HI,
I am trying to execute the following command:
MODEL=meta-llama/Llama-2-7b-hf TASK=SQuAD MODE=ft LR=1e-2 EPS=1e-1 bash mezo.sh --non_diff --evaluation_strategy no --save_strategy no --save_model
Getting the error:
mezo-ft-20000-16-1e-2-1e-1-0 BS: 16 LR: 1e-2 EPS: 1e-1 SEED: 0 TRAIN/EVAL STEPS: 20000/4000 MODE: ft Extra args: --train_as_classification False 2023-09-04 22:10:09,459 - INFO - Created a temporary directory at /tmp/tmpbaz9nwqu 2023-09-04 22:10:09,460 - INFO - Writing /tmp/tmpbaz9nwqu/_remote_module_non_scriptable.py OurArguments( _n_gpu=1, adafactor=False, adam_beta1=0.9, adam_beta2=0.999, adam_epsilon=1e-08, auto_find_batch_size=False, bf16=False, bf16_full_eval=False, data_seed=None, dataloader_drop_last=False, dataloader_num_workers=0, dataloader_pin_memory=True, ddp_bucket_cap_mb=None, ddp_find_unused_parameters=None, ddp_timeout=1800, debug=[], deepspeed=None, disable_tqdm=False, do_eval=False, do_predict=False, do_train=False, eos_token=<EOS_TOKEN>, eval_accumulation_steps=None, eval_delay=0, eval_steps=4000, evaluation_strategy=no, fp16=False, fp16_backend=auto, fp16_full_eval=False, fp16_opt_level=O1, fsdp=[], fsdp_config={'fsdp_min_num_params': 0, 'xla': False, 'xla_fsdp_grad_ckpt': False}, fsdp_min_num_params=0, fsdp_transformer_layer_cls_to_wrap=None, full_determinism=False, gradient_accumulation_steps=1, gradient_checkpointing=False, greater_is_better=False, group_by_length=False, half_precision_backend=auto, head_tuning=False, hub_model_id=None, hub_private_repo=False, hub_strategy=every_save, hub_token=<HUB_TOKEN>, icl_sfc=False, ignore_data_skip=False, include_inputs_for_metrics=False, jit_mode_eval=False, label_names=None, label_smoothing_factor=0.0, learning_rate=0.01, length_column_name=length, linear_probing=False, load_best_model_at_end=True, load_bfloat16=False, load_float16=True, load_int8=False, local_rank=-1, log_level=passive, log_level_replica=warning, log_on_each_node=True, logging_dir=result/SQuAD-Llama-2-7b-hf-mezo-ft-20000-16-1e-2-1e-1-0/runs/Sep04_22-10-09_ip-10-156-46-59.us-east-2.compute.internal, logging_first_step=False, logging_nan_inf_filter=True, logging_steps=10, logging_strategy=steps, lora=False, lora_alpha=16, lora_r=8, lp_early_stopping=False, lr_scheduler_type=constant, max_grad_norm=1.0, max_length=2048, max_new_tokens=50, max_steps=20000, metric_for_best_model=loss, model_name=meta-llama/Llama-2-7b-hf, mp_parameters=, no_auto_device=False, no_cuda=False, no_eval=False, no_reparam=True, non_diff=True, num_beams=1, num_dev=500, num_eval=1000, num_prefix=5, num_train=1000, num_train_epochs=3.0, num_train_sets=None, only_train_option=True, optim=adamw_hf, optim_args=None, output_dir=result/SQuAD-Llama-2-7b-hf-mezo-ft-20000-16-1e-2-1e-1-0, overwrite_output_dir=False, past_index=-1, per_device_eval_batch_size=8, per_device_train_batch_size=16, prediction_loss_only=False, prefix_init_by_real_act=True, prefix_tuning=False, push_to_hub=False, push_to_hub_model_id=None, push_to_hub_organization=None, push_to_hub_token=<PUSH_TO_HUB_TOKEN>, ray_scope=last, remove_unused_columns=True, report_to=['mlflow', 'wandb'], result_file=None, resume_from_checkpoint=None, run_name=result/SQuAD-Llama-2-7b-hf-mezo-ft-20000-16-1e-2-1e-1-0, sampling=False, save_model=True, save_on_each_node=False, save_on_interrupt=False, save_safetensors=False, save_steps=4000, save_strategy=no, save_total_limit=1, seed=42, sfc=False, sharded_ddp=[], skip_memory_metrics=True, tag=mezo-ft-20000-16-1e-2-1e-1-0, task_name=SQuAD, temperature=1.0, tf32=None, top_k=None, top_p=0.95, torch_compile=False, torch_compile_backend=None, torch_compile_mode=None, torchdynamo=None, tpu_metrics_debug=False, tpu_num_cores=None, train_as_classification=False, train_set_seed=0, trainer=zo, untie_emb=False, use_ipex=False, use_legacy_prediction_loop=False, use_mps_device=False, verbose=False, warmup_ratio=0.0, warmup_steps=0, weight_decay=0.0, xpu_backend=None, zo_eps=0.1, ) 2023-09-04 22:10:09,892 - WARNING - Found cached dataset squad (/home/ec2-user/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453) 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 651.90it/s] 2023-09-04 22:10:15,803 - INFO - Sample train set 1500/87599 2023-09-04 22:10:15,803 - INFO - ... including dev set 500 samples 2023-09-04 22:10:15,803 - INFO - Loading model with FP16... 2023-09-04 22:10:17,146 - WARNING - The model weights are not tied. Please use the tie_weightsmethod before using theinfer_auto_devicefunction. Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:06<00:00, 3.04s/it] 2023-09-04 22:10:23,337 - INFO - Done with 7.53s 2023-09-04 22:10:23,376 - INFO - Tokenizing training samples... 2023-09-04 22:10:27,600 - INFO - Done with 4.22s /opt/conda/envs/pytorch/lib/python3.10/site-packages/transformers/optimization.py:391: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or setno_deprecation_warning=Trueto disable this warning warnings.warn( 2023-09-04 22:10:27,610 - INFO - ***** Running training ***** 2023-09-04 22:10:27,610 - INFO - Num examples = 1000 2023-09-04 22:10:27,610 - INFO - Num Epochs = 318 2023-09-04 22:10:27,610 - INFO - Instantaneous batch size per device = 16 2023-09-04 22:10:27,610 - INFO - Total train batch size (w. parallel, distributed & accumulation) = 16 2023-09-04 22:10:27,610 - INFO - Gradient Accumulation steps = 1 2023-09-04 22:10:27,610 - INFO - Total optimization steps = 20000 2023-09-04 22:10:27,611 - INFO - Number of trainable parameters = 6738415616 wandb: Currently logged in as: raahul. Usewandb login --reloginto force relogin wandb: wandb version 0.15.9 is available! To upgrade, please run: wandb: $ pip install wandb --upgrade wandb: Tracking run with wandb version 0.15.5 wandb: Run data is saved locally in /home/ec2-user/rdp-works-llm-finetune/mezo/MeZO/large_models/wandb/run-20230904_221028-to4hrtwj wandb: Runwandb offlineto turn off syncing. wandb: Syncing run sunny-thunder-76 wandb: ⭐️ View project at https://wandb.ai/raahul/huggingface wandb: 🚀 View run at https://wandb.ai/raahul/huggingface/runs/to4hrtwj 0%| | 0/20000 [00:00<?, ?it/s]../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [64,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [65,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [66,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [67,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [68,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [69,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [70,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [71,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [72,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [73,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [74,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [75,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [76,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [77,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [78,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [79,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [80,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [81,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [82,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [83,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [84,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [85,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [86,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [87,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [88,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [89,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [90,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [91,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [92,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [93,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [94,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [106,0,0], thread: [95,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [0,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [1,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [2,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [3,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [4,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [5,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [6,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [7,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [8,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [9,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [10,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [11,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [12,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [13,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [14,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [15,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [16,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [17,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [18,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [19,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [20,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [21,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [22,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [23,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [24,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [25,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [26,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [27,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [28,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [29,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [30,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [26,0,0], thread: [31,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [0,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [1,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [2,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [3,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [4,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [5,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [6,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [7,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [8,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [9,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [10,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [11,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [12,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [13,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [14,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [15,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [16,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [17,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [18,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [19,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [20,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [21,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [22,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [23,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [24,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [25,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [26,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [27,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [28,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [29,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [30,0,0] AssertionsrcIndex < srcSelectDimSizefailed. ../aten/src/ATen/native/cuda/Indexing.cu:1146: indexSelectLargeIndex: block: [135,0,0], thread: [31,0,0] AssertionsrcIndex < srcSelectDimSizefailed. Traceback (most recent call last): File "/home/ec2-user/rdp-works-llm-finetune/mezo/MeZO/large_models/run.py", line 525, in <module> main() File "/home/ec2-user/rdp-works-llm-finetune/mezo/MeZO/large_models/run.py", line 491, in main framework.train(train_samples, dev_samples if dev_samples is not None else eval_samples) File "/home/ec2-user/rdp-works-llm-finetune/mezo/MeZO/large_models/run.py", line 428, in train trainer.train(resume_from_checkpoint=last_checkpoint) File "/opt/conda/envs/pytorch/lib/python3.10/site-packages/transformers/trainer.py", line 1662, in train return inner_training_loop( File "/home/ec2-user/rdp-works-llm-finetune/mezo/MeZO/large_models/trainer.py", line 529, in _inner_training_loop tr_loss_step = self.zo_step(model, inputs) File "/home/ec2-user/rdp-works-llm-finetune/mezo/MeZO/large_models/trainer.py", line 774, in zo_step loss1 = self.zo_forward(model, inputs) File "/home/ec2-user/rdp-works-llm-finetune/mezo/MeZO/large_models/trainer.py", line 722, in zo_forward return self.zo_forward_nondiff(model, inputs) File "/home/ec2-user/rdp-works-llm-finetune/mezo/MeZO/large_models/trainer.py", line 744, in zo_forward_nondiff outputs = self.model.generate( File "/opt/conda/envs/pytorch/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context return func(*args, **kwargs) File "/opt/conda/envs/pytorch/lib/python3.10/site-packages/transformers/generation/utils.py", line 1437, in generate return self.greedy_search( File "/opt/conda/envs/pytorch/lib/python3.10/site-packages/transformers/generation/utils.py", line 2248, in greedy_search outputs = self( File "/opt/conda/envs/pytorch/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl return forward_call(*args, **kwargs) File "/opt/conda/envs/pytorch/lib/python3.10/site-packages/accelerate/hooks.py", line 165, in new_forward output = old_forward(*args, **kwargs) File "/opt/conda/envs/pytorch/lib/python3.10/site-packages/transformers/models/llama/modeling_llama.py", line 687, in forward outputs = self.model( File "/opt/conda/envs/pytorch/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl return forward_call(*args, **kwargs) File "/opt/conda/envs/pytorch/lib/python3.10/site-packages/accelerate/hooks.py", line 165, in new_forward output = old_forward(*args, **kwargs) File "/opt/conda/envs/pytorch/lib/python3.10/site-packages/transformers/models/llama/modeling_llama.py", line 536, in forward attention_mask = self._prepare_decoder_attention_mask( File "/opt/conda/envs/pytorch/lib/python3.10/site-packages/transformers/models/llama/modeling_llama.py", line 464, in _prepare_decoder_attention_mask combined_attention_mask = _make_causal_mask( File "/opt/conda/envs/pytorch/lib/python3.10/site-packages/transformers/models/llama/modeling_llama.py", line 49, in _make_causal_mask mask = torch.full((tgt_len, tgt_len), torch.tensor(torch.finfo(dtype).min, device=device), device=device) RuntimeError: CUDA error: device-side assert triggered CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect. For debugging consider passing CUDA_LAUNCH_BLOCKING=1. Compile withTORCH_USE_CUDA_DSA` to enable device-side assertions.
╭─────────────────────────────── Traceback (most recent call last) ────────────────────────────────╮
│ /home/ec2-user/rdp-works-llm-finetune/mezo/MeZO/large_models/run.py:525 in │
│ │
│ 522 │ │ │ write_metrics_to_file(metrics, "result/" + result_file_tag(args) + "-onetrai │
│ 523 │
│ 524 if name == "main": │
│ ❱ 525 │ main() │
│ 526 │
│ │
│ /home/ec2-user/rdp-works-llm-finetune/mezo/MeZO/large_models/run.py:491 in main │
│ │
│ 488 │ │ │ │ │ dev_samples = None │
│ 489 │ │ │ │ │
│ 490 │ │ │ │ # Training │
│ ❱ 491 │ │ │ │ framework.train(train_samples, dev_samples if dev_samples is not None el │
│ 492 │ │ │ │ │
│ 493 │ │ │ │ if not args.no_eval: │
│ 494 │ │ │ │ │ metrics = framework.evaluate([], eval_samples) # No in-context learn │
│ │
│ /home/ec2-user/rdp-works-llm-finetune/mezo/MeZO/large_models/run.py:428 in train │
│ │
│ 425 │ │ if self.args.resume_from_checkpoint is not None: │
│ 426 │ │ │ last_checkpoint = self.args.resume_from_checkpoint │
│ 427 │ │ │
│ ❱ 428 │ │ trainer.train(resume_from_checkpoint=last_checkpoint) │
│ 429 │ │ │
│ 430 │ │ # Explicitly save the model │
│ 431 │ │ if self.args.save_model: │
│ │
│ /opt/conda/envs/pytorch/lib/python3.10/site-packages/transformers/trainer.py:1662 in train │
│ │
│ 1659 │ │ inner_training_loop = find_executable_batch_size( │
│ 1660 │ │ │ self._inner_training_loop, self._train_batch_size, args.auto_find_batch_size │
│ 1661 │ │ ) │
│ ❱ 1662 │ │ return inner_training_loop( │
│ 1663 │ │ │ args=args, │
│ 1664 │ │ │ resume_from_checkpoint=resume_from_checkpoint, │
│ 1665 │ │ │ trial=trial, │
│ │
│ /home/ec2-user/rdp-works-llm-finetune/mezo/MeZO/large_models/trainer.py:529 in │
│ _inner_training_loop │
│ │
│ 526 │ │ │ │ │
│ 527 │ │ │ │ # MeZO added: estimate gradient │
│ 528 │ │ │ │ if args.trainer == "zo": │
│ ❱ 529 │ │ │ │ │ tr_loss_step = self.zo_step(model, inputs) │
│ 530 │ │ │ │ else: │
│ 531 │ │ │ │ │ if ( │
│ 532 │ │ │ │ │ │ ((step + 1) % args.gradient_accumulation_steps != 0) │
│ │
│ /home/ec2-user/rdp-works-llm-finetune/mezo/MeZO/large_models/trainer.py:774 in zo_step │
│ │
│ 771 │ │ │
│ 772 │ │ # First function evaluation │
│ 773 │ │ self.zo_perturb_parameters(scaling_factor=1) │
│ ❱ 774 │ │ loss1 = self.zo_forward(model, inputs) │
│ 775 │ │ │
│ 776 │ │ # Second function evaluation │
│ 777 │ │ self.zo_perturb_parameters(scaling_factor=-2) │
│ │
│ /home/ec2-user/rdp-works-llm-finetune/mezo/MeZO/large_models/trainer.py:722 in zo_forward │
│ │
│ 719 │ │ model.eval() │
│ 720 │ │ if self.args.non_diff: │
│ 721 │ │ │ # Non-differentiable objective (may require autoregressive generation) │
│ ❱ 722 │ │ │ return self.zo_forward_nondiff(model, inputs) │
│ 723 │ │ │
│ 724 │ │ with torch.inference_mode(): │
│ 725 │ │ │ inputs = self._prepare_inputs(inputs) │
│ │
│ /home/ec2-user/rdp-works-llm-finetune/mezo/MeZO/large_models/trainer.py:744 in │
│ zo_forward_nondiff │
│ │
│ 741 │ │ with torch.inference_mode(): │
│ 742 │ │ │ inputs = self._prepare_inputs(inputs) │
│ 743 │ │ │ args = self.args │
│ ❱ 744 │ │ │ outputs = self.model.generate( │
│ 745 │ │ │ │ inputs["input_ids"], do_sample=args.sampling, temperature=args.temperatu │
│ 746 │ │ │ │ num_beams=args.num_beams, top_p=args.top_p, top_k=args.top_k, max_new_to │
│ 747 │ │ │ │ num_return_sequences=1, eos_token_id=[self.tokenizer.encode(args.eos_tok │
│ │
│ /opt/conda/envs/pytorch/lib/python3.10/site-packages/torch/utils/_contextlib.py:115 in │
│ decorate_context │
│ │
│ 112 │ @functools.wraps(func) │
│ 113 │ def decorate_context(*args, **kwargs): │
│ 114 │ │ with ctx_factory(): │
│ ❱ 115 │ │ │ return func(*args, **kwargs) │
│ 116 │ │
│ 117 │ return decorate_context │
│ 118 │
│ │
│ /opt/conda/envs/pytorch/lib/python3.10/site-packages/transformers/generation/utils.py:1437 in │
│ generate │
│ │
│ 1434 │ │ │ │ ) │
│ 1435 │ │ │ │
│ 1436 │ │ │ # 11. run greedy search │
│ ❱ 1437 │ │ │ return self.greedy_search( │
│ 1438 │ │ │ │ input_ids, │
│ 1439 │ │ │ │ logits_processor=logits_processor, │
│ 1440 │ │ │ │ stopping_criteria=stopping_criteria, │
│ │
│ /opt/conda/envs/pytorch/lib/python3.10/site-packages/transformers/generation/utils.py:2248 in │
│ greedy_search │
│ │
│ 2245 │ │ │ model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs) │
│ 2246 │ │ │ │
│ 2247 │ │ │ # forward pass to get next token │
│ ❱ 2248 │ │ │ outputs = self( │
│ 2249 │ │ │ │ **model_inputs, │
│ 2250 │ │ │ │ return_dict=True, │
│ 2251 │ │ │ │ output_attentions=output_attentions, │
│ │
│ /opt/conda/envs/pytorch/lib/python3.10/site-packages/torch/nn/modules/module.py:1501 in │
│ _call_impl │
│ │
│ 1498 │ │ if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks │
│ 1499 │ │ │ │ or _global_backward_pre_hooks or _global_backward_hooks │
│ 1500 │ │ │ │ or _global_forward_hooks or _global_forward_pre_hooks): │
│ ❱ 1501 │ │ │ return forward_call(*args, **kwargs) │
│ 1502 │ │ # Do not call functions when jit is used │
│ 1503 │ │ full_backward_hooks, non_full_backward_hooks = [], [] │
│ 1504 │ │ backward_pre_hooks = [] │
│ │
│ /opt/conda/envs/pytorch/lib/python3.10/site-packages/accelerate/hooks.py:165 in new_forward │
│ │
│ 162 │ │ │ with torch.no_grad(): │
│ 163 │ │ │ │ output = old_forward(*args, **kwargs) │
│ 164 │ │ else: │
│ ❱ 165 │ │ │ output = old_forward(*args, **kwargs) │
│ 166 │ │ return module._hf_hook.post_forward(module, output) │
│ 167 │ │
│ 168 │ module.forward = new_forward │
│ │
│ /opt/conda/envs/pytorch/lib/python3.10/site-packages/transformers/models/llama/modeling_llama.py │
│ :687 in forward │
│ │
│ 684 │ │ return_dict = return_dict if return_dict is not None else self.config.use_return │
│ 685 │ │ │
│ 686 │ │ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn) │
│ ❱ 687 │ │ outputs = self.model( │
│ 688 │ │ │ input_ids=input_ids, │
│ 689 │ │ │ attention_mask=attention_mask, │
│ 690 │ │ │ position_ids=position_ids, │
│ │
│ /opt/conda/envs/pytorch/lib/python3.10/site-packages/torch/nn/modules/module.py:1501 in │
│ _call_impl │
│ │
│ 1498 │ │ if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks │
│ 1499 │ │ │ │ or _global_backward_pre_hooks or _global_backward_hooks │
│ 1500 │ │ │ │ or _global_forward_hooks or _global_forward_pre_hooks): │
│ ❱ 1501 │ │ │ return forward_call(*args, **kwargs) │
│ 1502 │ │ # Do not call functions when jit is used │
│ 1503 │ │ full_backward_hooks, non_full_backward_hooks = [], [] │
│ 1504 │ │ backward_pre_hooks = [] │
│ │
│ /opt/conda/envs/pytorch/lib/python3.10/site-packages/accelerate/hooks.py:165 in new_forward │
│ │
│ 162 │ │ │ with torch.no_grad(): │
│ 163 │ │ │ │ output = old_forward(*args, **kwargs) │
│ 164 │ │ else: │
│ ❱ 165 │ │ │ output = old_forward(*args, **kwargs) │
│ 166 │ │ return module._hf_hook.post_forward(module, output) │
│ 167 │ │
│ 168 │ module.forward = new_forward │
│ │
│ /opt/conda/envs/pytorch/lib/python3.10/site-packages/transformers/models/llama/modeling_llama.py │
│ :536 in forward │
│ │
│ 533 │ │ │ attention_mask = torch.ones( │
│ 534 │ │ │ │ (batch_size, seq_length_with_past), dtype=torch.bool, device=inputs_embe │
│ 535 │ │ │ ) │
│ ❱ 536 │ │ attention_mask = self._prepare_decoder_attention_mask( │
│ 537 │ │ │ attention_mask, (batch_size, seq_length), inputs_embeds, past_key_values_len │
│ 538 │ │ ) │
│ 539 │
│ │
│ /opt/conda/envs/pytorch/lib/python3.10/site-packages/transformers/models/llama/modeling_llama.py │
│ :464 in _prepare_decoder_attention_mask │
│ │
│ 461 │ │ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len] │
│ 462 │ │ combined_attention_mask = None │
│ 463 │ │ if input_shape[-1] > 1: │
│ ❱ 464 │ │ │ combined_attention_mask = _make_causal_mask( │
│ 465 │ │ │ │ input_shape, │
│ 466 │ │ │ │ inputs_embeds.dtype, │
│ 467 │ │ │ │ device=inputs_embeds.device, │
│ │
│ /opt/conda/envs/pytorch/lib/python3.10/site-packages/transformers/models/llama/modeling_llama.py │
│ :49 in make_causal_mask │
│ │
│ 46 │ Make causal mask used for bi-directional self-attention. │
│ 47 │ """ │
│ 48 │ bsz, tgt_len = input_ids_shape │
│ ❱ 49 │ mask = torch.full((tgt_len, tgt_len), torch.tensor(torch.finfo(dtype).min, device=de │
│ 50 │ mask_cond = torch.arange(mask.size(-1), device=device) │
│ 51 │ mask.masked_fill(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0) │
│ 52 │ mask = mask.to(dtype) │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
wandb: Waiting for W&B process to finish... (failed 1). Press Control-C to abort syncing.
wandb: 🚀 View run sunny-thunder-76 at: https://wandb.ai/raahul/huggingface/runs/to4hrtwj
wandb: Synced 6 W&B file(s), 0 media file(s), 0 artifact file(s) and 0 other file(s)
wandb: Find logs at: ./wandb/run-20230904_221028-to4hrtwj/logs`
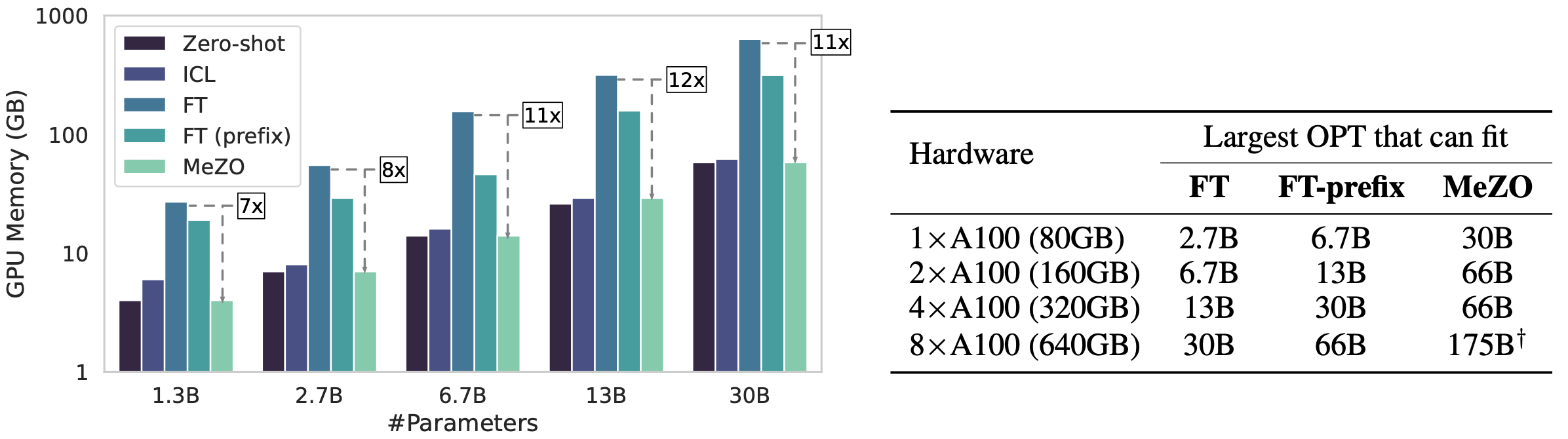 GPU memory usage comparison between zero-shot, in-context learning (ICL), Adam fine-tuning (FT), and our proposed MeZO.
GPU memory usage comparison between zero-shot, in-context learning (ICL), Adam fine-tuning (FT), and our proposed MeZO.
 OPT-13B results with zero-shot, in-context learning (ICL), MeZO (we report the best among MeZO/MeZO (LoRA)/MeZO (prefix)), and fine-tuning with Adam (FT). MeZO demonstrates superior results over zero-shot and ICL and performs on par with FT (within 1%) on 7 out of 11 tasks, despite using only 1/12 memory.
OPT-13B results with zero-shot, in-context learning (ICL), MeZO (we report the best among MeZO/MeZO (LoRA)/MeZO (prefix)), and fine-tuning with Adam (FT). MeZO demonstrates superior results over zero-shot and ICL and performs on par with FT (within 1%) on 7 out of 11 tasks, despite using only 1/12 memory.































































































































