sakila1012 / blog Goto Github PK
View Code? Open in Web Editor NEW记录自己学习工作中的心得
记录自己学习工作中的心得













加入苏研将近一个月,谈谈我对公司的看法吧
有时自己会加班,也会早点回到住的地方。
也许情感是我不愿意提的,因为,在即将离开学校,走向工作的时候,我的女朋友却跟我分手了,让我不知道如何打消时间。其实反而增加了我的不安,刚开的几天我会主动联系她,可她却没有回复我。
开发工作进行将近半个月,目前工作遇到的瓶颈还是挺过
上传文件的后缀名问题
设置 extentions: undefined,即可上传所有的文件类型
this.$refs.menu.updateActiveName()
vuex 可以使用插件,所以引入了vuex-along
比如
this.$store.commit('getCurrentUser', userInfo)
往往在触发事件时,都会报失败的信息,commit undefined,而且在调试的过程中,会发现this对象中没有$store,困了好久
直接在该组件中引入 store.js 就可以了。
在vue.config.js 中配置
具体配置如下
configureWebpack:(config)=>{
//入口文件
config.entry.app = ['babel-polyfill', './src/main.js'];
//删除console插件
let plugins = [
new UglifyJsPlugin({
uglifyOptions: {
compress: {
warnings: false,
drop_console:true,
drop_debugger:true
},
output:{
// 去掉注释内容
comments: false,
}
},
sourceMap: false,
parallel: true,
})
];
//只有打包生产环境才需要将console删除
if(process.env.VUE_APP_build_type=='production'){
config.plugins = [...config.plugins, ...plugins];
}
},
通过
window.navigator.userAgent
获取的结果不一致
IE 10 是包含 MSIE
IE 11 是包含 Trident
解决方法:
在 *.vue 中使用
我们可以通过 Vue CLI 提供的客户端环境变量 process.env.BASE_URL 来获取 baseUrl:
Vue.prototype.$baseUrl = process.env.BASE_URL
// 在 <template> 下使用
<img :src="`${$baseUrl}imgs/my_image.png`">
上面的解决方案还是有问题
<img :src="`${$baseUrl}imgs/my_image.png`">
上面的解决方案还是有问题的
<img :src="src">
在 script 引入该图片,并在data中定义
在 css 中是引入
url('~@/assets/img/toolbarButton-zoomOut.png');
2019 已经过了将近 1/4,感觉没有规划的过每一天,整天都是浑浑噩噩的,马上就要过而立之年,自己仍然没有成就。心有点慌,不知道接下来该怎么样,所以要给自己点压力,也要给自己点信心。制定下目标。
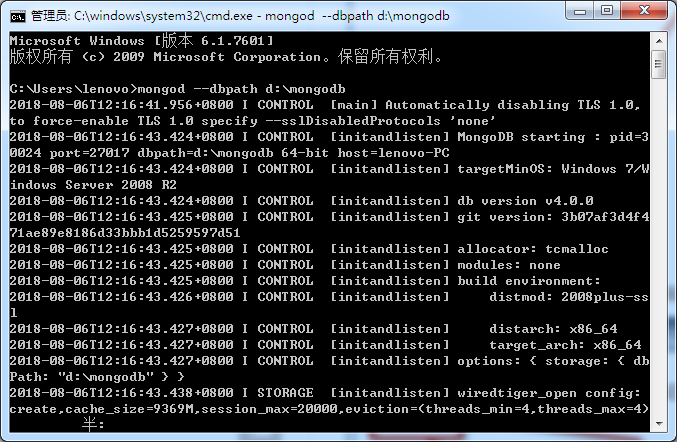
2.安装成功后,配置环境变量
在你的计算机上创建一个目录,用于存放MongoDB数据库文件的文件夹
执行命令
mongod --dbpath D:\mongodb
mongodump -h dbhost -d dbname -o dbdirectory
例如:mongodump -h 127.0.0.1 -d koa -o d:\koa (Windows环境)
导入
mongorestore -h dbhost -d dbname path
例如:mongorestore -h 127.0.0.1 -d koademo d:\koa\koa
在之前的工作中和面试的过程中,都会或多或少地涉及到这三方面的知识,但在遇到这些问题的时候,脑子确实一片空白,没有对这三个方面的内容有一个清晰的认识,仅仅停留在知道这三个字母而已。
需要对这三个方面的内容背景,功能,优势,不足深入的探究。
影响一个 HTTP 网络请求的因素主要有两个:带宽和延迟
带宽:如果说我们还停留在拨号上网的阶段,带宽可能会成为一个比较严重影响请求的问题,但是现在网络基础设施建设已经使得带宽得到极大的提升,我们不用担心由带宽而影响网速,那么只剩下延迟了。
延迟:
浏览器阻塞:浏览器会因为一些原因阻塞请求。浏览器对于同一个域名,同时只能有 4 个连接(这个根据浏览器内核不同可能会有所差异),超过浏览器最大连接限制,后续请求就会被阻塞。
DNS 查询:浏览器需要知道目标服务器的 IP 才能建立连接。将域名解析为 IP 的这个系统时 DNS。这个通常可以利用 DNS 缓存结果来达到减少这个时间的目的。
建立连接:HTTP是基于 TCP 协议的,浏览器最快也要在第三次握手时才能捎带 HTTP 请求报文,达到真正的建立连接,但是这些连接无法复用会导致每次请求都经历三次握手和慢启动。三次握手在高延迟的场景下影响较明显,慢启动则对文件类大请求影响较大。
为了解决以上问题,网景公司在 1994 年创建了 HTTPS,并应用在网景导航者浏览器中,最初,HTTPS 是与 SSL 一起使用的,在 SSL 逐渐演变成 TLS 时(其实两个是一个东西,只是名字不同而已),最新的 HTTPS 也由 2000 年 5 月公布的 RFC 2018 正式确定下来。简单地说,HTTPS 就是安全版的 HTTP,并且由于当代对安全性要求更高,Chrome 和 Firefox 都大力支持网站使用 HTTPS,苹果也在 iOS 10 系统中强制 app 使用 HTTPS 来传输数据。

如果一个网站要由 HTTP 换成 HTTPS,可能需要关注一下几点:
2012 年 Google 提出了 SPDY 的方案,它综合了 HTTPS 和 HTTP 两者优点于一体的传输协议,主要解决:

SPDY 位于 HTTP 之下,TCP 和 SSL之上,这样可以轻松兼容老版本的 HTTP 协议,同时可以使用已有的 SSL 功能。
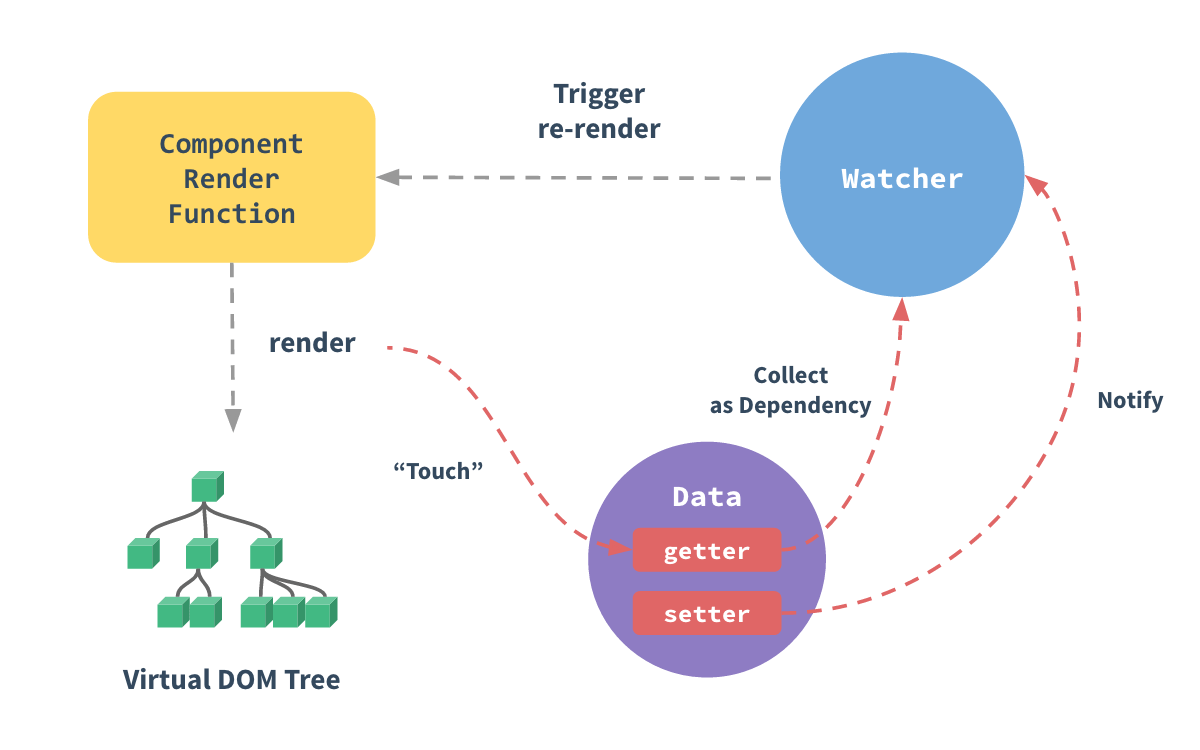
相信看过 vue 官方文档的同学,对这张图应该相当很熟悉了。
那么 vue 响应式是怎么实现的?
一般都会说数据劫持 + Object.defineProperty
下面是简单版的实现
<div>
<input type="text" id="txt">
<p id="show-txt"></p>
</div>
<script>
var obj = {};
Object.defineProperty(obj, 'txt', {
get: function(){
return obj;
},
set: function(newValue) {
document.getElementById('txt').value = newValue;
document.getElementById('show-txt').innerHTML = newValue;
}
})
document.addEventListener('keyup', function(e) {
obj.txt = e.target.value;
})
</script>
标准版的如下:
const Observer = function(data) {
for (var key in data) {
defineReactive(data, key);
}
}
const defineReactive = function(obj, key) {
const dep = new Dep();
let val = obj[key];
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get() {
console.log('in get');
dep.depend();
return val;
},
set(newVal) {
if (newVal === val) {
return;
}
val = newVal;
dep.notify();
}
});
}
const observe = function (data) {
return new Oserver(data)
}
const Vue = function (options) {
const self = this;
if (options && typeof options.data === 'function') {
this._data = options.data.apply(this);
}
this.mount = function () {
new Watcher(self, self.render);
}
this.render = function() {
with(self) {
_data.text;
}
}
observer(this._data);
}
const Watcher = function(vm, fn) {
const self = this;
this.vm = vm;
Dep.target = this;
this.addDep = function(dep) {
console.log('in watcher update');
fn();
}
this.value = fn();
Dep.target = null;
}
const Dep = function() {
const self = this;
this.target = null;
this.subs = [];
this.depend = function() {
if (Dep.target) {
Dep.target.addDep(self);
}
}
this.addSub = function(watcher) {
self.subs.push(watcher);
}
this.notify = function() {
for (var i=0; i<self.subs.length; i += 1) {
self.subs[i].update();
}
}
}
const vue = new Vue({
data() {
return {
text: 'hello world'
}
}
})
vue.mount();
vue._data.text = '123';
总是遇到 slot,但看官网上的描述,一直没有看懂,所以有必要好好看看,深入理解。
官网上,slot 作用是内容分发。看下例子
<script src="https://unpkg.com/vue/dist/vue.js"></script>
<div id="app">
<children>
<span>我是父组件放在子组件中,没有 slot 我不会显示</span>
</children>
</div>
...
var vm = new Vue({
el: '#app',
components: {
children: {
templete: '<button>我是一个没有 slot 的子组件模板</button>'
}
}
})
这里并没有显示 children 组件中的 span 内容,如果想显示 span 怎么办,那就是使用在组件模板中使用 slot 进行 span 内容的一个分发:
<script src="https://unpkg.com/vue/dist/vue.js"></script>
<div id="app">
<children>
<span>我是父组件放在子组件中,没有 slot 我不会显示</span>
</children>
</div>
...
var vm = new Vue({
el: "#app",
components: {
children: {
templete: '<button><slot></slot>我是一个没有 slot 的子组件模板</button>'
}
}
})
说明 span 的内容作为 button 的子标签已经显示 OK,那么问题来了,如果我们有好几个 slot 怎么办,父组件可能同时会在子组件中放置多个 span 标签,比如下面这种:
<div id="app">
<children>
<span>我是父组件放在子组件中的 slot 1111111111111</span>
<span>我是父组件放在子组件中的 slot 2222222222222</span>
</children>
</div>
在子组件中需要选择性的表示第一个 span 还是第二个 span,怎么办,直接这样试试:
var vm = new Vue({
el: '#app',
components: {
children: {
templete: '<button><slot></slot>我是一个没有 slot 的子组件模板 <slot></slot>'
}
}
})
以上写法肯定是错误,这样写的话相当于没有区分两个 span,这样在 slot 分发的时候会将两个 span 标签内容当做一个标签合并插入 2 处 slot 位置那里,正确的做法是为 slot 指定 name 属性:
<script src="https://unpkg.com/vue/dist/vue.js"></script>
<div id="app">
<children>
<span slot="1">我是一个父组件放在自组件中的 slot 1111111111</span>
<span slot="2">我是一个父组件放在自组件中的 slot 2222222222</span>
</children>
</div>
...
var vm = new Vue({
el: '#app',
components: {
children: {
templete: '<button><slot name="1"></slot>我是一个没有 slot 的子组件模板 <slot name="2"></slot></buttom>'
}
}
})
以上才可以正确输出如下
对于以下情景我们可以再测试下
1、子组件模板中指定 name 属性的 slot 不存在
<script src="https://unpkg.com/vue/dist/vue.js"></script>
<div id="app">
<children>
<span slot="1">我是一个父组件放在自组件中的 slot 1111111111</span>
<span slot="2">我是一个父组件放在自组件中的 slot 2222222222</span>
</children>
</div>
...
var vm = new Vue({
el: '#app',
components: {
children: {
templete: '<button><slot name="3"></slot>我是一个没有 slot 的子组件模板 </buttom>'
}
}
})
当在 children 内找不到匹配的 slot 时,相当于该 slot 无效,即以上两个 span 均不会显示
2、子组件模板中指定 name 属性的 slot 存在,但是父组件注入的另一个 slot 没有使用的情况:
<script src="https://unpkg.com/vue/dist/vue.js"></script>
<div id="app">
<children>
<span slot="1">我是一个父组件放在自组件中的 slot 1111111111</span>
<span slot="2">我是一个父组件放在自组件中的 slot 2222222222</span>
</children>
</div>
...
var vm = new Vue({
el: '#app',
components: {
children: {
templete: '<button><slot name="1"></slot>我是一个没有 slot 的子组件模板</buttom>'
}
}
})
同样地,相当于该具名 slot 没有生命而已,即 slot 等于 2 的 span 不会显示
以上我们提供了两种 slot,没有指定 name 属性的 slot 为“单个slot”,指定了 name 属性的 slot 称作为 “具名 slot”,具名 slot 会查找相应的 slot 属性相同的父组件内容进行匹配。
参考1
CSS 计数器是我们可以用特定属性递增或递减的变量。有了它,我们就可以像在编程语言里面一样,实现一些普通的迭代。
这种方法可以用于一些创造性的解决方案,其中包括代码中一些重复部分的计数。
为了控制你的计数器,你需要 counter-increment 和 counter-increment 属性,以及 counter() 和 counters() 函数。显示不出数值的话这些方法根本没啥用,所以我们要搭配简单的 content 属性。
特性很简单。比如你有一个无序的列表,你想要计数 li 的项,则需要在 ul 上声明一个计数器,然后就可以在其下的 li 增加它的数值了。
我们可以用 counter-reset 属性来定义我们的计数器变量;为此,我们必须给出任意的名字和可选的开始值。默认的开始值是 0。这个属性是包装器元素。
运用 counter-increment 属性,我们可以递增或者递减计数器的值。该属性还有一个可选的值,用于指定递增/递减量。
counter() 函数负责转储。转储的位置是内容属性,因为这是您可以通过 CSS 将数据返回给 HTML 的地方。该函数有两个参数,第一个参数是计数器变量名,第二参数是计数器类型(可选)。
注意: 在CSS中没有任何连接运算符,所以如果你想连接内容属性中的两个值只能使用空格。
这个函数跟 counter()函数实现同样的功能。主要区别在于用 counter() 你可以像嵌套ul一样把一个计数器插入到另一个。它有三个参数,第一个是计数器名称,第二个是分隔符,第三个是计数器类型(可选)。
当你需要处理一些重复元素的时候,并且你同样想统计他们的数量,那么这个方案会很好用。。
我们在我们的 .container 包裹元素创建一个 counter-reset。创建后,我们为具有问题类名的项目设置一个 counter-increment。最后,我们用.issues:before 条目的内容属性显示出计数器的值。
详见 Adam Laki (@adamlaki) on CodePen 的 CSS 计数器案例 文章。
使用 counters() 函数,我们可以像在文本编辑器程序那样制作嵌套列表计数器。
详见 Adam Laki (@adamlaki) on CodePen 的嵌套计数器文章。
使用输入框的:checked 伪类,我们可以检查复选框是否被选中,选中的话,我们计数器的数值就会增加。
详见 Adam Laki (@adamlaki) on CodePen 的复选框计数器 文章。
Steve Griffith 就这个话题做了一个很好的和内容丰富的整套视频。它涵盖了几乎所有你需要了解的 CSS 计数器。
<iframe width="911" height="537" src="https://www.youtube.com/embed/TJR7qGCOjTk" frameborder="0" allow="autoplay; encrypted-media" allowfullscreen></iframe>记录下,以后来看
a) 面临 XX 大促 /YY 业务节点的研发任务,你作为小 leader,通过如何如何的手段确保了高质量的版本研发上线,最终成功地支撑了多少多少的业务增长,同时为后续活动累积了经验 (这叫业务向导)
b) 主导并推动了某某组件 /某某框架 /某某重构的落地,使得原有耗时 XX 天,bug 率 YY 高的研发需求研发周期减少了 aa%,bug 减少了 bb% (这叫有成效的研发优化)
c) 面对小 a 离职 /小 b 不开心 /小 c 成长缓慢 /团队配合不默契的情况,采取了 XXOO 的手段,稳定了团队结构 /减少了小 a 的影响 /帮助小 c 迅速提升能力 /提升了团队总体的研发效率 (这叫团队建设)
d) 和 XYZ 团队配合,推动改进了需求评审研发测试上线的流程,使得原有流程变快了 aa%(这叫流程改进,不过要将这个记得商业互吹捧一下兄弟团队)
距离考试还有不到一个月的时间,抓紧时间好好整理,巩固学习基础知识。
设计模式:
分为三大类型:创建型、结构型、行为型
创建型:原来的建筑工人单独抽奖
结构型:带上适当的装备组合可以让外国侨胞享受(游戏)
行为型:多次命令和责备中,车模见状慌忙解开(衣服)
安全性与保密技术
加深对安全体系的认识和理解
在讨论回流重绘之前,我们要知道:
一句话:回流必将引起重绘,重绘不一定会引起回流。
当 Render Tree 中部分或全部元素的尺寸、结构、或某些属性发生变化时,浏览器重新渲染部分或全部文档的过程称为回流。
会导致回流的操作
一些常用并且会导致回流的属性和方法
当页面中元素样式的改变并不影响它在文档流中的位置时(例如:color、background-color、visibility等),浏览器会将新样式赋予给元素并重新绘制它,这个过程称为重绘。
回流会比重绘代价更高
有时即使仅回流一个单一的元素,它的父元素以及任何跟随它的元素也会产生回流
现代浏览器会对频繁的回流或重绘操作进行优化:
浏览器会维护一个队列,把所有引起回流和重绘的操作放入队列中,如果队列中的任务数量或者时间间隔达到一个阈值,浏览器就会将队列清空,进行一次批处理,这样可以把多次回流和重绘变成一次。
当你访问以下属性和方法时,浏览器会立刻清空队列:
因为队列中可能会产生有影响这些属性或方法返回值的操作,即使你希望获取的信息与队列中操作引发的改变无关,浏览器也会强行清空队列,确保你拿到的值最精确。
最近,我们发布了一些教程促使你了解 Git 基础知识和在团队环境中使用 Git。谈论的指令已经足够帮助一个开发者在 Git 世界中生存。在这次教程中,我们尝试如何在有效的时间内充分掌握提供的 Git 特性。
说明:文中一些指令包含指令的部分在方括号中(如:git add -p [file_name])。在这些案例中,你可以不用方括号,选择插入一些必要的数字,标识符等等,
将下列脚本运行在 Unix 系统中。
cd ~
curl https://raw.github.com/git/git/master/contrib/completion/git-completion.bash -o ~/.git-completion.bash
接下来,在你的 ~/.bash_profile 文件中添加下面几行:
if [ -f ~/.git-completion.bash ]; then
. ~/.git-completion.bash
fi
尽管之前提到过,我仍然不能强调其重要性:如果你想充分运用 Git 的特性,你应该明确地转变对命令行的交互!
*.pyc
*.exe
my_db_config/
!main.pyc
谁打乱了我的代码?
当某些事出现问题时,责备其他人是人类的本性。如果你的产品服务器坏掉了,很容易查明真凶 —— 只需执行下 git blame指令。这个命令会显示每一个文件中每一行代码的作者,提交会看到当前行的最后一次变化,同时也提交时间戳。
git blame [file_name]
git blame demonstration

在屏幕截图下,你会看到这个命令就像一个巨大的源:
git blame on the ATutor repository

-- online -- 将每次提交展示的信息压缩至精简的提交哈希和提交信息中,所有的展示在一行中。
-- graph -- 这个选项绘制了一个在输出左侧基于文本的图形展示的历史信息。如果你想看到每个分支的历史信息是无用的。
-- all -- 展示所有分支的历史信息。
下面是这些选项的组合:
Use of git log with all, graph and oneline

一个简单的 git log 命令可以显示最新的提交,上一次的提交,上上次的提交等等。然而,git reflog是一个被指向提交的列表。记住:这是你系统的局部,不是源的部分,不包含推送的和合并的。
如果执行 git log,我获取的提交信息是源的一部分。
Project history

然而,当你执行硬重置时,git reflog 展示了提交信息(b1b0ee9–HEAD@{4})是丢失的。
Git reflog

让我们看看你做的几个改变至单个文件中,并想让他们出现在分离的提交中。在这种情况下,我们可以通过添加前缀 -p 来添加文件。
git add -p [file_name]
让我们来证明一致性。我已经添加了三个新行至 file_name,而且我仅想第一和第三行出现在提交信息中。让我们看看 git diff 展示给我们的信息。
Changes in repo

让我们看看当我们添加一个前缀 -p 至 add 命令上发生了什么。
Running add with -p

似乎 Git 假设所有的改变都是同样的,因此,将它们分成一个大块。你有下列选择:
输入 y 分成块
输入 n 不分块
输入 e 手动编辑块
输入 d 退出或者进入下一个文件
输入 s 分离块
在我们的案例中,我们当然想将它分离成小块,可以有选择地添加一部分并忽略其余的。
Adding all hunks
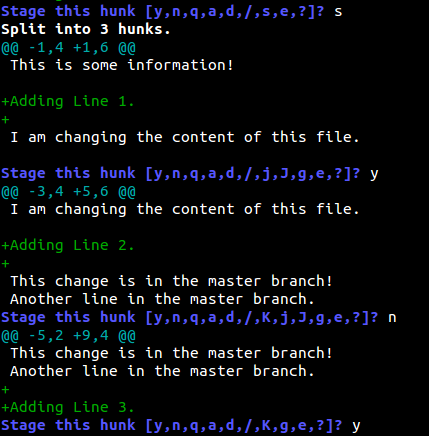
正如你所看到的,我们已经添加第一行和第三行的信息并忽略了第二行的信息。你可以查看源的状态并提交。
Repository after selectively adding a file

git rebase -i HEAD~[number_of_commits]
如果你想压缩上面两次的提交,你要执行的指令在下面。
git rebase -i HEAD~2
在运行这条指令时,会带你来到一个交互的界面中,列出提交的信息,并要求你压缩哪一个。理想地,你会选择最新的提交并压缩上一次的。
Git squash interactive

要求你为新提交的准备提交信息。这个处理基本上会覆盖你的提交历史。
Adding a commit message

git stash
为了核对保存的列表,你需要执行下面的命令:
git stash list
Stash list

如果你想不保存和恢复未提交的变化,你可以应用下面的保存:
git stash apply
在最后一个截图中,你可以看到每次保存都有个标识符,一个唯一的数字(尽管我们仅仅在这种情况下保存)。如果你想只选择有选择性的保存,你可以添加特殊的标识符到 apply 命令中。
git stash apply stash@{2}
After un-stashing changes

git fsck --lost-found
Git fsck results
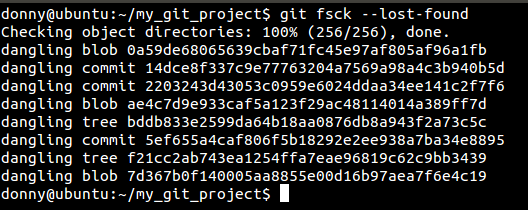
在这里,你可以看到丢失的提交信息。那你可以通过运行 git show [commit_hash] 来核对改变的提交信息,或者通过执行 git merge [commit_hash] 来回复它。
git fsck 相比 reflog 有一种优势。让我们看看你删除了一个远程的分支,然后克隆源。使用 fsck,你可以查询和恢复删除的远程分支。
用最简单的术语来说,cherry-pick 是从不同的分支中选择单个提交和将它和当前分支的合并。如果你在两个或更多的分支中工作,你可能会注意到 bug 会出现所有的分支。如果你在其中一个分支解决了这个 bug,你可以使用 cherry pick 提交至其他分支,不干扰其他文件或提交。
让我们想想可以运用的场景。我有两个分支,并且我想 cherry-pick 提交 b20fd14:清理垃圾:至另外一个分支。
Before cherry pick

切换分支至我想 cherry-pick 的提交,并执行以下指令:
git cherry-pick [commit_hash]
After cherry pick

尽管我们已经清除了 cherry-pick 的时间,但是你应该知道这个命令可能经常导致冲突,因此要慎用。
结论
以上,总结下小技巧清单,我认为可以帮你的 Git 技能达到一个新的台阶。Git 是最好的,可以实现任何你想象的。因此,要总是尝试挑战自己使用 Git。你很有可能会学到一些新的东西!
Shaumik Daityari
会见作者
Shaumik Daityari.
Shaumik 是一个乐观主义者,但是一直都是一个人。他是印度 Roorkee 理工学院的一名本科生,也是博客的创始人之一,他喜欢写作,当他不忙时,总是保持写作的习惯。
常见的vue通信,有父子,兄弟间,组件间。
而对于父子组件通信,通过 props 方式
兄弟间通信,如果项目不是很复杂的话,使用的是 Event Bus 来实现事件的监听和发布,实现组件之间的传递。如果项目比较复杂的话,使用的是状态管理器 vuex。但,但是,还有另外一种解决方式,我们很少用到。下面就让我来介绍下吧。
inheritAttrs:默认是 true
$listener:它包含了副作用域中的 v-on 事件监听器。它可以通过 v-on="$listener" 传入组件内部--在创建更高层次的组件时非常有用。
在开发好页面后,如何让项目的页面更快更好更流畅地运行,是区分一个程序员技术水平和视野的一个重要指标。
如果在面试过程中,头脑一片空白,或者靠死记硬背或之前的经历,回答下压缩代码,打包代码,雪碧图,cdn,事件代理,这说明对性能优化还缺乏一个整体,系统的掌握,对性能优化还只是处于一个方法就加上去的阶段。这样也就无法去更好的优化性能。
性能优化是什么?
从前端的角度来说,性能优化可以分为两个方向:用户角度,页面使用流畅,对于性能优化的探索,我们分为页面加载时间跟页面运行效率两个方向来进行研究
从浏览器打开到页面渲染完成,花费了多少时间:
浏览器解析->查询缓存->dns查询->建立链接->服务器处理请求->服务器发送响应->客户端收到页面->解析HTML->构建渲染树->开始显示内容(白屏时间)->首屏内容加载完成(首屏时间)->用户可交互(DOMContentLoaded)->加载完成(load)
如果需要进行加载时间的优化,我们需要从这里每一个步骤去思考,去总结,而避免东凑一点,西凑一点。
有一句话说的好:If You Can't Measure It, You Can't Manage It。
首先推荐一个 Performance Timing ,可以获取到更多页面加载相关的数据。比较常用的有:
DNS解析时间: domainLookupEnd - domainLookupStart
TCP建立连接时间: connectEnd - connectStart
白屏时间: responseStart - navigationStart
dom渲染完成时间: domContentLoadedEventEnd - navigationStart
页面onload时间: loadEventEnd - navigationStart
服务器端可以对缓存,DNS 查询时间,链接时间,处理请求时间,响应时间等进行优化
DNS 查询时间:可以使用 http dns 预加载,域名收敛等方法优化
链接时间:建立连接的重点是长连接和连接复用,keep-alive,long-polling,http-straming,websocket,或者自己写过别的协议,更好的是直接上 HTTP2。为了优化链接的环节,前端这里需要对资源使用 CDN,雪碧图,代码合并
服务器发送响应环节,可以使用 Transfer-Encoding=chunked,多次返回响应,具体操作查询 bigpipe。还有减少 cookie 的体积。
首屏时间,首屏时间,可交换时间,加载完成时间进行优化。
大家好,欢迎来到本系列的最后一部分。如果你还没进入状况,那么我告诉你,我们将为以太坊区块链创建一个简单的去中心化应用程序。您可以随时查看第 1 和第 2 部分!
到目前为止,我们的应用程序能够从 metamask 获取并显示帐户数据。但是,在更改帐户时,如果不重新加载页面,则不会更新数据。这并不是最优的,我们希望能够确保响应式地更新数据。
我们的方法与简单地初始化 web3 实例略有不同。Metamask 还不支持 websockets,因此我们将不得不每隔一段时间就去轮询数据是否有修改。我们不希望在没有更改的情况下调度操作,因此只有在满足某个条件(特定更改)时,我们的操作才会与它们各自的有效负载一起被调度。
也许上述方法并不是诸多解决方案中的最优解,但是它在严格模式的约束下工作,所以还算不错。在 util 文件夹中创建一个名为 pollWeb3.js 的新文件。下面是我们要做的:
import Web3 from 'web3'
import {store} from '../store/'
let pollWeb3 = function (state) {
let web3 = window.web3
web3 = new Web3(web3.currentProvider)
setInterval(() => {
if (web3 && store.state.web3.web3Instance) {
if (web3.eth.coinbase !== store.state.web3.coinbase) {
let newCoinbase = web3.eth.coinbase
web3.eth.getBalance(web3.eth.coinbase, function (err, newBalance) {
if (err) {
console.log(err)
} else {
store.dispatch('pollWeb3', {
coinbase: newCoinbase,
balance: parseInt(newBalance, 10)
})
}
})
} else {
web3.eth.getBalance(store.state.web3.coinbase, (err, polledBalance) => {
if (err) {
console.log(err)
} else if (parseInt(polledBalance, 10) !== store.state.web3.balance) {
store.dispatch('pollWeb3', {
coinbase: store.state.web3.coinbase,
balance: polledBalance
})
}
})
}
}
}, 500)
}
export default pollWeb3
现在,一旦我们的 web3 实例被初始化,我们就要开始轮询更新。所以,打开 Store/index.js ,导入 pollWeb3.js 文件,并将其添加到我们的 regierWeb3Instance() 方法的底部,以便在状态更改后执行。
import pollWeb3 from '../util/pollWeb3'
registerWeb3Instance (state, payload) {
console.log('registerWeb3instance Mutation being executed', payload)
let result = payload
let web3Copy = state.web3
web3Copy.coinbase = result.coinbase
web3Copy.networkId = result.networkId
web3Copy.balance = parseInt(result.balance, 10)
web3Copy.isInjected = result.injectedWeb3
web3Copy.web3Instance = result.web3
state.web3 = web3Copy
pollWeb3()
}
由于我们正在调度操作,所以需要将其添加到 store 中,并进行变异以提交更改。我们可以直接提交更改,但为了保持模式一致性,我们不这么做。我们将添加一些控制台日志,以便您可以在控制台中观看精彩的过程。在 actions 对象中添加:
pollWeb3 ({commit}, payload) {
console.log('pollWeb3 action being executed')
commit('pollWeb3Instance', payload)
}
现在我们只需要对传入的两个变量进行更改
pollWeb3Instance (state, payload) {
console.log('pollWeb3Instance mutation being executed', payload)
state.web3.coinbase = payload.coinbase
state.web3.balance = parseInt(payload.balance, 10)
}
搞定了!如果我们现在改变 Metamask 的地址,或者余额发生变化,我们将看到在我们的应用程序无需重新加载页面更新。当我们更改网络时,页面将重新加载,我们将重新注册一个新实例。但是,在生产中,我们希望显示一个警告,要求更改到部署协约的正确网络。
我知道这是一个漫长的道路。但在下一节,我们将最终深入到我们的智能协议连接到我们的应用程序。与我们已经做过的相比,这实际上相当容易了。
首先,我们将编写代码,然后部署协议并将 ABI 和 Address 插入到应用程序中。为了创建我们期待已久的 casino 组件,需要执行以下操作:
但是,首先,我们需要我们的应用程序能够与我们的智能协议交互。我们将用已经做过的同样的方法来处理该问题。在 util 文件夹中创建一个名为 getContract.js 的新文件。
import Web3 from ‘web3’
import {address, ABI} from ‘./constants/casinoContract’
let getContract = new Promise(function (resolve, reject) {
let web3 = new Web3(window.web3.currentProvider)
let casinoContract = web3.eth.contract(ABI)
let casinoContractInstance = casinoContract.at(address)
// casinoContractInstance = () => casinoContractInstance
resolve(casinoContractInstance)
})
export default getContract
首先要注意的是,我们正在导入一个尚不存在的文件,稍后我们将在部署协议时修复该文件。
首先,我们通过将 ABI(我们将回到)传递到 web3.eth.Contact() 方法中,为稳固性协议创建一个协议对象。然后,我们可以在一地址上初始化该对象。在这个实例中,我们可以调用我们的方法和事件。
然而,如果没有 action 和变体,这将是不完整的。因此,在 casino-component.vue 的脚本标记中添加以下内容。
export default {
name: ‘casino’,
mounted () {
console.log(‘dispatching getContractInstance’)
this.$store.dispatch(‘getContractInstance’)
}
}
现在 action 和变体在 store 中。首先导入 getContract.js 文件,我相信您现在已经知道如何做到这一点了。然后在我们创建的过程中,调用它:
getContractInstance ({commit}) {
getContract.then(result => {
commit(‘registerContractInstance’, result)
}).catch(e => console.log(e))
}
把结果传给我们的变体:
registerContractInstance (state, payload) {
console.log(‘Casino contract instance: ‘, payload)
state.contractInstance = () => payload
}
这将把我们的协议实例存储在 store 中,以便我们在组件中使用。
首先,我们将添加一个数据属性(在导出中)到我们的 casino 组件中,这样我们就可以拥有具有响应式属性的变量。这些值将是 winEvent、amount 和 Pending。
data () {
return {
amount: null,
pending: false,
winEvent: null
}
}
我们将创建一个 onclick 函数来监听用户点击数字事件。这将触发协议上的 bet() 函数,显示微调器,当它接收到事件时,隐藏微调器并显示事件参数。在 data 属性下,添加一个名为 methods 的属性,该属性接收一个对象,我们将在其中放置我们的函数。
methods: {
clickNumber (event) {
console.log(event.target.innerHTML, this.amount)
this.winEvent = null
this.pending = true
this.$store.state.contractInstance().bet(event.target.innerHTML, {
gas: 300000,
value: this.$store.state.web3.web3Instance().toWei(this.amount, 'ether'),
from: this.$store.state.web3.coinbase
}, (err, result) => {
if (err) {
console.log(err)
this.pending = false
} else {
let Won = this.$store.state.contractInstance().Won()
Won.watch((err, result) => {
if (err) {
console.log('could not get event Won()')
} else {
this.winEvent = result.args
this.pending = false
}
})
}
})
}
}
bet() 函数的第一个参数是在协议中定义的参数 u Number.Event.Target.innerHTML ,接下来,引用我们将在列表标记中创建的数字。然后是一个定义事务参数的对象,这是我们输入用户下注金额的地方。第三个参数是回调函数。完成后,我们将监听这一事件。
现在,我们将为组件创建 html 和 CSS。只是复制粘贴它,我认为它已经很浅显了。在此之后,我们将部署协议,并获得 ABI 和 Address。
<template>
<div class=”casino”>
<h1>Welcome to the Casino</h1>
<h4>Please pick a number between 1 and 10</h4>
Amount to bet: <input v-model=”amount” placeholder=”0 Ether”>
<ul>
<li v-on:click=”clickNumber”>1</li>
<li v-on:click=”clickNumber”>2</li>
<li v-on:click=”clickNumber”>3</li>
<li v-on:click=”clickNumber”>4</li>
<li v-on:click=”clickNumber”>5</li>
<li v-on:click=”clickNumber”>6</li>
<li v-on:click=”clickNumber”>7</li>
<li v-on:click=”clickNumber”>8</li>
<li v-on:click=”clickNumber”>9</li>
<li v-on:click=”clickNumber”>10</li>
</ul>
<img v-if=”pending” id=”loader” src=”https://loading.io/spinners/double-ring/lg.double-ring-spinner.gif”>
<div class=”event” v-if=”winEvent”>
Won: {{ winEvent._status }}
Amount: {{ winEvent._amount }} Wei
</div>
</div>
</template>
<style scoped>
.casino {
margin-top: 50px;
text-align:center;
}
#loader {
width:150px;
}
ul {
margin: 25px;
list-style-type: none;
display: grid;
grid-template-columns: repeat(5, 1fr);
grid-column-gap:25px;
grid-row-gap:25px;
}
li{
padding: 20px;
margin-right: 5px;
border-radius: 50%;
cursor: pointer;
background-color:#fff;
border: -2px solid #bf0d9b;
color: #bf0d9b;
box-shadow:3px 5px #bf0d9b;
}
li:hover{
background-color:#bf0d9b;
color:white;
box-shadow:0px 0px #bf0d9b;
}
li:active{
opacity: 0.7;
}
*{
color: #444444;
}
</style>
如果您不熟悉 metamask 或以太坊网络,请不要担心。
当所有的事情都熟悉了并做完之后,您的 Metamask 应该如下所示:
再打开 remix,我们的协议应该还在。如果不是,请转到此要点并复制粘贴。在 ReMix 的 rop 右边,确保我们的环境被设置为「InsistedWeb 3(Ropsten)」,并且选择了我们的地址。
部署与第1部分中的部署相同。我们在 Value 字段中输入几个参数来预装协议,输入构造函数参数,然后单击 Create。这一次,metamask 将提示接受/拒绝事务(约定部署)。单击「接受」并等待事务完成。
当 TX 完成后点击它,这将带你到那个 TX 的萎缩块链浏览器。我们可以在「to」字段下找到协议的地址。你的协议虽然不同,但看起来很相似。
我们的协议地址在「to」字段中。
这就给了我们地址,现在是 ABI。回到 remix 并切换到「编译」选项卡(右上角)。在协议名称旁边,我们将看到一个名为「Details」的按钮,单击它。第四个领域是我们的 ABI。
不错,现在我们只需要创建前一节还不存在的一个文件。因此,在 util/constents 文件夹中创建一个名为 casinoContract.js 的新文件。创建两个变量,粘贴必要的内容并导出变量,这样我们从上面导入的内容就可以访问它们。
const address = ‘0x…………..’
const ABI = […]
export {address, ABI}
现在,我们可以通过在终端中运行 npm start ,并在浏览器中运行 localhost:8080 来测试我们的应用程序。输入金额并单击一个数字。Metamask 将提示您接受事务,旋转器将启动。在 30 秒到 1 分钟之后,我们得到第一次确认,因此也得到了事件的确认。我们的余额发生了变化,所以 pollweb 3 触发它的 action 来更新余额:
最终结果(左)和生命周期(右)。
如果你能在这个系列中走到这一步,我会为您鼓掌。我不是一个专业的作家,所以有时阅读起来并不容易。我们的应用程序在主干网上已经设置好了,我们只需要让它更漂亮一些,更友好一些。我们将在下一节中这样做,尽管这是可选的。
我们很快就会讲完的。它将只是一些 html、css 和 vue 条件语句,带有 v-if/v-Else。
**在 App.vue **中,将容器类添加到我们的 div 元素中,在 CSS 中定义该类:
.container {
padding-right: 15px;
padding-left: 15px;
margin-right: auto;
margin-left: auto;
}
@media (min-width: 768px) {
.container {
width: 750px;
}
}
**在 main.js 中,**导入我们已经安装的 font-awesome 的库(我知道,这不是我们需要的两个图标的最佳方式):
import ‘font-awesome/css/font-awesome.css’
在 Hello-metanask.vue 中,我们将做一些更改。我们将在我们的 Computed 属性中使用 mapState 助手,而不是当前函数。我们还将使用 v-if 检查 isInjected ,并在此基础上显示不同的 HTML。最后的组件如下所示:
<template>
<div class='metamask-info'>
<p v-if="isInjected" id="has-metamask"><i aria-hidden="true" class="fa fa-check"></i> Metamask installed</p>
<p v-else id="no-metamask"><i aria-hidden="true" class="fa fa-times"></i> Metamask not found</p>
<p>Network: {{ network }}</p>
<p>Account: {{ coinbase }}</p>
<p>Balance: {{ balance }} Wei </p>
</div>
</template>
<script>
import {NETWORKS} from '../util/constants/networks'
import {mapState} from 'vuex'
export default {
name: 'hello-metamask',
computed: mapState({
isInjected: state => state.web3.isInjected,
network: state => NETWORKS[state.web3.networkId],
coinbase: state => state.web3.coinbase,
balance: state => state.web3.balance
})
}
</script>
<style scoped>
#has-metamask {
color: green;
}
#no-metamask {
color:red;
}</style>
我们将执行相同的 v-if/v-else 方法来设计我们的事件,该事件将在赌场内部返回 -Component.vue:
<div class=”event” v-if=”winEvent”>
<p v-if=”winEvent._status” id=”has-won”><i aria-hidden=”true” class=”fa fa-check”></i> Congragulations, you have won {{winEvent._amount}} wei</p>
<p v-else id=”has-lost”><i aria-hidden=”true” class=”fa fa-check”></i> Sorry you lost, please try again.</p>
</div>
#has-won {
color: green;
}
#has-lost {
color:red;
}
最后,在我们的 clickNumber() 函数中,在 this.winEvent=Result.args :下面添加一行:
this.winEvent._amount = parseInt(result.args._amount, 10)
首先,项目的完整代码可以在主分支下获得:https://github.com/kyriediculous/dapp-tutorial/tree/master !
输掉赌注后的最后申请:
在我们的应用程序中仍然有一些警告。我们没有在任何地方正确地处理错误,我们不需要所有的控制台日志语句,它不是一个非常完美的应用程序(我不是一个设计人员),等等。然而,这款应用程序做得很好。
希望本教程系列能够帮助您构建更多、更好的去中心化应用程序。我真诚地希望你和我一样喜欢读这篇文章。
我不是一个有 20 多年经验的软件工程师。因此,如果您有任何建议或改进,请随时发表意见。我喜欢学习新事物,在力所能及的范围内提高自己。谢谢。
更新:增加以太坊平衡显示
欢迎在Twitter上关注我们,访问我们的网站,如果您喜欢本教程,请留下提示!
TIPJAR: ETH — 0x6d31cb338b5590adafec46462a1b095ebdc37d50
之前会遇到 construct,现在在 ES6 的 constructor 中,对其认识也很模糊。
ES6 中的构造函数详解,其实在 ES5 中已经有类似的实现了,只是在 ES6 中换了一种实现方式。
在 ES5 中会像下面这样定义构造函数并生成实例的。
function Person(p) {
this.name = p.name;
this.age = p.age;
}
Person.prototype.say = function () {
console.log(this.name, this.age)
}
// 通过 new 来创建一个实例
var xiaoming = {
name: '小明',
age: 12
}
var xm = new Person(xiaoming);
xm.say();

ES6 就不用再像上面那样写了,让 JavaScript 更接近其他语言的写法。比如上面这个,用 ES6 的类写法就像下面这样。
class Person {
constructor (p) {
this.name = p.name;
this.age = p.age;
}
say () {
console.log(this,name, this.age);
}
}
// 不过在创建实例时还是沿用了 ES5 的写法,也是通过 new 关键字来创建
var xiaoming = {
name: '小明',
age: 12
}
const xm = new Person(xiaoming);
xm.say();

这里返回的是对象,跟 ES5 中有点不一样。
构造函数中创建的变量,函数等完全地拷贝一份到实例中,也就是说每个实例都会拥有一份构造函数中的变量和方法。相当于深度拷贝一份。而放在构造函数外的变量或者方法只属于 Person 类。但通过 Person 类创建的实例并使用这些变量和方法,因为实例可以通过原型链来调用这些方法。
prototype 对象的 constructor 属性指向类本身。
console.log(Person.prorotype.constructor === Person); // true
类内部默认使用严格模式。
constructor 方法是类的默认方法,通过 new 命令生成对象实例时会自动调用这个方法,类必须有 constructor 方法,如果一个类没有显式定义构造函数,那么一个空的 constructor 方法会自动添加到类中。类的默认方法都定义在 prototype 对象上,我们可以把新的方法添加到 prototype 。通过 Object.assign 方法可以很方便地一次向类中添加多个方法。
class Person {
constructor (p) {
this.name = p.name;
this.age = p.age;
}
say () {
console.log(this,name, this.age);
}
}
// 不过在创建实例时还是沿用了 ES5 的写法,也是通过 new 关键字来创建
var xiaoming = {
name: '小明',
age: 12
}
const xm = new Person(xiaoming);
xm.say();
Object.assign(Person.prototype, {
changeName () {
this.name = '李四';
console.log(this.name);
},
changeAge () {
this.age = 18;
console.log(this.age)
}
})
xm.changeName() // '李四'
xm.changeAge() // 18
在看源码的时候,总会看到一行注释 /*istanbul ignore next*/,遇到好几次,但都没有明白它的意思。实际的意思忽略当前的测试。
测试的时候,我们非常关心,是否所有的代码都测试到了。目前为止,我写的前端代码还没有被测试过。今年,要前端测试代码提上日程。
这个指标就是“代码覆盖率”(code coverage)。它有四个测试维度。
- 行覆盖率(line coverage):是否每一行都执行了?
- 函数覆盖率(function coverage):是否每个函数都调用了?
- 分支覆盖率(branch coverage):是否每个 if 代码块都执行了?
- 语句覆盖率(statement coverage):是否每个语句都执行了?
Istanbul 是 JavaScript 程序的代码覆盖率工具,本文介绍它的用法。
这个软件以土耳其最大的城市伊斯坦布尔命名,因为土耳其地毯世界闻名,而地毯是用来覆盖的。
Istanbul 是一个 npm 模块,安装非常简单,就一行命令
npm install -g istanbul
来看一个例子,怎么使用 Istanbul。下面是脚本文件 simple.js
var a = 1;
var b = 1;
if ((a+b) > 2) {
console.log("大于2")
}
使用 Istanbul cover 命令,就能得到覆盖率
istanbul cover simple.js
===== Coverage summary =====
Statements : 75% ( 3/4 )
Branches : 50% ( 1/2 )
Functions : 100% ( 0/0 )
Lines : 75% ( 3/4 )
=======================
返回结果显示,simple.js 有 4 个语句(statement),执行了 3 个;有 2 个分支(branch),执行了 1 个;有 0 个函数,调用了 0 个;有 4行代码,执行了3行。
这条命令同时还生成一个 coverage 子目录,其中的 coverage.json 文件包含覆盖率的原始数据,coverage/lcov-report 是可以在浏览器打开的覆盖率报告,其中有详细信息,到底哪些代码没有覆盖到。
随着开发的深入,和对业务框架的深入,慢慢接触到一个新的名词“中台”,刚开始不太清楚,也不太明台这个是什么意思,下面就来深入地了解中台到底是什么鬼?
1.30 道 Vue 面试题,内含详细讲解(涵盖入门到精通,自测 Vue 掌握程度)
2.Vue3 中的数据侦测
3.Vue 3 源码导读
4.Vue.js 技术揭秘
5.写给新手前端的各种文件上传攻略,从小图片到大文件断点续传
1.jawil/blog
2.dendoink
由于公司的产品需要兼容 IE8 浏览器,在做登陆时,发现一个问题,placeholder 在input = text 情况下,显示还算正常,但在 input = password 就变成了两个点,百度,gg很多,有的是通过lable 模拟,另外还有通过定位模拟,发现都不能很好地解决password 为点的问题。经过不断的尝试和参考别的产品在 IE 8 下兼容处理。我整理下,具体见下:
通过处理input focus时和 blur 时来控制文本的显示和隐藏。其中关键的时 input {background: none;} 和 z-index。
z-index 在父子元素中生效,需要在父级元素设置 position: relative
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<script type="text/javascript" src="jquery-1.9.1.js"></script>
<style type="text/css">
body {
font-family: Arial, Helvetica, sans-serif;
font-size: 12px;
background: #fff;
z-index: 1;
}
input {background: none;}
.box {
height: 300px;
width: 300px;
background: #f2f2f2;
margin: 0 auto;
padding-top: 20px;
}
.child {
position: relative;
margin: 20px;
z-index: 2;
border: 1px solid #ccc;
height: 35px;
background: #fff;
}
.ds-input {
border: none medium;
font-family: verdana;
ime-mode: disabled;
width: 243px;
height: 21px;
line-height: 21px;
color: #bebebe;
font-size: 14px;
position: absolute;
top: 0px;
left: 5px;
padding: 7px 0;
outline: none;
}
.tips {
position: absolute;
z-index: -999;
top: 2px;
_top: 4px;
left: 5px;
color: #C3C3C3;
font-size: 14px;
line-height: 33px;
visibility: visible;
cursor: text;
padding-left: 4px;
}
</style>
<script type="text/javascript">
$(function(){
$("input").focus(function(){
var id = "#tip_"+this.id;
$(id).hide();
});
$("input").blur(function(){
var id = "#tip_"+this.id;
if(this.value=="")
{
$(id).show();
}
});
});
</script>
</head>
<body>
<div class="box">
<div class="child">
<input type="text" class="ds-input" id="username" autocomplete="off">
<span class="tips" id="tip_username">手机号/邮箱</span>
</div>
<div class="child">
<input type="password" class="ds-input" id="password" autocomplete="off">
<span class="tips" id="tip_password">密码</span>
</div>
</div>
</body>
</html>
希望能够对大家有帮助。
记录最近一段时间,兼容IE8处理的问题
伪类,伪元素,placeholder,opacity,
placeholder 在 input type = password 显示的是两个点(兼容处理)
关于 placeholder 兼容性处理,参考彩讯的处理放式,通过定位来模拟显示提示的信息。
很多 ES5 的特性在 IE 8 浏览器是失效的
一些保留字,如果出现在代码中,也是会出现问题
addEvent addEventListener
DomEventLoded load
网盘接手已经将近2年的时间,但是,随着时间的推移,感觉自己在个项目上,进展不大,成长也很有限。说说最近关于维护IE浏览器上传的问题
仅仅能实现 chrome,Firefox的上传,大文件上传,IE 浏览器存在诸多问题,无法上传大文件,上传文件的数量有限,无法实现秒传(没有计算 MD5值)等等
引入百度的 web uploader 来实现,避免因为兼容性问题导致用户无法使用。
// 弹出模态框时,隐藏页面出现的滚动条
document.getElementsByTagName("body")[0].style.cssText='height:100%;overflow:hidden;';
// 关闭模态框时,隐藏页面出现的滚动条
document.getElementsByTagName("body")[0].style.cssText=''
center($('.qrcode-dialog'))
function center(obj) {
var screenWidth = $(window).width(), screenHeight = $(window).height(); //当前浏览器窗口的 宽高
var scrolltop = $(document).scrollTop();//获取当前窗口距离页面顶部高度
var objLeft = (screenWidth - obj.width())/2 ;
var objTop = (screenHeight - obj.height())/2 + scrolltop;
obj.css({left: objLeft + 'px', top: objTop + 'px','display': 'block'});
//浏览器窗口大小改变时
$(window).resize(function() {
screenWidth = $(window).width();
screenHeight = $(window).height();
scrolltop = $(document).scrollTop();
objLeft = (screenWidth - obj.width())/2 ;
objTop = (screenHeight - obj.height())/2 + scrolltop;
obj.css({left: objLeft + 'px', top: objTop + 'px','display': 'block'});
});
//浏览器有滚动条时的操作、
$(window).scroll(function() {
screenWidth = $(window).width();
screenHeight = $(window).height();
scrolltop = $(document).scrollTop();
objLeft = (screenWidth - obj.width())/2 ;
objTop = (screenHeight - obj.height())/2 + scrolltop;
obj.css({left: objLeft + 'px', top: objTop + 'px','display': 'block'});
});
}
之前的解决方式时设置 autocomplete=off,但是现在这种处理方式没有用
<input type="text" autocomplete="off" >
<input type="password" autocomplete="new-password" style="display: none"/>
由于 IE 9 不支持 placeholder,在input为空的情况下,通过jquery获取的val是 placeholder的值
解决方式,替换掉 placeholder
更换后出现了一个问题

原因:jquery 1.9*开始为了安全性,必须将script中的html内容parseHTML转换后使用。否则就报无法解析HTML内容的错误 。
$($.parseHTML(this.linkTemplate))
浏览器安全的基石是“同源策略”(same-origin policy)。
1995年,同源策略由 Netscape 公司引入浏览器。目前,所有的浏览器都支持这个政策。
最初,它的含义是指,A网页设置的 Cookie,B网页不能打开,除非这两个网页“同源”。同源指的是“三个相同”。
举例来说,http://www.example.com/dir/page.html这个网址,协议是 http://,域名是 www.example.com ,端口是 80(默认端口号可以省略)。它的同源情况如下。
* http://www.example.com/dir2/other.html:同源
* http://example.com/dir/other.html:不同源(域名不同)
* http://v2.www.example.com/dir/other.html:不同源(域名不同)
* http://www.example.com:81/dir/other.html:不同源(端口不同)
同源策略的目的,是为了保证用户信息的安全,防止恶意的网站窃取数据。
设想这样的一个情况:A网站是一家银行,用户登陆以后,又去浏览器其他网站。如果其他网站可以读取A网站的 Cookie,会发生什么?
很显然,如果 Cookie 包含隐私(比如存款总额),这些信息就会泄露。更可怕的是,Cookie 往往用来保存用户的登录状态,如果用户没有退出登录,其他网站就可以冒充用户,为所欲为。因为浏览器同时还规定,提交表单不受同源政策的限制。
由此可见,“同源策略”是必须的,否则 Cookie 可以共享,互联网就毫无安全可言了。
随着互联网的发展,“同源策略”越来越严格了。目前,如果非同源,共有三种行为受到限制。
(1) Cookie、LocalStorage 和 IndexDB 无法读取。
(2) DOM 无法获得。
(3) AJAX 请求不能发送
虽然这些限制是必要的,但是有时很不方便,合理的用途也受到影响。下面,将详细介绍,如何规避上面三种限制。
##二 、Cookie
Cookie 是服务器写入浏览器的一小段信息,只有同源的网页才能共享。但是两个网页一级域名相同,只是二级域名不同,浏览器允许通过设置 document.domain 共享 Cookie.
举例来说,A网页是 http://w1.example.com/a.html,B网页是 http://w2.example.com/b.html,那么只要设置相同的 document.domain,两个网页就可以共享 Cookie。
document.domain = "example.com";
现在,A 网页通过脚本设置一个 Cookie。
document.cookie = "test1=hello";
B 网页就可以读到这个 Cookie。
var allCookie = document.cookie;
注意,这种方法只适用于 Cookie 和 iframe 窗口,LocalStorage 和 IndexDB 无法通过这种方法,规避同源策略,而要使用下文介绍的 PostMessage API。
另外,服务器也可以设置 Cookie 的时候,指定 Cookie 的所有域名为一级域名,比如 .example.com
Set-Cookie: key=value;domain=.example.com.都可以读取这个 Cookie。
##三、iframe
如果两个网页不同源,就无法拿到对方的 DOM。典型的例子是 iframe 窗口和 window.open 方法打开的窗口,他们与父窗口无法通信。比如,父窗口运行下面的命令,如果 iframe 窗口不是同源,就会报错。
document.getElementById("myFrame").contentWindow.document
上面命令中,父窗口想获取子窗口的 DOM,因为跨源导致报错。
反之亦然,子窗口获取主窗口的 DOM 也会报错。
window.parent.document.body
如果两个窗口一级域名相同,只有二级域名不同,那么设置上一节介绍的 document.domain 属性,就可以规避同源策略,拿到 DOM。
对于完全不同源的网站,目前有三种方法,可以解决跨域窗口的通信问题。
片段识别符
window.name
跨文档通信 API(Cross-document messaging)
3.1 片段识别符
片段识别符(fragment indentifier)指的是,URL的 # 号后面的部分,比如 http://example.com/x.html#fragment 的 #fragment。
如果只是改变片段标识符,页面不会重新刷新。
父窗口可以把信息,写入子窗口的片段标识符。
var src = originURL + '#' + data;
document.getElementById('myIFrame').src = src;
子窗口通过监听 hashchange 事件得到通知。
window.onhashchange = checkMessage;
function checkMessage() {
var message = window.location.hash;
}
同样的,子窗口也可以改变父窗口的片段标识符。
parent.location.href = target + '#' + hash;
浏览器窗口有 window.name 属性。这个属性的最大特点是,无论是否同源,只要在同一个窗口里,前一个网页设置了这个属性,后一个网页就可以读取它。
window.name = data;
接着,子窗口跳回一个与主窗口同域的网址。
location = 'http://parent.url.com/xxx.html';
然后,主窗口就可以读取子窗口的 window.name 了。
var data = document.getElementById('myFrame').contentWindow.name;
这种方法的优点是,window.name 容量很大,可以放置非常长的字符串;缺点是必须监听子窗口 window.name 属性的变化,影响网页性能。
上面两种方法都属于破解,HTML5为了解决这个问题,引入一个全新的 API:跨文档通信 API(cross-document mesaging)。
这个 API 为 window 对象新增了一个 window.postMessage 方法,允许跨窗口通信,不论这两个窗口是否同源。
举例说,父窗口 http://aaa.com 向子窗口 http://bbb.com 发消息,调用 postMessage 方法就可以了。
var popup = window.open('http://bbb.com', 'title');
popup.postMessage('Hello World!', 'http://bbb.com');
postMessage 方法的第一个参数是具体信息内容,第二个参数是接受消息的窗口的源,即“协议+域名+端口”。也可以设为 *,表示不限制域名,向所有窗口发送。
子窗口向父窗口发送消息的写法类似。
window.opener.postMessage('Nice to see you', 'http://aaa.com');
父窗口和子窗口都可以通过 message 事件,监听对方的消息。
window.addEventListener('message', function(e){
console.log(e.data);
},false);
message 事件的事件对象 event,提供了以下三个属性。
event.source: 发送消息的窗口
event.origin: 消息发向的网址
event.data: 消息内容
下面的例子是: 子窗口通过 event.source 属性引用父窗口,然后发送消息。
window.addEventListener('message', receiveMessage);
function receiveMessage(event) {
event.source.postmessage('Nice to see you!', '*');
}
event.origin 属性可以过滤不是发送本窗口的消息。
window.addEventListener('message', receiveMessage);
function reeiveMessage(event) {
if(event.origin !== 'http://aaa.com') return;
if(event.data === 'Hello World') {
event.source.postMessage('Hello', event.origin);
} else {
console.log(event.data);
}
}
通过 window.postMessage,读写其他窗口的 LocalStorage 也成为了可能。
下面是一个例子,主窗口写入 iframe 子窗口的 localstorage。
window.onmessage = function(e) {
if(e.origin !== 'http://bbb.com') {
return;
}
var payload = JSON.parse(e.data);
localStorage.setItem(payload.key, JSON.stringify(payload.data));
}
上面代码中,子窗口将父窗口发来的信息,写入自己的 LocalStorage。
父窗口发送消息的代码如下。
var win = document.getElementsByTagName('iframe')[0].contentWindow;
var obj = {name: 'Jack'};
win.postMessage(JSON.stringify({key: 'storage', data: obj}), 'http://bbb.com');
加强版的子窗口接收消息的代码如下。
window.onmessage = function(e) {
if(e.origin !== 'http://bbb.com') return;
var payload = JSON.parse(e.data);
switch (payload.method) {
case 'set':
localStorage.setItem(payload.key, JSON.stringify(payload.data));
break;
case: 'get':
var parent = window.parent;
var data = localStorage.getItem(payload.key);
parent.postMessage(data, 'http://aaa.com');
break;
case: 'remove':
localStorage.removeItem(payload.key);
break;
}
}
加强版的父窗口发送消息代码如下:
var win = document.getElementsByTagName('iframe')[0].contentWindow;
var obj = {name: 'jack'};
//存入对象
win.postMesage(JSON.stringify({key: 'storage', method: 'set', data: obj}), 'http://bbb.com');
//读取对象
window.onmessage = function(e) {
if(e.origin != 'http://aaa.com') return;
console.log(JSON.parse(e.data).name);
}
同源策略规定,AJAX请求只能发送给同源的网址,否则就会报错。
除了架设服务器代理(浏览器请求同源服务器,再由后者请求外部服务),有三种方法规避这个限制。
JSONP
Websocket
CORS
JSONP是服务器与客户端跨源通信的常用方法。最大的特点就是简单适用,老式浏览器全部支持,服务器改造非常小。
它的基本**是,网页通过添加一个 <script>元素,向服务器请求 JSONP 数据,这种做法不受同源策略限制,服务器收到请求后,将数据放在一个指定名字的回调函数里传回来。
首先,网页动态插入<script>元素,由它向跨源网址发出请求。
function addScript(src) {
var script = document.createElement('script');
script.setAttribute('type','text/javascript');
script.src = src;
document.body.appendChild(script);
}
window.onload = function() {
addSciptTag('http://example.com/ip?callback=foo');
}
function foo(data) {
console.log('Your public IP address is : ' + data.ip);
}
上面代码通过动态添加<script>元素,向服务器 example.com 发出请求。注意,该请求的查询字符串有一个 callback 参数,用来指定回调函数的名字,这对于JSONP是必须的。
服务器收到这个请求以后,会将数据放在回调函数的参数位置返回。
foo({
'ip' : '8.8.8.8'
})
由于 元素请求的脚本,直接作为代码运行。这时,只要浏览器定义了 foo 函数,该函数就立即调用。作为参数的JSON数据视为JavaScript 对象,而不是字符串,因此避免使用 JSON.parse的步骤。
JSONP 缺点
JSONP实现跨域访问非常方便,简单易用,但是也有不足的地方:
首先,从它的实现方式可以看出,它是发起一个资源获取请求,是GET类型,在日常开发中常用的请求类型还有POST,PUT,DELETE,而JSONP只发起GET请求,是它的一大短板。
其次,JSONP是从其他域中加载代码并执行,如果其他域不安全,很有可能会在执行的代码中夹杂着一些恶意代码,所以在使用JSONP时一定要保证被请求方安全可靠。
最后,由于它的请求类型不是XHR,就缺少了一些事件处理程序,要追踪JSONP请求是否失败并不容易,或者为JSONP请求增加定时器,超时就视为请求失败,接下来就再次发送请求或者做其他事情,但是每个用户的网络情况并不能保证,这样做也不是万全之策。
WebSocket 是一种通信协议,使用ws://(非加密)和wss://(加密)作为协议前缀。该协议不实行同源策略,只要服务器支持,就可以通过它进行跨源通信。
下面是一个例子,浏览器发出的WebSocket 请求的头信息(摘自维基百科)
GET /chat HTTP/1.1
Host: server.example.com
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Key: x3JJHMbDL1EzLkh9GBhXDw==
Sec-WebSocket-Protocol: chat, superchat
Sec-WebSocket-Version: 13
Origin: http://example.com
上面的代码中,有一个字段是 Origin,表示该请求的请求源(origin),即发自哪个域名。
正是因为有了 Origin 这个字段,所以 WebSocket 才没有实行同源策略。因为服务器可以根据这个字段,判断是否许可这个字段,判断是否许可本次通信。如果该域名在白名单内,服务器会做出如下回应。
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: HSmrc0sMlYUkAGmm5OPpG2HaGWk=
Sec-WebSocket-Protocol: chat
CORS 是跨源资源分享(Cross-Origin Resource Sharing)的缩写。它是W3C标准,是跨源AJAX请求的根本解决方法。相比JSONP只能发 GET 请求,CORS允许任何类型的请求。
具体实现为:使用自定义的HTTP头部让浏览器与服务器进行沟通,从而决定跨域请求或响应时应该成功还是失败。
比如说发起一个 GET 跨域请求,Content-type 是 text/plain,在发送跨域请求前,浏览器会为http头部加上一个额外的Origin头部,其中包含了页面的源信息(协议、域名、端口),这个额外的 Origin 决定了服务器是否响应该请求。一个 Origin 头部实例:
Origin: https://www.somewhere-else.net
如果服务器认可该请求就会在响应头上加上 Access-Control-Allow-Origin标志字段,值可以是与请求头带来的Origin相同,如果该服务器上的是公共资源,值就是"*"。
Access-Control-Allow-Origin: https://www.somewhere-else.net
如果响应头中没有这个字段,说明服务器拒绝了这次跨域请求,会抛出一个错误,但是并不能被 xhr 的onerror 事件捕获。默认情况下跨域请求都是不带凭证(cookie,HTTP认证及服务端SSL证明等),通过修改 xhr 对象的 withCredentials (IE10以前的版本不支持该属性)设置为true,可以指定某个请求携带凭证。如果服务器允许跨域请求携带凭证响应头部会有标识。
Access-Control-Allow-Credentials: true
如果发送的是带凭证的请求,响应头里却没有这个字段,那么浏览器就不会把响应交给JS,意思是XHR获取到的 responseText 为空,status 为0,这个时候onerror可以捕获到该错误。
XHR对象在跨域时也是有限制的:
CORS 的实现
var xhr = new XMLHttpRequest();
xhr.onreadystateChange = function() {
if(xhr.readyState === 4) {
if(xhr.status >= 200 && xhr.status <= 300 || xhr.status === 304) {
alert(xhr.responseText);
} else {
alert("error ", xhr.status);
}
}
}
xhr.open("get", "http://www.somewhere-else.com/page", true);
xhr.send(null)
发送CORS 请求和发送普通的xhr对象差别不大,只需要在地址处写绝对地址即可。跨域所需要做的工作就交给浏览器,对于用户来说是透明。
IE浏览器是用 XDR(XDomainRequest)来实现CORS的,它和XHR相似,但是能提供安全可靠的跨域通信。
对于那些还不是很熟悉 JavaScript 的人,Google 提供了一套编写 JavaScript 风格的指南,列出了(Google认为)编写整齐、可理解代码的最佳实践风格。
这些并不是编写有效 JavaScript 的硬性规范和快速规范,只有在您的源文件中使得样式保持一致性和吸引人选择。对于 JavaScript 而言,这一点特别有趣,因为 JavaScript 是一个灵活且包容的语言,它允许各种文体选择。
谷歌(Google)和 Airbnb 有两款最受欢迎的风格指南。如果您花了大量的时间编写 JS,我建议您查看它们。
下面是 13 个我认为是来自谷歌的 JS 风格指南最有趣和最有意义的规范。
他们处理所有来自激烈争论的问题(标签和空格,以及分号应该如何使用的争议问题),以及一些令我惊讶,但晦涩难懂的规范。他们肯定会改变我写的我的 JS 的方式。
对于每条规范,我将简要介绍,然后是详细描述该规范的样式指南中的辅助引号。在适用的情况下,我还将提供一个样式示例实践,并将其与不遵循规范的代码进行对比。
除了行结束符序列外,ASCII 水平空格字符(0x20)是源文件中出现的唯一空白字符。这意味着…制表符不用于缩进。
指南稍后指定您应该使用两个空格(而不是4个)来缩进。
// bad
function foo() {
∙∙∙∙let name;
}
// bad
function bar() {
∙let name;
}
// good
function baz() {
∙∙let name;
}
每个语句必须以分号终止。依靠自动分号插入禁止。
虽然我无法想象为什么有人反对这个想法,但在JS中始终使用分号正在成为新的“空格对制表符”的争论。谷歌在这里坚决捍卫分号。
// bad
let luke = {}
let leia = {}
[luke, leia].forEach(jedi => jedi.father = 'vader')
// good
let luke = {};
let leia = {};
[luke, leia].forEach((jedi) => {
jedi.father = 'vader';
});
不要使用ES6模块(即导出和导入关键字),因为它们的语义尚未确定。请注意,一旦语义完全标准化,将重新讨论此策略。
// Don't do this kind of thing yet:
//------ lib.js ------
export function square(x) {
return x * x;
}
export function diag(x, y) {
return sqrt(square(x) + square(y));
}
//------ main.js ------
import { square, diag } from 'lib';
这种做法是允许的,但谷歌风格通常不鼓励这种做法。它甚至不需要在已经使用它的地方保持水平对齐。
水平比对是在代码中添加可变数量的附加空间的实践,以便使某些标记直接出现在前面行的某些其他令牌下面。
// bad
{
tiny: 42,
longer: 435,
};
// good
{
tiny: 42,
longer: 435,
};
用const或let声明所有局部变量。默认情况下使用Const,除非需要重新分配变量。不能使用var关键字。
我仍然看到人们在StackOverflow和其他地方的代码示例中使用var。我不知道是否有人会为它辩护,或者这只是一种旧习惯的消亡。
// bad
var example = 42;
// good
let example = 42;
箭头函数提供了简洁的语法,并解决了许多困难。更喜欢箭头函数而不是函数关键字,特别是对于嵌套函数。
老实说,我只是觉得箭头函数很棒,因为它们更简洁,看上去更好。结果他们也起到了非常重要的作用。
在复杂的字符串连接上使用模板字符串(用分隔),特别是在涉及多个字符串文本的情况下。模板字符串可能跨越多行。
`
// bad
function sayHi(name) {
return 'How are you, ' + name + '?';
}
// bad
function sayHi(name) {
return ['How are you, ', name, '?'].join();
}
// bad
function sayHi(name) {
return `How are you, ${ name }?`;
}
// good
function sayHi(name) {
return `How are you, ${name}?`;
}
不要在普通字符串或模板字符串文本中使用行延续(即以反斜杠结束字符串文本中的一行)。尽管ES5允许这样做,但如果任何尾随空格出现在斜杠之后,并且对读者来说不太明显,则可能会导致棘手的错误。
有趣的是,这是谷歌和Airbnb不同意的一条规则(以下是Airbnb的规范)。
虽然Google建议连接更长的字符串(如下所示),Airbnb的样式指南建议基本上什么也不做,只要需要就允许长字符串继续。
// bad (sorry, this doesn't show up well on mobile)
const longString = 'This is a very long string that \
far exceeds the 80 column limit. It unfortunately \
contains long stretches of spaces due to how the \
continued lines are indented.';
// good
const longString = 'This is a very long string that ' +
'far exceeds the 80 column limit. It does not contain ' +
'long stretches of spaces since the concatenated ' +
'strings are cleaner.';
在ES6中,该语言现在有三种不同的for循环。所有循环都可以使用,但在可能的情况下,应该首选for-of循环。
这是一个奇怪的,如果你问我,但我想我会包括它,因为它是非常有趣的,谷歌宣布一个首选类型的for循环。
我一直认为,对于 for … in循环来说,对于对象来说更好,而对于 for … of 更适合数组。一种“适合合适工作的工具”类型的情况。
虽然Google在这里的规范并不一定与这个想法相矛盾,但是知道他们特别喜欢这个循环还是很有趣的。
不要使用 eval 或函数(... string)构造函数(代码加载器除外)。这些特性可能是危险的,而且简单地不能在csp 环境中工作。
eval() 的 MDN 页面中甚至有一个名为“Don‘t use eval!”的部分。
// bad
let obj = { a: 20, b: 30 };
let propName = getPropName(); // returns "a" or "b"
eval( 'var result = obj.' + propName );
// good
let obj = { a: 20, b: 30 };
let propName = getPropName(); // returns "a" or "b"
let result = obj[ propName ]; // obj[ "a" ] is the same as obj.a
常量名称使用constant_case:所有大写字母,单词之间用下划线分隔。
如果您绝对确定变量不应该更改,则可以通过将常量的名称大写表示出来。这使得常量的不可变性在整个代码中使用时显而易见。
此规则的一个显著例外是常数是函数范围。在这种情况下,它应该写在CamelCase中。
// bad
const number = 5;
// good
const NUMBER = 5;
每个局部变量声明只声明一个变量:不使用像let a=1,b=2;这样的声明。
// bad
let a = 1, b = 2, c = 3;
// good
let a = 1;
let b = 2;
let c = 3;
普通字符串文字用单引号(‘)分隔,而不是双引号(“)。提示:如果字符串包含单引号字符,请考虑使用模板字符串以避免转义引号。
// bad
let directive = "No identification of self or mission."
// bad
let saying = 'Say it ain\u0027t so.';
// good
let directive = 'No identification of self or mission.';
// good
let saying = `Say it ain't so`;
正如我刚开始说的那样,这些不是任务授权。谷歌只是许多科技巨头之一,而这些只是建议。
这就是说,很有意思的是,看看谷歌这样的公司提出的风格建议,它雇佣了很多优秀的人,他们花了很多时间写优秀的代码。
如果你想遵循“谷歌兼容源代码” - 的指导方针,你可以遵循这些规则,但是,当然,很多人不同意,你可以随意忽略这一切。
我个人认为,在很多情况下,Airbnb的规范比谷歌的更有吸引力。无论您对这些特定规则采取了什么立场,在编写任何代码时保持风格一致性仍然很重要。
最近在开发的过程中遇到了一个问题,动态生成的select,无法控制单个,如何校验每个select有没有选择,如何保存选择的数据成为我一时头疼的问题。
代码如下
<div class="form-control mb_15 relative first-approve" v-for="(item, index) in copyOrMvData" :key="index">
<span class="item-left absolute pos-abs">【<span class="ellips" :title="cutStr(item.description)">{{cutStr(item.description)}}</span>】审批人:</span>
<Select v-model="selectId[index]" style="width:320px;margin-left:145px;" @on-change="selectApprover($event, item, index)" class="fl">
<Option :value="el.id" v-for="el in item.approvers" :key="el.id">{{ el.name }}</Option>
</Select>
<p v-if="approveIderr[index]" class="dlg-lessnameinpt-tip">请选择审批人!</p>
</div>
想了很久,首先控制单个选择不影响其他的内容
通过设置select 的v-model 加上 [index]就不会出现这个问题
但是还是有另外一个问题,如果给每个select 加上校验规则的话,点击选择反而会报错,搞得我有点头大,经过一番思考想到:需要在data中设置类型,去除iview 自带的 rules 规则校验,改成自己写的方式
data () {
return {
selectId: Array(this.opts.copyOrMv.tasks.length).fill(""),
approveIderr: Array(this.opts.copyOrMv.tasks.length).fill(false)
}
}
对于第二个问题,给每个select 加一个change 函数,对每个选择个项,将对应项设置为false,对应的js控制如下
selectApprover (e, ele, index){
if (e) {
this.$set(this.approveIderr, index, false)
}
},
点击提交确认,应该校验所有的数据,如果出现select没有选择,则对应的select应提示错误,方便用户进行统一的选择。具体如下:
methods: {
onConfirm () {
let selectData = {
tasks: []
}
// console.log(this.selectId)
// 如果没有选择则该项没有选择的提示错误
this.selectId.forEach((item, index) => {
if (item == '' ) {
self.$set(self.approveIderr, index, true)
}
})
if (this.approveIderr.indexOf(true) === -1) {
// 表示每个选择的数据都是成功的,没有出现没有选择的情况,可以进行下一步的操作了
this.copyOrMvData.forEach((item, index) => {
selectData.tasks.push({
"approverId": this.selectId[index],
"data": item.data,
"title": item.title,
"description": item.description
})
})
}
}
大功告成!!!
Taking that first step to understanding Functional Programming concepts is the most important and sometimes the most difficult step. But it doesn’t have to be. Not with the right perspective.
谈论的第一步是理解功能编程概念是最重要的,有时最困难的一步。但它不是必要的。没有正确的视野。
When we first learned to drive, we struggled. It sure looked easy when we saw other people doing it. But it turned out to be harder than we thought.
当我们第一次学习驾驶,我们惊慌失措。当我们看到别的人驾驶时,似乎很容易。但是结果是比我们想象的难得多。
We practiced in our parent’s car and we really didn’t venture out on the highway until we had mastered the streets in our own neighborhood.
我们在父母的车上练习,真的不敢在高速公路上冒险直到我们在我们自己的临近的街道熟练了。
But through repeated practice and some panicky moments that our parents would like to forget, we learned to drive and we finally got our license.
通过重复的练习和我们会忘记的一些恐慌的时刻,我们学会了驾驶,最终我们拿到了驾照。
With our license in hand, we’d take the car out any chance we could. With each trip, we got better and better and our confidence went up. Then came the day when we had to drive someone else’s car or our car finally gave up the ghost and we had to buy a new one.
驾照在手,我们可以随意的驾车出去。每一次开车,我们的车技越来越好,自信心也不断上升。我们不得不驾驶别人车的那一天会来临,或者最终我们的将会报废,我们不得不买一辆新车。
What was it like that first time behind the wheel of a different car? Was it like the very first time behind the wheel? Not even close. The first time, it was all so foreign. We’ve been in a car before that, but only as a passenger. This time we were in the driver seat. The one with all the controls.
第一次站在**不同车的后面是什么感觉?它是像第一次**站在车轮后面?甚至还没有接近。第一次,忘记的一干二净。我们曾经坐在车内,但仅仅是一个乘客。这次我们在驾驶位上。我们控制着车。
But when we drove our second car, we simply asked ourselves a few simple questions like, where does the key go, where are the lights, how do you use the turn signals and how do you adjust the side mirrors.
但是当我们驾驶第二辆汽车时,我们仅仅询问了一些问题,比如车钥匙在哪,灯光在哪如何使用转向灯和如何调整后视镜。
After that, it was pretty smooth sailing. But why was this time so easy compared to the first time?
后面,就是相当顺利的驾驶。但是相对于第一次,这一次为什么这么容易呢?
That’s because the new car was pretty much like the old car. It had all the same basic things that a car needs and they were pretty much in the same place.
那是因为新车很像那辆旧车。一辆车所需要的基本要求是一样的,几乎都在同一个地方。
A few things were implemented differently and maybe it had a few additional features, but we didn’t use them the first time we drove or even the second. Eventually, we learned all the new features. At least the ones we cared about.
有些东西的实现是不同,也许它有一些额外的功能,但我们没有在第一次我们开车使用他们,甚至第二次。最终,我们学会所有新的功能。至少是我们关心的。
Well, learning programming languages is sort of like this. The first is the hardest. But once you have one under your belt, subsequent ones are easier.
好吧,学习编程语言跟学车有很多相似之处。开头难,但是一旦处在安全区域下,后面就很容易了。
When you first start a second language, you ask questions like, “How do I create a module? How do you search an array? What are the parameters of the substring function?”
当你第一次开始学习第二门语言时,你可能会问类似的问题,“如何创建一个模块?你如何搜索数组?substring 函数的参数是什么?”
You’re confident that you can learn to drive this new language because it reminds you of your old language with maybe a few new things to hopefully make your life easier.
你对你可以学习一门新的语言很自信,因为它让你想起你的旧语言,也许有一些新的东西,让你的生活更容易。
Whether you’ve been driving one car your whole life or dozens of cars, imagine that you’re about to get behind the wheel of a spaceship.
不管你是一辈子开着一辆车还是几十辆车,想象一下你就要坐在宇宙飞船的后面了。
If you were going to fly a spaceship, you wouldn’t expect your driving ability on the road to help you much. You’d be starting over from square zero. (We are programmers after all. We count starting at zero.)
当你将要驾驶一架飞船,你不用期望你的驾驶能力在航行过程中帮助你很多。你将从零开始。(我们毕竟是程序员。需要从零计数。)
You would begin your training with the expectation that things are very different in space and that flying this contraption is very different than driving on the ground.
你可能会带着期望开始训练,但是在太空中是非常困难的,而且驾驶这玩意儿比在地面行驶非常不同
Physics hasn’t changed. Just the way you navigate within that same Universe.
物理没有改变。就像你在同一宇宙中航行一样。
And it’s the same with learning Functional Programming. You should expect that things will be very different. And that much of what you know about programming will not translate.
而且这跟学习函数编程一样。你应该期望编程不一样。而且你知道的很多关于编程将**不会_**翻译.
Programming is thinking and Functional Programming will teach you to think very differently. So much so, that you’ll probably never go back to the old way of thinking.
编程是思考,函数式编程将教你如何与众不同地思考。所以,你可能永远不会回到旧的思维方式。
People love saying this phrase, but it’s sort of true. Learning functional programming is like starting from scratch. Not completely, but effectively. There are lots of similar concepts but it’s best if you just expect that you have to relearn everything.
人们喜欢说这个短语,但这是真的。学习函数式编程就像从头开始。不是完全的,而是有效的。有很多类似的概念,但是最好的是你必须重新开始学习。
With the right perspective you’ll have the right expectations and with the right expectations you won’t quit when things get hard.
有了正确的观点,你就会有正确的期望,有了正确的期望,当事情变得困难时,你就不会放弃。
There are all kinds of things that you’re used to doing as a programmer that you cannot do any more with Functional Programming.
作为程序员,你已经习惯了用函数编程来做的事情。
Just like in your car, you used to backup to get out of the driveway. But in a spaceship, there is no reverse. Now you may think, “WHAT? NO REVERSE?! HOW THE HELL AM I SUPPOSED TO DRIVE WITHOUT REVERSE?!”
就像在你的车里一样,你曾经备份过离开车道。但是在飞船上,没有退路。现在你可能会想,“什么,没有退路?!我怎么不能开倒车呢?”
Well, it turns out that you don’t need reverse in a spaceship because of its ability to maneuver in three dimensional space. Once you understand this, you’ll never miss reverse again. In fact, someday, you’ll think back at how limiting the car really was.
事实上,你在宇宙飞船里不需要倒车,因为它在三维空间里有机动的能力。一旦你理解了这一点,你就再也不会错过逆转了。事实上,总有一天,你会想起汽车是如何被限制的。
Learning Functional Programming takes a while. So be patient.
学习函数式编程需要一段时间。所以耐心点。
So let’s exit the cold world of Imperative Programming and take a gentle dip into the hot springs of Functional Programming.
因此,让我们退出命令式编程的冷世界,并仔细考虑函数编程的温泉。
What follows in this multi-part article are Functional Programming Concepts that will help you before you dive into your first Functional Language. Or if you’ve already taken the plunge, this will help round out your understanding.
这篇多部分文章后面的内容是函数编程概念,这些概念在进入第一个函数式语言之前会对你有所帮助。或者,如果你已经采取了行动,这将有助于提高你的理解力。
Please don’t rush. Take your time reading from this point forward and take the time to understand the coding examples. You may even want to stop reading after each section to let the ideas sink in. Then return later to finish.
请不要急。从这一点开始阅读,并花时间去理解编码示例。你可能甚至想在每一节之后停止阅读,让**下沉。然后返回完成。
The most important thing is that you understand.
最重要的事情是你**理解**。
When Functional Programmers talk of Purity, they are referring to Pure Functions.
当函数编程人员谈到纯度时,它们指的是纯函数。
Pure Functions are very simple functions. They only operate on their input parameters.
纯函数是非常简单的函数。它们只对输入参数进行操作。
Here’s an example in Javascript of a Pure Function:
下面是纯函数JavaScript中的一个示例:
var z = 10;
function add(x, y) {
return x + y;
}
Notice that the add function does NOT touch the z variable. It doesn’t read from z and it doesn’t write to z. It only reads x and y, its inputs, and returns the result of adding them together.
注意: add 函数没有触发变量 z。并不从变量 z 开始读代码,也不写变量 z。仅仅读它的输入 x 和 y,然后一块返回他们求和的结果。
That’s a pure function. If the add function did access z, it would no longer be pure.
这是一个存函数。如果函数 add 确实访问了 z,该函数将不再是纯函数了。
Here’s another function to consider:
下面是另外一个函数:
function justTen() {
return 10;
}
If the function, justTen, is pure, then it can only return a constant. Why?
如果函数 justTen 是一个纯函数,那么它仅仅返回一个常量。为什么?
Because we haven’t given it any inputs. And since, to be pure, it cannot access anything other than its own inputs, the only thing it can return is a constant.
因为我们没有给出任何输出。而且,作为纯函数,它不能访问其他只有自己的输入,返回的只有一个常量。
Since pure functions that take no parameters do no work, they aren’t very useful. It would be better if justTen was defined as a constant.
Most useful Pure Functions must take at least one parameter.
大多数有用的纯函数必须至少有一个参数。
Consider this function:
考虑这个函数:
function addNoReturn(x, y) {
var z = x + y
}
Notice how this function doesn’t return anything. It adds x and y and puts it into a variable z but doesn’t return it.
注意,这个函数没有任何返回。它将 x 加 y 赋给变量 z,但是没有返回 z。
It’s a pure function since it only deals with its inputs. It does add, but since it doesn’t return the results, it’s useless.
这是一个纯函数,因为它只处理它的输入。它的确求和了,但是没有返回结果,这样是无效的。
All useful Pure Functions must return something.
所有有用的的纯函数必须又返回。
Let’s consider the first add function again:
让我们再次看看第一个函数 add:
function add(x, y) {
return x + y;
}
console.log(add(1, 2)); _// prints 3_
console.log(add(1, 2)); _// still prints 3_
console.log(add(1, 2)); _// WILL ALWAYS print 3_
Notice that add(1, 2) is always 3. Not a huge surprise but only because the function is pure. If the add function used some outside value, then you could never predict its behavior.
注意:add(1,2) 总是 3。不是很大的惊喜,只是因为这个函数是纯函数的。
Pure Functions will always produce the same output given the same inputs.
纯函数总是在给予同样的输入得到同样的输出。
Since Pure Functions cannot change any external variables, all of the following functions are impure:
因为纯函数不能改变额外的变量,所有下面的函数都不是纯函数:
writeFile(fileName);
updateDatabaseTable(sqlCmd);
sendAjaxRequest(ajaxRequest);
openSocket(ipAddress);
All of these function have what are called Side Effects. When you call them, they change files and database tables, send data to a server or call the OS to get a socket. They do more than just operate on their inputs and return outputs. Therefore, you can never predict what these functions will return.
Pure functions have no side effects.
纯函数没有副作用。
In Imperative Programming Languages such as Javascript, Java, and C#, Side Effects are everywhere. This makes debugging very difficult because a variable can be changed anywhere in your program. So when you have a bug because a variable is changed to the wrong value at the wrong time, where do you look? Everywhere? That’s not good.
在指令式编程语言,比如 JavaScript,Java,和 C#,均有副作用。这使得调试非常困难,因为在你的项目中,变量可以在**任何地方**改变。所以当你有一个错误时,因为变量在错误的时间被改变为错误的值,你在哪里发现的,处处?这样不好。
At this point, you’re probably thinking, “HOW THE HELL DO I DO ANYTHING WITH ONLY PURE FUNCTIONS?!”
在这点,你可能会想,“使用仅仅使用纯函数,我能做什么?!”
In Functional Programming, you don’t just write Pure Functions.
在函数式编程中,你不用编写纯函数。
Functional Languages cannot eliminate Side Effects, they can only confine them. Since programs have to interface to the real world, some parts of every program must be impure. The goal is to minimize the amount of impure code and segregate it from the rest of our program.
函数式编程不能根除副作用,它们仅仅能限制这些影响。由于程序必须有与现实世界接口,所以每个程序的某些部分必须是不纯的。我们的目标是最小化不纯代码的数量,并将其与程序的其他部分隔离开来。
Do you remember when you first saw the following bit of code:
你还记得你第一次看到下面一段代码的时候吗:
var x = 1;
x = x + 1;
And whoever was teaching you told you to forget what you learned in math class? In math, x can never be equal to x + 1.
无论是谁教你,你都要忘记你在数学课上学的东西?在数学上,x 永远不会等于**x+1**。
But in Imperative Programming, it means, take the current value of x add 1 to it and put that result back into x.
但是在命令式编程中,当前 **x**的值加 1,然后将这个值赋给返回的 x。
Well, in functional programming, x = x + 1 is illegal. So you have to remember what you forgot in math… Sort of.
事实上,在函数式编程中,x=x+1 是非法的。因此,你必须记住你在数学上忘记的。
There are no variables in Functional Programming.
在函数式编程中没有变量。
Stored values are still called variables because of history but they are constants, i.e. once x takes on a value, it’s that value for life.
由于历史,存储值仍然被称为变量,但它们是常量,也就是,一旦 **x**有一个值,那么它将在声明周周期中一直保持这个值。
Don’t worry, x is usually a local variable so its life is usually short. But while it’s alive, it can never change.
不用担心,x 通常用于局部变量,因此它的生命周期很短,尽管它在生命中,仍不能改变。
Here’s an example of constant variables in Elm, a Pure Functional Programming Language for Web Development:
这里有一个在 Elm 中关于常量变量,一个针对 Web 开发的纯函数编程语言:
addOneToSum y z =
let
x = 1
in
x + y + z
If you’re not familiar with ML-Style syntax, let me explain. addOneToSum is a function that takes 2 parameters, y and z.
如果你不熟悉 ML风格的语法,让我来给你解释。
Inside the let block, x is bound to the value of 1, i.e. it’s equal to 1 for the rest of its life. Its life is over when the function exits or more accurately when the let block is evaluated.
Inside the in block, the calculation can include values defined in the let block, viz. x. The result of the calculation x + y + z is returned or more accurately, 1 + y + z is returned since x = 1.
Once again, I can hear you ask “HOW THE HELL AM I SUPPOSED TO DO ANYTHING WITHOUT VARIABLES?!”
Let’s think about when we want to modify variables. There are 2 general cases that come to mind: multi-valued changes (e.g. changing a single value of an object or record) and single-valued changes (e.g. loop counters).
Functional Programming deals with changes to values in a record by making a copy of the record with the values changed. It does this efficiently without having to copy all parts of the record by using data structures that makes this possible.
Functional programming solves the single-valued change in exactly the same way, by making a copy of it.
Oh, yes and by not having loops.
“WHAT NO VARIABLES AND NOW NO LOOPS?! I HATE YOU!!!”
Hold on. It’s not like we can’t do loops (no pun intended), it’s just that there are no specific loop constructs like for, while, do, repeat, etc.
Functional Programming uses recursion to do looping.
Here are two ways you can do loops in Javascript:
// simple loop construct
var acc = 0;
for (var i = 1; i <= 10; ++i)
acc += i;
console.log(acc); _// prints 55_
// without loop construct or variables (recursion)
function sumRange(start, end, acc) {
if (start > end)
return acc;
return sumRange(start + 1, end, acc + start)
}
console.log(sumRange(1, 10, 0)); _// prints 55_
Notice how recursion, the functional approach, accomplishes the same as the for loop by calling itself with a new start (start + 1) and a new accumulator (acc + start). It doesn’t modify the old values. Instead it uses new values calculated from the old.
Unfortunately, this is hard to see in Javascript even if you spend a little time studying it, for two reasons. One, the syntax of Javascript is noisy and two, you’re probably not used to thinking recursively.
In Elm, it’s easier to read and, therefore, understand:
sumRange start end acc =
if start > end then
acc
else
sumRange (start + 1) end (acc + start)
Here’s how it runs:
sumRange 1 10 0 = -- sumRange (1 + 1) 10 (0 + 1)
sumRange 2 10 1 = -- sumRange (2 + 1) 10 (1 + 2)
sumRange 3 10 3 = -- sumRange (3 + 1) 10 (3 + 3)
sumRange 4 10 6 = -- sumRange (4 + 1) 10 (6 + 4)
sumRange 5 10 10 = -- sumRange (5 + 1) 10 (10 + 5)
sumRange 6 10 15 = -- sumRange (6 + 1) 10 (15 + 6)
sumRange 7 10 21 = -- sumRange (7 + 1) 10 (21 + 7)
sumRange 8 10 28 = -- sumRange (8 + 1) 10 (28 + 8)
sumRange 9 10 36 = -- sumRange (9 + 1) 10 (36 + 9)
sumRange 10 10 45 = -- sumRange (10 + 1) 10 (45 + 10)
sumRange 11 10 55 = -- 11 > 10 => 55
55
You’re probably thinking that for loops are easier to understand. While that’s debatable and more likely an issue of familiarity, non-recursive loops require Mutability, which is bad.
I haven’t entirely explained the benefits of Immutability here but check out the Global Mutable State section in Why Programmers Need Limits to learn more.
One obvious benefit is that if you have access to a value in your program, you only have read access, which means that no one else can change that value. Even you. So no accidental mutations.
Also, if your program is multi-threaded, then no other thread can pull the rug out from under you. That value is constant and if another thread wants to change it, it’ll have create a new value from the old one.
Back in the mid 90s, I wrote a Game Engine for Creature Crunch and the biggest source of bugs was multithreading issues. I wish I knew about immutability back then. But back then I was more worried about the difference between a 2x or 4x speed CD-ROM drives on game performance.
Immutability creates simpler and safer code.
不变性创建简单安全的代码。
Enough for now.
对于现在而言是足够的。
In subsequent parts of this article, I’ll talk about Higher-order Functions, Functional Composition, Currying and more.
在本文的后续部分,我将讨论高阶函数,函数组成,柯里化等。
Up Next: Part 2
If you liked this, click the? below so other people will see this here on Medium.
如果你喜欢,点击这?下面,其他人会在 Medium 上看到这个
If you want to join a community of web developers learning and helping each other to develop web apps using Functional Programming in Elm please check out my Facebook Group, Learn Elm Programming https://www.facebook.com/groups/learnelm/
如果你想加入 web 开发者学习社区,请在 ELM 函数编程使用相互帮助开发Web应用程序,请检查我的脸谱网组,学习 ELM 的编程 https://www.facebook.com/groups/learnelm/。
My Twitter: @cscalfani
One clap, two clap, three clap, forty?
一拍,两拍,三拍,四十拍?
By clapping more or less, you can signal to us which stories really stand out.
通过或多或少的掌声,你可以告诉我们哪些故事真的很突出。
下面是前端性能问题的概述,你可以参考以确保流畅的阅读本文。
依赖于你的组织优先性和战略性,你可能想考虑使用谷歌的 AMP 和 Facebook 的 Instant Articles 或者苹果的 Apple News。没有它们,你可以实现很好的性能,但是 AMP 确实提供了一个免费的内容分发网络(CDN)的性能框架,而 Instant Articles 将提高你在 Facebook 上的知名度和表现。
对于用户而言,这些技术主要的优势是确保性能,但是有时他们宁愿喜欢 AMP-/Apple News/Instant Pages 链路,也不愿是“常规”和潜在的臃肿页面。对于以内容为主的网站,主要处理很多第三方法内容,这些选择极大地加速渲染的时间。
对于网站的所有者而言优势是明显的:在各个平台规范的可发现性和增加搜索引擎的可见性。你也可以通过把 AMP 作为你的 PWA 数据源来构建渐进增强的 Web 体验。缺点?显然,在一个有围墙的区域里,开发者可以创造并维持其内容的单独版本,防止 Instant Articles 和 Apple News 没有实际的URLs。(谢谢 Addy,Jeremy)
根据你拥有的动态数据量,你可以将部分内容外包给静态站点生成器,将其放在 CDN 中并从中提供一个静态版本。因此可以避免数据的请求。你甚至可以选择一个基于 CDN 的静态主机平台,将交互组件作为增强来充实你的页面 (jamstack)。
注意,CDN 也可以服务(卸载)动态内容。因此,限制你的 CDN 到静态资源是不必要的。仔细检查你的 CDN 是否进行压缩和转换(比如:图像优化方面的格式,压缩和调整边缘的大小),智能 HTTP/2 交付,边侧包含,在 CDN 边缘组装页面的静态和动态部分(比如:离用户最近的服务端),和其他任务。
知道你应该优先处理什么是个好主意。管理你所有资产的清单(JavaScript,图片,字体,第三方脚本和页面中“昂贵的”模块,比如:轮播图,复杂的图表和多媒体内容),并将它们划分成组。
建立电子表格。针对传统的浏览器,定义基本的_核心_体验(比如:完全可访问的核心内容),针对多功能浏览器_提升_体验(比如:丰富多彩的,完美的体验)和其他的(不是绝对需要而且可以被延迟加载的资源,如 Web 字体、不必要的样式、旋转木马脚本、视频播放器、社交媒体按钮、大型图像。)。我们在“Improving Smashing Magazine's Performance”发布了一篇文章,上面详细描述了该方法。
虽然很老,但我们仍然可以使用 cutting-the-mustard 技术将核心经验带到传统浏览器并增强对现代浏览器的体验。严格要求加载的资源:优先加载核心传统的,然后是提升的,最后是其他的。该技术从浏览器版本中演变成了设备功能,这已经不是我们现在能做的事了。
例如:在发展**家,廉价的安卓手机主要运行 Chrome,尽管他们的内存和 CPU 有限。这就是 PRPL 模式可以作为一个好的选择。因此,使用设备内存客户端提示头,我们将能够更可靠地针对低端设备。在写作的过程中,只有在 Blink 中才支持 header(Blink 支持客户端提示)。因为设备存储也有一个在 Chrome 中可以调用的 JavaScript API,一种选择是基于 API 的特性检测,只在不支持的情况下回退到 “符合标准”技术(谢谢,Yoav!)。
但我们处理单页面应用时,在你可以渲染页面时,你需要一些时间来初始化 app。寻找模块和技术加快初始化渲染时间(例如:这里是如何调试 React 性能,以及如何提高 Angular 性能),因为大多数性能问题来自于启动应用程序的初始解析时间。
JavaScript 有成本,但不一定是文件大小会影响性能。解析和执行时间的不同很大程度依赖设备的硬件。在一个普通的手机上(Moto G4),仅解析 1MB (未压缩的)的 JavaScript 大概需要 1.3-1.4 秒,会有 15 - 20% 的时间耗费在手机的解析上。在执行编译过程中,只是用在JavaScript准备平均需要 4 秒,在手机上绘排需要 11 秒。解释:在低端移动设备上,解析和执行时间可以轻松提高 2 至 5 倍。
Ember 最近推出了一个实验,一种使用二进制模板巧妙的避免解析开销的方式。这些模板不需要解析。(感谢,Leonardo!)
这就是检查每个 JavaScript 依赖性的关键,工具像 webpack-bundle-analyzer,Source Map Explorer 和 Bundle Buddy 可以帮助你完成这些。度量 JavaScript 解析和编译时间。Etsy 的 DeviceTiming,一个小工具允许您指示 JavaScript 在任何设备或浏览器上测量解析和执行时间。重要的是,虽然大小重要,但它不是一切。解析和编译时间并不是随着脚本大小增加而线性增加。
<figure class="video-container"><iframe src="https://player.vimeo.com/video/249525818" width="640" height="384" frameborder="0" webkitallowfullscreen="" mozallowfullscreen="" allowfullscreen=""></iframe>
Webpack Bundle Analyzer visualizes JavaScript dependencies.
使用预编译器来减轻从客户端到服务端的渲染的开销,因此快速输出有用的结果。最后,考虑使用 Optimize.js 更快的加载,用快速地调用的函数(尽管,它可能不需要)。
Tree-shaking 是一种通过只加载生产中确实被使用的代码和在 Webpack 中清除无用部分,来整理你构建过程的方法。使用 Webpack 3 和 Rollup,我们还可以提升作用域允许工具检测 import 链接以及可以转换成一个内联函数,不影响代码。有了 Webpack 4,你现在可以使用 JSON Tree Shaking。UnCSS or Helium 可以帮助你去删除未使用 CSS 样式。
而且,你想考虑学习如何编写有效的 CSS 选择器以及如何避免臃肿和开销浪费的样式。感觉好像超越了这个?你也可以使用 Webpack 缩短类名和在编译时使用作用域孤立来动态地重命名 CSS 类名
Code-splitting 是另一种 Webpack 特性,可以基于“chunks”分割你的代码然后按需加载这些代码块。并不是所有的 JavaScript 必须下载,解析和编译的。一旦在你的代码中确定了分割点,Webpack 会全权负责这些依赖关系和输出文件。在应用发送请求的时候,这样基本上确保初始的下载足够小并且实现按需加载。另外,考虑使用 preload-webpack-plugin 获取代码拆分的路径,然后使用 <link rel="preload"> or <link rel="prefetch"> 提示浏览器预加载它们。
在哪里定义分离点?通过追踪使用哪些 CSS/JavaScript 块和哪些没有使用。Umar Hansa 解释了你如何可以使用 Devtools 代码覆盖率来实现。
如果你没有使用 Webpack,值得注意的是相比于 Browserify 输出结果 Rollup 展现的更加优秀。当使用 Rollup 时,我们会想要查看 Rollupify,它可以转化 ECMAScript 2015 modules 为一个大的 CommonJS module ——因为取决于打包工具和模块加载系统的选择,小的模块会有令人惊讶的高性能开销。
Addy Osmani 的从[快速默认:现代加载的最佳实践](https://speakerdeck.com/addyosmani/fast-by-default-modern-loading-best-practices)。幻灯片76。
最后,随着现代浏览器对 ES2015 支持越来越好,考虑使用babel-preset-env 只有 transpile ES2015+ 特色不支持现代浏览器的目标。然后设置两个构建,一个在 ES6 一个在 ES5。我们可以使用script type="module"让具有 ES 模块浏览器支持加载文件,而老的浏览器可以加载传统的建立script nomodule。
对于 loadsh,使用 babel-plugin-lodash将会加载你仅仅在源码中使用的。这样将会很大程度减轻 JavaScript 的负载。
研究 JavaScript 引擎在用户基础中占主导地位,然后探索优化它们的方法。例如,当优化的 V8 引擎是用在 Blink 浏览器,Node.js 运行和电子,对每个脚本充分利用脚本流。一旦下载开始,它允许 async 或 defer scripts 在一个单独的后台线程进行解析,因此在某些情况下,提高页面加载时间达 10%。实际上,在 <head> 中使用 <脚本延迟>,以致于浏览器更早地可以发现资源,然后在后台线程中解析它。
Caveat:Opera Mini 不支持 defement 脚本,如果你正在为印度和非洲开发,defer 将会被忽略,导致阻塞渲染直到脚本已经评估了(感谢 Jeremy)!_。
渐进引导:使用服务器端呈现获得第一个快速的有意义的绘排,而且还要包含一些最小必要的 JavaScript 来保持实时交互来接近第一次的绘排。
在两种场景下,我们的目标应该是建立渐进引导:使用服务器端呈现获得第一个快速的有意义的绘排,而且还要包含一些最小必要的 JavaScript 来保持实时交互来接近第一次的绘排。如果 JavaScript 在第一次绘排没有获取到,那么浏览器可能会在解析时锁住主线程,编译和执行最新发现的 JavaScript,因此限制互动的网站或应用程序。
为了避免这样做,总是将执行函数分离成一个个,异步任务和可能用到 requestIdleCallback的地方。考虑 UI 的懒加载部分使用 WebPack 动态 import 支持,避免加载,解析,和编译开销直到用户真的需要他们(感谢 Addy!)。
在本质上,交互时间(TTI)告诉我们导航和交互之间的时间长度。度量是通过在初始内容呈现后的第一个五秒窗口来定义的,在这个过程中,JavaScript 任务没有操作 50ms 的。如果发生超过 50ms 的任务,寻找一个五秒的窗口重新开始。因此,浏览器首先会假定它达到了交互式,只是切换到冻结状态,最终切换回交互式。
一旦我们达到交互式,然后,我们可以按需或随时间所允许的,启动应用程序的非必需部分。不幸的是,随着 Paul Lewis 提到的,框架通常没有优先出现的概念可以向开发人员展示,因此渐进式引导很难用大多数库和框架实现。如果你有时间和资源,使用该策略可以极大地改善前端性能。
尽管所有的性能得到很好地优化,我们不能控制来自商业需求的第三方脚本。第三方脚本度量不受终端用户体验的影响,所以,一个单一的脚本常常会以调用令人讨厌的,长长的第三方脚本为结尾,因此,破坏了为性能专门作出的努力。为了控制和减轻这些脚本带来的性能损失,仅异步加载(可能通过 defer)和通过资源提示,如:dns-prefetch 或者 preconnect 加速他们是不足够的。
正如 Yoav Weiss 在他的必须关注第三方脚本的通信中解释的,在很多情况下,下载资源的这些脚本是动态的。页面负载之间的资源是变化的,因此我们不必知道主机是从哪下载的资源以及这些资源是什么。
这时,我们有什么选择?考虑 通过间隔下载资源来使用 service workers,如果在特定的时间间隔内资源没有响应,返回一个空的响应告知浏览器执行解析页面。你可以记录或者限制那些失败的第三方请求和没有执行特定标准请求。
另一个选择是建立一个 内容安全策略(CSP) 来限制第三方脚本的影响,比如:不允许下载音频和视频。最好的选择是通过 <iframe> 嵌入脚本以致于脚本运行在 iframe 环境中,因此如果没有接入页面 DOM 的权限,在你的域下不能运行任何代码。Iframe 可以 使用 sandbox 属性进一步限制,因此你可以禁止 iframe 的任何功能,比如阻止脚本运行,阻止警告、表单提交、插件、访问顶部导航等等。
例如,它可能需要允许脚本运行 <iframe sandbox="allow-scripts">。每一个限制都可以通过'允许'值在 'sandbox' 属性中(几乎处处支持)解除,所以把他们限制在最低限度的允许他们去做的事情上。考虑使用 Safeframe 和交叉观察;这将使广告嵌入 iframe 的同时仍然调度事件或需要从 DOM 获取信息(例如广告知名度)。注意新的策略如特征策略),资源的大小限制,CPU 和带宽优先级限制损害的网络功能和会减慢浏览器的脚本,例如:同步脚本,同步 XHR 请求,document.write 和超时的实现。
为了压测第三方,在 DevTools 上自底向上概要地检查页面的性能,测试如果一个请求被阻塞了会发生什么或者对于后面的请求有超时限制,你可以使用 WebPageTest's Blackhole 服务器 72.66.115.13,同时可以在你的 hosts 文件中指定特定的域名。最好是自我主机和使用一个单一的主机名,但是同时生成一个请求映射,当脚本变化时,暴露给第四方调用和检测。
图片信用:Harry Roberts
再次检查一遍 expires,cache-control,max-age 和其他 HTTP cache 头部都是否设置正确。通常,资源应该是可缓存的,不管是短时间的(如果它们很可能改变),还是无限期的(如果它们是静态的)——你可以在需要更新的时候,改变它们 URL 中的版本即可。在任何资源上禁止头部 Last-Modified 都会导致一个 If-Modified-Since 条件查询,即使资源在缓存中。与 Etag 一样,即使它在使用中。
使用 Cache-control: immutable,该头部针对被标记指纹的静态资源设计,避免资源被重新验证(截至 2017年12月,在 FireFox,Edge 和 Safari 中支持;只有 FireFox 在 HTTPS 中支持)。你也可以使用 Heroku 的 HTTP 缓存头部,Jake Archibald 的 "Caching Best Practices" ,以及 Ilya Grigorik 的 HTTP caching primer 作为指导。而且,注意不同的头部,尤其是在关系到 CDN 时,并且注意关键头部有助于避免在新请求稍有差异时进行额外的验证,但从以前请求标准,并不是必要的(感谢,Guy!)。
前两个月一直学习vue,node.js,但没有真正地动手做项目,恰好赶上公司要求我们做一个的登录注册的独立运行系统,趁着这个机会学习巩固下自己之前学的内容。前端使用 vue,后端用 Express 做服务端提供数据接口,数据库用 MySql。
实现对数据库的增改查操作。
demo 要求
完成一套可以独立运行的前端系统,包括注册,登录,个人中心3个功能模块。
首先介绍下项目的目录结构

首先全局安装: npm install -g vue-cli
安装依赖,实现在package.json 中对应添加相应的版本,然后执行 npm install
"dependencies": {
"axios": "^0.15.3",
"babel-polyfill": "^6.23.0",
"body-parser": "^1.18.2",
"element-ui": "1.3.1",
"mysql": "^2.15.0",
"vue": "^2.3.2",
"vue-core-image-upload": "2.1.11",
"vue-datasource": "1.0.9",
"vue-router": "^2.3.1",
},
在项目根文件夹下创建一个 service 文件夹。然后创建下面四个文件:
db/db.js --- 用来添加 MySQL 配置
module.exports = {
mysql: {
host: 'localhost',
user: 'root',
password: '',
port: '3306',
database: 'login'
}
}
app.js --- Express服务器入口文件
const userApi = require('./api/userApi');
const fs = require('fs');
const path = require('path');
const bodyParser = require('body-parser');
const express = require('express');
const app = express();
app.use(bodyParser.json());
app.use(bodyParser.urlencoded())
app.use('/api/user', userApi);
app.listen(3000);
console.log('success listen at port: 3000')
db/sqlMap.js----SQL语句映射文件,这里主要是对数据库的增改查操作。
var sqlMap = {
user: {
add: 'insert into user (username, account, password, repeatPass, email, phone, card, birth, sex) values (?,?,?,?,?,?,?,?,?)',
select_name: 'select * from user',
update_user: 'update user set'
}
}
module.exports = sqlMap;
其中查询语句一直有问题
select_name: 'select * from user where username = ?',
node 一直报错,后来,将 where username = ?放在api中拼接
具体见下,如果你有更好的解决方案,也请多指教。
router.post('/login', (req, res) => {
var sql_name = $sql.user.select_name;
// var sql_password = $sql.user.select_password;
var params = req.body;
console.log(params);
if (params.name) {
sql_name += "where username ='"+ params.name +"'";
}
var keywords = JSON.parse(Object.keys(params)[0]);
conn.query(sql_name, params.name, function(err, result) {
if (err) {
console.log(err);
}
// console.log(result);
if (result[0] === undefined) {
res.send('-1') //查询不出username,data 返回-1
} else {
var resultArray = result[0];
console.log(resultArray.password);
// console.log(keywords);
if(resultArray.password === keywords.password) {
jsonWrite(res, result);
} else {
res.send('0') //username
}
}
})
});
api/userApi.js ---- 测试用api示例
var models = require('../db/db');
var express = require('express');
var router = express.Router();
var mysql = require('mysql');
var $sql = require('../db/sqlMap');
var conn = mysql.createConnection(models.mysql);
conn.connect();
var jsonWrite = function(res, ret) {
if(typeof ret === 'undefined') {
res.send('err');
} else {
console.log(ret);
res.send(ret);
}
}
// 增加用户接口
router.post('/addUser', (req, res) => {
var sql = $sql.user.add;
var params = req.body;
console.log(params);
conn.query(sql, [params.name, params.account, params.password, params.repeatPass,
params.email, params.phone, params.card, params.birth, params.sex], function(err, result) {
if (err) {
console.log(err);
}
if (result) {
jsonWrite(res, result);
}
})
});
//查找用户接口
router.post('/login', (req, res) => {
var sql_name = $sql.user.select_name;
// var sql_password = $sql.user.select_password;
var params = req.body;
console.log(params);
if (params.name) {
sql_name += "where username ='"+ params.name +"'";
}
var keywords = JSON.parse(Object.keys(params)[0]);
conn.query(sql_name, params.name, function(err, result) {
if (err) {
console.log(err);
}
// console.log(result);
if (result[0] === undefined) {
res.send('-1') //查询不出username,data 返回-1
} else {
var resultArray = result[0];
console.log(resultArray.password);
// console.log(keywords);
if(resultArray.password === keywords.password) {
jsonWrite(res, result);
} else {
res.send('0') //username
}
}
})
});
//获取用户信息
router.get('/getUser', (req, res) => {
var sql_name = $sql.user.select_name;
// var sql_password = $sql.user.select_password;
var params = req.body;
console.log(params);
if (params.name) {
sql_name += "where username ='"+ params.name +"'";
}
conn.query(sql_name, params.name, function(err, result) {
if (err) {
console.log(err);
}
// console.log(result);
if (result[0] === undefined) {
res.send('-1') //查询不出username,data 返回-1
} else {
jsonWrite(res, result);
}
})
});
//更新用户信息
router.post('/updateUser', (req, res) => {
var sql_update = $sql.user.update_user;
var params = req.body;
console.log(params);
if (params.id) {
sql_update += " email = '" + params.email +
"',phone = '" + params.phone +
"',card = '" + params.card +
"',birth = '" + params.birth +
"',sex = '" + params.sex +
"' where id ='"+ params.id + "'";
}
conn.query(sql_update, params.id, function(err, result) {
if (err) {
console.log(err);
}
console.log(result);
if (result.affectedRows === undefined) {
res.send('更新失败,请联系管理员') //查询不出username,data 返回-1
} else {
res.send('ok');
}
})
});
//更改密码
router.post('/modifyPassword', (req, res) => {
var sql_modify = $sql.user.update_user;
var params = req.body;
console.log(params);
if (params.id) {
sql_modify += " password = '" + params.pass +
"',repeatPass = '" + params.checkPass +
"' where id ='"+ params.id + "'";
}
conn.query(sql_modify, params.id, function(err, result) {
if (err) {
console.log(err);
}
// console.log(result);
if (result.affectedRows === undefined) {
res.send('修改密码失败,请联系管理员') //查询不出username,data 返回-1
} else {
res.send('ok');
}
})
});
module.exports = router;
此时在service文件夹下执行node app(这里也可以加载package.json中,然后使用npm执行)看到success listen at port:3000......即服务端启动成功。
这里主要介绍 登录login.vue组件
<template>
<div class="login-wrap">
<div class="ms-title">登录管理系统</div>
<div class="ms-login">
<el-form :model="ruleForm" :rules="rules" ref="ruleForm" label-width="0px" class="demo-ruleForm">
<div v-if="errorInfo">
<span>{{errInfo}}</span>
</div>
<el-form-item prop="name">
<el-input v-model="ruleForm.name" placeholder="账号" ></el-input>
</el-form-item>
<el-form-item prop="password">
<el-input type="password" placeholder="密码" v-model="ruleForm.password" @keyup.enter.native="submitForm('ruleForm')"></el-input>
</el-form-item>
<el-form-item prop="validate">
<el-input v-model="ruleForm.validate" class="validate-code" placeholder="验证码" ></el-input>
<div class="code" @click="refreshCode">
<s-identify :identifyCode="identifyCode"></s-identify>
</div>
</el-form-item>
<div class="login-btn">
<el-button type="primary" @click="submitForm('ruleForm')">登录</el-button>
</div>
<p style="font-size:14px;line-height:30px;color:#999;cursor: pointer;float:right;" @click="handleCommand()">注册</p>
</el-form>
</div>
</div>
</template>
<script>
export default {
name: 'login',
data() {
return {
identifyCodes: "1234567890",
identifyCode: "",
errorInfo : false,
ruleForm: {
name: '',
password: '',
validate: ''
},
rules: {
name: [
{ required: true, message: '请输入用户名', trigger: 'blur' }
],
password: [
{ required: true, message: '请输入密码', trigger: 'blur' }
],
validate: [
{ required: true, message: '请输入验证码', trigger: 'blur' }
]
}
}
},
mounted() {
this.identifyCode = "";
this.makeCode(this.identifyCodes, 4);
},
methods: {
submitForm(formName) {
const self = this;
self.$refs[formName].validate((valid) => {
if (valid) {
localStorage.setItem('ms_username',self.ruleForm.name);
localStorage.setItem('ms_user',JSON.stringify(self.ruleForm));
console.log(JSON.stringify(self.ruleForm));
self.$http.post('/api/user/login',JSON.stringify(self.ruleForm))
.then((response) => {
console.log(response);
if (response.data == -1) {
self.errorInfo = true;
self.errInfo = '该用户不存在';
console.log('该用户不存在')
} else if (response.data == 0) {
console.log('密码错误')
self.errorInfo = true;
self.errInfo = '密码错误';
} else if (response.status == 200) {
self.$router.push('/readme');
}
}).then((error) => {
console.log(error);
})
} else {
console.log('error submit!!');
return false;
}
});
},
handleCommand() {
this.$router.push('/register');
},
randomNum(min, max) {
return Math.floor(Math.random() * (max - min) + min);
},
refreshCode() {
this.identifyCode = "";
this.makeCode(this.identifyCodes, 4);
},
makeCode(o, l) {
for (let i = 0; i < l; i++) {
this.identifyCode += this.identifyCodes[
this.randomNum(0, this.identifyCodes.length)
];
}
console.log(this.identifyCode);
}
}
}
</script>
<style scoped>
.login-wrap{
position: relative;
width:100%;
height:100%;
}
.ms-title{
position: absolute;
top:50%;
width:100%;
margin-top: -230px;
text-align: center;
font-size:30px;
color: #fff;
}
.ms-login{
position: absolute;
left:50%;
top:50%;
width:300px;
height:240px;
margin:-150px 0 0 -190px;
padding:40px;
border-radius: 5px;
background: #fff;
}
.ms-login span {
color: red;
}
.login-btn{
text-align: center;
}
.login-btn button{
width:100%;
height:36px;
}
.code {
width: 112px;
height: 35px;
border: 1px solid #ccc;
float: right;
border-radius: 2px;
}
.validate-code {
width: 136px;
float: left;
}
</style>
执行完上述3步之后,在根目录下执行 npm run dev,,然后输入一组数据,点击保存,你会发现会报一个错误:vue-resource.common.js?e289:1071 POST http://localhost:8082/api/user/login 404 (Not Found).
这是由于直接访问8082端口,是访问不到的,所以这里需要设置一下代理转发映射.
vue-cli的config文件中有一个proxyTable参数,用来设置地址映射表,可以添加到开发时配置(dev)中
dev: {
// ...
proxyTable: {
'/api': {
target: 'http://127.0.0.1:3000/api/',
changeOrigin: true,
pathRewrite: {
'^/api': ''
}
}
},
// ...
}
即请求/api时就代表http://127.0.0.1:3000/api/(这里要写ip,不要写localhost),
changeOrigin参数接收一个布尔值,如果为true,这样就不会有跨域问题了。
项目中要求防止多次提交,实际上就是防抖操作:
具体请移步节流和防抖
//本地开发
//开启前端服务,浏览器访问 http://localhost:8082
npm run dev
//开启后端服务
cd service
node app
一整天加一个下午,终于调通了,在数据库那边遇到了好多问题,不过经过不断的尝试终于解决了。
效果图



源码不当之处,还请指正,欢迎 star
参考了以下vue-manage-system,海岛心hey,罗坤
var qs = require('qs');
axios.get('api/', {
'params': {'country': ['PL', 'RU']}
'paramsSerializer': function(params) {
return qs.stringify(params, {arrayFormat: 'repeat'})
},
})
/*
*
*/
<template>
<div class="dialog">
<!--外层的遮罩-->
<div class="dialog-cover back" v-if="isShow" @click="closeMyself"></div>
<!--transition 这里可以添加一些简单的动画效果-->
<transition name="drop">
<!--style 通过props 控制内容的样式-->
<div class="dialog-content" :style="{top:topDistance + '%',width:widNum + '%',left:leftSize + '%'}" v-if="isShow">
<div class="dialog_head back">
<!--弹窗头部 title-->
<slot name="header">提示信息</slot>
</div>
<div class="dialog_main" :style="{paddingTop:pdt + 'px',paddingBottom:pdb + 'px'}">
<!--弹窗的内容-->
<slot name="main">弹窗内容</slot>
</div>
<!--弹窗关闭按钮-->
<div class="foot_close" @click="closeMyself">
<div class="close_img back"></div>
</div>
</div>
</transition>
</div>
</template>
<script>
export default {
name: "dialog",
props: {
isShow: {
type: Boolean,
default: false,
required: true
},
widNum: {
type: Number,
default: 86.5
},
leftSite: {
// 左定位
type: Number,
default: 6.5
},
topDistance: {
// top上边距
type: Number,
default: 35
},
pdt: {
// 上padding
type: Number,
default: 22
},
pdb: {
type: Number,
default: 47
},
methods: {
closeMyself() {
this.$emit("on-close");
}
}
}
}
</script>
<style lang="scss" scoped>
.drop-enter-active {
// 动画进入过程
transition: all 0.5s ease;
}
.drop-leave-active {
transition: all 0.3s ease;
}
.drop-enter {
transform: translateY(-500px);
}
.drop-leave-active {
transform: transformY(-500px);
}
// 最外层 设置 position 定位
.dialog {
position: relative;
color: #2e2c2d;
font-size: 16px;
}
.dialog-cover {
background: regba(0, 0, 0, 0.8);
position: fixed;
z-index: 200;
top: 0;
left: 0;
width: 100%;
height: 100%;
}
.dialog-content {
position: fixed;
top: 35%;
display: flex;
flex-direction: column;
justify-content: center;
align-items: center;
z-index: 300;
.dialog_head {
// 头部 title 的背景 居中圆角等属性
background-image: url("../../static/gulpMin/image/dialog/dialog_head.png");
height: 86.5%;
width: 43px;
display: flex;
justify-content: center;
align-items: center;
border-top-left-radius: 10px;
border-top-right-radius: 10px;
}
.dialog_main {
// 主体内容样式设置
background: #fff;
display: flex;
justify-content: center;
align-content: center;
width: 86.5%;
padding: 22px 0 47px 0;
border-bottom-left-radius: 10px;
border-bottom-right-radius: 10px;
}
.foot_close {
width: 50px;
height: 50px;
border-radius: 50%;
background: #fcca03;
display: flex;
justify-content: center;
align-content: center;
margin-top: -25px;
.close_img {
background-image: url("../../static/gulpMin/image/dialog/dialog_close.png")
width: 42px;
height: 42px;
}
}
}
</style>
今天测试发现了一个很奇怪的问题,网盘上传文件夹,如果存在多级目录上传时。
会存在获取的路径不对。比如上传文件夹A,文件夹A中包含文件夹B,文件夹B中包含文件C,上传文件夹A时,获得路径时B/C,而不时A/B/C。
在MDNwebkitRelativePath上有说明:

所以在使用的时候还是要注意下的
另外:对于国产浏览器中:
特别提醒:假设文件路径是 C:\f1\f2\f3\file.txt, 用户选择的是f1 文件夹,则Chrome、Firefox、Edge 都能正确返回 f2/f3/file.txt值。而国产的QQ浏览器、360浏览器、UC浏览器、搜狗浏览器都只能返回 f3/file.txt。也就是国产浏览器调用webkitRelativePath返回的结果都不会是你希望得到的路径,请注意使用时的细微差距。
上面说明的还是有点问题,在chrome 71还是存在这个问题的,升级到chrome 72以上就不存在这个问题了。
所以有些属性没有完全标准化时最好还是不要使用,即使使用的话,也要注意可能存在的问题。
float CSS属性指定一个元素应沿其容器的左侧或右侧放置,允许文本和内联元素环绕它。该元素从网页的正常流动中移除,尽管仍然保持部分的流动性。参考MDN
一个浮动元素是 float 的值不是 none 的元素。
/* Keyword values */
float: left;
float: right;
float: none;
float: inline-start;//实验性API
float: inline-end;//实验性API
/* Global values */
float: inherit;
float: initial;
float: unset;
由于 float 意味着使用块布局,它在某些情况下修改 display 值的计算值:
| 指定值 | 计算值 |
|---|---|
| inline | block |
| inline-block | block |
| inline-table | block |
| table-row | block |
| table-row-group | block |
| table-column | block |
| table-column-group | block |
| table-cell | block |
| table-caption | block |
| flex | block |
| inline-flex | block |
float 属性的值被指定为单一的关键字,值从下面的值列表中选择。
left 表明元素必须浮动在其所在的块容器左侧的关键字
right 表明元素必须浮动其所在的块容器右侧的关键字
none 表明元素不进行浮动的关键字
浮动元素从普通文档流中脱离,但浮动元素影响的不仅是自己,它会影响周围的元素的元素对齐进行环绕。
不管一个元素是行内元素还是块级元素,如果被设置了浮动,那浮动元素会生成一个块级框,可以设置它的width和height,因此float常常用于制作横向配列的菜单,可以设置大小并且横向排列。
clear属性:确保当前元素的左右两侧不会有浮动元素。clear只对元素本身的布局起作用。取值:left、right、both。
为什么要清除浮动,父元素高度塌陷 解决父元素高度塌陷问题:一个块级元素如果没有设置height,其height是由子元素撑开的。对子元素使用了浮动后,子元素会脱离标准文档流,也就是说,父级元素中没有内容可以撑开其高度,这样父级元素的height就被忽略了,这就是所谓的高度塌陷。
1:给父级div定义 高度 原理:给父级DIV定义固定高度(height),能解决父级DIV无法获取高度的问题。优点:代码简洁。缺点:高度被固定死了,是适合内容固定不变的模块。(不推荐使用)
2: 使用空元素,如<div class="clear"></div> (.clear{clear:both}) 原理:添加一对空的DIV 标签,利用css的clear:both属性清除浮动,让父级DIV能够获取高度。优点:浏览器支持好。缺点:多出了很多空的DIV标签,如果页面中浮动模块多的话,就出现很多空置DIV了,这样感觉似乎不太令人满意(不推荐使用)
3: 让父级div也一并浮起来 这样做可以初步解决当前的浮动问题。但是也让父级浮动起来了,又会产生新的浮动问题。(不推荐使用)
4: 父级 DIV 定义 display:table 原理:将 div 属性强制变成表格 优点: 不解 缺点:会产生新的未知问题。(不推荐使用)
5: 父级元素设置 overflow:hidden、auto;原理:这个方法的关键在于触发了BFC。在IE6中还需要触发hasLayout(zoom:1)优点:代码简洁,不存在结构和语义化的问题。缺点无法显示需要溢出的元素(不太推荐使用)
6: 父级div定义 伪类:after和zoom
.clearfix:after{
content:'.';
display:block;
height:0;
clear:both;
visibility: hidden;
}
.clearfix {zoom:1;}
原理:IE8以上和非IE浏览器才支持:after,原理和方法2类似,zoom(IE专有的特性)可解决ie6,ie7浮动问题。优点:结构和语义化完全正确,代码量也适中,可重复利用率(建议定义公共类)缺点:代码不是非常简洁(极力推荐使用)
精益求精写法
.clearfix:after {
content:”\200B”;
display:block;
height:0;
clear:both;
}
.clearfix { *zoom:1; } 照顾IE6,IE7就可以了
一般而言,js 中的浅拷贝和深拷贝主要针对 object、array 这些更为复杂的数据类型,而在日常使用中浅拷贝使用更为频繁,以及相比于深拷贝,浅拷贝非常容易懂且问题少的多。
浅拷贝:只是复制了对象属性的引用,如果原对象改变了,目标对象也会跟着改变
let obj1 = {a : 'foo', b : {c : 'bar'} };
let obj2 = Object.assign({}, obj1);
obj2.b.c = 'foo';
console.log(obj1.b.c)
先分别看看 Array 和 Object 自有的方法支持不?
var arr1 = [1,2], arr2 = arr1.slice();
console.log(arr1); // [1,2];
console.log(arr2); // [1,2];
//修改
arr2[0] = 3;
console.log(arr1); // [1,2];
console.log(arr2); // [3,2];
此时 arr2 的修改并没有影响到 arr1,将 arr1 改成二维数组再来看看:
let arr1 = [1,2,[3,4]],arr2 = arr1.slice();
console.log(arr1); // [1,2,[3,4]];
console.log(arr2); // [1,2,[3,4]];
// 修改
arr1[2][1] = 5;
console.log(arr1); // [1,2,[3,5]];
console.log(arr2); // [1,2,[3,5]];
arr2 又跟 arr1 一样了,看来 slice 只能修改一维数组。
具备同等特性的还有:concat, Array.from。
let obj1 = {x : 1, y : 1}, obj2 = Object.assign({}, obj1);
console.log(obj1); // {x : 1, y : 1}
console.log(obj2); // {x : 1, y : 1}
//修改
obj2.x = 2;
console.log(obj1); // {x : 1, y : 1}
console.log(obj2); // {x : 2, y : 1}
var obj1 = {
x : 1,
y : {
m : 1
}
};
var obj2 = Object.assign({},obj1);
console.log(obj1); // {x : 1, y : {m : 1}}
console.log(obj2); // {x : 1, y : {m : 1}}
// 修改
obj2 .y.m = 2;
console.log(obj1); // {x : 1, y : {m : 2}}
console.log(obj2); // {x : 1, y : {m : 2}}
Object.assign() 只能实现一维对象的深拷贝
var obj1 = {
x : 1,
y : {
m : 1
}
};
var obj2 = JSON.parse(JSON.stringify(obj1);
console.log(obj1); // {x : 1, y : {m : 1}}
console.log(obj2); // {x : 1, y : {m : 1}}
// 修改
obj2 .y.m = 2;
console.log(obj1); // {x : 1, y : {m : 1}}
console.log(obj2); // {x : 1, y : {m : 2}}
JSON.parse(JSON.stringify(obj)) 看起来可以实现二维对象的深拷贝,不过 MDN有句话描述的很清楚。
undefined、任意的函数以及 symbol 值,在序列化过程中会被忽略(出现在非数组对象的属性值中时)或者被转换成null(出现在数组中时)。
将 obj1 改造下
var obj1 = {
x : 1,
y : undefined,
z : function(z1, z2) {
return z1 + z2;
},
a : Symbol('foo')
}
var obj2 = JSON.parse(JSON.stringify(obj1);
console.log(obj1) //{x: 1, y: undefined, z: ƒ, a: Symbol(foo)}
console.log(obj2) //{x: 1, y: undefined, z: ƒ, a: Symbol(foo)}
// 修改
console.log(JSON.stringify(obj1)); //{"x":1}
console.log(obj2) //{x: 1}
你会发现,在将 obj1 进行 JSON.stringify() 序列化的过程中,y,z,a 被忽略了,也验证了 MDN 文档上的描述。因此,JSON.parse(JSON.stringify(obj)) 使用起来也有局限性。不能深拷贝含有 undefined,function,Symbol 值的对象。不过 JSON.parse(JSON.stringify(obj)) 已经满足我们大部分使用场景了。
深拷贝: 是对象的层级复制,也就是说目标对象和原对象完全不相干。
上面提到的 javascript 自有方法并不能彻底解决 Array,Object 的深拷贝问题,只能使用递归了。
function deepCopy(obj) {
let result = {};
let keys = Object.keys(obj),
key = null,
temp = null;
for (let i = 0; i < keys.length; i ++) {
key = keys[i];
temp = obj[key];
// 如果字段的值也是一个对象,则递归调用
if (temp && typeof temp === 'object' ) {
result[key] = deepCopy(temp);
} else {
result[key] = temp;
}
}
return result;
}
var obj1 = {
x: {
m: 1
},
y: undefined,
z: function add(z1, z2) {
return z1 + z2
},
a: Symbol("foo")
};
var obj2 = deepCopy(obj1);
obj2.x.m = 2;
console.log(obj1); // {x: {m: 1}, y: undefined, z: ƒ, a: Symbol(foo)}
console.log(obj2); // {x: {m: 2}, y: undefined, z: ƒ, a: Symbol(foo)}
可以看到,递归可以完美地解决了前面的遗留问题,我们也可以使用第三方库:jQuery 的 $.extend 和 loadash 的 _.cloneDeep来解决深拷贝。上面虽然是用 Object 验证,但对于 Array 也同样适用,因为 Array 也是特殊的 Object。
但是还有一个非常特殊的场景:
var obj1 = {
x : 1,
y : 2
};
obj1.z = obj1;
var obj2 = deepCopy(obj1);
此时如果调用刚才的 deepCopy 函数的话,会陷入一个循环的递归过程,从而导致爆栈。jQuery 的 $.extend 也没有解决,解决这个问题:需要判断一个对象的字段是否引用这个对象或这个对象的任意父级即可,修改代码如下:
function DeepCopy(obj, parent = null) {
// 创建一个新对象
let result = {};
let keys = Object.keys(obj),
key = null,
temp= null,
_parent = parent;
// 该字段有父级则需要追溯该字段的父级
while (_parent) {
// 如果该字段引用了它的父级则为循环引用
if (_parent.originalParent === obj) {
// 循环引用直接返回同级的新对象
return _parent.currentParent;
}
_parent = _parent.parent;
}
for (let i = 0; i < keys.length; i++) {
key = keys[i];
temp= obj[key];
// 如果字段的值也是一个对象
if (temp && typeof temp=== 'object') {
// 递归执行深拷贝 将同级的待拷贝对象与新对象传递给 parent 方便追溯循环引用
result[key] = DeepCopy(temp, {
originalParent: obj,
currentParent: result,
parent: parent
});
} else {
result[key] = temp;
}
}
return result;
}
var obj1 = {
x: 1,
y: 2
};
obj1.z = obj1;
var obj2 = deepCopy(obj1);
console.log(obj1); //
console.log(obj2); //
function clone(value, isDeep) {
if(value === null) return null;
if(typeof value !== 'object') return value
if(Array.isArray(value)) {
if(isDeep) {
return value.map(item => clone(item, true))
}
return [].concat(value)
} else {
if(isDeep) {
var obj = {};
Object.keys(value).forEach(item => {
obj[item] = clone(value[item], true)
})
return obj;
}
return {...value}
}
}
var objects = { c: { 'a': 1, e: [1, {f: 2}] }, d: { 'b': 2 } }
var shallow = clone(objects, true)
console.log(shallow.c.e[1]) // { f: 2 }
console.log(shallow.c === objects.c) // false
console.log(shallow.d === objects.d) // false
console.log(shallow === objects) // false
// 另外一种深拷贝实现
function deepClone(data) {
var temp = type(data) , o, i, ni;
if(temp === 'array') {
o = [];
} else if (temp === 'object') {
o = {};
} else {
return data;
}
if(temp === 'array') {
for (i = 0, ni = data.length; i < ni; i ++) {
o.push(deepClone(data[i]));
}
return o;
} else if(temp === 'object'){
for(i in data) {
o[i] = deepClone(data[i]);
}
return o;
}
}
原文地址:Turning Design Mockups Into Code With Deep Learning - Part 1
使用深度学习自动生成 HTML 代码 - 第 1 部分
在未来三年来,深度学习将改变前端的发展。它将会加快原型设计的速度和降低开发软件的门槛。
Tony Beltramelli 去年发布了pix2code 论文,Airbnb 也发布了 sketch2code。
目前,自动化前端开发的最大屏障是计算能力。但我们可以使用目前的深度学习算法,以及合成训练数据来探索人工智能前端自动化的方法。
在本文中,作者将教大家神经网络学习如何基于一张图片和一个设计原型来编写一个 HTML 和 CSS 网站。下面是该过程的简要概述:
我们将分三个版本来构建神经网络。
在第 1 个版本,我们构建最简单地版本来掌握移动部分。第 2 个版本,HTML 专注于自动化所有步骤,并简要神经网络层。最后一个 Bootstrap 版本,我们将创建一个模型来思考和探索 LSTM 层。
所有的代码准备在 Github 上和在 Jupyter 笔记本上的 FloydHub。所有 FloydHub notebook 都在 floydhub 目录中,本地 notebook 在 local 目录中。
本文中的模型构建是基于 Beltramelli 的论文 pix2code 和 Jason Brownlee 的图像描述生成教程。代码是由 Python 和 Keras 编写,使用 TensorFolw 框架。
如果你是深度学习的新手,我建议你尝试使用下 Python,反向传播和卷积神经网络。可以从我早期个在 FloyHub 博客上发表的文章开始学习 [1] [2] [3]。
让我们回顾一下我们的目标。我们的目标是构建一个神经网络,能够生成与截图对应的 HTML/CSS。
当你训练神经网络时,你先提供几个截图和对应的 HTML 代码。
网络通过逐个预测所有匹配的 HTML 标记语言来学习。预测下一个标记语言的标签时,网络接收到截图和之前所有正确的标记。
这里是一个在 Google Sheet 简单的训练数据示例。
创建逐词预测的模型是现在最常用的方法。这里也有其他方法,但该方法也是本教程使用的方法。
注意:每次预测时,神经网络接收的是同样的截图。如果网络需要预测 20 个单词,它就会得到 20 次同样的设计截图。现在,不用管神经网络的工作原理,只需要专注于神经网络的输入和输出。
我们先来看前面的标记(markup)。假如我们训练神经网络的目的是预测句子“I can code”。当网络接收“I”时,预测“can”。下一次时,网络接收“I can”,预测“code”。它接收所有前面的单词,但只预测下一个单词。
神经网络根据数据创建特征。神经网络构建特征以连接输入数据和输出数据。它必须创建表征来理解每个截图的内容和它所需要预测的 HTML 语法,这些都是为预测下一个标记构建知识。
把训练好的模型应用到真实世界中和模型训练过程差不多。我们无需输入正确的 HTML 标记,网络会接收它目前生成的标记,然后预测下一个标记。预测从「起始标签」(start tag)开始,到「结束标签」(end tag)终止,或者达到最大限制时终止
现在让我们构建 Hello World 版实现。我们将发送一张带有「Hello World!」字样的截屏到神经网络中,并训练它生成对应的标记语言。

首先,神经网络将原型设计转换为一组像素值。且每一个像素点有 RGB 三个通道,每个通道的值都在 0-255 之间。
为了以神经网络能理解的方式表征这些标记,我使用了 one-hot 编码。因此句子「I can code」可以映射为以下形式。
在上图中,我们的编码包含了开始和结束的标签。这些标签能为神经网络提供开始预测和结束预测的位置信息。
对于输入的数据,我们使用语句,从第一个单词开始,然后依次相加。输出的数据总是一个单词。
语句和单词的逻辑一样。这也需要同样的输入长度。他们没有被词汇限制,而是受句子长度的限制。如果它比最大长度短,你用空的单词填充它,一个只有零的单词。
正如你所看到的,单词是从右到左打印的。对于每次训练,强制改变每个单词的位置。这需要模型学习序列而不是记住每个单词的位置。
在下图中有四个预测。每一列是一个预测。左边是颜色呈现的三个颜色通道:红绿蓝和上一个单词。在括号外面,预测是一个接一个,以红色的正方形表示结束。
#Length of longest sentence
max_caption_len = 3
#Size of vocabulary
vocab_size = 3
# Load one screenshot for each word and turn them into digits
images = []
for i in range(2):
images.append(img_to_array(load_img('screenshot.jpg', target_size=(224, 224))))
images = np.array(images, dtype=float)
# Preprocess input for the VGG16 model
images = preprocess_input(images)
#Turn start tokens into one-hot encoding
html_input = np.array(
[[[0., 0., 0.], #start
[0., 0., 0.],
[1., 0., 0.]],
[[0., 0., 0.], #start <HTML>Hello World!</HTML>
[1., 0., 0.],
[0., 1., 0.]]])
#Turn next word into one-hot encoding
next_words = np.array(
[[0., 1., 0.], # <HTML>Hello World!</HTML>
[0., 0., 1.]]) # end
# Load the VGG16 model trained on imagenet and output the classification feature
VGG = VGG16(weights='imagenet', include_top=True)
# Extract the features from the image
features = VGG.predict(images)
#Load the feature to the network, apply a dense layer, and repeat the vector
vgg_feature = Input(shape=(1000,))
vgg_feature_dense = Dense(5)(vgg_feature)
vgg_feature_repeat = RepeatVector(max_caption_len)(vgg_feature_dense)
# Extract information from the input seqence
language_input = Input(shape=(vocab_size, vocab_size))
language_model = LSTM(5, return_sequences=True)(language_input)
# Concatenate the information from the image and the input
decoder = concatenate([vgg_feature_repeat, language_model])
# Extract information from the concatenated output
decoder = LSTM(5, return_sequences=False)(decoder)
# Predict which word comes next
decoder_output = Dense(vocab_size, activation='softmax')(decoder)
# Compile and run the neural network
model = Model(inputs=[vgg_feature, language_input], outputs=decoder_output)
model.compile(loss='categorical_crossentropy', optimizer='rmsprop')
# Train the neural network
model.fit([features, html_input], next_words, batch_size=2, shuffle=False, epochs=1000)
在 Hello World 版本中,我们使用三个符号「start」、「Hello World」和「end」。字符级的模型要求更小的词汇表和受限的神经网络,而单词级的符号在这里可能有更好的性能。
以下是执行预测的代码:
# Create an empty sentence and insert the start token
sentence = np.zeros((1, 3, 3)) # [[0,0,0], [0,0,0], [0,0,0]]
start_token = [1., 0., 0.] # start
sentence[0][2] = start_token # place start in empty sentence
# Making the first prediction with the start token
second_word = model.predict([np.array([features[1]]), sentence])
# Put the second word in the sentence and make the final prediction
sentence[0][1] = start_token
sentence[0][2] = np.round(second_word)
third_word = model.predict([np.array([features[1]]), sentence])
# Place the start token and our two predictions in the sentence
sentence[0][0] = start_token
sentence[0][1] = np.round(second_word)
sentence[0][2] = np.round(third_word)
# Transform our one-hot predictions into the final tokens
vocabulary = ["start", "<HTML><center><H1>Hello World!</H1></center></HTML>", "end"]
for i in sentence[0]:
print(vocabulary[np.argmax(i)], end=' ')
10 epochs: start start start
100 epochs: start <HTML><center><H1>Hello World!</H1></center></HTML> <HTML><center><H1>Hello World!</H1></center></HTML>
300 epochs: start <HTML><center><H1>Hello World!</H1></center></HTML> end
**在收集数据之前构建第一个版本。**在本项目的早期阶段,我设法获得 Geocities 托管网站的旧版存档,它有 3800 万的网站。但我忽略了减少 100K 大小词汇所需要的巨大工作量。
**处理一个 TB 级的数据需要优秀的硬件或极其有耐心。**在我的 Mac 遇到几个问题后,最终用上了强大的远程服务器。我预计租用 8 个现代 CPU 和 1 GPS 内部链接以运行我的工作流。
**在理解输入与输出数据之前,其它部分都似懂非懂。**输入 X 是屏幕的截图和以前标记的标签,输出 Y 是下一个标记的标签。当我理解这一点时,其它问题都更加容易弄清了。此外,尝试其它不同的架构也将更加容易。
**注意兔子洞。**由于这个项目与深度学习有关联的,我在这个过程中被很多兔子洞卡住了。我花了一个星期从无到有的编程RNNs,太着迷于嵌入向量空间,并被一些奇奇怪怪的实现方法所诱惑。
**图片到代码的网络其实就是自动描述图像的模型。**即使我意识到了这一点,但仍然错过了很多自动图像摘要方面的论文,因为它们看起来不够炫酷。一旦我意识到了这一点,我对问题空间的理解就变得更加深刻了。
FloydHub 是一个深度学习训练平台,我自从开始学习深度学习时就对它有所了解,我也常用它训练和管理深度学习实验。我们可以安装并在 10 分钟内运行第一个模型,它是在云 GPU 上训练模型最好的选择。
如果读者没用过 FloydHub,你可以用 2 分钟安装 或者观看 5 分钟视频。
拷贝仓库
git clone https://github.com/emilwallner/Screenshot-to-code-in-Keras.git
登录并初始化 FloyHub 命令行工具
cd Screenshot-to-code-in-Keras
floyd login
floyd init s2c
在 FloydHub 云 GPU 机器上运行 Jupyter notebook:
floyd run --gpu --env tensorflow-1.4 --data emilwallner/datasets/imagetocode/2:data --mode jupyter
所有的 notebooks 都放在 floydbub 目录下。本地等同于本地目录下。一旦我们开始运行模型,那么在 floydhub/Hello_world/hello_world.ipynb 下可以找到第一个 Notebook。
如果你想了解更多的指南和对 flags 的解释,请查看我早期的文章。
在这个版本中,我们将从 Hello World 模型自动化很多步骤,并关注与创建一个可扩展的神经网络模型。
该版本并不能直接从随机网页预测 HTML,但它是探索动态问题不可缺少的步骤。

如果我们将前面的架构扩展为以下图展示的结构。
该架构主要有两个部分。首先,编码器。编码器是我们创建图像特征和前面标记特征(markup features)的地方。特征是网络创建原型设计和标记语言之间联系的构建块。在编码器的末尾,我们将图像特征传递给前面标记的每一个单词。
然后,解码器将结合原型设计特征和标记特征以创建下一个标签的特征,这一个特征可以通过全连接层预测下一个标签。
因为我们需要为每个单词插入一个截屏,这将会成为训练神经网络案例的瓶颈。因此我们抽取生成标记语言所需要的信息来替代直接使用图像。
这些抽取的信息将通过预训练的 CNN 编码到图像特征中。这个模型是在 Imagenet 上预先训练好的。
我们将使用分类层之前的层级输出以抽取特征。
我们最终得到 1536 个 8x8 的特征图,虽然我们很难直观地理解它,但神经网络能够从这些特征中抽取元素的对象和位置。
在 Hello World 版本中,我们使用 one-hot 编码以表征标记。而在该版本中,我们将使用词嵌入表征输入并使用 one-hot 编码表示输出。
我们构建每个句子的方式保持不变,但我们映射每个符号的方式将会变化。one-hot 编码将每一个词视为独立的单元,而词嵌入会将输入数据表征为一个实数列表,这些实数表示标记标签之间的关系。
上面词嵌入的维度为 8,但一般词嵌入的维度会根据词汇表的大小在 50 到 500 间变动。
以上每个单词的八个数值就类似于神经网络中的权重,它们倾向于刻画单词之间的联系(Mikolov alt el., 2013)。
这就是我们开始部署标记特征(markup features)的方式,而这些神经网络训练的特征会将输入数据和输出数据联系起来。现在,不用担心他们是什么,我们将在下一部分进一步深入挖掘。
我们现在将词嵌入馈送到 LSTM 中,并期望能返回一系列的标记特征。这些标记特征随后会馈送到一个 Time Distributed 密集层,该层级可以视为有多个输入和输出的全连接层。
对于另一个平行的过程,其中图像特征首先会展开成一个向量,然后再馈送到一个全连接层而抽取出高级特征。这些图像特征随后会与标记特征相级联而作为编码器的输出。
这个有点难理解,让我来分步描述一下。
如下图所示,现在我们将词嵌入投入到 LSTM 层中,所有的语句都填充上最大的三个记号。
为了混合信号并寻找高级模式,我们运用了一个 TimeDistributed 密集层以抽取标记特征。TimeDistributed 密集层和一般的全连接层非常相似,且它有多个输入与输出。
同时,我们需要将图像的所有像素值展开成一个向量,因此信息不会被改变,只是重组了一下。
如上,我们会通过全连接层混合信号并抽取更高级的概念。因为我们并不只是处理一个输入值,因此使用一般的全连接层就行了。
在这个案例中,它有三个标记特征。因此,我们最终得到的图像特征和标记特征是同等数量的。
所有的语句都被填充以创建三个标记特征。因为我们已经预处理了图像特征,所以我们能为每一个标记特征添加图像特征。
如上,在复制图像特征到对应的标记特征后,我们得到了三个新的图像-标记特征(image-markup features),这就是我们馈送到解码器的输入值。
现在,我们使用图像-标记特征来预测下一个标签。
在下面的案例中,我们使用三个图像-标签特征对来输出下一个标签特征。
注意 LSTM 层不应该返回一个长度等于输入序列的向量,而只需要预测预测一个特征。在我们的案例中,这个特征将预测下一个标签,它包含了最后预测的信息。
全连接层会像传统前馈网络那样工作,它将下一个标签特征中的 512 个值与最后的四个预测连接起来,即我们在词汇表所拥有的四个单词:start、hello、world 和 end。
词汇的预测值可能是 [0.1, 0.1, 0.1, 0.7]。密集层最后采用的 softmax 激活函数会为四个类别产生一个 0-1 概率分布,所有预测值的和等于 1。在这个案例中,例如将预测第四个词为下一个标签。然后,你可以将 one-hot 编码 [0, 0, 0, 1] 转译成映射的值,也就是 “end”。
# Load the images and preprocess them for inception-resnet
images = []
all_filenames = listdir('images/')
all_filenames.sort()
for filename in all_filenames:
images.append(img_to_array(load_img('images/'+filename, target_size=(299, 299))))
images = np.array(images, dtype=float)
images = preprocess_input(images)
# Run the images through inception-resnet and extract the features without the classification layer
IR2 = InceptionResNetV2(weights='imagenet', include_top=False)
features = IR2.predict(images)
# We will cap each input sequence to 100 tokens
max_caption_len = 100
# Initialize the function that will create our vocabulary
tokenizer = Tokenizer(filters='', split=" ", lower=False)
# Read a document and return a string
def load_doc(filename):
file = open(filename, 'r')
text = file.read()
file.close()
return text
# Load all the HTML files
X = []
all_filenames = listdir('html/')
all_filenames.sort()
for filename in all_filenames:
X.append(load_doc('html/'+filename))
# Create the vocabulary from the html files
tokenizer.fit_on_texts(X)
# Add +1 to leave space for empty words
vocab_size = len(tokenizer.word_index) + 1
# Translate each word in text file to the matching vocabulary index
sequences = tokenizer.texts_to_sequences(X)
# The longest HTML file
max_length = max(len(s) for s in sequences)
# Intialize our final input to the model
X, y, image_data = list(), list(), list()
for img_no, seq in enumerate(sequences):
for i in range(1, len(seq)):
# Add the entire sequence to the input and only keep the next word for the output
in_seq, out_seq = seq[:i], seq[i]
# If the sentence is shorter than max_length, fill it up with empty words
in_seq = pad_sequences([in_seq], maxlen=max_length)[0]
# Map the output to one-hot encoding
out_seq = to_categorical([out_seq], num_classes=vocab_size)[0]
# Add and image corresponding to the HTML file
image_data.append(features[img_no])
# Cut the input sentence to 100 tokens, and add it to the input data
X.append(in_seq[-100:])
y.append(out_seq)
X, y, image_data = np.array(X), np.array(y), np.array(image_data)
# Create the encoder
image_features = Input(shape=(8, 8, 1536,))
image_flat = Flatten()(image_features)
image_flat = Dense(128, activation='relu')(image_flat)
ir2_out = RepeatVector(max_caption_len)(image_flat)
language_input = Input(shape=(max_caption_len,))
language_model = Embedding(vocab_size, 200, input_length=max_caption_len)(language_input)
language_model = LSTM(256, return_sequences=True)(language_model)
language_model = LSTM(256, return_sequences=True)(language_model)
language_model = TimeDistributed(Dense(128, activation='relu'))(language_model)
# Create the decoder
decoder = concatenate([ir2_out, language_model])
decoder = LSTM(512, return_sequences=False)(decoder)
decoder_output = Dense(vocab_size, activation='softmax')(decoder)
# Compile the model
model = Model(inputs=[image_features, language_input], outputs=decoder_output)
model.compile(loss='categorical_crossentropy', optimizer='rmsprop')
# Train the neural network
model.fit([image_data, X], y, batch_size=64, shuffle=False, epochs=2)
# map an integer to a word
def word_for_id(integer, tokenizer):
for word, index in tokenizer.word_index.items():
if index == integer:
return word
return None
# generate a description for an image
def generate_desc(model, tokenizer, photo, max_length):
# seed the generation process
in_text = 'START'
# iterate over the whole length of the sequence
for i in range(900):
# integer encode input sequence
sequence = tokenizer.texts_to_sequences([in_text])[0][-100:]
# pad input
sequence = pad_sequences([sequence], maxlen=max_length)
# predict next word
yhat = model.predict([photo,sequence], verbose=0)
# convert probability to integer
yhat = np.argmax(yhat)
# map integer to word
word = word_for_id(yhat, tokenizer)
# stop if we cannot map the word
if word is None:
break
# append as input for generating the next word
in_text += ' ' + word
# Print the prediction
print(' ' + word, end='')
# stop if we predict the end of the sequence
if word == 'END':
break
return
# Load and image, preprocess it for IR2, extract features and generate the HTML
test_image = img_to_array(load_img('images/87.jpg', target_size=(299, 299)))
test_image = np.array(test_image, dtype=float)
test_image = preprocess_input(test_image)
test_features = IR2.predict(np.array([test_image]))
generate_desc(model, tokenizer, np.array(test_features), 100)
从 REST API 获取数据是一种很常见的编程模式,使用这些数据来绘制图表同样常见。
我们的很多用户可能正在为他们的 Web 应用程序这么做,所以我想我们(ZingChart)应该写一篇关于如何正确使用的教程。
REST API 基本上是一个公开的数据集(通常是 JSON),它位于某个 URL 中,并且可以通过 HTTP 请求以编程方式访问。
免责声明,本教程将在一般的 JavaScript 中运用。
我选择了 Star Wars REST API作为 REST 端点,从中获取数据。我之所以选择它,是因为它会返回易于使用的 JSON 数据,还不需要身份验证。
AJAX 是异步 JavaScript 和 XML。Ajax 是一组用于异步 HTTP 请求(GET,POST,PUT,DELETE)的方法。在这种情况下,异步意味着我们不必每次发出 HTTP 请求就重新加载页面。一个 AJAX 请求由 5 个步骤组成:
创建一个新的 HTTP 请求。
加载请求。
使用响应的数据。
创建请求。
发送请求。
要初始化一个 AJAX 请求,我们必须创建一个新的实例并将其存储在一个变量中,如下所示:
var xhr = new XMLHttpRequest();
将它存储在一个变量中允许我们后期使用其他的 AJAX 方法。我称之为 'xhr',因为这是一个简短的缩写,你也可以起一个你喜欢的变量名。
我们的 AJAX 过程的下一步将是添加一个事件监听器到我们的请求。我们的事件监听器将响应一个 load 事件,一旦我们的请求加载就会触发。接下来是一个回调函数。
在我们的事件监听器中,回调函数将在 if 语句流中运行。如果我们从 API 端点收到 “200” 状态(意味着请求完成),那么我们会做一些事情。
整个顺序将如下所示:
xhr.addEventListener('load', function() {
if (this.status == 200) {
// do something
}
});
每个 AJAX 请求都会将数据返回给我们。微妙的部分是确保我们能够以我们想要的方式处理这些数据。在这个过程中将会接收我们可以从这个响应中处理的数据有四个步骤:
将响应解析成 JSON 并将其存储在变量中。
创建空数组,可以存放我们想要的数据。
遍历响应并将值放入我们的空数组中。
将数组中的值转换为可用数据。
这里每个步骤都将在我们事件监听器内部的 if 语句中执行。*
每个响应都会返回一串数据。我们需要一个 JSON 对象,这样我们就可以遍历这些值。我们可以使用 JSON.parse() 方法将响应字符串转换为 JSON 格式。我们可以将它存储在一个名为 response 的变量中,以便后期我们可以像这样处理它:
var response = JSON.parse(this.responseText);
现在我们有一个存储在变量中的对象数组。你可以通过 console.log(response); 来查看完整的数组。
在这个数组中,有一个我们想要使用的特定对象叫做 results。这个对象包含 Star Wars 的 characters 和关于他们的信息。我们将把这个对象保存在一个变量中,这样我们就可以在接下来的步骤中循环。
我们可以在我们现有的 response 变量上使用 JSON 点符号来访问这个对象。我们将把它保存在一个名为 characters 的变量中。它看起来像这样:
var characters = response.results;
接下来我们需要创建一个变量来保存一个空数组,我们将称之为 characterInfo。当后期我们遍历对象时,可以将值推送到这个数组中。看看下面:
var characterInfo = [];
我们可以将数组中的数组直接放到 ZingChart 中,并使用x轴和y轴的值来绘制图表。这非常有用。
由于我们的 character 变量将被存储在一个对象数组中,我们可以使用 forEach 方法来遍历它。
forEach 方法需要一个回调函数,它将传入一个 character 参数。character 参数与 for 循环中的 character[i] 相同。它代表着它正在循环的对象。我们可以使用 JSON 点符号来访问我们在循环过程中需要的任何对象。
我们将从每个对象中提取两条数据:name 和 height。这是我们之前的空数组发挥作用的地方。在我们循环的每个对象中,我们可以使用回调函数内的array.push() 方法将值推送到我们空的 characterInfo 数组的末尾。
我们可以以数组格式插入值,以便我们可以有一个包含 character name 和 height 数组的数组。这些值将作为字符串值返回,这对于 name 属性是很好的。但是,我们可以使用 parseInt() 方法将每个高度值从一个字符串转换为一个数字。
我们的代码将如下所示:
xhr.addEventListener('load', function() {
if (this.status == 200) {
var response =
JSON.parse(this.responseText);
var characters = response.results;
var characterData = [];
characters.forEach(function(character) {
characterData.push([character.name,
parseInt(character.height)]);
});
});
AJAX 请求的最后两个步骤实际上是促使其发生的。首先是 open 方法,打开了我们的请求。这个请求是一个 GET 请求,是 XMLHttpRequest()方法的 HTTP 部分。
GET 请求是实际到达 API 端点并获取数据。我会告诉你它是什么样子,然后我们解析它。
xhr.open('GET', 'https://swapi.co/api/people/');
使用 .open,我们打开这个请求到指定的 URL: https://swapi.co/api/people/。这将返回一个包含 Star Wars characters 和一些额外的数据的对象数组。 REST API 通常具有一个可以获取数据的 API URL。如果您感兴趣,请查看 Star Wars API docs查看您可以获取的不同数据集。
REST API 几乎可以让你通过操作 URL 来指定你想要的数据。稍后在自己的 demo 中使用 Star Wars API,看看你能得到什么。
最后一步可以说是您的 AJAX 请求中最重要的一部分。如果你不这样做,这个教程将失效。我们必须在我们的 xhr 变量上使用 .send() 方法来实际发送请求,像这样:
xhr.send();
现在我们已经有了 AJAX 请求的框架,我们可以使用从 Star Wars REST API 端点返回的响应。
渲染图表包括四个步骤:
HTML:创建一个唯一 ID 的 <div>。
CSS:给这个 </div> 赋值高度和宽度。
JS:创建一个图表配置变量。
JS:使用 zingchart.render({}); 方法来呈现图表。
为了渲染一个图表,我们需要一个图表容器。我们可以用 <div> 做这个。我们还需要给这个 <div> 唯一的 ID:
<div id="chartOne"></div>
我使用编号图表方法,如果我们后期需要参考,在代码中很容易找到。
我们将在我们的 CSS 中使用这个唯一的 ID 来声明一个高度和宽度:
#chartOne {
height: 200px;
width: 200px;
}
如果我们不能声明高度和宽度,图表将不会呈现。
您可以在您的应用程序中为您命名这个演示。 我选择将其命名为 'chartOneData',因为我们可以轻松地将其绑定至 'chartOne' ID。
这个变量实际上只有两个重要的方面:
声明一个图表类型(在这个例子中我们使用的是柱形图)。
将值添加到我们的图表。
我们所有的图表信息将被放置在我们的事件监听器回调函数中。
ZingChart 有一个可声明的语法,所以选择一个图表类型就像声明一个键值对一样简单:
var chartOneData = {
type: 'bar'
};
向我们的图表添加值是以类似的方式来声明一个图表类型。这一次,我们将使用嵌套键值对来添加键值对。series 将采取一个名为值的对象。
在这个值对象中,我们可以将数据传入到数组中。这包含了我们所有的角色信息。它看起来像这样:
var chartOneData = {
type: 'bar',
series: [
{
values: characterInfo
}
]
}
渲染我们的图表也非常简单。我们可以使用一个内置的渲染方法,你所要做的就是传入几个键值对,它们是:
id:这是我们传入我们的 <div> 元素的 id。
data:他将是我们之前声明的图表变量的名称。
height:这将是 '100%' 的值来填充我们的容器。
width:这也将是 '100%' 的值来填补我们的容器。
zingchart.render({
id: 'chartOne',
data: chartOneData,
height: '100%',
width: '100%'
})
现在我们已经完成了,我们应该有一个完整的图表,它已经成功地从 REST API 中提取数据。太好了!
<iframe height="500" scrolling="no" title="REST API AJAX Request" src="//codepen.io/zingchart/embed/de8544d3f634ae7c88144b3b237f19c0/?height=500&theme-id=dark,result&embed-version=2" frameborder="no" allowtransparency="true" allowfullscreen="true" style="width: 100%;">See the Pen <a href='https://codepen.io/zingchart/pen/de8544d3f634ae7c88144b3b237f19c0/'>REST API AJAX Request</a> by ZingChart (<a href='https://codepen.io/zingchart'>@zingchart</a>) on <a href='https://codepen.io'>CodePen</a>.</iframe>
参加工作已经两年了,发现我还是存在一个问题,人云亦云,没有对事情加以深入,没有深入理解,在把问题讲述清楚前没有深入地理解,和在大脑中过一遍。所以在跟别人描述问题时,自己的思路就不是很清晰,很么可能把问题描述清楚呢。很多情况下就是词不达意,没有达到一阵见血的效果。多读多写,还要多去思考,什么才是最重要的。同时也要付诸实施,这样才能事半功倍,效果更加的明显。
之前面试中,工作都会遇到 web 安全方面的内容,但从未深入了解,也没有总结,仅仅停留在概念认知层面上。
xss:跨站脚本攻击(Cross Site Scripting)是最常见和最基本的攻击 WEB 网站方法,攻击者通过注入非法的 HTML 或 JavaScript 代码,从而当用户浏览该网页时,控制用户浏览器。
xss 主要分为三类:
DOM xss:
Dom即文本对象模型,DOM通常代表在HTML、XHTML 和 xml 中的对象,使用 DOM 可以允许程序和
脚本动态的访问和更新文档的内容、结构和样式。它不需要服务器解析响应的直接参与,触发 XSS 靠的
是浏览器端的 DOM 解析,可以认为完全是客户端的事情。
反射型 xss:
反射型 xss也被称为非持久性 XSS,是现在最容易出现的一种 XSS 漏洞。发出请求时,XSS 代码出现在
URL 中,最后输入提交到服务器,服务器解析后在响应内容中出现这段 XSS 代码,最后浏览器解析执
行。
存储型 xss:
存储型 XSS 又被称为持久性 XSS,它是最危险的一种跨站脚本,相比反射型 XSS 和 DOM 型 XSS 具有
更高的隐蔽性,所以危害更大,因为它不需要用户手动触发。允许用户存储数据的 web 程序都可能存
在存储型 XSS 漏洞,当攻击者提交一段 XSS 代码后,被服务器接收并存储,当所有浏览器访问某个页
面时都会被 XSS,其中最典型的例子就是留言板。
跨站脚本攻击可能造成以下影响:
按理说,只要有输入数据的地方,就可能存在 XSS 危险。
ctx.cookies.set(name, value, {
httpOnly: true //默认为 true
})
过滤
输入检查,一般是用于对输入格式的检查,例如:邮箱,电话号码,用户名,密码。。。等,按照规定
的格式输入。
不仅仅是前端负责,后端也要做相同的过滤检查。
因为攻击者完全可以绕过正常的输入流程,直接利用相关接口向服务器发送设置。
HtmlEncode
某些情况下,不能对用户数据进行严格过滤,需要对标签进行转换
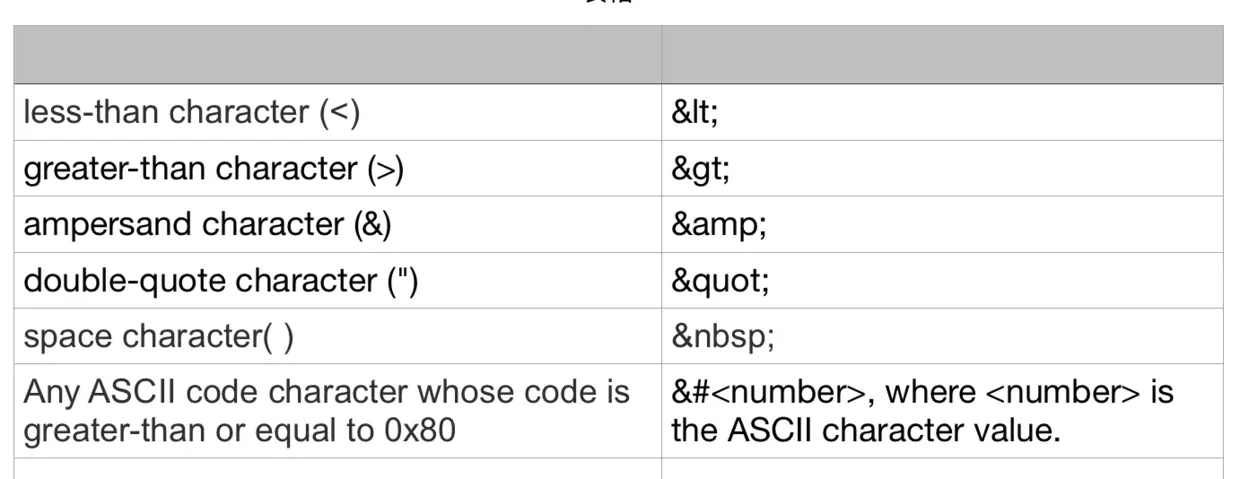
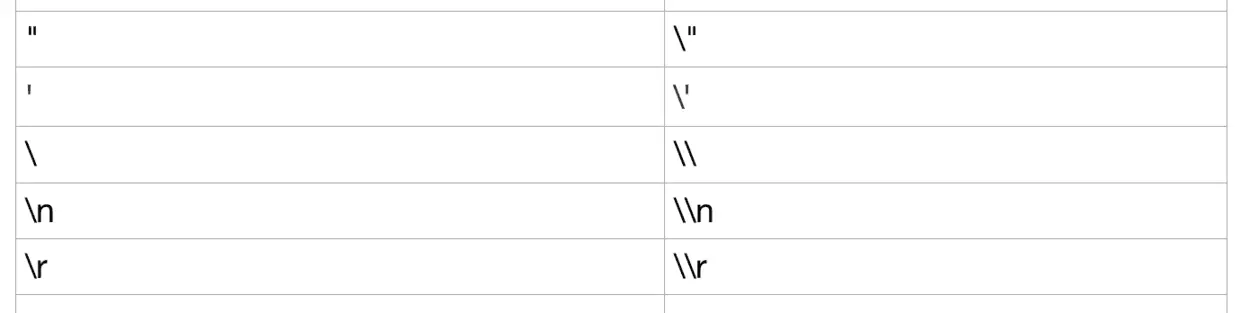
关于 更多 HtmlEncode 和 JavaScriptEncode,请参考HtmlEncode和JavaScriptEncode(预防XSS)
csrf:跨站点请求伪造(Cross-Site Request Forgeries),也被称为 one-click attack 或者 session riding。冒充用户发起请求(在用户不知情的情况下),完成一些违背用户意愿的事情(如修改用户信息,删除评论)。
可能会造成以下影响:
一张图了解原理:

简而言之:网站过分相信用户。
通常来说 CSRF 是由 XSS 实现的,CSRF 时常也被称为 XSRF(CSRF 实现的方式还可以是直接通过命令行发起请求等)。
本质上讲,XSS 是代码注入问题,CSRF 是 HTTP 问题。XSS 是内容没有过滤导致浏览器将攻击者的输入代码执行。CSRF 则是因为浏览器在发送 HTTP 请求时候自动带上 cookie,而一般网站的 session 都存在 cookie 里面。
防御
验证码:强制用户必须与应用进行交互,才能完成最终请求。此种方式能很好的遏制 csrf,但是用户体验比较差。
尽量使用 post,限制 get 使用;上一个例子可见,get 太容易被拿来做 csrf 攻击,但是 post 也并不是万无一失,攻击者只需要构造一个 form 就可以。
Referer check;请求来源限制,此种方法成本最低,但是并不能保证 100% 有效,因为服务器并不是什么时候都能取到 Referer,而且低版本的浏览器的浏览器存在伪造 Referer 的风险。
token:token 验证的 CSRF 防御机制是公认最合适的方案。
整体思路如下:
第一步:后端随机产生一个 token,把这个 token 保存到 session 状态中;同时后端把这个 token 交给前端页面;
第二步:前端页面提交请求时,把 token 加入到请求数据或者头信息中,一起传给后端;
后端验证前端传来的 token 与 session 能否一致,一致则合法,否则是非法请求。
若网站同时存在 XSS 漏洞的时候,这个方法也是空谈。
Clickjacking:点击劫持,是利用透明的按钮或链接做成陷阱,覆盖在 Web 页面之上。然后诱使用户在不知情的情况下,点击那个链接访问内容的一种攻击手段。这种行为又称为界面伪装(UI Redressing).
大概有两种方式
现在我们将用币创建一切。
需要一个像公民一样的身份平台?生成一个币
创建去中心化的域名系统(DNS)?生成一个币和首次币发行(ICO)!
在区块链应用程序上构建一个你自己的涂鸦?你需要一枚币,我的朋友!
实际上,你不需要一个币。
币将开始进入不同的元类别。 在这一点上,我只能看到需要四种类型的硬币,区块链(或区块链技术)可以根据需要无缝地交换它们以消耗服务:
通货紧缩的币用于囤积和投资。随着时间的推移,它们将会升值并为储户带来收益。每个人都需要这种投资,这也是比特币首先起步的原因。
今天通货膨胀的币反映了美元。没有人喜欢在平板电视上花费比特币,仅仅意识到他们几年后支付了 175,000 美元,因为比特币的价格上涨。我们需要稳定的,可用的货币。想象一下,作为经典的“价值储藏”,保罗克鲁格曼总是唠唠叨叨,知道我们实际上确实需要这样来购买和出售每一天的商品。
行为令牌适用于网络上应始终免费使用的操作,如投票或发送短信。 这些不是微交易。 重置我的密码不应该花费相当于两个便士。正如 EOS 人们所说:“如果你去亚马逊,花费三美分来加载页面,没有人会加载页面。”
奖励令牌旨在作为因果的数字化表示在系统周围流动,激励良好行为并惩罚不良行为。
只用这四个硬币,你就可以从字面上建立终极的通用系统。 每一枚硬币都可以简单地作为具有不同元数据的币的子组件。
谁又在乎答案呢?
**我们所有的经济学理论都是基于墨水和木浆模拟时代的有限数据进行的研究。**当前所有的经济理论将被证明与洞穴绘画一样先进,因为我们将在未来几年试验新的经济体系。。
这就是这些新币:战争时的微观经济体系。
这是达尔文的经济学。
一些基本的经济规律将会成立,但其中许多只会半途而废。这是因为在区块链支配系统中,我们将会获得全球范围内的实时经济数据,而不像一百年前那样,仅仅只能用铅笔和纸张进行的一系列猜测。
随着人工智能在全球范围内实时跟踪统计数据,我们将能够看到一个国家颁布的坚定关税的实际影响,因为在另一个依赖于该坚定关税的国家/地区建设的价格上涨。 我们将以令人难以置信的精确度跟踪全球生产和制造业,我们学到的东西将以这么多美妙的方式给我们带来惊喜。
达成这一里程碑的最有可能的 DAO 将是一个反映开放版 Visa 的 DAO,因为它可能会削减交易和矿工在最占主导地位的网络,并将有助于资助该网络的未来发展和管理。
它不会囤积所有资金,而是充当一种联系,通过智能合约将资金流向其他业务和 DAO,以及国家和地方政府,和其他有利于网络的非政府实体。
要做到这一点,DAO 必须发展。
现在我们认为 DAO 是一个智能合约,还差的很远。
“多么美好的人类!哦勇敢的新世界,有这样的人在!”
DAO 需要人工智能来帮助管理和减轻其规则集,它需要能够自动生成模板管理模型。在 DAO,管理是一切,而且目前还没有一个好的可扩展模型来管理一家大规模的公司,因为它是开源精英的工作场所。早期 DAO 失败是因为他们拥有我所谓的勇敢新世界问题。
每个人都认为他们很重要,没有人愿意放下姿态。
当每个人都是 DAO 中的国王时,很难否认。
**要有效发挥作用,团队需要角色扮演者和明星。**人们也必须理解他们的角色并接受它,即使他们在系统中建立价值和经验后会发生变化。
管理很难像企业环境一样。 你如何在 DAO 中解雇一个不履行职责人?你如何确保负责 ICO 安全的人实际上是合格的,而不是因为每个人都喜欢他而当选?你不能冒着流失 4,500 万美元的风险而让鲍勃当选,只是因为他那关于 Burning Man 的伟大故事和他的绘画技巧。
未来的自动化企业和非营利机构将不得不为持续管理和决策制定令人难以置信的工具,以及像代码一样运作的操作协议并成为现实。
二战时期的人们一生只有一两份工作。
今天我们有 5 个或者 6 个。
未来的人们同时会有五六份工作。
这些收入流中有一半是自动化和被动的,可能是某种加密 UBI。 我们也将看到 AI 就业匹配服务的兴起。 这些机器会知道你的能力和技能,并与短期表现相匹配,所以你甚至不需要找工作。
设想一个软件项目,需要大量的代码,比如 10 万亿行代码。 软件项目只会变得越来越复杂,并且会持续增长。AI 会写和测试它的一半,但人们会写另一半。该项目将被送入一个分布式的、非中心化的系统中,该系统可以将工作分成多个部分,并对其进行分析,就像一个项目经理,并根据声誉和技能的指纹,将工作交付给全世界范围内的程序员。
你可以把它想象成一个嫁给 UpWork 和 Mechanical Turk 系统的 AI Github。
它可以用于制造业和各种蓝领工作,这可以大大缩小我们今天看到的贫富差距。
[香港地铁人工智能](https://gizmodo.com/the-worlds-best-subway-system-is-powered-by-an- advanced-1601103048)也许是这种网络的第一个原型,即使它不是一个完美的类比。它预测地铁上会发生什么故障,并派遣工程师提前解决故障。这使全球最繁忙的地铁的正常运行时间达到 99%。
其中大部分将由外部化声誉银行管理,由区块链驱动,将成为未来的社会信用。
这将是好的,也是非常,非常邪恶的。
在房地产的邪恶一面,我们有**社会信用体系就像今天的 Black Mirror 一样。当民族国家利用声誉银行将意识形态灌输到人们的喉咙里时,情况将变得极其糟糕。
但公开管理的代表银行将帮助我们找到关系并开展工作,并找出在商业和生活中信任谁。
它将是双刃剑。
主要的挑战是很少有人能够就系统中的好或坏达成一致,意识形态倾向于将这些概念变为无法识别的混乱。如果我们不小心的话,创建一个可以奴役我们所有人的规则集非常容易。
我只是想通过一些更容易做出的预测。 现在让我们抛出一些可能引发社区激烈辩论和争议的东西。
加密爱好者将不得不接受这样的事实,即区块链能够并将尽可能多地利用邪恶。
没有什么是好的或坏的。一切都存在于一个连续体中。你可以用枪杀人,但你也可以通过狩猎养活你的家人。水可以维持生命,但它也会淹死你甚至毒死你。
如果你现在正在设计一个系统,并且采取“快速行动,打破东西”的 DevOps 方法,只要知道这对于可以在算法上控制我们生活中许多方面的系统而言是一场灾难。
相反,你应该缓慢采取行动,思考并且不要破坏事物的方法。
你应该开始考虑所有的方式来破坏你的系统,否则你将无法为它辩护。 如果你没有想象一个敌对团体将会使用区块链的力量,这个团队不会分享你对开放和自由以及合作的看法,那么你只是天真的。
我中途写了一篇名为 “ 如果希特勒拥有区块链 ?” 的文章。坦率地说,我不想发布它,因为我不想给坏人们任何新鲜的想法,但放心吧,可能无所谓。他们的黑暗头脑已经很难想象如何使用区块链作为压制和控制系统。
为了不把所有这些想法都放到集体无意识中,而是想想你的生活的各个方面,从你去哪儿做什么,到统计预测你的行为,以及旨在激励你遵守意识形态的行为算法,最后认为不可破解的数字版权管理和彻底的种族灭绝。
种族灭绝?
Yeah.
不要忘记 ** IBM 帮助纳粹管理大屠杀,用打孔卡追踪受害者**.
他们可以通过区块链做些什么? 答:我们现在只能想到更多可怕的暴行。
也许你认为一个开放的系统将永远防止滥用?
错。
如果互联网告诉了我们任何事情,那就是开放系统倾向于集中化,并且给予**权力足够的时间可以并且将颠覆和腐败任何系统)以达到自己的目的。
如果你在加密工作,并且你没有考虑所有滥用加密的方法,那么很可能不是设计一个拯救世界的系统,而是为它创建了一个监狱。
大多数真正的信徒不会喜欢这个,但老实说,50/50 存活率真的很高。
我知道,我知道。你以前听说过这一切!钱纠结不能停止!新的 ATH !!!!购买和 HODLz 永远!
看你卡住了这么久,所以我可以解释一下。
首先,我为比特币生存直到我死去,但让我们客观地看几分钟,看看为什么它可能会下降。这可能不是你的想法。
比特币具有先发优势。这是绝对的第一次,仍占据全球市场份额的主导地位,但同时也面临着一些可能杀死它的重大缺陷。
基本上,它是区块链演进的模型 T。
你今天在街上看到了多少个模型 T?
你能改装一个 T 型车,让它像兰博基尼一样燃烧橡胶吗?你能添加复杂的电子设备使它成为自动驾驶的特斯拉吗?不。
首先,比特币没有内置的管理。这是一个重要的缺陷。只有几种方法可以改变它。首先是提交提案,需要几乎每个人都同意,正如我们在 SegWit 看到的那样,这非常困难。花了四年时间才得到通过。
第二个是开始一个新项目并硬 fork 它。这可能是最终实际工作的唯一方式。一个团队可能会分叉并建立管理,但这是一个很长的过程。
、
具有设计良好,广泛内置的管理的币将比比特币具有巨大的优势,并且可以轻松取代它,因为它使升级更加顺畅。
对资金充足的敌对力量的攻击进行升级和应对,需要在数小时甚至数天而不是几年内迅速渗透整个网络。
如何扩展?我们已经讨论过这个问题。改变区块大小不会削减它。这将需要更激进的东西。
如果**改变了防火墙的话呢? 在这个后期阶段甚至有可能将专用中继和其他抗干扰代码加入系统中?
如果政府只是决定将数十亿美元投入数据中心并秘密设计 ASIC 来运行该系统呢?任何矿工都可以竞争吗?
如果敌对方决定召集所有核心开发者,会怎么样? 考虑到现在加密世界中人才的巨大短缺,替换它们有多容易?
这些只是我最喜欢的加密技术中几乎不可逾越的问题。我指出他们不要杀死它,而是让人们思考。让人们思考。如果你真的能看到一个问题,你可以找到解决它的方法。但是,如果我们只处理像区块大小限制这样的虚假问题,我们将一事无成。
比特币是一个美丽的,辉煌的想法,它已经改变了世界。 它不会失败,因为它是一种欺诈或骗局,但由于它自己的硬编码规则,内部斗争和缺乏管理。
当然,它不会失败。我们现在可以开始考虑如何拯救它。
正如我前面提到的那样,某种虚拟化或集装箱化让比特币能够适应和发展,通过迁移到一套抽象的协议和防御措施,有助于确保比特币不仅能够存活下来,而且还能够蓬勃发展。
我正在为此而生。我打赌,如果你正在阅读这篇文章,你也会有这样的想法。
确保它能够存活下来的最好方法是了解它可能发生故障的所有真正原因,并开始为当今的这些问题设计真正的解决方案,以便当它们到达时,我们已做好准备。
我有更多的预测,但我会保存他们我的小说 如果这篇文章发生病毒,也许我会做后续。
我还从桌面上留下了一些邪恶的想法,因为我不想看到他们成功。如果有人想到他们,我无能为力,但明天蒙特卡罗路线中最糟糕的情景不会来自我的键盘。
**加密货币是世界经济体系的根本升级。**一旦它们完全启动并融入到未来的全球和星际网络中,按照我们现在开始理解的方式,世界将会变得非常、非常不同。
从现在起数百年,今天的经济将看起来像过去的封建经济。
加密货币,去中心化应用程序和 DAO 甚至有可能将我们带入 Star Trek,就像后稀缺经济 一样,但这需要时间。
即使我将 Singularity 加入我的所有科幻作品中,我都不会以奇点级别的加速度下将我们带到那里,因为这是很棒的小说。但它可能不是现实。
如果我错了,那么我上传和快照的虚拟头脑,在 Matroishka 大脑上运行在全球大量的计算机上,只需要处理它。
但我怀疑它。
那么,我们在哪里?
加密将会像生活中的一切一样成为善与恶。
如果你正在研究加密,那么你正在构建明天的世界,但不要期待它会在下周到来。
惯性有一种放慢速度的办法,即使是最快的火箭也是如此。
只要我们大胆地走到没有人去过的地方,就可以享受骑行。
一如既往,感谢阅读。
首先需要对一些基础的内容了解下:
console.log('global')
setTimeout(function () {
console.log('timeout1')
new Promise(function (resolve) {
console.log('timeout1_promise')
resolve()
}).then(function () {
console.log('timeout1_then')
})
},2000)
for (var i = 1;i <= 5;i ++) {
setTimeout(function() {
console.log(i)
},i*1000)
console.log(i)
}
new Promise(function (resolve) {
console.log('promise1')
resolve()
}).then(function () {
console.log('then1')
})
setTimeout(function () {
console.log('timeout2')
new Promise(function (resolve) {
console.log('timeout2_promise')
resolve()
}).then(function () {
console.log('timeout2_then')
})
}, 1000)
new Promise(function (resolve) {
console.log('promise2')
resolve()
}).then(function () {
console.log('then2')
})
剪贴板有三种方式:ZeroClipboard.js,Clipboard.js,document.execCommand。
这三种复制剪贴板各有优势,但均是对 document.execCoomand指令的封装:
zeroclipboard 只要是结合 flash 来实现剪贴板功能,但是 flash 目前已经逐渐被各大浏览器抛弃了,而且火狐浏览器默认是不支持剪贴板的,该功能是禁止的。所以 zeroclipboard 在火狐浏览器是无法工作的,在Chrome,IE 浏览器,360 浏览器是可以的。
clipboard 插件,在弹框中存在聚焦的问题
document.execCommand 指令和 clipboard 插件类似,但是它是新兴的 API,在新版本的浏览器中不存在兼容性的问题。
top.ZeroClipboard.setMoviePath(parent.gMain.resourceUrl + '/js/control/clipboard/ZeroClipboard.swf');
var clip = null;
clip = new top.ZeroClipboard.Client();
clip.setHandCursor(true);
clip.addEventListener("load", function (client) {
jQuery('#copylink').show();
});
clip.addEventListener("mouseOver", function (client) {
clip.setText(linkurl);
});
clip.addEventListener("complete", function (client, text) {
parent.CC.showMsg(parent.Lang.Disk.copyChainSuccess, true, false, "option"); //复制成功
});
clip.glue('copylink', 'copylink');
<textarea id="bar">hello</textarea>
<button class="btn" data-clipboard-action="cut" data-clipboard-target="#bar">Cut</button>
var clipboard = new ClipboardJS('.btn');
clipboard.on('success', function(e) {
console.log(e);
});
clipboard.on('error', function(e) {
console.log(e);
});
当一个HTML文档切换到设计模式 designMode时,文档对象暴露 execCommand 方法,该方法允许运行命令来操纵可编辑区域的内容。大多数命令影响文档的选择(粗体,斜体等),而其他命令插入新元素(添加链接)或影响整行(缩进)。当使用contentEditable时,调用 execCommand() 将影响当前活动的可编辑元素。
copy
拷贝当前选中内容到剪贴板。启用这个功能的条件因浏览器不同而不同,而且不同时期,其启用条件也不尽相同。使用之前请检查浏览器兼容表,以确定是否可用。
<input type="text" id="inputText" value="测试文本"/>
<input type="button" id="btn" value="复制"/>
<textarea rows="4"></textarea>
<script type="text/javascript">
var btn = document.getElementById('btn');
btn.addEventListener('click', function(){
var inputText = document.getElementById('inputText');
var currentFocus = document.activeElement;
inputText.focus();
inputText.setSelectionRange(0, inputText.value.length);
document.execCommand('copy', true);
currentFocus.focus();
});
</script>
在 Firefox 41 之前,剪贴板功能需要在 user.js 配置文件中启用。参阅 Mozilla 配置概述。命令若未被支持或启用,execCommand 会抛出异常,而不是返回 false。自 Firefox 41 开始,只要是在能够创建窗口的事件回调函数里(半可信脚本里),剪贴板功能都是默认开启的。
[1]. document.execCommand
之前遇到很多次关于浏览器缓存和 304 的问题,但在开发的过程中没有深究,之前在开发的过程中,使用angularjs开发后台管理,在 IE 浏览器容易出现 304 问题,代码更新了,但页面仍然是之前内容,打开调试,发现是 304。
缓存对 web 有很重要的作用。
先来个简单的示意图

判断浏览器缓存:1、当前缓存是否过期?2、服务器中的文件是否改动

浏览器缓存分为强缓存和协商缓存。当客户请求某个资源时,获取缓存的流程如下:
Expire:该字段是http1.0 时的规范,值为一个绝对时间的 GMT 格式的时间字符串,代表缓存资源的过期时间
Cache-Control:max-age,该字段是 http1.1 的规范,强缓存利用其 max-age 值来判断缓存资源的最大生命周期,它的值是单位为秒。
之前遇到这几属性一直没有明白它们代表什么,以及它们之间的关联,今天在项目中正好遇到了,记录下对它们的理解。
鼠标相对于浏览器窗口可视区域的X,Y坐标(窗口坐标),表示页面可视区域的X,Y偏移量,可视区域不包含工具栏和滚动条,搜索栏等。并且与页面滚动无关,滚动后的clientY值不变。
类似于 clientX,clientY,但它们使用的是文档坐标而非窗口坐标。页面坐标Y,与clientY基本类似,唯一区别在于该值与页面滚动有关,具体来说,pageY = clientY + 页面滚动高度。
鼠标相对于事件源元素(srcElement)的X,Y坐标。

documentElement 和 body 的相关说明
body 是 DOM 对象里的 body 子节点,即 标签
documentElement 是整个节点树的根节点 root,即 标签
DOM 把层次中的每一个对象称之为节点,就是一个层次结构,可以理解为一个属性结构,就像我们的目录一样,一个根目录,根目录下有子目录,子目录下还有子目录。
除了 documentElement,body 在浏览器下的表现方式的不同和各个浏览器对这三个属性的解释不同
下面就看看各个浏览器这些个东西作怪下对这三个属性的表现
Chrome

Firefox


数组扁平化:使用递归实现
function flattenDepth(array, depth=1) {
let result = [];
array.forEach (item => {
let d = depth;
if(Array.isArray(item) && d > 0){
result.push(...(flattenDepth(item, --d)))
} else {
result.push(item);
}
})
return result;
}
console.log(flattenDepth([1,[2,[3,[4]],5]]]))
console.log(flattenDepth([1,[2,[3,[4]],5]],2))
console.log(flattenDepth([1,[2,[3,[4]],5]],3))
将每一项遍历,如果某一项为数组,则让该项继续调用,这里指定了depth作为扁平化的深度,因为这个参数对数组的每一项都要起作用。
参数够了就执行,参数不够就返回一个函数,之前的参数存起来,直到够了为止。
function curry(func) {
var l = func.length;
return function curried() {
var args = [].slice.call(arguments);
if(args.length < l) {
return function() {
var argsInner = [].slice.call(arguments)
return curried.apply(this, args.concat(argsInner))
}
} else {
return func.apply(this, args)
}
}
}
var f = function(a,b,c) {
return console.log([a,b,c])
}
var curried = curry(f);
curried(1)(2)(3)
在开发过程中会遇到频率很高的事件或者连续的事件,如果不进行性能的优化,就可能会出现页面卡顿的现象,比如:
翻译:[计] 防反跳;
在 Javascript 中,那些 DOM 频繁触发的事件,我们想在某个时间点上去执行我们的回调,而不是每次事件每次触发,我们就执行该回调。我们希望多次触发的相同事件的触发合并为一次触发(其实还是触发了好多次,只是我们只关注那一次)。简单地说,即在某段连续时间内,在事件触发后只执行一次。
在用户拖拽窗口时,一直在改变窗口的大小,如果我们在 resize 事件中进行一些操作,消耗将是巨大的。而且大多数可能是无意义的执行,因为用户还处于拖拽的过程中。
可以使用 函数防抖 来优化相关的处理。
// 普通方案
window.addEventListener('resize', () => {
console.log('trigger');
})
//函数防抖方案
let debounceIdentify = 0;
window.addEventListener('resize', () => {
debounceIdentify && clearTimeout(debounceIdentify)
debounceIdentity = setTimeout(() => {
console.log('trigger')
}, 300)
})
在 resize 事件中,我们添加了一个 300 ms 的延迟执行逻辑。
并且在每次事件触发时,都会重新计时,这样可以确保函数的执行肯定是在距离上次 resize 事件被触发的 300 ms 后。
两次 resize 事件间隔小于 300 ms 的都被忽略了,这样就会节省很多无意义的事件触发。
function debounce(func, delay) {
return function(args) {
var _this = this;
var _args = args;
clearTimeout(func.id);
func.id = setTimeout(function() {
func.call(_this, _args)
}, delay)
}
}
function ajax(value) {
console.log('ajax request' + value)
}
var debounceAjax = debounce(ajax, 1000);
var input = document.getElementById("search")
input.addEventListener('keyup', function(e) {
debounceAjax(e.target.value)
})
可以看到当你输入的时候,并不会发送 ajax 请求,当停止并且指定间隔内没有输入的时候,才会执行相应的回调函数。
在一些与用户的交互上,比如提交表单后,一般都会显示一个loading框来提示用户,用户提交的表单正在处理中。
但是发送表单请求后就显示loading是一件很不友好的事情,因为请求可能在几十毫秒内就会得到响应。
这样在用户看来就是页面中闪过一团黑色,所以可以在提交表单后添加一个延迟函数,在XXX秒后再显示loading框。
这样在快速响应的场景下,用户是不会看到一闪而过的loading框,当然,一定要记得在接收到数据后去clearTimeout
let identify = setTimeout(showLoadingModal, 500)
anxios('url').then(res => {
// doing something
// clear timer
clearTimeout(identify);
})
debounce(func, delay) {
return function(args) {
var _this = this
var _args = args
clearTimeout(func.id)
func.id = setTimeout(function() {
func.call(_this, _args)
}, delay)
}
}
function debounce(func, wait, leading, trailing) {
var timer, lastCall = 0, flag = true
return function() {
var context = this
var args = arguments
var now = + new Date()
if (now - lastCall < wait) {
flag = false
lastCall = now
} else {
flag = true
}
if (leading && flag) {
lastCall = now
return func.apply(context, args)
}
if (trailing) {
clearTimeout(timer)
timer = setTimeout(function() {
flag = true
func.apply(context, args)
}, wait)
}
}
}
翻译:
-- n. | 节流阀
throttle就是设置固定的函数执行速率,从而降低频繁事件回调的执行次数。
无论怎么触发,均按照指定的时间间隔来执行。简单地说,就是限制函数在一定时间内调用的次数。
在代码中,可以通过限制函数的调用频率,来抑制资源的消耗。
move 事件中进行重绘 DOM,但是这样做,程序的开销是非常大的。所以这里用到函数节流的方法,来减少重绘的次数。
//普通方案
$dragable.addEventListener('mousemove', () => {
console.log('trigger')
})
// 函数节流的实现方案
/**
*
* @param fn {Function} 实际要执行的函数
* @param delay {Number} 执行间隔,单位是毫秒(ms)
*
* @return {Function} 返回一个“节流”函数
*/
function throttle(fn, threshold) {
// 记录上次执行的时间
var last
// 定时器
var timer
// 默认间隔为 250ms
threshold || (threshold = 250)
// 返回的函数,每过 threshold 毫秒就执行一次 fn 函数
return function () {
// 保存函数调用时的上下文和参数,传递给 fn
var context = this
var args = arguments
var now = +new Date()
// 如果距离上次执行 fn 函数的时间小于 threshold,那么就放弃
// 执行 fn,并重新计时
if (last && now < last + threshold) {
clearTimeout(timer)
// 保证在当前时间区间结束后,再执行一次 fn
timer = setTimeout(function () {
last = now
fn.apply(context, args)
}, threshold)
// 在时间区间的最开始和到达指定间隔的时候执行一次 fn
} else {
last = now
fn.apply(context, args)
}
}
}
代码中,比较关键的部分是最后部分的if .. else ..,每次回调执行以后,需要保存执行的函数的时间戳,为了计算以后的事件触发回调时与之前执行回调函数的时间戳的间隔,从而根据间隔判断要不要执行回调。
$dragable.addEventListener('mousemove', throttle(function(e) {
// 代码
}, 500))
这样做的结果是,在拖拽的过程中,可以确保在 500 ms 内,只能重绘一次 DOM。
同时监听了 mousemove,两者最终的结果是一致的,但是在拖拽的过程中,函数节流版触发的事件次数会相对减少很多,相应地资源消耗会更少。
// ES6 版
function throttle (func, interval) {
let identify = 0;
return (...args) => {
if (identify) return;
identify = setTimeout(() => identify = 0, interval);
func.apply(this, args)
}
}
如果还是对防抖和节流不太明白,可以在下面看到 debounce 和 throttle 可视化区别

debounce 强制函数在某段时间内只执行一次,throttle 强制函数以固定的速率执行。在处理一些高频率触发的 DOM 事件的时候,它们都能极大提高用户体验。
参考资料
招聘的过程中,看到他们对招聘对象的要求中,包含了,了解,熟悉,掌握,精通,但对这些概念没有深入的理解,很多人也是仅停留在字面上的意思。
了解:听说过,看过相关文档,并且在自己的项目或者 playgournd 上试用、试玩过。
熟悉:已经在实际项目中使用相关技术,并且积累了一定程度的经验。
掌握:多次使用相关技术并且跟进最新的进展,了解它和竞品的优缺点,了解它的技术架构和潜在风险。
精通:深入该技术的源代码,能够为该技术贡献 code,性能调优,能够为这个技术布道。
项目是很早的项目,而且是从别人那接手的项目,代码很老的,框架用的是早期的 MVC 框架backbone。
两种解决方法
第一种 Chrome Firefox有效
$("#filepath").val("");
第二种 兼容 IE 360浏览器兼容模式
if (window.navigator.userAgent.indexOf("MSIE") > 0) {
$("#uploads")[0].reset();
$("#iptSearch").val(upFileName);
}
当时用的是
margin-bottom: -9999px;
padding-bottom: 9999px;
刚开始做的时候没有考虑到 IE,360,火狐 浏览器,结果测试时发现了这个问题,在这些浏览器中出现滚动条,以及页面下面出现大量的空白,所以这种方法无法实现两列等高的布局。
后来考虑到左侧是导航栏,固定布局,左侧使用 position: fixed,右侧使用margin-left: 150px 来处理,这样就解决之前出现的问题。
使用 texarea: auto 来解决这个问题。
简单的实现如下
function debounce(fn, wait) {
var timeout = null;
return function() {
if(timeout !== null)
clearTimeout(timeout);
timeout = setTimeout(fn, wait);
}
}
使用的是HTML5的download属性
function downloadFile(url, saveName){
if(typeof url == 'object' && url instanceof Blob) {
url = URL.createObjectURL(url); // 创建blob地址
}
var aLink = document.createElement('a');
aLink.href = url;
aLink.download = saveName || ''; // HTML5新增的属性,指定保存文件名,可以不要后缀,注意,file:///模式下不会生效
var event;
if(window.MouseEvent) event = new MouseEvent('click');
else {
event = document.createEvent('MouseEvents');
event.initMouseEvent('click', false, false, window, 0, 0, 0, 0, 0, false, false, false, false, 0, null);
}
aLink.dispatchEvent(event);
兼容IE写法
if('msSaveOrOpenBlob' in window.navigator) {
window.navigator.msSaveOrOpenBlob(blob, downloadUrl);
}
试了下,但在IE浏览器中没有生效
在 HTML5 中,download 属性是 标签的新属性。
download 属性规定被下载的超链接目标。
在 标签中必须设置 href 属性。
该属性也可以设置一个值来规定下载文件的名称。所允许的值没有限制,浏览器将自动检测正确的文件扩展名并添加到文件 (.img, .pdf, .txt, .html, 等等)。
此方法不支持IE、Opera、Safari,支持Firefox、google浏览器
解决方法(兼容 IE 浏览器)
function download_pic() {
var codeurl='文件服务器路径';
if(browserIsIe()){//假如是ie浏览器
DownLoadReportIMG(codeurl);
}else{
downloadFile(codeurl)
}
}
function DownLoadReportIMG(URL) {
//如果隐藏IFRAME不存在,则添加
if (!document.getElementById("IframeReportImg"))
$('<iframe style="display:none;" id="IframeReportImg" name="IframeReportImg" onload="DoSaveAsIMG();" width="0" height="0" src="about:blank"></iframe>').appendTo("body");
if (document.all.IframeReportImg.src != URL) {
//加载图片
document.all.IframeReportImg.src = URL;
}
else {
//图片直接另存为
DoSaveAsIMG();
}
}
function DoSaveAsIMG() {
if (document.all.IframeReportImg.src != "about:blank")
window.frames["IframeReportImg"].document.execCommand("SaveAs");
}
//判断是否为ie浏览器
function browserIsIe() {
if (!!window.ActiveXObject || "ActiveXObject" in window)
return true;
else
return false;
}
如果下载不是图片,则替换
最近发现download属性有一个新的问题,那就是同源策略限制问题,如果下载的链接跟当前页面不是同源,就会存在点击后无法下载。
解决方法:
通过另开新的窗口,来解决同源策略问题。
在做知识管理系统的过程中,发现兼容 IE 和 360 的不能下载
再网上又找了另外一种兼容性写法:
DownLoadReportIMG (url) {
var oPop = window.open(url, '', 'width=1, height=1, top=5000, left=5000')
for (; oPop.document.readyState !== 'complete';) {
if (oPop.document.readyState === 'complete') break
}
oPop.document.execCommand('SaveAs')
oPop.close()
}
这种写法可以正常使用
可以在不使用 js 的操作下实现原生的 url 跳转功能
具体见下:(3s跳转页面)
<Meta http-equiv="Refresh" Content="3; Url=http://www.baidu.com">
兼容写法如下
$(document).on('mouseover','#uploadMenu',function(e){
$("#uploadselect").show();
}).on('mouseout','#uploadMenu',function () {
$("#uploadselect").hide();
});
<meta name="renderer" content="webkit">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
::-ms-clear,::-ms-reveal{display:none;}[1]window.URL.createObjectURL Blob URL无法在Microsoft IE和Edge中打开
[2]JS下载文件的方法(浏览器兼容)
'use strict';
var isObj = require('is-obj');
var hasOwnProperty = Object.prototype.hasOwnProperty;
var propIsEnumerable = Object.prototype.propertyIsEnumerable;
function toObject(val) {
if (val === null || val === undefined) {
throw new TypeError('Cannot convert undefined or null to object');
}
return Object(val)
}
function assign(to, from, key) {
var val = from[key];
if (val === undefined || val === null) {
return;
}
if (hasOwnProperty.call(to, key)) {
if (to[key] === undefined || to[key] === null) {
throw new TypeError('Cannot convert undefined or null to object (' + key + ')');
}
}
if (!hasOwnProperty.call(to, key) || isObj(val)) {
to[key] = val;
} else {
to[key] = assign(Object(to[key]), from[key]);
}
}
function assign(to, from) {
if (to === from) {
return to;
}
from = Object(from);
for (var key in from) {
if (hasOwnProperty.call(from, key)) {
assignKey(to, from, key);
}
}
if (Object.getOwnPropertySymbols) {
var symbols = Object.getOwnPropertySymbols(from);
for (var i = 0; i < symbols.length; i++) {
if (propIsEnumerable.call(from, symbols[i])) {
assignKey(to, from, symbols[i]);
}
}
}
return to;
}
module.exports = function deepAssign(target) {
target = toObject(target);
for (var s = 1, s< arguments.length; s++) {
assign(target, arguments[s]);
}
return target;
}
JavaScript 是一门非阻塞单线程语言,因为最初的 JavaScript 就是为了和浏览器交互而诞生的。如果 JS 是门多线程语言的话,我们在多个线程中处理 DOM 就可能发生问题(一个线程中新加节点,另一个线程中删除节点),当然可以引入读写锁解决这个问题。
JavaScript 在执行的过程中会产生执行环境,这些执行环境会被顺序的加入到执行栈中。如果遇到异步的代码,会被挂起并加入到 Task (有多种 task)队列中。一旦执行栈为空,Event Loop 就会从 Task 队列中拿出需要执行的代码并放入执行栈中执行,所以本质上来说,JavaScript 中的异步是同步行为。
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0)
console.log('script end');
以上代码虽然 setTimeout 延时为 0,其实还是异步。这是因为 HTML5 标准规定这个函数第二个参数不得小于 4 毫秒,不足会自动增加。所以 setTimout 还是会在 script end 之后打印。
不同的任务源会被分配到不同的 Task 队列中,任务源可以分为微任务(microtask) 和 宏任务(macrotask)。在 ES6 规范中,microtask 成为 jobs,macrotask 称为 task。
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0)
new Promise((resolve) => {
console.log('promise');
resolve()
}).then(function(){
console.log('promise1');
}).then(function(){
console.log('promise2');
});
console.log('script end');
// script start => Promise => script end => promise1 => promise2 => setTimeout
以上代码虽然 setTimeout 写在 Promise 之前,但是因为 Promise 属于微任务而 setTimeout 属于宏任务,所以会有以上的打印。
微任务包括: process.nextTick,promise,Object.observe,MutationObserver
宏任务包括:script,setTimeout,setInterval,setImmediate, I/O ,UI rendering
很多人有个误区,认为微任务快于宏任务,其实是错误的,因为宏任务中包括了 script,浏览器会先执行一个宏任务,接下来有异步代码的话先执行微任务。
所以正确的一次 Event loop 顺序是这样的。
通过上述的 Event Loop 顺序可知,如果宏任务中的异步代码有大量的计算并且需要操作 DOM 的话,为了更快的界面响应,我们可以把操作 DOM 放入微任务中。
当James Titcumb在为他正在组织的会议举行谈话时表示,他指出相对于普通人,那些被选上的著名演讲者,由于他们在其他的事情上是可靠的(即他们不会取消)。我认为“除其他之外”会占更多的比重- 我相信大多数会议组织者都会选择这样的会谈和演讲者,因为他们喜欢安全和恐惧的风险。
我发现这是因为组织者做事谨慎,再来10年谈论,仍能承担风险。https://t.co/PXRhajhQXi
— Bruno Skvorc (@bitfalls) April 28,2017)
谨慎处理
更多来自作者
[创建自己的社交网络,游戏服务器或知识库!- Sourcehunt](https://www.sitepoint.com/make-social-network-game-server-knowledgebase/?utm_source=sitepoint&utm_medium=relatedinline&utm_term=&utm_campaign=relatedauthor)
了解和爱Xdebug
我从PHP世界中看到一个众所周知的名字的次数占有一席之地(而且最终也是一个“不冒险”)的言论是惊人的,它总是让我觉得对于我的提交,我太努力了。在这个几乎瞬间可用的录音的这个日子里,为什么会有几次演讲?在第二或第三次,无论如何,每个人都可以访问。为什么选择“安全”的主题 - 如果你不推动你自己的舒适区的限制,那么你是谁?邀请讨论,两极化和分歧 - 通过学习和教育这些与你分歧的人,找到共同点,从人们的各个角度看待事物,运用权威来防止争论的形成,来发展自己。不要像先知那样表现出来,而是像人类一样 - 错误,有能力学习,总是保持好奇心。
当你的整个职业生涯都是作为一名演讲者的时候,我认为有一个常青谈话你不需要准备是有道理的。旅行在世界各地,从你的头顶讲话是一个非常好的演出,我可以错过麦当劳继续卖汉堡包,但不能以这种方式错过这个演讲者。有用。但即使麦当劳也不时地介绍沙拉或鸡翅。
那么还有“泡沫”效应:
@bitfalls @asgrim 90%的人没有twitter帐户,绝对不要这样进行讨论。这是使我们觉得这些谈话冗余的过滤泡沫。
MalteBlättermann(@mablae)[2017年4月28日](https://twitter.com/mablae/status/857885399989047299)
我认为这两种方式都有用。接受同样的发言者(实际上,我在每次会议上都看到同样的10-20人)会吓走了新人,阻止他们谈论他们的想法。即使冒充者综合症已经不能足够压倒他们了,现在他们必须在有保证进来的人之后,把桌子清理干净。
在“多样性”积极推动每一个人的这些日子里,会议世界对于智力多样性似乎是陌生的敌意。我希望有一个会议,保证首次(或第一年)演讲者至少有90%的比例 - 哦,会议场景会更有趣!
朝九晚五
我对于会议的看法不一样,这导致我们进行另一次讨论,一些人认为这些谈话得到回收,不是因为说话者懒惰或组织者的懦弱,而是因为有很多与会者以前从未参加过会议,并且很幸运地不知道常见的主题为“PHP7新功能”,“为什么使用Composer”,“好OOP”,“什么是TDD”等。
@bitfalls @asgrim有人没有看过一个聊天。他们被派到“老板”的会议上,希望他们能学到一些有用的东西。
MalteBlättermann(@mablae)[2017年4月28日](https://twitter.com/mablae/status/857864784112480258)
对于我来说,这没有意义。如果一名雇员以前从未参加过会议,而且雇主最后派出了他们,那么做一个关于正在发表的话题,他们的演讲者和记录他们以前的谈话的谷歌搜索将会是微不足道的。为什么雇主知道员工对自我完善没有兴趣(显然,由于他们从未参加过会议),送员工参加会议,大部分会议都是在网上都是免费提供的?
可以说,这次会议可能是第一次,但让我们变得真实 - 我们在这里谈论PHP,这并不是讨论一些开创性的事情。
老板也可能希望员工在那里见到新朋友,也许是招聘人员,但是这对于新手也算不上一个角色。
所有这些都产生了一个问题 - 什么样的开发人员对自我完善感兴趣不大?马可·派维塔对此有所说:
@bitfalls @mablae @asgrim这是非常常见的。超过90%的开发者是朝九晚五。在我工作的大多数客户中,我是唯一一名去参加会议/做OSS的人员。
Stereotypo🎧(@Ocramius)[2017年4月28](https://twitter.com/Ocramius/status/857894383856832513)
这让我很困惑
你来上班。你知道你的任务。你完成它们。你回家了...重复第二天?如果准确地讲这不是一份工作,而且会有很多停工的时间,那么这样的开发者如何跟上节奏,并将最佳实践或新方法来推荐给老板,以改善app,或者宣称一些领导力,提升他们的职业生涯?结果,他们没有:
@bitfalls @Ocramius @asgrim在我的最后一份工作中没有这样的情况:停留在php 4.9 / 5.2习惯,“悠闲直到它似乎工作”的风格。
MalteBlättermann(@mablae)[2017年4月28日](https://twitter.com/mablae/status/857895926177968128)
等等,什么?这很糟糕。
为了在我们的领域保持相关性,我们必须不断的学习。我们要积极寻找新技术,学习它们,然后决定是它们否值得关注。我们不仅需要评估他们解决未来问题的潜力,还要运用新的潜在解决方案重新解决这些过去问题,以便找出更好的方法。
一个开发者下午5点以后停止开发,尤其是如果工作不够充分创新,在解决方案中缺乏个人自由表达,会建立良好的肌肉记忆,记住核心功能及其不一致的论证顺序,将能够将一切都钉入钉子的形状,然后将钉子推入任何东西,不论是否登上。但这样的开发者永远不会成为软件工程师。这样的开发者将无法简明扼要地提出新的解决方案和方法,并且无法以良好的方式影响公司的发展。
时间
我明白了马尔特提到的“没有办法,我结婚了”,或者“没有办法,我有孩子”,或者“我的时间很宝贵的,我想花一点做我喜欢的”情绪。时间是我们拥有的最宝贵的资源,与家人一起,其价值更加突出。
但是,我坚信,我们正处于一个科技泡沫中,而现在所赚取的钱可以买以后更多的时间与现在直接使用的时间相比是1:1。这一切都是一个平衡的问题,当然 - 在所有事情中都适度是重要的 - 但花时间在学习,改进和调整自己的时间(我不是说在这24/7,而是长期每天几个小时) - 特别是如果有人喜欢它 - 是一项值得投资的财富。如果你对你工作都不喜欢学习的新事物,那你把什么工作放在第一位呢?
在我看来,你不应该因为出售你的时间逃避,直到你有足够的钱购买比你出售的时间。但是你应该为它收取很多钱。
@bitfalls一个技巧:收费越多导致人们认为你更“权威”。作为一名员工,准备被忽视。/ cc @mablae
Stereotypo🎧(@Ocramius)[2017年4月28](https://twitter.com/Ocramius/status/857908104025001984)
结论
我认为,一个朝九晚五的开发者可以成为一个好的开发者,或者一个好的程序猿,但是不是一个好的软件工程师,或者一个好的社区成员。
希望待在相关领域和在职业生涯中取得进步的开发人员必须主动学习。他们需要长期学习知识,并意识到只有现在通过学习提升自己和获得职业发展,现在节省和使用“生命”的时间将会在未来浪费十倍,因为到那时候需要花费足够多的时间,才可以获得较高的收益。
它甚至不必去发展 - 相比那些下午5点编程的,有更多的方式去学习。阅读教程,撰写教程(并在另一方面赚取更多的钱),参加会议与别人交流并听取不同的想法(优秀的会议,如WebSummerCamp,甚至有一个同伴计划,所以你甚至不必离开家庭) - 在这里,每个志向远大的开发者都有很多选择。
您对同一位演讲者的会议和回收谈话感到如何?早九晚五开发者的命运怎么样?当你回家后是保持不断学习,还是放下一切?你最后的结局是什么?好好探讨!
_*想明白了么?还是分歧!而且,作为一个不可靠的人,我了解到我所看到的一些会议症状背后的新原因。
版权声明
由于业务需要,需要上传大文件,已有的版本无法处理IE版本,经过调研,百度的 webuploader 支持 IE 浏览器,而且支持计算MD5值,进而可以实现秒传的功能。
大文件上传主要分为三部分,预上传,分块上传,合并上传。
预上传:计算MD5值,同时获取服务器返回的参数,作为分块上传的参数
分块上传:对文件按照固定的大小进行分块,分块后并上传块,其中参数包含预上传计算的MD5值,如果上传的分块已经存在,则跳过执行,如果不存在,则执行分块上传。
合并上传:当所有的分块完成上传后,对文件进行合并上传。
其中,用到beforeSendFile,afterFileSend这两个监听函数,其中,监听函数beforeSendFile,主要是计算MD5值,同时进行预上传,用到defered,是为了等待异步执行的结果。uploadBeforeSend与beforeSendFile对应,uploadBeforeSend主要有以下功能:
默认的上传参数,可以扩展此对象来控制上传参数。
可以扩展此对象来控制上传头部。
当某个文件的分块在发送前触发,主要用来询问是否要添加附带参数,大文件在开起分片上传的前提下此事件可能会触发多次。
afterFileSend 是完成最终的大文件合并上传。
代码如下:
var fileMd5; //保存文件MD5名称
var uploader; //全局对象uploader
var dfsId;
var uploadId;
var rnd = GC.gRnd();
var uploadShardSize = parent.gMain.isCeph=="1"?5 * 1024 * 1024:4 * 1024 * 1024;
var discussContent = jQuery('#upload_discusscontent');
if (parent.gMain.diskType == 2) {
discussContent.parent().show();
}
WebUploader.Uploader.register({
"before-send-file" : "beforeSendFile", //文件上传之前执行
"before-send" : "beforeSend", //文件块上传之前执行
"after-send-file" : "afterSendFile", //上传完成之后执行
},
{
//时间点1:所有进行上传之前调用此函数
beforeSendFile : function(file) {
console.log(file);
var owner = this.owner
var deferred = WebUploader.Deferred();
// 计算文件的唯一标识,用于断点续传和妙传
(new WebUploader.Uploader()).md5File(file, 0,
10 * 1024 * 1024).progress(
function(percentage) {
jQuery("#" + file.id).find("div.state").text("正在扫描文件") ;
}).then(
function(val) {
fileMd5 = val;
file.fileMd5 = fileMd5
jQuery("#" + file.id).find("div.state").text("成功获取文件信息");
// 放行
var datas = {
//文件唯一标记
fileMd5 : fileMd5,
diskType: parent.gMain.diskType,
appFileId: '',
creatorUsn: parent.gMain.groupUsn,
uploadType: file.chunks == 1 ? 1 : 3,
comeFrom: 11,
parentId: (parent.gMain.currentFid == -2) ? -1 : parent.gMain.currentFid,
fileSize: file.size,
groupId: parent.gMain.groupId,
fileName: file.name,
discussContent: (parent.gMain.diskType == 2) ? discussContent.val() : '',
model: parent.gMain.uploadModel
};
jQuery.ajax({
type : "POST",
url : parent.gConst.ajaxPostUrl.file + "?func=common:upload&sid="+parent.gMain.sid +"&rnd="+rnd,
data: JSON.stringify(datas),
dataType : "json",
success : function(response) {
console.log(response)
if(response && response.code==='DFS_118'){
owner.skipFile( file );
deferred.reject();
jQuery("#" + file.id).find("div.state").text("秒传");
} else {
//分块不存在或不完整,重新发送该分块内容
dfsId = response.var.dfsFileId;
uploadId = response.var.uploadId;
deferred.resolve();
}
},
beforeSend: function (XMLHttpRequest) {
XMLHttpRequest.setRequestHeader("Content-Type", "text/javascript; charset=utf-8");
}
});
});
return deferred.promise();
},
//每一个分块发送之前执行该操作,检查当前块是否已经上传
beforeSend : function(block) {
var deferred = WebUploader.Deferred();
dfsId = dfsId;
deferred.resolve();
this.owner.options.formData = {
fileMd5: fileMd5,
start: block.start
};
return deferred.promise();
},
afterSendFile : function(file) {
// 通知合并分块
console.log(file)
var comepleteData = {
diskType: parent.gMain.diskType,
uploadType: file.blocks ? file.blocks.length == 1 ? 1 : 3 : 1,
creatorUsn: parent.gMain.groupUsn,
parentId: (parent.gMain.currentFid == -2) ? -1 : parent.gMain.currentFid,
fileSize: file.size,
groupId: parent.gMain.groupId,
fileName: file.name,
fileMd5: fileMd5,
comeFrom: 11,
uploadId: uploadId,
dfsFileId: dfsId,
model: parent.gMain.uploadModel,
partCount: file.blocks ? file.blocks.length : 1
}
jQuery.ajax({
type : "POST",
url : parent.gConst.ajaxPostUrl.file+ "?func=common:completeUpload&sid="+parent.gMain.sid,
data: JSON.stringify(comepleteData),
dataType: 'json',
success : function(response) {
var $li = jQuery('#' + file.id);
$li.find('p.state').text('上传完成');
jQuery("#ctlBtn").addClass('disabled');
},
beforeSend: function (XMLHttpRequest) {
XMLHttpRequest.setRequestHeader("Content-Type", "text/javascript; charset=utf-8");
}
});
}
});
uploader = WebUploader.create({
swf: '../resource_drive/js/control/fileupload/Uploader.swf',
server: 'service/common/onestfile.do?func=common:onestUpload&sid=' + parent.gMain.sid,
pick:{
id: '#asd', //这个id是你要点击上传文件按钮的外层div的id
multiple : true //是否可以批量上传,true可以同时选择多个文件
},
auto: true,
disableGlobalDnd: true, //禁用页面拖拽
chunked: true, // 开启分片上传
chunkSize: uploadShardSize, //分片大小
chunkRetry: 3, //重传次数
threads: 1, //同时上传进程
fileSizeLimit: 2000*1024*1024, //验证文件总大小
fileSingleSizeLimit: 2000*1024*1024, //验证单个文件大小
resize: false,
});
//当文件添加进队列
uploader.on("fileQueued", function(file) {
// fileList
jQuery("#divDialogfileupload").show();
jQuery("#sexwarning").css("display","block");
jQuery(".upfile_ul").css("display","block");
jQuery(".upfile_ul").append("<div id='" + file.id + "'class='fileInfo'><img/><span>" + file.name +
"</span><div class='state'>等待上传...</div><span class='text'><span></div>");
});
//文件上传过程中创建进度条
uploader.on("uploadProgress", function(file, progress){
var id = jQuery("#"+file.id);
id.find("span.text").text((progress.toFixed(2))*100+"%")
id.find("div.state").text("上传中...")
if (progress == 1) {
id.find("div.state").text("上传完成")
}
});
//发送前填充数据
uploader.on('uploadBeforeSend', function( block, data ) {
// block为分块数据。
console.log(block);
console.log(data);
var deferred = WebUploader.Deferred();
// file为分块对应的file对象。
var file = block.file;
var fileMd5 = file.fileMd5;
// 修改data可以控制发送哪些携带数据。
// 将存在file对象中的md5数据携带发送过去。
data.appFileId = "";//md5
data.fileMd5 = fileMd5;//md5
data.fileName = data.name;
data.diskType = parent.gMain.diskType;
data.uploadType = block.chunks == 1 ? 1 : 3;
data.creatorUsn = parent.gMain.groupUsn;
data.parentId = (parent.gMain.currentFid == -2) ? -1 : parent.gMain.currentFid;
data.fileSize = data.size;
data.groupId = parent.gMain.groupId;
data.model = parent.gMain.uploadModel;
data.fileRealPath = block.file.source.source.webkitRelativePath;
data.comeFrom = 11;
data.dfsFileId = dfsId;
data.blob = data.name;
if (block.chunks !== 1) {
data.uploadId = uploadId;
data.range = block.start + "-" + block.end;
data.partCount = block.chunks;
data.partNum = block.chunk + 1;
}
data.discussContent = (parent.gMain.diskType == 2) ? discussContent.val() : '';
deferred.resolve();
});
//上传成功
uploader.on("uploadSuccess", function(file) {
var id = jQuery("#"+file.id);
id.find("div.state").text("已上传")
});
//上传失败
uploader.on('uploadError', function( file ) {
var id = jQuery("#"+file.id);
id.find("div.state").text("上传失败")
});
// 上传完成
uploader.on("uploadComplete", function(file) {
var id = jQuery("#"+file.id);
id.find("div.state").text("上传完成")
});
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.

































