Please feel free to contribute
Original Authors:
Colossal team ☕
Modified by:
Renan Monteiro Barbosa
Requirements:
- GPU
Work in Progress, modifying it to self-deploy at AWS.
Run the self-contained notebook.ipynb file in your environment and follow the steps! Below contents are basic introduction into ColossalAI and a markdown-equivalent version of the notebook file. Feel free to skim to first have a sense of what will happen!
- Multi-dimensional Parallelism
- Know the components and sketch of Colossal-AI
- Step-by-step from PyTorch to Colossal-AI
- Try data/pipeline parallelism and 1D/2D/2.5D/3D tensor parallelism using a unified model
- Sequence Parallelism
- Try sequence parallelism with BERT
- Combination of data/pipeline/sequence parallelism
- Faster training and longer sequence length
- Large Batch Training Optimization
- Comparison of small/large batch size with SGD/LARS optimizer
- Acceleration from a larger batch size
- Auto-Parallelism
- Parallelism with normal non-distributed training code
- Model tracing + solution solving + runtime communication inserting all in one auto-parallelism system
- Try single program, multiple data (SPMD) parallel with auto-parallelism SPMD solver on ResNet50
- Fine-tuning and Serving for OPT
- Try pre-trained OPT model weights with Colossal-AI
- Fine-tuning OPT with limited hardware using ZeRO, Gemini and parallelism
- Deploy the fine-tuned model to inference service
- Go to hybrid_parallel folder in the tutorial directory.
- Install our model zoo.
pip install titans- Run with synthetic data which is of similar shape to CIFAR10 with the
-sflag.
colossalai run --nproc_per_node 4 train.py --config config.py -s- Modify the config file to play with different types of tensor parallelism, for example, change tensor parallel size to be 4 and mode to be 2d and run on 8 GPUs.
- Go to the sequence_parallel folder in the tutorial directory.
- Run with the following command
export PYTHONPATH=$PWD
colossalai run --nproc_per_node 4 train.py -s- The default config is sequence parallel size = 2, pipeline size = 1, let’s change pipeline size to be 2 and try it again.
- Go to the large_batch_optimizer folder in the tutorial directory.
- Run with synthetic data
colossalai run --nproc_per_node 4 train.py --config config.py -s- Go to the auto_parallel folder in the tutorial directory.
- Install
pulpandcoin-or-cbcfor the solver.
pip install pulp
conda install -c conda-forge coin-or-cbc- Run the auto parallel resnet example with 4 GPUs with synthetic dataset.
colossalai run --nproc_per_node 4 auto_parallel_with_resnet.py -sYou should expect to the log like this. This log shows the edge cost on the computation graph as well as the sharding strategy for an operation. For example, layer1_0_conv1 S01R = S01R X RR means that the first dimension (batch) of the input and output is sharded while the weight is not sharded (S means sharded, R means replicated), simply equivalent to data parallel training.
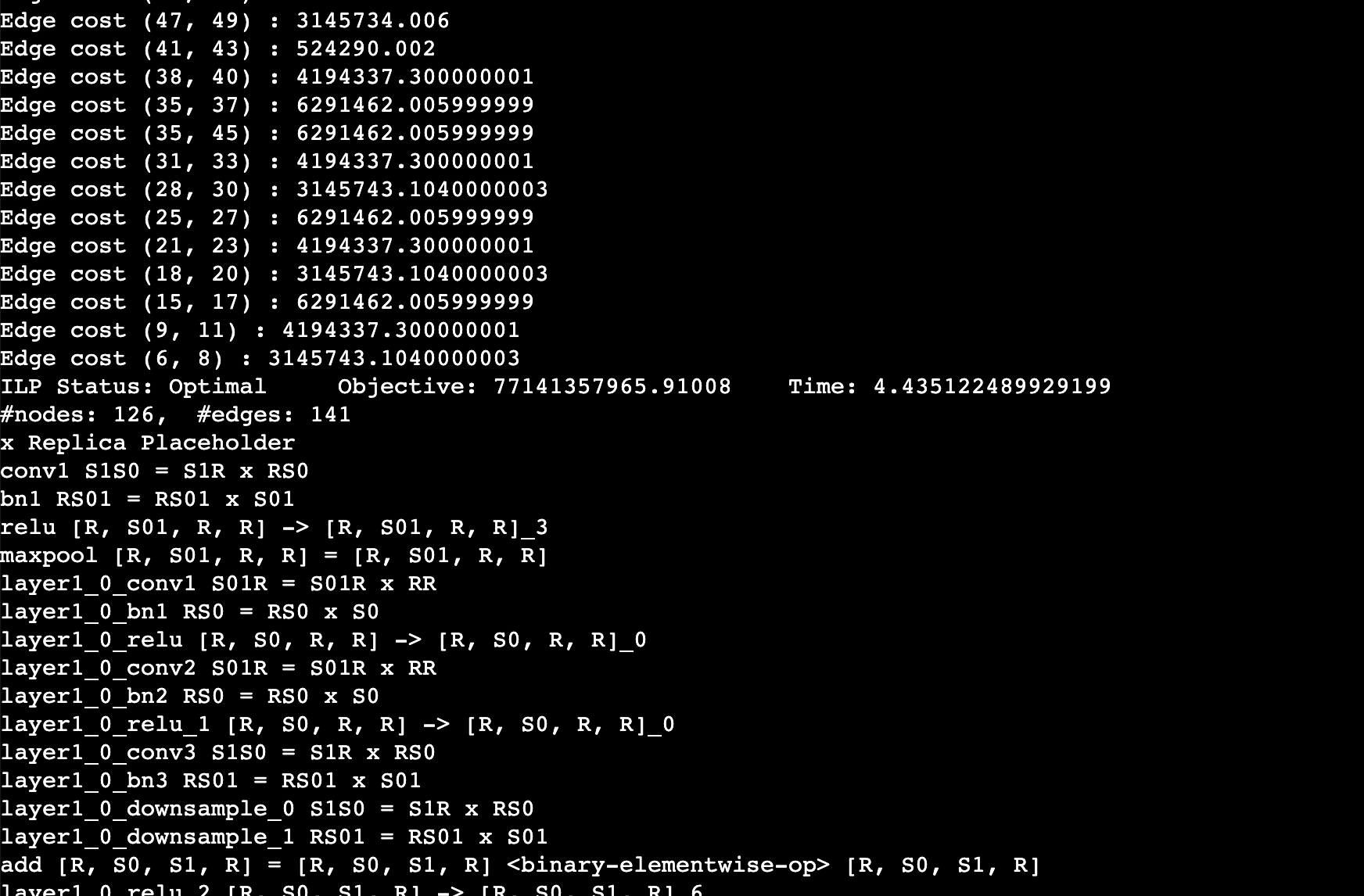
- Stay in the
auto_parallelfolder. - Install the dependencies.
pip install matplotlib transformers- Run a simple resnet50 benchmark to automatically checkpoint the model.
python auto_ckpt_solver_test.py --model resnet50You should expect the log to be like this
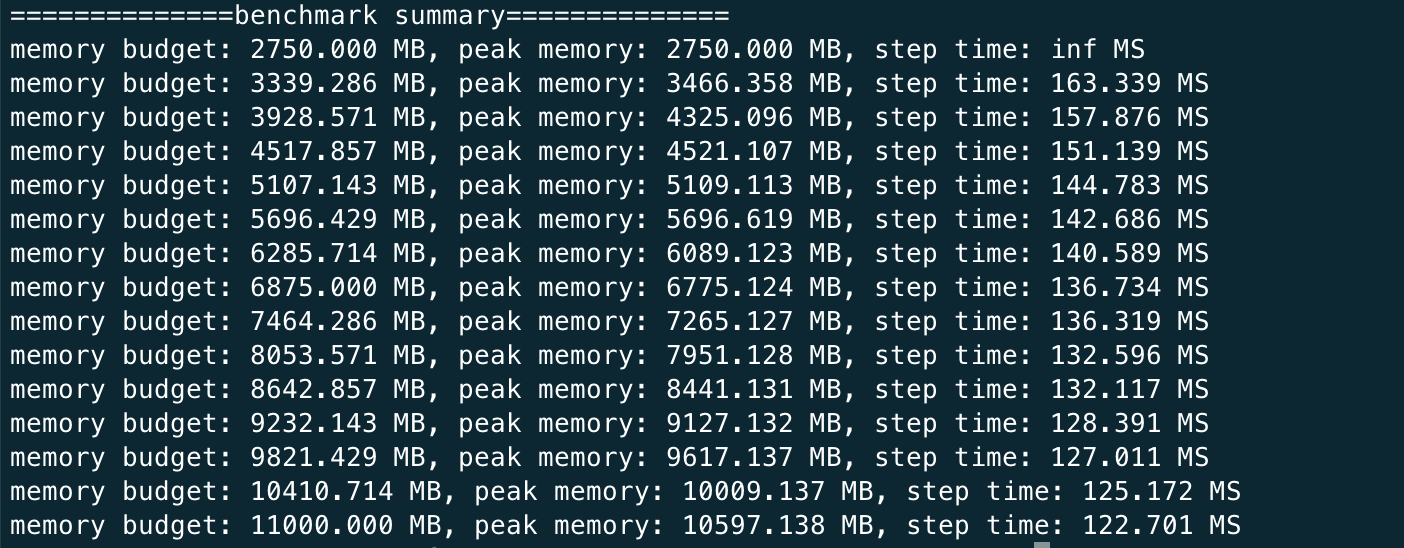
This shows that given different memory budgets, the model is automatically injected with activation checkpoint and its time taken per iteration. You can run this benchmark for GPT as well but it can much longer since the model is larger.
python auto_ckpt_solver_test.py --model gpt2- Run a simple benchmark to find the optimal batch size for checkpointed model.
python auto_ckpt_batchsize_test.pyYou can expect the log to be like

- Install the dependency
pip install datasets accelerate- Run finetuning with synthetic datasets with one GPU
bash ./run_clm_synthetic.sh- Run finetuning with 4 GPUs
bash ./run_clm_synthetic.sh 16 0 125m 4- Run inference with OPT 125M
docker hpcaitech/tutorial:opt-inference
docker run -it --rm --gpus all --ipc host -p 7070:7070 hpcaitech/tutorial:opt-inference- Start the http server inside the docker container with tensor parallel size 2
python opt_fastapi.py opt-125m --tp 2 --checkpoint /data/opt-125m