





Search files without indexing, but clever crawling:
- At least 1 thread per mount point
- Use as much RAM as possible for caching stuff
- Try to avoid "black hole folders" using a regex based blocklist in which the crawler will never come out and never scan useful files (
node_modules,Windows,etc) - Intended for desktop users, no obscure Linux files and system files scans
- Use priority lists to first scan important folders.
- Betting on the future: slowly being optimized for SSDs/M.2 or fast RAID arrays
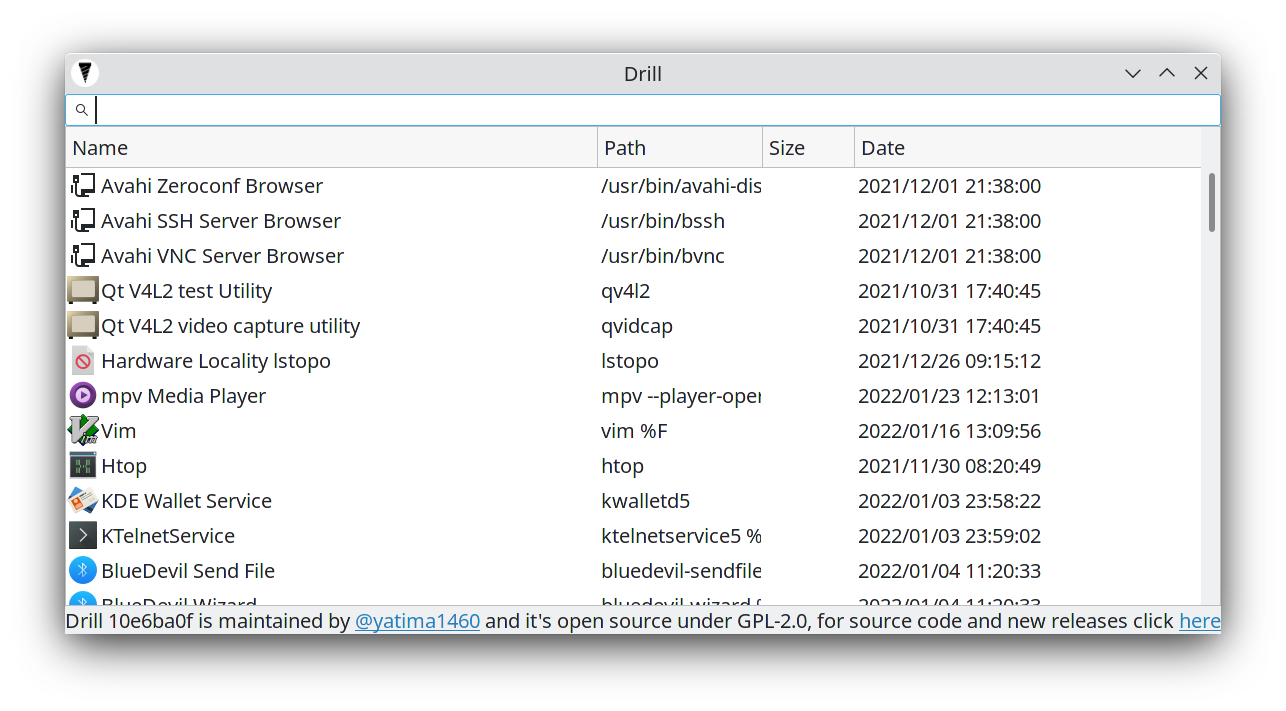
Use the provided AppImage, just double click it
If your distro doesn't ask you to mark it executable or nothing happens try:
chmod +x Drill.AppImage./Drill.AppImage
- Open = Left Double Click / Return / Enter / Space
Open containing folder = Right click
Some dependencies don't build with GDC!!! Use DMD or LDC!!!
The build chain is:
&& = parallel
datefmt && gtkd → drill-core → drill-cli && drill-gtk → zip cli && zip gtk && zip both → appimage && .deb && other formats
- The repo, remember to clone the submodules too with:
git clone --recurse-submodules -j8 https://github.com/yatima1460/Drill.git
- D
curl -fsS https://dlang.org/install.sh | bash -s dmd
Debug (not recommended)
cd source/WHAT_YOU_WANT_TO_BUILD
dub build
Release (no logs and faster)
cd source/WHAT_YOU_WANT_TO_BUILD
dub build -b release
Executables will spawn in the root git folder
I was stressed on Linux because I couldn't find the files I needed, file searchers based on system indexing (updatedb) are prone to breaking and hard to configure for the average user, so did an all nighter and started this.
Drill is a modern file searcher for Linux that tries to fix the old problem of slow searching and indexing. Nowadays even some SSDs are used for storage and every PC has nearly a minimum of 8GB of RAM and quad-core; knowing this it's time to design a future-proof file searcher that doesn't care about weak systems and uses the full multithreaded power in a clever way to find your files in the fastest possible way.
-
Heuristics: The first change was the algorithm, a lot of file searchers use depth-first algorithms, this is a very stupid choice and everyone that implemented it is a moron, why? You see, normal humans don't create nested folders too much and you will probably get lost inside "black hole folders" or artificial archives (created by software); a breadth-first algorithm that scans your hard disks by depth has a higher chance to find the files you need. Second change is excluding some obvious folders while crawling like
Windowsandnode_modules, the average user doesn't care about .dlls and all the system files, and generally even devs too don't care, and if you need to find a system file you already know what you are doing and you should not use a UI tool. -
Clever multithreading: The second change is clever multithreading, I've never seen a file searcher that starts a thread per disk and it's 2019. The limitation for file searchers is 99% of the time just the disk speed, not the CPU or RAM, then why everyone just scans the disks sequentially????
-
Use your goddamn RAM: The third change is caching everything, I don't care about your RAM, I will use even 8GB of your RAM if this provides me a faster way to find your files, unused RAM is wasted RAM, even truer the more time passes.
TODOs:
-
Core Backend
- Open file or path
Linux X11Open File- Select file if contained folder
- Error on file open
- Linux Wayland
- Open File
- Select file if contained folder
- Error on file open
- Windows
- Open File
- Select file if contained folder
- Error on file open
- MacOS
Open File- Select file if contained folder
- Error on file open
All comparisons need to be done in lower case stringsPriority lists specified in assets/prioritylistsMulti-token search (searching "a b" will find all files with "a" and "b" in the name)- /home/username needs to have higher priority over / crawler when /home isn't mounted on a secondary mountpoint
- Sorting by column
- Commas in numbers strings
- Correct separator based on current system internationalization
- AM/PM time base
- Linux
- Windows
- MacOS
- Folders actual size
- Icons image needs to be generic and in the backend
- 1 Threadpool per mount point
- 1 Threadpool PER DISK if possible
- Metadata searching and new tokens (mp3, etc...)
- Memoization/Cache
- Percentage of crawling
- About dialog in GUI
- Remove the synchronizations using a concurrency list
Split Drill in DrillGTK and DrillCore- Add documentation and comments
- Fix messy imports
Logging in debug mode- NVM could benefit when multiple threads are run for the same disk?
- No GC
- Open file or path
-
Cli Frontend
- More arguments
Better/bare printing
-
ncurses
-
GTK Frontend
Open file with double clickAdd to UI list when new results foundAppImage- Open containing folder with right click
- Alternate row colors
- ESC to close
- Error messagebox if opening file fails
Icons near the file name.deb- .rpm
- Snap
- Flatpak
- Drag and drop
-
Windows
- Open file with double click
- Add to UI list when new results found
- Portable .exe
- Installer
- Open containing folder with right click
- Alternate row colors
- ESC to close
- Error messagebox if opening file fails
- Icons near the file name
- Drag and drop
-
MacOS
- Open file with double click
- Add to UI list when new results found
- Portable executable
- Installer
- Open containing folder with right click
- Alternate row colors
- ESC to close
- Error messagebox if opening file fails
- Icons near the file name
- Drag and drop