In this project I have implemented a machine learning model to predict whether a message is spam or not. Furthermore, I have created a system that upon receipt of an email message will automatically flag it as spam or not, based on the prediction obtained from the machine learning model.
-
Implement a Machine Learning model for predicting whether an SMS message is spam or not.
a. Follow the following AWS tutorial on how to build and train a spam filter machine learning model using Amazon SageMaker: https://github.com/aws-samples/reinvent2018-srv404-lambda-sagemaker/blob/master/training/README.md
b. Deploy the resulting model to an endpoint (E1).
-
Implement an automatic spam tagging system.
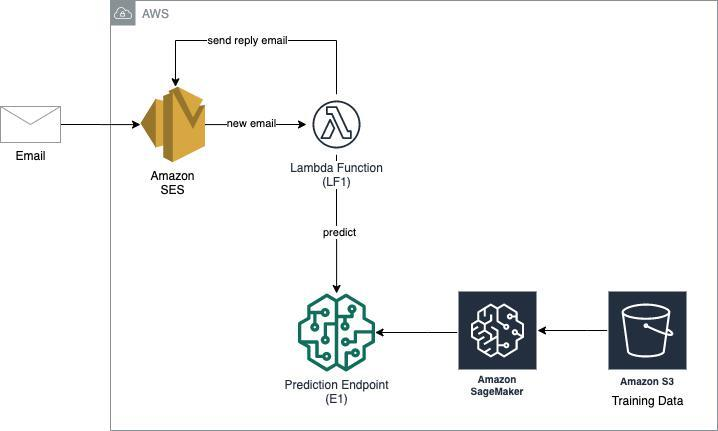
a. Create an S3 bucket (S1) that will store email files.
b. Using SES, set up an email address, that upon receipt of an email it stores it in S3. Confirm that the workflow is working by sending an email to that email address and seeing if the email information ends up in S3.
c. For any new email file that is stored in S3, trigger a Lambda function (LF1) that extracts the body of the email and uses the prediction endpoint (E1) to predict if the email is spam or not. Strip out new line characters “\n” in the email body, to match the data format in the SMS dataset that the ML model was trained on.
d. Reply to the sender of the email (it could be your email, the TA’s etc.) with a message as follows: “We received your email sent at [EMAIL_RECEIVE_DATE] with the subject [EMAIL_SUBJECT]. Here is a 240 character sample of the email body: [EMAIL_BODY] The email was categorized as [CLASSIFICATION] with a [CLASSIFICATION_CONFIDENCE_SCORE]% confidence.” Replace each variable “[VAR]” with the corresponding value from the email and the prediction. The purpose of this step is to facilitate easy testing.
-
Create an AWS CloudFormation template for the automatic spam tagging system.
a. Create a CloudFormation template (T1) to represent all the infrastructure resources (ex. Lambda, SES configuration, etc.) and permissions (IAM policies, roles, etc.).
b. The template (T1) takes the prediction endpoint (E1) as a stack parameter.
