qingmei2 / blogs Goto Github PK
View Code? Open in Web Editor NEW📝 The Android programing blogs(简体中文).
📝 The Android programing blogs(简体中文).












































































































































本文已授权 微信公众号 玉刚说 (@任玉刚)独家发布。
我是一个崇尚 开源 的Android开发者,在过去的一段时间里,我研究了Github上的一些优秀的开源库,这些库源码中那些 天马行空 的 设计 和 ** 令我沉醉其中。
在我职业生涯的 伊始,我没有接触过 技术大牛, 但是 阅读源码 可以让我零距离碰撞 全球行业 内 最顶尖工程师们 的**,我渐渐爱上了 源码阅读。
在感叹这些 棒极了 的设计方式时,我也尝试去 模仿 他们的代码风格。后来朋友问我代码中为什么有这么多 设计模式 时,我才发现,单例 ,代理 ,工厂 ,装饰,Builder ,甚至更多,当初这些书上怎么也捋不清的设计模式,现在的我正在潜移默化使用它们,这不是 夸张,我在写这些代码时,它们似乎就应该这么用。
今年年初,我尝试开源了一个 灵活可高度定制 的Android图片选择框架 RxImagePicker 。这个库获得了部分认可,当然意见和建议也接踵而来,我很快认识到了自己目前能力的不足—— 通过 组合 的方式 将多个优秀的库封装在一起 ,并不是就意味着真正拥有了 组织架构 的能力,而自己对于架构的掌握能力,目前还有很多不足之处。

我意识到自己的不足,于是我积极寻找 更多优秀的架构,试图通过 源码 学习更多API之外的一些东西:编程** 和 架构设计 。
很快,我找到了一个很优秀的库,Paging—— 它同样做到了 业务层与UI层之间 的隔离,并且,它的设计更为 优秀。
在不久前的Google 2018 I/O大会上,Google正式推出了AndroidJetpack ——这是一套组件、工具和指导,可以帮助开发者构建出色的 Android 应用,AndroidJetpack 隆重推出了一个新的分页组件:Paging Library。
我尝试研究了Paging Library,并分享给大家,本文的目标是阐述:
本文不是 Paging API 使用代码的展示,但通过本文 彻底搞懂 它的原理之后,API的使用也只是 顺手拈来。
一句话概述: Paging 可以使开发者更轻松在 RecyclerView 中 分页加载数据。
官方文档 永远是最接近 正确 和 核心理念 的参考资料 —— 在不久之后,本文可能会因为框架本身API的迭代更新而 毫无意义,但官方文档不会,即使在最恶劣的风暴中,它依然是最可靠的 指明灯:
https://developer.android.com/topic/libraries/architecture/paging/
其次,一个好的Demo能够起到重要的启发作用, 这里我推荐这个Sample:
项目地址:https://github.com/googlesamples/android-sunflower
因为刚刚发布的原因,目前Paging的中文教程 比较匮乏,许多资料的查阅可能需要开发者 自备梯子。
在使用之前,我们需要搞明白的是,目前Android设备中比较主流的两种 分页模式,用我的语言概述,大概是:
从语义上来讲,我的描述有点不太直观,不了解的读者估计会很迷糊。

举个例子,传统的 上拉加载更多 分页效果,应该类似 淘宝APP 这种,滑到底部,再上拉显示footer,才会加载数据:
而无限滚动 分页效果,应该像是 京东APP 这样,如果我们慢慢滑动,当滑动了一定量的数据(这个阈值一般是数据总数的某个百分比)时,会自动请求加载下一页的数据,如果我们继续滑动,到达一定量的数据时,它会继续加载下一页数据,直到加载完所有数据——在用户看来,就好像是一次就加载出所有商品一样:

很明显,无限滚动 分页效果带来的用户体验更好,不仅是京东,包括 知乎 等其它APP,所采用的分页加载方式都是 无限滚动 的模式,而 Paging 也正是以无限滚动 的分页模式而设计的库。
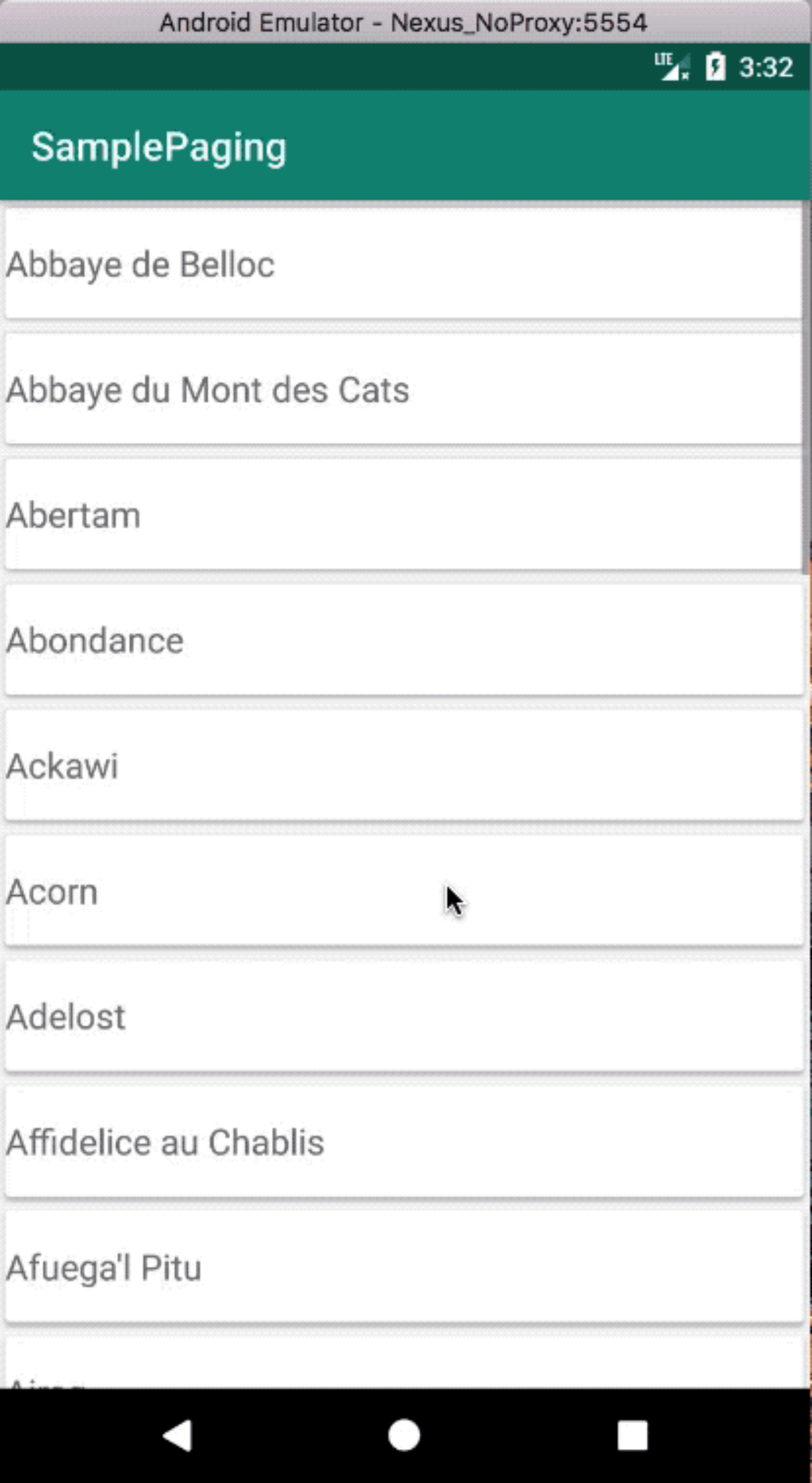
我写了一个Paging的sample,它最终的效果是这样:
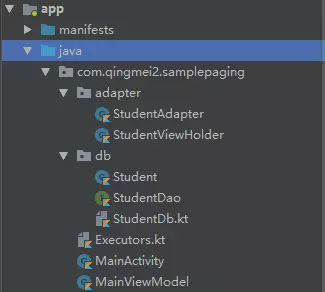
项目结构图如下,这可以帮你尽快了解sample的结构:
我把这个sample的源码托管在了我的github上,你可以通过 点我查看源码 。
现在你已经对 Paging 的功能有了一定的了解,我们可以开始尝试使用它了。
请注意,本小节旨在简单阐述Paging入门使用,读者不应该困惑于Kotlin语法或者Room库的使用——你只要能看懂基本流程就好了。
因此,我 更建议 读者 点击进入github,并将Sample代码拉下来阅读,仅仅是阅读—— 相比Kotlin语法和Room的API使用,理解代码的流程 更为重要。
def room_version = "1.1.0"
def paging_version = "1.0.0"
def lifecycle_version = "1.1.1"
//Paging的依赖
implementation "android.arch.paging:runtime:$paging_version"
//Paging对RxJava2的原生支持
implementation "android.arch.paging:rxjava2:1.0.0-rc1"
//我在项目中使用了Room,这是Room的相关依赖
implementation "android.arch.persistence.room:runtime:$room_version"
kapt "android.arch.persistence.room:compiler:$room_version"
implementation "android.arch.persistence.room:rxjava2:$room_version"
implementation "android.arch.lifecycle:extensions:$lifecycle_version"我们要展示在list中的数据,主要以 网络请求 和 本地持久化存储 的方式获取,本文为了保证简单,数据源通过 Room数据库中 获得。
创建Student实体类:
@Entity
data class Student(@PrimaryKey(autoGenerate = true) val id: Int,
val name: String)创建Dao:
@Dao
interface StudentDao {
@Query("SELECT * FROM Student ORDER BY name COLLATE NOCASE ASC")
fun getAllStudent(): DataSource.Factory<Int, Student>
}创建数据库:
@Database(entities = arrayOf(Student::class), version = 1)
abstract class StudentDb : RoomDatabase() {
abstract fun studentDao(): StudentDao
companion object {
private var instance: StudentDb? = null
@Synchronized
fun get(context: Context): StudentDb {
if (instance == null) {
instance = Room.databaseBuilder(context.applicationContext,
StudentDb::class.java, "StudentDatabase")
.addCallback(object : RoomDatabase.Callback() {
override fun onCreate(db: SupportSQLiteDatabase) {
ioThread {
get(context).studentDao().insert(
CHEESE_DATA.map { Student(id = 0, name = it) })
}
}
}).build()
}
return instance!!
}
}
}
private val CHEESE_DATA = arrayListOf(
"Abbaye de Belloc", "Abbaye du Mont des Cats", "Abertam", "Abondance", "Ackawi",
"Acorn", "Adelost", "Affidelice au Chablis", "Afuega'l Pitu", "Airag", "Airedale",
"Aisy Cendre", "Allgauer Emmentaler", "Alverca", "Ambert", "American Cheese",
"Ami du Chambertin", "Anejo Enchilado", "Anneau du Vic-Bilh", "Anthoriro", "Appenzell",
"Aragon", "Ardi Gasna", "Ardrahan", "Armenian String", "Aromes au Gene de Marc",
"Asadero", "Asiago", "Aubisque Pyrenees", "Autun", "Avaxtskyr", "Baby Swiss",
"Babybel", "Baguette Laonnaise", "Bakers", "Baladi", "Balaton", "Bandal", "Banon",
"Barry's Bay Cheddar", "Basing", "Basket Cheese", "Bath Cheese", "Bavarian Bergkase",
"Baylough", "Beaufort", "Beauvoorde", "Beenleigh Blue", "Beer Cheese", "Bel Paese",
"Bergader", "Bergere Bleue", "Berkswell", "Beyaz Peynir", "Bierkase", "Bishop Kennedy",
"Blarney", "Bleu d'Auvergne", "Bleu de Gex", "Bleu de Laqueuille",
"Bleu de Septmoncel", "Bleu Des Causses", "Blue", "Blue Castello", "Blue Rathgore",
"Blue Vein (Australian)", "Blue Vein Cheeses", "Bocconcini", "Bocconcini (Australian)"
)这一步就很简单了,就像往常一样,我们创建一个item的layout布局文件(已省略,就是一个TextView用于显示Student的name),同时创建对应的ViewHolder:
class StudentViewHolder(parent: ViewGroup) : RecyclerView.ViewHolder(
LayoutInflater.from(parent.context).inflate(R.layout.student_item, parent, false)) {
private val nameView = itemView.findViewById<TextView>(R.id.name)
var student: Student? = null
fun bindTo(student: Student?) {
this.student = student
nameView.text = student?.name
}
}我们的Adapter需要继承PagedListAdapter类:
class StudentAdapter : PagedListAdapter<Student, StudentViewHolder>(diffCallback) {
override fun onBindViewHolder(holder: StudentViewHolder, position: Int) {
holder.bindTo(getItem(position))
}
override fun onCreateViewHolder(parent: ViewGroup, viewType: Int): StudentViewHolder =
StudentViewHolder(parent)
companion object {
private val diffCallback = object : DiffUtil.ItemCallback<Student>() {
override fun areItemsTheSame(oldItem: Student, newItem: Student): Boolean =
oldItem.id == newItem.id
override fun areContentsTheSame(oldItem: Student, newItem: Student): Boolean =
oldItem == newItem
}
}
}我们创建一个ViewModel,它用于承载 与UI无关 业务代码:
class MainViewModel(app: Application) : AndroidViewModel(app) {
val dao = StudentDb.get(app).studentDao()
val allStudents = LivePagedListBuilder(dao.getAllStudent(), PagedList.Config.Builder()
.setPageSize(PAGE_SIZE) //配置分页加载的数量
.setEnablePlaceholders(ENABLE_PLACEHOLDERS) //配置是否启动PlaceHolders
.setInitialLoadSizeHint(PAGE_SIZE) //初始化加载的数量
.build()).build()
companion object {
private const val PAGE_SIZE = 15
private const val ENABLE_PLACEHOLDERS = false
}
}最终,在Activity中,每当观察到数据源中 数据的变化,我们就把最新的数据交给Adapter去 展示:
class MainActivity : AppCompatActivity() {
private val viewModel by lazy(LazyThreadSafetyMode.NONE) {
ViewModelProviders.of(this, object : ViewModelProvider.Factory {
override fun <T : ViewModel?> create(modelClass: Class<T>): T = MainViewModel(application) as T
}).get(MainViewModel::class.java)
}
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
val adapter = StudentAdapter()
recyclerView.adapter = adapter
// 将数据的变化反映到UI上
viewModel.allStudents.observe(this, Observer { adapter.submitList(it) })
}
}到这里,Paging 最基本的使用就已经讲解完毕了。您可以通过运行预览和示例 基本一致 的效果,如果有疑问,可以点我查看源码 。
阅读到这里,我相信不少朋友会有这样一个想法—— 这个库看起来感觉好麻烦,我为什么要用它呢?

我曾经写过一篇标题很浮夸的博客:0行Java代码实现RecyclerView—— 文中我提出了一种使用DataBinding 不需要哪怕一行Java代码就能实现列表/多类型列表的方式,但是最后我也提到了,这只是一种思路,这种简单的方式背后,可能会隐藏着 严重耦合 的情况—— "一行代码实现XXX" 的库屡见不鲜,它们看上去很 简单 ,但是真正做到 灵活,松耦合 的库寥寥无几,我认为这种方式是有缺陷的。
因此,简单并不意味着设计**的优秀,“看起来很麻烦” 也不能成为否认 Paging 的理由,本文不会去阐述 Paging 在实际项目中应该怎么用,且不说代码正确性与否,这种做法本身就会固定一个人的思维。但如果你理解了 Paging本身原理 的话,相信掌握其用法 也就不在话下了。
先上一张图
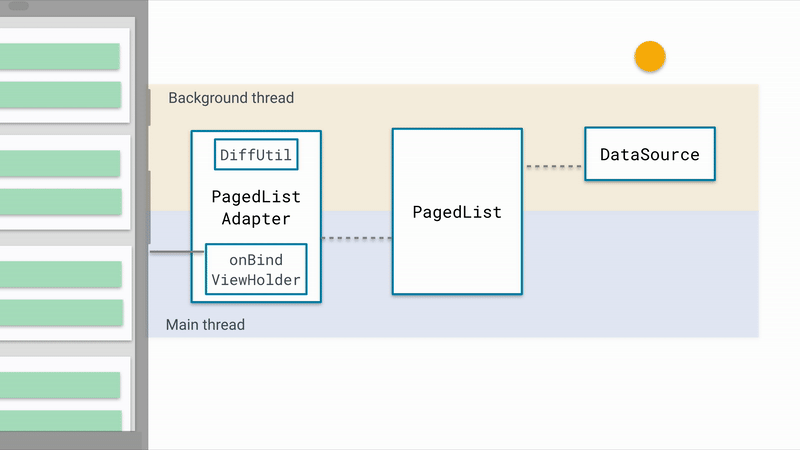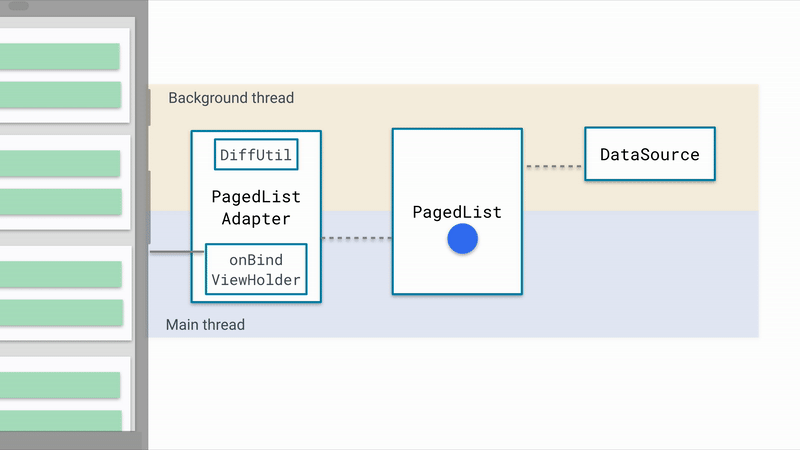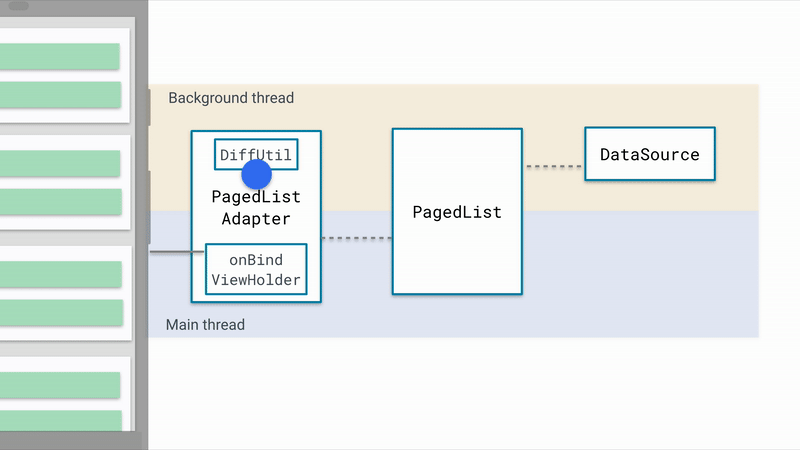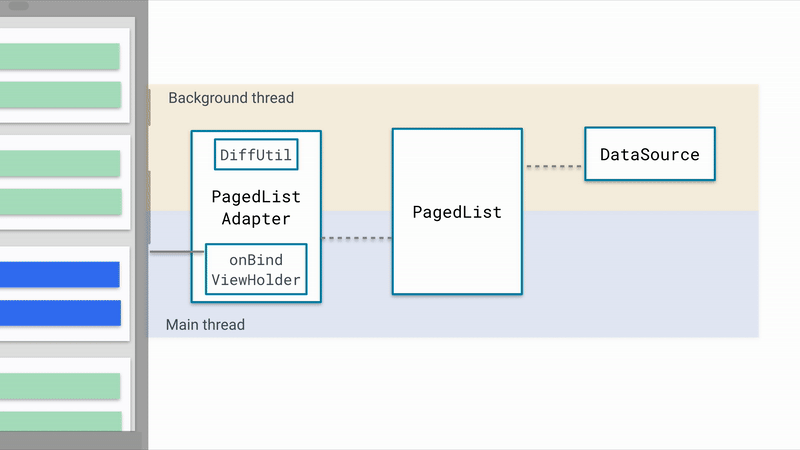
这是官方提供的非常棒的原理示意图,简单概括一下:
我们思考一个问题,将数据作为列表展示在界面上,我们首先需要什么。
数据源,是的,在Paging中,它被抽象为 DataSource , 其获取需要依靠 DataSource 的内部工厂类 DataSource.Factory ,通过create()方法就可以获得DataSource 的实例:
public abstract static class Factory<Key, Value> {
public abstract DataSource<Key, Value> create();
}数据源一般有两种选择,远程服务器请求 或者 读取本地持久化数据——这些并不重要,本文我们以Room数据库为例:
@Dao
interface StudentDao {
@Query("SELECT * FROM Student ORDER BY name COLLATE NOCASE ASC")
fun getAllStudent(): DataSource.Factory<Int, Student>
}Paging可以获得 Room的原生支持,因此作为示例非常合适,当然我们更多获取 数据源 是通过 API网络请求,其实现方式可以参考官方Sample,本文不赘述。
现在我们创建好了StudentDao,接下来就是展示UI了,在那之前,我们需要配置好PageList。
上文我说到了PageList的作用:
我们仔细想想,这是有必要配置的,因此我们需要初始化PageList:
val allStudents = LivePagedListBuilder(dao.getAllStudent(), PagedList.Config.Builder()
.setPageSize(15) //配置分页加载的数量
.setEnablePlaceholders(false) //配置是否启动PlaceHolders
.setInitialLoadSizeHint(30) //初始化加载的数量
.build()).build()我们按照上面分的三个职责来讲:
很显然,这对应的是 dao.getAllStudent() ,通过数据库取得最新数据,如果是网络请求,也应该对应API的请求方法,返回值应该是DataSource.Factory类型。
PageList提供了 PagedList.Config 类供我们进行实例化配置,其提供了4个可选配置:
public static final class Builder {
// 省略其他Builder内部方法
private int mPageSize = -1; //每次加载多少数据
private int mPrefetchDistance = -1; //距底部还有几条数据时,加载下一页数据
private int mInitialLoadSizeHint = -1; //第一次加载多少数据
private boolean mEnablePlaceholders = true; //是否启用占位符,若为true,则视为固定数量的item
}
经过以上操作,我们的PageList设置好了,接下来就可以配置UI相关了。
就像我们平时配置 RecyclerView 差不多,我们配置了ViewHolder和RecyclerView.Adapter,略微不同的是,我们需要继承PagedListAdapter:
class StudentAdapter : PagedListAdapter<Student, StudentViewHolder>(diffCallback) {
//省略 onBindViewHolder() && onCreateViewHolder()
companion object {
private val diffCallback = object : DiffUtil.ItemCallback<Student>() {
override fun areItemsTheSame(oldItem: Student, newItem: Student): Boolean =
oldItem.id == newItem.id
override fun areContentsTheSame(oldItem: Student, newItem: Student): Boolean =
oldItem == newItem
}
}
}当然我们还需要传一个 DifffUtil.ItemCallback 的实例,这里需要对数据源返回的数据进行了比较处理, 它的意义是——我需要知道怎么样的比较,才意味着数据源的变化,并根据变化再进行的UI刷新操作。
ViewHolder的代码正常实现即可,不再赘述。
这个就很简单了,我们在Activity中声明即可:
val adapter = StudentAdapter()
recyclerView.adapter = adapter
viewModel.allStudents.observe(this, Observer { adapter.submitList(it) })这样,每当数据源发生改变,Adapter就会自动将 新的数据 动态反映在UI上。
现在,我简单了解了它的原理,但是还不是很够—— 正如我前言所说的,从别人的 代码设计和** 中 取长补短,化为己用 ,这才是我的目的。
让我们回到最初的问题:
看起来很麻烦,那么我为什么用这个库?
我会有这种想法,我为什么不能把所有功能都封装到一个 RecyclerView的Adapter里面呢,它包含 下拉刷新,上拉加载分页 等等功能。
原因很简单,因为这样做会将 业务层代码 和 UI层 混在一起造 耦合 ,最直接就导致了 难以通过代码进行单元测试。
UI层 和 业务层 代码的隔离是优秀的设计,这样更便于 测试 ,我们可以从Google官方文档的目录结构中看到这一点:

接下来,我会尝试站在设计者的角度,尝试去理解 Paging 如此设计的原因。
将分页数据作为List展示在界面上,RecyclerView 是首选,那么实现一个对应的 PagedListAdapter 当然是不错的选择。
Google对 PagedListAdapter 的职责定义的很简单,仅仅是一个被代理的对象而已,所有相关的数据处理逻辑都委托给了 AsyncPagedListDiffer:
public abstract class PagedListAdapter<T, VH extends RecyclerView.ViewHolder>
extends RecyclerView.Adapter<VH> {
protected PagedListAdapter(@NonNull DiffUtil.ItemCallback<T> diffCallback) {
mDiffer = new AsyncPagedListDiffer<>(this, diffCallback);
mDiffer.mListener = mListener;
}
public void submitList(PagedList<T> pagedList) {
mDiffer.submitList(pagedList);
}
protected T getItem(int position) {
return mDiffer.getItem(position);
}
@Override
public int getItemCount() {
return mDiffer.getItemCount();
}
public PagedList<T> getCurrentList() {
return mDiffer.getCurrentList();
}
}当数据源发生改变时,实际上会通知 AsyncPagedListDiffer 的 submitList() 方法通知其内部保存的 PagedList 更新并反映在UI上:
//实际上内部存储了要展示在UI上的数据源PagedList<T>
public class AsyncPagedListDiffer<T> {
//省略大量代码
private PagedList<T> mPagedList;
private PagedList<T> mSnapshot;
}篇幅所限,我们不讨论数据是如何展示的(答案很简单,就是通过RecyclerView.Adapter的notifyItemChange()相关方法),我们有一个问题更需要去关注:
Paging 未滑到底部便开始加载数据的逻辑 在哪里?
如果你认真思考,你应该能想到正确的答案,在 getItem() 方法中执行。
public T getItem(int index) {
//省略部分代码
mPagedList.loadAround(index); //如果需要,请求更多数据
return mPagedList.get(index); //返回Item数据
}每当RecyclerView要展示一个新的Item时,理所应当的会通过 getItem() 方法获取相应的数据,既然如此,为何不在返回最新数据之前,判断当前的数据源是否需要 加载下一页数据 呢?
我们来看抽象类PagedList.loadAround(index)方法:
public void loadAround(int index) {
mLastLoad = index + getPositionOffset();
loadAroundInternal(index);
mLowestIndexAccessed = Math.min(mLowestIndexAccessed, index);
mHighestIndexAccessed = Math.max(mHighestIndexAccessed, index);
tryDispatchBoundaryCallbacks(true);
}
//这个方法是抽象的
abstract void loadAroundInternal(int index);需要再次重复的是,即使是PagedList,也有很多种不同的 数据分页策略:

这些不同的 PagedList 在处理分页逻辑上,可能有不同的逻辑,那么,作为设计者,应该做到的是,把异同的逻辑抽象出来交给子类实现(即loadAroundInternal方法),而把公共的处理逻辑暴漏出来,并向上转型交给Adapter(实际上是 AsyncPagedListDiffer)去执行分页加载的API,也就是loadAround方法。
好处显而易见,对于Adapter来说,它只需要知道,在我需要请求分页数据时,调用PagedList的loadAround方法即可,至于 是PagedList的哪个子类,内部执行什么样的分页逻辑,Adapter并不关心。
这些PagedList的不同策略的逻辑,是在PagedList.create()方法中进行的处理:
private static <K, T> PagedList<T> create(@NonNull DataSource<K, T> dataSource,
@NonNull Executor notifyExecutor,
@NonNull Executor fetchExecutor,
@Nullable BoundaryCallback<T> boundaryCallback,
@NonNull Config config,
@Nullable K key) {
if (dataSource.isContiguous() || !config.enablePlaceholders) {
//省略其他代码
//返回ContiguousPagedList
return new ContiguousPagedList<>(contigDataSource,
notifyExecutor,
fetchExecutor,
boundaryCallback,
config,
key,
lastLoad);
} else {
//返回TiledPagedList
return new TiledPagedList<>((PositionalDataSource<T>) dataSource,
notifyExecutor,
fetchExecutor,
boundaryCallback,
config,
(key != null) ? (Integer) key : 0);
}
}PagedList是一个抽象类,实际上它的作用是 通过Builder实例化PagedList真正的对象:
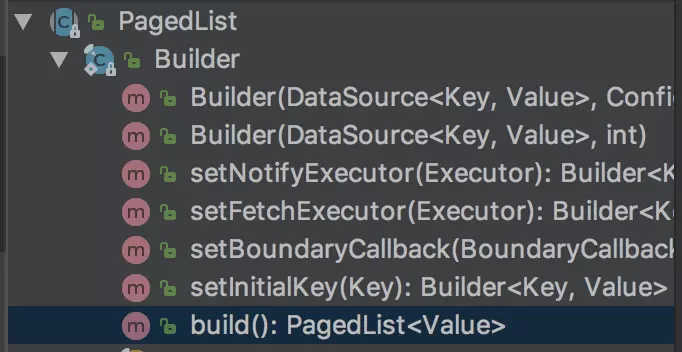
通过Builder.build()调用create()方法,决定实例化哪个PagedList的子类:
public PagedList<Value> build() {
return PagedList.create(
mDataSource,
mNotifyExecutor,
mFetchExecutor,
mBoundaryCallback,
mConfig,
mInitialKey);
}
Builder模式是非常耳熟能详的设计模式,它的好处是作为API的门面,便于开发者更简单上手并进行对应的配置。
不同的PagedList对应不同的DataSource,比如:
class ContiguousPagedList<K, V> extends PagedList<V> implements PagedStorage.Callback {
ContiguousPagedList(
//请注意这行,ContiguousPagedList内部需要ContiguousDataSource
@NonNull ContiguousDataSource<K, V> dataSource,
@NonNull Executor mainThreadExecutor,
@NonNull Executor backgroundThreadExecutor,
@Nullable BoundaryCallback<V> boundaryCallback,
@NonNull Config config,
final @Nullable K key,
int lastLoad) {
//.....
}
abstract class ContiguousDataSource<Key, Value> extends DataSource<Key, Value> {
//......
}
class TiledPagedList<T> extends PagedList<T> implements PagedStorage.Callback {
TiledPagedList(
//请注意这行,TiledPagedList内部需要PositionalDataSource
@NonNull PositionalDataSource<T> dataSource,
@NonNull Executor mainThreadExecutor,
@NonNull Executor backgroundThreadExecutor,
@Nullable BoundaryCallback<T> boundaryCallback,
@NonNull Config config,
int position) {
//......
}
}
public abstract class PositionalDataSource<T> extends DataSource<Integer, T> {
//......
}
回到create()方法中,我们看到dataSource此时也仅仅是接口类型的声明:
private static <K, T> PagedList<T> create(
//其实这时候dataSource只是作为DataSource类型的声明
@NonNull DataSource<K, T> dataSource,
@NonNull Executor notifyExecutor,
@NonNull Executor fetchExecutor,
@Nullable BoundaryCallback<T> boundaryCallback,
@NonNull Config config,
@Nullable K key) {
}实际上,create方法的作用是,通过将不同的DataSource,作为依赖实例化对应的PagedList,除此之外,还有对DataSource的对应处理,或者Wrapper(再次包装,详情请参考源码的create方法,篇幅所限本文不再叙述)。
这个过程中,通过Builder,将 多种数据源(DataSource),多种分页策略(PagedList) 互相进行组合,并 向上转型 交给 适配器(Adapter) ,然后Adapter将对应的功能 委托 给了 代理类的AsyncPagedListDiffer 处理——这之间通过数种设计模式的组合,最终展现给开发者的是一个 简单且清晰 的API接口去调用,其设计的精妙程度,远非笔者这种普通的开发者所能企及。
实际上,笔者上文所叙述的内容只是 Paging 的冰山一角,其源码中,还有很多很值得学习的优秀**,本文无法一一列举,比如 线程的切换(加载分页数据应该在io线程,而反映在界面上时则应该在ui线程),再比如库 对多种响应式数据类型的支持(LiveData,RxJava),这些实用的功能实现,都通过 Paging 优秀的设计,将其复杂的实现封装了起来,而将简单的API暴露给开发者调用,有兴趣的朋友可以去研究一下。
笔者水平有限,难免文中内容有理解错误之处,也希望能有朋友不吝赐教,共同讨论一起进步。
--------------------------广告分割线------------------------------
争取打造 Android Jetpack 讲解的最好的博客系列:
Android Jetpack 实战篇:
Hello,我是却把清梅嗅,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的个人博客或者Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
本文是 Android官方架构组件 系列的番外篇,因为目前国内关于DataBinding双向绑定的博客,讲的实在是五花八门,很多文章看完之后仍然一头雾水,特此专门写一篇文章进行总结。
此外,前几天在CSDN上看到 貌似掉线 老师发布了一篇文章《我为什么放弃在项目中使用Data Binding》,里面针对性指出了目前DataBinding的使用中一些痛点,很多地方我感同身受,但鉴于 事物的存在必然存在两面性 ,特此也在 本文的末尾 写了一些我个人的理解, 阐述了为什么我个人 还在坚持使用DataBinding , 希望对读者能有所裨益。
本文默认读者对DataBinding的使用有了初步的了解。
DataBinding的本身是对View层状态的一种观察者模式的实现,通过让View与ViewModel层可观察的对象(比如LiveData)进行绑定,当ViewModel层数据发生变化,View层也会自动进行UI的更新。
上述我讲的是DataBinding最基础的用法,即 单向绑定 ,其优势在于,将View层抽象为一个纯Java的可观察者——这意味着ViewModel层相关代码是完全可直接用于进行 单元测试。
但实际的开发中,单向绑定并非是足够的,在一些特定的场景,我们也需要用到 双向绑定。
比如说,对于一个TextView的内容展示,一般情况下,我们只是用来通过将一个String类型的数据对其进行渲染:
显而易见,数据的流向是单向的,换句话说,我们认为TextView对DataSource只进行了 读 操作——如果此时进行了网络请求,我们需要用到DataSource某个属性作为参数,我们依然可以毫无顾忌从DataSource取值。
但是换一个场景,如果我们把TextView换成一个EditText,接下来我们需要面对的则截然不同,比如登录界面:
这似乎没有什么问题,我们依然通过一个LiveData对EditText进行了单向绑定:
问题发生了,当我们对 输入框 进行编辑,EditText的UI发生了变更,但是LiveData内的数据却没有更新,当我们想要在ViewModel层请求登录的API接口时,我们就必须要去通过editText.getText()才能获取用户输入的密码。
于是我们希望,即使是EditText的内容发生了变更,但是LiveData内的数据也能和EditText保持内容的同步——这样我们就不需要让ViewModel层持有View层的引用,在请求接口时,直接从LiveData中取值即可:
这就是双向绑定的意义。
什么适合使用 双向绑定 呢,还记得上文中的一句话吗:
对于单向绑定来说,数据的流向是单向的,换句话说,我们认为
TextView对DataSource只进行了 读 操作。
现在我们定义,当 不确定的操作发生时 ——通常,这种操作代表着用户对UI控件的交互,这时UI的变化需要影响到ViewModel层的数据状态(除了 数据驱动视图 之外,视图也在驱动数据,以方便作为参数将来进行网络请求等等操作),这时 双向绑定 就可以大展身手了。
显然上文中的EditText的是 双向绑定 经典的使用场景之一,此外,双向绑定的使用场景非常常见,比如CheckBox:
当用户选中了CheckBox,我们当然希望ViewModel层的LiveData<Boolean>状态进行对应的更新,以便将来我们直接从LiveData中取值作为参数进行网络请求。
而如果没有双向绑定,用户操作了UI,我们就需要 手动添加代码保证状态的同步——比如checkBox.setOnCheckChangedListener(),否则,就会在接下来的操作中得到与预期不同的结果。
幸运的是,Android原生控件中,绝大多数的双向绑定使用场景,DataBinding都已经帮我们实现好了:
这意味着我们并不需要去手动实现复杂的双向绑定,以上文的EditText为例,我们只需要通过@={表达式}进行双向的绑定:
<EditText
android:id="@+id/etPassword"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:text="@={ fragment.viewModel.password }" />相比单向绑定,只需要多一个=符号,就能保证View层和ViewModel层的 状态同步 了。
双向绑定定义好之后,使用起来很简单,但定义却稍微比单向绑定麻烦一些,即使原生的控件DataBinding已经帮助我们实现好了,对于三方的控件或者自定义控件,还需要我们自己实现。
本文以SwipeRefreshLayout为例,让我们来看看其 双向绑定 实现的方式:
object SwipeRefreshLayoutBinding {
@JvmStatic
@BindingAdapter("app:bind_swipeRefreshLayout_refreshing")
fun setSwipeRefreshLayoutRefreshing(
swipeRefreshLayout: SwipeRefreshLayout,
newValue: Boolean
) {
if (swipeRefreshLayout.isRefreshing != newValue)
swipeRefreshLayout.isRefreshing = newValue
}
@JvmStatic
@InverseBindingAdapter(
attribute = "app:bind_swipeRefreshLayout_refreshing",
event = "app:bind_swipeRefreshLayout_refreshingAttrChanged"
)
fun isSwipeRefreshLayoutRefreshing(swipeRefreshLayout: SwipeRefreshLayout): Boolean =
swipeRefreshLayout.isRefreshing
@JvmStatic
@BindingAdapter(
"app:bind_swipeRefreshLayout_refreshingAttrChanged",
requireAll = false
)
fun setOnRefreshListener(
swipeRefreshLayout: SwipeRefreshLayout,
bindingListener: InverseBindingListener?
) {
if (bindingListener != null)
swipeRefreshLayout.setOnRefreshListener {
bindingListener.onChange()
}
}
}有点晦涩,是不是?我们先不要纠结于细节的实现,先来看看代码中是如何使用的吧:
<androidx.swiperefreshlayout.widget.SwipeRefreshLayout
android:layout_width="match_parent"
android:layout_height="match_parent"
app:bind_swipeRefreshLayout_refreshing="@={ fragment.viewModel.refreshing }">
<androidx.recyclerview.widget.RecyclerView/>
</androidx.swiperefreshlayout.widget.SwipeRefreshLayout>refreshing实际就只是一个LiveData:
val refreshing: MutableLiveData<Boolean> = MutableLiveData()这里的双向绑定,意义在于,当我们为LiveData手动设置值时,SwipeRefreshLayout 的UI也会发生对应的变更;同理,当用户手动下拉执行刷新操作时,LiveData的值也会对应的变成为true(代表刷新中的状态)。
相比于其它的方式,双向绑定将SwipeRefreshLayout的刷新状态抽象成为了一个LiveData<Boolean> ——我们只需要在xml中定义好,之后就可以在ViewModel中围绕这个状态进行代码的编写,不同于view.setOnRefreshListener()的方式,这种代码是纯Java的,我们可以针对每一行代码进行纯JVM的单元测试。
本小节的所有代码你都可以在 这里 获取。
说了这么多,但是我们一行代码都还没有实现,不着急,因为编码只是其中的一个步骤,最重要的是 整理一个流畅的思路,这样,在接下来的编码阶段,你会如有神助。
我们知道,双向绑定的前提是单向绑定,因此,我们先配置好对应单向绑定的接口:
@JvmStatic
@BindingAdapter("app:bind_swipeRefreshLayout_refreshing")
fun setSwipeRefreshLayoutRefreshing(
swipeRefreshLayout: SwipeRefreshLayout,
newValue: Boolean
) {
swipeRefreshLayout.isRefreshing = newValue
}我们通过将LiveData的值和DataBinding绑定在一起,每当LiveData的状态发生了变更,SwipeRefreshLayout的刷新状态也会发生对应的更新。
我们实现了数据驱动视图的效果,接下来我们需要思考的是,我们如何才能知道用户会执行下拉操作呢?
只有观察到View层的状态变更,我们才能驱动LiveData进行对应的更新,其实很简单,通过swipeRefreshlayout.setOnRefreshListener()即可:
@JvmStatic
@BindingAdapter(
"app:bind_swipeRefreshLayout_refreshingAttrChanged",
requireAll = false
)
fun setOnRefreshListener(
swipeRefreshLayout: SwipeRefreshLayout,
bindingListener: InverseBindingListener?
) {
if (bindingListener != null)
swipeRefreshLayout.setOnRefreshListener {
bindingListener.onChange() // 1
}
}注意我注释了 //1的地方,每当swipeRefreshLayout刷新状态被用户的操作改变,我们都能够在这里监听到,并交给InverseBindingListener这个 信使 去通知DataBinding:
嗨!View层的状态发生了变更,你快去通知
LiveData也进行对应数据的更新呀!
新的问题来了,现在DataBinding已经知道需要去通知LiveData进行对应数据的更新了,关键是——
是的,即使LiveData需要进行更新,但是它并不知道要新的状态是什么。
LiveData: 老哥,你倒是把数据给我啊!
我们急需将SwipeRefreshLayout最新状态告诉LiveData,因此我们通过InverseBindingAdapter注解和 步骤二 中去进行对接:
@JvmStatic
@InverseBindingAdapter(
attribute = "app:bind_swipeRefreshLayout_refreshing",
event = "app:bind_swipeRefreshLayout_refreshingAttrChanged" // 2 【注意!】
)
fun isSwipeRefreshLayoutRefreshing(swipeRefreshLayout: SwipeRefreshLayout): Boolean =
swipeRefreshLayout.isRefreshing注意到 //2 注释的那行代码没有,我们通过相同的tag(即app:bind_swipeRefreshLayout_refreshingAttrChanged这个字符串,步骤二中我们也声明了相同的字符串),和 步骤二 中的代码块形成了绑定对接。
现在,LiveData知道如何进行反向的数据更新了:
每当用户下拉刷新,
InverseBindingListener通知DataBinding,LiveData就会从swipeRefreshLayout.isRefreshing得知最新的状态,并进行数据的同步更新。
细心的你多少已经感觉到了不对劲的地方,现在的双向绑定有一个致命的问题,那就是无限循环会导致的ANR异常。
当View层UI状态被改变,ViewModel对应发生更新,同时,这个更新又回通知View层去刷新UI,这个刷新UI的操作又会通知ViewModel去更新.......
因此,为了保证不会无限的死循环导致App的ANR异常的发生,我们需要在最初的代码块中加一个判断,保证,只有View状态发生了变更,才会去更新UI:
@JvmStatic
@BindingAdapter("app:bind_swipeRefreshLayout_refreshing")
fun setSwipeRefreshLayoutRefreshing(
swipeRefreshLayout: SwipeRefreshLayout,
newValue: Boolean
) {
if (swipeRefreshLayout.isRefreshing != newValue) // 只有新老状态不同才更新UI
swipeRefreshLayout.isRefreshing = newValue
}本文的初始计划中,还有一个模块是关于 双向绑定的源码分析,写到后来又觉得没有必要了,因为即使是 源码,也只是将上文中实现的思路啰嗦复述了一遍而已。
双向绑定本身是一个极具争议的功能;事实上,DataBinding本身也极具争议——DataBinding的好用与否,用或者不用都不重要,重要的是我们需要去正视它展现出来的**:即如何将一个 难以测试,状态多变 的View, 通过代码抽象为 易于维护和测试 的纯Java的状态?
DataBinding将烦不胜烦的View层代码抽象为了易于维护的数据状态,同时极大减少了View层向ViewModel层抽象的 胶水代码,这就是最大的优势。
当然,DataBinding并不一定就是正解,事实上,RxBinding就是另外一个优秀的解决方案,同样以SwipeRefreshLayout为例,我依然可以将其抽象为一个可观察的Observable<Boolean>——前者通过在xml中对数据进行绑定和观察,后者通过RxJava对View的状态抽象为一个流,但最终,两者在**上殊途同归。
争取打造 Android Jetpack 讲解的最好的博客系列:
Android Jetpack 实战篇:
Hello,我是却把清梅嗅,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的个人博客或者Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
本文已授权「玉刚说」微信公众号独家发布
Paging是Google在2018年I/O大会上推出的适用于Android原生开发的分页库,随着越来越多的开发者着手使用Paging,越来越多的问题暴露出来,最直接的一个问题是:
如何管理列表额外的状态?
这样的需求随处可见,比如 侧滑删除、为评论点赞 等等:
本文将阐述:如何管理Paging分页列表的 状态,为何这样设计,以及设计的过程。
和市面上其它热门的分页库相比,Paging最大的亮点在于其 将列表分页加载的逻辑作为回调函数封装入 DataSource 中,开发者在配置完成后,无需通过代码手动控制分页的加载,列表会 自动加载 下一页数据并展示。
这种便利意味着开发者不需要自己持有 数据源 ,大多数时候这使得开发流程更加便利,但总有偶然,比如这样一个界面:
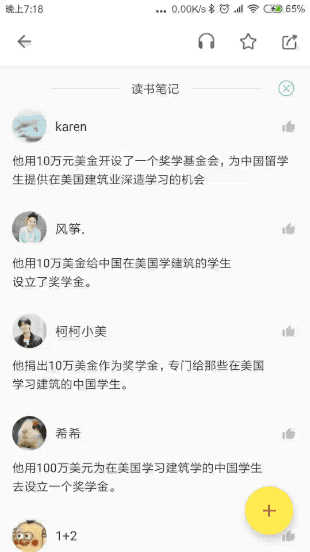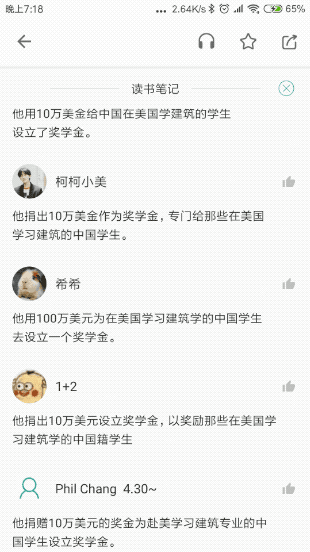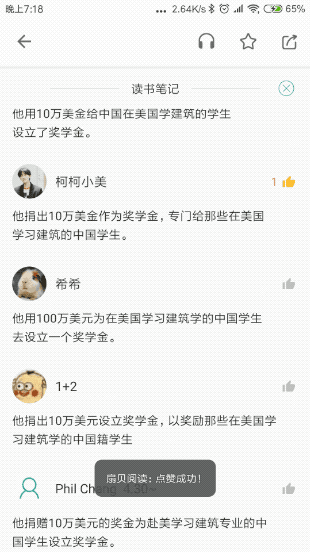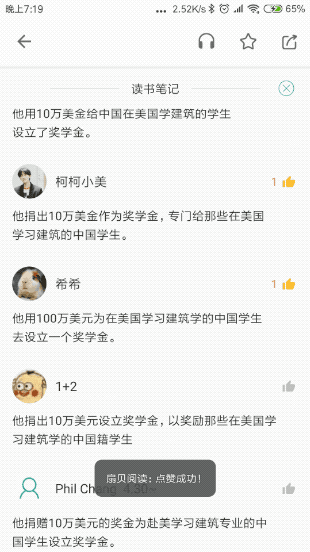
这种需求屡见不鲜,其本质是,列表本身展示服务端返回的列表数据之外,还需要 本地控制额外的状态。
什么叫 额外的状态 ? 我们先用简单的一张图展示没有额外状态的情形,这时,列表的所有UI元素都从服务端获取:
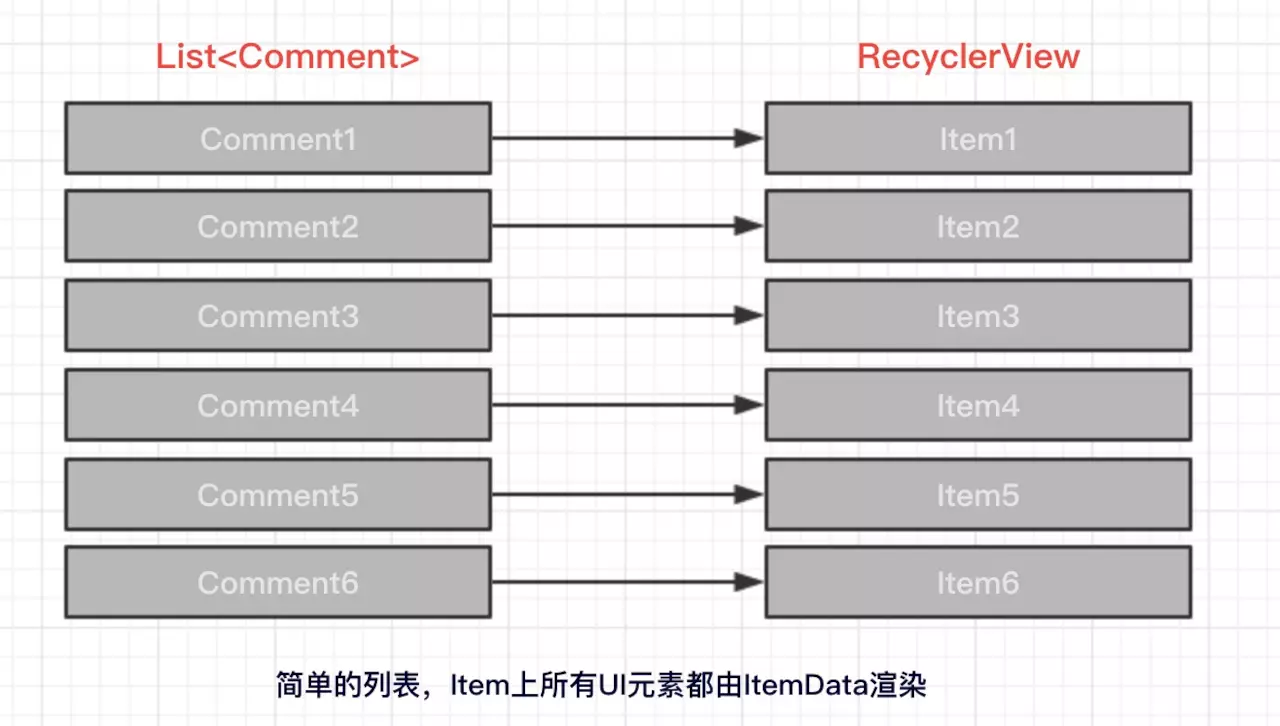
现在我们将上文Gif中的点赞效果也通过一张图表示:
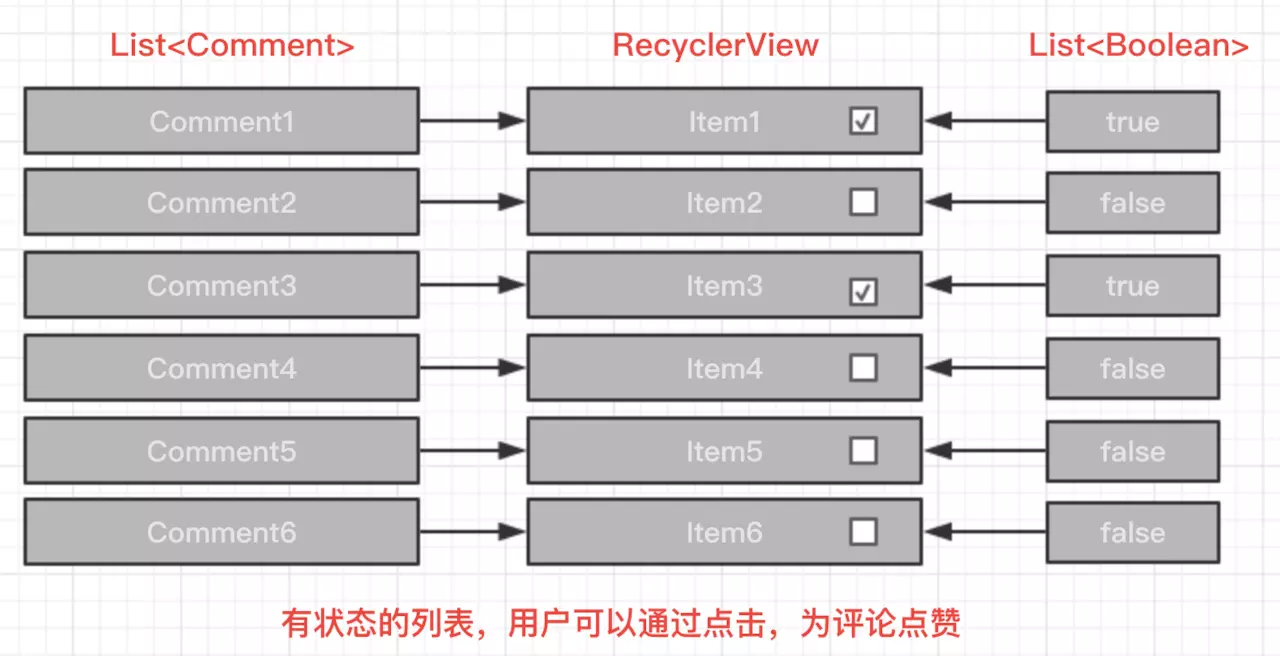
读者可能还未认识到两种业务场景之间的差异性:对于列表的初始化来讲,所有UI元素都被服务端返回的数据渲染,每条评论是否已经被点赞,服务端都通过Comment进行了描述。
需要注意的是,在某一刻,用户发现某个评论非常有趣,因此他选择对该评论进行了点赞的操作。
在业务代码中,我们需要向服务端POST一个点赞的请求,服务端返回了一个200的成功码,但问题来了,接下来我们 如何让列表中的那条评论状态发生变化(即点赞的icon由灰色变成绿色高亮,已告知用户点赞成功)?
这就引发了文章最开始的那个问题,当列表的状态发生了变更,如何管理并更新列表?
最简单的方案是再次请求API,每当列表状态发生了变更,重新拉取评论列表,服务端返回的最新数据中,该评论自然已经被点赞了(即列表正确进行了更新)。
读者应该清楚,该方案实际并不可行,原因有二:
Paging是一个分页列表,而刷新请求行为对于分页列表来说,是一个不符合产品预期的行为(比如,我的点赞操作是针对第5页的某个评论执行的,产品的设计不可能允许每次点赞都重置为列表的第一页数据,这意味着极度糟糕的用户体验)。现在我们理解了 每当列表状态发生了变更就刷新接口 并非良策,因为这种通过 远程重新拉取数据源 更新UI的方式成本太高了。
大概思路是在内存中为RecyclerView维护一个额外的List,用于一一映射对应position的Item状态:
class CommentPagedAdapter(
private val likedList: ArrayList<Boolean>
)通过在内存中维护这样一个List,的确可以实现需求,但读者需要认识到的是,Paging分页库本身最大的优点便是 随着列表的滚动自动加载分页数据,每次分页的行为开发者并不需要手动配置,并通过调用类似notifyItemRangeInserted()的方法更新UI。
很显然,每当分页数据获取后,开发者依然需要手动维护这个额外状态的List——方案2和选择使用Paging的初衷背道而驰,因此它并非最优先考虑的方案。
现在问题是,既不能通过 服务端 作为数据源,也不能在 内存中 额外维护一个状态的列表, 读者难免会质疑Paging库本身设计的问题。
我该如何控制列表额外的状态(包括修改、增加或者删除)?
事实上该问题已经在Github的这个 issue 中进行了讨论,Google的工程师的回复是:
从技术的角度而言 ,我们可以创建一个允许部分更改数据源的API,但之后我们需要记录这些改动并在主线程上重新传递给列表。这种方法的问题在于,如果你有一个已停止的
RecyclerView(也就是后堆栈),它将不会(也不应该)接收任何更新,因此PagedList将保留这个可能很长的数据列表并重新应用于主线程上的每个观察者。
这使问题变得非常复杂,这就是我们使用单个列表的原因。
显然,Paging考虑到了更多,和市面上 什么都能做 的框架相比,它 敢于收紧开发者API的调用权限,在开发者们发挥更多奇思妙想之前,将其紧紧束缚到了可控制的范围之内,这也是笔者非常推崇Paging的原因之一。
那么我们该如何处理我们的业务?此时引入一个新的角色似乎是一个不错的选择,那就是 持久层(即缓存)。
综上所述,对于分页列表的状态管理问题,需要做到的是:
List交给Paging去进行分页加载并渲染(不应在内存中手动维护一个额外状态的列表);因此,我们需要一个 中间件 进行业务的调度——在需要刷新整个数据源的时候(比如用户的下拉刷新操作),从服务端拉取数据;在不需要繁重的操作时(比如用户针对某个评论进行点赞),仅仅需要针对单个数据源进行简单的修改。
这已经不单单是业务业务的问题,并且涉及到了项目本身的架构,接下来, 持久层 (即本地缓存)闪亮登场。
Android平台的数据库框架有很多种,本文以官方的架构组件Room为例。
为什么要为项目的架构额外添加一个持久层?事实上,随着项目体系的日益庞大,数据库是终究需要添加进入项目中的,因此,在设计项目的架构之前,提前将数据库的框架配置进来是一个不错的选择——未雨绸缪总不是坏事。
以列表的渲染为例,让我们来看看项目之前的结构:
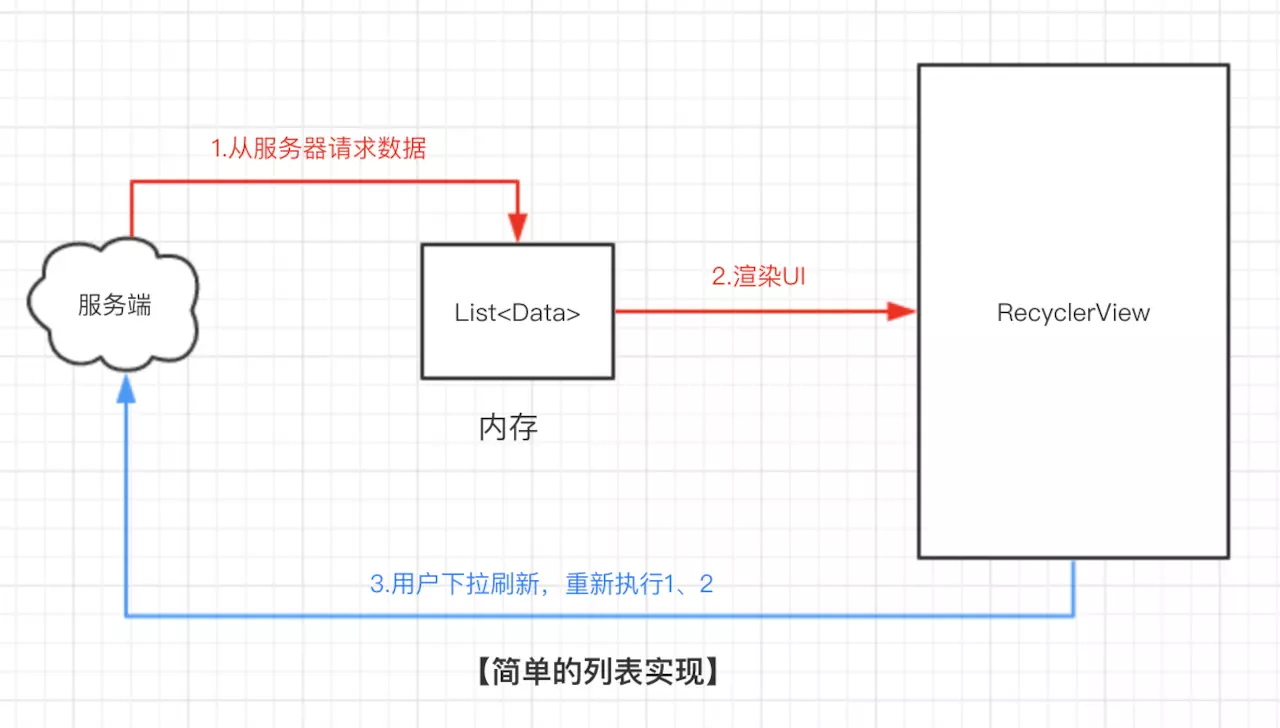
回到本文,对于Paging来讲,我们并无法直接获取数据源,因此对于列表状态的管理,我们需要额外的角色帮助,那就是本地的持久化缓存。
让我们看看添加了持久层之后的结构:
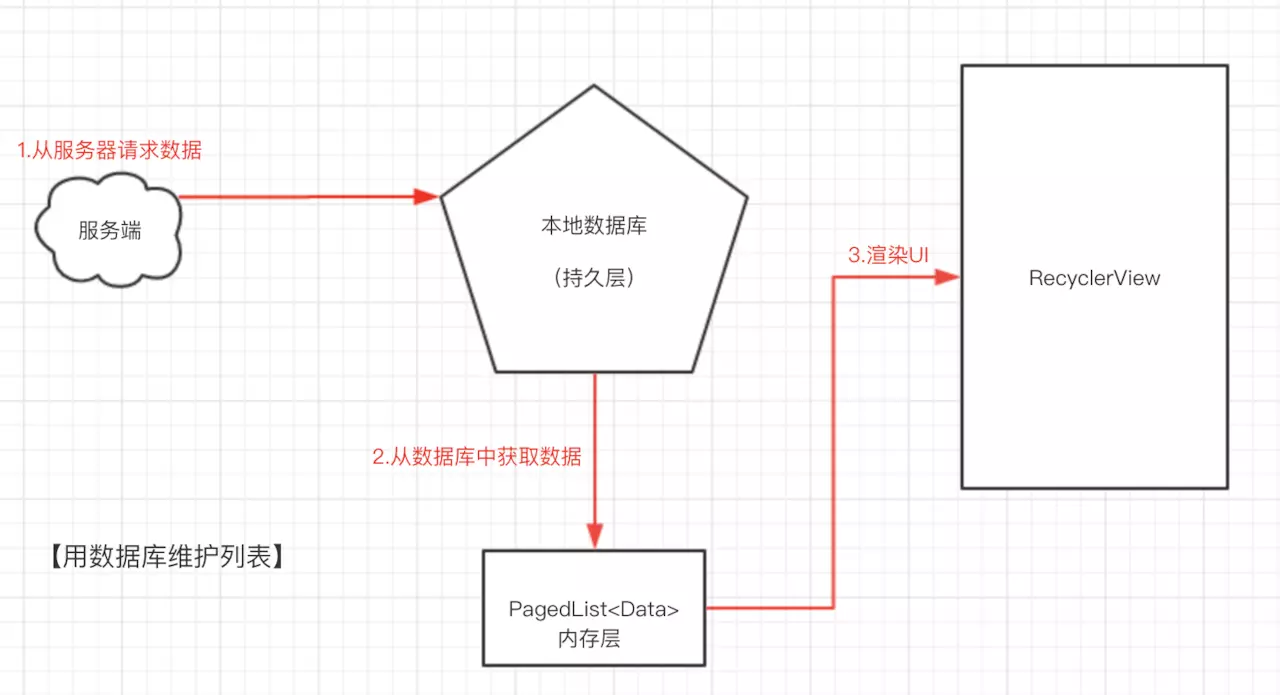
添加了缓存之后,每当我们尝试初始化一个分页列表,框架会从服务器拉取数据,之后数据被存储到了Room中。
请注意!Paging原生提供了对Room数据库框架的支持,因此它总是可以第一时间响应到数据库中数据的变化,并自动渲染在UI上。
现在,我们将 请求服务器API 和 数据的渲染 两者通过持久层进行了隔离,对于RecyclerView来说,持久层是唯一的数据源,即:
列表只反应了数据库的变更。
现在列表的显示和服务端的请求已经 完全无关 了,读者也许会有这样的疑问——这样做的好处是什么?
现在我们回到文中最初的问题,如何管理列表的状态?
对于一个拥有复杂状态的分页列表,无论是 服务端 作为数据源,还是在 内存中 额外维护一个状态列表,都不是很好的选择;而现在我们加入了Room,并作为列表唯一的数据源,局势发生了怎样微妙的变化呢?
让我们来看看加入了持久层之后,下拉刷新的逻辑发生了怎样的变化:
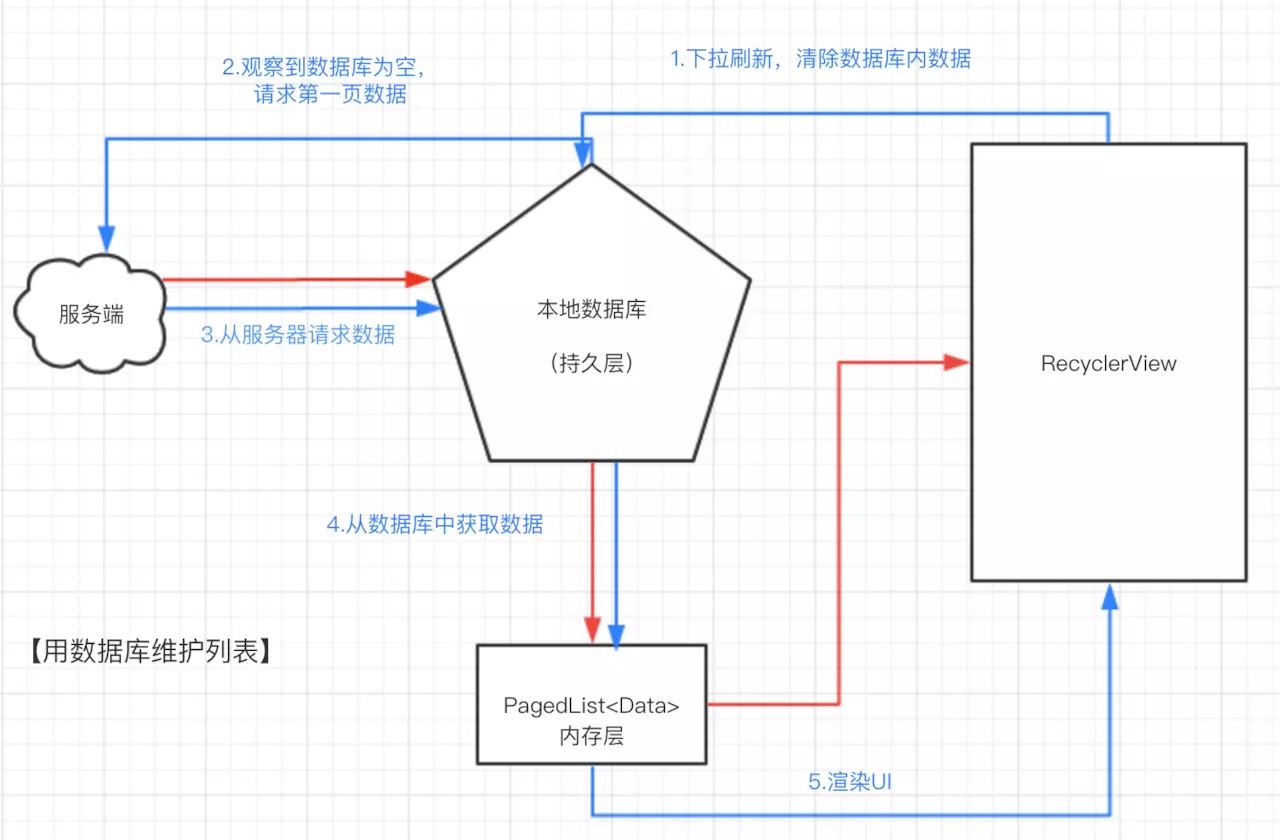
Paging会自动响应到数据的变化,因为没有了数据,所以Paging会自动向服务器请求数据;Paging会再次响应到数据库的变化,并将最新的数据渲染到UI上。看起来逻辑复杂了很多,实际上读者需要明确的是,步骤2、3、4都是我们作为开发者在初始化Paging时就配置好的,因此如果用户需要刷新页面,只需要进行第一步的操作即可,即类似这样的一行代码:
// 刷新操作,仅需清除表内的列表数据
fun swipeRefresh() {
// 运行一个事务
db.runInTransaction {
// 清除列表数据
db.getDao().clearDataList()
}
}现在我们将整个流程中,Paging自动执行的步骤用紫色标记出来:
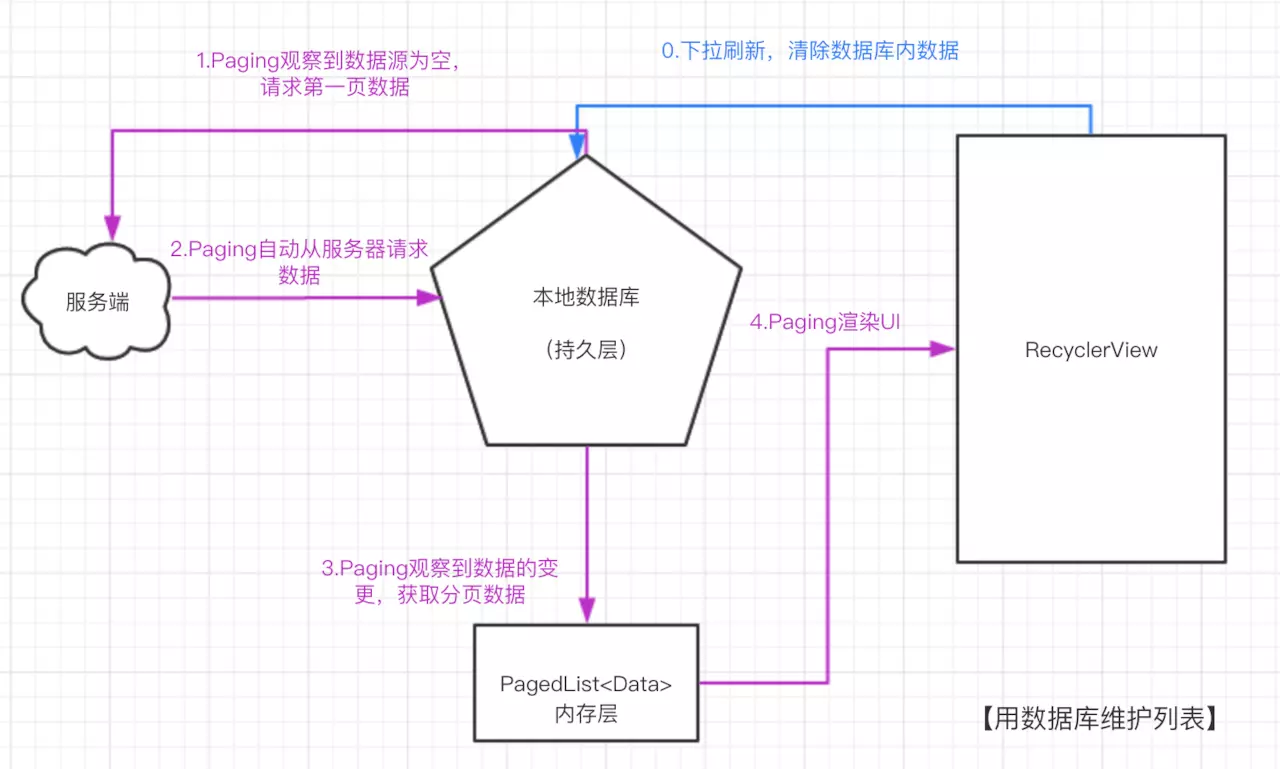
瞧,除了我们手动执行的逻辑,所有流程都交给了Paging去 响应式 地执行。
我们总是下意识认为复杂的业务逻辑用过程式的编码更容易实现,Paging用事实证明了并非如此——如果说项目中的某个页面追加了下拉刷新的需求,过程式的编码也许会花费更多的时间,并且代码也许会更分散、啰嗦且易出错。
接下来分析的是,对分页列表点赞这种相对 轻量级的行为 又该如何处理?
答案呼之欲出, 我们依然用熟悉的流程图表示代码的执行步骤:
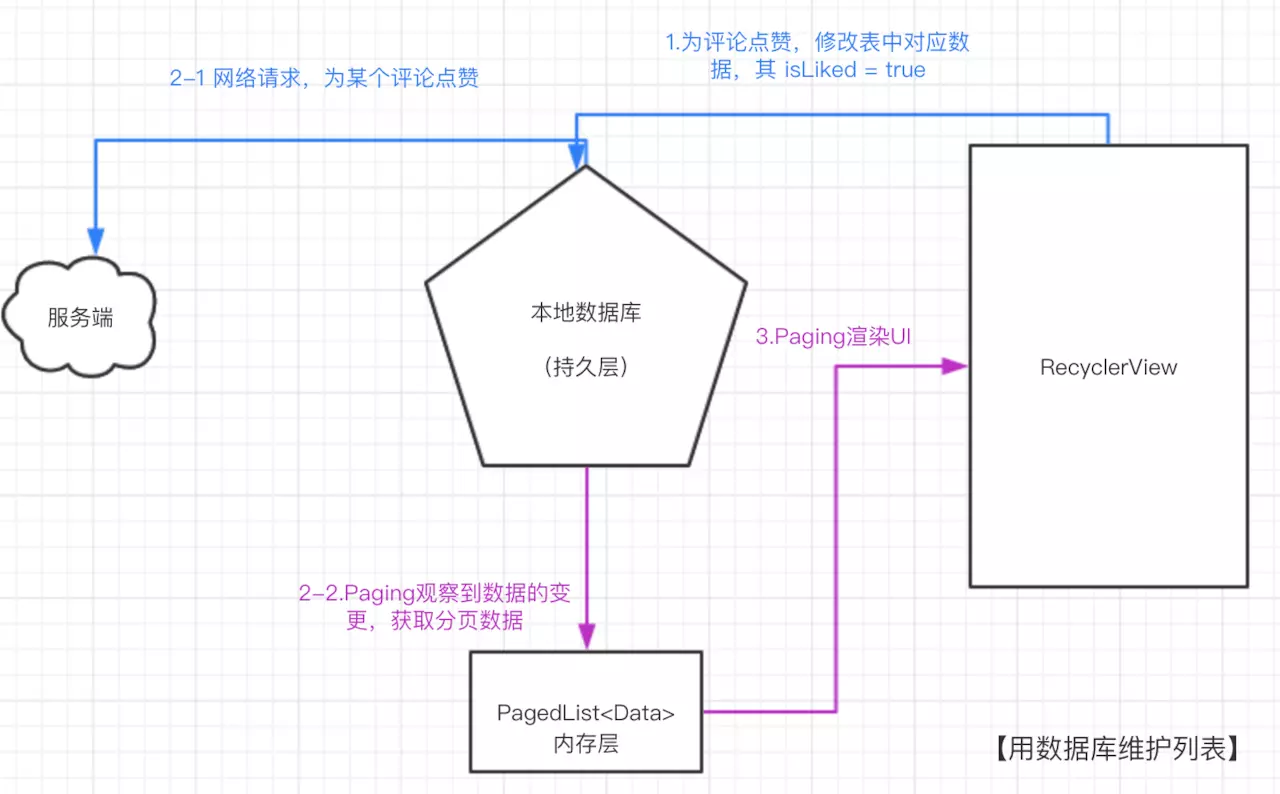
即使是复杂的状态,在这种模式下也不再是难题:首先,我们将数据库对应表中对应评论的isLike(是否被点赞)设置为true:
// 1.对本地的评论数据点赞
fun likeCommentLocal(comment: Comment) {
// 更新评论
comment.isLike = true
// 将评论更新到数据库中
db.runInTransaction {
db.getDao().updateLikeComment(o)
}
}与此同时,我们也向服务器请求接口,告知评论被用户点赞:
// 2.对评论点赞
fun likeCommentRemote(commentId: String) {
service.likeComment(commentId)
// ....
}当数据库中数据发生了变更,Paging仍然会响应到数据的更新,并第一时间更新了UI,同时我们也向服务器发起了请求,一个完整的 点赞 操作相关的业务代码实现完毕。
有了持久层作为中间件,代码组织的灵活性大大提升,同时也具备了更高的扩展性。列表状态的管理不再是问题,诸如 点赞 、 下拉刷新 、 侧滑删除 等等等等,都可以通过对持久层的数据源进行修改,paging总是可以第一时间自动响应到变更并更新UI。
也正如Room官方文档第一句话所说的,对于Paging分页列表(对app也一样)复杂的状态的展示和管理,开发者应该 将缓存作为列表的唯一真实的数据源:
This cache, which serves as your app's single source of truth.
如读者所看到的,本文尽量避免展示大篇幅的业务代码,原因有二:
比如,对于持久层框架的选型,
Room、GreenDao、DBFlow都是非常优秀的框架,对于业务代码的实现,RxJava、LiveData、协程都是优秀的实现方案...
本文的目的是阐述笔者遇到问题的解决步骤和思路,读者了解整体的方案之后,可以根据实际项目进行技术选型。
当然,如果有相关的疑惑,欢迎参考下面两个项目的具体实现,这是笔者基于上文的Paging+Room组件,实现了一个简单的Github的客户端,本文不细述。
1.MVVM架构的Sample: https://github.com/qingmei2/MVVM-Rhine
2.MVI架构的Sample:https://github.com/qingmei2/MVI-Rhine
争取打造 Android Jetpack 讲解的最好的博客系列:
Android Jetpack 实战篇:
Hello,我是却把清梅嗅,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的博客或者Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
「反思」 系列是笔者一个新的尝试,其起源与目录请参考 这里 。
完整的掌握 Android 事件分发体系并非易事,其整个流程涉及到了 系统启动流程(SystemServer)、输入管理(InputManager)、系统服务和UI的通信(ViewRootImpl + Window + WindowManagerService)、View层级的 事件分发机制 等等一系列的环节。
事件拦截机制 是基于View层级 事件分发机制 的一个进阶性的知识点,本文将对其进行更细致化的讲解。
事件拦截机制 本身就相对比较独立,因此本文不需要读者有 事件分发机制 相关的预备知识,对后者感兴趣的读者可以参考以下资料:
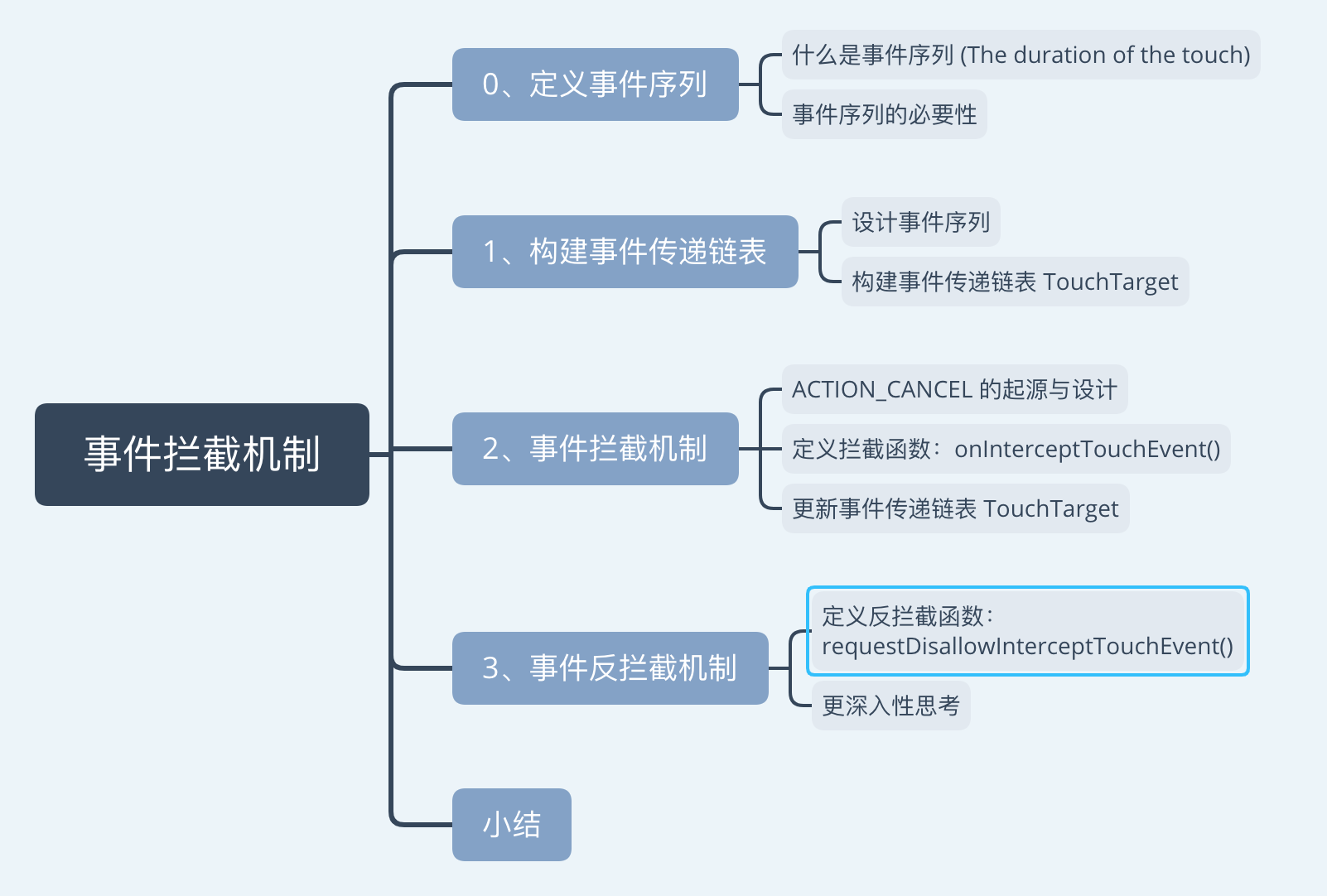
本文整体结构如下图:
想要说清 事件分发机制 和 事件拦截机制,事件序列 是首先要理解的概念。
什么是事件序列?Google官方文档中对其描述为 The duration of the touch,顾名思义,我们可以将其理解为 用户一次完整的触摸操作流程—— 举例来说,用户单击按钮、用户滑动屏幕、用户长按屏幕中某个UI元素等等,都属于该范畴。
为什么 事件序列 是一个非常重要的概念?
上一篇文章 中,读者已经了解事件分发的本质原理就是递归,对此简单的实现方式是:每接收一个新的事件,都需要进行一次递归才能找到对应消费事件的View,并依次向上返回事件分发的结果。
以每个触摸事件作为最基本的单元,都对View树进行一次遍历递归?这对性能的影响显而易见,因此这种设计是有改进空间的。
如何针对这个问题进行改进?将 事件序列 作为最基本的单元进行处理则更为合适。
首先,设计者根据用户的行为对MotionEvent中添加了一个Action的属性以描述该事件的行为:
ACTION_DOWN:手指触摸到屏幕的行为ACTION_MOVE:手指在屏幕上移动的行为ACTION_UP:手指离开屏幕的行为ACTION_CANCEL...我们知道,针对用户的一次触摸操作,必然对应了一个 事件序列,从用户手指接触屏幕,到移动手指,再到抬起手指 ——单个事件序列必然包含ACTION_DOWN、ACTION_MOVE ... ACTION_MOVE、ACTION_UP 等多个事件,这其中ACTION_MOVE的数量不确定,ACTION_DOWN和ACTION_UP的数量则为1。
熟悉了 事件序列 的概念,设计者就可以着手对现有代码进行设计和改进,其思路如下:当接收到一个ACTION_DOWN时,意味着一次完整事件序列的开始,通过递归遍历找到真正对事件进行消费的Child,并将其进行保存,这之后接收到ACTION_MOVE和ACTION_UP行为时,则跳过遍历递归的过程,将事件直接分发对应的消费者:
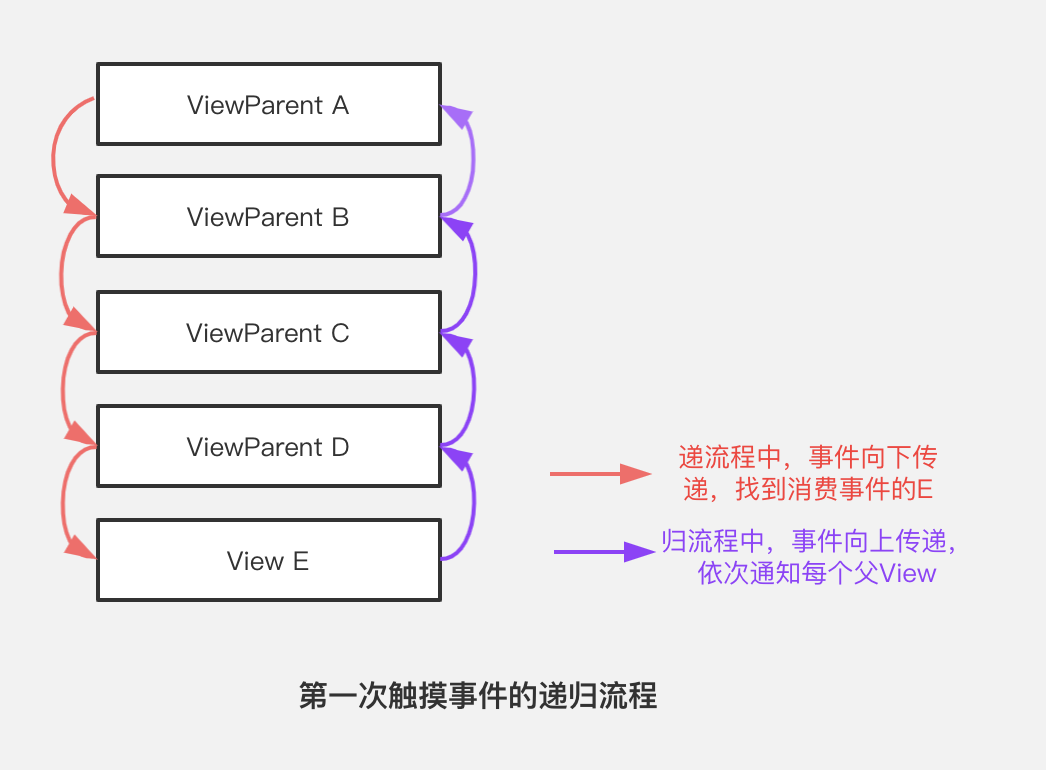
由此可见,事件序列 在 事件分发 的知识体系中的确是非常重要的核心概念(甚至没有之一),其最重要的意义是 足够节省性能:用户一次正常的触摸行为,其 事件序列 包含了若干个触摸事件,这些事件并非每次都通过递归算法去找到事件的消费者,因为这会消耗非常多的内存——当事件序列越复杂、或者View树的层级嵌套越深,这种优势愈发明显。
那么,源码的设计者是如何保证通过一次递归算法找到View树中对应事件消费者的子View,其数据结构又是如何的呢?
认真思考,读者不难得出答案:链表。
为什么采用链表,有没有更加简单粗暴的实现方案?
当然,最符合直觉 的实现方式似乎是:在通过递归完成第一次事件分发之后,将事件的消费者作为成员保存在当前父View中:
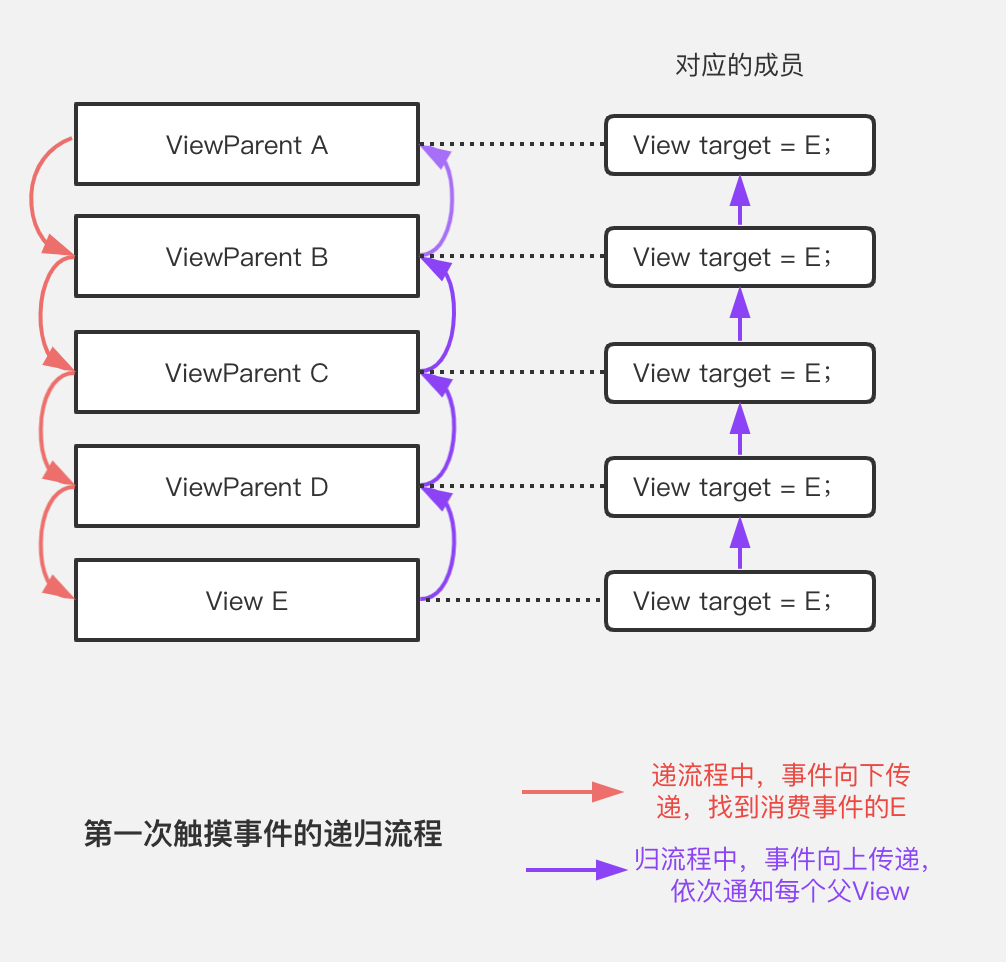
不可否认,这样的设计完全可以实现我们需要的效果,但读者仔细思考得知,这种设计最大的问题就是破坏了树形结构的 内部自治性。
最顶层View直接持有最下层某个View的引用合理吗?答案是否定的。首先,这导致View层级依赖之间的混乱;其次,顶层View本身持有了最下层某个View的引用,则这之间若干个层级的View的target属性都毫无意义。
更能将树结构应用淋漓尽致的方式是构建一个链表:
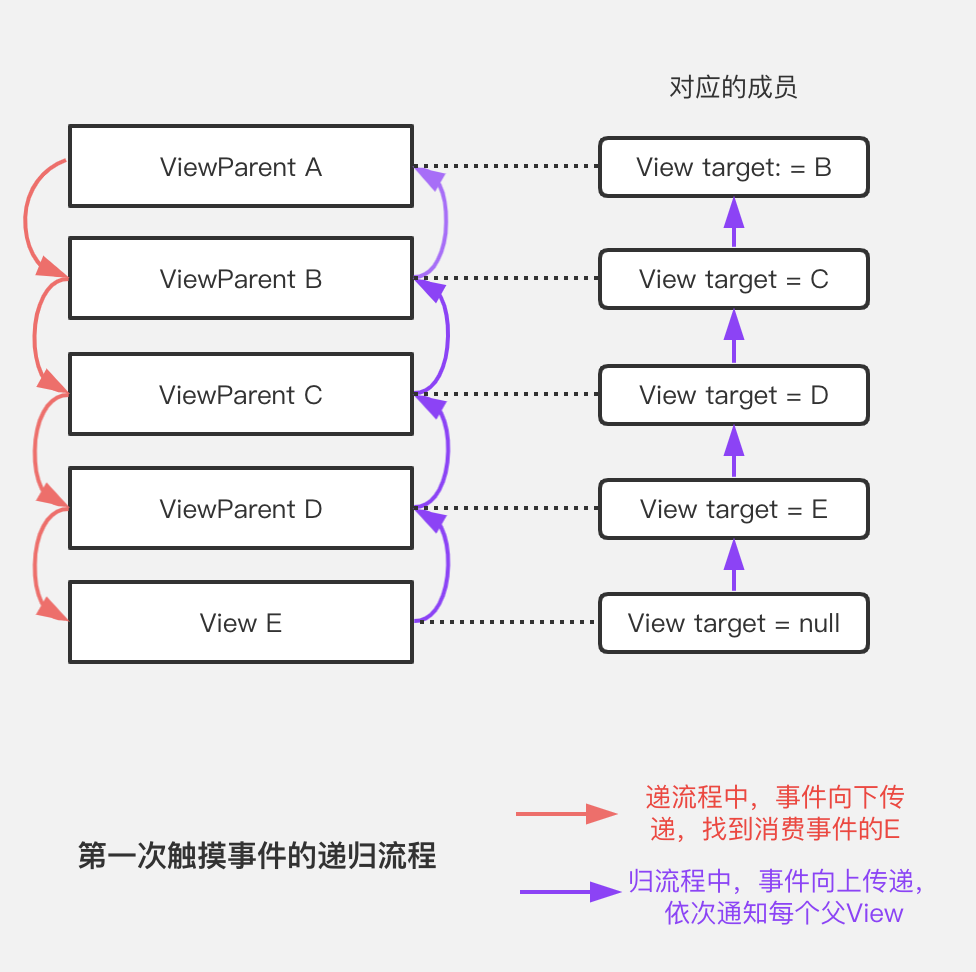
每个View节点都持有事件的下一级消费者,当同一事件序列后续的触摸事件抵达时,不再需要进行消耗性能的DFS算法,而是直接交给下一级的子View,子View则直接交给下下一级的子View,直到事件到达真正的消费者:
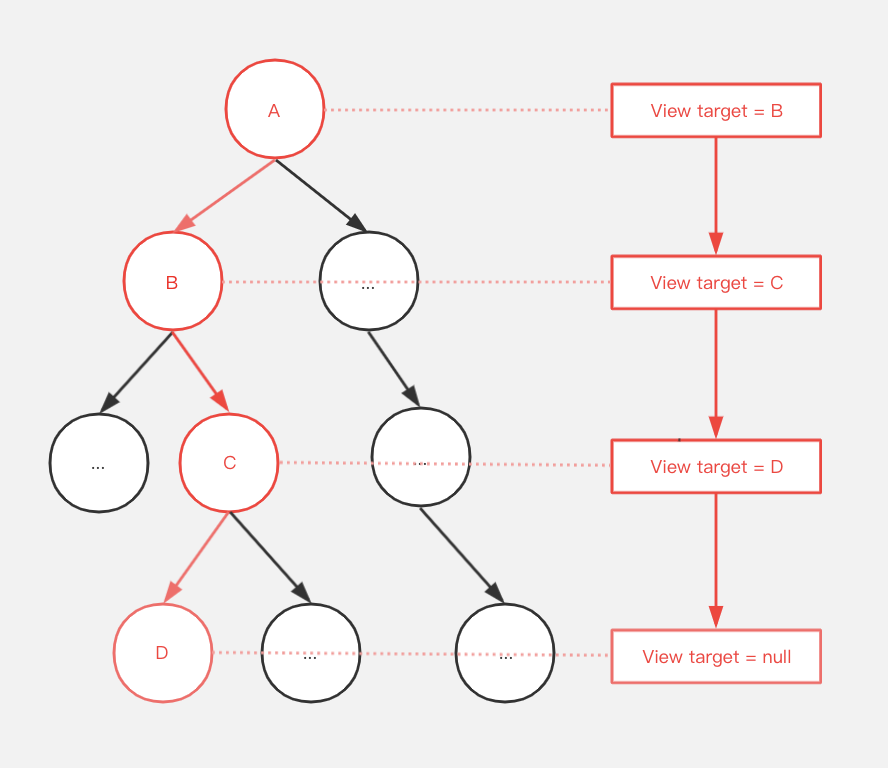
和链表的定义类似,设计者设计了TouchTarget类,同时为每一个ViewGroup都声明这样一个成员,作为链表的一个结点,以描述当前事件序列的传递方向:
public abstract class ViewGroup extends View {
// 链表的下一级结点
private TouchTarget mFirstTouchTarget;
private static final class TouchTarget {
// 描述接下来的触摸事件由哪一个子View接收并分发
public View child;
}
}那么这个链表是怎么构建的呢?正如上文所说,当接收到一个ACTION_DOWN时,意味着一次完整事件序列的开始,通过递归遍历找到真正对事件进行消费的Child
读者需认真揣摩 事件序列 的相关概念,因为这个知识点贯穿了整个 事件分发机制 流程,可以说是非常核心的知识点;同时,掌握它也是下文快速掌握 事件拦截机制 的关键。
大多数Android开发者对 事件拦截机制 都不会陌生,读者应该都有了解,ViewGroup层级额外设计了onInterceptTouchEvent()函数并向外暴露给开发者,以达到让ViewGroup不再将触摸事件交给View处理,而是自身决定是否消费事件,并将结果反馈给上层级的ViewGroup。
为什么设计出这样一种拦截机制?其实这是有必要的,以常规的ScrollView对应的滑动页面为例,当用户抛出了一个列表的滑动操作,这时,对应的触摸事件序列是否还有必要交给ScrollView的子View进行处理?
答案是否定的,当ScrollView接收到滑动操作时,理所当然,本次滑动操作相关事件都不再需要交给子View,而是直接交给ScrollView去处理滑动操作。
读者同样需要明白,并非所有事件序列都会被拦截——当用户点击ScrollView中的某个按钮时,设计者又期望这次的点击操对应的系列事件能够被ScrollView分发给子Button去处理,这样开发者最终能够在按钮本身的OnClickListener中观察到这次点击事件,并进行对应的业务操作。
因此,对于不同类型的ViewGroup,开发者需要在不同的场景下,做出是否拦截事件的决定,这种 父控件根据本身职责去拦截指定场景的事件序列 的行为,我们称之为 事件拦截机制。
那么开发者如何做,才能保证 不同场景的事件被合理的向下分发或直接拦截 呢?设计者据此提供了 onInterceptTouchEvent() 拦截函数:
public abstract class ViewGroup extends View {
public boolean onInterceptTouchEvent(MotionEvent ev) {
// ...
return false;
}
}其定义是,当触摸事件到来时,事件首先作为参数传入onInterceptTouchEvent函数中,开发者自定义onInterceptTouchEvent内部逻辑,以决定是否对该事件进行拦截,并将boolean类型的结果进行返回。当返回值为true时,该事件序列接下来所有的事件都会被当前的ViewGroup拦截;通常情况下,ViewGroup的该函数默认返回false,即不对事件进行拦截。
以上文为例,我们可以对ScrollView添加类似如下策略——当用户发起一个 点击事件 的操作时,onInterceptTouchEvent返回false,将事件交给下游的子控件去决定消费与否;而当用户 滑动屏幕 时,则将事件序列进行拦截:
public class ScrollView extends ViewGroup {
public boolean onInterceptTouchEvent(MotionEvent ev) {
// 这里模拟一个抽象的函数代替实际的业务逻辑
// 实际源码中,这里是根据对触摸事件序列的复杂判断,得出操作是否是滑动事件
if (isUserScrollAction(ev)) {
return true;
} else {
return false;
}
}
}事件序列 在这个过程中再次起到了 至关重要 的作用。针对单独一个触摸事件——例如 ACTION_DOWN或ACTION_MOVE而言,我们都无法确定这是否是我们希望拦截的操作。而当我们获取到 事件序列 中连续若干个事件后,我们则可以根据手势操作的方向和距离(判断是否是滑动)、触摸屏幕的时间(判断是点击事件还是长按事件)对用户的这次行为进行定义,最终决定是否进行拦截。
——这意味着,当ScrollView接收到最初的ACTION_DOWN事件时,父控件并没有立即对事件进行拦截,而是交给了子Button去消费;而当接收了若干个ACTION_MOVE事件时,ScrollView的onInterceptTouchEvent()函数中判断得出 本次触摸行为方向朝下,是滑动事件,然后该函数返回true,导致本次和接下来的触摸事件都会被拦截。
等等!到了这里,读者似乎推断出了一个怪异的结论: 针对一个完整事件序列的向下分发过程而言,触摸事件的消费者并不一定只有一个角色——这似乎不太符合直觉。
但事实的确如此。
既然一个完整的 事件序列 其事件可能会交给不同的角色,这是否意味着极端情况下,用户的一次 滑动行为 不但会触发了父控件本身的 滑动 效果,用户也会同时接收到Button子控件的 点击 效果?
目前为止的设计中确实存在这个缺陷,因此接下来我们需要增加新的逻辑单元去弥补这个问题,ACTION_CANCEL闪亮登场。
终于来到了ACTION_CANCEL的舞台,报幕员对这名演员的介绍是两个单词:弥补 和 终结。
现在我们希望,当Button的父控件ScrollView对滑动操作进行了拦截时,Button的点击事件不再会被响应。
正常的逻辑处理中,Button需要在接收到ACTION_UP时,判断整个事件序列持续的时间,如果符合一系列单击操作的前置定义(比如touchable = true或clickable = true等等),就直接交给单击事件的监听器View.OnClickListener去处理。
我们可以将ACTION_UP视为 事件序列 中的 终止事件,但很明显,这个逻辑在 事件拦截机制 中并不适用,因为当父控件对事件进行了拦截后,接下来整个序列中所有的事件都转交给了父控件,子控件再也接受不到任何事件,包括ACTION_UP。
我们总是希望有始有终(比如期待面试结果的及时反馈),事件分发机制 中也是一样,当子控件事件被父控件拦截,子控件也需要一个 终止事件 的通知以作出对应的行为。
因此,设计者额外提供了ACTION_CANCEL事件,以通知当前的View作出对 事件被拦截 之后的收尾工作,比如取消点击事件或长按事件相关判断逻辑中的计时器(如果有的话,下同),或者对当前控件滑动距离计算的重置等等,避免了「既发生父控件滑动」又「触发子控件点击」的尴尬场景。
现在,当父控件拦截了触摸事件后,子控件立即接收到一个额外的ACTION_CANCEL作为弥补,并草草进行了相关的收尾工作,之后的业务逻辑则统统交给了父控件去处理。
事件拦截机制 到此似乎告一段落,读者认真思考,这样的逻辑处理目前已经是完美的了么?
父控件:「我无效你的效果。」
子控件:「我无效你的无效。」
音乐播放器的进度条控件SeekBar提出了严重抗议。
当SeekBar与ScrollView搭配使用时,前者愕然发现,作为子控件,其最引以为豪的技能——滑动调整音频进度的功能完全被废掉了。
这是当然的,ScrollView接收到滑动事件时,会很自然的将接下来相关的所有事件都进行拦截,而作为子控件的SeekBar连汤都喝不上。
这是不合理的设计,父控件的权利实在太大了,而子控件对此完全束手无策。因此设计者为ViewGroup设计了一个另外一个API——requestDisallowInterceptTouchEvent(boolean)。
该函数的作用是,命令指定的ViewGroup 是否 不再针对事件序列进行拦截 ,而是正常将事件交给子控件去处理是否消费事件。
以SeekBar为例,其完全可以这样设计:
public abstract class AbsSeekBar extends ProgressBar {
// ...代码大幅简化,具体逻辑请参考源码...
@Override
public boolean onTouchEvent(MotionEvent event) {
switch (event.getAction()) {
// 当接收到ACTION_DOWN事件时,命令父控件不能拦截事件序列
case MotionEvent.ACTION_DOWN:
mParent.requestDisallowInterceptTouchEvent(true);
break;
// ...
}
}
}现在,即使ScrollView内部持有对 滑动操作 相关的拦截机制,但SeekBar依然可以通过更高等级的API对其进行压制,从而跳过父控件相关的拦截,并自己消费滑动事件——最终用户得到了他希望得到的操作体验(滑动调节播放进度)。
上一小节的叙述本身是存在瑕疵的,通常来说,调节进度的SeekBar处理的是横向滑动,而ScrollView处理的则是竖向滑动,本质上两者逻辑并不冲突。
这样描述,只是为了让读者能够更容易的理解 反拦截机制 对应的requestDisallowInterceptTouchEvent()函数设计的目的及意义,对此读者不必深究——当然,读者也可自定义实现一个横向滑动的HorizontalScrollView,以得到上一小节中滑动冲突的效果,本文不赘述。
另外一点需要思考的是,当子控件调用了父控件的requestDisallowInterceptTouchEvent(true)函数无效化了父控件的拦截机制之后,父控件拦截机制的无效化需要一直存在吗 ?
答案是否定的,正确的方式是应该在某个时间点 对父控件拦截机制进行重启——即调用requestDisallowInterceptTouchEvent(false),这样才能保证在触摸到其它子控件时,父控件依然能够对 事件拦截机制 进行正常的运转。
那么这个重置的时间点如何把握,在子控件接收到ACTION_UP时调用吗?
在子控件 事件序列的终止事件中重置状态,这听起来不错,但是需要注意的是,拦截机制被无效化的状态是存在父控件ViewGroup中的,因此换个思路,更好的时机会不会其实是隐藏在ViewGroup中的呢?
设计者最终将重置的时机放在了父控件 事件序列的起始事件——ACTION_DOWN的处理逻辑中。
public abstract class ViewGroup extends View {
@Override
public boolean dispatchTouchEvent(MotionEvent ev) {
// ...
if (actionMasked == MotionEvent.ACTION_DOWN) {
// 1.这个函数内部将事件拦截功能的开关进行了重置
resetTouchState();
}
// ...2.继续处理事件拦截和事件分发
}
}这确实是重置拦截机制的更好时机,既保证了其它子控件的触摸事件不会被之前的反拦截机制所影响,同时也维护了ViewGroup内部本身的自治性。
这也证明了 事件序列 中的起始事件 ACTION_DOWN 总是可以被父控件接收到并进行拦截处理,因此,开发者绝大多数情况下不能在 ViewGroup 的 onInterceptTouchEvent() 中,直接对ACTION_DOWN事件返回true,因为这将会导致父控件拦截了整个 事件序列 ,子控件连ACTION_DOWN都接受不到,反拦截机制彻底失效。
事件拦截机制 是一个非常重要的基础知识点,而 事件序列 又是其中最核心的概念,无论是 事件分发 还是 事件拦截,搞懂了 事件序列 的意义,其它逻辑概念的理解都不再困难。
这一篇文章就能让我理解Android事件拦截机制吗?
当然不能,在撰写本文的过程中,笔者最终删除了若干更细节知识点的讲解,比如:
mFirstTouchTarget发生了怎样的变化?(事件传递链表的更新操作)等等,这些细节同样十分重要,它们是填充 事件拦截机制 完整体系的血与肉,建议读者结合本文与下列相关资料,开启一次更细致的探究之旅。
Hello,我是 却把清梅嗅,女儿奴,源码的眷者,观众途径序列1,杀人游戏信徒,大头菜投机者,端茶递水工程师。欢迎关注我的 博客 或者 GitHub。
如果您觉得文章对您有价值,欢迎 ❤️,或通过下方打赏功能,督促我写出更好的文章 :)
反思 系列博客是我的一种新学习方式的尝试,该系列起源和目录请参考 这里 。
对于Android开发者而言,ANR是一个老生常谈的问题,站在面试者的角度,似乎说出 「不要在主线程做耗时操作」 就算合格了。
但是,ANR机制到底是什么,其背后的原理究竟如何,为什么要设计出这样的机制?这些问题时时刻刻会萦绕脑海,而想搞清楚这些,就不得不提到Android自身的 输入系统 (Input System)。
Android自身的 输入系统 又是什么?一言以蔽之,任何与Android设备的交互——我们称之为 输入事件,都需要通过 输入系统 进行管理和分发;这其中最靠近上层,并且最典型的一个小环节就是View的 事件分发 流程。
这样看来,输入系统 本身确实是一个非常庞大复杂的命题,并且,越靠近底层细节,越容易有一种 只见树木不见树林 之感,反复几次,直至迷失在细节代码的较真中,一次学习的努力尝试付诸东流。
因此,控制住原理分析的粒度,在宏观的角度,系统地了解输入系统本身的设计理念,并引申到实际开发中的ANR现象的原理和解决思路 ,是一个非常不错的理论与实践相结合的学习方式,这也正是笔者写作本文的初衷。
本文篇幅较长,思维导图如下:
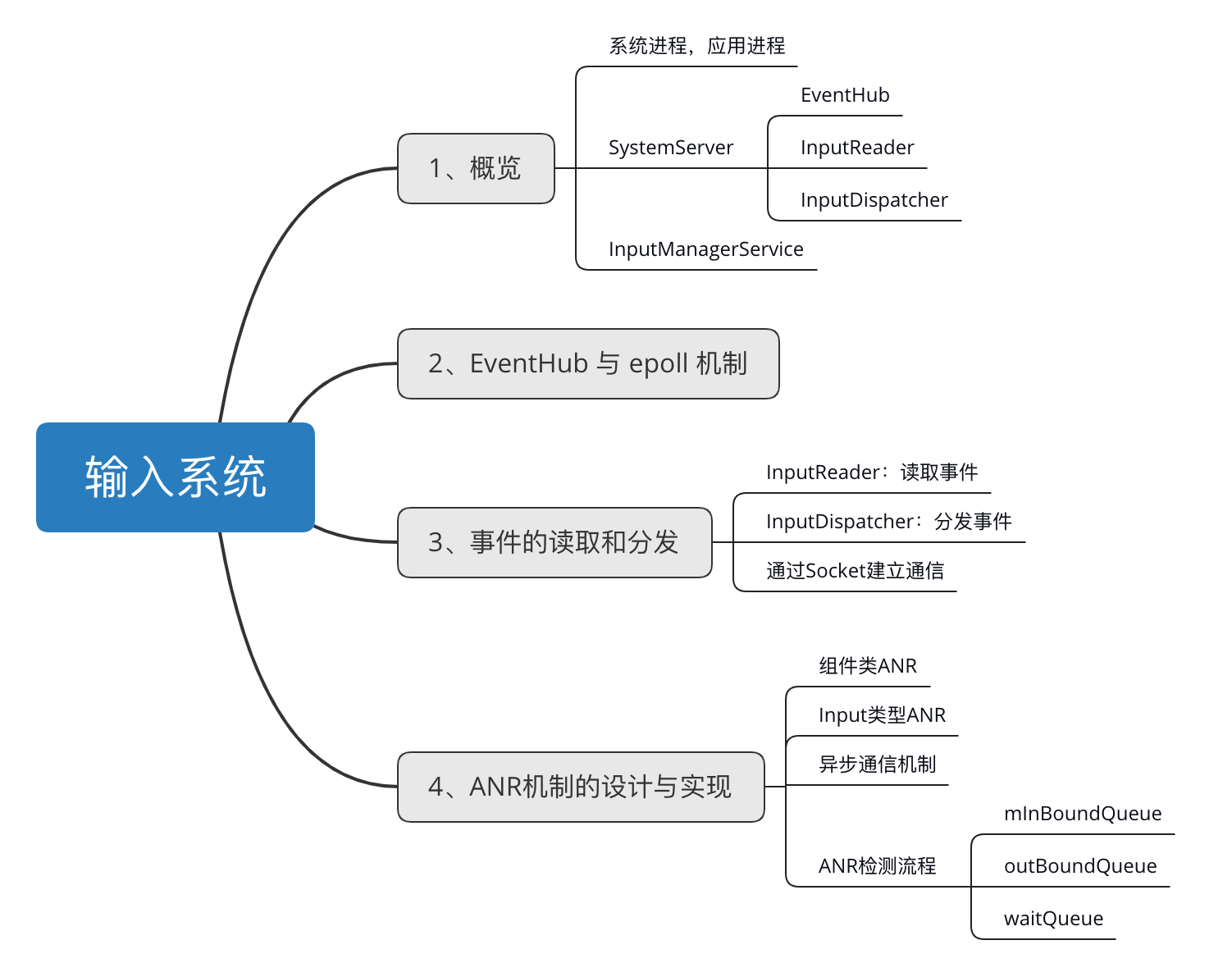
谈到Android系统本身,首先,必须将 应用进程 和 系统进程 有一个清晰的认知,前者一般代表开发者依托Android平台本身创造开发的应用;后者则代表 Android系统自身创建的核心进程。
这里我们抛开 应用进程 ,先将视线转向 系统进程,因为 输入系统 本身是由后者初始化和管理调度的。
Android系统在启动的时候,会初始化zygote进程和由zygote进程fork出来的SystemServer进程;作为 系统进程 之一,SystemServer进程会提供一系列的系统服务,而接下来要讲到的InputManagerService也正是由 SystemServer 提供的。
在SystemServer的初始化过程中,InputManagerService(下称IMS)和WindowManagerService(下称WMS)被创建出来;其中WMS本身的创建依赖IMS对象的注入:
// SystemServer.java
private void startOtherServices() {
// ...
InputManagerService inputManager = new InputManagerService(context);
// inputManager作为WindowManagerService的构造参数
WindowManagerService wm = WindowManagerService.main(context,inputManager, ...);
}在 输入系统 中,WMS非常重要,其负责管理IMS、Window与ActivityManager之间的通信,这里点到为止,后文再进行补充,我们先来看IMS。
顾名思义,IMS服务的作用就是负责输入模块在Java层级的初始化,并通过JNI调用,在Native层进行更下层输入子系统相关功能的创建和预处理。
在JNI的调用过程中,IMS创建了NativeInputManager实例,NativeInputManager则在初始化流程中又创建了EventHub和InputManager:
NativeInputManager::NativeInputManager(jobject contextObj, jobject serviceObj, const sp<Looper>& looper) : mLooper(looper), mInteractive(true) {
// ...
// 创建一个EventHub对象
sp<EventHub> eventHub = new EventHub();
// 创建一个InputManager对象
mInputManager = new InputManager(eventHub, this, this);
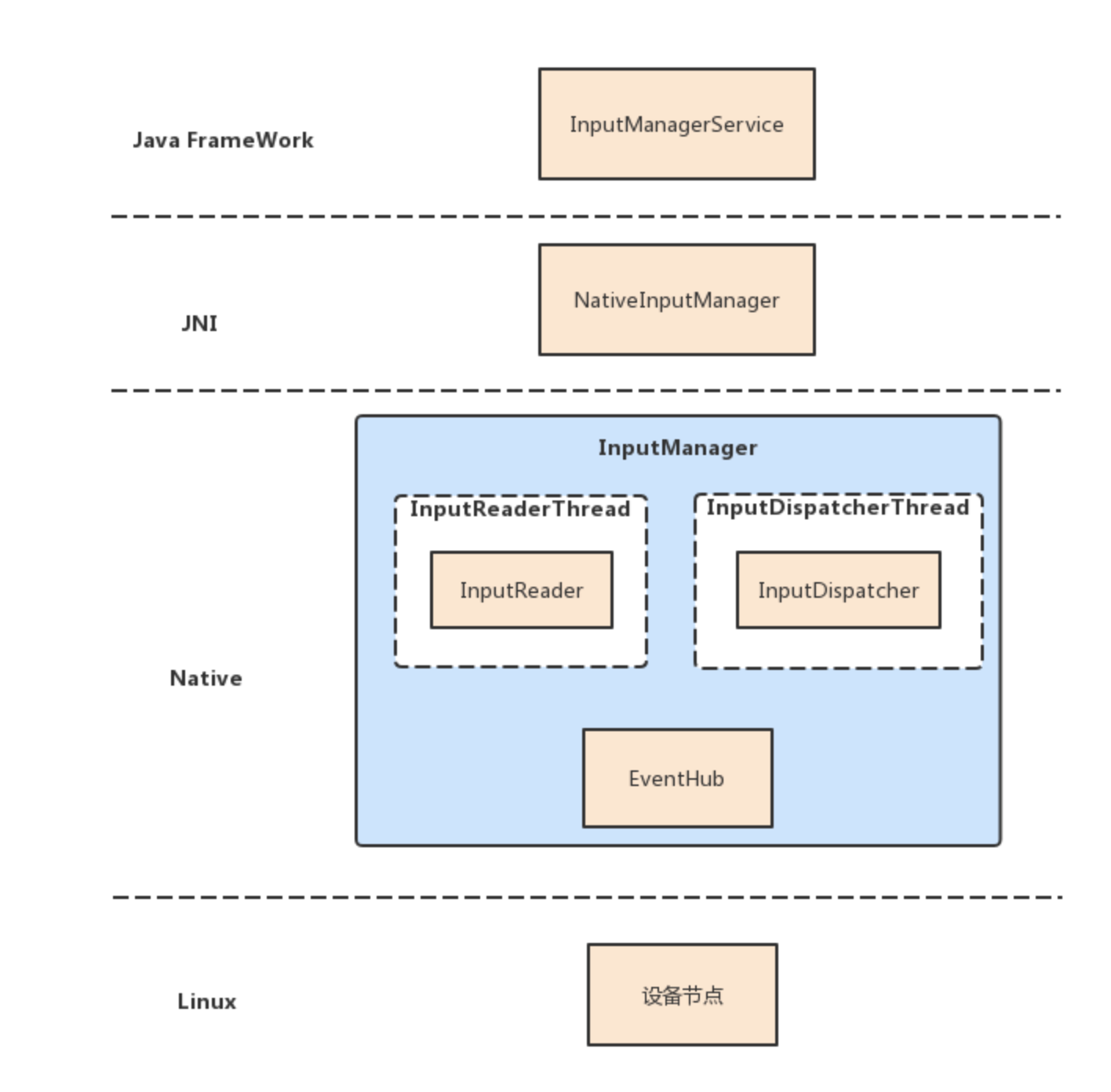
}此时我们已经处于Native层级。读者需要注意,对于整个Native层级而言,其向下负责与Linux的设备节点中获取输入,向上则与靠近用户的Java层级相通信,可以说是非常重要。而在该层级中,EventHub和InputManager又是最核心的两个角色。
这两个角色的职责又是什么呢?首先来说EventHub,它是底层 输入子系统 中的核心类,负责从物理输入设备中不断读取事件(Event),然后交给InputManager,后者内部封装了InputReader和InputDispatcher,用来从EventHub中读取事件和分发事件:
InputManager::InputManager(...) {
mDispatcher = new InputDispatcher(dispatcherPolicy);
mReader = new InputReader(eventHub, readerPolicy, mDispatcher);
initialize();
}简单来看,EventHub建立了Linux与输入设备之间的通信,InputManager中的InputReader和InputDispatcher负责了输入事件的读取和分发,在 输入系统 中,两者的确非常重要。
这里借用网上的图对此进行一个简单的概括:
对于EventHub的具体实现,绝大多数App开发者也许并不需要去花太多时间深入——简单了解其职责,然后一笔带过似乎是笔划算的买卖。
但是在EventHub的实现细节中笔者发现,其对epoll机制的利用是一个非常经典的学习案例,因此,花时间稍微深入了解也绝对是一举两得。
上文说到,EventHub建立了Linux与输入设备之间的通信,其实这种描述是不准确的,那么,EventHub是为了解决什么问题而设计的呢,其具体又是如何实现的?
我们知道,Android设备可以同时连接多个输入设备,比如 屏幕 、 键盘 、 鼠标 等等,用户在任意设备上的输入都会产生一个中断,经由Linux内核的中断处理及设备驱动转换成一个Event,最终交给用户空间的应用程序进行处理。
Linux内核提供了一个便于将不同设备不同数据接口统一转换的抽象层,只要底层输入设备驱动程序按照这层抽象接口实现,应用就可以通过统一接口访问所有输入设备,这便是Linux内核的 输入子系统。
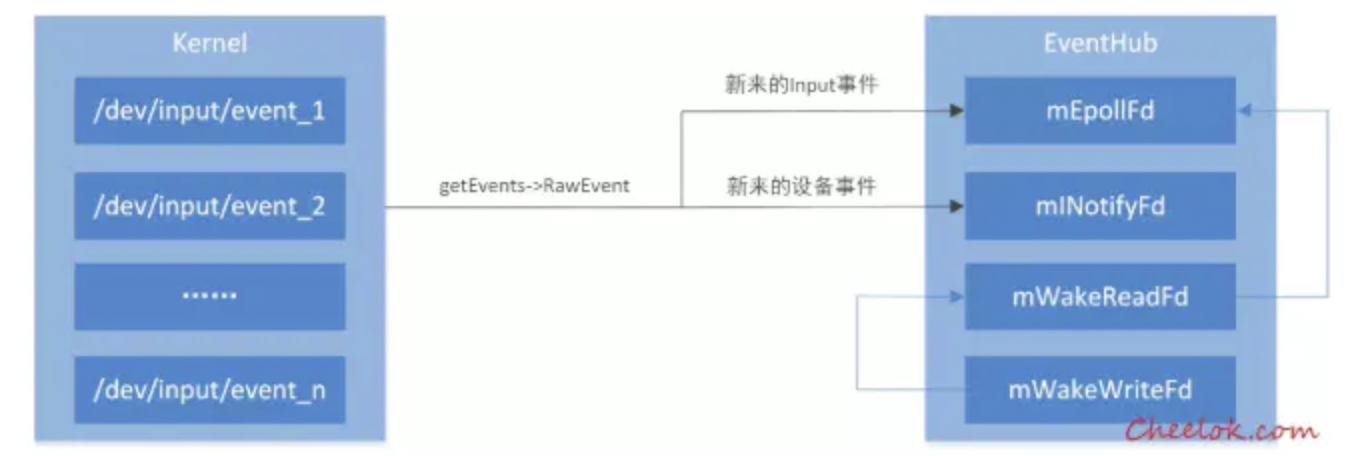
那么 输入子系统 如何是针对接收到的Event进行的处理呢?这就不得不提到EventHub了,它是底层Event处理的枢纽,其利用了epoll机制,不断接收到输入事件Event,然后将其向上层的InputReader传递。
这是常见于面试Handler相关知识点时的一道进阶题,变种问法是:「既然Handler中的Looper中通过一个死循环不断轮询,为什么程序没有因为无限死循环导致崩溃或者ANR?」
读者应该知道,Handler简单的利用了epoll机制,做到了消息队列的阻塞和唤醒。关于epoll机制,这里有一篇非常经典的解释,不了解其设计理念的读者 有必要 了解一下:
参考上文,这里我们对epoll机制进行一个简单的总结:
epoll可以理解为event poll,不同于忙轮询和无差别轮询,在 多个输入流 的情况下,epoll只会把哪个流发生了怎样的I/O事件通知我们。此时我们对这些流的操作都是有意义的。
EventHub中使用epoll的恰到好处——多个物理输入设备对应了多个不同的输入流,通过epoll机制,在EventHub初始化时,分别创建mEpollFd和mINotifyFd;前者用于监听设备节点是否有设备文件的增删,后者用于监听是否有可读事件,创建管道,让InputReader来读取事件:
本章节将对InputReader和InputDispatcher进行系统性的介绍。
InputReader是什么?简单理解InputReader的作用,通过从EventHub获取事件后,将事件进行对应的处理,然后将事件进行封装并添加到InputDispatcher的队列中,最后唤醒InputDispatcher进行下一步的事件分发。
乍得一看,在 输入系统 的Native层中,InputReader似乎平凡无奇,但越是看似朴实无华的事物,在整个流程中往往占据绝对重要的作用。
首先,EventHub传过来的Event除了普通的 输入事件 外,还包含了设备本身的增、删、扫描 等事件,这些额外的事件处理并没有直接交给InputDispatcher去分发,而是在InputReader中进行了处理。
当某个时间发生——可能是用户 按键输入,或者某个 设备插入,亦或 设备属性被调整 ,epoll_wait()返回并将Event存入。
这之后,InputReader对输入事件进行了一次读取,因为不同设备对事件的处理逻辑又各自不同,因此InputReader内部持有一系列的Mapper对事件进行 匹配 ,如果不匹配则忽略事件,反之则将Event封装成一个新的NotifyArgs数据对象,准备存入队列中,即唤醒InputDispatcher进行分发。
巧妙的是,在唤醒InputDispatcher进行分发之前,InputReader在自己的线程中先执行了一个很特殊的 拦截操作 环节。
读者知道,在应用开发中,一些特殊的输入事件是无法通过普通的方式进行拦截的;比如音量键,Power键,电话键,以及一些特殊的组合键,这里我们通称为 系统按键。
这点无可厚非,虽然Android系统对于开发者足够的开放,但是一切都是有限制的,绝大多数的 用户按键 通常可以被应用拦截处理,但是 系统按键 绝对不行——这种限制往往能够给予用户设备安全最后的保障。
因此,在InputReader唤醒InputDispatcher进行事件分发之前,InputReader在自己的线程中进行了两轮拦截处理。
首先的第一轮拦截操作就是对 系统按键 级别的 输入事件 进行处理,对于手机而言,这个工作是在PhoneWindowManager中完成;举例来说,当用户按了Power(电源)键,Android设备本身会切唤醒或睡眠——即亮屏和息屏。
这也正是「在技术论坛中,通常对 系统按键 拦截处理的技术方案,基本都是需要修改PhoneWindowManager的源码」的原因。
接下来输入事件进入到第二轮的处理中,如果用户在Setting->Accessibility中选择打开某些功能,以 手势识别 为例,Android的AccessbilityManagerService(辅助功能服务) 可能会根据需要转换成新的Event,比如说两根手指头捏动的手势最终会变成ZoomEvent。
需要注意的是,这里的拦截处理并不会真正将事件 消费 掉,而是通过特殊的方式将事件进行标记(policyFlags),然后在InputDispatcher中处理。
至此,InputReader对 输入事件 完整的一轮处理到此结束,这之后,InputReader又进入了新一轮等待。
当wake()函数将在Looper中睡眠等待的InputDispatcher唤醒时,InputDispatcher开始新一轮事件的分发。
准确来说,
InputDispatcher被唤醒时,wake()函数实际是在InputManagerService的线程中执行的,即整个流程的线程切换顺序为InputReaderThread->InputManagerServiceThread->InputDispatcherThread。
InputDispatcher的线程负责将接收到的 输入事件 分发给 目标应用窗口,在这个过程中,InputDispatcher首先需要对上个环节中标记了需要拦截的 系统按键 相关事件进行拦截,被拦截的事件至此不再向下分发。
这之后,InputDispatcher进入了本文最关键的一个环节——调用 findFocusedWindowTargetLocked()获取当前的 焦点窗口 ,同时检测目标应用是否有ANR发生。
如果检测到目标窗口处于正常状态,即ANR并未发生时,InputDispatcher进入真正的分发程序,将事件对象进行新一轮的封装,通过SocketPair唤醒目标窗口所在进程的Looper线程,即我们应用进程中的主线程,后者会读取相应的键值并进行处理。
表面来看,整个分发流程似乎干净简洁且便于理解,但实际上InputDispatcher整个流程的逻辑十分复杂,试想一次事件分发要横跨3个线程的流程又怎会简单?
此外,InputDispatcher还负责了 ANR 的处理,这又导致整个流程的复杂度又上升了一个层级,这个流程我们在后文的ANR章节中进行更细致的分析,因此先按住不提。
接下来,我们来看看整个 输入事件 的分发流程中, 应用进程 是如何与 系统进程 建立相应的通信链接的。
关于 跨进程通信的建立 这一节,笔者最初打算作为一个大的章节来讲,但是对于整个 输入系统 而言,其似乎又只是一个 重要非必需 的知识点。最终,笔者将其放在一个小节中进行简单的描述,有兴趣的读者可以在文末的参考链接中查阅更详尽的资料。
我们知道,InputReader和InputDispatcher运行在system_server 系统进程 中,而用户操作的应用都运行在自己的 应用进程 中;这里就涉及到跨进程通信,那么 应用进程 是如何与 系统进程 建立通信的呢?
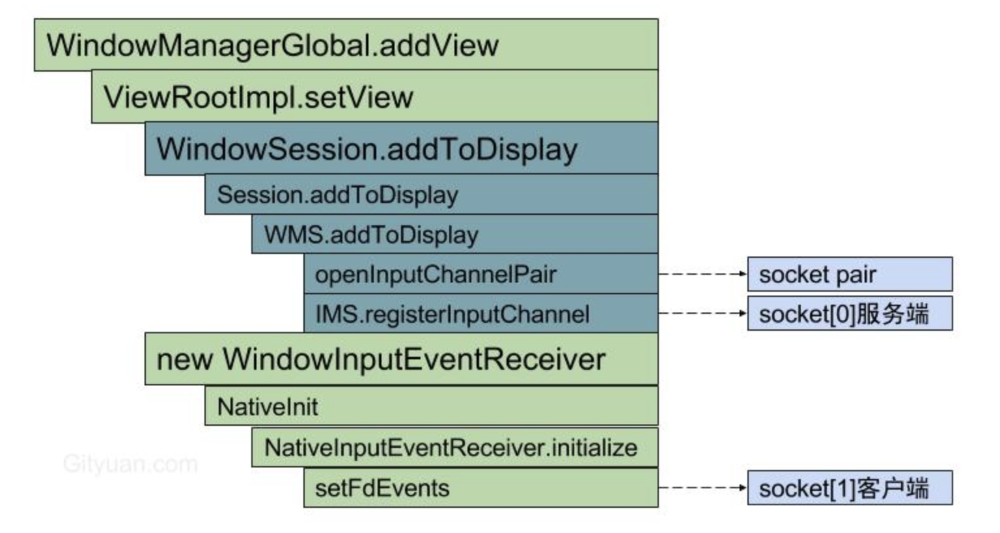
让我们回到文章最初WindowManagerService(WMS)和InputManagerService(IMS)初始化的流程中来,当IMS以及其他的系统服务初始化完成之后,应用程序开始启动。
如果一个应用程序有Activity(只有Activity能够接受用户输入),那么它要将自己的Window注册到WMS中。
在这里,Android使用了Socket而不是Binder来完成。WMS中通过OpenInputChannelPair生成了两个Socket的FD, 代表一个双向通道的两端:向一端写入数据,另外一端便可以读出;反之,如果一端没有写入数据,另外一端去读,则陷入阻塞等待。
最终InputDispatcher中建立了目标应用的Connection对象,代表与远端应用的窗口建立了链接;同样,应用进程中的ViewRootImpl创建了WindowInputEventReceiver用于接受InputDispatchor传过来的事件:
这里我们对该次 跨进程通信建立流程 有了初步的认知,对于Android系统而言,Binder是最广泛的跨进程通信的应用方式,但是Android系中跨进程通信就仅仅只用到了Binder吗?答案是否定的,至少在 输入系统 中,除了Binder之外,Socket同样起到了举足轻重的作用。
那么新的问题就来了,这里为什么选择Socket而不是选择Binder呢,关于这个问题的解释,笔者找到了一个很好的版本:
Socket可以实现异步的通知,且只需要两个线程参与(Pipe两端各一个),假设系统有N个应用程序,跟输入处理相关的线程数目是N+1(1是Input Dispatcher线程)。然而,如果用Binder实现的话,为了实现异步接收,每个应用程序需要两个线程,一个Binder线程,一个后台处理线程(不能在Binder线程里处理输入,因为这样太耗时,将会堵塞住发送端的调用线程)。在发送端,同样需要两个线程,一个发送线程,一个接收线程来接收应用的完成通知,所以,N个应用程序需要2(N+1)个线程。相比之下,Socket还是高效多了。
现在,应用进程 能够收到由InputDispatcher处理完成并分发过来的 输入事件 了。至此,我们来到了最熟悉的应用层级事件分发流程。对于这之后 应用层级的事件分发,可以阅读下述笔者的另外两篇文章,本文不赘述。
原文:REACTIVE APPS WITH MODEL-VIEW-INTENT - PART3 - STATE REDUCER
作者:Hannes Dorfmann
译者:却把清梅嗅
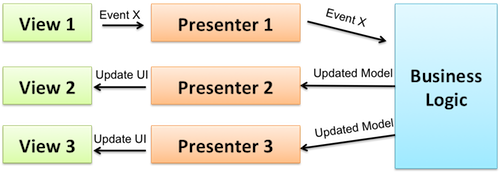
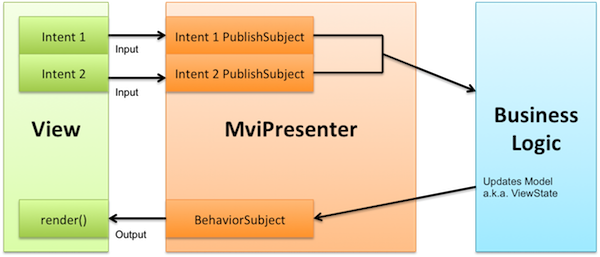
在上一章节中,我们针对 如何使用单向流和 Model-View-Intent 模式构建一个简单的页面 进行了探讨;本章节,我们将在reducer的帮助下实现MVI模式中更加复杂的页面。
如果你还未阅读前两个章节,阅读本文之前您应该先去阅读它们,从而对如下两个问题的答案有初步的了解:
Presenter将View层和业务逻辑相关联?如下图所示,现在我们构建这样一个复杂的页面:
如你所见,屏幕中显示的是按照类别进行归类的商品列表;App每次只会为每个分类展示3个条目,当用户点击了 加载更多 按钮时,将会通过网络请求去加载该分类下所有的条目。
此外,用户还可以执行 下拉刷新 的操作,并且一旦用户向下滚动到列表末尾,分页功能就会继续加载下一页的数据——当然,所有这些行为可以同时执行,并且每个行为都可能会收到失败(即没有互联网连接)。
让我们一步步来,首先,我们先对View层的接口进行实现:
public interface HomeView {
/**
* 加载第一页数据的intent
*
* @return 发射的数据是没有意义的,true或者false没有区别
*/
public Observable<Boolean> loadFirstPageIntent();
/**
* 分页加载下一页的intent
*
* @return 发射的数据是没有意义的,true或者false没有区别
*/
public Observable<Boolean> loadNextPageIntent();
/**
* 对下拉刷新的响应intent
*
* @return 发射的数据是没有意义的,true或者false没有区别
*/
public Observable<Boolean> pullToRefreshIntent();
/**
* 根据当前分类加载所有条目的intent
*
* @return 指定分类,String代表分类的名字
*/
public Observable<String> loadAllProductsFromCategoryIntent();
/**
* 对ViewState进行渲染
*/
public void render(HomeViewState viewState);
}View层具体的实现简单明了,本文将不进行展示(但你可以在Github上找到它)。
接下来让我们把目光转向Model,正如前文所提到的,Model应该反应了状态,现在我来介绍一下Model的具体实现:HomeViewState。
public final class HomeViewState {
private final boolean loadingFirstPage; // RecyclerView加载状态的指示器
private final Throwable firstPageError; // 如果非空,展示一个error
private final List<FeedItem> data; // 列表的数据
private final boolean loadingNextPage; // RecyclerView分页加载状态的指示器
private final Throwable nextPageError; // 如果非空,展示分页error的toast
private final boolean loadingPullToRefresh; // 展示下拉刷新状态的指示器
private final Throwable pullToRefreshError; // 非空意味着下拉刷新的error
// ... 构造器 ...
// ... getter方法 ...
}请注意,FeedItem 仅仅是一个接口,每个条目都需要实现该接口,然后交给RecyclerView去展示。比如 Product 实现了 FeedItem;此外,列表中的类别标题 SectionHeader 也实现了 FeedItem;还有,作为UI中的元素之一,表示 “可以加载该类别更多” 的指示器同样也是 FeedItem,其内部还持有了一个小状态——该状态代表了当前是否 正在加载更多条目 。
public class AdditionalItemsLoadable implements FeedItem {
private final int moreItemsAvailableCount;
private final String categoryName;
private final boolean loading; // true 代表item正处于加载状态
private final Throwable loadingError; // 标志loading时捕获到了error
// ... 构造器 ...
// ... getter方法 ...这之后便是压轴的业务逻辑组件 HomeFeedLoader ,它负责对 FeedItems 进行加载:
public class HomeFeedLoader {
// 通常由 下拉刷新 动作触发
public Observable<List<FeedItem>> loadNewestPage() { ... }
// 加载第一页
public Observable<List<FeedItem>> loadFirstPage() { ... }
// 加载下一页
public Observable<List<FeedItem>> loadNextPage() { ... }
// 加载某个分类的其它产品
public Observable<List<Product>> loadProductsOfCategory(String categoryName) { ... }
}现在,让我们一步步将这些点在Presenter中进行连接。请注意,接下来Presenter中展示的部分代码,在真实的开发中,应该被转移到Interactor(交互器)中(这并非是为了更好的可读性)。首先,我们先开始对初始化数据进行加载:
class HomePresenter extends MviBasePresenter<HomeView, HomeViewState> {
private final HomeFeedLoader feedLoader;
@Override protected void bindIntents() {
// 在真实的开发中,应该被转移到Interactor中
Observable<HomeViewState> loadFirstPage = intent(HomeView::loadFirstPageIntent)
.flatMap(ignored -> feedLoader.loadFirstPage()
.map(items -> new HomeViewState(items, false, null) )
.startWith(new HomeViewState(emptyList, true, null) )
.onErrorReturn(error -> new HomeViewState(emptyList, false, error))
subscribeViewState(loadFirstPage, HomeView::render);
}
}到目前为止感觉良好,和上一章节我们实现的Search界面相比,没有什么太大的不同。
现在我们尝试添加对 下拉刷新 的支持:、
class HomePresenter extends MviBasePresenter<HomeView, HomeViewState> {
private final HomeFeedLoader feedLoader;
@Override protected void bindIntents() {
// 在真实的开发中,应该被转移到Interactor中
Observable<HomeViewState> loadFirstPage = ... ;
Observable<HomeViewState> pullToRefresh = intent(HomeView::pullToRefreshIntent)
.flatMap(ignored -> feedLoader.loadNewestPage()
.map( items -> new HomeViewState(...))
.startWith(new HomeViewState(...))
.onErrorReturn(error -> new HomeViewState(...)));
Observable<HomeViewState> allIntents = Observable.merge(loadFirstPage, pullToRefresh);
subscribeViewState(allIntents, HomeView::render);
}
}稍微等一下:feedLoader.loadNewestPage() 仅仅返回了新的条目数据,但是之前我们已经加载了的条目怎么办?
“传统”的MVP模式中,我们可以调用类似view.addNewItems(newItems)的方法,但是在 第一篇文章 中,我们已经探讨了为什么这不是一个好主意(状态问题)。
我们当前面临的问题是,下拉刷新依赖了之前的状态,因为我们想要将下拉刷新返回的条目和之前已经加载的条目进行 合并。
女士们,先生们,现在,让我们热情地欢迎状态折叠器(State Reducer)的到来!
State Reducer是函数式编程中的一个概念,它 将前一个状态作为输入,并根据前一个状态计算得出一个新的状态,就像这样:
public State reduce( State previous, Foo foo ){
State newState;
// ... 根据前一个状态计算得出一个新的状态 ...
return newState;
}因此上述问题的解决方案是,我们定义一个Foo组件,通过其类似reduce()的函数,结合之前的状态计算出一个新的状态。
这个名为Foo的组件通常意味着我们希望对之前状态所进行的改变,在我们的案例中,我们希望将 最初通过loadFirstPageIntent计算得到的HomeViewState 和 下拉刷新得到的结果 进行reduce。
你猜怎么着,RxJava有一个名为 scan() 的操作符,让我们对我们的代码进行略微的重构,我们需要引入另外一个表示 部分改变 的类—— 上面我们将其称之为Foo,它将用于计算新的状态。
class HomePresenter extends MviBasePresenter<HomeView, HomeViewState> {
private final HomeFeedLoader feedLoader;
@Override protected void bindIntents() {
Observable<PartialState> loadFirstPage = intent(HomeView::loadFirstPageIntent)
.flatMap(ignored -> feedLoader.loadFirstPage()
.map(items -> new PartialState.FirstPageData(items) )
.startWith(new PartialState.FirstPageLoading(true) )
.onErrorReturn(error -> new PartialState.FirstPageError(error))
Observable<PartialState> pullToRefresh = intent(HomeView::pullToRefreshIntent)
.flatMap(ignored -> feedLoader.loadNewestPage()
.map( items -> new PartialState.PullToRefreshData(items)
.startWith(new PartialState.PullToRefreshLoading(true)))
.onErrorReturn(error -> new PartialState.PullToRefreshError(error)));
Observable<PartialState> allIntents = Observable.merge(loadFirstPage, pullToRefresh);
// 展示第一页数据加载中...
HomeViewState initialState = ... ;
Observable<HomeViewState> stateObservable = allIntents.scan(initialState, this::viewStateReducer)
subscribeViewState(stateObservable, HomeView::render);
}
private HomeViewState viewStateReducer(HomeViewState previousState, PartialState changes){
...
}
}我们在这里做了什么?相比较直接返回Observable<HomeViewState>,现在每个Intent返回的是Observable<PartialState>。这之后我们通过merge()操作符将其全部合并为一个可观察的流中,并最终应用到了reducer的函数中(即Observable.scan())。
这意味着,无论何时用户发起了一个intent,这个intent将会生产一个PartialState的实例,然后被reduced得到了HomeViewState,最终,被View层进行展示(HomeView.render(HomeViewState))。
唯一遗漏的部分应该就是state reducer的函数本身了,如上文中的定义一样,HomeViewState类本身并未发生了改变,但是我们通过Builder模式添加了一个Builder,这样我们就可以非常便捷地创建一个新的HomeViewState实例。
现在让我们开始实现state reducer的函数:
private HomeViewState viewStateReducer(HomeViewState previousState, PartialState changes){
if (changes instanceof PartialState.FirstPageLoading)
return previousState.toBuilder() // 根据当前状态复制一个内部同样状态的对象
.firstPageLoading(true) // 展示progressBar
.firstPageError(null) // 不展示error
.build()
if (changes instanceof PartialState.FirstPageError)
return previousState.builder()
.firstPageLoading(false) // 隐藏progressBar
.firstPageError(((PartialState.FirstPageError) changes).getError()) // 展示error
.build();
if (changes instanceof PartialState.FirstPageLoaded)
return previousState.builder()
.firstPageLoading(false)
.firstPageError(null)
.data(((PartialState.FirstPageLoaded) changes).getData())
.build();
if (changes instanceof PartialState.PullToRefreshLoading)
return previousState.builder()
.pullToRefreshLoading(true) // 展示下拉刷新的UI指示器
.nextPageError(null)
.build();
if (changes instanceof PartialState.PullToRefreshError)
return previousState.builder()
.pullToRefreshLoading(false) // 隐藏下拉刷新的UI指示器
.pullToRefreshError(((PartialState.PullToRefreshError) changes).getError())
.build();
if (changes instanceof PartialState.PullToRefreshData) {
List<FeedItem> data = new ArrayList<>();
data.addAll(((PullToRefreshData) changes).getData()); // 将新的数据插入到当前列表的顶部
data.addAll(previousState.getData());
return previousState.builder()
.pullToRefreshLoading(false)
.pullToRefreshError(null)
.data(data)
.build();
}
throw new IllegalStateException("Don't know how to reduce the partial state " + changes);
}我知道,这些代码看起来并不优雅,但这不是本文的重点——为什么博主会在他的文章中展示如此 “丑陋” 的代码?
因为我希望能够阐述一个观点,我认为 读者并不应该为源码中错综复杂的逻辑买单 ,比如,我们的购物车App中,也不需要读者对某些设计模式有额外的知识储备。
因此,我认为博客文章中最好避免出现设计模式,这的确会展示出更好的代码,但其本身就意味着 更高的阅读理解成本。
回顾本文,其重点是对State Reducer进行配置,通过上述的代码,大家都能够更快更准确地去了解它是什么。但你会在实际开发中这样编写代码吗?当然不会,我会去使用设计模式或者其它的解决方案,比如使用 public HomeViewState computeNewState(previousState) 之类的方法将PartialState定义为接口。
好吧,我想你已经了解了State Reducer是如何工作的,让我们实现剩下来的功能:分页以及能够加载某个指定分类更多的Item:
class HomePresenter extends MviBasePresenter<HomeView, HomeViewState> {
private final HomeFeedLoader feedLoader;
@Override protected void bindIntents() {
Observable<PartialState> loadFirstPage = ... ;
Observable<PartialState> pullToRefresh = ... ;
Observable<PartialState> nextPage =
intent(HomeView::loadNextPageIntent)
.flatMap(ignored -> feedLoader.loadNextPage()
.map(items -> new PartialState.NextPageLoaded(items))
.startWith(new PartialState.NextPageLoading())
.onErrorReturn(PartialState.NexPageLoadingError::new));
Observable<PartialState> loadMoreFromCategory =
intent(HomeView::loadAllProductsFromCategoryIntent)
.flatMap(categoryName -> feedLoader.loadProductsOfCategory(categoryName)
.map( products -> new PartialState.ProductsOfCategoryLoaded(categoryName, products))
.startWith(new PartialState.ProductsOfCategoryLoading(categoryName))
.onErrorReturn(error -> new PartialState.ProductsOfCategoryError(categoryName, error)));
Observable<PartialState> allIntents = Observable.merge(loadFirstPage, pullToRefresh, nextPage, loadMoreFromCategory);
// 展示第一页正在加载
HomeViewState initialState = ... ;
Observable<HomeViewState> stateObservable = allIntents.scan(initialState, this::viewStateReducer)
subscribeViewState(stateObservable, HomeView::render);
}
private HomeViewState viewStateReducer(HomeViewState previousState, PartialState changes){
// ... 第一页的部分状态处理和下拉刷新 ...
if (changes instanceof PartialState.NextPageLoading) {
return previousState.builder().nextPageLoading(true).nextPageError(null).build();
}
if (changes instanceof PartialState.NexPageLoadingError)
return previousState.builder()
.nextPageLoading(false)
.nextPageError(((PartialState.NexPageLoadingError) changes).getError())
.build();
if (changes instanceof PartialState.NextPageLoaded) {
List<FeedItem> data = new ArrayList<>();
data.addAll(previousState.getData());
// 将新的数据添加到list的尾部
data.addAll(((PartialState.NextPageLoaded) changes).getData());
return previousState.builder().nextPageLoading(false).nextPageError(null).data(data).build();
}
if (changes instanceof PartialState.ProductsOfCategoryLoading) {
int indexLoadMoreItem = findAdditionalItems(categoryName, previousState.getData());
AdditionalItemsLoadable ail = (AdditionalItemsLoadable) previousState.getData().get(indexLoadMoreItem);
AdditionalItemsLoadable itemsThatIndicatesError = ail.builder() // 创建所有item的副本
.loading(true).error(null).build();
List<FeedItem> data = new ArrayList<>();
data.addAll(previousState.getData());
data.set(indexLoadMoreItem, itemsThatIndicatesError); // 这将会展示一个loading的指示器
return previousState.builder().data(data).build();
}
if (changes instanceof PartialState.ProductsOfCategoryLoadingError) {
int indexLoadMoreItem = findAdditionalItems(categoryName, previousState.getData());
AdditionalItemsLoadable ail = (AdditionalItemsLoadable) previousState.getData().get(indexLoadMoreItem);
AdditionalItemsLoadable itemsThatIndicatesError = ail.builder().loading(false).error( ((ProductsOfCategoryLoadingError)changes).getError()).build();
List<FeedItem> data = new ArrayList<>();
data.addAll(previousState.getData());
data.set(indexLoadMoreItem, itemsThatIndicatesError); // 这将会展示一个error和重试的button
return previousState.builder().data(data).build();
}
if (changes instanceof PartialState.ProductsOfCategoryLoaded) {
String categoryName = (ProductsOfCategoryLoaded) changes.getCategoryName();
int indexLoadMoreItem = findAdditionalItems(categoryName, previousState.getData());
int indexOfSectionHeader = findSectionHeader(categoryName, previousState.getData());
List<FeedItem> data = new ArrayList<>();
data.addAll(previousState.getData());
removeItems(data, indexOfSectionHeader, indexLoadMoreItem); // 移除指定分类下的所有item
// 添加指定分类下的所有item (包括之前已经被移除的)
data.addAll(indexOfSectionHeader + 1,((ProductsOfCategoryLoaded) changes).getData());
return previousState.builder().data(data).build();
}
throw new IllegalStateException("Don't know how to reduce the partial state " + changes);
}
}实现分页加载和下拉刷新十分相似,异同之处仅仅在于前者是把加载到的数据添加在列表末尾,而下拉刷新则是把数据展示在界面顶部。
更有趣的是我们如何针对某个类别去加载更多条目:为了展示某个类别的加载指示器和错误/重试的按钮,我们只需在所有的FeedItems列表中找到对应的AdditionalItemsLoadable对象,然后我们将其改变为展示加载指示器或者错误/重试的按钮。
如果我们已成功加载某个类别的所有条目,我们将搜索SectionHeader和AdditionalItemsLoadable,并用新加载的列表替换这里的所有条目,仅此而已。
本文的目的是向您展示 状态折叠器(State Reducer) 如何帮助我们通过 简洁且易读 的代码构建复杂的页面。现在回过头来思考,“传统”的MVP或者MVVM针对这些功能,在不使用State Reducer的前提下是如何实现这些功能的。
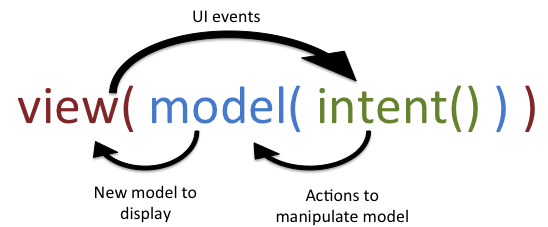
显然,能够使用State Reducer的关键是我们有一个反映状态的Model类,这也印证了该系列的第一篇文章中所阐述的,为什么理解 Model 是那么的重要。
此外,只有当我们确定状态(或准确的Model)来自单一的数据源时,才能使用State Reducer,因此单向数据流同样非常重要。
我希望我们花费在 阅读 并 理解 前两篇博客的时间是有意义的,现在,所有的点都成功的连在了一起,是时候欢呼了。
如果还没有,不用担心,对此我也花了相当长的时间才完全理解——还有很多次练习、错误和重试。
在第二篇博客中,针对搜索界面,我们并未使用State Reducer。这是因为如果我们以某种方式依赖于先前的状态,State Reducer是有意义的。而在“搜索界面”中,我们不依赖于先前的状态。
虽然在最后,但是我还是想重申,也许你还没有注意到,那就是我们的data都是不可变的——我们总是创建HomeViewState新的实例,而不是在已有的对象上调用其setter方法,这也使得多线程不再是问题。
用户可以在加载下一页的同时开始下拉刷新并加载某个类别的更多条目,因为State Reducer总是能够产生正确的状态,却不依赖于http响应的任何特定顺序。另外,我们用纯函数编写了代码,没有任何副作用。这使我们的代码非常具有可测试性、可重现性、易于推演和高度可并行化(即多线程)。
当然,State Reducer并非是MVI发明的,您可以在多种编程语言的许多三方库,框架和系统中找到其概念。它完全符合Model-View-Intent的理念,具有单向的数据流和表示状态的Model。
在下一个部分中,我们将聚焦于如何通过MVI 构建 可复用 和 响应式 的UI组件,敬请关注。
《使用MVI打造响应式APP》原文
《使用MVI打造响应式APP》译文
《使用MVI打造响应式APP》实战
Hello,我是却把清梅嗅,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的博客或者Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
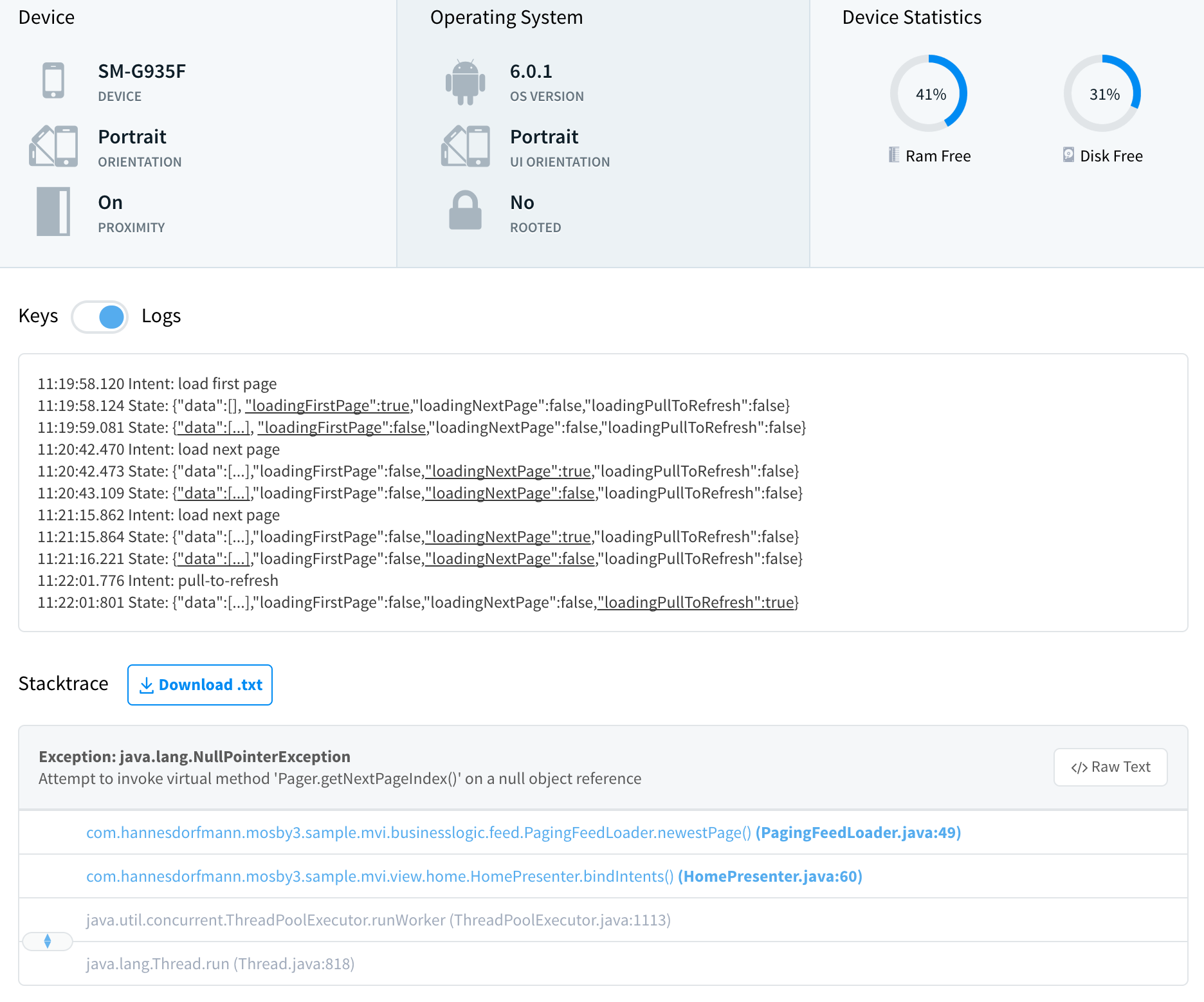
本文是Android Jetpack Paging系列的第二篇文章;强烈建议 读者将本系列作为学习Paging 阅读优先级最高的文章,如果读者对Paging还没有系统性的认识,请参考:
Paging是一个非常优秀的分页组件,与其它热门的分页相关库不同的是,Paging更偏向注重服务于 业务 而非 UI 。——我们都知道业务类型的开源库的质量非常依赖代码 整体的架构设计(比如Retofit和OkHttp);那么,如何说服自己或者同事去尝试使用Paging?显然源码中蕴含的优秀**更具有说服力。
反过来说,若从Google工程师们设计、研发和维护的源码中有所借鉴,即使不在项目中真正使用它,自己依然能受益匪浅。
本文章节如下:
创建流程毫无疑问是架构设计中最重要的环节。
作为组件的门板,向外暴露的API对于开发者越简单友善方便调用越好,同时,作为API调用者的我们也希望框架越灵活,可配置选项越多越好。
这听起来似乎有点违反常理—— 如何才能保证既保证 简单干净的接口设计 易于开发者上手,同时又有 足够多的可配置项 保证框架的灵活呢?
Paging的API设计中使用了经典的 建造者(Builder)模式,并通过依赖注入将依赖一层层向下传递,最终依次构建了各个层级的对象实例。
对于开发者而言,只需要配置自己关心的参数,而不关心(甚至可以是不知道)的参数配置,全交给Builder类使用默认参数:
// 你可以这样复杂地配置
val pagedListLiveData =
LivePagedListBuilder(
dataSourceFactory,
PagedList.Config.Builder()
.setPageSize(PAGE_SIZE) // 分页加载的数量
.setInitialLoadSizeHint(20) // 初始化加载的数量
.setPrefetchDistance(10) // 预加载距离
.setEnablePlaceholders(ENABLE_PLACEHOLDERS) // 是否启用占位符
.build()
).build()
// 也可以这样简单地配置
val pagedListLiveData =
LivePagedListBuilder(dataSourceFactory, PAGE_SIZE).build()需要注意的是,分页相关功能配置对象的构建 和 可观察者对象的构建 是否是两个不同的职责?显然是有必要的,因为:
LiveData<PagedList>=DataSource+PagedList.Config(即 分页数据的可观察者 = 数据源 + 分页配置)
因此,这里Paging的配置使用到了2个Builder类,即使是决定使用 建造者模式 ,设计者也需要对Builder类的定义有一个清晰的认知,这里也是设计过程中 单一职责原则 的优秀体现。
最终,Builder中的所有配置都通过依赖注入的方式对PagedList进行了实例化:
// PagedList.Builder.build()
public PagedList<Value> build() {
return PagedList.create(
mDataSource,
mNotifyExecutor,
mFetchExecutor,
mBoundaryCallback,
mConfig,
mInitialKey);
}
// PagedList.create()
static <K, T> PagedList<T> create(@NonNull DataSource<K, T> dataSource,
@NonNull Executor notifyExecutor,
@NonNull Executor fetchExecutor,
@Nullable BoundaryCallback<T> boundaryCallback,
@NonNull Config config,
@Nullable K key) {
// 这里我们仅以ContiguousPagedList为例
// 可以看到,所有PagedList都是将构造函数的依赖注入进行的实例化
return new ContiguousPagedList<>(contigDataSource,
notifyExecutor,
fetchExecutor,
boundaryCallback,
config,
key,
lastLoad);
}依赖注入 是一个非常简单而又朴实的编码技巧,Paging的设计中,几乎没有用到单例模式,也几乎没有太多的静态成员——所有对象中除了自身的状态,其它所有通过依赖注入的配置项都是 final (不可变)的:
// PagedList.java
public abstract class PagedList<T> {
final Executor mMainThreadExecutor;
final Executor mBackgroundThreadExecutor;
final BoundaryCallback<T> mBoundaryCallback;
final Config mConfig;
final PagedStorage<T> mStorage;
}
// ItemKeyedDataSource.LoadInitialParams.java
public static class LoadInitialParams<Key> {
public final Key requestedInitialKey;
public final int requestedLoadSize;
public final boolean placeholdersEnabled;
}上文说到 几乎没有用到单例模式,实际上线程切换的设计有些许例外,但其本身依然可以通过
Builder进行依赖注入以覆盖默认的线程获取逻辑。
通过 依赖注入 保证了对象的实例所需依赖有迹可循,类与类之间的依赖关系非常清晰,而实例化的对象内部 成员的不可变 也极大保证了PagedList分页数据的线程安全。
对于被观察者而言,只有当真正被订阅的时候,其数据的更新才有意义。换句话说,当开发者构建出一个LiveData<PagedList>时候,这时立即通过后台线程开始异步请求分页数据是没有意义的。
反过来理解,若没有订阅就请求数据,当真正订阅的时候,
DataSource中的数据已经过时了,这时还需要重新请求拉取最新数据,这样之前的一系列行为就没有意义了。
真正的请求应该放在LiveData.observe()的时候,即被订阅时才去执行,笔者这里更偏向于称其为“懒加载”——如果读者对RxJava比较熟悉的话,会发现这和Observable.defer()操作符概念比较相似:
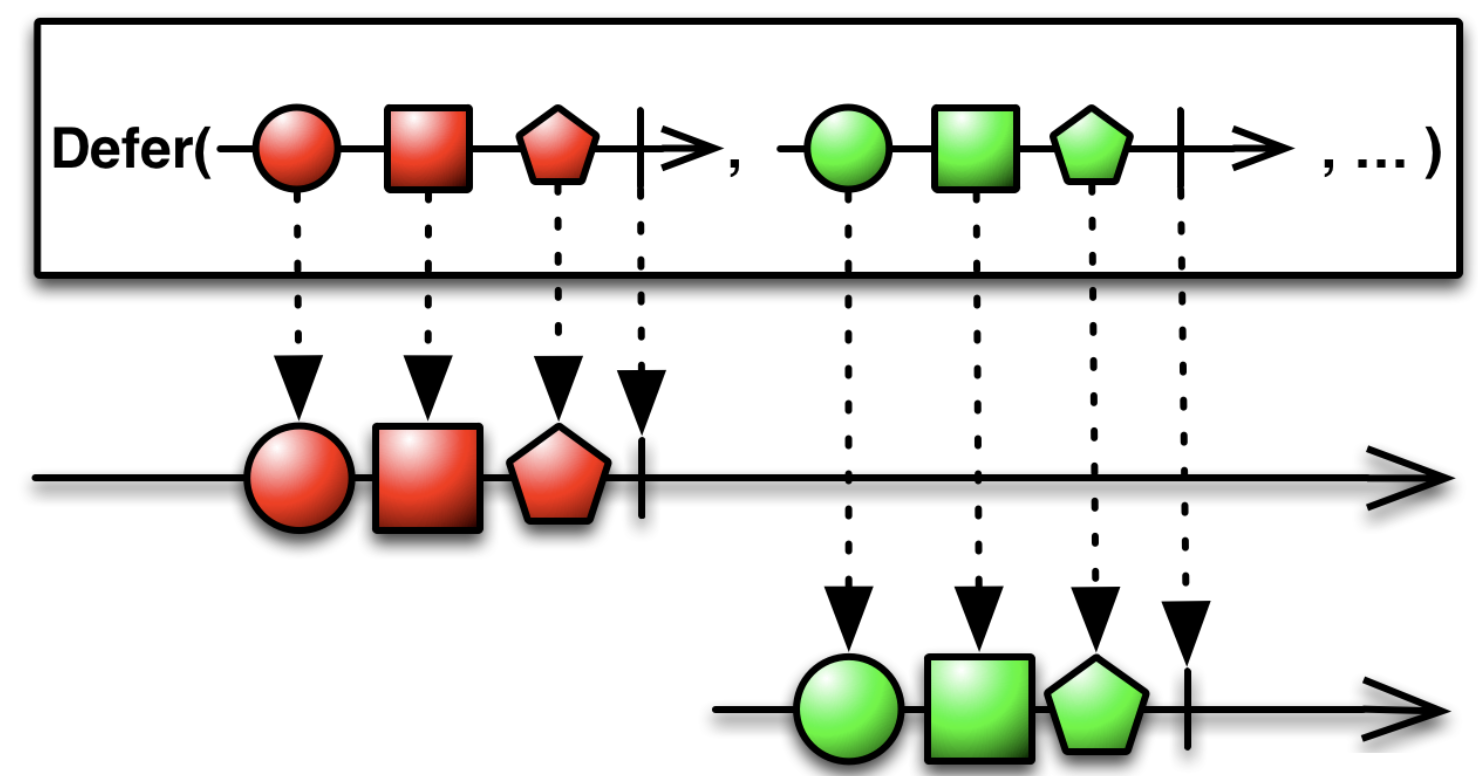
那么,如何构建“懒加载”的LiveData<PagedList>呢?Google的设计者使用了ComputableLiveData类对LiveData的数据发射行为进行了包装:
// @hide
public abstract class ComputableLiveData<T> {}
这是一个隐藏的类,开发者一般不能直接使用它,但它被应用的地方可不少,Room组件生成的源码中也经常可以看到它的身影。
用一句话描述ComputableLiveData的定义,笔者觉得 LiveData的数据源 比较适合,感兴趣的读者可以仔细研究一下它的源码,笔者有机会会为它单独开一篇文章,这里不继续展开。
总之,通过ComputableLiveData类,Paging实现了订阅时才执行异步任务的功能,更大程度上减少了做无用功的情况。
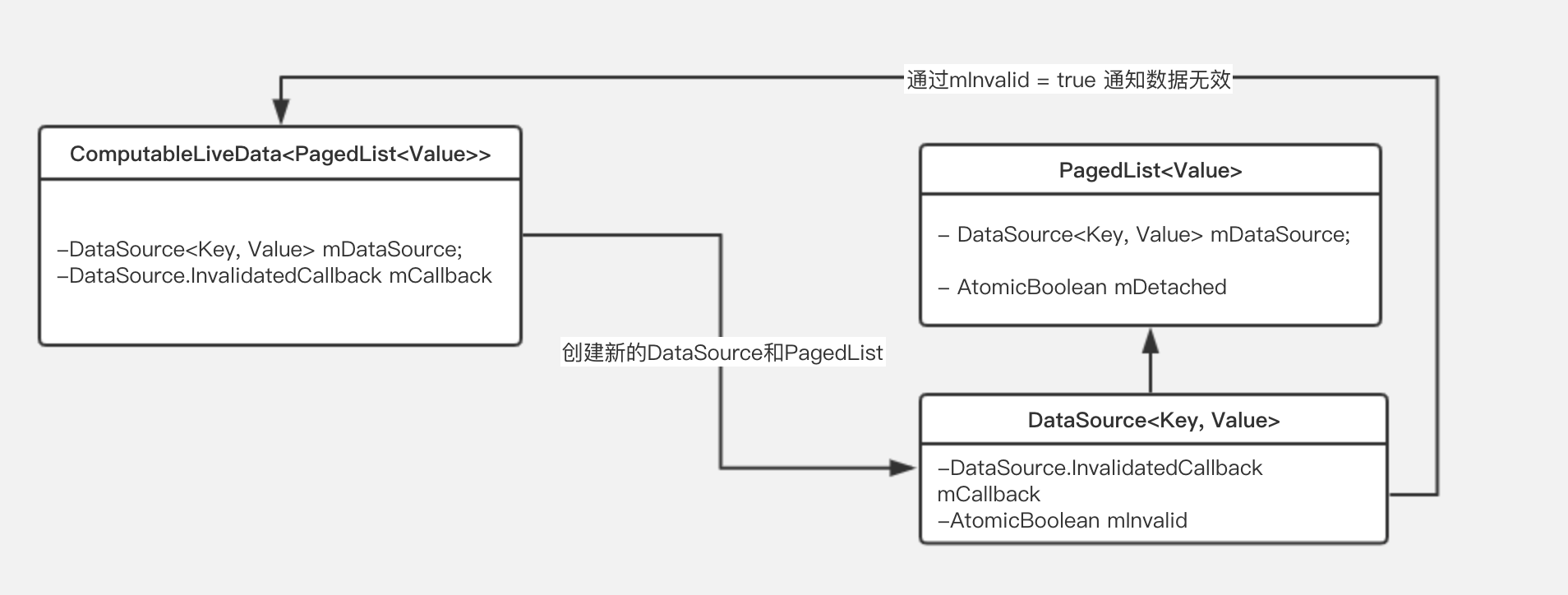
分页数据PagedList理应也有属于自己的生命周期。
正常的生命周期内,PagedList不断从DataSource中尝试加载分页数据,并展示出来;但数据源中的数据总有过期失效的时候,这意味着PagedList生命周期走到了尽头。
Paging需要响应式地创建一个新的DataSource数据快照以及新的PagedList,然后交给PagedListAdapter更新在UI上。
为此,PagedList类中增加了对应的一个mDetached字段:
public abstract class PagedList<T> extends AbstractList<T> {
//...
private final AtomicBoolean mDetached = new AtomicBoolean(false);
public boolean isDetached() {
return mDetached.get();
}
public void detach() {
mDetached.set(true);
}
}这个AtomicBoolean类型的字段是有意义的:我们知道PagedList对分页数据的加载是异步的,因此尝试加载下一页数据时,若此时mDetached.get()为true,意味着此时的分页数据已经失效,因此异步的分页请求任务不再需要被执行:
class ContiguousPagedList<K, V> extends PagedList<V> {
//...
public void onPagePlaceholderInserted(final int pageIndex) {
mBackgroundThreadExecutor.execute(new Runnable() {
@Override
public void run() {
// 不再异步加载分页数据
if (isDetached()) {
return;
}
// 若数据源失效,则将mDetached.set(true)
if (mDataSource.isInvalid()) {
detach();
} else {
// ... 加载下页数据
}
}
});
}
}通过上述代码片段读者也可以看到,PagedList的生命周期是否失效,则依赖DataSource的isInvalid()函数,这个函数表示当前的DataSource数据源是否失效:
public abstract class DataSource<Key, Value> {
private AtomicBoolean mInvalid = new AtomicBoolean(false);
private CopyOnWriteArrayList<InvalidatedCallback> mOnInvalidatedCallbacks =
new CopyOnWriteArrayList<>();
// 通知数据源失效
public void invalidate() {
if (mInvalid.compareAndSet(false, true)) {
for (InvalidatedCallback callback : mOnInvalidatedCallbacks) {
// 数据源失效的回调函数,通知上层创建新的PagedList
callback.onInvalidated();
}
}
}
// 数据源是否失效
public boolean isInvalid() {
return mInvalid.get();
}
}当数据源DataSource失效时,则会通过回调函数,通知上文我们提到的ComputableLiveData<T>创建新的PagedList,并通知给LiveData的观察者更新在UI上。
因此,PagedList作为分页数据,DataSource作为数据源,ComputableLiveData<T>作为PagedList的创建和分发者三者形成了一个闭环:
Room的响应式支持我们知道Paging原生提供了对Room组件的响应式支持,当数据库数据发生了更新,Paging能够响应到并自动构建新的PagedList,然后更新到UI上。
这似乎是一个神奇的操作,但原理却十分简单,上一小节我们知道,DataSource调用了invalidate()函数时,意味着数据源失效,DataSource会通过回调函数重新构建新的PagedList。
Room组件也是根据这个特性额外封装了一个新的DataSource:
public abstract class LimitOffsetDataSource<T> extends PositionalDataSource<T> {
protected LimitOffsetDataSource(...) {
// 1.定义一个"命令数据源失效"的回调函数
mObserver = new InvalidationTracker.Observer(tables) {
@Override
public void onInvalidated(@NonNull Set<String> tables) {
invalidate();
}
};
// 2.为数据库的失效跟踪器(InvalidationTracker)配置观察者
db.getInvalidationTracker().addWeakObserver(mObserver);
}
}这之后,每当数据库中数据失效,都会自动执行DataSource.invalidate()函数。
现在读者回顾最初学习Paging的时候,Room中开发者定义的Dao类,返回的DataSource.Factory到底是怎样的一个对象?
@Dao
interface RedditPostDao {
@Query("SELECT * FROM posts WHERE subreddit = :subreddit ORDER BY indexInResponse ASC")
fun postsBySubreddit(subreddit : String) : DataSource.Factory<Int, RedditPost>
}答案不言而喻,正是LimitOffsetDataSource的工厂类:
@Override
public DataSource.Factory<Integer, RedditPost> postsBySubreddit(final String subreddit) {
return new DataSource.Factory<Integer, RedditPost>() {
// 返回能够响应数据库数据失效的 LimitOffsetDataSource
@Override
public LimitOffsetDataSource<RedditPost> create() {
return new LimitOffsetDataSource<RedditPost>(__db, _statement, false , "posts") {
// ....
}
}原理上讲,这些代码平淡无奇,但设计者通过注解的一层封装,大幅简化了开发者的代码量。对于开发者而言,只需要配置一个接口,而无需去了解内部的代码实现细节。
上一篇文章中对DataSource进行了简单的介绍,很多朋友反应DataSource这一部分的源码过于晦涩,对于DataSource的选择也是懵懵懂懂。
复杂问题的解决依赖于问题的切割细分,本文将其细分成以下2个小问题,并进行一一探讨:
DataSource和其子类,它们的使用场景各是什么?PagedList和其子类?为什么设计出这么多的
DataSource和其子类,它们的使用场景各是什么?
Paging分页组件的设计中,DataSource是一个非常重要的模块。顾名思义,DataSource<Key, Value>中的Key对应数据加载的条件,Value对应数据集的实际类型, 针对不同场景,Paging的设计者提供了几种不同类型的DataSource实现类:
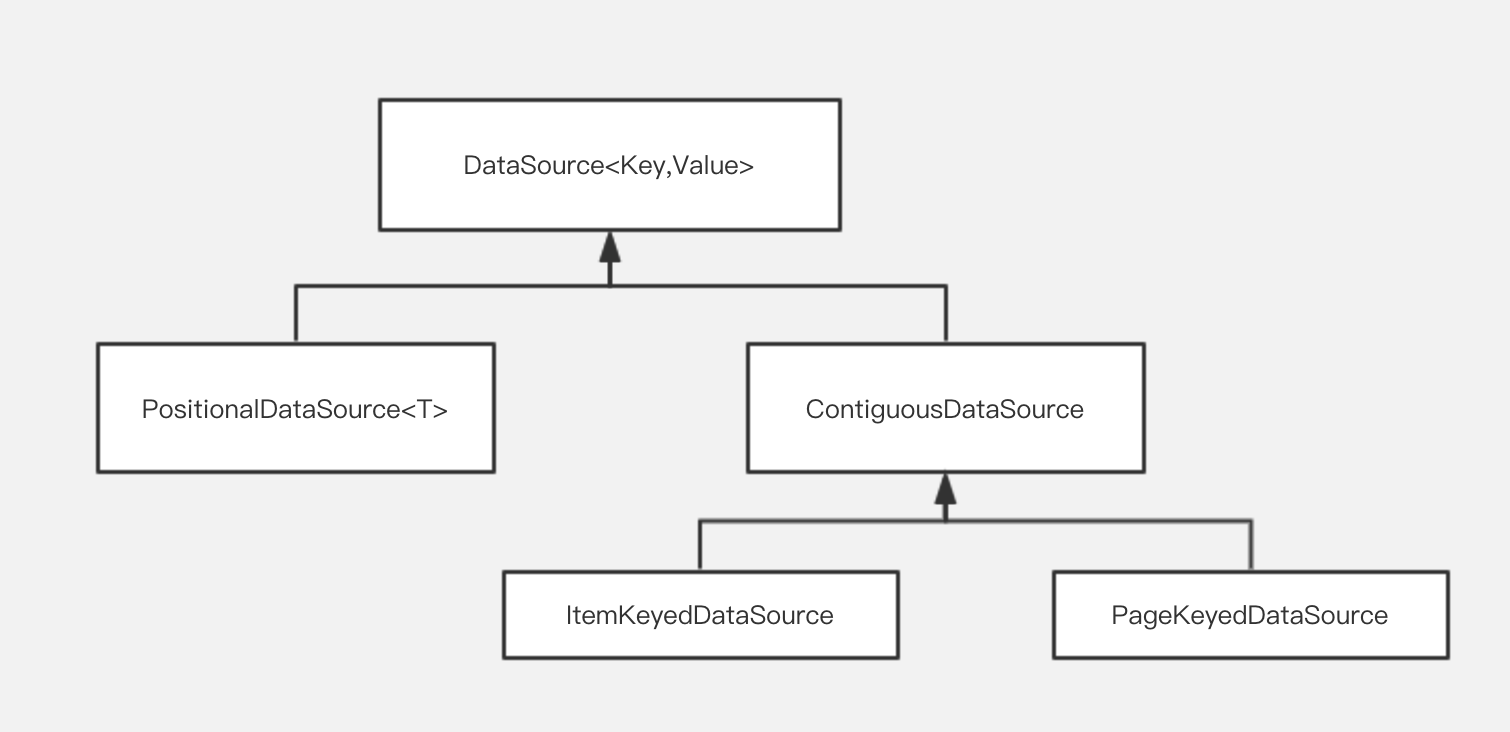
关于这些DataSource的介绍,请参考上一篇文章的这一小节,本文不再赘述。
第一次阅读这一部分源码时,笔者最困惑的是,ContiguousDataSource和PositionalDataSource的区别到底是什么呢?
翻阅过源码的读者也许曾经注意到,DataSource有这样一个抽象函数:
public abstract class DataSource<Key, Value> {
// 数据源是否是连续的
abstract boolean isContiguous();
}
class ContiguousDataSource<Key, Value> extends DataSource<Key, Value> {
// ContiguousDataSource 是连续的
boolean isContiguous() { return true; }
}
class PositionalDataSource<T> extends DataSource<Integer, T> {
// PositionalDataSource 是非连续的
boolean isContiguous() { return false; }
}那么,数据源的连续性 到底是什么概念?
对于一般的网络分页加载请求而言,下一页的数据总是需要依赖上一页的加载,这种时候,我们通常称之为 数据源是连续的 —— 这似乎毫无疑问,这也是ItemKeyedDataSource和PageKeyedDataSource被广泛使用的原因。
但有趣的是,在 以本地缓存作为分页数据源 的业务模型下,这种 分页数据源应该是连续的 常识性的认知被打破了。
每个手机都有通讯录,因此本文以通讯录APP为例,对于通讯录而言,所有数据取自于本地持久层,而考虑到手机内也许会有成千上万的通讯录数据,APP本身列表数据也应该进行分页加载。
这种情况下,分页数据源是连续的吗?
读者仔细思考可以得知,这时分页数据源 一定不能是连续的 。诚然,对于滑动操作而言,数据的连续分页请求没有问题,但是当用户从通讯录页面的侧边点击Z字母,尝试快速跳转Z开头的用户时,分页数据请求的连续性被打破了:
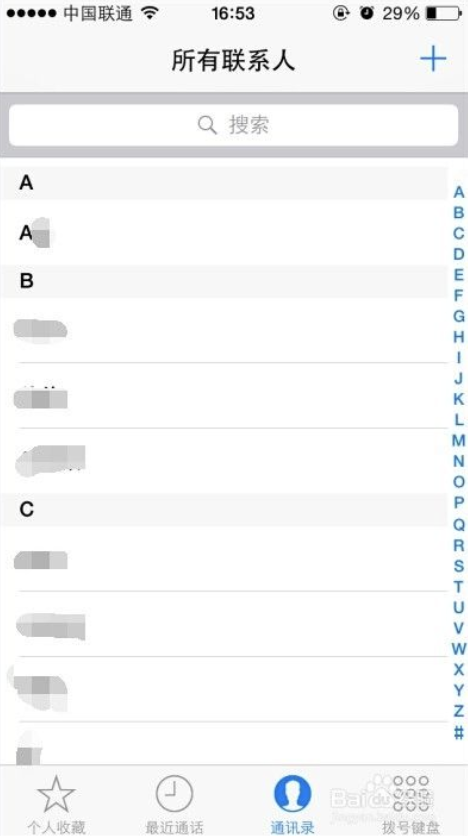
这便是PositionalDataSource的使用场景:通过特定的位置加载数据,这里Key是Integer类型的位置信息,每一条分页数据并不依赖上一条分页数据,而是依赖数据所处数据源本身的位置(Position)。
分页数据的连续性 是一个十分重要的概念,理解了这个概念,读者也就能理解DataSource各个子类的意义了:
无论是PositionalDataSource、ItemKeyedDataSource还是PageKeyedDataSource,这些类都是不同的 分页加载策略。开发者只需要根据不同业务的场景(比如 数据的连续性),选择不同的 分页加载策略 即可。
为什么设计出这么多的
PagedList和其子类?
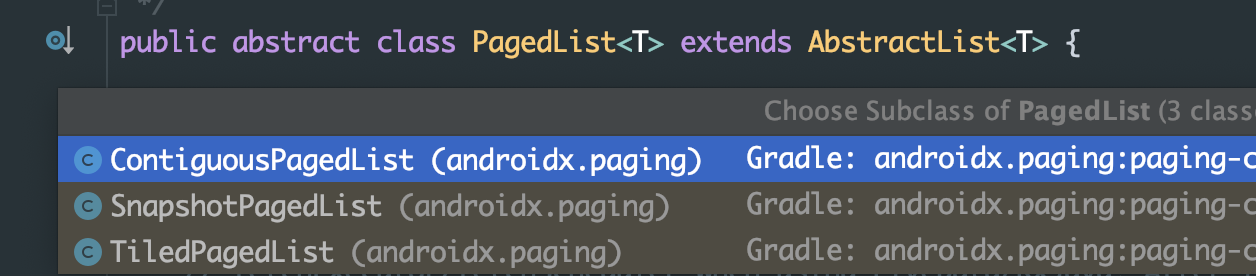
和DataSource相似,PagedList同样拥有一个isContiguous()接口:
public abstract class PagedList<T> extends AbstractList<T> {
abstract boolean isContiguous();
}
class ContiguousPagedList<K, V> extends PagedList<V> {
// ContiguousPagedList 内部持有 ContiguousDataSource
final ContiguousDataSource<K, V> mDataSource;
boolean isContiguous() { return true; }
}
class TiledPagedList<T> extends PagedList<T> {
// TiledPagedList 内部持有 PositionalDataSource
final PositionalDataSource<T> mDataSource;
boolean isContiguous() { return false; }
}读者应该理解,PagedList内部持有一个DataSource,而 分页数据加载 的行为本质上是从DataSource中异步获取数据—— 在分页数据请求的过程中,不同的DataSource也会有不同的参数需求,从而导致PagedList内部的行为也不尽相同;因此PagedList向下导出了ContiguousPagedList和TiledPagedList类,用于不同业务情况的分页请求处理。
那么SnapshotPagedList又是一个什么类呢?
PagedList额外有一个snapshot()接口,以返回当前分页数据的快照:
public abstract class PagedList<T> extends AbstractList<T> {
public List<T> snapshot() {
return new SnapshotPagedList<>(this);
}
}这个snapshot()函数非常重要,其用于保存分页数据的前一个状态,并且用于AsyncPagedListDiffer进行数据集的差异性计算,新的PagedList到来时(通过PagedListAdapter.submitList()),并未直接进行数据的覆盖和差异性计算,而是先对之前PagedList中的数据集进行拷贝。
篇幅原因不详细展示,有兴趣的读者可以自行阅读
PagedListAdapter.submitList()相关源码。
接下来简单了解下SnapshotPagedList内部的实现:
class SnapshotPagedList<T> extends PagedList<T> {
SnapshotPagedList(@NonNull PagedList<T> pagedList) {
// 1.这里我们看到,其它对象都没有改变堆内地址的引用
// 除了 pagedList.mStorage.snapshot(),最终执行 -> 2
super(pagedList.mStorage.snapshot(),
pagedList.mMainThreadExecutor,
pagedList.mBackgroundThreadExecutor,
null,
pagedList.mConfig);
mDataSource = pagedList.getDataSource();
mContiguous = pagedList.isContiguous();
mLastLoad = pagedList.mLastLoad;
mLastKey = pagedList.getLastKey();
}
}
final class PagedStorage<T> extends AbstractList<T> {
PagedStorage(PagedStorage<T> other) {
// 2.对当前分页数据进行了一次拷贝
mPages = new ArrayList<>(other.mPages);
}
}此外,mSnapshot还用于状态的保存,当差异性计算未执行完毕时,若此时开发者调用getCurrentList()函数,则会尝试将mSnapshot——即之前数据集的副本进行返回,有兴趣的读者可以研究一下。
Google的工程师们设计Paging的初衷就希望能够让开发者 无感知地进行线程切换 ,因此大部分线程切换的代码都封装在内部:
public class ArchTaskExecutor extends TaskExecutor {
// 主线程的Executor
private static final Executor sMainThreadExecutor = new Executor() {
@Override
public void execute(Runnable command) {
getInstance().postToMainThread(command);
}
};
// IO线程的Executor
private static final Executor sIOThreadExecutor = new Executor() {
@Override
public void execute(Runnable command) {
getInstance().executeOnDiskIO(command);
}
};
}有兴趣的读者可以研究ArchTaskExecutor内部的源码,其内部sMainThreadExecutor原理依然是通过Looper.getMainLooper()创建对应的Handler并向主线程发送消息,本文不赘述。
源码的设计者希望,使用Paging的开发者能够在执行数据的分页加载任务时,内部切换到IO线程,而分页数据加载成功后,则内部切换回到主线程更新UI。
从设计上讲,这是一个非常优秀的设计,但是开发者真正使用时,却很难注意到DataSource中对数据加载的回调方法,本身就是执行在IO线程的:
public abstract class PositionalDataSource<T> extends DataSource<Integer, T>{
// 通过注解提醒开发者回调在子线程
@WorkerThread
public abstract void loadInitial(...);
@WorkerThread
public abstract void loadRange(...);
}回调本身在子线程执行,意味着,开发者对分页数据的加载最好不要使用异步方法,否则很可能出问题。
对于OkHttp的使用者而言,开发者应该使用execute()同步方法:
override fun loadInitial(..., callback: LoadInitialCallback<RedditPost>) {
// 使用同步方法
val response = request.execute()
callback.onResult(...)
}对于
RxJava而言,则应该使用blocking相关的方法进行阻塞操作。
如果说PositionalDataSource还有@WorkerThread提醒,那么另外的ItemKeyedDataSource和PageKeyedDataSource干脆就没有@WorkerThread注解:
public abstract class ItemKeyedDataSource<Key, Value> extends ContiguousDataSource<Key, Value> {
public abstract void loadInitial(...);
public abstract void loadAfter(...);
}
// PageKeyedDataSource也没有`WorkerThread`注解,不赘述因此如果没有注意到这些细节,开发者很可能误入歧途,从而导致未知的一些问题,对此,开发者可以尝试参考Google这个示例代码。
奇怪的是,即使是Google官方的代码示例中,对于loadInitial和loadAfter两个函数,也只有loadInitial中使用了同步方法进行请求,而loadAfter中依然是使用enqueue()进行异步请求。尽管注释中明确声明了这点,但笔者还是无法理解这种行为,因为这的确有可能令一些开发者误入歧途。
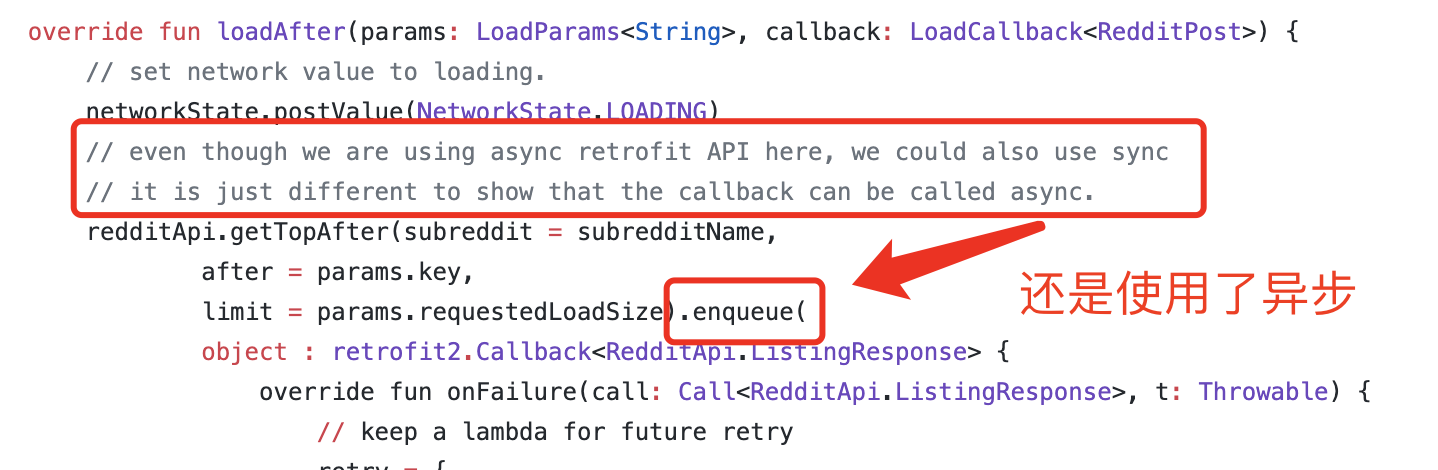
总之,Paging的设计中,其初衷将线程切换的实现细节进行隐藏是好的,但是结果的确没有达到很好的效果,相反还有可能导致错误的理解和使用(笔者踩坑了)。
也许线程切换不交给内部的默认参数去实现(尤其是不要交给Builder模式去配置,这太容易被忽视了),而是强制要求交给开发者去指定更好?
欢迎有想法的朋友在本文下方留言,**的交流会更容易让人进步。
本文对Paging的原理实现进行了系统性的讲解,那么,Paging的架构设计上,到底有哪些优点值得我们学习?
首先,依赖注入。Paging内部所有对象的依赖,包括配置参数、内部回调、线程切换,绝大多数都是通过依赖注入进行的,简单 且 朴实 ,类与类之间的依赖关系皆有迹可循。
其次,类的抽象和将不同业务的下沉,DataSource和PagedList分工明确,并向上抽象为一个抽象类,并将不同业务情况下的分页逻辑下沉到各自的子类中去。
最后,明确对象的边界:设计分页数据的生命周期,当数据源无效时,避免执行无效的异步分页任务;使用 懒加载的LiveData ,保证未订阅时不执行分页逻辑。
如果对Paging感兴趣,欢迎阅读笔者更多相关的文章,并与我一起讨论:
Hello,我是 却把清梅嗅 ,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的 博客 或者 Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
原文:Write an Android Studio Plugin Part 2: Persisting data
作者:Marcos Holgado
译者:却把清梅嗅
《编写AndroidStudio插件》系列是 IntelliJ IDEA 官方推荐的学习IDE插件开发的博客专栏,希望对有需要的读者有所帮助。
在本系列的第一部分中,我们了解了如何为Android Studio创建一个基本的插件,并编写了第一个Action。本文我们将了解如何在插件中对数据进行持久化。

请记住,您可以在GitHub上找到本系列的所有代码,还可以在对应的分支上查看每篇文章的相关代码,本文的代码在Part2分支中。
我们今天的目标是在插件中对数据进行持久化。在此过程中,我们将学习什么是component以及如何使用component来管理插件的生命周期。接下来我们将开始使用它,以保证Android Studio启动并且安装了新版本的插件时显示通知。您将来可用此功能向用户显示您插件更新了哪些内容。
在编写任何代码之前,我们需要了解什么是Component。 Component是插件集成的基本概念,Component让我们能够控制插件的生命周期并保持其状态,以便将其自动保存和加载。
一共有三种不同类型的Component:
IDE(Android Studio)启动时创建并初始化的Component;Component;Compoenent.首先我们要确定所需Component的类型,在本文中,我们想在Android Studio启动时做一些事情,因此,通过查看不同类型的Component,我们可以清楚地知道需要一个 Application级别的Component。
JetBrains官方文档这样描述:我们可以实现ApplicationComponent接口,这是可选的,但本文我们会这样做。ApplicationComponent接口将为我们提供之前提到的生命周期方法,便于我们在IDE启动时用于执行某些操作。这些方法来自ApplicationComponent的扩展类BaseComponent。
public interface BaseComponent extends NamedComponent {
/**
* Component should perform initialization and communication with other components in this method.
* This is called after {@link com.intellij.openapi.components.PersistentStateComponent#loadState(Object)}.
*/
default void initComponent() {
}
/**
* @see com.intellij.openapi.Disposable
*/
default void disposeComponent() {
}
}现在让我们对Component进行编码,第一次迭代将非常简单,我们通过继承ApplicationComponent并重写initComponent来检查是否有新版本。
class MyComponent: ApplicationComponent {
override fun initComponent() {
super.initComponent()
if (isANewVersion()) { }
}
private fun isANewVersion(): Boolean = true
}那么有意思的来了。我们将从声明两个新字段开始:localVersion和version。第一个将存储我们已安装的最新版本,而第二个将是我们插件的实际安装版本。
我想要比较它们,以检查版本号localVersion是否在version的后面,若如此我们就能知道用户是否刚刚安装了新版本的插件,以及是否向用户发送通知。我们还必须将localVersion更新为与version相同的值,以便下次用户启动Android Studio时不再收到欢迎信息。
首先,用户未安装我们的插件,因此我们将localVersion的值设置为0.0,因为我们的第一个版本是1.0-SNAPSHOT。您可以在build.gradle文件中更改插件的版本,但如果未更改,则应为:
version '1.0-SNAPSHOT'为了实现isANewVersion,我们将做一些简单的事情。如果你愿意,可以适当进行修改,但是这里只是针对版本号进行简单的比较,因此我没有对边界条件相关逻辑进行全方位覆盖。
首先,我摆脱了实际上要在版本上维护的-SNAPSHOT部分。之后,我使用.作为分隔符对每个版本号进行了分割。因此我们得到一个包含所有主数字和副数字的List<String>,以便我们可以比较它们并返回true或false。这并非最佳算法,但足以满足我们的需求。该算法的假设非常简单,两个版本号必须具有相同的长度,并且必须遵循相同的命名约定majorV.minorV。
private fun isANewVersion(): Boolean {
val s1 = localVersion.split("-")[0].split(".")
val s2 = version.split("-")[0].split(".")
if (s1.size != s2.size) return false
var i = 0
do {
if (s1[i] < s2[i]) return true
i++
} while (i < s1.size && i < s2.size)
return false
}现在是时候将isANewVersion方法以及两个新字段移到Component中了。您可以使用PluginManager获得插件的版本以及插件的ID,您还可以在plugin.xml文件中找到(和更改)插件的ID。我还建议此时将插件名称更改为更有意义的名称,例如My awesome plugin。
<idea-plugin>
<id>myplugin.myplugin</id>
<name>My awesome plugin</name>
...该Component的整个实现非常简单:我们从PluginManager获取版本,检查是否发生了版本更新,如果有,就同步更新本地版本号,以便下次启动Android Studio时不会再触发整个过程。最后,我们向用户显示一个简单的通知,整合完毕后,看起来像这样。
class MyComponent: ApplicationComponent {
private var localVersion: String = "0.0"
private lateinit var version: String
override fun initComponent() {
super.initComponent()
version = PluginManager.getPlugin(
PluginId.getId("myplugin.myplugin")
)!!.version
if (isANewVersion()) {
updateLocalVersion()
val noti = NotificationGroup("myplugin",
NotificationDisplayType.BALLOON,
true)
noti.createNotification("Plugin updated",
"Welcome to the new version",
NotificationType.INFORMATION,
null)
.notify(null)
}
}
private fun isANewVersion(): Boolean {
val s1 = localVersion.split("-")[0].split(".")
val s2 = version.split("-")[0].split(".")
if (s1.size != s2.size) return false
var i = 0
do {
val l1 = s1[i]
val l2 = s2[i]
if (l1 < l2) return true
i++
} while (i < s1.size && i < s2.size)
return false
}
private fun updateLocalVersion() {
localVersion = version
}
}现在,我们可以尝试测试我们的插件,由于两个原因,它无法正常工作。
首先是因为我们仍然必须注册Component,其次是因为我们还没有真正保留Component的状态。每次Android Studio初始化时,localVersion的值仍然是0.0。
那么,针对如何保存Component状态的问题,我们该怎么做呢?为此,我们必须实现PersistentStateComponent。这意味着我们必须重写两个新方法,即getState和loadState。我们还需要了解PersistentStateComponent的工作方式,
它将公共字段,带注释的私有字段和bean属性存储为XML格式。要从序列化中删除公共字段,可以使用@Transient注释该字段。
在我们的例子中,我将使用@Attribute注释localVersion,以便在存储它的同时将其保持私有状态,将组件本身返回到getState并使用XmlSerializerUtil加载状态,我们还必须使用@State注释组件,并指定xml的位置。
@State(
name = "MyConfiguration",
storages = [Storage(value = "myConfiguration.xml")])
class MyComponent: ApplicationComponent,
PersistentStateComponent<MyComponent> {
@Attribute
private var localVersion: String = "0.0"
private lateinit var version: String
override fun initComponent() {
super.initComponent()
version = PluginManager.getPlugin(
PluginId.getId("myplugin.myplugin")
)!!.version
if (isANewVersion()) {
updateLocalVersion()
val noti = NotificationGroup("myplugin",
NotificationDisplayType.BALLOON,
true)
noti.createNotification("Plugin updated",
"Welcome to the new version",
NotificationType.INFORMATION,
null)
.notify(null)
}
}
override fun getState(): MyComponent? = this
override fun loadState(state: MyComponent) = XmlSerializerUtil.copyBean(state, this)
private fun isANewVersion(): Boolean {
val s1 = localVersion.split("-")[0].split(".")
val s2 = version.split("-")[0].split(".")
if (s1.size != s2.size) return false
var i = 0
do {
if (s1[i] < s2[i]) return true
i++
} while (i < s1.size && i < s2.size)
return false
}
private fun updateLocalVersion() {
localVersion = version
}
}像往常一样,您可以按需定制,例如定义存储位置或自定义xml格式,更多信息请参考这里。
最后一步是在plugin.xml文件中注册Component。为此,我们只需要在文件的application-component部分内创建一个新Component,然后指定我们刚刚创建的Component类即可。
<application-components>
<component>
<implementation-class>
components.MyComponent
</implementation-class>
</component>
</application-components>大功告成!现在,您可以运行buildPlugin命令,使用Android Studio中生成的jar文件从磁盘安装插件,下次打开Android Studio时,您会看到此通知。之后,仅当您提高插件版本时,通知也会再次出现。
第2部分到此为止,在第3部分中,我们将学习如何为插件创建设置页面,当然在此之前我们还将了解如何为插件创建UI。
如果您有任何疑问,请访问Twitter或发表评论。
Hello,我是 却把清梅嗅 ,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的 博客 或者 GitHub。
如果您觉得文章还差了那么点东西,也请通过 关注 督促我写出更好的文章——万一哪天我进步了呢?

在之前的章节中,我们已经介绍了如何解决树的遍历问题。我们也已经尝试过使用递归解决树的为 前序遍历 、 中序遍历 和 后序遍历 问题。
事实上,递归 是解决树相关问题的最有效和最常用的方法之一。本节中,我们将会介绍两种典型的递归方法。
本小节内容节选自 LeetCode:运用递归解决树的问题 .
递归是解决树的相关问题最有效和最常用的方法之一。
我们知道,树可以以递归的方式定义为一个节点(根节点),它包括一个值和一个指向其他节点指针的列表。 递归是树的特性之一。 因此,许多树问题可以通过递归的方式来解决。 对于每个递归层级,我们只能关注单个节点内的问题,并通过递归调用函数来解决其子节点问题。
通常,我们可以通过 自顶向下 或 自底向上 的递归来解决树问题。
自顶向下 意味着在每个递归层级,我们将首先访问节点来计算一些值,并在递归调用函数时将这些值传递到子节点。 所以 自顶向下 的解决方案可以被认为是一种 前序遍历。 具体来说,递归函数 top_down(root, params) 的原理是这样的:
null值的情况下返回指定的值;answer;left_ans = top_down(root.left, left_params);right_ans = top_down(root.right, right_params);answer。自底向上 是另一种递归方法。 在每个递归层次上,我们首先对所有子节点递归地调用函数,然后根据返回值和根节点本身的值得到答案。 这个过程可以看作是 后序遍历 的一种。 通常, 自底向上 的递归函数 bottom_up(root) 为如下所示:
null值的情况下返回指定的值;left_ans = top_down(root.left, left_params);right_ans = top_down(root.right, right_params);answer。
class Solution {
private int answer = 0;
public int maxDepth(TreeNode root) {
max_depth(root, 0);
return answer;
}
private void max_depth(TreeNode root, int depth) {
if (root == null) return;
if (root.left == null && root.right == null) {
answer = Math.max(depth, answer);
return;
}
max_depth(root.left, depth + 1);
max_depth(root.right, depth + 1);
}
}class Solution {
public int maxDepth(TreeNode root) {
return max_depth2(root);
}
private int max_depth2(TreeNode root) {
if (root == null)
return 0;
int leftDepth = max_depth2(root.left) + 1;
int rightDepth = max_depth2(root.right) + 1;
return Math.max(leftDepth, rightDepth);
}
}
这道题笔者的思路是迭代,后来发现非常困难,看了题解才发现,将同一个树作为2次参数分别放入递归函数进行递归,确实是一个很棒的思路。
class Solution {
public boolean isSymmetric(TreeNode root) {
return isMirror(root, root);
}
private boolean isMirror(TreeNode t1, TreeNode t2) {
if (t1 == null && t2 == null) return true;
if (t1 == null || t2 == null) return false;
return t1.val == t2.val && isMirror(t1.left, t2.right) && isMirror(t1.right, t2.left);
}
}
比较简单,标准的dfs进行递归:
class Solution {
public boolean hasPathSum(TreeNode root, int sum) {
return dfs(root, 0, sum);
}
private boolean dfs(TreeNode root, int currentSum, int target) {
if (root == null) {
return false;
}
int sum = currentSum + root.val;
if (root.left != null || root.right != null) {
return dfs(root.left, sum, target) || dfs(root.right, sum, target);
} else {
return sum == target;
}
}
}文章绝大部分内容节选自LeetCode,概述:
例题:
Hello,我是 却把清梅嗅 ,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的 博客 或者 GitHub。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?

本文为博主算法学习过程中的学习笔记,主要内容来源于其他平台或书籍,出处请参考下方 参考&感谢 一节。
哈希映射 是用于存储 (key, value) 键值对的一种实现。
使用哈希映射的第一个场景是,我们 需要更多的信息,而不仅仅是键。然后通过哈希映射 建立密钥与信息之间的映射关系。
另一个常见的场景是 按键聚合所有信息。我们也可以使用哈希映射来实现这一目标。
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
你可以假设每种输入只会对应一个答案。但是,你不能重复利用这个数组中同样的元素。
示例:
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
HashMap入门的经典题。
简单的方式是使用双层循环进行暴力破解,这种算法时间复杂度为O(N^2)。
而使用HashMap则可以将问题在一层循环中进行解决,时间复杂度仅O(N):
class Solution {
public int[] twoSum(int[] nums, int target) {
HashMap<Integer, Integer> map = new HashMap<>();
int[] result = new int[2];
for (int i = 0; i < nums.length; i++) {
int value = nums[i];
int find = target - value;
if (map.containsKey(find) && map.get(find) != i) {
result[0] = i;
result[1] = map.get(find);
break;
}
map.put(nums[i], i);
}
return result;
}
}给定两个字符串 s 和 t,判断它们是否是同构的。
如果 s 中的字符可以被替换得到 t ,那么这两个字符串是同构的。
所有出现的字符都必须用另一个字符替换,同时保留字符的顺序。两个字符不能映射到同一个字符上,但字符可以映射自己本身。
你可以假设 s 和 t 具有相同的长度。
示例:
输入: s = "egg", t = "add"
输出: true
输入: s = "foo", t = "bar"
输出: false
通过2个HashMap存储各自字符对应最初的索引,然后进行比较,当字符对应的最初索引不同时,说明2个字符串不是同构的:
class Solution {
public boolean isIsomorphic(String s, String t) {
char[] char1 = s.toCharArray();
char[] char2 = t.toCharArray();
HashMap<Character, Integer> map1 = new HashMap<>();
HashMap<Character, Integer> map2 = new HashMap<>();
for (int i = 0; i < char1.length; i++) {
char c1 = char1[i];
char c2 = char2[i];
if (!map1.containsKey(c1))
map1.put(c1, i);
if (!map2.containsKey(c2))
map2.put(c2, i);
if (map1.get(c1) != map2.get(c2))
return false;
}
return true;
}
}https://leetcode-cn.com/problems/minimum-index-sum-of-two-lists/
这道题的难点是发现映射关系,即 最爱餐厅 -> 索引值 的映射关系。
通过遍历将该映射关系存储到HashMap中后,再次通过一次遍历找出索引值和最小的餐厅,因为索引值最小的情况可能不止一个,因此用一个List进行维护,最终将答案遍历输出:
class Solution {
public String[] findRestaurant(String[] list1, String[] list2) {
HashMap<String, Integer> map = new HashMap<>();
List<Integer> posList = new ArrayList<>();
int minPosNum = Integer.MAX_VALUE;
for (int i = 0; i < list1.length; i++) {
map.put(list1[i], i);
}
for (int i = 0; i < list2.length; i++) {
String favorite = list2[i];
Integer position = map.get(favorite);
if (position != null) {
int posNum = i + position;
if (minPosNum > posNum) {
minPosNum = posNum;
posList.clear();
posList.add(i);
} else if (minPosNum == posNum) {
posList.add(i);
}
}
}
String[] result = new String[posList.size()];
for (int i = 0; i < posList.size(); i++)
result[i] = list2[posList.get(i)];
return result;
}
}给定一个字符串,找到它的第一个不重复的字符,并返回它的索引。如果不存在,则返回 -1。
示例:
s = "leetcode"
返回 0.
s = "loveleetcode"
返回 2.
您可以假定该字符串只包含小写字母。
比较简单,通过2次遍历,第一次遍历将每个字符对应出现的次数进行存储,第二次遍历每个字符的出现次数,当出现次数为1,返回该字符的索引即可。
class Solution {
public int firstUniqChar(String s) {
char[] arr = s.toCharArray();
HashMap<Character, Integer> map = new HashMap<>();
// 遍历将所有字符的频率输出到Map中
for (int i = 0; i < arr.length; i++) {
char c = arr[i];
if (map.containsKey(c)) {
map.put(c, map.get(c) + 1);
} else {
map.put(c, 1);
}
}
for (int i = 0; i < arr.length; i++) {
char c = arr[i];
if (map.get(c) == 1)
return i;
}
return -1;
}
}给定两个数组,编写一个函数来计算它们的交集。
输入: nums1 = [1,2,2,1], nums2 = [2,2]
输出: [2,2]
输入: nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出: [4,9]
输出结果中每个元素出现的次数,应与元素在两个数组中出现的次数一致。
我们可以不考虑输出结果的顺序。
仍然是通过2次遍历,第一次遍历将nums1[]每个数字对应出现的次数进行存储,第二次遍历nums2[],然后和之前的结果进行匹配,最终返回结果。
class Solution {
public int[] intersect(int[] nums1, int[] nums2) {
HashMap<Integer, Integer> map = new HashMap<>();
// 遍历数组将所有元素和其数量存入map中
for (int i = 0; i < nums1.length; i++) {
int key = nums1[i];
if (map.containsKey(key)) {
map.put(key, map.get(key) + 1);
} else {
map.put(key, 1);
}
}
int[] result = new int[nums2.length];
int pos = 0;
for (int i = 0; i < nums2.length; i++) {
int key = nums2[i];
if (map.containsKey(key) && map.get(key) >= 1) {
result[pos] = key;
pos++;
map.put(key, map.get(key) - 1);
}
}
return Arrays.copyOf(result, pos);
}
}给定一个整数数组和一个整数 k,判断数组中是否存在两个不同的索引 i 和 j,使得 nums [i] = nums [j],并且 i 和 j 的差的绝对值最大为 k。
输入: nums = [1,2,3,1], k = 3
输出: true
输入: nums = [1,0,1,1], k = 1
输出: true
输入: nums = [1,2,3,1,2,3], k = 2
输出: false
题目理解了就好做了,关键是数组内相同的数字最小距离是否不大于k,做一次遍历,每次都将数字作为key,其索引作为value进行存储。
遍历结束前,只要有一个满足要求就可以返回true,否则最终返回false即可。
class Solution {
public boolean containsNearbyDuplicate(int[] nums, int k) {
HashMap<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
int key = nums[i];
if (map.containsKey(key)) {
int oldPos = map.get(key);
if (i - oldPos <= k) {
return true;
} else {
map.put(key, i);
}
} else {
map.put(key, i);
}
}
return false;
}
}文章绝大部分内容节选自LeetCode,概述:
例题:
Hello,我是 却把清梅嗅 ,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的 博客 或者 GitHub。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
接下来笔者的文章方向偏向于 Android & Java 面试相关知识点系统性的总结,欢迎关注。
ThreadLocal类是java.lang包下的一个类,用于线程内部的数据存储,通过它可以在指定的线程中存储数据,本文针对该类进行原理分析。
通过思维导图对其进行简单的总结:
ThreadLocal类最重要的几个方法如下:
ThreadLocal类比较简单,其最重要的就是get()和set()方法,顾名思义,起作用就是取值和设置值:
// 获取当前线程中的变量副本
public T get() {
// 获取当前线程
Thread t = Thread.currentThread();
// 获取线程中的ThreadLocalMap对象
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
// 获取变量副本并返回
T result = (T)e.value;
return result;
}
}
// 若没有该变量副本,返回setInitialValue()
return setInitialValue();
}这里先将ThreadLocalMap暂时理解为一个Map结构的容器,内部存储着该线程作用域下的的所有变量副本,我们从ThreadLocal类中取值的时候,实际上是从ThreadLocalMap中取值。
如果Map中没有该变量的副本,会从setInitialValue()中取值:
private T setInitialValue() {
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}可以看到,setInitialValue()中也非常的简单,依然是从当前线程中获取到ThreadLocalMap,略微不同的是,setInitialValue()会对变量进行初始化,存入ThreadLocalMap中并返回。
这个初始化的方法的执行,需要开发者自己重写initialValue()方法,否则返回值依然为null。
public class ThreadLocal<T> {
// ...
protected T initialValue() {
return null;
}
} 和setInitialValue()方法类似,set()方法也非常简单:
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
// map不为空,直接将ThreadLocal对象作为key
// 变量本身的值为value,存入map
map.set(this, value);
else
// 否则,创建ThreadLocalMap
createMap(t, value);
}可以看到,这个方法的作用就是将变量副本作为value存入Map,需要注意的是,key并非是我们下意识认为的Thread对象,而是ThreadLocal本身(Thread和Value本身是一对一的,我们更容易将其映射为key-value的关系)。
public void remove() {
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
m.remove(this);
}对于变量副本的移除,也是通过map进行处理的,和set()和get()相同,Entry的键值对中,ThreadLocal本身作为key,对变量副本进行检索。
可以看出,ThreadLocal本身内部的逻辑都是围绕着ThreadLocalMap在运作,其本身更像是一个空壳,仅作为API供开发者调用,内部逻辑都委托给了ThreadLocalMap。
接下来我们来探究一下ThreadLocalMap和Thread以及ThreadLocal之间的关系。
ThreadLocalMap内部代码和算法相对复杂,个人亦是一知半解,因此就不逐行代码进行分析,仅系统性进行概述。
首先来看一下ThreadLocalMap的定义:
public class ThreadLocal<T> {
// ThreadLocalMap是ThreadLocal的内部类
static class ThreadLocalMap {
// Entry类,内部key对应的是ThreadLocal的弱引用
static class Entry extends WeakReference<ThreadLocal<?>> {
// 变量的副本,强引用
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
}
}ThreadLocal中的嵌套内部类ThreadLocalMap本质上是一个map,依然是key-value的形式,其中有一个内部类Entry,其中key可以看做是ThreadLocal实例的弱引用。
和最初的设想不同的是,ThreadLocalMap中key并非是线程的实例Thread,而是ThreadLocal,那么ThreadLocalMap是如何保证同一个Thread中,ThreadLocal的指定变量唯一呢?
// 1.ThreadLocal的set()方法
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
// ...
}
// 2.getMap()实际上是从Thread中获取threadLocals成员
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
public class Thread implements Runnable {
// 3.每个Thread实例都持有一个ThreadLocalMap的属性
ThreadLocal.ThreadLocalMap threadLocals = null;
}Thread本身持有ThreadLocal.ThreadLocalMap的属性,每个线程在向ThreadLocal里setValue的时候,其实都是向自己的ThreadLocalMap成员中加入数据;get()同理。
在上一小节中,我们看到ThreadLocalMap中的Entry中,其ThreadLocal作为key,是作为弱引用进行存储的。
当ThreadLocal不再被作为强引用持有时,会被GC回收,这时ThreadLocalMap对应的ThreadLocal就变成了null。而根据文档所叙述的,当key == null时,这时就可以默认该键不再被引用,该Entry就可以被直接清除,该清除行为会在Entry本身的set()/get()/remove()中被调用,这样就能 一定情况下避免内存泄漏。
这时就有一个问题出现了,作为key的ThreadLocal变成了null,那么作为value的变量可是强引用呀,这不就导致内存泄漏了吗?
其实一般情况下也不会,因为即使再不济,线程在执行结束时,自然也会消除其对value的引用,使得Value能够被GC回收。
当然,在某种情况下(比如使用了 线程池),线程再次被使用,Value这时依然可以被获取到,自然也就发生了内存泄漏,因此此时,我们还是需要通过手动将value的值设置为null(即调用ThreadLocal.remove()方法)以规避内存泄漏的风险。
Hello,我是却把清梅嗅,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的博客或者Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
原文:Write an Android Studio Plugin Part 1: Creating a basic plugin
作者:Marcos Holgado
译者:却把清梅嗅
早在10月的时候,我就在Droidcon UK 2018上针对如何在Android Studio上创建自己的插件,以及如何使所有相关操作自动化进行了讨论。因为当时我并没有很多时间对其进行详细介绍,所以这个系列诞生了。
本文我们将编写一个非常基本的插件,这次内容也许并不多,但重要的是,我们将学习插件以及创建插件所需的知识。我们还将创建一个新的Action,该Action将显示一个带有消息的弹出框。
这只是一个非常长的系列文章的第一部分,我将深入研究并为我们的插件扩展更多功能。 您将看到的所有代码都在下方的GitHub仓库中:
随着进度的提升,虽然master会一直保持最新的代码,但我还将对每篇文章保留单独的分支。想要如此做,您可以随时返回查看Part1分支。
要创建我们的插件,我们将使用IntelliJ IDEA社区版。其主要原因是因为社区版是免费的,且非常容易使用,我们还可以利用gradle-intellij-plugin让这个过程变得更加轻松。
我将使用并非IntelliJ IDEA CE最新稳定版本的IntelliJ IDEA CE 2018.1.6。原因是因为Android Studio 3.2.1基于此IntelliJ版本,我不也想使用任何可能与Android Studio不兼容的新功能。
您可以从此处下载IntelliJ IDEA CE 2018.1.6:
译者注:上述链接会跳转最新的 IDEA Preview 版本,读者可根据自己喜好进行下载。
和往常一样,创建一个新的项目。
选择Gradle和IntelliJ Platform Plugin,我们唯一要做的,就是确定我们将使用哪种语言。本文我将选择Kotlin(Java)。
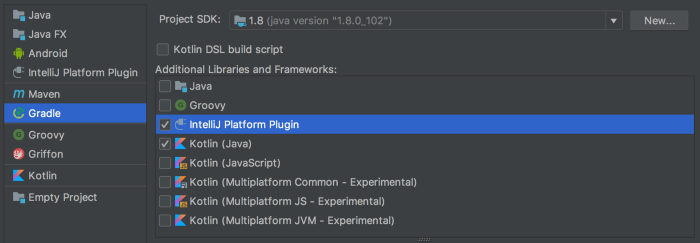
这之后,我们需要定义三个属性。
因为我不打算发布此插件,所以只将myplugin用作GroupId和ArtifactId,读者可按需自行定制。

在下一个弹窗,我将不做任何更改,仅保留默认选项。如果您想了解更多有关此步骤的信息,请访问这里。
最后一步就是给我们的插件起个名字。

恭喜你!您刚刚创建了一个新插件,不仅适用于Android Studio,而且还适用于基于IntelliJ的任何其他IDE——尽管您的插件还没有做其它任何事情。
现在,我们已经创建了项目,我们将快速浏览两个文件:plugin.xml和build.gradle。
我们从plugin.xml开始。该文件包含一些插件相关的元数据,以及我们必须注册插件不同元素的位置。在必要的时候,我们将更深入地研究此文件中的某些内容。
另一个文件是build.gradle,我们已经熟悉它了,所以我不解释它的作用。这是您将获得的默认build.gradle文件(版本不同,内容会略有不同):
plugins {
id 'org.jetbrains.intellij' version '0.3.12'
id 'org.jetbrains.kotlin.jvm' version '1.3.10'
}
group 'myplugin'
version '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
compile "org.jetbrains.kotlin:kotlin-stdlib-jdk8"
}
compileKotlin {
kotlinOptions.jvmTarget = "1.8"
}
compileTestKotlin {
kotlinOptions.jvmTarget = "1.8"
}
intellij {
version '2018.2.2'
}
patchPluginXml {
changeNotes """
Add change notes here.<br>
<em>most HTML tags may be used</em>"""
}一切似曾相识,因为我们习惯了Android项目。当我们开始添加更多依赖项时,我们将折回该文件,依此类推,但目前我只关注两件事。
首先,您可以看到我们的 依赖项 使用了compile而不是implementation/api,主要原因是gradle-intellij-plugin尚不支持implementation/api。
译者注:最新版本的 IDEA 插件已支持。
不过,如果您需要kapt进行任何类型的注解处理,则可以使用kapt(说的就是你,Dagger)。与任何Android项目中一样,您可以使用所需的任何库,但使用时务必小心,因为这不是Android项目。
其次,我们有一个新的部分称为intellij。 在这里,我们将在需要时添加更多属性,如插件依赖性等。现在,我们唯一拥有的属性是version,它指定了应该用作依赖性的IDEA的发行版本。
在继续之前,我将向intellij部分添加另一个属性。 我们现在拥有的插件只能在IntelliJ IDEA CE上调试。 如果我们想立即调试插件的行为,一个新的IntelliJ实例将被启动,我们将不得不在那里进行调试/测试。显然我们想在Android Studio上测试我们的插件,以便告诉gradle-intellij-plugin我们要使用Android Studio,我们必须添加一个新属性。
最终该部分声明如下:
intellij {
version '2018.1.6'
alternativeIdePath '/Applications/Android Studio.app'
}通过使用AlternativeIdePath并指向本地安装的Android Studio,我们告诉gradle-intellij-plugin每当运行插件或对其进行调试时都使用Android Studio,而不是使用默认的IntelliJ IDE。
如果您迫不及待要其他文章来查看可使用的其他属性,请访问这里以获取更多信息。
我们可以在插件中使用不同的元素,我们将在以后的文章中看到所有这些元素,但现在我们将重点介绍最常用的:actions。
当您单击工具栏或菜单项时,基本上就是一个动作,就这么简单,下列图片中您看到的所有内容都是Actions展示的:

通过Actions,我们可以将自己的项目应用到Android Studio的菜单和工具栏上,这些Action被组织成Group,这些Group可以包含其他Group,依此类推。
要创建一个新的Action,我们必须让这个类继承AnAction并重写actionPerformed方法。
class MyAction: AnAction() {
override fun actionPerformed(e: AnActionEvent) {
val noti = NotificationGroup("myplugin", NotificationDisplayType.BALLOON, true)
noti.createNotification("My Title",
"My Message",
NotificationType.INFORMATION,
null
).notify(e.project)
}
}在这里,我们创建了一个简单的Action,它将显示一个带有标题和消息的弹窗。我们要做的最后一件事是将此Action添加到我们的plugin.xml文件中。
<actions>
<group id="MyPlugin.TopMenu"
text="_MyPlugin"
description="MyPlugin Toolbar Menu">
<add-to-group group-id="MainMenu" anchor="last"/>
<action id="MyAction"
class="actions.MyAction"
text="_MyAction"
description="MyAction"/>
</group>
</actions>我们的Action必须属于一个Group,因此,首先,我创建了一个ID为MyPlugin.TopMenu的新Group。 我还将该Group添加到MainMenu Group,它是您可以在任何IntelliJ IDE上看到的主要工具栏。我将其位置锚定为最后一个,这样我们的Group将处于该Group的最后位置。 最后,我将Action添加到MyPlugin.TopMenu Group中,以便我们可以从那里访问它。
如果您想知道我如何知道MainMenu ID的存在,只需命令+单击MainMenu ID,它将带您进入一个名为PlatformActions.xml的文件,该文件包含绝大多数Action(类似于VcsActions.xml) 和IDE中的Group。
我们可以对Action和Group执行许多不同的操作,例如添加分隔符或复用它们。我将在以后的文章中对其进行探讨,但现在您可以在这里查看它们。

就这样,我们刚刚编写了一个非常简单的插件。现在我们可以使用run按钮运行它,也可以对其进行调试。这将创建一个新的Android Studio实例,它将安装我们的插件。另一个选项是运行buildPlugin gradle任务,该任务将生成一个.jar文件,您可以将其作为插件安装在Android Studio或任何其他IntelliJ IDE上。
安装插件并运行Android Studio后,您现在可以在主工具栏上看到包含MyAction的新MyPlugin group。
在单击MyAction之后,将显示一个新的弹窗,其包含您定义的标题和消息。请记住在log日志窗口上启用 Show balloons,否则,您将不会看到弹窗,而是一个日志事件。
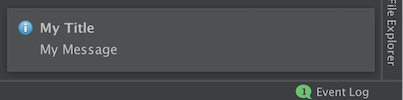
第一部分就是这样。在第二部分,我们将研究如何使用组件存储数据并保存插件的状态。同时,如果您有任何疑问,请访问twitter或发表评论。
如果您想观看我在Droidcon UK上发表的演讲,请点击这里。
Hello,我是 却把清梅嗅 ,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的 博客 或者 GitHub。
如果您觉得文章还差了那么点东西,也请通过 关注 督促我写出更好的文章——万一哪天我进步了呢?

本文为博主算法学习过程中的学习笔记,主要内容来源于其他平台或书籍,出处请参考下方 参考&感谢 一节。
哈希表 是一种使用哈希函数组织数据,以支持快速插入和搜索的数据结构。
有两种不同类型的哈希表:哈希集合 和 哈希映射。
(key, value)键值对。通过选择合适的哈希函数,哈希表可以在插入和搜索方面实现出色的性能。
哈希表的关键**是使用哈希函数 将键映射到存储桶。更确切地说,
哈希函数是哈希表中最重要的组件,该哈希表用于将键映射到特定的桶。
散列函数将取决于 键值的范围 和 桶的数量。
哈希函数的设计是一个开放的问题。其**是尽可能将键分配到桶中,理想情况下,完美的哈希函数将是键和桶之间的一对一映射。然而,在大多数情况下,哈希函数并不完美,它需要在桶的数量和桶的容量之间进行权衡。
理想情况下,如果我们的哈希函数是完美的一对一映射,我们将不需要处理冲突。不幸的是,在大多数情况下,冲突几乎是不可避免的。
冲突解决算法应该解决以下几个问题:
1、如何组织在同一个桶中的值?
2、如果为同一个桶分配了太多的值,该怎么办?
3、如何在特定的桶中搜索目标值?
根据我们的哈希函数,这些问题与 桶的容量 和可能映射到 同一个桶的键的数目 有关。
让我们假设存储最大键数的桶有 N 个键。
通常,如果 N 是常数且很小,我们可以简单地使用一个数组将键存储在同一个桶中。如果 N 是可变的或很大,我们可能需要使用 高度平衡的二叉树 来代替。
不使用任何内建的哈希表库设计一个哈希集合。
在本文中,我们使用单独链接法,来看看它是如何工作的。
HashSet的存储空间相当于连续内存数组,这个数组中的每个元素相当于一个桶。add,remove,contains。对于桶的设计,我们有几种选择,可以使用数组来存储桶的所有值。然而数组的一个缺点是需要O(N)的时间复杂度进行插入和删除,而不是O(1)。
因为任何的更新操作,我们首先是需要扫描整个桶为了避免重复。选择链表来存储桶的所有值是更好的选择,插入和删除具有常数的时间复杂度。
public class MyHashSet {
private int keyRange;
private Bucket[] buckets;
/**
* Initialize your data structure here.
*/
public MyHashSet() {
this.keyRange = 793;
this.buckets = new Bucket[this.keyRange];
for (int i = 0; i < keyRange; i++) {
buckets[i] = new Bucket();
}
}
protected int _hash(int key) {
return key % this.keyRange;
}
public void add(int key) {
int index = this._hash(key);
buckets[index].insert(key);
}
public void remove(int key) {
int index = this._hash(key);
buckets[index].delete(key);
}
public boolean contains(int key) {
int index = this._hash(key);
return buckets[index].contain(key);
}
class Bucket {
private LinkedList<Integer> container;
Bucket() {
this.container = new LinkedList<>();
}
void insert(Integer key) {
int index = container.indexOf(key);
if (index == -1)
container.addFirst(key);
}
void delete(Integer key) {
container.remove(key);
}
boolean contain(Integer key) {
return container.indexOf(key) != -1;
}
}
}不使用任何内建的哈希表库设计一个哈希映射。
class MyHashMap {
private int keyRange;
private Node[] nodes;
public MyHashMap() {
this.keyRange = 793;
this.nodes = new Node[this.keyRange];
}
protected int _hash(int key) {
return key % this.keyRange;
}
public void put(int key, int value) {
int index = this._hash(key);
Node curr = nodes[index];
if (curr == null) {
Node node = new Node(key, value);
nodes[index] = node;
return;
}
while (curr != null) {
if (curr.key == key) {
curr.value = value;
return;
}
if (curr.next == null) {
Node node = new Node(key, value);
node.prev = curr;
node.next = curr.next; // curr.next = null
curr.next = node;
return;
} else {
curr = curr.next;
}
}
}
public int get(int key) {
int index = this._hash(key);
Node curr = nodes[index];
while (curr != null) {
if (curr.key == key) {
return curr.value;
} else {
curr = curr.next;
}
}
return -1;
}
public void remove(int key) {
int index = this._hash(key);
Node curr = nodes[index];
if (curr != null && curr.key == key) {
Node next = curr.next;
if (next != null)
next.prev = null;
nodes[index] = next;
return;
}
while (curr != null) {
if (curr.key == key) {
Node prev = curr.prev;
Node next = curr.next;
if (prev != null)
prev.next = next;
if (next != null)
next.prev = prev;
return;
} else {
curr = curr.next;
}
}
}
class Node {
Integer key;
Integer value;
Node next;
Node prev;
Node(Integer key, Integer value) {
this.key = key;
this.value = value;
}
}
}文章绝大部分内容节选自LeetCode,概述:
例题:
Hello,我是 却把清梅嗅 ,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的 博客 或者 GitHub。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
学习Flutter一小段时间,对纯Flutter项目有了一些基本的了解,但更趋近实际开发的应该是将Flutter模块作为一个依赖库添加到原生的Android项目中。
本文笔者将尝试分享个人针对Flutter与Android混编时的配置步骤,以及踩坑过程。
参考 官方文档 ,首先需要确认Flutter-Module依赖库文件夹的位置,简单来说,这里有两种方式:
其实这些方式没什么区别,但是个人更倾向于第二种,我们在项目文件夹的目录层级下对Flutter-Module文件夹进行 创建 并 初始化:
$ flutter create -t module module_flutter成功后,Flutter-Module和Android项目本身应该是这样的(红框内的两个项目):
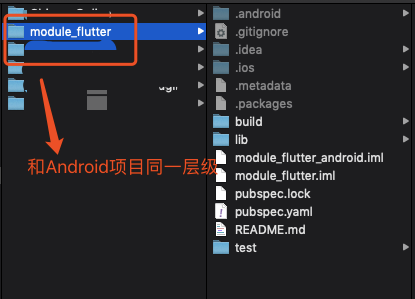
接下来我们需要将这个项目和刚刚创建的module-flutter进行依赖,我们先打开Android原生项目,并为项目根目录下的settings.gradle文件中添加如下配置:
setBinding(new Binding([gradle: this]))
evaluate(new File(
settingsDir.parentFile,
'module_flutter/.android/include_flutter.groovy'
))如果module-flutter模块是创建在项目内部,那么需要稍微改一改:
setBinding(new Binding([gradle: this]))
evaluate(new File(
settingsDir.path,
'module_flutter/.android/include_flutter.groovy'
))然后,我们需要打开app的build.gradle文件,添加对flutter的依赖:
dependencies {
implementation fileTree(dir: 'libs', include: ['*.jar'])
implementation 'androidx.appcompat:appcompat:1.0.0'
implementation 'androidx.annotation:annotation:1.0.0'
......
implementation project(':flutter')
}这样,对于简单的Android原生项目而言,Flutter已经配置成功了。
由于笔者的项目迁移了AndroidX, 但是低版本的Flutter命令生成的module默认依赖的是support包, 因此我们需要将默认support的依赖手动迁移到AndroidX。
截止笔者发文前,
FlutterV1.7已经提供了对AndroidX的支持,当创建Flutter项目的时候,你可以通过添加--androidx来确保生成的项目文件支持AndroidX,详情参考这里。
手动迁移的方式有两种:
Android Studio 自动迁移 过去。首先通过Android Studio打开flutter-module,这时候是不能直接迁移AndroidX的,需要通过flutter - Open Android module in AS 方式新打开一个窗口。

这样编译成功后,就可以点击Refactor - Migrate to AndroidX进行迁移了,后续步骤网上有很多,不赘述。
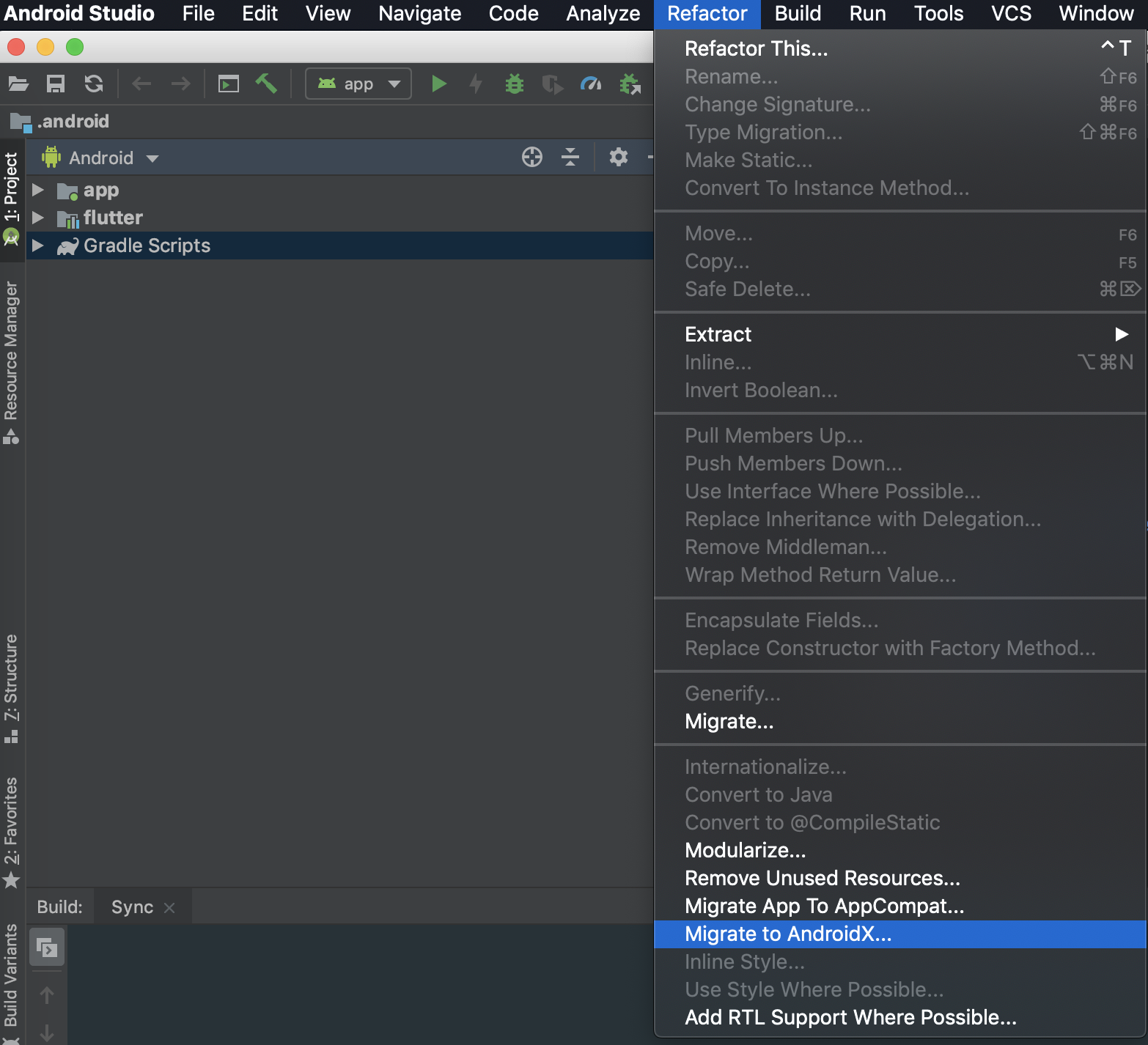
Flutter-build.gradle文件,对依赖进行更新:android {
//...
defaultConfig {
// ...
testInstrumentationRunner "androidx.test.runner.AndroidJUnitRunner"
}
// ...
}
dependencies {
testImplementation 'junit:junit:4.12'
implementation 'androidx.appcompat:appcompat:1.0.0'
implementation 'androidx.annotation:annotation:1.0.0'
// ...
}手动配置网上有很多博客,不赘述。
需要注意的是,一定要保证Flutter模块中对AndroidX相关依赖的版本和实际原生项目中相关依赖的版本是一致的,否则可能会导致依赖冲突。
上文说到,简单的项目已经配置完毕了,但是多模块的项目来说则稍显复杂,比如笔者的项目:
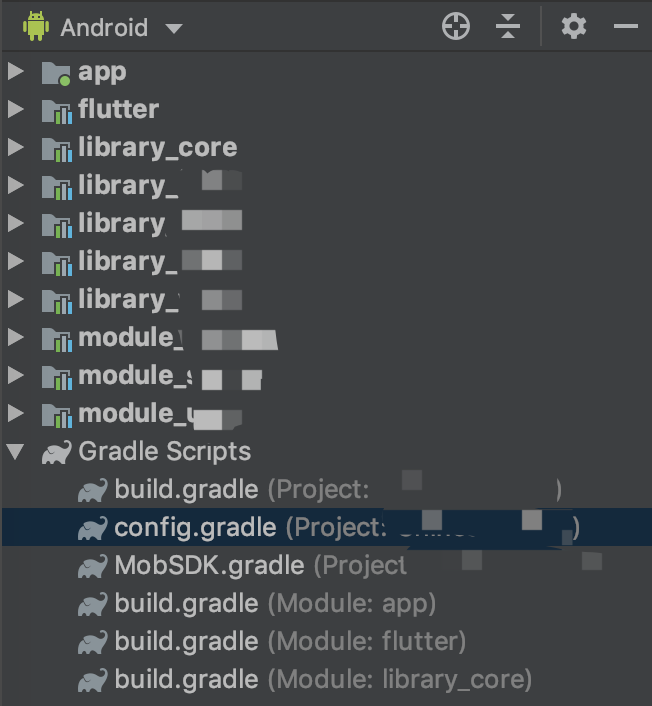
首先,需要在底层library(本文中是library-core)的build.gradle文件中添加对flutter的依赖:
dependencies {
// ...
api project(':flutter')
}添加之后并进行同步,原生的项目就会对settings.gradle文件中指向的module-flutter文件夹进行依赖。
同步、编译成功后,我运行了项目,但我很快遇到了问题:
[ERROR:flutter/runtime/dart_vm_data.cc(19)] VM snapshot invalid and could not be inferred from settings.
[ERROR:flutter/runtime/dart_vm.cc(241)] Could not setup VM data to bootstrap the VM from.
[ERROR:flutter/runtime/dart_vm_lifecycle.cc(89)] Could not create Dart VM instance.
[FATAL:flutter/shell/common/shell.cc(218)] Check failed: vm. Must be able to initialize the VM.
这个问题纠结了很久,最后在 这个issue中 找到了答案:
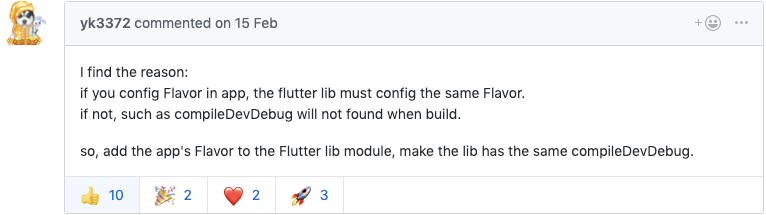
经 @yk3372 大佬提示,原来是以为项目中配置了ProductFlavors, 因此,Flutter模块中对应的build.gradle文件也需要进行对应的配置,比如这样:
buildTypes {
release {}
debug {}
}
flavorDimensions "environment"
productFlavors {
dev {}
qa {}
prod {}
}配置好之后,还需要手动将相关module的ProductFlavors配置相同,否则会提示一堆错误,比如我的一个原生的module依赖了flutter的module,它们就必须都保持同一个状态:
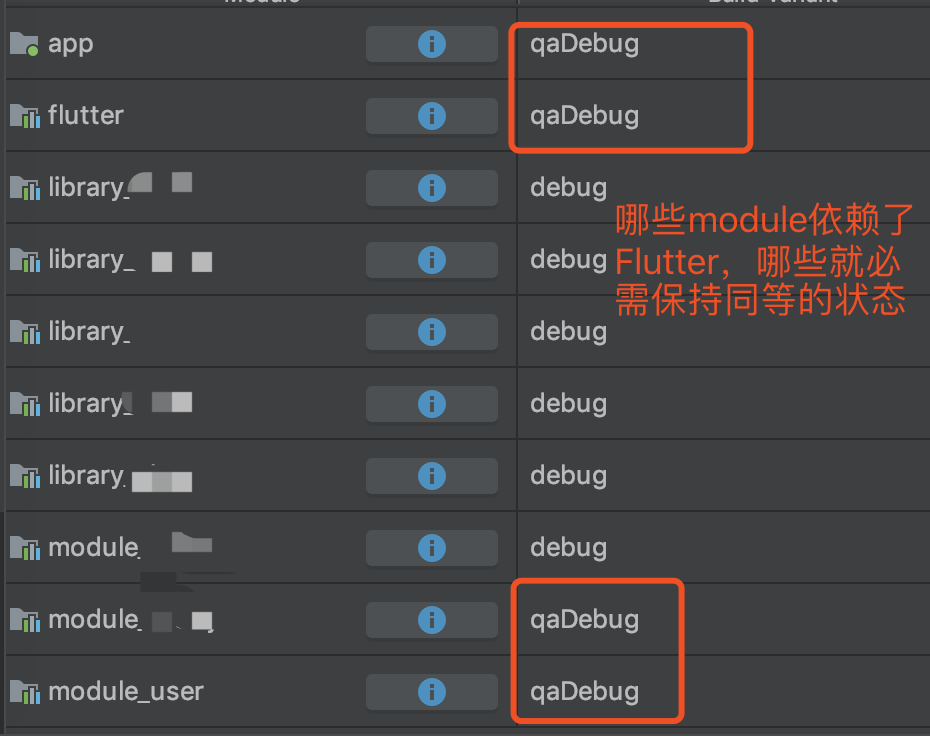
???这是不是意味着所有的module的build.gradle都配置相同的productFlavors信息?
实践给予我答案,是的。

虽然折腾了很久,还好前人栽树,后人乘凉,解决了问题还是happy ending, Github大法好。
本文提供了 官方文档 提供混合开发的集成方式,实际上,国内很多大厂都分享过相关的技术文章,这里也一并放出来:
Hello,我是却把清梅嗅,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的博客或者Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
原文:REACTIVE APPS WITH MODEL-VIEW-INTENT - PART5 - DEBUGGING WITH EASE
作者:Hannes Dorfmann
译者:却把清梅嗅
前文我们探讨了Model-View-Intent (MVI) 架构模式及其相关特性,在 第一篇文章 中,我们谈到了 单项数据流的重要性 和 应用状态应该被业务逻辑驱动。本文我们将展示这种架构模式会怎样回报开发者,它可以让开发者在开发过程中更轻而易举进行debug。
遇到过这样的情况嘛?你得到了一个崩溃的报告,但是你无法复现这个BUG。听起来似曾相识?我也是!在花了很多时间查看堆栈跟踪和项目的源码后,最终我选择了放弃——关闭了这个issue,并提交了一个类似 无法复现 或者 某个Android生产商的某种特定的机型导致的特殊错误 的备注。
以我们的购物App举例来说,在Home界面,用户以某种方式进行下拉刷新,但不知道为什么,崩溃报告告诉我,当用户执行下拉刷新获取最新数据的操作时,应用抛出了一个NullPointerException。
因此,作为开发人员,您启动App并尝试在Home界面进行下拉刷新,但App并没有崩溃, 它按照预期正常地运行。然后您开始仔细检查自己的代码,但是就是找不到哪里会导致NullPointerException的发生。你打开了debug模式,一行一行逐步执行该界面相关的代码,但App仍然正常的运行—— 到底怎么样才能让它在下拉刷新时崩溃?
问题的根本在于你不能在App崩溃发生之前复现状态,如果遇到崩溃的用户可以在崩溃报告中提供他App的状态(在崩溃发生之前)以及堆栈跟踪,那不是很棒吗?
通过 单向数据流 和 Model-View-Intent ,这简直轻而易举。
在 用户执行所有Intent 和 界面对Model进行渲染时,我们很方便地能够将它们进行打印,让我们通过在HomePresenter中添加Log来为Home界面执行这样的操作(具体代码请参考 第三节,该小节我们针对状态折叠器进行了探讨)。
在以下代码片段中,我们使用Crashlytics(译者注:一种崩溃报告工具),使用其它的崩溃报告工具也是一样的:
class HomePresenter extends MviBasePresenter<HomeView, HomeViewState> {
private final HomeViewState initialState; // Show loading indicator
public HomePresenter(HomeViewState initialState){
this.initialState = initialState;
}
@Override protected void bindIntents() {
Observable<PartialState> loadFirstPage = intent(HomeView::loadFirstPageIntent)
.doOnNext(intent -> Crashlytics.log("Intent: load first page"))
.flatmap(...); // 加载数据的业务逻辑
Observable<PartialState> pullToRefresh = intent(HomeView::pullToRefreshIntent)
.doOnNext(intent -> Crashlytics.log("Intent: pull-to-refresh"))
.flatmap(...); // 加载数据的业务逻辑
Observable<PartialState> nextPage = intent(HomeView::loadNextPageIntent)
.doOnNext(intent -> Crashlytics.log("Intent: load next page"))
.flatmap(...); // 加载数据的业务逻辑
Observable<PartialState> allIntents = Observable.merge(loadFirstPage, pullToRefresh, nextPage);
Observable<HomeViewState> stateObservable = allIntents
.scan(initialState, this::viewStateReducer) // 对状态进行折叠
.doOnNext(newViewState -> Crashlytics.log( "State: "+gson.toJson(newViewState) ));
subscribeViewState(stateObservable, HomeView::render); // 展示新的状态
}
private HomeViewState viewStateReducer(HomeViewState previousState, PartialState changes){
...
}
}通过RxJava的 .doOnNext() 操作符,我们可以很轻松将每个intent和每个intent的result——也就是即将渲染在view层上的状态进行打印。
我们将view的状态序列化为json字符串,现在,我们的崩溃报告变成了这样:
现在来看看这些日志,我们不仅能看到崩溃发生之前的最后一个状态,而且还能看到用户达到这个状态所经历的完整历史记录——为了保证可读性,我将data字段内的内容替换为了[...]:
1.用户启动了App,通过加载首页数据的intent,这样loadingFirstPage的值为true,使得加载指示器展示了出来,同时数据也被加载完毕(data[…])。
2.接下来用户滚动列表,并达到了列表的底部,这触发了加载下一页数据的intent,并开始加载更多的数据(分页),这也导致了loadingNextPage状态的改变,它的值变成了true。
3.一旦分页数据被加载成功,loadingNextPage状态改变成了false,用户再次重复操作达到了列表的底部,并又一次出发了触发了加载下一页数据的intent。
4.接下来用户开始尝试下拉刷新的intent,这导致loadingPullToRefresh状态变更为了true,然后,App突然发生了崩溃—— 这之后就没有更多日志了。
这些信息如何帮助我们解决这个bug呢?显然,我们知道用户触发了哪些操作,因此我们完全可以手动复现这个崩溃。此外,因为我们将App的状态用json进行表现,因此我们可以简单地使用最后一个状态,反序列化json并将此状态作为我们的初始状态来修复该错误:
String json =" {\"data\":[...],\"loadingFirstPage\":false,\"loadingNextPage\":false,\"loadingPullToRefresh\":false} ";
HomeViewState stateBeforeCrash = gson.fromJson(json, HomeViewState.class);
HomePresenter homePresenter = new HomePresenter(stateBeforeCrash);接下来我们打开了Debug调试工具,并尝试触发下拉刷新的intent,事实证明,如果用户向下滚动页面2次,则没有更多数据可用,并且我们的App并没有进行相应的处理,因此后续的下拉刷新操作导致了崩溃。
一个应用状态随时随地 可快照 的App可以使我们开发人员的生活更加轻松。我们不仅能够轻松的 复现崩溃,而且可以将状态进行序列化来 编写回归测试,并且这几乎没有什么成本。
请记住,这些便利只有在App的状态遵循 单项数据流 、不可变、纯函数 的原则的情况下才能享受到(即被业务逻辑驱动),Model-View-Intent让我们偏向了这种**流派,而这个架构模式中有一个非常棒并且有效的额外的效果,那就是本文所提到的构建了一个 可快照 的App。
可快照 的应用有什么缺陷呢?显然我们正在将App的状态序列化(比如通过Gson).这增加了一些额外的计算资源的负荷,平均来算的话,状态第一次被Gson序列化大约需要30毫秒,因为Gson必须使用反射来扫描类,以确定必须序列化的字段。
在Nexus 4上,状态的连续序列化平均需要大约6毫秒。由于序列化在.doOnNext()中运行,虽然这通常在后台线程上运行,但的确是这样:我的App用户必须比其它应用的用户多等待6毫秒,才能在屏幕上看到新的状态。
我的观点是,这对于用户来说也许并不明显,但是对状态进行 快照 的一个问题是,在崩溃时,崩溃报告工具从用户设备上传到其服务器的数据量要大得多—— 如果用户通过wifi连接,这无关痛痒,但如果用户处于移动网络下则可能会有一定的争议。
最后,将状态附加在崩溃报告中时,您可能会泄漏用户的一些敏感的数据。针对这个问题,一个方案是不序列化敏感数据,但这可能导致连接到崩溃报告的状态不完整(因此这些报告可能几乎无用),另外一个方案则是将敏感数据进行加密——但这可能需要一些额外的CPU占用。
总结一下:我个人认为这样 可快照 的App有很多优点,但是,你可能需要做出一些权衡。也许您开始为内部版本或beta版本启用App快照,以衡量它其产生的作用。
《使用MVI打造响应式APP》原文
《使用MVI打造响应式APP》译文
《使用MVI打造响应式APP》实战
Hello,我是却把清梅嗅,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的博客或者Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
本文笔者将尝试分享个人针对Flutter的 学习 并 搭建一个Flutter应用 的过程。
在这一个月学习Flutter的过程中,我不可避免的走了很多弯路,也许这并非坏事,但是还是希望将这些经历表述出来,有两个目的:
Flutter的读者一定实质性的参考。关于笔者总结的
Flutter入门学习计划,可直接跳转文末的 Flutter入门学习计划 小节进行查看。
上个月25号,任玉刚老师联系我,问我有没有兴趣翻译一篇Flutter的技术博客。
当时我还没有接触Flutter,觉得这是一个督促自己学习的机会,就尝试接下了这个任务。截止今天为止(6月25日)刚好一个月,在第一周保证翻译任务 完成 之后,三周之后的今天,我基本实现了自己的另外一个目标——搭建一个 Github客户端。
这个项目运行之后,App整体效果是这样的:
我将代码托管在了自己的Github上:
FlutterGitHubApp: Flutter开发的跨平台Github客户端.
因为这是一个入门的项目,所以接下来也会从各方面深入学习Flutter,并反过来继续完善和优化它。
最初学习Flutter的方式是通过学习 wendux 老师的 《Flutter实战》。
这是一本非常优秀的中文Flutter教程,对个人学习Flutter入门有非常大的帮助。
我根据这本小册中的内容完成了第一个 计数器 的入门案例,并对最常用的一些控件进行了熟悉和了解:
正如读者所见,我跟着《Flutter实战》 写了若干的demo代码,遗憾的是,效果并没有想象的那么好,原因也很明显,那就是我还没有完全熟悉Dart的语法。
学习Flutter的最开始,语法并非是最大的阻碍因素,因为对于熟悉Java语法的我们来说,Dart有很多相似之处,但随着Flutter学习的不断深入,有时一些Dart独有的语法特性会给我带来困惑,比如 级联操作符 、 var和dynamic关键字的区别 等等。
正如标题所言,我发现我走入了一个误区,Dart语法的学习势在必行。
我学习语法的方式是通过翻阅Dart中文网:
Dart中文社区:http://dart.goodev.org/
因为是空闲时间学习,因此严格来说学习时间并没有那么多,最初的第一周,笔者花了几个晚上,每天9点下班之后学2~3个小时,熟悉了Dart基本的语法和Flutter的最常用的基础组件。
严格来说,此时个人依然处于小白水平,勉强摸到了入门的门槛。
私下里也会偷偷吐槽一下Dart和Flutter,布局写着写着下面连续十数行的 ),),),);),),},),},);),),),;),},); 真的令人不寒而栗......
因为当初接翻译任务时,自己给自己设定了10天的期限(也是为了督促自己学习),因此第二周我需要在前3天内翻译完这篇博客:
坦白来说,第二周的开始,这篇文章我看不懂,因此我需要学习Flutter开发过程中的架构**。
正所谓窥一斑而知全豹,虽然还没有真正着手Flutter项目的开发,但是通过学习Flutter的核心——状态管理,以及将 业务逻辑 和 UI的渲染 分开学习,再加上作为一个Android开发者,理解这些概念本身就有很大的优势,学习效率自然非常的高。
学习Flutter中状态管理的资料,我强烈推荐 Vadaski 的系列文章。
冒昧推荐这几篇关于状态管理的文章,实际上 Vadaski 老师关于Flutter还有很多优秀的博客,这里不一一列举了,有兴趣的朋友可以去拜读一下。
如果读者之前学习或者了解过Redux和ReactiveX相关的**,状态管理并不是非常难理解的概念。
熟悉了一系列Flutter状态管理的实现方式之后,翻译文章时就顺畅很多了,幸不辱命,最终在第十天的凌晨将文章翻译完毕:
完成之后,因为工作和私人的原因,第二周接下来几天就没有什么时间学习Flutter了。
第二周的学习成果实际上和第一周差不多,因为前三天全神贯注,同时每天晚上多学了一会,再加上吃了之前的老本(之前对于Redux的状态管理和RxJava有一定的储备),学习效率还是比较高的。
这周的感觉就是,虽然自己没怎么上手项目,但是看了一些文章,对Flutter有了一些初步的认识,总结如下:
Flutter本身采用的是React的思路,和我们认知的 过程式开发 是不一样的, 状态管理 和 响应式编程 是非常重要的概念,如果之前有相关的知识储备,这个关键的知识点基本不会有什么难度,只需要关注API的使用就好了;当然,没了解过也没关系,本小节上方的几篇关于状态管理优秀的博客,也能够帮助开发者非常快的进入Flutter的节奏中去。Flutter中的一些概念或者库而言:2.1
RxDart和Stream相关的API和RxJava很相似;
2.2Future相关的API可以参考Kotlin的协程,通过同步的方式编写异步的代码;
2.3Provider其实也就是另一种方式的依赖注入.
2.4Redux就是参考前端的Redux引进的,没有什么变化......
从结果来看,第三周我走了不少弯路。
第三周的最初,我认为我需要开始深入学习Flutter中的Widget,因此我选择fork了著名的 flutter-go, 并且开始尝试跟着这个项目敲代码。
在敲了几天之后,我发现一个严重的问题,那就是这个学习过程中非常枯燥无聊,知识点之间没有关联性,感觉自己学了一个新的Widget,就忘了上一个Widget,没坚持多久,我就hold不住了......

这也难怪,这个项目本身的目的就是 常用组件的demo演示与中文文档, 我一个Widget一个Widget的用法跟着敲,这给了我一种 学习碎片没有组织起来 的感觉,说白了就是不成系统,效果并不明显。
因此我将 flutter-go 这个项目的定位变成了 工具书 ,接下来的学习过程中,每当我对一个Widget的使用有了疑问,就随手打开这个APP进行查阅这个Widget的用法,效果还不错。
第四周我选择了实战开发,了解我的朋友应该知道,我曾经通过不同的开发模式(MVVM和MVI)开发过两次Github的客户端,这次我也不例外。
选择以Github客户端作为实战的练手项目还有一个原因,那就是 恋猫de小郭 老师已经开源了一个更强大的Github客户端可以作为参考:
GSYGithubAppFlutter: 超完整的Flutter项目
同时,恋猫de小郭 老师也有非常优秀的Flutter系列博客,因为该系列文章太多了,就不一一列出了,强烈建议收藏阅读。
所谓前人栽树后人乘凉,GSYGithubAppFlutter 确实在我实践过程中提供了很大的帮助,同时,因为第四周工作阶段性告一段落,我有更多时间去学习Flutter,因此很快就把一个简单的Github客户端敲了出来:
https://github.com/qingmei2/FlutterGitHubApp
在一个月的学习过程中,我学习到了很多东西,也感觉很多地方需要慢慢改进,也感觉到有很多知识点需要去补。
但是令我振奋的一点是,我成功从舒适区跳了出来,并且度过了学习新知识过程中最痛苦的一段时间(畏难情绪+新领域的陌生感);
现在面对诸如 Kotlin和Flutter我学哪个比较好? 的问题,我也可以这样回答了:
小孩子才做选择,成年人当然是全都要啦!
最后,衷心感谢文中提到的各位老师对个人的帮助,其实在学习过程中,我还参考了更多Flutter先驱者们优秀的博客和代码,实在难以一一列举,在此深表感谢。
如何入门Flutter? 以个人经验来看,入门学习Flutter可以参考下面步骤:
Flutter基本概念;flutter-go,将App下载到手机中作为工具书随时随地查阅;Flutter博客系列,比如上文中 Vadaski 和 恋猫de小郭 两位老师的文章;Flutter开源项目学习源码;这个学习计划 一定是有改进空间 的,也诚挚的希望您能在评论区留下宝贵的想法和建议,这也能够为读者提供更多参考性的建议,感谢!
Hello,我是却把清梅嗅,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的博客或者Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
我是 却把清梅嗅 ,GitHub开源社区内的一个 功利 的爱好者。
去年的这个时候,我同样做了一个简短的年终总结:
我不是喜欢一个花时间写非技术类型文章的人,但是每年一篇年终总结于个人确实有所裨益——时隔一年再看,这篇文章段落中的一些吹嘘自己的文字,多少都让我有点尴尬。
同时,我看到了过去自己一些 不成熟的想法 ,与一年后的自己的理念有所冲突,我是一个文字上比较耿直的人,我希望借助这篇年终总结,表达一些自己一年来的对某些观念的改变和新的理解,以及我 以前错了哪里 ,和我 接下来会怎么做。
每个人都是在不断的 自省 中保持进步的,一年后的今天,我也希望能够再次回顾本文,到时候如果我还能够有新的想法新的观点,那就更好不过了。
照例先总结一下个人2019年的一些收获。
需要声明的是,我认为 功利 不应该是一个纯粹的贬义词,至少它于我个人专业领域的发展而言,是有不可磨灭推进作用的,熟悉我的人应该知道,我在GitHub上开源了几个Kotlin的项目:
至今为止断断续续收获了2k+的star,对于Kotlin这门语言来说,2k+的Star于我而言已是非常大的肯定。
其次,我今年一共发表了24篇博客文章,平均一个月2篇左右,我很满意这样的输出频率,因为这其中的一部分文章,尤其是我下半年来写的 反思系列,说是呕心沥血字字雕琢也毫不为过——以 这篇文章 为例,全文篇幅共1w字,从前期调研、到列提纲、绘制思维导图流程图、到撰写完毕,个人花费了整整一个月的时间。
我有 绝对自信 这些文章是对应领域内 最好的中文博客,包括短期内的将来,因此我也非常直白在文章的最开始中这样声明:
我不认为这种行为是狂悖的表现,好的东西理所应当受到鼓励和发扬光大 ,这不仅仅是为读者、技术社区负责,也是为自己负责。
同时我再次向 Android 开发领域的小伙伴们自荐 这些博客,我相信它值得您为它点上一个Star。
今年下半年,有幸受邀作为演讲嘉宾参加了 Droidcon Chengdu 2019 和 GDG Chengdu 2019 Flutter 专场,分别针对 Android 和 Flutter 相关专题进行了分享。


此外在生活方面,2019对我来说是一个非常重要的转折点,除了买房装修搬家诸如此类来来回回的折腾之外,我还结束了和我女朋友将近6年的爱情长跑,成功领证。
略显尴尬的吹逼好像成了大家年终总结的惯例,因为我看大家好像都是这么写的——我觉得这样其实也挺好,有谁会不喜欢别人的赞美呢。
到目前为止,我展示的都是 功利性 的内容,这些都是浮于表面的,它们对我非常有用,至少在简历上摆出这些能让我增加足够多的面试机会,和HR谈薪资待遇的时候也能给我足够的底气。
但是问题随之而来,无论是 开源项目 、 博客输出 还是 公开演讲,这些我都付出了足够多的时间和精力,而为此得到的这些 回报 真的值得吗?
武断的 全盘否定 或者 全盘肯定 都不太好,在我接下来的个人职业规划中,如何对它们进行权衡,怎样才能借助这些行为最大化提升自己,这些反思所得的结果才是至关重要的。
反思并不能改变已经发生了的现状,但却可以让自己去修正自己的意图,那么,类似 开源项目 、 文章输出 还是 公开演讲 ——这些行为最初创建的目的是什么呢?
从某种意义上说,面向Star开源没有什么问题——Star数量的多少本质上来源于社区内开发者对其的认可程度,一个优秀的开源项目理所应当收到足够多的Star。
当然,如果开源行为的目的纯粹是为了Star数量的多少(比如通过某宝花钱刷Star),则又是另外一种极端了。
这里我不想关于这一点深入讨论下去,我想引出的问题是,开源社区的最大优势是什么?
为什么这么问,因为我发现我在偏离 开源精神 的道路上越走越远了!2年来我维护了若干个开源项目,并且都有数量并不少的Star,但是我发现我越来越不开心,因为我被这些Star和虚假的优越感困住了。
陆陆续续的,我花费极大的精力去维护这几个项目,诚然它们的Star越来越多,但是我对这些代码 越来越不满意 ,因为随着我个人专业能力的提升,这些代码设计在我看来有各种各样的瑕疵。
一切都不同了!!!开源的伊始,我为我的这些代码骄傲,但是逐渐的我开始厌弃它们,我甚至觉得它们不值那么多的Star,我脑子里有更多有趣的想法,但是我没有精力去实现这些想法,虚荣感和责任感让我持续为开源项目付出越来越多的精力。
一切似乎都变得不再有趣,直到有一天我突然想到,我为什么要一个人闭门造车呢?GitHub上仍然有那么多优秀的开源项目和开源组织,也许尝试和社区内其它优秀的开发者,齐心协力开发维护一个更优秀的项目,远远比一个人闭门造车要好得多。
这也是我近半年来不再随便造轮子的原因,每当我有一个好玩的想法,我会问自己,它真的有花费时间去实现并开源的必要吗?它代表着对开源项目和开源社区的责任感,这也能隐性节约我非常多的时间。
逐利并不可耻。
在技术社区中,技术文标题的重要性不言而喻。
每个读者阅读时间都是有限的,他们总会优先阅读标题比较有趣的文章,当然,一篇文章阅读量多了,其它文章的阅读量自然就少了。
我真的没有想到,我今年24篇博客中,阅读量和点赞量最多的文章是 这篇 :
这篇文章从下笔到发表,我一共花费了不到2个小时,而它给我带来的流量的零头,也比其它花费10小时以上撰写的技术文章所得到的还多。
说实话,我并不感到兴奋,相反我对此感到恐惧,我看到很多优秀的文章,仅仅是因为标题不够吸睛,它们都随着时间被流放到在了博客平台不为人知的角落。甚至有的文章被洗稿的公众号换个标题党的名字发表,就能吸引过来巨大的流量和点赞。
不公平吗?其实很公平,因为这都是每位读者自己的选择。但是我希望这种现象能够被慢慢改变,好的文章不应该随意被埋没。
从个人而言,解决这种困境最好的方式,就是保持高质量的更新,没有啰里八嗦的闲聊,没有标题党,尝试 用纯粹获取读者的信任,上文中我多次提到的 反思系列 就是我一次努力的尝试。
每一次的输出都保证,对读者负责,也对自己负责,无论结果,尽力就好。
无论是大型的技术大会,还是一次小型的的交流会,指望参加一次,能够打通自己的一个技能栈是不现实的。
因此,如果问我,你作为演讲嘉宾参加这种公开的活动,除了露个脸赚了一些知名度,还能够收获到其它的什么吗?
我的回答是,能,而且收获非常庞大的好处,最简单的,它甚至能够打破你职业发展的天花板,让你重新定位自己。
两次公开演讲结束后,我最大的收获就是认识了同为演讲嘉宾的其它开发者,还有与会的各个行业内的前辈,他们的阅历和开发经验都丰富到令我震惊。
下面是我上周参加完GDG Flutter专场后的感慨:
原来,当我在一个人慢慢学习Flutter的时候,Flutter在其它更优秀的开发者手里已经运用到了驾轻就熟的程度了,优秀的技术人都在不断的涌现,每个人相对于这个时代的浪潮,真的就是:
寄蜉蝣于天地,渺沧海之一粟。
因此,借此机会,认识到技术的发展方向和发展程度,能够重新定位自己,并找到接下来为之努力的目标,调整自己的职业规划,这种好处是不言而喻的。
总而言之,善用”功利心”,它所带来的正向反馈能够帮助我坚持下去,无论是 写作能力 、 表达能力 、专业知识 ,甚至在 求职 和 谈薪 时都能带来非常大的好处。
但同时也要把握住这个度,坚守本心,不要为一时的虚荣心和满足感拖慢了前进的脚步,时时刻刻保持自省,认清自己,不急不缓,保持住自己的节奏,这很难,但随时想想那些专业领域内的天才们的成果,功利心就能被按捺住很多。
也没必要过分自卑,我很喜欢我的个性签名:
你微小,但你并不渺小。
本文是 《Android Jetpack 官方架构组件》 系列文章, LiveData本身很简单,但其代表却正是 MVVM 模式最重要的**,即 数据驱动视图(也有叫观察者模式、响应式等)——这也是摆脱 顺序性编程思维 的重要一步。
我们都知道Google在去年的 I/O 大会非常隆重地推出了一系列的 架构组件,本文的主角,LiveData 正是其中之一,和Lifecycle、ViewModel、Room比较起来,LiveData可以说是最受关注的组件也不为过,遗憾的是,在发布的最初,关注点是因为它饱含争议,相当一部分的开发者认为——LiveData 实在太 鸡肋 了!
2017年的 Android 技术领域,RxJava无疑是炙手可热的名词之一,其 观察者模式 和 链式调用 所表现出来的 API 优秀地设计,使得它位于很多 Android项目技术选型中的 第一序列。
这时 Google 隆重推出了具有类似功能的 LiveData (其本质就是观察者模式),可以说是有点初生牛犊不怕虎的感觉,开发者们不由自主将LiveData 和 RxJava 进行了对比,结论基本出奇的一致—— LiveData所提供的功能,RxJava完全足以胜任,而后者却同时具有庞大的生态圈,这是LiveData短时间内难以撼动(替代)的。
时至今日,LiveData的使用者越来越多,最主要的原因当然和Google的强力支持不无关系,但是LiveData本身优秀的设计和轻量级也吸引了越来越多开发者的青睐。
现在我们需要去了解它了,我们都知道,LiveData 本质是 观察者模式 的体现,可关键的问题是:
讨论这个问题之前,我们先看看 LiveData 的用法,这实在没什么技术难度,比如,你可以这样实例化一个LiveData并使用它:

如你所见,LiveData实际上就像一个 容器, 本文中它存储了一个String类型的引用,每当这个容器内 String的数据发生变化,我们都能在回调函数中进行对应的处理,比如 Toast。
这似乎和我们日常用到的 Button 控件的 setOnClickListener() 非常相似,实际上点击事件的监听也正是 观察者模式 的一种体现,对于观察者来说,它并不关心观察对象 数据是如何过来的,而只关心数据过来后 进行怎样的处理。
这也就是说,事件发射的上游 和 接收事件的下游 互不干涉,大幅降低了互相持有的依赖关系所带来的强耦合性。
我依然坚持学习原理比学习如何应用的优先级更高,因此我们先来一一探究LiveData本身设计中存在的那些闪光点背后的故事。
我们都知道,RxJava在使用过程中,避免内存泄漏是一个不可忽视的问题,因此我们一般需要借助三方库比如RxLifecycle、AutoDispose来解决这个问题。
而反观LiveData,当它被我们的Activity订阅观察,这之后Activity如果finish()掉,LiveData本身会自动“清理”以避免内存泄漏。
这是一个非常好用的特性,它的实现原理非常简单,其本质就是利用了Jetpack 架构组件中的另外一个成员—— Lifecycle。
让我们来看看LiveData被订阅时内部的代码:

源码中的逻辑非常复杂,我们只关注核心代码:
LiveData.observer()方法时,传递的第一个参数Acitivity实际被向上抽象成为了 LifecycleOwner,第二个参数Obserser实际就是我们的观察后的回调。这里我们需要注意的是,执行
LiveData.observer()方法时 必须处于主线程,否则会因为断言失败而抛出异常。
LifecycleBoundObserver对象,它实现了 Lifecycle 组件中的LifecycleObserver接口:
这里就解释了为什么LiveData能够 自动解除订阅而避免内存泄漏 了,因为它内部能够感应到Activity或者Fragment的生命周期。
这种设计非常巧妙——在我们初识 Lifecycle 组件时,总是下意识认为它能够对大的对象进行有效生命周期的管理(比如 Presenter),实际上,这种生命周期的管理我们完全可以应用到各个功能的基础组件中,比如大到吃内存的 MediaPlayer(多媒体播放器)、绘制设计复杂的 自定义View,小到随处可见的LiveData,都可以通过实现LifecycleObserver接口达到 感应生命周期并内部释放重的资源 的目的。
关于上述代码中注释了 更新LiveData的活跃状态 的源码,我们先跳过,稍后我们会详细探讨它。
LiveData来讲,当然存在多个观察者同时订阅观察的情况,因此考虑到这一点,Google的工程师们为每一个LiveData配置了一个Map存储所有的观察者。4.到了这一步,我们将第2步包装生成的对象交给我们传入的 Activity,让它在不同的生命周期事件中去逐一通知其所有的观察者,当然也包含了我们的LiveData。
LiveData原生的API提供了2种方式供开发者更新数据, 分别是 setValue()和postValue(),官方文档明确标明:setValue()方法必须在 主线程 进行调用,而postValue()方法更适合在执行较重工作 子线程 中进行调用(比如网络请求等)——在所有情况下,调用setValue()或postValue()都会 触发观察者并更新UI。
柿子挑软的捏,我们先看setValue()方法的实现原理:
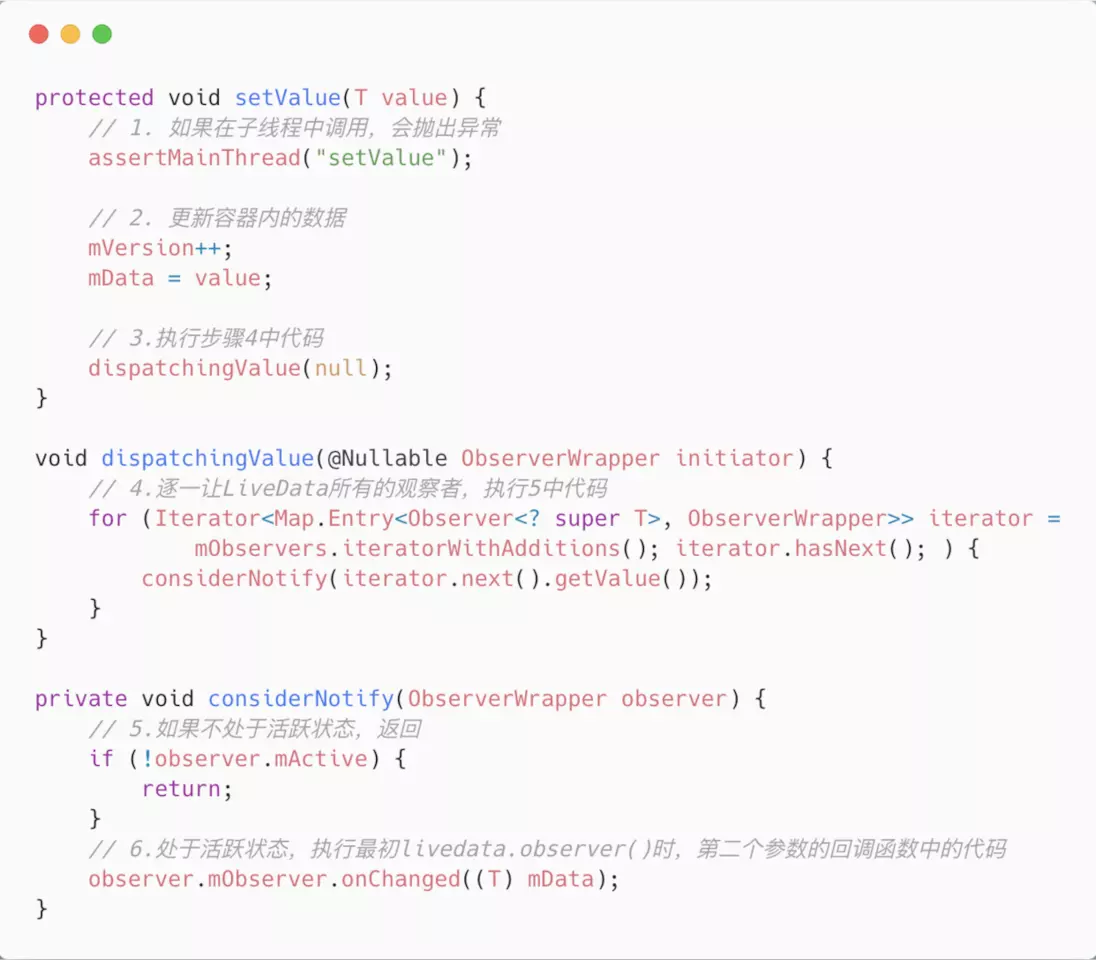
通过保留最终的核心代码,我们很清晰了解了setValue()方法为什么能更新LiveData的值,并且通知到回调函数中的代码去执行,比如更新UI。
但是我们知道,普遍情况下,Android不允许在子线程更新UI,但是postValue()方法却可以在子线程更新LiveData()的数据,并通知更新UI,这是如何实现的呢?
其实答案已经呼之欲出了,就是通过 Handler:
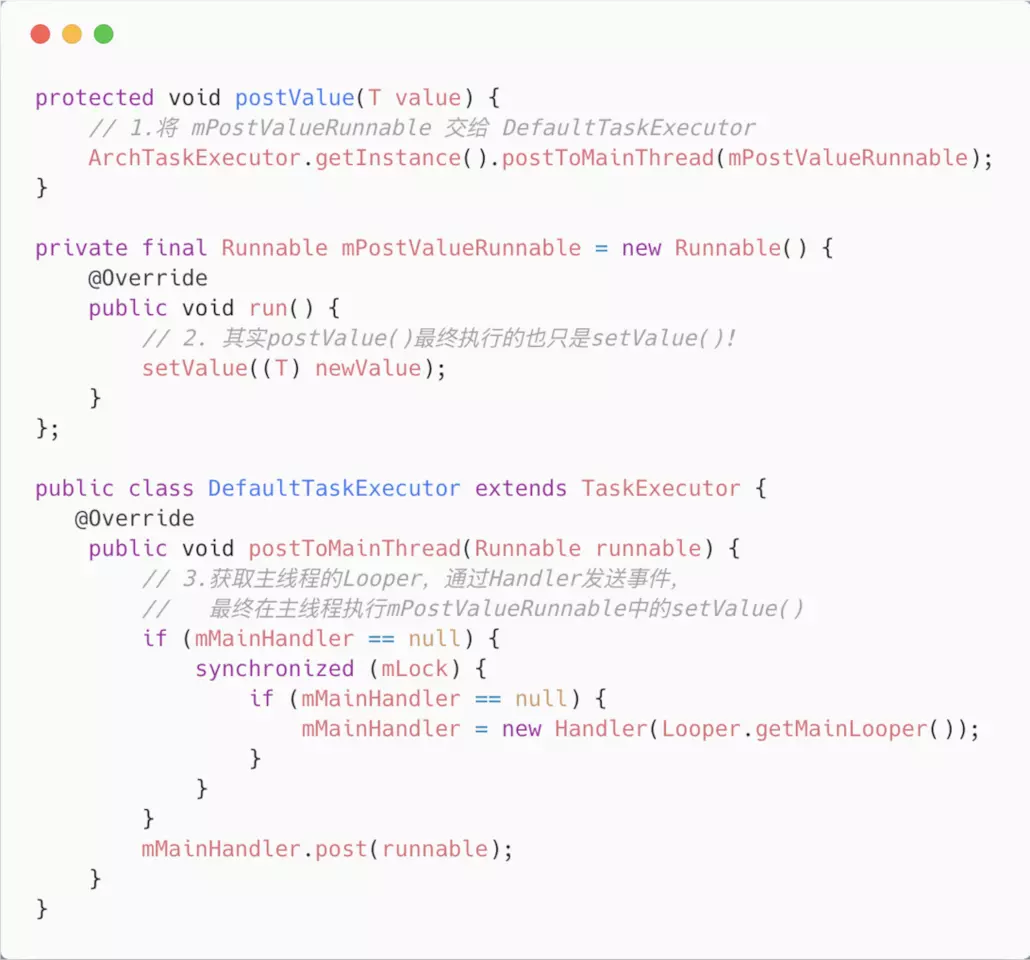
现在你已经对LiveData整体了一个基本的了解了,接下来让我们开始去探究更细节的闪光点。
LiveData本身非常简单,毕竟它本身的源码一共也就500行左右,也许你要说 准备面试粗读一遍源码就够了,很遗憾,即使是粗读了源码,也很难说能够完全招架更深入的提问...
让我们来看一道题目:在下述Activity完整的生命周期中,Activity一共观察到了几次数据的变更——即 一共打印了几条Log ?(补充纠正,onStop()方法中值应该为 "onStop")
公布答案:

意外的是,livedata.observer()的本次观察并没有观察到 onCreate、onStop 和 onDestroy 的数据变更。
还记得上文提到过2次的 LiveData的活跃状态(Active) 相关代码吗?实际上,LiveData内部存储的每一个LifecycleBoundObserver本身都有shouldBeActive的状态:

现在我们明白了,原来并不是只要在onDestroy()之前为LiveData进行更新操作,LiveData的观察者就能响应到对应的事件的。
虽然我们明白了这一点,但是如果更深入的思考,你会又多一个问题,那就是:
LiveData已经能够实现在onDestroy()的生命周期时自动解除订阅,为什么还要多此一举设置一个Active的状态呢?仔细想想,其实也不难得到答案,Activity并非只有onDestroy()一种状态的,更多时候,新的Activity运行在栈顶,旧的Activity就会运行在 background——这时旧的Activity会执行对应的onPause()和onStop()方法,我们当然不会关心运行在后台的Activity所观察的LiveData对象(即使数据更新了,我们也无从进行对应UI的更新操作),因此LiveData进入 **InActive(待定、非活跃)**状态,return并且不去执行对应的回调方法,是 非常缜密的优秀设计 。
当然,有同学提出,我如果希望这种情况下,Activity在后台依然能够响应数据的变更,可不可以呢?当然可以,LiveData此外还提供了observerForever()方法,在这种情况下,它能够响应到任何生命周期中数据的变更事件:

除此之外,源码中处处都是优秀的细节,比如对于observe()方法和observerForever()方法对应生成的包装类,后者方法生成的是AlwaysActiveObserver对象,统一抽象为ObserverWrapper。

这种即使只有2种不同场景,也通过代码的设计,将公共业务进行向上抽离为抽象类的严谨,也非常值得我们学习。
本来写了更多,篇幅所限,最终还是决定删除了相当一部分和 RxJava 有关的内容,这些内容并非是将 LiveData 和 RxJava 进行对比一决高下—— 例如,Google官方提供了 LiveData 和 RxJava 互相进行转换的工具类:
https://developer.android.com/reference/android/arch/lifecycle/LiveDataReactiveStreams
值得玩味的是,官方的工具类中,LiveData向RxJava的转换方法,返回值并非是一个Flowable,而是一个Publisher接口:

正如我在注释中标注的,这个工具方法返回的是一个接口,很大程度上限制了我们对RxJava众多强大操作符的使用,这是否是来自Google的恶意?
当然不是,对于这种行为,我的理解是Google对于LiveData本身严格的约束——它只应该用于进行数据的观察,而不是花哨的操作;转换为Flowable当然非常简单,但是这种行为是否属于LiveData本身职责的逾越,更准确来说,是否属于不必要的过度设计?这些是我们需要去细细揣度的。
我无从验证我的理解是否正确,但是我的这个理由已经足够说服我自己,再往下已不再是LiveData的范畴,关于这一点我将会专门起一篇文章去进行更深入的探讨,欢迎关注。
--------------------------广告分割线------------------------------
争取打造 Android Jetpack 讲解的最好的博客系列:
Android Jetpack 实战篇:
Hello,我是却把清梅嗅,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的个人博客或者Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?

广度优先搜索(BFS)的一个常见应用是找出从根结点到目标结点的最短路径。
在第一轮中,我们处理根结点。在第二轮中,我们处理根结点旁边的结点;在第三轮中,我们处理距根结点两步的结点;等等等等。
与树的层序遍历类似,越是接近根结点的结点将越早地遍历。
如果在第 k 轮中将结点 X 添加到队列中,则根结点与 X 之间的最短路径的长度恰好是 k。也就是说,第一次找到目标结点时,你已经处于最短路径中。
首先将根结点排入队列。然后在每一轮中,我们逐个处理已经在队列中的结点,并将所有邻居添加到队列中。值得注意的是,新添加的节点不会立即遍历,而是在下一轮中处理。
结点的处理顺序与它们添加到队列的顺序是完全相同的顺序,即先进先出(FIFO)。这就是我们在 BFS 中使用队列的原因。
int BFS(Node root, Node target) {
Queue<Node> queue = new LinkedList<>(); // 存储所有等待处理的节点
int step = 0; // 深度
// 初始化,将根节点存入队列
queue.offer(root);
// BFS
while (!queue.isEmpty()) {
step = step + 1;
// 迭代
int size = queue.size();
for (int i = 0; i < size; ++i) {
Node cur = queue.peek();
// 第一次找到该节点,将深度返回
if (cur == target)
return step
for (Node next : the neighbors of cur) {
queue.offer(next);
}
queue.remove();
}
}
return -1;
}1.如代码所示,在每一轮中,队列中的结点是等待处理的结点。
2.在每个更外一层的while循环之后,我们距离根结点更远一步。变量step指示从根结点到我们正在访问的当前结点的距离。
有时,确保我们 永远不会访问一个结点两次 很重要。否则,我们可能陷入无限循环。如果是这样,我们可以在上面的代码中添加一个哈希集来解决这个问题。这是修改后的伪代码:
int BFS(Node root, Node target) {
Queue<Node> queue = new LinkedList<>(); // 存储所有等待处理的节点
Set<Node> used = new HashSet<>(); // 存储已经访问了的节点
int step = 0; // 深度
// 初始化,将根节点存入队列和 HashSet 中
queue.offer(root);
used.add(root);
// BFS
while (!queue.isEmpty()) {
step = step + 1;
// 迭代
int size = queue.size();
for (int i = 0; i < size; ++i) {
Node cur = queue.peek();
// 第一次找到该节点,将深度返回
if (cur == target)
return step
for (Node next : the neighbors of cur) {
if(!used.contains(next)) {
queue.offer(next);
used.add(next);
}
}
queue.remove();
}
}
return -1;
}有两种情况你不需要使用哈希集:
1.你完全确定没有循环,例如,在树遍历中;
2.你确实希望多次将结点添加到队列中。
Medium给定一个由 '1'(陆地)和 '0'(水)组成的的二维网格,计算岛屿的数量。一个岛被水包围,并且它是通过水平方向或垂直方向上相邻的陆地连接而成的。你可以假设网格的四个边均被水包围。
示例 1:
输入:
11110
11010
11000
00000
输出: 1
示例 2:
输入:
11000
11000
00100
00011
输出: 3
这道题思路如下:线性扫描整个二维网格,如果一个结点包含 1,则以其为根结点启动广度优先搜索。将其放入队列中,并将值设为 0 以标记访问过该结点。迭代地搜索队列中的每个结点,直到队列为空。
实现代码:
class Solution {
public int numIslands(char[][] grid) {
int result = 0;
if (grid == null || grid.length == 0 || grid[0].length == 0) return result;
int nr = grid.length;
int nc = grid[0].length;
for (int c = 0; c < nc; c++) {
for (int r = 0; r < nr; r++) {
// 如果是岛,返回结果加1,并将默认的坐标点标记为0
if (isIsland(grid, c, r)) {
result++;
makeVisited(grid, c, r);
// 开始广度优先搜索算法
final LinkedList<Integer> queue = new LinkedList<>();
queue.add(r * nc + c);
while (!queue.isEmpty()) {
final int removed = queue.remove();
final int removedCol = removed % nc;
final int removedRow = removed / nc;
// top
// left removed right
// bottom
// top
final int removeTop = removedRow - 1;
if (removeTop >= 0 && isIsland(grid, removedCol, removeTop)) {
queue.add(removeTop * nc + removedCol);
makeVisited(grid, removedCol, removeTop);
}
// left
final int removeLeft = removedCol - 1;
if (removeLeft >= 0 && isIsland(grid, removeLeft, removedRow)) {
queue.add(removedRow * nc + removeLeft);
makeVisited(grid, removeLeft, removedRow);
}
// bottom
final int removeBottom = removedRow + 1;
if (removeBottom <= nr - 1 && isIsland(grid, removedCol, removeBottom)) {
queue.add(removeBottom * nc + removedCol);
makeVisited(grid, removedCol, removeBottom);
}
// right
final int removeRight = removedCol + 1;
if (removeRight <= nc - 1 && isIsland(grid, removeRight, removedRow)) {
queue.add(removedRow * nc + removeRight);
makeVisited(grid, removeRight, removedRow);
}
}
}
}
}
return result;
}
// 返回二维数组对应的位置是否为岛
private boolean isIsland(char[][] grid, int c, int r) {
return grid[r][c] == '1';
}
// 标记二维数组对应的位置非岛
private void makeVisited(char[][] grid, int c, int r) {
grid[r][c] = '0';
}
}Medium你有一个带有四个圆形拨轮的转盘锁。每个拨轮都有10个数字: '0', '1', '2', '3', '4', '5', '6', '7', '8', '9' 。每个拨轮可以自由旋转:例如把 '9' 变为 '0','0' 变为 '9' 。每次旋转都只能旋转一个拨轮的一位数字。
锁的初始数字为 '0000' ,一个代表四个拨轮的数字的字符串。
列表 deadends 包含了一组死亡数字,一旦拨轮的数字和列表里的任何一个元素相同,这个锁将会被永久锁定,无法再被旋转。
字符串 target 代表可以解锁的数字,你需要给出最小的旋转次数,如果无论如何不能解锁,返回 -1 。
我们可以将 0000 到 9999 这 10000 状态看成图上的 10000 个节点,两个节点之间存在一条边,当且仅当这两个节点对应的状态只有 1 位不同,且不同的那位相差 1(包括 0 和 9 也相差 1 的情况),并且这两个节点均不在数组 deadends 中。那么最终的答案即为 0000 到 target 的最短路径。
我们用广度优先搜索来找到最短路径,从 0000 开始搜索。对于每一个状态,它可以扩展到最多 8 个状态,即将它的第 i = 0, 1, 2, 3 位增加 1 或减少 1,将这些状态中没有搜索过并且不在 deadends 中的状态全部加入到队列中,并继续进行搜索。注意 0000 本身有可能也在 deadends 中。
public class B752OpenLock {
public int openLock(String[] deadends, String target) {
Set<String> dead = new HashSet<>();
for (String d : deadends) dead.add(d);
// 用于bfs的队列
Queue<String> queue = new LinkedList<>();
queue.add("0000");
queue.add(null);
// 额外的一个哈希集,确保我们永远不会访问一个结点两次。
// 否则,我们可能陷入无限循环
Set<String> seen = new HashSet<>();
seen.add("0000");
int depth = 0;
while (!queue.isEmpty()) {
final String node = queue.remove();
if (node == null) {
// null 作为单次广度搜索的尾巴标记
depth++;
if (queue.peek() != null) {
// 这意味着单轮搜索结束,队列末尾继续追加一个null
// 当轮训到下一个null时,意味着下轮的搜索结束
queue.offer(null);
}
} else if (node.equals(target)) {
return depth;
} else if (!dead.contains(node)) { // 如果某个节点不是死亡数字
// 对于每一个状态,它可以扩展到最多 8 个状态,即将它的第 i = 0, 1, 2, 3 位增加 1 或减少 1
for (int i = 0; i < 4; i++) { // 四个位置
for (int j = -1; j <= 1; j += 2) { // 每个位置分别 -1 , + 1
// 这里用到一个小技巧避免对字符进行额外的负数判断
// 这里统一加10求余,值一定是期望的值,否则结果会返回负数
// 比如,当node.charAt(i) = '0', j = -1 时,这时候结果仍然是期望的9,而不是 -1
int y = ((node.charAt(i) - '0') + j + 10) % 10;
// 取得对应的邻居节点,比如 i = 1, j = 1 时, '0000' -> '0100'
String nei = node.substring(0, i) + String.valueOf(y) + node.substring(i + 1);
if (!seen.contains(nei)) {
seen.add(nei);
queue.offer(nei);
}
}
}
}
}
return -1;
}
}Medium给定正整数 n,找到若干个完全平方数(比如 1, 4, 9, 16, ...)使得它们的和等于 n。你需要让组成和的完全平方数的个数最少。
示例 1:
输入: n = 12
输出: 3
解释: 12 = 4 + 4 + 4.
示例 2:
输入: n = 13
输出: 2
解释: 13 = 4 + 9.
如下图,详细实现参考代码:
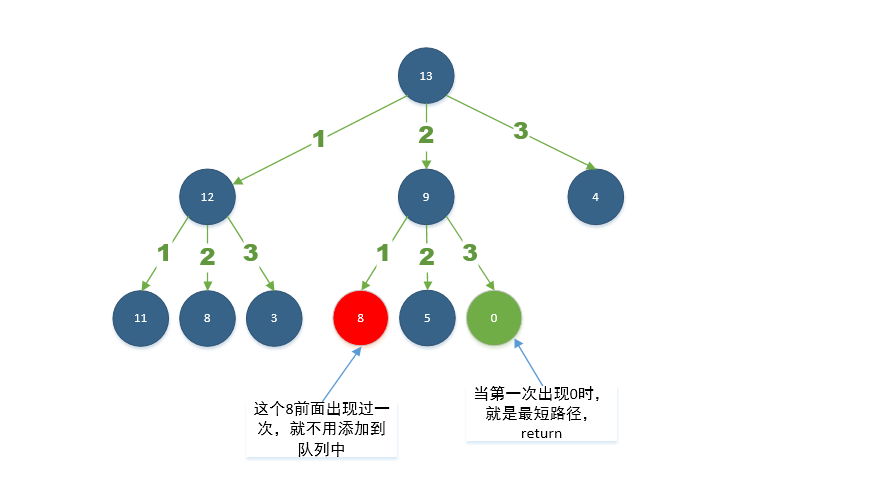
class Solution {
public int numSquares(int n) {
boolean[] visited = new boolean[n];
int step = 1;
Queue<Integer> queue = new LinkedList<>();
queue.add(n);
queue.add(null);
while (!queue.isEmpty()) {
Integer removed = queue.remove();
// bfs
for (int i = 1; ; i++) {
if (removed == null) {
step++;
if (queue.peek() != null) {
queue.offer(null);
}
break;
}
int nextValue = removed - (i * i);
if (nextValue == 0)
return step;
if (nextValue < 0) {
break;
}
// 关键点!
// 当再次出现时没有必要加入,因为在该节点的路径长度肯定不小于第一次出现的路径长
if (!visited[nextValue]) {
visited[nextValue] = true;
queue.add(nextValue);
}
}
}
return -1;
}
}文章绝大部分内容节选自LeetCode,概述:
例题:
Hello,我是 却把清梅嗅 ,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的 博客 或者 GitHub。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
反思 系列博客是我的一种新学习方式的尝试,该系列起源和目录请参考 这里 。
就在前几日,有幸拜读到 HiDhl 的文章,继腾讯开源类似功能的MMKV之后,Google官方维护的 Jetpack DataStore 组件横空出世——这是否意味着无论是腾讯三方还是Google官方的角度,SharedPreferences都彻底告别了这个时代?
无论是MMKV的支持者还是DataStore的拥趸,SharedPreferences似乎都不值一提;值得深思的是,笔者通过面试或者其它方式,和一些同行交流时,却遇到了以下的情形:
在谈及SharedPreferences和MMKV,大多数人都能对前者的 缺陷,以及后者性能上若干 数量级的优势 娓娓道来;但是,在针对前者的短板进行细节化的讨论时,往往却得不到更深入性的结果,简单列举几个问题如下:
SharedPreferences是如何保证线程安全的,其内部的实现用到了哪些锁?SharedPreferences?除此之外,站在 设计者的角度 上,还有一些与架构相关,且同样值得思考的问题:
SharedPreferences会有这些缺陷,如何对这些缺陷做改进的尝试?DataStore组件来代替前者?Google工程师掣肘,时隔今日,这些缺陷依然存在的最根本性原因是什么?而想要解除这些潜藏在内心最深处的困惑,就不得不从SharedPreferences本身的设计与实现讲起了。
本文大纲如下:
我们知道,就在不久前2019年的Google I/O大会上,官方推出了Jetpack Security组件,旨在保证文件和SharedPreferences的安全性,SharedPreferences的包装类,EncryptedSharedPreferences隆重登场。
不仅如此,Android 8.0前后的源码中,SharedPreferences内部的实现也略有不同。由此可见,Android官方一直在尽力“拯救”SharedPreferences。
因此,在毅然决然抛弃SharedPreferences投奔新的解决方案之前,我们有必要重新认识一下它。
SharedPreferences是Android平台上 轻量级的存储类,用来保存App的各种配置信息,其本质是一个以 键值对(key-value)的方式保存数据的xml文件,其保存在/data/data/shared_prefs目录下。
对于21世纪初,那个Android系统诞生的时代而言,使用xml文件保存应用轻量级的数据绝对是一个不错的主意。那个时代的json才刚刚出生不久,虽然也渐渐成为了主流的 轻量级数据交换格式 ,但是其更多的优势还是在于 可读性,这也是笔者猜测没有使用json而使用xml保存的原因之一。
现在我们为这个 轻量级的存储类 建立了最基础的模型,通过xml中的键值对,将对应的数据保存到本地的文件中。这样,每次读取数据时,通过解析xml文件,得到指定key对应的value;每次更新数据,也通过文件中key更新对应的value。
通过这样的方式,虽然我们建立了一个最简单的 文件存储系统,但是性能实在不敢恭维,每次读取一个key对应的值都要重新对文件进行一次读的操作?显然需要尽量避免笨重的I/O操作。
因此设计者针对读操作进行了简单的优化,当SharedPreferences对象第一次通过Context.getSharedPreferences()进行初始化时,对xml文件进行一次读取,并将文件内所有内容(即所有的键值对)缓到内存的一个Map中,这样,接下来所有的读操作,只需要从这个Map中取就可以了:
final class SharedPreferencesImpl implements SharedPreferences {
private final File mFile; // 对应的xml文件
private Map<String, Object> mMap; // Map中缓存了xml文件中所有的键值对
}读者不禁会有疑问,虽然节省了I/O的操作,但另一个视角分析,当xml中数据量过大时,这种 内存缓存机制 是否会产生 高内存占用 的风险?
这也正是很多开发者诟病SharedPreferences的原因之一,那么,从事物的两面性上来看,高内存占用 真的是设计者的问题吗?
不尽然,因为SharedPreferences的设计初衷是数据的 轻量级存储 ,对于类似应用的简单的配置项(比如一个boolean或者int类型),即使很多也并不会对内存有过高的占用;而对于复杂的数据(比如复杂对象反序列化后的字符串),开发者更应该使用类似Room这样的解决方案,而非一股脑存储到SharedPreferences中。
因此,相对于「SharedPreferences会导致内存使用过高」的说法,笔者更倾向于更客观的进行总结:
虽然 内存缓存机制 表面上看起来好像是一种 空间换时间 的权衡,实际上规避了短时间内频繁的I/O操作对性能产生的影响,而通过良好的代码规范,也能够避免该机制可能会导致内存占用过高的副作用,所以这种设计是 值得肯定 的。
针对写操作,设计者同样设计了一系列的接口,以达到优化性能的目的。
我们知道对键值对进行更新是通过mSharedPreferences.edit().putString().commit()进行操作的——edit()是什么,commit()又是什么,为什么不单纯的设计初mSharedPreferences.putString()这样的接口?
设计者希望,在复杂的业务中,有时候一次操作会导致多个键值对的更新,这时,与其多次更新文件,我们更倾向将这些更新 合并到一次写操作 中,以达到性能的优化。
因此,对于SharedPreferences的写操作,设计者抽象出了一个Editor类,不管某次操作通过若干次调用putXXX()方法,更新了几个xml中的键值对,只有调用了commit()方法,最终才会真正写入文件:
// 简单的业务,一次更新一个键值对
sharedPreferences.edit().putString().commit();
// 复杂的业务,一次更新多个键值对,仍然只进行一次IO操作(文件的写入)
Editor editor = sharedPreferences.edit();
editor.putString();
editor.putBoolean().putInt();
editor.commit(); // commit()才会更新文件了解到这一点,读者应该明白,通过简单粗暴的封装,以达到类似SPUtils.putXXX()这种所谓代码量的节省,从而忽略了Editor.commit()的设计理念和使用场景,往往是不可取的,从设计上来讲,这甚至是一种 倒退 。
另外一个值得思考的角度是,本质上文件的I/O是一个非常重的操作,直接放在主线程中的commit()方法某些场景下会导致ANR(比如数据量过大),因此更合理的方式是应该将其放入子线程执行。
因此设计者还为Editor提供了一个apply()方法,用于异步执行文件数据的同步,并推荐开发者使用apply()而非commit()。
看起来Editor+apply()方法对写操作做了很大的优化,但更多的问题随之而来,比如子线程更新文件,必然会引发 线程安全问题;此外,apply()方法真的能够像我们预期的一样,能够避免ANR吗?答案是并不能,这个我们后文再提。
随着业务复杂度的上升,需要面对新的问题是,xml文件中的数据量愈发庞大,一次文件的写操作成本也愈发高昂。
xml中数据是如何更新的?读者可以简单理解为 全量更新 ——通过上文,我们知道xml文件中的数据会缓存到内存的mMap中,每次在调用editor.putXXX()时,实际上会将新的数据存入在mMap,当调用commit()或apply()时,最终会将mMap的所有数据全量更新到xml文件里。
由此可见,xml中数据量的大小,的确会对 写操作 的成本有一定的影响,因此,设计者更建议将 不同业务模块的数据分文件存储 ,即根据业务将数据存放在不同的xml文件中。
因此,不同的xml文件应该对应不同的SharedPreferences对象,如果想要对某个xml文件进行操作,就通过传不同的文件标识符,获取对应的SharedPreferences:
@Override
public SharedPreferences getSharedPreferences(String name, int mode) {
// name参数就是文件名,通过不同文件名,获取指定的SharedPreferences对象
}因此,当xml文件过大时,应该考虑根据业务,细分为若干个小的文件进行管理;但过多的小文件也会导致过多的SharedPreferences对象,不好管理且易混淆。实际开发中,开发者应根据业务的需要进行对应的平衡。
SharedPreferences是线程安全的吗?
毫无疑问,SharedPreferences是线程安全的,但这只是对成品而言,对于我们目前的实现,显然还有一定的差距,如何保证线程安全呢?
——那,为了保证线程安全,怎么着不得加个锁吧。
加个锁?那是起步!3把锁,你还别嫌多。你得研究开发写代码时的心理,舍得往代码里吭哧吭哧加锁的开发,压根不在乎再加2把。
为了保证SharedPreferences是线程安全的,Google的设计者一共使用了3把锁:
final class SharedPreferencesImpl implements SharedPreferences {
// 1、使用注释标记锁的顺序
// Lock ordering rules:
// - acquire SharedPreferencesImpl.mLock before EditorImpl.mLock
// - acquire mWritingToDiskLock before EditorImpl.mLock
// 2、通过注解标记持有的是哪把锁
@GuardedBy("mLock")
private Map<String, Object> mMap;
@GuardedBy("mWritingToDiskLock")
private long mDiskStateGeneration;
public final class EditorImpl implements Editor {
@GuardedBy("mEditorLock")
private final Map<String, Object> mModified = new HashMap<>();
}
}对于这样复杂的类而言,如何提高代码的可读性?SharedPreferencesImpl做了一个很好的示范:通过注释明确写明加锁的顺序,并为被加锁的成员使用@GuardedBy注解。
对于简单的 读操作 而言,我们知道其原理是读取内存中mMap的值并返回,那么为了保证线程安全,只需要加一把锁保证mMap的线程安全即可:
public String getString(String key, @Nullable String defValue) {
synchronized (mLock) {
String v = (String)mMap.get(key);
return v != null ? v : defValue;
}
}那么,对于 写操作 而言,我们也能够通过一把锁达到线程安全的目的吗?
对于写操作而言,每次putXXX()并不能立即更新在mMap中,这是理所当然的,如果开发者没有调用apply()方法,那么这些数据的更新理所当然应该被抛弃掉,但是如果直接更新在mMap中,那么数据就难以恢复。
因此,Editor本身也应该持有一个mEditorMap对象,用于存储数据的更新;只有当调用apply()时,才尝试将mEditorMap与mMap进行合并,以达到数据更新的目的。
因此,这里我们还需要另外一把锁保证mEditorMap的线程安全,笔者认为,不和mMap公用同一把锁的原因是,在apply()被调用之前,getXXX和putXXX理应是没有冲突的。
代码实现参考如下:
public final class EditorImpl implements Editor {
@Override
public Editor putString(String key, String value) {
synchronized (mEditorLock) {
mEditorMap.put(key, value);
return this;
}
}
}而当真正需要执行apply()进行写操作时,mEditorMap与mMap进行合并,这时必须通过2把锁保证mEditorMap与mMap的线程安全,保证mMap最终能够更新成功,最终向对应的xml文件中进行更新。
文件的更新理所当然也需要加一把锁:
// SharedPreferencesImpl.EditorImpl.enqueueDiskWrite()
synchronized (mWritingToDiskLock) {
writeToFile(mcr, isFromSyncCommit);
}最终,我们一共通过使用了3把锁,对整个写操作的线程安全进行了保证。
篇幅限制,本文不对源码进行详细引申,有兴趣的读者可参考
SharedPreferencesImpl.EditorImpl类的apply()源码。
apply()方法设计的初衷是为了规避主线程的I/O操作导致ANR问题的产生,那么,ANR的问题真得到了有效的解决吗?
并没有,在 字节跳动技术团队 的 这篇文章 中,明确说明了线上环境中,相当一部分的ANR统计都来自于SharedPreference,由此可见,apply()并没有完全规避掉这个问题,那么导致ANR的原因又是什么呢。
经过我们的优化,SharedPreferences的确是线程安全的,apply()的内部实现也的确将I/O操作交给了子线程,可以说其本身是没有问题的,而其原因归根到底则是Android的另外一个机制。
在apply()方法中,首先会创建一个等待锁,根据源码版本的不同,最终更新文件的任务会交给QueuedWork.singleThreadExecutor()单个线程或者HandlerThread去执行,当文件更新完毕后会释放锁。
但当Activity.onStop()以及Service处理onStop等相关方法时,则会执行 QueuedWork.waitToFinish()等待所有的等待锁释放,因此如果SharedPreferences一直没有完成更新任务,有可能会导致卡在主线程,最终超时导致ANR。
什么情况下
SharedPreferences会一直没有完成任务呢? 比如太频繁无节制的apply(),导致任务过多,这也侧面说明了SPUtils.putXXX()这种粗暴的设计的弊端。
Google为何这么设计呢?字节跳动技术团队的这篇文章中做出了如下猜测:
无论是 commit 还是 apply 都会产生 ANR,但从 Android 之初到目前 Android8.0,Google 一直没有修复此 bug,我们贸然处理会产生什么问题呢。Google 在 Activity 和 Service 调用 onStop 之前阻塞主线程来处理 SP,我们能猜到的唯一原因是尽可能的保证数据的持久化。因为如果在运行过程中产生了 crash,也会导致 SP 未持久化,持久化本身是 IO 操作,也会失败。
如此看来,导致这种缺陷的原因,其设计也的确是有自身的考量的,好在 这篇文章 末尾也提出了一个折衷的解决方案,有兴趣的读者可以了解一下,本文不赘述。
SharedPreferences是否进程安全呢?让我们打开SharedPreferences的源码,看一下最顶部类的注释:
/**
* ...
* This class does not support use across multiple processes.
* ...
*/
public interface SharedPreferences {
// ...
}由此,由于没有使用跨进程的锁,SharedPreferences是进程不安全的,在跨进程频繁读写会有数据丢失的可能,这显然不符合我们的期望。
那么,如何保证SharedPreferences进程的安全呢?
实现思路很多,比如使用文件锁,保证每次只有一个进程在访问这个文件;或者对于Android开发而言,ContentProvider作为官方倡导的跨进程组件,其它进程通过定制的ContentProvider用于访问SharedPreferences,同样可以保证SharedPreferences的进程安全;等等。
篇幅原因,对实现有兴趣的读者,可以参考 百度 或文章末尾的 参考资料。
SharedPreferences再次迎来了新的挑战。
由于不可预知的原因(比如内核崩溃或者系统突然断电),xml文件的 写操作 异常中止,Android系统本身的文件系统虽然有很多保护措施,但依然会有数据丢失或者文件损坏的情况。
作为设计者,如何规避这样的问题呢?答案是对文件进行备份,SharedPreferences的写入操作正式执行之前,首先会对文件进行备份,将初始文件重命名为增加了一个.bak后缀的备份文件:
// 尝试写入文件
private void writeToFile(...) {
if (!backupFileExists) {
!mFile.renameTo(mBackupFile);
}
}这之后,尝试对文件进行写入操作,写入成功时,则将备份文件删除:
// 写入成功,立即删除存在的备份文件
// Writing was successful, delete the backup file if there is one.
mBackupFile.delete();反之,若因异常情况(比如进程被杀)导致写入失败,进程再次启动后,若发现存在备份文件,则将备份文件重名为源文件,原本未完成写入的文件就直接丢弃:
// 从磁盘初始化加载时执行
private void loadFromDisk() {
synchronized (mLock) {
if (mBackupFile.exists()) {
mFile.delete();
mBackupFile.renameTo(mFile);
}
}
}现在,通过文件备份机制,我们能够保证数据只会丢失最后的更新,而之前成功保存的数据依然能够有效。
综合来看,SharedPreferences那些一直被关注的问题,从设计的角度来看,都是有其自身考量的。
我们可以看到,虽然SharedPreferences其整体是比较完善的,但是为什么相比较MMKV和Jetpack DataStore,其性能依然有明显的落差呢?
这个原因更加综合且复杂,即使笔者也还是处于浅显的了解层面,比如后两者在其数据序列化方面都选用了更先进的protobuf协议,MMKV自身的数据的 增量更新 机制等等,有机会的话会另起新的一篇进行分享。
反过头来,相对于对组件之间单纯进行 好 和 不好 的定义,笔者更认为通过辩证的方式去看待和学习它们,相信即使是SharedPreferences,学习下来依然能够有所收获。
细心的读者应该能够发现,关于 参考&感谢 一节,笔者着墨越来越多,原因无他,笔者 从不认为 一篇文章就能够讲一个知识体系讲解的面面俱到,本文亦如是。
因此,读者应该有选择性查看其它优质内容的权利,甚至是为其增加一些简洁的介绍(因为标题大多都很相似),而不是文章末尾甩一堆
https开头的链接不知所云。这也是对这些内容创作者的尊重,如果你喜欢本文,也同样希望你能够喜欢下面这些文章。
1、请不要滥用SharedPreference @Weishu
我们如何定义好的文章?深度 和 引人入胜,笔者觉得缺一不可,深度保证了文章能够经久不衰,引人入胜代表了流畅的 文字功底 和 文章结构,这篇文章将apply()导致的ANR原理通过浅显易懂的方式解构的非常透彻,我认为它是最适合进阶学习SharedPreferences的文章。
2、Android源码分析之SharedPreferences @xiaoweiz
对于一门技术,如何系统掌握其 理论 ,笔者的理解是,学习理解其设计**,从零开始一步步完善整个系统解构,最终通过源码进行互相印证。
而对于SharedPreferences,学习设计**,看本文;源码解析,看这篇。
3、Android 之不要滥用 SharedPreferences(下) @godliness
标题和1很相似,但内容更有深度,该文针对 多进程下的文件安全问题 和 文件备份机制 进行了源码级别的解析,值得收藏。
4、剖析 SharedPreference apply引起的ANR问题 @字节跳动技术团队
针对apply()方法导致的ANR的问题,进行了原因定位和解决方案,非常值得阅读。
5、再见 SharedPreferences 拥抱 Jetpack DataStore @HiDhl
最近笔者非常关注的博主,文章都很有深度,文章中根据SharedPreferences的缺陷都进行了系统性的阐述,也是因为该文,引发了笔者写本文缅怀SharedPreferences的想法。
6、通过ContentProvider实现SharedPreferences进程共享数据 @king龙123
7、Android使用读写锁实现多进程安全的SharedPreferences @痕迹丶
针对保证SharedPreferences多进程安全的实现方案,有兴趣的读者可以作为引申阅读。
Hello,我是 却把清梅嗅 ,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的 博客 或者 GitHub。
如果您觉得文章还差了那么点东西,也请通过 关注 督促我写出更好的文章——万一哪天我进步了呢?
原文:REACTIVE APPS WITH MODEL-VIEW-INTENT - PART6 - RESTORING STATE
作者:Hannes Dorfmann
译者:却把清梅嗅
在前几篇文章中,我们讨论了Model-View-Intent(MVI)和单向数据流的重要性,这极大简化了状态的恢复,那么其过程和原理是什么呢,本文我们针对这个问题进行探讨。
我们将针对2个场景进行探讨:
Bundle中获取之前在Activity.onSaveInstanceState()保存的状态)这种情况处理起来非常简单。我们只需要保持我们的RxJava流随着时间的推移从Android生命周期组件(即Activity,Fragment甚至ViewGroups)种发射新的状态。
比如Mosby的 MviBasePresenter 类在内部就使用了类似这样的RxJava的流:使用 PublishSubject 发射intent,以及使用 BehaviorSubject 对View进行渲染。对此,在 第二部分 中我已经阐述了是如何实现的。其主要**是MviBasePresenter是一个和View生命周期隔离的组件,因此它能够被View脱离和附着。在Mosby中,当View被永久销毁时,Presenter被destroyed(垃圾收集)。同样,这只是Mosby的一个实现细节,您的MVI实现可能完全不同。
重要的是,像Presenter这样的组件存活在View的生命周期之外,因为这样很容易处理View脱离和附着的事件。每当View(重新)依附到Presenter时,我们只需调用view.render(previousState)(因此Mosby内部使用了BehaviorSubject)。
这只是处理屏幕方向改变的一种处理方案,它同样适用于返回栈导航中。例如,Fragment在返回栈中,我们如果从返回栈中返回,我们可以简单的再次调用view.render(previousState),并且,view也会显示正确的状态。
事实上,即使没有View对其进行依附,状态也依然会被更新,因为Presenter存活在View的生命周期之外,并被保存在RxJava流中。设想如果没有View附着,则会收到一个更改数据(部分状态)的推送通知,同样,每当View重新附着时,最新状态(包含来自推送通知的更新数据)将被移交给View进行渲染。
这种场景在MVI这种单向数据流模式下也很简单。现在我们希望View层的状态不仅仅存在于内存中,即使进程终止也能够对其持有。Android中通常的一种解决方案是通过调用Activity.onSaveInstanceState(Bundle)去保存状态。
与MVP、MVVM不同的是,在MVI中你持有了代表状态的Model,View有一个render(state)方法来记录最新的状态,这让持有最后一个状态变得简单。因此,显然易见的是打包和存储状态到一个bundle下面,并且之后恢复它:
class MyActivity extends Activity implements MyView {
private final static KEY_STATE = "MyStateKey";
private MyViewState lastState;
@Override
public void render(MyState state) {
lastState = state;
... // 更新UI控件
}
@Override
public void onSaveInstanceState(Bundle out){
out.putParcelable(KEY_STATE, lastState);
}
@Override
public void onCreate(Bundle saved){
super.onCreate(saved);
MyViewState initialState = null;
if (saved != null){
initialState = saved.getParcelable(KEY_STATE);
}
presenter = new MyPresenter( new MyStateReducer(initialState) ); // With dagger: new MyDaggerModule(initialState)
}
...
}我想你已得要领,请注意,在onCreate()中我们并不直接调用view.render(initialState), 我们让初始状态的逻辑下沉到状态管理的地方: 状态折叠器(请参考第三部分),我们将它与.scan(initialState,reducerFunction)搭配使用。
与其他模式相比,使用单向数据流和表示状态的Model,许多与状态相关的东西更容易实现。但是,我通常不会在我的App中将状态持久化,两个原因:首先,Bundle有大小限制,因此你不能将任意大的状态放入bundle中(或者你可以将状态保存到文件或像Realm这样的对象存储中);其次,我们只讨论了如何序列化和反序列化状态,但这不一定与恢复状态相同。
例如:假设我们有一个LCE(加载内容错误)视图,它会在加载数据时显示一个指示器,并在完成加载后显示条目列表,因此状态就类似MyViewState.LOADING。让我们假设加载需要一些时间,而就在此时进程刚好被终止了(比如突然一个电话打了进来,导致电话应用占据了前台)。
如果我们仅仅将MyViewState.LOADING进行序列化并在之后进行反序列化操作对状态进行恢复,我们的状态折叠器会调用view.render(MyViewState.LOADING),目前为止这是正确的,但实际上我们 永远不会通过这个状态对网络进行请求加载数据。
如您所见,序列化和反序列化状态与状态恢复不同,这可能需要一些额外的步骤来增加复杂性(当然对于MVI来说这实现起来同样比其它模式更简单),当重新创建View时,包含某些数据的反序列化状态可能会过时,因此您可能必须刷新(加载数据)。
在我研究过的大多数应用程序中,我发现相比之下这种方案更简单且友好:即,将状态仅仅保存在内存中,并且在进程死亡后以空的初始状态启动,好像应用程序将首次启动一样。理想情况下,App具有对缓存和离线的支持,因此在进程终止后加载数据的速度也会很快。
这最终导致了我和其它Android开发者针对一个问题进行了激烈的辩论:
如果我使用缓存或存储,我已经拥有了一个存活于
Android组件生命周期之外的组件,而且我不再需要去处理相关的状态存储问题,并且MVI毫无意义,对吗?
这其中大多数Android开发者推荐 Mike Nakhimovich 发表的 《Presenter 不是为了持久化》这篇文章介绍的 NyTimes Store,这是一个数据加载和缓存库。遗憾的是,那些开发人员不明白 加载数据和缓存不是状态管理。例如,如果我必须从缓存或存储中加载数据呢?
最后,类似NyTimes Store的库帮助我们处理进程终止了吗?显然没有,因为进程随时都有可能被终止。我们能做的仅仅是祈祷Android操作系统不要杀死我们的进程,因为我们还有一些需要通过Service做的事(这也是一个能够不生存于其它android组件生命周期的组件),或者我们可以通过使用RxJava而不再需要Android Service了,这可行吗?
我们将在下一章节探讨关于android services、RxJava以及MVI,敬请期待。
《使用MVI打造响应式APP》原文
《使用MVI打造响应式APP》译文
《使用MVI打造响应式APP》实战
Hello,我是却把清梅嗅,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的博客或者Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
你好最近在用paging 做分页!
用在聊天消息上,现在有需求是,有人回复当前用户会弹出一个按钮。 点击按钮 滚动到这条回复消息。
由于paging 是一页一页加载的,现在无法确定 回复的那条消息的position,无法用ScrollToPosition 。请问有什么办法吗?

本文为博主算法学习过程中的学习笔记,主要内容来源于其他平台或书籍,出处请参考下方 参考&感谢 一节。
哈希集 是集合的实现之一,它是一种存储 不重复值 的数据结构。
因此,通常,使用哈希集来检查该值是否已经出现过。
让我们来看一个例子:
给定一个整数数组,查找数组是否包含任何重复项。
这是一个典型的问题,可以通过哈希集来解决。
你可以简单地迭代每个值并将值插入集合中。 如果值已经在哈希集中,则存在重复。
给定一个整数数组,判断是否存在重复元素。
如果任何值在数组中出现至少两次,函数返回 true。如果数组中每个元素都不相同,则返回 false。
示例:
输入: [1,2,3,1]
输出: true
HashSet的入门题,最基本模版的实现。
class Solution {
public boolean containsDuplicate(int[] nums) {
HashSet<Integer> set = new HashSet<>();
for (int i = 0; i < nums.length; i++) {
if (set.contains(nums[i])) {
return true;
} else {
set.add(nums[i]);
}
}
return false;
}
}给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
示例:
输入: [2,2,1]
输出: 1
这道题解决方案有很多种,HashSet是其中的一种解法,也比较基础。
class Solution {
public int singleNumber(int[] nums) {
HashSet<Integer> set = new HashSet<>();
for (int i = 0; i < nums.length; i++) {
if (!set.contains(nums[i])) {
set.add(nums[i]);
} else {
set.remove(nums[i]);
}
}
return set.iterator().next();
}
}给定两个数组,编写一个函数来计算它们的交集。
示例:
输入: nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出: [9,4]
说明:
有点繁琐,HashSet的暴力破解法:
class Solution {
public int[] intersection(int[] nums1, int[] nums2) {
// 暴力破解之
int len1 = nums1.length;
int len2 = nums2.length;
if (len1 == 0 || len2 == 0) return new int[]{};
HashSet<Integer> set1 = new HashSet<>();
for (int i = 0; i < len1; i++)
set1.add(nums1[i]);
HashSet<Integer> set2 = new HashSet<>();
for (int i = 0; i < len2; i++)
set2.add(nums2[i]);
int[] result = new int[set1.size()];
int index = 0;
for (int value : set1) {
if (set2.contains(value)) {
result[index] = value;
index++;
}
}
return Arrays.copyOf(result,index);
}
}编写一个算法来判断一个数是不是“快乐数”。
一个“快乐数”定义为:对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和,然后重复这个过程直到这个数变为 1,也可能是无限循环但始终变不到 1。如果可以变为 1,那么这个数就是快乐数。
示例:
输入: 19
输出: true
解释:
12 + 92 = 82
82 + 22 = 68
62 + 82 = 100
12 + 02 + 02 = 1
这道题是非常有意思的一道题,可以思考不难得出,这种一个正整数的循环计算,每位上数字的平方和,计算结果最多也就3、4位数——也就是说,最终经过有限的步骤,最终都会进入循环。
因此我们每次计算都将结果存入HashSet,出现1时自然就是快乐数;而当出现循环时若结果还没有出现1,意味着接下来再也不会出现1,因此这个数字也就不是快乐数了:
class Solution {
public boolean isHappy(int n) {
HashSet<Integer> set = new HashSet<>();
set.add(n);
while (true) {
n = change(n);
if (n == 1)
return true;
if (set.contains(n)) {
return false;
} else {
set.add(n);
}
}
}
private int change(int n) {
int sum = 0;
while (n > 0) {
int bit = n % 10;
sum += bit * bit;
n = n / 10;
}
return sum;
}
}之所以说这道题有意思的地方在于,另外一种视角来看,我们可以将每次计算的结果串联起来,这样问题就转换为了 弗洛伊德的乌龟与兔子 问题,通过 快慢指针 进行解决。
文章绝大部分内容节选自LeetCode,概述:
例题:
Hello,我是 却把清梅嗅 ,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的 博客 或者 GitHub。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
原文:Write an Android Studio Plugin Part 4: Jira Integration
作者:Marcos Holgado
译者:却把清梅嗅
《编写AndroidStudio插件》系列是 IntelliJ IDEA 官方推荐的学习IDE插件开发的博客专栏,希望对有需要的读者有所帮助。
在本系列的第三部分中,我们学习了如何使用Component对数据进行持久化,并利用这些数据来创建新的设置页面。在今天的文章中,我们将使用这些数据将Jira与我们的插件快速集成在一起。

请记住,您可以在GitHub上找到本系列的所有代码,还可以在对应的分支上查看每篇文章的相关代码,本文的代码在Part4分支中。
今天这篇文章的目的是解释如何将第三方API和库集成到插件中。我将应用一个简单的MVP模式,您可以更改为MVC或任何您喜欢的开发模式。
今天,我们将Jira集成到我们的插件中,我们要做的是能够在Android Studio中将Jira Scrum板上的issue移至下一栏。因为Jira的issue ID将基于我们当前的git分支,所以我们的插件将从我们当前的分支中解析issue ID,而不是强迫用户手动输入或从其他位置选择issue ID。
在开始前,我们先进行一些假设。
issue(比如记录时间等)之前,您无需填写任何必填字段,否则你的UI将需要额外的字段供用户输入;Jira Cloud Platform API v3;Basic auth) ,因为我们的目标是学习如何集成第三方工具,而不是如何在Jira中进行正确的身份验证。除非您正在构建仅供内部使用的工具(例如脚本和机器人),否则我们(
Jira)不建议使用基本身份验证。
这就是我的面板页在Jira中展示出来的样子,issue只能向前推进,并且只能从一列移至下一列,您不能跳过流程中的任何一列。
首先,我们将在设置页面中添加更多字段。根据我们的目标,我们需要添加一个新的regex字段,其中将包含一个正则表达式以从当前分支中提取issue ID。我们还将需要一个Jira URL字段,该字段将用作API调用的基本URL。最后,Jira API需要使用auth令牌而不是密码,为了清楚起见,我将旧密码字段的名称更改为token。
这些变动应该简单直观,如下所示:
@State(name = "JiraConfiguration",
storages = [Storage(value = "jiraConfiguration.xml")])
class JiraComponent(project: Project? = null) :
AbstractProjectComponent(project),
Serializable,
PersistentStateComponent<JiraComponent> {
var username: String = ""
var token: String = ""
var url: String = ""
var regex: String = ""
override fun getState(): JiraComponent? = this
override fun loadState(state: JiraComponent) =
XmlSerializerUtil.copyBean(state, this)
companion object {
fun getInstance(project: Project): JiraComponent =
project.getComponent(JiraComponent::class.java)
}
}class JiraSettings(private val project: Project): Configurable, DocumentListener {
private val tokenField: JPasswordField = JPasswordField()
private val txtUsername: JTextField = JTextField()
private val txtUrl: JTextField = JTextField()
private val txtRegEx: JTextField = JTextField()
private var modified = false
override fun isModified(): Boolean = modified
override fun getDisplayName(): String = "MyPlugin Jira"
override fun apply() {
val config = JiraComponent.getInstance(project)
config.username = txtUsername.text
config.token = String(tokenField.password)
config.url = txtUrl.text
config.regex = txtRegEx.text
modified = false
}
override fun changedUpdate(e: DocumentEvent?) {
modified = true
}
override fun insertUpdate(e: DocumentEvent?) {
modified = true
}
override fun removeUpdate(e: DocumentEvent?) {
modified = true
}
override fun createComponent(): JComponent {
val mainPanel = JPanel()
mainPanel.setBounds(0, 0, 452, 254)
mainPanel.layout = null
val lblUsername = JLabel("Username")
lblUsername.setBounds(30, 25, 83, 16)
mainPanel.add(lblUsername)
val lblPassword = JLabel("Token")
lblPassword.setBounds(30, 74, 83, 16)
mainPanel.add(lblPassword)
val lblUrl = JLabel("Jira URL")
lblUrl.setBounds(30, 123, 83, 16)
mainPanel.add(lblUrl)
val lblRegEx = JLabel("RegEx")
lblRegEx.setBounds(30, 172, 83, 16)
mainPanel.add(lblRegEx)
txtUsername.setBounds(125, 20, 291, 26)
txtUsername.columns = 10
mainPanel.add(txtUsername)
tokenField.setBounds(125, 69, 291, 26)
mainPanel.add(tokenField)
txtUrl.setBounds(125, 118, 291, 26)
txtUrl.columns = 10
mainPanel.add(txtUrl)
txtRegEx.setBounds(125, 167, 291, 26)
txtRegEx.columns = 10
mainPanel.add(txtRegEx)
val config = JiraComponent.getInstance(project)
txtUsername.text = config.username
tokenField.text = config.token
txtUrl.text = config.url
txtRegEx.text = config.regex
tokenField.document?.addDocumentListener(this)
txtUsername.document?.addDocumentListener(this)
txtUrl.document?.addDocumentListener(this)
txtRegEx.document?.addDocumentListener(this)
return mainPanel
}
}在进行下一步之前,请确保这些更改确实有效,并且新字段的数据已正确进行了保存。
现在,我们可以创建一个新的Action,将所有代码插入其中,然后转到下一篇文章,但我们不会这样做,因为:
您仍在编写代码! -Marcos Holgado(就是我!)
仅仅因为这是一个插件,并不意味着您不必对其进行维护或遵循任何编码规范。我看到太多插件,其中所有代码都在一个Action中。我不明白,如果您不想将所有代码都放在Action中,为什么还要这么做?
今天,我将使用MVP模式,但您可以使用任何您喜欢的模式,只要您遵循经典的编码规范,就不会有太大的不同。我们的看起来像这样:
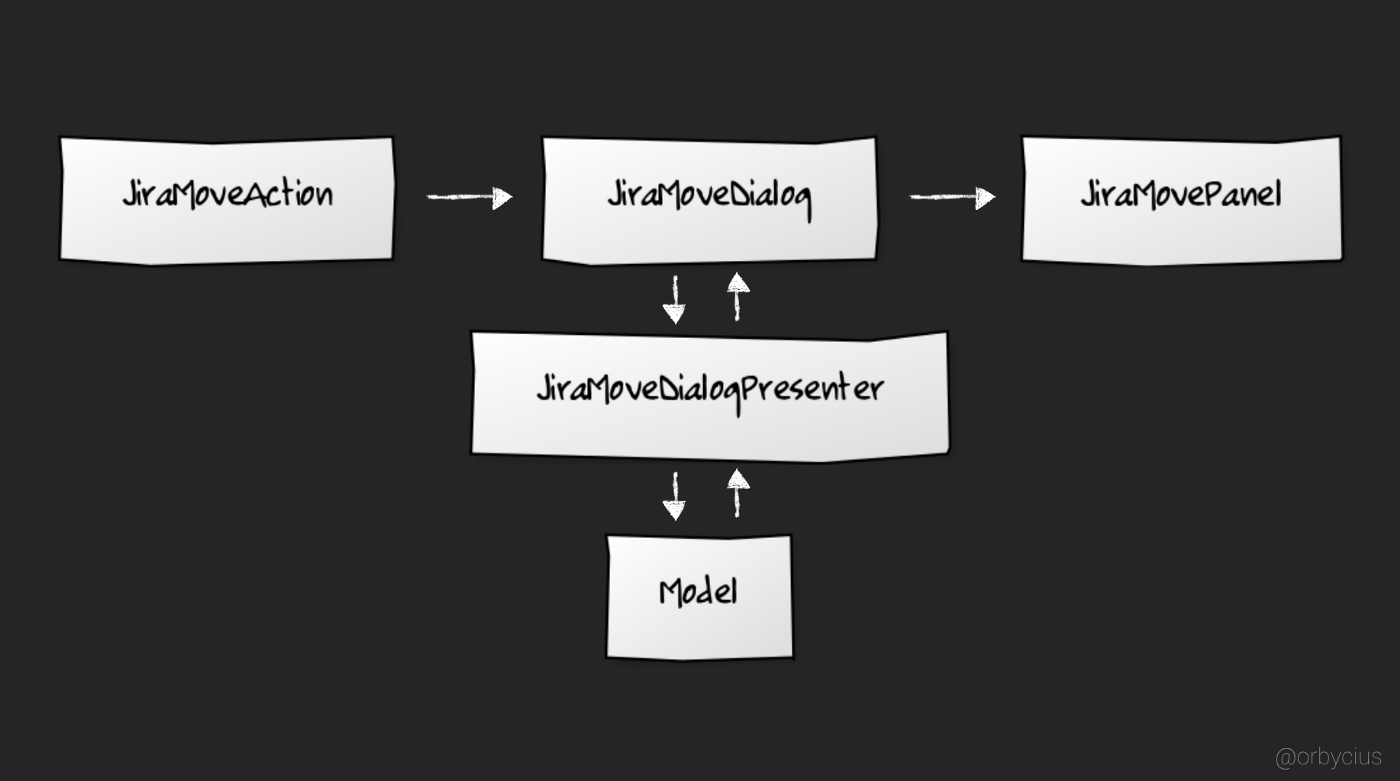
我们的JiraMoveAction将创建一个新的JiraMoveDialog,它将具有一个JiraMoveDialogPresenter,该JiraMoveDialogPresenter将与Model,网络等进行通信。此外,JiraMoveDialog将创建一个JiraMovePanel,其唯一原因是要分离更多的UI层,我将解释说在步骤4中。
除此之外,我们将使用Retrofit将对Jira API和Dagger2的网络请求用作DI框架(您知道我有点喜欢Dagger)。
首先,我们将在action package中创建一个新的package,以将Action与其余代码进一步分开,然后创建所有提及的文件。

我们的Model将非常简单,因为我们只需要处理Transition,并且由于不处理在Transition的必填字段。我们唯一需要的信息是Transition id和Transition name。如果您需要配置其他东西(例如添加评论),请点击这里查看文档。
我将把这些Model放在network包下的Models.kt文件中,实现如下:
data class Transition(val id: String, val name: String = "") {
override fun toString(): String = name
}
data class TransitionsResponse(val transitions: List<Transition>)
data class TransitionData(val transition: Transition)顾名思义,该文件将成为具有所需UI的JPanel。我们不会在此处创建任何 OK 或 Cancel 按钮,因为这将作为JiraMoveDialog的一部分出现,但我将在下一小节中进行讨论。
现在,我们将创建一个非常简单的UI,其包含一个combobox(用于显示可用的Transition)和一个 text field(用于显示issue ID),这个text field让用户根据需要手动进行配置。
我们的JiraMovePanel类继承自JPanel,根据上文,我们将在Eclipse中创建UI,复制粘贴代码并将其转换为Kotlin。
与我们在设置页面上所做的操作相比,存在一些差异,这是因为我们继承了JPanel,我们已经在Panel中,因此我们可以直接调用add()。
我们还必须重写getPreferredSize()来设置Panel的大小,不要忘记这样做!
最后,我添加了一些方法,这些方法将从JiraMoveDialog中调用以更改字段的值,最终文件如下所示:
class JiraMovePanel : JPanel() {
private val comboTransitions = ComboBox<Transition>()
val txtIssue = JTextField()
init {
initComponents()
}
private fun initComponents() {
layout = null
val lblJiraTicket = JLabel("Issue")
lblJiraTicket.setBounds(25, 33, 77, 16)
add(lblJiraTicket)
txtIssue.setBounds(114, 28, 183, 26)
add(txtIssue)
val lblTransition = JLabel("Transition")
lblTransition.setBounds(25, 75, 77, 16)
add(lblTransition)
comboTransitions.setBounds(114, 71, 183, 27)
add(comboTransitions)
}
override fun getPreferredSize() = Dimension(300, 110)
fun addTransition(transition: Transition) = comboTransitions.addItem(transition)
fun setIssue(issue: String) {
txtIssue.text = issue
}
fun getTransition() : Transition = comboTransitions.selectedItem as Transition
}让我们确保刚才所创用户界面显示的正确性,我们首先需要将JiraMoveDialog与JiraMovePanel链接起来,因此我们来实现JiraMoveDialog。
首先,我们需要继承DialogWrapper,IntelliJ提供了这个包装器,我们应该将其用于插件中的所有模式的对话框。IntelliJ还提供了一些免费功能,例如OK或Cancel按钮,因此我们不必在JPanel中创建它们。
我们还必须重写createCenterPanel()以返回刚刚创建的Panel,并在初始化对话框时调用init()。现在,这是我们的JiraMoveDialog类:
class JiraMoveDialog constructor(val project: Project):
DialogWrapper(true) {
init {
init()
}
override fun createCenterPanel(): JComponent? {
return JiraMovePanel()
}
}现在,我们可以在我们的JiraMoveAction中创建一个新对话框,这对您现在来说应该很简单,因此我不再赘述。
class JiraMoveAction : AnAction() {
override fun actionPerformed(event: AnActionEvent) {
val dialog = JiraMoveDialog(event.project!!)
dialog.show()
}
}最后一步是将新的Action添加到plugin.xml文件中。
您现在可以调试插件,执行Action,并且应该看到以下的内容:
到目前为止,我们已经完成了UI工作,让我们开始使用Presenter并将Dagger2集成到项目中。
注意:如果不需要,您不必使用
Dagger,但我建议像在其他任何项目中一样,使用某种形式的依赖注入。
要添加Dagger,我们只需像通常那样,在build.gradle文件中添加依赖项即可。别忘了也添加kapt。请注意,由于intellij-gradle-plugin尚不支持implementation或api,因此我们尚未使用它们。
apply plugin: 'kotlin-kapt'
dependencies {
compile 'org.jetbrains.kotlin:kotlin-stdlib-jdk8:1.3.10'
compile 'com.google.dagger:dagger:2.20'
kapt 'com.google.dagger:dagger-compiler:2.20'
}我们还希望从IDE中获取当前分支,为此,我们需要添加插件依赖。每当您需要第三方插件依赖(例如android插件或任何其他插件)时,都必须将该插件添加到gradle文件的插件列表中。在我们的例子中,我们将需要git4idea插件。
intellij {
version '2018.1.6'
plugins = ['git4idea']
alternativeIdePath '/Applications/Android Studio.app'
}我们还必须在plugin.xml文件中添加依赖。
<depends>Git4Idea</depends>添加了所有依赖后,我们可以专注于依赖注入。首先,我将创建一个新的Dagger Component以及一个Module,将来它将帮助我们进行测试,并使我们的架构更整洁。
现在,我们将只注入我们正在处理的project,即JiraMoveDialog(View层)和保存我们的设置的JiraComponent。 我还将Component命名为JiraDIComponent,因此我们不会把它和用于保存设置的JiraComponent相混淆。
@Component(modules = [JiraModule::class])
interface JiraDIComponent {
fun inject(jiraMoveDialog: JiraMoveDialog)
}@Module
class JiraModule(
private val view: JiraMoveDialog,
private val project: Project
) {
@Provides
fun provideView() : JiraMoveDialog = view
@Provides
fun provideProject() : Project = project
@Provides
fun provideComponent() : JiraComponent =
JiraComponent.getInstance(project)
}如果您对依赖注入或Dagger不熟悉,建议您看一下Jake Wharton的演讲:
https://www.youtube.com/watch?v=plK0zyRLIP8
现在,我们可以使用Dagger创建Presenter并将所需一切注入到构造函数中,要获得当前正在使用的分支实际上非常简单,只需从当前项目中获得一个repository manager即可。 通常,您将有一个repository,因此您只需调用first()并获取当前分支的名称。之后,通过使用存储在我们设置中的正则表达式,我们可以匹配并找到Jira中issue的ID。
我将在设置中存储的正则表达式为[a-zA-Z] +-[0-9] +,因为Jira ID的格式为Project-Number(即DROID-12),并且我为分支命名作为DROID-12-this-is-a-bug。
class JiraMoveDialogPresenter @Inject constructor(
private val view: JiraMoveDialog,
private val project: Project,
private val component: JiraComponent
) {
fun load() {
getBranch()
}
private fun getBranch() {
val repositoryManager = GitRepositoryManager.getInstance(project)
val repository = repositoryManager.repositories.first()
val ticket = repository.currentBranch!!.name
val match = Regex(component.regex).find(ticket)
match?.let {
view.setIssue(match.value)
}
}
}回到JiraMoveDialog,我们必须注入Presenter,并实现setIssue()方法以根据Git分支更改字段的值。为此,我们将创建一个JPanel的变量,而非在createCenterPanel()上返回新的JPanel,然后可以使用该Panel来更改字段的值。
我将isModal设置为true。每当我们将modal设置为true时,我们都会阻止UI,因此用户必须退出我们的对话框才能再次与IDE交互,如果需要,可以随意更改该值。然后,我们调用presenter.load()从IDE中获取分支,和之前一样,我们还须调用init()。
class JiraMoveDialog constructor(project: Project):
DialogWrapper(true) {
@Inject
lateinit var presenter: JiraMoveDialogPresenter
private val panel : JiraMovePanel = JiraMovePanel()
init {
DaggerJiraDIComponent.builder()
.jiraModule(JiraModule(this, project))
.build().inject(this)
isModal = true
presenter.load()
init()
}
override fun createCenterPanel(): JComponent? = panel
fun setIssue(issue: String) = panel.setIssue(issue)
}如果现在运行插件,并在设置中使用我之前提到的正则表达式,您将看到,每当启动JiraMoveAction时,它都会根据当前分支将issue字段设置为Jira正确的issue ID。
剩下唯一要做的事情就是为Jira的issue获取下一个Transition,并在用户按下OK按钮时移动issue。为此,我们将使用Retrofit和RxJava。
和往常一样,首先将新的依赖声明在build.gradle文件中。
compile 'com.squareup.retrofit2:retrofit:2.5.0'
compile 'com.squareup.retrofit2:adapter-rxjava2:2.5.0'
compile 'com.squareup.retrofit2:converter-gson:2.5.0'
compile 'io.reactivex.rxjava2:rxjava:2.2.5'
compile 'com.github.akarnokd:rxjava2-swing:0.3.3' // 译者注:注意这个compile最后compile的依赖,可能会让你耳目一新,在RxJava中,我们需要一组Scheduler来进行订阅和观察。我们显然不能使用Android的,而是需要在事件分发线程或EDT中运行代码,新库将为我们提供EDT的调度程序。
我们将从编写JiraService开始,查看Jira API文档后,实现起来并不复杂:
interface JiraService {
@GET("issue/{issueId}/transitions")
fun getTransitions(@Header("Authorization") authKey: String,
@Path("issueId") issueId: String): Single<TransitionsResponse>
@POST("issue/{issueId}/transitions")
fun doTransition(@Header("Authorization") authKey: String,
@Path("issueId") issueId: String,
@Body transitionData: TransitionData): Completable
}现在我们可以通过Dagger将JiraService的依赖向外暴露:
@Provides
fun providesJiraService(component: JiraComponent) : JiraService {
val jiraURL = component.url
val retrofit = Retrofit.Builder()
.addConverterFactory(GsonConverterFactory.create())
.addCallAdapterFactory(
RxJava2CallAdapterFactory.create())
.baseUrl(jiraURL)
.build()
return retrofit.create(JiraService::class.java)
}在Presenter中,我们现在可以注入JiraService并将其与RxJava一起使用,以获取给定issue的Transition。
请注意,我们使用SwingSchedulers.edt()进行线程切换。代码非常简单,使用Basic Auth,我们将获得所有Transition的响应,然后将其传递到视图(JiraMoveDialog),以将其添加到组合框。
如果发生error,我们在view.error()处理,它将显示带有错误详细信息的通知弹窗。
private fun getTransitions() {
val auth = getAuthCode()
disposable = jiraService.getTransitions(auth, issue)
.subscribeOn(Schedulers.io())
.observeOn(SwingSchedulers.edt())
.subscribe(
{ response ->
view.setTransitions(response.transitions)
},
{ error ->
view.error(error)
}
)
}
private fun getAuthCode() : String {
val username = component.username
val token = component.token
val data: ByteArray =
"$username:$token".toByteArray(Charsets.UTF_8)
return "Basic ${Base64.encode(data)}"
}对话框的新方法可以设置Transition并显示error:
fun setTransitions(transitionList: List<Transition>) {
for(transition in transitionList) {
panel.addTransition(transition)
}
}
fun error(throwable: Throwable) {
val noti = NotificationGroup("myplugin",
NotificationDisplayType.BALLOON, true)
noti.createNotification("Error", throwable.localizedMessage,
NotificationType.ERROR, null).notify(project)
}立即运行插件,完成需要的配置后,效果如下:
最后一步,当用户按下OK按钮时,将issue移到组合框中显示的Transition中,Presenter中的代码再次使用RxJava,如下所示。
fun doTransition(selectedItem: Transition, issue: String) {
val auth = getAuthCode()
val transition = TransitionData(selectedItem)
disposable = jiraService.doTransition(auth, issue, transition)
.subscribeOn(Schedulers.io())
.observeOn(SwingSchedulers.edt())
.subscribe(
{
view.success()
},
{ error ->
view.error(error)
}
)
}现在,在对话框中,我们必须重写doOKAction()以执行从Presenter传递过来的Transition,我们还创建了success()以关闭对话框并通知用户。
override fun doOKAction() =
presenter.doTransition(
panel.getTransition(), panel.txtIssue.text
)
fun success() {
close(DialogWrapper.OK_EXIT_CODE)
val noti = NotificationGroup("myplugin",
NotificationDisplayType.BALLOON, true)
noti.createNotification("Success", "Issue moved",
NotificationType.INFORMATION, null).notify(project)
}如果您现在运行插件,则无需离开Android Studio就可以进行Jira的更新。如果一切顺利,您现在应该会看到此弹出窗口,最重要的是,Jira中的issue现在应该移至下一阶段。
这就是所有的内容了!如有需要,您现在可以进行更多扩展,并创建Action以使所有issue都处于ToDo状态、显示说明并在选择它们后使用正确的issue id创建新分支(或查看我的Droidcon UK演讲以获取代码)。
请记住,本文的代码在该系列GitHub Repo的Part4分支中可用。
在下一篇文章中,我们将整理一下代码,并创建一些util方法以在代码中复用。我们还将研究如何以比硬编码更好的方式存储字符串。
在此之前,如果您有任何问题,请随时发表评论或在Twitter上关注我。
Hello,我是 却把清梅嗅 ,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的 博客 或者 GitHub。
如果您觉得文章还差了那么点东西,也请通过 关注 督促我写出更好的文章——万一哪天我进步了呢?
原文:REACTIVE APPS WITH MODEL-VIEW-INTENT - PART4 - INDEPENDENT UI COMPONENTS
作者:Hannes Dorfmann
译者:却把清梅嗅
这篇博客中,我们将针对如何 如何构建独立组件 进行探讨,我将阐述为什么在我看来 父子关系会导致坏味道的代码,以及为何这种关系是没有意义的。
有这样一个问题时不时涌现在我的脑海中—— MVI、MVP、MVVM这些架构设计模式中,多个Presenter(或者ViewModel)彼此之间是如何进行通讯的?更直白点说吧,Child-Presenter是如何与Parent-Presenter通讯的?
对我来说,这种 父子关系 会产生坏味道的代码,因为这直接 导致了父子层级之间的耦合,使得代码难以阅读和维护。
这种情况下,需求的更改会影响很多的组件(对于大型系统来说,这种情况下实现需求的变动简直难如登天);并非仅此而已,同时,这也 引入了难以预测的共享的状态,其导致的问题甚至难以重现和调试。
其实这也没那么不堪,但我实在不理解为何信息必须从Presenter A流向Presenter B呢?或者Presenter如何与另一个Presenter进行通信?
根本没必要! 什么情况下Presenter才会需要和Presenter进行直接的通讯,是什么事件发生了吗?Presenter根本不需要和其它的Presenter直接通讯,它们都观察了同一个Model(或者说是业务逻辑的相同部分),这就是它们如何获得变化的通知:通过底层。
当一些事件发生时(比如用户点击了View1按钮),Presenter将信息下沉到业务逻辑。因为其它的Presenter观察了相同的业务逻辑,因此它们从业务逻辑中接收到了同样变化的通知(Model被更新了)。
关于这一点,我们已经在 第一章节 讨论了 单向数据流 的原理的重要性。
让我们通过一个真实的案例实现它:在我们的购物App中,我们能够将商品加入购物车,此外,有这样一个页面,我们可以看到购物车商品的内容,并且能够一次选择或者删除多个商品条目:
我们如果能够将这样一个复杂的界面分割成更多 精巧、独立且可复用的UI组件 的话就太棒了。以Toolbar为例,它展示了被选中条目的数量,以及RecyclerView展示了购物车里条目的列表。
<LinearLayout>
<com.hannesdorfmann.SelectedCountToolbar
android:id="@+id/selectedCountToolbar"
android:layout_width="match_parent"
android:layout_height="wrap_content"
/>
<com.hannesdorfmann.ShoppingBasketRecyclerView
android:id="@+id/shoppingBasketRecyclerView"
android:layout_width="match_parent"
android:layout_height="0dp"
android:layout_weight="1"
/>
</LinearLayout>但是这些组件之间如何保持相互的通讯呢?很明显每个组件都有它自己的Presenter:SelectedCountPresenter 和 ShoppingBasketPresenter。这属于父子关系吗?不,它们仅仅是观察了同一个Model,该Model根据在的逻辑代码中进行更新:
public class SelectedCountPresenter
extends MviBasePresenter<SelectedCountView, Integer> {
private ShoppingCart shoppingCart;
public SelectedCountPresenter(ShoppingCart shoppingCart) {
this.shoppingCart = shoppingCart;
}
@Override protected void bindIntents() {
subscribeViewState(shoppingCart.getSelectedItemsObservable(), SelectedCountView::render);
}
}
class SelectedCountToolbar extends Toolbar implements SelectedCountView {
...
@Override public void render(int selectedCount) {
if (selectedCount == 0) {
setVisibility(View.VISIBLE);
} else {
setVisibility(View.INVISIBLE);
}
}
}ShoppingBasketRecyclerView 的代码和上述代码的实现非常类似,因此本文不对其进行展示。然而,如果我们认真去观察这段代码,你会发现SelectedCountPresenter和ShoppingCart有一定的耦合。
我们完全有可能会在其它的页面去复用这个UI组件,因此我们需要移除这个依赖的关系以达到复用该组件的目的。重构其实很简单:presenter持有一个 Observable<Integer> 作为Model代替之前构造器中所需要的ShoppingCart:
public class SelectedCountPresenter
extends MviBasePresenter<SelectedCountView, Integer> {
private Observable<Integer> selectedCountObservable;
public SelectedCountPresenter(Observable<Integer> selectedCountObservable) {
this.selectedCountObservable = selectedCountObservable;
}
@Override protected void bindIntents() {
subscribeViewState(selectedCountObservable, SelectedCountToolbarView::render);
}
}There you go (原文为法语,大概意思是“就是这样”),每当我们需要显示当前选择的条目数量时,我们就可以使用SelectedCountToolbar组件——这可以代表ShoppingCart中的条目数,也可以表示在App中的完全不同的上下文环境和页面中。
此外,此UI组件可以放入独立的库中,并在另一个App(如相册应用程序)中使用,以显示所选照片的数量:
Observable<Integer> selectedCount = photoManager.getPhotos()
.map(photos -> {
int selected = 0;
for (Photo item : photos) {
if (item.isSelected()) selected++;
}
return selected;
});
return new SelectedCountToolbarPresnter(selectedCount);本文的目的是证明通常情况下,代码的设计中根本不需要 父子关系 ,它们仅需要通过简单的对相同业务逻辑进行观察就能实现。
不需要EventBus,不需要从上层的Activity或者Fragment中调用findViewById(),不需要presenter.getParentPresenter()或者其它的解决方案。仅使用 观察者模式 就够了。借助于RxJava——它本身也是基于观察者模式**的体现,我们就能够轻而易举构建这样响应式的UI组件。
与MVP或MVVM相比,MVI的实现过程中,我们被迫(通过积极的方式)使用业务逻辑驱动某个组件的状态。因此,具有更多MVI经验的开发人员可以得出以下结论:
如果
View的状态是另一个组件的Model怎么办?如果一个组件的ViewState的变更是另一个组件的Intent怎么办?
举个例子:
Observable<Integer> selectedItemCountObservable =
shoppingBasketPresenter
.getViewStateObservable()
.map(items -> {
int selected = 0;
for (ShoppingCartItem item : items) {
if (item.isSelected()) selected++;
}
return selected;
});
Observable<Boolean> doSomethingBecauseOtherComponentReadyIntent =
shoppingBasketPresenter
.getViewStateObservable()
.filter(state -> state.isShowingData())
.map(state -> true);
return new SelectedCountToolbarPresenter(
selectedItemCountObservable,
doSomethingBecauseOtherComponentReadyIntent);乍一看,这似乎是一种可行的方案,但它不是父子关系的变体吗?当然不是,这并非传统分层的父子关系,也许将其比喻为洋葱更为恰当(洋葱的内层为外层提供了一种状态)。
但是,这依然是一种耦合的关系,不是吗?我还没有下定决心,但现在我认为避免这种洋葱般的关系更好。如果您有不同意见,请在下面留言,我很期待您的观点。
《使用MVI打造响应式APP》原文
《使用MVI打造响应式APP》译文
《使用MVI打造响应式APP》实战
Hello,我是却把清梅嗅,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的博客或者Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
Handler的原理分析这个标题,很多文章都写过,最近认真将源码逐行一字一句研究,特此自己也总结一遍。
首先是Handler整个Android消息机制的简单概括:
分三部分对消息机制的整个流程进行阐述:
Handler的创建,包括Looper、MessageQueue的创建;Handler发送消息,Message是如何进入消息队列MessageQueue的(入列);Looper轮询消息,Message出列,Handler处理消息。// 最简单的创建方式
public Handler() {
this(null, false);
}
// ....还有很多种方式,但这些方式最终都执行这个构造方法
public Handler(Callback callback, boolean async) {
// 1.检查内存泄漏
if (FIND_POTENTIAL_LEAKS) {
final Class<? extends Handler> klass = getClass();
if ((klass.isAnonymousClass() || klass.isMemberClass() || klass.isLocalClass()) &&
(klass.getModifiers() & Modifier.STATIC) == 0) {
Log.w(TAG, "The following Handler class should be static or leaks might occur: " +
klass.getCanonicalName());
}
}
// 2.通过Looper.myLooper()获取当前线程的Looper对象
mLooper = Looper.myLooper();
// 3.如果Looper为空,抛出异常
if (mLooper == null) {
throw new RuntimeException(
"Can't create handler inside thread " + Thread.currentThread()
+ " that has not called Looper.prepare()");
}
mQueue = mLooper.mQueue;
mCallback = callback;
mAsynchronous = async;
}首先,如何避免Handler的内存泄漏是一个非常常见的面试题,其实Handler的源码中已经将答案非常清晰告知给了开发者,即让Handler的导出类保证为static的,如果需要,将Context作为弱引用的依赖注入进来。
同时,在Handler创建的同时,会尝试获取当前线程唯一的Looper对象:
public final class Looper {
static final ThreadLocal<Looper> sThreadLocal = new ThreadLocal<Looper>();
public static @Nullable Looper myLooper() {
return sThreadLocal.get();
}
}关于ThreadLocal,我在上一篇文章中已经进行了分析,现在我们知道了ThreadLocal保证了当前线程内有且仅有唯一的一个Looper。
那就是需要调用Looper.prepare()方法:
public final class Looper {
public static void prepare() {
prepare(true);
}
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}
private Looper(boolean quitAllowed) {
mQueue = new MessageQueue(quitAllowed);
mThread = Thread.currentThread();
}
}这也就说明了,为什么当前线程没有Looper的实例时,会抛出一个异常并提示开发者需要调用Looper.prepare()方法了。
也正如上述代码片段所描述的,如果当前线程已经有了Looper的实例,也会抛出一个异常,提示用户每个线程只能有一个Looper(throw new RuntimeException("Only one Looper may be created per thread");)。
此外,在Looper实例化的同时,也创建了对应的MessageQueue,这也就说明,一个线程有且仅有一个Looper,也仅有一个MessageQueue。
sendMessage()流程如下:
// 1.发送即时消息
public final boolean sendMessage(Message msg)
{
return sendMessageDelayed(msg, 0);
}
// 2.实际上是发射一个延时为0的Message
public final boolean sendMessageDelayed(Message msg, long delayMillis)
{
if (delayMillis < 0) {
delayMillis = 0;
}
return sendMessageAtTime(msg, SystemClock.uptimeMillis() + delayMillis);
}
// 3.将消息和延时的时间进行入列(消息队列)
public boolean sendMessageAtTime(Message msg, long uptimeMillis) {
MessageQueue queue = mQueue;
if (queue == null) {
RuntimeException e = new RuntimeException(
this + " sendMessageAtTime() called with no mQueue");
Log.w("Looper", e.getMessage(), e);
return false;
}
return enqueueMessage(queue, msg, uptimeMillis);
}
// 4.内部实际上还是执行了MessageQueue的enqueueMessage()方法
private boolean enqueueMessage(MessageQueue queue, Message msg, long uptimeMillis) {
msg.target = this;
if (mAsynchronous) {
msg.setAsynchronous(true);
}
return queue.enqueueMessage(msg, uptimeMillis);
}注意第四步实际上将Handler对象最为target,附着在了Message之上;接下来看MessageQueue类内部是如何对Message进行入列的。
boolean enqueueMessage(Message msg, long when) {
//... 省略部分代码
synchronized (this) {
msg.markInUse();
msg.when = when;
// 获得链表头的Message
Message p = mMessages;
boolean needWake;
if (p == null || when == 0 || when < p.when) {
// 若有以下情景之一,将Message置于链表头
// 1.头部Message为空,链表为空
// 2.消息为即时Message
// 3.头部Message的时间戳大于最新Message的时间戳
msg.next = p;
mMessages = msg;
needWake = mBlocked;
} else {
// 反之,将Message插入到链表对应的位置
Message prev;
// for循环就是找到合适的位置,并将最新的Message插入链表
for (;;) {
prev = p;
p = p.next;
if (p == null || when < p.when) {
break;
}
}
msg.next = p; // invariant: p == prev.next
prev.next = msg;
}
if (needWake) {
nativeWake(mPtr);
}
}
return true;
}MessageQueue的数据结构本身是一个单向链表。
当Handler创建好后,若在此之前调用了Looper.prepare()初始化Looper,还需要调用Looper.loop()开始该线程内的消息轮询。
public static void loop() {
// ...省略部分代码
// 1. 获取Looper对象
final Looper me = myLooper();
if (me == null) {
throw new RuntimeException("No Looper; Looper.prepare() wasn't called on this thread.");
}
// 2.获取messageQueue
final MessageQueue queue = me.mQueue;
// 3. 轮询消息,这里是一个死循环
for (;;) {
// 4.从消息队列中取出消息,若消息队列为空,则阻塞线程
Message msg = queue.next();
if (msg == null) {
return;
}
// 5.派发消息到对应的Handler
msg.target.dispatchMessage(msg);
// ...
}
}比较简单,需要注意的一点是MessageQueue.next()是一个可能会阻塞线程的方法,当有消息时会轮询处理消息,但如果消息队列中没有消息,则会阻塞线程。
private native void nativePollOnce(long ptr, int timeoutMillis);
Message next() {
// ...省略部分代码
int nextPollTimeoutMillis = 0;
for (;;) {
// ...
// native方法
nativePollOnce(ptr, nextPollTimeoutMillis);
synchronized (this) {
final long now = SystemClock.uptimeMillis();
Message prevMsg = null;
Message msg = mMessages;
// 从消息队列中取出消息
if (msg != null) {
// 当时间小于message的时间戳时,获取时间差
if (now < msg.when) {
// 该值将会导致在下次循环中阻塞对应时间
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
// 取出消息并返回
mBlocked = false;
if (prevMsg != null) {
prevMsg.next = msg.next;
} else {
mMessages = msg.next;
}
msg.next = null;
msg.markInUse();
return msg;
}
}
// ...
}
}注意代码片段最上方的native方法——循环体内首先调用nativePollOnce(ptr, nextPollTimeoutMillis),这是一个native方法,实际作用就是通过Native层的MessageQueue阻塞nextPollTimeoutMillis毫秒的时间:
搞清楚这一点,其它就都好理解了。
正如上文所说的,msg.target.dispatchMessage(msg)实际上就是调用Handler.dispatchMessage(msg),内部最终也是执行了Handler.handleMessage()回调:
public void dispatchMessage(Message msg) {
if (msg.callback != null) {
handleCallback(msg);
} else {
if (mCallback != null) {
if (mCallback.handleMessage(msg)) {
return;
}
}
// 如果消息没有定义callBack,或者不是通过
// Handler(Callback)的方式实例化Handler,
// 最终会走到这里
handleMessage(msg);
}
}Hello,我是却把清梅嗅,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的博客或者Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
【标题党警告】本文主要内容为 Gradle依赖替换规则详解。
不久前RxJava正式发布了3.x版本,作为RxJava的爱好者,笔者第一时间对个人项目进行了3.x版本的迁移。
迁移过程中遇到了一个小问题,那就是RxAndroid因为没有及时升级,因此内部还是依赖2.x版本的RxJava,这就导致项目的依赖发生了冲突。
笔者的解决方式非常简单,既然RxAndroid依赖了不合适的RxJava版本,我就把它的依赖排除掉就可以了:
implementation ('io.reactivex.rxjava2:rxandroid:2.1.0') {
exclude group: 'io.reactivex.rxjava2', module: 'rxjava'
}这样做之后,项目成功将RxJava迁移到了3.x版本,笔者还第一时间在 这篇文章 中进行了如下的评论:
评论发出去了一段时间,并没有收到各路大神的批评,笔者便以为这就是 正确的升级方式,于是在 RxAndroid 的这个 issue 中 沾沾自喜 地进行了分享:
没想到 JakeWharton 竟然看到了我的回复,并且非常直接针对我提供的代码进行了点评:
翻译过来的意思就是:
长远来看,制定一个 替换规则 远比通过
exclude这种类似 打地鼠 的方式要好得多。
收到男神的回复令我受宠若惊,但我更迫切需要了解我的代码问题出在了哪里—— 我一直认为我的代码就是正确的处理方案,但事实却证明了我的无知。
我翻阅了对应的Gradle文档,Gradle中提供了对应的 依赖替换规则,而我之前一直没有了解过它,这也正是本文的主要内容。
依赖替换规则的适用场景分为以下几种:
我们先解释一下 外部依赖 和 本地依赖 是什么。
外部依赖,顾名思义,就是从远程仓库拉取的依赖,也被称为常用的 三方库:
// 从远程仓库拉取的开源代码库
implementation 'com.facebook.stetho:stetho:1.5.1'
implementation 'io.reactivex.rxjava3:rxjava:3.0.0-RC0'本地依赖,也就是我们项目中常见的module,按照**《阿里Java开发手册》**中来描述,也叫做 一方库:
implementation project(':library')好的,现在我们了解了这两个基本概念,问题来了:
有同学肯定会有这个困惑,这些概念我虽然都了解了,但实际开发过程中我并没有用到这些, 项目依然稳定的迭代和运行,那学习这些东西有什么用呢?
这些规则真的很有用,在实际开发过程中,我们肯定会遇到一些问题,这些问题我们通过baidu或者google的方式绕了过去,但是这真的解决了吗?
比如说 依赖冲突。
举个例子,很多UI三方库都会依赖RecyclerView,但这么多的依赖库,我们不可避免遇到版本不同导致依赖冲突的情况,一般情况下,我们是这么解决的:
// 将RecyclerView的依赖从这个三方库中排除掉
implementation "xxx.xxx:xxx:1.0.0",{
exclude group: 'com.android.support', module: 'recyclerview-v7'
}将RecyclerView的依赖从这个三方库中排除掉,令其使用项目本身的RecyclerView版本,这样项目就可以正常运行了,看起来并没有什么问题。
JakeWharton 非常敏锐地点出了问题的所在——试想,如果项目的依赖比较复杂,也许我们要面对的将是这样的依赖配置:
implementation "libraryA:xxx:1.0.0",{
exclude group: 'com.android.support', module: 'recyclerview-v7'
}
implementation "libraryB:xxx:2.2.0",{
exclude group: 'com.android.support', module: 'recyclerview-v7'
}
implementation "libraryC:xxx:0.0.8",{
exclude group: 'com.android.support', module: 'recyclerview-v7'
}我们需要将每个依赖了RecyclerView的三方库都通过exclude的方式移除掉本身对应的依赖,这种缝缝补补式地乱堵,不正是在 打地鼠 么。
针对类似这种情况,我们可以在gradle的构建过程中强制指定依赖的版本,以笔者的项目为例,我们针对RxJava的版本依赖进行了统一:
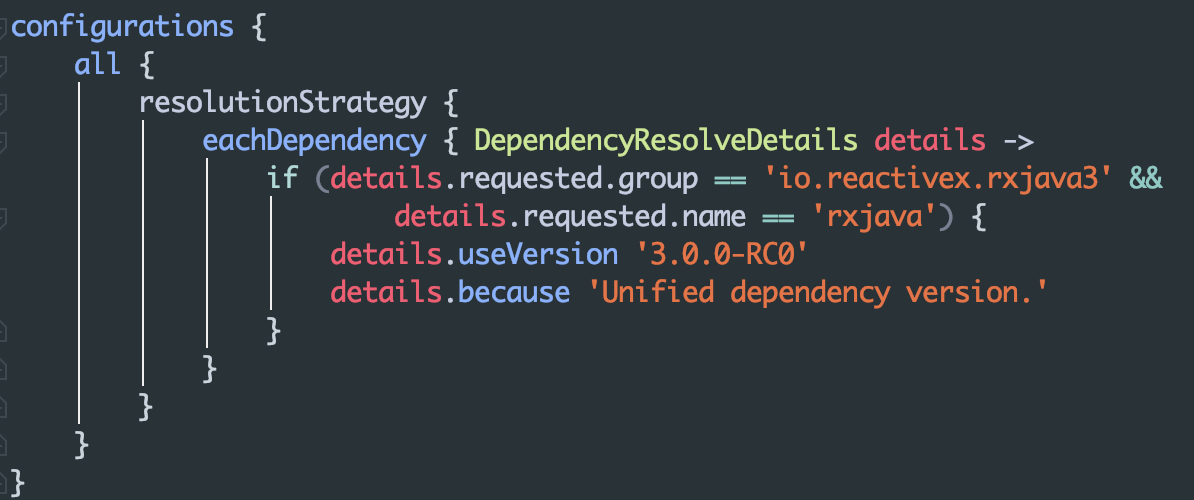
现在,项目中所有RxJava相关的依赖,在构建过程中版本都统一使用了3.0.0-RC0,这样就 避免了依赖冲突,开发者再也不需要针对每一个有RxJava依赖的三方库进行额外的exclude了。
本地依赖替换为外部依赖,最经典的场景就是SDK的发布测试,如果您有过开源项目的经历,对此一定不会陌生。
以笔者开源的 RxImagePicker 为例,日常开发过程中,sample代码依赖本地的module;新版本发布后,笔者的UI测试代码便需要通过依赖jcenter远程仓库的最新代码。
这种情况下,通过dependencySubstitution便可以非常方便对这两种场景进行切换:

useRemote只是定义在build.gradle文件中的一个变量,作为切换开发-测试环境的开关:
final boolean useRemote = true 当useRemote值为true时,sample依赖远程仓库,当值为false时,sample依赖本地module。
看起来代码量反而增加了,实际上,随着项目复杂度的提升,这种全局的配置优点显而易见。
该规则和2非常相似,只不过将依赖替换的双方调换了而已,下面是官方的示例代码:
configurations.all {
resolutionStrategy.dependencySubstitution {
substitute module("org.utils:api") because "we work with the unreleased development version" with project(":api")
substitute module("org.utils:util:2.5") with project(":util")
}
}故事的最后,笔者的解决方案如下:

group不同,所以需要先将2.x的rxjava全局exclude掉;3.x的rxjava的依赖版本都统一(文中是3.0.0-RC0);笔者并不知道这种方式是否就是 JakeWharton 描述的解决方案,但相比较之前而言效果确实更好,如果有更好的依赖管理方案,诚挚希望您能在评论区中进行分享。
GitHub确实是一个神奇的东西,它让我避免固步自封,毕竟世界上最顶尖的开发者们都聚焦于此,在他们眼里,你的代码永远都有着非常广阔的进步空间。
发现自己的短板不是坏事,它可以督促我不断去尝试自我超越,就像我常年放在文章末尾的那句话一样,万一哪天我进步了呢?
Hello,我是却把清梅嗅,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的个人博客或者Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
反思 系列博客是我的一种新学习方式的尝试,该系列起源和目录请参考 这里 。
诸如EventBus\RxBus\LiveDataBus的事件总线库在业内正遭滥用。
诚然,事件总线看起来 小而美 ,但随着业务复杂度上升,事件的发送和订阅到处分布,这个优势反而成为了负担,因此,笔者不建议在任何量级的项目中使用事件总线库。更多原因读者可参考 这篇文章 。
更合理的方案是什么呢?在量级较小的项目中,开发者应该通过 依赖注入 将Callback进行不同层级的依次传递,以保证 层级间的依赖关系足够清晰。
而对于体量逐渐增大的项目而言,项目的模块化、组件化、插件化改造被提上日程,各团队负责不同的业务线,将业务分割成组件,并基于组件本身进行开发,于是我们有了新的诉求,即 组件与组件保证是隔离的,同层级的组件间不应该持有其它组件中类的引用。
需要注意的是,即使项目组件化,组件间也仍有通信的场景,但这并非使用事件总线的借口——对大体量的项目而言,EventBus\RxBus\LiveDataBus这种事件总线库太局限了,其能力已完全满足不了项目架构的需求,因此,一个适用于组件化开发的 通信组件 的需求迫在眉睫。
本文将对组件化开发流程中 通信组件 的设计理念与实现方式进行完整的叙述。这里的 通信组件 并非特指某个已有的工具库(比如ARouter、WMRouter等),事实上,它们都是组件化开发流程的实践之一。
本文结构如下:
对于组件间通信,最经典的场景当属页面跳转,对于Android而言,Activity之间相互隔离,原生API对页面跳转提供了两种实现方式:
第一种方式是常用的 显式意图,通过 startActivity 或 startActivityForResult,这种方案简单且实用,但在组件化开发流程中,组件间未持有其它组件中Activity.class的引用,因此无法支持组件间的跳转。
第二种方式则是相对冷僻的 隐式意图,这种方式支持组件间以及跨进程通信,比如,开发者可以通过隐式意图唤起系统的呼叫页面:
// 唤起拨号页面
private void call() {
Intent intent = new Intent();
intent.setAction(Intent.ACTION_CALL);
intent.setData(Uri.parse("tel:" + 119));
startActivity(intent);
}由于代码中不存在类依赖的关系,隐式意图更适合组件间通信,但其缺陷也很明显:
Activity对应的配置规则和参数以action等标签的形式,集中声明在Manifest中,不利于参数的管理,且扩展性不佳,进而导致团队协作困难;现在看来,原生API对组件间页面跳转能力的提供,确实还略有不足,但这依然不是真正的问题所在。
能真正引爆这些定时炸弹的,只有 业务需求 本身。
即使Google推出了Navigation架构组件,很多开发者依然对这种单Activity多Fragment的开发模式不买账——平白无故增加项目复杂度毫无意义。
无论如何,一个简单的计算器app也无必要引入复杂的工程架构,以及组件/插件化的开发流程。
因此,与其热火朝天讨论某个新框架流行与否,读者更想看到它到底是解决了什么问题。
那就是业务的 爆炸性增长。
随着微信、支付宝等一众大型和中型应用规模逐渐扩大,即使是原生的跳转机制也无法满足组件化开发的需求,比如,首页的若干个Tab对应的不同Fragment身处不同组件,这时Fragment之间的通信该如何保障?
同时,随着业务粒度的愈发细分,甚至单个Fragment中的View都来自五湖四海(比如商品详情页面, 视频预览 和 商品评论 的控件分别由不同业务组件提供); 更深入思索一下,若商品介绍一栏是由WebView提供的——涉及到H5和原生的交互,我们又该如何定义H5与原生间通信的接口?
由此可见,Activity自身的通信机制确实已经不够用了。
对于多元化的通信需求而言,首先最重要的是将通信协议进行统一,无论是Activity间跳转,还是Fragment、View之间的通信,亦或是H5与原生的交互,我们都通过类似http的url的形式定义:
// 跳转 用户模块 - 登录页面
String loginUrl = "route://com.example.route/user/activity/login"
// 跳转 用户模块 - 注册页面
String registUrl = "route://com.example.route/user/activity/register"
// 跳转 商品模块 - 详情页面, id为商品的id
String detailUrl = "route://com.example.route/buy/activity/detail?id=xxxxx" 定义好了之后,对于组件间页面跳转,可以如下操作:
Router.route(detailUrl); // 在用户模块,发起商品模块中页面的跳转应用接收到这样自定义、且支持携带参数的url,通信库内部解析后统一分发,进行对应页面的跳转,这样我们就实现了最基础的通信功能。
接下来我们针对 隐式意图 对 错误处理能力不足 这点进行深入性讨论。
在组件化开发流程中,开发者通常在当前的组件的Demo上进行开发,虽然模块自身是可运行的,但是当涉及到其它组件的通信,问题随之而来。
和完整的工程相比,Demo上未持有其它组件中Activity的声明,直接通过 隐式意图 发起通信会导致系统抛出异常。
那么,我们希望当通信发生错误时,可以针对不同的环境提供不同的降级策略,以保证开发者和用户的体验,比如:
Demo工程的开发流程中,当尝试跳转其它组件时,获得一个「该url不在当前组件工程中」的提示;url时,则为用户跳转一个通用的404页面。如有可能,通信库在路由的过程中,能提供限速、屏蔽等 灵活 且 简单 控制的可能性,那么就更好了。
因此,以ARouter为首的绝大多数组件通信库都提供了这种能力,实现方式也使用了非常经典的 拦截器 机制,通过 递归 将通信事件向下分发,在需要处理的层级中进行拦截处理。
本小节笔者将以ARouter为例,阐述页面间路由库的一些局限性,以及导致这些局限性的原因。
毫无疑问,ARouter提供了足够强大的页面间路由跳转能力,它也确实揽括了业内绝大多数开发者的青睐,在开源之初,作者对其的定义就是Android平台上的 页面路由框架 。
这也变相导致自身对UI层级的跳转能力很强,但对数据通信的支持很薄弱。
什么是对数据通信的支持呢?读者知道,除了可见的UI交互,数据的交互也非常频繁,比如通过组件间通信,向用户组件获取当前用户信息、向订单组件获取某个订单数据等等。
ARouter并不支持这些吗?实际上并非如此,ARouter自身提供了IProvider接口实现组件间服务的管理,并提供服务的自动注册和依赖注入。
但遗憾的是,由于ARouter自身设计原因,其初始化只针对当前进程,这也导致了其路由表的自动注册和拦截器相关机制都是单进程的。
而在目前国内多进程、插件化的多元发展环境下,若想向其它进程的服务直接获取数据,ARouter是无能为力的,需要开发者通过AIDL等方式来自己实现。
那么导致这些局限性的原因,是因为ARouter这类页面路由库自身设计的不足吗,并非完全如此,从技术角度而言,为ARouter添加进程间通信的支持是可行的。
大而全的框架往往也是掺杂了各种私货的大杂烩,看似 功能强大 ,实则 臃肿不堪 —— 笔者更喜欢类似Retrofit的设计,将网络请求的功能 收敛,并将 反序列化、返回类型、网络请求扩展 等相关功能通过Converter、Adapter、Interceptor的方式抽象出来,交给开发者选择性依赖后,再自行组装,Retrofit自身则绝不多干涉一分一厘。
同样,作为 页面路由框架 ,ARouter目前的设计已满足现有需要。对于进程间通信,ARouter可以在IProvider的实现中,通过声明AIDL进行通信,最终将结果交还给ARouter去分发。这也正符合了其开源时所提倡的口号:简单 且 够用。
现在我们知道,对于业务量级不大,尚以 页面跳转 为主要通信手段的应用而言,ARouter这类 页面路由框架 已足够使用;但是,对于更为复杂的项目而言,组件间 数据获取 更加频繁,作为设计者,如何保证灵活性的同时,提供更便捷数据通信的可能呢?
从更高维度的视角来看,无论是UI层级的 页面跳转,还是业务层级的 数据获取,都可将其抽象为一种 通信:
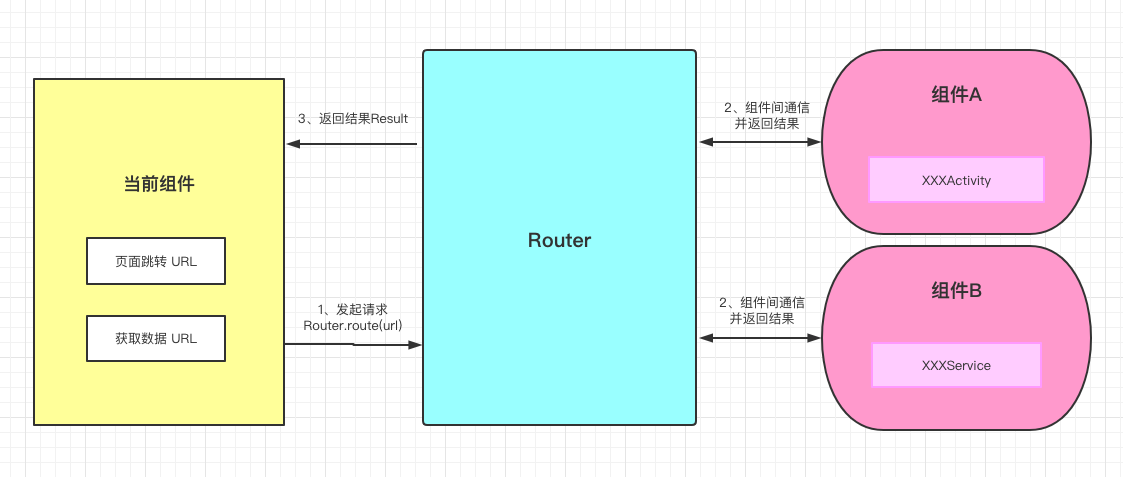
对此,我们可以对通信协议进行如下的定义:
// 跳转 用户模块 - 登录页面
String loginUrl = "route://com.example.route/user/activity/login"
// 获取 用户模块 - 用户数据
String getUserName = "route://com.example.route/user/service/getUserName"我们可以像http请求一样,对页面跳转通信的结果进行如下结构的定义:
// 跳转页面的返回值
{
"code" : "0000", // 跳转失败,可以定义一个错误码,比如 "4000"
"msg" : "success",
"data" : null
}而对于数据获取的定义,则可以充分利用data字段:
// 获取用户信息
{
"code" : "0000",
"msg" : "success",
"data" : {
"userName": "James Moriarty",
"token": "xxxxxxx"
}
}这样,无论是哪种通信,我们都将通信的结果抽象为了Result,并在代码中进行对应的处理:
class Result {
@NonNull String code;
@NonNull String msg;
@Nullable Object data;
}
// 根据不同种类的通信行为,分别处理result
Result result = Router.route(url); // url可以是跳转页面,也可以是获取数据现在我们提供了基本的 UI通信 和 数据通信 的支持,并将Result返回,但是目前的实现还是无法满足所有的场景——服务间的通信并非都是同步的。
对于异步的通信,我们通常理解为 网络请求 ,实际上,网络请求只是 数据异步通信 的一部分,除此之外还有 数据库操作 、 文件的读写 等等。
难道只有 数据通信 才有异步的场景吗?当然不是, UI通信 中的异步场景同样非常多,最简单的例子就是startActivityForResult,我们希望将登录的行为交给通信库,通信库异步跳转登录页面,登录成功后,返回如下定义的登录结果:
{
"code" : "0000", // 登录成功,也可对登录失败、取消定义不同code
"msg" : "success",
"data" : { // 返回用户登录信息
"userName": "James Moriarty",
}
}在我们的组件中,就可以针对异步行为进行如下通信:
Callback<Result> callback = Router.routeAsync(loginUrl);
// 执行异步通信
callback.excute(result -> {
// 登录页面登录结果(或网络请求结果)返回后,进行处理
});这样,无论是网络请求,还是异步UI登录,我们都将通信的结果,抽象为一个回调函数,将具体的实现内置在通信库中,其它组件的开发者无需关注实现的细节:
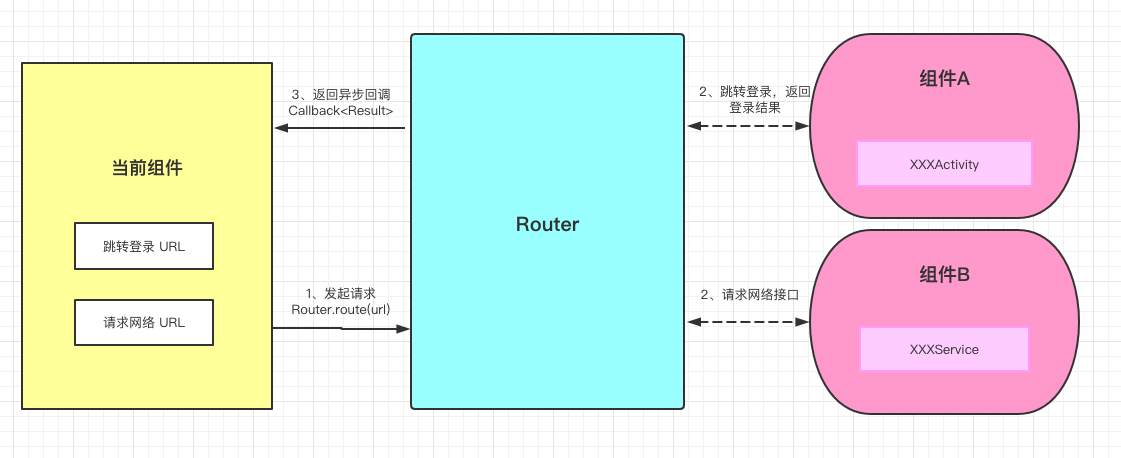
对于UI通信而言,如何实现成这样的API? 举例来说,我们可以将
Activity的onActivityResult()委托给一个不可见的Fragment处理,感兴趣的读者可参考Glide或者ViewModel的源码。
目前,因为本身是JVM级别的单例模式,因此我们Router并不支持跨进程通信。
上文我们也同样提到了,想进行跨进程通信也很简单,只需要在接收到需要跨进程通信的url时,自己实现跨进程的调用即可。
既然现在我们的Router已经脱离了类似ARouter这种 页面路由框架 的范畴,将UI和业务都在更高维度进行了抽象,那么,能否提供针对Router本身提供更强大的支持呢,比如跨进程通信?
其实解决的方法也并不复杂。原来的路由系统还可以继续使用,我们可以把整套架构想象成互联网,现在多个进程有多个Router,我们只需要把多个Router连接到一起,那么整个路由系统还是可以正常运行的。所以我们把原有的Router称之为本地路由LocalRouter。
现在,我们需要提供一个IPS、DNS供应商,那就创建一个进程,该进程的作用就是注册路由,链接路由,转发报文,我们称之为广域路由WideRouter。
我们先来看下路由连接架构图:
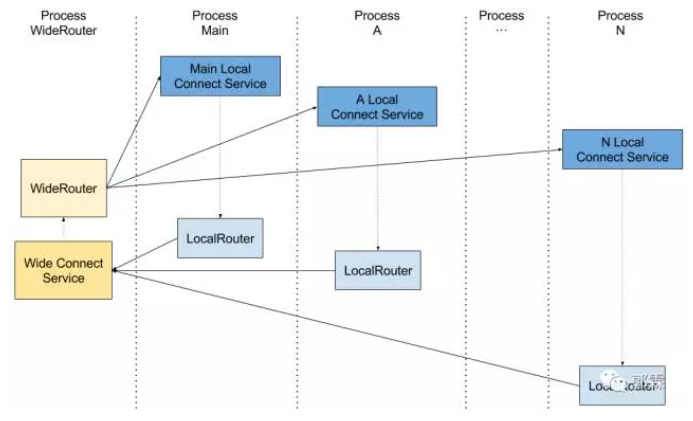
如图所示,竖直方向上,每一列,代表一个进程,通过虚线隔开,分别有 Process WideRouter、Process Main、Process A、···、Process N 这些进程。浅黄色的代表 WideRouter,深黄色 的代表 WideRouter 的守护 Service。浅蓝色 的代表每个进程的 LocalRouter,深蓝色 的代表每个 LocalRouter 的守护 Service。
WideRouter 通过 AIDL 与每个进程 LocalRouter 的守护 Service 绑定到一起,每个 LocalRouter 也是通过 AIDL 与 WideRouter 的守护 Service 绑定到一起,这样,就达到了所有路由都是双向互连的目的。
除了
AIDL之外,市场上的通信库还有各种各样跨进程通信的实现方案,例如BroadcastReceiver、Socket、ContentProvider、Binder等等,有兴趣的读者可以查看文末的参考链接,分别对比它们不同的实现方式。
目前,我们已经完成了组件间通信机制核心功能的实现。接下来我们针对其它部分的功能,针对不同开源框架中的不同实现方式,进行简单的讨论。
不同的组件各自向外暴露不同的功能,我们需要将url和对应的逻辑进行绑定,以保证Router能够在接收到对应通信的url时,作出对应的响应,这个流程我们称之为组件的注册。
举例来说,在完整的项目工程中,我们对所有组件的url进行注册;而在组件自身的demo中,我们对demo自身所需要的组件进行注册。
那么,对于高度组件化的项目而言,组件的粒度切分的非常细,这时在代码中手动对组件一一注册成为了一个苦力活,因此,是否有必要设计一个技术方案,保证在应用启动时,通信库能够对应用依赖的所有组件进行自动注册呢?
首先我们先讨论,通信库不实现自动注册的理由。
不提供自动注册是一种偷懒吗?笔者认为不完全是,手动注册的好处在于,首先,开发者对注册的组件总是已知的——这最简单且直接地提供了组件动态化可插拔的能力,且不易出错。
其次,手动注册的方式,能够更灵活对应用的启动性能优化进行保障,并非所有组件都需要在应用启动时进行立即注册,当组件很多时,组件的注册成本是否会影响App启动的速度?这些问题都是需要去考量的。
而对于自动注册,最大的问题在于如何找到所有组件中url的映射关系,然后对其自动注册处理,而如果在运行期处理则有可能会大量地运用 反射,因此这种方案并非首选。
对此,以ARouter为代表的通信库使用到了 注解处理器(AnnotationProcessor),通过在编译期对项目进行扫描处理,解析注解,找出所有组件中对应的映射关系,然后存入并生成对应的映射文件类;在运行时,对这些组件的映射文件类进行一一注册,从而完成整个项目的自动注册。
表面来看,注解处理器 已经满足了我们的需求,实际上还有一个隐藏的问题,那就是编译时注解的特性只在源码编译时生效,并不能针对aar文件中的注解进行扫描,因此,我们还需要保证APP在启动时能找到所有的映射文件类,否则注册根本无从谈起。
ARouter曾经的实现方案是第一次启动对所有dex文件进行读取,遍历每个entry查找指定包内的所有类名,然后反射获取指定的类对象,统一进行注册,虽然初次效率并不是非常高,但最后会进行本地缓存,以保证之后启动注册的效率。
有没有更高效的注册方式呢?
CC 组件通信库提供了另外一种 编译期修改字节码 的实现方案,大致思路是:在编译时,扫描所有类,将符合条件的类收集起来,并通过修改字节码生成注册代码到指定的管理类中,从而实现编译时自动注册的功能,不用再关心项目中有哪些组件类了。不会增加新的class,不需要反射,运行时直接调用组件的构造方法。
对这种方案感兴趣的读者可以参考这篇文章.
由此可见,即使是组件的注册流程,各个库的维护者都做出了各种各样的实践,而只有明白了每种方案的设计理念,才能对库本身的适用场景有更清晰的认知。
ARouter在页面的跳转上提供了一个不同于其它通信库的功能,那就是能够将发起页面跳转时传入的参数,通过依赖注入的方式自动注入到对应的Activity中。
这篇文章中阐述了该功能是如何实现的,很有趣的是,在该功能最初的实现方案中,是运行期通过反射拿到ActivityThread实例,最终在Activity实例化的时候,通过反射把Intent预先存好的参数值写入到需要自动装配的字段中实现的。
这种方案的缺点很明显,除了反射带来的性能影响外,甚至可能导致用户的代码出现NPE,因此这种实现方式后来被新的方案所代替。
新的方案依然是我们的老朋友AnnotationProcessor,在编译期间,其为Activity生成一个对应的注入辅助类,运行时通过辅助类对Activity中的字段进行赋值。
这也是Square最初推出的依赖注入库dagger,被Google后来居上的dagger2代替的原因。
还有另外一个问题,为什么其它通信库没有像ARouter一样提供这样一个依赖注入的功能呢,是因为做不到吗?
并非如此,在其它通信库中,我们将页面的跳转进行了更高维度的抽象,因此,如果设计一个新的功能,这个功能也更应该是针对 通信 整体的概念而服务,而非部分场景。
本文针对组件化开发流程中核心的 通信机制 进行了系统性的描述。
对于组件化而言,其目的在于在 业务模块间的解耦,而事件总线除了能给开发者带来开发上暂时的便利,以及 貌似解耦 的假象之外,更多埋下了组件间依赖关系 混乱的种子,并非长久之计——更合理的方案是针对性引入适合自身项目、且更全面的组件间通信库。
篇幅所限,很多优秀的开源项目中的功能和设计未能一一阐述,有兴趣的读者可以从下文的链接中进行选择性的参考。
细心的读者能够发现,关于 参考&感谢 一节,笔者着墨越来越多,原因无他,笔者 从不认为 一篇文章就能够讲一个知识体系讲解的面面俱到,本文亦如是。
因此,读者应该有选择性查看其它优质内容的权利,甚至是为其增加一些简洁的介绍(因为标题大多都很相似),而不是文章末尾甩一堆
https开头的链接不知所云。这也是对这些内容创作者的尊重,如果你喜欢本文,也同样希望你能够喜欢下面这些文章。
1、开源最佳实践:Android平台页面路由框架ARouter @刘志龙
对于ARouter的创作流程和设计理念,没有比作者本人更有发言权的了,这篇文章从理论到实践都讲解的非常清晰、流畅且自然,对于想要深入学习ARouter的读者不要错过。
相比较ARouter, ModularizationArchitecture 这个通信库及其作者似乎更低调,但从文章中可以得知,作者本人对组件化的理解非常深入,尤其是将进程间通信机制的实现,比喻为互联网,非常易于理解,因此直接将部分原文放在了 多进程的支持 一节,再次感谢!
3、Android组件化之(路由 vs 组件总线) @luckybilly
这篇文章是CC的作者的原创文章,针对 路由 和 组件总线 进行了深入的对比,非常深入,推荐。
4、多个维度对比一些有代表性的开源android组件化开发方案 @luckybilly
5、一种更高效的组件自动注册方案(android组件化开发)
luckybilly的另两篇好文,前者针对市面上一众主流的通信库进行了不同角度的对比,后者针对组件自动注册的不同实现进行了深入的对比,强烈推荐!
美团开源的WMRouter介绍文章,有兴趣的读者可作为引申阅读。
Hello,我是 却把清梅嗅 ,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的 博客 或者 GitHub。
如果您觉得文章还差了那么点东西,也请通过 关注 督促我写出更好的文章——万一哪天我进步了呢?
原文:Write an Android Studio Plugin Part 3: Settings
作者:Marcos Holgado
译者:却把清梅嗅
《编写AndroidStudio插件》系列是 IntelliJ IDEA 官方推荐的学习IDE插件开发的博客专栏,希望对有需要的读者有所帮助。
在本系列的第二部分中,我们学习了如何使用Component对数据进行持久化,以及通过这些数据,在用户更新我们的插件后展示更新了哪些新功能。在今天的文章中,我们将看到如何使用持久化的数据来创建设置页面。

请记住,您可以在GitHub上找到本系列的所有代码,还可以在对应的分支上查看每篇文章的相关代码,本文的代码在Part3分支中。
本文的目的是为我们的插件创建一个 设置页面,这将是我们迈向将JIRA搬运过来的第一步。我们的设置页面上只会有一个用户名和密码字段,我们的插件将使用该用户名和密码字段与Jira API进行交互。我们还希望能够为 每个项目 分别配不同的设置,从而允许用户根据项目使用不同的Jira帐户(这可能很有用)。
在本系列的第二部分中,我们已经了解了什么是Component,并且还了解了存在三种不同类型的Component。 因为我们希望能够根据我们的Android Studio的各Project进行不同的设置,因此显而易见的选择是创建一个新的Project Component。
我们基本上是在复制和粘贴我们先前创建的Component,但是删除了所有不必要的方法并添加了两个新字段。这些字段将是public的,因为我们将在插件的其它部分中使用它们。
另一处不同是这次我们实现ProjectComponent接口并实现AbstractProjectComponent方法,当然,它的构造方法中也有一个project参数。最后,我们有一个companion object,通过一个project参数,以获取我们的JiraComponent的实例。这将使我们能够从插件中其他位置访问存储的数据。新的JiraComponent看起来像这样:
@State(name = "JiraConfiguration",
storages = [Storage(value = "jiraConfiguration.xml")])
class JiraComponent(project: Project? = null) :
AbstractProjectComponent(project),
Serializable,
PersistentStateComponent<JiraComponent> {
var username: String = ""
var password: String = ""
override fun getState(): JiraComponent? = this
override fun loadState(state: JiraComponent) =
XmlSerializerUtil.copyBean(state, this)
companion object {
fun getInstance(project: Project): JiraComponent =
project.getComponent(JiraComponent::class.java)
}
}如我们在上文所做的一样,我们还必须在plugin.xml文件中注册Component:
<project-components>
<!-- Add your project components here -->
<component>
<implementation-class>
components.JiraComponent
</implementation-class>
</component>
</project-components>在针对我们的设置页面进行下一步之前,我们需要了解如何通过使用Java Swing在IntelliJ上创建UI。IntelliJ有许多可以使用的Swing组件,以保证插件UI与IDE中其它插件保持一致。 但不要被名字中带有Java给欺骗了,因为您仍可将代码转换为Kotlin。
创建新GUI(图形用户界面)的一种方法是,只需右键单击并转到New,然后单击GUI Form。该操作将创建一个名为YourName.form的新文件,该文件将链接到另一个名为YourName.java的文件。相比于按照IntelliJ给的编辑器模式进行开发,我更喜欢用我自己的方式,给一个提示:

我将会使用 Eclipse !(欢呼声)
我知道你在想什么,但老实说,它真的很棒。由于一些原因,IntelliJ的编辑器确实很难用,我无法获得预期的效果,但是,如果你对IntelliJ感到满意,请继续使用它!
译者注:我也并不喜欢
IDEA官方的编辑器,但也没有很大必要去使用Eclipse,因为使用Eclipse只是对UI预览而已。
回到Eclipse,您可以从这里下载它。 我目前有Oxygen.3a版本,该版本有些旧,但是对于我们要做的并不重要。只需创建一个新项目,然后右键单击New,Other,然后选择JPanel:
下图是我们的设置页预览:

接下来我们只需将创建好的源代码从Eclipse复制过来就行了,然后就可以关闭Eclipse了。
回到我们的插件,我们现在将创建一个名为settings的新包和一个名为JiraSettings的新类。 在该类中,我们将创建一个名为createComponent()的新方法,最后我们可以在该方法中粘贴从Eclipse复制的源代码。然后是时候将代码转换为Kotlin,您应该也可以自动将其成功转换为Kotlin。
完成所有这些操作后,您可能会遇到一些错误,因此请修复它们。
我们需要解决的第一件事是我们的createComponent()方法必须返回一个JComponent,具体原因接下来我们会说到。
因为Eclipse假定我们已经在JPanel中,所以您可以看到很多add方法或似乎并不存在的方法,原因是因为我们不在JPanel中。为解决该问题,我们必须创建一个新的JPanel并给它一些边界(您可以从在Eclipse中创建的JPanel中获取值),并且由于JPanel是JComponent的子类,因此我们将在我们的方法中将其返回。
最后,我们只需要进行一些调整就可以编译整个程序,最终效果应该如下:
class JiraSettings {
private val passwordField = JPasswordField()
private val txtUsername = JTextField()
fun createComponent(): JComponent {
val mainPanel = JPanel()
mainPanel.setBounds(0, 0, 452, 120)
mainPanel.layout = null
val lblUsername = JLabel("Username")
lblUsername.setBounds(30, 25, 83, 16)
mainPanel.add(lblUsername)
val lblPassword = JLabel("Password")
lblPassword.setBounds(30, 74, 83, 16)
mainPanel.add(lblPassword)
passwordField.setBounds(125, 69, 291, 26)
mainPanel.add(passwordField)
txtUsername.setBounds(125, 20, 291, 26)
mainPanel.add(txtUsername)
txtUsername.columns = 10
return mainPanel
}
}在继续开发设置页面前,我们必须讨论extensions和extension points。它们将允许您的插件与其他插件或与IDE本身进行交互。
IDE的功能,则必须声明一个或多个extensions。extension points。因为我们要将设置页面添加到Android Studio的Preferences中,所以我们真正要做的是扩展Android Studio的功能,因此我们必须声明一个extensions。
为此,我们必须实现Configurable,同时还必须重写一些方法。
createComponent()方法,因此我们只需添加override关键字就可以了。boolean的modified,其默认值为false,并作为isModified()的返回值。我们稍后会再讲到这一点,目前它代表了设置页面apply按钮是否被启用。getDisplayName()的返回值用于展示设置页的名字。apply方法中,我们需要编写将在用户单击Apply时执行的代码。很简单,我们为用户所在的Project获取JiraComponent的实例,然后将UI中的值保存到Component中。最后,我们将Modify设置为false,届时我们要禁用Apply按钮。最终展示效果如下:
class JiraSettings(private val project: Project): Configurable {
private val passwordField = JPasswordField()
private val txtUsername = JTextField()
private var modified = false
override fun isModified(): Boolean = modified
override fun getDisplayName(): String = "MyPlugin Jira"
override fun apply() {
val config = JiraComponent.getInstance(project)
config.username = txtUsername.text
config.password = String(passwordField.password)
modified = false
}
override fun createComponent(): JComponent {
val mainPanel = JPanel()
mainPanel.setBounds(0, 0, 452, 120)
mainPanel.layout = null
val lblUsername = JLabel("Username")
lblUsername.setBounds(30, 25, 83, 16)
mainPanel.add(lblUsername)
val lblPassword = JLabel("Password")
lblPassword.setBounds(30, 74, 83, 16)
mainPanel.add(lblPassword)
passwordField.setBounds(125, 69, 291, 26)
mainPanel.add(passwordField)
txtUsername.setBounds(125, 20, 291, 26)
mainPanel.add(txtUsername)
txtUsername.columns = 10
return mainPanel
}
}我们几乎完成了,只剩下最后几个问题。
首先,我们要保存用户的偏好设置,但目前我们还未对其加载。UI是在createComponent()方法中创建的,因此我们只需要在返回之前添加以下代码,即可使用先前存储的值设置UI:
val config = JiraComponent.getInstance(project)
txtUsername.text = config.username
passwordField.text = config.password接下来,我们将使用isModified()解决问题。 当用户修改设置页中的任何值时,我们需要以某种方式将值从false更改为true。一种非常简单的方法是实现 DocumentListener,该接口为我们提供了3种方法: changeUpdate ,insertUpdate 和 removeUpdate。
在这些方法中,我们唯一要做的就是简单地将Modify的值更改为true,最后将DocumentListener添加到我们的密码和用户名字段中。
override fun changedUpdate(e: DocumentEvent?) {
modified = true
}
override fun insertUpdate(e: DocumentEvent?) {
modified = true
}
override fun removeUpdate(e: DocumentEvent?) {
modified = true
}最终实现如下:
class JiraSettings(private val project: Project): Configurable, DocumentListener {
private val passwordField = JPasswordField()
private val txtUsername = JTextField()
private var modified = false
override fun isModified(): Boolean = modified
override fun getDisplayName(): String = "MyPlugin Jira"
override fun apply() {
val config = JiraComponent.getInstance(project)
config.username = txtUsername.text
config.password = String(passwordField.password)
modified = false
}
override fun changedUpdate(e: DocumentEvent?) {
modified = true
}
override fun insertUpdate(e: DocumentEvent?) {
modified = true
}
override fun removeUpdate(e: DocumentEvent?) {
modified = true
}
override fun createComponent(): JComponent {
val mainPanel = JPanel()
mainPanel.setBounds(0, 0, 452, 120)
mainPanel.layout = null
val lblUsername = JLabel("Username")
lblUsername.setBounds(30, 25, 83, 16)
mainPanel.add(lblUsername)
val lblPassword = JLabel("Password")
lblPassword.setBounds(30, 74, 83, 16)
mainPanel.add(lblPassword)
passwordField.setBounds(125, 69, 291, 26)
mainPanel.add(passwordField)
txtUsername.setBounds(125, 20, 291, 26)
mainPanel.add(txtUsername)
txtUsername.columns = 10
val config = JiraComponent.getInstance(project)
txtUsername.text = config.username
passwordField.text = config.password
passwordField.document?.addDocumentListener(this)
txtUsername.document?.addDocumentListener(this)
return mainPanel
}
}与Component相同,我们还必须在plugin.xml文件中声明extension。
<extensions defaultExtensionNs="com.intellij">
<defaultProjectTypeProvider type="Android"/>
<projectConfigurable
instance="settings.JiraSettings">
</projectConfigurable>
</extensions>大功告成!调试或安装插件时,您可以转到Android Studio中的Preferences/Other Settings,找到新的设置页。您也可以使用不同的Project进行测试,并且每个Project都会记住自身的设置。
这就是第三部分的全部内容。在下一篇文章中,我们将看到如何使用这些设置来创建新的Action,将Jira相关功能迁移过来。同时,如果您有任何疑问,请访问Twitter或发表评论。
Hello,我是 却把清梅嗅 ,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的 博客 或者 GitHub。
如果您觉得文章还差了那么点东西,也请通过 关注 督促我写出更好的文章——万一哪天我进步了呢?
反思 系列博客是我的一种新学习方式的尝试,该系列起源和目录请参考 这里 。
Android体系本身非常宏大,源码中值得思考和借鉴之处众多。以整体事件分发机制为例,其整个流程涉及到了 系统启动流程(SystemServer)、输入管理(InputManager)、系统服务和UI的通信(ViewRootImpl + Window + WindowManagerService)、事件分发 等等一系列的环节。
对于 事件分发 环节而言,不可否认非常重要,但Android系统完整的 事件分发机制 也是一名优秀Android工作者需要去了解的,本文笔者将针对Android 事件分发机制及设计思路 进行描述,其整体结构如下图:
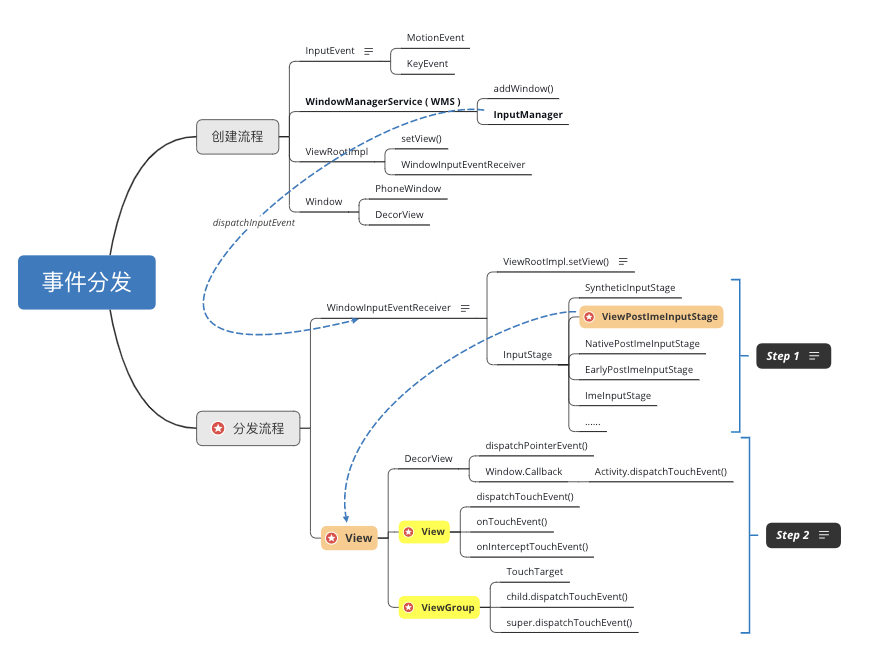
Android系统中将输入事件定义为InputEvent,而InputEvent根据输入事件的类型又分为了KeyEvent和MotionEvent,前者对应键盘事件,后者则对应屏幕触摸事件,这些事件统一由系统输入管理器InputManager进行分发。
在系统启动的时候,SystemServer会启动窗口管理服务WindowManagerService,WindowManagerService在启动的时候就会通过启动系统输入管理器InputManager来负责监控键盘消息。
InputManager负责从硬件接收输入事件,并将事件分发给当前激活的窗口(Window)处理,这里我们将前者理解为 系统服务,将后者理解为应用层级的 UI, 因此需要有一个中介负责 服务 和 UI 之间的通信,于是ViewRootImpl类应运而生。
ActivityThread负责控制Activity的启动过程,在performLaunchActivity()流程中,ActivityThread会针对Activity创建对应的PhoneWindow和DecorView实例,而之后的handleResumeActivity()流程中则会将PhoneWindow( 应用 )和InputManagerService( 系统服务 )通信以建立对应的连接,保证UI可见并能够对输入事件进行正确的分发,这之后Activity就会成为可见的。
如何在应用程序和系统服务之间建立通信?Android中Window和InputManagerService之间的通信实际上使用的InputChannel,InputChannel是一个pipe,底层实际是通过socket进行通信:
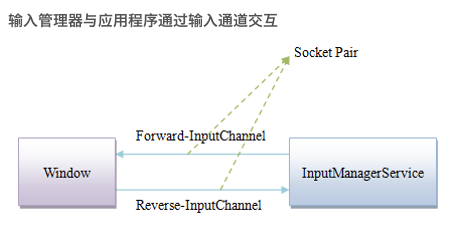
在ActivityThread的handleResumeActivity()流程中, 会通过WindowManagerImpl.addView()为当前的Window创建一个ViewRootImpl实例,当InputManager监控到硬件层级的输入事件时,会通知ViewRootImpl对输入事件进行底层的事件分发。
与View的 布局流程 和 测量流程 相同,Android事件分发机制也使用了 递归 的**,因为一个事件最多只有一个消费者,所以通过责任链的方式将事件自顶向下进行传递,找到事件的消费者(这里是指一个View)之后,再自底向上返回结果。
读到这里,读者应该觉得非常熟悉了,但实际上这里描述的事件分发流程为UI层级的事件分发——它只是事件分发流程整体的一部分。读者需要理解,ViewRootImpl从InputManager获取到新的输入事件时,会针对输入事件通过一个复杂的 责任链 进行底层的递归,将不同类型的输入事件(比如 屏幕触摸事件 和 键盘输入事件 )进行不同策略的分发,而只有部分符合条件的 屏幕触摸事件 最终才有可能进入到UI层级的事件分发:
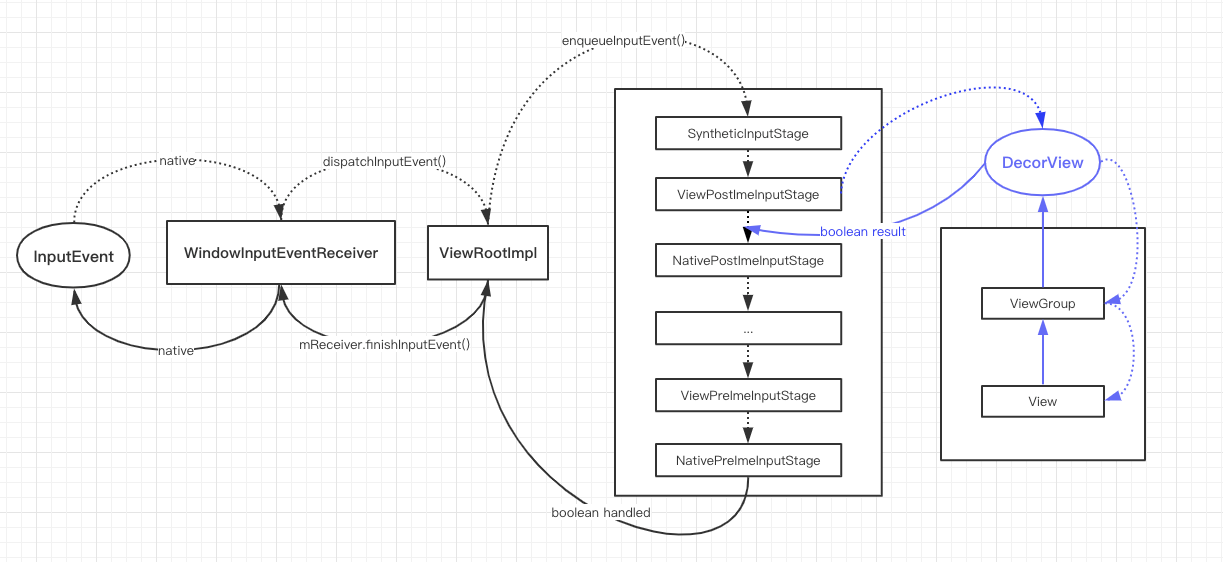
如图所示,蓝色箭头描述的流程才是UI层级的事件分发。
为了方便理解,本文使用了以下两个词汇:应用整体的事件分发 和 UI层级的事件分发 ——需要重申的是,这两个词汇虽然被分开讲解,但其本质仍然属于一个完整 事件分发的责任链,后者只是前者的一小部分而已。
Android系统中将输入事件定义为InputEvent,而InputEvent根据输入事件的类型又分为了KeyEvent和MotionEvent:
// 输入事件的基类
public abstract class InputEvent implements Parcelable { }
public class KeyEvent extends InputEvent implements Parcelable { }
public final class MotionEvent extends InputEvent implements Parcelable { }KeyEvent对应了键盘的输入事件,那么什么是MotionEvent?顾名思义,MotionEvent就是移动事件,鼠标、笔、手指、轨迹球等相关输入设备的事件都属于MotionEvent,本文我们简单地将其视为 屏幕触摸事件。
用户的输入种类繁多,由此可见,Android输入系统的设计中,将 输入事件 抽象为InputEvent是有必要的。
Android系统的设计中,InputEvent统一由系统输入管理器InputManager进行分发。在这里InputManager是native层级的一个类,负责与硬件通信并接收输入事件。
那么InputManager是如何初始化的呢?这里就要涉及到Java层级的SystemServer了,我们知道SystemServer进程中包含着各种各样的系统服务,比如ActivityManagerService、WindowManagerService等等,SystemServer由zygote进程启动, 启动过程中对WindowManagerService和InputManagerService进行了初始化:
public final class SystemServer {
private void startOtherServices() {
// 初始化 InputManagerService
InputManagerService inputManager = new InputManagerService(context);
// WindowManagerService 持有了 InputManagerService
WindowManagerService wm = WindowManagerService.main(context, inputManager,...);
inputManager.setWindowManagerCallbacks(wm.getInputMonitor());
inputManager.start();
}
}InputManagerService的构造器中,通过调用native函数,通知native层级初始化InputManager:
public class InputManagerService extends IInputManager.Stub {
public InputManagerService(Context context) {
// ...通知native层初始化 InputManager
mPtr = nativeInit(this, mContext, mHandler.getLooper().getQueue());
}
// native 函数
private static native long nativeInit(InputManagerService service, Context context, MessageQueue messageQueue);
}SystemServer会启动窗口管理服务WindowManagerService,WindowManagerService在启动的时候就会通过InputManagerService启动系统输入管理器InputManager来负责监控键盘消息。
对于本文而言,framework层级相关如WindowManagerService(窗口管理服务)、native层级的源码、SystemServer 亦或者 Binder跨进程通信并非重点,读者仅需了解 系统服务的启动流程 和 层级关系 即可,参考下图:
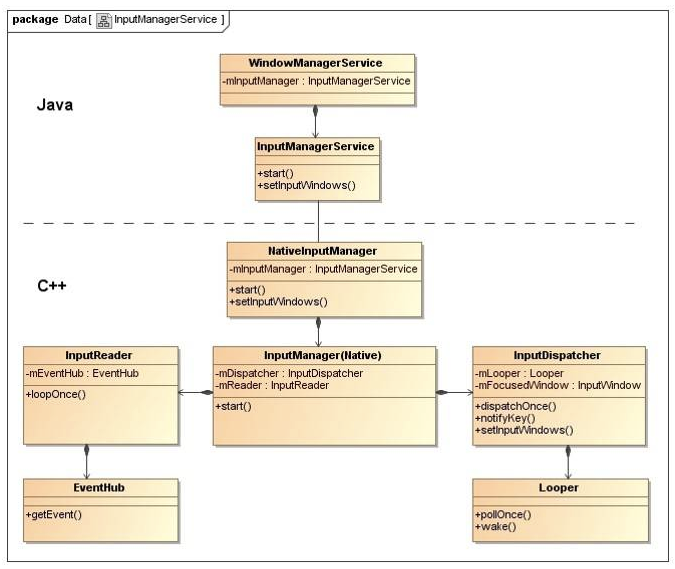
InputManager将事件分发给当前激活的窗口(Window)处理,这里我们将前者理解为系统层级的 (窗口)服务,将后者理解为应用层级的 窗口, 因此需要有一个中介负责 服务 和 窗口 之间的通信,于是ViewRootImpl类应运而生。
ViewRootImpl作为链接WindowManager和DecorView的纽带,同时实现了ViewParent接口,ViewRootImpl作为整个控件树的根部,它是View树正常运作的动力所在,控件的测量、布局、绘制以及输入事件的分发都由ViewRootImpl控制。
那么ViewRootImpl是如何被创建和初始化的,而 (窗口)服务 和 窗口 之间的通信又是如何建立的呢?
既然Android系统将 (窗口)服务 与 窗口 的通信建立交给了ViewRootImpl,那么ViewRootImpl必然持有了两者的依赖,因此了解ViewRootImpl是如何创建的就非常重要。
我们知道,ActivityThread负责控制Activity的启动过程,在ActivityThread.performLaunchActivity()流程中,ActivityThread会针对Activity创建对应的PhoneWindow和DecorView实例,而在ActivityThread.handleResumeActivity()流程中,ActivityThread会将获取当前Activity的WindowManager,并将DecorView和WindowManager.LayoutParams(布局参数)作为参数调用addView()函数:
// 伪代码
public final class ActivityThread {
@Override
public void handleResumeActivity(...){
//...
windowManager.addView(decorView, windowManagerLayoutParams);
}
}WindowManager.addView()实际上就是对ViewRootImpl进行了初始化,并执行了setView()函数:
// 1.WindowManager 的本质实际上是 WindowManagerImpl
public final class WindowManagerImpl implements WindowManager {
@Override
public void addView(@NonNull View view, @NonNull ViewGroup.LayoutParams params) {
// 2.实际上调用了 WindowManagerGlobal.addView()
WindowManagerGlobal.getInstance().addView(...);
}
}
public final class WindowManagerGlobal {
public void addView(...) {
// 3.初始化 ViewRootImpl,并执行setView()函数
ViewRootImpl root = new ViewRootImpl(view.getContext(), display);
root.setView(view, wparams, panelParentView);
}
}
public final class ViewRootImpl {
public void setView(View view, WindowManager.LayoutParams attrs, View panelParentView) {
// 4.该函数就是控测量(measure)、布局(layout)、绘制(draw)的开始
requestLayout();
// ...
// 5.此外还有通过Binder建立通信,这个下文再提
}
}Android系统的Window机制并非本文重点,读者可简单理解为ActivityThread.handleResumeActivity()流程中最终创建了ViewRootImpl,并通过setView()函数对DecorView开始了绘制流程的三个步骤。
完成了ViewRootImpl的创建之后,如何完成系统输入服务和应用程序进程的连接呢?
Android中Window和InputManagerService之间的通信实际上使用的InputChannel,InputChannel是一个pipe,底层实际是通过socket进行通信。在ViewRootImpl.setView()过程中,也会同时注册InputChannel:
public final class InputChannel implements Parcelable { }上文中,我们提到了ViewRootImpl.setView()函数,在该函数的执行过程中,会在ViewRootImpl中创建InputChannel,InputChannel实现了Parcelable, 所以它可以通过Binder传输。具体是通过addDisplay()将当前window加入到WindowManagerService中管理:
public final class ViewRootImpl {
public void setView(View view, WindowManager.LayoutParams attrs, View panelParentView) {
requestLayout();
// ...
// 创建InputChannel
mInputChannel = new InputChannel();
// 通过Binder在SystemServer进程中完成InputChannel的注册
mWindowSession.addToDisplay(mWindow, mSeq, mWindowAttributes,
getHostVisibility(), mDisplay.getDisplayId(),
mAttachInfo.mContentInsets, mAttachInfo.mStableInsets,
mAttachInfo.mOutsets, mInputChannel);
}
}这里涉及到了WindowManagerService和Binder跨进程通信,读者不需要纠结于详细的细节,只需了解最终在SystemServer进程中,WindowManagerService根据当前的Window创建了SocketPair用于跨进程通信,同时并对App进程中传过来的InputChannel进行了注册,这之后,ViewRootImpl里的InputChannel就指向了正确的InputChannel, 作为Client端,其fd与SystemServer进程中Server端的fd组成SocketPair, 它们就可以双向通信了。
对该流程感兴趣的读者可以参考 这篇文章。
App端与服务端建立了双向通信之后,InputManager就能够将产生的输入事件从底层硬件分发过来,Android提供了InputEventReceiver类,以接收分发这些消息:
public abstract class InputEventReceiver {
// Called from native code.
private void dispatchInputEvent(int seq, InputEvent event, int displayId) {
// ...
}
}InputEventReceiver是一个抽象类,其默认的实现是将接收到的输入事件直接消费掉,因此真正的实现是ViewRootImpl.WindowInputEventReceiver类:
public final class ViewRootImpl {
final class WindowInputEventReceiver extends InputEventReceiver {
@Override
public void onInputEvent(InputEvent event, int displayId) {
// 将输入事件加入队列
enqueueInputEvent(event, this, 0, true);
}
}
}输入事件加入队列之后,接下来就是对事件的分发了,设计者在这里使用了经典的 责任链 模式:对于一个输入事件的分发而言,必然有其对应的消费者,在这个过程中为了使多个对象都有处理请求的机会,从而避免了请求的发送者和接收者之间的耦合关系。将这些对象串成一条链,并沿着这条链一直传递该请求,直到有对象处理它为止。
因此,设计者针对事件分发的整个责任链设计了InputStage类作为基类,作为责任链中的模版,并实现了若干个子类,为输入事件按顺序分阶段进行分发处理:
// 事件分发不同阶段的基类
abstract class InputStage {
private final InputStage mNext; // 指向事件分发的下一阶段
}
// InputStage的子类,象征事件分发的各个阶段
final class ViewPreImeInputStage extends InputStage {}
final class EarlyPostImeInputStage extends InputStage {}
final class ViewPostImeInputStage extends InputStage {}
final class SyntheticInputStage extends InputStage {}
abstract class AsyncInputStage extends InputStage {}
final class NativePreImeInputStage extends AsyncInputStage {}
final class ImeInputStage extends AsyncInputStage {}
final class NativePostImeInputStage extends AsyncInputStage {}输入事件整体的分发阶段十分复杂,比如当事件分发至SyntheticInputStage阶段,该阶段为 综合性处理阶段 ,主要针对轨迹球、操作杆、导航面板及未捕获的事件使用键盘进行处理:
final class SyntheticInputStage extends InputStage {
@Override
protected int onProcess(QueuedInputEvent q) {
// 轨迹球
if (...) {
mTrackball.process(event);
return FINISH_HANDLED;
} else if (...) {
// 操作杆
mJoystick.process(event);
return FINISH_HANDLED;
} else if (...) {
// 导航面板
mTouchNavigation.process(event);
return FINISH_HANDLED;
}
// 继续转发事件
return FORWARD;
}
}比如当事件分发至ImeInputStage阶段,即 输入法事件处理阶段 ,会从事件中过滤出用户输入的字符,如果输入的内容无法被识别,则将输入事件向下一个阶段继续分发:
final class ImeInputStage extends AsyncInputStage {
@Override
protected int onProcess(QueuedInputEvent q) {
if (mLastWasImTarget && !isInLocalFocusMode()) {
// 获取输入法Manager
InputMethodManager imm = InputMethodManager.peekInstance();
final InputEvent event = q.mEvent;
// imm对事件进行分发
int result = imm.dispatchInputEvent(event, q, this, mHandler);
if (result == ....) {
// imm消费了该输入事件
return FINISH_HANDLED;
} else {
return FORWARD; // 向下转发
}
}
return FORWARD; // 向下转发
}
}当然还有最熟悉的ViewPostImeInputStage,即 视图输入处理阶段 ,主要处理按键、轨迹球、手指触摸及一般性的运动事件,触摸事件的分发对象是View,这也正是我们熟悉的 UI层级的事件分发 流程的起点:
final class ViewPostImeInputStage extends InputStage {
private int processPointerEvent(QueuedInputEvent q) {
// 让顶层的View开始事件分发
final MotionEvent event = (MotionEvent)q.mEvent;
boolean handled = mView.dispatchPointerEvent(event);
//...
}
}读到这里读者应该理解了, UI层级的事件分发只是完整事件分发流程的一部分,当输入事件(即使是MotionEvent)并没有分发到ViewPostImeInputStage(比如在 综合性处理阶段 就被消费了),那么View层的事件分发自然无从谈起,这里再将整体的流程图进行展示以方便理解:
现在我们理解了,新分发的事件会通过一个InputStage的责任链进行整体的事件分发,这意味着,当新的事件到来时,责任链已经组装好了,那么这个责任链是何时进行组装的?
不难得出,对于责任链的组装,最好是在系统服务和Window建立通信成功的时候,而上文中也提到了,通信的建立是执行在ViewRootImpl.setView()方法中的,因此在InputChannel注册成功之后,即可对责任链进行组装:
public final class ViewRootImpl implements ViewParent {
public void setView(View view, WindowManager.LayoutParams attrs, View panelParentView) {
// ...
// 1.开始根布局的绘制流程
requestLayout();
// 2.通过Binder建立双端的通信
res = mWindowSession.addToDisplay(...)
mInputEventReceiver = new WindowInputEventReceiver(mInputChannel, Looper.myLooper());
// 3.对责任链进行组装
mSyntheticInputStage = new SyntheticInputStage();
InputStage viewPostImeStage = new ViewPostImeInputStage(mSyntheticInputStage);
InputStage nativePostImeStage = new NativePostImeInputStage(viewPostImeStage,
"aq:native-post-ime:" + counterSuffix);
InputStage earlyPostImeStage = new EarlyPostImeInputStage(nativePostImeStage);
InputStage imeStage = new ImeInputStage(earlyPostImeStage,
"aq:ime:" + counterSuffix);
InputStage viewPreImeStage = new ViewPreImeInputStage(imeStage);
InputStage nativePreImeStage = new NativePreImeInputStage(viewPreImeStage,
"aq:native-pre-ime:" + counterSuffix);
mFirstInputStage = nativePreImeStage;
mFirstPostImeInputStage = earlyPostImeStage;
// ...
}
}这说明ViewRootImpl.setView()函数非常重要,该函数也正是ViewRootImpl本身职责的体现:
WindowManager和DecorView的纽带,更广一点可以说是Window和View之间的纽带;View的绘制过程,包括measure、layout、draw过程;InputEvent事件。最终整体事件分发流程由如下责任链构成:
SyntheticInputStage --> ViewPostImeStage --> NativePostImeStage --> EarlyPostImeStage --> ImeInputStage --> ViewPreImeInputStage --> NativePreImeInputStage
上文说到,真正从Native层的InputManager接收输入事件的是ViewRootImpl的WindowInputEventReceiver对象,既然负责输入事件的分发,自然也负责将事件分发的结果反馈给Native层,作为事件分发的结束:
public final class ViewRootImpl {
final class WindowInputEventReceiver extends InputEventReceiver {
@Override
public void onInputEvent(InputEvent event, int displayId) {
// 【开始】将输入事件加入队列,开始事件分发
enqueueInputEvent(event, this, 0, true);
}
}
}
// ViewRootImpl.WindowInputEventReceiver 是其子类,因此也持有finishInputEvent函数
public abstract class InputEventReceiver {
private static native void nativeFinishInputEvent(long receiverPtr, int seq, boolean handled);
public final void finishInputEvent(InputEvent event, boolean handled) {
//...
// 【结束】调用native层函数,结束应用层的本次事件分发
nativeFinishInputEvent(mReceiverPtr, seq, handled);
}
}上文已经提到,UI层级的事件分发 作为 完整事件分发流程的一部分,发生在ViewPostImeInputStage.processPointerEvent函数中:
final class ViewPostImeInputStage extends InputStage {
private int processPointerEvent(QueuedInputEvent q) {
// 让顶层的View开始事件分发
final MotionEvent event = (MotionEvent)q.mEvent;
boolean handled = mView.dispatchPointerEvent(event);
//...
}
}这个顶层的View其实就是DecorView(参见上文 建立通信-ViewRootImpl的创建 小节),读者知道,DecorView实际上就是Activity中Window的根布局,它是一个FrameLayout。
现在DecorView执行了dispatchPointerEvent(event)函数,这是不是就意味着开始了View的事件分发?
DecorView作为View树的根节点,接收到屏幕触摸事件MotionEvent时,应该通过递归的方式将事件分发给子View,这似乎理所当然。但实际设计中,设计者将DecorView接收到的事件首先分发给了Activity,Activity又将事件分发给了其Window,最终Window才将事件又交回给了DecorView,形成了一个小的循环:
// 伪代码
public class DecorView extends FrameLayout {
// 1.将事件分发给Activity
@Override
public boolean dispatchTouchEvent(MotionEvent ev) {
return window.getActivity().dispatchTouchEvent(ev)
}
// 4.执行ViewGroup 的 dispatchTouchEvent
public boolean superDispatchTouchEvent(MotionEvent event) {
return super.dispatchTouchEvent(event);
}
}
// 2.将事件分发给Window
public class Activity {
public boolean dispatchTouchEvent(MotionEvent ev) {
return getWindow().superDispatchTouchEvent(ev);
}
}
// 3.将事件再次分发给DecorView
public class PhoneWindow extends Window {
@Override
public boolean superDispatchTouchEvent(MotionEvent event) {
return mDecor.superDispatchTouchEvent(event);
}
}事件绕了一个圈子最终回到了DecorView这里,对于初次阅读这段源码的读者来说,这里的设计平淡无奇,似乎说它莫名其妙也不过分。事实上这里是 面向对象程序设计 中灵活运用 多态 这一特征的有力体现——对于DecorView而言,它承担了2个职责:
DecorView不同于其它View,它需要先将事件转发给最外层的Activity,使得开发者可以通过重写Activity.onTouchEvent()函数以达到对当前屏幕触摸事件拦截控制的目的,这里DecorView履行了自身(根节点)特殊的职责;Window接收到事件时,作为View树的根节点,将事件分发给子View,这里DecorView履行了一个普通的View的职责。实际上,不只是DecorView,接下来View层级的事件分发中也运用到了这个技巧,对于ViewGroup的事件分发来说,其本质是递归**的体现,在 递流程 中,其本身被视为上游的ViewGroup,需要自定义dispatchTouchEvent()函数,并调用child.dispatchTouchEvent(event)将事件分发给下游的子View;同时,在 归流程 中,其本身被视为一个View,需要调用View自身的方法已决定是否消费该事件(super.dispatchTouchEvent(event)),并将结果返回上游,直至回归到View树的根节点,至此整个UI树事件分发流程结束。
同时,读者应该也已理解,平时所说View层级的事件分发也只是 UI层的事件分发 的一个环节,而 UI层的事件分发 又只是 应用层完整事件分发 的一个小环节,更遑论后者本身又是Native层和应用层之间的事件分发机制的一部分了。
虽然View层级之间的事件分发只是 UI层级事件分发 的一个环节,但却是最重要的一个环节,也是本文的重点,上文所有内容都是为本节做系统性的铺垫 ——为了方便阅读,本小节接下来的内容中,事件分发 统一泛指 View层级的事件分发。
了解 事件分发 的代码流程细节,首先需要了解整个流程的最终目的,那就是 获知事件是否被消费 ,至于事件被哪个角色消费了,怎么被消费的,在外层责任链中的ViewPostImeInputStage不关心,其更上层ViewRootImpl.WindowInputEventReceiver不关心,native层级的InputManager自然更不会关心了。
因此,设计者设计出了这样一个函数:
// 对事件进行分发
public boolean dispatchTouchEvent(MotionEvent event);对于事件分发结果的接收者而言,其只关心事件是否被消费,因此返回值被定义为了boolean类型:当返回值为true,事件被消费,反之则事件未被消费。
上文中我们同样提到了,在ViewGroup的事件分发过程中,其本身的dispatchTouchEvent(event)和super.dispatchTouchEvent(event)完全是两个完全不同的函数,前者履行的是ViewGroup的职责,负责将事件分发给子View;后者履行的是View的职责,负责处理决定事件是否被消费(参见 应用整体的事件分发-DecorView的双重职责 小节)。
因此,对于事件分发整体流程,我们可以进行如下定义:
ViewGroup将事件分发给子View,当子View从ViewGroup中接收到事件,若其有child,则通过dispatchTouchEvent(event)再将事件分发给child...以此类推,直至将事件分发到底部的View,这也是事件分发的 递流程;View接收到事件时,通过View自身的dispatchTouchEvent(event)函数判断是否消费事件:true向上层的ViewGroup返回,ViewGroup接收到true,意味着事件已经被消费,因此跳过了是否要消费该事件的判断,直接向上一级继续返回true,以此类推直到将true结果通知到最上层的View节点;false,ViewGroup接收到false,意味着事件未被消费,因此其本身执行super.dispatchTouchEvent(event)——即执行View本身的dispatchTouchEvent(event)函数,并将结果向上级返回,以此类推直到将true结果通知到最上层的View节点。对于初次了解事件分发机制或者不熟悉递归**的读者而言,上述文字似乎晦涩难懂,实际上用代码实现却惊人的简单:
// 伪代码实现
// ViewGroup.dispatchTouchEvent
public boolean dispatchTouchEvent(MotionEvent event) {
boolean consume = false;
// 1.将事件分发给Child
if (hasChild) {
consume = child.dispatchTouchEvent();
}
// 2.若Child不消费该事件,或者没有child,判断自身是否消费该事件
if (!consume) {
consume = super.dispatchTouchEvent();
}
// 3.将结果向上层传递
return consume;
}上述代码中已经将 事件分发 最核心的流程表现的淋漓尽致,读者需认真理解和揣摩。View层级的事件传递的真正实现虽然复杂,但其本质却和上述代码并不不同,理解了这个基本的流程,接下来对于额外功能扩展的设计与实现也只是时间问题了。
在上一小节中,读者已经了解事件分发的本质原理就是递归,而目前其实现方式是,每接收一个新的事件,都需要进行一次递归才能找到对应消费事件的View,并依次向上返回事件分发的结果。
每个事件都对View树进行一次遍历递归?这对性能的影响显而易见,因此这种设计是有改进空间的。
如何针对这个问题进行改进?首先,设计者根据用户的行为对MotionEvent中添加了一个Action的属性以描述该事件的行为:
ACTION_CANCEL...定义了这些行为的同时,设计者定义了一个叫做 事件序列 的概念:针对用户的一次触摸操作,必然对应了一个 事件序列,从用户手指接触屏幕,到移动手指,再到抬起手指 ——单个事件序列必然包含ACTION_DOWN、ACTION_MOVE ... ACTION_MOVE、ACTION_UP 等多个事件,这其中ACTION_MOVE的数量不确定,ACTION_DOWN和ACTION_UP的数量则为1。
定义了 事件序列 的概念,设计者就可以着手对现有代码进行设计和改进,其思路如下:当接收到一个ACTION_DOWN时,意味着一次完整事件序列的开始,通过递归遍历找到View树中真正对事件进行消费的Child,并将其进行保存,这之后接收到ACTION_MOVE和ACTION_UP行为时,则跳过遍历递归的过程,将事件直接分发给Child这个事件的消费者;当接收到ACTION_DOWN时,则重置整个事件序列:
如图所示,其代表了一个
View树,若序号为4的View是实际事件的消费者,那么当接收到ACTION_DOWN事件时,上层的ViewGroup则会通过递归找到它,接下来该事件序列中的其它事件到来时,也交给4号View去处理。
这个思路似乎没有问题,但是目前的设计中我们还缺少一把关键的钥匙,那就是如何在ViewGroup中保存实际消费事件的View?
为此设计者根据View的树形结构,设计了一个TouchTarget类,为作为一个成员属性,描述ViewGroup下一级事件分发的目标:
public abstract class ViewGroup extends View {
// 指向下一级事件分发的`View`
private TouchTarget mFirstTouchTarget;
private static final class TouchTarget {
public View child;
public TouchTarget next;
}
}这里应用到了树的 深度优先搜索算法(Depth-First-Search,简称DFS算法),正如代码所描述的,每个ViewGroup都持有一个mFirstTouchTarget, 当接收到一个ACTION_DOWN时,通过递归遍历找到View树中真正对事件进行消费的Child,并保存在mFirstTouchTarget属性中,依此类推组成一个完整的分发链。
比如上文的树形图中,序号为1的
ViewGroup中的mFirstTouchTarget指向序号为2的ViewGroup,后者的mFirstTouchTarget指向序号为3的ViewGroup,依此类推,最终组成了一个 1 -> 2 -> 3 -> 4 事件的分发链。
对于一个 事件序列 而言,第一次接收到ACTION_DOWN事件时,通过DFS算法为View树事件的 分发链 进行初始化,在这之后,当接收到同一事件序列的其它事件如ACTION_MOVE、ACTION_UP时,则会跳过递归流程,将事件直接分发给 分发链 下一级的Child中:
// ViewGroup.dispatchTouchEvent
public boolean dispatchTouchEvent(MotionEvent event) {
boolean consume = false;
// ...
if (event.isActionDown()) {
// 1.第一次接收到Down事件,递归寻找分发链的下一级,即消费该事件的View
// 这里可以看到,递归深度搜索的算法只执行了一次
mFirstTouchTarget = findConsumeChild(this);
}
// ...
if (mFirstTouchTarget == null) {
// 2.分发链下一级为空,说明没有子`View`消费该事件
consume = super.dispatchTouchEvent(event);
} else {
// 3.mFirstTouchTarget不为空,必然有消费该事件的`View`,直接将事件分发给下一级
consume = mFirstTouchTarget.child.dispatchTouchEvent(event);
}
// ...
return consume;
}至此,本小节一开始提到的问题得到了解决。
读者应该都有了解,为了增加 事件分发 过程中的灵活性,Android为ViewGroup层级设计了onInterceptTouchEvent()函数并向外暴露给开发者,以达到让ViewGroup跳过子View的事件分发,提前结束 递流程 ,并自身决定是否消费事件,并将结果反馈给上层级的ViewGroup处理。
额外设计这样一个接口是否有必要?读者认真思考可以得知,这是有必要的,最经典的使用场景就是通过重写onInterceptTouchEvent()函数以解决开发中常见的 滑动冲突 事件,这里我们不再进行引申,仅探讨设计者是如何设计事件拦截机制的。
实际上事件拦截机制的实现非常简单,我们仅需要在正式的事件分发之前,通过条件分支判断是否需要拦截当前事件的分发即可:
// 伪代码实现
// ViewGroup.dispatchTouchEvent
public boolean dispatchTouchEvent(MotionEvent event) {
// 1.若需要对事件进行拦截,直接中止事件向下分发,让自身决定是否消费事件,并将结果返回
if (onInterceptTouchEvent(event)) {
return super.dispatchInputEvent(event);
}
// ...
// 2.若不拦截当前事件,开始事件分发流程
}此外,为了避免额外的开销,设计者根据 事件序列 为 事件拦截机制 做出了额外的优化处理,保证了 事件拦截的判断在一个事件序列中只处理一次,伪代码简单实现如下:
// ViewGroup.dispatchTouchEvent
public boolean dispatchTouchEvent(MotionEvent event) {
if (mFirstTouchTarget != null) {
// 1.若需要对事件进行拦截,直接中止事件向下分发,让自身决定是否消费事件,并将结果返回
if (onInterceptTouchEvent(event)) {
// 2.确定对该事件序列拦截后,因此就没有了下一级要分发的Child
mFirstTouchTarget = null;
// 下一个事件传递过来时,最外层的if判断就会为false,不会再重复执行onInterceptTouchEvent()了
return super.dispatchInputEvent(event);
}
}
// ...
// 3.若不拦截当前事件,开始事件分发流程
}为了令代码便于理解,上述伪代码中逻辑实际上是有瑕疵的,读者不必纠结于细节,详细实现请参考源码。
至此,事件分发 中 事件拦截机制 的设计初衷、流程的实现,以及性能的优化也阐述完毕。
在一步步对细节的填充过程中,事件分发 体系的设计已初显峥嵘,但回归本质,这些细节犹如血肉,而核心的**(即递归)才是骨架,只有骨架搭建起来,细节的血肉才能一点点覆于其上,最终演变为成为生机勃勃的 事件分发 完整体系。
Android 整体的事件分发机制十分复杂,单就一篇文章来说,本文也仅仅只能站在巨人的肩膀上,对整体的轮廓进行一个简略的描述,强烈建议参考本文开篇的思维导图并结合源码进行整体小结。
这一篇文章就能让我理解Android事件分发机制吗?
当然不能,即使是笔者对此也只是初窥门径而已,在撰写本文的过程中,笔者参考了许多优秀的学习资料,同样笔者也不认为本文比这些资料讲解的更透彻,读者可以参考这些资料 ——一千个人有一千个哈姆雷特,也许这些优秀的资料相比本文更适合你呢?
源码永远是学习过程中最好的老师,RTFSC。
神书,书中 View的事件分发机制 一节将源码分析到了极致,讲解的非常透彻,强烈建议 建议读者源码阅读时参考这本书。
framework层原理分析的神文,懂得自然懂。本文中的部分图片也引自该文。
非常好的博客系列。
对
ViewRootImpl讲解非常透彻的一篇博客,本文对于ViewRootImpl的主要职责的描述也是参考了此文。
非常欣赏 @KunMinX 老师博文的风格,大道至简,此文对事件消费过程中的 消费 二字的讲解非常透彻,给予了笔者很多启示——另,本文不是黑车(笑)。
Hello,我是 却把清梅嗅 ,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的 博客 或者 Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
反思 系列博客是我的一种新学习方式的尝试,该系列起源和目录请参考 这里 。
Android本身的View体系非常宏大,源码中值得思考和借鉴之处众多,以View本身的绘制流程为例,其经过measure测量、layout布局、draw绘制三个过程,最终才能够将其绘制出来并展示在用户面前。
相比 测量流程 ,布局流程 相对简单很多,如果读者不了解 测量流程 ,建议阅读这篇文章:
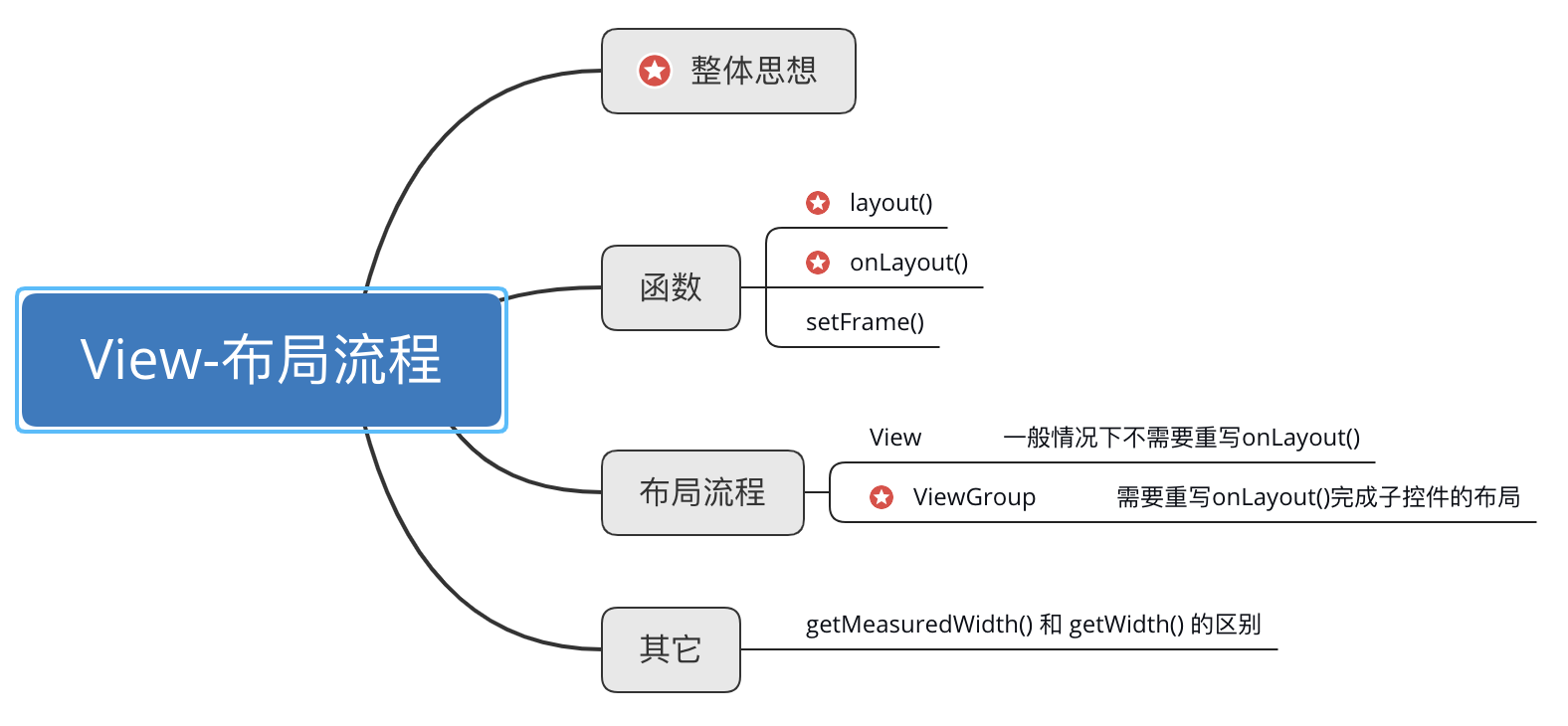
测量流程 的目的是 测量控件宽高 ,但只获取控件的宽高实际上是不够的,对于ViewGroup而言还需要一套额外的逻辑,负责对所有子控件进行对应策略的布局,这就是 布局流程(layout)。
View而言,其本身没有子控件,因此一般情况下仅需要记录自己在父控件的位置信息,并不需要处理为子控件布局的逻辑;Android中布局流程中也使用了递归**:对于一个完整的界面而言,每个页面都映射了一个View树,其最顶端的父控件开始布局时,会通过自身的布局策略依次计算出每个子控件的位置——值得一提的是,为了保证控件树形结构的 内部自治性,每个子控件的位置为 相对于父控件坐标系的相对位置 ,而不是以屏幕坐标系为准的绝对位置。位置计算完毕后,作为参数交给子控件,令子控件开始布局;如此往复一直到最底层的控件,当所有控件都布局完毕,整个布局流程结束。对于布局流程不甚熟悉的开发者而言,上述文字似乎晦涩难懂,但这些文字的概括其本质却是布局流程整体的设计**,读者不应该将本文视为源码分析,而应该将自己代入到设计的过程中 ,当深刻理解整个流程的设计思路之后,布局流程代码地设计和编写自然行云流水一气呵成。
首先思考一个问题,布局流程的本质是测量结束之后,将每个子控件分配到对应的位置上去——既然有子控件,那说明进行布局流程的主体理应是ViewGroup,那么作为叶子节点的单个View来说,为什么也会有布局流程呢?
读者认真思考可以得出,布局流程实际上是一个复杂的过程,整个流程主要逻辑顺序如下:
onMeasure();整个布局过程中,除了4是ViewGroup自身需要做的,其它逻辑对于View和ViewGroup而言都是公共的——这说明单个View也是有布局流程的需求的。
现在将整个布局过程定义三个重要的函数,分别为:
void layout(int l, int t, int r, int b):控件自身整个布局流程的函数;void onLayout(boolean changed, int left, int top, int right, int bottom):ViewGroup布局逻辑的函数,开发者需要自己实现自定义布局逻辑;void setFrame(int left, int top, int right, int bottom):保存最新布局位置信息的函数;为什么需要定义这样三个函数?
现在我们站在单个View的角度,首先父控件需要通过调用子控件的layout()函数,并同时将子控件的位置(left、right、top、bottom)作为参数传入,标志子控件本身布局流程的开始:
// 伪代码实现
public void layout(int l, int t, int r, int b) {
// 1.决定是否需要重新进行测量流程(onMeasure)
if(needMeasureBeforeLayout) {
onMeasure(mOldWidthMeasureSpec, mOldHeightMeasureSpec)
}
// 先将之前的位置信息进行保存
int oldL = mLeft;
int oldT = mTop;
int oldB = mBottom;
int oldR = mRight;
// 2.将自身所在的位置信息进行保存;
// 3.判断本次布局流程是否引发了布局的改变;
boolean changed = setFrame(l, t, r, b);
if (changed) {
// 4.若布局发生了改变,令所有子控件重新布局;
onLayout(changed, l, t, r, b);
// 5.若布局发生了改变,通知所有观察布局改变的监听发送通知
mOnLayoutChangeListener.onLayoutChange(this, l, t, r, b, oldL, oldT, oldR, oldB);
}
}这里笔者通过伪代码的方式对布局流程进行了描述,实际上View本身的layout()函数内部虽然多处不同,但核心**是一致的——layout()函数实际上代表了控件自身布局的整个流程,setFrame()和onLayout()函数都是layout()中的一个步骤。
为什么需要保存布局信息?因为我们总是有获取控件的宽和高的需求——比如接下来的onDraw()绘制阶段;而保存了布局信息,就能通过这些值计算控件本身的宽高:
public final int getWidth() { return mWidth; }
public final int getHeight() { return mHeight; }由此可见,保存控件的布局信息确实很有必要,Android中将layout()函数的四个参数所代表的位置信息,交给了setFrame()函数去保存:
protected boolean setFrame(int left, int top, int right, int bottom) {
// 布局是否发生了改变
boolean changed = false;
// 若最新的布局信息和之前的布局信息不同,则保存最新的布局信息
if (mLeft != left || mRight != right || mTop != top || mBottom != bottom) {
changed = true;
mLeft = left;
mTop = top;
mRight = right;
mBottom = bottom;
}
return changed;
}setFrame()函数被protected修饰,这意味着开发者可以通过重写该函数来定义View本身保存布局信息的逻辑,现在将目光转到mLeft、mTop、mRight、mBottom四个变量上。
顾名思义,这四个变量对应的自然是View自身所在的位置,那么View是如何通过这四个变量描述控件的位置信息呢?
通过一张图来看一下这四个变量所代表的意义:
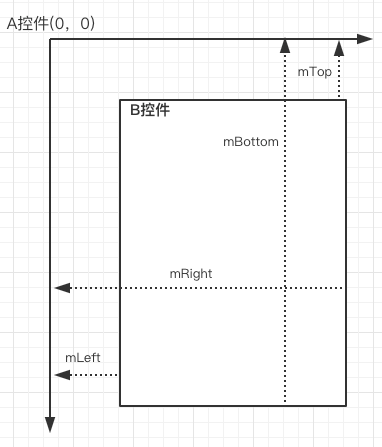
这时候不可避免的会面临另外一个问题,这个mLeft、mTop、mRight、mBottom的值所对应的坐标系是哪里呢?
这里需要注意的是,为了保证控件树形结构的 内部自治性,每个子控件的位置为 相对于父控件坐标系的相对位置 ,而不是以屏幕坐标系为准的绝对位置:
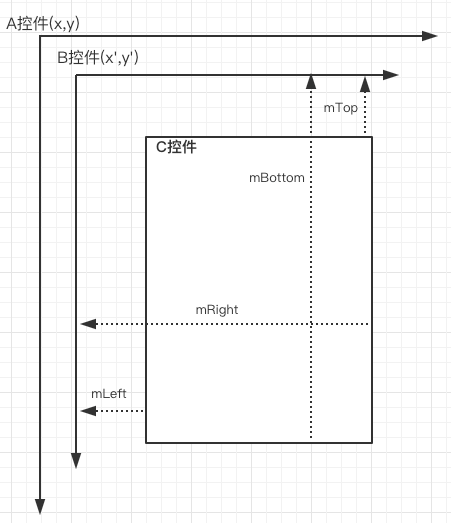
反过来想,如果这些位置信息是以屏幕坐标系为准,那么就意味着每个叶子节点的
View会持有保存从根节点ViewGroup直到自身父ViewGroup每个控件的位置信息,在计算布局时则更为繁琐,很明显是不合理的设计。
既然View自身持有了这样的位置信息,实际上前文中获取控件自身宽高的getWidth()和getHeight()方法就可以重新这样定义:
public final int getWidth() { return mRight - mLeft; }
public final int getHeight() { return mBottom - mTop; }这也说明了在布局流程中的setFrame()函数执行完毕后(且布局确实发生了改变),开发者才能通过getWidth()和getHeight()方法获取控件正确的宽高值。
对于叶子节点的View而言,其并没有子控件,因此一般情况下并没有为子控件布局的意义(特殊情况请参考AppCompatTextView等类),因此View的onLayout()函数被设计为一个空的实现:
protected void onLayout(boolean changed, int left, int top, int right, int bottom) { }而在ViewGroup中,不同类型的ViewGroup有不同的布局策略,这些布局策略的逻辑各不相同,因此该方法被设计为抽象接口,开发者必须实现这个方法以定义ViewGroup的布局策略:
@Override
protected abstract void onLayout(boolean changed,int l, int t, int r, int b);以
LinearLayout为例,其布局策略为 根据排布方向,将其所有子控件按照指定方向依次排列布局
至此单个View的测量流程结束,关于ViewGroup的onLayout函数细节将在下文进行描述。
相比较测量流程,布局流程相对比较简单,整体思路是,对于一个完整的界面而言,每个页面都映射了一个View树,最顶端的父控件开始布局时,会通过自身的布局策略依次计算出每个子控件的位置。位置计算完毕后,作为参数交给子控件,令子控件开始布局;如此往复一直到最底层的控件,当所有控件都布局完毕,整个布局流程结束。
ViewGroup虽然重写了View的layout()函数,但实质上并未进行大的变动,我们大抵可以认为ViewGroup和View的layout()逻辑一致:
@Override
public final void layout(int l, int t, int r, int b) {
if (!mSuppressLayout && (mTransition == null || !mTransition.isChangingLayout())) {
if (mTransition != null) {
mTransition.layoutChange(this);
}
// 仍然是执行View层的layout函数
super.layout(l, t, r, b);
} else {
mLayoutCalledWhileSuppressed = true;
}
}唯一需要注意的是,开发者必须实现onLayout()函数以定义ViewGroup的布局策略,这里以 竖直布局 的LinearLayout的伪代码为例:
@Override
protected void onLayout(boolean changed, int l, int t, int r, int b) {
int childTop;
int childLeft;
// 遍历所有子View
for (int i = 0; i < count; i++) {
// 获取子View
final View child = getVirtualChildAt(i);
// 获取子View宽高,注意这里使用的是 getMeasuredWidth 而不是 getWidth
final int childWidth = child.getMeasuredWidth();
final int childHeight = child.getMeasuredHeight();
// 令所有子控件开始布局
setChildFrame(child, childLeft, childTop, childWidth, childHeight);
// 高度累加,下一个子View的 top 就等于上一个子View的 bottom ,符合竖直线性布局从上到下的布局策略
childTop += childHeight;
}
}
private void setChildFrame(View child, int left, int top, int width, int height) {
// 这里可以看到,子控件的mRight实际上就是 mLeft + getMeasuredWidth()
// 而在getWidth()函数中,mRight-mLeft的结果就是getMeasuredWidth()
// 因此,getWidth() 和 getMeasuredWidth() 是一致的
child.layout(left, top, left + width, top + height);
}读者需要注意到一个细节,子控件的宽度的获取,我们并未使用getWidth(),而是使用了getMeasuredWidth(),这就引发了另外一个疑问,这两个函数的区别在哪里。
首先,从上文中我们得知,getWidth()和getHeight()函数的相关信息实际上是在setFrame()函数执行完毕才准备完毕的——我们大致可以认为是这两个函数 只有布局流程(layout)执行完毕才能调用,而在父控件的onLayout()函数中,获取子控件宽度和高度时,子控件还并未开始进行布局流程,因此此时不能调用getWidth()函数,而只能通过getMeasuredWidth()函数获取控件测量阶段结果的宽度。
那么当控件绘制流程执行完毕后,getWidth()和getMeasuredWidth()函数的值有什么区别呢?从上述setChildFrame()函数中的源码可以得知,布局流程执行后,getWidth()返回值的本质其实就是getMeasuredWidth()——因此本质上,当我们没有手动调用layout()函数强制修改控件的布局信息的话,两个函数的返回值大小是完全一致的。
在整个布局流程的设计中,设计者将流程中公共的业务逻辑(保存布局信息、通知布局发生改变的监听等)通过layout()函数进行了整合,同时,将ViewGroup额外需要的自定义布局策略通过onLayout()函数向外暴露出来,针对组件中代码的可复用性和可扩展性进行了合理的设计。
至此,布局流程整体实现完毕。借用 carson_ho 绘制的流程图对整体布局流程做一个总结:
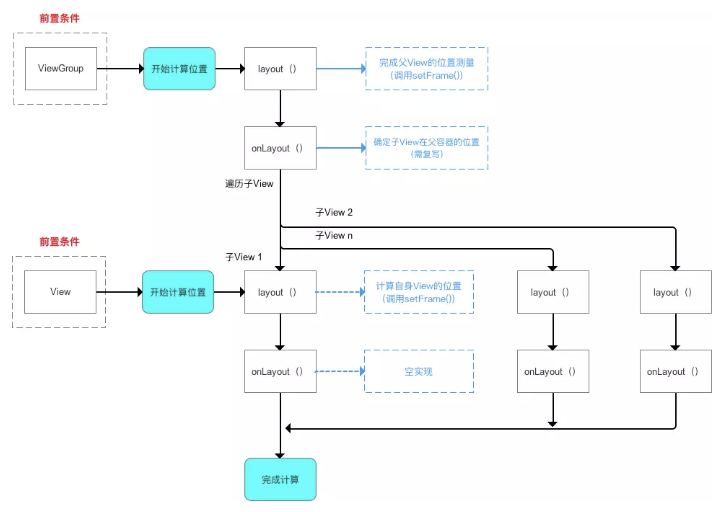
Hello,我是 却把清梅嗅 ,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的 博客 或者 Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?

Floyd 判圈算法(Floyd Cycle Detection Algorithm),又称龟兔赛跑算法(Tortoise and Hare Algorithm),是一个可以在有限状态机、迭代函数或者链表上判断是否存在环,以及判断环的起点与长度的算法。
ptr1 ,指向链表的头, ptr2 指向相遇点。然后,每次将它们往前移动一步,直到它们相遇,它们相遇的点就是环的入口。结论1是很显然的,结论2似乎有点匪夷所思,下面将针对以上结论分别进行证明。
一个跑得快的人和一个跑得慢的人在一个圆形的赛道上赛跑,会发生什么?在某一个时刻,跑得快的人一定会从后面赶上跑得慢的人。
下图说明了这个算法的工作方式。
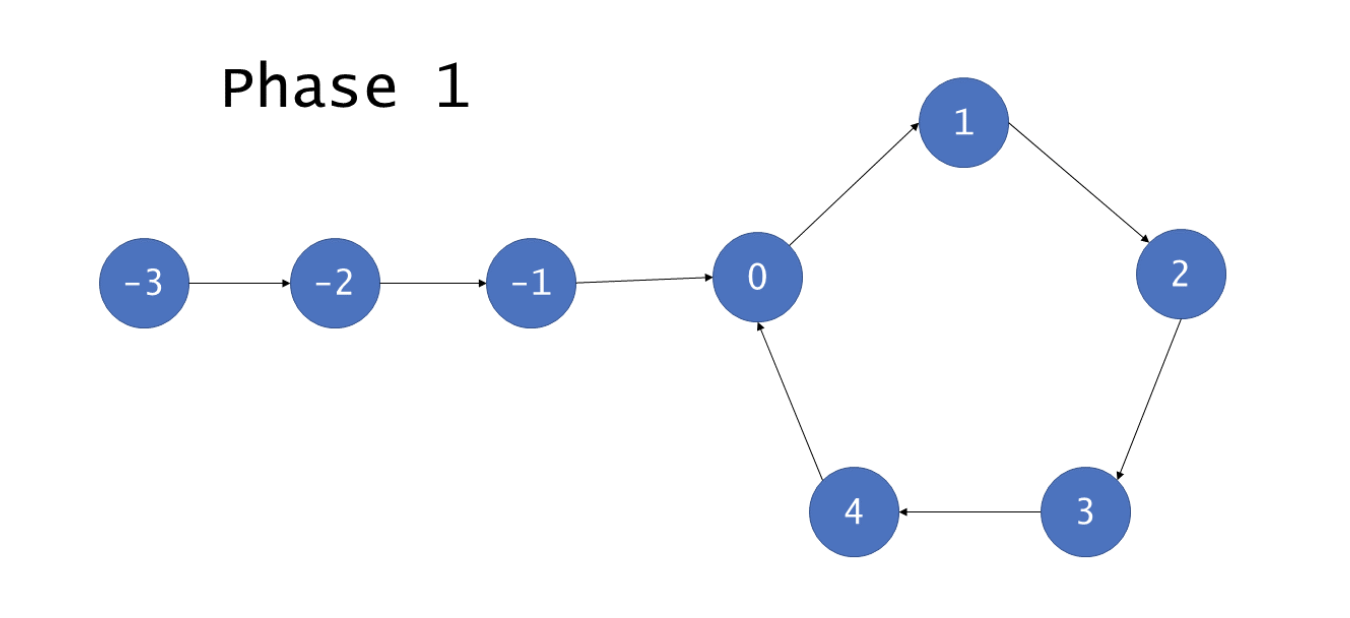
初始状态下,假设已知某个起点节点为节点F。现设两个指针 fast 和 slow,将它们均指向F。
同时让 fast 和 slow 往前推进,fast 的速度为 slow 的2倍),直到 fast 无法前进,即到达某个没有后继的节点时,就可以确定从F出发不会遇到环。反之当 fast 和 slow 再次相遇时,就可以确定从F出发一定会进入某个环,设其为环C( fast 和 slow 推进的步数差是环长的倍数)。
如何找到环的入口?
根据结论1找到的相遇点可找到环的入口,初始化额外的两个指针:
ptr1,指向链表的头,ptr2指向相遇点。然后,每次将它们往前移动一步,直到它们相遇,它们相遇的点就是环的入口。
下图对结论2进行证明。
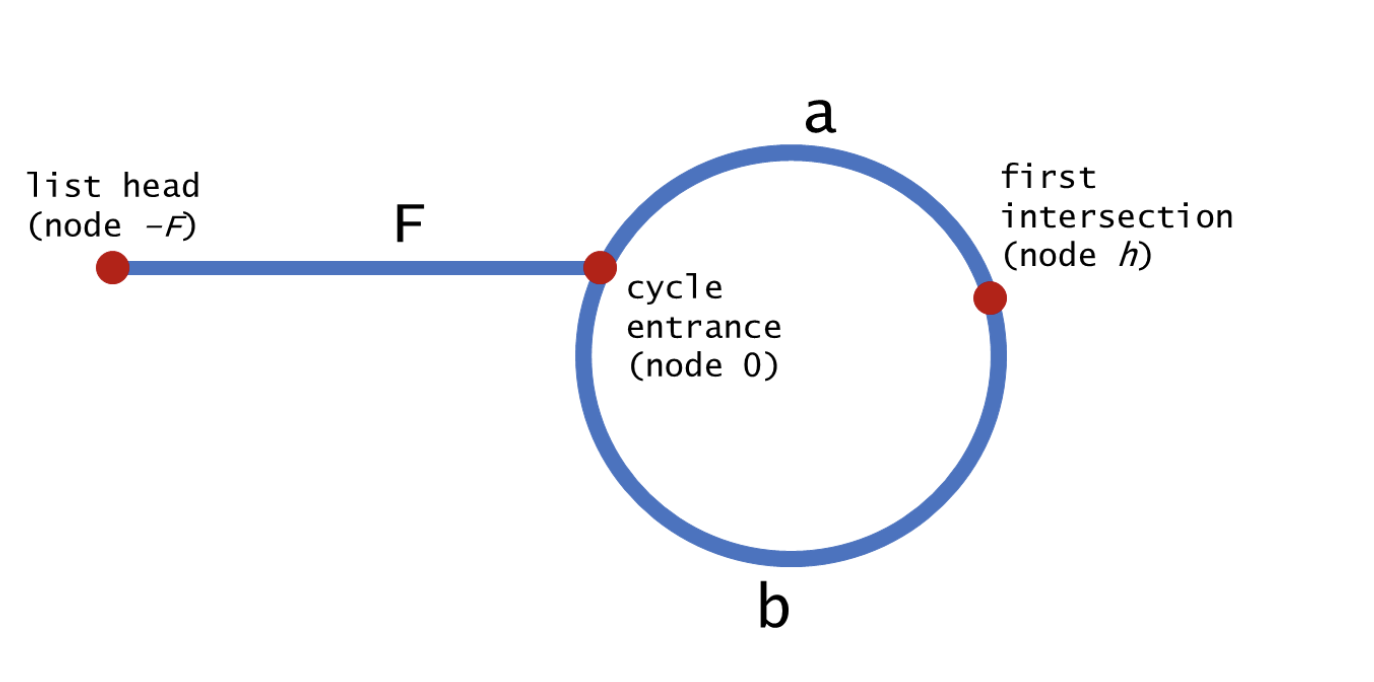
我们利用已知的条件:慢指针移动 1 步,快指针移动 2 步,来说明它们相遇在环的入口处:(下面证明中的 tortoise 表示慢指针,hare 表示快指针)
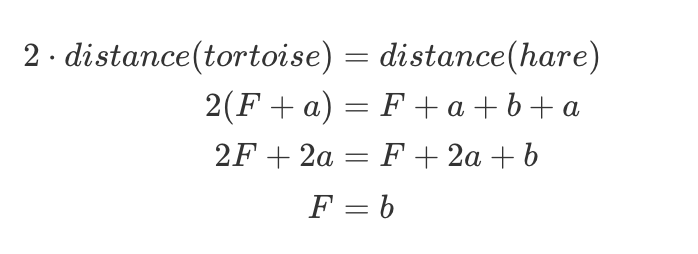
因为 F = b ,指针从 h 点出发和从链表的头出发,最后会遍历相同数目的节点后在环的入口处相遇。
public class Solution {
private ListNode getIntersect(ListNode head) {
ListNode tortoise = head;
ListNode hare = head;
while (hare != null && hare.next != null) {
tortoise = tortoise.next;
hare = hare.next.next;
if (tortoise == hare) {
return tortoise;
}
}
return null;
}
public ListNode detectCycle(ListNode head) {
if (head == null) {
return null;
}
// 通过结论1,找到相遇点
ListNode intersect = getIntersect(head);
// 相遇点为空,则链表为非循环链表
if (intersect == null) {
return null;
}
// 通过结论2,找到环的入口
// 分别定义两个指针,从head和相遇点开始前进,相遇点即为环的入口
ListNode ptr1 = head;
ListNode ptr2 = intersect;
while (ptr1 != ptr2) {
ptr1 = ptr1.next;
ptr2 = ptr2.next;
}
return ptr1;
}
}O(n)O(1)给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从0开始)。 如果 pos 是-1,则在该链表中没有环。
说明:不允许修改给定的链表。
Medium经典的 Floyd 算法的应用场景。
public class Solution {
public ListNode detectCycle(ListNode head) {
if (head == null || head.next == null) return null;
ListNode slow = head;
ListNode fast = head;
while (true) {
if (fast == null || fast.next == null) {
return null;
}
fast = fast.next.next;
slow = slow.next;
if (fast == slow) break;
}
fast = head;
while (fast != slow) {
fast = fast.next;
slow = slow.next;
}
return fast;
}
}给定一个包含 n + 1 个整数的数组 nums,其数字都在 1 到 n 之间( 包括 1 和 n ),可知至少存在一个重复的整数。假设只有一个重复的整数,找出这个重复的数。
输入: [1,3,4,2,2]
输出: 2
输入: [3,1,3,4,2]
输出: 3
Medium正常的思路是通过 HashSet , 或者通过排序以迅速找到重复数。
前者的时间和空间复杂度为 O(N),后者排序解决方案的时间复杂度为 O(NlogN) 空间复杂度为 O(1)。
可以取巧的是,这道题因为题目的关系,可以将题目中数组视为 索引 与 对应值 的关系视为一个 链表,因为重复数的关系,它还是一个 循环链表,因此依然可以通过 Floyd 算法解决:
class Solution {
public int findDuplicate(int[] nums) {
int fast = nums[0];
int slow = nums[0];
// 找到相遇节点
while (true) {
slow = nums[slow];
fast = nums[nums[fast]];
if (slow == fast) {}
}
// 找到重复数
int ptr1 = nums[0];
int ptr2 = fast;
while (ptr1 != ptr2) {
ptr1 = nums[ptr1];
ptr2 = nums[ptr2];
}
return ptr1;
}
}Hello,我是 却把清梅嗅 ,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的 博客 或者 Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
「反思」 系列是笔者对于 学习归纳 一种新的尝试,其起源与目录请参考 这里 。
随着Android项目 模块化 或 插件化 项目业务的愈发复杂,开发流程中通过版本控制工具(比如Git)管理项目的成本越来越高。
以大名鼎鼎的 Android源代码开源项目 (Android Open-Source Project,下文简称 ASOP)为例,截止2020年初,Android10的源码项目,其模块化分割出的 子项目 已接近800个,而每一个子项目都是一个独立的Git仓库。
这意味着Git的使用成本究竟有多高?如果开发者希望针对AOSP的一个分支进行开发,就需要手动将每个子项目进行checkout操作,如果本地分支尚未创建,开发者便需要手动地在每一个子项目里面去创建分支。
如此高昂的使用成本显然需要一种更自动化的方式去处理。为此,Google的工程师基于Git进行了一系列的代码补充,推出了名为Repo的代码版本管理工具,其本质是通过Python开发出一系列的脚本命令,便于开发者对复杂的模块化源码项目进行统一的调度和切换。
即使对于上文说到的AOSP而言,其同样使用了Repo工具进行项目的管理,由此可见,对于 高度模块化 开发的Android项目而言,Repo工具的确有一定的学习和借鉴意义。
本文以AOSP为例,对Repo工具的 使用流程 和 原理 进行系统性的分析,读者需要对Git和Repo工具有一定的了解。
官方文档:Repo入门及基本使用
https://source.android.com/]source/downloading.html
本文大纲如下:

Repo 是以 Git 为基础构建的代码库管理工具。其并非用来取代 Git,只是为了让开发者在多模块的项目中更轻松地使用 Git。Repo 命令是一段可执行的 Python 脚本,开发者可以使用 Repo 执行跨网络操作。例如,借助单个 Repo 命令,将文件从多个代码库下载到本地工作目录。
那么,Repo幕后原理究竟是怎么样的?想要真正的理解Repo,就必须理解Repo最核心的三个要素:Repo仓库、Manifest仓库 以及 项目源码仓库。
这里我们先将三者的关系通过一张图进行概括,该图已经将Repo工具本身的结构描述的淋漓尽致:
对于若干个模块化的子项目,也就是 项目源码仓库 而言,它们是开发者希望的 被统一调度的对象。
比如,通过一个简单的
Repo命令,统一完成所有子项目的分支切换、代码提交、代码远端更新等等。
因此,对于Repo工具整个框架的设计而言,项目源码仓库 明显应该处于最底层,它们是被Repo命令执行操作的最基本元素。
Manifest仓库 中最重要的是一个名为manifest.xml的清单文件,其存储了所有子项目仓库的元信息。
当Repo命令想要对所有子项目进行对应操作的时候,其总是需要知道 要操作的项目的相关信息——比如,我想要clone AOSP所有子项目的代码,首先我需要知道所有子项目仓库的名称和仓库地址;这时,Repo便会从manifest仓库中获取对应所有仓库的元信息,并进行对应的fetch操作。
对于
Android应用的开发者而言这很好理解,对于一个APP而言,其对应的组件通过在manifest中声明进行管理。
因此,想要通过Repo对模块化项目进行管理,项目的管理者必须提供一个对应的manifest清单文件,里面存储所有子项目的相关信息,这样,Repo工具才能通过对其进行解析,然后完成子项目的统一管理。
此外,读者应该知道,AOSP也是在迭代过程中不断变化的,因此,其每一个分支版本所包含的子项目信息可能都是不同的,这意味着Manifest仓库同样也是一个Git仓库,以达到AOSP不同分支版本中,该仓库对应存储的子项目元信息不同的目的。
Repo工具实际上是由一系列的Python脚本组成的,这些Python脚本通过调用Git命令来完成自己的功能。
Repo仓库的本质就是存储了各种各样的Python脚本,当开发者调用相关的Repo命令时,便会从Repo仓库中运行对应的脚本进行处理,并根据脚本中的代码逻辑,找到manifest中所有项目的元信息,然后将其中包含的子项目进行对应命令的处理——因此,我们可以称 Repo仓库是顶层命令的容器。
此外,和Manifest仓库相同,组成Repo工具的Python脚本本身也是一个Git仓库;每当开发者执行Repo命令的时候,Repo仓库都会对自己进行一次更新。
读者请务必深刻理解这三者的意义,这也是
Repo工具内部最核心的三个概念,也是阅读下文内容的基础。
现在,通过Repo工具完成项目模块化的管理需要分步构建以上三个角色,但是在这之前,我们需要先将Repo工具添加到自己的开发环境中。
正如 官方文档 所描述的,通过以下命令安装Repo工具,并确保它可执行:
curl https://storage.googleapis.com/git-repo-downloads/repo > ~/bin/repo
chmod a+x ~/bin/repo安装成功后,对应的目录下便会存在一个repo脚本文件,通过将其配置到环境中,开发者可以在终端中使用repo的基本命令。
整个流程如下图所示:
Repo脚本初始化完毕,接下来针对Repo仓库创建流程进行简单的分析。
以AOSP项目为例,开发者通过以下命令来安装一个Repo仓库:
repo init -u https://android.googlesource.com/platform/manifest -b master这个命令实际上是包含了两个操作:初始化 Repo仓库 和 Manifest仓库,其中Repo仓库完成初始化之后,才会继续初始化Manifest仓库。
这很好理解,Repo仓库的本质就是存储了各种各样的Python脚本,若它没有初始化,就不存在所谓的Repo相关命令,更遑论后面的Manifest仓库初始化和子项目代码初始化的流程了。
这一小节我们先分析 Repo仓库 的安装过程,在下一小节再分析 Manifest仓库 的安装过程。
本小节整体流程如下图所示:

上一节我们成功安装了repo脚本文件,这个脚本里面提供了例如version、help、init等最基本的命令:
def main(orig_args):
if cmd == 'help': // help命令
_Help(args)
if opt.version or cmd == 'version': // version命令
_Version()
if not cmd:
_NotInstalled()
if cmd == 'init' or cmd == 'gitc-init': // init命令
...由此可见Repo脚本最初提供的命令确实非常少,前两个命令十分好理解,分别是查看Repo工具相关依赖的版本或者查看帮助,比较重要的是init命令,这个命令的作用便是对本地Repo仓库的初始化。
那么Repo仓库如何才能初始化呢?设计者并没有尝试直接向远端服务器请求拉取代码,而是从当前目录开始 往上遍历直到根目录 ,若在这个过程中找到一个.repo/repo目录,并且该目录本身的确是一个Repo仓库,便尝试从该仓库 克隆一个新的Repo仓库 到执行Repo脚本的目录中。
反之,若从本地向上直到根目录不存在Repo仓库,则尝试向远端克隆一个新的Repo仓库到本地来。
回到本地克隆Repo仓库的流程中,代码是如何判断本地的.repo/repo目录的确是一个Repo仓库的呢,代码中已经描述的非常清晰了:
def _RunSelf(wrapper_path):
my_dir = os.path.dirname(wrapper_path)
my_main = os.path.join(my_dir, 'main.py')
my_git = os.path.join(my_dir, '.git')
if os.path.isfile(my_main) and os.path.isdir(my_git):
for name in ['git_config.py',
'project.py',
'subcmds']:
if not os.path.exists(os.path.join(my_dir, name)):
return None, None
return my_main, my_git
return None, None从这里我们就可以看出,判断的依据是对应的需要满足以下条件:
1、存在一个.git目录;
2、存在一个main.py文件;
3、存在一个git_config.py文件;
4、存在一个project.py文件;
5、存在一个subcmds目录。
读到这里,读者可以对Repo仓库进行一个简单的总结了。
从上文的源码中,读者了解了Repo脚本源码中判断是否是Repo仓库的五个依据,从这些判断条件中,我们可以简单对Repo仓库的定位进行一个总结。
首先,从条件1中我们得知,组成Repo工具的Python脚本本身也是一个Git仓库;每当开发者执行Repo命令的时候,Repo仓库都会对自己进行一次更新。
其次,Repo仓库本身作为存储Python脚本的容器,其内部必然存在一个入口的main函数可供运行。
对于条件3而言,我们直到Repo工具本质是对Git命令的封装,因此,必须有一个类负责Git相关的配置信息,和提供简单的Git相关工具方法,这便是git_config.py文件的作用。
对于条件4,Repo仓库目录下还需要一个project.py文件,负责Hook相关功能,细心的读者应该注意到,/.repo/repo目录下还有一个/hooks/目录。
最后也是最重要的,/.repo/repo目录下必须还存在一个subcmds目录,顾名思义,这个目录下存储了绝大多数repo重要的命令,比如sync、checkout、pull、commit等等;这也说明了,如果没有Repo仓库的初始化,使用Repo命令操作子项目代码仓库便是无稽之谈。
继续回到上一节我们使用到的命令:
repo init -u https://android.googlesource.com/platform/manifest -b master读者已经知道,通过init命令,我们在指定的目录下,成功初始化了Repo仓库。当安装好Repo仓库之后,就会调用该Repo仓库下面的main.py脚本,对应的文件为.repo/repo/main.py。
这样我们便可以通过init后面的-u -b参数,进行Manifest仓库的创建流程,其中-u指的是manifest文件所在仓库对应的Url地址,-b指的是对应仓库的默认分支。
本小节整体流程如下图所示:

上文中我们提到,想要通过Repo对模块化项目进行管理,项目的管理者必须提供一个对应的manifest清单文件,里面存储所有子项目的相关信息,这样,Repo工具才能通过对其进行解析,然后完成子项目的统一管理。
对于公司的业务而言,项目的管理者需要根据自己公司的实际业务模块构造出自己的manifest文件,并放置在某个git仓库内,这样开发者便可以通过指定对应的Url构建Manifest仓库。
本文以AOSP项目为例,其项目清单文件所在的Url为:
通过init命令和对应的参数,Repo便可以尝试从远端克隆Manifest仓库,然后从指定的Url克隆对应的manifest文件,切换到对应的分支并进行解析。
这里描述比较简单,实际上内部实现逻辑非常复杂;比如,在向远端克隆对应的Manifest仓库之前,会先进行本地是否存在Manifest仓库的判断,若已经存在,则尝试更新本地的Manifest仓库,而非直接向远程仓库中克隆。此外,当未指定分支时,则会checkout一个default分支。
这之后,Repo会根据远端的xml清单文件尝试构建自己本地的Manifest
仓库。
让我们看以下/.repo/目录下文件层级:

上文我们说到,Manifest仓库本身也是一个Git仓库,因此,当我们打开.repo/manifests/目录时,里面会存在一个.git的文件夹,远端的Manifest文件仓库中的所有文件都被克隆到了这个目录下。
这里重点说一下项目的Git仓库目录和工作目录的概念。一般来说,一个项目的Git仓库目录(默认为.git目录)是位于工作目录下面的,但是Git支持将一个项目的Git仓库目录和工作目录分开来存放。
在AOSP中,Repo仓库的Git目录位于工作目录.repo/repo下,Manifest仓库的Git目录有两份拷贝,一份.git位于工作目录.repo/manifests下,另外一份位于.repo/manifests.git目录。
同时,我们看到这里还有一个.repo/manifest.xml文件,这个文件是最终被Repo的文件,它是通过将.repo/manifest文件夹下的文件和local_manifest文件进行合并后生成的,关于local_manifest机制我们后文会讲到,这里仅需将.repo/manifest.xml文件视为最终被使用的配置文件即可。
回到上图,我们知道名字带有manifest相关的文件和文件夹代表了Manifest仓库,其内部存储了所有子项目仓库的元信息;而repo文件夹中存储了repo相关命令的脚本文件。
读者注意到,除此之外,还有一部分名字带有project的文件和文件夹,它们便是代表了Repo解析Manifest后生成的子项目信息和文件。
在Repo中,其管理的所有子项目,每一个子项目都被封装成为了一个Project对象,该对象内部存储了一系列相关的信息。
现在,Manifest仓库被创建并初始化完毕,接下来我们分析Repo的sync流程,看看子项目是如何被统一下载和管理的。
执行完成repo init命令之后,我们就可以继续执行repo sync命令来克隆或者同步子项目了:
repo sync当执行repo sync命令时,会默认尝试拉取远程仓库下载更新本地的Manifest
仓库,下载远端对应的default.xml文件。
下载完成后,会自动解析default.xml文件中项目管理者配置的所有子项目信息,然后每个子项目信息被解析成为一个Project对象,并整合到一个内存的集合中去。
接下来,根据本地是否已经存在对应的子项目源码,针对每一个子项目,Repo都会进行对应的更新操作或者克隆操作,而这些操作的本质,其实就是内部调用了Git的fetch、rebase或者merge等等命令。
值得关注的是,和Manifest仓库相似,AOSP子项目的工作目录和Git目录也都是分开存放的,其中,工作目录位于AOSP根目录下,Git目录位于.repo/projects目录下。
此外,每一个AOSP子项目的工作目录也有一个.git目录,不过这个.git目录是一个符号链接,链接到.repo/repo/projects对应的Git目录。这样,我们就既可以在AOSP子项目的工作目录下执行Git命令,也可以在其对应的Git目录下执行Git命令。
本小节整体流程如下图所示:

从上文中读者已经知道了,对于源码来讲,manifest.xml只是一个到.repo/manifests/default.xml的文件链接,真正的清单文件是通过manifests这个Git仓库托管起来的。
需要注意的是,在进行Android系统开发时,通常需要对清单文件进行自定义定制。例如,设备厂商会构建自己的manifest库,通常是基于AOSP的default.xml进行定制,去掉AOSP的一些Git库、增加一些自有的Git库。
这意味着,项目的管理者需要手动的对default.xml文件内容进行修改,然而这种方式在一些场景下存在弊端——对于AOSP而言,其本身可能存在几百个不同的分支,而项目的管理者需要修改的内容却基本是相同的。
比如,国内某个手机厂商需要删除
AOSP中某个不受**支持的功能,就需要对每个分支的default.xml文件内容进行相同的修改——删除某个project标签。
因此,Repo工具提出了另外一种本地的支持,这个机制便是LocalManifest机制。
在repo sync下载代码之前,会将.repo/manifests/default.xml、local_manifest.xml和.repo/local_manifests/目录下存在清单文件进行合并,再根据融合的清单文件进行代码同步。
这样一来,只需要将清单文件的修改项放到.repo/local_manifests/目录下, 就能够在不修改default.xml的前提下,完成对清单的文件的定制。
LocalManifest机制的原理图如下所示:
参考网上的资料,Local Manifests的隐含规则如下:
local_manifest.xml,再解析local_manifests/目录下的清单文件;local_manifests目录下的清单文件是没有命名限制的,但会按照字母序被解析,即字母序靠后的文件内容会覆盖之前的;repo定义的格式才能被正确解析。1.《Android源代码仓库及其管理工具Repo分析》 by 罗升阳:
https://blog.csdn.net/Luoshengyang/article/details/18195205
罗老师的这篇文章非常经典,文章针对源码进行了非常细致的讲解,本文前四个小节都是参考该文进行的参考总结,强烈建议阅读。
2.《Android Local Manifests机制》 by ZhangJianIsAStark:
https://blog.csdn.net/gaugamela/article/details/78593000
针对 LocalManifests机制 进行了非常详细的讲解,本文的第五节内容都是从中截取的,想要仔细了解的可以阅读本文。
3.AOSP Google 官方文档:
https://source.android.com/source/developing.html
4.《Google Git-Repo 多仓库项目管理》 by 郑晓鹏-Rocko:
https://juejin.im/post/5bf5913fe51d457dd7800a73
一篇非常不错的实践总结,该文并非针对Repo进行系统性的讲述,但是对于实践者而言是一篇不错的参考文章,从基础到集成到jenkins都有讲述。
Hello,我是 却把清梅嗅,女儿奴,源码的眷者,观众途径序列1,杀人游戏信徒,大头菜投机者,端茶递水工程师。欢迎关注我的 博客 或者 GitHub。
如果您觉得文章对您有价值,欢迎 ❤️,或通过下方打赏功能,督促我写出更好的文章 :)
本文将对Paging分页组件的设计和实现进行一个系统整体的概述,强烈建议 读者将本文作为学习Paging 阅读优先级最高的文章,所有其它的Paging中文博客阅读优先级都应该靠后。
本文篇幅 较长,整体结构思维导图如下:
手机应用中,列表是常见的界面构成元素,而对于Android开发者而言,RecyclerView是实现列表的不二选择。
在正式讨论Paging和列表分页功能之前,我们首先看看对于一个普通的列表,开发者如何通过代码对其进行建模:
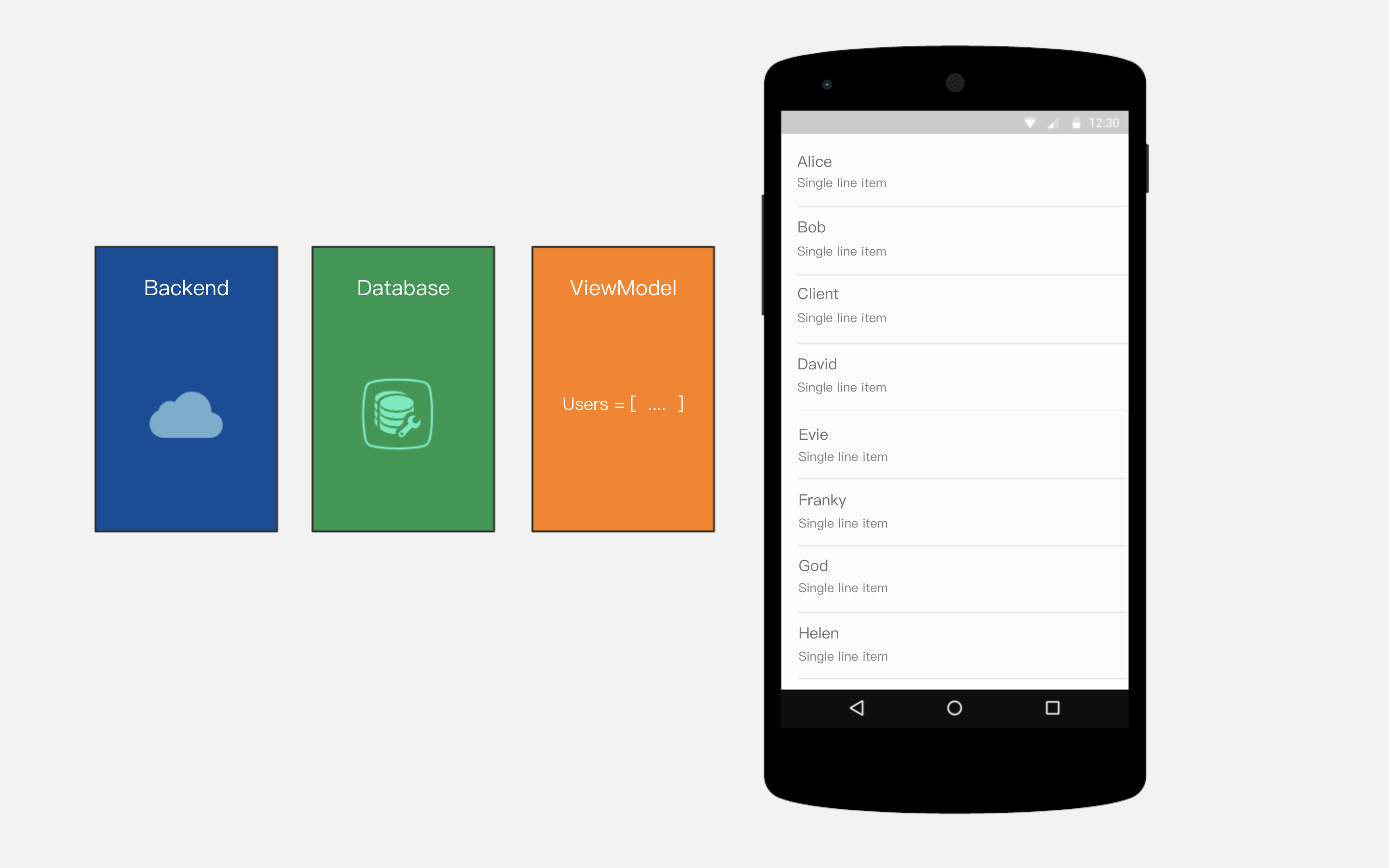
如图所示,针对这样一个简单 联系人界面 的建模,我们引出3个重要的层级:
为什么说 服务端组件、数据库 以及 内存 是非常重要的三个层级呢?
首先,开发者为当前页面创建了一个ViewModel,并通过成员变量在 内存 中持有了一组联系人数据,因为ViewModel组件的原因,即使页面配置发生了改变(比如屏幕的旋转),数据依然会被保留下来。
而 数据库 的作用则保证了App即使在离线环境下,用户依然可以看到一定的内容——显然对于上图中的页面(联系人列表)而言,本地缓存是非常有意义的。
对于绝大多数列表而言,服务端 往往意味着是数据源,每当用户执行刷新操作,App都应当尝试向服务端请求最新的数据,并将最新的数据存入 数据库,并随之展示在UI上。
通常情况下,这三个层级并非同时都是必要的,读者需正确理解三者各自不同的使用场景。
现在,借助于 服务端组件、数据库 以及 内存,开发者将数据展示在RecyclerView上,这似乎已经是正解了。
到目前为止,问题还没有完全暴露出来。
我们忽视了一个非常现实的问题,那就是 数据是动态的 ——这意味着,每当数据发生了更新(比如用户进行了下拉刷新操作),开发者都需要将最新的数据响应在UI上。
这意味着,当某个用户的联系人列表中有10000个条目时,每次数据的更新,都会对所有的数据进行重建——从而导致 性能非常低下,用户看到的只是屏幕中的几条联系人信息,为此要重新创建10000个条目?用户显然无法接受。
因此,分页组件的设计势在必行。
上文我们谈到,UI响应数据的变更,这种情况下,使用 观察者模式 是一个不错的主意,比如LiveData、RxJava甚至自定义一个接口等等,开发者仅需要观察每次数据库中数据的变更,并进行UI的更新:
class MyViewModel : ViewModel() {
val users: LiveData<List<User>>
}新的组件我们也希望能拥有同样的便利,比如使用LiveData或者RxJava,并进行订阅处理数据的更新—— 简单 且 易用。
我们希望新的组件能够处理多层,我们希望列表展示 服务器 返回的数据、 或者 数据库 中的数据,并将其放入UI中。
新的组件必须保证足够的快,不做任何没必要的行为,为了保证效率,繁重的操作不要直接放在UI线程中处理。
如果可能,新的组件需要能够对生命周期进行感知,就像LiveData一样,如果页面并不在屏幕的可视范围内,组件不应该工作。
足够的灵活性非常重要——每个项目都有不同的业务,这意味着不同的API、不同的数据结构,新的组件必须保证能够应对所有的业务场景。
这一点并非必须,但是对于设计者来说难度不小,这意味着需要将不同的业务中的共同点抽象出来,并保证这些设计适用在任何场景中。
定义好了需求,在正式开始设计Paging之前,首先我们先来回顾一下,普通的列表如何实现数据的动态更新的。
我们依然通过 联系人列表 作为示例,来描述普通列表 如何响应数据的动态更新。
首先,我们需要定义一个Dao,这里我们使用了Room组件用于 数据库 中联系人的查询:
@Dao
interface UserDao {
@Query("SELECT * FROM user")
fun queryUsers(): LiveData<List<User>>
}这里我们返回的是一个LiveData,正如我们前文所言,构建一个可观察的对象显然会让数据的处理更加容易。
接下来我们定义好ViewModel和Activity:
class MyViewModel(val dao: UserDao) : ViewModel() {
// 1.定义好可观察的LiveData
val users: LiveData<List<User>> = dao.queryUsers()
}
class MyActivity : Activity {
val myViewModel: MyViewModel
val adapter: ListAdapter
fun onCreate(bundle: Bundle?) {
// 2.在Activity中对LiveData进行订阅
myViewModel.users.observe(this) {
// 3.每当数据更新,计算新旧数据集的差异,对列表进行更新
adapter.submitList(it)
}
}
}这里我们使用到了ListAdapter,它是官方基于RecyclerView.Adapter的AsyncListDiffer封装类,其内创建了AsyncListDiffer的示例,以便在后台线程中使用DiffUtil计算新旧数据集的差异,从而节省Item更新的性能。
本文默认读者对
ListAdapter一定了解,如果不是很熟悉,请参考DiffUtil、AsyncListDiffer、ListAdapter等相关知识点的文章。
此外,我们还需要在ListAdapter中声明DiffUtil.ItemCallback,对数据集的差异计算的逻辑进行补充:
class MyAdapter(): ListAdapter<User, UserViewHolder>(
object: DiffUtil.ItemCallback<User>() {
override fun areItemsTheSame(oldItem: User, newItem: User)
= oldItem.id == newItem.id
override fun areContentsTheSame(oldItem: User, newItem: User)
= oldItem == newItem
}
) {
// ...
}That's all, 接下来我们开始思考,新的分页组件应该是什么样的。
上文提到,一个普通的RecyclerView展示的是一个列表的数据,比如List<User>,但在列表分页的需求中,List<User>明显就不太够用了。
为此,Google设计出了一个新的角色PagedList,顾名思义,该角色的意义就是 **分页列表数据的容器 ** 。
既然有了
List,为什么需要额外设计这样一个PagedList的数据结构?本质原因在于加载分页数据的操作是异步的 ,因此定义PagedList的第二个作用是 对分页数据的异步加载 ,这个我们后文再提。
现在,我们的ViewModel现在可以定义成这样,因为PagedList也作为列表数据的容器(就像List<User>一样):
class MyViewModel : ViewModel() {
// before
// val users: LiveData<List<User>> = dao.queryUsers()
// after
val users: LiveData<PagedList<User>> = dao.queryUsers()
}在ViewModel中,开发者可以轻易通过对users进行订阅以响应分页数据的更新,这个LiveData的可观察者是通过Room组件创建的,我们来看一下我们的dao:
@Dao
interface UserDao {
// 注意,这里 LiveData<List<User>> 改成了 LiveData<PagedList<User>>
@Query("SELECT * FROM user")
fun queryUsers(): LiveData<PagedList<User>>
}乍得一看似乎理所当然,但实际需求中有一个问题,这里的定义是模糊不清的——对于分页数据而言,不同的业务场景,所需要的相关配置是不同的。那么什么是分页相关配置呢?
最直接的一点是每页数据的加载数量PageSize,不同的项目都会自行规定每页数据量的大小,一页请求15个数据还是20个数据?显然我们目前的代码无法进行配置,这是不合理的。
回答这个问题之前,我们还需要定义一个角色,用来为PagedList容器提供分页数据,那就是数据源DataSource。
什么是DataSource呢?它不应该是 数据库数据 或者 服务端数据, 而应该是 数据库数据 或者 服务端数据 的一个快照(Snapshot)。
每当Paging被告知需要更多数据:“Hi,我需要第45-60个的数据!”——数据源DataSource就会将当前Snapshot对应索引的数据交给PagedList。
但是我们需要构建一个新的PagedList的时候——比如数据已经失效,DataSource中旧的数据没有意义了,因此DataSource也需要被重置。
在代码中,这意味着新的DataSource对象被创建,因此,我们需要提供的不是DataSource,而是提供DataSource的工厂。
为什么要提供
DataSource.Factory而不是一个DataSource? 复用这个DataSource不可以吗,当然可以,但是将DataSource设置为immutable(不可变)会避免更多的未知因素。
重新整理思路,我们如何定义Dao中接口的返回值呢?
@Dao
interface UserDao {
// Int 代表按照数据的位置(position)获取数据
// User 代表数据的类型
@Query("SELECT * FROM user")
fun queryUsers(): DataSource.Factory<Int, User>
}返回的是一个数据源的提供者DataSource.Factory,页面初始化时,会通过工厂方法创建一个新的DataSource,这之后对应会创建一个新的PagedList,每当PagedList想要获取下一页的数据,数据源都会根据请求索引进行数据的提供。
当数据失效时,DataSource.Factory会再次创建一个新的DataSource,其内部包含了最新的数据快照(本案例中代表着数据库中的最新数据),随后创建一个新的PagedList,并从DataSource中取最新的数据进行展示——当然,这之后的分页流程都是相同的,无需再次复述。
笔者绘制了一幅图用于描述三者之间的关系,读者可参考上述文字和图片加以理解:
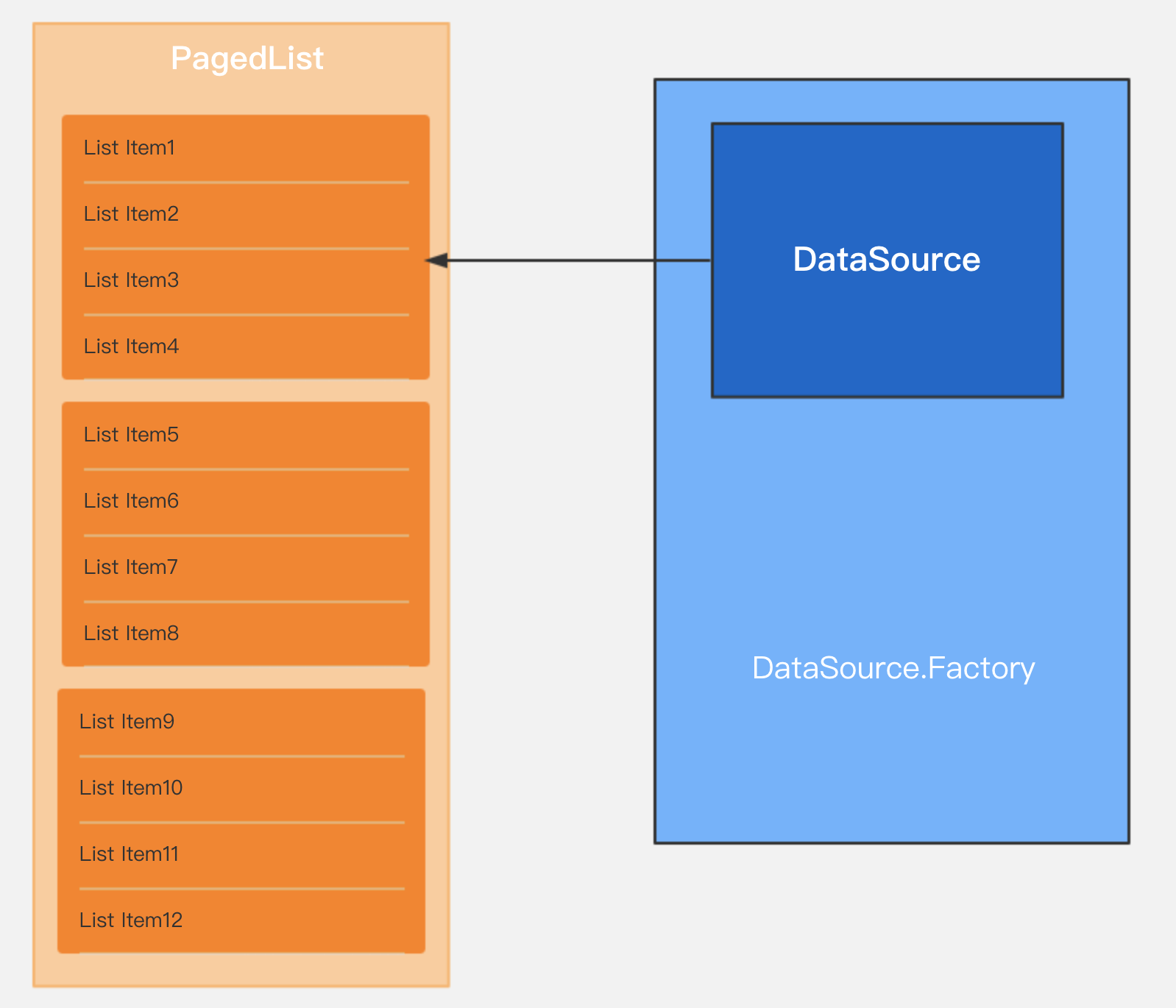
回归第一小节的那个问题,分页相关业务如何进行配置?我们虽然介绍了为PagedList提供数据的DataSource,但这个问题似乎还是没有得到解决。
此外,现在Dao中接口的返回值已经是DataSource.Factory,而ViewModel中的成员被观察者则是LiveData<PagedList<User>>类型,如何 将数据源的工厂和LiveData<PagedList>进行串联 ?
因此我们还需要定义一个新的角色PagedListBuilder,开发者将 数据源工厂 和 相关配置 统一交给PagedListBuilder,即可生成对应的LiveData<PagedList<User>>:
class MyViewModel(val dao: UserDao) : ViewModel() {
val users: LiveData<PagedList<User>>
init {
// 1.创建DataSource.Factory
val factory: DataSource.Factory = dao.queryUsers()
// 2.通过LivePagedListBuilder配置工厂和pageSize, 对users进行实例化
users = LivePagedListBuilder(factory, 30).build()
}
}如代码所示,我们在ViewModel中先通过dao获取了DataSource.Factory,工厂创建数据源DataSource,后者为PagedList提供列表所需要的数据;此外,另外一个Int类型的参数则制定了每页数据加载的数量,这里我们指定每页数据数量为30。
我们成功创建了一个LiveData<PagedList<User>>的可观察者对象,接下来的步骤读者驾轻就熟,只不过我们这里使用的是PagedListAdapter:
class MyActivity : Activity {
val myViewModel: MyViewModel
// 1.这里我们使用PagedListAdapter
val adapter: PagedListAdapter
fun onCreate(bundle: Bundle?) {
// 2.在Activity中对LiveData进行订阅
myViewModel.users.observe(this) {
// 3.每当数据更新,计算新旧数据集的差异,对列表进行更新
adapter.submitList(it)
}
}
}PagedListAdapter内部的实现和普通列表ListAdapter的代码几乎完全相同:
// 几乎完全相同的代码,只有继承的父类不同
class MyAdapter(): PagedListAdapter<User, UserViewHolder>(
object: DiffUtil.ItemCallback<User>() {
override fun areItemsTheSame(oldItem: User, newItem: User)
= oldItem.id == newItem.id
override fun areContentsTheSame(oldItem: User, newItem: User)
= oldItem == newItem
}
) {
// ...
}准确的来说,两者内部的实现还有微弱的区别,前者
ListAdapter的getItem()函数的返回值是User,而后者PagedListAdapter返回值应该是User?(Nullable),其原因我们会在下面的Placeholder部分进行描述。
目前的介绍中,分页的功能似乎已经实现完毕,但这些在现实开发中往往不够,产品业务还有更多细节性的需求。
在上一小节中,我们通过LivePagedListBuilder对LiveData<PagedList<User>>进行创建,这其中第二个参数是 分页组件的配置,代表了每页加载的数量(PageSize) :
// before
val users: LiveData<PagedList<User>> = LivePagedListBuilder(factory, 30).build()读者应该理解,分页组件的配置 本身就是抽象的,PageSize并不能完全代表它,因此,设计者额外定义了更复杂的数据结构PagedList.Config,以描述更细节化的配置参数:
// after
val config = PagedList.Config.Builder()
.setPageSize(15) // 分页加载的数量
.setInitialLoadSizeHint(30) // 初次加载的数量
.setPrefetchDistance(10) // 预取数据的距离
.setEnablePlaceholders(false) // 是否启用占位符
.build()
// API发生了改变
val users: LiveData<PagedList<User>> = LivePagedListBuilder(factory, config).build()对复杂业务配置的API设计来说,建造者模式 显然是不错的选择。
接下来我们简单了解一下,这些可选的配置分别代表了什么。
最易理解的配置,分页请求数据时,开发者总是需要定义每页加载数据的数量。
定义首次加载时要加载的Item数量。
此值通常大于PageSize,因此在初始化列表时,该配置可以使得加载的数据保证屏幕可以小范围的滚动。
如果未设置,则默认为PageSize的三倍。
顾名思义,该参数配置定义了列表当距离加载边缘多远时进行分页的请求,默认大小为PageSize——即距离底部还有一页数据时,开启下一页的数据加载。
若该参数配置为0,则表示除非明确要求,否则不会加载任何数据,通常不建议这样做,因为这将导致用户在滚动屏幕时看到占位符或列表的末尾。
该配置项需要传入一个boolean值以决定列表是否开启placeholder(占位符),那么什么是placeholder呢?
我们先来看未开启占位符的情况:

如图所示,没有开启占位符的情况下,列表展示的是当前所有的数据,请读者重点观察图片右侧的滚动条,当滚动到列表底部,成功加载下一页数据后,滚动条会从长变短,这意味着,新的条目成功实装到了列表中。一言以蔽之,未开启占位符的列表,条目的数量和PagedList中数据数量是一致的。
接下来我们看一下开启了占位符的情况:

如图所示,开启了占位符的列表,条目的数量和DataSource中数据的总量是一致的。 这并不意味着列表从DataSource一次加载了大量的数据并进行渲染,所有业务依然交给Paging进行分页处理。
当用户滑动到了底部尚未加载的数据时,开发者会看到还未渲染的条目,这是理所当然的,PagedList的分页数据加载是异步的,这时对于Item的来说,要渲染的数据为null,因此开发者需要配置占位符,当数据未加载完毕时,UI如何进行渲染——这也正是为何上文说到,对于PagedListAdapter来说,getItem()函数的返回值是可空的User?,而不是User。
随着PagedList下一页数据的异步加载完毕,伴随着RecyclerView的原生动画,新的数据会被重新覆盖渲染到placeholder对应的条目上,就像gif图展示的一样。
这里我专门开一个小节谈谈关于placeholder,因为这个机制和我们传统的分页业务似乎有所不同,但Google的工程师们认为在某些业务场景下,该配置确实很有用。
开启了占位符,用户总是可以快速的滑动列表,因为列表“持有”了整个数据集,因此不会像未开启占位符时,滑动到底部而被迫暂停滚动,直到新的数据的加载完毕才能继续浏览。顺畅的操作总比期望之外的阻碍要好得多 。
此外,开启了占位符意味着用户与 加载指示器 彻底告别,类似一个 正在加载更多... 的提示标语或者一个简陋的ProgressBar效果真的会提升用户体验吗?也许答案是否定的,相比之下,用户应该更喜欢一个灰色的占位符,并等待它被新的数据渲染。
但缺点也随之而来,首先,占位符的条目高度应该和正确的条目高度一致,在某些需求中,这也许并不符合,这将导致渐进性的动画效果并不会那么好。
其次,对于开发者而言,开启占位符意味着需要对ViewHolder进行额外的代码处理,数据为null或者不为null?两种情况下的条目渲染逻辑都需要被添加。
最后,这是一个限制性的条件,您的DataSource数据源内部的数据数量必须是确定的,比如通过Room从本地获取联系人列表;而当数据通过网络请求获取的话,这时数据的数量是不确定的,不开启Placeholder反而更好。
在本文的示例中,我们建立了一个LiveData<PagedList<User>>的可观察者对象供用户响应数据的更新,实际上组件的设计应该面向提供对更多优秀异步库的支持,比如RxJava。
因此,和LivePagedListBuilder一样,设计者还提供了RxPagedListBuilder,通过DataSource数据源和PagedList.Config以构建一个对应的Observable:
// LiveData support
val users: LiveData<PagedList<User>> = LivePagedListBuilder(factory, config).build()
// RxJava support
val users: Observable<PagedList<User>> = RxPagedListBuilder(factory, config).buildObservable()
栈的实现比队列容易。动态数组 足以实现堆栈结构。这里LeetCode官方提供了一个简单的实现供参考:
// "static void main" must be defined in a public class.
class MyStack {
private List<Integer> data; // store elements
public MyStack() {
data = new ArrayList<>();
}
/** Insert an element into the stack. */
public void push(int x) {
data.add(x);
}
/** Checks whether the queue is empty or not. */
public boolean isEmpty() {
return data.isEmpty();
}
/** Get the top item from the queue. */
public int top() {
return data.get(data.size() - 1);
}
/** Delete an element from the queue. Return true if the operation is successful. */
public boolean pop() {
if (isEmpty()) {
return false;
}
data.remove(data.size() - 1);
return true;
}
};Easy设计一个支持 push,pop,top 操作,并能在常数时间内检索到最小元素的栈。
官方 栈和队列 标签中,对栈的实现方式描述为:
栈的实现比队列容易。动态数组足以实现堆栈结构。
// 官方实现的描述,直接使用了ArrayList
class MyStack {
private List<Integer> data; // store elements
public MyStack() {
data = new ArrayList<>();
}
}因此做本题的时候,下意识觉得使用 ArrayList 就足够了,结果发现不通过,原因是题目中额外要求 在常数时间内检索到最小元素,而我则是 暴力循环遍历所有元素找到最小值 , 时间复杂度为O(N), 这样当然不行。
原来 getMin() 函数有时间限制,那么用一个成员记录最小值的状态应该就可以了吧...
试了一下竟然真的可以,这也算偷奸耍滑通过了......(我只是把循环的操作从getMin()转移到了pop())...
class MinStack {
private List<Integer> data;
// 1.用一个成员记录栈内最小值
private int min = Integer.MAX_VALUE;
public MinStack() {
data = new ArrayList<>();
}
// 2.写入时,看情况更新最小值
public void push(int x) {
if (min > x) {
min = x;
}
data.add(x);
}
// 3.出栈时,更新最小值,这里时间复杂度为 O(N)
public void pop() {
verifyNotEmpty();
data.remove(data.size() - 1);
min = Integer.MAX_VALUE;
for (Integer num : data) {
if (min > num) {
min = num;
}
}
}
public int top() {
verifyNotEmpty();
return data.get(data.size() - 1);
}
// 4.这样就能保证,获取最小值的函数,执行时间为常数时间了 =w=
public int getMin() {
verifyNotEmpty();
return min;
}
private void verifyNotEmpty() {
if (data.isEmpty()) {
throw new IllegalArgumentException("Stack is empty");
}
}
}Easy给定一个只包括 '(',')','{','}','[',']' 的字符串,判断字符串是否有效。
有效字符串需满足:
说实话栈相关的题目还是不太好第一时间联想到的,这里解决方案参考官方题解:
https://leetcode-cn.com/problems/valid-parentheses/solution/you-xiao-de-gua-hao-by-leetcode/
实现代码:
class Solution {
public boolean isValid(String s) {
Stack<Character> stack = new Stack<>();
Map<Character, Character> mapping = new HashMap<>();
mapping.put('}', '{');
mapping.put(')', '(');
mapping.put(']', '[');
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if (mapping.containsKey(c)) {
// 闭括号
char top = stack.isEmpty() ? '#' : stack.pop();
if (top != mapping.get(c)) {
return false;
}
} else {
// 新的开符号,直接压入栈中
stack.push(c);
}
}
return stack.isEmpty();
}
}Medium根据每日气温列表,请重新生成一个列表,对应位置的输入是你需要再等待多久温度才会升高超过该日的天数。如果之后都不会升高,请在该位置用 0 来代替。
例如,给定一个列表 temperatures = [73, 74, 75, 71, 69, 72, 76, 73],你的输出应该是 [1, 1, 4, 2, 1, 1, 0, 0]。
提示:气温 列表长度的范围是 [1, 30000]。每个气温的值的均为华氏度,都是在 [30, 100] 范围内的整数。
这道题难点在于题目的理解,题目看懂了,其实解决起来比较简单。
暴力破解法是最直接想到的方式,时间复杂度 O(N^2):
class Solution {
public int[] dailyTemperatures(int[] T) {
int[] ans = new int[T.length];
for (int i = 0; i < T.length; i++) {
// 最后一个元素,对应一定是0
if (i == T.length - 1) {
ans[T.length - 1] = 0;
continue;
}
int times = 0;
for (int j = i + 1; j < T.length; j++) {
if (T[j] > T[i]) {
ans[i] = ++times;
break;
}
if (j == T.length - 1) {
ans[i] = 0;
}
times++;
}
}
return ans;
}
}说实话这个解决方案真的没想到,并且是题目标签提示了的,参考官方题解:
https://leetcode-cn.com/problems/daily-temperatures/solution/mei-ri-wen-du-by-leetcode/
class Solution {
public int[] dailyTemperatures(int[] T) {
int[] ans = new int[T.length];
Stack<Integer> stack = new Stack();
for (int i = T.length - 1; i >= 0; --i) {
while (!stack.isEmpty() && T[i] >= T[stack.peek()]) stack.pop();
ans[i] = stack.isEmpty() ? 0 : stack.peek() - i;
stack.push(i);
}
return ans;
}
}通过使用和动态的更新栈,将数据在数组中的索引作为栈的元素进行处理,使得代码极大的被简化,并且思路更高级,因为每个索引最多做一次压栈和出栈的操作。因此时间复杂度为 O(N)。
Medium根据逆波兰表示法,求表达式的值。
有效的运算符包括 +, -, *, / 。每个运算对象可以是整数,也可以是另一个逆波兰表达式。
说明:
0 的情况。同样是使用栈解决,将数字元素压入栈,遇到符号时,从栈顶取出两个元素进行求值,并将结果再次存入栈顶,最终将栈顶的结果弹出进行返回即可:
class Solution {
public int evalRPN(String[] tokens) {
Stack<Integer> stack = new Stack<>();
Integer i1, i2;
for (String s : tokens) {
switch (s) {
case "+":
i1 = stack.pop();
i2 = stack.pop();
stack.push(i2 + i1);
break;
case "-":
i1 = stack.pop();
i2 = stack.pop();
stack.push(i2 - i1);
break;
case "*":
i1 = stack.pop();
i2 = stack.pop();
stack.push(i2 * i1);
break;
case "/":
i1 = stack.pop();
i2 = stack.pop();
stack.push(i2 / i1);
break;
default:
stack.push(Integer.parseInt(s));
break;
}
}
return stack.pop();
}
}文章绝大部分内容节选自LeetCode,概述:
例题:
Hello,我是 却把清梅嗅 ,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的 博客 或者 GitHub。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
反思 系列博客是我的一种新学习方式的尝试,该系列起源和目录请参考 这里 。
Android体系本身非常宏大,源码中值得思考和借鉴之处众多。以LayoutInflater本身为例,其整个流程中除了调用inflate()函数 填充布局 功能之外,还涉及到了 应用启动、调用系统服务(进程间通信)、对应组件作用域内单例管理、额外功能扩展 等等一系列复杂的逻辑。
本文笔者将针对LayoutInlater的整个设计思路进行描述,其整体结构如下图:
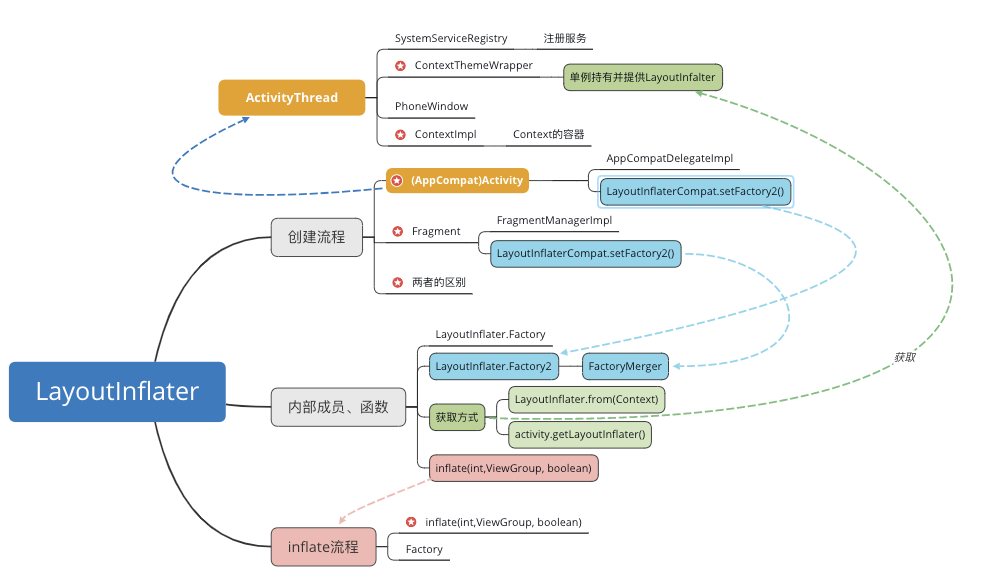
顾名思义,LayoutInflater的作用就是 布局填充器 ,其行为本质是调用了Android本身提供的 系统服务。而在Android系统的设计中,获取系统服务的实现方式就是通过ServiceManager来取得和对应服务交互的IBinder对象,然后创建对应系统服务的代理。
Android应用层将系统服务注册相关的API放在了SystemServiceRegistry类中,而将注册服务行为的代码放在了ContextImpl类中,ContextImpl类实现了Context类下的所有抽象方法。
Android应用层还定义了一个Context的另外一个子类:ContextWrapper,Activity、Service等组件继承了ContextWrapper, 每个ContextWrapper的实例有且仅对应一个ContextImpl,形成一一对应的关系,该类是 装饰器模式 的体现:保证了Context类公共功能代码和不同功能代码的隔离。
此外,虽然ContextImpl类作为Context类公共API的实现者,LayoutInlater的获取则交给了ContextThemeWrapper类,该类中将LayoutInlater的获取交给了一个成员变量,保证了单个组件 作用域内的单例。
开发者希望直接调用LayoutInflater#inflate()函数对布局进行填充,该函数作用是对xml文件中标签的解析,并根据参数决定是否直接将新创建的View配置在指定的ViewGroup中。
一般来说,一个View的实例化依赖Context上下文对象和attr的属性集,而设计者正是通过将上下文对象和属性集作为参数,通过 反射 注入到View的构造器中对View进行创建。
除此之外,考虑到 性能优化 和 可扩展性,设计者为LayoutInflater设计了一个LayoutInflater.Factory2接口,该接口设计得非常巧妙:在xml解析过程中,开发者可以通过配置该接口对View的创建过程进行拦截:通过new的方式创建控件以避免大量地使用反射,亦或者 额外配置特殊标签的解析逻辑以创建特殊组件(比如Fragment)。
LayoutInflater.Factory2接口在Android SDK中的应用非常普遍,AppCompatActivity和FragmentManager就是最有力的体现,LayoutInflater.inflate()方法的理解虽然重要,但笔者窃以为LayoutInflater.Factory2的重要性与其相比不逞多让。
对于LayoutInflater整体不甚熟悉的开发者而言,本小节文字描述似乎晦涩难懂,且难免有是否过度设计的疑惑,但这些文字的本质却是布局填充流程整体的设计**,读者不应该将本文视为源码分析,而应该将自己代入到设计的过程中 。
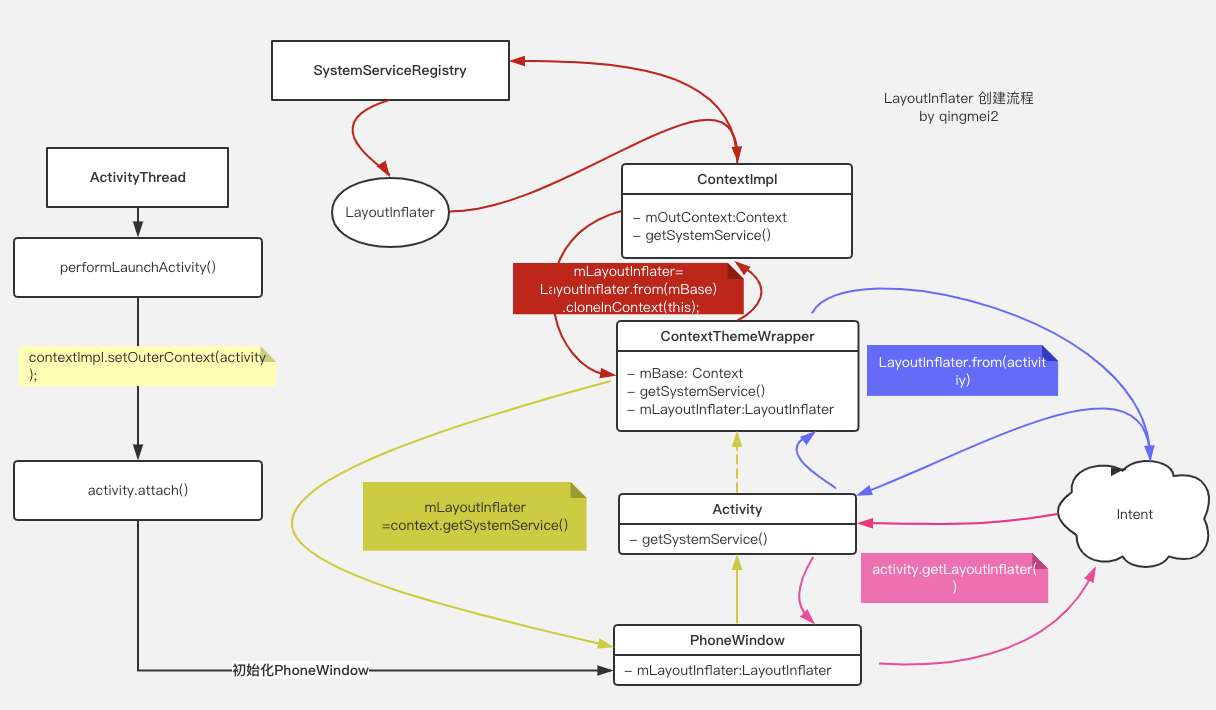
上文提到,LayoutInflater作为系统服务之一,获取方式是通过ServiceManager来取得和对应服务交互的IBinder对象,然后创建对应系统服务的代理。
Binder机制相关并非本文的重点,读者可以注意到,Android的设计者将获取系统服务的接口交给了Context类,意味着开发者可以通过任意一个Context的实现类获取系统服务,包括不限于Activity、Service、Application等等:
public abstract class Context {
// 获取系统服务
public abstract Object getSystemService(String name);
// ......
}读者需要理解,Context类地职责并非只针对 系统服务 进行提供,还包括诸如 启动其它组件、获取SharedPerferences 等等,其中大部分功能对于Context的子类而言都是公共的,因此没有必要每个子类都对其进行实现。
Android设计者并没有直接通过继承的方式将公共业务逻辑放入Base类供组件调用或者重写,而是借鉴了 装饰器模式 的**:分别定义了ContextImpl和ContextWrapper两个子类:
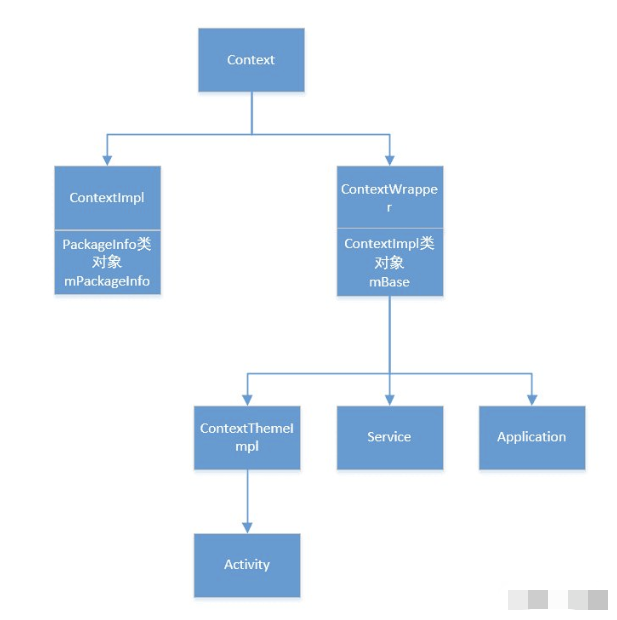
Context的公共API的实现都交给了ContextImpl,以获取系统服务为例,Android应用层将系统服务注册相关的API放在了SystemServiceRegistry类中,而ContextImpl则是SystemServiceRegistry#getSystemService的唯一调用者:
class ContextImpl extends Context {
// 该成员即开发者使用的`Activity`等外部组件
private Context mOuterContext;
@Override
public Object getSystemService(String name) {
return SystemServiceRegistry.getSystemService(this, name);
}
}这种设计使得 系统服务的注册(SystemServiceRegistry类) 和 系统服务的获取(ContextImpl类) 在代码中只有一处声明和调用,大幅降低了模块之间的耦合。
ContextWrapper则是Context的装饰器,当组件需要获取系统服务时交给ContextImpl成员处理,伪代码实现如下:
// class Activity extends ContextWrapper
class ContextWrapper extends Context {
// 1.将 ContextImpl 作为成员进行存储
public ContextWrapper(ContextImpl base) {
mBase = base;
}
ContextImpl mBase;
// 2.系统服务的获取统一交给了ContextImpl
@Override
public Object getSystemService(String name) {
return mBase.getSystemService(name);
}
}ContextWrapper装饰器的初始化如何实现呢?每当一个ContextWrapper组件(如Activity)被创建时,都为其创建一个对应的ContextImpl实例,伪代码实现如下:
public final class ActivityThread {
// 每当`Activity`被创建
private Activity performLaunchActivity() {
// ....
// 1.实例化 ContextImpl
ContextImpl appContext = new ContextImpl();
// 2.将 activity 注入 ContextImpl
appContext.setOuterContext(activity);
// 3.将 ContextImpl 也注入到 activity中
activity.attach(appContext, ....);
// ....
}
}读者应该注意到了第3步的
activity.attach(appContext, ...)函数,该函数很重要,在【布局流程】一节中会继续引申。
读者也许注意到,对于单个Activity而言,多次调用activity.getLayoutInflater()或者LayoutInflater.from(activity),获取到的LayoutInflater对象都是单例的——对于涉及到了跨进程通信的系统服务而言,通过作用域内的单例模式保证以节省性能是完全可以理解的。
设计者将对应的代码放在了ContextWrapper的子类ContextThemeWrapper中,该类用于方便开发者为Activity配置自定义的主题,除此之外还通过一个成员持有了一个LayoutInflater对象:
// class Activity extends ContextThemeWrapper
public class ContextThemeWrapper extends ContextWrapper {
private Resources.Theme mTheme;
private LayoutInflater mInflater;
@Override
public Object getSystemService(String name) {
// 保证 LayoutInflater 的局部单例
if (LAYOUT_INFLATER_SERVICE.equals(name)) {
if (mInflater == null) {
mInflater = LayoutInflater.from(getBaseContext()).cloneInContext(this);
}
return mInflater;
}
return getBaseContext().getSystemService(name);
}
}而无论activity.getLayoutInflater()还是LayoutInflater.from(activity),其内部最终都执行的是ContextThemeWrapper#getSystemService(前者和PhoneWindow还有点关系,这个后文会提), 因此获取到的LayoutInflater自然是同一个对象了:
public abstract class LayoutInflater {
public static LayoutInflater from(Context context) {
return (LayoutInflater) context.getSystemService(Context.LAYOUT_INFLATER_SERVICE);
}
}上一节我们提到了Activity启动的过程,这个过程中不可避免的要创建一个窗口,最终UI的布局都要展示在这个窗口上,Android中通过定义了PhoneWindow类对这个UI的窗口进行描述。
Activity将布局填充相关的逻辑委托给了PhoneWindow,Activity的setContentView()函数,其本质是调用了PhoneWindow的setContentView()函数。
public class PhoneWindow extends Window {
public PhoneWindow(Context context) {
super(context);
mLayoutInflater = LayoutInflater.from(context);
}
// Activity.setContentView 实际上是调用了 PhoneWindow.setContentView()
@Override
public void setContentView(int layoutResID) {
// ...
mLayoutInflater.inflate(layoutResID, mContentParent);
}
}读者需要清楚,activity.getLayoutInflater()和activity.setContentView()等方法都使用到了PhoneWindow内部的LayoutInflater对象,而PhoneWindow内部对LayoutInflater的实例化,仍然是调用context.getSystemService()方法,因此和上一小节的结论并不冲突:
而无论
activity.getLayoutInflater()还是LayoutInflater.from(activity),其内部最终都执行的是ContextThemeWrapper#getSystemService。
PhoneWindow是如何实例化的呢,读者认真思考可知,一个Activity对应一个PhoneWindow的UI窗口,因此当Activity被创建时,PhoneWindow就被需要被创建了,执行时机就在上文的ActivityThread.performLaunchActivity()中:
public final class ActivityThread {
// 每当`Activity`被创建
private Activity performLaunchActivity() {
// ....
// 3.将 ContextImpl 也注入到 activity中
activity.attach(appContext, ....);
// ....
}
}
public class Activity extends ContextThemeWrapper {
final void attach(Context context, ...) {
// ...
// 初始化 PhoneWindow
// window构造方法中又通过 Context 实例化了 LayoutInflater
PhoneWindow mWindow = new PhoneWindow(this, ....);
}
}设计到这里,读者应该对LayoutInflater的整体流程已经有了一个初步的掌握,需要清楚的两点是:
LayoutInflater,都是通过ContextImpl.getSystemService()获取的,并且在Activity等组件的生命周期内保持单例;Activity.setContentView()函数,本质上也还是通过LayoutInflater.inflate()函数对布局进行解析和创建。从**上来看,LayoutInflater.inflate()函数内部实现比较简单直观:
public View inflate(@LayoutRes int resource, ViewGroup root, boolean attachToRoot) {
// ...
}对该函数的参数进行简单归纳如下:第一个参数代表所要加载的布局,第二个参数是ViewGroup,这个参数需要与第3个参数配合使用,attachToRoot如果为true就把布局添加到ViewGroup中;若为false则只采用ViewGroup的LayoutParams作为测量的依据却不直接添加到ViewGroup中。
从设计的角度上思考,该函数的设计过程中,为什么需要定义这样的三个参数?为什么这样三个参数就能涵盖我们日常开发过程中布局填充的需求?
对于第一个资源id参数而言,UI的创建必然依赖了布局文件资源的引用,因此这个参数无可厚非。
我们先略过第二个参数,直接思考第三个参数,为什么需要这样一个boolean类型的值,以决定是否将创建的View直接添加到指定的ViewGroup中呢,不设计这个参数是否可以?
换个角度思考,这个问题的本质其实是:是否每个View的创建都必须立即添加在ViewGroup中?答案当然是否定的,为了保证性能,设计者不可能让所有的View被创建后都能够立即被立即添加在ViewGroup中,这与目前Android中很多组件的设计都有冲突,比如ViewStub、RecyclerView的条目、Fragment等等。
因此,更好的方式应该是可以通过一个boolean的开关将整个过程切分成2个小步骤,当View生成并根据ViewGroup的布局参数生成了对应的测量依据后,开发者可以根据需求手动灵活配置是否立即添加到ViewGroup中——这就是第三个参数的由来。
那么ViewGroup类型的第二个参数为什么可以为空呢?实际开发过程中,似乎并没有什么场景在填充布局时需要使ViewGroup为空?
读者仔细思考可以很容易得出结论,事实上该参数可空是有必要的——对于ActivityUI的创建而言,根结点最顶层的ViewGroup必然是没有父控件的,这时在布局的创建时,就必须通过将null作为第二个参数交给LayoutInlater的inflate()方法,当View被创建好后,将View的布局参数配置为对应屏幕的宽高:
// DecorView.onResourcesLoaded()函数
void onResourcesLoaded(LayoutInflater inflater, int layoutResource) {
// ...
// 创建最顶层的布局时,需要指定父布局为null
final View root = inflater.inflate(layoutResource, null);
// 然后将宽高的布局参数都指定为 MATCH_PARENT(屏幕的宽高)
mDecorCaptionView.addView(root, new ViewGroup.MarginLayoutParams(MATCH_PARENT, MATCH_PARENT));
}现在我们理解了 为什么三个参数就能涵盖开发过程中布局填充的需求,接下来继续思考下一个问题,LayoutInflater是如何解析xml的。
xml解析过程的思路很简单;
XmlPullParser解析器对象;View的解析而言,一个View的实例化依赖Context上下文对象和attr的属性集,而设计者正是通过将上下文对象和属性集作为参数,通过 反射 注入到View的构造器中对单个View进行创建;xml文件的解析而言,整个流程依然通过典型的递归**,对布局文件中的xml文件进行遍历解析,自底至顶对View依次进行创建,最终完成了整个View树的创建。单个View的实例化实现如下,这里采用伪代码的方式实现:
// LayoutInflater类
public final View createView(String name, String prefix, AttributeSet attrs) {
// ...
// 1.根据View的全名称路径,获取View的Class对象
Class<? extends View> clazz = mContext.getClassLoader().loadClass(name + prefix).asSubclass(View.class);
// 2.获取对应View的构造器
Constructor<? extends View> constructor = clazz.getConstructor(mConstructorSignature);
// 3.根据构造器,通过反射生成对应 View
args[0] = mContext;
args[1] = attrs;
final View view = constructor.newInstance(args);
return view;
}对于整体解析流程而言,伪代码实现如下:
void rInflate(XmlPullParser parser, View parent, Context context, AttributeSet attrs) {
// 1.解析当前控件
while (parser.next()!= XmlPullParser.END_TAG) {
final View view = createViewFromTag(parent, name, context, attrs);
final ViewGroup viewGroup = (ViewGroup) parent;
final ViewGroup.LayoutParams params = viewGroup.generateLayoutParams(attrs);
// 2.解析子布局
rInflateChildren(parser, view, attrs, true);
// 所有子布局解析结束,将当前控件及布局参数添加到父布局中
viewGroup.addView(view, params);
}
}
final void rInflateChildren(XmlPullParser parser, View parent, AttributeSet attrs, boolean finishInflate){
// 3.子布局作为根布局,通过递归的方式,层级向下一层层解析
// 继续执行 1
rInflate(parser, parent, parent.getContext(), attrs, finishInflate);
}至此,一般情况下的布局填充流程到此结束,inflate()方法执行完毕,对应的布局文件解析结束,并根据参数配置决定是否直接添加在ViewGroup根布局中。
LayoutInlater的设计流程到此就结束了吗,当然不是,更精彩更巧妙的设计还尚未登场。
读者需要清楚的是,到目前为止,我们的设计还遗留了2个明显的缺陷:
View的实例化都依赖了Java的反射机制,这意味着额外性能的损耗;xml布局中声明了fragment标签,会导致模块之间极高的耦合。什么叫做 fragment标签会导致模块之间极高的耦合 ?举例来说,开发者在layout文件中声明这样一个Fragment:
<?xml version="1.0" encoding="utf-8"?>
<android.support.constraint.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
tools:context=".MainActivity">
<!-- 声明一个fragment -->
<fragment
android:id="@+id/fragment"
android:name="com.github.qingmei2.myapplication.AFragment"
android:layout_width="match_parent"
android:layout_height="match_parent"/>
</android.support.constraint.ConstraintLayout>看起来似乎没有什么问题,但读者认真思考会发现,如果这是一个v4包的Fragment,是否意味着LayoutInflater额外增加了对Fragment类的依赖,类似这样:
// LayoutInflater类
void rInflate(XmlPullParser parser, View parent, Context context, AttributeSet attrs) {
// 1.解析当前控件
while (parser.next()!= XmlPullParser.END_TAG) {
//【注意】2.如果标签是一个Fragment,反射生成Fragment并返回
if (name == "fragment") {
Fragment fragment = clazz.newInstance();
// .....还会关联到SupportFragmentManager、FragmentTransaction的依赖!
supportFragmentManager.beginTransaction().add(....).commit();
return;
}
final View view = createViewFromTag(parent, name, context, attrs);
final ViewGroup viewGroup = (ViewGroup) parent;
final ViewGroup.LayoutParams params = viewGroup.generateLayoutParams(attrs);
// 3.解析子布局
rInflateChildren(parser, view, attrs, true);
// 所有子布局解析结束,将当前控件及布局参数添加到父布局中
viewGroup.addView(view, params);
}
}这导致了LayoutInflater在解析fragment标签过程中,强制依赖了很多设计者不希望的依赖(比如v4包下Fragment相关类),继续往下思考的话,还会遇到更多的问题,这里不再引申。
那么如何解决这样的两个问题呢?
考虑到 性能优化 和 可扩展性,设计者为LayoutInflater设计了一个LayoutInflater.Factory接口,该接口设计得非常巧妙:在xml解析过程中,开发者可以通过配置该接口对View的创建过程进行拦截:通过new的方式创建控件以避免大量地使用反射,亦或者 额外配置特殊标签的解析逻辑以创建特殊组件 :
public abstract class LayoutInflater {
private Factory mFactory;
private Factory2 mFactory2;
private Factory2 mPrivateFactory;
public void setFactory(Factory factory) {
//...
}
public void setFactory2(Factory2 factory) {
// Factory 只能被set一次
if (mFactorySet) {
throw new IllegalStateException("A factory has already been set on this LayoutInflater");
}
mFactorySet = true;
mFactory = mFactory2 = factory;
// ...
}
public interface Factory {
public View onCreateView(String name, Context context, AttributeSet attrs);
}
public interface Factory2 extends Factory {
public View onCreateView(View parent, String name, Context context, AttributeSet attrs);
}
}正如上文所说的,Factory接口的意义是在xml解析过程中,开发者可以通过配置该接口对View的创建过程进行拦截,对于View的实例化,最终实现的伪代码如下:
View createViewFromTag() {
View view;
// 1. 如果mFactory2不为空, 用mFactory2 拦截创建 View
if (mFactory2 != null) {
view = mFactory2.onCreateView(parent, name, context, attrs);
// 2. 如果mFactory不为空, 用mFactory 拦截创建 View
} else if (mFactory != null) {
view = mFactory.onCreateView(name, context, attrs);
} else {
view = null;
}
// 3. 如果经过拦截机制之后,view仍然是null,再通过系统反射的方式,对View进行实例化
if (view == null) {
view = createView(name, null, attrs);
}
}理解了LayoutInflater.Factory接口设计的思路,接下来一起来思考如何解决上文中提到的2个问题。
AppCompatActivity的源码中隐晦地配置LayoutInflater.Factory减少了大量反射创建控件的情况——设计者的思路是,在AppCompatActivity的onCreate()方法中,为LayoutInflater对象调用了setFactory2()方法:
// AppCompatActivity类
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
getDelegate().installViewFactory();
//...
}
// AppCompatDelegateImpl类
@Override
public void installViewFactory() {
LayoutInflater layoutInflater = LayoutInflater.from(mContext);
if (layoutInflater.getFactory() == null) {
LayoutInflaterCompat.setFactory2(layoutInflater, this);
}
}配置之后,在inflate()过程中,系统的基础控件的实例化都通过代码拦截,并通过new的方式进行返回:
switch (name) {
case "TextView":
view = new AppCompatTextView(context, attrs);
break;
case "ImageView":
view = new AppCompatImageView(context, attrs);
break;
case "Button":
view = new AppCompatButton(context, attrs);
break;
case "EditText":
view = new AppCompatEditText(context, attrs);
break;
// ...
// Android 基础组件都通过new方式进行创建
}源码也说明了,即使开发者在xml文件中配置的是Button,setContentView()之后,生成的控件其实是AppCompatButton, TextView或者ImageView亦然,在避免额外的性能损失的同时,也保证了Android版本的向下兼容。
为什么Fragment没有定义类似void setContentView(R.layout.xxx)的函数对布局进行填充,而是使用了View onCreateView()这样的函数,让开发者填充并返回一个对应的View呢?
原因就在于在布局填充的过程中,Fragment最终被视为一个子控件并添加到了ViewGroup中,设计者将FragmentManagerImpl作为FragmentManager的实现类,同时实现了LayoutInflater.Factory2接口。
而在布局文件中fragment标签解析的过程中,实际上是调用了FragmentManagerImpl.onCreateView()函数,生成了Fragment之后并将View返回,跳过了系统反射生成View相关的逻辑:
# android.support.v4.app.FragmentManager$FragmentManagerImpl
@Override
public View onCreateView(View parent, String name, Context context, AttributeSet attrs) {
if (!"fragment".equals(name)) {
return null;
}
// 如果标签是`fragment`,生成Fragment,并返回Fragment的Root
return fragment.mView;
}通过定义LayoutInflater.Factory接口,设计者将Fragment的功能抽象为一个View(虽然Fragment并不是一个View),并交给FragmentManagerImpl进行处理,减少了模块之间的耦合,可以说是非常优秀的设计。
实际上
LayoutInflater.Factory接口的设计还有更多细节(比如LayoutInflater.FactoryMerger类),篇幅原因,本文不赘述,有兴趣的读者可以研究一下。
LayoutInflater整体的设计非常复杂且巧妙,从应用启动到进程间通信,从组件的启动再到组件UI的渲染,都可以看到LayoutInflater的身影,因此非常值得认真学习一番,建议读者参考本文开篇的思维导图并结合Android源码进行整体小结。
Hello,我是 却把清梅嗅 ,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的 博客 或者 Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
原文:REACTIVE APPS WITH MODEL-VIEW-INTENT - PART2 - VIEW AND INTENT
作者:Hannes Dorfmann
译者:却把清梅嗅
在 上文 中,我们探讨了对Model的定义、与 状态 的关系以及如何在通过良好地定义Model来解决一些Android开发中常见的问题。本文将通过 Model-View-Intent ,即MVI模式,继续我们的 响应式App 构建之旅。
如果您尚未阅读上一小节,则应在继续阅读本文之前阅读该部分。总结一下:以“传统的”MVP为例,请避免写出这样的代码:
class PersonsPresenter extends Presenter<PersonsView> {
public void load(){
getView().showLoading(true); // 展示一个 ProgressBar
backend.loadPersons(new Callback(){
public void onSuccess(List<Person> persons){
getView().showPersons(persons); // 展示用户列表
}
public void onError(Throwable error){
getView().showError(error); // 展示错误信息
}
});
}
}我们应该创建能够反映 状态 的Model,像这样:
class PersonsModel {
// 在真实的项目中,需要定义为私有的
// 并且我们需要通过getter和setter来访问它们
final boolean loading;
final List<Person> persons;
final Throwable error;
public(boolean loading, List<Person> persons, Throwable error){
this.loading = loading;
this.persons = persons;
this.error = error;
}
}因此,Presenter层也应该像这样进行定义:
class PersonsPresenter extends Presenter<PersonsView> {
public void load(){
getView().render( new PersonsModel(true, null, null) ); // 展示一个 ProgressBar
backend.loadPersons(new Callback(){
public void onSuccess(List<Person> persons){
getView().render( new PersonsModel(false, persons, null) ); // 展示用户列表
}
public void onError(Throwable error){
getView().render( new PersonsModel(false, null, error) ); // 展示错误信息
}
});
}
}现在,仅需简单调用View层的render(personsModel)方法,Model就会被成功的渲染在屏幕上。在第一小节中我们同样探讨了 单项数据流 的重要性,同时您的业务逻辑应该驱动该Model。在正式将所有内容环环相扣连接之前,我们先简单了解一下MVI的核心**。
该模式最初被 andrestaltz 在他写的JavaScript框架 cycle.js 中所提出; 从理论(还有数学)上讲,我们这样对Model-View-Intent的定义进行描述:
此函数接受来自用户的输入(即UI事件,比如点击事件)并将其转换为可传递给Model()函数的参数,该参数可能是一个简单的String对Model进行赋值,也可能像是Object这样复杂的数据结构。intent作为意图,标志着 我们试图对Model进行改变。
model()函数将intent()函数的输出作为输入来操作Model,其函数输出是一个新的Model(状态发生了改变)。
不要对已存在的Model对象进行修改,我们需要的是不可变!对此,在上文中我们已经展示了一个计数器的具体案例,再次重申,不要修改已存在的Model!
根据intent所描述的变化,我们创建一个新的Model,请注意,Model()函数是唯一允许对Model进行创建的途径。然后这个新的Model作为该函数的输出——基本上model()函数调用我们App的业务逻辑(可以是交互、用例、Repository......您在App中使用的任何模式/术语)并作为结果提供新的Model对象。
该方法获取model()函数返回的Model,并将其作为view()函数的输入,这之后通过某种方式将Model展示出来,view()和view.render(model)大体上是一致的。
但是我们希望构建的是 响应式的App,不是吗?那么MVI是如何响应式的呢?响应式实际上意味着什么?
这意味着App的 UI反映了状态的变更。
因为Model反映了状态,因此,本质上我们希望 业务逻辑能够对输入的事件(即intents)进行响应,并创建对应的Model作为输出,这之后再通过调用View层的render(model)方法,对UI进行渲染。
我们希望我们的数据流的单向性,因此RxJava闪亮登场。我们的App必须通过RxJava保持 数据的单向性 和 响应式 来构建吗?或者必须用MVI模式才能构建吗?当然不,我们也可以写 命令式 和 程序性 的代码。但是,基于事件编程 的RxJava实在太优秀了,既然UI是基于事件的,因此使用RxJava也是非常有意义的。
本文我们将会构建一个简单的虚拟在线商店App,其UI界面中展示的商品数据,都来源于我们向后台进行的网络请求。
我们可以精确的搜索特定的商品,并将其添加到我们的购物车中,最终App的效果如下所示:
这个项目的源码你可以在Github上找到,我们从实现一个简单的搜索界面开始做起:
首先,就像上文我们描述的那样,我们定义一个Model用于描述View层是如何被展示的—— 这个系列中,我们将用带有 ViewState 后缀的类来替代 Model;举个例子,我们将会为搜索页的Model类命名为SearchViewState。
这很好理解,因为Model反应的就是状态(State),至于为什么不用听起来有些奇怪的名称比如SearchModel,是因为担心和MVVM中的SearchViewModel类在一起会导致歧义——命名真的很难。
public interface SearchViewState {
// 搜索尚未开始
final class SearchNotStartedYet implements SearchViewState {
}
// 搜索中
final class Loading implements SearchViewState {
}
// 返回结果为空
final class EmptyResult implements SearchViewState {
private final String searchQueryText;
public EmptyResult(String searchQueryText) {
this.searchQueryText = searchQueryText;
}
public String getSearchQueryText() {
return searchQueryText;
}
}
// 有效的搜索结果,包含和搜索条件匹配的商品列表
final class SearchResult implements SearchViewState {
private final String searchQueryText;
private final List<Product> result;
public SearchResult(String searchQueryText, List<Product> result) {
this.searchQueryText = searchQueryText;
this.result = result;
}
public String getSearchQueryText() {
return searchQueryText;
}
public List<Product> getResult() {
return result;
}
}
// 表示搜索过程中发生了错误
final class Error implements SearchViewState {
private final String searchQueryText;
private final Throwable error;
public Error(String searchQueryText, Throwable error) {
this.searchQueryText = searchQueryText;
this.error = error;
}
public String getSearchQueryText() {
return searchQueryText;
}
public Throwable getError() {
return error;
}
}
}因为Java是一种强类型的语言,因此我们可以选择一种安全的方式为我们的Model类拆分出多个不同的 子状态。
我们的业务逻辑返回的是一个 SearchViewState 类型的对象,它可能是SearchViewState.Error或者其它的一个实例。这只是我个人的偏好,们也可以通过不同的方式定义,例如:
class SearchViewState {
Throwable error; // 非空则意味着,出现了一个错误
boolean loading; // 值为true意味着正在加载中
List<Product> result; // 非空意味着商品列表的结果
boolean SearchNotStartedYet; // true意味着还未开始搜索
}再次重申,如何定义Model纯属个人喜好,如果你用Kotlin作为编程语言,那么sealed classes是一个不错的选择。
将目光聚集回到业务代码,让我们通过 SearchInteractor 去执行搜索的功能,其输出就是我们之前说过的SearchViewState对象:
public class SearchInteractor {
final SearchEngine searchEngine; // 执行网络请求
public Observable<SearchViewState> search(String searchString) {
// 如果是空的字符串,不进行搜索
if (searchString.isEmpty()) {
return Observable.just(new SearchViewState.SearchNotStartedYet());
}
// 搜索商品列表
// 返回 Observable<List<Product>>
return searchEngine.searchFor(searchString)
.map(products -> {
if (products.isEmpty()) {
return new SearchViewState.EmptyResult(searchString);
} else {
return new SearchViewState.SearchResult(searchString, products);
}
})
.startWith(new SearchViewState.Loading())
.onErrorReturn(error -> new SearchViewState.Error(searchString, error));
}
}来看下SearchInteractor.search()的方法签名:我们将String类型的searchString作为 输入 的参数,以及Observable<SearchViewState>类型的 输出,这意味着我们期望随着时间的推移,可以在可观察的流上会有任意多个SearchViewState的实例被发射。
在我们正式开始查询搜索之前(即SearchEngine执行网络请求),我们通过startWith()操作符发射一个SearchViewState.Loading,这将会使得View在执行搜索时展示ProgressBar。
onErrorReturn()会捕获在执行搜索时抛出的所有异常,并且发射出一个SearchViewState.Error——在订阅这个Observable时,我们为什么不去使用onError()回调呢?
这是一个对RxJava认知的普遍误解,实际上,onError()的回调意味着 整个可观察的流进入了不可恢复的状态,因此可观察的流结束了,而在我们的案例中,类似“没有网络连接”的error并非不可恢复的error:这只是我们的Model所代表的另外一个状态。
此外,我们还有另外一个可以转换到的状态,即一旦网络连接可用,我们可以通过 SearchViewState.Loading 跳转到的 加载状态。
因此,我们建立了一个可观察的流,这是一个每当状态发生了改变,从业务逻辑层就会发射一个发生了改变的Model到View层的流。
我们不想在网络连接错误时终止这个可观察的流,因此,在error发生时,类似这种可以被处理为 状态 的error(而不是终止流的那种致命的错误),可以反应为Model,被可观察的流发射。
通常,在MVI中,Model的Observable永远不会被终止(即永远不会执行onComplete()或者onError()回调)。
总结一下,SearchInteractor(即业务逻辑)提供了一个可观察的流Observable<SearchViewState>,每当状态发生了变化,就会发射一个新的SearchViewState。
接下来我们来讨论一下View应该是什么样的,View层的职责是什么?显然View层应该对Model进行展示,我们已经认可View层应该有类似 render(model) 这样的函数。此外,View应该提供一个给其他层响应用户输入的方法,在MVI中这个方法被称为 intents。
在这个案例中,我们只有一个intent:用户可以在输入框中输入一个用于检索商品的字符串进行搜索。MVP中的好习惯是为View层定义一个接口,所以在MVI中我们也可以这样做。
public interface SearchView {
// 搜索的intent
Observable<String> searchIntent();
// 对View层进行渲染
void render(SearchViewState viewState);
}我们的案例中View层只提供了一个intent,但通常View拥有更多的intent;在 第一小节 中我们讨论了为什么一个单独的render()函数是一个不错的实践,如果你对此还不是很清楚的话,请阅读该小节并通过留言进行探讨。
在我们开始对View层进行具体的实现之前,我们先看看最终界面的展示效果:
public class SearchFragment extends Fragment implements SearchView {
@BindView(R.id.searchView) android.widget.SearchView searchView;
@BindView(R.id.container) ViewGroup container;
@BindView(R.id.loadingView) View loadingView;
@BindView(R.id.errorView) TextView errorView;
@BindView(R.id.recyclerView) RecyclerView recyclerView;
@BindView(R.id.emptyView) View emptyView;
private SearchAdapter adapter;
@Override public Observable<String> searchIntent() {
return RxSearchView.queryTextChanges(searchView) // 感谢 Jake Wharton :)
.filter(queryString -> queryString.length() > 3 || queryString.length() == 0)
.debounce(500, TimeUnit.MILLISECONDS);
}
@Override public void render(SearchViewState viewState) {
if (viewState instanceof SearchViewState.SearchNotStartedYet) {
renderSearchNotStarted();
} else if (viewState instanceof SearchViewState.Loading) {
renderLoading();
} else if (viewState instanceof SearchViewState.SearchResult) {
renderResult(((SearchViewState.SearchResult) viewState).getResult());
} else if (viewState instanceof SearchViewState.EmptyResult) {
renderEmptyResult();
} else if (viewState instanceof SearchViewState.Error) {
renderError();
} else {
throw new IllegalArgumentException("Don't know how to render viewState " + viewState);
}
}
private void renderResult(List<Product> result) {
TransitionManager.beginDelayedTransition(container);
recyclerView.setVisibility(View.VISIBLE);
loadingView.setVisibility(View.GONE);
emptyView.setVisibility(View.GONE);
errorView.setVisibility(View.GONE);
adapter.setProducts(result);
adapter.notifyDataSetChanged();
}
private void renderSearchNotStarted() {
TransitionManager.beginDelayedTransition(container);
recyclerView.setVisibility(View.GONE);
loadingView.setVisibility(View.GONE);
errorView.setVisibility(View.GONE);
emptyView.setVisibility(View.GONE);
}
private void renderLoading() {
TransitionManager.beginDelayedTransition(container);
recyclerView.setVisibility(View.GONE);
loadingView.setVisibility(View.VISIBLE);
errorView.setVisibility(View.GONE);
emptyView.setVisibility(View.GONE);
}
private void renderError() {
TransitionManager.beginDelayedTransition(container);
recyclerView.setVisibility(View.GONE);
loadingView.setVisibility(View.GONE);
errorView.setVisibility(View.VISIBLE);
emptyView.setVisibility(View.GONE);
}
private void renderEmptyResult() {
TransitionManager.beginDelayedTransition(container);
recyclerView.setVisibility(View.GONE);
loadingView.setVisibility(View.GONE);
errorView.setVisibility(View.GONE);
emptyView.setVisibility(View.VISIBLE);
}
}render(SearchViewState)方法的作用显而易见,searchIntent()方法中,我们使用了Jake Wharton的 RxBinding ,这是一个对Android UI组件提供了RxJava响应式支持的库。
RxSearchView.queryText()创建了一个Observable<String>,每当用户在EditText上输入了一些文字,它就会发射一个对应的字符串;我们通过filter()去保证只有当用户输入的字符数达到三个以上时才进行搜索;同时,我们不希望每当用户输入一个字符,就去请求网络,而是当用户输入结束后再去请求网络(debounce()操作符会停留500毫秒以决定用户是否输入完成)。
现在我们知道了屏幕中的searchIntent()方法就是 输入 ,而render()方法则是 输出。我们如何从 输入 获得 输出 呢,如下所示:
剩下的问题就是:我们如何将View的intent和业务逻辑进行连接呢?如果你认真观看了上面的流程图,你应该注意到了中间的 flatMap() 操作符,这暗示了我们还有一个尚未谈及的组件: Presenter ;Presenter负责连接这些点,就和我们在MVP中使用的方式一样。
public class SearchPresenter extends MviBasePresenter<SearchView, SearchViewState> {
private final SearchInteractor searchInteractor;
@Override protected void bindIntents() {
Observable<SearchViewState> search =
intent(SearchView::searchIntent)
// 上文中我们谈到了flatMap,但在这里switchMap更为适用
.switchMap(searchInteractor::search)
.observeOn(AndroidSchedulers.mainThread());
subscribeViewState(search, SearchView::render);
}
}什么是 MviBasePresenter, intent() 和 subscribeViewState() 又是什么?这个类是我写的 Mosby 库的一部分(3.0版本后,Mosby已经支持了MVI)。本文并非为了讲述Mosby,但我向简单介绍一下MviBasePresenter是如何的便利——这其中没有什么黑魔法,虽然确实看起来像是那样。
让我们从生命周期开始:MviBasePresenter并未持有任何生命周期,它暴露出一个 bindIntent() 方法以供View层和业务逻辑进行绑定。通常,你通过flatMap()、switchMap()或者concatMap()操作符将intent “转移”到业务逻辑中,这个方法仅仅在View层第一次被附加到Presenter中时调用,而当View再次被附加在Presenter中时(比如,屏幕方向发生了改变),将不再被调用。
这听起来有些怪,也许有人会说:
MviBasePresenter在屏幕方向发生了改变后依然能够存活?如果是这样,Mosby如何保证Observable的流不会发生内存的泄漏?
这就是 intent() 和 subscribeViewState() 的作用所在了,intent() 在内部创建一个PublishSubject,就像是业务逻辑的“网关”一样;实际上,PublishSubject订阅了View层传过来的intent的Observable,调用intent(o1)实际返回了一个订阅了o1的PublishSubject。
屏幕发生旋转时,Mosby将View从Presenter中分离,但是,内部的PublishSubject只是暂时和View解除了订阅;而当View重新附着在Presenter上时,PublishSubject将会对View层的intent进行重新订阅。
subscribeViewState()方法做的是同样的事情,只不过将顺序调换了过来(Presenter向View层的通信)。它在内部创建一个BehaviorSubject作为从业务逻辑到View层的“网关”。
由于它是一个BehaviorSubject,因此,即使此时Presenter没有持有View,我们依然可以从业务逻辑中接收到Model的更新(比如View并未处于栈顶);BehaviorSubjects始终持有它最后的值,并在View重新依附后将其重新发射。
规则很简单:使用intent()来“包装”View层的所有intent,使用subscribeViewState()替代Observable.subscribe().
与bindIntent()相对应的是 unbindIntents() ,该方法只会执行一次,即View被永久销毁时才会被调用。举个例子,将一个Fragment放在栈中,直到Activity被销毁之前,该View一直不会被销毁。
由于intent()和subscribeViewState()已经对订阅进行了管理,因此您只需要实现unbindIntents()。
那么其它生命周期的事件,比如onPause()和onResume()又该如何处理?我依然认为Presenter不需要生命周期的事件,然而,如果你坚持认为你需要将这些生命周期的事件视为另一种形式的intent,您的View可以提供一个pauseIntent(),它是由android生命周期触发,而又不是按钮点击事件这样的由用户交互触发的intent——但两者都是有效的意图。
第二小节中,我们探讨了Model-View-Intent的基础,并通过MVI浅尝辄止实现了一个简单的页面。也许这个例子太简单了,所以你尚未感受到MVI模式的优点:代表 状态 的Model和与传统MVP或者MVVM相比的 单项数据流。
MVP和MVVM并没有什么问题,我也并非是在说MVI比其它架构模式更优秀,但是,我认为MVI可以帮助我们 为复杂的问题编写优雅的代码 ,这也正如我们将在本系列博客的 下一小节(第3小节)中探讨的那样——届时我们将针对 状态折叠器 (state reducers)的问题进行探讨,欢迎关注。
《使用MVI打造响应式APP》原文
《使用MVI打造响应式APP》译文
《使用MVI打造响应式APP》实战
Hello,我是却把清梅嗅,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的博客或者Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?

本文将针对二叉树中几种常见的遍历方法进行介绍。
前序遍历首先访问根节点,然后遍历左子树,最后遍历右子树。
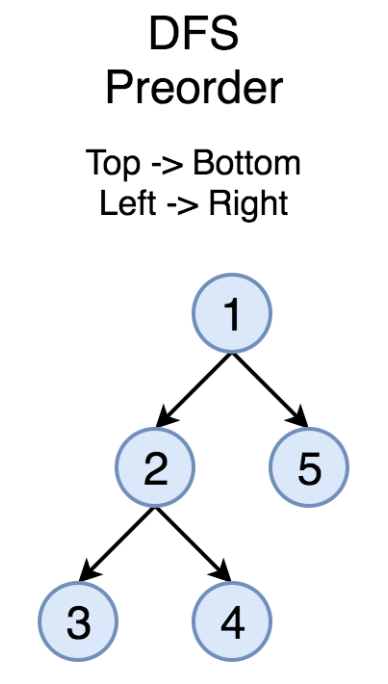
中序遍历是先遍历左子树,然后访问根节点,然后遍历右子树。
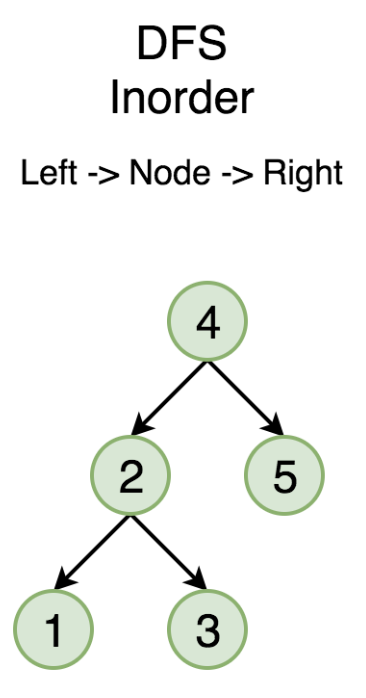
后序遍历是先遍历左子树,然后遍历右子树,最后访问树的根节点。
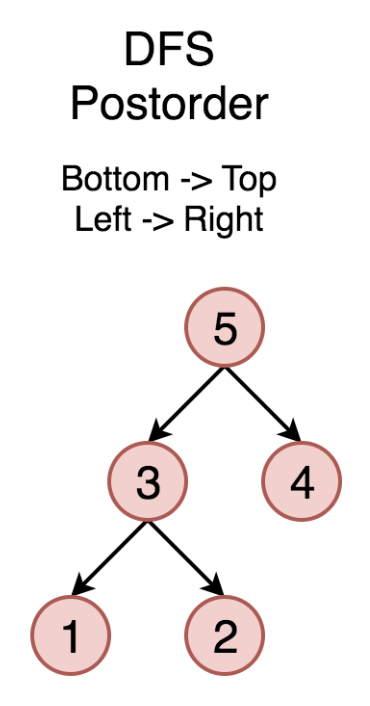
递归实现二叉树的遍历是非常简单的,其核心就是 深度优先搜索(DFS) 算法。
由于比较简单,三种遍历方式的实现代码只是 深度优先搜索 过程中执行顺序的区别,故模版如下:
public class Solution {
// 递归遍历二叉树
public List<Integer> preorderTraversal(TreeNode root) {
ArrayList<Integer> list = new ArrayList<>();
if (root == null) return list;
dfs(root, list);
return list;
}
private void dfs(TreeNode root, ArrayList<Integer> list) {
if (root == null) return;
// 前序遍历 根 -> 左 -> 右
list.add(root.val); // 根
dfs(root.left, list); // 左
dfs(root.right, list); // 右
// 中序遍历 右 -> 根 -> 右
// dfs(root.left, list);
// list.add(root.val);
// dfs(root.right, list);
// 后序遍历 左 -> 右 -> 根
// dfs(node.left, list);
// dfs(node.right, list);
// list.add(node.val);
}
}通过迭代对前序遍历需要一个栈进行辅助,其负责对不同层级父子节点进行迭代存储。
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
ArrayList<Integer> list = new ArrayList<>();
Stack<TreeNode> stack = new Stack<>();
TreeNode curr = root;
// 1.退出最外层迭代的条件是,指针指向null,且栈为空
while (curr != null || !stack.isEmpty()) {
// 2.内层循环按顺序入栈,同时更新当前指针
// 4.这时候也可能是开始遍历右节点
while (curr != null) {
stack.push(curr);
list.add(curr.val);
curr = curr.left;
}
// 3.返回父节点,并将指针指向右节点
curr = stack.pop();
curr = curr.right;
}
return list;
}
}中序遍历和前序遍历**是一致的,区别仅仅在于根节点在左叶子节点添加之后添加:
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
Stack<TreeNode> stack = new Stack<>();
TreeNode curr = root;
// 1.退出最外层迭代的条件是,指针指向null,且栈为空
while (!stack.isEmpty() || curr != null) {
// 2.内层循环按顺序入栈,同时更新当前指针
// 5.这时候也可能是开始遍历右节点
while (curr != null) {
stack.push(curr.left);
curr = curr.left;
}
// 3.返回父节点,并加入数组中
curr = stack.pop();
list.add(curr.val);
// 4.将指针指向右节点
curr = curr.right;
}
return list;
}
}后序遍历 LeetCode 官方题解给出了一个额外的思路,对于树的 后序遍历 而言,其遍历顺序与 广度优先搜索(BFS) 恰恰是相反的:
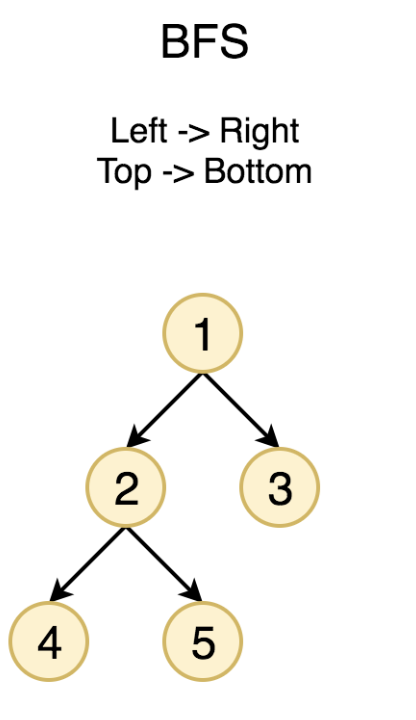
如图所示,BFS的遍历顺序是 1->2->3->4->5,而相同的树后序遍历顺序则是 4->5->2->3->1。
因此,后序遍历的思路如下:
从根节点开始依次迭代,弹出栈顶元素输出到输出列表中,然后依次压入它的所有孩子节点,按照从上到下、从左至右的顺序依次压入栈中。
因为深度优先搜索后序遍历的顺序是从下到上、从左至右,所以需要将输出列表逆序输出。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
LinkedList<Integer> output = new LinkedList<>();
// 和传统的bfs不同,这里并没有用 Queue
// 因为顺序是相反的,这里并不是取第一个元素,而是取栈顶的元素(即同层级节点从右->左遍历)
Stack<TreeNode> stack = new Stack<>();
if (root == null) return output;
stack.push(root);
while(!stack.isEmpty()) {
TreeNode node = stack.pop();
output.addFirst(node.val);
if (node.left != null) {
stack.push(node.left);
}
if (node.right != null) {
stack.push(node.right);
}
}
return output;
}
}文章绝大部分内容节选自LeetCode,概述:
例题:
Hello,我是 却把清梅嗅 ,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的 博客 或者 GitHub。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?

循环队列 是一种线性数据结构,其操作表现基于 FIFO(先进先出)原则并且队尾被连接在队首之后以形成一个循环。它也被称为 环形缓冲器。
循环队列的一个好处是我们可以利用这个队列之前用过的空间。在一个普通队列里,一旦一个队列满了,我们就不能插入下一个元素,即使在队列前面仍有空间。但是使用循环队列,我们能使用这些空间去存储新的值。
这里我们先对 队列 的简单实现进行简单展示,队列应支持两种操作:入队 和 出队 。
class MyQueue {
// store elements
private List<Integer> data;
// a pointer to indicate the start position
private int p_start;
public MyQueue() {
data = new ArrayList<Integer>();
p_start = 0;
}
/** Insert an element into the queue. Return true if the operation is successful. */
public boolean enQueue(int x) {
data.add(x);
return true;
};
/** Delete an element from the queue. Return true if the operation is successful. */
public boolean deQueue() {
if (isEmpty() == true) {
return false;
}
p_start++;
return true;
}
/** Get the front item from the queue. */
public int Front() {
return data.get(p_start);
}
/** Checks whether the queue is empty or not. */
public boolean isEmpty() {
return p_start >= data.size();
}
}上面的实现很简单,但在某些情况下效率很低。 随着起始指针的移动,浪费了越来越多的空间。 当我们有空间限制时,这将是难以接受的。

让我们考虑一种情况,即我们只能分配一个最大长度为 5 的数组。当我们只添加少于 5 个元素时,我们的解决方案很有效。 例如,如果我们只调用入队函数四次后还想要将元素 10 入队,那么我们可以成功。
但是我们不能接受更多的入队请求,这是合理的,因为现在队列已经满了。但是如果我们将一个元素出队呢?

实际上,在这种情况下,我们应该能够再接受一个元素。
循环队列 的需求迫在眉睫。
这里直接复制了 liweiwei1419 精彩的 题解 :
1、定义循环变量 front 和 rear 。一直保持这个定义,到底是先赋值还是先移动指针就很容易想清楚了。
front:指向队列头部第 1 个有效数据的位置;
rear:指向队列尾部(即最后 1 个有效数据)的下一个位置,即下一个从队尾入队元素的位置。
(说明:这个定义是依据“动态数组”的定义模仿而来。)
2、为了避免“队列为空”和“队列为满”的判别条件冲突,我们有意浪费了一个位置。
浪费一个位置是指:循环数组中任何时刻一定至少有一个位置不存放有效元素。
判别队列为空的条件是:front == rear;
判别队列为满的条件是:(rear + 1) % capacity == front;。可以这样理解,当 rear 循环到数组的前面,要从后面追上 front,还差一格的时候,判定队列为满。
3、因为有循环的出现,要特别注意处理数组下标可能越界的情况。指针后移的时候,索引 + 1,并且要注意取模。
本文的写作目的就是为了 再次手写一边算法练手。
Medium参考上述设计思路,很容易编写代码,需要注意的是取模代码的编写相对容易出问题。
实现代码:
class MyCircularQueue {
private int front;
private int tail;
private int capacity;
private int[] arr;
public MyCircularQueue(int k) {
this.capacity = k + 1;
this.arr = new int[capacity];
this.front = 0;
this.tail = 0;
}
public boolean enQueue(int value) {
if (isFull()) return false;
arr[tail] = value;
tail = (tail + 1) % capacity;
return true;
}
public boolean deQueue() {
if (isEmpty()) return false;
front = (front + 1) % capacity;
return true;
}
public int Front() {
if (isEmpty()) return -1;
return arr[front];
}
public int Rear() {
if (isEmpty()) return -1;
return arr[(tail - 1 + capacity) % capacity];
}
public boolean isEmpty() {
return front == tail;
}
public boolean isFull() {
return (tail + 1) % capacity == front;
}
}Medium和上题基本相似,除了多几个取模运算,几乎没什么变化。
class MyCircularDeque {
private int front;
private int tail;
private int capacity;
private int[] arr;
public MyCircularDeque(int k) {
this.capacity = k + 1;
this.arr = new int[capacity];
this.front = 0;
this.tail = 0;
}
public boolean insertFront(int value) {
if (isFull()) return false;
front = (front - 1 + capacity) % capacity;
arr[front] = value;
return true;
}
public boolean insertLast(int value) {
if (isFull()) return false;
arr[tail] = value;
tail = (tail + 1) % capacity;
return true;
}
public boolean deleteFront() {
if (isEmpty()) return false;
front = (front + 1) % capacity;
return true;
}
public boolean deleteLast() {
if (isEmpty()) return false;
tail = (tail - 1 + capacity) % capacity;
return true;
}
public int getFront() {
if (isEmpty()) return -1;
return arr[front];
}
public int getRear() {
if (isEmpty()) return -1;
return arr[(tail - 1 + capacity) % capacity];
}
public boolean isEmpty() {
return front == tail;
}
public boolean isFull() {
return (tail + 1) % capacity == front;
}
}文章绝大部分内容节选自LeetCode:
https://leetcode-cn.com/problems/design-circular-queue
https://leetcode-cn.com/problems/design-circular-deque
感谢 liweiwei1419 提供的精彩的 题解 。
Hello,我是 却把清梅嗅 ,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的 博客 或者 GitHub。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
原文:REACTIVE APPS WITH MODEL-VIEW-INTENT - PART 8 - NAVIGATION
作者:Hannes Dorfmann
译者:却把清梅嗅
在上一篇博客中,我们探讨了协调模式是如何在Android中应用的。这次我想展示如何在Model-View-Intent中使用它。
如果您还不知道协调器模式是什么,我强烈建议您回过头来阅读上文内容。
在MVI中应用此模式与MVVM或MVP没有太大区别:我们将lambda作为导航的回调传递给我们的MviBasePresenter。有趣的是我们如何在状态驱动的架构中触发这些回调?我们来看一个具体的例子:
class FooPresenter(
private var navigationCallback: ( () -> Unit )?
) : MviBasePresenter<FooView> {
lateinit var disposable : Disposable
override fun bindIntents(){
val intent1 = ...
val intent2 = ...
val intents = Observable.merge(intent1, intent2)
val state = intents.switchMap { ... }
// 这里就是有趣的部分
val sharedState = state.share()
disposable = sharedState.filter{ state ->
state is State.Foo
}.subscribe { navigationCallback!!() }
subscribeViewState(sharedState, FooView::render)
}
override fun unbindIntents(){
disposable.dispose() // disposable 导航
navigationCallback = null // 避免内存泄漏
}
}其**是:通过RxJava的 share() 操作符,我们对通常用来对View层渲染状态的Observable进行复用,再加上通过与 .filter() 操作符的组合使用,达到能够监听到确定的状态,这之后,当我们观察到该状态时,触发对应的导航操作,然后协调器模式就像我之前的博客文章中描述的那样进行工作。
《使用MVI打造响应式APP》原文
《使用MVI打造响应式APP》译文
《使用MVI打造响应式APP》实战
Hello,我是却把清梅嗅,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的博客或者Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
作者您好,看了您的《反思View的Measure过程》,很有帮助。
另外,我认为《关于纠错.md》的最后一行,『臂助』应改为『帮助』。纯属鸡蛋里挑骨头,请别介意。
2017年的Google I/O大会上,Google推出了一系列譬如 Lifecycle、ViewModel、LiveData等一系列 更适合用于MVVM模式开发 的架构组件。
本文的主角就是 ViewModel ,也许有朋友会提出质疑:
ViewModel 这么简单的东西,从API的使用到源码分析,相关内容都烂大街了,你这篇文章还能翻出什么花来?
我无法反驳,事实上,阅读本文的您可能对MVVM的代码已经 驾轻就熟,甚至是经历了完整项目的洗礼,但我依然想做一次大胆地写作尝试—— 即使对于MVVM模式的**噗之以鼻,或者已经熟练使用MVVM,本文也尽量让您有所收获,至少阅读体验不那么枯燥。
ViewModel,或者说 MVVM (Model-View-ViewModel),并非是一个新鲜的词汇,它的定义最早起源于前端,代表着 数据驱动视图 的**。
比如说,我们可以通过一个String类型的状态来表示一个TextView,同理,我们也可以通过一个List<T>类型的状态来维护一个RecyclerView的列表——在实际开发中我们通过观察这些数据的状态,来维护UI的自动更新,这就是 数据驱动视图(观察者模式)。
每当String的数据状态发生变更,View层就能检测并自动执行UI的更新,同理,每当列表的数据源List<T>发生变更,RecyclerView也会自动刷新列表:

对于开发者来讲,在开发过程中可以大幅减少UI层和Model层相互调用的代码,转而将更多的重心投入到业务代码的编写。
ViewModel 的概念就是这样被提出来的,我对它的形容类似一个 状态存储器 , 它存储着UI中各种各样的状态, 以 登录界面 为例,我们很容易想到最简单的两种状态 :
class LoginViewModel {
val username: String // 用户名输入框中的内容
val password: String // 密码输入框中的内容
}先不纠结于代码的细节,现在我们知道了ViewModel的重心是对 数据状态的维护。接下来我们来看看,在17年之前Google还没有推出ViewModel组件之前,Android领域内MVVM 百花齐放的各种形态 吧。
说到MVVM就不得不提Google在2015年IO大会上提出的DataBinding库,它的发布直接促进了MVVM在Android领域的发展,开发者可以直接通过将数据状态通过 伪Java代码 的形式绑定在xml布局文件中,从而将MVVM模式的开发流程形成一个 闭环:
<?xml version="1.0" encoding="utf-8"?>
<layout xmlns:android="http://schemas.android.com/apk/res/android">
<data>
<variable
name="user"
type="User" />
</data>
<TextView
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="@{ user.name }"
android:textSize="20sp" />
</layout>通过 伪Java代码 将UI的逻辑直接粗暴的添加进xml布局文件中达到和View的绑定,DataBinding这种实现方式引起了 强烈的争论。直至如今,依然有很多开发者无法接受DataBinding,这是完全可以理解的,因为它确实 很难定位语法的错误和运行时的崩溃原因。
MVVM模式并不一定依赖于DataBinding,但是除了DataBinding,开发者当时并没有足够多的选择——直至目前,仍然有部分的MVVM开发者坚持不使用 DataBinding,取而代之使用生态圈极为丰富的RxJava(或者其他)代替 DataBinding的数据绑定。
如果说当时对于 数据绑定 的库至少还有官方的DataBinding可供参考,ViewModel的规范化则是非常困难——基于ViewModel层进行状态的管理这个基本的约束,不同的项目、不同的依赖库加上不同的开发者,最终代码中对于 状态管理 的实现方式都有很大的不同。
比如,有的开发者,将 ViewModel 层像 MVP 一样定义为一个接口:
interface IViewModel
open class BaseViewModel: IViewModel也有开发者(比如这个repo)直接将ViewModel层继承了可观察的属性(比如dataBinding库的BaseObservable),并持有Context的引用:
public class CommentViewModel extends BaseObservable {
@BindingAdapter("containerMargin")
public static void setContainerMargin(View view, boolean isTopLevelComment) {
//...
}
}一千个人有一千个哈姆雷特,不同的MVVM也有截然不同的实现方式,这种百花齐放的代码风格、难以严格统一的 开发流派 导致代码质量的参差不齐,代码的可读性更是天差地别。
再加上DataBinding本身导致代码阅读性的降低,真可谓南门北派华山论剑,各种**喷涌而出——从**的碰撞交流来讲,这并非坏事,但是对于当时想学习MVVM的我来讲,实在是看得眼花缭乱,在学习接触的过程中,我也不可避免的走了许多弯路。
我们都知道Google在去年的 I/O 大会非常隆重地推出了一系列的 架构组件, ViewModel正是其中之一,也是本文的主角。
有趣的是,相比较于惹眼的 Lifecycle 和 LiveData, ViewModel 显得非常低调,它主要提供了这些特性:
Activity、Fragment等UI组件之间的通信如果让我直接吹捧ViewModel多么多么优秀,我会非常犯难,因为它表面展现的这些功能实在不够惹眼,但是有幸截止目前为止,我花费了一些笔墨阐述了ViewModel在这之前的故事——它们是接下来正文不可缺少的铺垫。
也许您尚未意识到,在官方的ViewModel发布之前,MVVM开发模式中,ViewModel层的一些窘境,但实际上我已经尽力通过叙述的方式将这些问题描述出来:
在官方的ViewModel发布之前,ViewModel层的基类多种多样,内部的依赖和公共逻辑更是五花八门。新的ViewModel组件直接对ViewModel层进行了标准化的规范,即使用ViewModel(或者其子类AndroidViewModel)。
同时,Google官方建议ViewModel尽量保证 纯的业务代码,不要持有任何View层(Activity或者Fragment)或Lifecycle的引用,这样保证了ViewModel内部代码的可测试性,避免因为Context等相关的引用导致测试代码的难以编写(比如,MVP中Presenter层代码的测试就需要额外成本,比如依赖注入或者Mock,以保证单元测试的进行)。
由系统响应用户交互或者重建组件,用户无法操控。当组件被销毁并重建后,原来组件相关的数据也会丢失——最简单的例子就是屏幕的旋转,如果数据类型比较简单,同时数据量也不大,可以通过onSaveInstanceState()存储数据,组件重建之后通过onCreate(),从中读取Bundle恢复数据。但如果是大量数据,不方便序列化及反序列化,则上述方法将不适用。
ViewModel的扩展类则会在这种情况下自动保留其数据,如果Activity被重新创建了,它会收到被之前相同ViewModel实例。当所属Activity终止后,框架调用ViewModel的onCleared()方法释放对应资源:

这样看来,ViewModel是有一定的 作用域 的,它不会在指定的作用域内生成更多的实例,从而节省了更多关于 状态维护(数据的存储、序列化和反序列化)的代码。
ViewModel在对应的 作用域 内保持生命周期内的 局部单例,这就引发一个更好用的特性,那就是Fragment、Activity等UI组件间的通信。
一个Activity中的多个Fragment相互通讯是很常见的,如果ViewModel的实例化作用域为Activity的生命周期,则两个Fragment可以持有同一个ViewModel的实例,这也就意味着数据状态的共享:
public class AFragment extends Fragment {
private CommonViewModel model;
public void onActivityCreated() {
model = ViewModelProviders.of(getActivity()).get(CommonViewModel.class);
}
}
public class BFragment extends Fragment {
private CommonViewModel model;
public void onActivityCreated() {
model = ViewModelProviders.of(getActivity()).get(CommonViewModel.class);
}
}上面两个Fragment
getActivity()返回的是同一个宿主Activity,因此两个Fragment之间返回的是同一个ViewModel。
我不知道正在阅读本文的您,有没有冒出这样一个想法:
ViewModel提供的这些特性,为什么感觉互相之间没有联系呢?
这就引发下面这个问题,那就是:
这些特性的本质是什么?
ViewModel层的根本职责,就是负责维护UI的状态,追根究底就是维护对应的数据——毕竟,无论是MVP还是MVVM,UI的展示就是对数据的渲染。
ViewModel的基类,并建议通过持有LiveData维护保存数据的状态;ViewModel不会随着Activity的屏幕旋转而销毁,减少了维护状态的代码成本(数据的存储和读取、序列化和反序列化);Fragment维护相同的数据状态,极大减少了UI组件之间的数据传递的代码成本。现在我们对于ViewModel的职责和**都有了一定的了解,按理说接下来我们应该阐述如何使用ViewModel了,但我想先等等,因为我觉得相比API的使用,掌握其本质的**会让你在接下来的代码实践中如鱼得水。
通过库提供的API接口作为开始,阅读其内部的源码,这是标准掌握代码内部原理的思路,这种方式的时间成本极高,即使有相关源码分析的博客进行引导,文章中大片大片的源码和注释也足以让人望而却步,于是我理所当然这么想:
先学会怎么用,再抽空系统学习它的原理和**吧......
发现没有,这和上学时候的学习方式竟然截然相反,甚至说本末倒置也不奇怪——任何一个物理或者数学公式,在使用它做题之前,对它背后的基础理论都应该是优先去系统性学习掌握的(比如,数学公式的学习一般都需要先通过一定方式推导和证明),这样我才能拿着这个知识点对课后的习题举一反三。这就好比,如果一个老师直接告诉你一个公式,然后啥都不说让你做题,这个老师一定是不合格的。
我也不是很喜欢大篇幅地复制源码,我准备换个角度,站在Google工程师的角度看看怎么样设计出一个ViewModel。
现在我们是Google工程师,让我们再回顾一下ViewModel应起到的作用:
ViewModel的基类;ViewModel不会随着Activity的屏幕旋转而销毁;这个简直太简单了:
public abstract class ViewModel {
protected void onCleared() {
}
}我们定义一个抽象的ViewModel基类,并定义一个onCleared()方法以便于释放对应的资源,接下来,开发者只需要让他的XXXViewModel继承这个抽象的ViewModel基类即可。
这是一个很神奇的功能,但它的实现方式却非常简单,我们先了解这样一个知识点:
setRetainInstance(boolean)是Fragment中的一个方法。将这个方法设置为true就可以使当前Fragment在Activity重建时存活下来
这似乎和我们的功能非常吻合,于是我们不禁这样想,可不可以让Activity持有这样一个不可见的Fragment(我们干脆叫他HolderFragment),并让这个HolderFragment调用setRetainInstance(boolean)方法并持有ViewModel——这样当Activity因为屏幕的旋转销毁并重建时,该Fragment存储的ViewModel自然不会被随之销毁回收了:
public class HolderFragment extends Fragment {
public HolderFragment() { setRetainInstance(true); }
private ViewModel mViewModel;
// getter、setter...
}当然,考虑到一个复杂的UI组件可能会持有多个ViewModel,我们更应该让这个不可见的HolderFragment持有一个ViewModel的数组(或者Map)——我们干脆封装一个叫ViewModelStore的容器对象,用来承载和代理所有ViewModel的管理:
public class ViewModelStore {
private final HashMap<String, ViewModel> mMap = new HashMap<>();
// put(), get(), clear()....
}
public class HolderFragment extends Fragment {
public HolderFragment() { setRetainInstance(true); }
private ViewModelStore mViewModelStore = new ViewModelStore();
}好了,接下来需要做的就是,在实例化ViewModel的时候:
1.当前Activity如果没有持有HolderFragment,就实例化并持有一个HolderFragment
2.Activity获取到HolderFragment,并让HolderFragment将ViewModel存进HashMap中。
这样,具有生命周期的Activity在旋转屏幕销毁重建时,因为不可见的HolderFragment中的ViewModelStore容器持有了ViewModel,ViewModel和其内部的状态并没有被回收销毁。
这需要一个条件,在实例化ViewModel的时候,我们似乎还需要一个Activity的引用,这样才能保证 获取或者实例化内部的HolderFragment并将ViewModel进行存储。
于是我们设计了这样一个的API,在ViewModel的实例化时,加入所需的Activity依赖:
CommonViewModel viewModel = ViewModelProviders.of(activity).get(CommonViewModel.class)我们注入了Activity,因此HolderFragment的实例化就交给内部的代码执行:
HolderFragment holderFragmentFor(FragmentActivity activity) {
FragmentManager fm = activity.getSupportFragmentManager();
HolderFragment holder = findHolderFragment(fm);
if (holder != null) {
return holder;
}
holder = createHolderFragment(fm);
return holder;
}这之后,因为我们传入了一个ViewModel的Class对象,我们默认就可以通过反射的方式实例化对应的ViewModel,并交给HolderFragment中的ViewModelStore容器存起来:
public <T extends ViewModel> T get(Class<T> modelClass) {
// 通过反射的方式实例化ViewModel,并存储进ViewModelStore
viewModel = modelClass.getConstructor(Application.class).newInstance(mApplication);
mViewModelStore.put(key, viewModel);
return (T) viewModel;
}如何保证在不同的Fragment中,通过以下代码生成同一个ViewModel的实例呢?
public class AFragment extends Fragment {
private CommonViewModel model;
public void onActivityCreated() {
model = ViewModelProviders.of(getActivity()).get(CommonViewModel.class);
}
}
public class BFragment extends Fragment {
private CommonViewModel model;
public void onActivityCreated() {
model = ViewModelProviders.of(getActivity()).get(CommonViewModel.class);
}
}其实很简单,只需要在上一步实例化ViewModel的get()方法中加一个判断就行了:
public <T extends ViewModel> T get(Class<T> modelClass) {
// 先从ViewModelStore容器中去找是否存在ViewModel的实例
ViewModel viewModel = mViewModelStore.get(key);
// 若ViewModel已经存在,就直接返回
if (modelClass.isInstance(viewModel)) {
return (T) viewModel;
}
// 若不存在,再通过反射的方式实例化ViewModel,并存储进ViewModelStore
viewModel = modelClass.getConstructor(Application.class).newInstance(mApplication);
mViewModelStore.put(key, viewModel);
return (T) viewModel;
}现在,我们成功实现了预期的功能——事实上,上文中的代码正是ViewModel官方核心部分功能的源码,甚至默认ViewModel实例化的API也没有任何改变:
CommonViewModel viewModel = ViewModelProviders.of(activity).get(CommonViewModel.class);当然,因为篇幅所限,我将源码进行了简单的删减,同时没有讲述构造方法中带参数的ViewModel的实例化方式,但对于目前已经掌握了设计**和原理的你,学习这些API的使用几乎不费吹灰之力。
ViewModel是一个设计非常精巧的组件,它功能并不复杂,相反,它简单的难以置信,你甚至只需要了解实例化ViewModel的API如何调用就行了。
同时,它的背后掺杂的**和理念是值得去反复揣度的。比如,如何保证对状态的规范化管理?如何将纯粹的业务代码通过良好的设计下沉到ViewModel中?对于非常复杂的界面,如何将各种各样的功能抽象为数据状态进行解耦和复用?随着MVVM开发的深入化,这些问题都会一个个浮出水面,这时候ViewModel组件良好的设计和这些不起眼的小特性就随时有可能成为璀璨夺目的闪光点,帮你攻城拔寨。
--------------------------广告分割线------------------------------
争取打造 Android Jetpack 讲解的最好的博客系列:
Android Jetpack 实战篇:
Hello,我是却把清梅嗅,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的个人博客或者Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
原文:《REACTIVE APPS WITH MODEL-VIEW-INTENT - PART1 - MODEL》
作者:Hannes Dorfmann
译者:却把清梅嗅
有朝一日,我突然发现我对于Model层的定义 全部是错误的,更新了认知后,我发现曾经我在Android平台上主题讨论中的那些困惑或者头痛都消失了。
从结果上来说,最终我选择使用 RxJava 和 Model-View-Intent(MVI) 构建 响应式的APP,这是我从未有过的尝试——尽管在这之前我开发的APP也是响应式的,但 响应式编程 的体现与这次实践相比,完全无法相提并论,在接下来我将要讲述的一系列文章中,你也会感受到这些。但作为系列文章的开始,我想先阐述一个观点:
所谓的
Model层到底是什么,我之前对Model层的定义出现了什么问题?
我为什么说 我对Model层有着错误的理解和使用方式 呢?当然,现在有很多架构模式将View层和Model层进行了分离,至少在Android开发的领域,最著名的当属Model-View-Controller (MVC)、Model-View-Presenter (MVP)和Model-View-ViewModel (MVVM)——你注意到了吗?这些架构模式中,Model都是不可或缺的一环,但我意识到 在绝大数情况下,我根本没有Model。
举例来说,一个简单的从后端拉取Person列表情况下,传统的MVP实现方式应该是这样的:
class PersonsPresenter extends Presenter<PersonsView> {
public void load(){
getView().showLoading(true); // 展示一个 ProgressBar
backend.loadPersons(new Callback(){
public void onSuccess(List<Person> persons){
getView().showPersons(persons); // 展示用户列表
}
public void onError(Throwable error){
getView().showError(error); // 展示错误信息
}
});
}
}但是,这段代码中的Model到底是指什么呢?是指后台的网络请求吗?不,那只是业务逻辑。是指请求结果的用户列表吗?不,它和ProgressBar、错误信息的展示一样,仅仅只代表了View层所能展示内容的一小部分而已。
那么,Model层究竟是指什么呢?
从我个人理解来说,Model类应该定义成这样:
class PersonsModel {
// 在真实的项目中,需要定义为私有的
// 并且我们需要通过getter和setter来访问它们
final boolean loading;
final List<Person> persons;
final Throwable error;
public(boolean loading, List<Person> persons, Throwable error){
this.loading = loading;
this.persons = persons;
this.error = error;
}
}Presenter层应该这样实现:
class PersonsPresenter extends Presenter<PersonsView> {
public void load(){
getView().render( new PersonsModel(true, null, null) ); // 展示一个 ProgressBar
backend.loadPersons(new Callback(){
public void onSuccess(List<Person> persons){
getView().render( new PersonsModel(false, persons, null) ); // 展示用户列表
}
public void onError(Throwable error){
getView().render( new PersonsModel(false, null, error) ); // 展示错误信息
}
});
}
}现在,View层持有了一个Model,并且能够借助它对屏幕上的控件进行rendered(渲染)。这并非什么新鲜的概念,Trygve Reenskaug在1979年时,其对最初版本的MVC定义中具有相似的概念:View观察Model的变化。
然而,MVC这个术语被用来描述太多种不同的模式,这些模式与Reenskaug在1979年制定的模式并不完全相同。比如后端开发人员使用MVC框架,iOS有ViewController,到了Android领域MVC又被如何定义了呢?Activity是Controller吗? 那这样的话ClickListener又算什么呢?如今,MVC这个术语变成了一个很大的误区,它错误地理解和使用了Reenskaug最初制定的内容——这个话题到此为止,再继续下去整个文章就会失控了。
言归正传,Model的持有将会解决许多我们在Android开发中经常遇到的问题:
要讨论这些关键的问题,我们先来看看“传统”的MVP和MVVM的实现代码中如何处理它们,然后再谈Model如何跳过这些常见的陷阱。
响应式App,这是最近非常流行的话题,不是吗?所谓的 响应式App 就是 应用会根据状态的改变作出UI的响应,这句话里有一个非常好的单词:状态。什么是状态呢?大多数时间里,我们将 状态 描述为我们在屏幕中看到的东西,例如当界面展示ProgressBar时的loading state。
很关键的一点是,我们前端开发人员倾向专注于UI。这不一定是坏事,因为一个好的UI体验决定了用户是否会用你的产品,从而决定了产品能否获得成功。但是看看上述的MVP示例代码(不是使用了PersonModel的那个例子),这里UI的状态由Presenter进行协调,Presenter负责告诉View层如何进行展示。
MVVM亦然,我想在本文中对MVVM的两种实现方式进行区分:第一种依赖DataBinding库,第二种则依赖RxJava;对于依赖DataBinding的前者,其状态被直接定义于ViewModel中:
class PersonsViewModel {
ObservableBoolean loading;
// 省略...
public void load(){
loading.set(true);
backend.loadPersons(new Callback(){
public void onSuccess(List<Person> persons){
loading.set(false);
// 省略其它代码,比如对persons进行渲染
}
public void onError(Throwable error){
loading.set(false);
// 省略其它代码,比如展示错误信息
}
});
}
}使用RxJava实现MVVM的方式中,其并不依赖DataBinding引擎,而是将Observable和UI的控件进行绑定,例如:
class RxPersonsViewModel {
private PublishSubject<Boolean> loading;
private PublishSubject<List<Person> persons;
private PublishSubject loadPersonsCommand;
public RxPersonsViewModel(){
loadPersonsCommand.flatMap(ignored -> backend.loadPersons())
.doOnSubscribe(ignored -> loading.onNext(true))
.doOnTerminate(ignored -> loading.onNext(false))
.subscribe(persons)
// 实现方式并不惟一
}
// 在View层订阅它 (比如 Activity / Fragment)
public Observable<Boolean> loading(){
return loading;
}
// 在View层订阅它 (比如 Activity / Fragment)
public Observable<List<Person>> persons(){
return persons;
}
// 每当触发此操作 (即调用 onNext()) ,加载Persons数据
public PublishSubject loadPersonsCommand(){
return loadPersonsCommand;
}
}当然,这些代码并非完美,您的实现方式可能截然不同;我想说明的是,通常在MVP或者MVVM中,状态 是由ViewModel或者Presenter进行驱动的。
这导致下述情况的发生:
1.业务逻辑本身也拥有了状态,Presenter(或者ViewModel)本身也拥有了状态(并且,你还需要通过代码去同步它们的状态使其保持一致),同时,View可能也有自己的状态(比方说,调用View的setVisibility()方法设置其可见性,或者Android系统在重新创建时从bundle恢复状态)。
2.Presenter(或ViewModel)有任意多个输入(View层触发行为并交给Presenter处理),这是ok的,但同时Presenter也有很多输出(或MVP中的输出通道,如view.showLoading()或view.showError();在MVVM中,ViewModel的实现中也提供了多个Observable,这最终导致了View层,Presenter层和业务逻辑中状态的冲突,在处理多线程的时候,这种情况更明显。
在好的情况下,这只会导致视觉上的错误,例如同时显示加载指示符(“加载状态”)和错误指示符(“错误状态”),如下所示:
在最糟糕的情况下,您从崩溃报告工具(如Crashlytics)接收到了一个严重的错误报告,但您无法重现这个错误,因此也几乎无从着手去修复它。
如果从 底层 (业务逻辑层)到 顶层 (UI视图层),有且仅有一个真实描述状态的源,会怎么样呢?事实上,我们已经在文章的开头谈论Model的时候,就已经通过案例,把相似的概念展示了出来:
class PersonsModel {
final boolean loading;
final List<Person> persons;
final Throwable error;
public(boolean loading, List<Person> persons, Throwable error){
this.loading = loading;
this.persons = persons;
this.error = error;
}
}你猜怎么了? Model映射了状态,当我想通了这点,许多状态相关的问题迎刃而解(甚至在编码之前就已经被避免了);现在Presenter层变得只有一个输出了:
getView().render(PersonsModel)
它对应了一个数学上简单的函数,比如f(x) = y,对于多个输入的函数,对应的则是f(a,b,c),但也是一个输出。
并非对所有人来说数学都是香茗,就好像数学家并不清楚bug是什么——但软件工程师需要去品尝它。
了解Model到底是什么以及如何建立对应的Model非常重要,因为最终Model可以解决 状态问题。
译者注:针对 屏幕旋转后的状态回溯 这个问题,已经可以通过Google官方发布的
ViewModel组件进行处理,开发者不再需要为此烦恼,但本章节仍值得一读。
Android设备上的 屏幕旋转 是一个有足够挑战性的问题;忽视它是一个最简单的解决方案,即 每次屏幕旋转,都对数据重新进行加载 。这确实行之有效,大多数情况下,您的APP也在离线状态下工作,其数据来源于数据库或者其它本地缓存,这意味着屏幕旋转后的数据加载速度是很快的。
但是,个人而言我不喜欢看到加载框,哪怕加载速度是毫秒级别的,因为我认为这并非完美的用户体验,因此大家(包括我)开始使用MVP,这其中包括了 保留性的Presenter——这样就可以 在屏幕旋转时分离和销毁View层,而Presenter则会保存在内存中不会被销毁,然后View层会再次连接到Presenter。
使用RxJava的MVVM也可以实现相同的概念,但请牢记,一旦View对ViewModel取消了订阅,可观察的流就会被销毁,这个问题你可以用Subject解决;对于DataBinding构建的MVVM来讲,ViewModel由DataBinding直接绑定到View层,为了避免内存泄露,需要我们在屏幕旋转时及时销毁ViewModel。
对于 保留性的Presenter 或者 ViewModel 的问题是: 我们如何将View的状态在屏幕旋转之后回溯,保证View和Presenter再次回到之前相同的状态?我编写了一个名为 Mosby 的MVP库,其包含一个名为ViewState的功能,它基本上将业务逻辑的状态与View同步。 Moxy,另一个MVP库,提出了一个非常有趣的解决方案——通过使用commands在屏幕方向更改后重现View的状态:
针对View层状态的问题,我很确定还有其他的解决方案。让我们退后一步,归纳一下这些库试图解决的问题:那就是我们已经讨论过的 状态问题。
再次重申,我们通过一个 能反映当前状态的Model 和一个渲染Model的方法 解决了这个问题,就像调用getView().render(PersonsModel)一样简单。
当View不再使用时,是否还有保留Presenter(或ViewModel)的必要?比如,用户跳转到了另外一个界面,这导致Fragment(View)被另外的Fragment给replace了,因此Presenter已经不在被任何View持有。
如果没有View层和Presenter进行关联,Presenter自然也无法根据业务逻辑,将最新的数据反映在View上。但如果用户又回来了怎么办(比如按下后退按钮),是 重新加载数据 还是 重用现有的Presenter?——这看起来像是一个哲学问题。
通常用户一旦回到之前的界面,他会期望回到之前的界面继续操作。这仍然像是第二小节关于View层 状态恢复 的问题,解决方案简明扼要:当用户返回时,我们得到 代表状态的Model ,然后只需调用 getView().render(PersonsModel) 对View层进行渲染。
进程终止是一件坏事,并且我们需要依赖一些库以帮助我们在进程终止后对状态进行恢复——我认为这是Android开发中常见的一种误解。
首先,进程终止的原因只有一个,并且有足够充分的理由——Android操作系统需要更多资源用于其他应用程序或节省电池。如果你的APP处于前台并且正在被用户主动使用时,这种情况永远不会发生,因此,遵纪守法,不要与平台作斗争了(就是不要执拗于所谓的进程保活了)。如果你真的需要在后台进行一些长时间的工作,请使用Service,这也是向操作系统发出信号,告知您的App仍处于“主动使用状态”的 唯一方式 。
如果进程终止了,Android会提供一些回调以供 保存状态,比如onSaveInstanceState()——没错,又是 状态 。我们应该将View的信息保存在Bundle中吗?我们是否也应该把Presenter中的状态保存到Bundle中?那么业务逻辑的状态呢?又是老生常谈的问题,就和上面三个小节谈到的一样。
我们只需要一个代表整个状态的Model类,我们很容易将Model保存在Bundle中并在之后对它进行恢复。但是,我个人认为大部分情况下最好不保存状态,而是 重新加载整个界面,就像我们第一次启动App一样。 想想显示新闻列表的 NewsReader App。 当App被杀掉,我们保存了状态,6小时后用户重新打开App并恢复了状态,我们的App可能会显示过时的内容。因此,这种情况下,也许不存储Model和状态、而对数据重新加载才是更好的策略。
在这里我不打算讨论不变性(immutabiliy)的优势,因为有很多资源讨论这个问题。我们想要一个不可变的Model(代表状态)。为什么?因为我们想要唯一的状态源,在传递Model时,我们不希望App中的其他组件可以改变我们的Model或者State。
让我们假设编写一个简单的计数器App,它具有递增和递减的功能按钮,并在TextView中显示当前计数器值。 如果我们的Model(在这种情况下只是计数器值,即一个整数)是不可变的,那么我们如何更改计数器?
我很高兴被问到这个问题,按钮被点击时,我们并非直接操作TextView。我的建议是:
View层应该有一个类似view.render(...)的方法;Model是不可变的,因此不可直接修改Model;View的渲染有且只有一个来源:即业务逻辑。我们将点击事件 下沉 到业务逻辑层。业务逻辑知道当前的Model(例如,持有一个私有的成员Model,它代表着当前的状态), 这之后根据旧的Model,创建一个新的带有增量/减量值的Model。
这样我们建立了一个 单向数据流,业务逻辑作为单一源用于创建不可变的Model实例,但对于一个计数器来讲未免有点小题大做,不是吗?诚然,是的,计数器只是一个简单的应用程序。大多数应用程序都是以简单的应用程序开始,但复杂性增长很快——从我的角度来看,单向数据流和不可变模型是必要的,这会使简单的应用程序,在复杂性递增的同时,依然保持着简单(对开发者而言)。
此外,单向数据流保证了我们的应用程序易于调试。下次我们从Crashlytics获得崩溃报告时,我们可以轻松地重现并修复此崩溃,因为所有必需的信息都已附加到崩溃报告中了。
什么叫做必需的信息?那就是当前的Model和用户用户在崩溃发生时想要执行的操作(比如,点击减量按钮)。这就是我们重现这次崩溃所需的全部信息,这些信息非常容易收集并附加在崩溃报告中。
如果没有单项数据流(比如,对EventBus的滥用,或者将CounterModels的私有域暴露出来),或者没有不变性(这会导致我们不知道谁实际更改了Model),那么bug的复现就没那么容易了。
“传统”的MVP或MVVM提高了应用程序的可测试性。MVC也是可测试的:没有人说我们必须将所有业务逻辑放入Activity中。使用表示状态的Model,我们可以简化单元测试的代码,因为我们可以简单地检查assertEqual(expectedModel,model)。这使我们避免了许多必须要Mock的对象。
此外,这也减少了很多验证的测试,即某些方法是否被调用(比如Mockito.verify(view, times(1)).showFoo()),最终,这使得我们的单元测试代码更具可读性,易于理解并且易于维护,因为我们不必处理很多实际代码的实现细节。
在这个博客文章系列的第一部分中,我们谈了很多关于理论的东西。我们真的需要关于专门讨论Model的博客吗?
我认为初步地理解Model的确很重要,这也有助于我们避免一些会遇到的问题。Model并不意味着业务逻辑,它是生成Model的业务逻辑(比如,一次交互,一个用例,一个仓库或者你在APP中调用的任何东西)。
在接下来的第二部分中,当我们最终使用Model-View-Intent构建一个响应式App 时,我们将看到Model的实际应用。演示的APP是一个虚构的在线商店的应用程序,敬请关注。
《使用MVI打造响应式APP》原文
《使用MVI打造响应式APP》译文
《使用MVI打造响应式APP》实战
Hello,我是却把清梅嗅,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的博客或者Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
本文已授权「玉刚说」微信公众号独家发布
Paging是Google在2018年I/O大会上推出的适用于Android原生开发的分页库,如果您还不是很了解这个 官方钦定 的分页架构组件,欢迎参考笔者的这篇文章:
笔者在实际项目中已经使用Paging半年有余,和市面上其它热门的分页库相比,Paging最大的亮点在于其 将列表分页加载的逻辑作为回调函数封装入 DataSource 中,开发者在配置完成后,无需控制分页的加载,列表会 自动加载 下一页数据并展示。
本文将阐述:为使用了Paging的列表添加Header和Footer的整个过程、这个过程中遇到的一些阻碍、以及自己是如何解决这些阻碍的——如果您想直接浏览最终的解决方案,请直接翻阅本文的 最终的解决方案 小节。
为RecyclerView列表添加Header或Footer并不是一个很麻烦的事,最简单粗暴的方式是将RecyclerView和Header共同放入同一个ScrollView的子View中,但它无异于对RecyclerView自身的复用机制视而不见,因此这种解决方案并非首选。
更适用的解决方式是通过实现 多类型列表(MultiType),除了列表本身的Item类型之外,Header或Footer也被视作一种Item,关于这种方式的实现网上已有很多文章讲解,本文不赘述。
在正式开始本文内容之前,我们先来看看最终的实现效果,我们为一个Student的分页列表添加了一个Header和Footer:
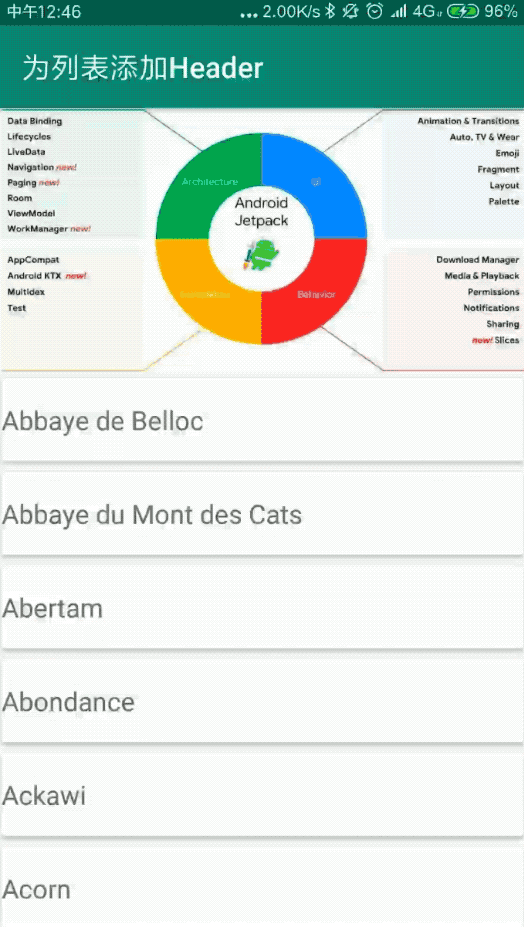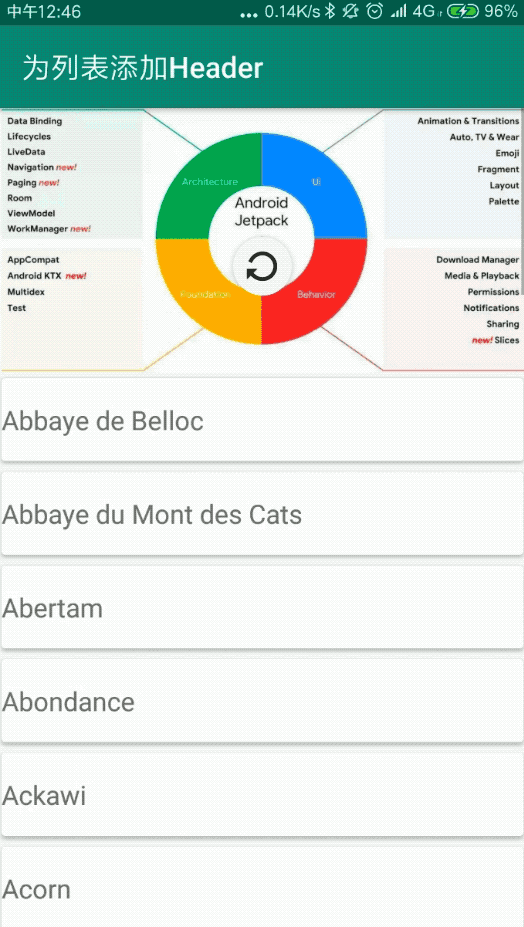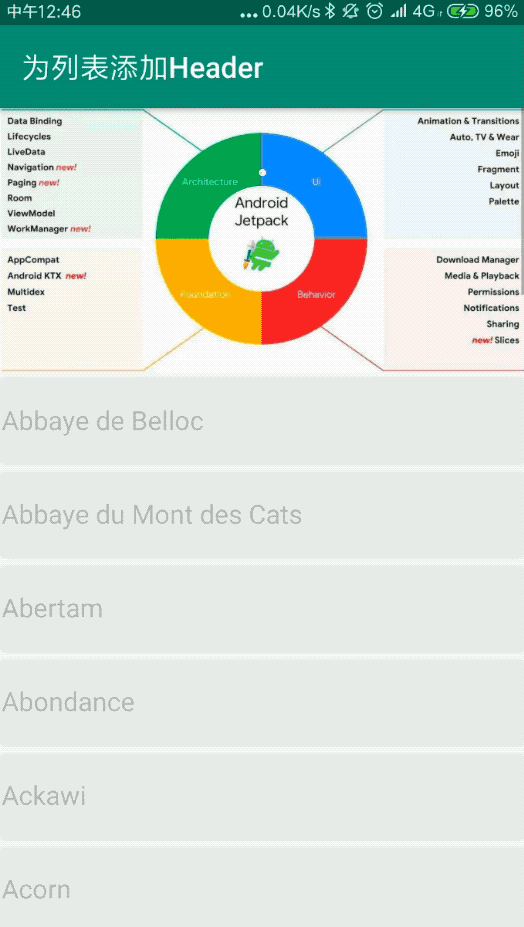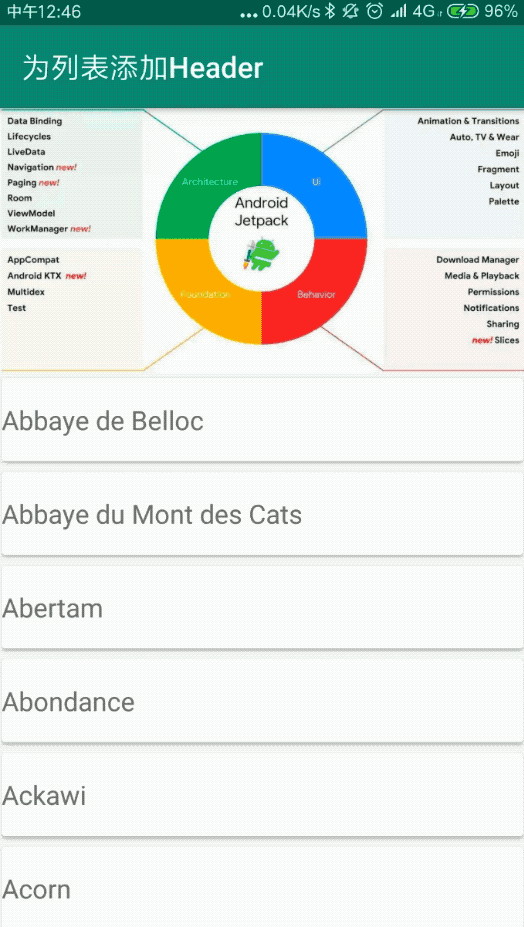
实现这种效果,笔者最初的思路也是通过 多类型列表 实现Header和Footer,但是很快我们就遇到了第一个问题,那就是 我们并没有直接持有数据源。
对于常规的多类型列表而言,我们可以轻易的持有List<ItemData>,从数据的控制而言,我更倾向于用一个代表Header或者Footer的占位符插入到数据列表的顶部或者底部,这样对于RecyclerView的渲染而言,它是这样的:
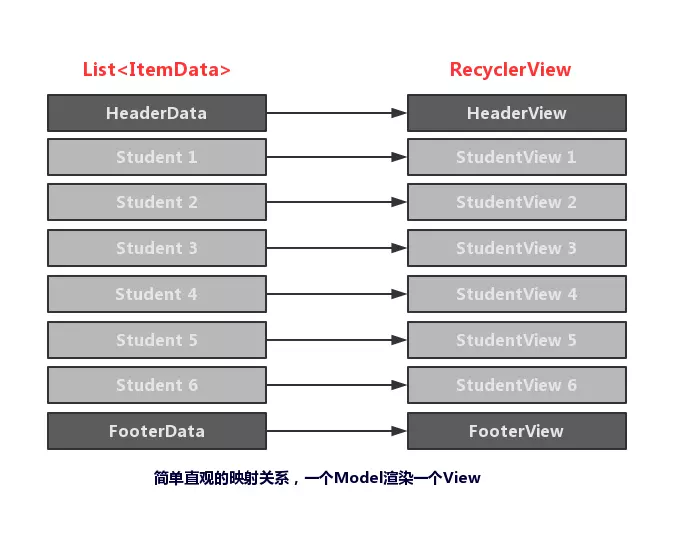
正如我所标注的,List<ItemData>中一个ItemData对应了一个ItemView——我认为为一个Header或者Footer单独创建对应一个Model类型是完全值得的,它极大增强了代码的可读性,而且对于复杂的Header而言,代表状态的Model类也更容易让开发者对其进行渲染。
这种实现方式简单、易读而不失优雅,但是在Paging中,这种思路一开始就被堵死了。
我们先看PagedListAdapter类的声明:
// T泛型代表数据源的类型,即本文中的 Student
public abstract class PagedListAdapter<T, VH extends RecyclerView.ViewHolder>
extends RecyclerView.Adapter<VH> {
// ...
}因此,我们需要这样实现:
// 这里我们只能指定Student类型
class SimpleAdapter : PagedListAdapter<Student, RecyclerView.ViewHolder>(diffCallback) {
// ...
}有同学提出,我们可以将这里的Student指定为某个接口(比如定义一个ItemData接口),然后让Student和Header对应的Model都去实现这个接口,然后这样:
class SimpleAdapter : PagedListAdapter<ItemData, RecyclerView.ViewHolder>(diffCallback) {
// ...
}看起来确实可行,但是我们忽略了一个问题,那就是本小节要阐述的:
我们并没有直接持有数据源。
回到初衷,我们知道,Paging最大的亮点在于 自动分页加载,这是观察者模式的体现,配置完成后,我们并不关心 数据是如何被分页、何时被加载、如何被渲染 的,因此我们也不需要直接持有List<Student>(实际上也持有不了),更无从谈起手动为其添加HeaderItem和FooterItem了。
以本文为例,实际上所有逻辑都交给了ViewModel:
class CommonViewModel(app: Application) : AndroidViewModel(app) {
private val dao = StudentDb.get(app).studentDao()
fun getRefreshLiveData(): LiveData<PagedList<Student>> =
LivePagedListBuilder(dao.getAllStudent(), PagedList.Config.Builder()
.setPageSize(15) //配置分页加载的数量
.setInitialLoadSizeHint(40) //初始化加载的数量
.build()).build()
}可以看到,我们并未直接持有List<Student>,因此list.add(headerItem)这种 持有并修改数据源 的方案几乎不可行(较真而言,其实是可行的,但是成本过高,本文不深入讨论)。
接下来我针对直接实现多类型列表进行尝试,我们先不讨论如何实现Footer,仅以Header而言,我们进行如下的实现:
class HeaderSimpleAdapter : PagedListAdapter<Student, RecyclerView.ViewHolder>(diffCallback) {
// 1.根据position为item分配类型
// 如果position = 1,视为Header
// 如果position != 1,视为普通的Student
override fun getItemViewType(position: Int): Int {
return when (position == 0) {
true -> ITEM_TYPE_HEADER
false -> super.getItemViewType(position)
}
}
// 2.根据不同的viewType生成对应ViewHolder
override fun onCreateViewHolder(parent: ViewGroup, viewType: Int): RecyclerView.ViewHolder {
return when (viewType) {
ITEM_TYPE_HEADER -> HeaderViewHolder(parent)
else -> StudentViewHolder(parent)
}
}
// 3.根据holder类型,进行对应的渲染
override fun onBindViewHolder(holder: RecyclerView.ViewHolder, position: Int) {
when (holder) {
is HeaderViewHolder -> holder.renderHeader()
is StudentViewHolder -> holder.renderStudent(getStudentItem(position))
}
}
// 4.这里我们根据StudentItem的position,
// 获取position-1位置的学生
private fun getStudentItem(position: Int): Student? {
return getItem(position - 1)
}
// 5.因为有Header,item数量要多一个
override fun getItemCount(): Int {
return super.getItemCount() + 1
}
// 省略其他代码...
// 省略ViewHolder代码
} 代码和注释已经将我的个人**展示的很清楚了,我们固定一个Header在多类型列表的最上方,这也导致我们需要重写getItemCount()方法,并且在对Item进行渲染的onBindViewHolder()方法中,对Sutdent的获取进行额外的处理——因为多了一个Header,导致产生了数据源和列表的错位差—— 第n个数据被获取时,我们应该将其渲染在列表的第n+1个位置上。
我简单绘制了一张图来描述这个过程,也许更加直观易懂:
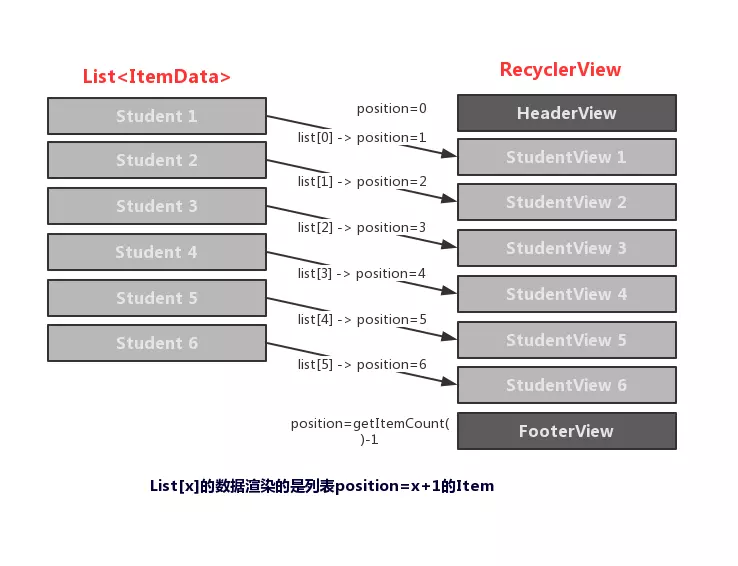
代码写完后,直觉告诉我似乎没有什么问题,让我们来看看实际的运行效果:
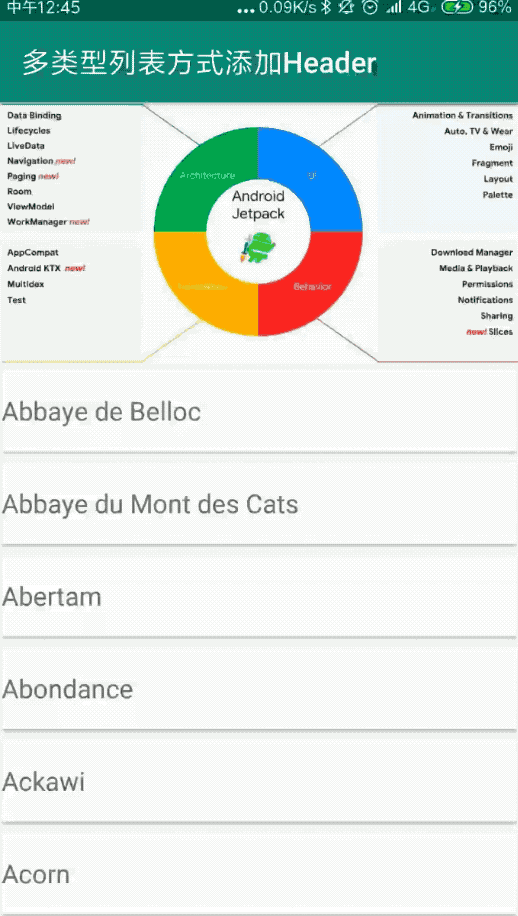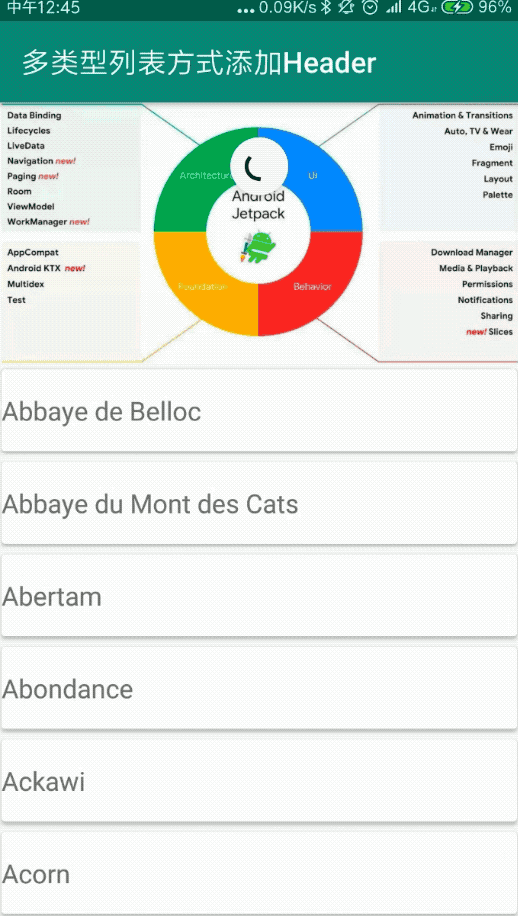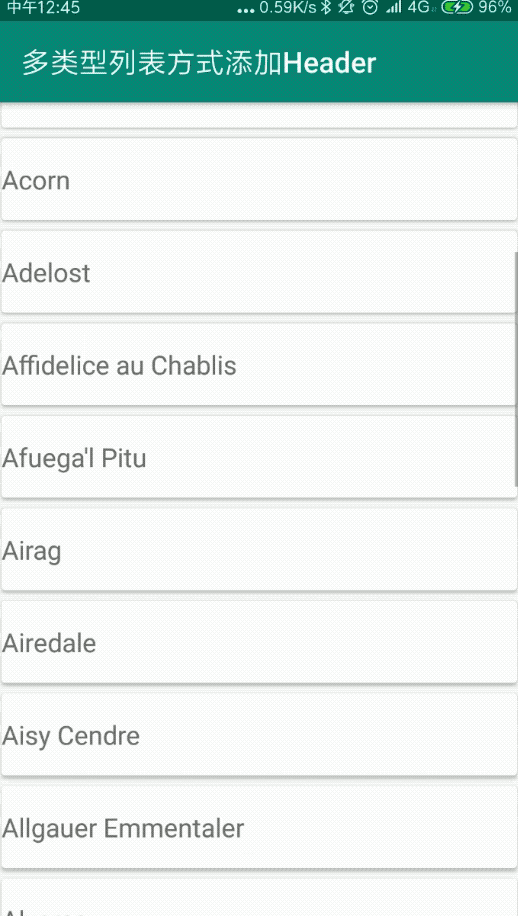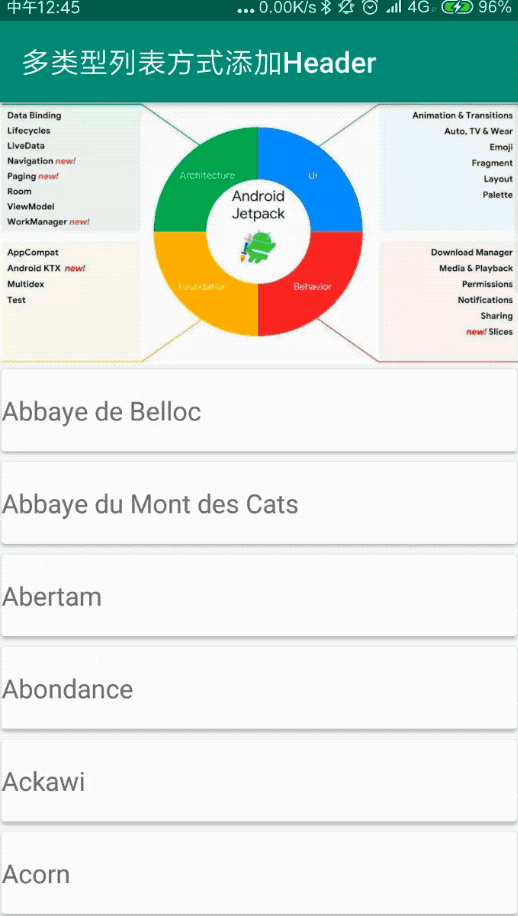
Gif也许展示并不那么清晰,简单总结下,问题有两个:
Header更应该是一个静态独立的组件,但实际上它也是列表的一部分,因此白光一闪,除了Student列表,Header作为Item也进行了刷新,这与我们的预期不符;导致这两个问题的根本原因仍然是Paging计算列表的position时出现的问题:
对于问题1,Paging对于列表的刷新理解为 所有Item的刷新,因此同样作为Item的Header也无法避免被刷新;
问题2依然也是这个问题导致的,在Paging获取到第一页数据时(假设第一页数据只有10条),Paging会命令更新position in 0..9的Item,而实际上因为Header的关系,我们是期望它能够更新第position in 1..10的Item,最终导致了刷新以及对新数据的展示出现了问题。
正如标题而言,我尝试求助于Google和Github,最终找到了这个链接:
PagingWithNetworkSample - PagedList RecyclerView scroll bug
如果您简单研究过PagedListAdapter的源码的话,您应该了解,PagedListAdapter内部定义了一个AsyncPagedListDiffer,用于对列表数据的加载和展示,PagedListAdapter更像是一个空壳,所有分页相关的逻辑实际都 委托 给了AsyncPagedListDiffer:
public abstract class PagedListAdapter<T, VH extends RecyclerView.ViewHolder>
extends RecyclerView.Adapter<VH> {
final AsyncPagedListDiffer<T> mDiffer;
public void submitList(@Nullable PagedList<T> pagedList) {
mDiffer.submitList(pagedList);
}
protected T getItem(int position) {
return mDiffer.getItem(position);
}
public int getItemCount() {
return mDiffer.getItemCount();
}
public PagedList<T> getCurrentList() {
return mDiffer.getCurrentList();
}
} 虽然Paging中数据的获取和展示我们是无法控制的,但我们可以尝试 瞒过 PagedListAdapter,即使Paging得到了position in 0..9的List<Data>,但是我们让PagedListAdapter去更新position in 1..10的item不就可以了嘛?
因此在上方的Issue链接中,onlymash 同学提出了一个解决方案:
重写PagedListAdapter中被AsyncPagedListDiffer代理的所有方法,然后实例化一个新的AsyncPagedListDiffer,并让这个新的differ代理这些方法。
篇幅所限,我们只展示部分核心代码:
class PostAdapter: PagedListAdapter<Any, RecyclerView.ViewHolder>() {
private val adapterCallback = AdapterListUpdateCallback(this)
// 当第n个数据被获取,更新第n+1个position
private val listUpdateCallback = object : ListUpdateCallback {
override fun onChanged(position: Int, count: Int, payload: Any?) {
adapterCallback.onChanged(position + 1, count, payload)
}
override fun onMoved(fromPosition: Int, toPosition: Int) {
adapterCallback.onMoved(fromPosition + 1, toPosition + 1)
}
override fun onInserted(position: Int, count: Int) {
adapterCallback.onInserted(position + 1, count)
}
override fun onRemoved(position: Int, count: Int) {
adapterCallback.onRemoved(position + 1, count)
}
}
// 新建一个differ
private val differ = AsyncPagedListDiffer<Any>(listUpdateCallback,
AsyncDifferConfig.Builder<Any>(POST_COMPARATOR).build())
// 将所有方法重写,并委托给新的differ去处理
override fun getItem(position: Int): Any? {
return differ.getItem(position - 1)
}
// 将所有方法重写,并委托给新的differ去处理
override fun submitList(pagedList: PagedList<Any>?) {
differ.submitList(pagedList)
}
// 将所有方法重写,并委托给新的differ去处理
override fun getCurrentList(): PagedList<Any>? {
return differ.currentList
}
}现在我们成功实现了上文中我们的思路,一图胜千言:
上一小节的实现方案是完全可行的,但我个人认为美中不足的是,这种方案 对既有的Adapter中代码改动过大。
我新建了一个AdapterListUpdateCallback、一个ListUpdateCallback以及一个新的AsyncPagedListDiffer,并重写了太多的PagedListAdapter的方法——我添加了数十行分页相关的代码,但这些代码和正常的列表展示并没有直接的关系。
当然,我可以将这些逻辑都抽出来放在一个新的类里面,但我还是感觉我 好像是模仿并重写了一个新的PagedListAdapter类一样,那么是否还有其它的思路呢?
最终我找到了这篇文章:
Android RecyclerView + Paging Library 添加头部刷新会自动滚动的问题分析及解决
这篇文章中的作者通过细致分析Paging的源码,得出了一个更简单实现Header的方案,有兴趣的同学可以点进去查看,这里简单阐述其原理:
通过查看源码,以添加分页为例,Paging对拿到最新的数据后,对列表的更新实际是调用了RecyclerView.Adapter的notifyItemRangeInserted()方法,而我们可以通过重写Adapter.registerAdapterDataObserver()方法,对数据更新的逻辑进行调整:
// 1.新建一个 AdapterDataObserverProxy 类继承 RecyclerView.AdapterDataObserver
class AdapterDataObserverProxy extends RecyclerView.AdapterDataObserver {
RecyclerView.AdapterDataObserver adapterDataObserver;
int headerCount;
public ArticleDataObserver(RecyclerView.AdapterDataObserver adapterDataObserver, int headerCount) {
this.adapterDataObserver = adapterDataObserver;
this.headerCount = headerCount;
}
@Override
public void onChanged() {
adapterDataObserver.onChanged();
}
@Override
public void onItemRangeChanged(int positionStart, int itemCount) {
adapterDataObserver.onItemRangeChanged(positionStart + headerCount, itemCount);
}
@Override
public void onItemRangeChanged(int positionStart, int itemCount, @Nullable Object payload) {
adapterDataObserver.onItemRangeChanged(positionStart + headerCount, itemCount, payload);
}
// 当第n个数据被获取,更新第n+1个position
@Override
public void onItemRangeInserted(int positionStart, int itemCount) {
adapterDataObserver.onItemRangeInserted(positionStart + headerCount, itemCount);
}
@Override
public void onItemRangeRemoved(int positionStart, int itemCount) {
adapterDataObserver.onItemRangeRemoved(positionStart + headerCount, itemCount);
}
@Override
public void onItemRangeMoved(int fromPosition, int toPosition, int itemCount) {
super.onItemRangeMoved(fromPosition + headerCount, toPosition + headerCount, itemCount);
}
}
// 2.对于Adapter而言,仅需重写registerAdapterDataObserver()方法
// 然后用 AdapterDataObserverProxy 去做代理即可
class PostAdapter extends PagedListAdapter {
@Override
public void registerAdapterDataObserver(@NonNull RecyclerView.AdapterDataObserver observer) {
super.registerAdapterDataObserver(new AdapterDataObserverProxy(observer, getHeaderCount()));
}
}我们将额外的逻辑抽了出来作为一个新的类,思路和上一小节的十分相似,同样我们也得到了预期的结果。
经过对源码的追踪,从性能上来讲,这两种实现方式并没有什么不同,唯一的区别就是,前者是针对PagedListAdapter进行了重写,将Item更新的代码交给了AsyncPagedListDiffer;而这种方式中,AsyncPagedListDiffer内部对Item更新的逻辑,最终仍然是交给了RecyclerView.Adapter的notifyItemRangeInserted()方法去执行的——两者本质上并无区别。
虽然上文只阐述了Paging library如何实现Header,实际上对于Footer而言也是一样,因为Footer也可以被视为另外一种的Item;同时,因为Footer在列表底部,并不会影响position的更新,因此它更简单。
下面是完整的Adapter示例:
class HeaderProxyAdapter : PagedListAdapter<Student, RecyclerView.ViewHolder>(diffCallback) {
override fun getItemViewType(position: Int): Int {
return when (position) {
0 -> ITEM_TYPE_HEADER
itemCount - 1 -> ITEM_TYPE_FOOTER
else -> super.getItemViewType(position)
}
}
override fun onCreateViewHolder(parent: ViewGroup, viewType: Int): RecyclerView.ViewHolder {
return when (viewType) {
ITEM_TYPE_HEADER -> HeaderViewHolder(parent)
ITEM_TYPE_FOOTER -> FooterViewHolder(parent)
else -> StudentViewHolder(parent)
}
}
override fun onBindViewHolder(holder: RecyclerView.ViewHolder, position: Int) {
when (holder) {
is HeaderViewHolder -> holder.bindsHeader()
is FooterViewHolder -> holder.bindsFooter()
is StudentViewHolder -> holder.bindTo(getStudentItem(position))
}
}
private fun getStudentItem(position: Int): Student? {
return getItem(position - 1)
}
override fun getItemCount(): Int {
return super.getItemCount() + 2
}
override fun registerAdapterDataObserver(observer: RecyclerView.AdapterDataObserver) {
super.registerAdapterDataObserver(AdapterDataObserverProxy(observer, 1))
}
companion object {
private val diffCallback = object : DiffUtil.ItemCallback<Student>() {
override fun areItemsTheSame(oldItem: Student, newItem: Student): Boolean =
oldItem.id == newItem.id
override fun areContentsTheSame(oldItem: Student, newItem: Student): Boolean =
oldItem == newItem
}
private const val ITEM_TYPE_HEADER = 99
private const val ITEM_TYPE_FOOTER = 100
}
}如果你想查看运行完整的demo,这里是本文sample的地址:
文末最终的方案是否有更多优化的空间呢?当然,在实际的项目中,对其进行简单的封装是更有意义的(比如Builder模式、封装一个Header、Footer甚至两者都有的装饰器类、或者其它...)。
本文旨在描述Paging使用过程中 遇到的问题 和 解决问题的过程,因此项目级别的封装和实现细节不作为本文的主要内容;关于Header和Footer在Paging中的实现方式,如果您有更好的解决方案,期待与您的共同探讨。
争取打造 Android Jetpack 讲解的最好的博客系列:
Android Jetpack 实战篇:
Hello,我是却把清梅嗅,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的个人博客或者Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
原文:REACTIVE APPS WITH MODEL-VIEW-INTENT - PART7 - TIMING (SINGLELIVEEVENT PROBLEM)
作者:Hannes Dorfmann
译者:却把清梅嗅
在之前的文章中,我们探讨了正确状态管理的重要性,以及我为什么认为使用类似 Github上Google架构组件的这个repo 中的 SingleLiveEvent 并不是一个好主意——这种解决方案只是隐藏了真正的潜在问题,那就是状态管理。本文我将会阐述SingleLiveEvent声称能解决的问题,在Model-View-Intent中如何通过状态管理正确地解决。
译者注:关于
SingleLiveEvent的这个issue 从17年讨论到19年至今还未close,各方大佬(还有google的巨佬)针对SingleLiveEvent进行了激烈的讨论,堪称Android论坛的一场神仙大战,非常值得一看。
当error发生时,Snackbar 将被展示—— 这是一个常见的场景可以用来描述这个问题。Snackbar并非一直展示,当错误信息被展示几秒钟之后它将消失,问题在于,我们如何模拟这种错误状态并控制Snackbar的消失呢?
通过下面的视频,你就能了解我在说什么:
这个示例显示了如何从 CountriesRepository 中加载国家的列表,当我们点击某个国家的条目时,程序将会跳转到第二个界面去展示“详情”(仅仅是国家的名称)。当我们返回到国家列表的界面时,我们希望和之前点击国家条目时的状态一致。
目前为止一切正常,但是当我们执行下拉刷新操作时,一个异常出现了,并通过在屏幕中展示一个Snackbar来展示错误信息。正如您在视频中看到的,当我们再次从国家详情返回国家列表时,Snackbar和相关的错误信息再次展示了出来,这和用户预期的并不一致,不是吗?
问题的根源是展示了错误的状态。Google基于ViewModel和LiveData的架构组件示例中使用了 SingleLiveEvent 来解决这个问题。其解决思路是:当View重新订阅了其ViewModel(当从“国家详情”界面返回时),SingleLiveEvent确保错误的状态不会再次被发射,这确实预防了SnakeBar的再次显示,但是这真的解决问题了吗?
SnakeBar)重申,我依然认为这种解决方案并不恰当,我们能做的更好吗?我认为合理的运用 状态管理 和 单向的数据流 是更好的答案,而Model-View-Intent架构模式遵循了这些规则。因此在MVI中我们如何解决SnakeBar的问题呢?首先,我们对Model状态进行定义:
public class CountriesViewState {
// true意味着Progress将被展示
boolean loading;
// 被加载的国家列表
List<String> countries;
// true意味着`SwipeRefreshLayout`将被展示
boolean pullToRefresh;
// true意味着下拉刷新出现了error,SnakeBar将被展示
boolean pullToRefreshError;
}MVI的**是View层同时只会展示一个不可变的CountriesViewState,因此当pullToRefreshError为true时SnakeBar将被展示,反之则会消失。
public class CountriesActivity extends MviActivity<CountriesView, CountriesPresenter>
implements CountriesView {
private Snackbar snackbar;
private ArrayAdapter<String> adapter;
@BindView(R.id.refreshLayout) SwipeRefreshLayout refreshLayout;
@BindView(R.id.listView) ListView listView;
@BindView(R.id.progressBar) ProgressBar progressBar;
...
@Override public void render(CountriesViewState viewState) {
if (viewState.isLoading()) {
progressBar.setVisibility(View.VISIBLE);
refreshLayout.setVisibility(View.GONE);
} else {
// 展示国家列表
progressBar.setVisibility(View.GONE);
refreshLayout.setVisibility(View.VISIBLE);
adapter.setCountries(viewState.getCountries());
refreshLayout.setRefreshing(viewState.isPullToRefresh());
if (viewState.isPullToRefreshError()) {
showSnackbar();
} else {
dismissSnackbar();
}
}
}
private void dismissSnackbar() {
if (snackbar != null)
snackbar.dismiss();
}
private void showSnackbar() {
snackbar = Snackbar.make(refreshLayout, "An Error has occurred", Snackbar.LENGTH_INDEFINITE);
snackbar.show();
}
}关键点在于 Snackbar.LENGTH_INDEFINITE,这意味着Snackbar将会一直显示直到我们主动控制其消失——我们不需要让Android系统控制它显示与否。
我们不会让Android系统将状态搞乱,也不会让系统为UI引入一个与业务逻辑状态不一致的状态。我们宁愿让业务逻辑将CountriesViewState.pullToRefreshError设置为true两秒钟,然后将其设置为false,而不愿使用Snackbar.LENGTH_SHORT来显示Snackbar两秒钟。
在RxJava中我们怎么做呢?我们可以使用 Observable.timer() 和 startWith() 操作符:
public class CountriesPresenter extends MviBasePresenter<CountriesView, CountriesViewState> {
private final CountriesRepositroy repositroy = new CountriesRepositroy();
@Override protected void bindIntents() {
Observable<RepositoryState> loadingData =
intent(CountriesView::loadCountriesIntent).switchMap(ignored -> repositroy.loadCountries());
Observable<RepositoryState> pullToRefreshData =
intent(CountriesView::pullToRefreshIntent).switchMap(
ignored -> repositroy.reload().switchMap(repoState -> {
if (repoState instanceof PullToRefreshError) {
// 展示snakebar2秒中,然后dismiss它
return Observable.timer(2, TimeUnit.SECONDS)
.map(ignoredTime -> new ShowCountries()) // 仅仅展示列表
.startWith(repoState); // repoState == PullToRefreshError
} else {
return Observable.just(repoState);
}
}));
// 作为初始状态,展示加载中
CountriesViewState initialState = CountriesViewState.showLoadingState();
Observable<CountriesViewState> viewState = Observable.merge(loadingData, pullToRefreshData)
.scan(initialState, (oldState, repoState) -> repoState.reduce(oldState))
subscribeViewState(viewState, CountriesView::render);
}CountriesRepositroy 的 reload() 方法返回了一个 Observable<RepoState>。RepoState(前文中叫做PattialViewState) 仅仅是个POJO类,用来表示repository是否取到数据,是成功的取到数据,或者产生了错误(点击查看源码)。
这之后,我们使用状态折叠器去计算View的状态(通过scan()操作符),如果您已阅读我之前的MVI系列文章,那么这应该此曾相识, “新”的东西是:
repositroy.reload().switchMap(repoState -> {
if (repoState instanceof PullToRefreshError) {
// 展示snakebar2秒中,然后dismiss它
return Observable.timer(2, TimeUnit.SECONDS)
.map(ignoredTime -> new ShowCountries()) // 仅仅展示列表
.startWith(repoState); // repoState == PullToRefreshError
} else {
return Observable.just(repoState);
}这段代码执行以下操作:如果我们得到了一个error(repoState instanceof PullToRefreshError),我们会发射一个错误的状态(PullToRefreshError),这使得状态折叠器设置 CountriesViewState.pullToRefreshError = true。2秒后,Observable.timer()将发射ShowCountries状态,状态折叠器会设置 CountriesViewState.pullToRefreshError = false。
OK, 现在你可以看到MVI中我们如何显示和隐藏SnakeBar:
请记住这并非像是SingleLiveEvent这样的解决方案。这是正确的状态管理,View只是显示或“渲染”给定的状态。因此用户如果再次从“国家详情”中返回,Snackbar不再会被展示,因为状态在 CountriesViewState.pullToRefreshError = false 时已经发生了改变。
如果我们希望用户能够通过滑动操作主动消除Snakebar呢。这非常简单,消除Snakebar 本身也是改变状态的一种intent,要将它添加到目前的代码中,我们只需要确保定时器或者滑动的意图能够设置CountriesViewState.pullToRefreshError = false。
我们唯一需要处理的是,如果在计时结束之前出发了滑动解除的intent,我们必须结束定时器的计时行为,这听起来很复杂,但得益于RxJava的优秀api和操作符,这轻而易举:
Observable<Long> dismissPullToRefreshErrorIntent = intent(CountriesView::dismissPullToRefreshErrorIntent)
...
repositroy.reload().switchMap(repoState -> {
if (repoState instanceof PullToRefreshError) {
// 展示Snakebar,并在2秒后dismiss它
return Observable.timer(2, TimeUnit.SECONDS)
.mergeWith(dismissPullToRefreshErrorIntent) // 合并计时器和滑动dismiss的intent
.take(1) // 二者只会触发其中一个
.map(ignoredTime -> new ShowCountries()) // 展示列表
.startWith(repoState); // repoState == PullToRefreshError
} else {
return Observable.just(repoState);
}使用mergeWith(),我们将计时器和滑动消失的intent组合成一个observable,然后使用take(1)仅将它们中的第一个事件进行发射。如果在计时器计时结束之前滑动Snakebar,则取消计时器,反之则取消滑动消失的intent。
现在让我们来尝试将UI搞乱,我们尝试下拉刷新、并在计时过程中手动取消Snakebar:
如你所见,无论我们如何尝试,都没有问题发生,由于 单向数据流 和 业务逻辑驱动的状态,View可以正确显示UI小部件(View层是无状态的,它从底层获取状态并只能对它进行展示)。比如,我们从未看到下拉刷新指示器和Snakebar同时显示(除了Snackbar退出过程中,两者的叠加情况)。
当然,Snackbar这个示例非常简单,但我认为它证明了像Model-View-Intent这样 严格规范下对状态进行管理 的架构模式的强大。不难想象这种模式对于更复杂的屏幕和使用场景同样也会非常棒。
本文的示例源码你可以从这里获取。
《使用MVI打造响应式APP》原文
《使用MVI打造响应式APP》译文
《使用MVI打造响应式APP》实战
Hello,我是却把清梅嗅,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的博客或者Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
本文已授权 微信公众号 玉刚说 (@任玉刚)独家发布。
在不久前的Google 2018 I/O大会上,Google正式推出了AndroidJetpack ——这是一套组件、工具和指导,可以帮助开发者构建出色的 Android 应用,这其中就包含了去年推出的 Lifecycle, ViewModel, LiveData 以及 Room。除此之外,AndroidJetpack 还隆重推出了一个新的架构组件:Navigation。
从名字来看,我翻译它叫导航, 我们来看看Google官方对它的描述:
今天,我们宣布推出Navigation组件,作为构建您的应用内界面的框架,重点是让单 Activity 应用成为首选架构。利用Navigation组件对 Fragment 的原生支持,您可以获得架构组件的所有好处(例如生命周期和 ViewModel),同时让此组件为您处理 FragmentTransaction 的复杂性。此外,Navigation组件还可以让您声明我们为您处理的转场。它可以自动构建正确的“向上”和“返回”行为,包含对深层链接的完整支持,并提供了帮助程序,用于将导航关联到合适的 UI 小部件,例如抽屉式导航栏和底部导航。
抛开比较性的话题不谈(StoryBoard VS Navigation?),Navigation的发布让我意识到 这是一个契机,我觉得我有必要花时间去深入了解它——既能 学习新的技术及理念 ,同时又能 查漏补缺,完善自己的Android知识体系(Fragment的管理)。

这件事立即被我列上日程,过去的一周,我闲暇之际仔细研究了 Navigation, 并略有心得,我尝试写下本文,在总结的同时,希望能够给后来的朋友们一些 系统性的指导建议 。如果可能,我甚至希望这篇文章能够做到:
本文不是详细的API说明文档,但仅通过阅读本文,能够对 Navigation 有一个系统性地学习—— 了解它,理解它,最后搞懂它。
这对读写双方都是 一次挑战。完成它的第一步是做到:知道Navigation这个导航组件 怎么用。
官方文档 永远是最接近 正确 和 核心理念 的参考资料 —— 在不久之后,本文可能会因为框架本身API的迭代更新而 毫无意义,但官方文档不会,即使在最恶劣的风暴中,它依然是最可靠的 指明灯:
https://developer.android.com/topic/libraries/architecture/navigation/
其次,一个好的Demo能够起到重要的启发作用, 这里我推荐 Google实验室 的这个Sample:
项目地址:https://github.com/googlecodelabs/android-navigation
项目教程:https://codelabs.developers.google.com/codelabs/android-navigation/#0
这个教程Demo的优势在于,官方为这个Demo提供了 一系列详细的教程,通过一步步,引导学习每一个类或者组件的应用场景,最终完全上手 Navigation。
因为刚刚发布的原因,目前Navigation的中文教程 极其匮乏,许多资料的查阅可能需要开发者 自备梯子。不过请不必担心,本文会力争做到比其它同类文章讲解的 更加全面。
我写了一个Navigation的sample,它最终的效果是这样:
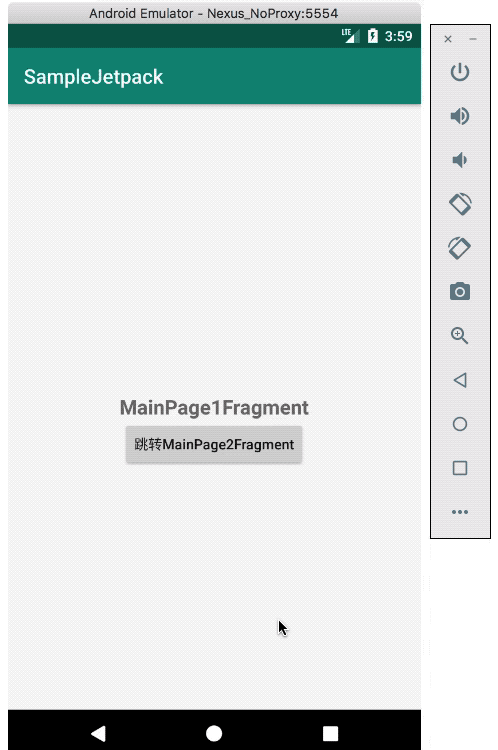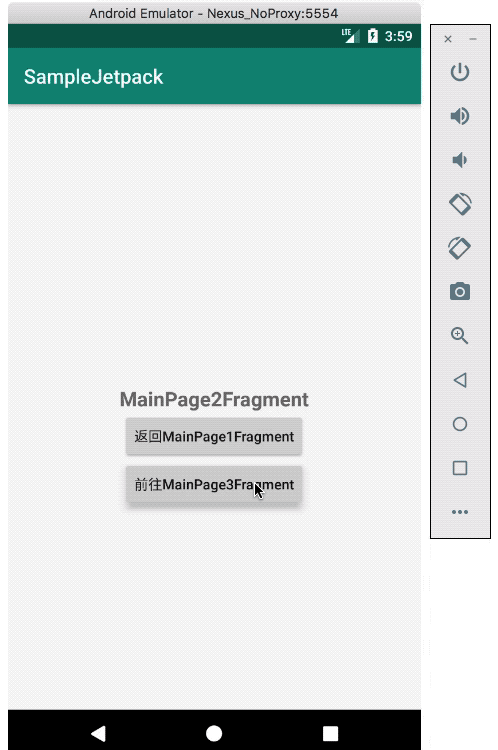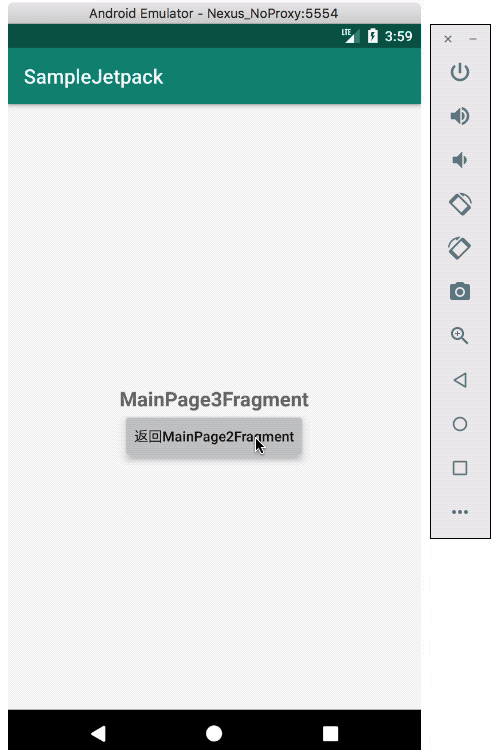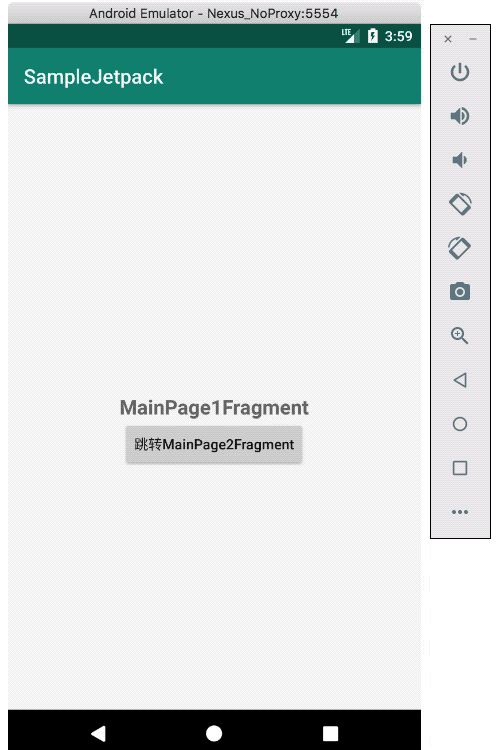
这是3个简单的Fragment之间跳转的情景,经过 转场动画 的修饰,它们之前的切换非常 流畅 且 自然。在展示的最后,我们可以看到,Fragment2 -> Fragment1的时候,实际上是由 用户 点击手机Back键 触发的。
项目结构图如下,这可以帮你尽快了解sample的结构:
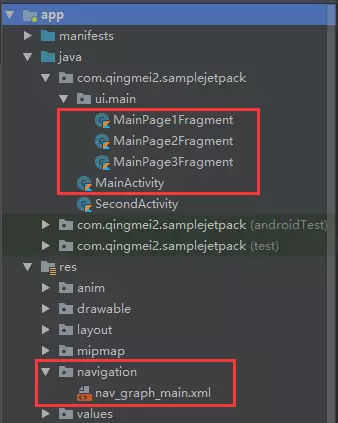
我把这个sample的源码托管在了我的github上,你可以通过 点我查看源码 。
Navigation目前仅AndroidStudio 3.2以上版本支持,如果您的版本不足3.2,请点此下载预览版AndroidStudio
首先介绍Navigation的使用:
无论是否认可,我们都必须承认,Google已经在尝试让Kotlin上位,无论是今年IO大会的 数据展示,还是官方文档上的 代码示例片段,亦或是Google最新 开源Demo的源码,使用语言清一色 Kotlin,本文亦然。

dependencies {
def nav_version = '1.0.0-alpha01'
implementation "android.arch.navigation:navigation-fragment:$nav_version"
implementation "android.arch.navigation:navigation-ui:$nav_version"
}//3个Fragment,它们除了layout不同,没有其它区别
class MainPage1Fragment : Fragment() {
override fun onCreateView(inflater: LayoutInflater, container: ViewGroup?,
savedInstanceState: Bundle?): View {
return inflater.inflate(R.layout.fragment_main_page1, container, false)
}
}
class MainPage2Fragment : Fragment() {
override fun onCreateView(inflater: LayoutInflater, container: ViewGroup?,
savedInstanceState: Bundle?): View? {
return inflater.inflate(R.layout.fragment_main_page2, container, false)
}
}
class MainPage3Fragment : Fragment() {
override fun onCreateView(inflater: LayoutInflater, container: ViewGroup?,
savedInstanceState: Bundle?): View? {
return inflater.inflate(R.layout.fragment_main_page3, container, false)
}
}在res目录下新建navigation文件夹,然后新建一个navigation的resource文件,我叫它 nav_graph_main.xml :
打开导航视图文件,我们可以在AndroidStudio 3.2版本上,进行可视化编辑,包括选择新增Fragment,或者拖拽,连接Fragment:
我们打开Text标签,进入xml编辑的页面,并这样配置:
<?xml version="1.0" encoding="utf-8"?>
<navigation xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
app:startDestination="@id/page1Fragment">
<fragment
android:id="@+id/page1Fragment"
android:name="com.qingmei2.samplejetpack.ui.main.MainPage1Fragment"
android:label="fragment_page1"
tools:layout="@layout/fragment_main_page1">
<action
android:id="@+id/action_page2"
app:destination="@id/page2Fragment" />
</fragment>
<fragment
android:id="@+id/page2Fragment"
android:name="com.qingmei2.samplejetpack.ui.main.MainPage2Fragment"
android:label="fragment_page2"
tools:layout="@layout/fragment_main_page2">
<action
android:id="@+id/action_page1"
app:popUpTo="@id/page1Fragment" />
<action
android:id="@+id/action_page3"
app:destination="@id/nav_graph_page3" />
</fragment>
<navigation
android:id="@+id/nav_graph_page3"
app:startDestination="@id/page3Fragment">
<fragment
android:id="@+id/page3Fragment"
android:name="com.qingmei2.samplejetpack.ui.main.MainPage3Fragment"
android:label="fragment_page3"
tools:layout="@layout/fragment_main_page3" />
</navigation>
</navigation>注意:请保证fragment标签下,android:name属性内包名的正确声明。
在Activity中配置 Navigation 非常简单,我们首先编辑Activity的布局文件,并在布局文件中添加一个 NavHostFragment :
<?xml version="1.0" encoding="utf-8"?>
<android.support.constraint.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:id="@+id/container"
android:layout_width="match_parent"
android:layout_height="match_parent"
tools:context=".MainActivity">
<fragment
android:id="@+id/my_nav_host_fragment"
android:name="androidx.navigation.fragment.NavHostFragment"
android:layout_width="0dp"
android:layout_height="0dp"
app:layout_constraintBottom_toBottomOf="parent"
app:layout_constraintLeft_toLeftOf="parent"
app:layout_constraintRight_toRightOf="parent"
app:layout_constraintTop_toTopOf="parent"
app:defaultNavHost="true"
app:navGraph="@navigation/nav_graph_main" />
</android.support.constraint.ConstraintLayout>这是一个宽和高都 match_parent 的Fragment,它的作用就是 导航界面的容器。
这并不难以理解,我们需要在Activity中通过 Navigation 展示一系列的Fragment,但是我们需要告诉Navigation 和Activity,这一系列的 Fragment 展示在哪——NavHostFragment应运而生,我把它的作用归纳为 导航界面的容器。
这之后,在Activity中添加如下代码:
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
}
override fun onSupportNavigateUp() =
findNavController(this, R.id.my_nav_host_fragment).navigateUp()
}onSupportNavigateUp()方法的重写,意味着Activity将它的 back键点击事件的委托出去,如果当前并非栈中顶部的Fragment, 那么点击back键,返回上一个Fragment。
class MainPage1Fragment : Fragment() {
//隐藏了onCreateView()方法的实现,下同
override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
super.onViewCreated(view, savedInstanceState)
btn.setOnClickListener {
//点击跳转page2
Navigation.findNavController(it).navigate(R.id.action_page2)
}
}
}
class MainPage2Fragment : Fragment() {
override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
super.onViewCreated(view, savedInstanceState)
btn.setOnClickListener {
//点击返回page1
Navigation.findNavController(it).navigateUp()
}
btn2.setOnClickListener {
//点击跳转page3
Navigation.findNavController(it).navigate(R.id.action_page3)
}
}
}
class MainPage3Fragment : Fragment() {
override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
super.onViewCreated(view, savedInstanceState)
//点击返回page2
btn.setOnClickListener { Navigation.findNavController(it).navigateUp() }
}
}可以看到,我们对于Fragment 并非是通过原生的 FragmentManager 和 FragmentTransaction 进行控制的。而是通过以下API进行的控制:
到这里,Navigation最基本的使用就已经讲解完毕了。您可以通过运行预览和示例 基本一致 的效果,如果遇到问题,或者有疑问,可以点我查看源码 。
我对于 通过博客归纳总结 的学习方式已近两年,我不断反思,一篇优秀的文章不仅是做到 完整叙述,同时,它更应该体现的是 对思路的整理 并 简洁干净地阐述它们。
做到这点并不容易,首先需要做到的就是 不要仅局限于API的使用——最初的学习中,通过上面的代码,我已经 实现了Fragment的导航。但是,上面的代码中,除了Activity 和 Fragment,其它的东西我一个都不认识。
我感觉很难受, 所谓 行百里路半九十,别说九十,这个Navigation,我一窍不通。

仅有上述示例代码毫无意义,通过它们,更应该将其理解为 入门;接下来我们需要做到 了解每一个类的职责,理解框架设计者的**。
我们先思考这样一个问题:如果让我们实现一个Fragment的导航库,首先要实现什么?
答案近在眼前。
即使我们使用原生的API,想展示一个Fragment,我们首先也需要 定义一个容器承载它。以往,它可能是一个 RelativeLayout 或者 FrameLayout,而现在,它被替换成了 NavGraphFragment。
这也就说明了,我们为什么要往Activity的layout文件中提前扔进去一个NavGraphFragment,因为我们需要导航的这些Fragment都展示在NavGraphFragment上面。
实际上它做了什么呢?来看一下NavGraphFragment的onCreateView()方法:
public View onCreateView(@NonNull LayoutInflater inflater, @Nullable ViewGroup container,
@Nullable Bundle savedInstanceState) {
FrameLayout frameLayout = new FrameLayout(inflater.getContext());
frameLayout.setId(getId());
return frameLayout;
}NavGraphFragment内部实例化了一个FrameLayout, 作为ViewGroup的载体,导航并展示其它Fragment。
除此之外,你 应当注意 到在layout文件中,它还声明了另外两个属性:
app:defaultNavHost="true"
app:navGraph="@navigation/nav_graph_main"
app:defaultNavHost="true"这个属性意味着你的NavGraphFragment将会 拦截系统Back键的点击事件(因为系统的back键会直接关闭Activity而非切换Fragment),你同时 必须重写 Activity的 onSupportNavigateUp() 方法,类似这样:
override fun onSupportNavigateUp()
= findNavController(R.id.nav_host_fragment).navigateUp()app:navGraph="@navigation/nav_graph_main"这个属性就很好理解了,它会指向一个navigation_graph的xml文件,这之后,NavGraphFragment就会 导航并展示对应的Fragment。
在我们使用Navigation的第一步,我们需要:
在Activity的布局文件中显示声明NavGraphFragment,并配置 app:defaultNavHost 和 app:navGraph属性。
NavGraphFragment作为Activity导航的 容器 ,然后,其 app:navGraph 属性指向一个navigation_graph的xml文件,以声明其 导航的结构。
NavGraphFragment在 获取 并 解析 完这个xml资源文件后,它首先需要知道的是:
类似APP的home界面,NavGraphFragment首先要导航到哪里?
<?xml version="1.0" encoding="utf-8"?>
<navigation xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
app:startDestination="@id/page1Fragment">
<fragment
android:id="@+id/page1Fragment"
android:name="com.qingmei2.samplejetpack.ui.main.MainPage1Fragment"
android:label="fragment_page1"
tools:layout="@layout/fragment_main_page1">
<action
android:id="@+id/action_page2"
app:destination="@id/page2Fragment" />
</fragment>
//省略...
</navigation>在navigation的根节点下,我们需要处理这样一个属性:
app:startDestination="@id/page1Fragment"
Destination 是一个很关键的单词,它的直译是 目的地。app:startDestination属性便是声明这个id对应的 Destination 会被作为 默认布局 加载到Activity中。这也就说明了,为什么我们的sample,默认会显示 MainPage1Fragment。
现在,我们的app默认展示了MainPage1Fragment, 那么接下来,我们如何实现跳转逻辑的处理呢?
我们声明了这样一个Action标签,这是一个 导航的行为:
<action
android:id="@+id/action_page2"
app:destination="@id/page2Fragment" />app:destination的属性,声明了这个行为导航的 destination(目的地),我们可以看到,它会指印跳转到 id 为 page2Fragment 的Fragment(也就是 MainPage2Fragment)。
android:id 这个id作为Action唯一的 标识,在Fragment的某个点击事件中,我们通过id指向对应的行为,就像这样:
btn.setOnClickListener {
//点击跳转page2Fragment
Navigation.findNavController(it).navigate(R.id.action_page2)
}此外,Navigation还提供了一个 app:popUpTo 属性,它的作用是声明导航行为 将 返回到 id对应的Fragment,比如,直接从Page3 返回到 Page1。
此外,Navigation 对导航行为还提供了 转场动画 的支持,它可以通过代码这样实现:
<action
android:id="@+id/confirmationAction"
app:destination="@id/confirmationFragment"
app:enterAnim="@anim/slide_in_right"
app:exitAnim="@anim/slide_out_left"
app:popEnterAnim="@anim/slide_in_left"
app:popExitAnim="@anim/slide_out_right" />篇幅原因,这些anim的xml文件我并未展示在文中,如有需求,请参考Sample代码。
其实Navigation 还提供了对Destination之间 参数传递 的支持,以及对SubNavigation标签的支持,以方便开发者在xml文件中 复用fragment标签 ——甚至是对 Deep Link 的支持,但这些拓展功能本文不再叙述。
其实在3中我们已经讲解了导航代码的使用,我们以Page2为例,它包含了2个按钮,分别对应 返回Page1 和 进入Page3 两个事件:
btn.setOnClickListener {
Navigation.findNavController(it).navigateUp()
}
btn2.setOnClickListener {
Navigation.findNavController(it).navigate(R.id.action_page3)
}
Navigation.findNavController(View) 返回了一个 NavController ,它是整个 Navigation 架构中 最重要的核心类,我们所有的导航行为都由 NavController 处理,这个我们后面再讲。
我们通过获取 NavController,然后调用 NavController.navigate()方法进行导航。
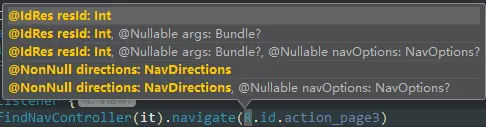
我们更多情况下通过传入ActionId,指定对应的 导航行为 ;同时可以通过传入Bundle以 数据传递;或者是再传入一个 NavOptions配置更多(比如 转场动画,它也可以通过这种方式进行代码的动态配置)。
NavController.navigate()方法更多时候应用在 向下导航 或者 指定向上导航(比如Page3 直接返回 Page1,跳过返回Page2的这一步);如果我们处理back事件,我们应该使用 NavController.
navigateUp()。
恭喜您,您已对 Navigation 十分熟悉,并能通过熟练使用其 暴露的API,灵活地处理您应用中的 页面导航 行为。
我美滋滋的在个人履历上填上了这样一条:
面试官对此十分感动,然后让我谈谈 对它架构设计的一些个人观点。

到了这一步,我们算得上是 API的搬运工 ,我们已经 了解每一个类的职责,还没有完全 理解框架设计者的**。
在我们熟悉Navigation的API之后,我们整装待发,准备 源码级攻克 Navigation。
正如我所说的,在这之前,您首先需要达到 熟练使用Navigation,本文地初衷并非是 一步到位,而是尝试 循序渐进。
声明 —— 我拒绝 大段大段地源码分析,我认为这种行为 严重降低 了文章的 质量 和 深度。
我花了一些时间绘制了 Navigation的UML类图,我坚信,这种方式能帮助你我 更深刻的理解 Navigation的整体架构:
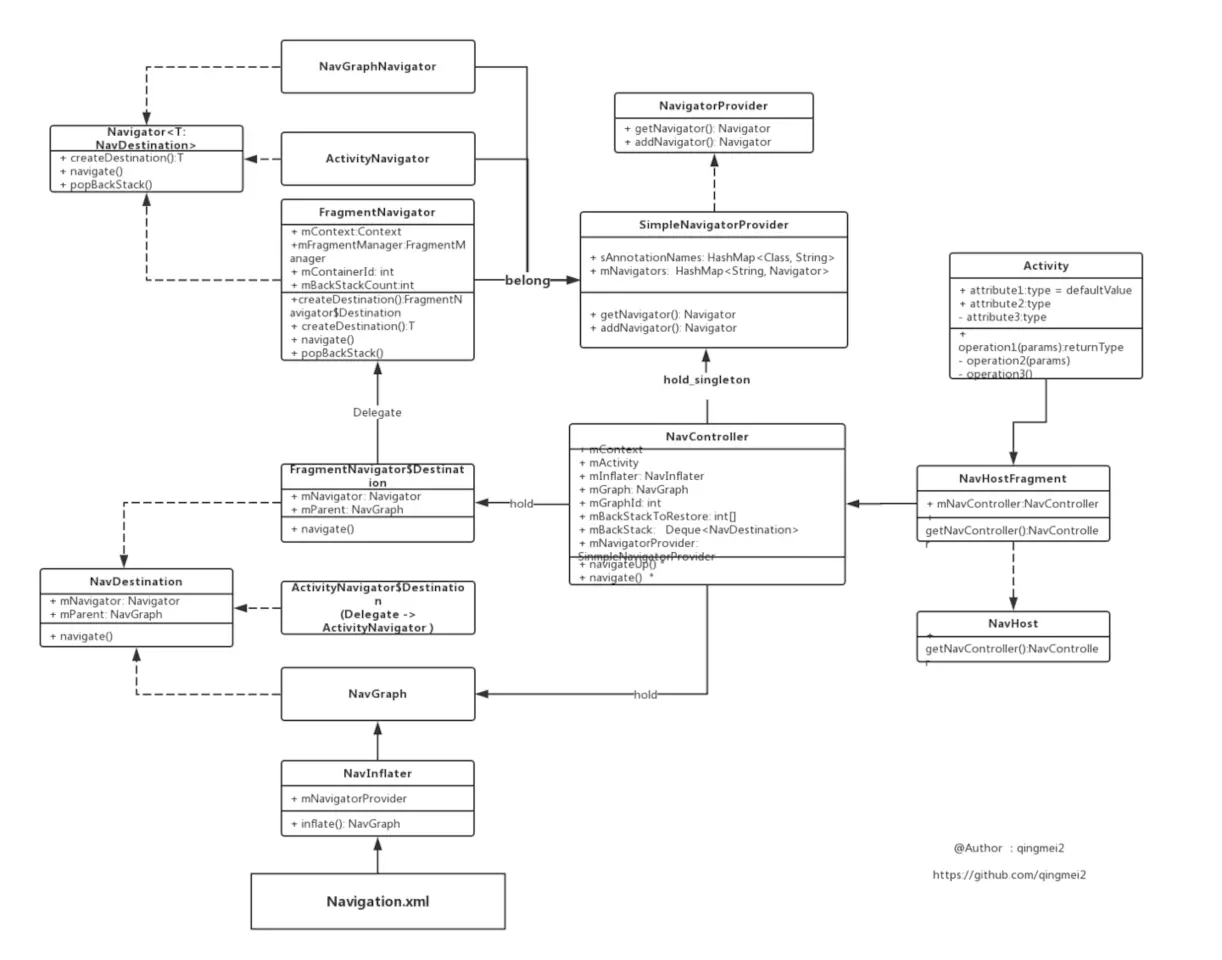
让我们换个角度,我们的身份不再是 源码的观众,而是 架构的设计者。
NavHostFragment 应当有两个作用:
前者的作用我们已经说过了,我们通过在NavHostFragment的创建时,为它创建一个对应的FrameLayout作为 导航界面的载体:
public View onCreateView(@NonNull LayoutInflater inflater, @Nullable ViewGroup container,
@Nullable Bundle savedInstanceState) {
FrameLayout frameLayout = new FrameLayout(inflater.getContext());
frameLayout.setId(getId());
return frameLayout;
}
我们都知道代码设计应该遵循 单一职责原则,因此,我们应该将 管理并控制导航的行为 交给另外一个类,这个类的作用应该仅是 控制导航行为,因此我们命名为 NavController。
Fragment理应持有这个NavController的实例,并将导航行为 委托 给它,这里我们将 NavController 的持有者抽象为一个 接口,以便于以后的拓展。
于是我们创造了 NavHost 接口,并让NavHostFragment实现了这个接口:
public interface NavHost {
NavController getNavController();
}为了保证导航的 安全,NavHostFragment 在其 作用域 内,理应 有且仅有一个NavController 的实例。
这里我们驻足一下,请注意API的设计,似乎 Navigation.findNavController(View),参数中传递任意一个 view的引用似乎都可以获取 NavController——如何保证 NavController 的局部单例呢?
事实上,findNavController(View)内部实现是通过 遍历 View树,直到找到最底部 NavHostFragment 中的NavController对象,并将其返回的:
private static NavController findViewNavController(@NonNull View view) {
while (view != null) {
NavController controller = getViewNavController(view);
if (controller != null) {
return controller;
}
ViewParent parent = view.getParent();
view = parent instanceof View ? (View) parent : null;
}
return null;
}
站在 设计者 的角度,NavController 的职责是:
NavController 持有了一个 NavInflater ,并通过 NavInflater 解析xml文件。
这之后,获取了所有 Destination(在本文中即Page1Fragment , Page2Fragment , Page3Fragment ) 的 Class对象,并通过反射的方式,实例化对应的 Destination,通过一个队列保存:
private NavInflater mInflater; //NavInflater
private NavGraph mGraph; //解析xml,得到NavGraph
private int mGraphId; //xml对应的id,比如 nav_graph_main
//所有Destination的队列,用来处理回退栈
private final Deque<NavDestination> mBackStack = new ArrayDeque<>();
这看起来没有任何问题,但是站在 设计者 的角度上,还略有不足,那就是,Navigation并非只为Fragment服务。
先不去吐槽Google工程师的野心,因为现在我们就是他,从拓展性的角度考虑,Navigation是一个导航框架,今后可能 并非只为Fragment导航。
我们应该为要将导航的 Destination 抽象出来,这个类叫做 NavDestination ——无论 Fragment 也好,Activity 也罢,只要实现了这个接口,对于NavController 来讲,他们都是 **Destination(目标点)**而已。
对于不同的 NavDestination 来讲,它们之间的导航方式是不同的,这完全有可能(比如Activity 和 Fragment),如何根据不同的 NavDestination 进行不同的 导航处理 呢?
有同学说,我可以这样设计,通过 instanceof 关键字,对 NavDestination 的类型进行判断,并分别做出处理,比如这样:
if (destination instanceof Fragment) {
//对应Fragment的导航
} else if (destination instanceof Activity) {
//对应Activity的导航
}
这是OK的,但是不够优雅,Google的方式是通过抽象出一个类,这个类叫做 Navigator :
public abstract class Navigator<D extends NavDestination> {
//省略很多代码,包括部分抽象方法,这里仅阐述设计的思路!
//导航
public abstract void navigate(@NonNull D destination, @Nullable Bundle args,
@Nullable NavOptions navOptions);
//实例化NavDestination(就是Fragment)
public abstract D createDestination();
//后退导航
public abstract boolean popBackStack();
}
Navigator(导航者) 的职责很单纯:
你看,我的 NavController 获取了所有 NavDestination 的Class对象,但是我不负责它 如何实例化 ,也不负责 如何导航 ,也不负责
如何后退 ——我仅仅持有向上的引用,然后调用它的接口方法,它的实现我不关心。
以 FragmentNavigator为例,我们来看看它是如何执行的职责:
public class FragmentNavigator extends Navigator<FragmentNavigator.Destination> {
//省略大量非关键代码,请以实际代码为主!
@Override
public boolean popBackStack() {
return mFragmentManager.popBackStackImmediate();
}
@NonNull
@Override
public Destination createDestination() {
// 实际执行了好几层,但核心代码如下,通过反射实例化Fragment
Class<? extends Fragment> clazz = getFragmentClass();
return clazz.newInstance();
}
@Override
public void navigate(@NonNull Destination destination, @Nullable Bundle args,
@Nullable NavOptions navOptions) {
// 实际上还是通过FragmentTransaction进行的跳转处理
final Fragment frag = destination.createFragment(args);
final FragmentTransaction ft = mFragmentManager.beginTransaction();
ft.replace(mContainerId, frag);
ft.commit();
mFragmentManager.executePendingTransactions();
}
}
不同的 Navigator 对应不同的 NavDestination,FragmentNavigator 对应的是 FragmentNavigator.Destination,你可以把他理解为案例中的 Fragment ,有兴趣的朋友可以自己研究一下。
至此,Navigation 整体的架构设计 也已经通过 UML类图 + 设计的角度分析 的方式学习完了。
当然,Navigation 还有很多其它的类我没有去阐述,它们已经无法阻拦你我的脚步。
我更建议 读者在这之后,能够尝试自己阅读源码,通过借鉴上文中的 UML类图,当然,自己通过思路的整理,自己绘制出一份,会对理解它更有帮助。
Navigation 是一个优秀的库,这从API上无法体现,因为它和其它优秀的三方 Fragment 管理库 都能达到 固定的目标。
并且,随着技术的不断发展,它们也早晚会被历史所淹没,我们能够做到的,就是使用API的同时,学习它的**,并收为己用。
--------------------------广告分割线------------------------------
争取打造 Android Jetpack 讲解的最好的博客系列:
Android Jetpack 实战篇:
Hello,我是却把清梅嗅,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的个人博客或者Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
在过去的谷歌IO大会上,Google官方向我们推出了 Android Architecture Components,其中谈到Android组件处理生命周期的问题,向我们介绍了 Handling Lifecycles。
同时,如何利用 android.arch.lifecycle 包提供的类来控制数据、监听器等的 lifecycle。同时,LiveData 与 ViewModel 的 lifecycle 也依赖于 Lifecycle 框架。
我们在处理Activity或者Fragment组件的生命周期相关时,不可避免会遇到这样的问题:
我们在Activity的onCreate()中初始化某些成员(比如MVP架构中的Presenter,或者AudioManager、MediaPlayer等),然后在onStop中对这些成员进行对应处理,在onDestroy中释放这些资源,这样导致我们的代码也许会像这样:
class MyPresenter{
public MyPresenter() {
}
void create() {
//do something
}
void destroy() {
//do something
}
}
class MyActivity extends AppCompatActivity {
private MyPresenter presenter;
public void onCreate(...) {
presenter= new MyPresenter ();
presenter.create();
}
public void onDestroy() {
super.onDestroy();
presenter.destory();
}
}代码没有问题,关键问题是,实际生产环境中 ,这样的代码会非常复杂,你最终会有太多的类似调用并且会导致 onCreate() 和 onDestroy() 方法变的非常臃肿。
Lifecycle 是一个类,它持有关于组件(如 Activity 或 Fragment)生命周期状态的信息,并且允许其他对象观察此状态。
我们只需要2步:
public interface IPresenter extends LifecycleObserver {
@OnLifecycleEvent(Lifecycle.Event.ON_CREATE)
void onCreate(@NotNull LifecycleOwner owner);
@OnLifecycleEvent(Lifecycle.Event.ON_DESTROY)
void onDestroy(@NotNull LifecycleOwner owner);
@OnLifecycleEvent(Lifecycle.Event.ON_ANY)
void onLifecycleChanged(@NotNull LifecycleOwner owner,
@NotNull Lifecycle.Event event);
}
public class BasePresenter implements IPresenter {
private static final String TAG = "com.qingmei2.module.base.BasePresenter";
@Override
public void onLifecycleChanged(@NotNull LifecycleOwner owner, @NotNull Lifecycle.Event event) {
}
@Override
public void onCreate(@NotNull LifecycleOwner owner) {
Log.d("tag", "BasePresenter.onCreate" + this.getClass().toString());
}
@Override
public void onDestroy(@NotNull LifecycleOwner owner) {
Log.d("tag", "BasePresenter.onDestroy" + this.getClass().toString());
}
}这里我直接将我想要观察到Presenter的生命周期事件都列了出来,然后封装到BasePresenter 中,这样每一个BasePresenter 的子类都能感知到Activity容器对应的生命周期事件,并在子类重写的方法中,对应相应行为。
public class MainActivity extends AppCompatActivity {
private IPresenter mPresenter;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
Log.d("tag", "onCreate" + this.getClass().toString());
setContentView(R.layout.activity_main);
mPresenter = new MainPresenter(this);
getLifecycle().addObserver(mPresenter);//添加LifecycleObserver
}
@Override
protected void onDestroy() {
Log.d("tag", "onDestroy" + this.getClass().toString());
super.onDestroy();
}
}
如此,每当Activity发生了对应的生命周期改变,Presenter就会执行对应事件注解的方法:
除onCreate和onDestroy事件之外,Lifecycle一共提供了所有的生命周期事件,只要
通过注解进行声明,就能够使LifecycleObserver观察到对应的生命周期事件:
//以下为logcat日志
01-08 23:21:01.702 D/tag: onCreate class com.qingmei2.mvparchitecture.mvp.ui.MainActivity
01-08 23:21:01.778 D/tag: onCreate class com.qingmei2.mvparchitecture.mvp.presenter.MainPresenter
01-08 23:21:21.074 D/tag: onDestroy class com.qingmei2.mvparchitecture.mvp.presenter.MainPresenter
01-08 23:21:21.074 D/tag: onDestroy class com.qingmei2.mvparchitecture.mvp.ui.MainActivity
public enum Event {
/**
* Constant for onCreate event of the {@link LifecycleOwner}.
*/
ON_CREATE,
/**
* Constant for onStart event of the {@link LifecycleOwner}.
*/
ON_START,
/**
* Constant for onResume event of the {@link LifecycleOwner}.
*/
ON_RESUME,
/**
* Constant for onPause event of the {@link LifecycleOwner}.
*/
ON_PAUSE,
/**
* Constant for onStop event of the {@link LifecycleOwner}.
*/
ON_STOP,
/**
* Constant for onDestroy event of the {@link LifecycleOwner}.
*/
ON_DESTROY,
/**
* An {@link Event Event} constant that can be used to match all events.
*/
ON_ANY
}
借鉴Android 架构组件(一)——Lifecycle, @ShymanZhu的一张图进行简单的概括:
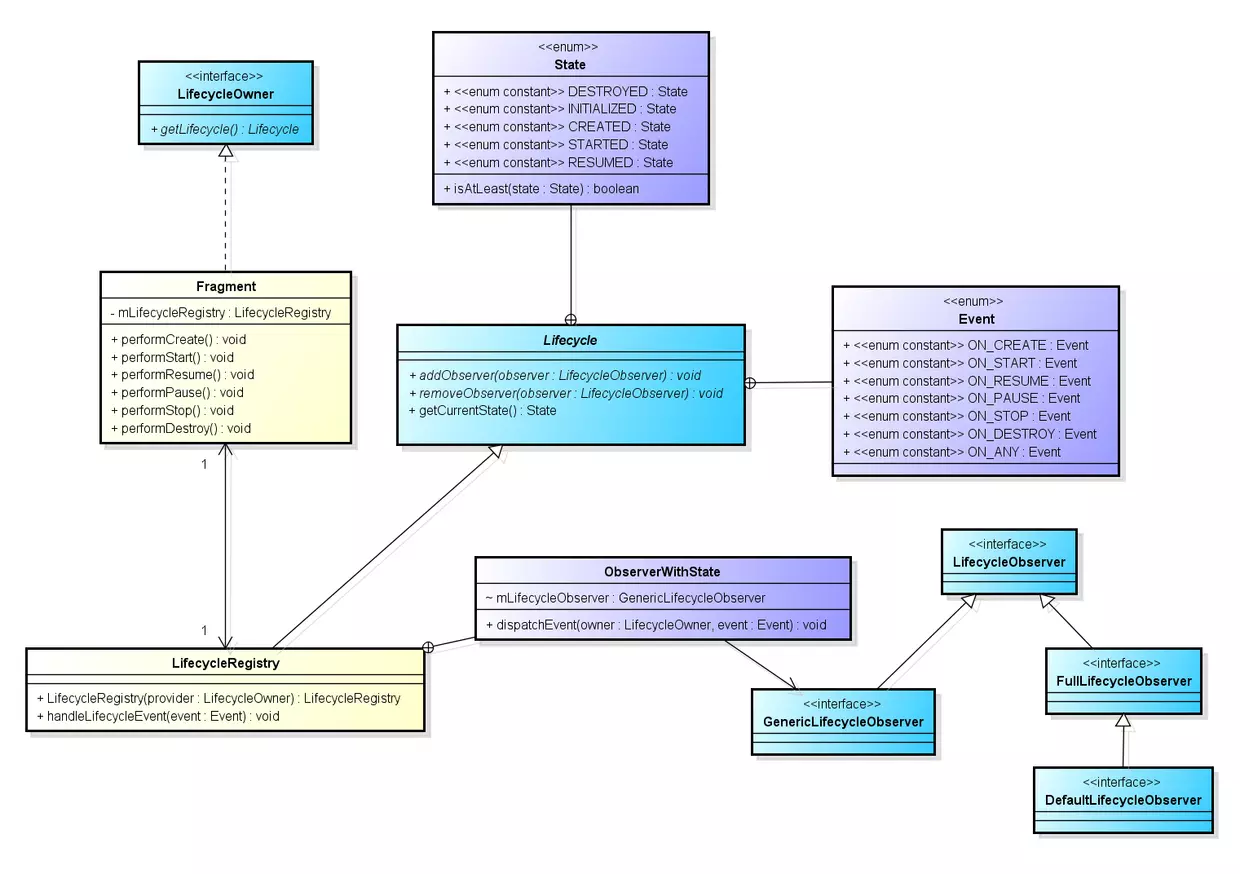
我们先将重要的这些类挑选出来:
LifecycleObserver接口( Lifecycle观察者):实现该接口的类,通过注解的方式,可以通过被LifecycleOwner类的addObserver(LifecycleObserver o)方法注册,被注册后,LifecycleObserver便可以观察到LifecycleOwner的生命周期事件。
LifecycleOwner接口(Lifecycle持有者):实现该接口的类持有生命周期(Lifecycle对象),该接口的生命周期(Lifecycle对象)的改变会被其注册的观察者LifecycleObserver观察到并触发其对应的事件。
Lifecycle(生命周期):和LifecycleOwner不同的是,LifecycleOwner本身持有Lifecycle对象,LifecycleOwner通过其Lifecycle getLifecycle()的接口获取内部Lifecycle对象。
State(当前生命周期所处状态):如图所示。
Event(当前生命周期改变对应的事件):如图所示,当Lifecycle发生改变,如进入onCreate,会自动发出ON_CREATE事件。
了解了这些类和接口的职责,接下来原理分析就简单很多了,我们以Fragment为例,来看下实际Fragment等类和上述类或接口的联系:
public class Fragment implements xxx, LifecycleOwner {
//...省略其他
LifecycleRegistry mLifecycleRegistry = new LifecycleRegistry(this);
@Override
public Lifecycle getLifecycle() {
return mLifecycleRegistry;
}
}
public interface LifecycleOwner {
@NonNull
Lifecycle getLifecycle();
}可以看到,实现的getLifecycle()方法,实际上返回的是 LifecycleRegistry 对象,LifecycleRegistry对象实际上继承了 Lifecycle,这个下文再讲。
持有Lifecycle有什么作用呢?实际上在Fragment对应的生命周期内,都会发送对应的生命周期事件给内部的 LifecycleRegistry对象处理:
public class Fragment implements xxx, LifecycleOwner {
//...
void performCreate(Bundle savedInstanceState) {
onCreate(savedInstanceState); //1.先执行生命周期方法
//...省略代码
//2.生命周期事件分发
mLifecycleRegistry.handleLifecycleEvent(Lifecycle.Event.ON_CREATE);
}
void performStart() {
onStart();
//...
mLifecycleRegistry.handleLifecycleEvent(Lifecycle.Event.ON_START);
}
void performResume() {
onResume();
//...
mLifecycleRegistry.handleLifecycleEvent(Lifecycle.Event.ON_RESUME);
}
void performPause() {
//3.注意,调用顺序变了
mLifecycleRegistry.handleLifecycleEvent(Lifecycle.Event.ON_PAUSE);
//...
onPause();
}
void performStop() {
mLifecycleRegistry.handleLifecycleEvent(Lifecycle.Event.ON_STOP);
//...
onStop();
}
void performDestroy() {
mLifecycleRegistry.handleLifecycleEvent(Lifecycle.Event.ON_DESTROY);
//...
onDestroy();
}
}
随着Fragment不同走到不同的生命周期,除了暴露给我们的生命周期方法onCreate/onStart/..../onDestroy等,同时,Fragment内部的Lifecycle对象(就是mLifecycleRegistry)还将生命周期对应的事件作为参数传给了 handleLifecycleEvent() 方法。
同时,你会发现Fragment中performCreate()、performStart()、performResume()会先调用自身的onXXX()方法,然后再调用LifecycleRegistry的handleLifecycleEvent()方法;而在performPause()、performStop()、performDestroy()中会先LifecycleRegistry的handleLifecycleEvent()方法 ,然后调用自身的onXXX()方法。
参照Android 架构组件(一)——Lifecycle, @ShymanZhu文中的时序图:
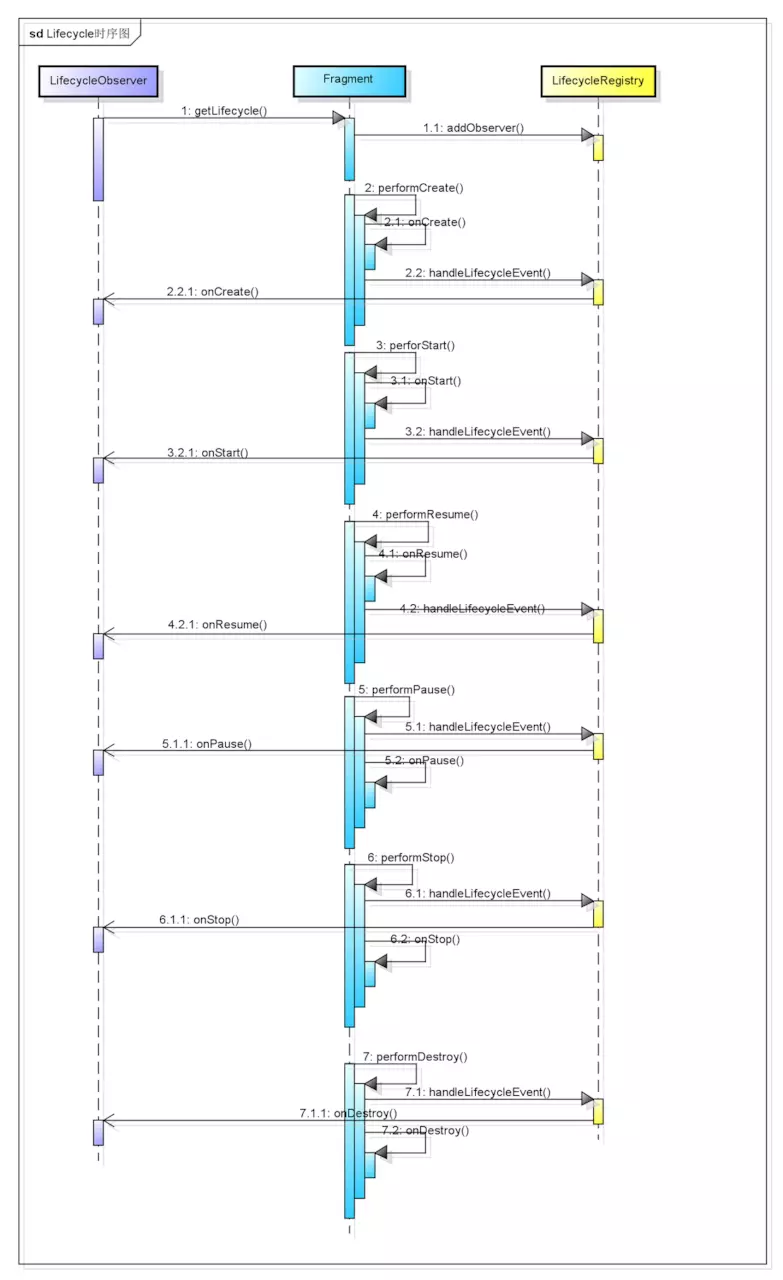
我们从图中可以看到,当Fragment将生命周期对应的事件交给其内部的Lifecycle处理后, LifecycleObserver (就是我们上文自定义的Presenter),就能够接收到对应的生命周期事件,这是如何实现的呢?
首先确认一点,LifecycleRegistry 就是 Lifecycle 的子类:
public class LifecycleRegistry extends Lifecycle {
}
我们看一下 Lifecycle 类
public abstract class Lifecycle {
//注册LifecycleObserver (比如Presenter)
public abstract void addObserver(@NonNull LifecycleObserver observer);
//移除LifecycleObserver
public abstract void removeObserver(@NonNull LifecycleObserver observer);
//获取当前状态
public abstract State getCurrentState();
public enum Event {
ON_CREATE,
ON_START,
ON_RESUME,
ON_PAUSE,
ON_STOP,
ON_DESTROY,
ON_ANY
}
public enum State {
DESTROYED,
INITIALIZED,
CREATED,
STARTED,
RESUMED;
public boolean isAtLeast(@NonNull State state) {
return compareTo(state) >= 0;
}
}
}
Lifecycle没什么要讲的,几个抽象方法也能看懂,作为Lifecycle的子类,LifecycleRegistry 同样也能通过addObserver方法注册LifecycleObserver (就是Presenter),当LifecycleRegistry 本身的生命周期改变后(可以想象,内部一定有一个成员变量State记录当前的生命周期),LifecycleRegistry 就会逐个通知每一个注册的LifecycleObserver ,并执行对应生命周期的方法。
我们看一下LifecycleRegistry 的handleLifecycleEvent()方法:
public void handleLifecycleEvent(@NonNull Lifecycle.Event event) {
State next = getStateAfter(event);
moveToState(next);
}
看方法的名字我们就可以知道,handleLifecycleEvent方法会通过 getStateAfter 获取当前应处的状态并修改 Lifecycle本身的State 值,紧接着遍历所 LifecycleObserver 并同步且通知其状态发生变化,因此就能触发LifecycleObserver 对应的生命周期事件。
实际上LifecycleRegistry 本身还是有很多值得一提之处,本文只阐述清楚原理,暂不涉及源码详解。
首先,LifecycleRegistry 本身就是一个成熟的 Lifecycle 实现类,它被实例化在Activity和Fragment中使用,如果我们需要自定义LifecycleOwner 并实现接口需要返回一个Lifecycle实例,完全可以直接在自定义LifecycleOwner中new一个LifecycleRegistry成员并返回它(简而言之就是:直接拿来用即可)。
以下是Google官方文档:
LifecycleRegistry: An implementation of Lifecycle that can handle multiple observers. It is used by Fragments and Support Library Activities. You can also directly use it if you have a custom LifecycleOwner.
其次,Google的Lifecycle库中提供了一个 DefaultLifecycleObserver 类,方便我们直接实现LifecycleObserver接口,相比较于文中demo所使用的注解方式,Google官方更推荐我们使用 DefaultLifecycleObserver 类,并声明
一旦Java 8成为Android的主流,注释将被弃用,所以介于DefaultLifecycleObserver和注解两者之间,更推荐使用 DefaultLifecycleObserver 。
官方原文:
/*
* If you use <b>Java 8 Language</b>, then observe events with {@link DefaultLifecycleObserver}.
* To include it you should add {@code "android.arch.lifecycle:common-java8:<version>"} to your
* build.gradle file.
* <pre>
* class TestObserver implements DefaultLifecycleObserver {
* {@literal @}Override
* public void onCreate(LifecycleOwner owner) {
* // your code
* }
* }
* </pre>
* If you use <b>Java 7 Language</b>, Lifecycle events are observed using annotations.
* Once Java 8 Language becomes mainstream on Android, annotations will be deprecated, so between
* {@link DefaultLifecycleObserver} and annotations,
* you must always prefer {@code DefaultLifecycleObserver}.
*/
本小节内容节选自《[译] Architecture Components 之 Handling Lifecycles》
作者:zly394
链接:https://juejin.im/post/5937e1c8570c35005b7b262a
保持 UI 控制器(Activity 和 Fragment)尽可能的精简。它们不应该试图去获取它们所需的数据;相反,要用 ViewModel来获取,并且观察 LiveData将数据变化反映到视图中。
尝试编写数据驱动(data-driven)的 UI,即 UI 控制器的责任是在数据改变时更新视图或者将用户的操作通知给 ViewModel。
* 将数据逻辑放到 ViewModel 类中。ViewModel 应该作为 UI 控制器和应用程序其它部分的连接服务。注意:不是由 ViewModel 负责获取数据(例如:从网络获取)。相反,ViewModel 调用相应的组件获取数据,然后将数据获取结果提供给 UI 控制器。
* 使用Data Binding来保持视图和 UI 控制器之间的接口干净。这样可以让视图更具声明性,并且尽可能减少在 Activity 和 Fragment 中编写更新代码。如果你喜欢在 Java 中执行该操作,请使用像Butter Knife 这样的库来避免使用样板代码并进行更好的抽象化。
* 如果 UI 很复杂,可以考虑创建一个 Presenter 类来处理 UI 的修改。虽然通常这样做不是必要的,但可能会让 UI 更容易测试。
* 不要在 ViewModel 中引用View或者 Activity的 context。因为如果ViewModel存活的比 Activity 时间长(在配置更改的情况下),Activity 将会被泄漏并且无法被正确的回收。
总而言之,Lifecycle还是有可取之处的,相对于其它架构组件之间的配合,Lifecycle更简单且独立(实际上配合其他组件味道更佳)。
本文旨在分析Lifecycle框架相关类的原理,将不会对Lifecycle每一行的源码进行深入地探究,如果有机会,笔者将尝试写一篇源码详细解析。
Lifecycle-aware Components 源码分析 @chaosleong
Android 架构组件(一)——Lifecycle @ShymanZhu
--------------------------广告分割线------------------------------
争取打造 Android Jetpack 讲解的最好的博客系列:
Android Jetpack 实战篇:
Hello,我是却把清梅嗅,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的个人博客或者Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?

与 BFS 类似,深度优先搜索(DFS)是用于在树/图中遍历/搜索的另一种重要算法。也可以在更抽象的场景中使用。
正如树的遍历中所提到的,我们可以用 DFS 进行 前序遍历,中序遍历 和 后序遍历。在这三个遍历顺序中有一个共同的特性:除非我们到达最深的结点,否则我们永远不会回溯。
这也是 DFS 和 BFS 之间最大的区别,BFS永远不会深入探索,除非它已经在当前层级访问了所有结点。
有两种实现 DFS 的方法。第一种方法是进行递归:
boolean DFS(Node cur, Node target, Set<Node> visited) {
return true if cur is target;
for (next : each neighbor of cur) {
if (next is not in visited) {
add next to visted;
return true if DFS(next, target, visited) == true;
}
}
return false;
}当我们递归地实现 DFS 时,似乎不需要使用任何栈。但实际上,我们使用的是由系统提供的隐式栈,也称为调用栈(Call Stack)。
递归解决方案的优点是它更容易实现。 但是,存在一个很大的缺点:如果递归的深度太高,你将遭受堆栈溢出。 在这种情况下,您可能会希望使用 BFS,或使用 显式栈 实现 DFS。
boolean DFS(int root, int target) {
Set<Node> visited;
Stack<Node> s;
add root to s;
while (s is not empty) {
Node cur = the top element in s;
return true if cur is target;
for (Node next : the neighbors of cur) {
if (next is not in visited) {
add next to s;
add next to visited;
}
}
remove cur from s;
}
return false;
}Medium给定一个由 '1'(陆地)和 '0'(水)组成的的二维网格,计算岛屿的数量。一个岛被水包围,并且它是通过水平方向或垂直方向上相邻的陆地连接而成的。你可以假设网格的四个边均被水包围。
示例 1:
输入:
11110
11010
11000
00000
输出: 1
示例 2:
输入:
11000
11000
00100
00011
输出: 3
笔者曾经在 这篇文章 中展示了如何使用 BFS 解决这道题,事实上该题使用 DFS 更简单,因为前者还需要一个队列维护 广度优先搜索 过程中搜索的层级信息。
使用 DFS 解题如下:
public class B200NumIslands {
public int numIslands(char[][] grid) {
int nr = grid.length;
if (nr == 0) return 0;
int nc = grid[0].length;
if (nc == 0) return 0;
int result = 0;
for (int r = 0; r < nr; r++) {
for (int c = 0; c < nc; c++) {
if (grid[r][c] == '1') {
result++;
dfs(grid, r, c);
}
}
}
return result;
}
private void dfs(char[][] grid, int r, int c) {
int nr = grid.length;
int nc = grid[0].length;
// 排除边界外的情况
if (r >= nr || c >= nc || r < 0 || c < 0) return;
// 排除边界外指定位置为 '0' 的情况
if (grid[r][c] == '0') return;
// 该位置为一个岛,标记为已探索
grid[r][c] = '0';
dfs(grid, r - 1, c); // top
dfs(grid, r + 1, c); // bottom
dfs(grid, r, c - 1); // left
dfs(grid, r, c + 1); // right
}
}Medium给你无向 连通 图中一个节点的引用,请你返回该图的 深拷贝(克隆)。
图中的每个节点都包含它的值 val(int) 和其邻居的列表(list[Node])。
class Node {
public int val;
public List<Node> neighbors;
}更详细的题目描述参考 这里 :
https://leetcode-cn.com/problems/clone-graph/
题目比较难理解,需要注意的是:
new 进行实例化,即需要遍历图中的每个节点,因此解决方案就浮现而出了,使用 DFS 或者 BFS 即可;用 DFS 实现代码如下:
class Solution {
public Node cloneGraph(Node node) {
HashMap<Node,Node> map = new HashMap<>();
return dfs(node, map);
}
private Node dfs(Node root, HashMap<Node,Node> map) {
if (root == null) return null;
if (map.containsKey(root)) return map.get(root);
Node clone = new Node(root.val, new ArrayList());
map.put(root, clone);
for (Node nei: root.neighbors) {
clone.neighbors.add(dfs(nei, map));
}
return clone;
}
}Medium给定一个非负整数数组,a1, a2, ..., an, 和一个目标数,S。现在你有两个符号 + 和 -。对于数组中的任意一个整数,你都可以从 + 或 - 中选择一个符号添加在前面。
返回可以使最终数组和为目标数 S 的所有添加符号的方法数。
示例 1:
输入: nums: [1, 1, 1, 1, 1], S: 3
输出: 5
解释:
>-1+1+1+1+1 = 3
+1-1+1+1+1 = 3
+1+1-1+1+1 = 3
+1+1+1-1+1 = 3
+1+1+1+1-1 = 3
一共有5种方法让最终目标和为3。
注意:
1.数组非空,且长度不会超过20。
2.初始的数组的和不会超过1000。
3.保证返回的最终结果能被32位整数存下。
说实话这道题真没想到使用 DFS 暴力解决,还是经验太少了,这道题暴力解法是完全可以的,而且不会超时,因为题目中说了数组长度不会超过20,20个数字的序列,组合方式撑死了也就 2^20 种组合:
public class Solution {
int count = 0;
public int findTargetSumWays(int[] nums, int S) {
dfs(nums, 0, 0, S);
return count;
}
private void dfs(int[] nums, int index, int sum, int S) {
if (index == nums.length) {
if (sum == S) count++;
} else {
dfs(nums, index + 1, sum + nums[index], S);
dfs(nums, index + 1, sum - nums[index], S);
}
}
}Medium给定一个二叉树,返回它的中序遍历。
进阶: 递归算法很简单,你可以通过迭代算法完成吗?
二叉树相关真的是非常有趣的一个算法知识点(因为这道题非常具有代表性,我觉得面试考到的概率最高2333......),后续笔者会针对该知识点进行更详细的探究,本文列出两个解决方案。
public class Solution {
// 1.递归法
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
dfs(root, list);
return list;
}
private void dfs(TreeNode node, List<Integer> list) {
if (node == null) return;
// 中序遍历:左中右
if (node.left != null)
dfs(node.left, list);
list.add(node.val);
if (node.right != null)
dfs(node.right, list);
}
}public class Solution {
// 2.使用栈
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
Stack<TreeNode> stack = new Stack<>();
TreeNode curr = root;
while (!stack.isEmpty() || curr != null) {
while (curr != null) {
stack.push(curr);
curr = curr.left;
}
curr = stack.pop();
list.add(curr.val);
curr = curr.right;
}
return list;
}
}文章绝大部分内容节选自LeetCode,栈和深度优先搜索 概述:
例题:
Hello,我是 却把清梅嗅 ,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的 博客 或者 GitHub。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
反思 系列博客是我的一种新学习方式的尝试,该系列起源和目录请参考 这里 。
Android本身的View体系非常宏大,源码中值得思考和借鉴之处众多,以View本身的绘制流程为例,其经过measure测量、layout布局、draw绘制三个过程,最终才能够将其绘制出来并展示在用户面前。
本文将针对绘制过程中的 测量流程 的设计**进行系统地归纳总结,读者需要对View的measure()相关知识有初步的了解:
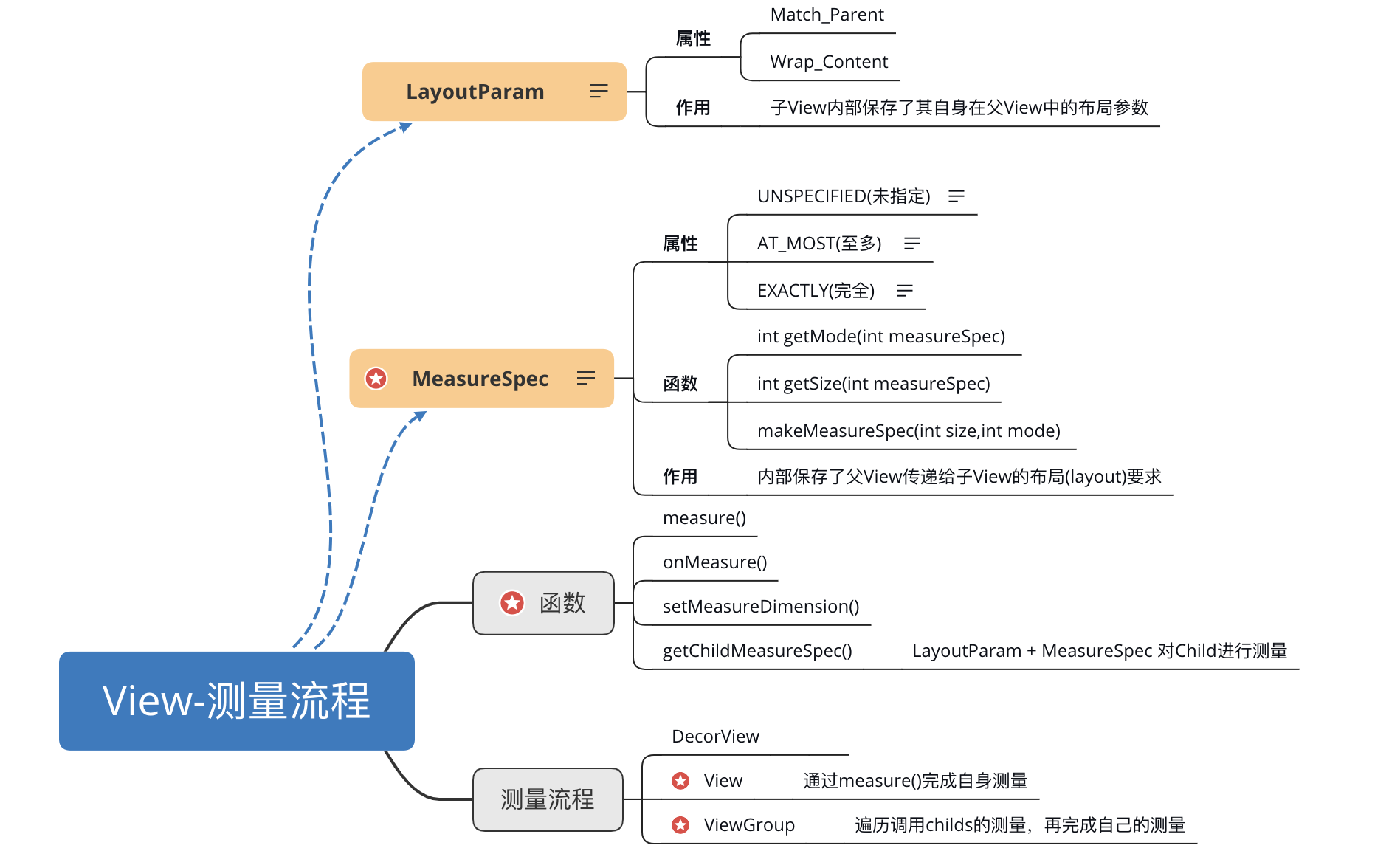
View的测量机制本质非常简单,顾名思义,其目的便是 测量控件的宽高值,围绕该目的,View的设计者通过代码编织了一整套复杂的逻辑:
1、对于子View而言,其本身宽高直接受限于父View的 布局要求,举例来说,父View被限制宽度为40px,子View的最大宽度同样也需受限于这个数值。因此,在测量子View之时,子View必须已知父View的布局要求,这个 布局要求, Android中通过使用 MeasureSpec 类来进行描述。
2、对于完整的测量流程而言,父控件必然依赖子控件宽高的测量;若子控件本身未测量完毕,父控件自身的测量亦无从谈起。Android中View的测量流程中使用了非常经典的 递归**:对于一个完整的界面而言,每个页面都映射了一个View树,其最顶端的父控件测量开始时,会通过 遍历 将其 布局要求 传递给子控件,以开始子控件的测量,子控件在测量过程中也会通过 遍历 将其 布局要求 传递给它自己的子控件,如此往复一直到最底层的控件...这种通过遍历自顶向下传递数据的方式我们称为 测量过程中的“递”流程。而当最底层位置的子控件自身测量完毕后,其父控件会将所有子控件的宽高数据进行聚合,然后通过对应的 测量策略 计算出父控件本身的宽高,测量完毕后,父控件的父控件也会根据其所有子控件的测量结果对自身进行测量,这种从底部向上传递各自的测量结果,最终完成最顶层父控件的测量方式我们称为测量过程中的“归”流程,至此界面整个View树测量完毕。
对于绘制流程不甚熟悉的开发者而言,上述文字似乎晦涩难懂,但这些文字的概括其本质却是绘制流程整体的设计**,读者不应该将本文视为源码分析,而应该将自己代入到设计的过程中 ,当深刻理解整个流程的设计思路之后,测量流程代码地设计和编写自然行云流水一气呵成。
在整个 测量流程 中, 布局要求 都是一个非常重要的核心名词,Android中通过使用 MeasureSpec 类来对其进行描述。
为什么说 布局要求 非常重要呢,其又是如何定义的呢?这要先从结果说起,对于单个View来说,测量流程的结果无非是获取控件自身宽和高的值,Android提供了setMeasureDimension()函数,开发者仅需要将测量结果作为参数并调用该函数,便可以视为View完成了自身的测量:
protected final void setMeasuredDimension(int measuredWidth, int measuredHeight) {
// measuredWidth 测量结果,View的宽度
// measuredHeight 测量结果,View的高度
// 省略其它代码...
// 该方法的本质就是将测量结果存起来,以便后续的layout和draw流程中获取控件的宽高
mMeasuredWidth = measuredWidth;
mMeasuredHeight = measuredHeight;
}需要注意的是,子控件的测量过程本身还应该依赖于父控件的一些布局约束,比如:
${x}px,子控件设置为layout_height="${y}px";wrap_content(包裹内容),子控件设置为layout_height="match_parent";match_parent(填充),子控件设置为layout_height="match_parent";这些情况下,因为无法计算出准确控件本身的宽高值,简单的通过setMeasuredDimension()函数似乎不可能达到测量控件的目的,因为 子控件的测量结果是由父控件和其本身共同决定的 (这个下文会解释),而父控件对子控件的布局约束,便是前文提到的 布局要求,即MeasureSpec类。
从面向对象的角度来看,我们将MeasureSpec类设计成这样:
public final class MeasureSpec {
int size; // 测量大小
Mode mode; // 测量模式
enum Mode { UNSPECIFIED, EXACTLY, AT_MOST }
MeasureSpec(Mode mode, int size){
this.mode = Mode;
this.size = size;
}
public int getSize() { return size; }
public Mode getMode() { return mode; }
}在设计的过程中,我们将布局要求分成了2个属性。测量大小 意味着控件需要对应大小的宽高,测量模式 则表示控件对应的宽高模式:
- UNSPECIFIED:父元素不对子元素施加任何束缚,子元素可以得到任意想要的大小;日常开发中自定义View不考虑这种模式,可暂时先忽略;
* EXACTLY:父元素决定子元素的确切大小,子元素将被限定在给定的边界里而忽略它本身大小;这里我们理解为控件的宽或者高被设置为match_parent或者指定大小,比如20dp;- AT_MOST:子元素至多达到指定大小的值;这里我们理解为控件的宽或者高被设置为
wrap_content。
巧妙的是,Android并非通过上述定义MeasureSpec对象的方式对 布局要求 进行描述,而是使用了更简单的二进制的方式,用一个32位的int值进行替代:
public static class MeasureSpec {
private static final int MODE_SHIFT = 30; //移位位数为30
//int类型占32位,向右移位30位,该属性表示掩码值,用来与size和mode进行"&"运算,获取对应值。
private static final int MODE_MASK = 0x3 << MODE_SHIFT;
//00左移30位,其值为00 + (30位0)
public static final int UNSPECIFIED = 0 << MODE_SHIFT;
//01左移30位,其值为01 + (30位0)
public static final int EXACTLY = 1 << MODE_SHIFT;
//10左移30位,其值为10 + (30位0)
public static final int AT_MOST = 2 << MODE_SHIFT;
// 根据size和mode,创建一个测量要求
public static int makeMeasureSpec(int size, int mode) {
return size + mode;
}
// 根据规格提取出mode,
public static int getMode(int measureSpec) {
return (measureSpec & MODE_MASK);
}
// 根据规格提取出size
public static int getSize(int measureSpec) {
return (measureSpec & ~MODE_MASK);
}
}这个int值中,前2位代表了测量模式,后30位则表示了测量的大小,对于模式和大小值的获取,只需要通过位运算即可。
以宽度举例来说,若我们设置宽度=5px(二进制对应了101),那么mode对应EXACTLY,在创建测量要求的时候,只需要通过二进制的相加,便可得到存储了相关信息的int值:

而当需要获得Mode的时候只需要用measureSpec与MODE_TASK相与即可,如下图:

同理,想获得size的话只需要只需要measureSpec与~MODE_TASK相与即可,如下图:

现在读者对MeasureSpec类有了初步地认识,在Android绘制过程中,View宽或者高的 布局要求 实际上是通过32位的int值进行的描述, 而MeasureSpec类本身只是一个静态方法的容器而已。
至此MeasureSpec类所代表的 布局要求 已经介绍完毕,这里我们浅尝辄止,其在后文的 整体测量流程 中占有至关重要的作用,届时我们再进行对应的引申。
只考虑单个控件的测量,整个过程需要定义三个重要的函数,分别为:
final void measure(int widthMeasureSpec, int heightMeasureSpec):执行测量的函数;void onMeasure(int widthMeasureSpec, int heightMeasureSpec):真正执行测量的函数,开发者需要自己实现自定义的测量逻辑;final void setMeasuredDimension(int measuredWidth, int measuredHeight):完成测量的函数;为什么说需要定义这样三个函数?
首先父控件需要通过调用子控件的measure()函数,并同时将宽和高的 布局要求 作为参数传入,标志子控件本身测量的开始:
// 这个是父控件的代码,让子控件开始测量
child.measure(childWidthMeasureSpec, childHeightMeasureSpec);对于View的测量流程,其必然包含了2部分:公共逻辑部分 和 开发者自定义测量的逻辑部分,为了保证公共逻辑部分代码的安全性,设计者将measure()方法配置了final修饰符:
public final void measure(int widthMeasureSpec, int heightMeasureSpec) {
// ... 公共逻辑
// 开发者需要自己重写onMeasure函数,以自定义测量逻辑
onMeasure(widthMeasureSpec, heightMeasureSpec);
}开发者不能重写measure()函数,并将View自定义测量的策略通过定义一个新的onMeasure()接口暴露出来供开发者重写。
onMeasure()函数中,View自身也提供了一个默认的测量策略:
protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) {
setMeasuredDimension(getDefaultSize(getSuggestedMinimumWidth(), widthMeasureSpec),
getDefaultSize(getSuggestedMinimumHeight(), heightMeasureSpec));
}以宽度为例,通过这样获取View默认的宽度:
getDefaultSize(getSuggestedMinimumWidth(), widthMeasureSpec)
minWidth或者background属性),View需要通过getSuggestedMinimumWidth()函数作为默认的宽度值:protected int getSuggestedMinimumWidth() {
return (mBackground == null) ? mMinWidth : max(mMinWidth, mBackground.getMinimumWidth());
}getDefaultSize(minWidth, widthMeasureSpec)函数中,根据 布局要求 计算出View最后测量的宽度值:public static int getDefaultSize(int size, int measureSpec) {
// 宽度的默认值
int result = size;
int specMode = MeasureSpec.getMode(measureSpec);
int specSize = MeasureSpec.getSize(measureSpec);
// 根据不同的测量模式,返回的测量结果不同
switch (specMode) {
// 任意模式,宽度为默认值
case MeasureSpec.UNSPECIFIED:
result = size;
break;
// match_parent、wrap_content则返回布局要求中的size值
case MeasureSpec.AT_MOST:
case MeasureSpec.EXACTLY:
result = specSize;
break;
}
return result;
}上述代码中,View的默认测量策略也印证了,即使View设置的是
layout_width="wrap_content",其宽度也会填充父布局(效果同match_parent),高度依然。
setMeasuredDimension(width,height)函数的存在意义非常重要,在onMeasure()执行自定义测量策略的过程中,调用该函数标志着View的测量得出了结果:
protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) {
// 普遍意义上,setMeasuredDimension()标志着测量结束
setMeasuredDimension(getDefaultSize(getSuggestedMinimumWidth(), widthMeasureSpec),
getDefaultSize(getSuggestedMinimumHeight(), heightMeasureSpec));
}
protected final void setMeasuredDimension(int measuredWidth, int measuredHeight) {
// measuredWidth 测量结果,View的宽度
// measuredHeight 测量结果,View的高度
// 省略其它代码...
// 该方法的本质就是将测量结果存起来,以便后续的layout和draw流程中获取控件的宽高
mMeasuredWidth = measuredWidth;
mMeasuredHeight = measuredHeight;
}该函数被设计为由protected final修饰,这意味着只能由子类进行调用而不能重写。
函数调用完毕,开发者可以通过getMeasuredWidth()或者getMeasuredHeight()来获取View测量的宽高,代码设计大概是这样:
public final int getMeasuredWidth() {
return mMeasuredWidth;
}
public final int getMeasuredHeight() {
return mMeasuredHeight;
}
// 如何使用
int width = view.getMeasuredWidth();
int height = view.getMeasuredHeight()经过measure() -> onMeasure() -> setMeasuredDimension()函数的调用,最终View自身测量流程执行完毕。
对于一个完整的界面而言,每个页面都映射了一个View树,见微知著,了解了单个View的测量过程,从宏观的角度思考,View树整体的测量流程将如何实现?
首先需要理解的是,每种ViewGroup的子类的测量策略(也就是onMeasure()函数内的逻辑)不尽相同,比如RelativeLayout或者LinearLayout宽高的测量策略自然不同,但整体思路都大同小异,即 遍历 测量所有子控件,根据父控件自身测量策略进行宽高的计算并得出测量结果。
以 竖直方向布局 的LinearLayout为例,如何完成LinearLayout高度的测量?本文抛去不重要的细节,化繁为简,将LinearLayout高度的测量策略简单定义为 遍历获取所有子控件,将高度累加 ,所得值即自身高度的测量结果——如果不知道每个子控件的高度,LinearLayout自然无法测量出本身的高度。
因此对于View树整体的测量而言,控件的测量实际上是 自底向上 的,正如文章开篇 整体思路 一节所描述的:
对于完整的测量流程而言,父控件必然依赖子控件宽高的测量;若子控件本身未测量完毕,父控件自身的测量亦无从谈起。
此外,因为子控件的测量逻辑受限于父控件传过来的 布局要求(MeasureSpec), 因此整体逻辑应该是:
setMeasuredDimension()函数,其父控件根据自己的测量策略,将所有child的宽高和布局属性进行对应的计算(比如上文中LinearLayout就是计算所有子控件高度的和),得到自己本身的测量宽高;setMeasuredDimension()函数完成测量,这之后,它的父控件再根据其自身测量策略完成测量,如此往复,直至完成顶层级View的测量,自此,整个页面测量完毕。这里的设计体现出了经典的 递归**,1、2步骤,开始测量的通知自顶至下,我们称之为测量步骤的 递流程,3、4步骤,测量完毕的顺序却是自底至顶,我们称之为测量步骤的 归流程。
现在根据上一小节的设计思路,开始对 递流程 进行编码实现。
在整个递流程中,MeasureSpec所代表的 布局要求 占有至关重要的作用,了解了它在这个过程中的意义,也就理解了为什么我们常说 子控件的测量结果是由父控件和其本身共同决定的。
依然以 竖直方向布局 的LinearLayout为例,我们需要遍历测量其所有的子控件,因此,在onMeasure()函数中,第一次我们编码如下:
// 1.0版本的LinearLayout
protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) {
// 1.通过遍历,对每个child进行测量
for(int i = 0 ; i < getChildCount() ; i++){
View child = getChildAt(i);
// 2.直接测量子控件
child.measure(widthMeasureSpec, heightMeasureSpec);
}
// ...
// 3.所有子控件测量完毕...
// ...
}这里关注int heightMeasureSpec参数,我们知道,这个32位int类型的值,包含了父布局传过来高度的 布局要求:测量的大小和模式。现在我们思考,若父布局传过来大小的是屏幕的高度,那么将其作为参数直接执行child.measure(widthMeasureSpec, heightMeasureSpec),让子控件直接开始测量,是合理的吗?
答案当然是否定的,试想这样一个简单的场景,若LinearLayout本身设置了padding值,那么子控件的最大高度便不能再达到heightMeasureSpec中size的大小了,但是如果像上述代码中的步骤2一样,直接对子控件进行测量,子控件就可以从heightMeasureSpec参数中取得屏幕的高度,通过setMeasuredDimension()将自己的高度设置和父控件高度一致——这导致了padding值配置的失效,并不符合预期。
因此,我们需要额外设计一个可重写的函数,用于自定义对child的测量:
protected void measureChild(View child, int parentWidthMeasureSpec,
int parentHeightMeasureSpec) {
// 获取子元素的布局参数
final LayoutParams lp = child.getLayoutParams();
// 通过padding值,计算出子控件的布局要求
final int childWidthMeasureSpec = getChildMeasureSpec(parentWidthMeasureSpec,
mPaddingLeft + mPaddingRight, lp.width);
final int childHeightMeasureSpec = getChildMeasureSpec(parentHeightMeasureSpec,
mPaddingTop + mPaddingBottom, lp.height);
// 将新的布局要求传入measure方法,完成子控件的测量
child.measure(childWidthMeasureSpec, childHeightMeasureSpec);
}我们定义了measureChild()函数,其作用是计算子控件的布局要求,并把新的布局要求传给子控件,再让子控件根据新的布局要求进行测量,这样就解决了上述的问题,由此也说明了为什么 子控件的测量结果是由父控件和其本身共同决定的。
这里我们注意到我们设计了一个getChildMeasureSpec()函数,那么这个函数是做什么的呢?
getChildMeasureSpec()函数的作用是根据父布局的MeasureSpec和padding值,计算出对应子控件的MeasureSpec,因为这个函数的逻辑是可以复用的,因此将其定义为一个静态函数:
public static int getChildMeasureSpec(int spec, int padding, int childDimension) {
//获取父View的测量模式
int specMode = MeasureSpec.getMode(spec);
//获取父View的测量大小
int specSize = MeasureSpec.getSize(spec);
//父View计算出的子View的大小,子View不一定用这个值
int size = Math.max(0, specSize - padding);
//声明变量用来保存实际计算的到的子View的size和mode即大小和模式
int resultSize = 0;
int resultMode = 0;
switch (specMode) {
//如果父容器的模式是Exactly即确定的大小
case MeasureSpec.EXACTLY:
//子View的高度或宽度>0说明其实一个确切的值,因为match_parent和wrap_content的值是<0的
if (childDimension >= 0) {
resultSize = childDimension;
resultMode = MeasureSpec.EXACTLY;
//子View的高度或宽度为match_parent
} else if (childDimension == LayoutParams.MATCH_PARENT) {
resultSize = size;//将size即父View的大小减去边距值所得到的值赋值给resultSize
resultMode = MeasureSpec.EXACTLY;//指定子View的测量模式为EXACTLY
//子View的高度或宽度为wrap_content
} else if (childDimension == LayoutParams.WRAP_CONTENT) {
resultSize = size;//将size赋值给result
resultMode = MeasureSpec.AT_MOST;//指定子View的测量模式为AT_MOST
}
break;
//如果父容器的测量模式是AT_MOST
case MeasureSpec.AT_MOST:
if (childDimension >= 0) {
resultSize = childDimension;
resultMode = MeasureSpec.EXACTLY;
} else if (childDimension == LayoutParams.MATCH_PARENT) {
resultSize = size;
// 因为父View的大小是受到限制值的限制,所以子View的大小也应该受到父容器的限制并且不能超过父View
resultMode = MeasureSpec.AT_MOST;
} else if (childDimension == LayoutParams.WRAP_CONTENT) {
resultSize = size;
resultMode = MeasureSpec.AT_MOST;
}
break;
//如果父容器的测量模式是UNSPECIFIED即父容器的大小未受限制
case MeasureSpec.UNSPECIFIED:
//如果自View的宽和高是一个精确的值
if (childDimension >= 0) {
//子View的大小为精确值
resultSize = childDimension;
//测量的模式为EXACTLY
resultMode = MeasureSpec.EXACTLY;
//子View的宽或高为match_parent
} else if (childDimension == LayoutParams.MATCH_PARENT) {
//因为父View的大小是未定的,所以子View的大小也是未定的
resultSize = 0;
resultMode = MeasureSpec.UNSPECIFIED;
} else if (childDimension == LayoutParams.WRAP_CONTENT) {
resultSize = 0;
resultMode = MeasureSpec.UNSPECIFIED;
}
break;
}
//根据resultSize和resultMode调用makeMeasureSpec方法得到测量要求,并将其作为返回值
return MeasureSpec.makeMeasureSpec(resultSize, resultMode);
}逻辑分支相对较多,注释中已经将子控件 布局要求 的计算逻辑写清楚了,总结如下图,原图链接:
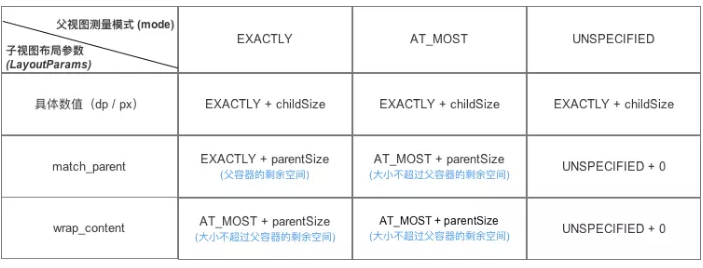
为什么说这个函数非常重要?因为这个函数才是 子控件的测量结果是由父控件和其本身共同决定的 最直接的体现,同时,在不同的布局模式下(
match_parent、wrap_content、指定dp/px),其对应子控件的布局要求的返回值亦不同,建议读者认真理解这段代码。
回到前文,现在我们对onMeasure()的方法定义如下:
// 2.0版本的LinearLayout
protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) {
// 1.通过遍历,对每个child进行测量
for(int i = 0 ; i < getChildCount() ; i++){
View child = getChildAt(i);
// 2.计算新的布局要求,并对子控件进行测量
measureChild(child, widthMeasureSpec, heightMeasureSpec);
}
// ...
// 3.所有子控件测量完毕...
// ...
}现在,所有子控件测量完毕,接下来 归流程 的实现就很简单了,将所有child的height进行累加,并调用 setMeasuredDimension()结束测量即可:
// 3.0版本的LinearLayout
protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) {
// 1.通过遍历,对每个child进行测量
for(int i = 0 ; i < getChildCount() ; i++){
View child = getChildAt(i);
// 2.计算新的布局要求,并对子控件进行测量
measureChild(child, widthMeasureSpec, heightMeasureSpec);
}
// 3.完成子控件的测量,对高度进行累加
int height = 0;
for(int i = 0 ; i < getChildCount() ; i++){
height += child.getMeasuredHeight();
}
// 4.完成LinearLayout的测量
setMeasuredDimension(width, height);
}乍一看,似乎很难体现出整个流程的 递归 性,实际上当我们宏观从View树的树顶顺着往下整理思路,代码逻辑的执行顺序一目了然:
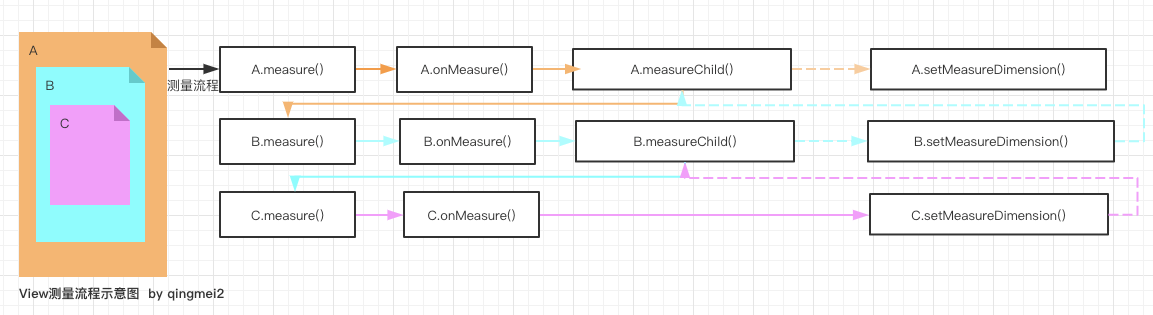
如图所示,实线代表了测量流程中整体自顶向下的 递流程, 而虚线代表了自底向上的 归流程。
至此,测量流程整体实现完毕。
Hello,我是 却把清梅嗅 ,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的 博客 或者 Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.