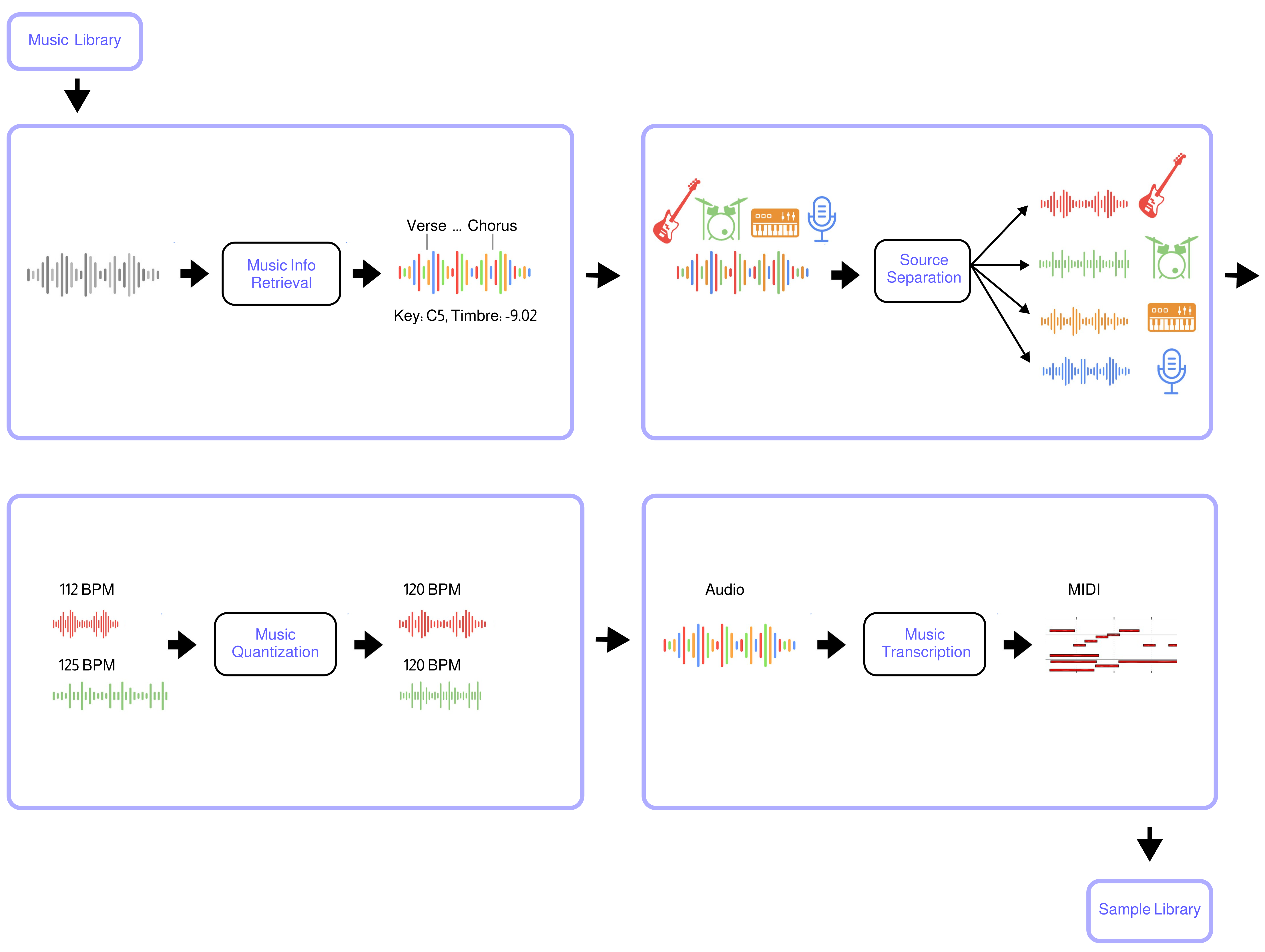
Polymath uses machine learning to convert any music library (e.g from Hard-Drive or YouTube) into a music production sample-library. The tool automatically separates songs into stems (beats, bass, etc.), quantizes them to the same tempo and beat-grid (e.g. 120bpm), analyzes musical structure (e.g. verse, chorus, etc.), key (e.g C4, E3, etc.) and other infos (timbre, loudness, etc.), and converts audio to midi. The result is a searchable sample library that streamlines the workflow for music producers, DJs, and ML audio developers.
Polymath makes it effortless to combine elements from different songs to create unique new compositions: Simply grab a beat from a Funkadelic track, a bassline from a Tito Puente piece, and fitting horns from a Fela Kuti song, and seamlessly integrate them into your DAW in record time. Using Polymath's search capability to discover related tracks, it is a breeze to create a polished, hour-long mash-up DJ set. For ML developers, Polymath simplifies the process of creating a large music dataset, for training generative models, etc.
- Music Source Separation is performed with the Demucs neural network
- Music Structure Segmentation/Labeling is performed with the sf_segmenter neural network
- Music Pitch Tracking and Key Detection are performed with Crepe neural network
- Music to MIDI transcription is performed with Basic Pitch neural network
- Music Quantization and Alignment are performed with pyrubberband
- Music Info retrieval and processing is performed with librosa
Join the Polymath Community on Discord
You need to have the following software installed on your system:
ffmpeg
You need python version >=3.7 and <=3.10. From your terminal run:
git clone https://github.com/samim23/polymath
cd polymath
pip install -r requirements.txtIf you run into an issue with basic-pitch while trying to run Polymath, run this command after your installation:
pip install git+https://github.com/spotify/basic-pitch.gitMost of the libraries polymath uses come with native GPU support through cuda. Please follow the steps on https://www.tensorflow.org/install/pip to setup tensorflow for use with cuda. If you have followed these steps, tensorflow and torch will both automatically pick up the GPU and use it. This only applied to native setups, for dockerized deployments (see next section), gpu support is forthcoming
If you have Docker installed on your system, you can use the provided Dockerfile to quickly build a polymath docker image (if your user is not part of the docker group, remember to prepend sudo to the following command):
docker build -t polymath ./In order to exchange input and output files between your hosts system and the polymath docker container, you need to create the following four directories:
./input./library./processed./separated
Now put any files you want to process with polymath into the input folder.
Then you can run polymath through docker by using the docker run command and pass any arguments that you would originally pass to the python command, e.g. if you are in a linux OS call:
docker run \
-v "$(pwd)"/processed:/polymath/processed \
-v "$(pwd)"/separated:/polymath/separated \
-v "$(pwd)"/library:/polymath/library \
-v "$(pwd)"/input:/polymath/input \
polymath python /polymath/polymath.py -a ./input/song1.wavpython polymath.py -a n6DAqMFe97Epython polymath.py -a /path/to/audiolib/song.wavpython polymath.py -a n6DAqMFe97E,eaPzCHEQExs,RijB8wnJCN0
python polymath.py -a /path/to/audiolib/song1.wav,/path/to/audiolib/song2.wav
python polymath.py -a /path/to/audiolib/Songs are automatically analyzed once which takes some time. Once in the database, they can be access rapidly. The database is stored in the folder "/library/database.p". To reset everything, simply delete it.
Quantize a specific songs in the library to tempo 120 BPM (-q = database audio file ID, -t = tempo in BPM)
python polymath.py -q n6DAqMFe97E -t 120python polymath.py -q all -t 120python polymath.py -q n6DAqMFe97E -kSongs are automatically quantized to the same tempo and beat-grid and saved to the folder “/processed”.
Search for 10 similar songs based on a specific songs in the library (-s = database audio file ID, -sa = results amount)
python polymath.py -s n6DAqMFe97E -sa 10Search for similar songs based on a specific songs in the library and quantize all of them to tempo 120 BPM
python polymath.py -s n6DAqMFe97E -sa 10 -q all -t 120python polymath.py -s n6DAqMFe97E -sa 10 -q all -t 120 -st -kSimilar songs are automatically found and optionally quantized and saved to the folder "/processed". This makes it easy to create for example an hour long mix of songs that perfectly match one after the other.
python polymath.py -a n6DAqMFe97E -q all -t 120 -mGenerated Midi Files are currently always 120BPM and need to be time adjusted in your DAW. This will be resolved soon. The current Audio2Midi model gives mixed results with drums/percussion. This will be resolved with additional audio2midi model options in the future.
The Demucs Neural Net has settings that can be adjusted in the python file
- bass
- drum
- guitare
- other
- piano
- vocalsThe audio feature extractors have settings that can be adjusted in the python file
- tempo
- duration
- timbre
- timbre_frames
- pitch
- pitch_frames
- intensity
- intensity_frames
- volume
- avg_volume
- loudness
- beats
- segments_boundaries
- segments_labels
- frequency_frames
- frequency
- keyPolymath is released under the MIT license as found in the LICENSE file.







































































































































