A maliciously secure framework for efficient 3-party protocols tailored for neural networks. This work builds off SecureNN, ABY3 and other prior works. This work is published in Privacy Enhancing Technologies Symposium (PETS) 2021. Paper available here. If you're looking to run Neural Network training, strongly consider using this GPU-based codebase Piranha.
This codebase is released solely as a reference for other developers, as a proof-of-concept, and for benchmarking purposes. In particular, it has not had any security review, has a number of implementational TODOs, has a number of known bugs (especially in the malicious implementation), and thus, should be used at your own risk. You can contribute to this project by creating pull requests and submitting fixes and implementations. The code has not run end-to-end training and we expect this to require some parameter tuning, hence training and inference won't work out of the box (however, inference from pre-trained networks can be repreduced easily).
-
The code should work on most Linux distributions (It has been developed and tested with Ubuntu 16.04 and 18.04).
-
Required packages for Falcon:
Install these packages with your favorite package manager, e.g,
sudo apt-get install <package-name>.
To install and run Falcon using docker, first build the container:
docker build -t falcon .
then run
docker run -it falcon '/bin/bash'.
From the prompt, you can execute any of the commands specified in Running the code.
files/- Shared keys, IP addresses and data files.files/preload- Contains data for pretrained network from SecureML. The other networks can be generated usingscriptsand functions insecondary.cpplib_eigen/- Eigen library for faster matrix multiplication.src/- Source code.util/- Dependencies for AES randomness.scripts/- Contains python code to generate trained models for accuracy testing over a batch.- The
godscript makes remote runs simpler (as well as themakefile)
To build Falcon, run the following commands:
git clone https://github.com/snwagh/falcon-public.git Falcon
cd Falcon
make all -j$(nproc)
To run the code, simply choose one of the following options:
-
make: Prints all the possible makefile options. -
make terminal: Runs the 3PC code on localhost with output from$P_0$ printed to standard output. -
make file: : Runs the 3PC code on localhost with output from$P_0$ printed to a file (inoutput/3PC.txt) -
make valg: Useful for debugging the code for set faults. Note that the -03 optimization flag needs to be suppressed (toggle lines 42, 43 inmakefile) -
make command: Enables running a specific network, dataset, adversarial model, and run type (localhost/LAN/WAN) specified through themakefile. This takes precedence over choices in thesrc/main.cppfile. - To run the code over tmux over multiple terminals,
make zero,make one, andmake twocome in handy. - Finally, the
makefile(line 4-15) contains the descriptions of the arguments accepted by the executable.
Note that given the size of the larger networks (AlexNet, VGG16) and the need to explicitly define network parameters, these networks can only be run for the CIFAR10 and Tiny ImageNet dataset. On the contrary, the smaller datasets (SecureML, Sarda, MiniONN, and LeNet) can only be run for the MNIST dataset. Running them otherwise should result in assertion errors. The following configuration was sufficient to produce the results for the larger networks: 2.9 GHz Intel Xeon E5-2666 v3 Processor, 36 cores, 60 GB RAM (in particular, a similar processor with 16 GB RAM was insifficient).
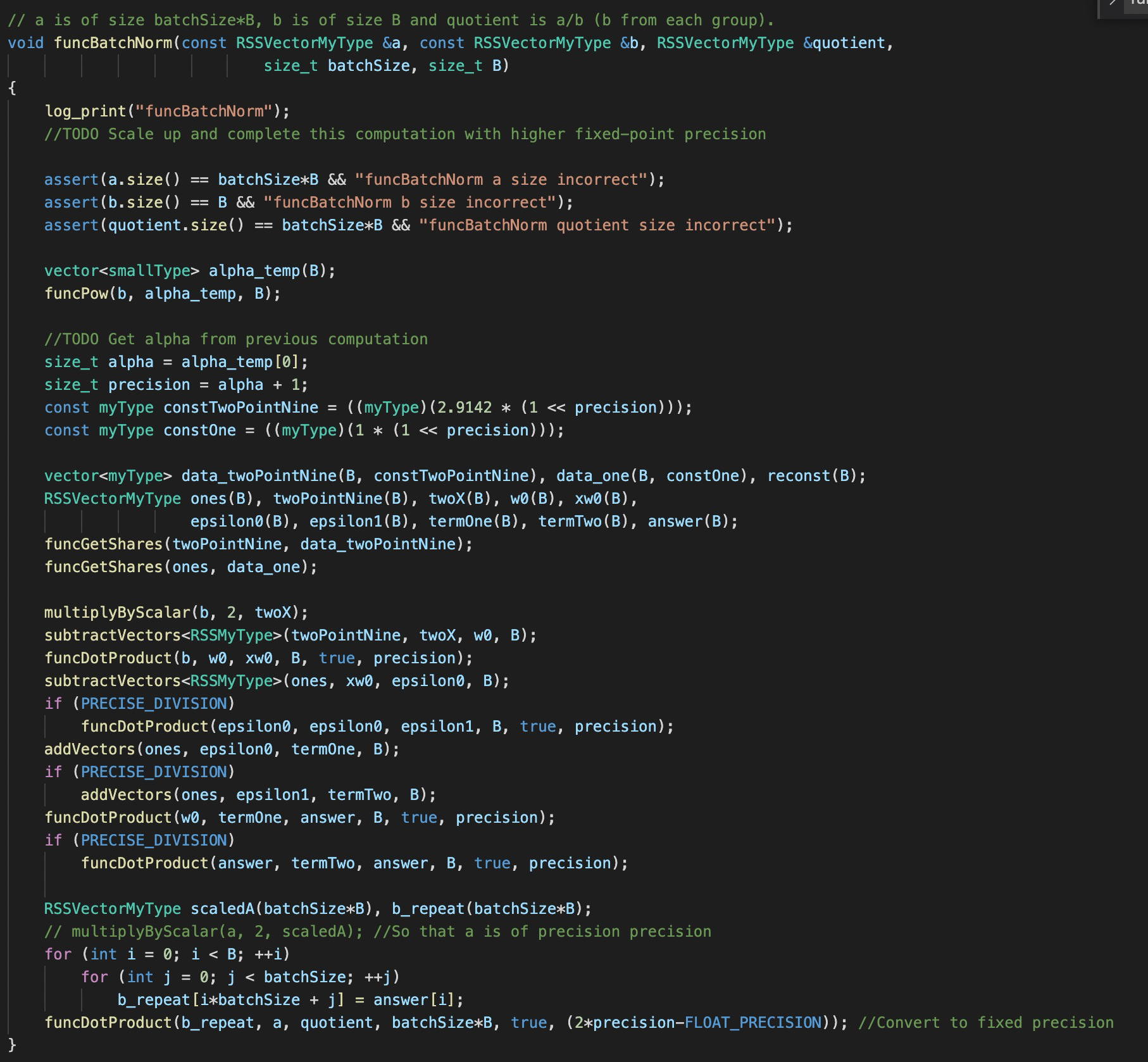
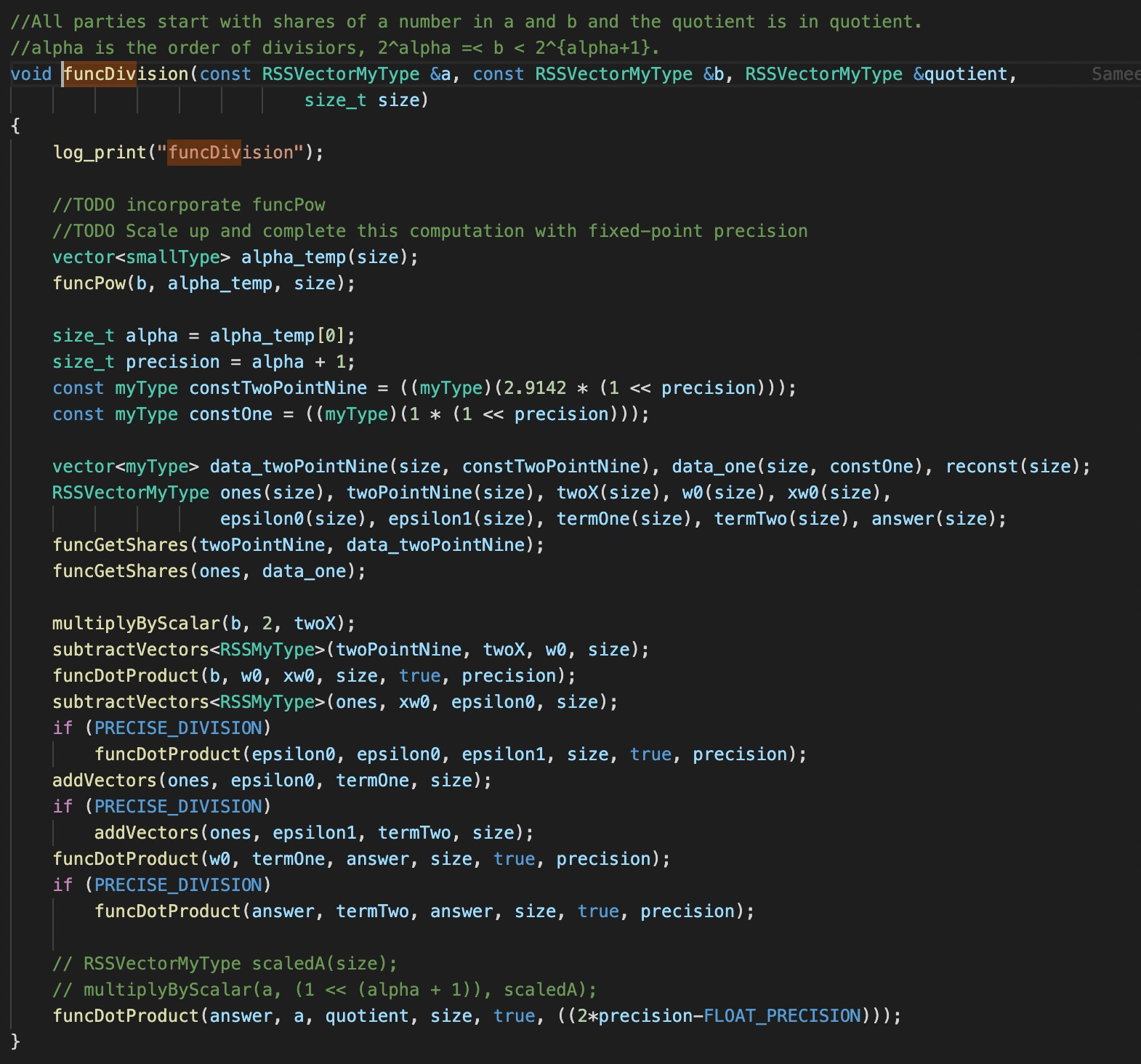
Comparison with SecureNN
While a bulk of the Falcon code builds on SecureNN, it differs in two important characterastics (1) Building on replicated secret sharing (RSS) (2) Modularity of the design. The latter enables each layer to self contained in forward and backward pass (in contrast to SecureNN where layers are merged for the networks to be tested). The functions are reasonably tested (including ReLU) however they are more tested for 32-bit datatype so the 64-bit might have minor bugs.
If there are compile/installation/runtime errors, please create git issues. Some of the common errors and their resolutions are listed below:
cannot findsomething error: This would be a linker error, make sure your code has access to the right paths in the$PATHenvironment variable.Binding error: There is probably an execution running in the background. Kill the process withpkill Falcon.out(this happens since the socket ports are hardcoded in the program and a number of the makefile commands run code in the background andCtrl+conly kills the Party 0 code)Bad alloc: This is probably a memory issue. If you're running one of the larger networks (AlexNet, VGG16) on a laptop, try running them on a server/cluster/machine with more memory.
- Remove size argument from all functions (generate it inside functions)
- Clean-up tools and functionalities file -- move reconstruction functions to tools
- Pointers to layer configurations are never deleted --> needs to be fixed
- Precompute implementation
- Incorrect communication numbers for parallel implememntations
- ...
You can cite the paper using the following bibtex entry (the paper links to this repo):
@inproceedings{wagh2021falcon,
title={{FALCON: Honest-Majority Maliciously Secure Framework for Private Deep Learning}},
author={Wagh, Sameer and Tople, Shruti and Benhamouda, Fabrice and Kushilevitz, Eyal and Mittal, Prateek and Rabin, Tal},
journal={Proceedings on Privacy Enhancing Technologies},
year={2021}
}
For questions, please create git issues; for eventual replies, you can also reach out to [email protected]