sunshinewyf / issue-blog Goto Github PK
View Code? Open in Web Editor NEW技术积累和沉淀
技术积累和沉淀

































































































































近来喜欢看些闲书,于是在周末的临睡前和闲隙看完了这本书。刘同和郭敬明还有韩寒一样,都是用淡淡忧伤的文字触摸人们内心最柔软的轨迹。曾经知道他有一本《谁的青春不迷茫》,而且还配有极其文艺的插图,但是单看书名,总觉得是对于青春无奈的一种无病呻吟而已,多少会有一些消极的成分在,而我是最厌恶消极和负面的,所以一直不曾接触过这本书,而这一本,应该更多的是一种激励和共勉吧。事实证明,确实如此。
书的内容主要是涉及作者本人33岁之前的回忆,通过回忆来剖析和讲解各种孤单,有和父母之间的,上级之间的以及和同龄人之间不被理解的经历,除此之外,还有一些作者遇到的人或者事带给他的关于孤独的思考。孤独呢,有关于爱情,亲情,友情还有同事之情的,可以说,这本书可以称之为一本回忆录。而我最喜欢的就是他回忆毕业后大学同学聚会的场景。他以一种过来人的视角在品味人生,而我却是以一种正在经历的视角在寻找某些雷同。我从不曾想像过毕业10年的班级聚会会是怎样的一番场景,但是我知道时间会改变很多东西,譬如梦想,譬如友谊。很是被里面的一些独具一格的人所感动,包括小五,二毛,都是人群中特立独行的人,在他们的人生轨迹里,诠释着一种special。但是青春总是这样匆匆,还来不及回味就已经消失殆尽,只有年龄的不停增长在说明你已经走过了这段最为绚丽的日子。
“在人生的旅途中,回首张望需要勇气,直视而悠长,像是某种神圣的仪式”就像刘同在书中说的,有的时候,回忆需要很大的勇气,无论是那些别人给的伤还是美好,每回想一遍都会引发物是人非的惆怅,与其这样让自己心累,还不如永远没心没肺地一往直前,这样会更显示出一种潇洒。
不知道为什么,很难给孤单下一个定义,不能说独自一人就是孤单,但是之于我,孤单这个词太遥远,无论何时何地,我都有东西陪着,或者是电脑,或者是音乐,即使独自一人。很喜欢里面的一句话:
要相信这些年你都能一个人度过所有,当时你恐慌害怕的最终会成为你面对这个世界的盔甲“。
是的,或许你现在正在一个人奋斗着,没有与你并肩作战的人,但是这只是你现在能看到的风景,因为,孤独之前是迷茫,孤独之后就是成长,你用你最好的时光在犯错,那么以后犯的错就会变少,而年龄越大,犯错就越无法被原谅,因为每个人都要经历这些,只是时间早晚的问题。只有学会享受孤独的人才会建立起内心最为强大的精神堡垒,以至于被扔在人流中的时候,可以最早地被别人所看到。
"30 岁之后,风景于我只是几道走马观花得残影,少有流连忘返的停留”
我不知道,30岁的我会是什么样一番景象,但是我现在可以做到,等那个时候再来回忆这段时光的时候,我可以问心无愧地说:我尽力了。
你的孤独,虽败犹荣,为自己点个赞!!!
redux-saga 是一个管理 Redux 应用异步操作的中间件,功能类似
redux-thunk + async/await, 它通过创建 Sagas 将所有的异步操作逻辑存放在一个地方进行集中处理。
redux-saga中的 Effects 是一个纯文本 JavaScript 对象,包含一些将被 saga middleware 执行的指令。这些指令所执行的操作包括如下三种:
Effects 中包含的指令有很多,具体可以异步API 参考进行查阅
assert.deepEqual(iterator.next().value, call(Api.fetch, '/products'))假如现在有一个场景:用户在登录的时候需要验证用户的 username 和 password 是否符合要求。
获取用户数据的逻辑(user.js):
// user.js
import request from 'axios';
// define constants
// define initial state
// export default reducer
export const loadUserData = (uid) => async (dispatch) => {
try {
dispatch({ type: USERDATA_REQUEST });
let { data } = await request.get(`/users/${uid}`);
dispatch({ type: USERDATA_SUCCESS, data });
} catch(error) {
dispatch({ type: USERDATA_ERROR, error });
}
}验证登录的逻辑(login.js):
import request from 'axios';
import { loadUserData } from './user';
export const login = (user, pass) => async (dispatch) => {
try {
dispatch({ type: LOGIN_REQUEST });
let { data } = await request.post('/login', { user, pass });
await dispatch(loadUserData(data.uid));
dispatch({ type: LOGIN_SUCCESS, data });
} catch(error) {
dispatch({ type: LOGIN_ERROR, error });
}
}异步逻辑可以全部写进 saga.js 中:
export function* loginSaga() {
while(true) {
const { user, pass } = yield take(LOGIN_REQUEST) //等待 Store 上指定的 action LOGIN_REQUEST
try {
let { data } = yield call(loginRequest, { user, pass }); //阻塞,请求后台数据
yield fork(loadUserData, data.uid); //非阻塞执行loadUserData
yield put({ type: LOGIN_SUCCESS, data }); //发起一个action,类似于dispatch
} catch(error) {
yield put({ type: LOGIN_ERROR, error });
}
}
}
export function* loadUserData(uid) {
try {
yield put({ type: USERDATA_REQUEST });
let { data } = yield call(userRequest, `/users/${uid}`);
yield put({ type: USERDATA_SUCCESS, data });
} catch(error) {
yield put({ type: USERDATA_ERROR, error });
}
}对于 redux-saga, 还是有很多比较难以理解和晦涩的地方,下面笔者针对自己觉得比较容易混淆的概念进行整理:
take 和 takeEvery 都是监听某个 action, 但是两者的作用却不一致,takeEvery 是每次 action 触发的时候都响应,而 take 则是执行流执行到 take 语句时才响应。takeEvery 只是监听 action, 并执行相对应的处理函数,对何时执行 action 以及如何响应 action 并没有多大的控制权,被调用的任务无法控制何时被调用,并且它们也无法控制何时停止监听,它只能在每次 action 被匹配时一遍又一遍地被调用。但是 take 可以在 generator 函数中决定何时响应一个 action 以及 响应后的后续操作。
例如在监听所有类型的 action 触发时进行 logger 操作,使用 takeEvery 实现如下:
import { takeEvery } from 'redux-saga'
function* watchAndLog(getState) {
yield* takeEvery('*', function* logger(action) {
//do some logger operation //在回调函数体内
})
}使用 take 实现如下:
import { take } from 'redux-saga/effects'
function* watchAndLog(getState) {
while(true) {
const action = yield take('*')
//do some logger operation //与 take 并行
})
}其中 while(true) 的意思是一旦到达流程最后一步(logger),通过等待一个新的任意的 action 来启动一个新的迭代(logger 流程)。
call 操作是用来发起异步操作的,对于 generator 来说,call 是阻塞的操作,它在 Generator 调用结束之前不能执行或处理任何其他事情。,但是 fork 却是非阻塞操作,当 fork 调动任务时,该任务会在后台执行,此时的执行流可以继续往后面执行而不用等待结果返回。
例如如下的登录场景:
function* loginFlow() {
while(true) {
const {user, password} = yield take('LOGIN_REQUEST')
const token = yield call(authorize, user, password)
if(token) {
yield call(Api.storeItem({token}))
yield take('LOGOUT')
yield call(Api.clearItem('token'))
}
}
}若在 call 在去请求 authorize 时,结果未返回,但是此时用户又触发了 LOGOUT 的 action,此时的 LOGOUT 将会被忽略而不被处理,因为 loginFlow 在 authorize 中被堵塞了,没有执行到 take('LOGOUT')那里
如若遇到某个场景需要同一时间执行多个任务,比如 请求 users 数据 和 products 数据, 应该使用如下的方式:
import { call } from 'redux-saga/effects'
//同步执行
const [users, products] = yield [
call(fetch, '/users'),
call(fetch, '/products')
]
//而不是
//顺序执行
const users = yield call(fetch, '/users'),
products = yield call(fetch, '/products')当 yield 后面是一个数组时,那么数组里面的操作将按照 Promise.all 的执行规则来执行,genertor 会阻塞知道所有的 effects 被执行完成
在每一个使用 redux-saga 的项目中,主文件中都会有如下一段将 sagas 中间件加入到 Store 的逻辑:
const sagaMiddleware = createSagaMiddleware({sagaMonitor})
const store = createStore(
reducer,
applyMiddleware(sagaMiddleware)
)
sagaMiddleware.run(rootSaga)其中 createSagaMiddleware 是 redux-saga 核心源码文件 src/middleware.js 中导出的方法:
export default function sagaMiddlewareFactory({ context = {}, ...options } = {}) {
...
function sagaMiddleware({ getState, dispatch }) {
const channel = stdChannel()
channel.put = (options.emitter || identity)(channel.put)
sagaMiddleware.run = runSaga.bind(null, {
context,
channel,
dispatch,
getState,
sagaMonitor,
logger,
onError,
effectMiddlewares,
})
return next => action => {
if (sagaMonitor && sagaMonitor.actionDispatched) {
sagaMonitor.actionDispatched(action)
}
const result = next(action) // hit reducers
channel.put(action)
return result
}
}
...
}这段逻辑主要是执行了 sagaMiddleware(),该函数里面将 runSaga 赋值给 sagaMiddleware.run 并执行,最后返回 middleware。 接着看 runSaga() 的逻辑:
export function runSaga(options, saga, ...args) {
...
const task = proc(
iterator,
channel,
wrapSagaDispatch(dispatch),
getState,
context,
{ sagaMonitor, logger, onError, middleware },
effectId,
saga.name,
)
if (sagaMonitor) {
sagaMonitor.effectResolved(effectId, task)
}
return task
}这个函数里定义了返回了一个 task 对象,该 task 是由 proc 产生的,移步 proc.js:
export default function proc(
iterator,
stdChannel,
dispatch = noop,
getState = noop,
parentContext = {},
options = {},
parentEffectId = 0,
name = 'anonymous',
cont,
) {
...
const task = newTask(parentEffectId, name, iterator, cont)
const mainTask = { name, cancel: cancelMain, isRunning: true }
const taskQueue = forkQueue(name, mainTask, end)
...
next()
return task
function next(arg, isErr){
...
if (!result.done) {
digestEffect(result.value, parentEffectId, '', next)
}
...
}
}其中 digestEffect 就执行了 effectTriggerd() 和 runEffect(),也就是执行 effect,其中 runEffect() 中定义了不同 effect 执行相对应的函数,每一个 effect 函数都在 proc.js 实现了。
除了一些核心方法之外,redux-saga 还提供了一系列的 helper 文件,这些文件的作用是返回一个类 iterator 的对象,便于后续的遍历和执行, 在此不具体分析。

之前一直听说这本书很出色,朋友也是力推这本书,于是就下载了电子版的三部曲,真正看下去之后,就不能自拔了,这本书确实写得很精彩,如果没有一定的科学方面的知识和人文方面的素养,是绝不会有这样的著作的。在首页的导读中,姚海军写到:
**科幻与美国科幻的差距。在科幻作品方面,**虽然需求很大,但是可以摆在市面上的作品确是寥寥无几。
但是刘慈欣的这部作品确是给**的科幻作品添上了浓墨重彩的一笔,值得赞叹和喝彩。
实习的生活还是比较忙的,而且我也不想贪恋着一口气读完,所以一般是利用早上挤地铁的时候来欣赏一下,看到动情处,总是感叹作者的想象力和文笔,惊叹这么浩渺磅礴的场景描述。
第一部的主人公是汪淼,一个研究纳米材料的教授。却被卷入一场阴谋当中,一个处于地球之外的三体文明,策划着一场即将侵蚀和禁锢地球文明的阴谋。故事在一开始是很悬疑的,汪淼被一个诡异的倒计时折磨着,就像幽灵,在他所在之处跳跃着。
这种感觉,让人害怕和惊悚。之后,杨冬和一些著名科学家的死更加增添了这层诡异。汪淼在三体世界这个游戏中体验的一些三体世界的生活更是让人惊讶。人可以在乱纪元中脱水储藏,在恒纪元中浸泡让自己复活,这种“异想天开”的想象让我佩服,这种因为自然环境的因素而演化出来的存活和死亡,居然是这样地神奇。随着汪淼在三体游戏玩的次数越来越多,故事的真相也在慢慢揭晓。最后水落石出是叶文洁说出来的
自己在红岸基地上研究,并且向三体文明发出了地球文明的回应,除此之外,她还亲手杀了她的丈夫杨卫宁和一名军官雷志成。最后伊文斯知道了叶文洁的秘密之后,居然建立了地球上的三体组织,他们把三体文明奉为主,并且在地球上建立起拥护三体文明的组织,并通过这个组织不断地向远在地球之外的三体人发送着地球上一切。这还不算什么,在从伊文斯被截断的船上获取最新的他们和三体人的最后一次交流中可以获知,三体人已经研发出一种叫做"质子"的东西,它可以监视地球上的一举一动,阻碍地球上的物理学领域的发展,甚至因此让地球上一些出色的科学家在精神上迷乱甚至因此自杀,只有这样,地球上的科学才会停滞不前。
戳穿了三体人民的阴谋之后,一切都真相大白了。但是面对如此强大的敌人,地球人显得手足无措甚至恐慌,这太不可思议了,在宇宙之中,居然还存在着除了地球文明之外的文明,并且这个文明即将毁灭地球文明。知道真相的汪淼和丁仪感到很挫败,
甚至产生了失败主义,他们不知道怎么去对付这个强大的质子和三体文明的入侵,但是大史带着他们去他家乡看蝗虫的繁衍,将人和蝗虫之间的对峙和人与三体人民的对峙进行对比
“是地球人和三体人的技术水平差距大呢,还是蝗虫和咱们人的技术水平差距大?”
这句话让汪淼和丁仪顿时自惭形秽,于是第一部就在这种未知胜负的结局中结束了。。。
看完第一部之后,真的很震撼,这部书中,充满着很多的物理知识以及一些其他领域的知识,比如宇宙领域的,文学领域的,三体游戏中出现的各种场景,不论是**历史还是外国历史,作者都很熟悉并很自然地结合自己的想象力揉在字里行间中,简直是太神奇了。看完之后很赞叹。
故事的帷幕在一点点拉开,期待和第二部的相见。。。。。

看到这本书的时候就想买了,因为喜欢白岩松。而且去年的时候,白岩松刚好在我学校演讲过,对他的仰慕更深了一层。看到这本书更是惊喜,然后就毫不犹豫地买了,当然,也很值得。
由于在实习,大多数的时间都占据在需求上面,只有周末陆陆续续的时间来看一下这本书,但是说到底还是挤时间看完了,收益良多。在字里行间里感受到的是白岩松的睿智和从容,那是一种**,一种成熟。除此之外,他的经历和人生都是那么地精彩,在他的经历中,每一件都和国家大事挂钩,那是一种将自己融入到国家的伟岸。而且即使在收获了那么多的赞誉和仰慕之后,他还是可以做到宠辱不惊和淡定,这是一种怎样平淡和从容的心。
这本书是基于作者的经历和思考写成的,配有很清晰的图,让读者在阅读的时候思考人生,他的思考永远是建立在大格局上面的,不是一种小商小贩的庸俗,也不是一种妇人的短浅,他是站在国家的甚至世界的角度诉说着世界的好与坏,没有一丝做作和犹豫,相对于很多人,他活得更明白和清楚,从他的文字里,我看到的是一种理性,理性中带着厚重,带着对未来的思考,让人很容易静下心来,思考自己的人生。。。。
下面摘录一些经典的话:
- 首先要解决人和物的问题,接下来要解决人和人的问题,最后一定要解决人和自己内心的问题。
- 不平静,就不会幸福,也因此,当下的时代,平静才是真正的奢侈品。
- 人的一生,不管贫富贵贱,最后加减乘除,一算分,都一样。
- 如果让人感动的人,负责获奖,而让人愤怒或者厌倦的人们,却获得利益,那么,感动,又有何意义?
- 过去了的终究过去,当初的期待实现与否,也同样被时光带走,不管你愿不愿意,一个新的起跑线又画在这里。人们之所以可以忍受苦难,在于还可以拥有希望。
还有很多比较鞭辟入里的思考,虽然尖锐,但是却可以引发读者的思考。“幸福”这个东西,说大就很大,说小也很容易,每个人对幸福的定义不同,自然人生也就不一样。对于幼童来说,一个微笑就是幸福,但是对于很多人来说,幸福往往是那么遥不可及,因为金钱,私欲,诱惑占据着人们的全部神经,在这个物欲横流的世界,节奏快得让人不能静下心来思考,其次,现在的人缺少一份责任心,因为个人的私欲已经凌驾于对国家和社会的责任之上了,所以就会有那么多的犯罪和欺凌。。。这是个人的幸福。对于整个**来说,她的幸福就建立在一个很大的环境之下了,作者通过剖析**最近几年发生的几件大事:汶川大地震,申奥成功,举办北京奥运会,包括**足球,与日本和美国以及**的关系,作者通过自己的采访经历剖析出**该怎么对待这些事情以及在未来的发展中应该以什么姿态前进。
“有人形容说:**想一辆自行车,只要保持一定速度向前骑行,它就会稳定,而一旦有一天,向前的动力慢下来,它就左右摇摆,速度再慢下来,它就终会倒下。”
读白岩松的书,会增长见识,最重要的是他会引导你以一种新的高度来思考人生,而不是始终觊觎自己的一己私利。人生短短十几载,随着年龄的增长,你对太阳和温暖的感觉都会不一样,在不断经历过程中,你会渐渐走向成熟,那么到了那个时候,所有让你苦苦追求的东西都会成为过眼云烟。
人生,最重要的是看透,然后拥有一份属于自己的豁达。。。。
dva 初探
前言: 最近正在学习 dva ,整理出一些学习笔记,笔者默认阅读此文的读者有一定的react , redux , redux-saga 基础,如果没有,可先自行了解这些技术,本文不再赘述。
dva是基于现有应用框架(redux+react-router+redux-saga等)封装的一个框架(不是库),基本上没有引入新概念,也没有创建新语法,对于熟悉前言中涉及的技术栈的童鞋来说会非常容易上手。详细介绍可移步dva介绍
在处理复杂异步请求的业务中,一开始我们是使用 redux-thunk + async/await 结合使用,比如在异步登录的逻辑中,使用 redux-thunk 处理如下:
// action/auth.js
import request from 'axios';
import { loadUserData } from './user';
export const login = (user, pass) => async (dispatch) => {
try {
dispatch({ type: LOGIN_REQUEST });
let { data } = await request.post('/login', { user, pass });
await dispatch(loadUserData(data.uid));
dispatch({ type: LOGIN_SUCCESS, data });
} catch(error) {
dispatch({ type: LOGIN_ERROR, error });
}
}这种处理之后,组件调用的是dispatch(action creator),此时的 action 被赋予了太多的逻辑功能,不再是一个 pure action 。为了保持 action 的简洁性,继而引入 redux-saga ,它提供了一个 saga 文件用来存放异步逻辑,引入 redux-saga 之后,上面的验证用户登录逻辑就变成如下:
// sagas/index.js
import { take, call, put } from 'redux-saga/effects'
import Api from '...'
export function* login(user, pass) {
try {
const data = yield call(Api.authorize, user, pass)
yield put({type: 'LOGIN_SUCCESS', data.uid})
} catch(error) {
yield put({type: 'LOGIN_ERROR', error})
}
}使用 redux-saga 之后,action 又回归其纯粹性。并且将异步操作全部抽离在 sagas 中一层进行处理,这样方便我们进行多种异步处理操作。
redux-saga 虽然在处理较为复杂的异步逻辑时提供了比较好的解决方案,但是当业务变复杂时,随着模块的逐渐增加,由于项目通常要分 reducer, action, saga, component 等等,所以项目中的文件个数也会变得很多,如下:
+ src
+ actions
- user.js
- detail.js
+ reducers
- user.js
- detail.js
+ sagas
- user.js
- detail.js
+ components这样在项目开发过程中,就需要不断地切换文件目录,大大影响开发效率。于是 dva 应运而生,dva 的主要解决的项目开发中的痛点:
上面的例子使用 dva 来实现如下:
// models/login.js
import Api from '...'
export default {
namespace: 'login',
state: {
user: null
},
effects: {
*login(){
const data = yield call(Api.authorize, user, pass)
yield put({type: 'LOGIN_SUCCESS', data.uid})
},
},
reducers: {}
}其中,reducers 可以看成是同步的请求逻辑,effects 可以看成是异步的请求逻辑,所有的逻辑都放在了 models 目录下的文件中,省去了文件之间的切换成本,让开发人员可以专注于业务逻辑。
具体可以参考支付宝前端应用架构的发展和选择
dva中只有5个 API,8个新的概念,其中所有的 API 如下:
app = dva(Opts) 创建应用,返回 dva 实例app.use(Hooks) 配置 hooks 或者注册插件app.model(ModelObject) 注册 modelapp.router(Function) 注册路由表app.start([HTMLElement], opts) 启动应用具体的使用可以移步这里
8个概念如下所示:
{
type: String,
payload: Any?,
error? Error,
}调用的时候有如下两种方式:
dispatch(Action);dispatch({ type: 'todos/add', payload: 'todo content' });如何基于 dva 开发一个项目,dva 的作者给出了一个一步步开发 dva 项目的教程, 笔者仿照该教程,并且基于 dva2.0, 做出了一个 demo,该 demo 类似于 dva中的范例,只是初步体验一下 dva 的开发。
借用描述 dva 数据流动的一张图,如下所示:
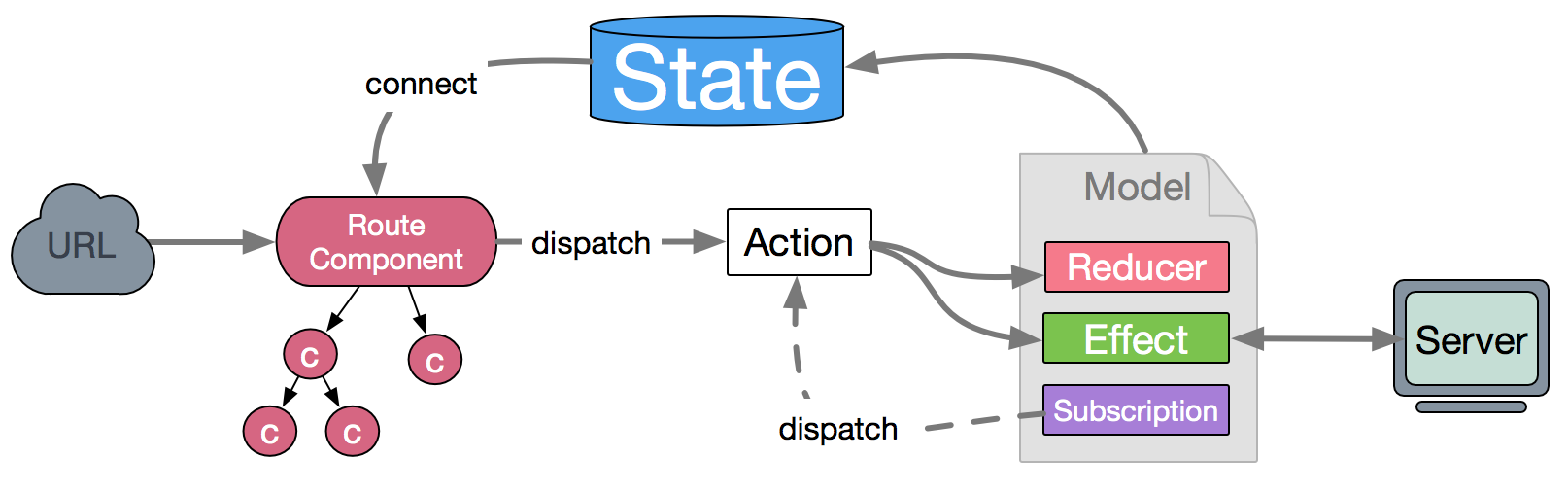
如图所示:用户在浏览器中访问某个 URL,由此渲染一个页面,该页面可能包含多个 Components, 当用户在页面进行操作的时候,由此 dispatch 某个 action,同步的 action 逻辑放在 Reducer 中,异步的 action 逻辑存放在 Effect 中。通过 model 中的数据处理,将新的 state 传入页面中,从而触发页面数据的更新。
这次的解读主要是针对 [email protected] 和 [email protected]。
首先是 dva 中的入口文件所暴露出来的方法,主要是const app = dva();这行代码的作用,返回一个 app实例。该方法如下:
export default function (opts = {}) {
const history = opts.history || createHashHistory(); //history默认是HashHistory
const createOpts = {
initialReducer: {
routing,
},
setupMiddlewares(middlewares) {
return [
routerMiddleware(history),
...middlewares,
];
},
setupApp(app) {
app._history = patchHistory(history);
},
};
const app = core.create(opts, createOpts);
const oldAppStart = app.start;
app.router = router;
app.start = start;
return app;
}
// 此处略去一些方法的定义这个函数很简单,主要是调用了 dva-core 里面的 create 方法,并且返回了一个包含如下方法的 app 对像:
var app = {
_models: [(0, _prefixNamespace2.default)((0, _extends3.default)({}, dvaModel))],
_store: null,
_plugin: plugin,
use: plugin.use.bind(plugin),
model: model,
start: start
};对 app 的初始化定义在 dva-core/lib/index.js 文件中。在这个文件中,实现了 app 对象的所有方法。接下来一个一个进行分析:
这个方法比较简单,只是将传进来的 model push 进 _models 这个属性中。这就意味着每次我们注册 model 时,只能单个进行传递,不能以数组的形式进行传递,例如:
app.model(Model1); app.model(Model2);
//而不是
app.model([Model1,Model2])其实 app.model 在调用 app.start 之后会变成 injectModel(), 它的源码如下:
function injectModel(createReducer, onError, unlisteners, m) {
model(m);
var store = app._store;
if (m.reducers) {
store.asyncReducers[m.namespace] = (0, _getReducer2.default)(m.reducers, m.state);
store.replaceReducer(createReducer(store.asyncReducers));
}
if (m.effects) {
store.runSaga(app._getSaga(m.effects, m, onError, plugin.get('onEffect')));
}
if (m.subscriptions) {
unlisteners[m.namespace] = (0, _subscription.run)(m.subscriptions, m, app, onError);
}
}这个函数里面调用了上面的 model() ,除此之外,该函数还将 model 定义的 reducers,effects, subscriptions 进行分别处理。
sagaMiddleware.run() 来执行管理一部 action,在这之前,先调用了 app._getSaga()方法:export default function getSaga(resolve, reject, effects, model, onError, onEffect) {
return function *() {
for (const key in effects) {
if (Object.prototype.hasOwnProperty.call(effects, key)) {
const watcher = getWatcher(resolve, reject, key, effects[key], model, onError, onEffect);
const task = yield sagaEffects.fork(watcher);
yield sagaEffects.fork(function *() {
yield sagaEffects.take(`${model.namespace}/@@CANCEL_EFFECTS`);
yield sagaEffects.cancel(task);
});
}
}
};
}这个方法主要实现了 saga 那一套的watch/worker(监听->执行) 的工作形式。其中该函数传入的 resolve,reject 是 createPromiseMiddleware.js 这个文件生成的。之所以有这个文件,主要是提供一种机制,提供给某些需要 effect 返回 resolve, reject 等方法的场景。
这个函数用来启动整个应用, 其中 dva 中的 start() 主要是根据传入的 container 容器来渲染页面,核心代码如下:
if (container) {
render(container, store, app, app._router);
app._plugin.apply('onHmr')(render.bind(null, container, store, app));
} else {
return getProvider(store, this, this._router);
}如果传入的参数是 DomElement 或者 DomQueryString,那么直接启动应用,渲染页面,否则就返回一个 <Provider /> (React Component)。
除此之外,dva-core 中的 start(), 则是将 dva 的所涉及的一些概念全部整合到一个 store 的对象中,并执行一些赋值操作,具体源码移步这里
这是 dva-core 中唯一暴露的一个函数,里面包含了上面介绍的三个函数,并且还夹杂了一些其他的逻辑。比如插件的使用,关于插件,它的主要逻辑是放在了 dva-core/Plugin.js 这个文件里面,这个文件提供了一个插件管理类,提供了 apply(), get(), use() 成员方法,这个类主要对钩子函数进行了一些处理,并且限制了钩子函数的几个可选项:
const hooks = [
'onError',
'onStateChange',
'onAction',
'onHmr',
'onReducer',
'onEffect',
'extraReducers',
'extraEnhancers',
];关于 hooks 的概念,可以移步这里进行查阅
以上只是笔者在这几天的学习中总结的一些技术要点,由于时间比较仓促,所以有些地方可能总结得有点问题,如有错误,欢迎指正~
上一篇简单地介绍了一下 React Hooks 的背景和 API 的使用,这一篇深入探索一下 React Hooks 的实践和原理。
有的时候还是需要根据不同的生命周期来处理一些逻辑,React Hooks 几乎可以模拟出全部的生命周期。
使用 useEffect 来实现,如下:
useEffect(()=> {
//ComponentDidMount do something
},[]);useEffect 第二个参数传空数组时,表示只会在执行一次。
同样可以使用 useEffect 来实现,如下:
useEffect(()=> {
return ()=> {
// ComponentWillUnMount do something
}
},[])componentDidUpdate 生命周期在组件每次更新之后执行,除了初始化 render 的时候不执行,所以可以设置一个标志位来判断是否是第一次 render,使用 useEffect + useRef 配合就可以实现:
const firstRenderRef = useRef(true)
useEffect(()=>{
if(firstRenderRef.current){
// 如果是第一次 render,就设置为 false
firstRenderRef.current = false;
} else {
// componentDidUpdate do something
}
})getDeriverdStateFromProps 是 react 新版本中用来替代 componentWillReceiveProps,它可以感知 props 的变化,从而更新组件内部的 state,用 hooks 模拟这个生命周期,可以这样实现:
function Child(props){
const [count,setCount] = useState(0);
if(props.count !== count){
setCount(props.count);
}
}React 16.6 引入 React.memo,是用来控制 Function Component 的重新渲染的,类似于 Class Component 的 PureComponent,可以跳过 props 没有变化时的更新,为了支持更加灵活的 props 对比,它还提供了第二个函数参数 areEqual(prevProps, nextProps),和 shouldComponentUpdate 相反的是,当该函数返回 true 时表示不更新函数,返回 false 则重新更新,用法如下:
function Child(props){
return <h2>{props.count}</h2>
}
// 模拟shouldComponentUpdate
const areEqual = (prevProps, nextProps) => {
//比较
};
const PureChild = React.memo(Child, areEqual)除了上面这种方法可以模拟 shouldComponentUpdate 之外,React Hooks 还提供一个 useMemo 用来控制子组件重新渲染的,举一个例子如下:
// Parent 组件
function Parent() {
const [count,setCount] = useState(0);
const child = useMemo(()=> <Child count={count} />, [count]);
return <>{count}</>
}
// Child 组件
function Child(props) {
return <div>Count:{props.count}</div>
}在上面的例子中,只有 Parent 组件中的 count state 更新了,Child 才会重新渲染,否则不会。
还记得我们之前讲过的使用 React Hooks 的两条规则吗?
翻到 ReactHooks 对应的源码,贴出 Hooks 的定义如下:
// useState
export function useState<S>(initialState: (() => S) | S) {
const dispatcher = resolveDispatcher();
return dispatcher.useState(initialState);
}
// useEffect
export function useEffect(
create: () => (() => void) | void,
inputs: Array<mixed> | void | null,
) {
const dispatcher = resolveDispatcher();
return dispatcher.useEffect(create, inputs);
}
// useRef
export function useRef<T>(initialValue: T): {current: T} {
const dispatcher = resolveDispatcher();
return dispatcher.useRef(initialValue);
}
...
//其他的都类似所有的 Hooks 基本都调用了这个 resolveDispatcher(),定位到 resolveDispatcher,代码如下:
function resolveDispatcher() {
const dispatcher = ReactCurrentDispatcher.current;
invariant(
dispatcher !== null,
'Invalid hook call. Hooks can only be called inside of the body of a function component. This could happen for' +
' one of the following reasons:\n' +
'1. You might have mismatching versions of React and the renderer (such as React DOM)\n' +
'2. You might be breaking the Rules of Hooks\n' +
'3. You might have more than one copy of React in the same app\n' +
'See https://fb.me/react-invalid-hook-call for tips about how to debug and fix this problem.',
);
return dispatcher;
}如果 ReactCurrentDispatcher.current 是空的,就会得出我们使用 Hooks 的方式不对,只有在 React 环境中才会给 ReactCurrentDispatcher 的 current 赋值,所以就可以解这个问题。
为什么不能在循环、条件或者嵌套函数中调用 Hook,我们还是从源码出发寻找原因:
Hooks 的实现源码在 ReactFiberHooks.js。
在这个文件中,定义了 firstWorkInProgressHook 和 workInProgressHook 这两个全局变量,观察所有的 Hooks 实现,发现都执行了 const hook = mountWorkInProgressHook(),首先来看一下这个函数的实现:
function mountWorkInProgressHook(): Hook {
const hook: Hook = {
memoizedState: null,
baseState: null,
queue: null,
baseUpdate: null,
next: null,
};
if (workInProgressHook === null) {
// This is the first hook in the list
firstWorkInProgressHook = workInProgressHook = hook;
} else {
// Append to the end of the list
workInProgressHook = workInProgressHook.next = hook;
}
return workInProgressHook;
}我们来模拟一下定义多个 Hooks 时的流程:
这种结构就是一个链表结构,而每一个 Hook 的结构如下:
type Hook = {
memoizedState: any,
baseState: any,
baseUpdate: Update<any, any> | null,
queue: UpdateQueue<any, any> | null,
next: Hook | null,
};
type Effect = {
tag: HookEffectTag,
create: () => (() => void) | void,
destroy: (() => void) | void,
deps: Array<mixed> | null,
next: Effect,
};其中 memoizedState 存储当前 Hook 的结果,next 则连接到下一个 Hook,从而将所有 Hook 进行串联起来。这个链表结果存储在 Fiber 对象的 memoizedState 属性中,在 React 中,每个节点都对应一个 Fiber 对象,而 Fiber 的 memoizedState 用来存储该节点在上次渲染中的 state,这个属性是 Class Component 用来存储节点的 state 的,这也就是为什么 Hook 可以拥有 Class Component 功能的原因。
链表结构用图形显示如下:
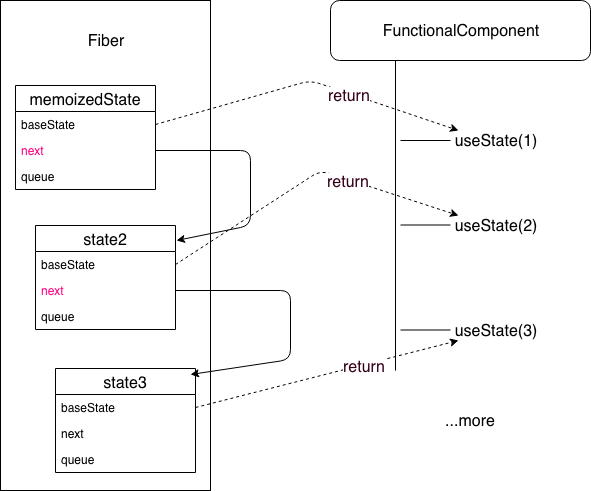
在第二次渲染时,也就是 update 的时候,此时调用的是 Hook 对应的 update 方法,而 update 方法又分别执行了 updateWorkInProgressHook(),先来看看这个方法的实现:
function updateWorkInProgressHook(): Hook {
if (nextWorkInProgressHook !== null) {
// There's already a work-in-progress. Reuse it.
workInProgressHook = nextWorkInProgressHook;
nextWorkInProgressHook = workInProgressHook.next;
currentHook = nextCurrentHook;
nextCurrentHook = currentHook !== null ? currentHook.next : null;
} else {
// Clone from the current hook.
invariant(
nextCurrentHook !== null,
'Rendered more hooks than during the previous render.',
);
currentHook = nextCurrentHook;
const newHook: Hook = {
memoizedState: currentHook.memoizedState,
baseState: currentHook.baseState,
queue: currentHook.queue,
baseUpdate: currentHook.baseUpdate,
next: null,
};
if (workInProgressHook === null) {
// This is the first hook in the list.
workInProgressHook = firstWorkInProgressHook = newHook;
} else {
// Append to the end of the list.
workInProgressHook = workInProgressHook.next = newHook;
}
nextCurrentHook = currentHook.next;
}
return workInProgressHook;
}在这个方法中,它会获取渲染时生成的 Hooks,并获取当前 update 的是处于链表的哪个节点,然后返回。
假如在条件语句中使用 Hook,如下:
let condition = true;
const [state1,setState1] = useState(0);
if(condition){
const [state2,setState2] = useState(1);
condition = false;
}
const [state3,setState3] = useState(2);初始渲染时,拿到的是 state1 => hook1,state2 => hook2,state3 => hook3,再次渲染时,condition 条件不满足,那么执行 state3 时拿到的就是 hook2,那整个逻辑就乱套了...
React Hooks 解决了一部分问题,但同时自身也有一定的缺陷,比如要遵守一定规则、组件嵌套层次不明显导致 bug 定位难。所以在实际的开发实践中,还是要评估再选型。

这真是一本神奇的书,在地铁上虽然被挤得只能贴近地铁门,但还是被里面的故事情节给深深吸引,所以即使沙河离西二旗算得上是很长的一段距离,有了它便觉得这段时间也是那么短。三体第二部
《黑暗森林》主要写的是地球文明和三体文明之间的战争。
在识破三体人安插质子的真正阴谋之后,人类文明开展了面壁计划,这个计划主要是挑选四位面壁者作为挑战甚至破解三体的阴谋。其他三位当然是实至名归,都是在政治或者科学方面有一定造诣的人,当罗辑被选中的时候,我也是感到很惊讶,他在科学方面没有很大的造诣,甚至在品质方面有点自我享乐的劣迹,但是当故事帷幕渐渐拉开的时候,甚至就是因为他和叶文洁在杨冬坟墓前的一次对话让事情有了真相。他甚至成为四个面壁者中对三体世界有着最大威胁的人。当然,其他三个面壁者都通过调用一定的资源开展着自己的面壁计划,唯有罗辑要求在一个世外桃源中与自己的爱人享乐,不问世事,直至联合国对他进行了强制要求,他才开始了一个所谓的咒语计划。最后的结局是,在面壁计划展开的同时,三体文明也展开了破壁计划,除了罗辑,每一个面壁者都有自己的破壁人,他们通过质子的监视对自己的面壁者进行分析,最终识破他们的计划而最终让他们的精神崩溃。从此展开了地球文明和三体文明之间的拉锯战。
结果很令人惊讶,面壁计划失败了:
在罗辑和其他人被冬眠后苏醒的世界里,真正的三体和地球的世界末日之战并没有来临,罗辑醒来之后看到的生活是十分现代化的:人们生活在叶子上,各种高科技,人们的衣服是可以任意调换大小的。。。。种种高科技,让罗辑一时难以适从。之后才知道,人们在经历臆测世界末日来临的同时,经历各种恐慌和大范围的逃亡主义和失败主义的挣扎,但是最后在经历了大低谷时期之后,他们开始技术发展,让世界飞速发展,并建立了很多太空舰队。甚至在意识上认为人类是必胜的,在这种必胜信心的笼罩下,没人再谈起面壁计划,面壁计划由此而废除。然而,三体的第一颗水滴到达地球时,它在很短的时间内摧毁了人类几个世纪建立起来的几千艘舰队,这种战斗力让人们瞠目结舌。
"水滴就像一枚死神的绣花针,灵巧地上下翻飞,用一条毁灭的折线把第三队列的一百艘战舰贯穿起来。"
这是原文的描述。对于水滴撞击战舰的场景,作者的文笔和想象力真是让我敬佩,那么磅礴和宏伟的场景,让读者仿佛身临其境一样,简直精彩。就在全世界都被水滴的强大攻势所恐慌而绝望甚至开启了超级性派对的**堕落的生活时,罗辑以为水滴会来刺杀自己的时候,剧情有一次戏剧性地逆转了,罗辑之前的咒语生效了,水滴在靠近地球的时候又转向了,并没有攻击地球,而是封锁了太阳系。。。罗辑再一次被奉为救世主,面壁计划再次开始,全世界的人们都把罗辑作为整个地球的唯一救世主,但是失败的局势无法扭转,罗辑也是无能为力。但是,最后,罗辑再次用氢弹计划威胁三体,避免了地球文明的消失。。。
第二部写得很精彩,无论是故事情节还是写作手法,作者擅长用不同的视角来叙述,比如第二部开始是用一只蚂蚁的视角,然后是蜘蛛,最后变成罗辑,而且在这部中,一些人物的塑造也是很成功
的,比如章北海,丁仪,大史。让我最为惊叹的是水滴撞击战舰时候的场景,简直是神来之笔。
总之,这真是一本神书,强烈推荐。。。。
express中的路由还是很强大的,express中的路由实现主要有如下几种形式:
直接上代码:
var express = require('express');
var app = express();
// get路由
app.get('/', function(req, res) {
res.send('get');
});
//post路由
app.post('/', function (req, res) {
res.send('post');
});这种是比较简单的,所以不多说
app.route()app.route()的功能是创建路由路径的链式路由句柄,我个人觉得就是将上面那种方法的分开写转化为一种链式形式,示例代码如下:
app.route('/Article')
.get(function(req, res) {
res.send('获取文章列表');
})
.post(function(req, res) {
res.send('添加文章');
})
.put(function(req, res) {
res.send('更新文章');
});express.Router()express中的Router实例是完整的中间件和路由系统,因此也被称为“微型应用程序",使用示例如下:
router/index.js文件:
var express = require('express');
var router = express.Router();
//get路由
router.get('/a', function(req, res) {
res.send('get');
});
router.post('/b',function(req, res) {
res.send('post');
})
module.exports = router;app.js
var index = require('./routes/index');
//.... other codes
app.use('/', routes);express.Router实现系统登录前的拦截功能,也就是说当用户未登录时,没有权限访问一些页面。只有登录后才可以访问。要实现这种功能,需要使用express-session记录当前登录的用户信息,关于这个库的详细信息,可以点击这里,下面用两种方法实现
login表单(由于比较简单,所以就不贴代码了)route/index.js路由文件中的代码如下:// 登录页面
//如果直接访问/login时则显示登录页面
router.get('/login',function(req,res){
res.render('login', { title:'用户登录' });
});
// 查看文章页面
//用户未登录时跳转到登录页面
router.get('/write',function(req,res){
var user = req.session.user; //获取session中的user信息
if(!user){
res.render('login',{title:'用户登录'});
}else{
res.render('article',{ title:'文章页面'});
}
})login表单app.js中进行拦截,定义一个中间件,在中间件中执行一些参数检查和登录拦截的逻辑即可,具体代码如下:app.use(session({
secret:"myzhibie",
store:new MongoStore({
mongooseConnection:db.dbCon //这里使用了connect-mongo库,
})
}));
app.use(function(req,res,next){
var url = req.originalUrl;
var user = req.session.user; //记录登录的信息
if((url == '/article') && !req.session.user){ //在这里进行拦截判断
req.session.error = '还没登录,请先登录';
return res.redirect('/login');
}
next();
})但是我个人比较倾向于第二种方法,因为具有更大的灵活性,可以根据自己的业务复杂程度添加自己的逻辑,而且使用的是中间件,对理解中间件的原理有较大的帮助
express.Router()是在express4.0中才添加的,但是相比于应用路由有更大的优势,具体可以总结为如下几点:
express.Router()可以创建多组路由request做一些验证和过滤处理Egret是一套HTML5游戏开发解决方案,旨在为h5提供更加方便的开发体验。总的来说egret的功能还是很强大的,最近接手的一个需求的时候使用了egret,使用完之后感觉很棒,把自己的一些经验积累下来。
egret的官方文档地址在这里,API很详细。
既然是写使用总结,还是从最简单的安装到使用吧,虽然官方文档里面也写得很清楚(捂脸)。
安装地址移步这里
Egret Engine即可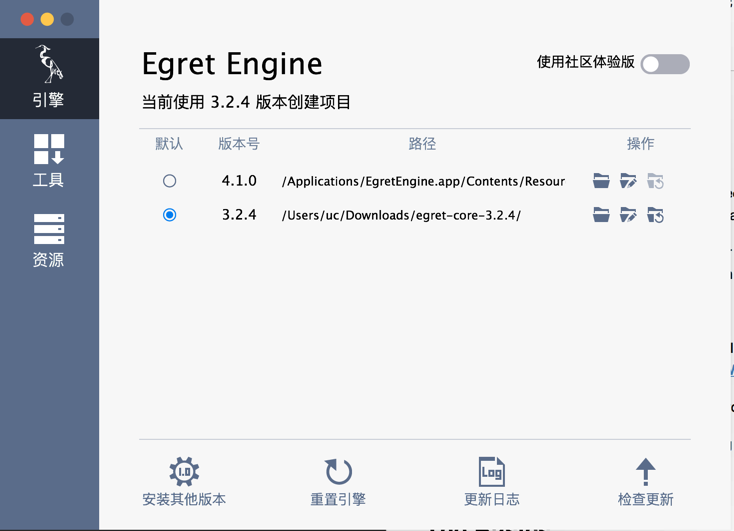
此时我的egret引擎有两个版本,如果你想安装新的版本,可以点击上面图片面板中的"安装其他版本",进行下载,然后将解压之后的安装包拖进安装面板即可。
还要说的一点就是建议安装一个开发egret的编辑器egret wing,安装方式如下:
点击上面图片面板中的左侧边栏的“工具”栏,就会出现对应的一些工具:
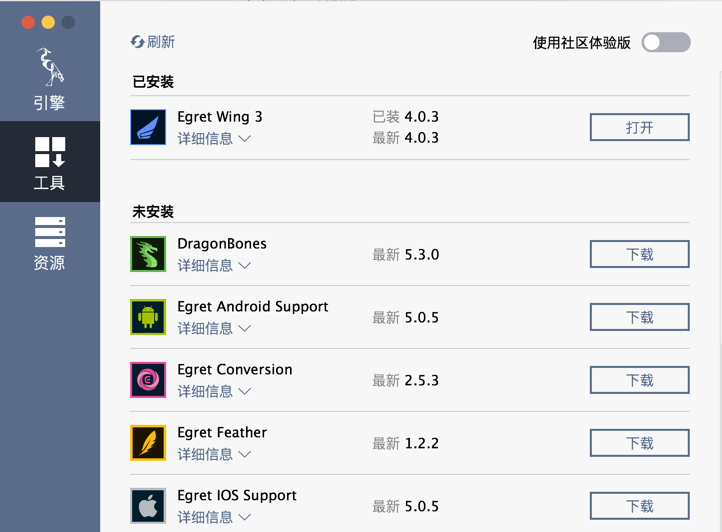
找到相对应的这个工具,并点击下载即可
打开安装的egret wing,并且点击如下位置或者直接到“文件->新建项目"中进行建立新的项目:
此时会弹出一个项目类型的面板,根据你的需要选择一种项目类型就行。这里我选择的是Egret Eui项目,然后会弹出如下面板:
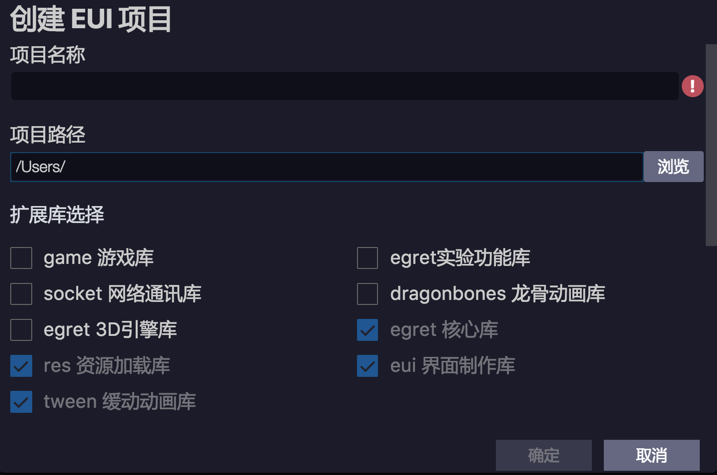
选择你所需要的库并填写相应的项目目录以及项目名称就大功告成了
你可以直接在egret wing中进行构建,也可以直接在命令行中进行运行:
egret startserver 项目名称 --port 端口号 -a-a表示会实时监听你文件的变化并且构建编译。
回车之后就会自动跳转到浏览器中,打开的就是你项目的初始的样子:

这说明项目已经运行成功了。
egret使用的是typescript实现的,初始项目目录结构如下:
其中不同文件夹对应的功能如下:
打开main.js文件(项目的入口文件),项目运行的时候是首先执行的createChildren()函数,该函数主要功能是加载了一些资源,并且监听了配置文件加载的事件,主要是下面这行代码进行起监听作用:
RES.addEventListener(RES.ResourceEvent.CONFIG_COMPLETE, this.onConfigComplete, this);当配置文件加载完成之后就会执行下面的onConfigComplete(),在这个函数里面你就可以load一些图片资源了。并进行监听图片资源组是否加载成功:
RES.addEventListener(RES.ResourceEvent.GROUP_COMPLETE, this.onResourceLoadComplete, this);
RES.addEventListener(RES.ResourceEvent.GROUP_LOAD_ERROR, this.onResourceLoadError, this);
RES.addEventListener(RES.ResourceEvent.GROUP_PROGRESS, this.onResourceProgress, this);
RES.addEventListener(RES.ResourceEvent.ITEM_LOAD_ERROR, this.onItemLoadError, this);
RES.loadGroup("preload");这里面监听了图片的"加载完成、加载中、资源组加载出错、单个资源加载出错“的事件。所以若是项目中有加载资源的进度条的要求,就可以通过onResourceProgress这个函数进行相应的处理
记住,对于已经监听的事件,若是不需要了或者监听完了,要及时取消,否则就会触发很多问题。
例如在onConfigComplete()函数里面就及时地取消了CONFIG_COMPLETE事件。
RES.removeEventListener(RES.ResourceEvent.CONFIG_COMPLETE, this.onConfigComplete, this);当图片资源组加载完成之后,就可以获取图片并且渲染到页面中。
移步到onResourceLoadComplete(),代码如下:
private onResourceLoadComplete(event:RES.ResourceEvent):void {
if (event.groupName == "preload") {
this.stage.removeChild(this.loadingView);
RES.removeEventListener(RES.ResourceEvent.GROUP_COMPLETE, this.onResourceLoadComplete, this);
RES.removeEventListener(RES.ResourceEvent.GROUP_LOAD_ERROR, this.onResourceLoadError, this);
RES.removeEventListener(RES.ResourceEvent.GROUP_PROGRESS, this.onResourceProgress, this);
RES.removeEventListener(RES.ResourceEvent.ITEM_LOAD_ERROR, this.onItemLoadError, this);
this.isResourceLoadEnd = true;
this.createScene();
}
}如上,首先是先取消了事件的监听(足以可见及时取消事件的监听是有多么重要),然后开始渲染页面。
根据代码逻辑直接跳转到startCreateScene(),在这个函数里面,只是获取了一些资源并且绘制了一些图案,然后add到舞台中。这样整个项目就完成的构建到渲染页面的整个过程。
首选我们在渲染页面的函数startCreateScene()将this和this.stage进行打印,如下所示:
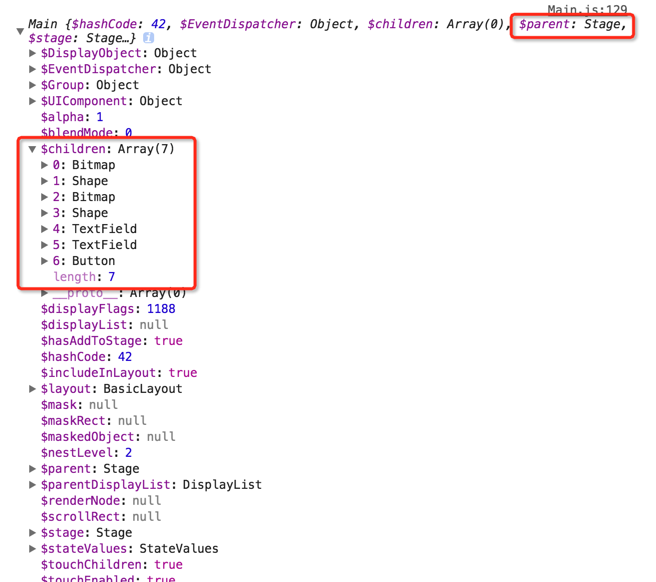
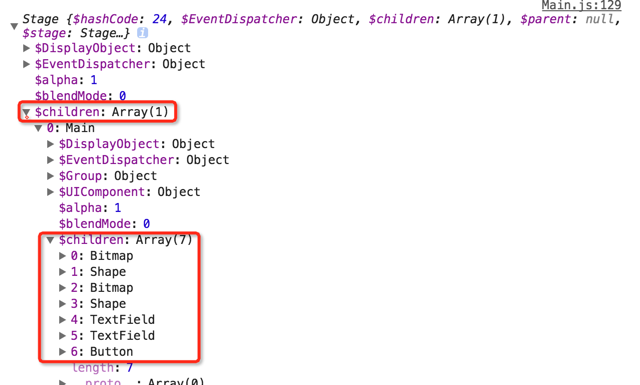
从上图可以看出,this.stage是包含this,至少从视图的层级上来看。7个children分别是执行this.addChild('元素')之后的结果。而且越排在后面的child深度越浅。也是官网中深度管理的这一章讲述的内容,越在后面,层级越高,也就是在z轴方向上处于最上面。当然你也可以按照如下方式自己设计元素的显示层级:
this.addChildAt(元素,层级数);也可以如下面所以获取层级对象:
this.getChildAt(层级数);在一个h5页面中,难免少不了对事件的一些处理,比如对按钮的点击事件。
项目示例中已经列举了一个demo,如下:
let button = new eui.Button();
button.label = "Click!";
button.horizontalCenter = 0;
button.verticalCenter = 0;
this.addChild(button);
button.addEventListener(egret.TouchEvent.TOUCH_TAP, this.onButtonClick, this);至于点击之后要触发的逻辑可以卸载onButtonClick中。这里是引用了eui.Button这个组件,默然可以进行点击。但是不是所有的点击事件只能建立在按钮这种元素上呢,其实不是。例如对于egret.Bitmap类的元素,也可以监听其点击事件,只需要如下设置:
let BitmapObj:egret.Bitmap;
BitmapObj = this.createBitmapByName("button_png");
BitmapObj.touchEnabled = true; //关键是这个
BitmapObj.addEventListener(egret.TouchEvent.TOUCH_TAP, this.onButtonClick, this);对于元素是否含有点击事件,可以到官网的对应api查看。
对于这个部分的内容,我还是觉得直接使用一个文档的地址会比较直观一点。
对于不同的项目,可能需要的显示模式也不一样。
对于强制横屏显示的h5可以直接在html中设置data-orientation="landscape"即可
this.loadGroup('preload');resourceList: Array<RES.ResourceItem> = RES.getGroupByName(groupName);
this.resourceTextureList = [];
for (let item of resourceList) {
this.resourceTextureList.push(RES.getRes(item.name));
}上面代码是获取资源的纹理对象,RES.getRes是针对的已经加载完成的资源,没有加载完成会显示为空。获取成功之后并存放在对应数组中。
this.stage.addEventListener(egret.Event.ENTER_FRAME, this.repeatPlaying, this);let index = 0;
let bitmap = egret.Bitmap;
this.stage.addChild(bitmap);
index ++;
bitmap.texture = this.resourceTextureList[index];
if(index >= this.resourceTextureList.length){
index = 0;
}不断遍历,就会重复播放。
对于只播一次的情况,就需要在播放完最后一帧的情况下取消事件的监听即可。
this.stage.removeEventListener(egret.Event.ENTER_FRAME, this.repeatPlaying, this);对于建立了eui项目的文件目录,就会在resource-skins中找到对应的exml文件。如果想自定义一个组件,就需要执行如下步骤:
exml文件就行,,然后在egret wing中进行绘画视图。如下图所示: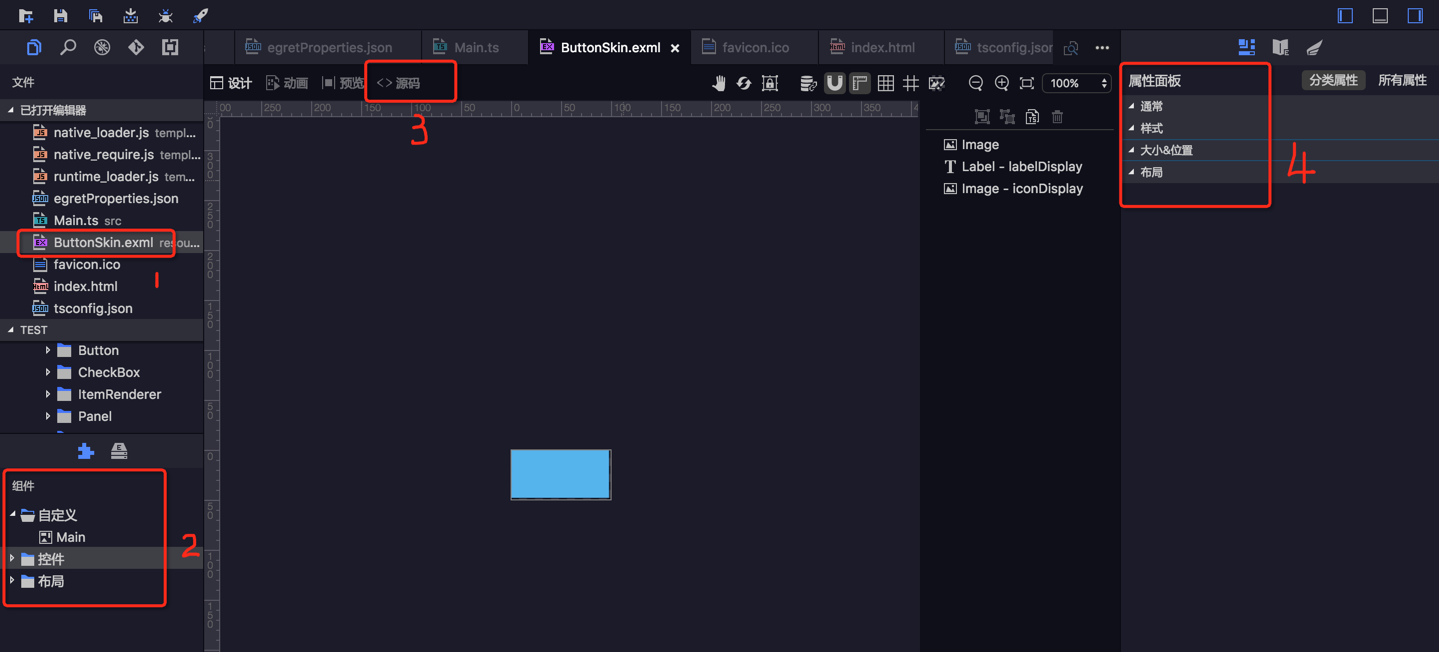
例如对于button控件来说,你可以自定义其他的控件,并且在2中选择需要添加的控件元素,在中间面板进行编辑,然后在 4 区域中进行设置属性(如width,height,x,y等属性),最后在 3 中就会自动生成相应的源码了。
src文件夹中建立相应的ts文件,并且使其继承eui.component,代码如下:class PopBoxPanel extends eui.Component{
public constructor(orientation:string ,instance:egret.DisplayObjectContainer){
super();
this.addEventListener(egret.Event.COMPLETE,this.onCreateComplete,this);
this.skinName = "resource/skins/PopBox.exml";
}
private onCreateComplete(event: any){
this.removeEventListener(egret.Event.COMPLETE,this.onCreateComplete,this);
}
}resource-default.thm.json中按照所给格式添加你定义的组件即可declare module skins{
class ButtonSkin extends eui.Skin{
}
}egret.runEgret({renderMode:"webgl", audioType:0});将webgl改为canvas即可
this.stage.removeEventListener(egret.Event.ENTER_FRAME, this.repeatPlaying, this);在资源未加载完成就使用RES.getRES()
需要在资源加载完成之后的回调里面再使用,否则资源会为空。
ios不能自动播放背景音乐
需要给当前的stage添加一个事件(如点击事件)来设置其开始播放
scroller组件滑动默认是可以上下左右滑动,需要设置一个属性值来控制只能在垂直方向进行滑动
bounces : boolean是否启用回弹,当启用回弹后,ScrollView中内容在到达边界后允许继续拖动,在用户拖动操作结束后,再反弹回边界位置
在ios端播放音频会出现下面的问题,如下图所示:
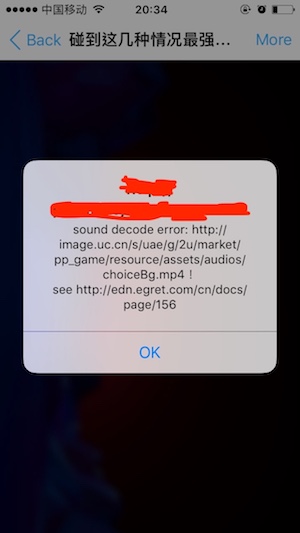
这个egret官方给出的回应是如下:
使用格式工厂。选择 44100Hz,96kbps 转换。
android的uc浏览器播放不出声音,需要将音频改成如下格式:12000hz双声道mp3,比特率20kps
仍在试坑中,后续bug会补上
egret对于一些h5场景还是很使用的。而且文档详尽,上手比较简单。

花一天时间看完了第二部,巨人的陨落II 主要是讲述了发动战争之后的一些事情,战争包括英德两国和俄德两国之间的战争,当然还有作为中立者的美国以及其他国家之间的战争。在这部中,一些主要的主人公都投入到战争当中,其中包括比利・威廉姆斯、格雷戈里・别斯科夫、菲茨赫伯特伯爵以及沃尔特・冯・乌尔里希。在几大国交战的过程中,他们在战争中的英勇表现以及对整个国家的影响牵动着整个故事的紧张发展。
在这部中,一些女主人公也表现出了自己坚强和向往自由的伟大精神,其中典型的就是艾瑟尔・威廉姆斯,虽然被爱的人抛弃,被父母逐出家门,但是她仍然在异国他乡坚强地战胜着一切生活赋予的苦难,不仅生下了可爱的儿子,而且和茉黛・菲茨赫伯特女勋爵一起宣传着解放女性,宣扬女性平等的运动,她们在战乱时期表现出来的那种强大的独立精神让我深深折服。
“最后,她只得忍气吞声,勉强在一向雇佣女性的行业里寻找机会,并发誓有生之年一定要改变这种不公正的制度。”
当她看到了女性受到不平等待遇的时候,在心底就萌发了要为解放女性而奋斗的决心,在那个战乱的时代,有这种觉悟和追求让我简直是不可置信,作为一个单身妈妈,虽然自己还爱着菲茨赫伯特伯爵,但是当她看到菲茨赫伯特伯爵反对英国求和的时候,认定菲茨赫伯特伯爵是一个冷漠自私的人的时候,她毅然决然地坚定了自己不再爱他的立场,这种理性而又有政治立场的态度让我为她着迷。
同样的,格雷戈里・别斯科夫也是我比较喜欢的一个男主人公,父母去世后,仍未成年的他担当着抚养弟弟的重任,甚至在弟弟拿着他的梦想跑掉的时候,他还能一如既往地照顾心仪弟弟的卡捷琳娜和她的孩子,并且从未变过心,在打仗的时候,照顾卡捷琳娜和孩子成为他努力让自己活着的信念。同时,在看到沙皇的暴政的时候,他也是时刻站在苦难群众的立场上,并最终作为领袖成为了推翻沙皇暴政的关键人物。
“格雷戈里仿佛回到了十二年前。他看见冬宫前面的广场上成百上千的男男女女跪在地上祈祷,对面的士兵端着步枪,他母亲躺倒在地,鲜血在雪地上漫开。他耳边回荡着十一岁列夫的惊叫声:“她死了!妈死了,我母亲死了!”
“他在战场上学会了先反击,再悲伤”
这些片段深刻地反映了格雷戈里・别斯科夫至始至终想为底层苦难群众谋福利的信念,因为他从小就是深受沙皇压迫长大的,他不想后一代人重复他苦难的生活,所以他必须带头革命。
于此同时,由于战争沃尔特・冯・乌尔里希和茉黛・菲茨赫伯特女勋爵已经有好长时间未见了,在第一部的时候,两人跨越国籍的爱情故事让我唏嘘不已,但是在第二部中,沃尔特・冯・乌尔里希因为家人介绍的原因,似乎开始移情别恋。
“这番碰触就像一丝温暖的电流。两年来没有任何家人之外的女人碰过他。他突然想到,如果能把莫妮卡搂在怀里,让她温暖的身体贴着自己,吻着她的嘴唇,那该多好啊。她那双琥珀色的眼睛坦诚地回应着他的目光,过了一会儿他才发觉,她一定猜出他在想什么了。”
上面这些细节足以说明沃尔特・冯・乌尔里希在精神上的出轨,这让我再一次怀疑了这世界上是否存在真正坚定的爱情,当爱情遇到了爱情和家庭的阻挠时,曾经的海誓山盟还有效么,男人似乎永远都是在爱情中容易出轨的那一方,哎,我还能说什么呢。。。
从来只是接触到**的暴政和战争,在这次通过阅读这本小说了解到外国在战争和战乱时期的人民生活的时候,让我深刻地明白了一个道理:一旦发生战争,受苦的必定是基层人民群众,但是正是这种暴乱的战争生活孕育了伟人的诞生。
这一部总体感觉还是很好的,相比第一部的背景铺垫,这一部结合战争似乎更加让我陷入其中了,期待第三部的故事情节发展。

想到要看这本书也是一个朋友推荐的,而且之前也恰巧看了东野圭吾的一部小说《嫌疑人x的献身》拍的电影。当时确实被那部电影里面设计的悬疑情节所惊叹。原本以为这本书应该不是悬疑类的推理小说,然而一口气读完后才知道也是。而且是真的一口气读完的,前后用了不到一天的时间,仿佛是一个吸铁石,没读几页就被彻底吸引住了。读完之后有一种震惊和恐怖在心头萦绕。
这部小说主要是写主人公前岛老师在女子高中教书,但他本人对教书无一点兴趣,私下被学生称作“机器”,但由于前岛三次在放学后遭人暗算,内心十分紧张。前岛是射箭社的指导老师,在一次放学后的社团活动结束时,与射箭设社长惠子同学一同前往更衣室时,发现在男更衣室中毒身亡的村桥老师,警方随即展开一系列调查,因为一直遭到暗算,所以前岛老师对此案也十分挂心,并了解到该校麻生老师与村桥老师关系密切,但案子总是并无大的进展。之后猜测出几个嫌疑人,分别是麻生老师和一个问题学生高原阳子,但是仅仅只是怀疑而已,案情并没有水落石出。然而不久后的学校运动会上,原本扮演乞丐的竹井老师提出要与前岛老师更换角色扮演小丑,却不料被小丑的道具酒瓶中的毒水毒死。而这毒刚好与村桥老师所中之毒一样,警方知情后,认为凶手真正的目标可能是前岛。没过几天,前岛又遭到一辆小轿车的撞击,幸好得到学生高原阳子的救助,同时从高原口中听到案件的真正隐情。前岛经过自己的分析与取证,终于找出了杀害那两位老师的凶手,案件已破。可是前岛却仍被暗算,被人所伤,凶手居然是他的妻子。
这部小说其实语言平实,没有很华丽的词藻,基本上行文都是采用对话来开展的。但是情节却设计得极其巧妙,一波三折,悬疑色彩凸显而出。另外,小说中的案情也是在主人公的猜测下不断深入并最终解开谜底。但在案情水落石出的过程中,却让读者一再从已经相信这应该就是事情的真相中醒悟过来:凶手原来另有其人,这事情并非如此简单。最后谁也想不到,凶手竟然是没有毫无嫌疑的惠子和慧美。刚开始的确以为是高原阳子或者麻生老师,甚至还猜测过主人公的妻子裕美子。但是最后一一被否决了。而且案情的线索设计得十分巧妙,以至于需要结合图片还有仔细研读主人公的推理以及联系前后发生的所有蛛丝马迹才能真正领悟出来。最绝的是在真相即将大白的时候,作者故意隐藏主人公内心的一切猜测,最后在主人公和慧子中的谈话中全盘抛出,让读者有一种顿悟和惊叹之感---事情原来是这样的。整本书的结构十分清晰严密,并且暗藏了好几道伏笔,这些伏笔与后面的真相前后呼应,环环相扣,让人咋舌的同时又觉得十分在理。最妙的是,故事最后的真相是在主人公和慧子一边练箭一遍道出的,一边是练箭的紧张动作,一边是案情的紧张和高潮,让读者也在主人公的一问一答中始终保持着紧张的心情,得知真相后又不免后怕,在惊叹情节的曲折的同时又不免为作者的独具匠心而拍案叫好。而且小说的结局也没有完全道破,主人公最后是否生还给读者无尽的想象和猜测,给人一种意犹未尽的感觉。
这部小说的主人公性格较为怯懦,不仅工作上是将就的‘机器’,就连婚姻也是将就的,而且在和学生的关系上也是处理得不是很恰当。书中的凶手的杀人动机是保卫住自己最纯洁的东西。这似乎在情理之中。不过这种阴谋的设计让人不免心生恐惧。小说的主题似乎是在说如何与处于青春期的少女相处,但是也有人说是在表述“当想去珍惜的时候却已来不及”,当然,每个人的想法都不一样,一千个读者就有一千个哈姆雷特。
但是不管怎样,这部小说写得还是很赞的,强烈推荐。

很少涉猎哲学和思辨的书,总觉得是在玩文字游戏而且字里行间随处可见枯燥。这本书确实出乎我意料,不仅文笔优美,又有理有据,结合古今中外的事例,将一种无形而又伟大的孤独感描述得可触可感,真实存在而又不晦涩难懂。让人拍案叫好的同时又不得不心悦诚服。
书中主要讲了6种孤独:
在每一种孤独中,作者不仅阐述着自己的见解、亲身经历,还结合一些名著、现实中的事例加以佐证。原本以为,孤独无非是夜深人静,独自一人,在郁结于心的难受时刻无人倾述的一种可怜。然而读罢全书,才明白我的**过于狭隘了。孤独分为很多种,除此之外,孤独并不意味着寂寞,相反享受孤独的人,才会更加懂得透过自己的灵魂看世界。在现实生活的我们,常常叫嚣着要摆脱孤独,于是将自己置身于闹市、琴瑟和鸣的处境中,然而却发现随之而来的却是更大的孤独感。
孤独并非寂寞孤独和寂寞不一样。寂寞会发慌,孤独则是饱满的,是庄子说的「独与天地精神往来」,是确定生命与宇宙间的对话,已经到了最完美的状态。
伟大的人都是孤独的,如项羽,如屈原,亦如高渐离,这些人用自己的生命诠释着孤独如史诗般绚烂的最高境界。让读者不再猥亵孤独,不是对孤独的人投以同情的一瞥,而是以一种虔诚、仰望的姿态去尊敬他们、敬仰他们。伟大的人都是孤独的,只有在孤独中,他们才能真正知道自己内心深处的诉求并为之追求一生,不惜牺牲自己的生命。
孤独的人注定是要受到争议的,“永远也不要做第一个人和最后一个人”,这句话足以说明现在的人更愿意随波逐流而不是特立独行,不合群的人注定会受到排挤,众口铄金的现实使得我们都随着大流,隐忍着自己内心最真实的追求。于是,在我们活得都想是社会的复制品的时候,我们也就不再是最初的那个自己了。
对于孤独,我们永远排斥,孤独意味着清冷、落寞,于是很多人都去逃避孤独或者去追随其他东西从而来填满自己的孤独感。然而,孤独是自己和自己的一种对话。
有时候你会发现,速度与深远似乎是冲突的,当你可以和自己对话,慢慢地储蓄一种情感、酝酿一种情感时,你便不再孤独;而当你不能这么做时,永远都在孤独的状态,你跑得愈快,孤独追得愈紧,你将不断找寻柏拉图寓言中的另外一半,却总是觉得不对;即使最后终于找到「对的」另外一半,也失去耐心,匆匆就走了。
我更相信,我们心灵一旦不再那么慌张地去乱抓人来填补寂寞,我们会感觉到饱满的喜悦,是狂喜,是一种狂喜。就像气球,被看起来什么都没有的气体充满,整个心灵也因为孤独而鼓胀了起来,此时便能感觉到生命的圆满自足。孤独圆满,思维得以发展。
孤独并不可怕,可怕的是我们从来不愿意给自己留丝毫孤独对话的空间,然而现在快节奏的社会里,越来越多的人宁愿选择和几个陌生人一起尬聊,也不愿意真实地面对自己。
生命里第一个爱恋的对象应该是自己,写诗给自己,与自己对话,在一个空间里安静下来,聆听自己的心跳与呼吸,我相信,这个生命走出去时不会慌张
所以我说孤独是一种福气,怕孤独的人就会寂寞,愈是不想处于孤独的状态,愈是去碰触人然后放弃,反而会错失两千年来你寻寻觅觅的另一半。有时候我会站在忠孝东路边,看着人来人往,觉得城市比沙漠还要荒凉,每个人都靠得那么近,但完全不知彼此的心事,与孤独处在一种完全对立的位置,那是寂寞。
学会享受孤独,才能体会到一种精神食粮的真实存在。
异步在前端中的发展历史不是很长,但是发展的速度还是很快的
所谓异步,简单点说就是在做一件事情的过程中中断去做另外一件事情。js是单线程的,当然也有异步的概念。异步和同步的区别用图示表示如下:
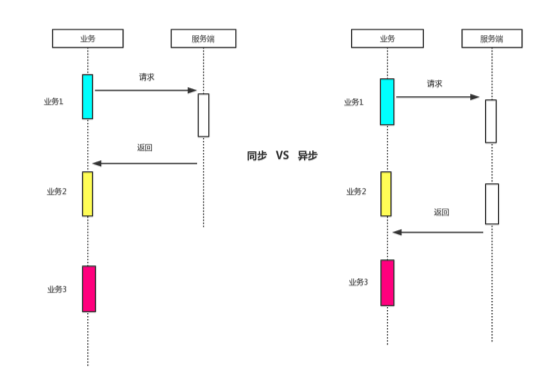
由图示可以得出,同步过程时:业务二必须等待业务一的请求结果返回之后才可以开始,而异步过程中,在业务一的请求过程中,当前线程可以先去处理业务二,免去了等待过程中的时间浪费。
为什么要引入异步的,异步有下面几点优点:
从上面图示可以看出,在异步过程中,没有等待数据返回的过程,在请求数据的时候,当前线程又去处理其他业务了,这样就提高了cpu的利用率,cpu的性能必定也会提升。其次,在之前的网站中,我们时常要处理ajax请求,一旦采用同步思路,那么在请求数据返回之前,网页都是一片空白而得不到相应,那样会给用户一种相应很慢的感觉,导致用户体验很差。而异步就使得页面在请求数据的空隙也可以渲染页面,大大提升了用户体验。
####callback时代
回调函数是异步发展的起源,最初源自ajax,对于下面的代码,相信每一个FEer都不会感到陌生:
$.ajax('url',function () {
//do something
})但是这样的请求一旦嵌套过多,就会出现下面的callbacks hell
asyncOperation1(data1,function (result1) {
asyncOperation2(data2,function(result2){
asyncOperation3(data3,function (result3) {
asyncOperation4(data4,function (result4) {
//do something
})
})
})
})这种代码不仅可读性很差,而且在团队中很不好维护。
之后还衍生中一种事件监听事件,比如:
element.addEventListener('click',function(){
//response to user click
});也就是click事情的回调函数只在触发了click事件之后才执行,当然了,这也是回调函数的一种变种。
Promise时代promise,顾名思义,就是承诺,这个承诺有成功初始(pending)(fulfilled)和失败(rejected)三种状态。当由pending->fulfilled状态时,会触发resolved,当由pending->rejected状态时,会触发rejected.具体规范可以参见promise/A+规范。
promise有一个then函数,它返回一个promise对象,就是因为这样,promise才可以实现链式调用。promise的链式调用可以用如下图示表示:
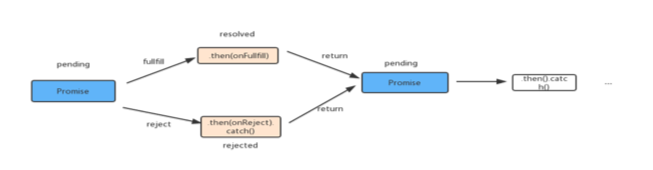
根据promise的概念,上面的回调函数嵌套过深的问题可以写成如下:
asyncOperation1(data)
.then(function (data1) {
return asyncOperation2(data1)
}).then(function(data2){
return asyncOperation3(data2)
}).then(function(data3){
return asyncOperation(data3)
})generator/yield时代ES6语法中引入了generator,一个普通的generator函数表示如下:
function* gen(){
yield 1;
yield 2;
return 'ending';
}
var g = gen();
g.next(); //{value:1,done:false}
g.next(); //{value:2,done:false}
g.next(); //{value:ending,done:true}调用 Generator 函数,会返回一个内部指针 。即执行它不会返回结果,返回的是指针对象。调用指针 gnext 方法,将会指向第一个遇到的 yield 语句,yield的作用是暂停此处,只有调用next函数才会执行下一个yield。每次调用 next 方法,会返回一个对象,表示当前阶段的信息( value 属性和 done 属性)。value 属性是yield语句后面表达式的值,表示当前阶段的值;done 属性是一个布尔值,表示 Generator 函数是否执行完毕,即是否还有下一个阶段。上面的深度嵌套的例子改写为generator如下:
function* generateOperation(data1) {
var result1 = yield asyncOperation1(data1);
var result2 = yield asyncOperation2(result1);
var result3 = yield asyncOperation3(result2);
var result4 = yield asyncOperation4(result3);
//more
}async/awaitES7出现了async/await,从字面意思就可以看出来代码在执行过程中等待,上面的代码变成async./await形式如下:
async generateOperation(data1) {
var result1 = await asyncOperation1(data1);
var result2 = await asyncOperation2(result1);
var result3 = await asyncOperation3(result2);
var result4 = await asyncOperation4(result3);
//more
}generator和async虽然在形式和代码结构上很相似,但是两者还是有区别的:
async的语义化更好async内置了自动执行器,之前我们说过generator需要手动调用next()方法来执行下一个yield语句,但是async会自动执行内部的异步函数,而generator需要结合co来实现自动执行所有的异步函数async 扩展性更好,generator和co结合时候,要求在yield语句后面是一个thunk函数或者promise,而await后面则可以是任何数据类型,比如String,Number等
又是在一口气的情况下看完这本书的,故事情节很传奇,主要内容主要如下:该书讲述了在僻静街道旁的一家杂货店,只要写下烦恼投进店前门卷帘门的投信口,第二天就会在店后的牛奶箱里得到回答:
他们将困惑写成信投进杂货店,并且得到了回答。而且很巧妙的,解忧杂货店让过去和现在进行相通,致使翔太、敦也、幸平这三个人可以借助现代人的角度来给过去忧愁的人提供一些意见。
整本书的行文思路很奇特,从来没有想过还有这等奇怪的想法,但是东野圭吾似乎用他的这本小说来诠释这种神奇。看完小说后,我唯一的感触就是虽然书中的文本很朴实,没有过多华丽的辞藻,大部分的行文还是一如既往地使用对话,但是故事情节的巧妙让人有点意想不到。而且让我觉得:这个世界上的每一个人的人生,似乎有它既定的方向和结局
“无论你是什么人,懦弱自恋疯狂失意;无论你做着什么工作,白领蓝领灰领,无论你身在何处,只要你相信自己,热情的用心的真诚的活着,那就是成功的;不论你在人生的岔路口怎样选择,真实的面对自己、面对现实,跟随心的脚步,心之所向,那就是你的人生,那就是你的存在。”
正如文中所说,你的人生已经就是这样存在着,仿佛有一种神秘的力量在操纵着这一切,所以无需为自己的人生太过迷茫,每个人都有每个人的宿命。作者通过6个小故事来讲解着及其奇妙的事情。构文思路上很独特,值得一看。
React 在 16.70-alpha 中首次提出 Hooks 这个新特性,并且在 16.8.0 正式发布 Hooks 稳定版本。React Hooks 指的是在 Function Component 中插入一些 Hooks,通过使用这些 Hooks 可以让 Function Component 拥有 state 和生命周期等 React 特性。
React Hooks 要解决的问题是状态逻辑复用,是继 render-props 和 higher-order components 之后的第三种状态共享方案。它主要解决了如下一些痛点:
在一个 React Componet 中,会在 state 中存储状态,并且在组件的各个 lifecycle 函数中执行特有的逻辑,比如在 componentDidMount 去请求数据、在 componentWillUnMount 中卸载实例、取消事件监听器等。这些 state 和 生命周期和组件强耦合,使得 state 和生命函数的逻辑无法抽离得到复用。而 Hooks 可以从组件中提取状态逻辑,从而达到复用。
React 的组件带来的好处是模块化,但是当逻辑比较复杂时,就会出现组件嵌套地狱,看看 Devtool 里面的嵌套,是不是有点吓人。

除此之外,复杂组件会在不同的生命周期中执行很复杂的逻辑,比如在 componentDidMount 请求数据,或者在 componentWillReceiveProps 中根据 nextProps 改变组件 state 等等,后期维护和理解的成本会非常高。
再加上 class Component 的 this 指向问题,为了保证指向正确,需要用 bind 绑定或者使用箭头函数,如果没有绑定,就会出现各种 bug。
首先使用 class Component 来实现一个最简单的组件:
import React, { useState } from 'react';
import { Button } from 'antd';
function Demo() {
const [count, setCount] = useState(0);
return (
<div>
<Button type="primary" onClick={() => {
setCount(count => count + 1)
}}>Add</Button>
<div className="number">{count}</div>
</div>
)
}在上面这个例子中,useState 就是一个 Hook,它接受一个参数作为 state 的初始值,返回一个数组,结构为 [value,setValue],其中 value 对应的 state,相当于 Class Component 中的 this.state,setValue 是修改 state 的函数,相当于 class Component 中 this.setState。 其他的就按照 Function Component 写就好了,是不是看起来很清爽?
现在介绍一下 React 内置的几种 Hooks 以及它们的用法。
上面的例子就是用的 useState,当然是最简单的用法,总结一下 useState 的特性,如下:
const [complexState, setComplexState] = useState(()=> {
const initialValue = complexFunction(props);
return initialValue;
})function Demo() {
const [count, setCount] = useState(0);
const [type, setType] = useState('default')
const [list, setList] = useState([1])
....
}useEffect 是用来执行副作用操作的,通过这个 Hook,可以执行一些组件渲染之后的逻辑,比如事件监听、设置标题等。它相当于是 Class Component 中的 componentDidMount、componentDidUpdate、componentWillUnMount 这三个生命周期的集合。举个最简单的例子,如下:
import React, { useEffect, useState } from 'react';
import axios from 'axios'
function UseEffectDemo() {
const [list, setList] = useState([]);
useEffect(() => {
async function fetchData() {
const result = await axios('https://hn.algolia.com/api/v1/search?query=react');
setList(result.data.hits);
}
fetchData()
}, [])
return <div className="movie-container">
{list.map(item => {
return <div className="item">{item.title}</div>
})}
</div>
}这个 Hook 的特性如下:
useEffect(() => {
// do something
}, [type]); // 只有 type 发生改变才执行 useEffect 里面的逻辑useEffect(() => {
//do something
return function cleanup(){
//do something clean up
}
})useContext 主要是为了使用 context,而且不用像以前一样用 Provider、Consumer 包裹组件,可以大大提高代码的简洁性。使用 createContext 实现一个简单的例子,如下:
const themeContext = React.createContext('light')
// App 组件
class App extends React.Component {
state = {
theme: 'red'
}
changeThme = (type) => {
this.setState({ theme: type })
}
render() {
return (<themeContext.Provider value={this.state.theme}>
<Button onClick={this.changeThme.bind(this, 'black')}>黑色</Button>
<Button onClick={this.changeThme.bind(this, 'red')}>红色</Button>
<Consumer />
</themeContext.Provider>);
}
}
// Consumer 组件
class Consumer extends React.Component {
render() {
return <themeContext.Consumer>
{theme => {
return <div>{theme}</div>
}}
</themeContext.Consumer>
}
}使用 context,就可以避免 props 的多层传递。对上面的例子使用 useContext 进行改造,代码如下:
export const ThemeContext = createContext('light')
// App组件
function UseContextDemo() {
const [theme, setTheme] = useState('red');
return (<ThemeContext.Provider value={theme}>
<Button onClick={() => setTheme('black')}>黑色</Button>
<Button onClick={() => setTheme('red')}>红色</Button>
<Consumer />
</ThemeContext.Provider>);
}
// Consumer 组件
function Consumer() {
// 直接通过 useContext 获取值即可,不需要使用 Context.Consumer 包裹
const theme = useContext(ThemeContext)
return <div>{theme}</div>
}使用 useContext 可以直接获取值,不需要用 ThemeContext.Consumer 包裹组件。代码看起来更加简洁。
useReducer 主要是 useState 的语法糖,主要是针对复杂 state 或者下一个 state 依赖之前 state 的场景,主要有如下特点:
function reducer(state, action) {
switch (action.type) {
case "increment":
return {
...state,
count: count + 1
};
default:
return state;
}
}举个🌰如下:
const initialState = { count: 0 }
const init = (initialState) => {
return initialState;
}
const reducer = (state, action) => {
switch (action.type) {
case 'ADD':
return { ...state, count: state.count + 1 };
break;
case 'DEC':
return { ...state, count: state.count - 1 };
break;
case 'RESET':
return init(action.payload)
default:
return state;
}
}
function UseReducerDemo() {
const [state, dispatch] = useReducer(reducer, initialState, init)
return (
<div>
<div>Count: {state.count}</div>
<button onClick={() => dispatch({ type: 'ADD' })}>Add</button>
<button onClick={() => dispatch({ type: 'DEC' })}>DEC</button>
// 传入 initialState,进行复位
<button onClick={() => dispatch({ type: 'RESET', payload: initialState })}>RESET</button>
</div>
);
}如上例子所示,定义一个 reduce 函数,接收一个 state 和 action 参数,返回一个新的 state。通过传递 init 初始化函数,可以对 state 进行复位。
在 Class Component 中,我们可以使用 shouldComponentUpdate 来控制组件重新渲染的条件,从而避免复杂逻辑带来性能性能上的损耗,而在 Function Component 中没有 shouldComponentUpdate 这个生命周期,怎么办?useCallback 和 useMemo 就是用来解决这个问题的。
useCallback 和 useMemo 会在组件首次渲染的时候执行,然后会根据依赖项是否发生改变而再次执行,并且这两个 Hook 都返回缓存的值,useCallback 返回缓存的函数,useMemo 返回缓存的变量。
首先举一个🌰,如下:
function UseMemoDemo() {
const [count, setCount] = useState(1);
const [value,setValue] = useState('')
//第一种,没有使用 useMemo
const computing = () => {
let sum = 0;
for(let i=0;i<count*100;i++){
sum += i;
}
console.log(sum, 'computing')
return sum;
}
// 第二种使用 useMemo
const computing =useMemo( () => {
let sum = 0;
for(let i=0;i<count*100;i++){
sum += i;
}
console.log(sum, 'computing')
return sum;
},[count])
return <div>
<div>Count: {count}</div>
<div> SUM: {expensive}</div>
<button onClick={() => setCount(count + 1)}>Add</button>
<input className="input" onChange={(e)=>setValue(e.target.value)}/>
</div>
}如上所示:expensive 是计算量很大的函数,并且当 state 发生改变时,组件就会重新渲染,从而导致 computing 函数重新执行,而 computing 只和 count 相关,但是 value 发生改变,computing 还是会重新计算。这是没必要的,所以我们可以使用 useMemo 来控制没必要的执行,第二个参数表示依赖项,只有依赖项发生改变时才会执行。
useCallback 和 useMemo 不同的是,它返回一个缓存的函数,并且 useCallback(fn,deps) = useMemo(()=>fn(),deps),它有什么作用呢,举一个例子:
function UseCallbackDemo() {
const [count, setCount] = useState(0);
const [value, setValue] = useState('')
// 第一种,没有使用 useCallback
// const callback = () => {
// return count + 1;
// }
// 第一种,没有使用 useCallback
const callback = useCallback(() => {
return count + 1
}, [count]);
return (<div>
<div>Parent Count: {count} </div>
<button onClick={() => { setCount(count + 1) }}>Add</button>
<input className="input-container" onChange={(e) => { setValue(e.target.value) }} />
<Child callback={callback} />
</div>)
}
// Child 组件
function Child(props) {
const [value, setValue] = useState(0)
useEffect(() => {
setValue(props.callback())
},[props.callback])
return <div>Child Count: {value}</div>
}如上所示,父组件将 callback 函数传递给子组件,然后子组件在 useEffect 中判断 callback 是否发生改变,从而更新自身的 state,当父组件的 value state 发生改变是,并不会触发 useEffect 的更新操作,所以使用 useCallback 可以避免子组件不必要的重复渲染。
useRef 相当于是一个存储属性的地方,它在组件的整个生命周期内都保持不变,它的特性如下:
它的用法如下:
function UseRefDemo() {
const inputRef = useRef(null)
const onClick = () => {
inputRef.current.focus()
}
return <div>
<input ref={inputRef}></input>
<button onClick={onClick}>Focus</button>
</div>
}如上,在点击 button 时,设置 inputRef 获取焦点,其中 input 这个实例就保存在 inputRef 中。
useImperativeHandle 用于自定义暴露给父组件的 ref 属性,该 hooks 需要和 forwardRef 一起使用,例子如下:
function UseImperativeHandleDemo() {
const parentRef = createRef()
return (<div>
<Child ref={parentRef} />
<br />
<button onClick={() => { parentRef.current.focus() }} >获取焦点</button>
</div>)
}
//Child 组件
import React, { useRef, useImperativeHandle, forwardRef } from 'react';
const Child = (props, ref) => {
const inputRef = useRef(null);
useImperativeHandle(ref, () => ({
focus: () => {
inputRef.current.focus();
}
}))
return <input ref={inputRef} />
}
export default forwardRef(Child)如上面所示,父组件可以直接调用在 Child 里面定义的 Ref.current.focus 方法。
useLayoutEffect 和 useEffect 类似,两者不同的地方是:
用户在 react devtools 中显示 hooks 属性,第二个参数可以进行格式化能力,例子如下:
const [date] = useState(new Date());
useDebugValue(date, date => date.toDateString());除了上面提到的官方已有的 hooks,我们还可以自定义 hooks,通过自定义,可以将组件逻辑提取到可重用的函数中。并且自定义的 hooks 之间也是相互独立的,举个例子:
function CustomHookDemo() {
const [hoverRef, isHover] = useHover();
return <div ref={hoverRef}>{isHover ? 'I am hovered' : 'I am not hovered'}</div>
}
//useHover 的 hook
import React, { useState, useRef, useEffect } from 'react';
const useHover = () => {
const [isHover, setIsHover] = useState(false)
const ref = useRef(null);
const handleMouseOver = () => {
setIsHover(true)
}
const handleMouseOut = () => {
setIsHover(false)
}
useEffect(() => {
const node = ref.current;
if (node) {
node.addEventListener('mouseover', handleMouseOver);
node.addEventListener('mouseout', handleMouseOut);
return () => {
node.removeEventListener('mouseover', handleMouseOver);
node.removeEventListener('mouseout', handleMouseOut);
};
}
}, [ref.current]);
return [ref, isHover]
}
export default useHover如上所示,我们把 hover 的逻辑抽离到 useHover 这个 hook 中,并且把 hover 的 DOM 实例和 isHover 的值返回,这样其他组件想要这个逻辑就可以直接复用。
自定义 Hooks,需要遵循如下规则:
虽然 Hooks 比较强大,但是在使用过程中,还是有一些点需要注意,比如:

本来是来实习了的,并且加上论文的压力,应该是没有时间再看闲书的了。但是由于暂住在华南理工附近,恰巧在华南理工还有同学,于是就借看了这本书。第一次看日本作家写的书,之前也有很多人推荐过我看日本作家的书,但是一直都没有去尝试,这次看完后,确实还是有一种不一样的体会。恰巧前一阵子看了《东京女子图鉴》这部剧,对日本的一些风土人情和生活习性算是有一些概念上的铺垫了。
说实话,这部书并没有什么很深刻的内容,甚至可以说是对生活琐碎的一种碎碎念,再加上及其丰富的心理活动的描写,让我更加觉得这本书像是在对心理剖析的书。但是在细碎中有很真实,让人觉得仿佛书中的主人公就是自己,因为你知道他的所有想法甚至一些腹诽。
书中的主要内容是主人公相木悠介放弃了大学医院医生的工作,然后抛家弃子和情人来到东京开始半医半写作的生活,最后慢慢走上文坛之路,在上京后的一年内,先后和三个女人之间爱恨纠葛的故事。写的大多都是生活的琐事外加很详细的心理展示,说实话,对于这本书的感觉,并没有很深的感触,排除不怎么健康的精神实质,文中情节也是很一般。并没有给我一种很惊叹的感觉。所以对这本书并没有很高的评价。
但是文中还是有些许亮点的。比如说第一章中悠介刚来东京的时候,原本以为脱离了原先那种忙碌的生活,会有更多的时间投入到写作当中,但是最后发现时间总是被一些琐碎的日常给霸占,或者被自己的惰性心理给浪费掉了。
“事实上,辞去大学医院医生工作的一个理由就是想有充足的事件可以写小说。这个愿望现在实现了,可现实却是游手好闲的过着每一天”。
这是他内心挣扎的真实写照。之后又描写到他怀念自己过去的生活。
“人类在习惯新的事物的时候,往往会怀念旧的;在习惯新的生活的时候,往往会怀念过去。当每天规定应做的事情持续不断的时候会觉得厌烦透顶,而当它停止发生的时候,却又眷恋无比”
这一段感慨说得很在理。仿佛有一种很强烈的共鸣。确实,我也是这样,当在学校那种规律的生活过久了之后,那种每天上完课就吃饭,然后睡觉的生活让我觉得无比没劲,然后强烈出来实习,但是当真正出来实习的时候,又特别想回学校。人的心理及其矛盾。我曾经以为是不是只有我才这么纠结,当读到这段的时候仿佛找到了知音一样,或者说证明了似乎不是只有我才这么病态。
文中在写到和几名女子的情感纠葛时,似乎暴露了一位男性血液里真实丑陋的一面:花心。但是他最后也为此付出了代价。
“若把女人比做洋葱,那自己则只是剥开了表层窥探了一下而已,并不是越往里剥越了解女人,也有剥得泪流满面,头晕目眩的时候啊”
这句话却是说得也很经典啊。
总之,这本书很成功地从人物心理入手,通过心里活动来剖析了人物的性格,也很好反应了日本人的一些生活习惯。有兴趣的还是可以看一下的。

从前一本书中看到萧红的前世今生,比较凄惨,恰好之前也看过汤唯演的关于萧红和萧军的电影,很是凄惨,然后一个文学素养很高的同学和我讨论了一下萧红的凄惨生活,而且向我推荐了她的《生死场》,然后才有了这篇读后感。
读完这本书给我的第一感觉就是深深的沉重感,这本书描述了乡村人民的贫苦生活。萧红为人们展示的是一幅旧**东北农村的风俗画,画面中,贫苦无靠的农民背向蓝天,面朝黑土,辛勤操劳,累弯了腰,累跛了腿,还是得不到温饱,受着饥饿和疾病的煎熬,生存十分艰难。其中的女主人公王婆,是一个饱受磨难的妇人,她的第一个丈夫虐待她,抛弃了她和孩子,独自跑进关内去了。她为了生存,不得不嫁给第二个丈夫,这个丈夫却病死了。她又不得不嫁给第三个丈夫赵三。可在她老年的时候,儿子因为反抗官府,被枪毙了,她觉得生活无望,愤而自杀,就在将要埋葬的时候,她又活过来了。另一个贫农家的少女金枝,只有十七岁,梦想着青春和幸福。她还没有过门就怀了孕,受到母亲和同村妇女们冷落和嘲讽。嫁过去之后,丈夫嫌她和刚出生的女儿拖累自己,竟把不满一个月的小金枝活活摔死了。还有一个贫农家的少妇月英,本来是村里最美丽、性情最温和的妇女,因为患了瘫病,成了丈夫的累赘,不给她饭吃,不给她水喝,后来死了。
好惨啊!这幅画中圈定的是呼兰还是别的地方,可以不假思索,但这个“场”是旧**地主的天堂,农民的地狱。读着这些人物,感悟画面中的风俗,思考着人物的命运,心头涌出不尽的忧伤。也为萧红将自己坚强背后的敏感,嬴弱背后的率真,通过笔端将她对“人生荒凉感”与女性的悲剧巧妙地融为一体,由衷地赞叹,我想这样一种对人生痛楚的绝妙稀释,让我感到了“活着”的悲哀。
书中的字里行间里面处处充斥着一种坚强和挣扎的感觉,在这里,人的命是那么卑微,
“母亲一向是这样很爱护女儿 可是当女儿败坏了菜棵 母亲便去爱护菜棵了 ! 农家无论是菜棵 或是一株茅草也要超过人的价值 ”
从这段文字里面,还有一个月大的小金枝被摔死的惨景,种种这些,都暗示着生命在那个年代的卑微。但是他们并没有放弃,他们在生的坚强和死的挣扎里面仍在坚持战斗,在最后,赵三变成了找三爷,他老了,但依然鼓励年轻人起来反抗,去参加革命。还有二里半,他在最后毅然决定去找革命军,他们的精神代表着那个年代人们不屈的一致与反抗日军的斗志和民族气节。
萧红的文字,体现着当时人们悲苦的生活场景,让现今处于幸福生活的我们显得更加幸运。。。。

接触到这本书和白鹿原电视剧,完全归功于我的闺蜜,她强烈推荐这部被誉为秦川史诗的电视剧,一时兴起,我翻出了这本小说。
这本小说主要是以陕西关中地区白鹿原上白鹿村为时代背景,讲述了白鹿两家长达半个多世纪的恩怨纠葛以及当时社会的一些世事变化。以主人公白嘉轩为核心,白嘉轩代表着原上的宗法家族制度和道德伦理,一生为人耿直。他一生娶过7个女人为妻,这也是故事的开头。最终娶了仙草为妻并生下三男一女。作为族长,白嘉轩无疑是具有标榜作用的,无论是为人处世,还是胸襟谋略,他都是以一种以声作则的态势赢得了白鹿村全体乡民的尊重和爱戴。而与白家相对的鹿家,祖先是通过轮勺伺候人而发家致富的,祖人鹿马勺一直希望后代能逃脱这种命运,一旦后人有考上秀才为官的都要到他坟上放铳。然而不幸的是,鹿家子孙鹿子霖却心胸狭隘,有着一身的毛病,这也奠定了鹿家永远不能赢得了白家的命运。
小说一边描述着白鹿原上的一些家常琐事,一边反映着整个社会的态势,比如刚开始清朝皇帝下架,然后废除一些旧习如男人留辫子,女人裹脚,再接着是百灵上学堂,鹿兆鹏参共,鹿兆海参加国民党、百灵参共反映国共两党之间的合作和对立,最后到共产党完全胜利。整本小说以一种朴实无华接地气的手法真实地展现了陕西地区的人们在当时的生活情况和风土人情,他们勤劳朴实,通过自己的双手面朝黄土背朝天,只求农作物丰收日子越过越好,那时候的人们没有太多的欲望,没有浮躁的病态心理,只有一心过日子的满足和殷实。。。
书中有很多让我感动的地方,比如鹿三和白嘉轩主仆之间深厚的,不分你我的感情,犹记得白嘉轩腰被黑娃打弯的时候,为了尊严白嘉轩依然下地干活的时候,鹿三担心他所以一直站在他身边:
“你跟在我旁边我不舒服,你走开去抽你的烟!”鹿三无奈挺住脚步,研究紧紧瞅着渐渐融进霞光里的白嘉轩,还是攥着空烟袋记不起来装烟。
不仅仅是鹿三对白嘉轩关心备至,白嘉轩对鹿三也是没当外人。当鹿三被小娥鬼混缠绕的时候,他开始变得疯癫混沌,儿子白孝义和鹿三儿子兔娃都对他很嫌弃,唯有白嘉轩仍然对鹿三嘘寒问暖,甚至教育他们要改变对鹿三的态度。虽然鹿三是白嘉轩家里的长工,但是白嘉轩从来没有将鹿三当成是雇佣关系的工人,而是任何时候都当成是自己家里的一份子,农作物丰收了先送到鹿三那里,一起做农活,一起闹农民起义,连最后鹿三去世的时候,两人也是喝醉后在一个炕上畅聊到深夜的。。。。
同样让人感动的还有朱先生的两袖清风,他的一生是传奇的,不仅可以占卜未来,而且可以化解灾难。他一生都被人爱戴和尊崇,从来不接受贿赂,宁愿在自己的白鹿书院舞文弄墨,也不愿成为权大势大的大官。即使死了,也是极为简朴,不要棺材,不穿洋装,只带书籍,让人感叹。
小说的内容虽然平凡朴实,但是真实地揭示了一些道理,而这些道理不仅在当时那个时代受用,在以后乃至任何时候都是至理名言:
你看,个个人都是哇哇大哭着来这世上,没听说哪个人落地一声不是哭是笑。咋哩?人都不愿意到世上来,世上大苦情了,不及在天上清净悠闲,天爷就一脚把人蹬下来......既是人到世上来注定要受苦,明白人不论遇见啥样的灾苦都能想得开.....
好好活着!活着就要记住,人生最痛苦最绝望的那一刻是最难熬的一刻,但不是生命结束的最后一刻;熬过去挣过去就会开体验呼唤未来的生活
人行事不在旁人知道不知道,而在自家知道不知道,自家做下好事刻在自家心里,做下瞎事也刻在自家心里,都抹不掉;其实天知道地也知道,既在天上刻在地上,也是抹不掉的。
这些道理虽然简单易懂,但是不是每个人都能深知其中奥秘,唯有经历过,体会过,才会得知其中酸甜苦辣。
整本书极其真实地反映了秦川人民的质朴无华,让我们在领略那个时代的风土人情的同时,也受到了人生的启迪。担当得起秦川史诗这个称号,强推。。。。
process对象是一个global(全局变量),它对于Node.js应用程序始终是可用的,所以在使用时无需使用require()。
对于process部分的API,这里不详细讲,具体可移步这里
js中的console.log和node中的console.log还是有一些区别的。
js中的console.log在一些情况下执行时存在异步情况,根据《你不知道的JavaScript中卷》中的描述:
并没有什么规范或一组需求指定console.* 方法族如何工作——它们并不是JavaScript 正式
的一部分,而是由宿主环境(请参考本书的“类型和语法”部分)添加到JavaScript 中的。因此,不同的浏览器和JavaScript 环境可以按照自己的意愿来实现,有时候这会引起混淆。
尤其要提出的是,在某些条件下,某些浏览器的console.log(..) 并不会把传入的内容立即输出。出现这种情况的主要原因是,在许多程序(不只是JavaScript)中,I/O 是非常低速的阻塞部分。所以,(从页面/UI 的角度来说)浏览器在后台异步处理控制台I/O 能够提高性能,这时用户甚至可能根本意识不到其发生。
下面这种情景不是很常见,但也可能发生,从中(不是从代码本身而是从外部)可以观察到这种情况:
PS:可以试试这个
var a = {
index: 1
};
// 然后
console.log( a ); // ??
// 再然后
a.index++;我们通常认为恰好在执行到console.log(..) 语句的时候会看到a 对象的快照,打印出类
似于{ index: 1 } 这样的内容,然后在下一条语句a.index++ 执行时将其修改,这句的执
行会严格在a 的输出之后。
多数情况下,前述代码在开发者工具的控制台中输出的对象表示与期望是一致的。
但是,这段代码运行的时候,浏览器可能会认为需要把控制台I/O 延迟到后台,在这种情况下,等到浏览器控制台输出对象内容时,a.index++ 可能已经执行,因此会显示{ index: 2 }。
到底什么时候控制台I/O 会延迟,甚至是否能够被观察到,这都是游移不定的。
如果在调试的过程中遇到对象在console.log(..) 语句之后被修改,可你却看到了意料之外的结果,要意识到这可能是这种I/O 的异步化造成的。
可见,js中的console.log并不是严格同步或者异步,而是取决于执行环境和I/O之间的异步化。
在node中,console.log的底层实现代码如下:
Console.prototype.log = function log(...args) {
write(this._ignoreErrors,
this._stdout,
util.format.apply(null, args),
this._stdoutErrorHandler,
this[kGroupIndent]);
};底层使用的是process.stdout.write。node中的console.log是同步还是异步的呢,也就是process.stdout.write是同步的还是异步的。官方文档给出的解释是:
写操作是否为同步,取决于连接的是什么流以及操作系统是 Windows 还是 POSIX :
- Files: 同步 在 Windows 和 POSIX 下
- TTYs (Terminals): 异步 在 Windows 下, 同步 在 POSIX 下
- Pipes (and sockets): 同步 在 Windows 下, 异步 在 POSIX 下
child_process是node中一个比较重要的模块,众所周知,node有一个一直被人诟病的地方就是“单进程单线程”,但是有了child_process之后,node就可以实现在程序中直接创建子进程,除此之外,子进程和主进程之间还可以进行通信,这样就榨干了cpu的资源,使资源得到了充分地利用。
如何创建一个子进程,创建同步进程:
创建异步进程:
各个不同的方法之间的关系如下:
exec、execFile、fork都是通过spawn封装而成,由此可见,spawn是最基础的,它只能运行指定的程序,参数需要在列表中列出,但是exec在执行时则衍生出一个shell并在shell上运行。和exec类似的是execFile,但它执行命令,无需衍生出一个shell,所以execFile比exec更加安全,也更高效。fork也是在spawn中封装出来的,专门用于衍生新的Node.js进程,跟 child_process.spawn() 一样返回一个 ChildProcess 对象。 返回的 ChildProcess 会有一个额外的内置的通信通道,它允许消息在父进程和子进程之间来回传递。
详细的可以参见官方文档
在unix/linux中,子进程是父进程创建的,子进程的结束和父进程的运行是一个异步过程,即父进程永远无法预测子进程 到底什么时候结束。 当一个 进程完成它的工作终止之后,它的父进程需要调用wait()或者waitpid()系统调用取得子进程的终止状态。
cluster是node内置的一个模块,用于node多核处理,它的工作进程由child_process.fork()方法创建,因此它们可以使用IPC和父进程通信,从而使各进程交替处理连接服务。cluster中创建worker的源码如下:
function createWorkerProcess(id, env) {
//省略一些代码
return fork(cluster.settings.exec, cluster.settings.args, {
env: workerEnv,
silent: cluster.settings.silent,
execArgv: execArgv,
stdio: cluster.settings.stdio,
gid: cluster.settings.gid,
uid: cluster.settings.uid
});
}而且手动传了一些环境变量的参数值。如下是根据cluster.isMaster标识来fork子进程的代码:
if (cluster.isMaster) {
for (var i = 0; i < numCPUs; i++) {
cluster.fork();
}
//master和worker之间的通信
cluster.on('fork', function (worker) {
console.log('[master] ' + 'fork: worker' + worker.id);
});
cluster.on('online', function (worker) {
console.log('[master] ' + 'online: worker' + worker.id);
});
cluster.on('listening', function (worker, address) {
console.log('[master] ' + 'listening: worker' + worker.id + ',pid:' + worker.process.pid + ', Address:' + address.address + ":" + address.port);
});
cluster.on('disconnect', function (worker) {
console.log('[master] ' + 'disconnect: worker' + worker.id);
});
cluster.on('exit', function (worker, code, signal) {
console.log('[master] ' + 'exit worker' + worker.id + ' died');
});
} else {
http.createServer((req, res) => {
res.writeHead(200);
res.end('hello world\n');
}).listen(8000);
}
console.log('hello'); cluster模块支持两种连接分发模式(将新连接安排给某一工作进程处理)。
第一种方法(也是除Windows外所有平台的默认方法),是循环法。由主进程负责监听端口,接收新连接后再将连接循环分发给工作进程。在分发中使用了一些内置技巧防止工作进程任务过载。
第二种方法是,主进程创建监听socket后发送给感兴趣的工作进程,由工作进程负责直接接收连接。
理论上第二种方法应该是效率最佳的,但在实际情况下,由于操作系统调度机制的难以捉摸,会使分发变得不稳定。我们遇到过这种情况:8个进程中的2个,分担了70%的负载。
这里只是集合一些知识点,结合饿了么前端面试整理了一些自己对这一块不太清楚的知识点,权当笔记用了,以后可以方便回顾~
参考文档:

花了一天的时间看完这本书。这本书里,萧红给我们描述的是她童年里对呼伦河这个村庄里的种种回忆。有慈祥的祖父,有可怜的团员媳妇,有古怪的有二伯,还有老实的冯歪嘴子。她笔下记录的一切关于这个村庄的,有人性丑陋的一面也有善良的一面,萧红在这里度过了她的童年。
童年是萧红过得比较幸福的一段人生时期了。在这里,她的祖父给了她早期的启蒙教育,祖父对她的爱让萧红在悲凉的人生里面寻找到了一丝安慰。小镇的人们过着日复一日年复一年的生活,虽然悲凉,虽然贫穷,但是依然不悲不喜地过着人生的一个个春夏秋冬。在直言不讳地描述着小镇的日常的同时,字里行间又及其明显地透露着封建农民无知愚昧的性情。他们喜欢成为看客,对于周围中发生的人和事,他们喜欢看热闹,即便自己很害怕,也是非要看的。
后三章描述的三个典型的人物也是及其具有震撼力的。比如团员媳妇的惨死。作为一个12岁的童养媳,本该好好享受生活的幸福的美好时光的,却被婆婆虐待,最后因为各种迷信的偏方致死。婆婆毒打她,用针刺她,并且用烧红的烙铁烙她的脚心。最后因为信大神的所谓的偏方,三次用滚烫的热水浇浸团员媳妇,最后惨死的故事。在那个时代,人的生命有如草芥一般。而有二伯古怪的性格则是对坎坷的命运的一种愤怒。当他不小心踢到路边的石块时,总要对着石块说让下次去撞穿着鞋和袜的人。这里看出有二伯是痛恨那些地主阶级的。而冯歪嘴子呢,则作为勤奋老实的代表,即使生活再怎么艰难,还是很乐观坚强地活着。当村里的人一直在对他风言风语的时候,或者他的老婆因为难产而死的时候,他还是照例地过好自己的生活,几年如一日地磨磨。
“他觉得在这个世界上,他一定要生根的。要长得牢牢的。他不管他自己有这份能力没有,他看看别人也都是这样做的,他觉得他也应该这样做”
这句话虽然无奈,但是诠释出了冯歪嘴子面对现实,仍在不断坚持着的品性。而这一点正是难能可贵的地方。
萧红的一生是坎坷的,但是在她的童年回忆里,始终充斥着祖父浓浓的爱,在呼伦河这个小村庄里,她以小孩子的视角,间接披露着小村庄的一切黑暗与美好的地方。人性的冷漠和封建,让人感到窒息,作为读者的我们,也能深深感受到这种悲凉和凄惨。这本书很值得一读。。。
继上一次的koa源码解读,今天来聊一下koa-router。
从源码文件中可以看到,koa-router只有两个文件,layer.js和router.js,分别定义了Router和Layer两个对象。相对于express的内置路由,koa-router少了一个route对象,使得逻辑更加简单,下面通过一张图来解释Router和Layer对象之间的关系。
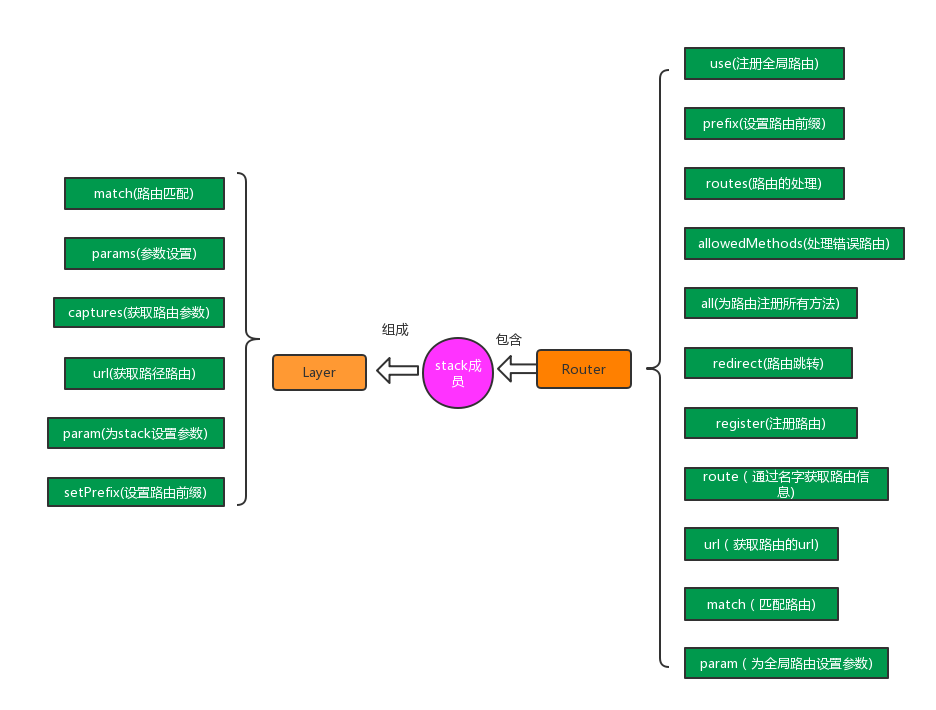
正如上图显示,Router对象中有一个stack的成员属性,而stack又是一个由Layer组成的数组,这样就使两者关联起来了。两个对象之间的原型函数函数也列举出来了,比较直观和简单。
在我们的项目路由文件中引入koa-router的时候,如下:
const router = require('koa-router')()然后执行定义如下路由的时候:
router.get('/', async (ctx, next) => {
await ctx.render('users/index',{
title:'用户中心'
})
})其实首先调用的是router.js/routes这个入口函数。下面为routes函数的源码:
Router.prototype.routes = Router.prototype.middleware = function () {
var router = this;
var dispatch = function dispatch(ctx, next) {
debug('%s %s', ctx.method, ctx.path);
var path = router.opts.routerPath || ctx.routerPath || ctx.path;
var matched = router.match(path, ctx.method); //通过path=users/index和method=GET来判断匹配
var layerChain, layer, i;
if (ctx.matched) {
ctx.matched.push.apply(ctx.matched, matched.path);
} else {
ctx.matched = matched.path;
}
ctx.router = router;
if (!matched.route) return next();
var matchedLayers = matched.pathAndMethod
var mostSpecificLayer = matchedLayers[matchedLayers.length - 1]
ctx._matchedRoute = mostSpecificLayer.path;
if (mostSpecificLayer.name) {
ctx._matchedRouteName = mostSpecificLayer.name;
}
layerChain = matchedLayers.reduce(function(memo, layer) {
memo.push(function(ctx, next) {
ctx.captures = layer.captures(path, ctx.captures);
ctx.params = layer.params(path, ctx.captures, ctx.params);
return next();
});
return memo.concat(layer.stack);
}, []);
return compose(layerChain)(ctx, next);
};
dispatch.router = this;
return dispatch;
};其中定义了一个dispatch函数用来处理路由。其中this对象为当前文件定义的路由对象。例如w我的项目文件中定义了一个路由的user.js文件,并且内容如下:
const router = require('koa-router')()
router.prefix('/users')
router.get('/', async (ctx, next) => {
await ctx.render('users/index',{
title:'用户中心'
})
})
router.get('/register/:id', async (ctx, next) => {
await ctx.render('users/register',{
title:'用户注册'
})
})
router.get('/login',async (ctx,next) => {
await ctx.render('users/login',{
title:'用户登录'
})
})
router.get('/setting',async (ctx,next) => {
await ctx.render('users/setting',{
title: '用户设置'
})
})
module.exports = router那么这个router对象结构如下:
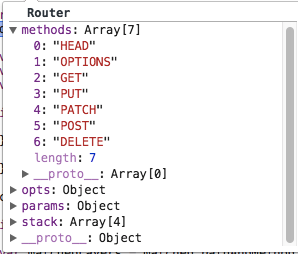
其中method为Router对象构造函数中定义的:
this.methods = this.opts.methods || [
'HEAD',
'OPTIONS',
'GET',
'PUT',
'PATCH',
'POST',
'DELETE'
];stack数组就是user.js中定义的四个Layer,接下来就是进行遍历并且匹配。找到可以匹配当前path和method的layer并且放到layerChain中。最后将这个layerChain交由compose去处理,也就是遍历中间件。
值得一提的是,在调用compose之前,会首先给matchedLayers添加一个中间件,具体代码如下:
layerChain = matchedLayers.reduce(function(memo, layer) {
memo.push(function(ctx, next) {
ctx.captures = layer.captures(path, ctx.captures);
ctx.params = layer.params(path, ctx.captures, ctx.params);
return next();
});
return memo.concat(layer.stack);
}, []);这一段代码主要是给先给中间件数组添加一个中间件函数,用于获取路由中的参数并且赋值给ctx中的params。此时传入compose的middleware数组结构如下:
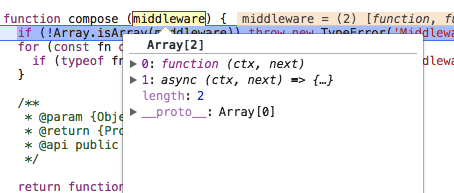
其中function(ctx,next)就是上面我们push进去的函数,然后下面的async (ctx,next) =>{}就是我们传入的中间件函数。
例如,对于下面这种情况:
router.get('/register/:id', async (ctx, next) => {
await ctx.render('users/register',{
title:'用户注册'
})
})如我们访问127.0.0.1:3001/users/register/id=123就可以得出ctx.params为{id:123}的这个参数对象。
所以koa中首先会给每个路由添加一个获取路由参数的中间件,然后依次处理后面自定义的中间件。
总结一下,正常的路由流程大概是如下图所示:
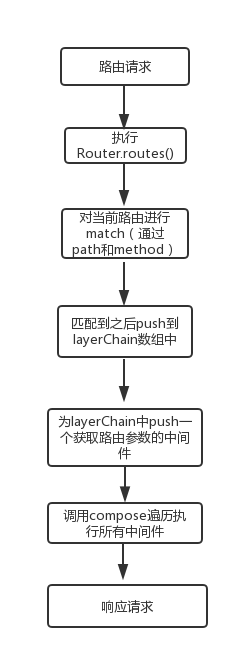
代码如下:
Router.prototype.register = function (path, methods, middleware, opts) {
opts = opts || {};
var router = this;
var stack = this.stack;
// support array of paths
if (Array.isArray(path)) {
path.forEach(function (p) {
router.register.call(router, p, methods, middleware, opts);
});
return this;
}
// create route
var route = new Layer(path, methods, middleware, {
end: opts.end === false ? opts.end : true,
name: opts.name,
sensitive: opts.sensitive || this.opts.sensitive || false,
strict: opts.strict || this.opts.strict || false,
prefix: opts.prefix || this.opts.prefix || "",
ignoreCaptures: opts.ignoreCaptures
});
if (this.opts.prefix) {
route.setPrefix(this.opts.prefix);
}
// add parameter middleware
Object.keys(this.params).forEach(function (param) {
route.param(param, this.params[param]);
}, this);
stack.push(route);
return route;
};可以看到,这个函数还是比较简单的,首先是判断传进来的path是否是数组,否则就递归执行自身,直到数组中的每一个值都完成注册为止。否则就创建一个Layer对象push进当前router对象的
stack数组中。从而完成注册功能。
对于router中的其他原型函数,就不再具体分析了
上面只是个人的一些探索,若有不对的地方,欢迎私聊拍砖。
最近翻阅 antv 的文档比较多,主要是一些 API 不太熟悉,还有 G2 的概念理得不太清楚,在此进行一个总结~
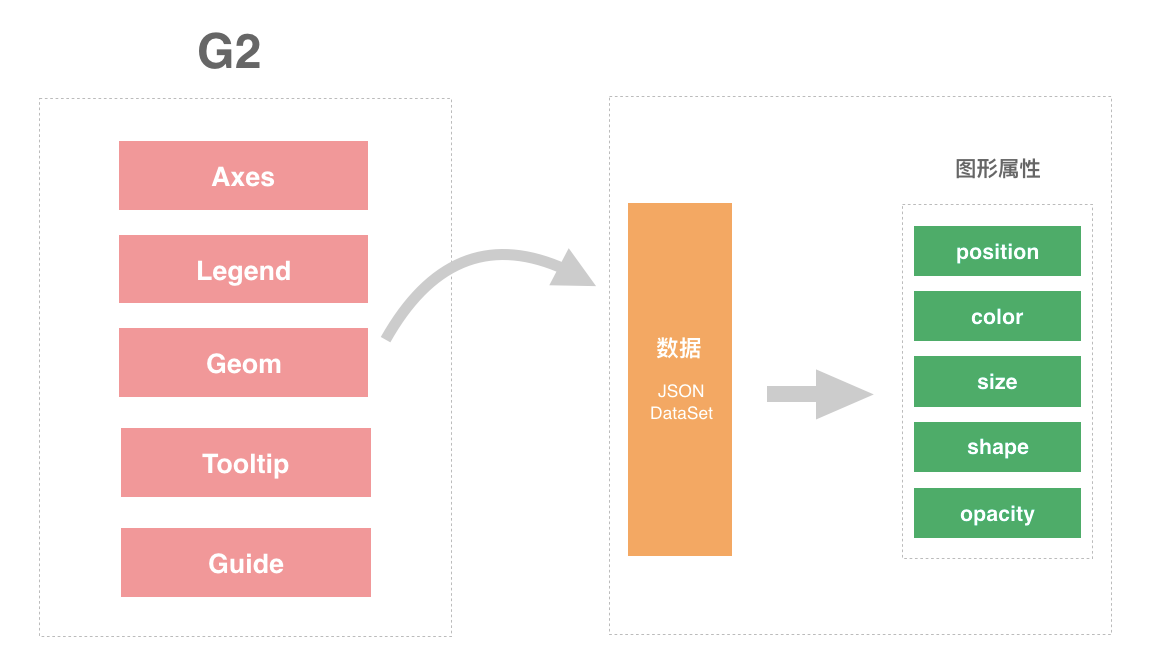
G2 图表由如下元素组成:
G2 的核心是将数据映射为图形,实现将数据中的一系列变量映射为图形属性(position、color、size、shape、opacity),而图形属性是属于每一个几何标记(geom)的,geom 指的是点、线、面这些几何图形,只有确定了几何标记对象,才能决定图表的类型。而上面提到的“数据”有两种形式:
为了将数据更好地反映在图表上,具有视觉上的美感,G2 还引入了 Scale 的功能,它主要完成了如下功能:
翻了一下 G2 的源码,底层主要是使用了 g 这个库,而 g 这个库提供最基础的可视化技术,比如 canvas 和 svg 等。
使用一张图简单表示如下:

其中 g2 的源码主要是基于对文档中api 的一些封装,在此就不细节到具体代码了,而 g 的源码主要是针对 canvas 的基础功能进行了一些封装,也不具体深入了。
这篇文章质量不高,求不喷。反正就是开始学习可视化的知识了,愿自己可以深入进去,加油吧~
在项目过程中,对 react-router 这个库了解甚少,只是停留在一些基础的用法层面,源码层面的东西还是云里雾里,对它如何运作的原理也是知之甚少,所以趁着最近修 bug 的空档期深入学习一下。
此文基于 react-router 4 进行讲解,如果对 react-router 还不太熟悉的童鞋可以移步 初探 React Router 4.0 和 react-router 的 API 文档地址 先学习一下。
react-router-dom 中包含了 web 端所有路由相关的东西,它基于 react-router 进行了一些包装,所以项目中只需要引入 react-router-dom 即可。react-router 4 中强调万物即组件,其暴露的几乎所有东西都是一个 react 组件,正是因为这种 Just Components 的**使得开发者更容易在项目中使用路由。
一张图显示出他们之间的关系:
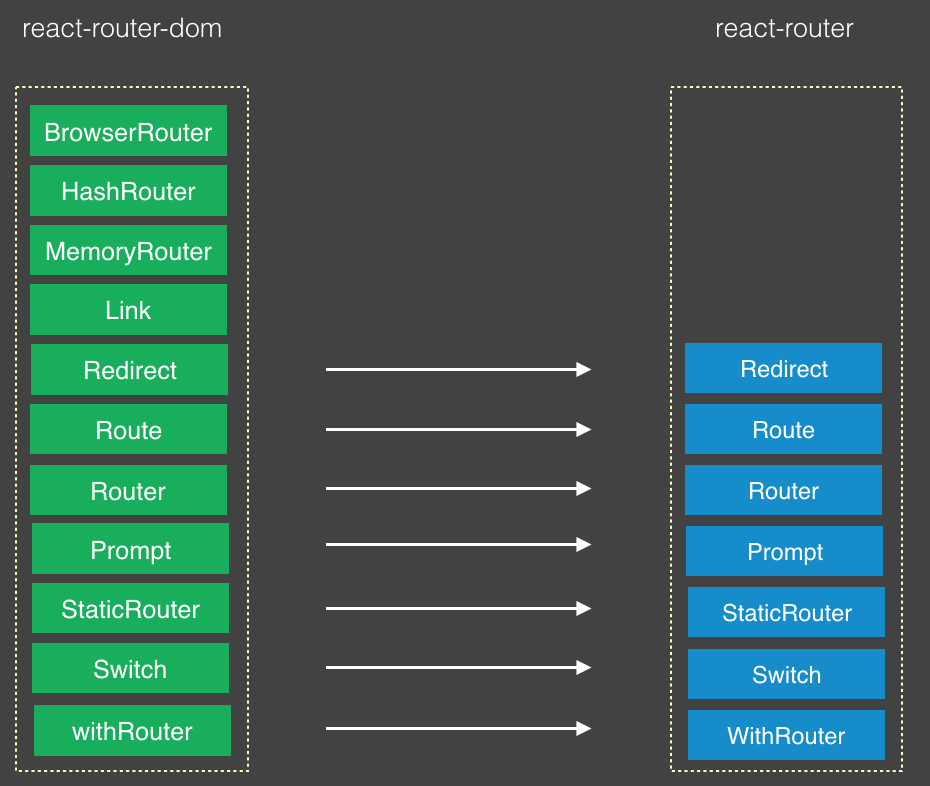
从上图可知,react-router-dom 中的很多元素都是直接从 react-router 中拿过来的,只是在它的基础上进行了一些功能上的扩展。
Router 是创建路由最外面的包裹层组件,有点类似 Provider 的感觉,它的作用是监听路由的变化,从而渲染的页面组件。其源码如下:
class Router extends React.Component {
static propTypes = {
history: PropTypes.object.isRequired,
children: PropTypes.node
};
state = {
match: this.computeMatch(this.props.history.location.pathname)
};
computeMatch(pathname) {
return {
path: "/",
url: "/",
params: {},
isExact: pathname === "/"
};
}
componentWillMount() {
const { children, history } = this.props;
this.unlisten = history.listen(() => {
this.setState({
match: this.computeMatch(history.location.pathname)
});
});
}
componentWillUnmount() {
this.unlisten();
}
render() {
const { children } = this.props;
return children ? React.Children.only(children) : null;
}
}源码部分中包含声明接受的 props 数据为 history 对象和要显示的 child 节点内容。并且在组件渲染之前(componentWillMount) 的时候,监听路由( history 是一个记录浏览器记录的一个库)的改变,当 url 发生更改时可以执行传递过去的 setState 回调,当 state 进行更新时,就会重新执行 render 对应的逻辑,从而引发页面的重新渲染。在 Router 组件销毁期间,取消对浏览器的监听。
history 有三种形式,分别是:
import { createBrowserHistory as createHistory } from "history";
class BrowserRouter extends React.Component {
static propTypes = {
basename: PropTypes.string,
forceRefresh: PropTypes.bool,
getUserConfirmation: PropTypes.func,
keyLength: PropTypes.number,
children: PropTypes.node
};
history = createHistory(this.props);
render() {
return <Router history={this.history} children={this.props.children} />;
}
}内容很简单,结合 Router 源码很好理解。HashRouter 和 MemoryRouter 的套路一样,在此不再赘述。
Route 是嵌在 Router 里面的元素,如下:
<Router history={browserHistory}>
<Route path="/" component={App}>
<Route path="about" component={About}/>
<Route path="users" component={Users}>
<Route path="/user/:userId" component={User}/>
</Route>
</Route>
</Router>它的作用是根据 url 进行匹配,如果匹配到当前路由,就展示对应的组件或者内容,否则显示 null。主要源码如下:
class Route extends React.Component {
static propTypes = {
computedMatch: PropTypes.object, // private, from <Switch>
path: PropTypes.string,
exact: PropTypes.bool,
strict: PropTypes.bool,
sensitive: PropTypes.bool,
component: PropTypes.func,
render: PropTypes.func,
children: PropTypes.oneOfType([PropTypes.func, PropTypes.node]),
location: PropTypes.object
};
state = {
match: this.computeMatch(this.props, this.context.router)
};
computeMatch(
{ computedMatch, location, path, strict, exact, sensitive },
router
) {
if (computedMatch) return computedMatch; // <Switch> already computed the match for us
const { route } = router;
const pathname = (location || route.location).pathname;
return matchPath(pathname, { path, strict, exact, sensitive }, route.match);
}
componentWillReceiveProps(nextProps, nextContext) {
this.setState({
match: this.computeMatch(nextProps, nextContext.router)
});
}
render() {
const { match } = this.state;
const { children, component, render } = this.props;
const { history, route, staticContext } = this.context.router;
const location = this.props.location || route.location;
const props = { match, location, history, staticContext };
if (component) return match ? React.createElement(component, props) : null;
if (render) return match ? render(props) : null;
if (typeof children === "function") return children(props);
if (children && !isEmptyChildren(children))
return React.Children.only(children);
return null;
}
}Route 在 componentWillReceiveProps 这个生命周期通过接受父级组件传来的 router 数据,从而来不断更新自己的 state 数据,进而达到重新渲染组件的效果。
其中 matchPath 这个方法,主要是用 path-to-regexp 这个库来匹配路由参数,并且将已经访问过的路由进行缓存,下次再匹配到这个路由的时候直接返回匹配的数据,其中缓存限制为 10000,具体的逻辑可以看 matchPath 源码,这里不贴出。
其中, strict, exact, sensitive 只是限定了一些匹配的规则,然后在 render 中进行渲染对应的渲染函数,根据传入的渲染规则不同,执行不同的渲染方式。
Link 在浏览器中渲染出来就是一个 a 标签,只是动态赋给 a 一个 href 进行页面跳转,源码如下:
class Link extends React.Component {
static propTypes = {
onClick: PropTypes.func,
target: PropTypes.string,
replace: PropTypes.bool,
to: PropTypes.oneOfType([PropTypes.string, PropTypes.object]).isRequired,
innerRef: PropTypes.oneOfType([PropTypes.string, PropTypes.func])
};
handleClick = event => {
if (this.props.onClick) this.props.onClick(event);
if (
!event.defaultPrevented && // onClick prevented default
event.button === 0 && // ignore everything but left clicks
!this.props.target && // let browser handle "target=_blank" etc.
!isModifiedEvent(event) // ignore clicks with modifier keys
) {
event.preventDefault();
const { history } = this.context.router;
const { replace, to } = this.props;
if (replace) {
history.replace(to);
} else {
history.push(to);
}
}
};
render() {
const { replace, to, innerRef, ...props } = this.props; // eslint-disable-line no-unused-vars
const { history } = this.context.router;
const location =
typeof to === "string"
? createLocation(to, null, null, history.location)
: to;
const href = history.createHref(location);
return (
<a {...props} onClick={this.handleClick} href={href} ref={innerRef} />
);
}
}如上所示:渲染一个 a 标签,并获取一个 href,当点击的时候,触发点击的回调函数,为了防止页面刷新,需要禁掉浏览器的默认行为,所以在 handleClick 中执行了 event.preventDefault(),并根据传进的 props 是 to 还是 replace 进行不同的操作。
NavLink 是基于 Link 的一个特殊版本,会在匹配当前 url 的元素添加一些传递的属性和样式:activeClassName 和 activeStyle ,源码部分是 Link 和 Route 的组合版本,这里就不深入了。
Redirect 在渲染时将会跳转到一个新的 url,这个新的 url 将会覆盖掉历史信息里面本该访问的那个地址。源码如下:
class Redirect extends React.Component {
static propTypes = {
computedMatch: PropTypes.object, // private, from <Switch>
push: PropTypes.bool,
from: PropTypes.string,
to: PropTypes.oneOfType([PropTypes.string, PropTypes.object]).isRequired
};
isStatic() {
return this.context.router && this.context.router.staticContext;
}
componentWillMount() {
if (this.isStatic()) this.perform();
}
componentDidMount() {
if (!this.isStatic()) this.perform();
}
componentDidMount() {
if (!this.isStatic()) this.perform();
}
componentDidUpdate(prevProps) {
//省略校验
this.perform();
}
computeTo({ computedMatch, to }) {
if (computedMatch) {
if (typeof to === "string") {
return generatePath(to, computedMatch.params);
} else {
return {
...to,
pathname: generatePath(to.pathname, computedMatch.params)
};
}
}
return to;
}
perform() {
const { history } = this.context.router;
const { push } = this.props;
const to = this.computeTo(this.props);
if (push) {
history.push(to);
} else {
history.replace(to);
}
}
render() {
return null;
}
}如上源码,Redirect 在组件的几个生命周期中都去执行了 perform 函数,perform 的功能就是通过判断是跳转路由还是覆盖路由从而进行 history 的相应操作,computeTo 功能主要是返回一个 url 进行页面跳转或者替换。和 matchPath 方法类似, computeTo 里调用的 generatePath 也有缓存的操作,对新产生的路由进行缓存,下次再进行 redirect 的时候直接返回,不需要再次通过 pathToRegexp 构造。
Switch 用来嵌套在 Route 外面,找出第一个匹配的 Route 进行渲染,其他的 Route 就不会去渲染。源码如下:
class Switch extends React.Component {
static propTypes = {
children: PropTypes.node,
location: PropTypes.object
};
render() {
const { route } = this.context.router;
const { children } = this.props;
const location = this.props.location || route.location;
let match, child;
React.Children.forEach(children, element => {
if (match == null && React.isValidElement(element)) {
const {
path: pathProp,
exact,
strict,
sensitive,
from
} = element.props;
const path = pathProp || from;
child = element;
match = matchPath(
location.pathname,
{ path, exact, strict, sensitive },
route.match
);
}
});
return match
? React.cloneElement(child, { location, computedMatch: match })
: null;
}
}首先会对 Children 进行遍历,然后使用上文提到的 matchPath 方法进行匹配,然后在 render 时只渲染匹配的那个 child。
整个 react-router 的源码还是比较简单的,没有什么特别晦涩的地方,基本上都能看懂,了解其内部源码的原理,在项目中就可以比较得心应手地使用了~
最近在需求开发的过程中,踩了很多因为更新引用数据但是页面不重新渲染的坑,所以对这块的内容进行深入探究了一下。
在谈及 Immutable 数据之前,我们先来聊聊 React 组件是怎么渲染更新的。
React 组件的更新是由状组件态改变引起,这里的状态一般指组件内的 state 对象,当某个组件的 state 发生改变时,组件在更新的时候将会经历如下过程:
state 的更新一般是通过在组件内部执行 this.setState 操作, 但是 setState 是一个异步操作,它只是执行将要修改的状态放在一个执行队列中,React 会出于性能考虑,把多个 setState 的操作合并成一次进行执行。
除了 state 会导致组件更新外,外部传进来的 props 也会使组件更新,但是这种是当子组件直接使用父组件的 props 来渲染, 例如:
render(){
return <span>{this.props.text}</span>
}当 props 更新时,子组件将会渲染更新,其运行顺序如下:
示例代码
根据示例中的输出显示,React 组件的生命周期的运行顺序可以一目了然了。
还有一种就是将 props 转换成 state 来渲染组件的,这时候如果 props 更新了,要使组件重新渲染,就需要在 componentWillReceiveProps 生命周期中将最新的 props 赋值给 state,例如:
class Example extends React.PureComponent {
constructor(props) {
super(props);
this.state = {
text: props.text
};
}
componentWillReceiveProps(nextProps) {
this.setState({text: nextProps.text});
}
render() {
return <div>{this.state.text}</div>
}
}这种情况的更新也是 setState 的一种变种形式,只是 state 的来源不同。
当某个 React 组件发生更新时(state 或者 props 发生改变),React 将会根据新的状态构建一棵新的 Virtual DOM 树,然后使用 diff 算法将这个 Virtual DOM 和 之前的 Virtual DOM 进行对比,如果不同则重新渲染。React 会在渲染之前会先调用 shouldComponentUpdate 这个函数是否需要重新渲染,整个链路的源码分析可参照这里,React 中 shouldComponentUpdate 函数的默认返回值是 true,所以组件中的任何一个位置发生改变了,组件中其他不变的部分也会重新渲染。
当一个组件渲染的机构很简单的时候,这种因为某个状态改变引起整个组件改变的影响可能不大,但是当组件渲染很复杂的时候,比如一个很多节点的树形组件,当更改某一个叶子节点的状态时,整个树形都会重新渲染,即使是那些状态没有更新的节点,这在某种程度上耗费了性能,导致整个组件的渲染和更新速度变慢,从而影响用户体验。
基于上面提到的性能问题,所以 React 又推出了 PureComponent, 和它有类似功能的是 PureRenderMixin 插件,PureRenderMixin 插件实现了 shouldComponentUpdate 方法, 该方法主要是执行了一次浅比较,代码如下:
function shallowCompare(instance, nextProps, nextState) {
return (
!shallowEqual(instance.props, nextProps) ||
!shallowEqual(instance.state, nextState)
);
}PureComponent 判断是否需要更新的逻辑和 PureRenderMixin 插件一样,源码如下:
if (this._compositeType === CompositeTypes.PureClass) {
shouldUpdate =
!shallowEqual(prevProps, nextProps) ||
!shallowEqual(inst.state, nextState);
}利用上述两种方法虽然可以避免没有改变的元素发生不必要的重新渲染,但是使用上面的这种浅比较还是会带来一些问题:
假如传给某个组件的 props 的数据结构如下所示:
const data = {
list: [{
name: 'aaa',
sex: 'man'
},{
name: 'bbb',
sex: 'woman'
}],
status: true,
}由于上述的 data 数据是一个引用类型,当更改了其中的某一字段,并期望在改变之后组件可以重新渲染的时候,发现使用 PureComponent 的时候,发现组件并没有重新渲染,因为更改后的数据和修改前的数据使用的同一个内存,所有比较的结果永远都是 false, 导致组件并没有重新渲染。
要解决上面这个问题,就要考虑怎么实现更新后的引用数据和原数据指向的内存不一致,也就是使用Immutable数据,下面列举自己总结的几种方法;
这种方式的实现代码如下:
import _ from "lodash";
const data = {
list: [{
name: 'aaa',
sex: 'man'
},
{
name: 'bbb',
sex: 'woman'
}],
status: true,
}
const newData = _.cloneDeepWith(data);
shallowEqual(data, newData) //false
//更改其中的某个字段再比较
newData.list[0].name = 'ccc';
shallowEqual(data.list, newData.list) //false这种方式就是先深拷贝复杂类型,然后更改其中的某项值,这样两者使用的是不同的引用地址,自然在比较的时候返回的就是 false,但是有一个缺点是这种深拷贝的实现会耗费很多内存。
这种方式相当于一种黑魔法了,使用方式如下:
const data = {
list: [{
name: 'aaa',
sex: 'man'
}, {
name: 'bbb',
sex: 'woman'
}],
status: true,
c: function(){
console.log('aaa')
}
}
const newData = JSON.parse(JSON.stringify(data))
shallowEqual(data, newData) //false
//更改其中的某个字段再比较
newData.list[0].name = 'ccc';
shallowEqual(data.list, newData.list) //false这种方式其实就是深拷贝的一种变种形式,它的缺点除了和上面那种一样之外,还有两点就是如果你的对象里有函数,函数无法被拷贝下来,同时也无法拷贝copyObj对象原型链上的属性和方法
Object 解构是 ES6 语法,先上一段代码分析一下:
const data = {
list: [{
name: 'aaa',
sex: 'man'
}, {
name: 'bbb',
sex: 'woman'
}],
status: true,
}
const newData = {...data};
console.log(shallowEqual(data, newData)); //false
console.log(shallowEqual(data, newData)); //true
//添加一个字段
newData.status = false;
console.log(shallowEqual(data, newData)); //false
//修改复杂类型的某个字段
newData.list[0].name = 'abbb';
console.log(shallowEqual(data, newData)); //true通过上面的测试可以发现:
当修改数据中的简单类型的变量的时候,使用解构是可以解决问题的,但是当修改其中的复杂类型的时候就不能检测到(曾经踩过一个大坑)。
因为解构在经过 babel 编译后是 Object.assign(), 但是它是一个浅拷贝,用图来表示如下:
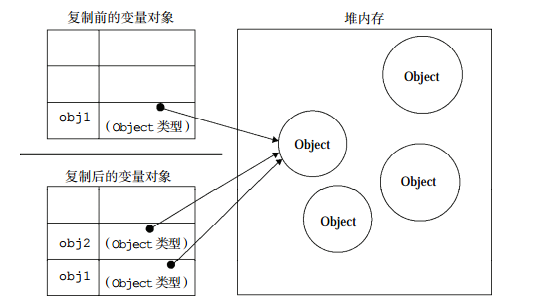
这种方式的缺点显而易见了,对于复杂类型的数据无法检测到其更新。
业界提供了一些库来解决这个问题,比如 immutability-helper , immutable 或者 immutability-helper-x 。
一个基于 Array 和 Object 操作的库,就一个文件但是使用起来很方便,例如上面的例子就可以写成下面这种:
import update from 'immutability-helper';
const data = {
list: [{
name: 'aaa',
sex: 'man'
}, {
name: 'bbb',
sex: 'woman'
}],
status: true,
}
const newData = update(data, { list: { 0: { name: { $set: "bbb" } } } });
console.log(this.shallowEqual(data, newData)); //false
//当只发生如下改变时
const newData = update(data,{status:{$set: false}});
console.log(this.shallowEqual(data, newData)); //false
console.log(this.shallowEqual(data.list, newData.list)); //true同时可以发现当只改变 data 中的 status 字段时,比较前后两者的引用字段,发现是共享内存的,这在一定程度上节省了内存的消耗。而且 API 都是熟知的一些对 Array 和 Object 操作,比较容易上手。
相比于 immutability-helper, immutable 则要强大许多,但是与此同时,也增加了学习的成本,因为需要学习新的 API,由于没怎么用过,在此不再赘述,具体知识点可移步这里
最后推荐下另一个开源库immutability-helper-x,API更好用哦~可以将
const newData = update(data, { list: { 0: { name: { $set: "bbb" } } } });简化为可读性更强的
const newData = update.$set(data, '0.name', "bbb");
或者
const newData = update.$set(data, ['0', 'name'], "bbb");在 React 项目中,还是最好使用 immutable 数据,这样可以避免很多浑然不知的 bug。以上只是个人在实际开发中的一些总结和积累,如有阐述得不对的地方欢迎拍砖~
最近在研究代码重构之路,发现自己的一些代码写得有点丑陋而且可读性不强,于是去学习了一些经验,整理如下
可读性强而且简洁的代码让人有阅读的欲望,也可以显示出代码的一种美感,同时便于后期的维护和扩展。如何让其他人看到你的代码不难受、易接受,是开发者的一种能力,也是一种修养~
通过对变量取有含义的名字,不仅可以免除注释带来的代码不美观的弊端,还能提高可读性。所谓顾名思义,就是这个道理。
//Bad
const yyyymmdstr = moment().format('YYYY/MM/DD');
//Good
const currentDate = moment().format('YYYY/MM/DD');
//遍历的情况
//Bad
tagList.forEach(i=>{
doSomething(i);
})
//Good
tagList.forEach(tag=>{
doSomething(tag);
})在代码中,我们常常需要使用一些常量(配置项),这些常量不宜直接出现在代码中,否则会难以知晓它的意思,也不便于之后的管理。最好是将这些常量使用全大写字符串命名,并将其抽取到一个配置项文件中,防止日后更改~
//Bad
setTimeout(blastOff, 86400000);
//Good
//在 config.js 中配置 MILLISECONDS_IN_A_DAY = 86400000;
import { MILLISECONDS_IN_A_DAY } from 'config.js'
setTimeout(blastOff, MILLISECONDS_IN_A_DAY);对于一些有默然参数的函数,最好把参数的默认值直接写上,而不是在函数体里面写条件语句,如下:
//Bad
function queryUser(userId) {
const userId = userId || '11111';
// do something
}
//Good
function queryUser(userId = '11111') {
// do something
}当需要给一个函数传递一个对象结构的参数时,可以使用 ES6 的解构语法,使用解构有如下好处:
//Bad
function queryUser(userId, userName, age, sex) {
// ...
}
//Good
function queryUser({userId, userName, age, sex}){
// ...
}
queryUser({'11111', '恬竹', '18', 'woman'})在给某个函数传递一个引用对象时,可能会给该引用对象带来一些副作用
//Bad
const addItemToCart = (cart, item) => {
cart.push({ item, date: Date.now() });
};
//Good
const addItemToCart = (cart, item) => {
return [...cart, { item, date: Date.now() }];
};组件中的函数最好使用箭头函数,可以避免手动绑定 this 上下文
//Bad
export default class MyContainer extends Component {
contructor (props) {
super(props)
this.state = {
stateItemA: undefined,
stateItemB: 'default string'
}
this.someMethod = this.someMethod.bind(this)
this.anotherMethod = this.anotherMethod.bind(this)
}
someMethod () {
// ...
}
anotherMethod () {
// ...
}
render () {
return (
<SomeComponent />
)
}
}
//Good
export default class MyContainer extends Component {
state = {
stateItemA: undefined,
stateItemB: 'default string'
}
someMethod = () => {
// ...
}
anotherMethod = () => {
// ...
}
render () {
return (
<SomeComponent />
)
}在给组件传递 props 时,为每个 props 或者 state 进行单个声明显然和冗余,可以直接使用扩展运算符进行传递:
//Bad
class MyContainer extends Component {
state = {
itemA: 'A',
itemB: 'B',
itemC: 'C'
}
_onPress = () => {
// ...
}
render () {
return (
<MyComponent
itemA={this.state.itemA}
itemB={this.state.itemB}
itemC={this.state.itemC}
onPress={this._onPress}
/>
)
}
}
//Good
class MyContainer extends Component {
state = {
itemA: 'A',
itemB: 'B',
itemC: 'C'
}
_onPress = () => {
// ...
}
render () {
return (
<MyComponent
{...this.state}
onPress={this._onPress}
/>
)
}
}持续更新中~
最近遇到一个问题,在一个webpack的项目中,当执行如下命令:
npm install webpack -g然后使用webpack执行代码的时候,会提示webpack command not found,一脸懵逼,什么情况????
经过一番google之后,最终将问题定位在npm的全局安装目录的问题。
所以开始重装node,卸载和使用nvm重新安装node在此就不再赘述了,具体可戳这里,现在主要是记录一下在这其中踩到的坑
nvm command not found当你在执行下面命令之后:
# vim .bash_profile后增加下面这两行
export NVM_DIR="$HOME/.nvm"
source $(brew --prefix nvm)/nvm.sh然后再查看nvm --version的时候,会报错nvm command not found,这种情况是因为你的bash_profile还没激活,需要执行下面命令进行激活:
source .bash_profilenpm command not found当你使用nvm安装完node之后,并且可以得到node安装的版本号,但是在执行npm -v的时候,会报错npm command not found,原本npm就是node里面自带的一个模块,最后会报这样的错误,简直是有点怀疑人生,然后又是一番google,内心挣扎到不行。。。。这是因为node安装有问题,重新执行如下命令进行安装:
brew update
brew uninstall node
brew install node
sudo brew postinstall node然后再执行npm,可以发现可以了,惊喜+激动
webpack command not found执行命令npm install webpack -g之后还是提示webpack命令找不到(心里一万头草泥马奔腾而过),为啥,然后开始改bash_profile里面的路径如下:
export NODE_PATH=$(npm prefix -g)/lib/node_modules
export NVM_DIR="$HOME/.nvm"
source $(brew --prefix nvm)/nvm.sh
并执行source .bash_profile使之生效。此时又报错了,错误如下:
nvm is not compatible with the npm config "prefix" option: currently set to "/Users/mac/~/.nvm/versions/node/v5.0.0"
Run `npm config delete prefix` or `nvm use --delete-prefix v5.0.0` to unset it.这种说明npm config命令和nvm有冲突,你直接执行nvm use --delete-prefix v5.0.0就行
var cwd = process.cwd();再上一步中再次全局安装webpack,并执行webpack之后,心塞地又报错了,错误如下:
node.js:289
var cwd = process.cwd();
^
Error: No such file or directory
at Function.resolveArgv0 (node.js:289:23)
at startup (node.js:43:13)
at node.js:448:3想哭的心都有了,然后各种查找资料,终于找到了一种终极解决方案。
sudo npm cache clean -f
sudo npm install -g nwebpack就好了满脸的辛酸泪,最后看到webpack命令跑起来的时候,简直想随便拉个人亲一下(哈哈哈~~~)
只是记录一下过程,希望可以帮到有相同问题的人~~~
egg-init是egg的一个脚手架,用于快速生成一个egg项目或者插件
在剖析egg-init之前,先介绍一下脚手架的相关知识
脚手架主要是在项目启动过程中生成一些初始文件的,而且一旦生成了初始化文件之后,脚手架就没有用武之地了。但是在一个工程化体系过程中,脚手架的作用还是很大的:
脚手架一般运行在本地,并且有一些配置选项可以选用。
目前比较流行的脚手架就是yeoman,具体怎么使用可以移步这里
npm binpackage.json中声明bin字段的命令"bin": {
"init": "bin/init.js"
},init.js文件#!/usr/bin/env node //首行必须加上
//具体逻辑在init.js里面可以添加一些具体的逻辑,如读取文件路径,获取开发者的一些动态设置选项等
npm link或者全局安装创建软链接,我们配置的init命令才能生效egg-initegg-init提供的options有如下几种:
选项:
--type boilerplate type [字符串]
--dir target directory [字符串]
--force, -f force to override directory [布尔]
--template local path to boilerplate [字符串]
--package boilerplate package name [字符串]
--registry, -r npm registry, support china/npm/custom, default to auto detect
[字符串]
--silent do not ask, just use default value [布尔]
--version 显示版本号 [布尔]
-h, --help 显示帮助信息 [布尔]可以根据个人情况选择相应的配置
egg-init实现的方式也和前面说的方法一样,入口文件就是bin/egg-init.js,但是这个文件很简单,最终调用的是lib/init-command.js。
首先是在构造函数中初始化了一些参数,然后在run主函数里面获取了注册地址,并在terminal中打印出了use registry:的信息,然后是根据用户输入的项目名来生成相应的项目dir。
egg-init支持四种项目类型,分别是:
其中四种项目类型的一些定义都放在boilerplateMapping这个变量中。并且会通过交互式命令行工具yargs记录用户的选择,从而在指定的dir下面下载不同的项目类型文件包。并且会在控制台中打印出下载地址,比如当选择simple时,下载包地址为:http://registry.npm.taobao.org/egg-boilerplate-simple/download/egg-boilerplate-simple-3.0.0.tgz
在下载文件之前会通过askForVariable这个函数来收集用户的一些自定义信息,比如project name、project description等,当设置完了所有的这些配置项之后,就开始在指定的目录中生成文件了。
egg-init初始化的文件当选择项目类型为simple时,生成的文件如下图所示:
app,config,test这些文件,就不说了,基本上也是初始化了egg的一些示例文件。eslintrc里面声明了如下扩展:{
"extends": "eslint-config-egg"
}对于eslintrc配置的一些说明,可以移步这里
eslint-config-egg这个npm包则是声明了一些书写egg时需要遵循的一些书写规范。
.autod.conf.js则是声明了autod的配置方式,对于autod的学习,可以参见这里和这里,主要是给用户提供自行升级依赖版本的便利package.json,里面已经配备好了一些字段,比如dependencies、devDependencies以及script等命令。egg-init脚手架的功能主要是生成项目的初始化文件,比较好的是为开发者生成了一些配置,比如说eslint以及gitignore等,会比较方便。相较于自己新建每个文件要快得多。

最近返回学校,闲来无事,想改变一下自己的纯屌丝气息,于是一口气跑到图书馆借来了这本高中时代传得及其火的莫言的书。这本自选集里面包含着莫言的一篇长篇小说,几篇短篇小说和中篇小说以及散文。但是这次的书评只是针对长篇小说《丰乳肥臀》。
看完这本书的感受就是很长一段时间都有一股悲怆萦绕在心头,或许这段时间的迷恋仅仅是为了补救高中时代无暇拜读这位大家作品的遗憾,但是不管怎么说,他的这篇小说确实在某种程度上对我产生了心灵上的震撼和对人生的反思。甚至让我即使生活在天平盛世也感受到了那个动荡年代的悲苦和无奈。
主人公上官金童是上官鲁氏在接连生下8个女儿之后的第一个男孩,在那个封建时代,重男轻女的**如同高密东北乡森林百年的粗壮大树,深深扎根在人们的**当中,在那个动荡又贫穷的时代,生命如同蝼蚁,对家中女娃的重视程度还没有家中的驴子高。在这个注定坎坷的家庭中,上官鲁氏经历了上官家三代生命的兴起和凋零,在这三代中,上官家的8个女儿经历了从长大到结婚到死亡的全过程。由于上官鲁氏的丈夫寿喜生育功能有问题,在婆婆的欺压威逼下,上官鲁氏不得不偷偷和其他男人发生关系并且生孩子,然而命运的捉弄,使得她连连生了7个女儿,最后在和马洛亚牧师发生关系后生下一队龙凤胎,上官玉女和上官金童。在整个故事过程中,都是围绕着上官家的几个女儿和女婿展开的,然而不管怎样,最后都难逃一死的命运。主人公上官金童由于是唯一的男孩,在那个时代极受宠溺,以致患上了恋乳症,到了10多岁还是靠喂乳生活。除此之外,上官金童懦弱,胆小,多疑,没有一点作为,最终碌碌无为,潦倒终生。在这期间,他的8个姐姐受尽磨难,但即使是这样,上官家的女儿们在爱情面前依旧是敢爱敢恨,一旦爱上某个人,就绝对不会回头甚至不惜牺牲自己的生命。其余的人物还有上官家女儿们生下的孩子们。虽然最终都惨死,但是极具个性,在整篇小说中添上了浓墨重彩的一笔。
整篇小说的字里行间里都弥漫着淡淡的哀伤气息,朴实无华的文字却极其不平凡地描绘出高密东北乡的生活情景和风土人情,在这个动荡的年代里,人们虽然忍受着贫穷,寒冷,战乱的痛苦,但是他们依然追求着自己迷恋甚至拥护的东西,比如上官鲁氏在面对亲情时所表现的那种大无畏精神,无论在何种情景下,她都能忍下艰辛和苦难,为自己的后代贡献自己的一份力量。当写到上官鲁氏为了不让家中的孩子饿死,而秘密吞食大豆,然后吐出来煮给孩子说
“母亲的胃已经成为了一个装粮食的袋子”。
当面对宝贝儿子上官金童恋乳症的痴呆时,她表现出的睿智和长远的目光让我叹服:
“几十年了,我一直犯糊涂,现在我明白了,与其养活一个一辈子吊在女人奶头上的窝囊废,还不如让他死了!”
这种魄力让我佩服。其次,主人公的八姐上官玉女,虽然和上官金童一起出生,生来就是瞎子,但是她从来都没有享受一天好生活,甚至为了不成为家中的累赘,投河自尽,让自己永远沉睡在高密东北乡河里的一具灵魂。
读完之后,深深感慨。既为人物命运多舛的人生而感慨,也为人们当时受到封建**深受毒害而愤慨。但是每一代人似乎都有每一代人的命运和使命。莫言的文笔无疑是非常优秀的,让我仿佛即使是书中之外的读者,也能真实地感受到那一份凄苦和控诉,控诉着封建**和当时动荡生活对人们的毒害。
其实还有很多感悟,多得不知道怎么用语言来表达,但是真心推荐其他人去拜读一下,让我们领略一下我们的祖宗都是过着怎样的水生火热的生活,那样,是不是生活在和平盛世今天的我们,会多一份幸福的感慨。
React 在触发更新的时候执行的主要源码
精简主要代码如下:
updateComponent: function(
transaction,
prevParentElement,
nextParentElement,
prevUnmaskedContext,
nextUnmaskedContext
) {
var inst = this._instance;
var willReceive = false;
var nextContext;
//省略
var prevProps = prevParentElement.props;
var nextProps = nextParentElement.props;
//如果是 props 发生更新,而不是 state 的简单更新
if (prevParentElement !== nextParentElement) {
willReceive = true;
}
//如果是 props 更新,则触发 componentWillReceiveProps()
if (willReceive && inst.componentWillReceiveProps) {
if (__DEV__) {
measureLifeCyclePerf(
() => inst.componentWillReceiveProps(nextProps, nextContext),
this._debugID,
'componentWillReceiveProps',
);
} else {
inst.componentWillReceiveProps(nextProps, nextContext);
}
}
var nextState = this._processPendingState(nextProps, nextContext);
var shouldUpdate = true;
if (!this._pendingForceUpdate) {
if (inst.shouldComponentUpdate) {
//如果组件实例有 shouldComponentUpdate 则调用
shouldUpdate = inst.shouldComponentUpdate(nextProps, nextState, nextContext);
} else {
//如果使用了 PureComponent
if (this._compositeType === CompositeTypes.PureClass) {
shouldUpdate =
!shallowEqual(prevProps, nextProps) ||
!shallowEqual(inst.state, nextState);
}
}
}
this._updateBatchNumber = null;
if (shouldUpdate) {
//执行更新操作
this._performComponentUpdate(
nextParentElement,
nextProps,
nextState,
nextContext,
transaction,
nextUnmaskedContext
);
} else {
this._currentElement = nextParentElement;
this._context = nextUnmaskedContext;
inst.props = nextProps;
inst.state = nextState;
inst.context = nextContext;
}
},在这个函数里,主要是判断是 state 还是 props 引起的变化,如果是 props,则执行实例的 componentWillReceiveProps() ,然后再判断实例是否提供了 shouldComponentUpdate 方法,如果提供,则直接调用,否则再判断是否使用了 PureComponent, 如果使用了,则使用浅比较来判断是否更新。 当前面两者都不满足,则执行 performComponentUpdate。
继续追踪代码,会发现 performComponentUpdate 里面调用了 _updateRenderdComponent ,源码如下:
_performComponentUpdate: function(
nextElement,
nextProps,
nextState,
nextContext,
transaction,
unmaskedContext
) {
var inst = this._instance;
var hasComponentDidUpdate = Boolean(inst.componentDidUpdate);
var prevProps;
var prevState;
var prevContext;
if (hasComponentDidUpdate) {
prevProps = inst.props;
prevState = inst.state;
prevContext = inst.context;
}
if (inst.componentWillUpdate) {
inst.componentWillUpdate(nextProps, nextState, nextContext); }
}
this._currentElement = nextElement;
this._context = unmaskedContext;
inst.props = nextProps;
inst.state = nextState;
inst.context = nextContext;
if (inst.unstable_handleError) {
this._updateRenderedComponentWithErrorHandling(transaction, unmaskedContext);
} else {
this._updateRenderedComponent(transaction, unmaskedContext);
}
if (hasComponentDidUpdate) {
if (__DEV__) {
transaction.getReactMountReady().enqueue(() => {
measureLifeCyclePerf(
inst.componentDidUpdate.bind(inst, prevProps, prevState, prevContext),
this._debugID,
'componentDidUpdate'
);
});
} else {
transaction.getReactMountReady().enqueue(
inst.componentDidUpdate.bind(inst, prevProps, prevState, prevContext),
inst
);
}
}
},_updateRenderedComponent 里又调用了 _updateRenderedComponentWithNextElement ,_updateRenderedComponentWithNextElement 里面 又通过 shouldUpdateReactComponent
来判断组件是否需要更新:
_updateRenderedComponentWithNextElement: function(
transaction,
context,
nextRenderedElement,
safely
) {
var prevComponentInstance = this._renderedComponent;
var prevRenderedElement = prevComponentInstance._currentElement;
if (shouldUpdateReactComponent(prevRenderedElement, nextRenderedElement)) {
ReactReconciler.receiveComponent(
prevComponentInstance,
nextRenderedElement,
transaction,
this._processChildContext(context)
);
} else {
var oldHostNode = ReactReconciler.getHostNode(prevComponentInstance);
ReactReconciler.unmountComponent(
prevComponentInstance,
safely,
false /* skipLifecycle */
);
var nodeType = ReactNodeTypes.getType(nextRenderedElement);
this._renderedNodeType = nodeType;
var child = this._instantiateReactComponent(
nextRenderedElement,
nodeType !== ReactNodeTypes.EMPTY /* shouldHaveDebugID */
);
this._renderedComponent = child;
var nextMarkup = ReactReconciler.mountComponent(
child,
transaction,
this._hostParent,
this._hostContainerInfo,
this._processChildContext(context),
debugID
);
this._replaceNodeWithMarkup(
oldHostNode,
nextMarkup,
prevComponentInstance
);
}
},shouldUpdateReactComponent 的源码
如下:
function shouldUpdateReactComponent(prevElement, nextElement) {
var prevEmpty = prevElement === null || prevElement === false;
var nextEmpty = nextElement === null || nextElement === false;
if (prevEmpty || nextEmpty) {
return prevEmpty === nextEmpty;
}
var prevType = typeof prevElement;
var nextType = typeof nextElement;
if (prevType === 'string' || prevType === 'number') {
return (nextType === 'string' || nextType === 'number');
} else {
return (
nextType === 'object' &&
prevElement.type === nextElement.type &&
prevElement.key === nextElement.key
);
}
}由此发现 React.Component 在这里使用了深比较, 然后之后的更新流程就是使用 diff 算法来比较两次的 Virtual DOM 是否改变从而执行更新操作。
继上次对express进行简单地了解和深入之后,又开始倒腾koa了。对于koa的印象是极好的,简洁而有表现力。和express相比它有几个比较明显的特征:
koa1中使用了generator,拥抱es6语法,使用同步语法来避免callback hell的层层嵌套。在koa2中又拥抱了es7的async-await语法,语法表现形式更为简洁。express,koa抽离了原先内置的中间件,一些比较重要的中间件都使用单独的中间件插件,使得开发者可以根据自己的实际需要使用中间件,更加灵活。就比如给开发者建造了一个简单的地基,之后的装修设计都由开发者自己决定,精简灵活。hapi的比较,读者可以移步这里在源码方面,koa变得更加轻量化,但是还是很有特点的。目录结构如下:
- lib/
- application.js
- context.js
- request.js
- response.js从目录结构来看,只有四个文件,摒弃了express中的路由模块,显得简单而有表现力。四个文件中分别定义了四个对象,分别是app对象,context,request以及response。深入源码查看,你会发现更加简单,每个文件的代码行数也是很少,而且逻辑嵌套并不复杂。
首先定义了一个构造函数,源码如下:
function Application() {
if (!(this instanceof Application)) return new Application;
this.env = process.env.NODE_ENV || 'development';
this.subdomainOffset = 2;
this.middleware = [];
this.proxy = false;
this.context = Object.create(context); //koa的上下文对象
this.request = Object.create(request); //koa.request
this.response = Object.create(response); //koa.request
}在这段里面只是单纯地定义了一个实例化app的一些属性。如上下文,中间件数组等。
然后是注册了一些中间件,中间件的use源码很简单,就是将当前的中间件函数push到该应用实例的middleware数组中,在此不再赘述。
最后定义了开启服务的lisen函数,在这个函数里面没有什么特殊的,只是有一点需要注意:它将自身原型的一个callback作为参数传入:
var server = http.createServer(this.callback());这一句很关键,它表示每次在开启koa服务的时候,就会执行传入的callback,而callback都干了些啥,具体看源码:
app.callback = function(){
if (this.experimental) {
console.error('Experimental ES7 Async Function support is deprecated. Please look into Koa v2 as the middleware signature has changed.')
}
var fn = this.experimental
? compose_es7(this.middleware)
: co.wrap(compose(this.middleware));
var self = this;
if (!this.listeners('error').length) this.on('error', this.onerror);
return function handleRequest(req, res){
res.statusCode = 404;
var ctx = self.createContext(req, res);
onFinished(res, ctx.onerror);
fn.call(ctx).then(function handleResponse() {
respond.call(ctx);
}).catch(ctx.onerror);
}
};在这个函数里面,通过experimental参数作为是否使用es7的async的标准,当然了,这种折中处理的方式是koa1中的,在koa2中,由于完全摒弃了generator,转而拥抱async-await,所以直接使用的const fn = compose(this.middleware);就简单进行处理了。对于使用es7语法的情况,使用的compose_es7对app中的中间件数组进行处理:
function compose(middleware) {
return function (next) {
next = next || new Wrap(noop);
var i = middleware.length;
while (i--) next = new Wrap(middleware[i], this, next);
return next
}
}也就是将中间件进行遍历,compose函数的作用如下:
compose([f1,f2,...,fn])(args) =====> f1(f2(f3(..(fn(args))))); 也就是将数组里面的函数依次执行,通过一个next中间值不断将执行权进行传递。如果传入的中间件数组不是generator函数,那么应该是依次执行,但是generator有暂停执行的功能,所以一旦执行yield next的时候,就会去执行下一个函数。等下一个中间件执行完成时,再在原来中断的地方继续执行。这种执行方式导致形成了koa中著名的洋葱模型。

举例子如下:
first step before
second step before
second step after
first step after当使用es7语法时,处理也是一样的。
context对象相比在express中,koa多了一个上下文对象,创建上下文的源码如下:
app.createContext = function(req, res){
var context = Object.create(this.context);
var request = context.request = Object.create(this.request);
var response = context.response = Object.create(this.response);
context.app = request.app = response.app = this;
context.req = request.req = response.req = req;
context.res = request.res = response.res = res;
request.ctx = response.ctx = context;
request.response = response;
response.request = request;
context.onerror = context.onerror.bind(context);
context.originalUrl = request.originalUrl = req.url;
context.cookies = new Cookies(req, res, {
keys: this.keys,
secure: request.secure
});
context.accept = request.accept = accepts(req);
context.state = {};
return context;
};从中可以看出,ctx.req、ctx.res代表的是node的request和response对象,而ctx.request和ctx.response则代表的是koa的对应对象。在express中,获取一些参数是通过访问传入的res或者req的对应参数。但是在koa中,则是访问的ctx上下文里面的相应参数。只是两者的封装不一样而已。
以上是我的一些分析,不对的地方希望大神交流和指出。
前言:egg-bin是一个本地开发者工具,集成到
egg中,里面涵盖了很多功能,比如调试,单元测试和代码覆盖率等这些功能,可以说是比较强大了。
下面就egg-bin源码分析一些东西(针对的是 4.3.0 的版本)
egg-bin如何工作的在本地运行egg项目的时候,我们往往会根据不同的场景(调试,测试等)来选择不同的命令(egg-bin dev、egg-bin debug)启动项目,从而达到我们需要的效果,但是egg-bin是如何让命令运作起来的呢?
比如在命令行中回车下面的命令:
$ egg-bin dev --port 7001开始进入node_modules/egg-bin/bin/egg-bin.js文件,文件代码比较简单:
#!/usr/bin/env node
'use strict';
const Command = require('..');
new Command().start();其中,Command对应的是node_modules/egg-bin/bin/egg-bin.js中的EggBin这个对象。首先理清一下egg-bin中对应的几个对象之间的关系,如下图:
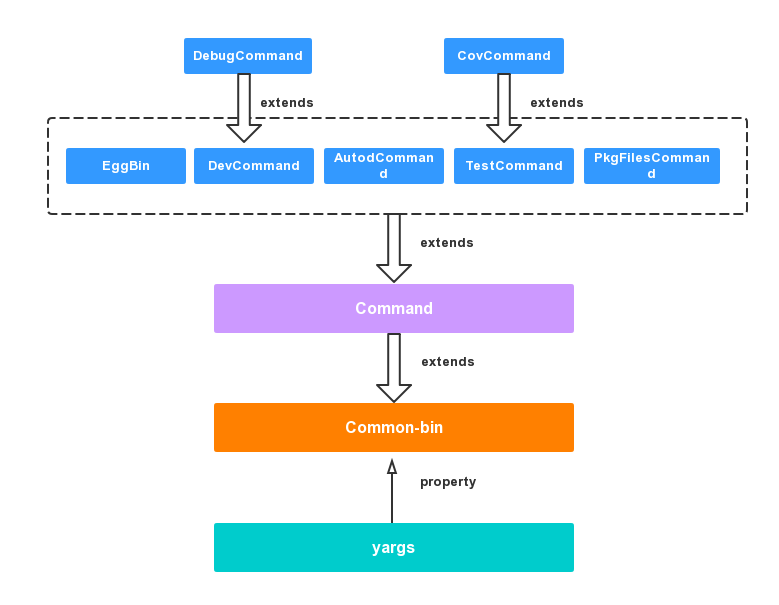
其中最后导出的EggBin对象以及DevCommand、AutodCommand、TestCommand、PkgFilesCommand继承于egg-bin/lib/command.js里面导出的Command对象,而egg-bin/lib/command.js里面导出的Command又是继承于第三方库(其实也是egg核心contributors开发的)common-bin,而common-bin中导出的CommonBin对象又有一个yargs属性,该属性是目前比较流行的命令行工具yargs。DebugCommand和CovCommand则分别继承自DevCommand和TestCommand。
进入index.js文件源代码,该文件只是定义了EggBin这个对象,并且将一些sub command挂载到EggBin这个导出对象中,有如下几个子命令:
common-bin的基础命令对象接着就是执行new Command().start()这一行,首先会先去执行EggBin构造函数中的内容:
class EggBin extends Command {
constructor(rawArgv) {
// 获取用户输入的option
super(rawArgv);
this.usage = 'Usage: egg-bin [command] [options]';
// load对应目录下面的command文件
this.load(path.join(__dirname, 'lib/cmd'));
}
}由于上面的继承关系,第一行就会直接执行到Common-bin/command.js中的构造函数中的参数获取:
this.rawArgv = rawArgv || process.argv.slice(2);此时this.rawArgv的值如下:
0:"dev"
1:"--port"
2:"7001"load配置文件获取到这个参数之后就会直接将该参数传给yargs并将yargs对象赋给自己的一个yargs属性
然后就开始load命令行文件了,通过追踪,也可以发现最后执行的也是common-bin中的load成员函数,该函数要求参数是所需要获取的命令文件的绝对路径,其中common-bin/command.js中的load源码如下:
load(fullPath) {
// 省略对参数的校验
// load entire directory
const files = fs.readdirSync(fullPath);
const names = [];
for (const file of files) {
if (path.extname(file) === '.js') {
const name = path.basename(file).replace(/\.js$/, '');
names.push(name);
this.add(name, path.join(fullPath, file));
}
}
// 省略
}其中files文件的值为:
0:"autod.js"
1:"cov.js"
2:"debug.js"
3:"dev.js"
4:"pkgfiles.js"
5:"test.js"然后将files进行遍历,执行下面的addCommand的操作:
add(name, target) {
assert(name, `${name} is required`);
if (!(target.prototype instanceof CommonBin)) {
assert(fs.existsSync(target) && fs.statSync(target).isFile(), `${target} is not a file.`);
debug('[%s] add command `%s` from `%s`', this.constructor.name, name, target);
target = require(target);
assert(target.prototype instanceof CommonBin,
'command class should be sub class of common-bin');
}
this[COMMANDS].set(name, target);
}其中要求参数target也是某个子命令对应的文件的绝对路径。在进行条件判断之后直接使用set将该命令挂载在this[COMMANDS]变量中。遍历完成后this[COMMANDS]的值如下所示:

start()最重要的start操作,追根溯源也是执行的common-bin里面的start(),start()里面主要是使用co包了一个generator函数,并且在generator函数中执行了this[DISPATCH],然后,重头戏来了,this[DISPATCH]的源码如下:
* [DISPATCH]() {
// define --help and --version by default
this.yargs
// .reset()
.completion()
.help()
.version()
.wrap(120)
.alias('h', 'help')
.alias('v', 'version')
.group([ 'help', 'version' ], 'Global Options:');
// get parsed argument without handling helper and version
const parsed = yield this[PARSE](this.rawArgv);
const commandName = parsed._[0]; //获取命令行参数
if (parsed.version && this.version) {
console.log(this.version);
return;
}
// if sub command exist
if (this[COMMANDS].has(commandName)) {
const Command = this[COMMANDS].get(commandName);
const rawArgv = this.rawArgv.slice();
rawArgv.splice(rawArgv.indexOf(commandName), 1);
debug('[%s] dispatch to subcommand `%s` -> `%s` with %j', this.constructor.name, commandName, Command.name, rawArgv);
const command = new Command(rawArgv);
yield command[DISPATCH]();
return;
}
// register command for printing
for (const [ name, Command ] of this[COMMANDS].entries()) {
this.yargs.command(name, Command.prototype.description || '');
}
debug('[%s] exec run command', this.constructor.name);
const context = this.context;
// print completion for bash
if (context.argv.AUTO_COMPLETIONS) {
// slice to remove `--AUTO_COMPLETIONS=` which we append
this.yargs.getCompletion(this.rawArgv.slice(1), completions => {
// console.log('%s', completions)
completions.forEach(x => console.log(x));
});
} else {
// handle by self
//对不同类型的函数进行调用(generator/promise)
yield this.helper.callFn(this.run, [ context ], this);
}
}首先会去执行yargs中一些方法,这里common-bin只是保留了yargs中一些对自己有用的方法,比如completion()、wrap()、alias()等,具体关于yargs的API可以移步这里。接着是执行this[PARSE]将rawArgv进行处理,处理后的parse对象结构如下:
接着就是对获取到的命令进行校验,如果存在this[COMMAND]对象中就执行。在当前例子中也就是去执行DevCommand,而由于DevCommand最终也是继承于common-bin的,然后执行 yield command[DISPATCH]();又是递归开始执行this[DISPATCH]了,直到所有的子命令递归完毕,才会去使用helper(common-bin中支持异步的关键所在)类继续执行每个command文件中的* run()函数。
dev.js作为在egg项目中本地开发最为重要的开发命令,dev.js无疑肩负着比较重要的职责。在dev.js中,主要是定义了一些默认端口号,以及入口命令等。* run()的源码如下:
* run(context) {
const devArgs = yield this.formatArgs(context);
const options = {
execArgv: context.execArgv,
env: Object.assign({ NODE_ENV: 'development' }, context.env),
};
debug('%s %j %j, %j', this.serverBin, devArgs, options.execArgv, options.env.NODE_ENV);
yield this.helper.forkNode(this.serverBin, devArgs, options);
}主要是对当前的上下文参数进行转化并对端口进行了一些处理,然后就开始调用helper的forkNode来执行入口命令,其中this.serverBin的值为:/Users/uc/Project/egg-example/node_modules/egg-bin/lib/start-cluster,下面的事情可以移步这里进行了解
debug.js由上分析可知,DebugCommand继承于DevCommand,所以在constructor的时候就会去执行dev中的一些options,而且在debug.js中的* run()函数中直接调用的是dev.js中的formatArgs()参数处理。关键源码(有删减)如下:
* run(context) {
const proxyPort = context.argv.proxy;
context.argv.proxy = undefined;
const eggArgs = yield this.formatArgs(context);
//省略部分
// start egg
const child = cp.fork(this.serverBin, eggArgs, options);
// start debug proxy
const proxy = new InspectorProxy({ port: proxyPort });
// proxy to new worker
child.on('message', msg => {
if (msg && msg.action === 'debug' && msg.from === 'app') {
const { debugPort, pid } = msg.data;
debug(`recieve new worker#${pid} debugPort: ${debugPort}`);
proxy.start({ debugPort }).then(() => {
console.log(chalk.yellow(`Debug Proxy online, now you could attach to ${proxyPort} without worry about reload.`));
if (newDebugger) console.log(chalk.yellow(`DevTools → ${proxy.url}`));
});
}
});
child.on('exit', () => proxy.end());
}此处首先是开启egg,做的是和dev里面一样的东西。然后则是实例化InspectorProxy进行debug操作,在命令行打印出一行devtools的地址。
test.js这个命令主要是用来运行egg项目中的*test文件的,也就是跑我们自己写的测试用例,关于如何写单元测试,可以移步单元测试,在这个文件,* run()形式也和上面类似,然后调用this.formatTestArgs(),formatTestArgs源码如下(有删减):
formatTestArgs({ argv, debug }) {
//省略
// collect require
let requireArr = testArgv.require || testArgv.r || [];
/* istanbul ignore next */
if (!Array.isArray(requireArr)) requireArr = [ requireArr ];
// clean mocha stack, inspired by https://github.com/rstacruz/mocha-clean
// [mocha built-in](https://github.com/mochajs/mocha/blob/master/lib/utils.js#L738) don't work with `[npminstall](https://github.com/cnpm/npminstall)`, so we will override it.
if (!testArgv.fullTrace) requireArr.unshift(require.resolve('../mocha-clean'));
requireArr.push(require.resolve('co-mocha'));
if (requireArr.includes('intelli-espower-loader')) {
console.warn('[egg-bin] don\'t need to manually require `intelli-espower-loader` anymore');
} else {
requireArr.push(require.resolve('intelli-espower-loader'));
}
testArgv.require = requireArr;
// collect test files
let files = testArgv._.slice();
if (!files.length) {
files = [ process.env.TESTS || 'test/**/*.test.js' ];
}
// expand glob and skip node_modules and fixtures
files = globby.sync(files.concat('!test/**/{fixtures, node_modules}/**/*.test.js'));
// auto add setup file as the first test file
const setupFile = path.join(process.cwd(), 'test/.setup.js');
if (fs.existsSync(setupFile)) {
files.unshift(setupFile);
}
testArgv._ = files;
// remove alias
testArgv.$0 = undefined;
testArgv.r = undefined;
testArgv.t = undefined;
testArgv.g = undefined;
return this.helper.unparseArgv(testArgv);
}代码里面的英文注释很清楚了,就是将单元测试的一些库push进requireArr中,requireArr的值如下:

其中mocha-clean是清除上一次mocha遗留的堆栈了,后面两个就是egg选用的测试框架和断言库了。
然后就是加载egg项目中除掉node_modules和fixtures里面的test文件,即项目层面的*.test.js,后面也就是开启进程来进行单元测试。
cov.js是用来测试代码覆盖率的。其中CovCommand继承自TestCommand,在cov的* run()中主要定义了字段,比如excludes、nycCli、coverageDir、outputDir等,根据英文命名也知道是什么意思了。然后继续执行getCovArgs是对参数的一些处理,源码也很简单,就不贴出来了,在getCovArgs中将上面test.js中的参数一起concat进来了,最后返回的covArgs的样子是这样的:
然后又是开启进程了。
autod.js和pkgfiles.js这两个比较简单,这里就不赘述了
整个egg-bin看下来,还是很厉害的,涉及的都是我之前没听过或者听过但是没用过的高大尚的东西,比如commander.js,yargs,mocha,co-mocha,power-assert,istanbuljs,nyc,所以分析起来还是比较吃力的。肯定也有很多分析不到位的地方或者有很多厉害的功能被一笔带过了,还望大神们指出~

刚看到这本书的时候,作为一个女生,我是很感兴趣的,毕竟,没有一个女生会拒绝自己成为女神,不管是在美貌方面还是在气质方面。
这本书写的是26位女神的故事,其中有张幼仪,林徽因,唐瑛,宋美龄等等这些智慧与美貌共存的奇异女子,文笔细腻柔美,如诗一般,字里行间不仅将女神们的一生描述得及其详细,还体现出各位女神内在的气质与神韵。这里挑出几处来进行摘录:
林徽因版:
唐瑛版:
江冬秀:
张爱玲:
宋庆龄:
孟小冬:
“重新开始”,而不是“破镜重圆”,前者是过去,后者是未来于凤至:
许广平:
读完这26位女子的传奇人生,在感叹作者厚实文学素养功底的同时,也感叹书里面提及的26位智慧女神,同样身为女生的我,要怎么提高自己的气质和素养,成为一个有着自己**和智慧的女性呢,在前行的道路上,我一直在思考中。。。。
前言:最近对
node底层一些东西不是很深入,趁这段时间整理一些理论知识
Event Loop是指在js执行环境中存在主执行线程和任务队列(Task Queue),其中所有同步任务都在主执行线程中形成一个执行栈,所有异步任务都会放到任务队列中。Event Loop会经历如下过程:
参考资料:
macrotask和microtask上面说的异步任务中,分为macrotask(宏任务)和microtask(微任务)两类,在挂起任务中,Js引擎会按照类别将任务分别存放在这两种类型任务中。这两种任务执行的顺序如下:
macrotask任务队列中的第一个任务进行执行microtask中的所有任务顺序执行macrotask中的剩余任务执行这个步骤通过一个图来展示会比较直观:
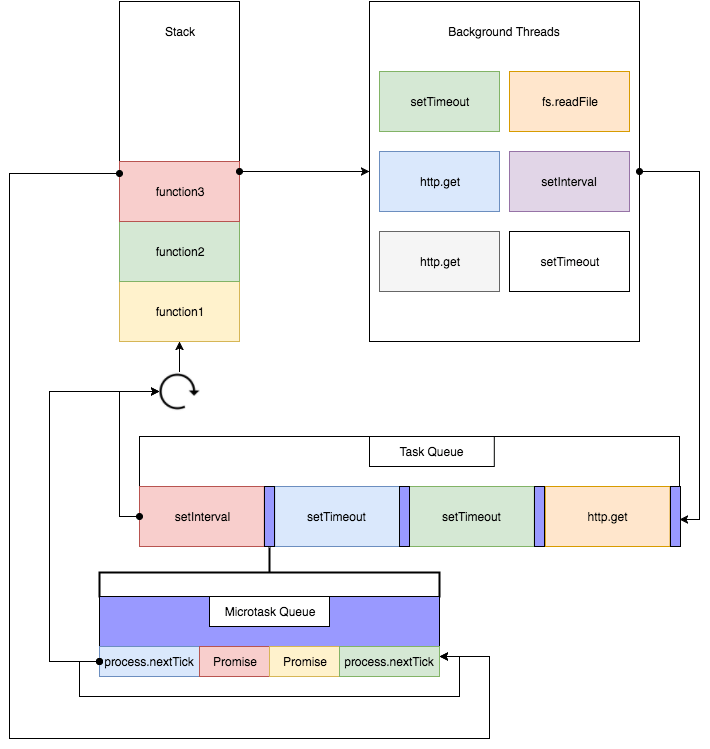
图中stack表示主执行线程中的同步任务,而Background Threads则是指macrotask,在执行完主线程之后,会取出Macrotask Queue(也叫Task Queue)中的第一个任务setInterval执行,执行完毕之后就会顺序执行下面的Microtask Queue,直到所有Microtask Queue中的任务都执行完毕了之后,才会执行下一个Macrotask。
其中macrotask类型包括:
script整体代码setTimeoutsetIntervalsetImmediateI/OUI renderingmicrotask类型包括:
process.nextTickPromise(这里指浏览器实现的原生promise)Object.observeMutaionObserver参考资料:
通过一段代码来验证一下上面的理论:
console.log('start')
setTimeout(() => {
console.log('setTimeout1');
},0);
const myInterval = setInterval(() => {
console.log('setInterval');
},0)
setTimeout(() => {
console.log('setTimeout2');
Promise.resolve().then(() => {
console.log('promise3');
})
setTimeout(() => {
console.log('setTimeout3');
clearInterval(myInterval);
},0)
},0)
Promise.resolve()
.then(() => {
console.log('promise1');
}).then(() => {
console.log('promise2');
})
console.log('end');这段代码最后的输出结果如下:
start
end
promise1
promise2
setTimeout1
setInterval
setTimeout2
promise3
setInterval
setTimeout3大概讲解一下流程:
script相当于一个Macrotask,它是Macrotask Queue中的第一个任务,先执行,所以打印出 start、endPromise相当于一个Microtask,按照之前的理论,会先顺序执行完所有的Microtask,所以此时会打印promise1和promise2。Microtask之后,会将setTimeout1和setInterval推进Macrotask Queue中,并且会执行此时Macrotask Queue的第一个任务,也就是setTimeout1,此时打印出setTimeout1。Microtask还是为空,所以会继续执行下一个Macrotask,也就是setInterval,此时打印出setIntervalsetInterval的task时,会将下一个setTimeout继续推进Macrotask Queue,而且此时Microtask仍然为空,继续执行下一个Macrotask,所以打印出setTimeout2setTimeout2的时候,setTimeout2里面的promise已经推进Microtask Queue中,所以此时会执行完Microtask Queue中的任务,打印出promise3Microtask Queue的时候,一直执行的setInterval后面的setTimeout3会继续被推进Macrotask Queue中,并且依次执行,直到setInterval被取消。Event Loop根据node官方文档的描述,node中的Event Loop主要有如下几个阶段:
┌───────────────────────┐
┌─>│ timers │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ I/O callbacks │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ idle, prepare │
│ └──────────┬────────────┘ ┌───────────────┐
│ ┌──────────┴────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └──────────┬────────────┘ │ data, etc. │
│ ┌──────────┴────────────┐ └───────────────┘
│ │ check │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
└──┤ close callbacks │
└───────────────────────┘各个阶段执行的任务如下:
timers 阶段: 这个阶段执行setTimeout和setInterval预定的callback;close事件的callbacks、被timers设定的callbacks、setImmediate()设定的callbacks这些之外的callbacks;idle, prepare 阶段: 仅node内部使用;poll 阶段: 获取新的I/O事件, 适当的条件下node将阻塞在这里;check 阶段: 执行setImmediate() 设定的callbacks;close callbacks 阶段: 执行socket.on('close', ...)这些 callbackprocess.nextTick()process.nextTick()并没有在Event Loop的执行阶段中,而是在Event Loop两个阶段之间运行,根据上面说的,process.nextTick()属于microtask任务类型。
根据process.nextTick()的运行性质,可以整理出下面的简图:
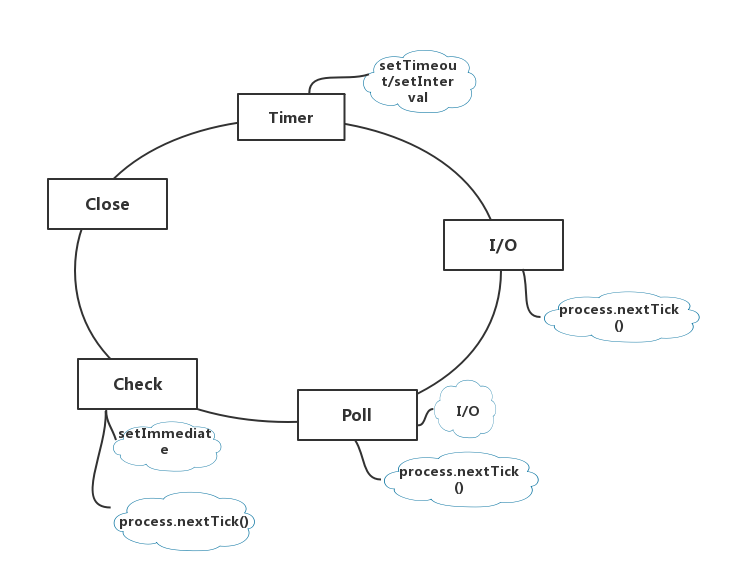
也就是process.nextTick()有可能插入在Event Loop各个阶段中
setTimeout(fn,0) Vs setImmediate Vs process.nextTick()setTimeout(fn,0) Vs setImmediatesetTimeout(fn,0)在timer阶段执行,并且是在poll阶段进行判断是否达到指定的time时间才会执行setImmediate在check阶段才会执行两者的执行顺序要根据当前的执行环境才能确定,根据官方文档总结得出的结论是:
setImmediate Vs process.nextTick()setImmediate()属于check观察者,其设置的回调函数,会插入到下次事件循环的末尾,每次事件循环只执行链表中的一个回调函数。process.nextTick()所设置的回调函数会存放到数组中,一次性执行所有回调函数。process.nextTick()调用深度的限制,上限是1000,而setImmediate没有;先来看一段代码:
setImmediate(() => console.log('immediate1'));
setImmediate(() => console.log('immediate2'));
setTimeout(() => console.log('setTimeout1'), 1000);
setTimeout(() => {
console.log('setTimeout2');
process.nextTick(() => console.log('nextTick1'));
}, 0);
setTimeout(() => console.log('setTimeout3'), 0);
process.nextTick(() => console.log('nextTick2'));
process.nextTick(() => {
process.nextTick(console.log.bind(console, 'nextTick3'));
});
process.nextTick(() => console.log('nextTick4'));在控制台中执行node index.js,得到的结果如下:
nextTick2
nextTick4
nextTick3
setTimeout2
setTimeout3
nextTick1
immediate1
immediate2
setTimeout1分析如下:
node中,nextTick的优先级高于setTimeout和setImmediate(),所以会先执行nextTick里面的信息打印。nextTick,会慢于同步的nextTick,所以nextTick4会先于nextTick3Event Loop过程,首先执行timer阶段,而此时setTimeout所需要等待的时间是0,所以立即执行setTimeout2和setTimeout3里面的逻辑。而setTimeout1由于设置了执行时间,不满足执行条件,被放到下一轮Event LoopEvent Loop执行到check阶段,于是打印出immediate1、immediate2Event Loop,当setTimeout1达到执行条件时执行参考资料:
-Node.js的event loop及timer/setImmediate/nextTick
-Node.js Event Loop 的理解 Timers,process.nextTick()
对node事件基础的一些总结,有不正确的地方还望指出,共同学习。

期间因为要准备考试,所以第三部花了很长的时间.
第三部的主要内容是第二部结束黑暗森林威慑建立起后,人类与三体文明进入了一段较和平的时期,期间三体主要学习人类文明,人类学习三体科技,并建造了由智子控制的AI智子,为日本女性形象。由罗辑担任掌控引力波发射器的开关的执剑人,后来名为程心的圣母形形象的人接任执剑人,立刻遭到了水滴袭击,地球威慑纪元结束。智子将人类全大利亚,三体舰队准备入侵地球,与此同时在外太空的万有引力号飞船以引力波形式发出了三体坐标。三体在不久后遭到黑暗森林打击,智子在临走前邀请程心与云天明(危机纪元时他的大脑被发送向三体舰队,后失去联系,曾暗恋程心)通过智子进行对话,向程心讲述了三个暗含向宇宙发出安全声明的方法(与曲率驱动飞船留下的航迹是象征这个文明高技术水平的危险声明相对),但是人类并没有完全解读出来故事的核心,最后地球还是遭到了黑暗森林的打击,由三维变成二维,地球上的所有东西都变成了画上的东西。
总的来说,我个人感觉第三部太过于戏剧化,情节设置上太过突兀,但是在一些细节上写得确实是很好的。比如在人们被移民到澳大利亚的时候以及当黑暗森林的警报响起的时候,人们在生死面前就会暴露出自己的本性:宁愿牺牲别人也要保全自己。这让我想起了电影《釜山行》,里面的人物刻画也是非常精彩而且传神的。
最后的结局我有点没有想到,我以为最后程心会和云天明在一起,然而并没有,云天明在整个故事中都是一个神奇的角色,但是一直没有
在后面详细描述,让人感觉很迷惑,我觉得这是不太好的点。但是还是很倾佩作者的想象力,那么宏大的场景也能描述出来,可见功底非一般,
极力推荐大家去读
node.js中的模块机制是基于CommonJs,对于CommonJs的module部分,可以戳这里进行查看。
对于js的模块部分,有好多这方面的文章,所以在这里我就不再赘述了,对于几种模块的加载规范之间的差别,可移步这里
module 定义在node中,每一个文件都被当成一个独立的模块,而且每个模块都有自己的作用域,这就很好地保证了不同模块之间变量的相互污染。因为每个模块被node包装成如下所示:
(function (exports, require, module, __filename, __dirname) {
//the code of singal file
});exports属性上的任何方法和属性都可以在外部被调用,模块中的其余变量或属性则不可直接被调用。但是被加载模块中的全局变量可以被外部调用
//a.js
name = 'test';
//b.js
var a = require('./a.js');
console.log(name);此时可以打印出test,但是将a.js改为如下:
//a.js
var name = 'test';
此时就会报错。
对于node中模块的基础知识,比如文件加载方式这里不展开说,具体可以查看这篇文章
exports、module和module.exportsmodule是当前模块的对象的引用,结构如下:Module {
id: '.',
exports: {},
parent: null,
filename: '/Users/uc/Project/index.js',
loaded: false,
children: [],
paths:
[ ... ] }module.exports是module的一个属性对象(如上可知),它是由模块系统创建的,并且最终返回给调用的模块exports是module.exports的一个引用,相当于一个快捷键:exports = module.exports = {}
//类似于
b = a = {};
//类似于
a = {}
b = a;最终返回给require的是module.exports模块。
两者之间的相互改变有如下几种情况:
exports的引用时(即exports指向了一个新的对象空间),此时不会影响到module.exports:module.exports = {
name: 'a'
}
exports = {
age: '21'
}此时module中的exports对象中只有一个name属性,而不会有age属性。因为exports指向了一个新的空间。
exports的引用时,并且添加一个module.exports中(并且此时module.exports有显式声明为一个对象实例)没有的属性时,不会改变module.exports:module.exports = {
name: 'a'
}
exports.age = 21此时module中的exports对象中只有name属性,而没有age属性,因为原先的module.exports中没有age属性,无法添加
exports的引用时,并且添加一个module.exports中(并且此时module.exports没有显式声明为一个对象实例)没有的属性时,会改变module.exports:module.exports.name = 'a';
exports.age = 21此时module中的exports对象中既有name属性又有age属性
exports的引用,并且添加一个module.exports中(并且此时module.exports没有显式声明为一个对象实例)有的属性时,会覆盖module.exports原有的属性:module.exports.name = 'a';
exports.age.name = 'b';此时module中的exports对象中既有name属性,并且值为b;
总结:其实也就是两个对象之间相互引用的关系,上面的几种情况也是基于这几种情况来说的而已。为了防止这种改变了值但是不生效的情况,可以采用如下策略:
exports对象上module.exports进行导出即可exports导出类,需要使用exports = module.exports = obj进行hack即可之前在做项目的时候,遇到一个场景:a模块中引入了b模块,然后b模块又引入了a,然后在b中访问不到a的属性,当时还花了好长时间来排查(捂脸)...
上面这个场景可以被简单复现为如下:
//a.js
const b = require('./b.js');
console.log('在 a 中,b.done = ', b.name);
console.log(b);
exports.name = 'a';
//b.js
const a = require('./a.js');
console.log('在 b 中,a.done = ', a.name);
exports.name = 'b';此时运行b.js,会发现打印出的b.name=undefined, b={}。
因为在b在require a的时候,发现a也require了b,为了防止循环引用,a中此时的b只是一个exports未加载完成的副本{},所以没有任何值打印,但是在b中,可以获取到a.name属性。
所以为了避免出现这种情况,应该尽量避免模块之间的相互引用
官方文档中对于其实有描述,只是有点简单,之后通过实验了一下,才领会了说的啥。
也就是如果当前要执行当前文件,比如a.js,如果此时执行a.js,那么它的require.main === module就为true,但是对于如下场景:
//a.js
exports.a = require.main === module
//b.js
var a = require('./a.js');
console.log(a);此时打印出来的就是false。
因为每个文件模块都会被包装成一个函数,并且会有一个__filename的参数,而且__filename === require.main.filename,所以可以通过检查 require.main.filename 来获取当前应用程序的入口点。
模块在第一次被加载之后就被缓存起来了,这意味着以后每一次再调用相同的模块将会返回同样的一个对象。这种处理方式在大多数情况下是很好的。但是如果有一些比较特殊的场景需要删除这个缓存,要怎么做呢
delete require.cache[moduleName]
其中moduleName是你想要删除缓存的模块名,并且是真实存在的。
具体的讨论可以移步这里
以上只是总结一下我对模块这块存在的有误区或者不太了解的地方,涉及的点不太深,只是自己的一点记录,有不对的地方欢迎斧正。

这本书是一个学长推荐的,很受用,而且第一次看完的时候是在4月份的时候,但是这两天又重温了一遍,第一次看这本书的时候,完全被震撼了,感觉句句都说到我的心坎里.从小到大,我都很要强,并且都付出了自己百分之百的努力,而且收获也很可观.从小学到现在,我一直是名列前茅,基本上不甘于落后,一方面是不想让我母亲失望,更多地是想改变我自己的命运.但是在这个过程中,我一直表现得很拘束,当某人称赞我的时候,我会谦虚地说这只是运气罢了,正如和作者在文中谈到的那样.除此之外,我虽然相对来说优秀,但是在我的内心里有一种莫名的自卑感,总是小心翼翼地行事.除此之外,当听到被人说:"你真是一个女强人".觉得局促不安,甚至有的时候害怕或者抑制自己完全展示我的才能,只是为了害怕别人讨厌我.这本书从各个方面剖析了女性之所以不想成为职场领导人的方方面面的原因, 而且从自己出发,将自己的经历或者身边的相似例子拿出来剖析,讲得很激励人.前一部分主要是讲女性在职场中很少有职场高级领导人的现状,然后剖析原因,最后就是鼓励现代女性勇于追求自己的梦想,不应该被束缚住自己的**.
"当男人成功了,人们会分析他内在的才能与品质;当女人成功了,人们首先会问:她有什么靠山
这句话说得很精辟,这是世人公认的行为,他们认为女生不可能达到这种超乎预期的程度,这是一种歧视,对我们女性是完全不公平的
- "男性的晋升基于其自身的潜力,而女性的晋升则是基于其已获得的成就,除了社会竖起的外部障碍之外,女性还为存在于自身的障碍所影响.由于缺乏自信,不敢争取表达的机会,在应该前行的时候往后"
- "一直以来,我们都认为:女人说话坦率是错误的,女人有进取心也是错误的,女人比男人权利更大也是错误的"
- "'她很有抱负'这句话在我们的文化里并不是一句赞美之言.积极进取.作风强硬的女性违反了那些关于'可接受行为'的不成文规则.男性的进取,强大,成功会不断收到人们的称赞,喝彩,表现出相同特点的女性却常常收到社会的惩罚,这意味着,女性在获得成就的同时,都要付出一定的代价"
- "女性被包围在各式大标题和不同的故事中,并被警告"女性不可同时投入到家庭和事业当中,一再的警告让她们不得不在二者当中做出选择,因为如果做得太多,她们就会身心疲惫,不会感到快乐"
- "当她们所取得的成绩别人称赞是,会感觉那些称赞是骗取来的.她们常常感到自己不值得被认可,不配受到称赞,并且心存负疚,就好像是犯了什么错,即便那些在自己的领域成就斐然,甚至已经是专家级别的女性,她们仍然摆脱不了这样一种感觉:我其实只是个技术水平或者能力都很有限的冒牌货,现在的荣誉不过是因为碰巧被大家发现了而已"
- "如果她的工作能力相当强,如果她专注与结果而非取悦他人,她就表现得像个男人,而且如果她像一个男人那样行动,人们就会不喜欢她,由于顾及这种反应,女性会让自己表在职场中的进取心表现得更为收敛"
上面的所有都是书中摘录的我认为很共鸣的话.说实话,一直以来,当我表现得稍微强大的时候,就会有人给我提意见:不要表现得太强,或者你是个女强人.所以我有很深的作者的体会.除此之外,当你表现得比你周围的女生稍微强一点的时候,你就会有很明显的感觉,他们在无意中会给你一种错觉:"她们在集体远离你,甚至在集体弹劾你",无论是出自于女生天生的嫉妒性还是其他的什么因素,我都明确地感受到女性要想成功,必须要经受各种不同的阻挠,而且要有强大的内心.
但是只要你想成功,你想改变自己的现状,无论碰到任何困难,你都会坚定地走下去.这本书,给了我很大的激励,它告诉我:只要有梦想,就要用于去追求,走自己的路,让别人说去吧
redux虽然强大,但是它的源码确实很简单
createStorecreateStore返回的是一个对象,并且这个对象有如下成员函数dispatch,subscribe,getState,replaceReducer和observable
下面看它的核心源码(已经去掉一些对参数的判断):
if (typeof preloadedState === 'function' && typeof enhancer === 'undefined') {
enhancer = preloadedState
preloadedState = undefined
}
if (typeof enhancer !== 'undefined') {
if (typeof enhancer !== 'function') {
throw new Error('Expected the enhancer to be a function.')
}
return enhancer(createStore)(reducer, preloadedState)
}这一段是通过传入的参数类型来做判断的如果只传入两个参数,并且第二个参数是函数而不是对象的时候,此时直接进行替换赋值。并且当检测到第三个参数enhancer不为空并且符合规范的时候,直接执行
enhancer(createStore)(reducer, preloadedState)
这一段其实是为之后的中间件进行服务的
然后是定义了一系列变量:currentState,currentListener,nextListener等。然后就开始依次实现store暴露的几个函数
getState函数很简单,只是返回currentState而已
function subscribe(listener) {
if (typeof listener !== 'function') {
throw new Error('Expected listener to be a function.')
}
let isSubscribed = true
ensureCanMutateNextListeners()
nextListeners.push(listener)
return function unsubscribe() {
if (!isSubscribed) {
return
}
isSubscribed = false
ensureCanMutateNextListeners()
const index = nextListeners.indexOf(listener)
nextListeners.splice(index, 1)
}
}subscribe函数的实现是通过nextListener数组来实现对当前listeners来进行增删,之所有需要一个currentListener又需要一个nextListener,是因为如果直接在currentListener上进行修改,会导致由于数组是复杂类型,一旦进行更改会使整个数组发生改变。
if (isDispatching) {
throw new Error('Reducers may not dispatch actions.')
}
try {
isDispatching = true
currentState = currentReducer(currentState, action)
} finally {
isDispatching = false
}
const listeners = currentListeners = nextListeners
for (let i = 0; i < listeners.length; i++) {
const listener = listeners[i]
listener()
}上面是dispatch的核心源码,去掉了一些类型检测,这个函数主要是通过设置了一个isDispatching 标志位,来判断传入的action是否已经被监听过,否则则直接调用reducer函数,并且将listener数组都执行一遍
再继续往下看,replaceReducer也很简单,略过
combineReducers这部分的代码很长,但是大部分都是在对参数做一些校验处理,核心源码是下面几行
const finalReducerKeys = Object.keys(finalReducers)
...
let hasChanged = false
const nextState = {}
for (let i = 0; i < finalReducerKeys.length; i++) {
const key = finalReducerKeys[i]
const reducer = finalReducers[key]
const previousStateForKey = state[key]
const nextStateForKey = reducer(previousStateForKey, action)
if (typeof nextStateForKey === 'undefined') {
const errorMessage = getUndefinedStateErrorMessage(key, action)
throw new Error(errorMessage)
}
nextState[key] = nextStateForKey
hasChanged = hasChanged || nextStateForKey !== previousStateForKey
}
return hasChanged ? nextState : state
}主要的过程如下:
reducer是否是合法的,然后将合法的reducer放进finalReducer中,并获取对应的key值reducer获取对应key值的statestate第一种:
function todoApp(state = {}, action) {
return {
visibilityFilter: visibilityFilter(state.visibilityFilter, action),
todos: todos(state.todos, action)
}
}
第二种:
const todoApp = combineReducers({
visibilityFilter,
todos
})bindActionCreators这个函数的作用,主要是弱化了store.dispatch的作用,直接在bindActionCreators中进行封装了,源码如下:
function bindActionCreator(actionCreator, dispatch) {
return (...args) => dispatch(actionCreator(...args))
}
export default function bindActionCreators(actionCreators, dispatch) {
if (typeof actionCreators === 'function') {
return bindActionCreator(actionCreators, dispatch)
}
const keys = Object.keys(actionCreators)
const boundActionCreators = {}
for (let i = 0; i < keys.length; i++) {
const key = keys[i]
const actionCreator = actionCreators[key]
if (typeof actionCreator === 'function') {
boundActionCreators[key] = bindActionCreator(actionCreator, dispatch)
}
}
return boundActionCreators
}actionCreators这个参数是function还是一系列function数组function,那就直接执行bindActionCreator,可以看到bindActionCreator中实现了dispatch的功能作用:自动把
action创建函数绑定到dispatch中,省略通过store.dispatch()进行手动dispatch
applyMiddleware这是唯一一个很绕的API,虽然代码很简洁,下面对它进行分析:
export default function applyMiddleware(...middlewares) {
return (createStore) => (reducer, preloadedState, enhancer) => {
const store = createStore(reducer, preloadedState, enhancer)
let dispatch = store.dispatch
let chain = []
const middlewareAPI = {
getState: store.getState,
dispatch: (action) => dispatch(action)
}
chain = middlewares.map(middleware => middleware(middlewareAPI))
dispatch = compose(...chain)(store.dispatch)
return {
...store,
dispatch
}
}
}createStore来生成一个store,并且获取到dispatch,定义了一个空数组chain,store和dispatch作为参数传入middleware中,先来看看中间件的统一格式:function createThunkMiddleware(extraArgument) {
return ({ dispatch, getState }) => next => action => {
if (typeof action === 'function') {
return action(dispatch, getState, extraArgument);
}
return next(action);
};
}上面这个格式是采用了ES6的语法格式,解析应该是下面这样:
return function (next) {
return function (action) {
return next(action);
}
}
}middleware经过处理后push到chain数组compose对chain数组进行处理compose的实现源码:export default function compose(...funcs) {
return funcs.reduce((a, b) => (...args) => a(b(...args)))
}compose底层调用的是Array.prototype.reduceRight
举例:
Dispatch = compose([fn1,fn2,fn3])(store.dispatch)会被解析成如下所示:
dispatch = f1(f2(f3(store.dispatch)),也就是f3的返回值作为f2的参数,f2返回值作为f1的参数
compose处理后返回return next(action)function(action){
if (typeof action === 'function') {
return action(dispatch, getState, extraArgument);
}
return next(action);
}这个也是包装后的store.dispatch,与原先的store.dispatch不同,通过这种方式一直进行传递
为什么
middlewareApi中要使用这一行dispatch: (action) => dispatch(action),而不是直接dispatch:dispatch
因为store.dispatch是一直在改变的,并且需要获取到最新的store.dispatch,这一句正是实现这个功能,每次都可以获取最新的,而不是最先的那个store.dispatch
至此,完结
前言:之前并没有接触过
chrome扩展,第一次接触chrome插件也只是使用二维码生成器,然后是老大给了一篇教程之后开始尝试,然后觉得还是蛮好玩的,便尝试了一个demo,是对自己收藏的书签进行美化还有添加的一些操作
对于chrome开发入门的一些知识,直接看教程和这里即可,这里不赘述。
下面记录一些开发过程中踩过的坑以及解决方案:
manifest.json文件中,对于图标的定义,仅仅定义一个default-icon并不能生效,还需要定义一个icons的值,例如: "icons": {
"48": "icon.png"
},chrome.storage.sync undefined?这是因为在
manifest.json文件中没有声明如下定义:
"permissions": [
"storage"
],manifest.json中定义permissions,否则会获取不到数据 "permissions": [
"storage",
"bookmarks"
],“Not allowed to load local resource: chrome://favicon/”查找错误原因,
stackoverflow给出的讨论是需要在manifest.json中添加权限,讨论地址,按照讨论方案设置如下权限:
"permissions": [
"storage",
"bookmarks",
"http://*/",
"chrome://favicon/",
"chrome://favicon/*",
"tabs",
"<all_urls>"
],仍然不生效,还在继续查找原因
后面的一些经验和总结会不断汇总到这里

初遇这本书的时候,是在火车站,你敢信?当时等车无聊,然后看到候车厅里面有一个书店,然后随手翻了翻这本书,竟然开始看下去了,只是没有看完就先坐上火车了。。。。之后再来搜索并且看完的时候倒觉得非常庆幸那一次的不经意了。
整本书写得非常奇幻,大致内容就是一个叫做迪伦女孩,在去见她和母亲离异已久的父亲图中发生了车祸,并且最后死亡了,死亡之后由一位名叫崔斯坦的男孩引渡到另一个世界,在这途中,两人一起战胜困难,躲避恶魔的追捕,并且两人擦出了爱情的火花,当到达目的地之后,迪伦因为不愿意和崔斯坦分离而逃脱新世界,打破原有的既定规律,和崔斯坦一起逃离并最终成功回生的奇迹旅程。
看完整本书,不由得惊叹,无论从构思上还是思路设想上,整本书是作者假想的一种人死后需要被一个摆渡人引渡到世界的另一端,当到达那里时,就会和自己的摆渡人分开,然后在那个世界里等着真实世界的亲人经历死亡之后来这里找自己。然后摆渡人则需要继续去引渡另外一个即将死亡的人。这种大胆的构思不得不让人叹服,说实话,对于人死之后的去向,在**,只是看到过电视剧里说要和孟婆汤或者继续投胎的一些设想,但是还是觉得非常好奇,在这里看到这种设想倒是让我觉得惊讶而且赞叹。
作者的想象力确实是非常丰富了,男女主人公在长期跋涉中各种所看到的景象以及在和恶魔争斗的一些场面,无疑是十分生动形象的,而且感觉不到任何生硬。除此以外,作者非常善于勾住读者的阅读欲望,不断地在设置悬念,然后再解开谜团,一次又一次地将读者带入一个难以想象的谜团但是又帮着读者解开,这种惊喜以及神奇,让我神往。比如当迪伦遭遇车祸之后,然后醒来,但是经过在隧道里面跋涉已久之后,居然只看到了一个生还者,在由崔斯坦带着走之后,也是十万个为什么在脑中盘旋,然而你永远想不到居然是摆渡人在引导灵魂到世界的另一端去。在设置悬念,埋下伏笔的同时又随着两人的对话将真相全盘脱出,简直精彩。
在整个过程中,都需要在天黑之前赶到“安全屋”,以防止恶魔的攻击,迪伦从一开始很怯懦的小女孩变成了一个为了爱情而不顾牺牲自己生命的勇敢的形象,正是这份勇敢,让她重生,并且可以和爱人永远在一起,这就是爱情的力量。
整本书不仅思路新奇,而且对于细节的把控也是驾轻就熟,描述得非常到位,特别是当迪伦和崔斯坦刚刚坠入爱河时的忐忑心理:
他确信她对自己也是有好感的,他觉得这是自己从她的眼神中读出来的。但他也可能会误判,她对他表现出的关切可能只是因为不愿承受孤身一人的恐惧,她对他的信任可能也只不过是处于无奈----她还有别的选择吗?她对他的亲近,她试图抚摸他时的样子,可能不过是孩童害怕时向成年人寻求慰藉的那种感觉。
当迪伦向崔斯坦表白并恳切得到肯定回答的时候,迪伦的忐忑心理:
她对他的话语和触碰完全会错了意。她的眼睛开始感到一阵刺痛,泪水夺眶而出。她紧咬牙关,努力克制自己,她的手指攥成拳头,紧紧握着,指甲刺进了手掌里。可是光这点痛还不算完,胸口的疼痛才让她苦不堪言,如同一把灼热的匕首刺进了胸膛正中。这种痛盖过了其他感官的不适,让她的呼吸倍感艰难。
当听到崔斯坦的肯定答复时,她兴奋雀跃的心态又溢于言表:
他爱她。她先是脸上闪过了一丝微笑,接着微笑又变成了眉飞色舞的大笑。她胸口的疼痛消失得无影无踪,取而代之的是一道柔和的光顺着喉咙换换升起,最后从笑容中绽放。
文字细腻而热烈,仿佛置身其中感受着两颗心渐渐走进。除了这些描述之外,字里行间同样显示着一些哲学道理:
很久以来他第一次为自己的命运黯然神伤。他的生活简直就是一座监狱,永无止境地轮回。他看到那些自私的灵魂说谎、欺骗、浪费上天赐予他们的生命,而这却是他梦寐以求又求之不得的。
作为一个摆渡人,崔斯坦没有自己的生命,所以他羡慕有生命的人。那么同样有生命的我们,是不是应该更多地珍惜一下现在已经拥有的生活,少一些抱怨多一些感恩。
最后,在迪伦的勇敢和对爱情的向往追求中,他们毫无畏惧地战胜了旅途中的困难,摆脱了既定的命运,走向了幸福的生活。
整本书充满着爱和亲情的回归,结局也很美好,让人爱不释手。很好的一本书,强烈推荐。
最近在一些项目中遇到高阶组件的身影,不是很了解,于是深入钻研了一番,以下权当是学习记录了~
在谈及高阶组件之前,我们先来讲讲它的前身 mixin ~
mixin 的作用是:如果多个组件中包含相同的方法(包括普通函数和组件生命周期函数),就可以把这一类函数提取到 mixin 中,然后在需要公共方法的组件中使用 mixin, 就可以避免每个组件都去声明一次,从而达到复用。
React 在早期是使用 createClass 来创建一个 Component 的,而且 createClass 支持 mixin 属性,最常见的就是 react-addons-pure-render-mixin 库提供的 PureRenderMixin 方法,用来减少组件使用中一些不必要的渲染,使用方式如下:
import PureRenderMixin from 'react-addons-pure-render-mixin';
React.createClass({
mixins: [PureRenderMixin],
render: function() {
return <div>{this.props.name}</div>;
}
});和需要在每一个组件中都重复实现一遍 PureRenderMixin 中浅比较的逻辑相比,上面 mixin 中的使用显得更加简便和明了,同时减少了代码的冗余和重复。
minin 既可以定义多个组件**享的工具方法,同时还可以定义一些组件的生命周期函数(例如上例的 shouldComponentUpdate), 以及初始的 props 和 states。
如下所示:
var propsMixin1 = {
getDefaultProps: () => {
return {
name: "Amy"
};
}
};
var propsMixin2 = {
getDefaultProps: () => {
return {
title: "mixin"
};
}
};
var MixinExample = createReactClass({
mixins: [propsMixin1, propsMixin2],
render: function() {
return (
<div>
<p>{this.props.name}</p>
<p>{this.props.title}</p>
</div>
);
}
});但是在使用 mixin 的时候,会有如下的几点需要注意:
不同 mixin 中有相同的函数
不同 mixin 中设置 props 或者 states
附上具体示例代码地址
虽然 mixin 在一定程度上解决了 React 实践中的一些痛点,但是 React 从 v0.13.0 开始,ES6 class 组件写法中不支持 mixins, 但是还是可以使用 createClass 来使用 mixin。之后,React 社区提出了一种新的方式来取代 mixin,那就是高阶组件 Higher-Order Components。
高阶组件 (Higher-Order Components) 是接受一个组件作为参数,然后经过一些处理,返回一个相对增强的组件的函数。它是 React 中的一种模式,而不是 API 的一部分。React 官方给出一个公式描述如下:
const EnhancedComponent = higherOrderComponent(WrappedComponent);一个最简单的 HOC 例子如下:
function HOC(WrappedComponent) {
return class PP extends React.Component {
render() {
return <WrappedComponent {...this.props}/>
}
}
}
class Example extends React.PureComponent {
render() {
return (
<div>
<p>{this.props.age}</p>
</div>
);
}
}
const HocComponent = HOC(Example);
ReactDom.render(<HocComponent age={24} />, document.getElementById("root"));
它的使用场景有如下几点:
高阶组件有两种实现方式: 属性代理 (Props Proxy) 和反向继承 (Inheritance Inversion)
属性代理是指所有的数据都是从最外层的 HOC 中传给被包裹的组件,它有权限对传入的数据进行修改,对于被包裹组件来说,HOC 对传给自己的属性 (Props) 起到了一层代理作用。
属性代理可以实现如下一些功能:
class Example extends React.PureComponent {
constructor(props) {
super(props);
}
render() {
const { name, age, github } = this.props;
return (
<div>
<p>{name}</p>
<p>{age}</p>
<p>{github}</p>
</div>
);
}
}
function HOC(WrappedComponent) {
class EnhancedComponent extends React.PureComponent {
render() {
const props = Object.assign({}, this.props, {
name: "SunShinewyf",
github: "http://github.com/SunShinewyf"
});
return <WrappedComponent {...props} />;
}
}
return EnhancedComponent;
}
const HocComponent = HOC(Example);
ReactDom.render(<HocComponent age={24} />, document.getElementById("root"));如上面的例子中,HOC 对最外层传入的 props 进行了二次组装,扩展了 props 的数据能力。
class Example extends React.PureComponent {
constructor(props) {
super(props);
this.consoleFun.bind(this);
}
consoleFun() {
console.log("hello world");
}
render() {
const { age } = this.props;
return (
<div>
<p>{age}</p>
</div>
);
}
}
function HOC(WrappedComponent) {
class EnhancedComponent extends React.PureComponent {
initFunc(instance) {
instance.consoleFun();
}
render() {
const props = Object.assign({}, this.props, {
ref: this.initFunc.bind(this)
});
return <WrappedComponent {...props} />;
}
}
return EnhancedComponent;
}
const HocComponent = HOC(Example);
ReactDom.render(<HocComponent age={24} />, document.getElementById("root"));如果想要在 HOC 中执行被包裹组件的一些方法,就可以在 props 上组装一下 ref 这个属性,就可以获取到被包裹组件的实例,从而获取到实例的 props 以及它的方法。
function HOC(WrappedComponent) {
return class PP extends React.Component {
render() {
<div> //添加一些样式
return <WrappedComponent {...this.props}/>
</div>
}
}
}这个比较简单,不详述~
反向继承是指 HOC 继承被包裹组件,这样被包裹的组件 (WrappedComponent) 就是 HOC 的父组件了,子组件就可以直接操作父组件的所有公开的方法和字段。
反向继承可以实现如下功能:
class Example extends React.PureComponent {
constructor(props) {
super(props);
}
componentDidMount() {
console.log("wrappedComponent did mount");
}
render() {
const { age } = this.props;
return (
<div>
<p>{age}</p>
</div>
);
}
}
function HOC(WrapperComponent) {
return class Inheritance extends WrapperComponent {
componentDidMount() {
console.log("HOC did mount");
super.componentDidMount();
}
render() {
return super.render();
}
};
}
const HocComponent = HOC(Example);
ReactDom.render(<HocComponent age={24} />, document.getElementById("root"));
// HOC did mount
// wrappedComponent did mount由上面可以看到,HOC 中定义的生命周期方法可以访问到 WrappedComponent 中的生命周期方法。两者的执行顺序由代码的执行顺序决定。
class Example extends React.PureComponent {
constructor(props) {
super(props);
}
render() {
const { age } = this.props;
return <input />;
}
}
function HOC(WrapperComponent) {
return class Inheritance extends WrapperComponent {
render() {
const elementsTree = super.render();
let newProps = {};
if (elementsTree && elementsTree.type === "input") {
newProps = { defaultValue: "the initialValue of input" };
}
const props = Object.assign({}, elementsTree.props, newProps);
const newElementsTree = React.cloneElement(
elementsTree,
props,
elementsTree.props.children
);
return newElementsTree;
}
};
}
const HocComponent = HOC(Example);
ReactDom.render(<HocComponent age={24} />, document.getElementById("root"));运行如上代码,就可以得到一个默认值为 the initialValue of input 的 input 标签。因为 HOC 在 render 之前获取了 WrappedComponent 的 Dom 结构,从而可以自定义一些自己的东西,然后再执行本身的渲染操作。
HOC 的功能虽然很强大,但是在使用过程中还是需要注意,React 官方给出了一些注意事项,在此不赘述~
附上具体示例代码地址
mixin 和 HOC 都能解决代码复用的问题,但是 mixin 存在如下缺点:
除了上面的显著缺点外,还有一些其他的,详见 Mixins Considered Harmful
而且 HOC 更接近于函数式编程的**,在使用上也更加灵活,包括的功能点也更多。一张图可以很形象地表达出两者的区别:
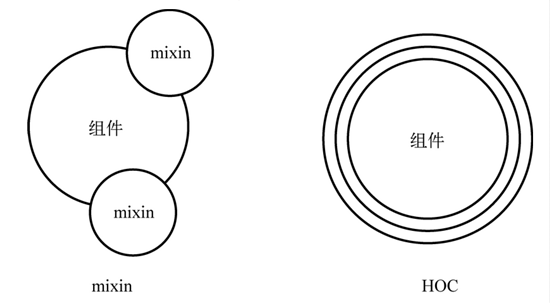
虽然在 React 实践中,选择实现的方式有很多种,但是为了考虑可维护性和扩展性,还是推荐使用 HOC 的方式。目前暂无很深刻的实践经验,这篇只是纯理论知识+一些简单的 demo,后续会持续踩坑~
最近在研究experss,在造过一个简单的轮子之后,想通过研究一下它的源码来了解一下内部的实现原理,如有不对的地方希望得到大家的指正。
研究的express版本为4.15.0,应该算是比较新的版本了。
- lib/
- middleware/
- init.js
- query.js
- router/
- index.js
- layer.js
- route.js
- application.js
- express.js
- request.js
- response.js
- utils.js
- view.js
- index.js上图中的目录结构比较清晰,router目录中主要是router路由的功能,middleware目录是中间件的一些功能。比较重要的是express.js和application.js还有router文件夹中的文件。express.js中很简单,只是暴露了一个工厂函数createApplication,这个函数虽然简洁,但是却完成了生成一个完成app的整个过程,具体代码如下:
function createApplication() {
var app = function(req, res, next) {
app.handle(req, res, next);
};
...
return app;
}在application.js中,可以看到app.listen的实现:
app.listen = function(){
var server = http.createServer(this);
return server.listen.apply(server, arguments);
};由此就可以知道使用express实例化一个项目,其实和使用原生node创建一个应用的步骤差不多,只是express进行了一层封装而已。
application.js这个文件主要是暴露了express内部的一些api,比如app.render(),app.param(),app.set()等。
express的router中总共包含了三个文件,index.js,route.js和layer.js,并且分别定义了router,route,layer三个构造函数,其中router和route这两个对象都包含stack这个成员属性,也就是中间件数组。并且router和route里面的stack也不一样,如下图:
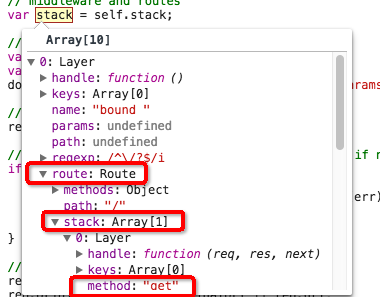
如上图可见,router中的stack数组是由route对象组成的,而route中的stack则是由layer数组组成的。三者关系可以描述成下图:
route对象代表的是路由对象,每一条路由都会实例化一个route对象,而router则是一个路由集合,在上一篇中曾提到router是一个“微型应用程序”,这说明router和route之间的关系是一个包含与被包含的关系,前者的功能更强大,后者只是处理单条路由的一些功能。
路由的整个功能和逻辑顺序大概如下:
在触发一个路由的时候,比如访问/login时,会执行router的成员函数handle(),在这个函数中会将传进来的req的url做一些处理,比如获取url里面的参数,并会遍历stack数组中的每一个layer,遍历主要是通过next()实现的,这个next()主要是非路由中间件的next()函数,具体代码如下:
function next(err) {
....//省略了一些代码
// find next matching layer
var layer;
var match;
var route;
while (match !== true && idx < stack.length) {
layer = stack[idx++];
match = matchLayer(layer, path);
route = layer.route;
if (typeof match !== 'boolean') {
// hold on to layerError
layerError = layerError || match;
}
if (match !== true) {
continue;
}
if (!route) {
// process non-route handlers normally
continue;
}
....//省略一些源码
}
// no match
if (match !== true) {
return done(layerError);
}
// store route for dispatch on change
if (route) {
req.route = route;
}
.....
// this should be done for the layer
self.process_params(layer, paramcalled, req, res, function (err) {
if (err) {
return next(layerError || err);
}
if (route) {
return layer.handle_request(req, res, next);
}
trim_prefix(layer, layerError, layerPath, path);
});
}遍历过程中会执行一个match(),如果匹配成功(断点发现当stack.name=router的时候会匹配成功),则会去执行route中的dispatch方法,则获取当前route的stack数组并通过next()再进行遍历一次。当再次匹配成功之后,就会去调用layer对象的handle_request()方法。也就是调用中间件函数,这个函数的代码如下:
var fn = this.handle;
if (fn.length > 3) {
// not a standard request handler
return next();
}
try {
fn(req, res, next);
} catch (err) {
next(err);
}上面也是执行中间件的主要部分,首先是判断路由函数中传进来的回调函数的参数个数,若大于3,则属于路由中间件,则首先处理next(),这里的next()函数代码如下(定义在route.js文件中:
function next(err) {
if (err && err === 'route') {
return done();
}
var layer = stack[idx++];
if (!layer) {
return done(err);
}
if (layer.method && layer.method !== method) {
return next(err);
}
if (err) {
layer.handle_error(err, req, res, next);
} else {
layer.handle_request(req, res, next);
}
}
};这个next()主要是处理路由中间件的,不断遍历,使得中间件一个个执行。对于路由中间件和非路由中间件,两者也是有区别的,路由中间件的定义是在router/index.js中的route原型方法中,具体代码如下:
proto.route = function route(path) {
var route = new Route(path);
var layer = new Layer(path, {
sensitive: this.caseSensitive,
strict: this.strict,
end: true
}, route.dispatch.bind(route));
layer.route = route; //含有route属性
this.stack.push(layer);
return route;
};从上面代码可以看出,路由中间件中的route不为空值,且为一个route对象,并且该对象中有methods的一个成员属性,用来定义一些路由方法。再来看看非路由中间件的定义方法,放在了router/index.js中的use原型方法中,具体代码如下:
proto.use = function use(fn) {
var offset = 0;
var path = '/';
....//省略部分源码
for (var i = 0; i < callbacks.length; i++) {
var fn = callbacks[i];
var layer = new Layer(path, {
sensitive: this.caseSensitive,
strict: false,
end: false
}, fn);
layer.route = undefined; //其中的route属性为undefined
this.stack.push(layer);
}
return this;
};从上面源码可以看出,非路由中间件中的route属性值为undefined,当使用app.use()时其实也就是触发了router.use()方法。
method源码中并没有直接遍历路由中的每一种方法,比如get,post,put,而是动态添加,不论是最后导出的app示例,还是route中对方法的处理,都是使用的这种方式,具体代码如下:
methods.forEach(function(method){
app[method] = function(path){
if (method === 'get' && arguments.length === 1) {
// app.get(setting)
return this.set(path);
}
this.lazyrouter();
var route = this._router.route(path);
route[method].apply(route, slice.call(arguments, 1));
return this;
};
});在route对象中,同样定义了这样一个处理method的操作:
methods.forEach(function(method){
Route.prototype[method] = function(){
var handles = flatten(slice.call(arguments));
for (var i = 0; i < handles.length; i++) {
var handle = handles[i];
if (typeof handle !== 'function') {
var type = toString.call(handle);
var msg = 'Route.' + method + '() requires callback functions but got a ' + type;
throw new Error(msg);
}
....
var layer = Layer('/', {}, handle);
layer.method = method;
this.methods[method] = true;
this.stack.push(layer);
}
return this;
};
});这种方法比较灵活,不需要将所有的method遍历一遍。
express的源码还是有点复杂的,新手初涉,可能有一些地方理解得不是很到位的,欢迎一起交流
EventEmitter是node中比较核心的模块,除此之外,net.Server、fs.ReadStram、stream也是EventEmitter的实例,可见EventEmitter的核心重要性了
node中的事件模块是发布/订阅的一种模式,这个模块比前端中的大量DOM事件简单一些,不存在事件冒泡,也不存在preventDefault()、stopPropagation() stopImmediatePropagation()这些控制事件传递的方法。它包含了emit,on,once,addListener等方法。具体的用法可以移步官网
node中涉及EventEmitter的代码位于lib/events.js,其中的代码也很简单,主要是构造了一个EventEmitter对象,并且暴露了一些原型方法。源码比较简单,这里只解析一些自己觉得有必要记录的地方。
emit原型方法emit方法中做了一些参数的初始化以及容错处理,核心部分是根据所传参数个数不同而做的不同处理,代码如下: switch (len) {
// fast cases
case 1:
emitNone(handler, isFn, this);
break;
case 2:
emitOne(handler, isFn, this, arguments[1]);
break;
case 3:
emitTwo(handler, isFn, this, arguments[1], arguments[2]);
break;
case 4:
emitThree(handler, isFn, this, arguments[1], arguments[2], arguments[3]);
break;
// slower
default:
args = new Array(len - 1);
for (i = 1; i < len; i++)
args[i - 1] = arguments[i];
emitMany(handler, isFn, this, args);
}代码注释只是说,根据所传不同参数个数有相应的处理,处理起来会使速度变快,但是我个人觉得这种处理方式很傻(闭嘴)。且不论对错,先追踪到emitMany函数看看(emitNone,emitOne,emitTwo,emitThree都长得一样):
function emitMany(handler, isFn, self, args) {
if (isFn)
handler.apply(self, args);
else {
var len = handler.length;
var listeners = arrayClone(handler, len);
for (var i = 0; i < len; ++i)
listeners[i].apply(self, args);
}
}这个函数是触发on函数中对不同事件类型定义的回调函数,并将emit中传入的参数传入回调函数。这里有一个逻辑分支,就是当listener是函数类型的话,则直接执行,也就是对应下面的简单情形:
const EventEmitter = require('events');
let emitter = new EventEmitter();
emitter.on('test',function(){
console.log('aaaa');
});
emitter.emit('test');第二个分支刚开始一直想不到是什么情形下触发的,因为在定义on,也就是为事件类型定义监听事件的时候,传入的listener必须是函数类型的,也就是必然会符合isFn为true从而执行第一种逻辑分支。但是当同事对一种事件类型声明多个监听事件时,此时的isFn就是false,这种情形代码如下:
const EventEmitter = require('events');
let emitter = new EventEmitter();
emitter.on('test', () => {
console.log(1111);
})
emitter.on('test', function test(){
console.log(2222);
})
emitter.emit('test');此时的handler如下:

源码中有一行代码比较关键:
var listeners = arrayClone(handler, len);之所以将handle进行拷贝并且执行,主要是为了防止在触发监听器的时候,原始注册的监听器发生了修改,如下面的情形:
const EventEmitter = require('events');
let emitter = new EventEmitter();
function fun1(){
emitter.removeListener('test',fun2);
}
function fun2(){
console.log('uuuu');
}
emitter.on('test',fun1);
emitter.on('test',fun2);
emitter.emit('test');执行上面这段代码的时候,并不会因为提前删除了fun2而报错。
对于这篇博文里面提到的arrayClone的作用不太认同,里面提出的示例是:
let emitter = new eventEmitter;
emitter.on('message1', function test () {
// some codes here
// ...
emitter.on('message1', test}
});
emitter.emit('message1');这段代码根本不会执行到arrayClone中去。(在这一块纠结了好久,断点调试发现根本不符合执行条件)
on和addListener这两个函数是相同的,用于添加新的监听器。两者都是直接调用的_addListener,源码如下:
function _addListener(target, type, listener, prepend) {
var m;
var events;
var existing;
if (typeof listener !== 'function')
throw new TypeError('"listener" argument must be a function');
events = target._events;
if (!events) {
//先判断EventEmitter对象是否存在_events成员函数
events = target._events = Object.create(null);
target._eventsCount = 0;
} else {
if (events.newListener) {
target.emit('newListener', type,
listener.listener ? listener.listener : listener);
events = target._events;
}
existing = events[type];
}
if (!existing) {
// Optimize the case of one listener. Don't need the extra array object.
existing = events[type] = listener;
++target._eventsCount;
} else {
if (typeof existing === 'function') {
// Adding the second element, need to change to array.
existing = events[type] =
prepend ? [listener, existing] : [existing, listener];
// If we've already got an array, just append.
} else if (prepend) {
existing.unshift(listener);
} else {
existing.push(listener);
}
// Check for listener leak
if (!existing.warned) {
m = $getMaxListeners(target);
if (m && m > 0 && existing.length > m) {
existing.warned = true;
const w = new Error('Possible EventEmitter memory leak detected. ' +
`${existing.length} ${String(type)} listeners ` +
'added. Use emitter.setMaxListeners() to ' +
'increase limit');
w.name = 'MaxListenersExceededWarning';
w.emitter = target;
w.type = type;
w.count = existing.length;
process.emitWarning(w);
}
}
}
return target;
}这个函数代码比较简单,在每次添加监听器的时候,都触发newListener,所以如果需要在某个事件类型之前执行一些东西,例如:
const EventEmitter = require('events');
let emitter = new EventEmitter();
emitter.on('newListener', (event, listener) => {
if (event === 'test') {
console.log('before test');
}
});
emitter.on('test', () => {
console.log('test!');
});
emitter.emit('test');打印出来的就是:
before test
test!除此之外,就是对maxListener的一个限定的判断,比较简单,在此不赘述。
once用来限制事件监听器只被执行一次,其源码如下:
EventEmitter.prototype.once = function once(type, listener) {
if (typeof listener !== 'function')
throw new TypeError('"listener" argument must be a function');
this.on(type, _onceWrap(this, type, listener));
return this;
};通过代码可以看出once调用的on方法,并把_onceWrap作为listener传过去,最后执行的是onceWrapper。源码如下:
function onceWrapper() {
if (!this.fired) {
this.target.removeListener(this.type, this.wrapFn);
this.fired = true;
switch (arguments.length) {
case 0:
return this.listener.call(this.target);
case 1:
return this.listener.call(this.target, arguments[0]);
case 2:
return this.listener.call(this.target, arguments[0], arguments[1]);
case 3:
return this.listener.call(this.target, arguments[0], arguments[1],
arguments[2]);
default:
const args = new Array(arguments.length);
for (var i = 0; i < args.length; ++i)
args[i] = arguments[i];
this.listener.apply(this.target, args);
}
}
}这个函数和emit的核心部分是一样的,只是设置了一个fired字段来标记是否是第一次执行,如果是,则对当前事件进行移除并设置fired为true。
Eventemitter 的 emit 是同步的这是为了保证正确的事件排序以及避免资源抢夺和逻辑错误。
执行下面这段代码就可以看出来:
const EventEmitter = require('events');
let emitter = new EventEmitter();
emitter.on('test',function(){
console.log(222);
});
console.log(111)
emitter.emit('test');
console.log(333)打印的分别是:111 222 333
同时也可以通过使用setImmediate()或者process.nextTick()方法来实现异步。例如:
const EventEmitter = require('events');
let emitter = new EventEmitter();
emitter.on('async',function(){
setImmediate(function(){
console.log('执行异步方法');
});
})
emitter.emit('async');如下面代码:
const EventEmitter = require('events');
let emitter = new EventEmitter();
emitter.on('test',function(){
console.log(222);
emitter.emit('test');
});
emitter.emit('test');这个例子会触发死循环调用,不断打印出222。因为在监听回调里面不断执行了emit进行事件的触发,导致不断循环调用。
但是下面这段代码就不会死循环:
const EventEmitter = require('events');
let emitter = new EventEmitter();
emitter.on('test',function test(){
console.log(222);
emitter.on('test',test)
});
emitter.emit('test');因为在emit触发事件回调的时候,此时执行 emitter.on('test',test)这行代码的时候,只是在当前的test这个事件类型中多加了一个事件监听器而已,通过打印test的监听器数量时:
emitter.listenerCount('test')会打印出2
fs模块继承了eventEmitter模块,具体调用方式如下:
function FSWatcher(){
EventEmitter.call(this);
}
util.inherits(FSWatcher, EventEmitter);调用比较简单
node中的event模块的源码比较简单,但是一些实现的细节还是值得去深究的,会有很多借鉴的地方所谓双向绑定,是指:用户在视图(View)层触发更改时能让数据模型(Model)检测到其更新并发生变化,同时数据模型(Model)层对数据的改变也能实时更新到视图层。也就是 MVVM 的核心概念,MVVM 的示意图如下:

实现双向绑定有如下几种方式:
这种方式是通过使用 get 和 set 的方式获取数据然后更新数据,其原理就是监听页面中某个具体元素的事件,然后将其最新的值手动 set 到 数据中,同时订阅 model 层的改变,然后触发页面的渲染更新,具体详见这里,具体的示意图如下所示:
这种方式虽然实现了双向绑定的功能,但是不能通过设置 model: vm.data = 'value' 的形式修改数据, 进而更新视图,存在一定的劣势。
赃检查的主要原理是在将数据绑定到 View 的时候,就在监听器列表(scope 作用域中的监听队列 watchList) 中插入一条监听器,当触发 UI 事件或者 Ajax 请求时,就会触发脏检查($digest cycle), 在 $digest 流程中,将遍历每个数据变量的 watcher,比较它的新旧值。当新旧值不同时,触发 listener 函数,执行相关的更新逻辑。这个过程将会一直重复,直到所有数据指令的新旧值都相同为止。具体详见 这里,脏检查的原理示意图如下所示:
脏检查虽然可以达到实现双向绑定,但是当页面中绑定的 watcher 过多时,就会引发性能问题。所以 angular 在进行 $digest 检测时,会限制循环检查的次数最少2次,最多10次,防止无效的检查。
这种方式是利用 ES5 的 Object.defineProperty() 来劫持数据属性的 getter 和 setter, 在数据变动时触发订阅者,从而触发相应的监听回调。vue 也是使用的这种思路实现的双向绑定,下面来详细讲述一下这种方法的原理和实现。
先上一张图:
如上图所示:数据劫持主要实现了如下几个功能:
下面分别从上图中涉及到的一些类来从代码层面介绍一下其实现细节:
一般在 html 中,会实例化 MVVM 类,从而传递一些参数,如下所示:
<script>
let vm = new MVVM({
el: '#app',
data: {
message: { a: { b: 'hello world' } },
className: 'btn',
more: 'mvvm',
htmlStr: '<span style="color: #f00;">red</span>',
},
method: {
clickBtn: function (e) {
let strArr = ['one', 'two', 'three'];
this.message.a.b = strArr[parseInt(Math.random() * 3)]
}
}
})
</script>这里面只是向 MVVM 传递了一些参数,包括 el(页面对应的元素),data( 修改的数据),method(要传递的方法),下面是 MVVM 的定义:
function MVVM(options) {
this.$el = options.el; //页面对应的元素
this.$data = options.data; //传入的数据
this.$method = options.method; //传入的方法
if (this.$el) {
//对所有数据进行劫持
new Observer(this.$data);
//将数据直接代理到实例中,无需通过vm.$data来操作
this.proxyData(this.$data);
new Compile(this.$el, this);
}
}
MVVM.prototype = {
proxyData: function(data) { //方法代理
Object.keys(data).forEach(key => {
Object.defineProperty(this, key, {
get() {
return data[key];
},
set(newValue) {
data[key] = newValue;
}
});
});
}
};如代码所示,MVVM 的构造函数中只是执行了 Observer 类的实例化和 Compile 类的实例化,并且执行了原型方法中的 proxyData,该方法主要是做了一层数据的代理,也就是可以直接通过设置 vm.message.a.b 的形式进行 get 和 set 操作,相当于对 vm.$data.message.a.b 进行相应的操作。
Compile 主要是做了编译指令的工作,指令类型包括 v-html、v-class、v-model、v-on:click、{{}} 的多种形式。
function Compile(el, vm) {
this.el = this.isElementNode(el) ? el : document.querySelector(el);
this.vm = vm;
if (this.el) {
//将真实DOM移入内存 fragment 中
let fragment = this.node2Fragment(this.el);
this.compile(fragment);
//将编译后的 fragment 再次转化为 DOM 塞回到页面中
this.el.appendChild(fragment);
}
}Compile 的构造函数中主要做了如下工作:
//将 DOM 转化为 fragment
node2Fragment: function(el) {
let fragment = document.createDocumentFragment();
//每次获取DOM节点树中的第一个元素并移除,直到移除完毕为止
while (el.firstChild) {
fragment.appendChild(el.firstChild);
}
//返回一个文档碎片容器,存储DOM树的所有节点
return fragment;
}, compile: function(fragment) {
let childNodes = fragment.childNodes;
Array.from(childNodes).forEach(node => {
//是否是元素节点
if (this.isElementNode(node)) {
this.compileElement(node);
this.compile(node); //递归编译
} else {
//是否是文本节点
this.compileText(node);
}
});
},
//编译节点元素
compileElement: function(node) {
// 带v-model v-text
let attrs = node.attributes; // 取出当前节点的属性
Array.from(attrs).forEach(attr => {
let attrName = attr.name;
if (this.isDirective(attrName)) {
// 取到指令对应的值放到节点中
let expr = attr.value;
const attrArr = attrName.split('-');
//说明此时不是 v-model 的这种形式,而是 v-model-v-model
if (attrArr.length !== 2) {
return;
}
let type = attrArr[1]; //获取指令是哪种类型,比如v-model,v-text
//如果是事件指令
if (this.isEventDirective(type)) {
CompileUtil.eventHandler(node, this.vm, expr, type);
} else {
// 调用对应的编译方法 编译哪个节点,用数据替换掉表达式
CompileUtil[type](node, this.vm, expr);
}
}
});
},
//编译文本元素
compileText: function(node) {
let expr = node.textContent; // 取文本中的内容 todo:和 innerHTML 的区别
let reg = /\{\{([^}]+)\}\}/g; // 不能直接检测 {{}} 这种情况,还要考虑这种情况 {{a}} {{b}} {{c}}
if (reg.test(expr)) {
// 调用编译文本的方法 编译哪个节点,用数据替换掉表达式
CompileUtil['text'](node, this.vm, expr);
}
}
//指令处理集合
var CompileUtil = {
//model指令处理
model: function(node, vm, expr) {
let updateFn = Updater['modelUpdater'];
//实例化 Watcher
new Watcher(vm, expr, newValue => {
updateFn && updateFn(node, newValue);
});
//监听输入框的input事件,并将值回填到数据中
node.addEventListener('input', e => {
let newValue = e.target.value;
this.setVal(vm, expr, newValue);
});
updateFn && updateFn(node, this.getVal(vm, expr));
},
...代码省略
};编译模块主要是针对 v-html、v-class、v-model、v-on:click、{{}} 这几种情况做分别编译处理。这里不详述,注释也写得比较清楚,直接戳文末的代码链接吧。
注:这里在 CompileUtil 里面实例化了一个 Watcher,主要是添加事件监听的绑定,这里之后再讲。
这个类主要是劫持数据所有属性的 setter 和 getter 方法,具体代码如下:
function Observer(data) {
this.data = data;
this.observe(this.data);
}
Observer.prototype = {
observe: function(data) {
if (!data || typeof data !== 'object') return;
//为每一个属性设置数据监听
Object.keys(data).forEach(key => {
this.defineReactive(data, key, data[key]);
this.observe(data[key]); //深度递归劫持属性
});
},
/**
* @param {data} 要监听的数据对象
* @param {key} 要监听的对象属性key值
* @param {value} 要监听的对象属性值
*/
defineReactive: function(data, key, value) {
let dep = new Dep();
let self = this;
//如果是该属性值是对象类型,则遍历
Object.defineProperty(data, key, {
enumerable: true,
configurable: false,
get: () => {
//由于需要在闭包内添加watcher,所有需要 Dep 定义一个全局 target 属性,暂存 watcher ,添加完移除
if (Dep.target) {
//如果为true,则说明是实例化 watcher 引起的,所以需要添加进消息订阅器中
dep.depend();
}
return value;
},
set: newVal => {
if (newVal === value) return;
value = newVal;
//对新值进行监听
self.observe(newVal);
//通知所有订阅者
dep.notify();
}
});
}
};这里面在 Observer 的构造函数里面就执行了 observe 的遍历方法,遍历传进数据的所有属性,然后使用 ES5 的 defineProperty() 进行劫持。重点关注 get 和 set 的方法,有一个 Dep 的概念,我们先来看看 Dep 都干了啥
Dep 的作用是一个存储 watcher 的容器,代码如下:
let uid = 0;
//订阅类
function Dep() {
this.id = uid++;
this.subs = [];
}
Dep.prototype = {
addSub: function(sub) {
if (this.subs.indexOf(sub) === -1) {
//避免重复添加
this.subs.push(sub);
}
},
removeSub: function(sub) {
const index = this.subs.indexOf(sub);
if (index > -1) {
this.subs.splice(index, 1);
}
},
depend: function() {
Dep.target.addDep(this); //执行 watcher 的 addDep 方法
},
notify: function() {
this.subs.forEach(sub => {
sub.update(); //执行 watcher 的 update 方法
});
}
};
//Dep 类的全局属性 target,是一个 Watch 实例
Dep.target = null;里面有一些对数组的添加、删除和通知的方法,比较简单,不详述。这里面的 Dep.target 是用来存储当前操作的 Watcher 的,是一个全局变量。
Watcher 作为 Compile 和 Observer 的桥梁,是用来监听数据层的变化,并触发页面更新的开关。代码如下:
function Watcher(vm, expr, cb) {
this.depIds = {}; //存储deps订阅的依赖
this.vm = vm; //component 实例
this.cb = cb; //更新数据时的回调函数
this.expr = expr; //表达式还是function
this.value = this.get(vm, expr); //在实例化的时候获取老值
}
Watcher.prototype = {
//暴露给 Dep 类的方法,用于在订阅的数据更新时触发
update: function() {
const newValue = this.get(this.vm, this.expr); //获取到的新值
const oldValue = this.value; //获取到的旧值
if (newValue !== oldValue) {
//判断新旧值是否相等,不相等就执行回调
this.value = newValue;
this.cb(newValue);
}
},
addDep: function(dep) {
//检查depIds对象是否存在某个实例,避免去查找原型链上的属性
if (!this.depIds.hasOwnProperty(dep.id)) {
dep.addSub(this); //在 dep 存储 watcher 监听器
this.depIds[dep.id] = dep; //在 watcher 存储订阅者 dep
}
},
//获取data中的值,可能出现 hello.a.b的情况
getVal: function(vm, expr) {
expr = expr.split('.');
return expr.reduce((prev, next) => {
return prev[next];
}, vm.$data);
},
//获取值
get: function(vm, expr) {
Dep.target = this;
const val = this.getVal(vm, expr);
Dep.target = null;
return val;
}
};原型中主要是定义了一些方法,比较简单,这里也不详述。
现在我们要串一下这些类是怎么关联起来的了。流程如下:
当数据改变时,页面如何改变的,也来串一下整体流程:
当页面改变时,数据是如何改变的呢:
//model指令处理
model: function(node, vm, expr) {
let updateFn = Updater['modelUpdater'];
new Watcher(vm, expr, newValue => {
updateFn && updateFn(node, newValue);
});
//监听输入框的input事件,并将值回填到数据中
node.addEventListener('input', e => {
let newValue = e.target.value;
this.setVal(vm, expr, newValue);
});
updateFn && updateFn(node, this.getVal(vm, expr));
},
//设置值
setVal: function(vm, expr, value) {
expr = expr.split('.');
//将新值回填到数据中,并且回填到最后一个值,如:hello.a.b,就需要把值回填到b中
return expr.reduce((prev, next, index) => {
if (index === expr.length - 1) {
return (prev[next] = value);
}
return prev[next];
}, vm.$data);
}这段代码是在 Compile 中,对页面元素进行事件监听,从而触发 Model 层的数据更新。
至此整个流程串起来了,一气呵成!
但是上面的处理还是没有考虑到当 data 是 数组的情况,所以还不是很完善,需要进一步加强,以上功能所有源码地址
最近接触到关于异步处理的一些业务,发现对异步的解决方案的用法还不是很熟悉,借此机会巩固一下关于
Promise的用法,文章中的示例代码地址
对于PromiseA+规范的一些讲解,这里不会涉及,如果对Promise原理性的东西还不太了解的,可以直接移步这里
Promise众所周知,js中最原始的异步解决方案就是回调函数,但是回调函数引发的问题就是臭名昭著的callback hells,关于异步的演化可以移步我之前比较早的这篇介绍,这里不再赘述。
Promise是一种异步解决方案,它有resolve和reject两个回调参数,resolve是Promise从pending状态变为fulfilled状态后触发的回调函数。而reject则是状态从pending状态变为rejected后触发的。 而且一个Promise对象的状态只能从pending->fulfilled或者从pending->reject,不可能同时达到两种状态,例如:
let promise = function () {
return new Promise((resolve, reject) => {
resolve(1);
throw new Error('err');
})
}
promise().then((res) => {
console.log(res);
}).catch((err) => {
console.log(err);
})
//打印 1,而不会打印出 Error:err上面的例子,之后打印出1而不会捕捉到抛出的异常,也就是在执行resolve(1)的时候,Promise的状态已经从pending状态变为fulfilled的了,所以此时抛出异常也不会再将状态变为rejected。
Promise的then()then是Promise类原型对象的一个方法,它主要是为Promise对象实例添加状态改变时的回调函数,其函数声明为:then(resolve,reject),resolve参数是状态变为fulfilled时的回调函数,reject参数是状态变为rejected时的回调函数,而且第二个参数reject是可选参数。查看例子。当数字大于3的时候就会被进入reject,否则就会进入resolve的回调。
但是当Promise的状态一直是pending的时候,就会无法进入到then的任何一个回调中.例如:
let promise = function () {
return new Promise((resolve, reject) => {
console.log('I am pending');
})
}
promise().then((res) => {
console.log('resolve', res);
}, (err) => {
console.log('reject', err);
})上面的例子,由于Promise实例没有从pending进入到任何一个结果状态,所以也就不会执行then里面的任何一个回调。
当fulfilled的回调中不返回任何值时,在then的第一个回调函数中就会得到一个undefined
例如:
let promise = new Promise((resolve, reject) => {
resolve('promise')
})
promise.then(function () {
//dosomething
}).then((res) => {
console.log(res)
})
//undefinedPromise里面的catch()catch用于指定发生错误时的回调函数,它是then(null, rejection)的别名,也就是:
promise.then((res) => { console.log('resolve', res) })
.catch((err) => { console.log('reject', err) });
//等同于,其中promise是一个Promise实例
promise.then((res) => { console.log('resolve', res) })
.then(null, (err) => { console.log('reject', err) });Promise的错误具有冒泡机制,也就是前面产生的错误,可以一直向后传递,直到被catch捕获为止。要是最外层没有catch用来捕获错误,错误就会冒泡到最外层,然后就会触发unhandledRejection事件。除此之外,catch方法返回的仍旧是一个promise实例,所以后面可以继续接catch()或者then(),详见示例代码
Promise.all()Promise.all方法接受一个数组作为参数,数组中的值如果不是Promise对象,就会先调用下面讲到的Promise.resolve方法,将参数转为Promise实例。Promise.all()是将多个Promise对象包装成一个Promise实例。例如:
let promise1 = new Promise((resolve, reject) => {
resolve('promise1');
})
let promise2 = new Promise((resolve, reject) => {
resolve('promise2');
})
Promise.all([promise1, promise2]).then((res) => {
console.log('promise-all', res)
}).catch((err) => {
console.log('err', err);
})
//promise-all ['promise1','promise2'];对于Promise.all()返回的Promise对象的状态,是一种与门的返回结果,也就是只有promise1和promise2都是fulfilled,Promise.all()才会变成fulfilled状态,只要有一个是rejected,那么它最终的状态也将是rejected状态。
Promise.race()和Promise.all()类似,Promise.race()也是接受一个数组作为参数,并且如果数组中的值类型不是Promise对象,仍然会先调用Promise.resolve()将数组中的值转为一个Promise实例。
和Promise.all()不同的是,Promise.race()是看谁执行得快,它的最终状态也是随着最先一个实例的状态的改变而改变:
let promise1 = new Promise((resolve, reject) => {
resolve('promise1');
})
let promise2 = new Promise((resolve, reject) => {
resolve('promise2');
})
Promise.race([promise1, promise2]).then((res) => {
console.log('promise-race', res);
}).catch((err) => {
console.log('err', err);
})
// promise-race promise1Promise的值穿透值穿透的场景有以下两种:
Promise实例的状态已经是fulfilled或者rejected的时候,通过then会返回thisthen的代码如下:Promise.prototype.then = function (onFulfilled, onRejected) {
if (!isFunction(onFulfilled) && this.state === FULFILLED ||
!isFunction(onRejected) && this.state === REJECTED) {
return this;
}
...
};实例讲解:
const func1 = function () {
return new Promise((resolve, reject) => {
resolve('promise1');
})
}
const func2 = function () {
return new Promise((resolve, reject) => {
resolve('promise2');
})
}
func1().then(func2()).then((res) => {
console.log(res)
})
//promise1在第一个then中由于传入了一个promise类型(非Function),所以func2()的Promise不会传递到后面,而此时promise的状态已经是fulfilled了,从而打印出func1()中的resolve的值,
当改成如下这样就可以了:
const func1 = function () {
return new Promise((resolve, reject) => {
resolve('promise1');
})
}
const func2 = function () {
return new Promise((resolve, reject) => {
resolve('promise2');
})
}
func1().then(func2).then((res) => {
console.log(res)
})Promise衍生出的子Promise,并且当子Promise实例状态为pending时,子Promise的状态由父Promise设定:let promise1 = new Promise((resolve, reject) => {
resolve('promise1');
})
let promise2 = promise1.then();
promise2.then((res) => {
console.log(res)
})
//promise1这种情况其实是上面情况的一种变种,不解释。
总结:.then 或者 .catch 的参数期望是函数,传入非函数则会发生值穿透。
Promise实践这种场景类似于:taskB要依靠taskA的数据去请求,taskC又要依靠taskB返回的数据来请求数据,这种是典型的关联串行的模式,但是又是可知长度的,这种可以直接采取下面这种模式:
taskA().then((res1) => {
return taskB(res1)
}).then((res2) => {
return taskC(res2)
}).then((res3) => {
console.log(res3);
})
其中`taskA,taskB,taskC`的结构都是类似如下:
let taskA = new Promise((resolve, reject) => {
rp(urlA).then((res) => {
resolve(res)
})
})在这种情况下,在then()中都需要返回一个Promise实例,否则会出现掉链
场景示例:在请求某个接口数据时,需要分页去请求,传递offset值和count值去请求,每次请求返回的结果是数据以及nextOffset,这种情况下,就是判断最终这个nextOffset是否为-1来终止循环次数,从而形成了一种有关联的但是是未知长度的串行请求。
function eachTask(offset) {
let option = {
url: 'yourUrl',
offset: offset,
count: 30
}
return new Promise((resolve, reject) => {
rp(option).then(function (res) {
resolve(res);
})
})
}
let list = [];
const allTask = (offset = 0) => eachTask(offset).then(res => {
res && (list = list.concat(res.data));
if (res.nextOffset && res.nextOffset != -1) {
return eachTask(res.nextOffset);
} else {
return Promise.resolve(list);
}
})
allTask(0).then(res => {
console.log(res)
}).catch((err) => {
console.log('err', err);
})使用Promise实现并行请求,需要使用到Promsie.all(),处理方式类似于下面这种:
getPromiseArr()
.then((arr) => {
return Promise.all(arr);
})
.then((res) => {
console.log(res);
}).catch((err) => {
console.log('err', err);
})其中getPromiseArr()可以返回一个Promise类型的数组。
基于对Promise用法不太熟悉的基础上,整理出以上内容,有觉得不太正确的地方的可以一起交流~
上文中的示例代码地址

本来最近时间都被一些琐事给分散了,根本也没有什么心思去看什么文学作品。然后不禁感叹:一旦走上了程序员道道路,就离文艺越来越远了。通嫂给我介绍这本书是在刚刚从家里返回学校的时候,刚收到他给我买的棉手套,离家的丝丝愁绪加上远方好友带来的感动,看看书名觉得确实也符合现在的心境,再加上他说是很扣人心弦,而且篇幅不是很长,于是就决定看看吧。
然而一看之后,就伤感了,躲在毛概课的角落里,一边默默流泪,一边看完了。整篇小说都是围绕着福贵这个主人公来展开的,描述了福贵的一生,但是却经历了**最动荡的时期:
大地主时期->大锅饭->**
感觉又重温了那段黑暗的历史。文章开头很是巧妙,通过一个虚拟的“我”引发偶遇福贵的遭遇,然后再通过倒叙和间接插叙来完成了接下来的叙述。开头起始我是不看好的,写的是福贵在少爷时期的各种令人发指的恶习。都是朴实的语言,像记流水账一样,和电视里演的那种败家子的段子是一样一样的,感觉也没有什么新意,但是越到后面,就越发赞叹:确实,作者的语言功底不是盖的
一家人,福贵,妻子家珍,母亲,儿子有庆,女儿凤霞,女婿二喜,外甥苦根。无论是基于什么样的原因,最后所有人都死了,只留下福贵和一头老牛,结局是凄惨的,福贵的一生充满了曲折。从浪子回头到多灾多难,每一段时期都是浸泡在苦水中。家珍,代表着的则是古代最传统和贤淑的**女性,在她的内心里蕴藏着最为广博而宽广的爱和坚韧,我被她的耐心,宽容之心所打动。有好几次我都感动得眼角湿润,比如在得知了儿子有庆死讯之后夫妇两个在儿子坟前失声痛哭的情景,女儿凤霞因生儿而死的场景,一幕幕,满眼的悲凉,无尽的凄苦,我不知道一个人的忍耐苦难的极致是什么,但是我确实为他们那种坚韧的品格给震撼了,我只想说,相比于他们,我们人生路上遇到的那些事都不算是事。
然而这就是福贵的一生,我常常在想,人生是什么,应该怎样度过自己的人生才算是真正的人生,我一直都难以找到属于自己的答案,从福贵的一生中,我感悟到:人的一生,因时事不同而异,他的一生是艰苦的,曲折的,有过浪荡,有过错误,有过荣耀,有过辱骂,但是在岁月的长河中,这些所有一切的一切都显得那么微不足道,当看到福贵被抓去打仗时看到几千号伤员在一夜之间全死了的时候,我感叹,人相之于宇宙,是那么微小和卑微,但是不论怎样,处于什么样的逆境,可以活着就是最大的幸福。在看到“福贵和家珍对害死自己儿子有庆的春生一遍又一遍地嘱托:“要好好活着”的时候,我哭了,不管怎样,活着是最幸福的。
因为只有活着,才可以创造其他奇迹,我庆幸,我活着。
egg
egg是阿里开源的一个框架,为企业级框架和应用而生,相较于express和koa,有更加严格的目录结构和规范,使得团队可以在基于egg定制化自己的需求或者根据egg封装出适合自己团队业务的更上层框架
egg所处的定位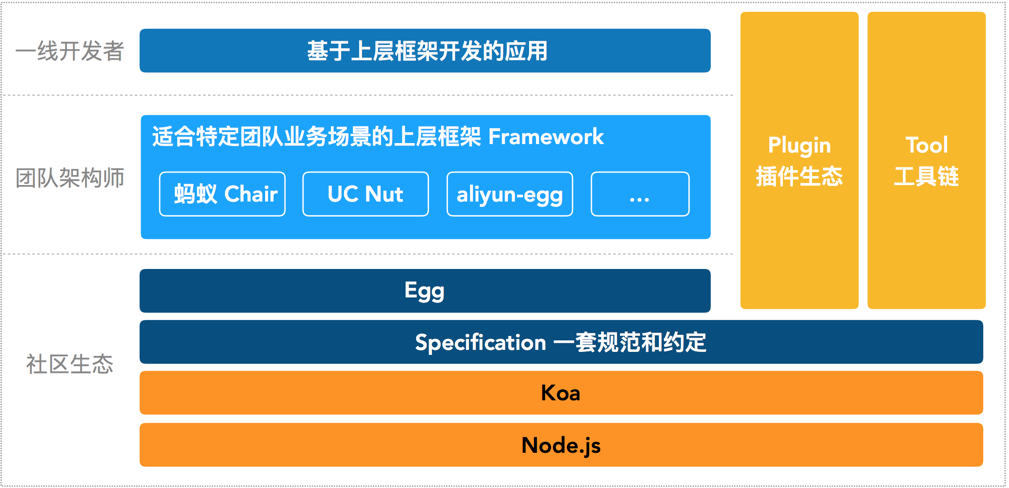
可以看到egg处于的是一个中间层的角色,基于koa,不同于koa以middleware为主要生态,egg根据不同的业务需求和场景,加入了plugin,extends等这些功能,可以让开发者摆脱在使用middleware功能时无法控制使用顺序的被动状态,而且还可以增加一些请求无关的一些功能。除此之外,egg还有很多其他优秀的功能,在这里不详述。想了解更多可以移步这里
egg有直接生成整个项目的脚手架功能,只需要执行如下几条命令,就可以生成一个新的项目:
$ npm i egg-init -g
$ egg-init helloworld --type=simple
$ cd egg-helloworld
$ npm i启动项目:
$ npm run dev
$ open localhost:7001egg是如何运行起来的下面通过追踪源码来讲解一下egg究竟是如何运行起来的:
查看egg-init脚手架生成的项目文件,可以看到整个项目文件是没有严格意义上的入口文件的,根据package.json中的script命令,可以看到执行的直接是egg-bin dev的命令。找到egg-bin文件夹中的dev.js,会看到里面会去执行start-cluster文件:
//dev.js构造函数中
this.serverBin = path.join(__dirname, '../start-cluster');
// run成员函数
* run(context) {
//省略
yield this.helper.forkNode(this.serverBin, devArgs, options);
}移步到start-cluster.js文件,可以看到关键的一行代码:
require(options.framework).startCluster(options);其中options.framework打印信息为:
/Users/wyf/Project/egg-example/node_modules/egg
找到对应的egg目录中的index.js文件:
exports.startCluster = require('egg-cluster').startCluster;继续追踪可以看到最后运行的其实就是egg-cluster中的startCluster,并且会fork出agentWorker和appWorks,官方文档对于不同进程的fork顺序以及不同进程之间的IPC有比较清晰的说明,
主要的顺序如下:
通过代码逻辑也可以看出它的顺序:
//在egg-ready状态的时候就会执行进程之间的通信
this.ready(() => {
//省略代码
const action = 'egg-ready';
this.messenger.send({ action, to: 'parent' });
this.messenger.send({ action, to: 'app', data: this.options });
this.messenger.send({ action, to: 'agent', data: this.options });
});
this.on('agent-exit', this.onAgentExit.bind(this));
this.on('agent-start', this.onAgentStart.bind(this));
this.on('app-exit', this.onAppExit.bind(this));
this.on('app-start', this.onAppStart.bind(this));
this.on('reload-worker', this.onReload.bind(this));
// fork app workers after agent started
this.once('agent-start', this.forkAppWorkers.bind(this));通过上面的代码可以看出,master进程会去监听当前的状态,比如在检测到agent-start的时候才去fork AppWorkers,在当前状态为egg-ready的时候,会去执行如下的进程之间的通信:
master---> parentmaster ---> agentmaster ---> appfork出了appWorker之后,每一个进程就开始干活了,在app_worker.js文件中,可以看到进程启动了服务,具体代码:
//省略代码
function startServer() {
let server;
if (options.https) {
server = require('https').createServer({
key: fs.readFileSync(options.key),
cert: fs.readFileSync(options.cert),
}, app.callback());
} else {
server = require('http').createServer(app.callback());
}
//省略代码
}然后就回归到koa中的入口文件干的事情了。
除此之外,每一个appWorker还实例化了一个Application:
const Application = require(options.framework).Application;
const app = new Application(options);在实例化application(options)时,就会去执行node_modules->egg模块下面loader目录下面的逻辑,也就是agentWorker进程和多个appWorkers进程要去执行的加载逻辑,具体可以看到app_worker_loader.js文件中的load():
load() {
// app > plugin > core
this.loadApplicationExtend();
this.loadRequestExtend();
this.loadResponseExtend();
this.loadContextExtend();
this.loadHelperExtend();
// app > plugin
this.loadCustomApp();
// app > plugin
this.loadService();
// app > plugin > core
this.loadMiddleware();
// app
this.loadController();
// app
this.loadRouter(); // 依赖 controller
}
}这也是下面要讲的东西了
在真正执行业务代码之前,egg会先去干下面一些事情:
egg中内置了如下一系列插件:
加载插件的逻辑是在egg-core里面的plugin.js文件,先看代码:
loadPlugin() {
//省略代码
//把本地插件,egg内置的插件以及app的框架全部集成到allplugin中
this._extendPlugins(this.allPlugins, eggPlugins);
this._extendPlugins(this.allPlugins, appPlugins);
this._extendPlugins(this.allPlugins, customPlugins);
//省略代码
//遍历操作
for (const name in this.allPlugins) {
const plugin = this.allPlugins[name];
//对插件名称进行一些校验
this.mergePluginConfig(plugin);
//省略代码
}
if (plugin.enable) {
//整合所有开启的插件
enabledPluginNames.push(name);
}
}如上代码(只是贴出了比较关键的地方),这段代码主要是将本地插件、egg中内置的插件以及应用的插件进行了整合。其中this.allPlugins的结果如下:

可以看出,this.allPlugins包含了所有内置的插件以及本地开发者自定义的插件。先获取所有插件的相关信息,然后将所有插件进行遍历,执行this.mergePluginConfig()函数,这个函数主要是对插件名称进行一些校验。之后还对项目中已经开启的插件进行整合。plugin.js文件还做了一些其他事情,比如获取插件路径,读取插件配置等等,这里不一一讲解。
包括插件里面定义的扩展以及开发者自己写的扩展,这也是这里讲的内容。
在对内置对象进行扩展的时候,实质上执行的是extend.js文件,扩展的对象包括如下几个:
通过阅读extend.js文件可以知道,其实最后每个对象的扩展都是直接调用的loadExtends这个函数。拿Application这个内置对象进行举例:
loadExtend(name, proto) {
// All extend files
const filepaths = this.getExtendFilePaths(name);
// if use mm.env and serverEnv is not unittest
const isAddUnittest = 'EGG_MOCK_SERVER_ENV' in process.env && this.serverEnv !== 'unittest';
for (let i = 0, l = filepaths.length; i < l; i++) {
const filepath = filepaths[i];
filepaths.push(filepath + `.${this.serverEnv}.js`);
if (isAddUnittest) filepaths.push(filepath + '.unittest.js');
}
const mergeRecord = new Map();
for (let filepath of filepaths) {
filepath = utils.resolveModule(filepath);
if (!filepath) {
continue;
} else if (filepath.endsWith('/index.js')) {
// TODO: remove support at next version
deprecate(`app/extend/${name}/index.js is deprecated, use app/extend/${name}.js instead`);
}
const ext = utils.loadFile(filepath);
//获取内置对象的原有属性
const properties = Object.getOwnPropertyNames(ext)
.concat(Object.getOwnPropertySymbols(ext));
//对属性进行遍历
for (const property of properties) {
if (mergeRecord.has(property)) {
debug('Property: "%s" already exists in "%s",it will be redefined by "%s"',
property, mergeRecord.get(property), filepath);
}
// Copy descriptor
let descriptor = Object.getOwnPropertyDescriptor(ext, property);
let originalDescriptor = Object.getOwnPropertyDescriptor(proto, property);
if (!originalDescriptor) {
// try to get descriptor from originalPrototypes
const originalProto = originalPrototypes[name];
if (originalProto) {
originalDescriptor = Object.getOwnPropertyDescriptor(originalProto, property);
}
}
//省略代码
//将扩展属性进行合并
Object.defineProperty(proto, property, descriptor);
mergeRecord.set(property, filepath);
}
debug('merge %j to %s from %s', Object.keys(ext), name, filepath);
}
},将filepaths进行打印,如下图:
可以看出,filepaths包含所有的对application扩展的文件路径,这里会首先将所有插件中扩展或者开发者自己自定义的扩展文件的路径获取到,然后进行遍历,并且对内置对象的一些原有属性和扩展属性进行合并,此时对内置对象扩展的一些属性就会添加到内置对象中。所以在执行业务代码的时候,就可以直接通过访问application.属性(或方法)进行调用。
对中间件的加载主要是执行的egg-core中的middleware.js文件,里面的代码**也是和上面加载内置对象是一样的,也是将插件中的中间件和应用中的中间件路径全部获取到,然后进行遍历。
遍历完成之后执行中间件就和koa一样了,调用co进行包裹遍历。
对控制器的加载主要是执行的egg-core中的controller.js文件
egg的官方文档中,插件的开发这一节提到:
插件没有独立的 router 和 controller
所以在加载controller的时候,主要是load应用里面的controller即可。详见代码;
loadController(opt) {
opt = Object.assign({
caseStyle: 'lower',
directory: path.join(this.options.baseDir, 'app/controller'),
initializer: (obj, opt) => {
if (is.function(obj) && !is.generatorFunction(obj) && !is.class(obj)) {
obj = obj(this.app);
}
if (is.promise(obj)) {
const displayPath = path.relative(this.app.baseDir, opt.path);
throw new Error(`${displayPath} cannot be async function`);
}
if (is.class(obj)) {
obj.prototype.pathName = opt.pathName;
obj.prototype.fullPath = opt.path;
return wrapClass(obj);
}
if (is.object(obj)) {
return wrapObject(obj, opt.path);
}
if (is.generatorFunction(obj)) {
return wrapObject({ 'module.exports': obj }, opt.path)['module.exports'];
}
return obj;
},
}, opt);
const controllerBase = opt.directory;
this.loadToApp(controllerBase, 'controller', opt);
this.options.logger.info('[egg:loader] Controller loaded: %s', controllerBase);
},这里主要是针对controller的类型进行判断(是否是Object,class,promise,generator),然后分别进行处理
加载service的逻辑是egg-core中的service.js,service.js这个文件比较简单,代码如下:
loadService(opt) {
// 载入到 app.serviceClasses
opt = Object.assign({
call: true,
caseStyle: 'lower',
fieldClass: 'serviceClasses',
directory: this.getLoadUnits().map(unit => path.join(unit.path, 'app/service')),
}, opt);
const servicePaths = opt.directory;
this.loadToContext(servicePaths, 'service', opt);
},首先也是先获取所有插件和应用中声明的service.js文件目录,然后执行this.loadToContext()
loadToContext()定义在egg-loader.js文件中,继续追踪,可以看到在loadToContext()函数中实例化了ContextLoader并执行了load(),其中ContextLoader继承自FileLoader,而且load()是声明在FileLoader类中的。
通过查看load()代码可以发现里面的逻辑也是将属性添加到上下文(ctx)对象中的。也就是说加载context对象是在加载service的时候完成的。
而且值得一提的是:在每次刷新页面重新加载或者有新的请求的时候,都会去执行context_loader.js里面的逻辑,也就是说ctx上下文对象的内容会随着每次请求而发生改变,而且service对象是挂载在ctx对象下面的,对于service的更新,这里有一段代码:
// define ctx.service
Object.defineProperty(app.context, property, {
get() {
// distinguish property cache,
// cache's lifecycle is the same with this context instance
// e.x. ctx.service1 and ctx.service2 have different cache
if (!this[CLASSLOADER]) {
this[CLASSLOADER] = new Map();
}
const classLoader = this[CLASSLOADER];
//先判断是否有使用
let instance = classLoader.get(property);
if (!instance) {
instance = getInstance(target, this);
classLoader.set(property, instance);
}
return instance;
},
});在更新service的时候,首先会去获取service是否挂载在ctx中,如果没有,则直接返回,否则实例化service,这也就是service模块中的延迟实例化
加载路由的逻辑主要是egg-core中的router.js文件
loadRouter() {
// 加载 router.js
this.loadFile(path.join(this.options.baseDir, 'app/router.js'));
},可以看出很简单,只是加载应用文件下的router.js文件
直接加载配置文件并提供可配置的方法。
对egg应用信息的设置逻辑是对应的egg-core中的egg-loader.js,里面主要是提供一些方法获取整个app的信息,包括appinfo,name,path等,比较简单,这里不一一列出
然后就会去执行如渲染页面等的逻辑
这里只是我个人针对源代码以及断点调试总结的一些东西,如有不同见解或者觉得有哪些错误的地方,可以私聊拍砖。

花两天的时间读完了这本被称作法国最畅销的书。于是乎又找回了那种读书的宁静感觉。已经好久没有读这种充满文艺范的书了,而我,作为一个初中作文文艺范爆棚,甚至于老师给的作文评语上还说“如若一直保持下去,必有大成”的我,如今已在叼丝这条路上越走越远,文艺的词也是搜肠刮肚也无法想出来了,但是之于看书,依旧还是一如既往地迷恋,只是基于一些无谓的托词一直陷于课本和几寸大小的电子屏幕之间不能自拔!
前几天看到冰玉在看这本书,就借来一口气搞定了,里面的故事情节,无论是友情,爱情,亲情,都无不在某种程度上给于我一定的震撼。让我想起许多以前的人和事,想起童年时候的美好时光。譬如以前每天跟在老妈屁股后面,和她一起聊长大后的梦想,给她剖析各种幸福,那个时候,阳光透过浓密的树叶缝隙,投下一圈圈我信誓旦旦神情的影子,我依然记得!再譬如,那个时候,和华香,丽群她们一起在上学路上的疯疯癫癫,那个时候我们一起玩弹珠,一起玩纸牌,一起做自己的家务,我还记得,只是现在的相互见面只是一年中的几次运气较佳的碰面。她们已身为人妇,而我依然在坚持。还譬如那个时候一起在田野山间和你们一起玩过的游戏,我还记得。作者在书中有一个属于他自己的私人场所--阁楼,那个时候我也有,我也会对着山上的树叶说话,对着我的小羊聊天,那段时光那么美好,我还记得!
这本书有一个很好的结局,但我还是为作者母亲的去世感到遗憾,是的,家人是我们最容易忽视的珍贵,多少次,我们以忙碌为借口,离家越远,借口越多,越容易忽视,什么什么等到以后,都是扯淡。
我希望那些美好的记忆可以一直保留下来,即使一个人在外面的世界坚持也可以以这些为精神支柱。这本书给我带来了某种心灵上的宁静,并让我学会缅怀过去的一些人和事,愿爱我的人和我爱的人都安好,我会记得你们的,即使我很长时间没有和你们联系。但我心里一直有你们!真的。

说实话,刚看第一章的时候我是觉得很恶心的,因为除了各种赞美和夸耀之类的词之外,就是各种无厘头的描述,让人摸不着头脑,不仅没有先抑后扬的技巧,也没有比较新奇的铺陈,一来就是各种夸大形象的“陈词滥调”,让我觉得很反感,而且看这本书之前也没有想到是写人物传记的,然而坚持到第二章甚至更后一点,就开始慢慢被吸引了。。。
整本书的内容都是围绕查理斯.思特里克兰德而展开的,从作者到刚开始和他有交集到和他初识并亲眼见证过他落魄的几年,最后一直到从他人口中得知主人公的晚年生活到病逝的全过程,给读者塑造了一个伟大而怪异的画家天才形象。文笔平实简单而又不显得啰嗦冗余,作者以一个中立的旁观者的形象,见证了一个伟人的诞生和最终被全世界认可的神奇之旅。
说实话,对“伟人”这个概念也只是有一种比较模糊的印象,总觉得或者有几分被神化的成分在,也比较少接触到一些个人传记的书籍,所以也无从对比来评判这本书何其优劣。但是整体上还是比较吸引我的,至少是从作者亲身经历,亲眼所见、所感而展现出来的形象,所以便少了几分质疑的心理因素。这本书最吸引我的应该是比较详尽的叙事部分,通过描述事件的发生经历来展示人物的性格魅力,让读者在细节之处领略人物精神上的伟大。
说实话,和作者一样,刚开始对思特里克兰德的印象还是不怎么看好的,总觉得比较自私、冷漠而又怪异,这或者就是天才和平凡人之间的显著差别吧(精神层次无法达到,捂脸)。思特克兰德在四十岁的时候放弃了比较优渥的证券经纪人的生活,在所有人都不解的情形之下抛家弃子,独自一人开始了追求画画的生涯,所有人都以为思特里克兰德是因为和其他女人去过享受的生活时,其实他却为了追求画画过着穷困潦倒的生活,差点贫困交加到饿死病死,最后在斯特略夫的帮助下得所幸免于难。让人没有想到的是,斯特略夫的妻子却因为他而背叛了自己的丈夫,甚至最后因情而死。之后的之后,思特里克兰德去了一个叫塔希提的小岛度过了比较幸福的晚年生活。
人的一生似乎看似漫长实则转瞬即逝,每个人对生活评判的幸福标准并不一样,比如有些人比较在意别人的眼光和言论,就会尽其所能地去活成一个好儿子、好公民、好丈夫。但是有的人就可以在精神层次上乐不思蜀,他们不会在意别人的眼光,只要自己活得舒坦和从容就是最大的满足,我很佩服这类人。思特里克兰德在这一点上尤其突出,他无视所有的一切,生活的舒适度、爱情、女人、性都没有成为他对创作执迷的羁绊,相反他却始终义无反顾地抛开这些东西而去追寻属于自己的精神之旅,当然,他成为了一个伟人。。。。
使思特里克兰德着了迷的是一种创作欲,他热切地想创造出美来,这种激情叫他一刻也不能宁静,逼着他东奔西走,他好像是一个终生跋涉的朝圣者,永远思慕着一块圣地,盘踞在他心头的魔鬼对他毫无怜悯之情。世上有些人渴望寻获真理,他们的要求非常强烈,为了达到这个目的,就是叫他们把生活的基础完全打翻,也在所不惜。
这就是思特里克兰德对创作执迷的真实写照了吧。
我们每个人生在世界上都是孤独的。每个人都被囚禁在一座铁塔里,只能靠一些符号同别人传达自己的**;而这些符号并没有共同的价值,因此它们的意义是模糊的、不确定的。我们非常可怜地想把自己心中的财富传送给别人,但是他们却没有接受这些财富的能力。因此我们只能孤独的行走,尽管身体相互依傍却并不在一起,既不了解别的人也不能为别人所了解。
天才的人和其他人之间总有着一种难以逾越的鸿沟,他们不能相互理解,所以对于这类人来说,内心是非常孤独的。
最后以文中的一句话做总结:
上帝的磨盘转动很慢,但是却磨得很细。
每个人的生活都不一样,重要的不在乎长短,而是在这一段人生旅程里面,你是否活成了你想要的样子。。。
dva 初探
前言: 最近正在学习 dva ,整理出一些学习笔记,笔者默认阅读此文的读者有一定的react , redux , redux-saga 基础,如果没有,可先自行了解这些技术,本文不再赘述。
dva是基于现有应用框架(redux+react-router+redux-saga等)封装的一个框架(不是库),基本上没有引入新概念,也没有创建新语法,对于熟悉前言中涉及的技术栈的童鞋来说会非常容易上手。详细介绍可移步dva介绍
在处理复杂异步请求的业务中,一开始我们是使用 redux-thunk + async/await 结合使用,比如在异步登录的逻辑中,使用 redux-thunk 处理如下:
// action/auth.js
import request from 'axios';
import { loadUserData } from './user';
export const login = (user, pass) => async (dispatch) => {
try {
dispatch({ type: LOGIN_REQUEST });
let { data } = await request.post('/login', { user, pass });
await dispatch(loadUserData(data.uid));
dispatch({ type: LOGIN_SUCCESS, data });
} catch(error) {
dispatch({ type: LOGIN_ERROR, error });
}
}这种处理之后,组件调用的是dispatch(action creator),此时的 action 被赋予了太多的逻辑功能,不再是一个 pure action 。为了保持 action 的简洁性,继而引入 redux-saga ,它提供了一个 saga 文件用来存放异步逻辑,引入 redux-saga 之后,上面的验证用户登录逻辑就变成如下:
// sagas/index.js
import { take, call, put } from 'redux-saga/effects'
import Api from '...'
export function* login(user, pass) {
try {
const data = yield call(Api.authorize, user, pass)
yield put({type: 'LOGIN_SUCCESS', data.uid})
} catch(error) {
yield put({type: 'LOGIN_ERROR', error})
}
}使用 redux-saga 之后,action 又回归其纯粹性。并且将异步操作全部抽离在 sagas 中一层进行处理,这样方便我们进行多种异步处理操作。
redux-saga 虽然在处理较为复杂的异步逻辑时提供了比较好的解决方案,但是当业务变复杂时,随着模块的逐渐增加,由于项目通常要分 reducer, action, saga, component 等等,所以项目中的文件个数也会变得很多,如下:
+ src
+ actions
- user.js
- detail.js
+ reducers
- user.js
- detail.js
+ sagas
- user.js
- detail.js
+ components这样在项目开发过程中,就需要不断地切换文件目录,大大影响开发效率。于是 dva 应运而生,dva 的主要解决的项目开发中的痛点:
上面的例子使用 dva 来实现如下:
// models/login.js
import Api from '...'
export default {
namespace: 'login',
state: {
user: null
},
effects: {
*login(){
const data = yield call(Api.authorize, user, pass)
yield put({type: 'LOGIN_SUCCESS', data.uid})
},
},
reducers: {}
}其中,reducers 可以看成是同步的请求逻辑,effects 可以看成是异步的请求逻辑,所有的逻辑都放在了 models 目录下的文件中,省去了文件之间的切换成本,让开发人员可以专注于业务逻辑。
具体可以参考支付宝前端应用架构的发展和选择
dva中只有5个 API,8个新的概念,其中所有的 API 如下:
app = dva(Opts) 创建应用,返回 dva 实例app.use(Hooks) 配置 hooks 或者注册插件app.model(ModelObject) 注册 modelapp.router(Function) 注册路由表app.start([HTMLElement], opts) 启动应用具体的使用可以移步这里
8个概念如下所示:
{
type: String,
payload: Any?,
error? Error,
}调用的时候有如下两种方式:
dispatch(Action);dispatch({ type: 'todos/add', payload: 'todo content' });如何基于 dva 开发一个项目,dva 的作者给出了一个一步步开发 dva 项目的教程, 笔者仿照该教程,并且基于 dva2.0, 做出了一个 demo,该 demo 类似于 dva中的范例,只是初步体验一下 dva 的开发。
借用描述 dva 数据流动的一张图,如下所示:
如图所示:用户在浏览器中访问某个 URL,由此渲染一个页面,该页面可能包含多个 Components, 当用户在页面进行操作的时候,由此 dispatch 某个 action,同步的 action 逻辑放在 Reducer 中,异步的 action 逻辑存放在 Effect 中。通过 model 中的数据处理,将新的 state 传入页面中,从而触发页面数据的更新。
这次的解读主要是针对 [email protected] 和 [email protected]。
首先是 dva 中的入口文件所暴露出来的方法,主要是const app = dva();这行代码的作用,返回一个 app实例。该方法如下:
export default function (opts = {}) {
const history = opts.history || createHashHistory(); //history默认是HashHistory
const createOpts = {
initialReducer: {
routing,
},
setupMiddlewares(middlewares) {
return [
routerMiddleware(history),
...middlewares,
];
},
setupApp(app) {
app._history = patchHistory(history);
},
};
const app = core.create(opts, createOpts);
const oldAppStart = app.start;
app.router = router;
app.start = start;
return app;
}
// 此处略去一些方法的定义这个函数很简单,主要是调用了 dva-core 里面的 create 方法,并且返回了一个包含如下方法的 app 对像:
var app = {
_models: [(0, _prefixNamespace2.default)((0, _extends3.default)({}, dvaModel))],
_store: null,
_plugin: plugin,
use: plugin.use.bind(plugin),
model: model,
start: start
};对 app 的初始化定义在 dva-core/lib/index.js 文件中。在这个文件中,实现了 app 对象的所有方法。接下来一个一个进行分析:
app.model(Model1); app.model(Model2);
//而不是
app.model([Model1,Model2])其实 app.model 在调用 app.start 之后会变成 injectModel(), 它的源码如下:
function injectModel(createReducer, onError, unlisteners, m) {
model(m);
var store = app._store;
if (m.reducers) {
store.asyncReducers[m.namespace] = (0, _getReducer2.default)(m.reducers, m.state);
store.replaceReducer(createReducer(store.asyncReducers));
}
if (m.effects) {
store.runSaga(app._getSaga(m.effects, m, onError, plugin.get('onEffect')));
}
if (m.subscriptions) {
unlisteners[m.namespace] = (0, _subscription.run)(m.subscriptions, m, app, onError);
}
}这个函数里面调用了上面的 model() ,除此之外,该函数还将 model 定义的 reducers,effects, subscriptions 进行分别处理。
sagaMiddleware.run() 来执行管理一部 action,在这之前,先调用了 app._getSaga()方法:export default function getSaga(resolve, reject, effects, model, onError, onEffect) {
return function *() {
for (const key in effects) {
if (Object.prototype.hasOwnProperty.call(effects, key)) {
const watcher = getWatcher(resolve, reject, key, effects[key], model, onError, onEffect);
const task = yield sagaEffects.fork(watcher);
yield sagaEffects.fork(function *() {
yield sagaEffects.take(`${model.namespace}/@@CANCEL_EFFECTS`);
yield sagaEffects.cancel(task);
});
}
}
};
}这个方法主要实现了 saga 那一套的watch/worker(监听->执行) 的工作形式。
这本书也是朋友推荐的,看它之前先去大概了解了一下人们对它的评价:“最新畅销书,据说平均三个通宵读完“。想来估计是比较值得读的鸿篇巨著,然后下载了电子版开始了阅读之旅。
看完第一章的序幕的时候,觉得还是比较好看的,比利刚下矿井工作的勇敢和出乎人意料的男子汉气概让我有一种重温《钢铁是怎么炼成的》感觉,总之冥冥之中感觉有一个”旷世奇才“类的英雄在等待着改变世界,感觉还是很值人们对它的评价的。但是看到第二章第三章,就有一点累和乏味的感觉,脑海里只有一种感觉”人物名字实在是太长了,而且关系错综复杂“,即使后面配了人物关系表,但还是一脸懵逼。真的,可能是由于第一部主要是讲述背景的铺叙,所以有点摸不着头脑。
整套书的内容是讲述第一次世界大战前后六个家族兴衰变化的故事。作者巧妙地将历史与虚构相结合,讲述了在大的时代背景下小人物经历的悲欢离合。在阅读之前可能还得去了解一下历史。然而我的历史恰恰不是很好(捂脸)
第一部主要是介绍了几个关键人物的出场,比如“菲茨赫伯特伯爵”还有其妹妹“茉黛・菲茨赫伯特女勋爵”,“格雷戈里・别斯科夫”,“比利・威廉姆斯”,“艾瑟尔・威廉姆斯”,虽然背景的陈述可能有些枯燥,但是还是不能掩饰一个优秀作品的闪光点。在第一部中,比利从一个读书少年加入到旷工的一系列改变,并且在一个事故中成为英雄,在这一个过程中,他从一个比较胆小怯懦的男孩子形象成长为一个勇敢,果断而又富有正义感的男子汉。这点让我印象十分深刻。
比利的解决艾瑟尔,菲茨赫伯特伯爵家的女管家助手,因为她机灵,漂亮,能干,正因为这些,她马上得到了伯爵主人的赏识,并且迅速地成为了伯爵的地下情妇。当她一心以为自己收获的是爱情的时候,却在得知自己怀孕的时候,受到了男主人的无情抛弃。
菲茨怎么能这么残忍?难道他真的不想再见到她?见到他的孩子?难道他以为一年二十四英镑就能把他们之间发生的一切通通抹去?
这一段话显示了作为一个未婚先孕少女的不知所措和被欺骗后的悲凉。但是在得知自己怀孕之后,艾瑟尔虽然有过伤心和绝望,但是她马上从这种痛苦中脱离出来,开始为自己和自己孩子的未来做打算。并且最后只身一人去了伦敦。在这个过程中充分体现了艾瑟尔的独立和强大的人格,让我惊讶不已。
同时让我印象深刻的还有茉黛和沃尔特两人之间的爱情,由于他们两人分别是英国人和德国人,但是在相爱的时候恰好处于英德两国即将交战的尴尬时刻,但是两人还是不畏艰险,偷偷地结婚。在战争爆发的前一天他们毅然决然地举行了婚礼,在筹办婚礼秘密的时候,有过一些计划即将被拆穿的插曲,跌宕起伏的同时让读者真心为他们捏了一把汗。但是最终他们还是成功了。
第一部虽然情节不是处处都精彩,但是还是很值得一读的。期待后两部可以带来更加惊艳的阅读体验。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.