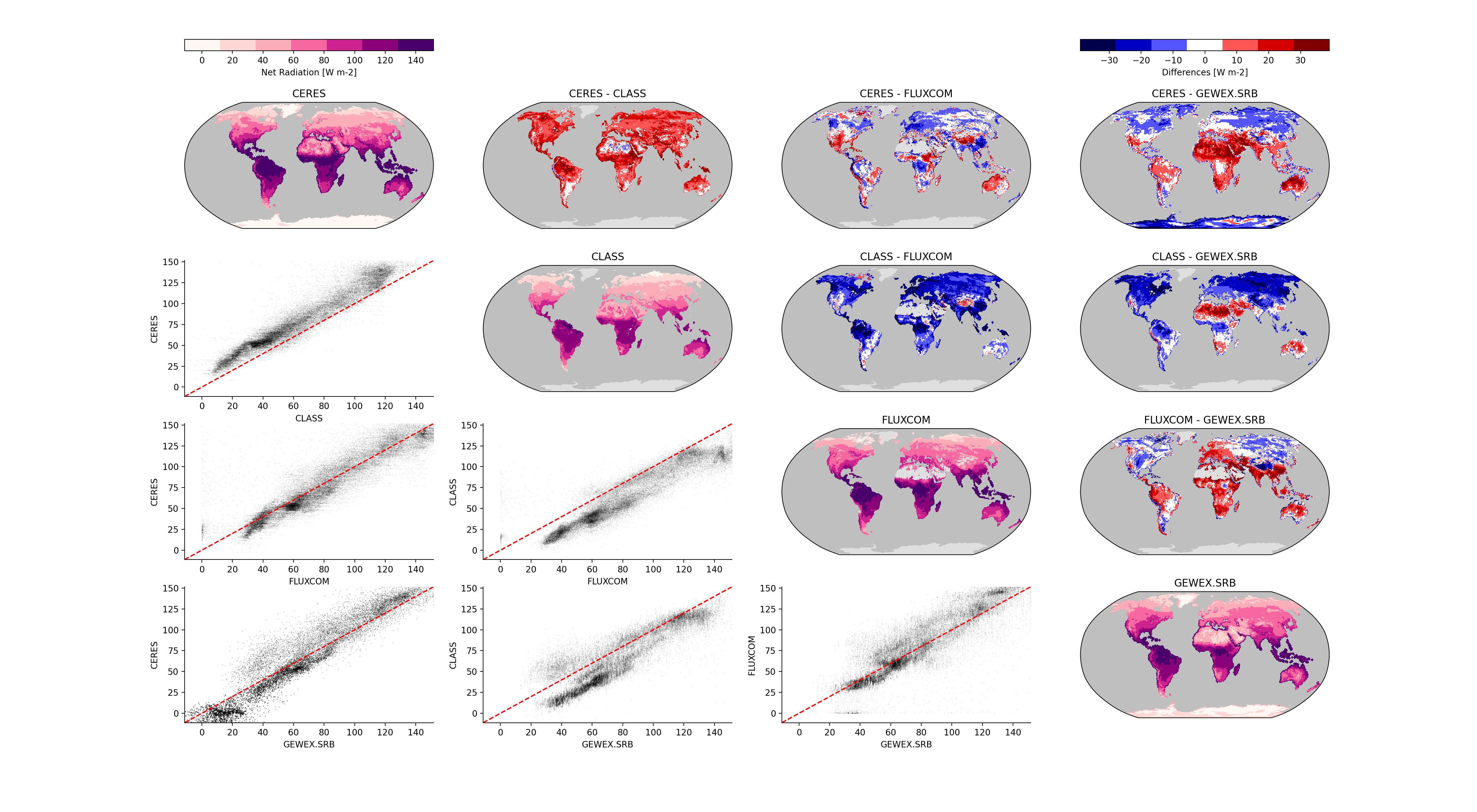
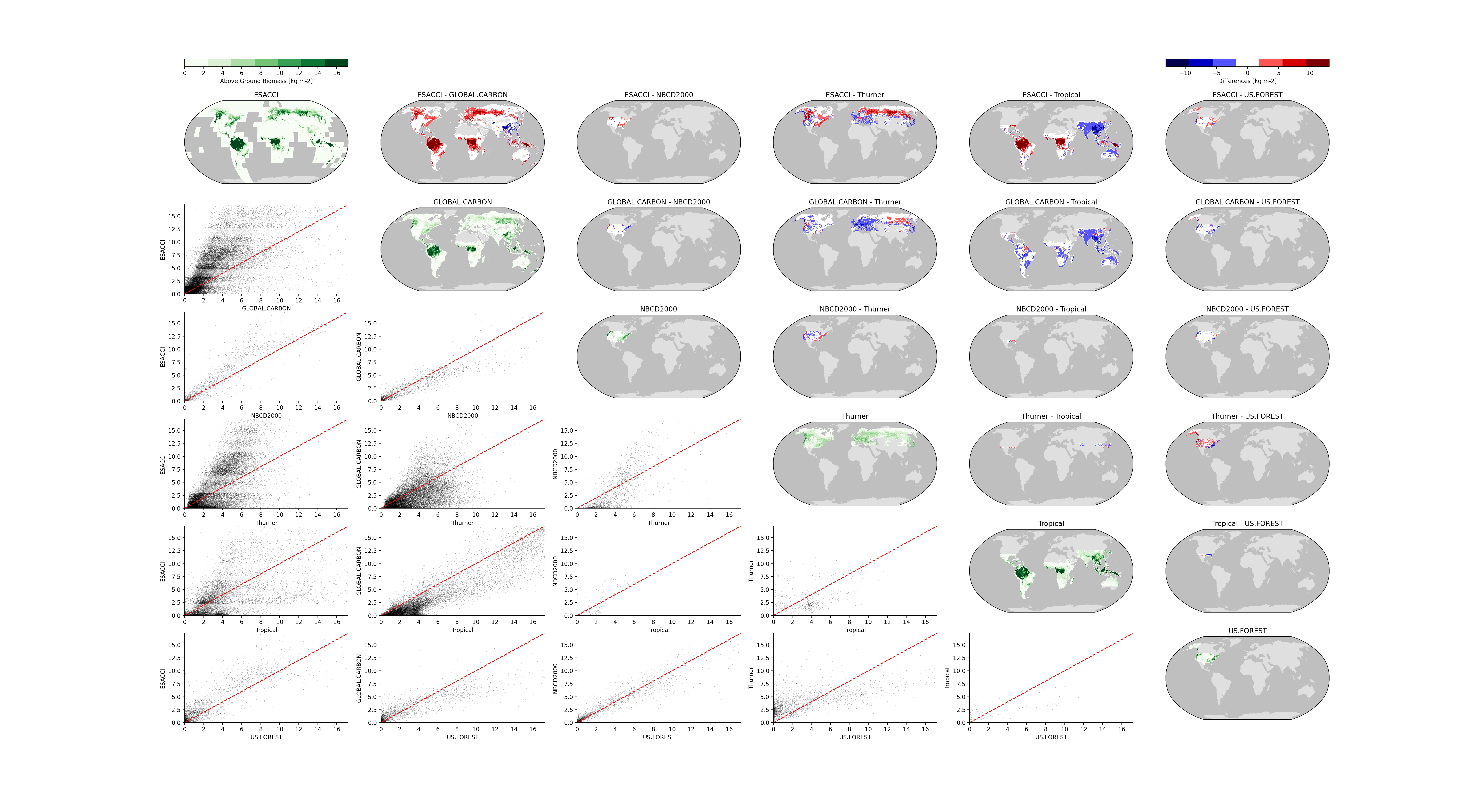
This repository stores the scripts used to download observational data from various sources and format it into a CF-compliant netCDF4 file which can be used for model benchmarking via ILAMB.
Please note that the repository contains no data. If you need to download our observational data, see the ilamb-fetch tutorial. This collection of scripts is to:
- archive how we have produced the model comparison datasets with ILAMB
- expose the details of our formatting choices for transparency
- provide the community a path to contributing new datasets as well as pointing out errors in the current collection
If you have a suggestion or issue with the observational data ILAMB uses, we encourage you to use the issue tracker associated with this repository rather than that of the ILAMB codebase. This is because the ILAMB codebase is meant to be a general framework for model-data intercomparison and is ignorant of observational data sources. Here are a few ways you can contribute to this work:
If you notice an irregularity/bug/error with a dataset in our collection:
- Raise an issue with the dataset name included in the title (e.g., "Netcdf read error in wang2021.nc") for record keeping and discussion
- Tag the issue with
bug - (Optional) Fork the ILAMB-Data repo and fix the erroneous convert.py
- (Optional) Submit a pull request for our review
If you know of a dataset that would be a great addition to ILAMB:
- Raise an issue with the proposed dataset name included in the title (e.g., New Global Forest Watch cSoil dataset).
- Tag the issue with
new dataset. - Provide us with details of the dataset as well as some reasoning for the recommendation; consider including hyperlinks to papers, websites, etc.
- (Optional) Fork the ILAMB-Data repo, create a new directory named after the dataset (e.g., GFW), and create a
convertfile to preprocesses and formats the data for ILAMB. - (Optional) Submit a pull request with the new directory and
convertscript for our review.
See below for specific guidelines on adding new datasets
We appreciate the community interest in improving ILAMB. We believe that more quality observational constraints will lead to a better Earth system model ecosystem, so we are always interested in new observational data. We ask that you follow this procedure for adding new datasets:
- Before encoding the dataset, search the open and closed issues in the issue tracker. We may already have someone assigned to work on this and do not want to waste your effort. Or, we have considered adding the dataset and reasoned against it after discussion.
- If no open or closed issue is found, raise a new issue with the new dataset name in the title, and be sure to add the
new datasettag. - Create a new directory to work in. We generally name it after the folks/project who made the dataset; name it whatever you like.
- Write the conversion (e.g.,
convert.py) file inside the folder you created, which (optionally) downloads the dataset; loads the dataset; formats it into a netcdf that follows updated CF Conventions; and, if a gridded dataset, it's helpful to resample to 0.5 degrees (EPSG:4326). Lastly, try to format variable names and units accoding to the accepted MIP variables for easier model comparison. - Submit a pull request for us to review the script and outputted dataset.
You may use any language you wish to encode the dataset, but we strongly encourage the use of python3. You can find examples in this repository to use as a guide. The GFW convert.py is a recent gridded data example, and this Ameriflux convert.py is a recent point dataset example. See this tutorial for help, and feel free to ask questions in the issue you've created for the dataset.
- Once you have formatted the dataset, we recommend running it against a collection of models, along with other relevant observational datasets using ILAMB. There are tutorials to help you do this. This will allow the community to evaluate the new addition and decide if or how it should be included in the curated collection.
- After you have these results, consider attending one of our conference calls. Here, you can present the results of the intercomparison, and the group can discuss.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}