rLLM (Documentation|Paper)
Note: we will release our first version (v0.1) at August 11, 2024.
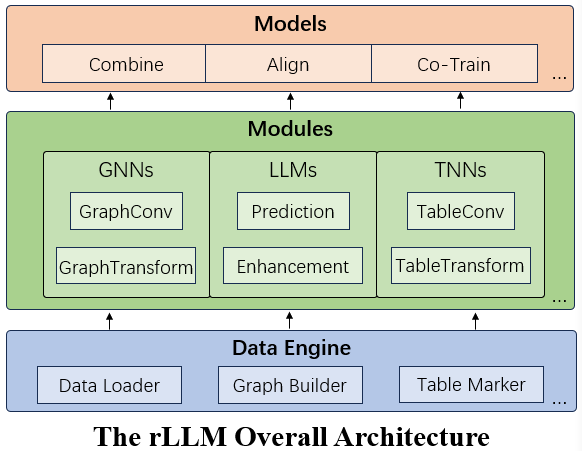
rLLM (relationLLM) is an easy-to-use Pytorch library for Relational Table Learning (RTL) with LLMs, by performing two key functions:
- Breaks down state-of-the-art GNNs, LLMs, and TNNs as standardized modules.
- Facilitates novel model building in a "combine, align, and co-train" way using these modules.
Let's run an RTL-type method BRIDGE as an example:
# cd ./examples
# set parameters if necessary
python bridge/bridge_tacm12k.py
python bridge/bridge_tlf2k.py
python bridge/bridge_tml1m.py- LLM-friendly: Modular interface designed for LLM-oriented applications, integrating smoothly with LangChain and Hugging Face transformers.
- One-Fit-All Potential: Processes various graphs (like Social/Citation/E-commerce Networks) by treating them as multiple tables linked by foreigner keys.
- Novel Datasets: Introduces three new relational table datasets useful for RTL model design. Includes the standard classification task, with examples.
- Community Support: Maintained by students and teachers from Shanghai Jiao Tong University and Tsinghua University. Supports the SJTU undergraduate course "Content Understanding (NIS4301)" and the graduate course "Social Network Analysis (NIS8023)".
@article{rllm2024,
title={rLLM: Relational Table Learning with LLMs},
author={Weichen Li and Xiaotong Huang and Jianwu Zheng and Zheng Wang and Chaokun Wang and Li Pan and Jianhua Li},
year={2024},
eprint={2407.20157},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2407.20157},
}



















































































































