shamangary / keras-mnist-center-loss-with-visualization Goto Github PK
View Code? Open in Web Editor NEWAn implementation for mnist center loss training and visualization
An implementation for mnist center loss training and visualization
大大您好,謝謝你提供這麼棒的source code,讓我受益良多 :)
以下我有一些關於fit generator的問題,還望大大能夠解惑~
hist = model.fit_generator(generator=data_generator_centerloss(X=[x_train, y_train_a_class_value], Y=[y_train_a_class,y_train_a, random_y_train_a], batch_size=batch_size),
steps_per_epoch=train_num // batch_size,
validation_data=([x_test,y_test_a_class_value], [y_test_a_class,y_test_a, random_y_test_a]),
epochs=nb_epochs, verbose=1,
callbacks=callbacks)
以上是大大提供fit_generator的範本,我好奇的是為何Y=[y_train_a_class,y_train_a, random_y_train_a]有3個輸出 ? y_train_a代表什麼意思?
會有這個好奇點是因為我看在TTY.mnist.py是用.fit實踐的 --> model_centerloss.fit([x_train,y_train_value], [y_train, random_y_train], batch_size=batch_size, epochs=epochs, verbose=1, validation_data=([x_test,y_test_value], [y_test,random_y_test]), callbacks=[histories]) ,照我的理解,其為雙輸入雙輸出的格式。故我覺得.fit_generator也要為雙輸入雙輸出~
我依照雙輸入和雙輸出的想法建構自己的fit_generator,出現一個很奇怪的問題

以下是我輸入和輸出的 .shape,感覺大小是正確的
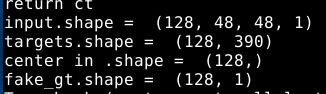
所以有點摸不著頭緒,是不是我的generator和l2_loss的格是不相符,不過我看l2_loss的型態都是?,感覺怪怪的QQ
以下是我實作generator的方式:,我的generator會return這些東西

然後我的fit_generator是這樣實踐的
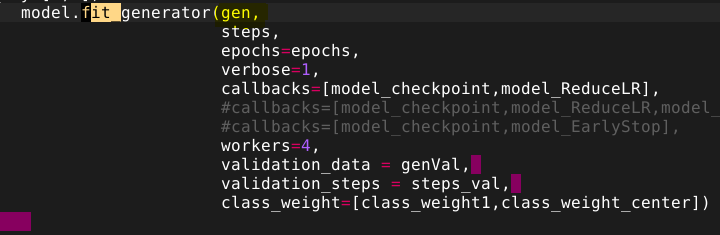
不好意思打擾您,真的很謝謝你提供那麼棒的程式,讓我在實踐center loss時有一個很棒的參考對象~謝謝
,Tina
按照上诉的方法,中心值没有更新,每次还是取随机值,更新需要进行梯度更新或者每次重新计算中心值
history_softmax = resnet_model.fit_generator(
train_generator,
steps_per_epoch=123520//BATCH_SIZE,
epochs=EPOCHS,
validation_data=val_generator,
validation_steps=7119//BATCH_SIZE,
callbacks=[lr]
)
history2 = model_centerloss.fit_generator(train_generator, [y_train, random_y_train],
batch_size=batch_size, epochs=epochs,
verbose=1, validation_data=(val_generator, [y_test, random_y_test]),
callbacks=[lr, modelcheckpoint])
您好:
有看了您在3/2更新的中文解說,非常清楚也讓我了解了許多,但我想請問一下我記得center loss 會在訓練過程中不斷更新center feature,可是在您的程式中並沒有看到相關的代碼,因此想請問這部份是否出現了一些問題,還是是我沒注意到,謝謝
hi @shamangary
我用我自己的数据集,训练。在测试集上的结果很差,只有14%,而且发现dense_2_acc 不提高,最高到19%。如果,我不用center_loss,在测试集上的准确率有50%。

加载数据集
训练集和验证集
train,trainlabel = xrp.loadtrain()
train = densenet.preprocess_input(train)
index = [i for i in range(len(train))]
random.shuffle(index)
train = train[index]
trainlabel = trainlabel[index]
(x_train,x_test)=(train[0:11000],train[11000:])
(y_train,y_test)=(trainlabel[0:11000],trainlabel[11000:])
y_train_value = y_train
y_test_value = y_test
y_train = np_utils.to_categorical(y_train,nb_classes)
y_test = np_utils.to_categorical(y_test,nb_classes)
测试集
X_test,Y_test = xrp.loadtest()
Z_test_value = Y_test
Y_test = np_utils.to_categorical(Y_test,nb_classes)
X_test = densenet.preprocess_input(X_test)
网络结构如下
base_model = VGG16(weights='imagenet',include_top=False)
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = BatchNormalization(axis=1)(x)
ip1 = Dense(1024,activation='relu')(x)
predictions = Dense(8,activation='softmax')(ip1)
model = Model(input=base_model.input,output=predictions)
for layer in base_model.layers:
layer.trainable = True
sgd = SGD(lr=0.0001, decay=1e-6, momentum=0.9,nesterov=True)
model.compile(optimizer='rmsprop',loss='categorical_crossentropy')
#this is the center_loss
isCenterloss = True
if isCenterloss:
lambda_c = 0.2
input_target = Input(shape=(1,))
centers = Embedding(8,1024)(input_target)
l2_loss = Lambda(lambda x: K.sum(K.square(x[0]-
x[1[:,0]),1,keepdims=True),name='l2_loss')
model_centerloss = Model(inputs=[base_model.input,input_target],outputs=[predictions,l2_loss])
sgd_1 = SGD(lr=0.00001, decay=1e-6, momentum=0.9,nesterov=True)
model_centerloss.compile(optimizer=sgd_1, loss=["categorical_crossentropy", lambda y_true,,y_pred: y_pred],loss_weights=[1,lambda_c],metrics=['accuracy'])
if isCenterloss:
random_y_train = np.random.rand(x_train.shape[0],1)
random_y_test = np.random.rand(x_test.shape[0],1)
model_centerloss.fit([x_train,y_train_value], [y_train, random_y_train], batch_size=batch_size,epochs=nb_epoch, verbose=1, validation_data=([x_test,y_test_value], [y_test,random_y_test]))
预测代码如下:
privateLabel_0
= model_centerloss.predict([X_test,Z_test_value],batch_size=1,verbose=1) print (len(privateLabel_0)
privateLabel = privateLabel_0[0]
list_label1 = []
list_label2 = []
x= len(privateLabel)
for j in range(x):
list_label1.append(np.argmax(Y_test[j]))
list_label2.append(np.argmax(privateLabel[j]))
privateAcc
= len([1 for i in range(len(Y_test)) if list_label2[i]==list_label1[i]])/float(len(Y_test))
print ('the privateAcc is ',privateAcc)
我调整了learning_rate = 0.00001,可是效果不好,dense_2_acc 不提高。
请问一下,是哪方面的问题。谢谢。
Hello,
Thanks for your code. I just have a very quick question.
The paper mentions that there should be a scalar alpha to control the learning rate of the centers. This is interesting to me. However I don't think you implement such a thing. If you do please correct me.
Plus do you know how to implement that? I am very curious about this but right now I don't have a concrete idea about doing so.
Thx
@shamangary
Thanks.
input_target = Input(shape=(1,)) # single value ground truth labels as inputs
这一行代码不是很懂。
center_loss 公式中 是C,代码中你解释是为 single value ground truth labels as inputs
C是聚类的中心,你是将single value ground truth label 作为初始值么?
谢谢
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.