 정적 함수 참조를 유지하는 것이 부족할 뿐이다.
아래의 두 경우 모두 함수 참조가 유지되지만, 각 반복에서 재정의 되므로 정적이 아니다.
// For illustration only: Note "MISTAKE" of [j] for [i] thus causing desired events to all attach to SAME element
// Case 3
for(var i=0, j=0 ; i<els.length ; i++){
/*do lots of stuff with j*/
els[j].addEventListener("click", processEvent = function(e){/*do something*/}, false);
}
// Case 4
for(var i=0, j=0 ; i<els.length ; i++){
/*do lots of stuff with j*/
function processEvent(e){/*do something*/};
els[j].addEventListener("click", processEvent, false);
}세 번째 경우에는 익명 함수에 대한 참조가, 반복될 때 마다 다시 할당된다. 네 번쨰 경우에는 전체 함수 정의가 변경되지 않지만, 새로운 것처럼 반복적으로 정의되고 있고 그래서 정적이지 않다. 따라서 간단하게 여러개의 동일한 이벤트 리스너인 것처럼 보이지만. 두 경우 모두 각 반복은 핸들러 함수에 대한 고유한 참조로 새로운 리스너를 생성한다. 그러나 함수 정의 자체는 변경되지 않으므로, 모든 중복 리스너에 대해 같은 함수가 여전히 호출될 수 있다.
또란 두 경우 모두 함수 참조가 우지되었지만, 각 가산에 대해 반복적으로 재정의 되었습니다. 위에서 사용했던 remove문으로는 리스너를 제거할 수 있지만, 마지막으로 추가한 리스너만 제거됩니다.
현대에 설계된 많은 프로그래밍 언어들은 표현식과 문장의 차이는 따로 TIL에 정리하여 올릴 정도로 차이가 모호하다.
결론부터 말하겠다.
ALGOL-60을 제작할때 사용된 BNF에 따르면, 표현식은 그 존재로 값을 들어내는 식 (ex : 1, 2 + 3) 이고, 문장은 작업을 수행하는 문장을 말한다. (ex : console.log('asdf'))
초기의 프로그래밍 언어들은 이 점을 구문적으로만이 아닌, 프로그래밍적으로 매우 명확히 나눴다.
예로 포트란은 표현식을 문장으로 사용하면 오류를 발생시킨다.
하지만 C언어는 표현식을 문장으로 사용해도 설령 그 값이 아무런 작업 수행을 하지 않더라도, 실행에 아무런 오류가 생기지 않는다.
1 + 3; // 이게 된답니다.현대의 C로부터 파생된 대부분의 프로그래밍 언어는 C언어처럼 구문적으로만 표현식과 문장을 구분하게 되었다
이 글은 비동기 처리와 Promise에 대한 이해 기반이 깔려있다는것을 전제로 작성한 글이다.
사전 지식은 미리 숙지하고 오는것이 좋다.
async와 await은 자바스크립트의 비동기 처리 패턴 중 가장 최근에 나온 문법이다. 기존의 비동기 처리방식인 콜백 함수와 프로미스의 단점을 보완하고 사용시 높은 가독성을 가진 코드를 작성가능하다.
개발자들은 위에서부터 아래로 한 줄 한 줄 절차적으로 차근히 읽으면서 사고하는 것이 이해하기 편리하다.
하지만 콜백은 한 줄 한 줄 읽기 쉽지 않다.
function logName() {
// 아래의 user 변수는 위의 코드와 비교하기 위해 일부러 남겨놓았습니다.
var user = fetchUser("domain.com/users/1", function (user) {
if (user.id === 1) {
console.log(user.name);
}
});
}콜백을 모르는 사람이라면 위 코드가 이해되지 않을 것이다.
한번 아래와 같이 간단하게 생각해보자
// 비동기 처리를 콜백으로 안해도 된다면..
function logName() {
var user = fetchUser("domain.com/users/1");
if (user.id === 1) {
console.log(user.name);
}
}서버에서 사용자 데이터를 불러와서 변수에 담고, 사용자 아이디가 1이면 사용자 이름을 출력한다.
이럴때 async await 사용하면 된다.
async function logName() {
var user = await fetchUser("domain.com/users/1");
if (user.id === 1) {
console.log(user.name);
}
}async function 함수명() {
await 비동기_처리_메서드_명();
}먼저 함수의 앞에 async라는 예약어를 붙인다. 그러고 나서 함수의 내부 로직 중 HTTP 통신이나 파일읽기등 비동기 처리 코드 앞에 await을 붙인다. 여기서 주의할점은 비동기 처리 메서드가 꼭 프로미스 객체를 반환해야 await가 의도한 대로 동작한다.
await를 사용하지 않았다면 데이터를 받아온 시점에 콘솔을 출력할 수 있게 콜백 함수나 .then()등을 사용해야 했을 것이다. 하지만 async await 문법 덕택에 비동기에 대해 따로 걱정할 필요가 없다.
async & await에서 예외를 처리하는 방법은 바로 try catch이다. 프로미스에서 에러 처리를 위해 .catch()를 사용했던 것처럼 async에서는 catch {} 를 사용하면 된다.
js에서 함수를 생성하는 방법은 기본적으로 3가지가 있다.
아래와 같이 변수에 함수를 담는 방식이 함수 표현식이다.
var func1 = () => {
console.log("함수");
}
var func2 = func1();아래와 같이 우리가 일반적으로 function 키워드를 이용하여 선언하는 방식이 함수 선언문이다.
function func() {
console.log("함수");
}Function() 생성자는 아래와 같이 n개의 매개변수와 하나의 실행문들을 문자열로 받는다.
new Function(functionBody)
new Function(arg1, functionBody)
new Function(arg1, ... argN, functionBody)매개변수 부분에서 주의깊게 알고 있어야 할 부분이 있는데, 만약 매개변수로 a, b = 42, [x, y]를 전달하고 싶다면 다음과 같은 방법들이 있다.
"a", "b = 42", "[x, y]" 또는 "a, b = 42", "[x, y]" 또는 "a, b = 42, [x, y]" 와 같이 , 로 구분만 해준다면 문자열 안에 적어도 밖에 적어도 상관이 없다.
const func = new Function('console.log("함수")');create-react-app의 public 디렉토리 안을 확인해보면 Robots.txt가 있는것을 알 수 있다.
이 파일의 용도는 검색엔진봇에게 사이트 및 웹페이지를 수집할 수 있도록 허용하거나 제한하는 여부를 명시해주기 위함이다. 항상 웹사이트의 루트 디렉토리에 위치해야 한다.
간혹 특정 목적을 위하여 개발된 웹 스크래퍼 또는 일부 불완전한 검색엔진봇은 Robots.txt의 규칙을 준수하지 않을 수 있다. 그러므로 Robots.txt 에 보안적으로 의존해서는 안된다.
Robots.txt 파일에 작성된 규칙은 같은 호스트, 프로토콜 및 포트 번호 하위의 페이지에 대해서만 적용된다.
http://www.example.com/robots.txt 의 내용은 http://example.com/ 와 https://example.com/ 에는 적용되지 않는다는 말이다.
User-agent 속성은 규칙을 설정할 사용자 에이전트를 적는 용도이다. 모든 사용자 에이전트에 적용시키기 위해선 애스터리스크를 작성해주면 된다.
Allow 속성은 사용자에이전트에게 수집을 허용하고 싶은 페이지를 설정할 수 있고, Disallow 속성은 허용하고 싶지 않은 페이지를 설정할 수 있다.
위 두 속성의 값으로 /asdf*를 작성하면 /asdf 로 시작하는 모든 페이지들 (ex : /asdfqwer, asdf-asdf)를 해당시킬 수 있다. 루트페이지를 타게팅 하고 싶다면 /$를 사용하면된다.
정규 표현식 (Regular Expression)는 문자열을 검색하거나, 혹은 치환하거나 어떠한 문자열을 추출하고자 할때 주로 쓰인다.
문자열 그대로를 regex에 사용할 수 있다.
Regex
Text
Text
ABC(Text) (Text) | (Text)y
plaintext가 아닌 모르는 문자까지 찾고 싶다면 '.' (Any Chracter) 을 사용하면 된다. ('.' 문자는 모든 문자 "하나"와 일치한다.)
Regex
h.s
Text
I was fifty years old to-day. Half a century (has) hurried by since I first lay in my mother's wondering arms. To be sure, I am not old; but I can no longer deceive myself into believing that I am still young. After all, the illusion of youth is a mental habit consciously encouraged to defy and face down the reality of age. If, at twenty, one feels that he (has) reached man's estate he, nevertheless, tests (his) strength and abilities, (his) early successes or failures, by the temporary and fictitious standards of youth.
'.' 문자 자체를 검색하고 싶다면, 역슬래시(\)를 사용하면 된다.
참고로 역슬래시 또한 '\' 를 붙여서 사용하면 '\' 문자 자체를 검색가능하다.
모든 문자를 나타낼 수 있는 '.' 과 달리, 대괄호([])를 사용하여 문자 집합을 표현할 수 있다.
Regex
f[ie]
Text
(fi)re
siren
(fe)male
(fi)nally
apple
airport
문자 집합은 한마디로 문자 집합 중 하나가 일치하는 경우를 의미한다고 생각하면 된다.
Regex
...[0123456789]
Text
abcd.txt
abce.txt
(abc0).txt
abcf.txt
(abc1).txt
(abc2).txt
(abc3).txt
매치된 문자열을 살펴보면, 아무 문자 3개 뒤에 숫자가 등장해야만 매치가 되는 것을 볼 수 있다. 하지만 저렇게 일일히 숫자를 다 쓰는것은 효율적이지 않기 때문에 regex에서는 하이픈(-) 을 제공한다.
Regex
...[0123456789]
Regex
...[0-9]
위 두 코드는 똑같은 동작을 하는 regex 코드이다. 또한 숫자가 아닌 문자에서도 [a-z]나 [A-Z] 같이 사용가능하다. (영어가 아니더라도 아스키 문자라면 무엇이든지 사용할 수 있다. Range의 범위 지정시 앞에는 작은 값이 나와야 한다.)
문자 범위 여러개를 [a-zA-Z0-9]와 같이 문자 집합 하나에 포함시킬 수 있다.
특정 문자들을 제외하고 문자열을 검색하고 싶을때는 캐럿(^) 을 사용하면 된다.
Regex
...[^0-9]\.
Text
(abcd.)txt
(abce.)txt
abc0.txt
(abcf.)txt
abc1.txt
abc2.txt
abc3.txt
정규 표현식에서의 메타 문자는 이미 사전에 약속되어진 문자를 뜻합니다. 사전에 약속된 문자이기에, 메타 문자는 그대로 쓸 수 없으며 만약 문자로 쓰려면 역슬래시를 덧붙여 주어야 합니다.
| 메타 문자 | 설명 |
|---|---|
| \v | 수직 탭 |
| \n | 개행 |
| \f | 폼 피드 |
| \r | 캐리지 리턴 |
| \t | 탭 |
| [\b] | 백스페이스 |
| \d | [0-9]와 동일한 기능 |
| \D | [^0-9]와 동일한 기능 |
| \w | [a-zA-Z0-9_]와 동일한 기능 |
| \W | [^a-za-z0-9_]와 동일한 기능 |
| \s | [\f\n\r\t\v]와 동일한 기능 |
| \S | [^\f\n\r\t\v]와 동일한 기능 |
| \x | 16진수 숫자와 일치 |
| \0 | 8진수 숫자와 일치 |
연속된 문자를 찾고 싶을때는 '+' 란 메타 문자를 사용할 수 있다.
Regex
\w+@\w+\.\w+
Text
([email protected])
id@daumnet
([email protected])
([email protected])
id@google
'+' 문자는 문자가 하나 이상 일치해야만 하는데 문자가 아예 없거나 하나 이상일 경우에는 '*' 문자를 문자 또는 문자 집합 뒤에 써주면 된다.
Regex
bo+
Text
b
(bo)
(boo)
Regex
bo*
Text
(b)
(bo)
(boo)
문자가 없거나, 하나만 있으면 일치하게 하고 싶은 경우에는 '?'를 사용하면 된다.
Regex
aabb?cc
Text
(aabcc)
(aabbcc)
aabbbbcc
| 수량자 | 설명 |
|---|---|
| {n} | n개만을 찾는다. |
| {n,} | n개 이상을 찾는다. |
| {n, m} | 최소 n개, 최대 m개의 경우를 찾는다. |
Regex
[0-9]{3}
Text
12
(123)
(123)4
(456)
(456)7
(456)78
Regex
[0-9]{3,}
Text
12
(123)
(1234)
(456)
(4567)
(45678)
Regex
[0-9]{3,4}
Text
12
(123)
(1234)
(456)
(4567)
(4567)8
+와 _ 그리고 {n,}은 탐욕적 수량자에 속한다. 왜 이렇게 불리우냐 하면 가능한 가장 큰 덩어리를 찾으려 하기 때문이다. 반면에 게으른 수량자는 가능한 가장 적은, 최소의 덩어리를 찾는다.+, _, {n,}은 탐욕적 수량자지만, 뒤에 ? 문자를 덧붙이면 게으른 수량자(+?, *?, {n,}?)가 된다. 예시를 보는게 쉽다.
Regex
<b>.*</b>
Text
(<b>BOLD!</b><hr><b>BOLD!</b>)
Regex
<b>.*?</b>
Text
(<b>BOLD!</b>)<hr>(<b>BOLD!</b>)
탐욕적 수량자와는 달리 최소의 문자 덩어리만 일치하는게 게으른 수량자이다.
하위 표현식이란, 특정 패턴, 표현식을 하나의 항목으로 처리하는 것을 말한다. 이 하위 표현식을 사용하려면 소괄호를 사용해야 한다. 소괄호 역시 메타 문자이기 때문에, 소괄호 그 자체를 찾으려면 '\'로 이스케이프 해줘야 한다.
Regex
(abcc)
abcabc
Text
(<b>BOLD!</b><hr><b>BOLD!</b>)
Regex
(abc){2}
Text
abcc
(abcabc)
위에 쓰인 정규 표현식에서 (abc)는 하위 표현식이다. 하위 표현식으로 사용되었기에, abc는 하나의 항목으로 처리된다.
하위 표현식의 중첩이란 말 그대로 표현식의 자식으로 표현식을 둘 수 있다는 얘기다.
둘 중 하나라도 일치할 경우를 생각해서 OR 연산자 '|'를 사용할 수 있다.
Regex
a|b
Text
(a)(b)
(a)
(a)|(b)
말 그대로 역으로 참조하는 것을 나타냅니다. 정규 표현식에서는 패턴의 일부를 하위 표현식으로 묶으면, 첫번째로 나타나는 부분 문자열을 버퍼에 저장하고 따라오는 문자열에서 인덱스를 사용하여 버퍼에 저장된 문자열과 같은 문자열을 역참조 할 수 있다.
Regex
\b([a-z]+) \1\b
Text
why (so so) serious
위의 정규표현식을 자세히 살펴보면, \b라는 메타 문자가 사용되었다. 이 \b는 단어의 경계를 구분짓는 메타 문자로, 여기 텍스트에선 공백이 단어와 단어를 구분짓는 문자이므로 공백은 \b와 같다.
위에 예시에서는 [a-z]+를 하위 표현식으로 묶었다. 이렇게 묶은 하위 표현식은 임시 버퍼에 저장되고, 이 임시 버퍼에 접근하려면 \n 을 통해 각 버퍼에 접근할 수 있습니다. 여기서 n은 개행 문자가 아니라 n은 1이상 99이하의 인덱스 번호이다. 이런 역참조를 통해, 반복되는 문자를 쉽게 찾을 수 있다. 참고로, 두자리 이상이 넘어가는 숫자에 해당하는 역참조가 존재하고 해당 그룹 숫자에 해당하는 그룹이 있을 경우 역참조로 간주되나, 아닐 경우에는 구문 분석 오류로 간주된다.
전방 탐색이란 작성한 패턴에 일치하는 영역이 존재햐여도 그 값이 제외되어서 나오는 패턴입니다. 전방 탐색 기호는 ?= 이며, = 다음에 오는 문자가 일치하는 영역에서 제외됩니다.
Regex
.+(?=:)
Text
(http)://www.abc.com
(https)://www.abc.com
(http)://www.abc.net
위에 쓰인 정규 표현식을 살펴보자면, 아무 문자가 한번 이상 연속적으로 등장하고 콜론 문자가 등장하는 문자열 중에서, 콜론 문자는 일치하는 영역에서 제외된다. 만약, 전방 탐색 기호를 쓰지 않고 콜론을 그대로 썼었다면, 콜론이 일치되는 영역에서 제외되지 않고 포함되어 버린다.
후방 탐색은 뒤에 있는 문자열을 탐색한다. 후방 탐색의 기호는 ?<=이다. 전방 탐색 기호의 ?와 = 사이에 < 기호가 추가된 것이다. 후방 탐색도, 전방 탐색의 사용법과 똑같다.
Regex
(?<=\$)[0-9.]+
Text
1: $(600.4)
2: $(10.25)
3: $(47.33)
4: $(112.34)
위에 쓰인 정규 표현식을 살펴보니, 후방 탐색 기호 뒤에 메타 문자인 $ 가 쓰였다. 그렇기에, \로 이스케이프 해주어야한다.
그 후에, 숫자와 점으로 구성된 문자 집합이 연속된 문자열을 탐색한다. 일치된 텍스트를 살펴보면, $ 기호 뒤에있는 문자들만 일치했음을 확인할 수 있다.
참고로, 전방 탐색과 후방 탐색은 너비가 0이며, 역참조가 불가능 하다.
너비가 0이라는 말이 정규표현식을 배우면서 조금씩 나오게되는 표현일텐데 본인은 검색문자열에서 차지하는 부분이 0이다라고 이해했다.
이번에는 "부정형" 전후방탐색이라는 것에 주의를 기울여야 한다. 전에 보았던 탐색 기호들은 모두 "긍정형" 탐색이었다.
밑에 표를 봐보자.
| 탐색 기호 | 설명 |
|---|---|
| (?=) | 긍정형 전방탐색 |
| (?!) | 부정형 후방탐색 |
| (?<=) | 긍정형 전방탐색 |
| (?<!) | 부정형 후방탐색 |
위의 표에서 부정형 탐색 기호에 ! 문자가 들어갔음을 확인할 수 있다. 긍정형 전후방탐색이 = 뒤 혹은 앞에 있는 문자와 일치하는 텍스트를 탐색하는 것이라면, 부정형 전후방탐색은 일치하지 않는 텍스트를 탐색하는 것이다.
Regex
\b(?<!\$)\d+
Text
$10 (5) $6 (77) $788
위에 쓰인 정규 표현식을 살펴보면, 단어 경계(\b)와 부정형 후방탐색(?<!)이 쓰였고, 부정형 후방탐색 기호 뒤에 $ 문자가 등장했다. 그 후에는 연속된 숫자(\d+)를 의미하므로 $ 뒤에 숫자가 들어간 영역은 제외하겠다는 소리다. $ 가 안들어가고 숫자만 달랑 있는 영역만 탐색하는 것이다. 단어 경계만 설명을 보충하자면, 단어와 단어를 구분짓는 경계이다. 여기서는 공백이 단어와 단어를 구분짓는 경계인 셈이다.
the-moment 테스팅 서버와 연결하던중에 겪은 오류이다.
localhost 에서 새로운 기능을 테스트하기 위해 baseURL을 변경후 서버를 실행시켰을때 다음과 같은 에러가 떴다.
말 그대로 SSL/TLS(https) 프로토콜 예외로 인해 발생하는 에러이다.
Cipher Suites를 브라우저에서 처리 할 수 없는경우1번 서버가 낮은 버전의 프로토콜을 사용하는 경우에는 브라우저에서 낮은 버전의 프로토콜을 사용 가능하도록 옵션을 변경해 준다.
2번 서버에서 응답한 Cipher Suites를 브라우저에서 처리할 수 없는경우에는 두 가지 해결 방법이 있다.
IE Edge, FireFox, Opera 등등 다른 브라우저를 사용해보자.
서버관리자가 수정 할 수 있는 방법으로 최신 프로토콜을 사용할 수 있도록 WAS를 업그레이드, 설정하거나, 대부분의 브라우저에서 지원하는 Cipher Suites를 사용하도록 설정한다.
3번 본인의 경우가 3번이었다. 접근하려는 테스팅 서버에는 ssl이 적용되지 않은 상태였는데 친구가 baseURL을 잘못 수정하여 http"s"를 제거하지 않은 상태에서 접근하려하여 발생한 에러였다.
http://1004lucifer.blogspot.com/2018/11/chrome-errsslprotocolerror.html
script 태그 엘리먼트를 공부하던중 이건 나중에 까먹을것 같아서 TIL에 정리한다.
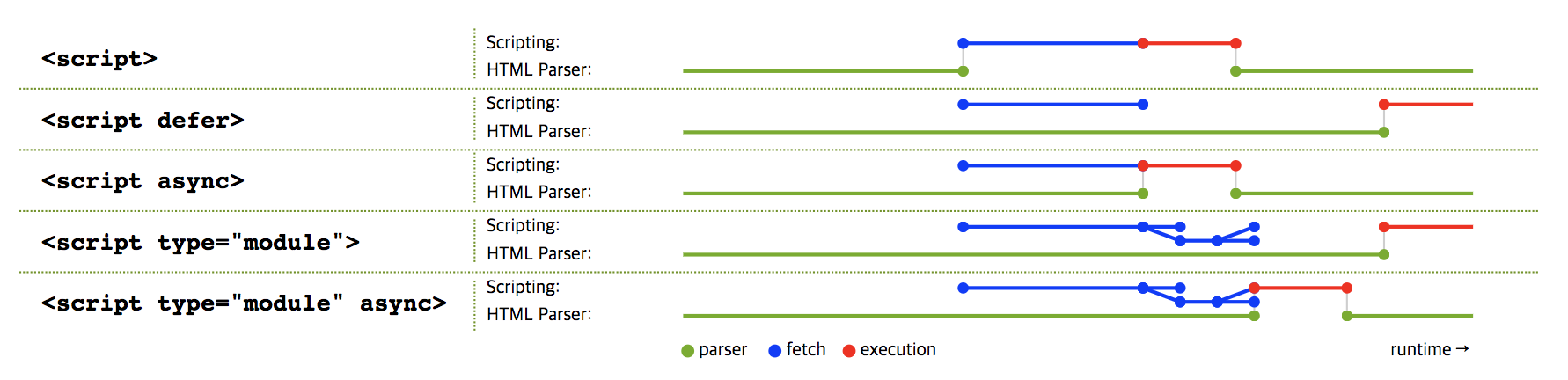
async, defer 스크립트를 논-블로킹으로 읽어들이고 싶을 때 사용하는 불리언 속성들이다.
스크립트 엘리먼트는 default로 HTML parser의 동작을 중단하고 스크립트를 다운로드하는 블로킹 모드로 동작한다.
이 방법은 여러 스크립트 엘리먼트가 있을 경우에도 실행 순서를 보장할 수 있다는 장점은 있지만 (</body> 앞에 작성했을때의 경우) , 스크립트 파일을 다운로드하는 동안에 파싱이 중단되므로 웹 페이지의 성능을 저하시킬 수 있다.
ㄴ 각각의 방법의 프로세스 시각화
그런데 async 또는 defer 속성을 사용하면 다운로드는 백그라운드에서 진행되고 스크립트를 실행하는 동안만 HTML 파싱을 중단하는 소위 논-블로킹 모드로 동작한다. 따라서 웹 페이지는 두 속성을 사용하지 않았을 때보다 더 빠르게 표시될 수 있다.
두 속성에는 두 가지 차이가 있다. 하나는 defer 는 다운로드가 먼저 끝나더라도 파싱이 완료될 때까지 기다렸다가 스크립트를 실행하지만, async 는 다운로드가 끝나면 바로 스크립트를 실행한다는 것이다.
나머지 하나는 defer 는 두 속성 중 아무 것도 사용하지 않았을 때와 마찬가지로 실행 순서를 보장해주지만 (</body> 앞에 작성했을때의 경우가 아니면 async의 문제점이 일어날 수 있다.) , async는 다운로드 받은 순서대로 실행되기 때문에 실행 순서가 스크립트 엘리먼트의 출현 순서와 다를 수 있다는 것이다.
구식 브라우저에서는
defer만 지원하기도 해서 다음과 같이 두 속성을 모두 적어두기도 한다.
<script defer async src="async.js"></script>위 예제와 같이 작성하면 async를 지원하는 최신 브라우저에서는 async가 defer에 우선하기 때문에 async의 특성을 따르고 구식 브라우저에서는 defer의 특성을 따른다.
모듈 스크립트에는 async만 사용할 수 있는데, async가 설정되어 있으면 관련 모듈의 다운로드가 끝난 후 바로 스크립트를 실행하지만 default인 경우 마치 defer 처럼 웹 페이지 파싱이 끝날 때까지 기다렸다가 실행한다(위 이미지 참조).
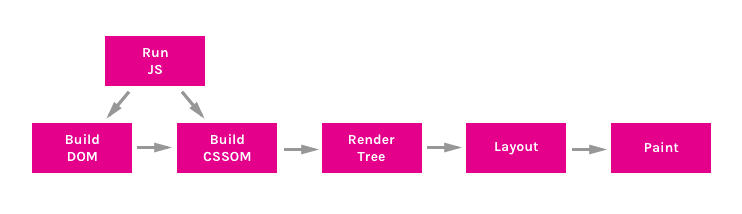
브라우저가 화면에 나타나는 요소를 렌더링 할 때, 웹킷(Webkit)이나 게코(Gecko) 등과 같은 렌더링 엔진을 사용한다. 렌더링 엔진이 HTML, CSS, JS로 렌더링할 때 CRP 라는 프로세스를 사용하며 다음 단계들로 이루어진다.
1. DOM 트리 구축
DOM 트리는 완전히 구문 분석된 HTML의 Object 모델이다. 루트 요소로 시작하여 elem/txt에 대한 노드가 만들어진다.
HTML에서 다른 요소 내에 중첩된 요소는 자식 노드로 표시되며 각 노드에는 해당 요소의 속성이 포함된다.
HTML은 부분적으로 실행될 수 있다.
2. CSSOM 트리 구축
CSSOM은 DOM과 연관된 스타일의 Object 모델이다.
CSS는 렌더링 차단 리소스로 간주된다. 즉, 리소스를 완전히 파싱하지 않으면 렌더링 트리를 구성 할 수 없다.
CSS는 현재 장치에 적용되는 경우에만 렌더링 차단 리소스로 간주된다.
미디어 쿼리가 해당하지 않는 경우 해당 미디어 쿼리의 스타일 시트는 렌더링 차단 리소스로 간주되지 않는다.
CSS “script blocking”일 수도 있다. 왜냐면 js파일은 CSSOM이 생성 될 때까지 기다려야 하기 때문이다.
3. Javascript 실행
JS는 파서 차단 리소스로 간주된다.
4. 렌더링 트리 구축
렌더링 트리는 DOM과 CSSOM을 조합하여 페이지에 표시되는 내용을 나타내는 트리다. display: none을 사용하여 CSS로 숨겨진 요소를 포함되지 않는다.
5. 뷰포트를 기준으로 렌더트리의 각 노드들의 위치나 크기를 계산
자원 다운로드를 연기함으로써 주요 리소스들의 수를 최소화하기, 필수적인 요청 횟수 최적화하기, 중요 자원 불러오는 순서를 최적화하고, 중요 경로 길이를 최소화하기
MDN CRP : https://developer.mozilla.org/ko/docs/Web/Performance/Critical_rendering_path
구글 CRP/렌더트리 생성 : https://developers.google.com/web/fundamentals/performance/critical-rendering-path/render-tree-construction
naver 브라우저 동작 원리 : https://d2.naver.com/helloworld/59361
스택오버플로우 답변이 아주 야무짐 : https://stackoverflow.com/questions/34269416/when-does-parsing-html-dom-tree-happen
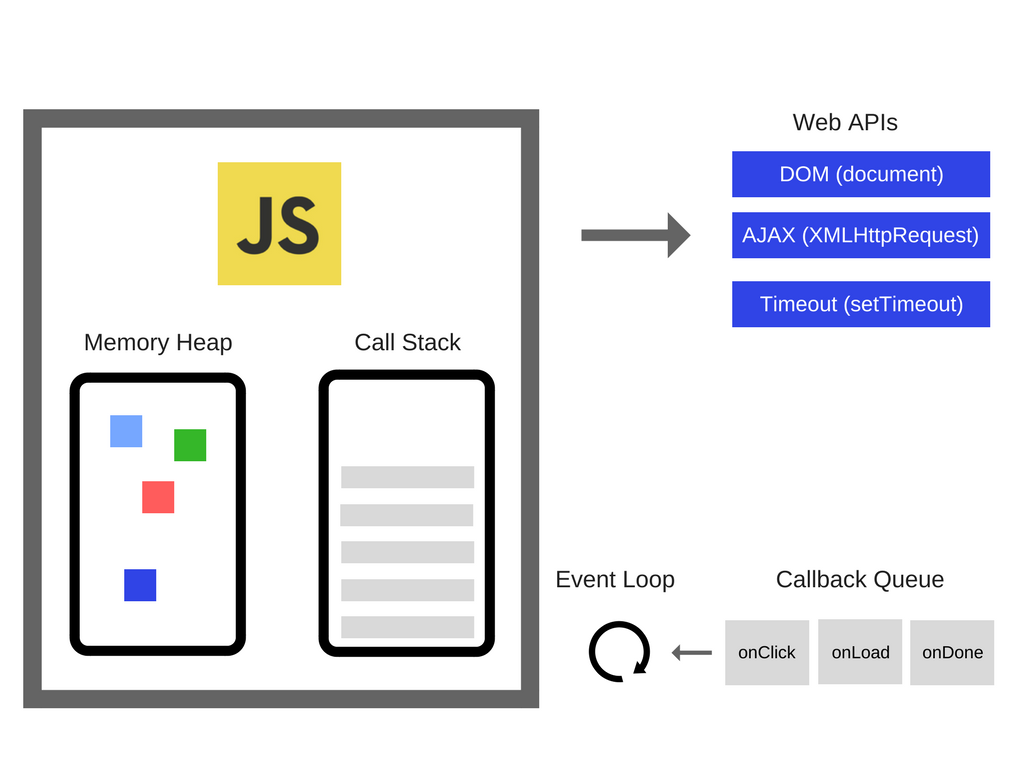
자바스크립트 엔진은 Memory Heap과 Call Stack으로 구성되어 있다.
자바스크립트는 싱글 스레드 프로그래밍 언어이다.
이 의미는 즉 Call Stack이 하나라는 이야기이다.
(하나하나씩 처리한다는 의미로 생각하면 될 것 같다.)
Memory Heap : 메모리 할당이 일어나는 곳
프로그램에 선언한 변수, 함수 등이 담겨져 있다.
Call Stack : 코드가 실행될 때 쌓이는 곳이다. Stack으로 쌓이기 때문에 이름에 Stack이 들어간다.
그림의 오른쪽에 있는 Web API는 JS Engine의 밖에 그려져 있다.
즉, 자바스크립트 엔진이 아니다.
Web API는 브라우저에서 제공하는 API로, DOM, Ajax, Timeout 등이 있다.
Call Stack에서 실행된 비동기 함수는 Web API에 보내고 Web API는 콜백함수를 Callback Queue에 보관한다.
비동기적으로 실행된 콜백함수가 보관되는 영역이다.
예를 들어 setTimeout에서 타이머 완료 후 실행되는 함수, 이벤트 리스너에 등록된 핸들러 함수(콜백 함수)등이 보관된다.
Event Loop는 Call Stack과 계속 반복하여(Loop) Callback Queue의 상태를 체크하여, Call Stack이 빈 상태가 되면, Callback Queue의 첫번째 콜백을 Call Stack으로 밀어넣는다. 이러한 반복적인 행동을 틱(tick) 이라 부른다.
자바스크립트는 싱글 스레드 프로그래밍 언어라 한번에 하나씩 밖에 실행할 수 없다. 그러나 Web API, Callback Queue, Event Loop 덕분에 멀티 스레드처럼 보여진다.
HTML <base> 요소는 문서 안의 모든 상대 URL이 사용할 URL을 지정한다. 문서에는 하나의 `요소만 존재할 수 있다.
문서의 기준 URL을 스크립트에서 접근해야할 땐 document.baseURI을 사용할 수 있다. 문서에 <base>요소가 존재하지 않을 때 baseURI의 기본값은 location.href이다.
이 요소는 전역 특성을 포함한다.
다음 특성 중 하나라도 지정한 경우, tkdeo URL을 특성에 사용한 모든 요소보다
<base>가 앞에 위치해야 한다.
href
문서 내 상대 URL이 사용할 기준 URL. 절대 및 상대 URL을 사용할 수 있다.
target
target 속성을 명시하지 않은 , , 또는
요소가 탐색을 유발했을 때, 그 결과를 보여줄 기본 브라우징 맥락. 키워드나 저작자 정의 이름으로 지정한다.<base>요소가 여러 개 존재하는 경우 첫 href와 첫 target만 사용하며 나머지는 모두 무시한다.
HTML의 Canvas.md 파일에 오타가 있습니다.

application softwar 혹은 application program 의 준말이다.
응용 소프트웨어란 말이 바로 이 application software 의 번역어로, 운영체제를 제외한 나머지 소프트웨어/프로그램을 말한다.
특정 목적을 위해 제작된 프로그램을 의미한다. 프로그램이란 거시적으로는 명령 코드의 집합체를 의미하고, 이를 세분화 하면 크게 시스템 프로그램과 응용 프로그램으로 나뉜다.
시스템 프로그램은 운영체제를 의미하고 응용 프로그램이 바로 애플리케이션을 의미한다.
그렇다면 왜 하필 '응용' 프로그램일까? 답은 간단하다.
시스템 프로그램을 이용하고 응용해서 특정 기능만 하도록 새로 만들어낸 프로그램이니 응용 프로그램이라고 하는 것이다.
액션이라는 객체를 사용하여 어플리케이션 상태를 관리하고 업데이트하기 위한 패턴이자 라이브러리를 redux라고 한다.
상태가 예축 가능한 방식으로만 업데이트될 수 있도록 보장하는 규칙과 함께 전체 어플리케이션에서 사용해야 하는 상태를 가지고 있는 중앙 저장소 역할을 한다.
하지만 동일한 상태를 공유하고 사용해야 하는 각각의 구성 요소가 있는 경우, 특히 해당 구성 요소가 어플리케이션의 다른 부분에 있는 경우 복잡해질 수 있다. 때때로 이것은 상위 구셩 요소에서 상태를 끌어올리는것으로 해결할 수 있지만 항상 도움이 되는 것은 아니다.
이를 해결하는 한 가지 방법으로 구성 요소에서 공유 상태를 추출하여 구성 요소 트리 외부의 중앙 위치에 두는 것이 있다. 이를 통해 구성 요소 트리는 큰 보기가 되고 모든 구성 요소는 트리의 위치에 관계없이 상태에 액세스하거나 작업을 트리거할 수 있다.
상태 관리와 관련된 개념을 정의하고 분리하여 view와 state간의 독립성을 유지하는 규칙을 적용, 코드에 더 많은 구조와 유지 관리성을 제공한다. 이것이 Redux의 기본 아이디어이다. 어플리케이션의 전역 상태를 포함하는 중앙 집중식 단일 위치와 코드를 예측 가능하게 만들기 위해 해당 상태를 업데이트할 때 따라야할 특정 패턴이다.
JS 객체와 배열은 기본적으로 모두 변경 가능하다. 객체를 생성하면 해당 필드의 내용을 변경할 수 있다. 배열을 생성하면 배열 내용을 변경할 수 있다.
이것을 객체 또는 배열의 변형이라고 한다.
불변값을 업데이트하기 위해 코드는 기존 객체, 배열을 복사하고 사본을 수정하는 방식을 취해야 한다.
Js의 배열/객체 확산 연산자와 원래 배열을 변경하는 대신 배열의 새 복사본을 반환하는 spread 연산자를 사용하여 이 작업을 직접 수행해야 한다.
Redux는 모든 상태가 불변하게 업데이트 될거라 예상한다.
Action은 type필드를 지닌 일반 자바스크립트 객체이다. 어플리케이션에서 일어난 어떠한 이벤트의 설명이라고 생각하면 된다.
type필드는 문자열이어야만 하며, 대부분 "domain/eventName" 으로 작성한다. 여기서 도메인은 이 작업이 속한 기능 또는 범주이고 두 번째 부분은 발생한 특정 항목이다.
액션 객체는 일어난 이벤트에 대한 정보를 추가할 수 있는 또 다른 필드를 추가할 수 있다. 컨벤션에 따라 이 필드명을 payload라고 부른다.
전형적인 Action 객체의 모습
const addTodoAction = {
type: 'todos/todoAdded',
payload: 'Buy milk'
}Action Creators는 Action 객체를 생성하고 반환하는 함수이다. 일반적으로 직접 Action 객체를 작성하지 않고 Action Creators를 사용한다.
Reducer는 현재 상태와 액션 객체를 파라미터로 받는 함수이다. 필요할 경우 상태를 업데이트하는 방법을 결정한다. 또한 새로운 상태를 반환한다.
제공받은 Action type에 근간한 event를 다루는 eventListener라고 생각할 수 있다.
Reducer 함수는 Array.reduce() 메서드에 전달하는 콜백 함수의 종류와 유사하기 때문에 해당 이름을 얻었다.
Reducer는 항시 몇몇 특정한 규칙이 따라 온다.
Reducer 함수 내부 로직은 일반적으로 동일한 일련의 단계를 따른다.
const initialState = { value: 0 }
function counterReducer(state = initialState, action) {
// reducer가 action에 관심이 있는지 확인한다.
if (action.type === 'counter/increment') {
// 그렇다면 상태의 복사본을 만들고
return {
...state,
// 복사본을 새 값으로 업데이트하고 반환한다.
value: state.value + 1
}
}
// 그렇지 않은 경우 그냥 변하지 않은 상태를 반환한다.
return state
}앱의 현재 Redux state는 store라는 객체에 있다.
store는 reducer를 전달하여 생성한다. 그리고 현재 상태값을 반환하는 getStete라는 메서드가 있다.
Redux store에는 dispatch라는 메서드가 있다. store.dispatch()에 action 객체를 전달하여 액션을 호출하는것이 redux에서 유일하게 상태를 바꾸는 방법이다.
Seletors는 store의 상태 값에서 특정 정보를 추출하는 방법을 알고 있는 함수이다. 앱이 커지면 앱의 서로 다른 부분이 동일한 데이터를 읽게 될 수 있고 이때 반복되는 로직를 방지하는 데 도움이 된다.
디버깅이란 스크립트 내 에러를 검출해 제거하는 일련의 과정을 의미한다.
개발자 도구를 열어 여러가지 탭 중에 sources 탭을 열면 다음과 같은 화면이 보이게 될 것 이다.
토글 버튼을 누르면 navgator가 열리면서 현재 사이트의 소스를 볼 수 있다.
sources 패널은 크게 세 개의 영역으로 구성된다.
이 상태에서 esc 키를 누르면 개발자 도구 하단부에 콘솔 창이 열린다.
단언컨데 디버깅에서 가장 중요하다.
위에서 말했던 코드 에디터 부분의 줄 번호를 클릭하면, 코드 중단점을 설정할 수 있다.
중단점은 말 그대로 자바스크립트의 실행이 중단되는 코드 내 지점을 의미한다.
중단점을 이용하여 실행이 중단된 시점에서 여러가지를 파악, 실행 가능하다. 디버깅 영역의 scope를 사용하여 중단된 시점에서 변수가 어떤 값을 담고 있는지 알 수 있으며, 명령어를 실행할 수 있다.
디버깅 영역의 break point를 통하여 중단점 목록을 쉽게 확인 가능하다.
조건부로 중단점을 설정할 수 있는데 줄 번호에 커서를 옮긴 후 마우스 오른쪽 버튼을 클릭하면 조건부 중단점(conditional breakpoint)이 생성된다. (이미 중단점이 설정되어 있는 경우 중단점을 삭제한 후 조건부 중단점을 설정할 수 있다.)
특정 줄에서 마우스 오른쪽 버튼을 클릭하여 컨텍스트 메뉴를 열면 "Continue to here" 라는 옵션이 있다. 중단점을 설정하기는 귀찮은데 해당 줄에서 실행을 재개하고 싶을때 아주 유용한 옵션이다.
debugger를 이용하면 개발자 도구를 열고 소스 코드 영역을 띄워 중단점을 설정하는 수고를 하지 않아도 된다.
Watch - 표현식을 평가하고 결과를 보여준다.
+ 버튼을 클릭해 표현식을 입력하고 Enter 키를 누르면 결과가 보여집니다. 입력한 표현식은 실행 과정 중에 계속하여 결과가 재평가된다.
Call Stack - 코드를 중단점으로 안내한 실행 경로를 역순으로 표시한다.
콜 스택 내의 항목을 클릭하면 디버거가 해당 코드로 포커싱하고, 변수 또한 재평가된다.
Scope - 현재 정의된 모든 변수를 출력한다.
Local 은 함수의 지역변수를 보여준다. 지역 변수 정보는 소스 코드 영역애서도 확인할 수 있다.
Global 은 함수 바깥에 정의된 전역 변수를 보여준다.
Resume - 실행을 재개한다.Step - 다음 명령어를 실행한다.Step Over - 다음 명령어를 실행하되, 함수 안으로 들어가지 않는다.Step Into - Step은 비동기 함수를 무시하는 반면, Step Into은 비동기 코드로 진입하고, 비동기 동작이 완료될 때까지 대기한다.Step Out - 실행 중인 함수의 실행이 끝날 때 까지 실행을 계속한다.이벤트 캡처링은 이벤트 버블링과 반대 방향으로 진행되는 이벤트 전파 방식이다.
위 그림처럼 특정 이벤트가 발생했을 때 최상위 요소인 body 태그에서 해당 태그를 찾아 내려간다. 그럼 이벤트 캡처링은 코드로 어떻게 구현할 수 있을까.
<body>
<div class="one">
<div class="two">
<div class="three">
</div>
</div>
</div>
</body>var divs = document.querySelectorAll('div');
divs.forEach(function(div) {
div.addEventListener('click', logEvent, {
capture: true // default 값은 false입니다.
});
});
function logEvent(event) {
console.log(event.currentTarget.className);
}addEventListener() api에서 옵션 객체에 capture: true 를 설정해주면 된다. 그러면 해당 이벤트를 감지하기 위해 이벤트 버블링과 반대 방향으로 탐색한다.
따라서, 아까와 동일하게 <div class="three"></div> 를 클릭해도 아래와 같은 결과가 나타난다.
트리쉐이킹은 쉽게 말해 번들파일의 불필요한 코드를 제거해주는 것을 말한다. 나무를 흔들어서 말라 죽은 잎들을 떨어트리는 것을 비유해서 지은 이름이다.
웹팩에서는 기본적으로 트리쉐이킹을 제공해주지만, 모든 경우에서 작동이 잘 되는 것은 아니다.
그래서 웹팩의 트리쉐이킹을 잘 이해해야 번들파일의 크기를 최소화 할 수 있다.
한마디로 쓸모없는 소스코드를 털어주는 작업
트리쉐이킹은 ESM(ECMAscript Module)이 아닐 때 트리쉐이킹은 실패한다.
사용되는 모듈이 ESM이 아니거나 사용하는 쪽에서 ESM 이 아닌 다른 모듈 시스템을 사용해도 트리쉐이킹이 제대로 이루어지지 않는다.
util_ESM.js
export function func1() {
console.log("func1");
}
export function func2() {
console.log("func2");
}util_common.js
function func1() {
console.log("func1");
}
function func2() {
console.log("func2");
}
module.exports = { func1, func2 };npx webpack 실행 후
`index.js``
import { func1 } from "./util_ESM";
func1();트리쉐이킹이 제대로 이루어져 사용되지않은
func2함수가 번들파일에 포함되지 않는다.
`index.js
import fill from "lodash/fill";
//...
lodash패키지에서fill함수만 불러왔다.
lodash-es가 ESM이라 트리쉐이킹이 잘 동작한다.
바벨로 컴파일을 했을 때 작성한 코드가 ESM 모듈 문법으로 남아있어야 트리쉐이킹이 제대로 이루어진다.
만약 @babel/preset-env 플러그인을 사용한다면 babel.config.js 파일에서 다음과 같이 설정해야한다.
babel.config.js
const presets = [
"@babel/preset-env",
{
// ...
modules: false,
},
];
modules를 false로 설정하면 ESM 모듈 문법을 유지하게 되어 트리쉐이킹에 영향을 주지 않는다.
microsoft/vscode 📎 에 컨트리뷰팅하기 위하여 소스코드서핑을 하다가 package.nls.json 📎 라는 파일을 보게 되었습니다.
안에 내용은 다음과 같은 형식으로 이루어져 있었다.
{
"displayName": "Git",
"description": "Git SCM Integration",
...
"변수": "변수에 대한 설명"
}nls가 무엇인지 궁금하여 구글링을 하게 되었고, 찾던중에 National Language Support 즉 연어현지화를 알게되었다.
언어현지화란 쉽게 말해서 여러분들이 게임을 할때 원어보다는 더빙이 이해하기 편하고, 책을 읽을때는 번역본이 읽기 편하듯 언어를 현지에 맞게 변형, 번역하여 이해하기 쉽게 하는것을 뜻한다.
언어 현지화(言語現地化)는 특정한 언어로 제작된 프로그램이나 제품을 다른 언어로 사용할 수 있게 하는 과정을 말한다. (번역 참조) 언어 패치는 그에 따른 패치를 말하며, 한국어로 사용할 수 있게 만들어 주는 패치를 흔히 한글 패치, 한글화 패치라고 부른다.
microsoft/vscode 📎 에서는 소스코드에서 쓰이고 있는 variable 들을 설명한다. 즉 변수라는 언어 를 현지화 하기 때문에 package.nls.json 📎 로 작명했을거라 생각한다.
Canvas API는 Js와 HTML canvas엘리먼트를 통해 그래픽을 그리기위한 수단을 제공한다. 무엇보다도 애니메이션, 게임 그래픽, 데이터 시각화, 사진 조작 및 실시간 비디오 처리를 위해 사용된다.
Canvas API는 주로 2D 그래픽에 중점을 두고 있다. WebGL API 또한 <canvas>엘리먼트를 사용하며, 하드웨어 가속 및 2D 및 3D 그래픽을 그린다.
font-, margin- 등과 같이 동일한 네임 스페이스를 가지는 속성들을 다음과 같이 사용할 수 있다.
SCSS:
.box {
font: {
weight: bold;
size: 10px;
family: sans-serif;
}
margin: {
top: 10px;
left: 20px;
}
padding: {
bottom: 40px;
right: 30px;
}
}Compiled to:
.box {
font: {
weight: bold;
size: 10px;
family: sans-serif;
}
margin: {
top: 10px;
left: 20px;
}
padding: {
bottom: 40px;
right: 30px;
}
}동기, 비동기 그리고 블로킹, 논블로킹은 어떤걸 개발하는 개발자이든 프로그램을 개발할 때 중요한 개념이다.
많은 개발자들이 동기 비동기 == 블로킹 논블로킹 이라고 곧잘 생각하곤 하는데 이 둘은 별개의 개념이다.
동기와 비동기는 작업을 수행하는 두 개 이상의 주체에 초점이 맞추어져 있다.
동기 작업이란 서로 동시에 수행하거나, 동시에 끝나거나, 끝나는 동시에 시작할 때를 의미한다.
비동기 작업이란 작업을 수행하는 두 개 이상의 주체가 서로의 시작, 종료시간과는 아무런 관계없이 별도의 수행 시작/종료시간을 가지고 있을 때를 의미한다.
블로킹과 논블로킹은 다른 작업을 수행하는 주체를 어떻게 상대하는지에 초점이 맞추어져 있다.
블로킹은 자신의 작업을 하다가 다른 작업 주체가 하는 작업의 시작부터 끝까지 기다렸다가 다시 자신의 작업을 시작하는것을 말한다.
논블로킹은 다른 주체의 작업과 관계없이 자신의 작업을 계속하는것을 말한다.
React는 JS만을 이용하여 웹 화면을 구성하는 원리를 가지고 있다. 그래서 CRA로 생성한뒤 public/ 디렉토리 하위의 HTML코드는 <div id="root"></div> 말고는 body 태그안에 아무런 내용이 없다.
// public/index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Title</title>
</head>
<body>
<div id="root"></div>
</body>
</html>위 코드처럼 public/index.html에는 아무 내용 없는 기본 뼈대만 있고, 나머지는 src/index.js의 자바스크립트 코드에서 모든 화면을 렌더링 한 뒤 HTML DOM 요소 중 root라는 아이디를 가진 엘리먼트를 찾아서 하위로 주입을 하게 된다.
react-snap이나 Next.js를 사용하면 클라이언트에게 웹 페이지를 보내기 전에 미리 웹 페이지를 pre-rendering 한다. 그리고 pre-rendering 으로 인해 생성된 HTML document를 클라이언트에게 전송한다.
그런데 여기서 중요한 것은 현재 클라이언트가 받은 웹 페이지는 단순히 웹 화면만 보여주는 HTML뿐이고, 자바스크립트 요소들이 하나도 없는 상태이다. 이는 웹 화면을 보여주고 있지만, 이벤트들이 하나도 작동이 되지 않는 상태임을 말한다.
그러면 이렇게 페이지만 보여주고 동작조차 하지 못하는 마치 빈 껍데기 같은 웹 페이지가 나중에는 어떻게 정상적으로 동작하게 되는 것일까?
예를 들어서 설명하자면 Next.js Server에서는 사전 렌더링된 웹 페이지를 클라이언트에게 보내고 나서, 바로 리액트가 번들링 된 자바스크립트 코드들을 클라이언트에게 전송한다.
네트워크 탭을 보면, 맨 처음 응답받는 요소가 dom type의 파일이고, 이후에 React 코드들이 렌더링 된 JS 파일들이 Chunk 단위로 다운로드되는 것을 확인할 수 있다.
그리고 이 자바스크립트 코드들이 이전에 보내진 HTML DOM 요소 위에서 한번 더 렌더링을 하면서, 각자 자기 자리를 찾아가며 매칭이된다.
바로 이 과정을 Hydrate 라고 한다.
이것은 마치 자바스크립트 코드들이 DOM 요소 위에 물을 채우듯 필요로 하던 요소들을 채운다 하여 Hydrate(수화)라는 용어를 쓴다고 한다.
물은 아니지만 이런 느낌이랄까..
어쩌면 두번 렌더링 하는 것이 비효율적으로 보일 수 있다.
그러나 서버 단에서 빠르게 Pre-Rendering하고 유저에게 빠른 웹 페이지로 응답할 수 있다는 것에 더욱 큰 이점을 가져갈 수 있다.
심지어 이 Pre-Rendering 한 Document는 모든 자바스크립트 요소들이 빠진 굉장히 가벼운 상태이므로 클라이언트에게 빠른 로딩이 가능하다.
이는 같은 화면에 대해 두 번 렌더링이 일어난다는 단점을 보완하고도 남는다.
Callback 함수를 알기 위해서는 (비)동기와 (논)블로킹의 [개념]이 필요하다.(#8)
독서와 커피마시기를 한다고 가정해보자. 당신이 독서를 하고 있을때 커피를 마시고 싶으면 책을 내려놓고 커피를 마시거나, 책을 한손으로 보며 커피를 마시는 일 두가지를 시행할 수 있다. 전자가 블로킹 Js에서 말하는 동기적처리이고, 후자가 논블로킹 Js에서 말하는 비동기적 처리이다.
전자의 상황에서 커피를 마시던 도중 커피맛이 너무 좋아 음미하며 커피를 마시는 시간에 극단적으로 30분을 사용했다고 치자. 그러면 그 30분의 시간 동안 당신은 책을 볼 수 없는 상태가 된다. 하지만 후자의 경우에는 커피가 너무 맛있어 음미하며 마시는 커피를 마시는 시간에 몇시간을 투자해도 커피를 다 마실때까지 독서를 멈추지 않아도 된다.
코드로 짜보면 다음과 같다.
// 블로킹 (Js에서 동기)
console.log("독서");
console.log("커피 마시기 시작"); // 30분이 걸린다고 치자
console.log("커피 마시기 끝");
console.log("독서");// 논블로킹 (Js에서 비동기)
console.log("독서");
console.log("커피 마시기 시작");
setTimeout(() => {
console.log("커피 마시기 끝");
}, 1800000); // 30분 소요
console.log("독서");위 비동기적으로 처리한 로직을 보면 setTimeout을 사용한것을 알 수 있다.
setTimeout은 다음과 같은 방식으로 선언하는데 setTimeout(fn, delay), 이때 인자로 받는 fn 즉 함수가 콜백함수이다.
Callback 함수를 Call과 Back으로 나누어 살펴보자
Call은 호출하다. 라는 뜻을 가지고 있고, Back은 되돌다. 라는 뜻을 가지고 있다. 두가지를 합치면 되돌아와서 호출하다. 가 된다.
const arr = ["이", "선", "우", "최", "고"];
const printArray = () => {
console.log(arr.shift());
if (!arr.length) {
clearInterval(timer);
}
};
const timer = setInterval(printArray, 1000);printArray 함수를 콜백으로 setInterval에 넘겨주게되면 prinArray의 제어권은 setInterval 에게 넘어가게 된다.
비동기로 처리할 로직이 많게 된다면 setTimeout과 같은 함수를 많이 사용하게 되는건 당연하다. 하지만 위에서 봤듯이 setTimeout과 같은 함수를 사용하게 된다면 코드 가독성이 현저하게 떨어지게 된다.
이를 해결하기 위해 세상에 등장한것이 바로 Promise API 이다.
이 둘은 모두 데이터 수집과 상호 작용하는 방법을 나타내지만 동일한 의미를 가지고 있지 않다.
metrics 는 수치 형태로 객관적으로 측정할 수 있는 모든 데이터를 말한다. 예시로
analytics 는 데이터를 분석하는 과정이다. 데이터 수집과는 실제로는 아무 관련이 없으며 수집된 데이터에 의미가 부여되는 다음 단계일 뿐이다.
Shadow DOM 에 대해서 공부중 추가로 slot에 대해서 알게 되었고, 더불어 svelte의 slot 개념과 같은것 같아 공부한다.
슬롯은 사용자가 컴포넌트 내부에 원하는 마크업을 채울 수 있도록 미리 선언해놓은 자리 표시자라고 할 수 있다.
주로 사용자 커스텀 요소를 생성할 때 유용합니다. 사용자 커스텀 요소에 필요한 최소한의 마크업만 제공하고, 작성자가 원하는 대로 그룹화하고 스타일을 적용하여 사용할 수 있다.
슬롯을 설명하기 전에 <template>을 사용한 마크업 예시를 먼저 살펴보자
<!-- 렌더링할 템플릿 선언 -->
<template id="my-template">
<style>
p { color: green; }
</style>
<p>Hello, Shadow DOM!</p>
</template>
<!-- 사용자 커스텀 요소 사용 -->
<my-template></my-template>// 사용자 커스텀 요소를 정의하고 준비한 템플릿 코드를 가져와 shadow DOM을 생성한다.
// shadow DOM으로 인해 템플릿 내의 코드는 캡슐화된다.
class myTemplate extends HTMLElement {
constructor() {
super();
let template = document.getElementById('my-template');
let templateContent = template.content;
const shadowRoot = this.attachShadow({mode: 'open'})
.appendChild(templateContent.cloneNode(true));
}
}
customElements.define('my-template', myTemplate);템플릿 요소는 마크업 조각 형태로 이루어집니다. 이는 페이지 로딩 시 렌더링 되지 않으며 자바스크립트를 이용해 런타임 시 인스턴스화할 수 있다.
따라서 자주 사용되는 마크업 조각들을 템플릿 요소에 추가하고 복제함으로써 재사용성을 증가시킨다. 또한 템플릿 요소가 shadow host로 지정되어 내부 스타일을 가질 수 있다.
하지만 템플릿은 단순히 작성된 요소만 화면에 표시하기 때문에 유연하지 않다. 슬롯은 이러한 템플릿 코드에 유연성을 제공합니다.
슬롯을 사용한 템플릿 코드 예시를 살펴보겠다.
<!-- 빈 슬롯이 추가된 템플릿 선언 -->
<template id="my-template">
<style>
:host { color: green; }
</style>
<slot></slot>
</template>
<!-- 각각의 사용자 커스텀 요소마다 다른 요소를 삽입 -->
<my-template>
<h1>Hello Shadow DOM!</h1>
</my-template>
<my-template>
<p>Hello, Shadow DOM!</p>
</my-template>하나의 슬롯을 사용했지만, 결과적으로는 다른 두 요소를 렌더링한다.
다양한 콘텐츠로 이루어진 복잡한 요소는 명명된 슬롯을 사용하여 쉽게 생성할 수 있습니다. 슬롯을 통해 다양한 요소들이 하나의 템플릿에서 구현 가능하므로 매우 유용하다.
<!-- 템플릿 선언 -->
<template id="my-template">
<slot name="title"></slot>
<hr>
<slot></slot>
</template>
<!-- 사용자 커스텀 요소 -->
<my-template>
<h1 slot="title">제목</h1>
<p>이 텍스트는 이름 없는 빈 슬롯에 들어가게 됩니다.</p>
</my-template>참고 :
<my-template>내의<h1>,<p>과 같은 자식 요소들을 Light DOM이라고 합니다. 이들은 템플릿 코드에 있는 지정된 slot을 찾아간다.
스타일 지정
웹 구성 요소와 shadow DOM 내부 요소에 스타일을 지정하는 다양한 방법이 있다.
:host : shadow root로 지정된 웹 구성 요소에 스타일을 적용한다.
:host-context() : 웹 구성 요소 혹은 상위 요소의 선택자가 와 일치하면, 웹 구성 요소의 자식 요소에 스타일을 적용한다.
::slotted() : 지정한 복합 선택자와 일치하는 슬롯 콘텐츠에 스타일을 적용한다.
간단한 예시를 살펴보면,
<!-- 템플릿 선언 -->
<template id="my-template">
<style>
:host {
all: initial;
display: block;
contain: content;
color: green;
}
:host(:hover) {
border: 1px solid blue;
}
:host-context(.orange-theme) {
color: orange;
}
::slotted(a) {
color: red;
text-decoration: none;
}
</style>
<slot></slot>
</template>
<!-- 사용자 커스텀 요소 -->
<my-template>
<h1>Hello Shadow DOM!</h1>
</my-template>
<my-template class="orange-theme">
<div>
<span>text 1</span>
<span>text 2</span>
<span>text 3</span>
</div>
</my-template>
<my-template>
<a href="#">Hello, Shadow DOM!</a>
</my-template>the-moment 테스팅 서버와 연결하던중에 겪은 오류이다.
localhost 에서 새로운 기능을 테스트하기 위해 baseURL을 변경후 서버를 실행시켰을때 다음과 같은 에러가 떴다.
ERR_CONNECTION_REFUSED은 오류! 연결 거부! 라고 해석할 수 있다.
ERR_CONNECTION_REFUSED은 메시지는 웹 사이트가 호스팅 되는 서버가 요청하게 되는데 해당 웹페이지를 서비스하는 웹 서버에서 웹 서비스를 제공하지 못하면 Google 크롬에 ERR_CONNECTION_REFUSED라는 오류 메시지가 표시된다.
1번 본인의 경우가 1번이었다. IP주소에 문제가 있을 경우는 IP주소를 확인하고 옳은 IP주소를 바꾸는 방법이 있다.
그리고 특히 port가 정확한지 확인해야한다.
저의 경우 같이 작업하는 멤버가 port 번호를 붙이지 않아서 발생한 에러였다.
2번 이 경우에는 좀 복잡한데 ISP에 문제가 있을 경우에는 VPN또는 프록시 서버를 사용하여 접근하여야합니다.
만약 이 경우에 해당된다면 DNS 캐시를 비워야 한다.
메타데이터의 가장 단순한 정의는 데이터를 설명하는 데이터다.
HTML의 경우.. HTML은 하나의 데이터이다. HTML의 <head> 안에는 문서 작성자나 문서 요약과 같이 HTML에 대한 데이터를 넣을 수 있는데 이때 넣는 데이터들이 메타데이터이다.
HTML<meta>요소는 <base>, <link>, <script>, <style>, <title>과 같은 다른 meta 관련 요소로 나타낼수 없는 메타데이터를 나타낸다.
meta요소가 제공하는 메타데이터는 다음 네 유형 중 하나이다.
이 요소는 전역 특성을 포함한다.
참고 : name 특성은 <meta> 요소에 대해 특정한 의미를 가집니다. 하나의 <meta> 요소에서, itemprop 특성을 name, http-equiv 또는 charset 특성과 함께 설정할 수 없다.
charset
페이지의 문자 인코딩을 선언한다. 이 특성이 존재할 경우, 그 값은 반드시 문자열 "UTF-8"로 하는게 좋다. 이유는 UTF-8의 장점에 있다.
content
`http-equiv` 또는 `name` 특성의 값을 담는다.
name
name과 content 특성을 함께 사용하면 문서의 메타데이터를 이름-값 쌍으로 제공할 수 있다.
name은 이름,content는 값을 담당한다.
http-equivalent는 그냥 환경에 지시를 내린다고 알아두자.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.