stumpapp / stump Goto Github PK
View Code? Open in Web Editor NEWA free and open source comics, manga and digital book server with OPDS support (WIP)
Home Page: https://stumpapp.dev
License: MIT License
A free and open source comics, manga and digital book server with OPDS support (WIP)
Home Page: https://stumpapp.dev
License: MIT License



























































































































The server needs a new set of endpoints to manage user creation/management:
Permissions of these managed user accounts will be handled in #41
One of my test files has markdown and I never noticed. I think it would be a really nice feature to allow for rendering and editing media descriptions as markdown.
Will consider this for all entities with description fields.
Decided to convert this to an actual issue to track it. Leaving the original content at the bottom of the issue, it overviews why I wanted to do this in the first place.
The general TODO list off the top of my head:
rocket from coreJsonSchema derives from coreextract::Query for pagination paramsheader::ContentType for content type calculationNote: I split #63 into separate issue.
As the project grows, working with Rocket has proven to be quite the headache. I don't love the macros pattern with Rocket, I don't like the uncertainty of the Rocket's maintenance status, and I don't love that I have to hoist the rocket dependency everywhere. I like the more headless approach Axum has, and I am hearing that switching to Axum would potentially save some compile time, as well, which is desperately needed for the docker builds.
Things that need to be considered:
- How would the auth flow / setup change?
- How would the OpenAPI setup change?
- How would my responses change? My quick glances seem to find that it would initially be a headache, but once completed would help standardize my responses better than currently
- I would have to rethink the configuration method for Stump in some ways. I LOVE that the whole
Rocket.tomlwould go away, I hated(!) that.- How easy is SPA serving in Axum?
Making this a real issue to hopefully get more visibility. I haven't quite figured out how to get cross-compilation (in Docker) working, an absolutely essential thing to get working so Stump can run on arm systems (e.g. rpi-4).
see https://github.com/aaronleopold/stump/tree/aleopold--arm64-can-sma
The server needs to be able to: process, properly handle and serve PDF files. This issue is for basic support, page streaming support will either roll out separately or, depending on how the rest of the below goes, at the same time.
Core Tasks:
Interface Tasks:
I've started to hone the locale json file structure for English, something that just has to get done before any other languages are supported (so the json files keys are 1:1).
Currently, this work is being done in al/bye-chakra branch, specifically the locale files here.
Once en.json (English) is completed, I think I will just mass translate that file to a handful of other languages using whatever AI is best suited for language processing. I'll start with languages that use alphabets I am personally familiar with (e.g. Spanish, French, Italian, etc) and potentially add a few with alphabets I am not / those without alphabets (e.g. Russian, Chinese, Japanese, etc). This should kickstart the language support, but as with most AI things these translations will need to be checked by someone who actually knows the language.
will this be similar to Kavitareader ? or different
I'd like to add additional configuration options around thumbnail generation. Primarily, I'd like to support the following:
I will need to decide whether this should be library or server level options.
General tasks:
image crate that handles the conversion
When Stump used Rocket, I used okapi to both automatically generate openapi.json and serve an embedded rapidoc page. Axum is pretty much all done now (#61) and with that goes away what I've done for the openapi stuff.
I'm looking at utoipa, but it looks like it isn't as hand hold-y (i.e. I need to do more manual definitions).
I've encountered a very strange bug with the new websocket route I've implemented from #64. The server reports an IO error, that the message failed to send, but when I double check the client the message was recieved. So, I am not sure why the sender thinks it failed? Just something to look into, not too concerning since I can see the 'failed' message went through to the client.
2022-10-03T19:30:15.126661Z ERROR stump_server::routers::ws: Failed to send message: IO error: Broken pipe (os error 32)
at apps/server/src/routers/ws.rs:40It's deno, so probably not the same issue, but found this for reference: denoland/deno#14240
The CI workflow(s) for Stump are currently at a much better state than they were before, but there is still a lot of work to be done. I'll outline some of the areas that need work below, and create separate issues for tracking as needed. This overly time critical, but it eventually will be when I feel ready for an initial release.
Lol this is annoying. So, as of #92, docker caching works only when running builds locally. In CI, the only time the cache actually works is when you rerun a build for the same commit.
Locally, this is not the case. I can run a build, make a change, run a consecutive build, and the cache is properly used and the build is much faster. I have no idea why this is the case, but it is very annoying and gives me agita.
Honestly this is pretty decent right now. Not much I would change here. The checks are rather basic, but they are sufficient for now. All it does is lint the code. I guess the one thing I want it to do is run tests, but those don't exist yet lol well, if they do they are not great tests. See https://github.com/aaronleopold/stump/tree/al/testing-overhaul.
As of #92, we have a nightly release workflow that will build and publish nightly docker image(s) whenever a PR lands in develop.
The general flow at the moment is:
linux/amd64 only. This will not be pushed to a registry, rather just be cached. I consider this a smoke test to ensure basic build functionality before merging and running the full build(s) for all platforms.nightly release, and will be tagged as such.Note that all operations are currently performed on a single, self-hosted runner. This is a great start, but there are a few things that need to be done to make this more robust:
stump_server
macos, linux, and windows.macos and windows builds.stump_desktop
macos, linux, and windows.
stump_server CI is in a good state, but I wanted to call it out here.nightly releases replace any existing nightly releases for the same platform.The release workflow is currently non-existent and I imagine it will be more annoying.
In general, what I am envisioning is:
latest and the release tag will be pushed to the registry.The checklist for the release, following the above outline, would be:
stump_server and stump_desktop executables for all supported platforms to the GH release page.stump_server and stump_desktop docker images for all supported platforms, tagged with latest and the release tag.Animation wasn’t really even complete, so not really a fix lol but the animation needs LOTS of tlc. I'm trying to mimic Panels animation
See ImageBasedReader.tsx -> AnimatedImageBasedReader
Users should have control over what collections / reading lists other users have access to. E.g. User A can't access X library or media with the tag X.
- [ ] A user can control access of their reading lists / collections using tags and/or explicit sharing
- [ ] A server owner can control access of libraries, series
Update 10/01/2023
Very basic RBAC should be added for more top-level, server actions. See this comment for additional context.
Bite the bullet lol it will be incredibly useful to have this in place. In order to run integration tests in rust, you need to have a library, not a binary. This causes me to have to restructure (I know, another one? well, you live and you learn) in a way that separates the server aspects of the core into a separate application.
apps/server
core more 'library' like:
api related logicintegration-tests crate and add the basics, just to get started:
Ctx::mock to use test directorytest directoryDigging through a, potentially massive, log file is really not ideal. Not only for troubleshooting, but if something were fail to be inserted I'd like an easily accessible way for a user to know immediately.
The current, basic log model in the prisma schema should be updated to have the following:
All throughout the core, logic will need to be added to persist these logs to the DB instead of only logging to the log file as it currently does. Because that is a large undertaking, I am separating the interface aspects of this into a separate issue.
I would like to add support for selecting between two generalized library structure patterns that will affect how Stump determines what is a series. The naming I am considering currently is Collection Based Library vs Series Based Library, but I don't love the latter.
Note: For the time being this option will not be reversible for a library. If you create a library with one pattern, Stump will not let you change it afterwards. This is because if you change how Stump defines a series in your library after having created the series, then it will potentially result in lost and/or duplicated data, as well as disconnects from other DB relations (e.g. read progress, reading lists, etc). In the future, I might add a migration tool to support this switch,
Collection based libraries, during a scan, will take the top most folder and collapse everything into that as a single series. I personally like this for my ebook collection since I have /Author/Series/novel_file and /Author/novel_file.
The series based library would effectively be the opposite, creating series from the bottom-most level.
Consider the following:
.LIBRARY ROOT
└── Top Level Folder
└── Publisher
├── Some Category / Folder
│ └── A Cool Comic 001.cbz
└── Some Category / Folder 2
└── Some Comic 001.cbz
The collection based library would create a single series, Top Level Folder:
Top Level Folder
├── A Cool Comic 001.cbz
└── Some Comic 001.cbz
The series based library will create two series Some Category / Folder and Some Category / Folder 2:
Some Category / Folder
└── A Cool Comic 001.cbz
Some Category / Folder 2
└── Some Comic 001.cbz
Core tasks:
libraryPattern to prisma schema (part of LibraryOptions)LibraryPattern
SeriesBasedLibraryInterface tasks:
This has been a major chore/headache and I've been putting it off, but I really just don't like Chakra's DX and want to replace it. I have settled on radix-ui as the more headless replacement.
To expedite things, I'll be using shadcn/ui for a large chunk of the base components. Honestly super impressed by their work.
Add support for streaming pieces of an epub to a client. This is already partially implemented in the Rust core.
Sump already supports very basic epub fetching and rendering (#34). It consumes the entire epub file, which is NOT ideal. I would like to be able to stream parts of the epub file as the user reads it, as opposed to downloading the entire thing to read it on the client. This will require a lot of research on epub file structure, as the core will likely have a lot of work required to support that kind of flow. Some work has already been started towards this.
Once there is a proof of concept for some sort of in house ebpub engine, I'll probably separate it into a standalone library that can be installed for both Rust and JavaScript/TypeScript projects (using likely https://github.com/getditto/safer_ffi).
References:
- https://github.com/getditto/safer_ffi -> for using Rust library in node
- https://readium.firebaseapp.com/?epub=epub_content%2Fpage-blanche&goto=epubcfi(/6/2!/4/2/2)
above link appears to: grab the container.xml, grab the package.opf, grab encryption.xml, grab nav.xhtml, grabs a page, like page 6, grabs epub styles
The book overview page is the page located at books/:id
In general, it should display the following:
Continue Reading buttonStart Reading button that goes to first pageAt this point I'm not sure what else should go here, open to suggestions. Design contributions, without code, are also acceptable for hacktoberfest.
Wanted to just take a look at the app, and find out that there's no binary in "releases" page, and docker hub have only "amd64" so.. trying to build it with "build: https://github.com/aaronleopold/stump.git#develop"
version: '3.3'
services:
stump:
# image: aaronleopold/stump-preview # this will be `aaronleopold/stump` when it is released
**build: https://github.com/aaronleopold/stump.git#develop**
container_name: stump
# Replace my paths (prior to the colons) with your own
volumes:
- ./config:/config
- ./data:/data
ports:
- 8009:10801
user: '668:966'
# This `environment` field is optional, remove if you don't need it. I am using
# them as an example here, but these are actually their default values.
environment:
- STUMP_CONFIG_DIR=/config
restart: unless-stopped
full log (if needed for some reason) https://pastebin.com/2gZcs8ZZ
Compiling sql-query-connector v0.1.0 (https://github.com/Brendonovich/prisma-engines?rev=51d3b4bb966f7a5d29b4059822af6dd1d3c9642c#51d3b4bb)
Compiling mongodb-query-connector v0.1.0 (https://github.com/Brendonovich/prisma-engines?rev=51d3b4bb966f7a5d29b4059822af6dd1d3c9642c#51d3b4bb)
Compiling query-core v0.1.0 (https://github.com/Brendonovich/prisma-engines?rev=51d3b4bb966f7a5d29b4059822af6dd1d3c9642c#51d3b4bb)
Compiling prisma-client-rust v0.6.1 (https://github.com/Brendonovich/prisma-client-rust?tag=0.6.1#9d8068bc)
Compiling unrar v0.4.4 (https://github.com/aaronleopold/unrar.rs?branch=aleopold--read-bytes#cf9ff0ef)
Compiling webp v0.2.2
Compiling stump v0.0.0 (/app)
error[E0583]: file not found for module `prisma`
--> src/main.rs:34:1
|
34 | pub mod prisma;
| ^^^^^^^^^^^^^^^
|
= help: to create the module `prisma`, create file "src/prisma.rs" or "src/prisma/mod.rs"
error[E0432]: unresolved import `prisma::log`
--> src/config/context.rs:70:7
|
70 | use prisma::log;
| ^^^^^^^^^^^ no `log` in `prisma`
error[E0432]: unresolved import `crate::prisma::migration`
--> src/db/migration.rs:10:17
|
10 | prisma::{self, migration},
| ^^^^^^^^^ no `migration` in `prisma`
error[E0432]: unresolved import `crate::prisma::PrismaClient`
--> src/db/utils.rs:10:2
|
10 | prisma::PrismaClient,
| ^^^^^^^^^^^^^^^^^^^^ no `PrismaClient` in `prisma`
error[E0432]: unresolved import `crate::prisma::media`
--> src/fs/image.rs:12:2
|
12 | prisma::media,
| ^^^^^^^^^^^^^ no `media` in `prisma`
error[E0432]: unresolved imports `crate::prisma::library`, `crate::prisma::media`, `crate::prisma::series`
--> src/fs/scanner/library.rs:25:11
|
25 | prisma::{library, media, series},
| ^^^^^^^ ^^^^^ ^^^^^^ no `series` in `prisma`
| | |
| | no `media` in `prisma`
| no `library` in `prisma`
error[E0432]: unresolved imports `crate::prisma::library`, `crate::prisma::media`, `crate::prisma::series`
--> src/fs/scanner/utils.rs:10:11
|
10 | prisma::{library, media, series},
| ^^^^^^^ ^^^^^ ^^^^^^ no `series` in `prisma`
| | |
| | no `media` in `prisma`
| no `library` in `prisma`
error[E0432]: unresolved import `crate::prisma::user`
--> src/guards/auth.rs:9:17
|
9 | prisma::{self, user},
| ^^^^ no `user` in `prisma`
error[E0432]: unresolved import `crate::prisma::job`
--> src/job/mod.rs:133:6
|
133 | use crate::prisma::job;
| ^^^^^^^^^^^^^^^^^^ no `job` in `prisma`
error[E0432]: unresolved import `crate::prisma::job`
--> src/job/mod.rs:156:6
|
156 | use crate::prisma::job;
| ^^^^^^^^^^^^^^^^^^ no `job` in `prisma`
error[E0432]: unresolved import `crate::prisma::job`
--> src/job/mod.rs:188:6
|
188 | use crate::prisma::job;
| ^^^^^^^^^^^^^^^^^^ no `job` in `prisma`
error[E0432]: unresolved imports `crate::prisma::library`, `crate::prisma::media`, `crate::prisma::series`
--> src/opds/entry.rs:9:11
|
9 | prisma::{library, media, series},
| ^^^^^^^ ^^^^^ ^^^^^^ no `series` in `prisma`
| | |
| | no `media` in `prisma`
| no `library` in `prisma`
error[E0432]: unresolved imports `crate::prisma::library`, `crate::prisma::series`
--> src/opds/feed.rs:4:11
|
4 | prisma::{library, series},
| ^^^^^^^ ^^^^^^ no `series` in `prisma`
| |
| no `library` in `prisma`
error[E0432]: unresolved imports `crate::prisma::user`, `crate::prisma::user_preferences`
--> src/routes/api/auth.rs:6:11
|
6 | prisma::{user, user_preferences},
| ^^^^ ^^^^^^^^^^^^^^^^ no `user_preferences` in `prisma`
| |
| no `user` in `prisma`
error[E0432]: unresolved imports `crate::prisma::media`, `crate::prisma::read_progress`
--> src/routes/api/epub.rs:9:11
|
9 | prisma::{media, read_progress},
| ^^^^^ ^^^^^^^^^^^^^ no `read_progress` in `prisma`
| |
| no `media` in `prisma`
error[E0432]: unresolved imports `crate::prisma::library`, `crate::prisma::library_options`, `crate::prisma::media`, `crate::prisma::series`, `crate::prisma::series`, `crate::prisma::tag`
--> src/routes/api/library.rs:13:3
|
13 | library, library_options, media,
| ^^^^^^^ ^^^^^^^^^^^^^^^ ^^^^^ no `media` in `prisma`
| | |
| | no `library_options` in `prisma`
| no `library` in `prisma`
14 | series::{self, OrderByParam},
| ^^^^^^ ^^^^ no `series` in `prisma`
| |
| could not find `series` in `prisma`
15 | tag,
| ^^^ no `tag` in `prisma`
error[E0432]: unresolved imports `crate::prisma::media`, `crate::prisma::media`, `crate::prisma::read_progress`, `crate::prisma::user`
--> src/routes/api/media.rs:11:3
|
11 | media::{self, OrderByParam},
| ^^^^^ ^^^^ no `media` in `prisma`
| |
| could not find `media` in `prisma`
12 | read_progress, user,
| ^^^^^^^^^^^^^ ^^^^ no `user` in `prisma`
| |
| no `read_progress` in `prisma`
error[E0432]: unresolved imports `crate::prisma::media`, `crate::prisma::media`, `crate::prisma::read_progress`, `crate::prisma::series`
--> src/routes/api/series.rs:10:3
|
10 | media::{self, OrderByParam},
| ^^^^^ ^^^^ no `media` in `prisma`
| |
| could not find `media` in `prisma`
11 | read_progress, series,
| ^^^^^^^^^^^^^ ^^^^^^ no `series` in `prisma`
| |
| no `read_progress` in `prisma`
error[E0432]: unresolved imports `crate::prisma::user`, `crate::prisma::user_preferences`
--> src/routes/api/user.rs:6:11
|
6 | prisma::{user, user_preferences},
| ^^^^ ^^^^^^^^^^^^^^^^ no `user_preferences` in `prisma`
| |
| no `user` in `prisma`
error[E0432]: unresolved imports `crate::prisma::library`, `crate::prisma::media`, `crate::prisma::read_progress`, `crate::prisma::series`
--> src/routes/opds.rs:13:17
|
13 | prisma::{self, library, media, read_progress, series},
| ^^^^^^^ ^^^^^ ^^^^^^^^^^^^^ ^^^^^^ no `series` in `prisma`
| | | |
| | | no `read_progress` in `prisma`
| | no `media` in `prisma`
| no `library` in `prisma`
error[E0432]: unresolved import `crate::prisma::media`
--> src/types/models/epub.rs:8:13
|
8 | use crate::{prisma::media, types::errors::ProcessFileError};
| ^^^^^^^^^^^^^ no `media` in `prisma`
error[E0432]: unresolved imports `crate::prisma::media`, `crate::prisma::series`
--> src/types/query.rs:6:11
|
6 | prisma::{media, series},
| ^^^^^ ^^^^^^ no `series` in `prisma`
| |
| no `media` in `prisma`
error: cannot determine resolution for the macro `library::include`
--> src/routes/api/library.rs:449:12
|
449 | .include(library::include!({
| ^^^^^^^^^^^^^^^^
|
= note: import resolution is stuck, try simplifying macro imports
error[E0433]: failed to resolve: could not find `media` in `prisma`
--> src/event/mod.rs:37:23
|
37 | CreatedMedia(prisma::media::Data),
| ^^^^^ could not find `media` in `prisma`
error[E0433]: failed to resolve: could not find `series` in `prisma`
--> src/event/mod.rs:41:24
|
41 | CreatedSeries(prisma::series::Data),
| ^^^^^^ could not find `series` in `prisma`
error[E0433]: failed to resolve: could not find `user` in `prisma`
--> src/guards/auth.rs:109:26
|
109 | .find_unique(prisma::user::UniqueWhereParam::UsernameEquals(
| ^^^^ could not find `user` in `prisma`
error[E0433]: failed to resolve: could not find `job` in `prisma`
--> src/job/mod.rs:89:19
|
89 | impl From<prisma::job::Data> for JobReport {
| ^^^ could not find `job` in `prisma`
error[E0433]: failed to resolve: could not find `job` in `prisma`
--> src/job/mod.rs:90:24
|
90 | fn from(data: prisma::job::Data) -> Self {
| ^^^ could not find `job` in `prisma`
error[E0433]: failed to resolve: could not find `job` in `prisma`
--> src/job/mod.rs:132:28
|
132 | ) -> Result<crate::prisma::job::Data, ApiError> {
| ^^^ could not find `job` in `prisma`
error[E0433]: failed to resolve: could not find `job` in `prisma`
--> src/job/mod.rs:155:28
|
155 | ) -> Result<crate::prisma::job::Data, ApiError> {
| ^^^ could not find `job` in `prisma`
error[E0433]: failed to resolve: could not find `job` in `prisma`
--> src/job/mod.rs:187:28
|
187 | ) -> Result<crate::prisma::job::Data, ApiError> {
| ^^^ could not find `job` in `prisma`
error[E0433]: failed to resolve: could not find `series` in `prisma`
--> src/routes/opds.rs:360:21
|
360 | .order_by(prisma::series::updated_at::order(Direction::Desc))
| ^^^^^^ could not find `series` in `prisma`
error[E0433]: failed to resolve: could not find `library_options` in `prisma`
--> src/types/models/library.rs:190:39
|
190 | impl Into<LibraryOptions> for prisma::library_options::Data {
| ^^^^^^^^^^^^^^^ could not find `library_options` in `prisma`
error[E0433]: failed to resolve: could not find `library_options` in `prisma`
--> src/types/models/library.rs:203:40
|
203 | impl Into<LibraryOptions> for &prisma::library_options::Data {
| ^^^^^^^^^^^^^^^ could not find `library_options` in `prisma`
error[E0433]: failed to resolve: could not find `library` in `prisma`
--> src/types/models/library.rs:216:32
|
216 | impl Into<Library> for prisma::library::Data {
| ^^^^^^^ could not find `library` in `prisma`
error[E0433]: failed to resolve: could not find `media` in `prisma`
--> src/types/models/media.rs:59:56
|
59 | pub fn into_action<'a>(self, ctx: &'a Ctx) -> prisma::media::Create<'a> {
| ^^^^^ could not find `media` in `prisma`
error[E0433]: failed to resolve: could not find `media` in `prisma`
--> src/types/models/media.rs:67:13
|
67 | prisma::media::checksum::set(self.checksum),
| ^^^^^ could not find `media` in `prisma`
error[E0433]: failed to resolve: could not find `media` in `prisma`
--> src/types/models/media.rs:68:13
|
68 | prisma::media::description::set(self.description),
| ^^^^^ could not find `media` in `prisma`
error[E0433]: failed to resolve: could not find `media` in `prisma`
--> src/types/models/media.rs:69:13
|
69 | prisma::media::series::connect(prisma::series::id::equals(
| ^^^^^ could not find `media` in `prisma`
error[E0433]: failed to resolve: could not find `series` in `prisma`
--> src/types/models/media.rs:69:44
|
69 | prisma::media::series::connect(prisma::series::id::equals(
| ^^^^^^ could not find `series` in `prisma`
error[E0433]: failed to resolve: could not find `media` in `prisma`
--> src/types/models/media.rs:77:30
|
77 | impl Into<Media> for prisma::media::Data {
| ^^^^^ could not find `media` in `prisma`
error[E0433]: failed to resolve: could not find `read_progress` in `prisma`
--> src/types/models/read_progress.rs:24:37
|
24 | impl Into<ReadProgress> for prisma::read_progress::Data {
| ^^^^^^^^^^^^^ could not find `read_progress` in `prisma`
error[E0433]: failed to resolve: could not find `series` in `prisma`
--> src/types/models/series.rs:52:31
|
52 | impl Into<Series> for prisma::series::Data {
| ^^^^^^ could not find `series` in `prisma`
error[E0433]: failed to resolve: could not find `series` in `prisma`
--> src/types/models/series.rs:102:32
|
102 | impl Into<Series> for (prisma::series::Data, i64) {
| ^^^^^^ could not find `series` in `prisma`
error[E0433]: failed to resolve: could not find `tag` in `prisma`
--> src/types/models/tag.rs:14:28
|
14 | impl Into<Tag> for prisma::tag::Data {
| ^^^ could not find `tag` in `prisma`
error[E0433]: failed to resolve: could not find `user` in `prisma`
--> src/types/models/user.rs:27:29
|
27 | impl Into<User> for prisma::user::Data {
| ^^^^ could not find `user` in `prisma`
error[E0433]: failed to resolve: could not find `user_preferences` in `prisma`
--> src/types/models/user.rs:57:40
|
57 | impl Into<UserPreferences> for prisma::user_preferences::Data {
| ^^^^^^^^^^^^^^^^ could not find `user_preferences` in `prisma`
error[E0433]: failed to resolve: could not find `user` in `prisma`
--> src/types/models/user.rs:88:42
|
88 | impl Into<AuthenticatedUser> for prisma::user::Data {
| ^^^^ could not find `user` in `prisma`
error[E0412]: cannot find type `PrismaClient` in module `prisma`
--> src/config/context.rs:21:22
|
21 | pub db: Arc<prisma::PrismaClient>,
| ^^^^^^^^^^^^ not found in `prisma`
error[E0412]: cannot find type `PrismaClient` in module `prisma`
--> src/config/context.rs:45:35
|
45 | pub fn get_db(&self) -> &prisma::PrismaClient {
| ^^^^^^^^^^^^ not found in `prisma`
error[E0412]: cannot find type `PrismaClient` in module `prisma`
--> src/db/migration.rs:35:42
|
35 | pub async fn run_migrations(db: &prisma::PrismaClient) -> Result<()> {
| ^^^^^^^^^^^^ not found in `prisma`
error[E0412]: cannot find type `PrismaClient` in module `prisma`
--> src/db/mod.rs:7:41
|
7 | pub async fn create_client() -> prisma::PrismaClient {
| ^^^^^^^^^^^^ not found in `prisma`
error[E0425]: cannot find function `new_client_with_url` in module `prisma`
--> src/db/mod.rs:17:11
|
17 | prisma::new_client_with_url(&format!("file:{}/stump.db", &config_dir))
| ^^^^^^^^^^^^^^^^^^^ not found in `prisma`
error[E0425]: cannot find function `new_client` in module `prisma`
--> src/db/mod.rs:22:11
|
22 | prisma::new_client()
| ^^^^^^^^^^ not found in `prisma`
version: '3.3'
error[E0119]: conflicting implementations of trait `std::convert::Into<opds::feed::OpdsFeed>` for type `(std::string::String, std::string::String, std::string::String, std::vec::Vec<_>, i64, i64)`
--> src/opds/feed.rs:226:1
|
226 | / impl<T> Into<OpdsFeed> for (String, String, String, Vec<T>, i64, i64)
227 | | where
228 | | OpdsEntry: From<T>,
229 | | // T: Into<OpdsEntry>,
... |
270 | | }
271 | | }
| |_^
|
= note: conflicting implementation in crate `core`:
- impl<T, U> Into<U> for T
where U: From<T>;
Some errors have detailed explanations: E0119, E0412, E0425, E0432, E0433, E0583.
For more information about an error, try `rustc --explain E0119`.
error: could not compile `stump` due to 55 previous errors
The command '/bin/sh -c cargo build --release --target aarch64-unknown-linux-musl && cp target/aarch64-unknown-linux-musl/release/stump .' returned a non-zero code: 101
ERROR: Service 'stump' failed to build : Build failed
The server needs to be able to: process, properly handle and serve epub files. This issue is for basic support, page streaming support will either roll out separately or, depending on how the rest of the below goes, at the same time. While epub files aren't really supported in an OPDS context, the goal is to have Stump internally support them.
Also, apparently Panels plans to bring in epub support as well. When they launch that it will be important to make sure Stump can properly serve epub for that client.
Core Tasks:
epubcfi to database scemaInterface Tasks:
Update: Feb 25, 2023
I think proper docker caching is just the way to go here. The only reason Stump takes so long to compile is because all of the dependencies, even if they have not changed, get recompiled each build. If I can get caching of the dependencies to work, then this will drastically decrease the build times.
I want to investigate potentially creating my own base images with some of the heavy, time-consuming dependencies precompiled. This will alleviate some of the headaches I have spending 2+ hours building arm images for every iterative development change. I would only have to rebuild these base images when I update the big dependencies (rocket, prisma, etc).
Similar to how stump pulls a base image dependent of the platform, I would need to create an image per supported platform.
This would have to live in a separate repository I think, so this issue would get transferred over there if any progress gets made.
Describe the bug
On the 404 page the "Copy error details" button does not copy anything to the clipboard on Safari.
To Reproduce
Steps to reproduce the behavior:
http://<ip>:10801/whateverExpected behavior
Copies error log to the system clipboard
Desktop (please complete the following information):
the homepage needs some TLC. In general, should display:
Should have some sort of group of empty states:
Design contributions, without code, are also acceptable for hacktoberfest.

Hey @aaronleopold, feel free to submit a PR to showcase your project!
Users should be able to specify what fields to order items inside Stump grids/lists. For example, when viewing the media of a series, the Order By button in the TopBar should contain the allowed media entity fields as options for selection. When an option is selected, the media would be sorted by that field.
Additionally, the OrderDirectionToggle button should update the direction for this ordering.
The API does currently accept the required query params for a minimally viable solution, however it is not overly type safe. I’d like to look into reworking the current implementation while working on this task to make it safer between Rust and TypeScript. Maybe something like:
// Note: I am separating these options / exclusions in case I want to use either independently.
export type MediaOrderByExclusions = Extract<
keyof Media,
'currentPage' | 'series' | 'readProgresses' | 'tags'
>;
export type MediaOrderBy = keyof Omit<Media, MediaOrderByExclusions>;
export type SeriesOrderByExclusions = Extract<
keyof Series,
'library' | 'media' | 'mediaCount' | 'tags'
>;
export type SeriesOrderBy = keyof Omit<Series, SeriesOrderByExclusions>;
export type LibraryOrderByExclusions = Extract<keyof Library, 'series' | 'tags' | 'libraryOptions'>;
export type LibraryOrderBy = keyof Omit<Library, LibraryOrderByExclusions>;Interface tasks:
Note: There are only a few queries where this is currently applicable. This will likely change as Stump grows, but this issue is more so about creating the infrastructure to make is easier to use throughout in the future.
useQueryParamStore to store query configuration, it can then output the resulting url search params for relevant API callsgetLibrarySeriesgetSeriesMediauseQueryParamStore in relevant common/client react-query hooks
useLibrarySeriesuseSeriesMediaCore tasks:
library/<id>/seriesI've decided to do a major restructuring of the Stump monorepo. Primarily, in order to reuse a large chunk of code between the web client and future desktop app, I followed the Spacedrive monorepo structure closely to extract the interface and other relevant configs as separate common packages. This will result in one shared React component for those two applications. Once this is done, I’d like to resume core development features like PDF support.
I think it would be a nice-to-have to implement some sort of support for a .stumpignore file.
.stumpignore during the scan_series and scan_series_batch functionssome_folder/* and !some_folder/target.cbz.stumpignore contents.stumpignore at the root of a libraryPotential resources:
pseudo code
let mut builder = GlobSetBuilder::new();
if path.join(".stumpignore").exists() {
func_to_populate_builder(&mut builder, path.join(".stumpignore"));
}
let glob_set = builder.build()?;
... further down the code ...
if !builder.is_empty() && set.matches(current_path) {
// ignore this entry
}Describe the bug
Trying to get to the swagger-ui page as described in the docs returns with a 404 page.
To Reproduce
Go to http(s)://your-server(:10801)/swagger-ui
Expected behavior
Show the Swagger API page
Screenshots
If applicable, add screenshots to help explain your problem.
Desktop (please complete the following information):
Additional context
I've explicitly set the ENABLE_SWAGGER_UI to true just to make sure.
r@http://192.168.178.192:10801/assets/FourOhFour.a5712a44.js:1:57 Ox@http://192.168.178.192:10801/assets/index.407e6789.js:30:19537 Yy@http://192.168.178.192:10801/assets/index.407e6789.js:32:3175 CL@http://192.168.178.192:10801/assets/index.407e6789.js:32:44933 kL@http://192.168.178.192:10801/assets/index.407e6789.js:32:40044 DN@http://192.168.178.192:10801/assets/index.407e6789.js:32:39972 Ah@http://192.168.178.192:10801/assets/index.407e6789.js:32:39826 l1@http://192.168.178.192:10801/assets/index.407e6789.js:32:36161 yL@http://192.168.178.192:10801/assets/index.407e6789.js:32:35109 yL@[native code] C@http://192.168.178.192:10801/assets/index.407e6789.js:17:1582 B@http://192.168.178.192:10801/assets/index.407e6789.js:17:1946
This issue will serve as a roadmap outlining the major features planned for the first release candidate of Stump, v0.1.0, as well as some notes regarding potential post-release goals. This should be treated as a mostly static document, as the features listed are what I consider to be the minimum set to reach a viable release. The section dedicated to post-release features may receive more updates, though. Also note that a few features listed will be more-so nice to haves, rather than hard requirements.
Below are all of the essential features that will need to be completed with at least minimal functionality before the first v0.1.0 release candidate is slated:
client code, its very messy
api into separate package to house all the axios functionsuseQueryprelude crate, organize in other crates where it makes sensecargo report future-incompatibilities --id 4 --package [email protected]local-ip-address check if release yoinked comes back okaycoreStumpConfig for more efficient environment parsingserver upgrades
integration_testscoreservercomponents
HomeScene
TopBar
BookOverviewScene
cursor page param?)ImageBasedReader
AnimatedImageBasedReader
EpubLazyReader
epubcfi and progress_percentage tracking updates with server as readingepubcfi)SeriesOverviewScene
LibraryOverviewScene
LibraryExplorerScene
CreateLibraryScene
UpdateLibraryScene
GeneralSettingsScene
UserManagementScene
JobsAndConfigurationScene
SeverConfigurationScene
Loading... placeholders 🤢/some-page/1, and get redirected to /auth, should redirect instead with query params to restore state: /auth?redirect=/some-page/1
.stumpignore files to alter what the scanner will look atwebp generation0.5 x 0.75)0.5, equal to 0.5 x 0.5 above)331.5 x 512)pngjpgwebp0.5 unrar release lands:
read_bytes implementationepubcfi and progress_percentage for progress trackingFirst and foremost, the top priority after the initial release will be bug fixes and maintenance. If you've read the entire Pre-Release Items section, you'll know that v0.1.0 is intended to be a sort of MVP, and not a fully featured option yet. That being said, the following are things I'd like to explore afterwards, also not necessarily in priority order:
benchmarks crateOriginally posted by Relwi March 15, 2023
Hey, is there the possibility that we have in a future an AUR package?
At some point, it would be a nice to have if CI can also publish the zipped(?) linux binary + webapp bundle to AUR.
I think a really fun, opt-in feature for the desktop app would be having a discord rich presence. Stump already has a very basic functionality for this using the discord_rich_presence crate.
The remaining work for this is along the lines of:
browser and preference is true, connect to discord presenceBeyond that, I won't focus on features surrounding the context for the presence (like status message and what not). It will just connect to discord and set the application name. In the future, I'll add options like allowing Stump to report the book being read and what not.
Docker seems to create stump's config directory, on the host machine, with root privilege, making root the owner. This becomes a big problem during runtime, as stump won't have permissions to modify/access the config folder, which causes a ton of errors.
Changing the permissions manually fixes this, but this is really not ideal.
I have only been able to reproduce this issue on Linux (both a dedicated install, as well as WSL). Config folder must not already be present (~/.stump), otherwise issue won't occur.
how can i read normal pdf file, no comic with folder structure. It seems like it don't detect any books if i put all my pdf to root folder
I recently tried clippy and found it to be incredibly useful. Stump has 158 clippy detected smells, so making an issue to fix it.
Converting this to an issue for tracking. I am going to be removing the docs from this repo and making a separate one. I think the shear amount of stuff in this repo has gotten to be little bit of clutter. Will live here. Once Stump is release ready, it will be too cluttered to have all the separate app releases in this repo, as well, so figured as I get closer to that point I'll move everything over there, as well. See original notes for this at the bottom, as well.
Astro seems to have a really nice DX for documentation sites. It would be nice to not have to maintain my own set of components JUST for documentation (e.g. Code rendering, prismjs highlighting, etc).
Creating separate issue off of #21.
Currently, building the multi-arch docker images takes over 2 hours, mainly due to the arm platforms (the amd64 takes about 15 minutes). This is awful, and will pretty much prevent me implementing any sort of automated CI docker builds for Stump. Running the builds on my M1 laptop greatly reduces the build time for those architectures (arm64, arm/v7), but then the amd64 build fails from what I believe is related to qemu bug, based on my searches, but am unsure.
This issue is to, in general, overhaul the docker setup to allow for a CI pipeline to eventually be added once Stump is ready:
My current Dockerfile creates an image that is ~2GB on my machine, which is certainly better than the 7GB original take but still not nearly small enough (if it can be helped). It does not even include serving the frontend static content 😢
Ideally I just need an image that has the server executable to run and the static content to serve. I use sqlite, but ideally would mount a directory on the container to one on the host machine? I am not a docker wizard yet
Current server/Dockerfile (at time of writing):
FROM rust:1-alpine3.15
# https://github.com/rust-lang/docker-rust/issues/85
ENV RUSTFLAGS="-C target-feature=-crt-static"
RUN apk add --no-cache --verbose musl-dev build-base sqlite openssl-dev
WORKDIR /app/server
COPY ./src /app/server/src
COPY ./Cargo.lock /app/server/Cargo.lock
COPY ./Cargo.toml /app/server/Cargo.toml
COPY ./Rocket.toml /app/server/Rocket.toml
# TODO: what to do with frontend?
RUN cargo build --release
RUN strip target/release/stumpA user should be able to add media to a reading list, like a playlist but for books. Reading lists may be either for a user or for a set of users
Core tasks:
ReadingList model to prisma schemaImportCblJob should be created.cbl parsing functions need to be createdBasic REST endpoints:
# get all reading lists *created* by session user
GET /api/reading-list -> ReadingList[]
# get reading list by id IF *created* by session user
GET /api/reading-list/:id -> ReadingList
# create reading list, take in something like: { media_ids: string[]; }
POST /api/reading-list -> ReadingList
# update reading list, take in something like: { media_ids: string[]; }. replace with input
PUT /api/reading-list -> ReadingList
# delete reading list by id IF *created* by session user
DELETE /api/reading-list/:id -> ReadingListInterface tasks:
After some helpful testing from people in discord, this nasty little bug was found. It seems to only present when running Stump in Docker, which is super annoying lol. I've narrowed it down to when I try and extract the byte content of a file within the rar archive without unpacking it.
I think a potential work around might be to not use the unrar library in Docker? Or to try and rework the read_bytes work around I wrote (as it isn't wonderful)

See Komga example extension for reference
Looks to be just a kotlin app that would invoke various endpoints on a Stump instance, should be straightforward enough to do once a larger set of core features are done
https://github.com/stumpapp/tachiyomi-extensions
Will likely be part of v0.2.0 or beyond, so the API will be somewhat stable, and will be added to the appropriate milestone for tracking. This should take priority over any potential in-house mobile application development. However, if someone would like to do some work towards this for hactoberfest, that's totally fine.
Seems fairly straight-forward, even a few easy library choices:
https://www.npmjs.com/package/dockerhub-webhook
Navigation is really not ideal right now. The nav icons mimic the native browser navigation, but that is incorrect.
If I am at /books/:id/pages/:page and I go backward, it should take me to /books/:id, not the literal previous history (which might just be the previous page).
If I am on /books/:id, going backward should take me to /series/:id, etc
Stump will have another viewing option available for libraries that will essentially let users navigate through their libraries as they would a native file explorer. I'm adding this as a hopeful work around for those who have more niche library patterns that would be too cumbersome to explicitly support.
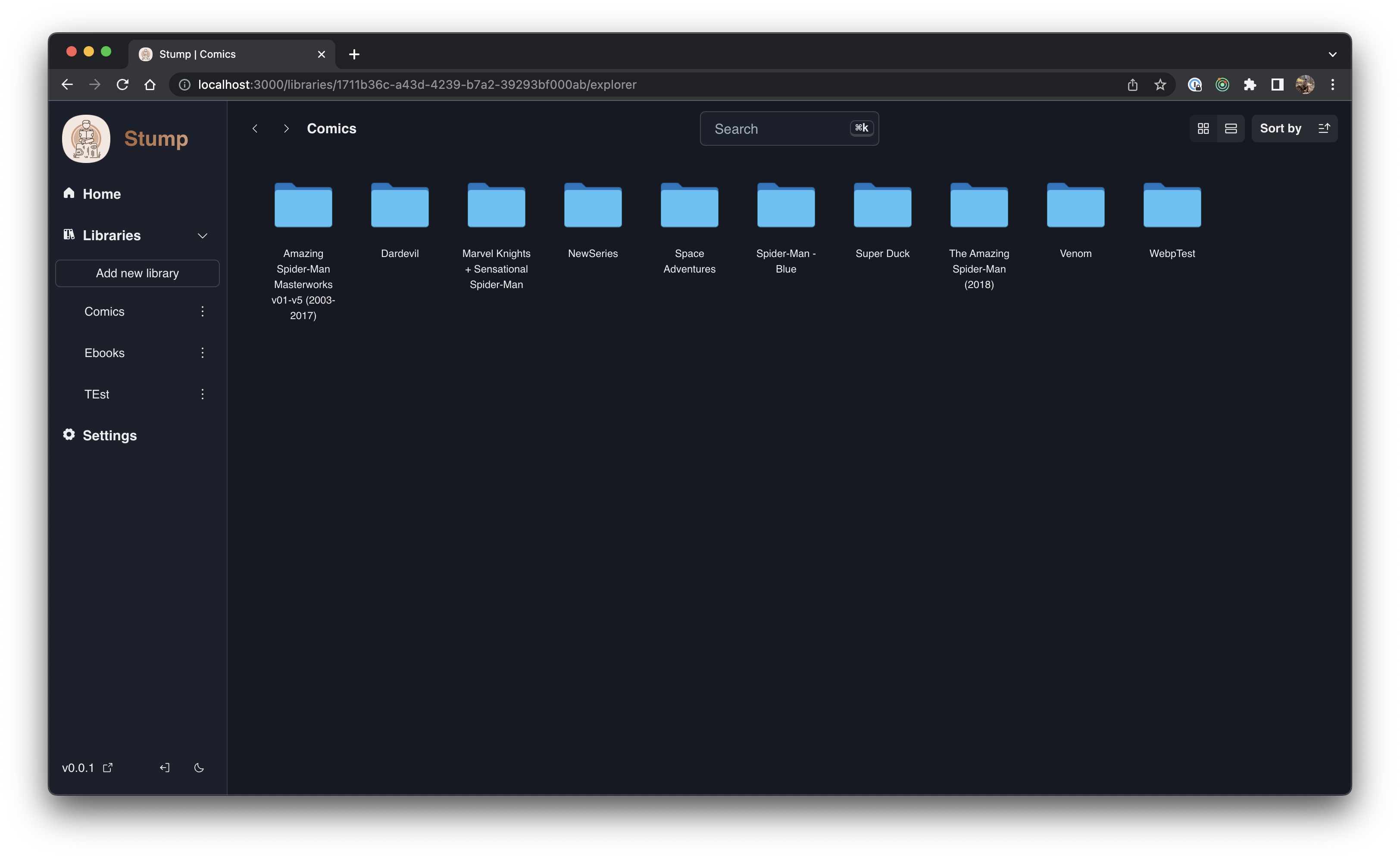
Look into https://tanstack.com/virtual/v3
There might require some additional API routes to be defined, however majority of the work is confined to to the interface package.
If you are considering looking at this for hacktoberfest:
common/interface/src/components/FileExplorer.tsxI want to add a simple CI pipeline that effectively mimics the pre-commit hook:
commonIn the future I'll add the tests to this pipeline, but since those aren't done / functional that will have to wait. I am very unfamiliar with CI pipelines with GitHub, but I want to have some sort of cache layer so CI minutes are not wasted (I am not rich lol)
If I ever want to make a release, I'll need to have some sort of automated system for doing it. This would honestly be super useful for testing/nightly releases or something, as well. Like #68, I am not very knowledgable in this area.
In general, when a release is made the following needs to happen:
server build
web builddesktop build
server build
Some constraints that I have no idea how to go about yet:
include_str! macros might mess things up but also 🤷There are two main areas relating to jobs and the scanner job specifically that need addressing:
Jobs are kind of stateless right now. Sure, they have access to a minimal subset of context, but are stateless with respect to the jobs own state (e.g. what task it is currently working on, how many are left, etc). This lack of state prevents me from properly implementing features like:
The current implementation of the scanner and the jobs is not overly flexible and simply won't scale down the road, as exemplified by testers with enormous libraries. It's definitely quick, but I'd rather sacrifice on a little speed for memory efficiency for those larger libraries. I think part of the issue is that for really large libraries, there are simply too many threads being spawned, degrading memory efficiency and performance.
I already have the concept of a JobWrapper which handles the kickoff of the actual job process as well as simple things like duration and what not. I think this should be extended to also manage some sort of state for the job, which can be mutated with on_progress callbacks, perhaps. The state, in general, needs to store the following:
This needs to be MORE than just a numeric value, as it currently is.
A shutdown signal should also be added to the JobWrapper which listens for a signal of two kinds:
EDIT: I am making this an actual issue in case any potential hacktoberfest contributors would like to start on this. If that interests you, review the criteria at the bottom.
I think it would be cool to have a little CLI app that people can use to check on their server. See apps/tui. Some features I am thinking:
Core technologies I plan on using:
This would mostly be just for fun, and if it goes further than the silly little template in the repository it would be a small headache. The core crate will need to be converted into a library, so that the types may be shared between the applications. This means the rocket server part would become a separate application in the apps directory.
One issue with this is that the core is a rather large library, so might want to make some opt-in features to reduce the size when used in this way.
General criteria:
For hacktoberfest, not everything on the list must be completed.
clap should take in a few sub commands:
config:
base_url of the Stump serverconvert:
impl SSEHandler {
pub fn new(base_url: &str, ..args..) -> Arc<Self> {
let this = Arc::new(Self {
..fields..
});
tokio::spawn(async move {
// https://docs.rs/reqwest-eventsource/latest/reqwest_eventsource/
// Note: can be hard coded for now
let mut source = EventSource::get(&format!("{}/api/jobs/listen", base_url));
while let Some(event) = source.next().await {
match event {
// handle events here
}
}
});
this
}
}For files in the root folder (i.e. the folder where the top of the library is located), files not in folders are not being included in the scan.
I am unsure if this is intended or unintended behavior, but for someone with a non-standard file ordering, this is limiting for the utility of stump.
I would hope that the scanner would find all acceptable files in the library and display them as available.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.